GCSAM: Gradient Centralized Sharpness Aware Minimization
MOHAMED HASSAN, ALEKSANDAR VAKANSKI, BOYU ZHANG, MIN XIAN

TL;DR
This paper introduces GCSAM, an improved optimization method that enhances the generalization and efficiency of deep learning models, especially in medical imaging.
Contribution
GCSAM integrates Gradient Centralization with Sharpness-Aware Minimization to reduce noise and improve training stability.
Findings
GCSAM outperforms SAM and Adam in generalization on vision and medical imaging datasets.
Gradient Centralization stabilizes training and reduces computational overhead.
Results show consistent improvements in robustness and efficiency for critical applications like medical image analysis.
Abstract
The generalization performance of deep neural networks (DNNs) is a critical factor in achieving robust model behavior on unseen data. Recent studies have highlighted the importance of sharpness-based measures in promoting generalization by encouraging convergence to flatter minima. Among these approaches, Sharpness-Aware Minimization (SAM) has emerged as an effective optimization technique for reducing the sharpness of the loss landscape, thereby improving generalization. However, SAM’s computational overhead and sensitivity to noisy gradients limit its scalability and efficiency. To address these challenges, we propose Gradient-Centralized Sharpness-Aware Minimization (GCSAM), which incorporates Gradient Centralization (GC) to stabilize gradients and accelerate convergence. GCSAM normalizes gradients before the ascent step, reducing noise and variance, and improving stability during…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
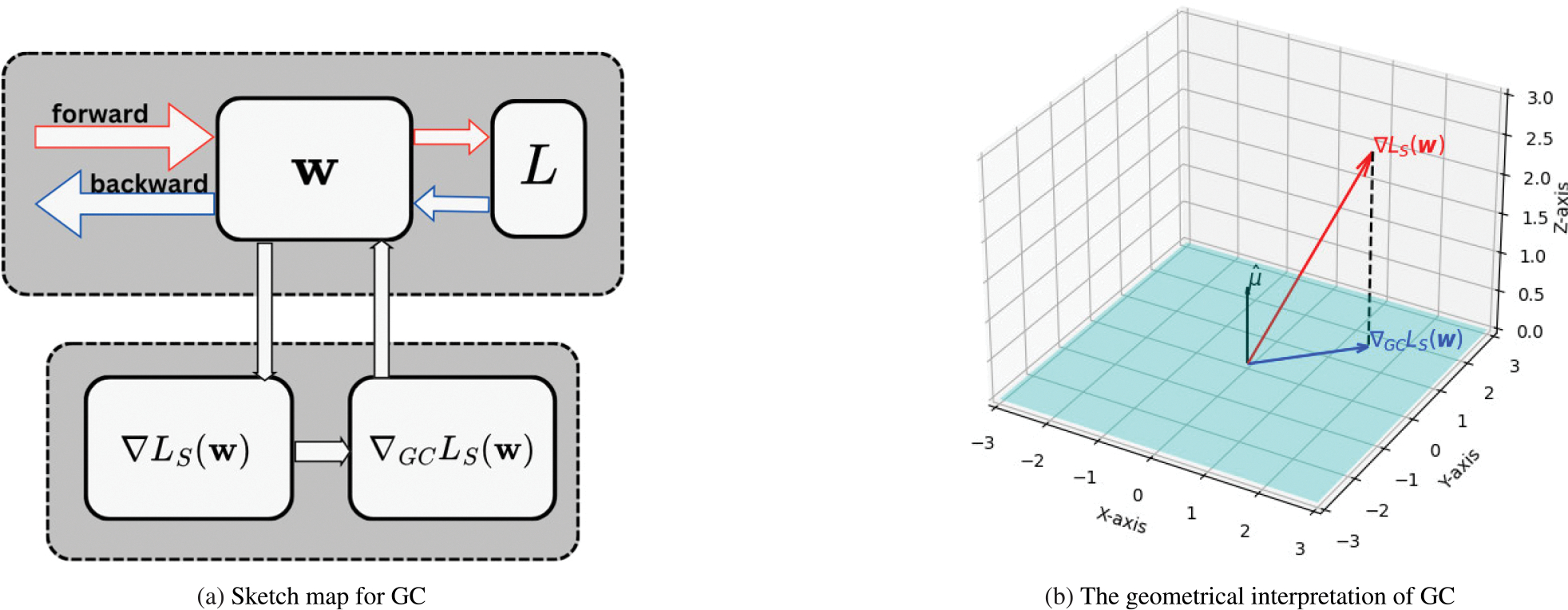 Figure 1
Figure 1 Figure 2
Figure 2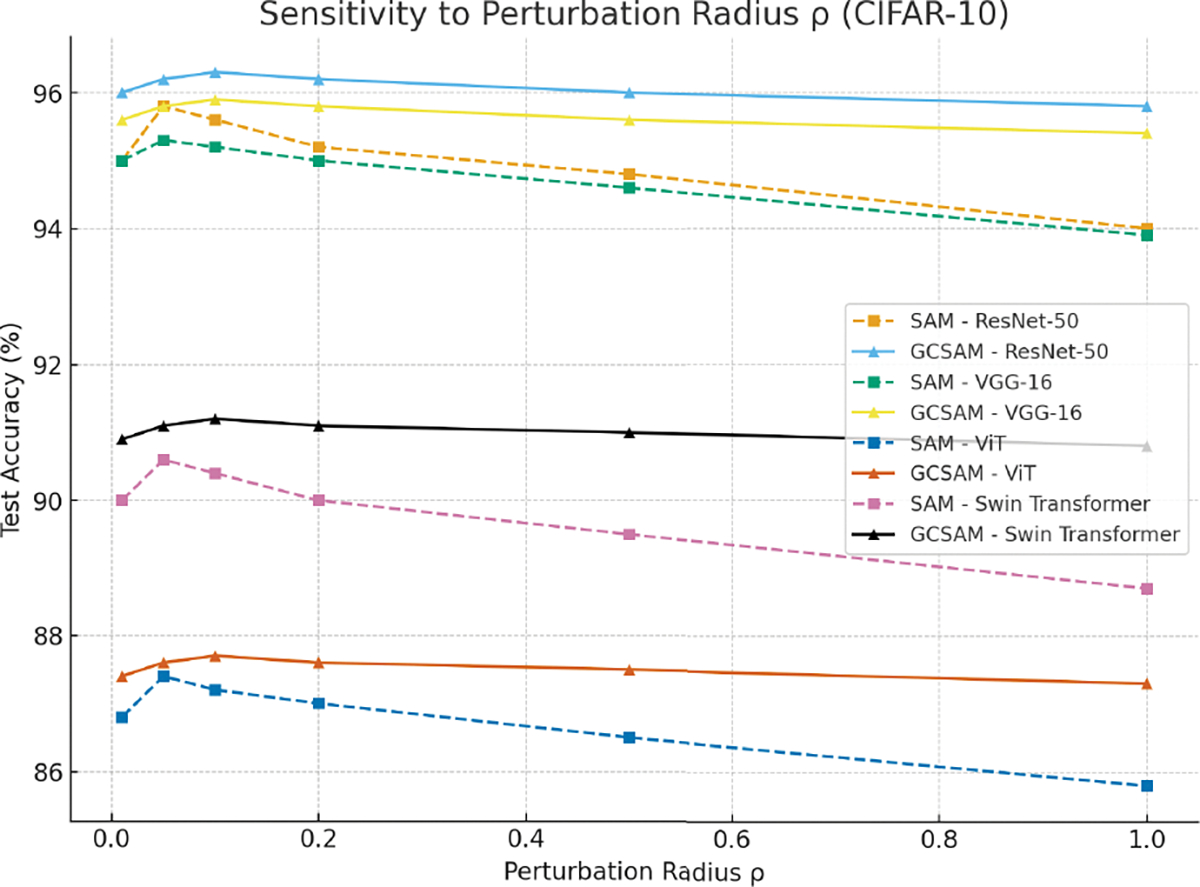 Figure 3
Figure 3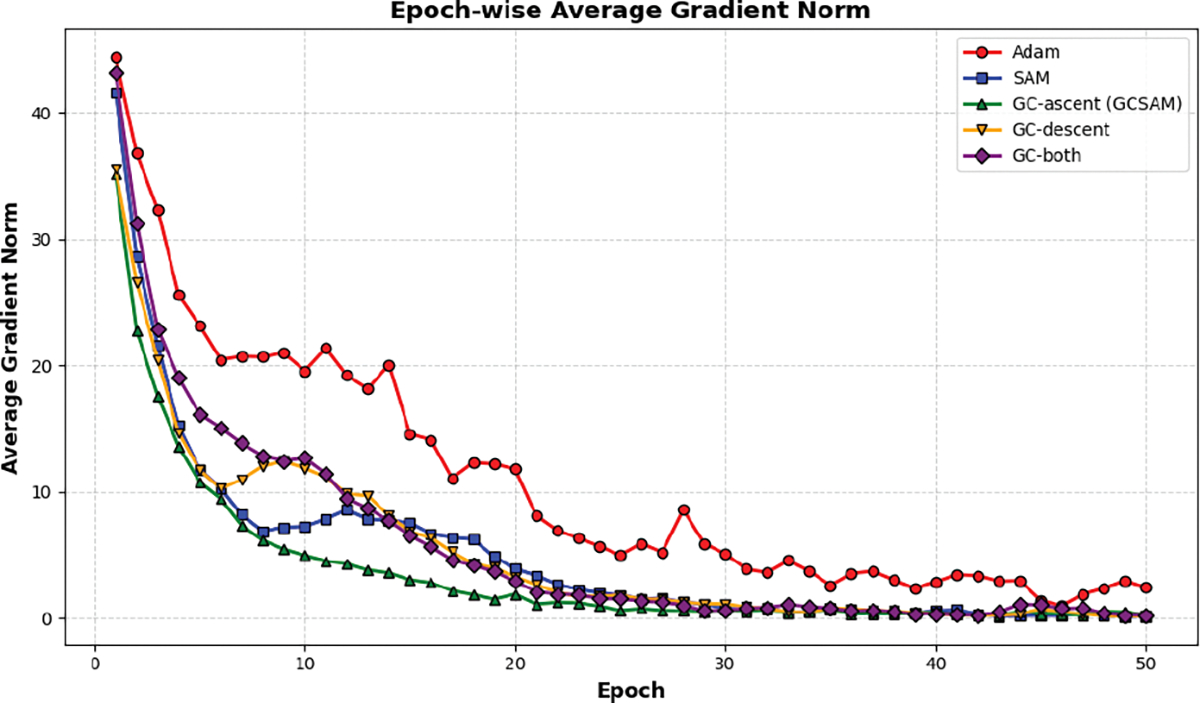 Figure 4
Figure 4 Figure 5
Figure 5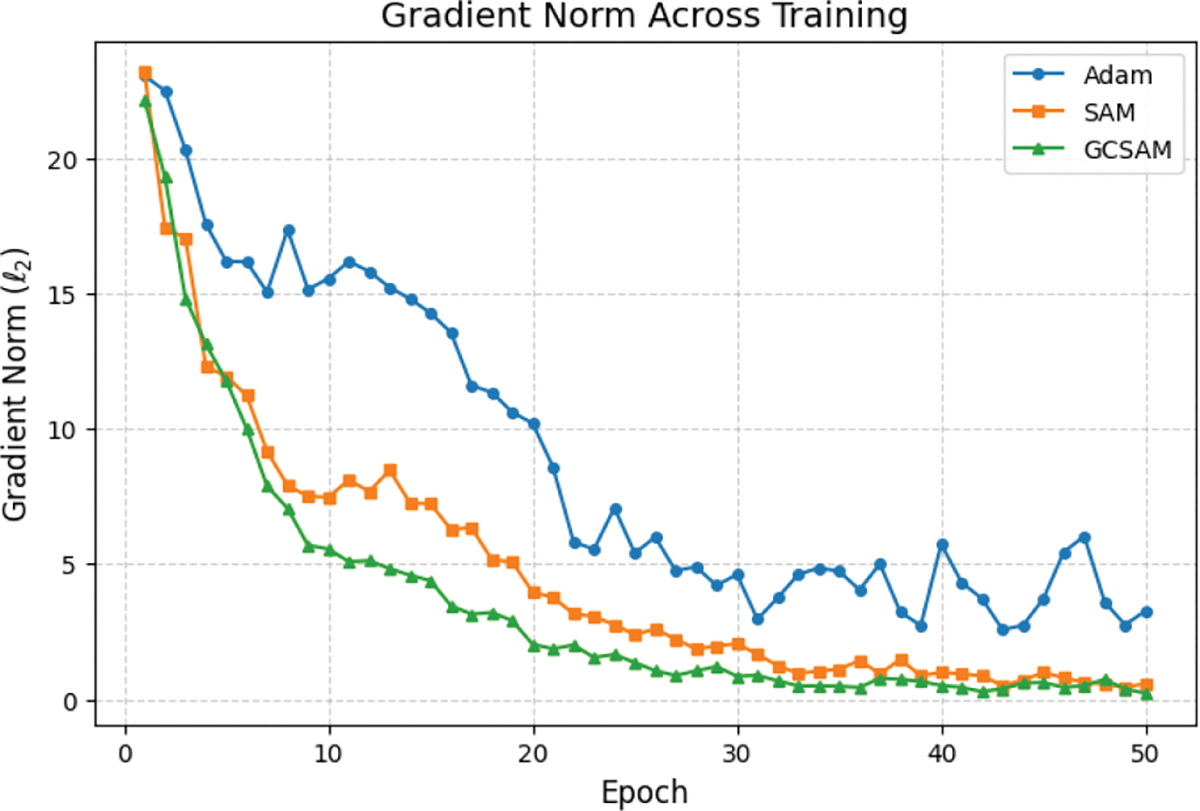 Figure 6
Figure 6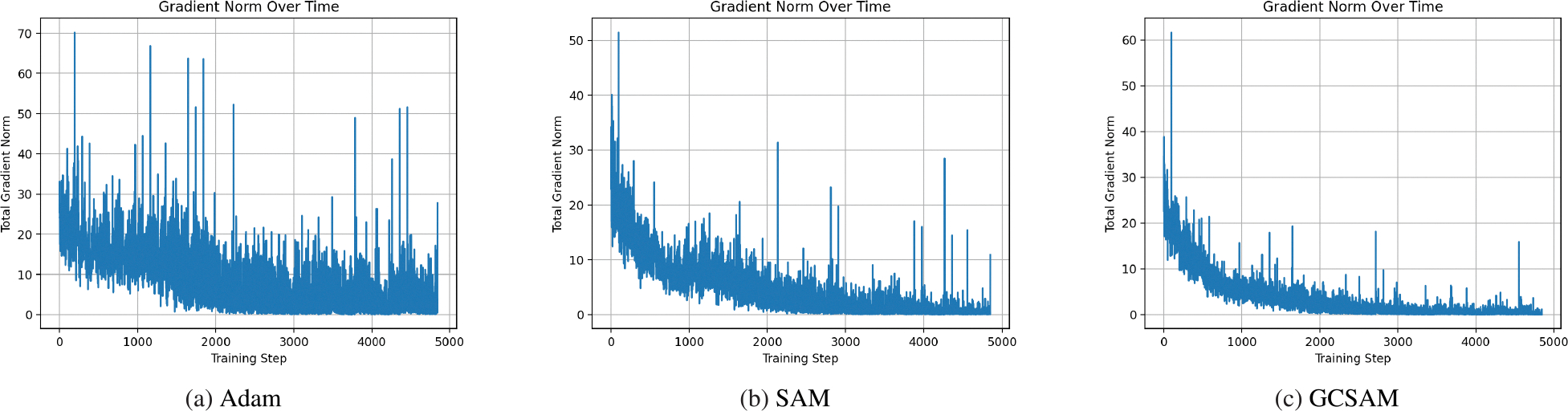 Figure 7
Figure 7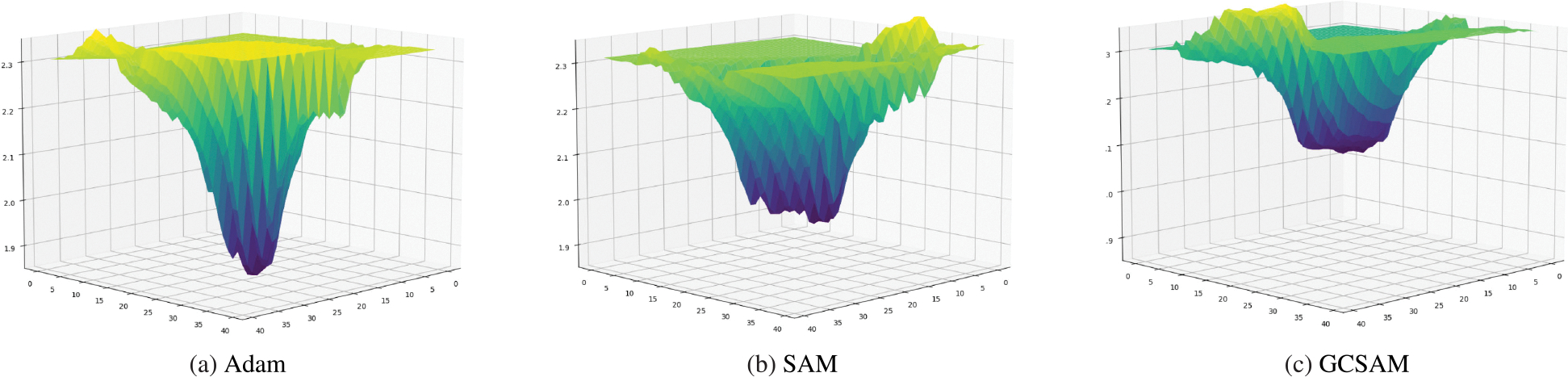 Figure 8
