An infrastructure for qualified data sharing and team science in late-stage translational spinal cord injury research
J. Russell Huie, Abel Torres-Espin, Jeffrey Sacramento, Anastasia V. Keller, Wilsaan M. Joiner, Ryan North, David J. Reinkensmeyer, Ephron S. Rosenzweig, Jacob Koffler, Mark H. Tuszynski, Carolyn J. Sparrey, Jessica L. Nielson, Michael S. Beattie, Jacqueline C. Bresnahan

TL;DR
This paper introduces a private data sharing infrastructure for spinal cord injury research to support collaborative and sensitive data analysis.
Contribution
The novel Private Data Commons for SCI (PDC-SCI) enables secure and scalable data sharing for multi-lab translational research.
Findings
The PDC-SCI infrastructure supports sharing of sensitive and multimodal SCI data across distributed teams.
The VA Gordon Mansfield SCI Consortium demonstrates successful integration and analysis of diverse SCI datasets.
The system facilitates rapid knowledge discovery through organized data sharing in closed research environments.
Abstract
The complex and heterogeneous nature of spinal cord injury has limited translational bench-to-bedside results. The wide variety of data, including injury parameters, biochemical, histological, and behavioral outcome measures represent a ‘big data’ problem, calling for modern data science solutions. There are some instances in which SCI researchers collect sensitive data that needs to remain private, such as datasets designed to meet regulatory approval, sensitive intellectual property, and non-human primate studies. For these types of data, we have developed a Private Data Commons for SCI (PDC-SCI). Our objective is to