Unlocking Tropical Forest Complexity: How Tree Assemblages in Secondary Forests Boost Biodiversity Conservation
Maïri Souza Oliveira, Maxime Lenormand, Sandra Luque, Nelson A. Zamora, Samuel Alleaume, Adriana C. Aguilar Porras, Marvin U. Castillo, Eduardo Chacón‐Madrigal, Diego Delgado, Luis Gustavo Hernández Sánchez, Marie‐Ange Ngo Bieng, Ruperto Quesada‐Monge, Gilberth S. Solano

TL;DR
This study presents a national method to identify and characterize tropical forest ecosystems using dominant tree species, highlighting the role of secondary forests in biodiversity conservation.
Contribution
A replicable national approach using dominant tree species to delineate and characterize tropical forest ecosystems is developed.
Findings
In Costa Rica, 495 dominant tree species defined 10 in situ clusters, with 7 main clusters successfully modelled.
The approach aligns with local forest classifications and highlights ecological trends based on species dominance, topography, and climate.
Secondary forest distribution analysis revealed ecosystem vulnerability and the importance of these forests in maintaining biodiversity.
Abstract
Secondary forests now dominate tropical landscapes and play a crucial role in achieving COP15 conservation objectives. This study develops a replicable national approach to identifying and characterising forest ecosystems, with a focus on the role of secondary forests. We hypothesised that dominant tree species in the forest canopy serve as reliable indicators for delineating forest ecosystems and untangling biodiversity complexity. Using national inventories, we identified in situ clusters through hierarchical clustering based on dominant species abundance dissimilarity, determined using the Importance Variable Index. These clusters were characterised by analysing species assemblages and their interactions. We then applied object‐oriented Random Forest modelling, segmenting the national forest cover using NDVI to identify the forest ecosystems derived from in situ clusters. Freely…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
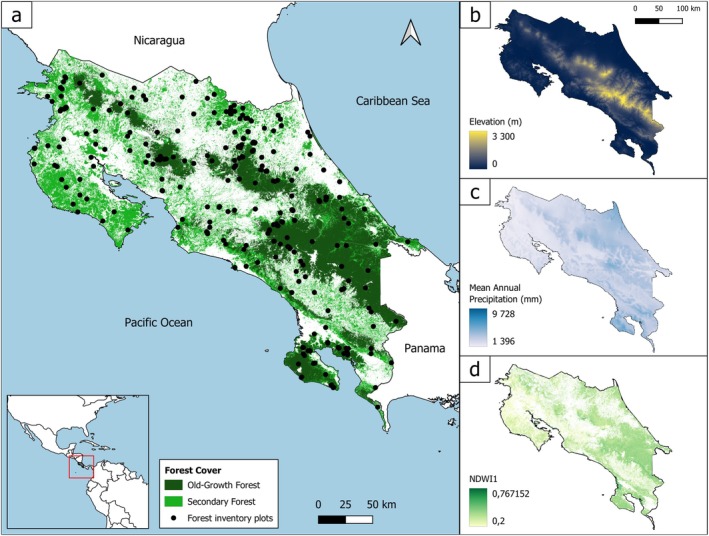 FIGURE 1
FIGURE 1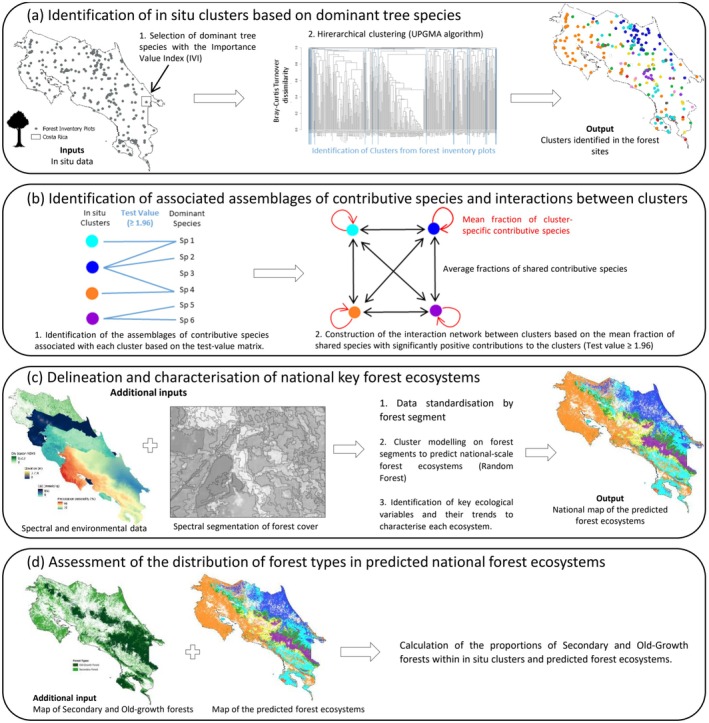 FIGURE 2
FIGURE 2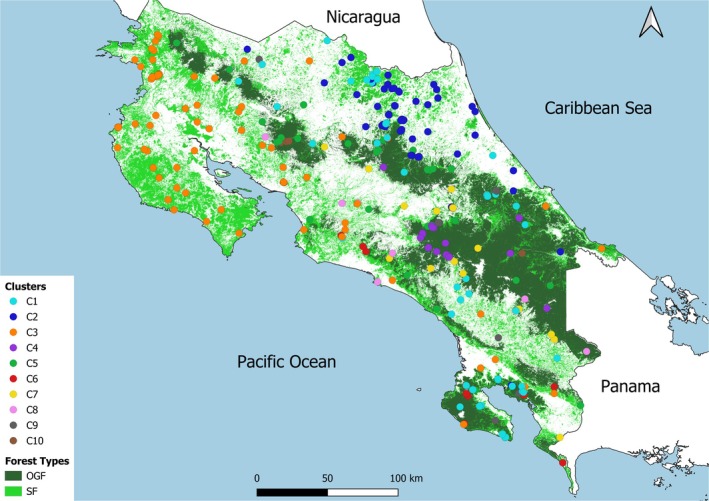 FIGURE 3
FIGURE 3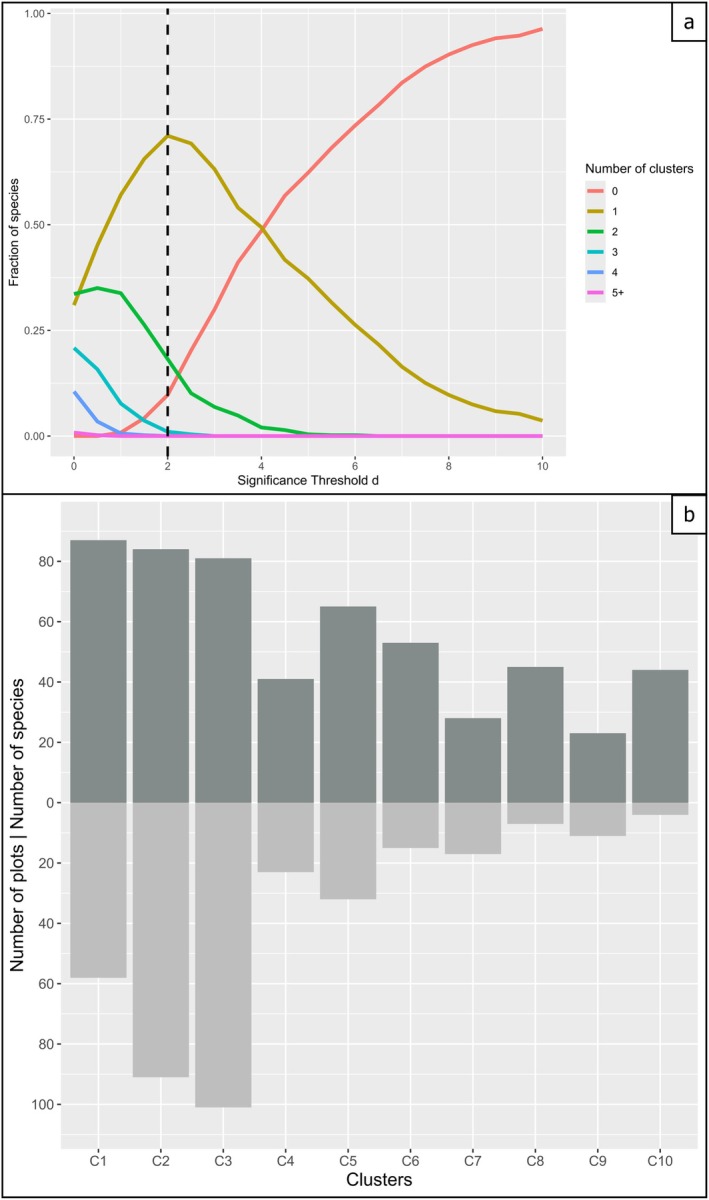 FIGURE 4
FIGURE 4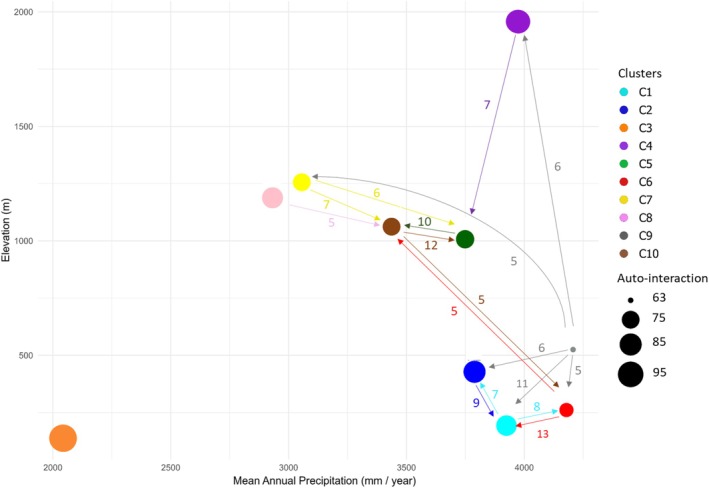 FIGURE 5
FIGURE 5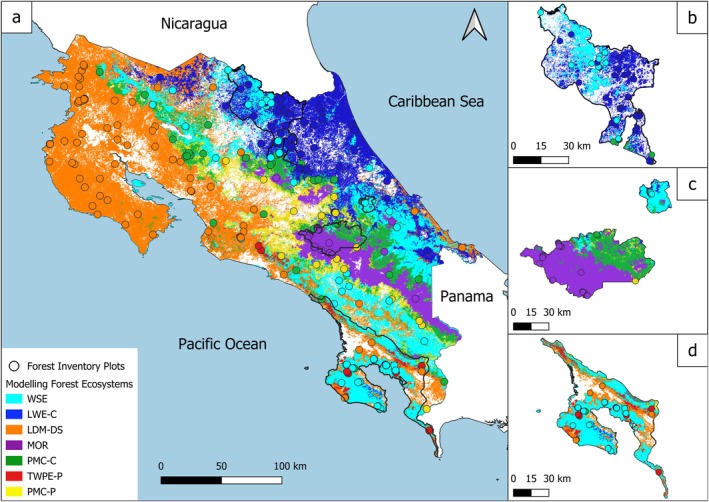 FIGURE 6
FIGURE 6| Type | Variable | Unit | |
|---|---|---|---|
| Topography | DEM | Elevation | m |
| Slope | — | degrees (°) | |
| Aspect | — | degrees (°) | |
| TWI | Topographic Wetness Index | — | |
| TRI | Terrain Ruggedness Index | m | |
| TPI | Topographic Position Index | — | |
| Soil (0‐30 cm, 30‐200 cm, 0‐200 cm) | C | Soil Organic Carbon | dg/kg |
| CEC | Cation Exchange Capacity | mmolc/kg | |
| Clay | — | g/kg | |
| N | — | cg/kg | |
| pH | — | — | |
| Silt | — | g/kg | |
| Climate | anPR | Mean annual precipitation | mm/year |
| MAT | Mean annual temperature | °C | |
| Prsea | Precipitation seasonality (CV) | % | |
| Tsea | Temperature seasonality (SD) | °C | |
| Vegetation dynamics (Wet and Dry seasons) | CCI | Canopy Chlorophyll Content Index | — |
| NDVI | Normalised Difference Vegetation Index | — | |
| NDWI | Normalised Difference Water Index | — | |
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | F1‐score | |
|---|---|---|---|---|---|---|---|---|
| C1 | 63.74 | 10.53 | 7.60 | 0.00 | 5.85 | 7.02 | 5.26 | 0.60 |
| C2 | 7.04 | 86.38 | 5.63 | 0.00 | 0.94 | 0.00 | 0.00 | 0.83 |
| C3 | 7.50 | 6.67 | 81.67 | 0.00 | 0.83 | 2.50 | 0.83 | 0.81 |
| C4 | 1.59 | 0.00 | 0.00 | 69.84 | 22.22 | 0.00 | 6.35 | 0.74 |
| C5 | 17.20 | 9.68 | 9.68 | 6.45 | 47.31 | 6.45 | 3.23 | 0.50 |
| C6 | 58.33 | 0.00 | 12.50 | 0.00 | 12.50 | 16.67 | 0.00 | 0.19 |
| C7 | 9.52 | 9.52 | 11.90 | 14.29 | 14.29 | 7.14 | 33.33 | 0.38 |
| Variables | C1 | C2 | C3 | C4 | C5 | C6 | C7 | Mean decrease accuracy | Mean decrease gini | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Imp |
| Imp |
| Imp |
| Imp |
| Imp |
| Imp |
| Imp |
| Value |
| Value |
| |
| q50.DEM | 15.10 | 0.01* | 25.66 | 0.01* | 11.77 | 0.01* | 35.50 | 0.01* | 17.08 | 0.01* | 2.76 | 0.14 | 13.65 | 0.01* | 41.87 | 0.01* | 38.16 | 0.01* |
| q25.PRSea | 15.42 | 0.01* | 35.39 | 0.01* | 20.23 | 0.01* | 14.42 | 0.01* | 4.61 | 0.04* | 1.19 | 0.26 | 6.08 | 0.02* | 37.66 | 0.01* | 40.64 | 0.01* |
| q25.NDWIw | 18.37 | 0.01* | 24.36 | 0.01* | 7.42 | 0.07 | 1.22 | 0.31 | 10.53 | 0.01* | 5.55 | 0.02* | 8.97 | 0.01* | 30.25 | 0.01* | 30.38 | 1.00 |
| q75.anPR | 17.36 | 0.01* | 13.18 | 0.01* | 21.07 | 0.01* | 11.48 | 0.01* | 5.49 | 0.02* | 1.70 | 0.20 | 4.93 | 0.06 | 27.24 | 0.01* | 37.20 | 0.01* |
| q50.pH 30 | 15.19 | 0.01* | 15.37 | 0.01* | 18.45 | 0.01* | 15.48 | 0.01* | −3.43 | 0.79 | 0.06 | 0.39 | 8.04 | 0.01* | 25.37 | 0.01* | 34.79 | 0.05* |
| q50.CEC30 | 6.71 | 0.03* | 18.79 | 0.01* | 11.76 | 0.01* | 4.43 | 0.05* | 6.99 | 0.03* | 0.28 | 0.38 | 4.77 | 0.04* | 22.45 | 0.01* | 26.93 | 1.00 |
| q25.slope | 5.46 | 0.07 | 20.89 | 0.01* | −3.57 | 0.91 | 11.83 | 0.01* | −2.60 | 0.79 | −0.59 | 0.46 | 7.08 | 0.01* | 20.03 | 0.01* | 24.10 | 1.00 |
| Clusters | Ecosystems | Acronyms | Characterisation | |||||
|---|---|---|---|---|---|---|---|---|
| Contributive species | Tropography | Climate | Vegetation dynamic | Soil | Location | |||
| C1 | Wet Seasonal Evergreen forest | WSE | Majority of evergreen species (predominated by | Broad median elevation ranges from low to intermediate (504 ± 361 m) |