Figure 8Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRetinal Imaging and Analysis · Brain Tumor Detection and Classification · Advanced Neural Network Applications
INTRODUCTION
I.
Understanding the generalization behavior of overparameterized deep neural networks (DNNs) has recently become a important area of study, as it offers valuable insights into handling overfitting and enhancing performance on unseen data [1], [2]. As the scale of models and datasets continues to expand, the development of optimization algorithms that enhance generalization capabilities becomes increasingly critical. To better understand the generalization behavior of DNNs, comprehensive empirical studies by Jiang et al. [3] and Dziugaite et al. [4] have evaluated various generalization metrics, finding that sharpness-based measures exhibit the strongest correlation with generalization performance. Based on these findings, optimizers that lead to flatter minima, rather than sharp minima, are particularly effective in promoting generalization, as flatter minima have been shown to correlate strongly with improved model performance in overparameterized setting [5], [6].
Sharpness-Aware Minimization (SAM) [7] is a promising optimization technique for finding flatter minima to improve generalization, which achieved consistent improvement in generalization performance across various natural image and language benchmarks [8], [9], [10], [11]. SAM regularizes the sharpness of the loss landscape by simultaneously minimizing the training loss and the loss sharpness. SAM achieves this by employing adversarial perturbations to maximize the training loss , where is the weight vector. It then minimizes the loss of this perturbed objective using an update step from a base optimizer, such as Adam [12]. To compute , SAM takes a linear approximation of the loss objective, and uses the gradient as the ascent direction for computing , where is the radius of the maximization region, and .