give an overview of this novel data commons, describing how this type of commons works, how it can benefit the research community, and the cases in which it would be most useful. This private infrastructure is ideal for multi-lab transdisciplinary studies that require a…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
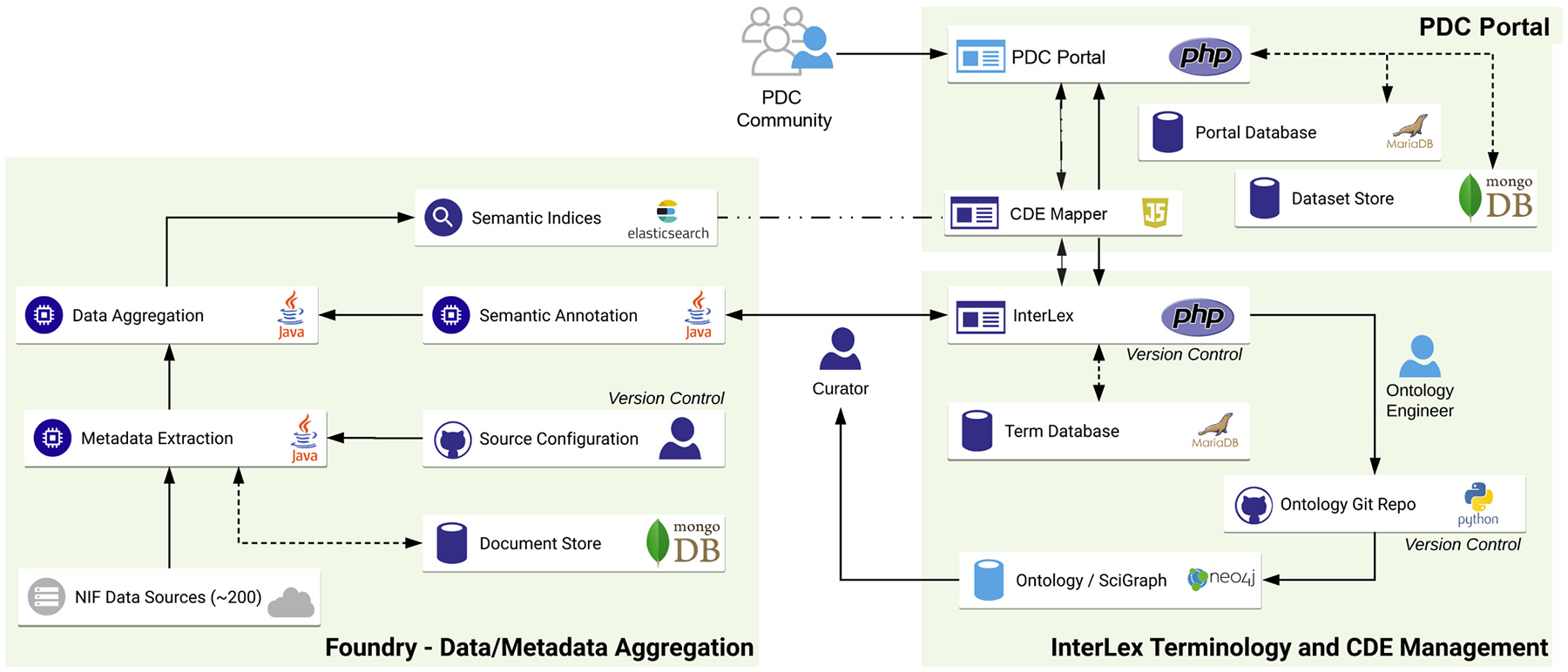 Figure 1
Figure 1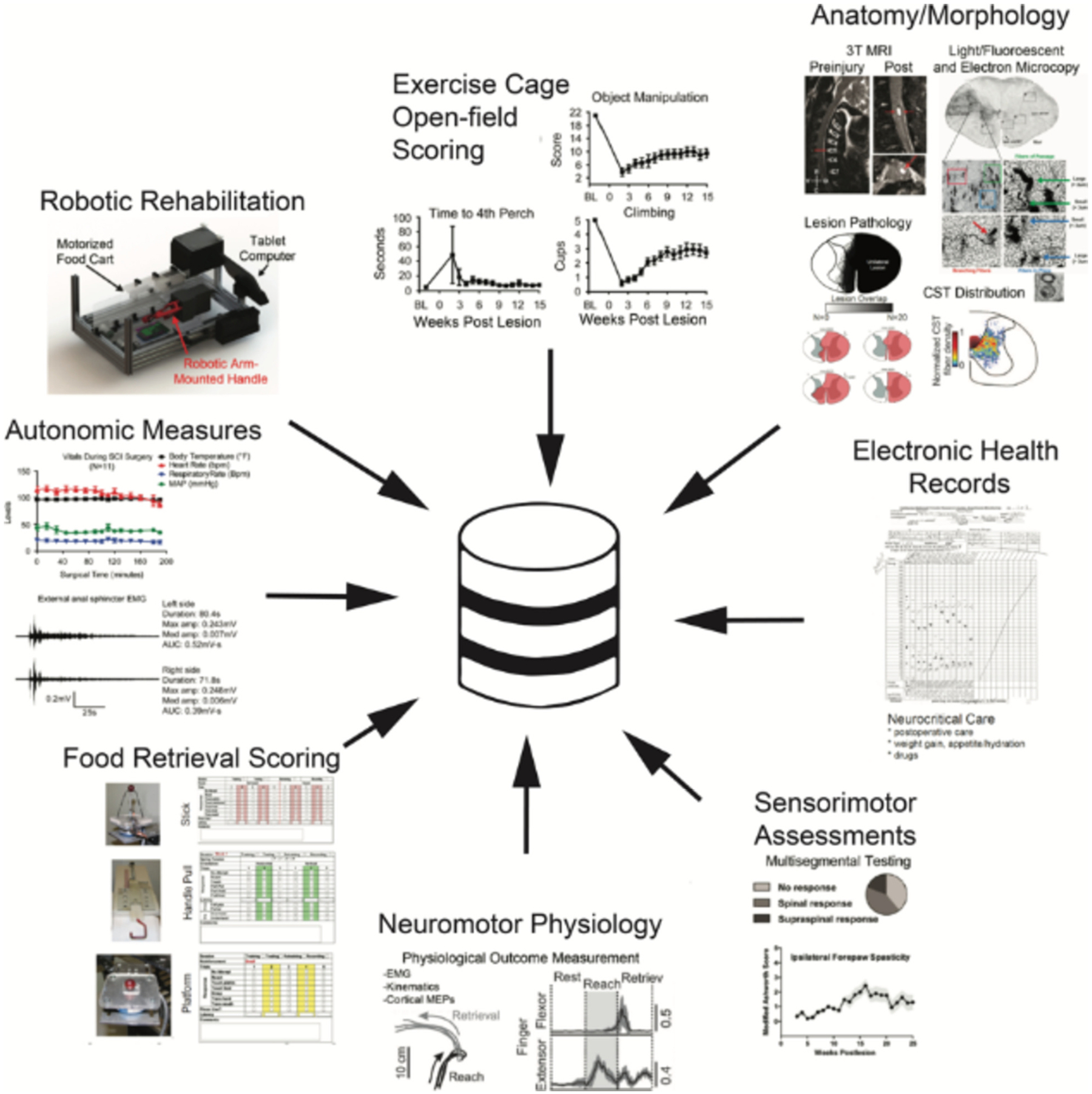 Figure 2
Figure 2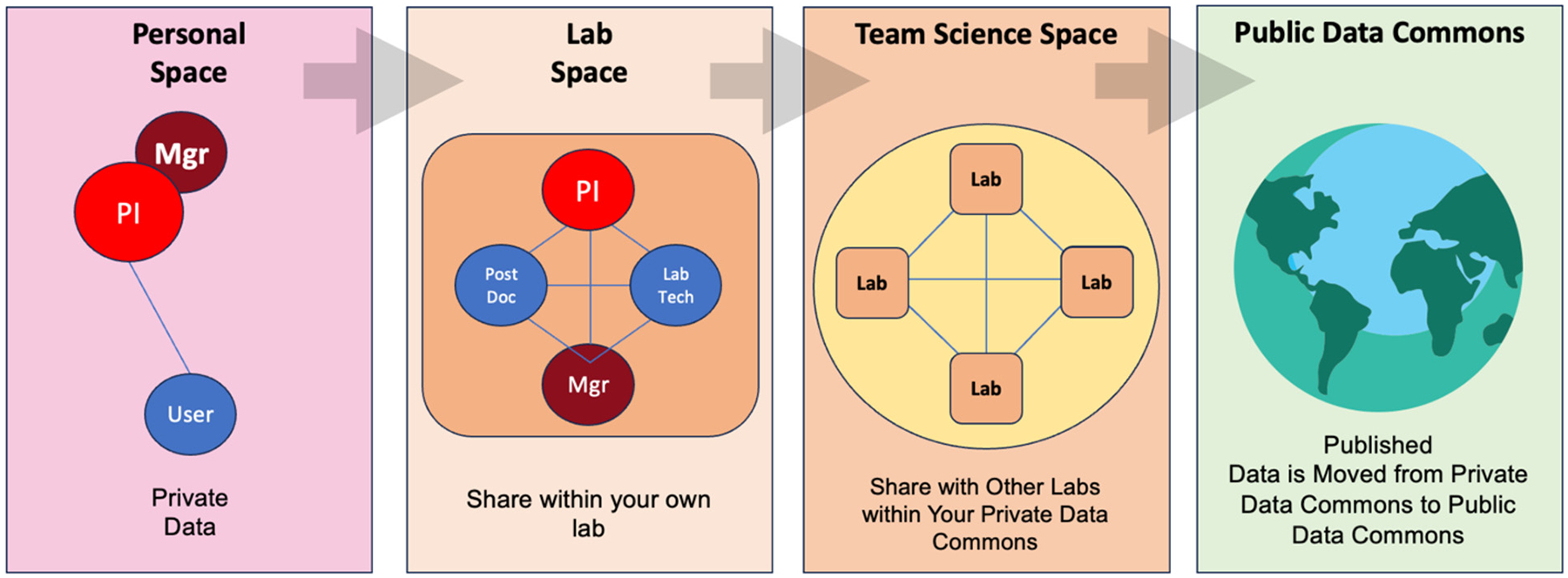 Figure 3
Figure 3 Figure 4
Figure 4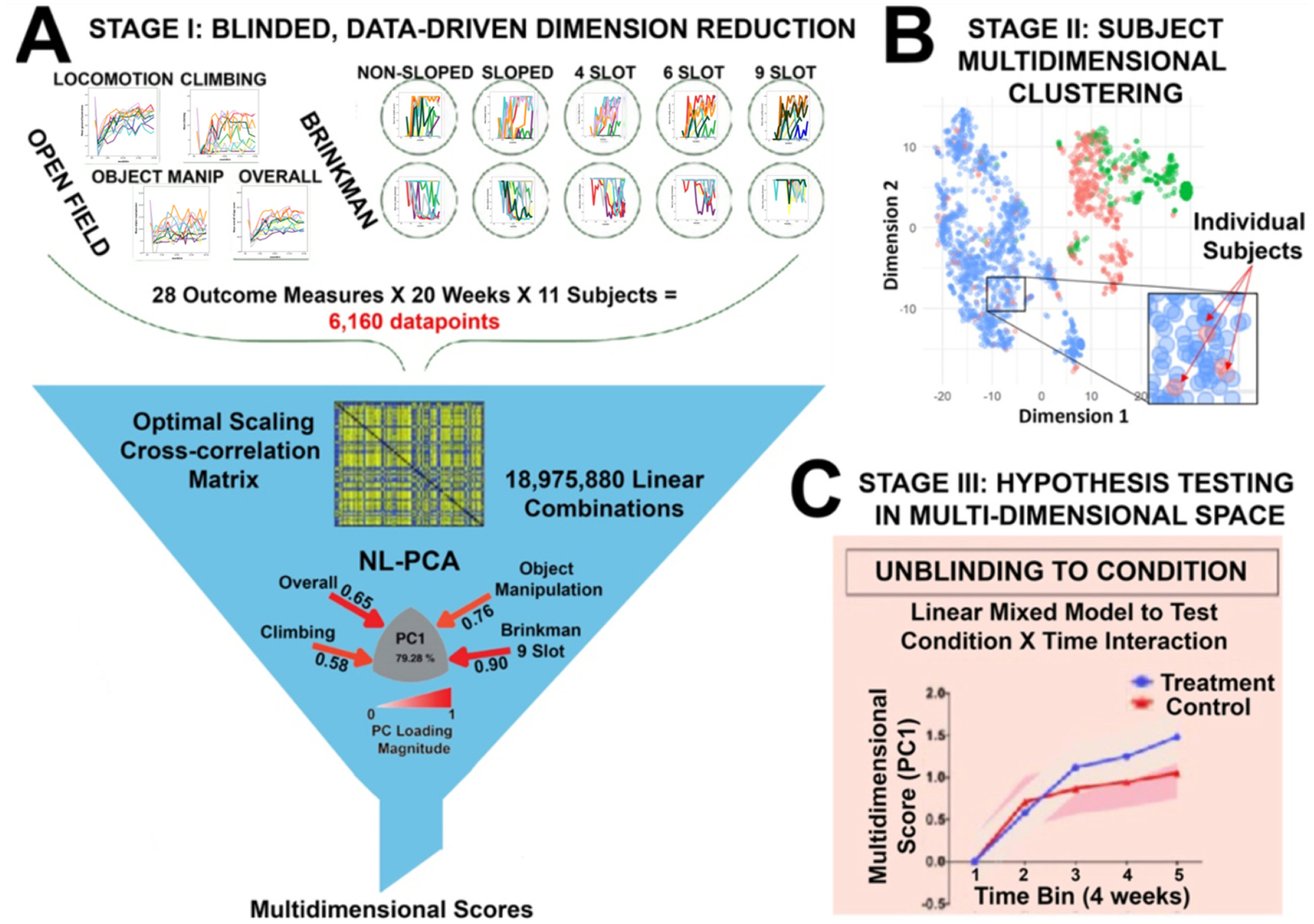 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHealth and Medical Research Impacts · Ethics in Clinical Research · Biomedical and Engineering Education
Introduction
As research continues to expand beyond the walls of a single lab, the need for cloud-based data management for team science has never been greater. The COVID-19 pandemic has shown that while generating data remotely can be done, the work of organizing, sharing, and analyzing data from disparate environments remains challenging (Alhomdy et al., 2021). In clinical informatics, cloud-based solutions for human-subjects research such as the Research Electronic Data Capture (REDCap) enable large scale sharing of targeted clinical endpoints (Harris et al., 2009). In addition, the NIH has long supported data-sharing in genomics through the gene expression omnibus (GEO) and the DataBase of Genotypes and Phenotypes (DBGaP) (Edgar et al., 2002; Mailman et al., 2007). However, multisite preclinical and translational projects require unique data solutions that do not fit neatly into these existing biomedical informatics infrastructures.