Maximum mean annual precipitation of 3611 ± 707 mm/year. Minimum precipitation seasonality variation of 51% ± 13%. | Minimum NDWI range during the wet season of 0.31 ± 0.11 |
Median pH of 5.21 ± 0.62 Median CEC of 134 ± 44 mmolc/kg | Southern Pacific and Caribbean coasts |
| C2 | Lowland Wet Evergreen forest of the Caribbean slope | LWE‐C | Evergreen species (predominated by |
Low median elevation (≤ 346 m) Low minimal slope (4° ± 4°) |
Maximum mean annual precipitation of 3522 ± 726 mm/year. Minimum precipitation seasonality variation of 34% ± 9% | Minimum NDWI range during the wet season of 0.31 ± 0.07 |
Median pH of 5.27 ± 0.62 Median CEC of 132 ± 49 mmolc/kg | Caribbean coast |
| C3 | Lowland Dry‐to‐Moist Deciduous‐to‐Semi‐deciduous forest | LDM‐DS | Mainly composed of deciduous to semi‐deciduous species (predominated by | Low median elevation (≤ 519 m) |
Maximum mean annual precipitation of 2308 ± 542 mm/year. Minimum precipitation seasonality variation of 75% ± 14% | Minimum NDWI range during the wet season of 0.22 ± 0.09 |
Median pH of 5.73 ± 0.69 Median CEC of 212 ± 60 mmolc/kg | Mainly on the southern Pacific coast |
| C4 | Mountain Oak Rainforest | MOR | Predominantly composed of oak species (dominated by |
High median elevation (2269 ± 463 m) High minimal slope (20° ± 8°) |
Maximum mean annual precipitation of 3804 ± 614 mm/year. Minimum precipitation seasonality variation of 45% ± 10% | — |
Median pH of 5.12 ± 0.17 Median CEC of 192 ± 39 mmolc/kg | Talamanca cordillera |
| C5 | Premontane‐to‐mountain Mixed‐to‐evergreen Cloud forest of the Caribbean slope | PMC‐C | Mix of evergreen and deciduous species with a large altitudinal gradient (predominated by | Intermediate median elevation (1142 ± 361 m) |
Maximum mean annual precipitation of 3616 ± 547 mm/year. Minimum precipitation seasonality variation of 48% ± 13% | Minimum NDWI range during the wet season of 0.37 ± 0.05 | Median CEC of 171 ± 45 mmolc/kg | Caribbean slope |
| C6 | Transitional wet premontane evergreen forest of the Pacific slope | TWPE‐P | Evergreen species (predominated by | — | — | Minimum NDWI range during the wet season of 0.39 ± 0.03 | — | Southern Pacific coast |
| C7 | Premontane‐to‐mountain Mixed‐to‐evergreen Cloud forest of Pacific slope | PMC‐P | Mix of evergreen and deciduous species with a large altitudinal gradient (predominated by |
Intermediate median elevation (1360 ± 372) High minimal slope (16° ± 8°) | Minimum precipitation seasonality variation of 55% ± 12% | Minimum NDWI range during the wet season of 0.26 ± 0.08 |
Median pH of 5.29 ± 0.31 Median CEC of 162 ± 33 | Pacific slope |
| Ecosystems | Forest types | Proportion (%) | |
|---|---|---|---|
| Clustering | Random forest | ||
| WSE | OGF | 0.79 | 0.69 |
| SF | 0.21 | 0.31 | |
| LWE‐C | OGF | 0.74 | 0.25 |
| SF | 0.26 | 0.75 | |
| LDM‐DS | OGF | 0.23 | 0.14 |
| SF | 0.77 | 0.86 | |
| MOR | OGF | 1 | 0.95 |
| SF | 0 | 0.05 | |
| PMC‐C | OGF | 0.66 | 0.85 |
| SF | 0.34 | 0.15 | |
| TWPE‐P | OGF | 0.93 | 0.63 |
| SF | 0.07 | 0.37 | |
| PMC‐P | OGF | 0.18 | 0.79 |
| SF | 0.82 | 0.21 | |
- —Centre National d’Etudes Spatiales10.13039/501100002830
- —Centre de Coopération Internationale en Recherche Agronomique pour le Développement10.13039/501100007204
- —Institut National de Recherche pour l’Agriculture, l’Alimentation et l’Environnement10.13039/501100022077
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsConservation, Biodiversity, and Resource Management
Introduction
1
Tropical forests play a crucial role in preserving global biodiversity, harbouring a significant portion of terrestrial diversity, often estimated to be more than half of existing species (Myers et al. 2000). They are central to conservation strategies to achieve the Convention on Biological Diversity (COP15) goals, in particular the identification of priority ecosystems required to achieve the target of protecting 30% of land by 2030 (Mrema et al. 2020; CBD 2022; Pendrill et al. 2022). However, their degradation and deforestation remain among the leading drivers of global biodiversity loss (Bourgoin et al. 2024). As a result, many forest species are constrained to persist in human‐modified landscapes, where forests survive within a matrix that varies significantly in its capacity to support biodiversity (Arroyo‐Rodríguez et al. 2020). This raises critical questions about whether these anthropogenically influenced forested landscapes can sustain ambitious conservation objectives and at what spatial scale this support might be feasible (Perino et al. 2022).