However, SAM introduces a significant computational overhead, as the ascent step requires additional forward and backward passes, which doubles the training time. Furthermore, the two-step training process requires tuning additional hyper-parameters, which if not selected correctly, can lead to suboptimal performance or inefficient training. For instance, Wu et al. [13] and Chen et al. [14] demonstrate that the perturbation radius should be adjusted beyond the range initially proposed by Foret et al. [7] to achieve optimal results. Additionally, while SAM successfully regularizes the sharpness of the loss landscape, it does not address the issue of noisy and high-variance gradients, which can hinder the generalization performance.
To address these limitations, we propose Gradient Centralized Sharpness Aware Minimization (GCSAM), which integrates Gradient Centralization (GC) [15] into the ascent step of SAM. GCSAM reduces gradient noise and stabilizes the perturbation direction. This results in more reliable sharpness estimation, smoother optimization trajectories, and faster convergence. References [15], [16], and [17] Moreover, the use of GC makes GCSAM less sensitive to the perturbation radius , improving robustness across different datasets and architectures.
Crucially, the integration of GC into SAM is not merely additive. We show that GC directly addresses a key shortcoming of SAM, the amplification of gradient noise during sharpness-aware ascent, by smoothing the perturbation direction and improving the Lipschitzness of both the loss and its gradient. This leads to smaller, more stable perturbations and tighter generalization bounds, as we formally prove in Appendix A. Unlike prior work such as GSAM, ASAM, or CRSAM, which focus on reparameterizing or regularizing the sharpness objective, GCSAM improves the core optimizer behavior by stabilizing the curvature-sensitive components of SAM itself. In summary, our main contributions are as follows:
- We propose GCSAM, a novel algorithm that combines Gradient Centralization (GC) with Sharpness-Aware Minimization (SAM). This integration targets both sharpness reduction and gradient stabilization, resulting in improved generalization.
