Diagnostic Accuracy of a Multi-Target Artificial Intelligence Service for the Simultaneous Assessment of 16 Pathological Features on Chest and Abdominal CT
Valentin A. Nechaev, Nataliya Y. Kashtanova, Evgenii V. Kopeykin, Umamat M. Magomedova, Maria S. Gribkova, Anton V. Hardin, Marina I. Sekacheva, Varvara D. Sanikovich, Valeria Y. Chernina, Victor A. Gombolevskiy

TL;DR
This study evaluates an AI system's ability to detect 16 pathological features in chest and abdominal CT scans, finding it performs well overall except for detecting kidney stones.
Contribution
The study introduces a multi-target AI service for simultaneous assessment of multiple pathological features in CT scans, showing high diagnostic accuracy.
Findings
The AI service achieved an overall AUC of 0.88 for detecting 16 pathological features in CT scans.
Most AI errors were classified as minor or intermediate, with only 5.4% being clinically significant.
The AI performed poorly for urolithiasis detection compared to other features.
Abstract
Background/Objectives: Chest, abdominal, and pelvic computed tomography (CT) with intravenous contrast is widely used for tumor staging, treatment planning, and therapy monitoring. The integration of artificial intelligence (AI) services is expected to improve diagnostic accuracy across multiple anatomical regions simultaneously. We aimed to evaluate the diagnostic accuracy of a multi-target AI service in detecting 16 pathological features on chest and abdominal CT images. Methods: We conducted a retrospective study using anonymized CT data from an open dataset. A total of 229 CT scans were independently interpreted by four radiologists with more than 5 years of experience and analyzed by the AI service. Sixteen pathological features were assessed. AI errors were classified as minor, intermediate, or clinically significant. Diagnostic accuracy was evaluated using the area under the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