In this context, secondary forests (SF), typically resulting from natural regeneration following anthropogenic pressures, primarily develop on fallow lands abandoned after agricultural use (Brown and Lugo 1990; Chazdon 2014). Today, SF constitutes the majority of tropical forest cover, while old‐growth forests (OGF) are increasingly restricted to inaccessible and non‐arable areas (Edwards et al. 2019). While OGF, recognised for their complex structure and key role in sustaining biodiversity (Clark and Clark 1996; Chazdon 2014), SF are still often perceived as degraded systems (Pain et al. 2021). Although their species richness can recover relatively quickly, their species composition converges with that of OGF only over several centuries (Rozendaal et al. 2019; Poorter et al. 2021). Their regeneration dynamics are influenced by multiple interacting factors operating across spatial scales, contributing to the uncertainty of their trajectories (Walker et al. 2010; Arroyo‐Rodríguez et al. 2017; Balvanera et al. 2021). As such, SF cannot replace OGF (Gibson et al. 2011), reinforcing the justification for prioritising OGF in conservation policies, often through “land‐sparing” strategies (Mertz et al. 2021). However, this approach contributes to SF marginalisation, leaving them vulnerable to conversion into more economically lucrative land uses and undermining their potential contribution to long‐term conservation efforts (Laurance et al. 2014; Reid et al. 2019). Located within human‐modified tropical landscapes, SF are often cleared during the early stages of succession and struggle to fully restore ecosystem functions and biodiversity (Arroyo‐Rodríguez et al. 2017). The limited recognition of the biodiversity value of these early stages and the uncertainty surrounding their trajectories, combined with conflicts between conservation and human land use, highlight a gap in conservation strategies regarding the integration of SF (Vieira et al. 2014; Sandoval et al. 2019; Shebitz et al. 2023). Nevertheless, despite the increase in protected forest areas, mainly OGF, contributing to biodiversity conservation, this measure remains insufficient to halt its rapid decline (Jenkins and Joppa 2009; Gibson et al. 2011; Barber et al. 2014). Disturbances in the surrounding landscape continue to affect species within protected areas, calling into question the effectiveness of conservation strategies focused on OGF, particularly threatened by deforestation (Chazdon 2014; Arroyo‐Rodríguez et al. 2020; Pain et al. 2021). In this context, SF are crucial as biological corridors, linking OGF fragments and facilitating genetic flow and species movement (Arroyo‐Rodríguez et al. 2017). However, do SF have the capacity to preserve the specific flora composition that characterises tropical ecosystems, thereby complementing conservation efforts in OGF?
To address this question and better understand the role of SFs in conserving tropical forest ecosystems and their contribution to international objectives, it is essential to develop robust and reproducible indicators and methods at the national scale capable of guiding the identification of priority ecosystems and supporting the implementation of conservation strategies aligned with global targets (Carroll and Noss 2022; Eckert et al. 2023). Nevertheless, despite numerous initiatives at international, continental, regional, and local levels to develop such tools, their lack at the national scale remains a significant challenge (Perino et al. 2022; Shen et al. 2023).
Segmenting the forest cover into coherent ecosystems can guide conservation plans by integrating ecological and biological specificities unique to each forest ecosystem. Since the 1970s, studies on vegetation interactions with various environmental factors have shown that they reflect the complexity of biophysical processes (Monteith 1972; Droissart et al. 2018). Ecological, environmental, and historical filtering contribute to the distribution and spatial organisation of distinct species assemblages, representing large‐scale biogeographical structures (Kreft and Jetz 2010; Araújo and Rozenfeld 2014), which influence the structure of ecosystems. Preserving the diversity of these ecosystems is essential to prevent the homogenisation of plant communities that structure them and to combat biodiversity loss (Jakovac et al. 2022). This approach, applied to tropical forests, is documented in the scientific literature at different spatial scales, including regional (e.g., Moonlight et al. 2020), national (e.g., Pérez Chaves et al. 2020) and continental (e.g., Jakovac et al. 2022). However, it faces several limitations. The high complexity of elevated biodiversity and intricate species interactions in tropical forest ecosystems makes comprehensive biodiversity identification challenging (Pérez Chaves et al. 2020; Yang et al. 2023; Aguirre‐Gutiérrez et al. 2025). In addressing this challenge, the trees that compose the forest canopy, as key structural elements of forest ecosystems, provide crucial insights into large‐scale patterns of forest biodiversity (Rüger et al. 2020; Keppel et al. 2021; van Tiel et al. 2024). The specific composition of dominant tree species assemblages in the forest canopy, in terms of abundance and structure, evolves based on forest succession stages, disturbance levels, and variations in environmental and historical factors (Chazdon 2008; Crouzeilles et al. 2016; Rosenfield et al. 2023). In tropical landscapes under anthropogenic pressures, the heterogeneity and turnover of these assemblages between plots are key factors determining forest resilience and stability (Lohbeck et al. 2016).
While ecological network analysis has mainly focused on species interactions at local scales (Schmid et al. 2020), methodological tools to assess interactions between ecosystems at national scales, particularly in tropical forests, remain underdeveloped. The approach proposed by Lenormand et al. (2019), applying species contributions and network theory to relationships between bioregions provides an innovative avenue to address this gap by quantifying ecosystem interactions and specificity, thereby informing more integrated conservation strategies.