- GCSAM addresses limitations in SAM by reducing computational overhead and mitigating issues of gradient noise. By centralizing gradients, GCSAM provides a more stable optimization process that reduces gradient explosion, enhancing both efficiency and robustness.
- We validate GCSAM’s performance on a range of benchmarks, demonstrating improved generalization in both general and medical imaging datasets. Our results indicate GCSAM’s ability to outperform SAM and baseline optimizers in achieving higher test accuracy with enhanced computational efficiency.
RELATED WORK
II.
LOSS SHARPNESS AND GENERALIZATION
A.
The connection between the geometry of the loss landscape and generalization has been the subject of extensive research effort. Chaudhari et al. [18] proposed Entropy-SGD, an approach aimed at minimizing the local entropy of the loss landscape to guide the optimization process toward flatter regions, thereby improving generalization. Similarly, Smith and Le [19] demonstrated that incorporating noise in SGD prevents optimization from entering sharp valleys. Furthermore, Lyu et al. [20] revealed that gradient descent has an inherent bias toward reducing sharpness, especially in the presence of normalization layers [21] and weight decay [22], which further supports the importance of managing the sharpness of the loss landscape to improve generalization in DNNs.
IMPROVING SAM
B.
Several variants of SAM have been proposed to enhance its performance and address its limitations. Adaptive-SAM (ASAM) [8] modifies SAM by introducing a scaling operator that eliminates sensitivity to model parameter rescaling, allowing more robust generalization across different models. Kim et al. [23] refined both SAM and ASAM by leveraging Fisher information geometry, providing a more effective method of minimizing sharpness in the parameter space. Zhuang et al. [9] highlighted that minimizing the perturbed loss in SAM does not always guarantee a flatter loss landscape, leading to the development of Surrogate-Gap SAM (GSAM), which incorporates a measure akin to the dominant eigenvalue of the Hessian matrix to capture sharpness more accurately. Additionally, Wu et al. observed that SAM’s one-step gradient approach may lose effectiveness due to the non-linearity of the loss landscape. To address this, they proposed Curvature Regularized SAM (CR-SAM) [10], which integrates a normalized Hessian trace to more precisely measure and regulate the curvature of the loss landscape. Kaddour et al. introduced Weight-Averaged SAM (WASAM) [24], which integrates SAM with Stochastic Weight Averaging (SWA) [25]. Their findings demonstrate that WASAM enhances SAM’s generalization performance, particularly in Natural Language Processing (NLP) tasks.
In addition to improving performance, several algorithms have been proposed to mitigate the computational overhead associated with SAM. Liu et al. introduced LookSAM [26], which accelerates SAM by periodically computing the inner gradient ascent at every kth iteration instead of at each step, reducing the frequency of expensive updates. Du et al. proposed Efficient SAM (ESAM) [27], which minimizes the number of input samples in the second forward and backward passes by utilizing Stochastic Weight Perturbation (SWP) and Sharpness-sensitive Data Selection (SDS) to balance efficiency and sharpness minimization. Furthermore, Becker et al. developed Momentum SAM (MSAM) [28], incorporating Nesterov Accelerated Gradient (NAG) [29] to perturb parameters along the direction of the accumulated momentum vector, which improves both the convergence rate and computational efficiency of SAM.
GRADIENT OPTIMIZATION
C.
Significant research effort has been dedicated to stabilizing and accelerating DNN training through operations on gradients. Gradient clipping [30], [31], [32] was introduced to mitigate the issue of exploding gradients by limiting their magnitude during backpropagation. Qian [33] explored the use of momentum to accelerate gradient descent optimizers and reduce oscillations, enhancing convergence speed. Further, Riemannian methods [34] and projected gradient techniques [35], [36], [37] were employed to regulate weight learning by projecting gradients onto subspaces, promoting more stable learning trajectories. Smith et al. [38] leveraged the gradient norm to derive an implicit regularization term in stochastic gradient descent (SGD), aiding generalization. Additionally, regularization of weight gradients remains one of the most widely adopted strategies to improve the generalization capabilities of DNNs [22], [39].
METHOD
III.
In this section, we outline the methodological approaches of three techniques: Sharpness-Aware Minimization (SAM), Gradient Centralization (GC), and our proposed Gradient Centralized Sharpness-Aware Minimization (GCSAM).
SHARPNESS AWARE MINIMIZATION (SAM)
A.
While empirical risk minimization algorithms, such as SGD and Adam, effectively reduce the empirical loss to achieve low training error, addressing the generalization gap remains a challenge in DNN training. Keskar et al. [40] proposed that there is a connection between the sharpness of minimized empirical loss and the generalization gap, as the large sensitivity of the training function at a sharp minimizer negatively impacts the trained model’s ability to generalize on new data. To formalize this connection, sharpness is defined within an -ball as:
where is the radius of maximization region of an ball. From the above definition, sharpness is the difference between the maximum empirical loss in the ball and the empirical loss.
Foret et al. [7] introduced Sharpness-Aware Minimization (SAM), which integrates sharpness minimization with a PAC-Bayes norm to improve generalization. SAM is designed to enhance generalization by minimizing the sharpness of the loss landscape, encouraging convergence to flat minima. This is achieved by optimizing the following PAC-Bayesian generalization error bound:
where the monotonic nature of allows substitution with an weight-decay regularizer. Thus, SAM can be formulated as a minimax optimization problem, aiming to mitigate generalization error while maintaining training stability:
GRADIENT CENTRALIZATION (GC)
B.
Gradient Centralization (GC) [15] is an optimization technique that improves training stability and generalization by enforcing zero-mean gradients during backpropagation. Unlike batch normalization and gradient normalization methods [41], [42], which directly modify activation matrices, GC operates directly on gradient vectors or matrices.
Let denote the mini-batch gradient at training step , where is the number of elements in . For an individual weight vector , the centralized gradient is computed by subtracting the mean of its entries:
Equivalently, letting denote the mean gradient, we can express GC compactly as
where is the projection matrix and is the allones unit vector. This shows that GC removes the component of that lies in the direction of , constraining updates to a hyperplane orthogonal to the mean direction, as illustrated in Fig. 1b and Fig. 2b.
In practice, GC is applied per parameter tensor and per step, excluding 1-D tensors such as bias and batch-norm parameters to avoid degenerate centralization. The averaging operator in Eq. (4) denotes the per-tensor mean computed from a single mini-batch gradient tensor and subtracted immediately. This per-step operation is conceptually distinct from an exponential moving average (EMA) computed across training iterations. A GC-EMA variant would maintain a running mean
and subtract from at step . While this may further smooth temporal fluctuations, it introduces the additional hyperparameter and interacts nontrivially with optimizer moment estimates (e.g., Adam’s moving averages). For clarity and consistency with prior GC work, we adopt the per-step formulation as default and discuss GC-EMA as a variant in Sec. IV (Ablation Study/GC-EMA variants).