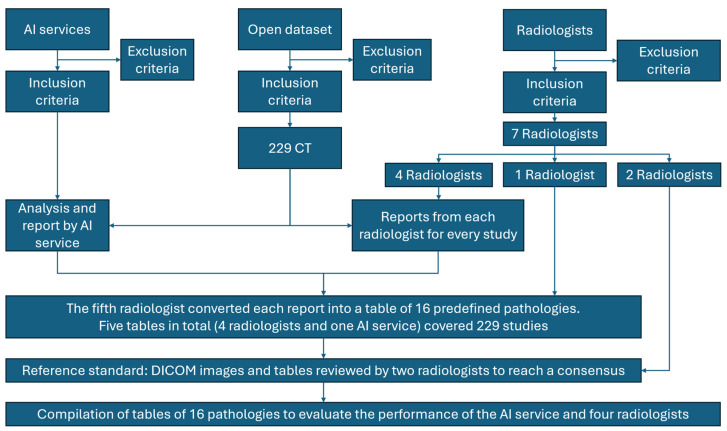 Figure 1
Figure 1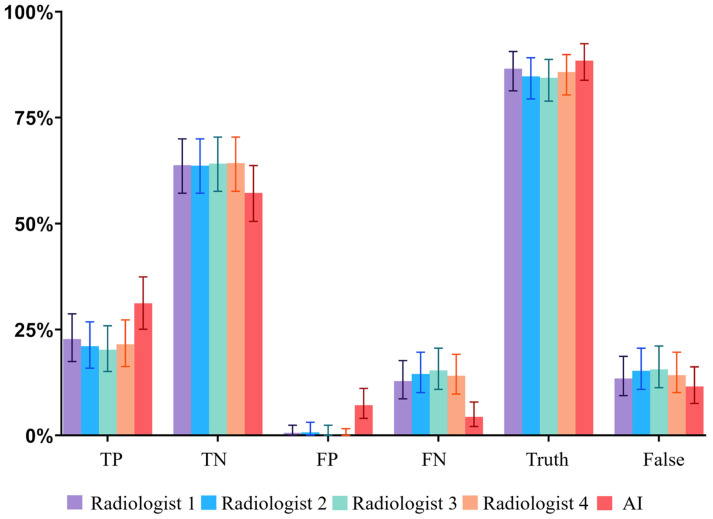 Figure 2
Figure 2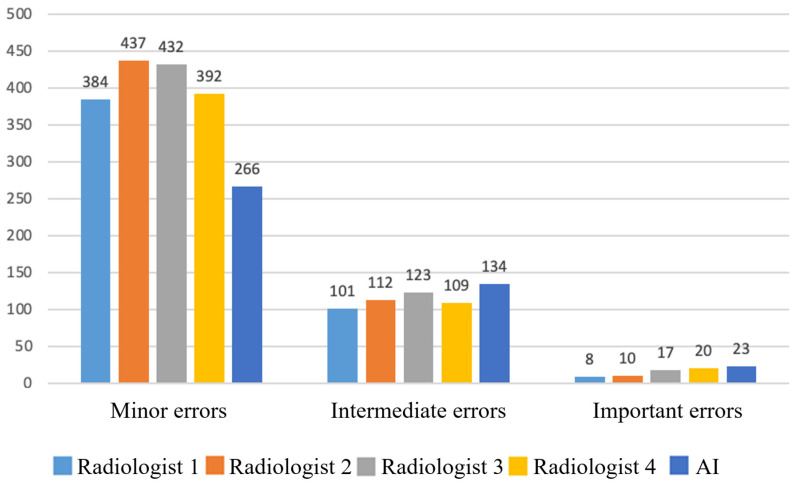 Figure 3
Figure 3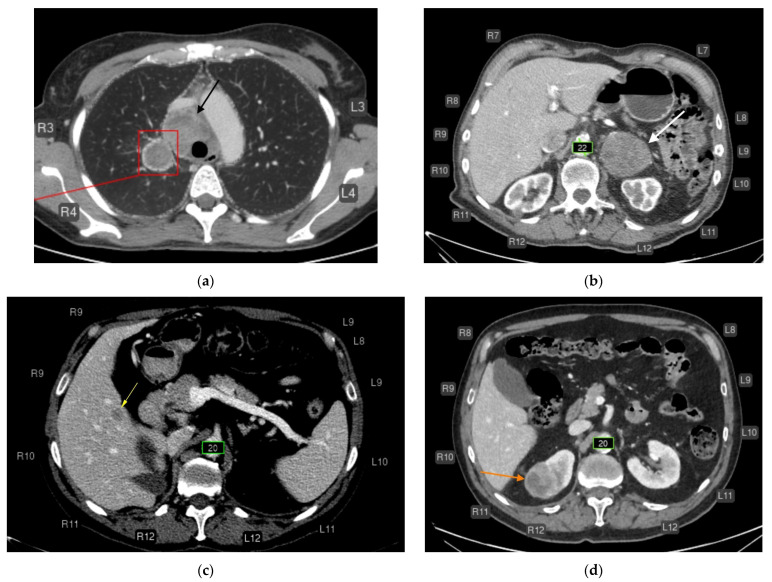 Figure 4
Figure 4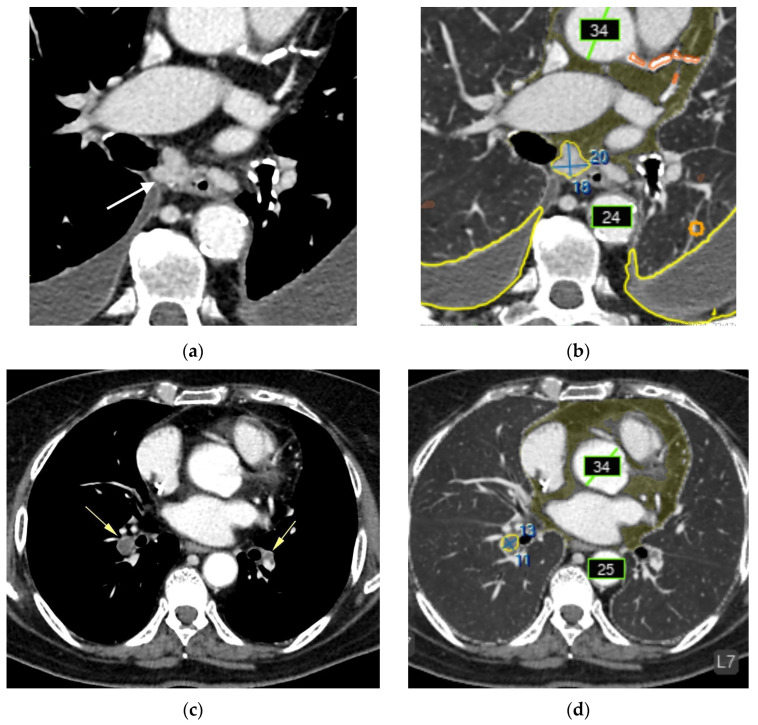 Figure 5
Figure 5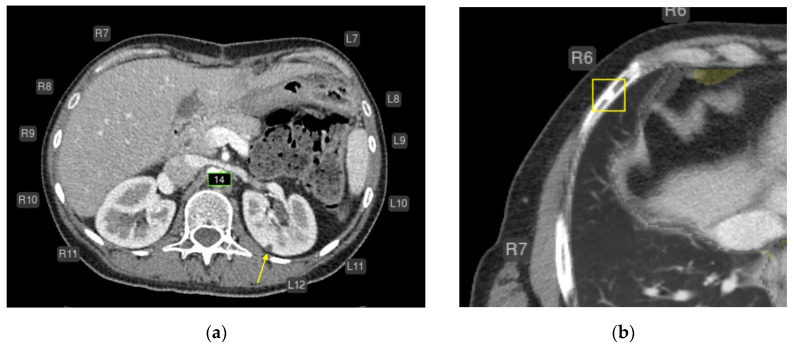 Figure 6
Figure 6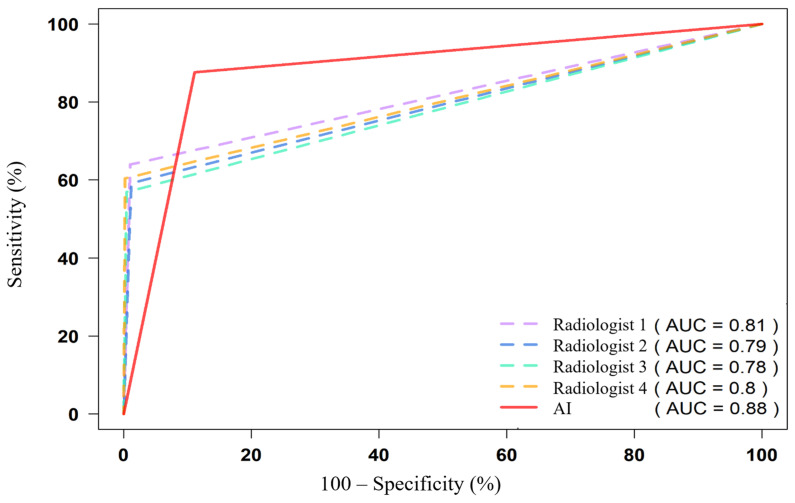 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Radiomics and Machine Learning in Medical Imaging · Advanced X-ray and CT Imaging
1. Introduction
Artificial intelligence (AI) technologies have introduced novel opportunities in radiology, including enhanced diagnostic accuracy, workflow optimization, and the advancement of medical research [1,2]. The integration of AI algorithms into clinical practice is necessitated by the steadily increasing volume of imaging studies, the persistent shortage of radiologists, and the ongoing demand for greater diagnostic precision in imaging modalities [1,2]. Among these modalities, contrast-enhanced computed tomography (CT) of the chest, abdomen, and pelvis remains one of the most accessible and accurate techniques. CT is recommended for the assessment of tumor extent, treatment planning, and evaluation of therapeutic efficacy and is therefore considered an indispensable component of comprehensive patient management [3]. Nonetheless, radiology reports based on chest CT [4] and abdominal CT [5] are frequently subject to diagnostic errors, most commonly false-negative findings. In this context, the implementation of multipurpose AI-based systems capable of detecting pathological changes across multiple anatomical regions concurrently appears highly relevant. Such systems not only have the potential to reduce diagnostic error rates but may also contribute to mitigating the increasing clinical workload of radiologists [6]. However, the diagnostic performance of AI tools requires rigorous evaluation, including systematic assessment of potential sources of error and identification of limitations that may constrain their widespread clinical adoption [2].
