A New Approach to the Nonparametric Behrens–Fisher Problem With Compatible Confidence Intervals
Stephen Schüürhuis, Frank Konietschke, Edgar Brunner

TL;DR
This paper introduces a new statistical method for comparing two groups when their distributions differ, offering better accuracy and confidence intervals.
Contribution
A novel nonparametric test for the Behrens–Fisher problem with improved type-I error control and compatible confidence intervals.
Findings
The proposed test maintains accurate type-I error rates even with small or unbalanced samples.
It outperforms the Brunner–Munzel test in controlling type-I errors at low significance levels.
Compatible confidence intervals show improved coverage compared to existing methods.
Abstract
We propose a new method to address the nonparametric Behrens–Fisher problem, allowing for unequal distribution functions across the two samples. The procedure tests the null hypothesis H0:θ=1/2, where θ=P(X<Y)+1/2P(X=Y) denotes the Mann–Whitney effect. Apart from the trivial case of one‐point distributions, no restrictions are imposed on the underlying data distribution. The test is derived by evaluating the ratio of the true variance σN2 of the Mann–Whitney effect estimator θ^N to its theoretical maximum, as derived from the Birnbaum–Klose inequality. Through simulations, we demonstrate that the proposed test effectively controls the type‐I error rate under various conditions, including small and unbalanced sample sizes, and different data‐generating mechanisms. Notably, it provides better control of the type‐I error rate than the widely used Brunner–Munzel test, particularly at small…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
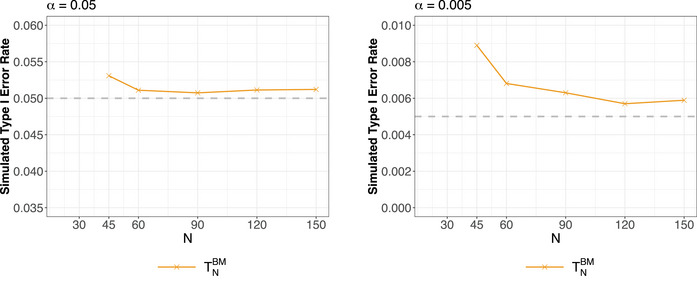 FIGURE 1
FIGURE 1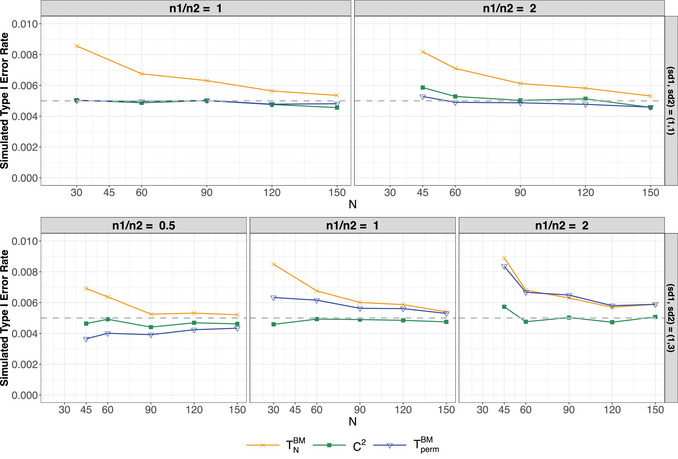 FIGURE 2
FIGURE 2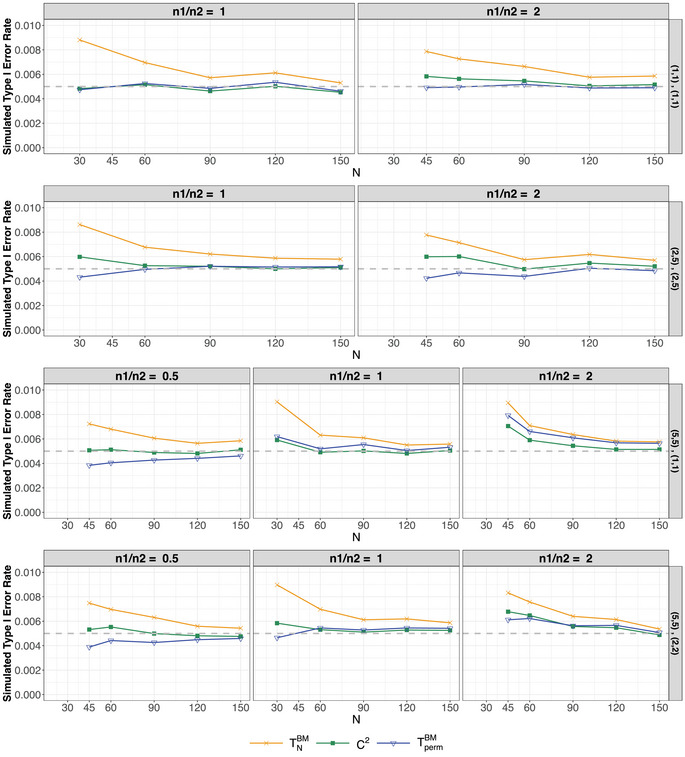 FIGURE 3
FIGURE 3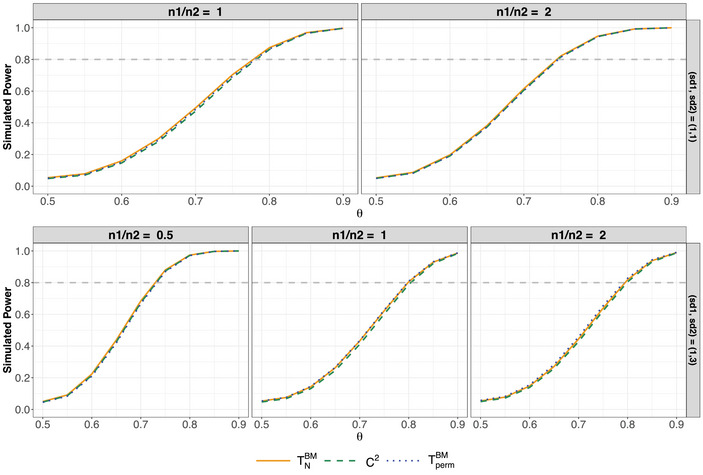 FIGURE 4
FIGURE 4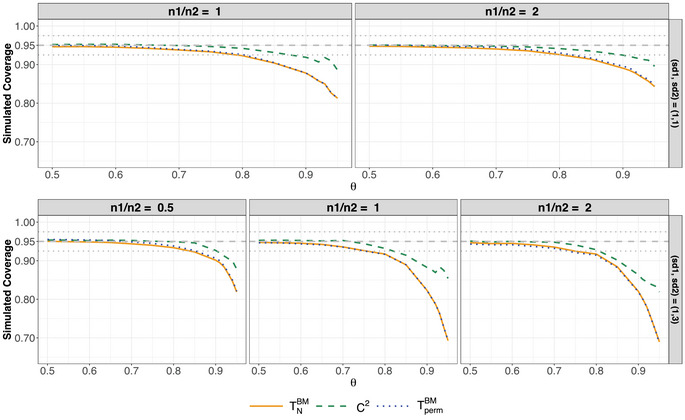 FIGURE 5
FIGURE 5| Pain score | ||||||
|---|---|---|---|---|---|---|
| Treatment arm | 1 | 2 | 3 | 4 | 5 | Total |
| Specific suction | 16 | 5 | 0 | 1 | 0 | 22 |
| Control | 4 | 1 | 5 | 7 | 2 | 19 |
| Groups | Outcome |
|---|---|
| Group 1 | 1956, 3828, 2051, 3721, 3233, 2000, 4000, 4428, 2603, 2370 |
| Group 2 | 820, 3364, 1957, 1851, 2984, 744, 2044 |
| Setting | Distribution | Parameters | |
|---|---|---|---|