This operation leads to two key benefits. First, GC reduces the magnitude of the gradient, which suppresses gradient explosion and stabilizes optimization. As formally shown in Appendix (A.4):
ensuring that the centralized gradient is always smaller in magnitude than the original gradient. This suppression leads to more stable optimization steps and prevents abrupt parameter shifts during training.
Second, as proven in prior work [15], GC improves the Lipschitz smoothness of both the loss and its gradient:
where refers to the Hessian matrix. By improving the Lipschitzness of the loss and its gradients, GC yields a smoother and more predictable optimization trajectory, enabling faster and more reliable convergence toward flatter minima. Moreover, when GC is applied only to the ascent step of SAM, it stabilizes the perturbation direction without altering the descent update, which is empirically shown to produce the best balance of stability and generalization in Sec. IV (Ablation Study/GC Placement).
GRADIENT CENTRALIZED SHARPNESS AWARE MINIMIZATION (GCSAM)
C.
While SAM improves generalization by optimizing for flatter minima, it is often sensitive to noisy gradients, especially in the early stages of training. The sharpness objective amplifies such noise during the inner maximization step, leading to unstable perturbations and inefficient convergence. To address this, we propose Gradient Centralized Sharpness-Aware Minimization (GCSAM), which integrates GC into the sharpness-aware optimization framework. Specifically, GCSAM applies GC to the gradient used in SAM’s ascent step, resulting in a reformulated objective:
where denotes perturbations aligned with the centralized gradient :
This centralized perturbation suppresses noise and improves the quality of the sharpness estimation. As a result, GCSAM benefits from tighter sharpness control and more stable updates. Importantly, because gradient centralization reduces gradient variance (Eq. (6)), the perturbation is less amplified by noisy directions, leading to stable updates even when takes larger or smaller values. This theoretical property explains the empirical robustness of GCSAM to perturbation radius choices, as demonstrated later in Fig. 3.
The final GCSAM algorithm is formulated by integrating a standard numerical optimizer, such as SGD or Adam, as the base optimizer for the GCSAM objective. This combination allows for efficient gradient-based optimization while leveraging the benefits of gradient centralization within the SAM framework. The pseudo-code for the GCSAM algorithm, provided in Fig. 2a, outlines the proposed approach with SGD as the base optimizer, highlighting the procedural steps involved in each update cycle. Additionally, Fig. 2b provides a schematic illustration of a single GCSAM parameter update, visually capturing the interaction between gradient centralization and sharpness-aware minimization in the update process.
To better understand the generalization behavior of GCSAM, we provide a PAC-Bayesian generalization bound that highlights the advantages of applying Gradient Centralization in the SAM framework. By projecting the gradient onto a subspace orthogonal to its mean, GCSAM effectively suppresses sharp gradient directions, leading to a tighter bound on the loss under perturbations.
Theorem 1:
Let , where and is a unit vector. If for some , then with probability :
where , , and .
Theoretical analysis in Appendix A further confirms that the GCSAM bound is strictly tighter than the SAM bound due to the reduced centralized gradient norm.
EXPERIMENTAL RESULTS
IV.
To evaluate the effectiveness of GCSAM, we apply it across a diverse set of tasks, including image classification on CIFAR-10 and CIFAR-100, and medical imaging challenges with Breast Ultrasound (BUS) and COVID-19 datasets. In each case, we benchmark GCSAM against multiple baselines: the Adam optimizer, Gradient Centralization (GC) [15] applied to Adam, the original SAM, and recent SAM variants including Adaptive SAM (ASAM) [8], Surrogate-Gap SAM (GSAM) [9], Curvature-Regularized SAM (CRSAM) [10], and Momentum SAM (MSAM) [28]. We evaluate these methods across a variety of architectures, including CNN-based models such as ResNet-50 [43] and VGG-16 [44], as well as Vision Transformer architectures like ViT [45] and Swin Transformer [46]. This experimental setup enables a systematic assessment of GCSAM’s benefits relative to both classical optimizers and advanced sharpness-aware methods in both general-purpose and domain-specific applications.
HYPERPARAMETER TUNING STRATEGY
A.
To ensure fair and unbiased comparisons, all hyperparameters were tuned using a unified grid-search procedure. For sharpness-aware optimizers (SAM, ASAM, GSAM, CRSAM, MSAM, and GCSAM), the perturbation radius was searched over {0.05, 0.1, 0.2, 0.5}; for the sensitivity analysis in Fig. 3 we extended this to {0.01, 0.05, 0.1, 0.2, 0.5, 1.0}. Learning rates were tuned under cosine decay: for CIFAR we considered {0.01, 0.1}, with 0.1 consistently selected, and we considered {10^−2^, 10^−3^, 10^−4^} for BUS and COVID-19 due to smaller dataset size. Batch sizes were fixed at 128 for CIFAR and drawn from {8, 16, 64} for medical datasets to respect GPU memory constraints. For Adam-based methods, we tuned the weight decay parameter over {1 × 10^−4^, 5 × 10^−4^, 1 × 10^−3^}, while momentum parameters were fixed at and .
VALIDATION PROTOCOL
For CIFAR-10/100, we followed the standard dataset split (50k train / 10k test). During hyperparameter selection, we carved out 10% of the training set (45k train / 5k validation / 10k test). After selecting the best hyperparameters, the final models were trained once on the full 50k training set and evaluated on the 10k test set. For BUS and COVID-19, we first created a fixed 80%–20% stratified train–test split. Hyperparameters were then selected by stratified 5-fold cross-validation within the 80% training partition, and the final model was trained on the entire 80% training portion with the chosen hyperparameters and evaluated once on the held-out 20% test set.
SELECTION RULE
Grid search was performed jointly across candidate values. Each candidate configuration was trained three times with different random seeds, and the mean validation accuracy was used for comparison. When two configurations produced statistically indistinguishable results (i.e., mean validation accuracies differing by less than one pooled standard deviation across seeds), we chose the simpler configuration (e.g., larger batch size or higher learning rate) to favor efficiency and reproducibility. Early stopping was applied uniformly to prevent overfitting. Final test results throughout the paper are reported as mean ± standard deviation over three independent runs.
This unified strategy ensures that all optimizers were tuned under the same protocol, and that the improvements of GCSAM reflect algorithmic advantages rather than hyperparameter bias.
IMAGE CLASSIFICATION IN GENERAL DOMAIN
B.
To evaluate the general effectiveness of GCSAM across multiple architectures and tasks, we conduct comparative experiments on both the CIFAR-10 and CIFAR-100 datasets [47]. CIFAR-10 contains 60000 images across 10 classes, while CIFAR-100 includes 100 classes with finer-grained visual categories. We compare GCSAM against several baselines: the Adam optimizer, Gradient Centralization (GC) applied to Adam, the original SAM, and four SAM variants (ASAM, GSAM, CRSAM, and MSAM). These methods are evaluated on four widely adopted deep learning architectures: ResNet-50 [43], VGG-16 [44], Vision Transformer (ViT) [45], and Swin Transformer [46]. For CIFAR-10 and CIFAR-100, we followed the unified hyperparameter tuning strategy described in Section IV-A. All models were trained from scratch with a fixed batch size of 128 and cosine learning rate decay [48]. Standard CIFAR augmentations were applied, including random crop with 4-pixel padding, horizontal flip, and normalization. Label smoothing [49] with a factor of 0.1 was used to improve generalization and calibration. Final results are reported as mean ± standard deviation.