At the national scale, ecosystem delimitation is hindered by the lack of sufficient and reliable field data. The approach based on multispectral remote sensing, widely implemented through pixel‐based classifications (e.g., Sentinel‐2, Random Forest), has therefore become the dominant approach, with in situ data largely confined to calibration and validation roles (Massey et al. 2023; Saim and Aly 2025). However, the ecological value of the maps remains limited, constraining the information available for conservation (Pang et al. 2023). Multi‐source approaches, combining in situ data with modelling based on spectral information, generate more interpretable classes that can reflect species assemblages, thereby enhancing their usefulness for management and conservation planning (Pérez Chaves et al. 2020; Pang et al. 2023). The integration of multisource data, including environmental variables, in this multi‐source approach allows the limitations of spectral information alone—which under tropical conditions is often affected by cloud cover—to be overcome (Ferrer Velasco et al. 2022; Silveira et al. 2023). The use of object‐oriented modelling based on spectral segmentation of the forest canopy enables the integration of data sources at different spatial resolutions and produces ecologically meaningful classes, while automating large‐scale mapping (Waśniewski et al. 2020). This approach thus facilitates the operational delimitation of ecosystems at the national scale by incorporating ecological and environmental filters into precise and interpretable maps (Flores‐Tolentino et al. 2021).
This study proposes a national‐level approach for assessing the potential of SF in maintaining national tropical forest ecosystems. Our goal is to unravel the complexity of biodiversity by analysing the assemblages of tree species that shape and structure the forest canopy. The Costa Rica case study serves as the demonstrator for this approach. To achieve this, we identified and characterised high‐level forest ecosystems and evaluated the distribution of OGF and SF across these ecosystems through four main steps: (i) using forest inventory data and botanical expertise, we identified clusters based on the dominant tree species of sites, (ii) we then characterised the clusters based on species distribution by identifying the associated assemblages of contributive species and analysing the interactions between these clusters, (iii) we modelled these clusters at the national forest cover level, using freely available spectral and environmental information to delineate and characterise key forest ecosystems defined by dominant species assemblages, and (iv) we assessed the distribution of forest types (OGF and SF) within these ecosystems. We hypothesised (i) that the dominant tree species in the forest canopy serve as reliable indicators for delineating forest ecosystems at a national scale and (ii) that the interactions between forest ecosystems and the presence of SF are influenced by anthropogenic factors, linked to the specific environmental characteristics of each ecosystem. The developed pipeline for this multi‐source approach is designed to be reproducible, innovative by relying on open multisource data (Sentinel‐2, global environmental databases) and on well‐established methods, but integrated in a novel way to enable the operational delineation of forest ecosystems at the national scale. To our knowledge, Pérez Chaves et al. (2020) also applied a multi‐step approach to map floristic patterns at the national scale in Peru. However, the originality of the present study lies in its delineation and characterisation of ecosystems based on canopy‐dominant species assemblages, as well as its analysis of interactions among ecosystems. This approach is designed to translate ecosystem delineation into operational information for national conservation planning, grounded in the floristic patterns that structure the canopy, while incorporating ecological filters, local knowledge, and alignment with international conservation frameworks.
Materials and Methods
2
A National‐Level Demonstrator
2.1
Costa Rica, located in Central America, represents an exceptional world biodiversity hotspot on just 0.03% of the Earth's surface, due to significant topographic and environmental gradients, as well as the ecological transition undertaken since the 1990s (Myers et al. 2000). The country is traversed by a central mountain range, composed of four main cordilleras (Guanacaste, Tilarán, Central, and Talamanca), creating a substantial altitudinal gradient, ranging from sea level to 3820 m above sea level and essentially two main slopes, Pacific and Caribbean (Figure 1b). Costa Rica also exhibits a broad environmental spectrum, ranging from the dry, highly seasonal biome of the northwestern Pacific coast to the very humid, seasonal biome of the southern Pacific coast and the nearly perennially wet conditions of the Caribbean slope. The major climatic gradient is along the Pacific slope, characterised by annual precipitation ranging from 1475 mm in the northwestern to 5070 mm in the southwestern (Figure 1c). Costa Rica has transitioned from a deforestation pioneer in the 1970s–1980s to a reforestation pioneer in the tropics by the 2000s (Redo et al. 2012). The current forest cover in Costa Rica reaches 52%, with 36% being SF (Figure 1a—Stan and Sanchez‐Azofeifa 2019). However, this forest cover remains highly fragmented and mixed, with the landscape dominated by agricultural areas, pastures, and secondary forests (Stan and Sanchez‐Azofeifa 2019).
Presentation and environmental characteristics of the study area, Costa Rica: (a) Spatial distribution of 364 forest inventory plots across the national forest cover, (b) elevation (m), (c) Mean annual precipitation (mm/year), (d) Normalised Difference Water Index (NDWI) calculated as the median of the time series over the most stable months of the 2018 dry season (February and April).
Data
2.2
Tree Species Forest Data
2.2.1
We compiled data from the national inventory of Costa Rica (Programa REDD/CCAD‐GIZ—SINAC, 2015) along with data from regional and local forest research projects. The resulting dataset includes 364 georeferenced plots (Figure 1a), ranging from 0.1 to 1.6 ha, carried out between 2004 and 2021. To standardise the data across the different inventories, we retained only trees with a DBH greater than 10 cm (DBH = diameter at breast height, at 1.3 m). Taxonomic identification was performed at the species level in all the selected plots. For the current study, we only accounted for individuals identified to the species level with confirmed taxonomic validation by botanical expertise. Consequently, our final database consists of 58,773 trees belonging to 1333 species.
Environmental Data
2.2.2
To define and characterise the identified forest ecosystems, we selected variables representing vegetation dynamics, topography, soil and climatic conditions. We represented vegetation dynamics during the dry and wet seasons by computing several vegetation spectral indices. These indices were computed, using multitemporal images from the Copernicus Sentinel‐2 L2A satellite with 10 m and 20 m spatial resolution (CEOS 2024). These data were processed through Planetary Computer, which includes atmospheric correction using Sen2Cor (Main‐Knorn et al. 2017). The vegetation indices were calculated by median over the multitemporal optical image series from 2018. To reduce spectral variability and ensure proper representation of the different seasons, two three‐month periods were used: November to January for the wet season (Figure 1d) and February to April for the dry season. These vegetation indices are available as open access (“costarica‐sentinel‐2‐l2‐spectral‐indices”). Elevation, along with several associated topographic metrics was derived from the NASADEM Merged DEM Global 1 Arc‐Second V001, with a spatial resolution of 30 m (NASA JPL 2020). Climate variables, with a spatial resolution of 1 km, were obtained from CHELSA V1.0 (Karger et al. 2017), while soil variables, with a spatial resolution of 250 m, were sourced from SoilGrids v0.5.5 (Hengl et al. 2017). The full set of variables used is presented in Table 1. We also used the 2021 forest‐type map of Costa Rica, produced by SINAC at a spatial resolution of 10 m. This map was generated through a classification of Sentinel‐2 and Sentinel‐1 image mosaics (SINAC 2021) and is available as open access (“SNIT”). From this dataset, we selected SF and OGF forest types (Figure 1a).
Biogeographical Network Analysis of In Situ Data
2.3
Identification of the Dominant Tree Species in the Forest Canopy
2.3.1
Our objective was to identify the global floristic patterns of the forest canopy across the country. Due to the complexity of tropical forest diversity and the local biodiversity richness, some species were expected to have low prevalence, which could bias the delineation of forest ecosystems. To avoid this issue, we used the Importance Value Index (IVI) to determine which species contributed most to each plot's composition, structure, and dynamics of the tree communities (Figure 2a). The IVI combines three parameters: (i) relative density, measured by abundance, (ii) relative dominance, measured by basal area, and (iii) relative frequency, which represents the proportion of subplots where the species are present (Curtis and McIntosh 1951).
Schematic workflow used in this study, illustrating the key methodological steps.
We set an IVI threshold of 5% to select the dominant species in each forest plot, which was then used for the forest ecosystems delineation. We performed a sensitivity analysis to evaluate the impact of selecting a 5% IVI threshold on the delineation of forest ecosystems. For each plot, we calculated the cumulative IVI captured by species exceeding thresholds of 5% and 10%, and found that the 5% threshold retained on average 60% of the cumulative IVI, whereas the 10% threshold retained only 47% (Figure S1). We also assessed the stability of the forest cluster composition using pairwise comparisons (Adjusted Rand Index, ARI) between clustering results obtained with thresholds of 0%, 5%, and 10%. The ARI values showed high similarity between the 5% and 10% thresholds (ARI = 0.64), indicating that the overall cluster structure is robust to variations in the threshold. These results support the choice of a 5% threshold for selecting dominant species, as it captures the majority of canopy dominance, balances the inclusion of the most influential species, ensures stability of the clustering results, and avoids excluding moderately abundant species.