For example, late-stage translational development of regenerative therapies for spinal cord injury (SCI) requires researchers to manage data collected across multiple geographical regions, as well as across different areas of expertise. This type of research is characterized by unique data elements reflecting novel biological measurements including robotic rehabilitation devices (Fong et al., 2005; Reinkensmeyer et al., 2006), stem cell technologies (Rosenzweig et al., 2018), tissue scaffold engineering (Koffler et al., 2019; Yousefifard et al., 2020) and neuromodulation device data (Capogrosso et al., 2016; Wenger et al., 2016). These heterogenous data represent ‘big data’ characterized by the 3 V’s of high data volume, rapid data velocity, and wide data variety (Huie et al., 2018). The problem of high data volume is often associated with imaging and large clinical trials research where there is a single primary domain of study and the goal is to acquire high number of subjects (high ‘n’) to achieve a pre-defined level of statistical power on the primary outcome metric. In contrast, late-stage discovery and translational research typically involves a small number of large-animal subjects studied in great detail on numerous endpoints, and the problem becomes managing wide data variety (Huie et al., 2018). This is evident in stem cell biology and neuromodulation projects for neurological trauma, where data collected on a single subject span molecular and cellular endpoints, morphology, neurophysiology, behavior, and heath records. Managing such data, sharing them among team members, and making them interoperable with advanced analytics such as machine learning and artificial intelligence tools remain central challenges.
To facilitate data sharing within and between labs, we have previously developed the Open Data Commons for Spinal Cord Injury (odc-sci.org (Fouad et al., 2020; Torres-Espín et al., 2022) and the Open Data Commons for Traumatic Brain Injury (odc-tbi.org (Chou et al., 2021), which provide mechanisms for data management, open data publishing, and data citation. However, there are instances in which researchers collect sensitive data that needs to remain private, such as datasets designed to meet regulatory approval (e.g., FDA), sensitive intellectual property, and non-human primate studies, among others. To meet these challenges, we have created a private data commons (PDC) and deployed it for spinal cord injury research as a first use-case. The PDC is a cloud-based infrastructure that allows a team to store, manage, and share data from a wide variety of data types, where each type of data is generated at separate sites. The PDC acts as a central repository for all data collected and is designed to facilitate sharing and data integration within and across member sites that make up a team as a whole. The goal of this paper is to give an overview of this novel domain specific data commons for the SCI field, describing how this type of commons works, how it can benefit the research community, and the cases in which it would be most useful.
Methods
The Private Data Commons is built upon software architecture previously developed for the Open Data Commons for spinal cord injury (odc-sci.org), the NIH-supported, domain specific repository for the field of of SCI (Repositories for Sharing Scientific Data | Data Sharing, 2024; Torres-Espín et al., 2022). The repository infrastructure, known as the FAIR Data Informatics (FDI) Commons infrastructure, is built on top of the SciCrunch cyberinfrastructure housed in the Cal-IT2 datacenter and the San Diego Supercomputer Center at the University of California, San Diego. As with odc-sci.org, the private data commons leverages e-commerce grade encryption, full data provenance tracking and change logging, offsite backup and data recovery among other features to ensure data security and integrity. The FDI Commons infrastructure, is built in 3 modules (Fig. 1): The Private Data Commons Portal, which serves the end user and can host analytical applications via application programming interfaces (APIs); Interlex, which manages terminologies and common data elements for use by the Portal and APIs; and Foundry, which aggregates information from external data resources and enables integration with these resources.
Results
Resource infrastructure and governance
3.1.
The private data commons for spinal cord injury (PDC-SCI) addresses the data management needs for multisite team science, in a private repository. The need for privacy arises in research cases such as: data pending FDA approval, safeguarding intellectual property, or sensitive data including non-human primate research. Data sharing is facilitated by proper data governance, and the principles of proper data governance should be applied not only when sharing data publicly to the broader community, but also within a multisite, team science project. To this end, the PDC has been designed to adhere to the FAIR principles of data governance (Wilkinson et al., 2016). Briefly, FAIR states that data must be Findable, Accessible, Interoperable, and Reusable. First, data must be findable. That means data and metadata need to be sufficiently annotated and tagged such that it can be searchable, commonly by using search algorithms. Data then needs to be accessible; users should be able to visualize and download the data, ideally in a standardized format that users can retrieve easily. Third, data need to be interoperable. This means that data are structured in a way that allows it to be aggregated with other datasets, operated on using different computer algorithms, easily readable by both humans and computers, and must also be in a format that allows for use with other programs, such as analytical software. Finally, data must be reusable. This is ultimately the goal of data sharing, to allow for users to combine datasets and create new analyses that are reproducible. This requires that metadata are clear and concise so that users are fully informed as to what the data represent.
