Quadratic decomposition based TCN-Transformer for time series prediction of micro-seismic signals in coal mines
Yuanping Gan, Chao Huang, Zuoli Zhang, Weidong Lu, Bingpeng Gao, Xin Cai, Tao Xu

TL;DR
This paper introduces a new model for predicting micro-seismic signals in deep coal mines to improve safety by detecting potential rock bursts.
Contribution
A novel TCN-Transformer model combined with quadratic decomposition techniques for enhanced micro-seismic signal prediction.
Findings
The model effectively captures both local and global features of micro-seismic signals.
Validation with real coal mine data shows strong fitting ability and robustness.
The method demonstrates early warning capabilities for geological hazards like rock bursts.
Abstract
As shallow coal reserves are diminishing in China, mining operations are extended to deeper levels, such that characteristics like high geopressure, intense gas adsorption, and reduced permeability become obvious. The mining environment alters significantly. To monitor geological hazards including rock burst during coal mining, this paper presents a time series prediction model for micro-seismic signals by quadratic modal decomposition and a TCN-Transformer network. At first, the micro-seismic signal is primarily decomposed by CEEMDAN. The decomposed Intrinsic Mode Functions (IMFs) are classified and reconstructed by fuzzy entropy. Then, a secondary decomposition is performed by VMD to uncover the signal’s latent features. Thereafter, the time series prediction model is developed by integrating the TCN network’s multi-scale feature extraction capabilities with the self-attention…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 10
Figure 10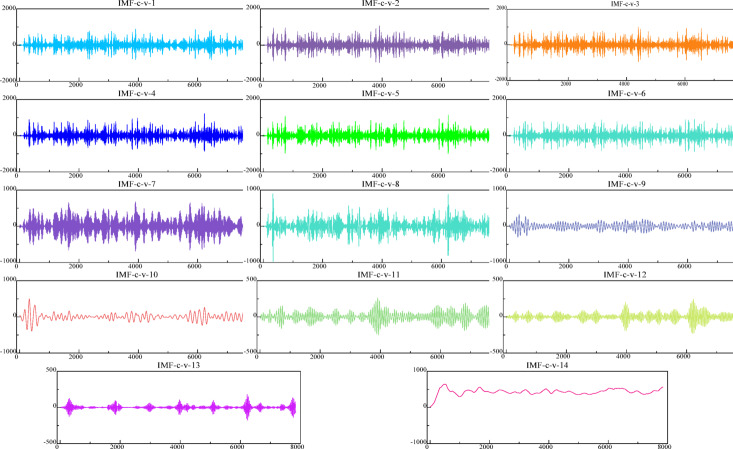 Figure 11
Figure 11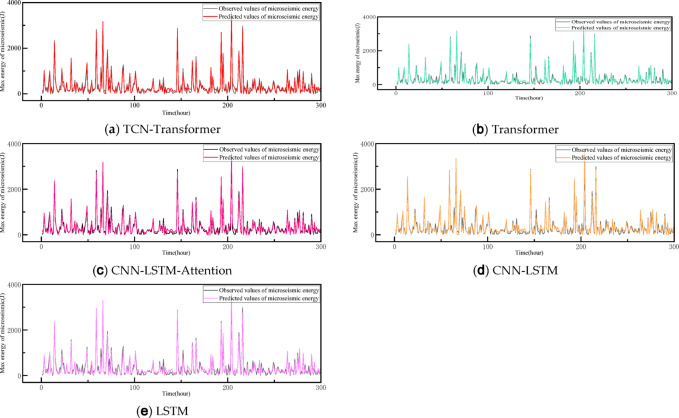 Figure 12
Figure 12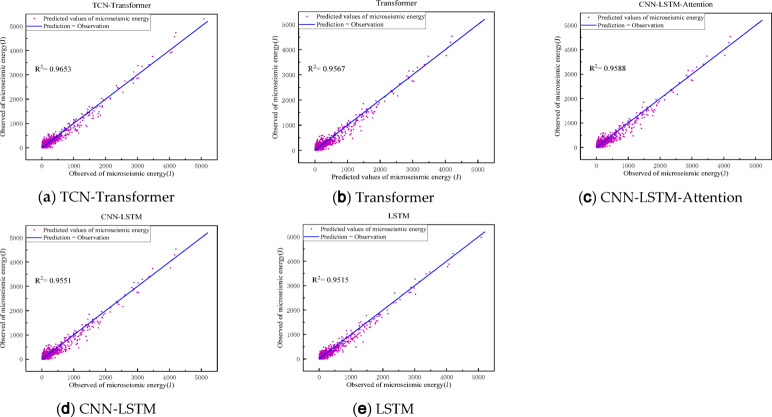 Figure 13
Figure 13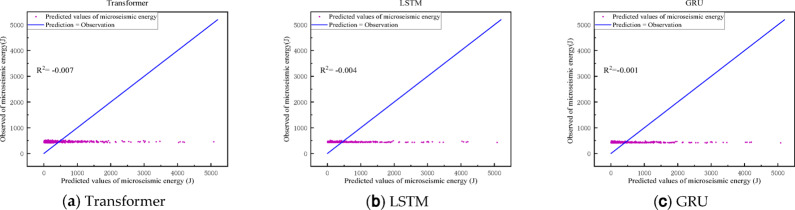 Figure 14
Figure 14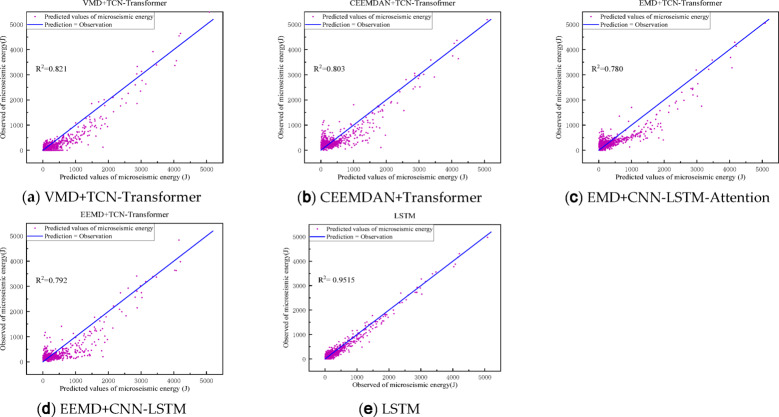 Figure 15
Figure 15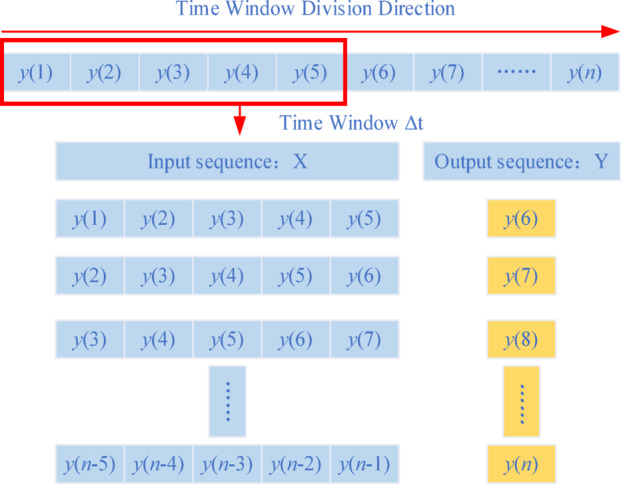 Figure 1
Figure 1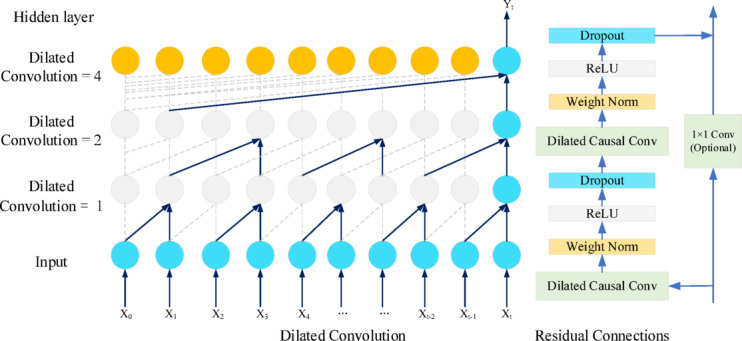 Figure 2
Figure 2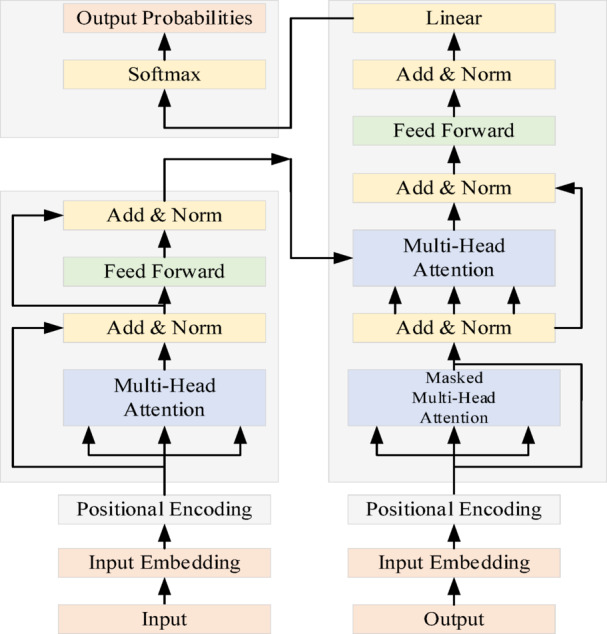 Figure 3
Figure 3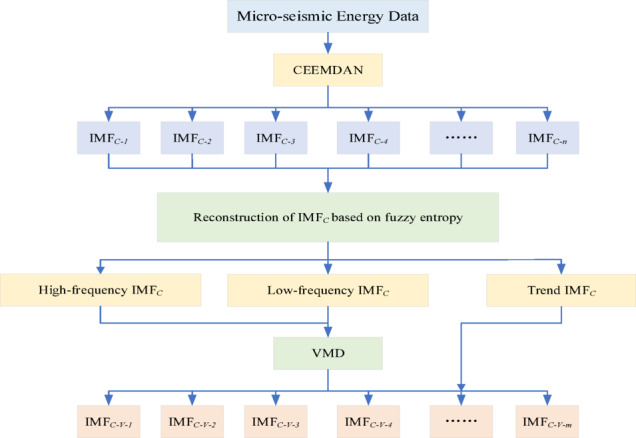 Figure 4