2. Materials and Methods
2.1. The Study Design
This single-center retrospective diagnostic accuracy study followed the CLAIM and STARD guidelines [7,8]. The study workflow is illustrated in Figure 1. Prior to the analysis, dataset preparation and radiologist training were performed according to predefined inclusion and exclusion criteria.
2.2. Study Registration
This retrospective diagnostic accuracy study analyzed publicly available, anonymized CT data and therefore did not require separate protocol registration (e.g., ClinicalTrials.gov). Ethical approval was obtained from the local ethics committee of Moscow City Clinical Hospital No. 1. (protocol dated 1 March 2024). The BIMCV-COVID-19+ dataset had prior approval from the Hospital Arnau de Vilanova ethics committee (CElm 12/2020, Valencia, Spain) and was funded through regional and EU Horizon 2020 grants. All data were anonymized before release, so informed consent was waived.
2.3. Data Source
Anonymized CT scans were acquired in 2020. Retrospective evaluation by radiologists and the AI system was carried out between 14 March 2024, and 2 November 2024. All CT examinations originated from the publicly available BIMCV-COVID-19+ dataset (Valencia Region, Spain), collected in 2020 from 11 public hospitals and standardized to UMLS terminology [9].
2.3.1. Inclusion Criteria
Adult chest and abdominal CT images; slice thickness ≤ 1 mm; scan coverage extending from the lung apices to the ischial bones, acquired during deep inspiratory breath-hold.
2.3.2. Exclusion Criteria
CT studies with protocol deviations (slice thickness > 1 mm or incomplete anatomic coverage), severe motion or beam-hardening artifacts, non-standard patient positioning, or upload/parse failures. Studies with corrupted DICOM tags or missing key series were also excluded.