Use case: veterans affairs gordon mansfield spinal cord injury consortium
3.2.
The PDC-SCI has been a crucial organizing element behind one of the most sophisticated and complex late-stage translational spinal cord injury research projects: the Gordon Mansfield Spinal Cord Injury Consortium (VAGMSCI). This team science project consists of multiple labs across 5 University of California campuses (UC San Diego, UC Irvine, UC Los Angeles, UC San Francisco, and UC Davis). The VAGMSCI is a transdisciplinary effort to test cutting-edge therapies for spinal cord injury in non-human primates. The group collects a wealth of data across a number of research domains, including: complete veterinary health records, highly granular time series data on the biomechanics of injury, a battery of behavioral outcomes, physiological measures, pre- and post-injury MR imaging, and histological outcome measures, including axonal sprouting, stem cell survival/proliferation, and detailed connectome data (Fig. 2). Each of these data domains is managed at separate universities, and the PDC is organized into separate lab spaces for each of these units. As new data is generated, organized, and analyzed, the data are pushed to the PDC and housed within these labs. While each separate domain can go from raw data collection to analysis and final publishable results, it is the sharing of data across labs that is crucial to the mission of the consortium, and it is the integration of these multimodal data that will generate unique knowledge discovery. Thus, a major tenet of the PDC is that although this is a private community, data sharing is guided by the same FAIR governance principles that undergird public data sharing. In this way, the PDC acts as a microcosm of the broader neurotrauma community.
The SFVAMGC PDC currently houses seven distinct labs that represent the different data domains (Veterinary Health Records, Demographics, Injury Biomechanics, Imaging, Biofluid Biomarkers, Behavior, Robotic Rehabilitation Training, and Informatics/Analytics). As of June 2024, a total of 169 datasets have been collected and uploaded across these virtual labs. Each lab is headed by a principal investigator (PI) from the team and is accessed by lab members that have been approved and verified. Any of these lab members have the authority to upload data into their respective labs. As a dataset is uploaded, the lab member and PI work together to decide the extent to which the data can be accessed by others, moving from most private to fully public ‘spaces’. When a dataset is first uploaded it is initially accessible only to the uploader (the ‘Personal Space’). When data are ready to be shared within the lab, it can then be moved by the lab member to the ‘Lab Space’. From here, any lab member, manager, or PI within the lab can access and update the dataset. When labs are prepared to integrate and share datasets, the data can then be virtually moved to the ‘Community Space’. At this point anyone with user permission to access the private data commons can now access and interact with the dataset (Fig. 3).
Data publishing
3.3.
The open sharing of the data that underlie published works is a growing mandate in scientific research. The National Institutes of Health now require that all data collected with NIH funding be made public as the results of these data are published (Final NIH Policy for Data Management and Sharing, 2024). Given this mandate, the PDC was created with the ultimate goal of dataset publishing in mind. When your scientific journal article is published, the underlying dataset that was used to generate figures and results will be published as well through a partnership with the Open Data Commons for SCI (odc-sci.org), the NIH-supported repository for spinal cord injury data management and sharing. Data creators work closely with the PDC editors to ensure that the dataset meets minimum FAIR standards. This package, that includes the dataset, data dictionary, study metadata, and provenance, is then minted a digital object identifier (DOI), which is linked to this information in perpetuity. Much like a copyrighted published journal, a published dataset can be reused under a Creative Commons Attribution (CC-BY) open license (https://creativecommons.org/licenses/by/4.0/?ref=chooser-v1), which allows for anyone to reuse the dataset as long it is cited. The citation allows the dataset creators to receive credit for their work, and just as with journal authorship, citation of a dataset will be recognized as scientific contribution (e.g., driving metrics such as H-index) of all listed contributors to a dataset, as long as the data citation is listed in the references of a publication.