Figure 4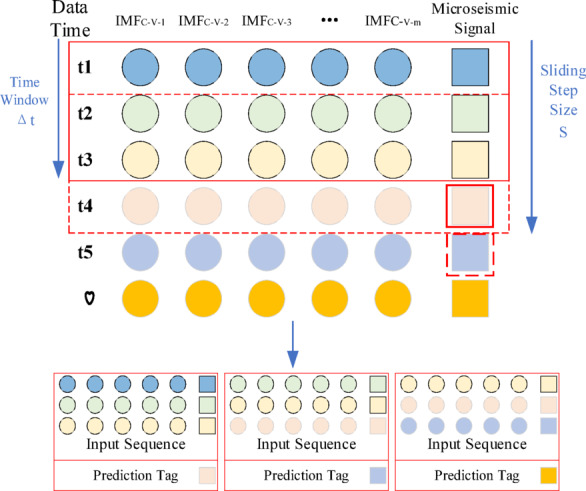 Figure 5
Figure 5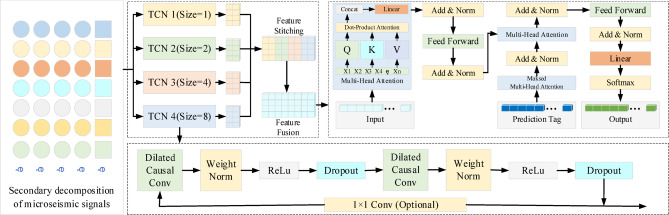 Figure 6
Figure 6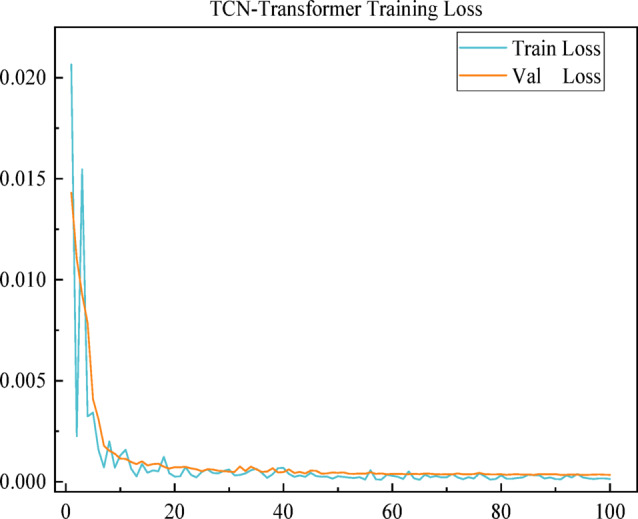 Figure 7
Figure 7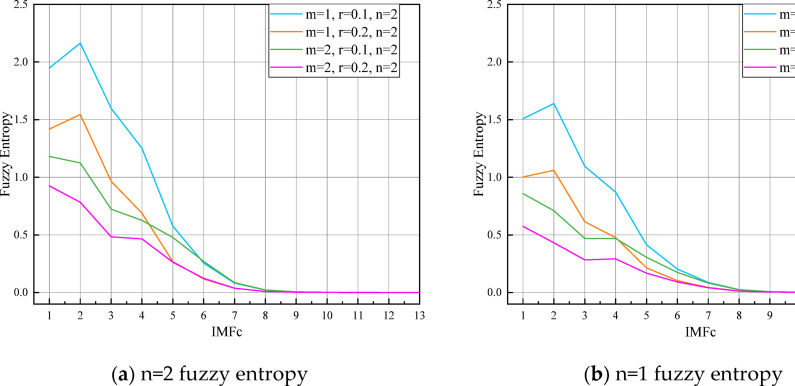 Figure 8
Figure 8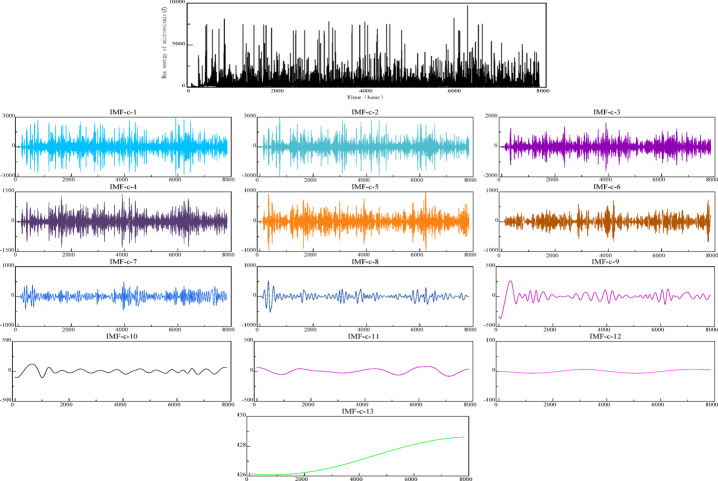 Figure 9
Figure 9- —Tianshan Young Talents-Outstanding Young Talent Project
- —https://doi.org/10.13039/501100001809National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSeismology and Earthquake Studies · Seismic Imaging and Inversion Techniques · Machine Fault Diagnosis Techniques
Introduction
As a major energy consumer, China has a natural energy structure characterized by an abundance of coal, scarcity of oil, and limited gas, which indicates that coal will remain the primary energy source for an extended period in the future^1,2^. As the depletion of China’s shallow coal resources intensifies, mining operations are moving deeper into the earth, where coal seams exhibit increasingly pronounced characteristics of high ground stress, strong gas adsorption, and low permeability, such that a significant transformation occurs in the mining environment^3–7^. The mining environment has undergone significant changes, particularly during coal extraction. The buildup of stress within the coal rock mass comprising the coal seam and adjacent rocks can exceed the strength of these rocks, to suddenly release, which leads to the occurrence of geological hazards like rock bursts. These events pose a severe risk to the safety of underground mining operations^8–10^. Micro-seismic monitoring is a geophysical technique used for monitoring subterranean activities. This real-time geophysical monitoring technology utilizes micro-seismic signals emitted during the stress-induced fracturing of coal and rock to assess their stability. The seismic signals obtained by sensors within the mining area are used to analyze the timing, location, and energy source of micro-seismic events, for monitoring and early warning of potential geological hazards including rock bursts during coal mining^11,12^. In recent years, micro-seismic monitoring technology has been widely used in coal mines. For monitoring low-pressure conditions such as coal mine impact ground pressure and other mining-related disasters^13,14^.