2.4. Data Preprocessing
No additional data preprocessing was applied beyond standard DICOM parsing of the publicly available BIMCV-COVID-19+ dataset; images were analyzed as provided.
2.5. Data Partitions
2.5.1. Assignment of Data to Partitions
All 229 eligible CT examinations were used solely as an independent test set for the locked AI system. No additional training or validation split was performed.
2.5.2. Level of Disjointness Between Partitions
Each examination (one patient) was treated as a single unit of analysis; no overlap existed between cases.
2.6. Intended Sample Size
The required sample size was calculated a priori as 236 examinations to estimate sensitivity and specificity with 95% confidence and ±10% error. To account for possible data loss (artifacts, upload failures, or absent non-contrast series), 250 CTs were selected; after exclusions, 229 remained for final analysis.
2.7. De-Identification Methods
All CT examinations were provided as part of the publicly available BIMCV-COVID-19+ dataset, which had been fully anonymized by the data provider before release. Personal identifiers—including patient name, date of birth, medical record numbers, and examination dates—were removed from DICOM headers. Only anonymous study IDs linking imaging data to accompanying radiology reports were retained for analysis. The de-identification procedure of the BIMCV dataset was reviewed and approved by the local ethics committee (CElm: 12/2020, Valencia, Spain).
2.8. Handling of Missing Data
Studies lacking mandatory series (e.g., contrast-enhanced scans without a corresponding non-contrast series) or with missing annotations/upload failures were treated as technical exclusions. No additional data imputation or image reconstruction was performed; such cases were not included in endpoint analyses.
2.9. Image Acquisition Protocol
Detailed scanning parameters can be obtained from the original publicly available dataset [9]. Examinations were performed on multislice CT scanners routinely used in hospitals of the Valencia region. Slice thickness was ≤1 mm, and coverage extended from the lung apices to the ischial bones. Scans were obtained during deep-inspiration breath-hold. Both non-contrast and contrast-enhanced studies were included; contrast-enhanced examinations lacking a non-contrast series were excluded. Detailed scanner models, reconstruction kernels, and exposure parameters were not available in the public dataset; all scans followed standard clinical protocols for chest–abdomen–pelvis CT in the region.
2.10. Human Readers
Seven radiologists participated in the study. Inclusion criteria comprised at least three years of experience in interpreting chest and abdominal CT scans. Exclusion criteria included failure to complete calibration or training according to the study protocol. The radiologists were assigned to three roles: annotators (n = 4), compiler (n = 1), and referees (n = 2). The annotators, all board-certified radiologists with 5–8 years of experience, independently interpreted all CT examinations using RadiAnt DICOM Viewer 2023.1 outside their routine clinical duties. Prior to the study, all readers attended a short calibration session with sample clinical cases to standardize interpretation criteria. Case order was randomized individually, and readers were blinded to AI outputs, clinical data, and one another’s results. For each of the 16 predefined pathologies, findings were recorded for ROC AUC analysis. The compiler (8 years of experience) reviewed all radiologist and AI reports to compile structured tables containing the same 16 pathologies, resulting in five tables (four radiologists and one AI system) covering 229 CT studies. The referees (each with over 8 years of experience) independently reviewed DICOM images and resolved discrepancies by consensus, after which they were granted access to all five result tables for comparative evaluation.
2.11. Annotation Workflow
Each of the six radiologists (annotators, n = 4; referees, n = 2) reviewed every CT slice of all 229 examinations to ensure comprehensive assessment. The compiler (n = 1) subsequently analyzed the outputs from the four annotators and from the AI system (IRA LABS AI service), which processed the same 229 CT studies and produced both DICOM SEG annotations and DICOM SR structured reports. For each study, the compiler registered the presence or absence (binary classification) of all 16 predefined pathologies.
2.12. Reference Standard
The reference standard for performance evaluation was the consensus of two senior radiologists (>8 years’ experience) who were not involved in the initial readings. They independently reviewed all CT examinations without access to AI outputs or initial reader reports using RadiAnt DICOM Viewer 2023.1. Disagreements were resolved by consensus or, if unresolved, by a third adjudicator. Formal inter-reader variability was not a primary objective; however, prior work highlights substantial variability in CT reporting [10].
Expert annotations for all 229 examinations were documented in a standardized table covering 16 predefined pathological features. Performance comparisons were made among: (1) initial annotations from four radiologists, (2) AI system outputs, and (3) the expert consensus reference standard.
For exploratory error analysis only, the same experts re-examined cases after reviewing AI outputs to categorize AI detections and errors; these post-AI reviews were not used to generate reference standard metrics.