Hierarchical Clustering of Sites
2.3.2
In this study, we considered forest inventory plots as sites. The delineation of forest ecosystems was based on automatic discrimination of tree species assemblages, aiming to minimise the taxonomic turnover rate within ecosystems while maximising it between them (Kreft and Jetz 2010). We performed hierarchical clustering based on the dominant tree species assemblages to cluster the sites according to their floristic similarities in an unsupervised approach (i.e., without incorporating environmental variables) (Figure 2a). To achieve this, we applied the UPGMA (Unweighted Pair Group Method with Arithmetic Mean) agglomerative algorithm using the turnover component of the Bray–Curtis dissimilarity index (βBrayTurn). βBrayTurn specifically focuses on changes in species composition by quantifying the minimal difference in presence and abundance. This approach emphasises the species unique to each site (Equation 1) (Baselga 2013). This metric is particularly suitable for our data because it allows the analysis of variations in species composition without being influenced by abundance differences related to site size.
In Equation (1), A represents the sum of the minimum abundances of species shared between two sites, while B and C correspond to the abundances of species present exclusively on each site of the pair. The function minB,C measures the turnover between the two sites, that is, the total number of individuals of species present only on one of the two sites.
The UPGMA method has proven more effective for detecting consistent biogeographical patterns than other hierarchical classification methods and does not weight clusters based on their size (Kreft and Jetz 2010). Since this method is influenced by site order in the distance matrix, we performed 1000 randomisations of the order in the dissimilarity matrix (Dapporto et al. 2013). To quantitatively assess each resulting tree, we calculated the cophenetic correlation coefficient, which measures the correlation between the distance at which the sites are connected in the tree and the distance between the sites in the initial dissimilarity matrix (Sokal and Rohlf 1962).
The optimal number of clusters was selected using the Elbow Method based on the pc_distance metric, in order to maximise the dissimilarity between clusters. This metric calculates the ratio between the sum of β dissimilarities between clusters and the total sum of β dissimilarities for the entire dissimilarity matrix (Holt et al. 2013).
Single‐site clusters were further assessed for their representativeness using pairwise similarity tests based on species composition (Simpson's distance with Bonferroni correction) between the isolated sites and the main clusters. A 50% similarity threshold, supported by botanical expertise, was used to determine whether isolated sites represented genuine floristic specificity or simply exhibited a high rate of unique species due to random sampling and could therefore be associated with existing clusters (see Table S1). Isolated plots deemed not representative of broader floristic patterns were excluded from further analysis, as we did not have a sufficient number of plots to adequately represent these specific floras in the modelling.
Test Value Matrix
2.3.3
To analyse the contribution of species to each cluster and characterise the associated species assemblages, we used test values ρ, which measures the under‐ or over‐representation of species in the clusters (Lebart et al. 2000) (Figure 2b). The test value ρ for a species i in a cluster j quantifies the difference between the mean abundance X μij of species i in nj samples from the cluster j and its mean abundance μ in n samples from the entire study area, standardised to assess whether the species is over‐ or under‐represented in this cluster compared to all samples (Equation 2). Since this quantity depends on the size of the clusters (nj), it is normalised by the standard deviation associated with the expected mean abundance if the variability in the cluster j were comparable to that of the total population represented by {n, μ, σ ^2^}, taking into account the difference in cluster sizes.
To define the representative species in the assemblages associated with the clusters, we qualified the species that contributed positively and significantly to one or more clusters by introducing a significance threshold δ applied to the test values ρ corresponding to a one‐tailed significance level of 2.5% in a Gaussian distribution, that is, δ = 1.96. Thus, the matrix of test values ρ highlights the sets of species that best characterise the clusters (Lenormand et al. 2019).
Interaction Network Between Clusters
2.3.4
To quantify the relationships between the clusters, we examined the distribution among clusters of species with contributions were significantly positive (ρij ≥ 1.96) (Lenormand et al. 2019). ρ+ that represents these significantly positive contributions of species to the clusters (Figure 2b). To obtain the relative contribution ρ^ij+ of a species i to a cluster j, we normalised the contributions ρ+ by the sum of ρ^+^ for all clusters k (Equation 3).
Subsequently, we calculated for each cluster j the mean fraction of contribution to the cluster from species that also contribute significantly to the cluster j′, denoted as λij′, based on Equation (4). In this equation, Aj represents the set of species for which the contribution to cluster j is significant, i.e., those for which ρij≥1.96. The normalisation of contributions by Aj ensures that the similarity measure is independent of the size of Aj. Thus, λjj expresses the specificity of cluster j. These fractions are expressed as percentages with a vector λj for a given cluster that sums to 1. Therefore, the values of λj provide measures of both specificity and connectivity between the clusters, based on the representative species they share.
We then used the values from the matrix to construct an interaction network illustrating the relationships between site clusters and the associated species assemblages. This network was then projected into a two‐dimensional space, using altitude derived from the DEM and annual precipitation, taking the median of these variables for each cluster, in order to explore the main environmental gradients of the country.
Delimitation of Forest Ecosystems Using Spectral and Environmental Data
2.4
Data Standardisation
2.4.1
To address the difference in spatial resolution between floristic and environmental data, we used segmentation to create an object‐oriented approach (Figure 2c). This process divided the forest cover, derived from the national forest‐type map, into spectrally uniform segments, helping to standardise the data for ecosystem modelling and validating environmental factors. The segmentation was based on an NDVI mosaic derived from the median of Sentinel‐2 images from the dry season of 2018, using the Large Scale Generic Region Merging (LSGRM) algorithm from the Moringa Land Cover Toolbox (Gaetano et al. 2019). Subsequently, for each segment, we performed statistical zoning by extracting the 25th (q25), 50th (q50), and 75th (q75) percentiles for each numerical explanatory variable. This approach reduced biases from local variability and captured environmental trends representative of each segment, aiding in the characterisation of forest ecosystems. Each segment containing a site adopted the cluster value and species assemblage of that site, based on the assumption that it accurately represents the entire segment.
Modelling Clusters at the National Scale
2.4.2
A Random Forest model (Breiman 2001) was developed using the clustering results from the sites to predict the clusters within the Costa Rica forest cover, aiming to produce a map of the main forest ecosystems (Figure 2c). For the modelling, we selected only the main clusters with a minimum of 15 sites. Most of the 34 predictive variables were highly correlated. To limit overfitting, we applied a two‐step variable selection procedure. First, we used a recursive feature elimination (RFE) procedure with a Random Forest model, optimising the F1‐score to identify the best‐performing subsets of predictors (sizes between 5 and 30 variables were tested). The best‐performing subset was then examined for multicollinearity using Pearson's correlation coefficients. Variables with |r| > 0.7 were considered redundant and manually removed based on ecological relevance and interpretability. Model evaluation was performed using 10‐fold cross‐validation, with performance assessed through the F1‐score and the macro F1‐score. The macro F1‐score, calculated as the arithmetic mean of the F1 scores for all classes, which treats all classes equally, is mainly well suited to unbalanced classes (Sokolova and Lapalme 2009). For each predicted forest ecosystem, we assessed the variable importance using 100 permutations per variable (Ramosaj and Pauly 2023), as well as the marginal effects of the most important variables by constructing partial dependence plots (B. M. Greenwell 2017). This final step allows better characterisation of these ecosystems and establishes links with botanical expertise.
Analysis of the Distribution of Forest Types Within Predicted Forest Ecosystems
2.5
We calculated the proportions of SF and OGF in the in situ clusters and the derived forest ecosystems to assess the concordance between the prediction results and clustering results and to analyse their distribution across different forest ecosystems (Figure 2d). To do this, the vector layer of the main Costa Rican forest ecosystems was converted into a raster with a spatial resolution of 10 m to be compatible with the forest cover raster of the same resolution. The proportions of forest types were then calculated based on the number of corresponding pixels.
All analyses were performed using R version 4.3.3 (R Core Team 2024), with several specific packages, including “bioregion” (Denelle et al. 2025) for biogeographical network analysis, “caret” (Kuhn et al. 2024) for variable selection, training and prediction of the Random Forest model, and “rfPermute” (Archer 2023) for variable importance assessment, and finally the “pdp” package (B. M. Greenwell 2024) for calculating the marginal effects of the variables.
Results
3
Biogeographical Network Analysis
3.1
We identified 18 optimal clusters from the hierarchical clustering analysis applied to the forest inventory data. This analysis was based on the distribution of 495 dominant tree species selected from the 1333 species present at the sites, using a threshold IVI of 5%. These clusters explained 85.74% of the observed variation in species composition (Figure S2a). However, 8 of these clusters were not usable, represented by a single site, and were either merged with the main clusters if they showed sufficient floristic similarity, or excluded when they did not meet the representativeness threshold (details in Table S1). As a result, we retained 10 clusters for subsequent analysis (Figure 3a) that explained 69.77% of the observed variation (Figure S2). The cluster sizes ranged from 4 to 101 sites. These clusters, although highly unbalanced (Figure 4b), were obtained using the UPGMA algorithm, which preserves the structure of the dissimilarity matrix.