Micro-seismic signals, as typical time-series data, evolve over time to reflect the dynamic properties of geological structures at specific moments^15^. In recent years, many work focused on time correlation analysis of micro-seismic signals by using deep learning algorithms. Lin et al.^16^ designed a self-similar convolutional neural network (SS-Net) to reduce the adverse effect of random noises. Zhu et al.^17^ introduced logistic regression into mine pressure hazard prediction in order to provide early warning signals of mine safety accidents. Batch gradient descent and Adagrad optimization algorithms were used in to enhance the model’s predictive performance and computational speed and accuracy. To enhance the prediction accuracy of micro-seismic events in rock burst prone mines, a MEA-BP neural network model was developed in^18^.
Micro-seismic signals, differing from typical industrial process signals, exhibit nonlinear and nonsmooth time series traits that complicate the accurate prediction of microseismic signals using a single model algorithm with significant short-term fluctuations. Similar approaches have been successfully applied in coal mine safety monitoring, where Chen et al.^19^. demonstrated the effectiveness of dual variational mode decomposition combined with LSTM for time series prediction, while Zhang et al.^20,21^. and Xu et al.^22^. showed that modal decomposition methods can significantly improve prediction accuracy for complex mining environment data.
In recent years, research efforts have been dedicated to analyzing nonlinear non-stationary signals through signal decomposition methods, such as Empirical Mode Decomposition (EMD). EMD retains the time-scale features of signals and can be integrated with time series prediction algorithms to improve prediction^23,24^. Zang et al.^25^ designed a long- and short-term memory network (LSTM) with residual attention mechanism for short-term prediction. Additionally, re-decomposing high-frequency intrinsic modal functions were used to improve the prediction accuracy of nonstationary time series data after empirical modal decomposition^26^. This approach has an advantage on extracting hidden information and potential temporal features from complex data. Wang et al.^27^. used the fuzzy entropy affiliation function as the threshold criterion of entropy to improve the adaptive ability of the model to the nonlinear and non-stationary data such that the prediction accuracy is improved.
To deal with the challenges posed by nonlinear and non-stationary characteristics of micro-seismic signals, this study employs a quadratic modal decomposition approach to process the data. Building upon the success of modal decomposition methods in similar applications, particularly the effectiveness of CEEMDAN in handling complex mining environment data^22^, this approach aims to extract more comprehensive temporal features from micro-seismic signals. The micro-seismic data is firstly decomposed into multiple Intrinsic Mode Functions (IMFs) by using the Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN). These IMFs are then clustered into high-frequency, low-frequency, and trend components by using fuzzy entropy. Subsequently, the high-frequency and low-frequency components are further decomposed by using the Variational Mode Decomposition (VMD) method. The obtained new IMFs are merged with historical micro-seismic signal data to form new multivariate time-series prediction data. A time-series prediction model integrating Temporal Convolutional Network (TCN) and Transformer is utilized to forecast the sequences. The model’s predictive performance is validated through analysis of micro-seismic monitoring data collected from an actual coal mine working face in Xinjiang.
Materials and methods
CEEMDAN
Empirical mode decomposition (EMD) is an adaptive decomposition method for analysing nonlinear and non-stationary time series data by decomposing a complex signal into a series of simple integrated mean modal functions (IMFs). The adaptive noise-complete ensemble empirical modal decomposition (CEEMDAN) is an improved algorithm of EMD, which removes the modal aliasing problem in EMD by adaptively adding Gaussian white noise to the original signal data; at the same time, the IMFs obtained by averaging the data with multiple additions of Gaussian white noise are more stable and accurate, and the mitigation of the boundary effects in EMD improves the stability and reproducibility of the decomposition. stability and repeatability of the decomposition^28^. Given the nonlinear and non-stationary nature of micro-seismic signals, this study employs CEEMDAN as the initial decomposition method. Compared to EMD, CEEMDAN effectively resolves modal aliasing issues; relative to EEMD, CEEMDAN utilizes an adaptive noise mechanism that automatically adjusts according to signal characteristics, thereby reducing computational complexity while maintaining decomposition quality; and compared to VMD, CEEMDAN requires no predefined parameters, rendering it more suitable for processing micro-seismic signals with complex time–frequency characteristics. Furthermore, CEEMDAN’s advantages in handling boundary effects and delivering reproducible results render it more robust within practical coal mine monitoring environments.
The specific CEEMDAN decomposition process for micro-seismic energy time series data is as follows:
- First, Gaussian white noise with mean 0 is added to the time series data set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{Y}}(t)$$\end{document} to construct \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n$$\end{document} sequences to be decomposed:
where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} is the weight coefficient matrix of Gaussian white noise; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon {{\varvec{\updelta}}}(t)$$\end{document} is the added Gaussian white noise. 2. The EMD decomposition of the added noise data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{\mathbf{Y}}}(t)$$\end{document} is performed to obtain the first order modal function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{1}^{i} (t)$$\end{document} , the resulting \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n$$\end{document} modal functions are summed and averaged to obtain the first IMFs of the CEEMDAN decomposition \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C1} (t)$$\end{document} , and the resulting \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C1} (t)$$\end{document} is subtracted from the original signal, i.e.:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C1} (t) = \frac{1}{n}\sum\limits_{i = 1}^{n} {\mathbf{IMF}}_{1}^{i} (t)$$\end{document}- The remaining signal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{R}}_{{\mathbf{1}}} (t)$$\end{document} is used as the new original signal, and so on repeating Eqs. (4) and (5) to extract the remaining CEEMDAN intrinsic modal components \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{Cn} (t)$$\end{document} until the remaining signal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{R}}_{k} (t)$$\end{document} cannot satisfy the decomposition condition. Finally, the original signal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{Y}}(t)$$\end{document} is decomposed into a number of eigenmodal components \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{S}$$\end{document} and a residual trend \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{R}}_{k} (t)$$\end{document} , which is decomposed by the CEEMDAN algorithm with the expression:
Principles of micro-seismic signal time series prediction
The methods and principles of mine impact pressure monitoring are mainly divided into rock mechanics and geophysical methods, and the micro-seismic method belongs to one of the geophysical methods. The micro-seismic method mainly captures the electromagnetic radiation and vibration wave signals transmitted outward when the fissures are produced by the mining stress of the coal rock body, and realizes the continuous monitoring of the stress and deformation state of the coal rock body, so as to achieve the real-time early warning of the underground impact ground pressure. The energy intensity of the collected micro-seismic signals represents the degree of rupture of the coal rock body, and the continuous large intensity of the micro-seismic energy signals represents that the coal rock body is susceptible to secondary disasters caused by the impact ground pressure. At present, the mine mainly deploys multiple sets of sensors on the acquisition and monitoring surface to achieve real-time monitoring of vibration waves, and the acquired data contain information on the time, location and energy intensity of micro-seismic events. Therefore, the monitoring signals generated by micro-seismic activities can be recognized as a collection of micro-seismic time series data within a certain period of time.