2.13. Model
2.13.1. Model Description
A multipurpose AI service (IRA LABS, registered medical device RU №2024/22895) was used for simultaneous detection of 16 predefined pathologies on chest–abdominal CT (Table 1).
The final release version (v6.1, January 2024) identical to the one deployed in clinical practice was applied without retraining or parameter changes. Input consisted of DICOM CT series; output was generated as DICOM SEG annotations and DICOM SR structured reports.
2.13.2. AI Service Inclusion and Exclusion Criteria
Inclusion Criteria
Software registered as a certified medical device (MD) utilizing artificial intelligence (AI) technology in the official national registry of medical software. Software tested and validated within the Moscow Experiment—a large-scale governmental initiative for clinical deployment of computer vision AI in radiology [13]. Demonstrated diagnostic performance with ROC AUC ≥ 0.81 for each target pathology, in accordance with methodological recommendations [11,12]. Capability to analyze both chest and abdominal CT examinations within a single inference pipeline.
Exclusion Criteria
AI products whose participation in the Moscow Experiment was suspended, discontinued, or failed official performance verification [13]. Systems limited to single-region analysis (e.g., chest-only AI) or lacking multiclass pathology detection capability.
The IRA LABS AI service (version 6.1, January 2024) was selected because it fulfilled all inclusion criteria and provided the broadest pathology coverage among eligible AI services participating in the Moscow Experiment [13].
2.13.3. Software and Environment
The proprietary system was executed as an off-the-shelf product. Internal architecture, model parameters, and potential ensemble methods are not publicly disclosed by the developer. Inference was run on a workstation with AMD Ryzen 7 7700, 64 GB RAM, 480 GB SSD, and NVIDIA RTX 4060 (8 GB) GPU, using Ubuntu 22.04.
2.13.4. Initialization of Model Parameters
The pre-trained production version of the AI model was used as released by the developer. No fine-tuning, weight reinitialization, or hyperparameter modification was performed for this study. The operating point (decision thresholds) was the vendor’s default, locked a priori and not tuned on the test set.
2.13.5. Training
Details of Training Approach
No additional training or fine-tuning was performed for this study. The AI service was applied as an off-the-shelf production version (v6.1, January 2024) identical to the clinically deployed release.
Method of Selecting the Final Model
The version used was previously chosen and locked by IRA LABS during its clinical validation within the Moscow Experiment on computer-vision technologies. No modifications were made for the present evaluation [13].
Ensembling Techniques
The developer has not disclosed whether internal ensemble methods were used. For this study, a single instance of the AI service was applied for CT analysis, providing DICOM SEG annotations and structured text reports.
2.14. Evaluation
2.14.1. Metrics
Diagnostic performance of the AI system and radiologists was quantified using the area under the ROC curve (AUC, 95% CI via DeLong) [14]. For each of the 16 pathologies, True positives (TP), false positives (FP), true negatives (TN), and false negatives (FN) counts were recorded, and classification errors stratified as minor, intermediate, or major.
2.14.2. Robustness Analysis
AUC was additionally calculated for clinically significant findings only to assess robustness for critical pathologies.
2.14.3. Methods for Explainability
AI outputs were interpreted via DICOM SEG visualizations and structured text reports. Errors were cross-checked against the reference standard and categorized by clinical significance.
2.14.4. Data Independence
BIMCV-COVID-19+ had not been used in model training; all 229 CT studies were independent of the AI development data. Testing was limited to this single external dataset; no further external validation was available.
2.14.5. Comparison and Evaluation Methodology
Comparative analysis was performed using five structured 229 × 16 matrices (four human readers and one AI system), each containing binary presence/absence determinations for all predefined pathologies. These matrices were compared with the expert consensus reference standard established by the two referees to derive the metrics described above.
For pathologies with quantitative thresholds (Table 1), the AI system applied predefined anatomical cut-offs (e.g., ≥40 mm for ascending aorta) based on DICOM SR measurements, while radiologists relied on visual assessment and manual measurements.
2.14.6. Conversion of AI Outputs to Binary Labels
The fifth radiologist (compiler) converted the AI outputs into binary presence/absence labels for all 16 pathologies. Binary classification was based primarily on DICOM SR measurements and text findings, cross-referenced against thresholds specified in Table 1. DICOM SEG masks served as visual confirmation but were not used for independent volumetric analysis.
Example 1: Aortic dilatation/aneurysm The DICOM SR contained a quantitative measurement: “Ascending aorta diameter: 42 mm.” According to the predefined threshold (≥40 mm for ascending aorta, Table 1), this measurement was classified as “positive” for aortic dilatation. Cases with measurements below threshold were labeled “negative.”
