Extracting TNFi switching reasons and trajectories from real-world data using large language models
Brenda Y Miao, Marie Binvignat, Augusto Garcia-Agundez, Maxim Bravo, Christopher Yk Williams, Claire Q Miao, Ahmed Alaa, Vivek Rudrapatna, Atul J Butte, Gabriela Schmajuk, Jinoos Yazdany

TL;DR
This study shows that large language models like GPT-4 can accurately extract patterns and reasons for switching TNFi treatments from real-world medical records.
Contribution
Demonstrates the effectiveness of LLMs in automating chart review for TNFi switching patterns and reasons in real-world data.
Findings
GPT-4 achieved high micro-F1 scores (0.75-0.83) in identifying TNFi switches and reasons from clinical notes.
Lack of efficacy was the most common reason for switching TNFi treatments (56.9%).
Open-source models like Starling-7B-beta and Llama-3-8B also performed competitively with GPT-4.
Abstract
To evaluate whether large language models (LLMs) can automate chart review to identify tumor necrosis factor inhibitor (TNFi) switching patterns and reasons for switching in a large real-world cohort. We conducted an observational study using de-identified electronic health record (EHR) data from 2012 to 2023 at a single academic medical center (University of California, San Francisco). TNFi medication orders and linked clinical notes were extracted, requiring at least 6 months of follow-up to identify treatment switches, defined as a change from one TNFi to another at consecutive encounters. Using GPT-4, we extracted which TNFi was stopped and started and classified the reason for switching. Performance was benchmarked against eight open-source LLMs, structured EHR data, and expert annotation. A total of 9187 patients (mean [SD] age, 39.9 [19.0] years; 57.1% female) received ≥1 TNFi…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
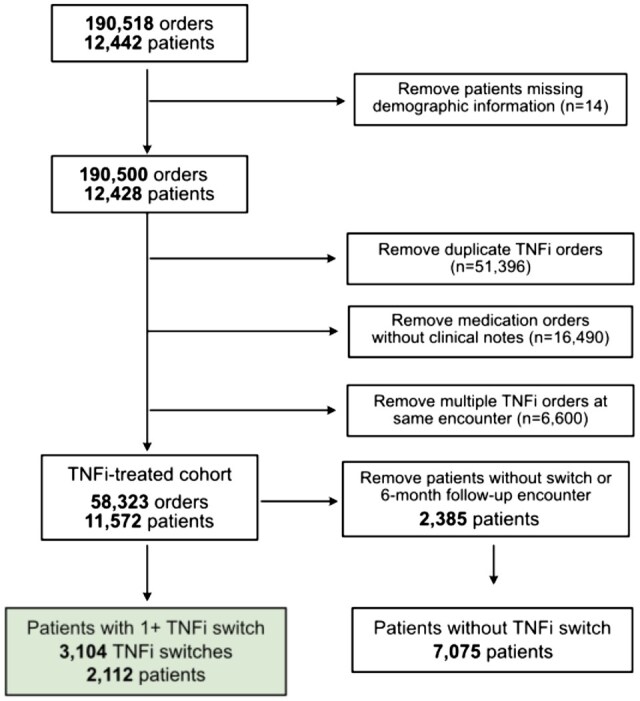 Figure 1
Figure 1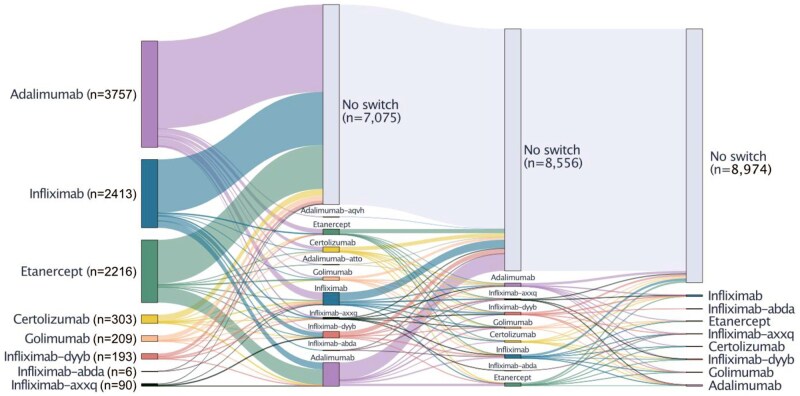 Figure 2
Figure 2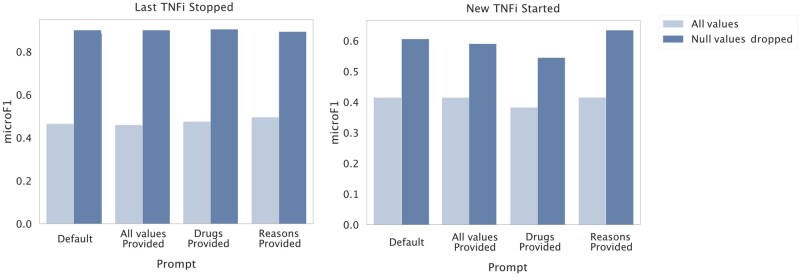 Figure 3
Figure 3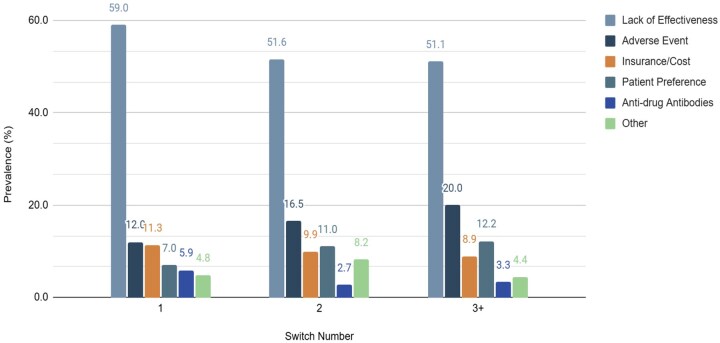 Figure 4
Figure 4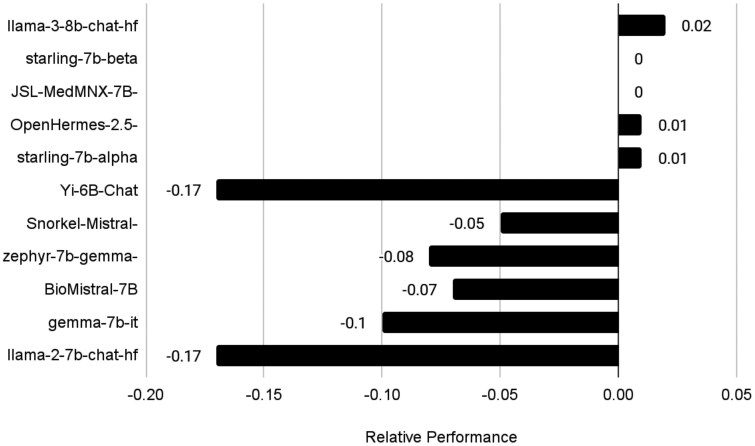 Figure 5
Figure 5| Total (n = 9187) | No TNFi switch (n = 7075) | TNFi switch (n = 2112) |
| |
|---|---|---|---|---|