There is a certain pattern of change in the intensity of micro-seismic energy over time, and there is a correlation between the energy of the micro-seismic event that occurs at the next time step and the energy of the micro-seismic event that occurs at the previous time step^29^. The energy of the micro-seismic event at the next time step is related to that of the previous time step. Assuming that the micro-seismic energy signals sampled by the micro-seismic monitoring system with a given time length of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T$$\end{document} are represented by the time-series data set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{Y}}(T)$$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{Y}}(T) = \{ y(t_{1} ),y(t_{2} ),y(t_{3} ), \ldots ,y(t_{n} )\}$$\end{document}By dividing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{Y}}(T)$$\end{document} by a time window of fixed size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Delta t$$\end{document} , there exists a nonlinear mapping \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f$$\end{document} such that the time series data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y(t_{j} )$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y(t_{j - 1} )$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y(t_{j - 2} )$$\end{document} ,… \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y(t_{j - Dt} )$$\end{document} within the time window is mapped to give the micro-seismic energy data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y(t_{j + 1} )$$\end{document} for the next time step, denoted as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y(t_{j + 1} ) = f(\{ y(t_{j} ),y(t_{j - 1} ),y(t_{j - 2} ),\ldots,y(t_{j - Dt} )\} )$$\end{document}Therefore, a time window can be used to divide the overall time series dataset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{Y}}(T)$$\end{document} , and the time series prediction of the future time step energy signal data can be achieved by constructing a neural network model. The specific time series data window division is shown in Fig. 1.
Fig. 1. Segmentation of the time series data window.
To avoid feature redundancy and ensure the validity of extracted features, this study employs fuzzy entropy to assess the complexity of IMFs obtained through CEEMDAN decomposition. Components are categorised into three types—high-frequency, trend, and low-frequency—based on their information content. The high-frequency and low-frequency components, possessing higher information content, undergo secondary VMD decomposition; the trend component, being relatively stable, is retained directly. This strategy aims to minimise ineffective expansion and information duplication.
Fuzzy entropy
In signal processing and data analysis, entropy is used to measure the complexity and predictability of data. Fuzzy entropy is a method used to measure the complexity of a time series, which evaluates the complexity of the series by considering the similarity between points in the time series. Compared to sample entropy, which directly uses a hard threshold to determine similarity, fuzzy entropy defines the similarity between vectors by using a fuzzy function, which makes it more robust to noise. The fuzzy entropy can classify and reorganize the components more accurately after the micro-seismic data have been decomposed by CEEMDAN with the intrinsic modal function.
For the time series data set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{Y}}(t) = \{ y(t_{1} ),y(t_{2} ),...,y(t_{n} )\}$$\end{document} , the fuzzy entropy is used as follows:
- Embedding the time series \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{Y}}(t)$$\end{document} in the dimension \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m$$\end{document} and initializing it, the resulting reconstructed sequence is:
where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{\overset{\lower0.5em\hbox{\smash{\scriptscriptstyle\frown}}}{Y} }}(t)$$\end{document} is the reconstructed sequence, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n \in [1,n - m + 1]$$\end{document} ; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{u}}(n)$$\end{document} is the mean value of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m$$\end{document} continuous variable \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{y}}(t_{n} )$$\end{document} . 2. Calculate the distance between any two vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\mathbf{Y}}}(t_{i} )$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\mathbf{Y}}}(t_{j} )$$\end{document} using the maximal paradigm \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_{ij}^{m}$$\end{document} with the expression:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_{ij}^{m} = \max [{\hat{\mathbf{Y}}}(t_{i} ) - {\hat{\mathbf{Y}}}(t_{j} )]{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} 1 \le i,j \le n - m + 1,i \ne j$$\end{document}- Define a fuzzy affiliation function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu$$\end{document} to measure the similarity between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\mathbf{Y}}}(t_{i} )$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\mathbf{Y}}}(t_{j} )$$\end{document} , viz:
where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r$$\end{document} is a constant parameter to adjust the sensitivity of the affiliation function to distance. 4. For the sequence \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\mathbf{Y}}}(t)$$\end{document} the fuzzy similarity between each vector is calculated in turn, i.e.:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Phi^{m} (r) = \frac{1}{n - m + 1}\sum\limits_{i = 1}^{n - m} { \left(\frac{1}{n - m + 1}\sum\limits_{{{\mathbf{j = 1}}}}^{{{\mathbf{n - m + 1}}}} {u(d_{ij}^{m} )} \right)}$$\end{document}where: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n$$\end{document} is the parameter of the fuzzy function to adjust the steepness of the fuzzy function. 5. Increase the embedding dimension by 1, and repeat the above calculation of fuzzy similarity between vectors for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m + 1$$\end{document} dimensional vectors to get \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Phi^{{{\mathbf{m + 1}}}} (r)$$\end{document} , and obtain the fuzzy entropy and then complete the reclassification of the intrinsic components after CEEMDAN decomposition according to the proximity of the entropy value.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$FE(m,r,n){\mathbf{ = }}{\text{l}} {\text{n}} \left( {\frac{{\Phi^{m} (r)}}{{\Phi^{m + 1} (r)}}} \right)$$\end{document}The size of the fuzzy entropy value measures the complexity between the time series data, and the larger the fuzzy entropy value is, the more information the corresponding IMF component decomposed by CEEMDAN has. Therefore, the IMF components obtained by primary decomposition of time series data are determined by calculating the fuzzy entropy value of the components, reclassifying the IMF components of different sizes according to the entropy value, and secondary decomposition of IMF components with higher entropy value using the VMD variational modal decomposition, to further obtain the time series features in the sequence.
During the secondary decomposition process, the original signal and IMF components may exhibit differences in their characteristic scales. The ‘CEEMDAN → fuzzy entropy clustering → VMD’ strategy employed herein constrains each component within relatively stable frequency bands. The fixed-length sliding window further ensures consistency in the temporal scale, thereby mitigating the risk of cross-channel scale inconsistencies.
VMD
Variational mode decomposition (VMD) is a completely non-recursive and adaptive signal decomposition method for non-stationary time series data^30^. VMD mainly decomposes a series of IMF components with different center frequencies from complex time series data, and obtains the optimal center frequencies by iterating the IMF components through the alternating direction multiplier algorithm, so as to facilitate further analysis and processing of the time series data.