Example 2: Pulmonary nodules The DICOM SEG file displayed a 3D segmentation mask outlining a pulmonary nodule. The accompanying DICOM SR reported: “In the right lung, a 10 × 8 mm node (average size 9 mm according to Fleischner).” Since the threshold is ≥6 mm (Table 1), this case was classified as “positive.” The compiler visually verified that the segmentation mask adequately encompassed the nodule before assigning the label.
2.14.7. Handling of Small Segmentations and Borderline Cases
Segmentations that partially extended beyond lesion boundaries were accepted if the DICOM SR measurement remained above the predefined threshold (Table 1) and the core pathology was adequately captured. Cases where segmentation contours substantially misrepresented the pathology (e.g., including adjacent structures or anatomically incorrect regions) were flagged as false positives during expert consensus review. No additional voxel-based or volumetric filtering beyond the diameter thresholds specified in Table 1 was applied.
2.15. Outcomes
2.15.1. Primary Outcome
TP, FP, TN, and FN for AI and human readers in detecting each of the 16 predefined pathologies (Table 1). All errors were stratified by clinical significance:
- Minor—no change in patient management or follow-up needed (examples: missed simple cysts < 5 mm, false-positive osteosclerosis misclassified as rib fracture).
- Intermediate—unlikely to affect primary disease treatment but requiring further testing or follow-up (examples: false-positive enlarged lymph nodes, over-detection of small pulmonary nodules).
- Major—likely to change treatment strategy or primary diagnosis (examples: missed liver/renal masses, missed intrathoracic lymphadenopathy suggestive of metastases).
Expert radiologists assigned these classifications during consensus review based on potential impact on clinical decision-making.
2.15.2. Secondary Outcomes
Area under the ROC curve (AUC) with 95% confidence intervals for each pathology and for the aggregated set, for both AI and radiologists.
Comparative analysis of AI versus radiologists using multi-reader multi-case (MRMC) methods.
Exploratory error review by experts after viewing AI outputs to categorize AI detections (not used as reference standard).
2.16. Sample Size Calculation
The minimum required sample size was estimated using the formula for a single proportion: n = Z^2^ × P × (1 – P)/d^2^, where Z = 1.96 (95% confidence), P = 0.81 (expected sensitivity/specificity), and d = 0.10 (margin of error). This yielded approximately 59 cases with pathology. Assuming an average disease prevalence of 25% across the evaluated pathologies, the total required sample size was N = 59/0.25 ≈ 236 examinations. To compensate for potential data loss (artifacts, annotation errors) and the multifocal nature of the study (chest + abdomen), the planned sample was increased to 250. After exclusions, 229 studies remained for final analysis.
2.17. Statistical Analysis
Statistical analysis was performed using RStudio (version 2025.09.2+418; Posit Software, PBC, Boston, MA, USA) [15] with the irr [16] and pROC [17] packages. Data visualization was carried out with GraphPad Prism version 10.2.2 (GraphPad Software Inc., San Diego, CA, USA) [18]. Descriptive statistics were reported as absolute numbers (n) and proportions (%). Diagnostic performance was assessed using ROC analysis with calculation of AUC and 95% confidence intervals via DeLong’s method [14]. Comparisons between AI and radiologists used multi-reader multi-case DBM/OR analysis (RJafroc) [19]. To control for multiple testing across 16 pathologies, Benjamini–Hochberg correction (q = 0.05) was applied. A two-sided p < 0.05 was considered statistically significant.
3. Results
3.1. Overall Diagnostic Performance
In 229 chest–abdominal CT examinations independently interpreted by four radiologists and the AI system, the AI system produced 423 errors (11.5% of all evaluated features). The prevalence of evaluated pathologies ranged from 9.6% (urolithiasis) to 70.7% (coronary artery calcium) (Table 2).
False positives predominated (n = 262; 61.9%) over false negatives (n = 161; 38.1%), whereas radiologists showed more false negatives (470–562) than false positives (5–27) (Figure 2). Contingency tables (TP, FP, TN, FN) for each pathology across all features, 4 radiologists, and the AI are provided in Supplementary Files (Tables S1 and S2).
3.2. Clinical Significance of Errors
All errors were stratified by clinical significance. For both radiologists and AI, minor errors were most frequent, followed by intermediate, with major errors being rare (Figure 3).
3.3. Breakdown of Clinically Significant AI Errors
Major errors (false negatives, n = 20):
- Liver lesions (8);
- Renal lesions (2);
- Adrenal lesions (2);
- Impaired lung aeration (atelectasis, 2);
- Enlarged intrathoracic lymph nodes (3);
- Pulmonary nodule (1);
- Low vertebral body density (1);
- Urolithiasis (1) (Figure 4).