| Mean age, First TNFi (SD) | 39.9 (19.0) | 41.0 (19.0) | 36.3 (18.4) |
|
| Mean follow-up Time, years (SD) | 5.7 (4.9) | 5.3 (4.6) | 7.1 (5.6) |
|
| Sex (%) |
| |||
| Female | 5244 (57.1) | 3969 (56.1) | 1275 (60.5) |
|
| Male | 3939 (42.9) | 3105 (43.9) | 834 (39.5) | |
| Race (%) |
| |||
| White | 5268 (60.2) | 4076 (60.9) | 1192 (57.7) |
|
| Hispanic | 1220 (13.9) | 881 (13.2) | 339 (16.4) | |
| Other | 952 (10.9) | 726 (10.9) | 226 (10.9) | |
| Asian | 612 (7.0) | 492 (7.4) | 120 (5.8) | |
| Black or African American | 417 (4.8) | 310 (4.6) | 107 (5.2) | |
| Multi-Race/Ethnicity | 212 (2.4) | 159 (2.4) | 53 (2.6) | |
| Southwest Asian and North African | 72 (0.8) | 44 (0.7) | 28 (1.4) | |
| First documented TNFi (%) |
| |||
| Adalimumab | 3757 (40.9) | 3089 (43.7) | 668 (31.6) | |
| Infliximab- biooriginator | 2413 (26.3) | 1883 (26.6) | 530 (25.1) | |
| Etanercept | 2216 (24.1) | 1545 (21.8) | 671 (31.8) | |
| Certolizumab | 303 (3.3) | 236 (3.3) | 67 (3.2) | |
| Infliximab -biosimilar | 289 (3.1) | 149 (2.1) | 140 (6.6) | |
| Golimumab | 209 (2.3) | 173 (2.4) | 36 (1.7) | |
| Primary Diagnosis |
| |||
| Inflammatory Bowel Disease | 1418 (15.4) | 923 (13.0) | 495 (23.4) |
|
| Multiple | 684 (7.4) | 348 (4.9) | 336 (15.9) | |
| Rheumatoid Arthritis | 524 (5.7) | 296 (4.2) | 228 (10.8) | |
| Juvenile Idiopathic Arthritis | 284 (3.1) | 184 (2.6) | 100 (4.7) | |
| Psoriasis | 312 (3.4) | 257 (3.6) | 55 (2.6) | |
| SA | 212 (2.3) | 130 (1.8) | 82 (3.9) | |
| Hidradenitis | 160 (1.7) | 83 (1.2) | 77 (3.6) | |
| Psoriatic arthritis | 154 (1.7) | 82 (1.2) | 72 (3.4) | |
| Other | 123 (1.3) | 104 (1.5) | 19 (0.9) | |
| Uveitis | 59 (0.6) | 44 (0.6) | 15 (0.7) | |
| Unspecified | 5256 (57.2) | 4623 (65.4) | 633 (30.0) | |
| Number of switches | ||||
| 0 | 7075 (77.0) | 7075 (100) | – | |
| 1 | 1481 (16.1) | – | 1481 (70.1) | |
| 2 | 418 (4.5) | – | 418 (19.8) | |
| >2 | 150 (1.6) | – | 150 (7.1) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Learning in Healthcare · Artificial Intelligence in Healthcare and Education · Genomics and Rare Diseases
Introduction