The specific VMD decomposition core process focuses on constructing the variational model and solving the variational problem. The constrained model is shown in Eq. 13, and the detailed solution process is described in the literature^31^:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left\{ \begin{gathered} \mathop {\min }\limits_{{\{ u_{k} ,\omega_{k} \} }} \left\{ {\sum\limits_{k = 1}^{K} {\left\| {\partial_{t} \left[ {\left( {(\delta (t) + \frac{j}{\pi t}} \right)u_{k} (t)} \right]e^{{ - j\omega_{k} t}} {\kern 1pt} } \right\|_{2}^{2} } } \right\} \hfill \\ {\text{s}} .t.\sum\limits_{k}^{K} {u_{k} = f.} \hfill \\ \end{gathered} \right.$$\end{document}TCN network
Temporal Convolution Network (TCN) is a neural network architecture specifically designed for processing time series data. Compared with the traditional convolutional neural network which only uses causal convolution for local feature extraction of time series data, TCN introduces residual connection and expansion convolution on top of the causal convolution structure. By adjusting the expansion coefficient of the expansion convolution to expand the receptive field, the temporal correlation can be captured from different receptive fields. Secondly, the residual connection added between the convolutional layers also avoids the possible gradient vanishing problem of CNN networks as much as possible, which effectively accelerates the training of model^32^. Taking the convolutional kernel size as 2 and the expansion factor as^1,2,4^ as an example, the TCN network model is shown in Fig. 2.
Fig. 2. Structure of TCN network.
In our implementation, each residual block contains two layers of one-dimensional causal convolution, with a kernel size of k = 2 and an expansion factor of^1,2,4,8^. The effective receptive field R calculation is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R \approx 1 + 2\left( {k - 1} \right)\sum d = 1 + 2\left( {2 - 1} \right)\left( {1 + 2 + 4 + 8} \right) = 31$$\end{document} steps, providing sufficient coverage for capturing long-term time dependencies.
Transformer network
Transformer is an end-to-end model suitable for solving time series. Different from traditional recurrent neural networks, Transformer relies on the self-attention mechanism to capture the information of different locations in space, which effectively solves the problem of the dependence of traditional recurrent neural networks and their transformer networks on medium- and long-term time prediction. As shown in Fig. 3, the Transformer model is mainly composed of two parts, encoder and decoder, which can be stacked together with multiple encoders and decoders of the same number, and contains a multi-head attention mechanism consisting of multiple self-attention mechanisms running in parallel.
Fig. 3. Transformer network structure diagram.
Transformer’s self-attention mechanism can be formulated as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{A(Q,K,V)}} = \mathbf{S}\left(\frac{\mathbf{Q}\mathbf{K}^T}{\sqrt{d_K}}\right)\mathbf{V}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{A}}$$\end{document} represents the attention mechanism; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{S}}$$\end{document} represents the SoftMax function that calculates the attention weights; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{Q}},{\mathbf{K}},{\mathbf{V}}$$\end{document} calculates the matrix of the attention mechanism, the keys of the matrix and the values, respectively; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_{K}$$\end{document} is the dimension of the keys.
The multi-attention mechanism can be formulated as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{M}}_{h} = {\mathbf{C}}({\mathbf{h}}_{1} ,{\mathbf{h}}_{2} ,{\mathbf{h}}_{3} ,\ldots,{\mathbf{h}}_{i} ){\mathbf{W}}_{o}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{h}}_{i} = {\mathbf{A}}({\mathbf{QW}}_{Qi} ,{\mathbf{QW}}_{Ki} ,{\mathbf{QW}}_{Vi} )$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{M}}_{h}$$\end{document} is the multi-attention mechanism; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{C}}$$\end{document} is the connection mechanism between the attention; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{h}}_{i}$$\end{document} denotes the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} attention mechanism; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{W}}_{o}$$\end{document} is the linear transformation weight matrix after the connection of the multi-attention mechanism; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{W}}_{Qi} ,{\mathbf{W}}_{Ki} ,{\mathbf{W}}_{Vi}$$\end{document} is the linear transformation weight matrix.
For micro-seismic signals exhibiting non-stationary and non-linear characteristics, this study employs standard absolute position coding. The quadratic decomposition method effectively addresses non-stationarity by mapping slow-varying and non-stationary components to low-frequency and trend channels respectively. A fixed sliding window strategy ensures that segments entering the attention layer are approximately stationary within the window, thereby reducing sensitivity to specific position encoding variants. The TCN component captures local ordered dependencies, while the trend channel provides long-term background information. This enables standard absolute position encoding to sufficiently meet task requirements while maintaining implementation simplicity and reproducibility.
For unavoidable residual weak coupling, the TCN and Transformer components at the model end undergo adaptive alignment during end-to-end training through the local constraints of convolutions, the global weighting of attention mechanisms, and LayerNorm normalization. This further mitigates their detrimental impact on prediction performance.
It is worth noting that although the attention mechanism of the Transformer can effectively capture the dependencies among temporal features, its attention weights mainly reflect the intensity of the model’s use of context information rather than a direct mapping of specific physical mechanisms. In practical applications, the physical interpretation of attention weights should be treated with caution to avoid directly equating them with the specific frequency band characteristics of rock fractures.
Model
Data decomposition
Based on the principle of micro-seismic signal time series prediction, it is evident that the process involves segmenting the input features and output labels of micro-seismic signals according to the time window size, and utilizing these segments as proportionally divided training, testing, and validation sets for the deep learning algorithm. Empirical Mode Decomposition (EMD) is a method for analyzing non-smooth and non-linear signals through the decomposition into a series of Intrinsic Mode Functions (IMFs).While EMD performs well in many aspects, it faces limitations, particularly with signals that have nested frequencies or similar-scale frequency components. Extensive research indicates that, in contrast to the feature sequences derived from primary decomposition, those from secondary decomposition more effectively capture the signal’s internal characteristics, leading to enhanced time series prediction accuracy. Consequently, this study employs a quadratic modal decomposition approach to process micro-seismic signals, extract multiple IMFs, and integrate these with the raw micro-seismic signals to construct a multi-input single-output dataset, applying a fixed time window to segment the dataset, thereby fulfilling the training requirements of deep learning models.
The overall secondary decomposition process of the micro-seismic signal is shown in Fig. 4. Firstly, the micro-seismic signal data are subjected to a primary empirical modal decomposition using CEEMDAN, and the obtained \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n$$\end{document} IMFs and residual components after decomposition are denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C}$$\end{document} . Then, the obtained \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C}$$\end{document} are evaluated for signal complexity and irregularity using fuzzy entropy, and based on the results of fuzzy entropy value calculation, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C}$$\end{document} can be further classified into high frequency, low frequency and trend sequences. Among them, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C}$$\end{document} , which contains high frequency components, usually has high fuzzy entropy value, reflecting the fast changes and high dynamic characteristics of the signal; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C}$$\end{document} , which contains low frequency components, has low fuzzy entropy value, reflecting the slow changes and stability of the signal; and the final trend sequence, which represents the baseline trend of the signal, usually contains the information of the lowest frequency. Finally, the distinguished high-frequency \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C}$$\end{document} and low-frequency \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C}$$\end{document} components are fed into the VMD for quadratic decomposition, and the trend sequence is directly merged into the obtained \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m$$\end{document} newly generated IMFs, denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C - V}$$\end{document} .
Fig. 4. Flow chart of secondary decomposition of micro-seismic signal.
The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C - V}$$\end{document} component obtained after quadratic decomposition is combined with the original micro-seismic signal data to become a time series prediction dataset. The sampling sliding window method divides the training set by setting a window with a fixed size of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Delta t$$\end{document} and a sliding step size of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S$$\end{document} . The time series data within the obtained fixed window is continuous, where the same color indicates the temporal correlation between the features, and the delineated \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C - V}$$\end{document} component is used as the input feature data for the time series prediction, and the next time step micro-seismic signal data is used as the output label data. input feature data for time series prediction, and the micro-seismic signal data of the next time step is used as the output labelled data. The dataset construction process is shown in Fig. 5.