| 1 | Normal distribution | and | 1 |
| 2 | Normal distribution | and | 9 |
| 3 | Beta distribution | and | 1 |
| 4 | Beta distribution | and | 1 |
| 5 | Beta distribution | and | 3.67 |
| 6 | Beta distribution | and | 2.20 |
| 7 | Ordered categorical data | Based on and | 1 |
| 8 | Ordered categorical data | Based on and | 1 |
| 9 | Ordered categorical data | Based on and | 3.67 |
| 10 | Ordered categorical data | Based on and | 2.20 |
| 11 | Poisson distribution | and | 1 |
| 12 | Exponential distribution | and | 1 |
| 13 | Laplace distribution | and | 1 |
| 14 | Laplace distribution | and | 9 |
| Setting | Distribution | Control | Treatment |
|---|---|---|---|
| 1 | Normal distribution | ||
| 2 | Normal distribution | ||
| 3 | Ordered categorical data | Based on | Based on |
| 4 | Exponential distribution |
| Descriptive results | ||
|---|---|---|
| Sample sizes | (Control) | (Treatment) |
| Mann–Whitney effect | ||
| Variance estimates | (Brunner–Munzel test) | |
| (‐test) | ||
- —Deutsche Forschungsgemeinschaft10.13039/501100001659
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Mechanics and Entropy · Statistical Methods and Inference · Statistical Distribution Estimation and Applications
Introduction
1
Comparing the means (expectations) of two independent groups with potentially different distributions (variances) is a fundamental problem in statistics, commonly encountered in fields such as medicine, biology, psychology, social sciences, and education. When the assumption of equal variances between groups is questionable in case of underlying normal distributions, the classical t‐test may no longer be appropriate, leading to the well‐known parametric Behrens–Fisher problem. However, the assumption of normality itself may not hold in many practical data analysis scenarios, as the underlying distributions from which the data are sampled can be skewed or exhibit heavy tails. Moreover, the assumption of the normal distribution is inappropriate for ordinal data such as data observed on Likert scales. In such cases, means do not offer a meaningful definition of a treatment effect. Instead, it appears more appropriate to frame the problem as the nonparametric Behrens–Fisher problem of testing
where θ represents the Mann–Whitney effect, a measure that offers a meaningful assessment of treatment effects, regardless of the underlying data distribution.