Tumor necrosis factor inhibitors (TNFi) are a class of biologic therapies indicated for managing multiple autoimmune diseases, including Inflammatory Bowel Disease1^,^2 (IBD) and Rheumatoid Arthritis (RA).3^,^4 While there are now many TNFi and biosimilars available, there are few biomarkers or clinical recommendations to guide therapeutic selection of specific medications within this drug class for individual patients. It is therefore not surprising that the initial choice of agent varies among physicians.3^,^5 Previous studies indicate that approximately 14.5% of patients with IBD switch medications at least once, primarily to another TNFi.6 In a cohort of US patients with RA, 39.3% who did not respond to a first-line TNFi switched to another TNFi.7 There are several additional reasons that could explain switches between TNFi. Some patients may develop anti-TNFi antibodies, leading to a loss of drug efficacy.2^,^8 Insurance coverage policies may also lead to switching. While several risk factors have been associated with TNFi switching, such as female sex, age, or high disease activity,5^,^9 patient switch trajectories are not easily predictable. In addition, a high TNFi switch rate is associated with poorer disease control and higher annual treatment costs.10
Most studies of switching between different TNFi are based on structured analyses of medical record data or clinical trial results, and can overlook potential reasons for switching that may not be available in these data sources but may be discussed in clinical notes, such as insurance issues, patient preferences, adverse events, and other real-world factors influencing treatment changes.11 Clinical notes are an underutilized resource to elicit reasons for medication switching because they require time-consuming manual clinical review, making their use prohibitively long and costly. In this context, Large Language Models (LLMs) such as GPT-4 may offer a promising, cost-effective approach to automatically extract information from clinical notes, such as reasons for medication switching. Related work in other contexts shows that LLMs are capable of accurate clinical information extraction.12^,^13 In this study, we aim to profile patterns of switching between different TNFi and to use LLMs to understand the reasons for these switches. We also aim to perform a comparative analysis of different open-source LLMs on this task.