Geographical distribution of the 10 identified site clusters, determined through hierarchical clustering based on dissimilarity in species composition.
Analysis of species contribution to identified clusters: (a) Fraction of species contributing positively and significantly to a given number of clusters (from 0 to 5 or more) as a function of the significance threshold. The vertical line represents the significance threshold δ = 1.96. (b) Barplot of the numbers of contributive species (ρij ≥ 1.96) and sites according to identified clusters.
According to the significance threshold δ set at 1.96, 71% of the species contributed to a single cluster, and 18% contributed to two clusters. The maximum number of species contributing to only one cluster was reached at the specified threshold, indicating that the majority of the dominant canopy species were mainly associated with a single cluster (Figure 4a). As a result, the species assemblages associated with the clusters included between 20 and 88 contributive species, i.e., species that contributed positively and significantly to the clusters (Figure 4b). Details of the contributive species and their contribution values ρij are available in Table S2. In total, 322 species were identified as contributing among the 495 species dominating the forest canopy. The interaction network between clusters, based on the fraction of contributing species (λjj′), validated the strong specificity of the clusters, with a mean of 79.2%, ranging from 63% for cluster C9 to 98% for cluster C3 (Figure 5). Despite these variations in specificity, the network revealed weak interactions between clusters, with the maximum sharing of contributing species reaching 13% for λ6,1. Clusters C5, C6, C9, and C10 appear as transition zones between clusters associated with the high, medium, and low‐altitude wet biomes. In contrast, cluster C3, isolated, seems representative of the low‐altitude dry biome. All λjj′ interactions and shared species are presented respectively in Tables S3 and S4.
Interaction network illustrating the relationships between clusters and the associated contributive species assemblages. λjj′, expressed as a percentage, represents the mean fraction of contribution to the cluster j of species that also contribute significantly to the cluster j′. Only interaction with a value λjj′ higher than 5% are shown. The network is represented in two‐dimensional space, with altitude (in m) and Mean Annual Precipitation (in mm/year). The median of these variables is used for each cluster.
Delimitation and Characterisation of Forest Ecosystems Using Spectral and Environmental Data
3.2
Only clusters C1 to C7 had a sufficient number of plots to be modelled across the forest cover. The random forest classification models showed optimal performance when they included only the variables selected through a recursive feature elimination (RFE) procedure combined with manual removal of collinearity (Figure S3). The model achieved an overall F1‐score of 0.73 and a macro F1‐score of 0.58, although performance varied significantly across the clusters. Significant classification errors were observed for clusters C5, C7, and particularly C6, with respective error rates of 52.7%, 66.7%, and 83.3% (Table 2). Frequent classification errors observed in the confusion matrix, particularly from C1 to C2, from C6 to C1, from C4 to C5, as well as from C7 to C5 and C4, align with the cluster interactions highlighted in previous analyses. A notable proportion of classification errors was also observed from C5 to C1. In contrast, clusters C2 and C3 were distinguished with high accuracy by the model.
This classification model allowed to define, characterise, and delineate the forest ecosystems of Costa Rica based on the seven main clusters modelled. The seven explanatory variables selected for the model input show varying levels of discrimination depending on the clusters (Table 3). According to Mean Decrease Accuracy, which measures the impact of a variable on model accuracy by randomly permuting its values, all variables are globally significant. Altitude (q50.DEM) is the most discriminant variable on average, followed by precipitation seasonality (q25.PRSea), the NDWI index during the wet season (q25.NDWIw), and annual precipitation (q75.anPR). The least discriminant variables on average are pH (q50.pH 30), CEC (q50.CEC30) of the topsoil layer, and slope (q25.slope). According to Mean Decrease Gini, which measures the reduction in node impurity in decision trees when a variable is used for splitting, only four variables are significantly discriminant, precipitation seasonality (q25.PRSea) and altitude (q50.DEM), followed by annual precipitation (q75.anPR) and soil pH (q50.pH 30). The variable importance for each cluster highlights the model's difficulty in predicting clusters C5 to C7 using topographic, environmental, and seasonal vegetation dynamics variables.
Table 4 presents the identification and characterisation of the predicted forest ecosystems by combining (i) the significant variable importance (Table 3) and the marginal effects of key ecological variables retained by the model, whose log‐odds define the main ecological trends (Figure S4), (ii) the analysis of contributive species associated with the clusters (Table S2), (iii) the mean values of each explanatory variable for each cluster (Table S5), and (iv) the distribution of the seven forest ecosystems across Costa Rica (Figure 6a). Although the model's performance is relatively weak for clusters C5 to C7, it still captured certain ecological gradients that contributed to the definition of the associated forest ecosystems: PMC‐C, TWPE‐P, and PMC‐P.
Map of Costarican forest ecosystems based on a classification model of seven main clusters, derived from dissimilarity between inventoried forest sites in terms of dominant tree species composition, using a random forest model. WSE: Wet seasonal evergreen forest. LWE‐C: Lowland wet evergreen forest of the Caribbean slope. LDM‐DS: Lowland dry‐to‐moist deciduous‐to‐semi‐deciduous forest. MOR: Mountain oak rainforest. PMC‐C: Premontane‐to‐mountain mixed‐to‐evergreen cloud forest of the Caribbean slope. TWPE‐P: Transitional wet premontane evergreen forest of the Pacific slope. PMC‐P: Premontane‐to‐mountain mixed‐to‐evergreen cloud forest of Pacific slope. The table provides the names of ecosystems and their acronyms. a, b, and c represent three areas where forests were characterised at the local scale, and the results will be interpreted in the discussion section.
Analysis of the Distribution of Forest Types Within Predicted Forest Ecosystems
3.3
The analysis of the distribution of OGF and SF across the clusters and derived forest ecosystems revealed notable inversions in the proportions of OGF and SF for ecosystems LWE‐C and PMC‐P between the results of the two methods (Table 5). Overall, all main clusters and associated forest ecosystems exhibit a dominance of one forest type, with an average difference in OGF and SF proportions of 63% ± 23% in the clustering results and 58% ± 22% in those from Random Forest. A mean difference of 26% ± 22% in the proportions of forest types is observed between the clustering approach and the Random Forest approach, with this variation primarily due to the inverse predictions for two ecosystems, LWE‐C and PMC‐P.
Discussion
4
The objective of this study was to propose a replicable national approach to evaluate the potential of SF in maintaining dominant tree species structuring the forest ecosystems. Our approach was applied to Costa Rica. For that, we analysed dominant canopy species assemblages to better understand their contribution to the preservation and dynamics of forest ecosystems. Based on 364 plots, we identified and modelled seven major forest ecosystems in Costa Rica. These results relied on an approach that combined accessible data with local expertise. By integrating free environmental geodata sources, such as satellite spectral information, global spatial environmental databases, and open‐access digital elevation model (DEM), we produced a consistent forest mapping. Our approach achieved robust performance with an overall F1‐score of 0.73 and a macro F1‐score of 0.58, demonstrating the reliability of the model despite the imbalance between clusters. The challenge of differing spatial resolutions between floristic and environmental data was addressed using a segmentation method, dividing forest cover into spectrally homogeneous segments. This oriented objects approach was completed by statistical zoning based on percentiles, effectively capturing ecological trends specific to each segment and ensuring better representation of forest variations. The integration of expert knowledge was crucial for interpreting these data, refining models, and validating clusters through field campaigns. This method offers the advantage of being highly replicable; any country with local expertise and national forest inventory data can adopt it. Furthermore, the use of open‐source software such as R and QGIS enhances its accessibility and global applicability.
Defining Forest Ecosystems Through Dominant Tree Assemblages
4.1
The delineation of forest ecosystems was carried out using higher‐level clusters to ensure a good balance between sampling size and satisfactory modelling performance across the entire forest cover. The classification performance of clusters was influenced by sampling biases in terms of accessibility and altitude (Table S6), with only 4% of plots between 1000 and 1500 m and 14% between 500 and 1000 m. This primarily affected the classification of ecosystems PMC‐C, TWPE‐P, and PMC‐P within these ranges. Despite these limitations, the overall forest‐type characterisation remains robust, supported by local‐scale studies. Three well‐documented sites in Costa Rica, located in ecologically diverse areas, confirm this consistency and demonstrate the effectiveness of our approach in complex contexts.
In the San Juan‐La Selva Biological Corridor in northeastern Costa Rica, two forest ecosystems (WSE and LWE‐C) coexist (Figure 6b). Three lowland forest types have been identified (Sesnie et al. 2008): Pentaclethra macroloba forests, dominant in LWE‐C; Qualea paraensis, Vochysia ferruginea, and Couma macrocarpa forests, characteristic of WSE; and Dialium guianense , Brosimum alicastrum , and Tachigali costaricensis forests, spanning WSE and LWE‐C. Additionally, piedmont and premontane species like Vochysia allenii and Macrohasseltia macroterantha are abundant in WSE.