Many authors have developed methods for the nonparametric Behrens–Fisher problem, offering robust alternatives that relax the restrictive assumptions of parametric approaches (see, e.g., Fligner and Policello, 1981; Brunner and Munzel, 2000; Neubert and Brunner, 2007; Pauly et al., 2016). These nonparametric methods are particularly valuable in settings like preclinical phases or rare diseases, where accurate comparisons between treatment groups with limited sample sizes are essential. Among various procedures, the test proposed by Brunner and Munzel (2000) is widely recommended for comparing two heteroscedastic samples due to its accurate control of the type‐I error rate for α≥0.05 and sufficiently large‐sample sizes (Karch, 2021; Wilcox, 2003). However, the Brunner–Munzel test has two main weaknesses: (1) it behaves liberally and over‐rejects the null hypothesis at small‐sample sizes and/or low‐significance levels and (2) its compatible confidence intervals are not range‐preserving and show poor coverage for large effects θ (Noguchi et al., 2021; Pauly et al., 2016). Those properties are particularly noteworthy given recent developments advocating for the adoption of more stringent significance levels (see, e.g., Johnson, 2013; Benjamin et al., 2018; Held, 2019). Moreover, in the setting of multiple hypothesis testing, standard correction methods often produce adjusted α‐levels that fall well below the conventional threshold of α=0.05. Accordingly, it is the goal of this paper to address the limitations of the Brunner–Munzel test in detail, proposing a new closed‐form procedure that improves performance also at small significance levels and provides range‐preserving compatible confidence intervals.
Previous approaches addressing the nonparametric Behrens–Fisher problem include the tests by Fligner and Policello (1981) which is valid only for continuous distributions and Funatogawa and Funatogawa (2023), who developed a testing procedure for ordered categorical data. In contrast, the Brunner–Munzel test imposes no restrictions on the underlying distributions (with the trivial exception of one‐point distributions) and is often regarded as the preferred method (Karch, 2021; Wilcox, 2003), underpinned by being implemented in various software packages, such as brunnermunzel (Ara 2022), lawstat (Gastwirth et al. 2023), or rankFD by Konietschke and Brunner (2023). In their paper, they propose approximating the distribution of the test statistic using a Satterthwaite–Welch–Smith t‐approximation (Satterthwaite, 1946; Welch, 1938; Smith, 1936), which works well for sufficiently large‐sample sizes but may prove inadequate for small‐sample sizes and low‐significance levels. In response, Neubert and Brunner (2007) proposed approximating the distribution of the test statistic using a studentized permutation approach, demonstrating improved type‐I error rate control for small‐sample sizes and low‐significance levels (see Pauly et al., 2016; Noguchi et al., 2021). However, permutation tests rely on resampling for p‐value computation, which can be computationally intensive and limit their practicality in certain applications. Additionally, the associated confidence intervals are not necessarily range‐preserving, requiring range‐preserving transformations, such as the logit‐tranformation as proposed by Pepe (2003) and also discussed by Kaufmann et al. (2005) and Pauly et al. (2016). Yet, it seems reasonable to conclude that the Brunner–Munzel test, as a closed‐form procedure, and the studentized permutation test, as a resampling method, currently serve as benchmark approaches for addressing the nonparametric Behrens–Fisher problem.