Methods
TNFi cohort selection
We identified a TNFi-treated patient cohort using the University of California, San Francisco (UCSF) Information Commons dataset, which contains longitudinal, de-identified medical record data and clinical notes between 2012 and 2023.14 We selected all TNFi medication orders and administrations, using a string search of all TNFi generic or brand names derived from data provided by the Food and Drug Administration.15 Medication names were mapped to appropriate generic or biosimilar categories (Table S1), and encounters where a patient switched from one TNFi to another, defined as a change in TNFi prescribed between two consecutive encounters, and had an associated clinical note were identified. Patients without any clinical and demographic data (including age, sex, race, ethnicity) were excluded. We also excluded patients who did not have an encounter at least 6 months following the medication order, since in cases with insufficient follow up time it could not be determined whether the patient switched TNFi in these cases. We excluded, for consistency purposes, encounters where multiple TNFi were ordered on the same date. In addition, for encounters with multiple notes, only the last note was used, as it is the most complete and version available. Diagnosis codes linked to TNFi prescriptions were manually reviewed by a physician (MB) and categorized into the following groups: IBD, Psoriatic Arthritis, Juvenile Idiopathic Arthritis (JIA), Rheumatoid Arthritis (RA), Spondyloarthritis (SA), Uveitis, Hidradenitis suppurativa, Sarcoidosis, Vasculitis, and Unspecified. Disease categories with fewer than 10 individuals who switched were consolidated into “Other” in accordance with de-identification guidelines. Patient demographic information was tabulated using the tableone package,16 with continuous distributions reported as means and standard deviations, and categorical values represented as proportions. All data used in this study was performed using deidentified data and was thus determined to be exempt from further review by the UCSF IRB.
Prompt selection for TNFi switching reason extraction using GPT-4
The GPT-4 LLM was used to extract information about TNFi switching from associated clinical notes in a zero-shot manner (ie without dedicated training or examples of the task being provided). Data were split into 5%/95% validation and test sets, with the validation set used for evaluation of 4 different prompts (Table S2) and final metrics reported on the test set. Each prompt was used to extract the new TNFi started, the previous TNFi stopped, and one of the following categories for switching: adverse event, lack of efficacy, insurance/cost, drug resistance (defined by the documentation of anti-drug antibodies), patient preference, other, or unknown (“NA”). An example of a prompt used (“Reasons provided” prompt) is as follows:“Task: Tumor necrosis factor inhibitors (TNFis) are biologic drugs targeting TNF proteins. Using the clinical note provided, extract the following information into this JSON format: {"new_TNFi":"What new TNFi was prescribed or started? If the patient is not starting a new TNFi, write "NA"","last_TNFi":"What was the last TNFi the patient used? If none, write "NA"","Reason for Switching":"Which best describes why the last TNFi was stopped or planned to be stopped? "Adverse event", "Drug resistance", "Insurance/Cost","Lack of efficacy","Patient preference","Other", "NA"","full_reason_last_TNFi_stopped":"Provide a description for why the last TNFi was stopped or planned to be stopped?"} Answer:”
Examples of extracted reasons are presented in Table S3. Model performance was assessed against silver-standard labels from associated medication order information as well as gold-standard annotations provided by a physician (MB) according to annotation guidelines on 146 clinical notes representing approximately 5% of 2112 TNFi switch patients (Figure S1) and microF1 scores were assessed. For silver-standard labels, we reported separate microF1 scores for all notes and only notes determined by GPT-4 to contain medication information. This aligns with previous studies showing that silver-standard labels derived from medication order data are a more reliable proxy of information extraction performance when used to assess for clinical notes containing medication information.17^,^18 The prompt with the highest microF1 scores calculated using gold-standard annotations was used to extract TNFi switching information from the test set for downstream analysis.