Intermediate errors (mostly false positives, n = 91):
- Intrathoracic lymph nodes (16);
- Pulmonary nodules (15);
- Impaired aeration (15);
- Aortic dilatation/aneurysm (10);
- Adrenal thickening (10) (Figure 5).
Minor errors (n = 266):
- Missed small simple cysts (<5 mm) in kidney or liver (70 cases) (Figure 6a);
- Incorrect segmentation of rib fractures (32 cases) misclassified from bone islands, artifacts, or costal cartilage transitions (Figure 6b).
3.4. ROC Analysis and AUC Values
AUCs were calculated for each pathology and in aggregate for radiologists and AI (Table 3).
Aggregate AUC: AI = 0.88; highest radiologist = 0.81 (Figure 7).
Clinically significant findings only: mean AI AUC = 0.90 (Table 4).
3.5. Diagnostic Performance Categories
According to standard diagnostic categories, AI performance was predominantly excellent or good.
Urolithiasis was the only feature where AI showed inadequate performance.
Radiologists demonstrated poor or inadequate performance for several features, including:
- Aortic dilatation/aneurysm;
- Vertebral compression fractures;
- Rib fractures;
- Pulmonary artery dilatation;
- Low vertebral body density;
- Increased epicardial fat volume here.
4. Discussion
In this multi-reader evaluation of 229 chest and abdominal CT examinations comprising 3664 feature-level assessments, the multi-target AI service achieved an aggregate AUC of 0.88 (95% CI 0.87–0.89), outperforming the four independent radiologists (AUC 0.78–0.81) (Table 2, Figure 7). Diagnostic performance was good to excellent for most of the 16 predefined targets. The AI demonstrated clear advantages in vascular, osseous, and morphometric findings, while showing relative deficits for solid-organ masses and airspace disease. The only unsatisfactory target was urolithiasis (AUC ≈ 0.52), which persisted in sensitivity analysis (AUC 0.55). Across modalities, commercial AI shows target-dependent performance, e.g., for airspace disease on chest radiographs [20].
Although the AI system produced more false positives than false negatives (61.9% vs. 38.1%), clinically important AI errors were rare—only 0.63% of all assessed instances—and were mainly missed focal lesions. Stratification of errors revealed that 94.6% of AI mistakes were minor or intermediate. Intermediate false positives often reflected adjacency or merging artifacts and vascular–nodal confusion, whereas minor errors were primarily tiny cysts and rib fracture overcalls. The AI’s superiority in measuring diameters, densities, calcifications, and vertebral deformities likely stems from stable morphometric cues, whereas parenchymal textures and small solid-organ lesions remain more challenging. Its underperformance in urolithiasis plausibly relates to protocol sensitivity: many cases were contrast-enhanced only, whereas optimal stone detection requires non-contrast CT [21].
Although our final sample size (n = 229) was slightly below the a priori calculated requirement (n = 236), the impact on precision was minimal, increasing the margin of error from ±10.0% to ±10.2%. The narrow confidence intervals observed for most AUC estimates suggest adequate statistical power was maintained.
Our aggregate results align with recent meta-analyses [22,23] reporting that state-of-the-art imaging AI reaches AUC ≈ 0.86–0.94 and, in selected tasks, can match or surpass individual radiologists [23,24]. The complementary patterns of liberal AI (more FP) and conservative readers (more FN) suggest that hybrid strategies—such as triage or double-reading—may reduce important misses while managing FP burden [24]. Incorrect AI outputs can influence readers’ decisions, underscoring the need for guardrails in hybrid workflows [25]. Similar FP–FN patterns have been synthesized in systematic reviews of AI error characteristics [26].
4.1. Strengths and Limitations
Key strengths include:
Multi-reader design with blinded interpretation and expert consensus reference standard;
Simultaneous evaluation of 16 diverse targets, enabling a comprehensive view of performance;
Stratification of errors by clinical significance, which provides insights beyond raw sensitivity and specificity;
Interpretive pitfalls and potential automation bias necessitate procedural safeguards and reader training [27].
Limitations include:
Single external dataset, limiting generalizability across protocols and institutions;
Protocol heterogeneity within BIMCV-COVID-19+ and incomplete non-contrast phases for some studies;
Lack of transparency regarding the proprietary model’s architecture and potential ensembling strategies;
The perfect ROC AUC scores (1.00) reflect the small sample size of clinically significant cases available for analysis, rather than necessarily indicating superior model performance. These findings require validation with substantially larger datasets.
Translation from curated datasets to clinical applicability can vary across modalities and tasks [28];
Absence of formal inter-reader variability analysis and external validation on independent cohorts. Limitations of AI services observed in radiography evaluations further argue for protocol-aware validation [29].