We present the results of our experiments on CIFAR-10 and CIFAR-100 using Adam, GC, SAM, four SAM variants (ASAM, GSAM, CRSAM, MSAM), and our proposed GCSAM optimizer, as shown in Table 1. Across all architectures, Adam provides the lowest performance, while applying GC alone yields modest but consistent improvements, confirming its utility as a standalone technique. The original SAM improves further, and some SAM variants (e.g., ASAM, GSAM) provide occasional gains over SAM depending on the architecture, though the improvements are not consistent across all variants and datasets. Nevertheless, GCSAM consistently achieves the highest test accuracies on both CIFAR-10 and CIFAR-100. For example, on CIFAR-10, GCSAM reaches 96.24% with ResNet-50, 95.87% with VGG-16, 87.67% with ViT, and 91.12% with Swin Transformer, surpassing the best-performing SAM variant in each case. On CIFAR-100, GCSAM also leads, obtaining 82.03% with ResNet-50, 79.52% with VGG-16, 74.25% with ViT, and 75.76% with Swin Transformer. These results demonstrate that while SAM and some of its variants can provide improvements over Adam, integrating gradient centralization within the sharpness-aware framework yields consistently stronger and more stable gains, highlighting the effectiveness of GCSAM across both convolutional and transformer-based architectures.
To analyze robustness to the perturbation radius , we evaluated SAM and GCSAM across 0.01, 0.05, 0.1, 0.2, 0.5, 1.0 on CIFAR-10 with four architectures (ResNet-50, VGG-16, ViT, Swin Transformer). Results in 3 show that SAM achieves its best accuracy around but exhibits sharp performance drops as increases or decreases. In contrast, GCSAM achieves peak accuracy around while maintaining stable performance across the full range of values, confirming that gradient centralization reduces sensitivity to this hyperparameter. The smaller variance of GCSAM across architectures indicates its robustness and practical advantage, as less fine-tuning of is required.
IMAGE CLASSIFICATION IN MEDICAL DOMAIN
C.
Generalization is particularly challenging in the medical domain, where images are collected using a variety of devices, imaging protocols, and across diverse patient populations. These factors introduce unique complexities that impact model performance on unseen data. Prior studies have demonstrated that SAM consistently outperforms traditional optimizers like Adam and SGD across various models due to its ability to achieve flatter minima [50], [51]. To assess the efficacy of GCSAM in tackling these domain-specific challenges, we conduct extensive experiments using two medical datasets: breast ultrasound (BUS) images and COVID-19 chest X-ray images. These datasets are chosen to evaluate the algorithm’s robustness under varying imaging conditions and domain shifts. Both BUS and COVIDx datasets are publicly available, anonymized, and released under institutional ethical approvals, ensuring compliance with ethical standards for research using de-identified medical data.
BREAST ULTRASOUND (BUS) DATASET
We constructed a comprehensive breast ultrasound dataset by combining 3,641 images from [52] with 2,405 images from the GDPH&SYSUCC dataset [53], resulting in a total of 6,046 images labeled as benign or malignant. To ensure fair and consistent evaluation, we applied an 80%–20% stratified train–test split, preserving the original class distribution. Hyperparameter tuning followed the unified protocol described in Section IV-A, with the learning rate sweep restricted to {10^−2^, 10^−3^, 10^−4^} and batch sizes to {8, 16, 64} due to dataset size and memory constraints. Final test accuracies are reported as mean ± standard deviation over three runs with different random seeds.
The results in Table 2 show that GCSAM consistently achieves the highest performance across all architectures on the BUS dataset. Applying GC alone yields modest gains over Adam, while the original SAM improves further. Some recent SAM variants (e.g., ASAM, GSAM) provide modest improvements over SAM in certain architectures, but the gains are not consistent across all variants and models. Nevertheless, GCSAM surpasses all baselines. For example, ResNet-50 improves from 77.14% with Adam and 78.65% with SAM to 80.07% with GCSAM. VGG-16 reaches the highest overall accuracy of 83.28% with GCSAM, compared to 82.71% with SAM and 82.87% with the best SAM variant (GSAM). For transformer-based models, which are generally more sensitive to optimization settings, GCSAM still yields clear improvements: ViT increases from 70.43% (Adam) and 71.10% (best variant, GSAM) to 72.18%, while Swin Transformer improves from 69.33% (Adam) and 70.21% (best variant, SAM) to 70.74%. These results highlight that while SAM variants can provide occasional accuracy gains, integrating gradient centralization within the sharpness-aware framework yields more consistent and robust improvements, even in challenging medical imaging tasks with relatively small datasets. The low standard deviations across all runs further confirm the stability and reproducibility of our approach.
COVID-19 CHEST X-RAY DATASET
We conducted additional experiments on the COVIDx CXR-4 dataset [54], comprising 16,955 chest X-ray images categorized into COVID-positive and negative cases. To evaluate the generalization ability of our optimizer, we trained ResNet-50, VGG-16, Vision Transformer (ViT), and Swin Transformer models. We compared the performance of GCSAM against the Adam optimizer, SAM, and several notable SAM variants, including Adaptive SAM (ASAM) [8], Surrogate-Gap SAM (GSAM) [9], Curvature-Regularized SAM (CRSAM) [10], and Momentum SAM (MSAM) [28]. To quantify model sharpness, we employed the PyHessian framework [55] to compute the top eigenvalue of the Hessian matrix, providing a principled measure of the loss landscape’s curvature. This allowed us to analyze how well each optimizer controls sharpness and contributes to better generalization. In addition to accuracy and sharpness, we assessed the computational efficiency of GCSAM relative to SAM and its variants. Using Adam as a baseline with a normalized relative speed of 1.0, we benchmarked training times to evaluate any computational overhead introduced by GCSAM. This comprehensive evaluation highlights GCSAM’s effectiveness in improving both generalization and sharpness, while maintaining competitive training efficiency.
We followed the unified hyperparameter tuning strategy described in Section IV-A for the COVID-19 dataset. In line with the smaller dataset size, the learning rate sweep was restricted to {10^−2^, 10^−3^, 10^−4^} and batch sizes to {8, 16, 64}. All sharpness-aware optimizers were tuned over ρ ∈ {0.05, 0.1, 0.2, 0.5}, consistent with the global protocol. Final test accuracies are reported as mean ± standard deviation over three runs with different random seeds.