Comparison of open-source LLMs on TNFi switching information extraction
Several open-source models were also assessed using the manually annotated validation data. These included three models trained from scratch (“Yi-6B-Chat,” “Llama-2-7B-Chat,” “Gemma-7B-IT”), as well as updated versions (“Llama-3-8B-Instruct”) or further fine-tuned versions of some models (“zephyr-7b-gemma-v0.1,” “OpenHermes-2.5-Mistral-7B,” “Snorkel-Mistral-PairRM-DPO,” “Starling-7B-alpha,” “Starling-7B-beta”). Two models, “JSL-MedMNX-7B-SFT” and “BioMistral-7B” were specifically trained or fine-tuned on biomedical data. The prompt was applied uniformly across all models, with only model-specific template tags varied. Additional details on models and parameters usage can be found in the supplemental figures (Table S4). Open source models were compared using microF1 scores, as well as average pairwise win rates compared to GPT-4 for each response, following comparative open-source benchmarks.18 The pairwise win rate is an assessment of how often a model provides a correct response when another model does not. Model “ties” were recorded when both models provide correct or incorrect values. We report mean win rates of each model against all other models.
Results
TNFi switching cohort from UCSF information commons
We identified 190 518 relevant TNFi medication orders (Figure 1), from 12 442 unique patients. These orders were mapped to generic names, ignoring dosage information and modality (Table S1). After removing 14 patients without demographic information, 190 500 total medication orders remained. Multiple and duplicate TNFi orders and orders without associated clinical notes were dropped, leaving 64 983 unique medication orders. When there were different TNFi order notes at the same encounter, only the last associated clinical note was considered for downstream analysis (often considered as the most informative). This left a TNFi treatment dataset consisting of 58 323 medication orders from 11 572 patients. Of these patients, 2112 (18.25%) had a documented TNFi switch, while 7075 (61.14%) had no documented switch with a follow-up encounter at least 6 months after the TNFi order. The remaining 2385 (20.61%) patients also did not have a medication switch but were lost to follow-up and were excluded from further analysis.
Flow chart and cohort selection. We identified 190 518 TNFi medication orders from 12 442 unique patients in the UCSF Information Commons dataset. After excluding 14 patients without demographic information, 190 500 orders from 12 428 patients remained. We further removed 51 396 duplicate TNFi orders, 16 490 orders without associated clinical notes, and 6600 orders where multiple TNFi medications were ordered at the same encounter. The resulting TNFi-treated cohort consisted of 58 323 orders from 11 572 patients. Among these patients, 2112 (18.3%) experienced at least one TNFi switch, representing 3104 total switches.
TNFi cohort demographics
The TNFi treatment cohort (n = 9187) had a mean age of 39.9 years (SD 19.0), with a slightly higher proportion of female patients (57.1%) (Table 1). Regarding self-reported race and ethnicity, the cohort was composed of 60.2% White, 13.9% Hispanic, 7.0% Asian, and 4.8% Black or African American individuals. For the majority of TNFi orders, associated disease was not filled out from medication switching order and structured data. Within known diseases, the most common primary diagnosis was inflammatory bowel disease (IBD) (15.4%), followed by rheumatoid arthritis (RA) (5.7%) and juvenile idiopathic arthritis (JIA) (3.1%). Additional diagnoses included psoriasis, spondyloarthritis, and uveitis. A subset of patients (7.4%) had multiple diagnoses. The mean follow-up time was 5.7 years (SD 4.9). The most common first TNFi across all patients was adalimumab (40.9%). Infliximab (26.3%) and etanercept (24.1%) were the next most prescribed. Statistical testing was performed using chi-square tests for categorical variables and two-sided t-tests for continuous values. A p-value of less than 0.05 was considered statistically significant.
Within this cohort, 1481 patients (16.1%) had at least one TNFi switch. Among these, 418 patients (19.8%) had two switches, and 150 patients (7.1%) had three or more switches (Figure 2, Table S5).