In the rainforests of the Talamanca Cordillera, where ecosystems WSE, MOR, and PMC‐C coexist along an altitudinal gradient up to 2520 m (Figure 6c), three main forest types have been characterised (Veintimilla et al. 2019): Lowland forests (440–1120 m) are dominated by Pourouma bicolor, Vochysia allenii, and Calophyllum brasiliense (WSE); intermediate forests (1400–1660 m) host both lowland and montane species, primarily Oreomunnea mexicana (MOR), alongside Billia rosea (MOR), Alchornea latifolia , and Cecropia insignis (PMC‐C); montane forests (2150–2950 m) define MOR, dominated by Quercus bumeliodes, Drimys granadensis, Ocotea austinii, and Weinmannia pinnata (MOR).
The Osa Peninsula, home to WSE, LWE‐C, LDM‐DS, TWPE‐P, and PMC‐P (Figure 6d), is among Costa Rica's most biodiverse regions due to its environmental and topographical variability (Hofhansl et al. 2020). With 28 forest types, no single canopy species dominates (Gilbert and Kappelle 2016). Despite high endemism and wet forest dominance, lowland forests also include species from drier and moister habitats of Nicoya and the Central Valley, explaining LDM‐DS continuity into the peninsula (Zamora et al. 2004). Some moist and wet lowland forest species of the Osa Peninsula also occur on the Caribbean coast, indicating a floristic and climatic affinity across the Talamanca Range, consistent with WSE, LWE‐C, and TWPE‐P distributions (Table S7).
The analysis of these examples shows that the local heterogeneity of forests is well represented by forest ecosystems based on dominant canopy species. It highlights the key role of oligarchic species in structuring assemblages across diverse, sometimes discontinuous, regions within the same ecosystem type. Specifically, Vochysia spp. and Pourouma bicolor define the WSE ecosystem, Goethalsia meiantha characterises LWE‐C, and * Cordia alliodora, Spondias* spp., and Brosimum spp. dominate LDM‐DS (Sesnie et al. 2008; Gilbert and Kappelle 2016). The distribution of oligarchic species is strongly correlated with geographical and topographical variables, particularly in the lowland forests of the Osa Peninsula (Hofhansl et al. 2019; Morera‐Beita et al. 2019). These findings enhance the understanding of the regional spatial complex distribution of ecosystems at large spatial scales (Figure 6). The contribution values of species are available in Table S2.
Importance of Spectral and Environmental Factors in Ecosystem Characterisation and Their Interactions
4.2
Our approach identifies contributive species assemblages that significantly define forest ecosystems, enabling analysis of their interactions and specificities. Using abundance data from forest inventories, we calculate the average fraction of species contributing to cluster j that also contribute to cluster j' (Lenormand et al. 2019). In Costa Rica, assemblages show greater specificity in lowland (WSE, LWE‐C, LDM‐DS) and in high‐mountain (MOR) forests but are less distinct in intermediate ecosystems (PMC‐C, TWPE‐P, PMC‐P). Low interaction rates between ecosystems at the national level reflect abiotic filters shaping habitat diversity, which drives high biodiversity (Araújo and Rozenfeld 2014).
Forest ecosystems are mostly structured by environmental gradients that directly influence the contribution of dominant canopy species, which have played a key role in their definition. Through Random Forest modelling, we observe that topography, followed by climate and the NDWI index—used here to estimate water content in vegetation and, consequently, water stress—are the most determining factors in the turnover of tree species composition that structure ecosystems. However, edaphic properties also play an important role, as evidenced by the selection of pH and CEC among the seven variables chosen for the modelling. Our results are consistent with previous studies conducted in tropical forests across South and Central America, where tree species turnover has been associated with these environmental variables, as well as canopy reflectance, at spatial scales ranging from regional to continental (e.g., Pérez Chaves et al. 2020; Bañares‐de‐Dios et al. 2022; Jakovac et al. 2022; Nuñez et al. 2024). The integration of these environmental determinants with the analysis of contributive species assemblages allowed for the characterisation and naming of forest ecosystems derived from in situ clusters (Table 4). This designation is based on two national, well‐established ecological‐vegetation mapping systems: life zones (Holdridge 1967), defined by bioclimatic factors, and phytogeographic units (Zamora 2008), determined by floristic composition associated with topographic, climatic, and soil type factors. A detailed description of these ecosystems, integrating the contribution of key environmental variables in the modelling as well as the assemblages of species that significantly characterise them, is provided in Table S8.
Contribution of Secondary Forests to the Dynamics and Conservation of National Forest Ecosystems
4.3
Anthropogenic pressures shape forest ecosystems by influencing species composition, distribution, and interactions. The spread of SF, driven by past and present disturbances (Arroyo‐Rodríguez et al. 2017), helps assess human impact. While SF distribution differs minimally between in situ clusters and model‐derived ecosystems, LWE‐C and PMC‐P show inverse trends: modelling predicts more SF in LWE‐C and more OGF in PMC‐P, contrasting with clustering results obtained from in situ data. This may stem from sampling bias favouring OGF plots in accessible, lower‐altitude areas, particularly in LWE‐C. However, for PMC‐P, botanical expertise and national disturbance records confirm its accuracy. In Costa Rica, colonisation history has influenced land use, shaping the distribution of OGF and SF (Redo et al. 2012; Aide et al. 2013; Shaver et al. 2015). Since pre‐Columbian times, human activity on the northern Pacific coast and central highlands (LDM‐DS) converted dry forests mainly into cattle pastures, later abandoned and replaced by SF mosaics. During colonial times, deforestation expanded to pre‐mountain Pacific areas (PMC‐P) due to their proximity to the central valley, mild climate, and fertile soils, ideal for coffee cultivation, which fuelled SF expansion. On the Caribbean coast (LWE‐C), intense deforestation (1960s–1980s) in particular for banana and pineapple monocultures fragmented OGF, restricting it to inaccessible high‐altitude zones (PMC‐C, MOR). In Osa Peninsula lowlands, about half the forest remains OGF (WSE and TWPE‐P), though degradation from logging and oil palm plantations has driven SF expansion in LWE‐C, LDM‐DS, and TWPE‐P. These findings align with Random Forest modelling, which corrected OGF bias in LWE‐C using ecological variables. However, for PMC‐P, model limitations persisted, reflected in a low F1‐score (0.38). The SF proportion in each ecosystem reflects the level of anthropogenic pressure reshaping the forested landscape, playing a crucial role in floristic dynamics and significantly influencing the evolution of forest floras.
Analysis of SF contributions to forest ecosystems revealed their limited ability to maintain OGF‐specific tree assemblages, identified through clustering and Random Forest modelling. In Costa Rica, OGF dominates WSE, MOR, PMC‐C, and TWPE‐P, while SF prevails in LWE‐C, LDM‐DS, and PMC‐P. This suggests SF, in its current stages, remains compositionally distinct from OGF (Rozendaal et al. 2019; Mertz et al. 2021) especially in MOR, where OGF fully dominates due to inaccessibility. However, SF ecosystems like LWE‐C and LDM‐DS should not be seen as degraded but as distinct ecosystems with their own species assemblages (Pain et al. 2021). OGF and SF distinctions blur at the canopy level, as both share many species, though one tends to dominate per ecosystem. Some plots classified as OGF are likely forests that have undergone a certain degree of human intervention, which explains the significant presence of species typical of SF or fast‐growing species. In OGF‐dominated landscapes with low‐intensity land use, SF could follow optimal successional paths, helping preserve native flora (Rosenfield et al. 2023).
This study provides a first assessment of forest ecosystem vulnerability at the national level. In the case of Costa Rica, MOR appears the most threatened, with its contributive species strictly confined to high altitudes (> 2150 m) and a 90% specificity rate. Its high vulnerability arises from SF's inability to sustain itself and the potential loss of its ecological niche due to climate change, despite low anthropogenic pressure. In contrast, PMC‐C seems the least vulnerable, dominated by OGF with an 85% specificity rate and benefiting from natural protection due to inaccessibility. Its species adapt to a wider altitudinal range (< 1300 m), enhancing resilience to climate change. Lowland and mid‐mountain ecosystems (WSE, LWE‐C, LDM‐DS, TWPE‐P, PMC‐P) face high anthropogenic pressures, with specificity rates of 78%–99%. In these areas, young SF are particularly vulnerable, often seen as fallow lands (Reid et al. 2019), threatening their regeneration potential and long‐term ecosystem stability.