In Table 3, we report the test accuracy, computational cost, and top hessiane eigenvalue for each optimizer across four models: ResNet50, VGG16, ViT, and Swin Transformer, trained on the COVID-19 CXR-4 dataset. We observe that GCSAM consistently achieves higher test accuracy than the baseline Adam optimizer, SAM and its variants across all models, highlighting its effectiveness in improving generalization performance on medical image classification tasks. For ResNet50, GCSAM yields an accuracy of 90.81%, surpassing all other optimizers, with ASAM being the closest competitor at 90.21%. Similarly, for VGG16, GCSAM achieves 92.03%, which is higher than the next best, SAM at 91.43%. The trend continues with ViT, where GCSAM outperforms all optimizers with 82.52%, and on the Swin Transformer, it achieves 85.93%, surpassing SAM at 85.59% and MSAM at 83.87%. In terms of computational cost, GCSAM introduces a moderate overhead relative to Adam but generally exhibits better efficiency compared to SAM. To facilitate a clear comparison, we present the training speed of each optimizer relative to Adam, with Adam’s speed normalized to 1.0. This normalization allows for a direct evaluation of the computational impact of each optimizer. The results indicate that GCSAM strikes an optimal balance, maintaining competitive efficiency while achieving significant improvements in accuracy.
Additionally, the Hessian values provide crucial insights into the geometry of the loss landscape. A lower Hessian value is indicative of a flatter, more stable loss landscape, which is desirable for the optimization process as it suggests that the model is less likely to get trapped in sharp, narrow minima that could lead to poor generalization. GCSAM consistently demonstrates the lowest Hessian values across all models, with values of 164.32 for ResNet50 and 139.72 for VGG16, which are substantially lower than those of other optimizers. For comparison, GSAM and CRSAM exhibit much higher Hessian values, indicating sharper loss landscapes. These results suggest that GCSAM promotes a smoother and more stable optimization path, potentially leading to better generalization performance by encouraging the model to converge to flatter minima. This further underscores the advantages of GCSAM in terms of both accuracy and the optimization stability it provides across different neural network architectures on the COVID-19 dataset.
ABLATION STUDY
D.
GC PLACEMENT
Sharpness-Aware Minimization (SAM) requires two gradient computations per update: an ascent gradient to form the perturbation , and a descent gradient to update the parameters. Gradient Centralization (GC) can, in principle, be applied to either or both of these gradients. To determine the optimal placement, we conducted an ablation study on ResNet-50 using the BUS and CIFAR-10 datasets, comparing five configurations: Adam, SAM without GC, GC applied only in the ascent step (our proposed GCSAM), GC applied only in the descent step, and GC applied in both ascent and descent steps.
As shown in Table 4, applying GC only in the ascent step achieves the highest performance on both datasets, reaching 80.07% on BUS and 96.24% on CIFAR-10. Descent-only GC provides minor improvements over Adam but fails to match SAM, while GC in both steps improves stability but yields no additional accuracy gains beyond ascent-only. These results indicate that the ascent step is the critical locus for applying GC to enhance generalization.
To further assess training stability, Fig. 4 shows the epoch-wise average gradient norm on BUS, while Fig. 5 provides detailed step-wise traces for the three GC placement strategies. Descent-only GC modestly reduces scale but leaves instability largely intact. Both-step GC smooths the trajectory but still produces higher variance than ascent-only. In contrast, ascent-only GC achieves the lowest and most stable gradient norms, eliminating early-stage spikes while preserving effective descent steps.
These findings align with our theoretical analysis in Appendix A. Instability in SAM arises when the ascent gradient used to define contains redundant or noisy components. Applying GC to the ascent step regularizes this perturbation, ensuring that the adversarial neighborhood is probed stably while leaving the descent update intact. By contrast, descent-only GC alters the update direction itself, which may suppress informative directions, and both-step GC combines these drawbacks. Consequently, ascent-only GC provides the best balance between stability and generalization, validating the core design of GCSAM.
SCHEDULING
SAM is known to sometimes exhibit instability in the early stages of training, especially when combined with SGD. A common remedy is to warm-start with a vanilla optimizer before switching to SAM or its variants. To evaluate whether this improves GCSAM, we conducted an ablation on the BUS dataset using ResNet-50, comparing always-GCSAM against a 10-epoch warm-start with Adam followed by GCSAM or SAM. Results are reported in Table 5.
As shown in Table 5, warm-starting with Adam for the first 10 epochs yields only a marginal improvement over always-GCSAM, with overlapping standard deviations. Warm → SAM improves stability compared to always-SAM but still underperforms GCSAM-based methods. This suggests that ascent-based GC already suppresses early-stage perturbation noise, making explicit warm-start scheduling largely redundant.
GC-EMA VARIANTS
We also evaluated a temporal smoothing variant of GC, denoted GC-EMA, which maintains an exponential moving average (EMA) of the gradient mean with momentum . At each step , GC-EMA updates
and subtracts from instead of the instantaneous mean. Results for and on BUS (ResNet-50) are reported in Table 6.
Table 6 shows that GC-EMA yields nearly identical test accuracy to per-step GC, with differences well within the margin of standard deviation. Although GC-EMA produces slightly smoother gradient-norm traces, it adds an additional hyperparameter and complicates interactions with optimizer moments. For clarity and efficiency, we adopt per-step GC as the default throughout the paper, noting that GC-EMA remains a potential variant for applications where temporal smoothing is specifically required.
Together, these ablations indicate that ascent-based per-step GC already mitigates early-stage instability, reducing the need for scheduling or optimizer switching, and per-step GC is a simpler and equally effective choice compared to GC-EMA. These findings further validate the design decisions underlying GCSAM.
DISCUSSION
V.
In this section, we analyze the results presented in Table 1, Table 2, and Table 3, highlighting the improved generalization and training efficiency offered by the GCSAM optimizer in comparison to SAM and the baseline Adam optimizer.
BETTER GENERALIZATION PERFORMANCE
A.
Across the CIFAR-10 and CIFAR-100 datasets (Table 1), GCSAM achieves higher test accuracies than both SAM and Adam on all four tested architectures: ResNet50, VGG16, ViT, and Swin Transformer. This demonstrates that GCSAM’s ability to mitigate gradient explosion in the ascent step of SAM results in more effective training and better model robustness on unseen data. Moreover, GCSAM’s generalization improvements are more pronounced in medical imaging tasks, where domain shifts and data variability pose significant challenges to traditional optimization methods. For instance, in breast ultrasound (BUS) images (Table 2) and COVID-19 chest X-rays (Table 3), GCSAM consistently outperforms SAM and Adam, demonstrating its resilience to the inherent variability of medical image datasets. Specifically, for the COVID-19 dataset, GCSAM surpasses all tested SAM variants, further establishing its effectiveness in challenging domains.
While GCSAM improves both CNNs and ViTs, the latter show smaller absolute gains in medical imaging tasks. This performance gap can be attributed to two main factors. First, ViTs typically require much larger training datasets to achieve optimal performance, whereas our medical datasets (BUS: 6,046 images, COVID-19: 16,955 images) are relatively small for transformer-based models and limit their ability to exploit global attention effectively. Second, CNNs possess stronger inductive biases for local feature extraction through convolutional operations, making them better suited for capturing the texture and edge-level information that is especially important in medical images. Nevertheless, GCSAM consistently improves the stability and generalization of ViTs compared to SAM and Adam, demonstrating its effectiveness even in data-limited regimes.