Sankey diagram for TNFi switching trajectories. TNFi treatment patterns among 9187 patients identified from UCSF information commons through the GPT-4-turbo-128k (“GPT-4”) model. The diagram displays the relative proportion of patients switching or not switching TNFi.
Prompt development
The GPT-4-turbo-128k (“GPT-4”) model was used to test four different prompts for extracting information about TNFi switching strategies and reasons for switching (Table S2). Prompts were developed in collaboration with clinical experts to ensure clinical relevance. and with the use of the prompt development set for validation. The resulting prompts are provided in Table S2. The selected prompts were applied uniformly across all models, with only model-specific template tags varied to maintain comparability. Out of the default prompt, prompt that provided specific categories for names of TNFi to extract (“Drugs provided”), a prompt that specified categorical reasons for switching (“Reasons provided”), or both drugs and reason categories provided (“All values provided”), the prompt providing the reason categories had the best overall performance (Figure 3). With this prompt, microF1 scores were 0.42 for TNFi stopping information extraction and 0.50 for extracting which new TNF was prescribed (n = 146). When excluding notes that did not contain a reason for a switch, as determined by GPT-4, microF1 scores increased to 0.63 (n = 71) and 0.89 (n = 56), respectively for TNFi stopping and new TNFi order information (Table S6). This was comparable to GPT-4 performance assessed against gold-standard clinical annotations, which showed microF1 scores up to 0.75 and 0.80, for TNFi stopped and started, respectively (Table S7). Although performance across all prompts were all within 0.05 by microF1 score, the “Reasons provided” prompt had the highest average microF1 score across all tasks and was used for all downstream tasks.
Automated evaluation of GPT-4-turbo-128k performance across different prompts. GPT-4-turbo-128k was used to extract TNFi switching information, including which TNFi was stopped and which was started. microF1 scores evaluated against structured data are shown, with LLM extracted null values included (“All values”) and counted as incorrect, or when excluding notes that did not contain a reason for switching (“Null values dropped”).
Reasons for TNFi switching using GPT-4 abstracted information
When the best prompt (“Reasons provided”) was applied to the test dataset (n = 2958), GPT-4 performance on TNFi started and stopped information extraction, compared to structured medication order information, demonstrated microF1 scores of 0.51 and 0.37, respectively. Analysis of all the reasons for TNFi switching extracted by GPT-4 for the validation and test sets uncovered that 1759 (59%) of the notes appeared to contain no reasons for switching. When excluding these notes, microF1 scores increased to 0.90 (n = 1184) and 0.60 (n = 1331), respectively. The most commonly extracted reason for switching was lack of efficacy (n = 568, 56.9%) and adverse events (n = 135, 13.5%). Insurance or cost issues accounted for 10.8% (n = 108) of the TNFi switches and patient preference for another 8.2% (n = 82) (Table S8, Figure 4).
Reason for TNFi switching bar plot from GPT-4-turbo-128k model. Proportion of reasons for TNFi switching in UCSF information commons extracted by GPT-4-turbo-128k, categorized based on the sequences of switches in the patient’s trajectory (first, second, and third or more switches). Identified reasons for switching included adverse events, drug resistance (defined as documented presence of anti-drug antibodies), insurance/cost, lack of efficacy, patient preference or other.
Comparison of TNFi information extraction across LLMs
The best prompt previously selected (“Reasons provided”) was also used to understand how different open source LLMs (Figure 5, Figure S2) performed on these treatment information extraction tasks compared to GPT-4. MicroF1 scores of this prompt across open-source models showed that the “Starling-7b-beta” model had the highest average microF1 score of 0.52 while “Llama-2-7B-chat” had the lowest average score of 0.07 (Table S3). Again, only evaluating notes that contained reasons for TNFi switching increased microF1 scores, which ranged from 0.42 for “Llama-2-7B-chat” to 0.85 for “Starling-7b-beta.” When compared to gold-standard annotations, “starling-7b-alpha” had the highest F1 score in which previous TNFi was stopped (0.897), while GPT-4 had the highest F1 scores identifying which TNFi was started (0.801) and reasons for switching (0.825) (Table S5).