As an example, we include here the underlying raw data from a seminal work by Rosenzweig et al. in 2019 (20). This study was designed to test the effects of an enzyme (chondroitinase) that was hypothesized to have beneficial effects after spinal cord injury. The dataset consists of functional recovery tasks measured over time, as well as corticospinal tracing data that measured changes in axon and synaptic density in response to chondroitinase treatment.
These data were collected and stored in the PDC throughout the course of the study, and were then formatted for publication, at which time a DOI was requested. The metadata (see Fig. 4) and data dictionary were then reviewed by independent data analysts to check that 1) the metadata were sufficiently descriptive for future use, 2) the data dictionary accurately and thoroughly represented and described the variables that were included in the dataset. This quality assurance process is important to make the data reusable, by ensuring that all aspects of the data that were collected are clear and concise.
The dataset is publically accessible under a persistent digital object identifier (DOI) at https://doi.org/10.34945/F57S3T.
Interoperability with multidimensional analysis
3.4.
As our ability to collect and manage big data improves, so too does the need for analytics that leverage the complexity of these data. The analytics core of the VAGMSCI has worked over the past decade to advocate the idea of syndromic analyses, in which a multi-modal, multidimensional, integrated approach to knowledge discovery is favored over running large numbers of univariate analyses (Ferguson et al., 2011; Torres-Espín et al., 2021). The multimodal nature of this consortium is well-suited for multivariate analytics, and the PDC is designed to facilitate these analyses. In the past 8 years, a number of research articles have been published by this consortium that take advantage of the opportunity for data integration to drive multidimensional analytical workflows across multimodal data including medical imaging, electrophysiology, veterinary medical records, multi-omics, neurobehavioral assessments, neuromodulation technology development, and neuromorphology and pathoanatomy after SCI (Brock et al., 2018; Kumamaru et al., 2018; Nielson et al., 2015; Rosenzweig et al., 2019; Rosenzweig et al., 2018) (Fig. 5). The combination of high volume and wide variety allows for a first stage data-driven dimension reduction. For example, combining disparate open field locomotion and object manipulation with tests of finer motor control created a correlation matrix consisting of over 18 million linear combinations. This high dimensionality was then reduced using principal component analysis to produce single composite scores for each individual that represented the unique pattern of interaction between these tasks that accounted for nearly 80 % of the variance in the data (Fig. 5A). In stage 2, individual subjects can be plotted based on these multidimensional scores, where methods such as topological data analysis can then be used to identify unique clusters of individuals (Fig. 5B). Finally, in stage 3, only after the complexity and variability across outcome measures and individuals have been modeled and accounted for, will hypothesis testing be performed (Fig. 5C). This workflow, made possible by close and careful data management within the PDC, has the power to detect effects that may have been lost or diluted by the initial variety of outcome measures, and perhaps more importantly, avoids the possible pitfalls of multiple univariate comparisons that are a major driver of the current reproducibility crisis (Haefeli et al., 2017; Ioannidis, 2005)
Discussion
From the outset, the PDC was designed with the importance of proper data governance in mind. Much like an open data commons, the PDC is dedicated to ensuring that the sharing and ownership of data, as well as data provenance, are transparent and legally sound. Clear and concise documentation, including Data Use Agreements and Memoranda of Understanding, is foundational to our data management and data sharing efforts.
Any data commons that is designed to intake sensitive data, such as de-identified human patient data, must navigate the regulatory hurdles that are in place to ensure that privacy is maintained. But there are a number of burgeoning efforts and tools that are helping researchers to ensure de-identification. Tools such as the Protected Health Information Filter (or PHIlter) a software algorithm that scans free-text clinical notes and removes identifying information, are making the de-identification process easier and clearer (Norgeot et al., 2020). Similarly, the NIH has introduced the NLM Scrubber, a tool that can also scan electronic health records to make them de-identified, and other similar tools have also been developed (Heider et al., 2020). These tools enable open data reuse for a wealth of big-data across all health fields for assessment and analysis, while maintaining patient privacy. While the PDC aims to help support researchers and educate them about data privacy issues, ultimately the responsibility for de-identification of data rests with the uploader. Users of the PDC must adhere to the data sharing rules that are put in place by the institutional review boards and privacy laws that govern their data stewardship. As more sensitive data becomes available and shared, both within consortia and the broader research community, there will be a continued need for better ways to monitor and assess these privacy issues. To that end the NIH Office of Data Science Strategy have created calls to further fund the development of tools to help in biomedical data stewardship these efforts (Home Page | Grants and Funding, 2024).