Fig. 5. Flow chart of micro-seismic signal data construction.
In VMD secondary decomposition, the selection of the number of modes K follows three principles: determining the quantity of primary frequency components within the signal by analyzing the spectral characteristics of reconstructed modes, employing center frequency matching to evaluate decomposition quality and prevent mode aliasing, and utilizing residual entropy values to assess decomposition completeness to ensure no information loss.
Spectral analysis of the reconstructed components reveals that primary energy concentrates within two frequency bands (15–25 Hz and 35–45 Hz), indicating the presence of two dominant frequency components. When K = 1, the center frequency of the decomposed mode highly aligns with the original signal frequency with a matching error below 3%, while when K = 2, the two modes correspond to the two distinct frequency components identified in spectral analysis with a center frequency interval exceeding 10 Hz to avoid mode overlap. The residual entropy values for K = 1 and K = 2 were 0.12 and 0.15 respectively, both maintained at acceptably low levels.
The decomposition process successfully captured core signal information without significant loss. Considering the practical characteristics of micro-seismic signals, this study selected K = 1 and K = 2 as decomposition parameters, ensuring adequate decomposition while avoiding computational redundancy caused by over-decomposition.
Time series prediction module
Based on the previously constructed multivariate IMFs of micro-seismic signals and their input–output dataset, this study employs the TCN-Transformer algorithm as the predictive model for micro-seismic signals. The model comprises two main components: TCN and Transformer. The TCN is responsible for multi-scale feature extraction from the input time series data, The Transformer network, leveraging the attention mechanism, performs parallel computations on these features to accomplish time series prediction. The TCN model incorporates expansion convolution and residual linkage, with expansion convolution capable of adjusting receptive fields based on its expansion coefficient, allowing for the extraction of time series features across various scales. In contrast to traditional multi-scale CNNs, the TCN network directly propagates gradients through residual connections, unaffected by intermediate layers. This approach mitigates the issue of gradient vanishing, enabling the model to achieve a more profound representation of temporal features. The Transformer component receives the feature matrix extracted by TCN, and employs positional encoding to incorporate sequential information into the time series, followed by the application of multi-head attention mechanisms post-encoding. Once encoding is complete, the input features undergo processing through the multi-head attention mechanism, which concurrently considers the features at each time point along with their interrelationships, thereby enabling the model to learn from diverse representational subspaces. Concurrently, the Transformer decoder employs a masking attention mechanism to prevent the leakage of future information, ensuring that predictions for the current time point are based solely on information available up to that point. Additionally, the decoder incorporates an additional attention layer to focus on the encoder’s output. The final output of the decoder is presented in Fig. 6.
Fig. 6. Network timing prediction process of TCN-Transformer.
The components derived through secondary decomposition exhibit relatively stable scale characteristics within fixed sliding windows. The integration of TCN’s local feature extraction with Transformer’s global attention mechanism achieves effective fusion of multi-scale features. LayerNorm and attention weighting mechanisms dynamically adjust the contribution of each component during training, avoiding the complexity of manual weighting fusion while preserving the model’s end-to-end trainability.
Experiment
Experimental setup and dataset
The micro-seismic signal originated from a coal mine in Urumqi, Xinjiang. The production conditions of this mine are complex, and the lithology of the coal-bearing strata of its mine is mainly claystone, mudstone, muddy siltstone and siltstone, which are plastic rocks; the structure of the rock body is a thin bedded structure, and the top and bottom plates of the coal beds are mostly claystone, mudstone, and silty sandy mudstone, with local pseudo-topping of charcoal mudstone, which are all low-mechanical-strength rocks.
The ARAMIS M/E micro-seismic monitoring system has been installed in the underground working face of the mine, with a strike length of 728.84 m and a mineable length of 519.82 m. To validate the effectiveness and accuracy of the model presented in this paper for predicting micro-seismic signals, micro-seismic monitoring data from the working face for the year 2022 has been selected for the experiment.
The selection of baseline models is based on three key factors: application scenario compatibility, computational resource constraints, and real-time deployment requirements. Micro-seismic signal prediction falls within the realm of short-sequence, high-frequency real-time industrial monitoring scenarios, necessitating low-latency response capabilities. While large-scale models such as Informer and Autoformer demonstrate exceptional performance in large-scale, long-sequence prediction tasks, they present risks of overfitting in short sequences, excessive computational resource demands, and insufficient real-time capabilities, rendering them unsuitable for micro-seismic signal prediction applications. This study selected LSTM, CNN-LSTM, CNN-LSTM-Attention, and Transformer as baseline models. These models feature moderate parameter scales and reasonable computational complexity, are widely applied in micro-seismic signal prediction, and are representative of the field.
All baseline models (LSTM, CNN-LSTM, CNN-LSTM-Attention, Transformer) were trained and selected under identical data partitioning and training protocols as the proposed model. Consistent data preprocessing, fixed sliding windows, and training/validation/test split ratios were employed. Baseline models underwent lightweight grid/range searches on their respective key structural hyperparameters (e.g., learning rate, hidden dimensions/layers, attention heads, dropout, etc.). Optimal configurations were selected based on validation metrics (prioritising MAE while considering RMSE), with results reported on the test set to ensure fair comparison.
All experiments were performed on an AMD Ryzen 7 6800H CPU with a 3.2 GHz clock speed, an NVIDIA GeForce GTX 3060 GPU with 6 GB of RAM, 16 GB of system RAM, Python 3.9.15, and Pytorch 1.13.1 with CUDA 11.6. The key parameters for the TCN and Transformer models encompass the TCN’s input dimensions, network layers, expansion coefficient, output dimensions, and the Transformer’s embedding dimensions, hidden layer size, number of attention mechanism heads, encoder-decoder stacks, and training iterations, among others. Specific hyperparameters are detailed in Table 1. An early stopping strategy was employed during experiments to prevent overfitting and enhance training efficiency. The optimal model was subsequently evaluated using the validation set, with the overall training loss depicted in Fig. 7.
Fig. 7. Training loss curve of TCN-Transformer model.
Table 1TCN-Transformer parameters.ParametersTCN-transformerTCN Input Dimension15TCN Network Layers4Dilation Convolution Factor1,2,4,8TCN Output Dimension15Dimension64Transformer Hidden Layer Size64Heads of Attention Mechanisms8Number of Encoder-Decoder Stacks2Max/Min Learning Rate1e-3/5e-5Epoch100
Evaluation metrics
This paper assesses the prediction accuracy of the TCN-Transformer model using the goodness of fit \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^{2}$$\end{document} , mean square error \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$MSE$$\end{document} , mean absolute error \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$MAE$$\end{document} and mean absolute percentage error \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$MAPE$$\end{document} as evaluation metrics. These metrics indicate model performance, and the lower the value or closer to 1, the better the accuracy. The calculation formulas for these metrics are as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R^{2} = 1 - \frac{{\sum\limits_{i = 1}^{n} {(\tilde{y}_{i} - y_{i} )^{2} } }}{{\sum\limits_{i = 1}^{n} {(\tilde{y}_{i} - y)^{2} } }}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$MSE = \frac{1}{n}\sum\limits_{i = 1}^{n} {\left( {\hat{y}_{i} - y_{i} } \right)^{2} }$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$MAE = \frac{1}{n}\sum\limits_{i = 1}^{n} {\left| {\hat{y}_{i} - y_{i} } \right|}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$MAPE = \frac{1}{n}\sum\limits_{i = 1}^{n} {\left| {\frac{{\hat{y}_{i} - y_{i} }}{{y_{i} }}} \right|} \times 100\%$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{y}_{i}$$\end{document} is the value of blind denoising process; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{i}$$\end{document} is the value of pure data; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{y}_{i}$$\end{document} is the value of time series prediction.