Binary classification prioritized clinical relevance over volumetric precision. No quantitative segmentation assessment (e.g., Dice coefficient) was performed; minor imperfections were tolerated if DICOM SR measurements exceeded thresholds. This pragmatic approach may introduce measurement variability and warrants future voxel-level validation.
4.2. Public Health Implications
Use of multi-target CT AI may improve early detection of significant findings, speed up reporting, and optimize resource use—critical for systems facing radiologist shortages. Such deployment could enhance population-level outcomes and reduce costs from delayed diagnoses, but requires careful monitoring of error profiles, protocol harmonization, and adherence to evidence-based standards to ensure equitable, safe benefits.
4.3. Future Directions
Perform multi-center replication with protocol-aware validation to ensure robustness across scanners and acquisition techniques;
Explore operating point calibration or task-specific thresholds to optimize the FP–FN balance;
Develop targeted refinements for small solid-organ lesions, parenchymal textures, and urolithiasis detection;
Investigate workflow integration strategies, including triage, double reading, or AI-assisted decision support, to translate performance gains into clinical benefit.
Evaluate the economic and public health impact of multi-target AI deployment, including cost-effectiveness analyses, resource allocation, and potential reductions in population-level morbidity and healthcare expenditures.
5. Conclusions
A clinically deployed multi-target AI service demonstrated high diagnostic accuracy on chest and abdominal CT across 16 predefined features, outperforming individual radiologists on several vascular, osseous, and morphometric targets while underperforming on urolithiasis and small solid-organ lesions. Clinically important AI errors were rare and predominantly involved missed focal lesions. These findings support the use of multi-target AI as a complementary second reader, provided protocol alignment is ensured and error profiles are prospectively monitored. Future multi-center validations and workflow studies are warranted to confirm generalizability and define optimal integration strategies in routine practice.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Katal S. York B. Gholamrezanezhad A. AI in Radiology: From Promise to Practice—A Guide to Effective Integration Eur. J. Radiol.202418111179810.1016/j.ejrad.2024.11179839471551 · doi ↗ · pubmed ↗
- 2Buijs E. Maggioni E. Mazziotta F. Lega F. Carrafiello G. Clinical Impact of AI in Radiology Department Management: A Systematic Review Radiol. Med.20241291656166610.1007/s 11547-024-01880-139243293 PMC 11554795 · doi ↗ · pubmed ↗
- 3Pokataev I.A. Dudina I.A. Kolomiets L.A. Morkhov K.Y. Nechushkina V.M. Rumyantsev A.A. Tyulyadin S.A. Urmancheeva A.F. Khokhlova S.V. Ovarian Cancer, Primary Peritoneal Cancer, and Fallopian Tube Cancer: Practical Recommendations of RUSSCO, Part 1.2Malig. Tumors 20241482101(In Russian)10.18027/2224-5057-2024-14-3s 2-1.2-02 · doi ↗
- 4Chernina V.Y. Belyaev M.G. Silin A.Y. Avetisov I.O. Pyatnitskiy I.A. Petrash E.A. Basova M.V. Sinitsyn V.E. Omelyanovskiy V.V. Gombolevskiy V.A. Diagnostic and Economic Evaluation of a Comprehensive Artificial Intelligence Algorithm for Detecting Ten Pathological Findings on Chest Computed Tomography Diagnostics 20234105132(In Russian)10.17816/DD 321963 · doi ↗
- 5Wildman-Tobriner B. Allen B.C. Maxfield C.M. Common Resident Errors When Interpreting Computed Tomography of the Abdomen and Pelvis: A Review of Types, Pitfalls, and Strategies for Improvement Curr. Probl. Diagn. Radiol.2019484910.1067/j.cpradiol.2017.12.01029397268 · doi ↗ · pubmed ↗
- 6Nechaev V.A. Vasiliev A.Y. Risk Factors for Perception Errors among Radiologists in the Analysis of Imaging Studies Vestnik Surgu. Med.2024171422(In Russian)10.35266/2949-3447-2024-4-2 · doi ↗
- 7Mongan J. Moy L. Kahn C.E.Jr. Checklist for Artificial Intelligence in Medical Imaging (CLAIM): A Guide for Authors and Reviewers Radiol. Artif. Intell.20202 e 20002910.1148/ryai.202020002933937821 PMC 8017414 · doi ↗ · pubmed ↗
- 8Bossuyt P.M. Reitsma J.B. E Bruns D. A Gatsonis C. Glasziou P.P. Irwig L. Lijmer J.G. Moher D. Rennie D. de Vet H.C.W. STARD 2015: An Updated List of Essential Items for Reporting Diagnostic Accuracy Studies BMJ 2015351 h 552710.1136/bmj.h 552726511519 PMC 4623764 · doi ↗ · pubmed ↗