The PDC continues to grow and expand, not just in the number of datapoints it manages, but with new features as well. The PDC portal is equipped with API capability, which allows developers (including those with Python coding skills within the community) to build data visualization and analytical tools that can be used directly within the PDC. These new features will give researchers in the consortium the ability to monitor updates to the data in near real-time. For instance, as daily behavioral performance measures are uploaded to the PDC, PIs in the group will have the opportunity to generate time-series graphs and remain abreast of individual progress. This will also allow researchers to detect trends in the data that may help guide future healthcare decisions for the subjects. The PDC is also enabled with the capacity for two-factor authentication, to further secure access and verify users.
The PDC continues to develop best practices for the storage, management, and sharing of data types that are not quite as amenable to summarization in a tidy, flat spreadsheet as well. Current projects on this front include MR image analysis and storage, waveform data from injury biomechanics, and highly-granular neuromonitoring time-series data. Solving these data issues will provide even greater level of understanding of the nature of the evolving spinal cord injury.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Alhomdy S, Thabit F, Abdulrazzak FH, Haldorai A, Jagtap S, 2021. The role of cloud computing technology: a savior to fight the lockdown in COVID 19 crisis, the benefits, characteristics and applications. Int. J. Intelligent Networks 2, 166–174. 10.1016/j.ijin.2021.08.001. · doi ↗
- 2Brock JH, Rosenzweig ES, Yang H, Tuszynski MH, 2018. Enhanced axonal transport: a novel form of “plasticity” after primate and rodent spinal cord injury. Exp. Neurol 301, 59–69. 10.1016/j.expneurol.2017.12.009.29277625 PMC 7291621 · doi ↗ · pubmed ↗
- 3Capogrosso M, Milekovic T, Borton D, Wagner F, Moraud EM, Mignardot J-B, Buse N, Gandar J, Barraud Q, Xing D, Rey E, Duis S, Jianzhong Y, Ko WKD, Li Q, Detemple P, Denison T, Micera S, Bezard E, Bloch J, Courtine G, 2016. A brain–spine interface alleviating gait deficits after spinal cord injury in primates. Nature 539, 284–288. 10.1038/nature 20118.27830790 PMC 5108412 · doi ↗ · pubmed ↗
- 4Chou A, Espin AT, Huie JR, Krukowski K, Lee S, Nolan A, Guglielmetti C, Hawkins BE, Chaumeil MM, Manley GT, Beattie MS, Bresnahan JC, Martone ME, Grethe JS, Rosi S, Ferguson AR, 2021. Open data commons for preclinical traumatic brain injury research: empowering data sharing and big data analytics. Biorxiv. 10.1101/2021.03.15.435178, 2021.03.15.435178. · doi ↗
- 5Edgar R, Domrachev M, Lash AE, 2002. Gene expression omnibus: NCBI gene expression and hybridization array data repository. Nucleic Acids Res. 30, 207–210. 10.1093/nar/30.1.207.11752295 PMC 99122 · doi ↗ · pubmed ↗
- 6Ferguson AR, Stück ED, Nielson JL, 2011. Syndromics: a bioinformatics approach for Neurotrauma research. Transl. Stroke Res 2, 438–454. 10.1007/s 12975-011-0121-1.22207883 PMC 3236294 · doi ↗ · pubmed ↗
- 7Final NIH Policy for Data Management and Sharing, 2024. URL. https://grants.nih.gov/grants/guide/notice-files/NOT-OD-21-013.html. accessed 7.8.22.
- 8Fong AJ, Cai LL, Otoshi CK, Reinkensmeyer DJ, Burdick JW, Roy RR, Edgerton VR, 2005. Spinal cord-transected mice learn to step in response to quipazine treatment and robotic training. J. Neurosci 25, 11738–11747. 10.1523/jneurosci.1523-05.2005.16354932 PMC 6726027 · doi ↗ · pubmed ↗