Average win minus loss rates of large language models compared to GPT-4. Positive numbers indicate the model is superior to GPT-4 (win rate is higher than loss rate), negative numbers indicate the contrary. A complete heatmap with all model comparisons is available in Figure S2.
The concordance between models was also explored. Given GPT-4 performance on the previous tasks, outputs from this model were used as a baseline to further evaluate pairwise concordance between other models (Table S9). Llama-3-8B-Instruct and Starling-7B-beta showed the highest mean concordance with GPT-4 extracted information, with concordance rates of 82.4% (SD: 0.6%) and 77.0% (SD: 6.0%), respectively. Llama-2-7b-Chat showed the lowest concordance, with only 55.3% of values concordant (SD: 7.6%). We also evaluated pairwise win and tie rates of these models compared to GPT-4 extracted values. Mean tie rates ranged from 66.3% (SD: 16.2%) for llama-2-7b-chat-hf to 80.0% (SD: 12.8%) for JSL-MedMNX-7B-SFT. Llama-3-8B-Instruct had the highest average win rate at 15.5% (SD: 11.4%), followed by zephyr-7b-gemma-v01 at 12.7% (SD: 9.0%).
Discussion
This study demonstrates the feasibility of using LLMs to extract TNFi switching reasons from clinical notes, offering insights into the predominant reasons for switching across a diverse population of patients. Our findings reveal that lack of efficacy, followed by adverse events, and insurance or cost considerations are among the most frequently documented reasons for TNFi switching. These results align with prior literature indicating that treatment failure and immunogenicity drive many TNFi switches.4^,^6
In our comparisons of proprietary and open-source LLMs, several open-source models performed nearly as well as GPT-4 in extracting TNFi switches (Figure 5) but displayed greater variability in identifying specific reasons for switching. For example, some models achieved higher F1 scores in identifying the previous TNFi or the newly started TNFi, while GPT-4 remained the most robust overall in capturing the reasons for switching—particularly when clinical documentation was sparse. Models like Llama-3-8B-Instruct and Starling-7B-beta showed relatively high concordance rates with GPT-4, suggesting these models can approximate GPT-4’s capabilities for identifying new TNFi orders. Still, GPT-4’s consistency across all facets of extraction underscores the potential advantage of larger, more general-purpose models when complete accuracy—especially in nuanced fields such as clinical pharmacovigilance—is needed.
These findings point to practical uses of LLMs in clinical care and research. First, patients with chronic inflammatory conditions, such as RA or IBD, often accumulate lengthy and intricate treatment histories over many years, making it challenging for clinicians to quickly review prior medication trials, side effects, and other complex factors that led to changes in therapy. By harnessing LLMs to summarize historical treatment notes, providers can more rapidly glean why prior regimens were discontinued—allowing for more informed decision-making and improved continuity of care. Second, enabling scalable and automated extraction of real-world reasons for treatment changes can expand the research utility of clinical notes, supporting investigations into health services challenges like insurance approvals, adverse drug reactions, and the emergence of anti-drug antibodies. Finally, with the rapid expansion of biosimilars in TNFi therapy, LLM-based systems could serve as a cornerstone of modern pharmacovigilance, proactively identifying patterns of drug resistance, adverse effects, or cost barriers. By unlocking unstructured data at scale, these approaches may inform more personalized treatment strategies and facilitate ongoing surveillance of newer therapeutics.
This study has several strengths. First, it demonstrates that GPT-4 and some open-source LLMs can extract clinically meaningful treatment information with high concordance. Second, our findings suggest that LLM-extracted insights may provide richer contextual information compared to structured medication data alone, particularly regarding reasons for TNFi switching. Third, the comparative analysis of open-source LLMs provides valuable, detailed insights into their performance relative to GPT-4, showing that some models achieve comparable accuracy for this specific task at a much lower computational cost.