Limits and Perspectives
4.4
The approach used has limitations related to the quantity and distribution of available field data. With only 364 sampling plots at the national scale, the classification of forest ecosystems in Costa Rica faced a sampling power imbalance between clusters, impacting the modelling performance in particularly for clusters C5 to C7. This imbalance is partly due to sampling biases related to the accessibility and altitudinal distribution of the plots, favouring forests located at low and medium altitudes. Moreover, the variability of the plots by forest types (OGF and SF) in the sampling also affects the species composition in each assemblage. Classification effectiveness depends on the quantity and representativeness of available data. Well‐sampled clusters (C1–C3) show clear ecological trends and high performance, while underrepresented clusters (C5–C7) have broader, harder‐to‐distinguish trends. Cluster C4 is an exception—despite being undersampled, its strict ecological characteristics enable better classification. In Costa Rica, these findings underscore the need for greater financial investment in forest inventories to enhance model accuracy by increasing plot numbers and improving representation of mid‐ and high‐altitude forests, which are harder to access.
Data acquisition remains a major challenge, highlighting countries' difficulties in collecting essential biodiversity data for monitoring, tracking, and modelling. Significant disparities exist in generating in situ data due to high costs, lack of standardisation, and coordination challenges. These limitations hinder comprehensive data collection, affecting national biodiversity strategies and global assessments (Chapman et al. 2024). As a result, global biodiversity data remains highly uneven, hindering accurate assessments of ecosystem status, extent, and distribution (Gonzalez and Londoño 2022). This data gap weakens efforts to guide conservation actions and monitor progress toward protecting 30% of land by 2030, a core target of the Kunming‐Montreal Global Biodiversity Framework (GBF) adopted in 2022 (CBD 2022). The GBF emphasises ecosystem integrity and connectivity, yet lacks explicit targets for national biodiversity monitoring systems (Perino et al. 2022). The Ecosystem Extent Indicator, a key metric for tracking ecosystem loss and degradation at the global level, highlights the urgency of strengthening standardised monitoring frameworks to assess ecosystem trends effectively. However, disparities in data availability, financial resources, and technical capacity create major obstacles for many countries. International financial and technical support is therefore essential to enable comprehensive biodiversity monitoring, ecosystem extent assessments, and effective conservation planning (Gonzalez and Londoño 2022; Cardona Santos et al. 2023). Without these investments, achieving the GBF 2030 targets and reversing biodiversity loss will remain a significant challenge. In the absence of such funding, the deployment of cost‐effective monitoring systems relies on integrating remote sensing with biodiversity surveillance models at national scales, complementing in situ data to enhance spatial representativeness (Fernández et al. 2020). These large‐scale extrapolated quantitative models must be incorporated into participatory approaches that engage both expert and local knowledge to strengthen the effective implementation of the GBF at the national level (Rosa et al. 2017; Xu et al. 2021).
In this context, the approach developed and tested in this study—designed to be operational and replicable in other tropical countries—aims to enhance the identification and assessment of tropical forest ecosystems by analysing the contribution of SF. Importantly, this operational framework represents a critical step toward prioritising tropical forest conservation at the national level, directly supporting the goal of protecting 30% of terrestrial land. By integrating national forest inventories, spectral data, and global environmental databases, the approach enables the identification and characterisation of forest ecosystems based on contributive species assemblages, ecosystem interactions, and ecological specificity. Moreover, it provides key insights into the role of SF in maintaining and shaping forest dynamics. Besides, the network of interactions (Figure 5) highlights the specificity of different clusters or bioregions in terms of species assemblages and their interrelationships. This approach allows rapid identification of highly specific clusters as well as transition areas, providing a concise summary of ecological relationships across the country. While the primary focus of this study is on mapping and characterising species assemblages, these network patterns offer valuable insights for future conservation planning. In particular, key network metrics (e.g., λjj′) could help identify priority areas and guide biodiversity management at regional and national scales, representing an important avenue for subsequent research.
From a conservation prioritisation perspective, developing a vulnerability categorisation for ecosystems facing anthropogenic pressures and climate change (Guariguata and Ostertag 2001; Edwards et al. 2019) is essential. This can be achieved using vulnerability indices (Kumar et al. 2021; Roshani et al. 2024) that incorporate ecosystem specificity, interaction strength, and detailed analyses of how contributive species respond to disturbances (Fremout et al. 2020; Pang et al. 2023). Future research should aim to explicitly link the identified tree assemblages to key ecosystem functions and biodiversity metrics (Lohbeck et al. 2016; Fichtner and Härdtle 2021; Zhang and Zang 2021; Cooper et al. 2024). Such analyses would help clarify whether different assemblages contribute in complementary or redundant ways to ecosystem multifunctionality, thereby strengthening the conservation implications of the delineated forest ecosystems. To further reduce sampling biases, the integration of citizen science data, such as those available through GBIF, should be considered in future studies (Fraisl et al. 2022). Additionally, a fully remote sensing‐based approach could be employed to generate spectral clusters that capture spectral diversity, which may strongly correlate with species richness, beta diversity, and functional diversity derived from in situ observations (Féret and de Boissieu 2020; Chraibi et al. 2021; Perrone et al. 2023; Lenormand et al. 2025). These perspectives represent a first step toward improving understanding of the role of secondary forests in conserving tropical forest ecosystems at the national scale.
Author Contributions
Maïri Souza Oliveira: conceptualization (lead), data curation (lead), formal analysis (lead), investigation (equal), methodology (equal), validation (equal), visualization (equal), writing – original draft (equal), writing – review and editing (equal). Maxime Lenormand: investigation (equal), methodology (equal), software (lead), writing – review and editing (equal). Sandra Luque: conceptualization (equal), funding acquisition (equal), investigation (equal), methodology (equal), project administration (lead), supervision (lead), visualization (equal), writing – review and editing (equal). Nelson A. Zamora: conceptualization (equal), investigation (equal), methodology (equal), resources (equal), validation (equal), writing – review and editing (equal). Samuel Alleaume: methodology (equal), resources (equal), writing – review and editing (equal). Adriana C. Aguilar Porras: investigation (equal), resources (equal). Marvin U. Castillo: resources (equal). Eduardo Chacón‐Madrigal: resources (equal), writing – review and editing (equal). Diego Delgado: investigation (equal), resources (equal). Luis Gustavo Hernández Sánchez: resources (equal). Marie‐Ange Ngo Bieng: conceptualization (equal), funding acquisition (equal), investigation (equal), supervision (equal), writing – review and editing (equal). Ruperto Quesada‐Monge: resources (equal). Gilberth S. Solano: resources (equal). Pedro M. Zúñiga: resources (equal).
Conflicts of Interest
The authors declare no conflicts of interest.
Supporting information
Data S1: ece372428‐sup‐0001‐Supinfo.docx.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Aguirre‐Gutiérrez, J. , S. W. Rifai , X. Deng , et al. 2025. “Canopy Functional Trait Variation Across Earth's Tropical Forests.” Nature 641: 129–136. https://www.nature.com/articles/s 41586‐025‐08663‐2.40044867 10.1038/s 41586-025-08663-2PMC 12043511 · doi ↗ · pubmed ↗
- 2Aide, T. M. , M. L. Clark , H. R. Grau , et al. 2013. “Deforestation and Reforestation of Latin America and the Caribbean (2001–2010).” Biotropica 45: 262–271. 10.1111/j.1744-7429.2012.00908.x. · doi ↗
- 3Araújo, M. B. , and A. Rozenfeld . 2014. “The Geographic Scaling of Biotic Interactions.” Ecography 37: 406–415. 10.1111/j.1600-0587.2013.00643.x. · doi ↗
- 4Archer, E. 2023. “rf Permute: Estimate Permutation p‐Values for Random Forest Importance Metrics.” https://cran.r‐project.org/web/packages/rf Permute/index.html.
- 5Arroyo‐Rodríguez, V. , L. Fahrig , M. Tabarelli , et al. 2020. “Designing Optimal Human‐Modified Landscapes for Forest Biodiversity Conservation.” Ecology Letters 23: 1404–1420. 10.1111/ele.13535.32537896 · doi ↗ · pubmed ↗
- 6Arroyo‐Rodríguez, V. , F. P. L. Melo , M. Martínez‐Ramos , et al. 2017. “Multiple Successional Pathways in Human‐Modified Tropical Landscapes: New Insights From Forest Succession, Forest Fragmentation and Landscape Ecology Research.” Biological Reviews 92: 326–340. 10.1111/brv.12231.26537849 · doi ↗ · pubmed ↗
- 7Balvanera, P. , H. Paz , F. Arreola‐Villa , et al. 2021. “Social Ecological Dynamics of Tropical Secondary Forests.” Forest Ecology and Management 496: 119369. https://www.sciencedirect.com/science/article/pii/S 0378112721004576.
- 8Bañares‐de‐Dios, G. , M. J. Macía , G. M. de Carvalho , G. Arellano , and L. Cayuela . 2022. “Soil and Climate Drive Floristic Composition in Tropical Forests: A Literature Review. Frontiers in Ecology and Evolution.” Frontiers 10: 866905. 10.3389/fevo.2022.866905/full. · doi ↗