Secondary empirical decomposition of micro-seismic signals
The micro-seismic signal undergoes initial decomposition via the Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN) technique. The resultant 13 intrinsic modal functions (IMFs), represented as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C}$$\end{document} , are presented in Fig. 8. For each \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C}$$\end{document} , the fuzzy entropy is computed to assess the complexity of the information within the time series data. Key parameters for calculating fuzzy entropy include the embedding dimension \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m$$\end{document} , similarity threshold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r$$\end{document} , and parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n$$\end{document} of the fuzzy function. Fuzzy entropy values for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C}$$\end{document} components, calculated under varying parameters, are displayed in Fig. 8.
Fig. 8. Fuzzy entropy of IMF-c after a decomposition.
Observing the figure, one can note that the fuzzy entropy values for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C}$$\end{document} components decrease sequentially, aligning with the frequency characteristics revealed by the CEEMDAN decomposition. This pattern indicates a progressive reduction in the complexity of the feature information encapsulated within the time series data.
Qin, et al.^33^ and Wang et al.^34^. have demonstrated that calculating the sample entropy for the IMFs resulting from CEEMDAN decomposition, and subsequently recombining similar simple modes based on their entropy complexity, can enhance computational efficiency and accuracy while mitigating the risk of overfitting.
Consequently, this paper employs fuzzy entropy calculations on the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C}$$\end{document} components derived from CEEMDAN-decomposed micro-seismic signals. The calculated entropy values categorize the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C}$$\end{document} into high-frequency, trending, and low-frequency components.
As illustrated in Fig. 9 by the fuzzy entropy values, the first four components, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C - 1}$$\end{document} through \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C - 4}$$\end{document} , exhibit high fuzzy entropy. This indicates that these \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}$$\end{document} components are characterized by frequent and irregular fluctuations and the time series undergoes rapid changes within these components, a hallmark of the time series’ nonlinear dynamics. The fuzzy entropy values for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C - 5}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C - 6}$$\end{document} are lower than those of the high-frequency components. However, they are higher than those of the subsequent \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}$$\end{document} components. In time series analysis, components with moderate fuzzy entropy values often indicate the periodicity and trends within the series, thus they are identified as the trend components. Fuzzy entropy values that are lower, particularly from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C - 7}$$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C - 13}$$\end{document} , tend to expose the fundamental trends and the most regular patterns within the time series data. As such, these are categorized as low-frequency \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}$$\end{document} components. The high-frequency and low-frequency \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C}$$\end{document} components, once identified, are individually reconstructed through a cumulative process. The outcomes of these reconstructions are visually presented in Fig. 10.
Fig. 9CEEMDAN decomposition results.
Fig. 10. Reconstruction components of high and low frequency IMF-c.
Ultimately, the reconstructed components undergo a two-stage decomposition process utilizing Variational Mode Decomposition (VMD). The resultant \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C - V}$$\end{document} component, derived from this secondary decomposition, is combined with the trend \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}$$\end{document} component to create a comprehensive input sequence. This sequence is then fed into the subsequent time series prediction network. The outcomes of the VMD’s secondary decomposition are graphically represented in Fig. 11.
Fig. 11VMD secondary decomposition results of high and low frequency components.
Time series prediction of micro-seismic signals
Following the quadratic decomposition, the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{IMF}}_{C - V}$$\end{document} component, extracted from the micro-seismic signal source data, serves as the dataset for multi-featured time series prediction. A sliding time window method is employed to segment the dataset into time series windows. These windows are then allocated to the training, validation, and test sets at a ratio of 65%, 15%, and 20%, respectively, to facilitate model training.
To further assess the performance of the models presented in this paper, we introduce and train several models using the same dataset: the Transformer ablation model, an enhanced LSTM based on recurrent neural networks, a multiscale convolutional long short-term memory network (CNN-LSTM), and a CNN-LSTM incorporating an attention mechanism. The outcomes of these models are depicted in Figs. 12 and 13, while the average predictive performance is detailed in Table 2.
Fig. 12. Prediction results of maximum energy of micro-seismic signals by each method.
Fig. 13. Prediction results of maximum energy of micro-seismic signals by each method.
Table 2. Comparison of prediction accuracy of different algorithms.MethodologiesR^2^RMSEMAEMAPELSTM0.952135.899.40.883CNN-LSTM0.955130.696.50.850CNN-LSTM-Attention0.959125.193.90.845Transformer0.957128.396.20.849TCN-Transformer 0.965
114.7
84.7
0.835
The LSTM model generally maintains stable prediction results, thanks to its ability to capture temporal data characteristics through state retention. However, enhancements to recurrent neural network-based models can introduce latency, potentially degrading predictive performance. The enhanced CNN-LSTM model, equipped with a multi-scale convolutional neural network, efficiently extracts temporal features across various scales, particularly the CNN-LSTM-Attention model, which benefits significantly from the inclusion of an attention mechanism. This allows it to effectively process both global and local features, thereby rendering the prediction outcomes of both the CNN-LSTM-Attention and the attention-based Transformer models more precise.
The TCN-Transformer model advantages stem from the TCN’s capacity to capture feature information across various scales via its diverse receptive fields, enabling the TCN-Transformer to process comprehensive feature information akin to the CNN-LSTM-Attention model. It also effectively leverages local feature information within the data for learning purposes. Furthermore, compared to traditional CNNs, the TCN’s residual connections and dilated convolutions not only capture the causal relationships within temporal data, but also reduce the model’s parameter count, thereby enhancing predictive accuracy and maintaining a lightweight network architecture, making it particularly well-suited for real-time data prediction in practical applications.
Ablation experiment
To assess the effectiveness of the quadratic decomposition, fuzzy entropy, and TCN-Transformer models introduced in this paper, this section examines: (1) the prediction of maximum energy in micro-seismic time series data without decomposition, (2) the prediction of maximum energy in micro-seismic time series data using initial decomposition methods, (3) a comparison of various quadratic decomposition techniques, employing fuzzy entropy(FE) and sample entropy(SE) as criteria for predicting maximum energy in micro-seismic time series.
Time series forecasting without empirical modal decomposition
In this section, we predict the original micro-seismic signal’s maximum energy values using GRU, LSTM, and Transformer models, which are key players in the deep learning time series prediction domain. The dataset is split into training, testing, and validation sets at the original scale for input into these various models. The predictions made by each model are detailed in Table 3, with corresponding plots of predicted versus actual values presented in Fig. 14. Utilizing the original one-dimensional signals directly in deep learning prediction methods, these models struggle to capture temporal features, and the predictions fail to exhibit temporal correlation with actual values. This suggests that micro-seismic energy signals, being inherently nonlinear and nonsmooth, pose challenges to directly derive temporal correlations. Thus, employing empirical modal decomposition or similar techniques to extract intrinsic temporal features is essential for ensuring accurate predictions.
Table 3. Comparison of prediction accuracy of different algorithms.MethodologiesR^2^RMSEMAEMAPELSTM− 0.004618.1397.64.053GRU− 0.001617.2389.93.910Transformer− 0.007619.2403.84.177
Fig. 14. Prediction results of maximum energy of micro-seismic signals by each method.
Time series forecasting with empirical modal decomposition
In this section, we aim to assess the impact of various primary empirical modal decomposition techniques on the final prediction outcomes, we apply the commonly used EMD, EEMD, VMD, and CEEMDAN methods to decompose the signals individually, and then organize the decomposed data into training, testing, and validation sets as described in the previous section, Subsequently, these sets are input into the TCN-Transformer model for prediction. The predictions from each model are presented in Table 4, with corresponding plots of predicted versus actual values in Fig. 15. The findings indicate that VMD-decomposed data yields the most effective predictions, Other methods perform slightly less effectively than VMD, highlighting that micro-seismic energy signals without feature modal decomposition pose challenges for time series prediction models to discern intrinsic temporal features, whereas empirical modal decomposition prior to modeling enables the model to more precisely capture these temporal characteristics, thereby facilitating the micro-seismic energy signal time series prediction task.