Our study also has limitations. Firstly, our approach does not capture changes in medication doses, which may be relevant for treatment modifications. It also does not capture discontinuations or patients lost to follow-up. In some cases, documentation of visits may not include reasons for switching anywhere. However, given that the proportion of “other” reasons for switching was low and we performed manual chart review, the risk of missing key information is likely low. An additional limitation of our approach is that we did not study the impact of patients with multiple TNFi orders in the same encounter. However, this event is uncommon (n = 6600 of total medication orders, 3.4%) and we do not expect these cases to substantially affect our overall findings. Another limitation is that our study did not explore disease-specific switching patterns in depth, nor did it account for changes to or from medications other than TNFi. Our future work will explore this possibility for a broader scope of medications and diseases. Structured medication order data are also not always reflective of medication usage and more reliable information could come from patient reported data or only relying on medication administration data. Finally, while we compared multiple LLMs, their performance was benchmarked primarily against GPT-4 rather than expert annotations. While GPT-4 is the state of the art in LLMs, expert annotations could provide a more definitive assessment of their accuracy, since GPT-4 extracted treatment information from notes is often poorly aligned with structured medical data around medication switching, particularly medication stopping.19^,^20 Given the prohibitive cost of large-scale manual chart review, a combination of both evaluation methods may be the best course.21–23
Despite these limitations, this study highlights the potential for LLMs to extract complex treatment patterns from clinical notes at scale. As LLMs continue to improve, their integration into clinical research workflows could enhance real-world evidence generation, informing both personalized treatment strategies and healthcare policy decisions. Future studies should explore the generalizability of these methods across other institutions and treatment classes to further validate their clinical utility.
Supplementary Material
ooaf132_Supplementary_Data
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Rudrapatna VA , Velayos F. Biosimilars for the treatment of inflammatory bowel disease. Pract Gastroenterol. 2019;43:84-91.31435122 PMC 6703165 · pubmed ↗
- 2Atiqi S , Hooijberg F, Loeff FC, et al Immunogenicity of TNF-Inhibitors. Front Immunol. 2020;11:312. 10.3389/fimmu.2020.0031232174918 PMC 7055461 · doi ↗ · pubmed ↗
- 3Fraenkel L , Bathon JM, England BR, et al 2021 American college of rheumatology guideline for the treatment of rheumatoid arthritis. Arthritis Rheumatol. 2021;73:1108-1123. 10.1002/art.4175234101376 · doi ↗ · pubmed ↗
- 4Tesser J , Lin I, Shiff NJ, et al Improvement in disease activity among patients with rheumatoid arthritis who switched from intravenous infliximab to intravenous golimumab in the ACR RISE registry. Clin Rheumatol. 2022;41:2319-2327. 10.1007/s 10067-022-06116-z 35312895 PMC 9287251 · doi ↗ · pubmed ↗
- 5Law-Wan J , Sparfel M-A, Derolez S, et al Predictors of response to TNF inhibitors in rheumatoid arthritis: an individual patient data pooled analysis of randomised controlled trials. RMD Open., 2021; 7: e 001882. 10.1136/rmdopen-2021-00188234789535 PMC 8601061 · doi ↗ · pubmed ↗
- 6Meijboom RW , Gardarsdottir H, Becker ML, et al Switching TNFα inhibitors: patterns and determinants. Pharmacol Res Perspect. 2021;9:e 00843. 10.1002/prp 2.84334302442 PMC 8305431 · doi ↗ · pubmed ↗
- 7Caporali R , Conti F, Iannone F. Management of patients with inflammatory rheumatic diseases after treatment failure with a first tumour necrosis factor inhibitor: a narrative review. Mod Rheumatol. 2023;34:11-26. 10.1093/mr/road 03337022142 · doi ↗ · pubmed ↗
- 8Bellur S , Mc Harg M, Kongwattananon W, et al Antidrug antibodies to tumor necrosis factor α inhibitors in patients with noninfectious uveitis. JAMA Ophthalmol. 2023;141:150-156. 10.1001/jamaophthalmol.2022.558436547953 PMC 9936342 · doi ↗ · pubmed ↗