To enhance generalization across all tested models, GCSAM focuses on three core aspects: sharpness reduction, gradient centralization, and suppression of gradient explosion. GCSAM promotes convergence to flatter minima in the loss landscape, which are associated with better generalization and reduced sensitivity to input perturbations. It also applies gradient centralization by subtracting the mean of the gradient elements for each layer, which reduces redundancy in updates and encourages smoother optimization dynamics. Crucially, GCSAM mitigates the risk of gradient explosion, particularly during the ascent step of SAM where gradients are perturbed to explore sharp regions. By stabilizing these updates, GCSAM prevents the emergence of excessively large gradients and ensures more controlled parameter changes. This stabilizing effect is visually supported by the gradient norm trends in Fig. 6, where GCSAM consistently maintains lower gradient norms compared to both Adam and SAM throughout training. Together, these improvements result in better test accuracy and more robust generalization across both general-purpose and medical imaging datasets.
To provide a comprehensive view of optimization stability, we analyze the full trajectory of the gradient norm throughout training (i.e., over all iterations rather than epoch-wise averages). This allows us to directly observe instances of gradient explosion or instability across different optimizers.
Fig. 7 illustrates the norm of the gradients computed at each training step for Adam, SAM, and the proposed GCSAM. It is evident that both Adam and SAM exhibit significantly higher fluctuations and, in some cases, signs of gradient explosion, especially in the early or mid-training stages. In contrast, GCSAM maintains a more stable gradient magnitude throughout the optimization process, indicating improved robustness and smoother convergence.
These results further support our claim that incorporating gradient centralization into sharpness-aware optimization mitigates instability and prevents the optimizer from entering regions with extreme curvature or sharp loss landscapes.
BETTER COMPUTATIONAL EFFICIENCY
B.
GCSAM provides computational advantages over SAM, as demonstrated in Table 3, by achieving lower relative training times across all models. By suppressing gradient spikes, GCSAM promotes faster convergence and reduces the number of required iterations. This is especially beneficial for large-scale models and datasets, where SAM’s ascent step incurs significant overhead. Additionally, GCSAM’s use of gradient centralization stabilizes updates, further lowering computational costs by guiding optimization toward stable regions of the loss landscape. Overall, GCSAM achieves an effective balance between generalization and efficiency.
VISUALIZATION OF LOSS LANDSCAPES
C.
To analyze the geometry of the loss surface achieved by GCSAM, we visualized the loss landscapes of ResNet50 models trained with Adam, SAM, and GCSAM on the COVID-19 dataset. Following the methodology in [6], loss values were computed along two orthogonal Gaussian perturbation directions centered at the final trained weights. As shown in Fig. 8, GCSAM leads to consistently flatter minima than both Adam and SAM. This visual flatness is consistent with the lower dominant Hessian eigenvalues observed in our sharpness analysis, further supporting GCSAM’s ability to guide optimization toward flatter and more generalizable solutions.
ABLATION INSIGHTS: GC PLACEMENT, SCHEDULING, AND EMA
D.
Our ablation studies further clarify the design choices underlying GCSAM. First, we evaluated different placements of gradient centralization and found that applying GC only to the ascent step yields the best generalization performance. This configuration stabilizes the perturbation direction in SAM without altering the descent update itself, striking an optimal balance between stability and accuracy. By contrast, applying GC in the descent step or in both steps produced either reduced test accuracy or negligible additional gains, despite sometimes yielding smoother gradient-norm traces. Second, we examined warm-start scheduling (switching from a vanilla optimizer to GCSAM after a few epochs) and observed only marginal improvements over always-GCSAM, indicating that ascent-based GC already mitigates early-stage instability. Finally, we tested an EMA variant of GC (GC-EMA), which maintains a running mean of gradients rather than per-step subtraction. While GC-EMA slightly smooths gradient trajectories, it provided no meaningful accuracy improvements and introduced an additional hyperparameter. Together, these findings reinforce that the core design of GCSAM offers the best trade-off between simplicity, stability, and generalization, without requiring additional scheduling or smoothing mechanisms.
LIMITATIONS
E.
Although GCSAM consistently improves generalization and training stability across diverse architectures and datasets, several practical considerations remain. Like other sharpness-aware optimizers, GCSAM requires two backward passes per iteration, which increases training cost compared to single-pass optimizers. Future work could explore incorporating momentum-based strategies within GCSAM to further reduce computational costs, making it more efficient for large-scale applications. In addition, while GCSAM reduces sensitivity to the perturbation radius , adaptive strategies for automatic hyperparameter tuning could further enhance its usability across diverse problem domains. Finally, extending GCSAM beyond vision tasks to natural language processing and multimodal learning represents a promising direction for broadening its impact.
CONCLUSION
VI.
In this work, we introduced Gradient-Centralized Sharpness-Aware Minimization (GCSAM), a novel optimizer designed to enhance model generalization and training stability. Across both standard vision benchmarks (CIFAR-10, CIFAR-100) and challenging medical imaging datasets (breast ultrasound and COVID-19 chest X-rays), GCSAM consistently outperformed Adam and SAM in terms of test accuracy and convergence behavior. By stabilizing gradients during the ascent step, GCSAM reduces variance, accelerates convergence, and alleviates the sensitivity of SAM to the perturbation radius, thereby simplifying practical deployment. These properties make GCSAM particularly valuable in domains where robust generalization is essential, such as medical imaging, where domain shifts and acquisition variability are common. Looking ahead, GCSAM provides a foundation for developing more efficient sharpness-aware methods, with opportunities to integrate momentum-based updates, adaptive hyperparameter tuning, and extensions to non-vision modalities.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Kawaguchi K, Kaelbling L, and Bengio Y, “Generalization in deep learning,” in Mathematical Aspects of Deep Learning. Cambridge, U.K.: Cambridge Univ. Press, 2022.
- 2Zhang C, Bengio S, Hardt M, Recht B, and Vinyals O, “Understanding deep learning requires rethinking generalization,” 2016, ar Xiv:1611.03530.
- 3Jiang Y, Neyshabur B, Mobahi H, Krishnan D, and Bengio S, “Fantastic generalization measures and where to find them,” 2019, ar Xiv:1912.02178.
- 4Dziugaite GK, Drouin A, Neal B, Rajkumar N, Caballero E, Wang L, Mitliagkas I, and Roy DM, ‘‘In search of robust measures of generalization,” in Proc. Annu. Conf. Neural Inf. Process. Syst. (Neur IPS), vol. 33, 2020, pp. 11723–11733.
- 5Dinh L, Pascanu R, Bengio S, and Bengio Y, ‘‘Sharp minima can generalize for deep nets,” in Proc. Int. Conf. Mach. Learn. (ICML), 2017, pp. 1019–1028.
- 6Li H, Xu Z, Taylor G, Studer C, and Goldstein T, “Visualizing the loss landscape of neural nets,” 2017, ar Xiv:1712.09913.
- 7Foret P, Kleiner A, Mobahi H, and Neyshabur B, “Sharpness-aware minimization for efficiently improving generalization,” in Proc. Int. Conf. Learn. Represent., 2021, pp. 1–14.
- 8Kwon J, Kim J-S, Park H, and Choi IK, ‘‘ASAM: Adaptive sharpness-aware minimization for scale-invariant learning of deep neural networks,” in Proc. 38th Int. Conf. Mach. Learn. (ICML), 2021, pp. 5905–5914.