Table 4. Comparison of prediction accuracy of different algorithms.MethodologiesR^2^RMSEMAEMAPEEMD0.780289.2185.31.411EEMD0.792280.9196.11.861VMD 0.821
265.6
183.4
0.798 CEEMDAN0.803273.2189.81.880
Fig. 15. Prediction and fitting diagram of the maximum energy of a decomposition micro-seismic signal.
Time series forecasting under quadratic decomposition
The purpose of this section is to evaluate the efficacy of fuzzy entropy and sample entropy in component reconstruction following initial empirical mode decomposition, as well as their role in predicting micro-seismic energy signal time series when applied to secondary decomposition of the reconstructed results. This assessment serves to validate the theoretical advantages of the CEEMDAN selection discussed in Section “CEEMDAN”. This process begins with the initial decomposition of the raw signal through EMD, EEMD, VMD, and CEEMDAN, followed by the reconstruction of these decomposed components using fuzzy entropy and sample entropy. Subsequently, a secondary decomposition is conducted on these reconstructed results using EMD, EEMD, VMD, and CEEMDAN in sequence. The components derived from this final decomposition are analyzed for consistency with the initial method, and the resultant dataset is then input into the TCN-Transformer model for predictive analysis. The outcomes of these experiments are presented in Tables 5, 6, 7, 8, demonstrating a marked enhancement in prediction accuracy for the time series post-secondary decomposition as opposed to predictions made after primary decomposition alone.
Table 5. Prediction results of EMD and different quadratic decomposition algorithms.MethodologiesR^2^RMSEMAEMAPEEMD + SE + EMD0.790279.3175.21.51EMD + SE + EEMD0.802274.1170.11.47EMD + SE + VMD0.883210.6145.41.23EMD + SE + CEEMDAN0.871220.5150.31.42EMD + FE + EMD0.783285.0180.21.57EMD + FE + EEMD0.795278.7173.41.54EMD + FE + VMD 0.892
202.0
141.5
1.10 EMD + FE + CEEMDAN0.865215.3148.51.37
Table 6. Prediction results of EEMD and different quadratic decomposition algorithms.MethodologiesR^2^RMSEMAEMAPEEEMD + SE + EMD0.815273.1173.61.33EEMD + SE + EEMD0.805276.8176.21.36EEMD + SE + VMD0.850250.3160.11.11EEMD + SE + CEEMDAN0.831260.7170.41.21EEMD + FE + EMD0.801279.5179.81.39EEMD + FE + EEMD0.815273.0173.01.33EEMD + FE + VMD 0.855
248.7
158.4
1.07 EEMD + FE + CEEMDAN0.835258.0168.51.17
Table 7. Prediction results of VMD and different quadratic decomposition algorithms.MethodologiesR^2^RMSEMAEMAPEVMD + SE + EMD0.865202.3142.11.12VMD + SE + EEMD0.875192.7132.41.07VMD + SE + VMD0.925150.6100.30.91VMD + SE + CEEMDAN0.948131.891.20.89VMD + FE + EMD0.870198.6137.81.10VMD + FE + EEMD0.880188.9127.61.04VMD + FE + VMD0.930145.295.40.89VMD + FE + CEEMDAN 0.953
126.7
90.5
0.87
Table 8. Prediction results of CEEMDAN and different quadratic decomposition algorithms.MethodologiesR^2^RMSEMAEMAPECEEMDAN + SE + EMD0.871198.6137.81.10CEEMDAN + SE + EEMD0.880188.9127.61.04CEEMDAN + SE + VMD0.952125.090.10.87CEEMDAN + SE + CEEMDAN0.950130.792.40.88CEEMDAN + FE + EMD0.873195.6135.11.08CEEMDAN + FE + EEMD0.885185.3122.41.03CEEMDAN + FE + VMD 0.965
114.7
84.7
0.83 CEEMDAN + FE + CEEMDAN0.947135.294.90.91
It is important to note that micro-seismic energy signals are often sampled amidst some noise interference. The use of fuzzy entropy in the primary decomposition components is more effective at handling noise interference in real-world downhole conditions than sample entropy, leading to enhanced prediction accuracy and overall model robustness. Among empirical modal decomposition methods, EMD is straightforward but noise-sensitive, potentially resulting in unstable decomposition and less refined predictive outcomes. EEMD addresses EMD’s limitations by incorporating noise auxiliary signals, significantly enhancing final prediction results. VMD and CEEMDAN demonstrate greater robustness and stability against noise interference, with prediction accuracy notably surpassing that of EMD and EEMD. VMD excels at managing nonlinear and nonsmooth signals through variational mode decomposition, albeit with increased computational complexity. CEEMDAN integrates the benefits of EEMD and adaptive noise, further bolstering decomposition stability and accuracy, and achieves the highest prediction accuracy and robustness, particularly when combined with VMD.
Conclusions and future work
With the rapid development of information technology, micro-seismic monitoring and early warning systems are facing new opportunities and challenges. Based on the quadratic mode decomposition and TCN-Transformer framework proposed in this paper, its application potential in multi-source data fusion can be further explored. By combining micro-seismic signals with geophysical data such as electromagnetic radiation, acoustic emission, and ground deformation, a more comprehensive rock behaviour analysis system can be constructed. This fusion can not only make up for the limitations of a single data source, but also improve the reliability of the early warning system through the complementary information between different sensors. The main contributions of this paper are reflected in the following three aspects:
- CEEMDAN was used for the initial decomposition of micro-seismic signals. The IMFs were classified and reconstructed by using fuzzy entropy, and subsequently decomposed secondary with VMD. Simulation results indicated that secondary modal decomposition more effectively uncovers latent features within micro-seismic signals, substantially enhancing time series prediction accuracy.
- The TCN network captured multi-scale temporal features via dilated convolution and residual connections. At the same time, the Transformer network parallelized time series data processing through its self-attention mechanism. This combined approach effectively captured both local and global features within time series data, thereby enhancing model prediction accuracy.
- Compared to traditional time series prediction models, the quadratic modal decomposition and TCN-Transformer-based framework presented here exhibited superior fitting and prediction accuracy with micro-seismic signals. From verification with micro-seismic monitoring data from an active coal mine in Xinjiang, the presented model showed the capacity to accurately forecast future micro-seismic signal states for enhancing early warning systems for geological hazards, including impact ground pressure.
Based on the results and limitations of the current study, future work can be carried out in the following aspects. Existing fusion algorithms are still insufficient in dealing with the heterogeneity of different data sources, and there is a need to develop smarter fusion strategies that can dynamically adjust the weights of each data source according to data quality and relevance. Meanwhile, the adaptive ability of the model also needs to be improved, as there are obvious differences in the geological conditions and states of different mining environments, and neural network architectures that can adapt to these changes need to be developed. Additionally, future research should focus on systematic early warning threshold optimization strategies and ROC/PR curve analysis based on specific mining areas’ actual requirements, as well as conducting attention mechanism and physical mechanism correlation experiments to obtain qualitative/quantitative consistency evidence. These future research directions will not only help to advance micro-seismic monitoring and early warning technology, but will also make an important contribution to the safety and efficiency of mining operations.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bai, S., Kolter, J. Z. & Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modelling (2018). ar Xiv:1803.01271.