Conceptually, the Brunner–Munzel test and the corresponding studentized permutation test are similar, as both seek to correct for liberal tendencies by approximating the distribution of the test statistic: the former uses a t‐approximation, while the latter employs a studentized permutation distribution. For both tests, the need for approximations partly arises from using the DeLong et al. (1988) variance estimator, which may be biased in both directions, with a positive bias in the case of continuous distributions (Brunner and Konietschke 2025). Moreover, the t‐approximation of the Brunner–Munzel test statistic is theoretically arguable, as the numerator, which includes the asymptotically normal effect estimator, and the denominator, which contains the DeLong variance estimator, are not stochastically independent.
Here, we approach the nonparametric Behrens–Fisher problem from a different perspective: rather than proposing a new approximation of the distribution of the test statistic, we derive a new test by considering the ratio of the variance of the Mann–Whitney effect estimator, σN2, to its theoretical upper bound as derived from the Birnbaum–Klose inequality (Birnbaum and Klose 1957). Unlike existing approaches relying on the variance estimator by DeLong et al. (1988), we employ the unbiased rank‐based variance estimator introduced by Brunner and Konietschke (2025). Additionally, we provide compatible confidence intervals for the new method and show that they are range‐preserving. To narrow the focus of our study, we concentrate on a test with a closed‐form solution, excluding resampling‐based methods in the present paper. Using simulation, we illustrate that the new test procedure has an improved type‐I error rate control, while maintaining power comparable to the Brunner–Munzel and studentized permutation tests. Furthermore, we compare the coverage probability of the associated confidence intervals, illustrating that the new confidence intervals provide satisfactory coverage for an increased range of true effects θ as compared to the confidence intervals obtained by inverting the Brunner–Munzel test.
This paper is organized as follows. Section 2 presents a motivating data example. The statistical model, estimators, and methods under consideration are detailed in Sections 3 and 4. A comprehensive simulation study targeting the type‐I error rate and power of the tests, as well as the coverage probability of the compatible confidence intervals, is presented in Section 5. The data example is revisited in Section 6. Finally, the paper closes with a discussion and an outlook on potential developments. Proofs and more detailed derivations are deferred to the Appendix.
Data Example
2
To illustrate the application of all the methods under consideration, we reanalyze the data from a shoulder tip pain study conducted by Jorgensen et al. (1995) and later reported by Lumley (1996), which was also used in the papers by Brunner and Munzel (2000) and Neubert and Brunner (2007). This randomized controlled trial introduces a specific suction procedure to remove air from the abdomen after a laparoscopic surgery as a new intervention. A total of n=22 patients are randomized to the treatment group, while n=19 patients are in the control group. Pain is assessed using a score ranging from 1 (no pain) to 5 (severe pain) on the evening of the second‐day post‐surgery. That is, this trial's primary endpoint has an ordinal measurement level. For details on the procedure and the trial, we refer to Lumley (1996) and the original trial by Jorgensen et al. (1995). Table 1 summarizes the trial data utilizing absolute frequencies of the different pain score values. The boxplot illustrates the empirical distribution of the data demonstrating that the pain score is highly skewed in the intervention group.
Notation and Nonparametric Model
3
The Mann–Whitney Effect
3.1
We consider the nonparametric model stated by Brunner and Munzel (2000) and consider independent random variables Xik∼Fi,k=1,⋯,ni, where i=1,2 denotes the treatment arms and N=n1+n2 the total sample size. Note that the distributions Fi may be arbitrary, excluding the case of one‐point distributions. The estimand most naturally associated with the nonparametric Behrens–Fisher problem is the Mann–Whitney effect
where Fi=(Fi++Fi−)/2 represents the normalized version of the right and left continuous cumulative distribution functions (Ruymgaart 1980). Note that this definition provides a unified notation that covers continuous and discrete data. In practice, θ can be interpreted as the probability that a random observation drawn from F2 will be larger than a random observation drawn from F1 while accounting for the probability of ties. That is, if θ>(<)0.5, X11 is said to tend to smaller (larger) values than X21. If θ=0.5, X11 and X21 are said to be stochastically comparable. Correspondingly, the nonparametric Behrens–Fisher problem can be formulated in terms of the null hypothesis H0:θ=1/2, representing the two‐sided hypothesis of no tendency toward larger values in either population. The commonly used estimator θ^N of θ can be derived by replacing the theoretical distribution functions Fi by their empirical counterparts F^i, resulting in
where R¯2·=1n2∑i=1n2Rik is the mean of all ranks Rik and Rik is the rank of observation Xik among all i=1,⋯,N observations, see Brunner et al. (2019) (Section 3.3, Result 3.1) for details. For asymptotic results, we assume that N/ni is uniformly bounded, that is, N/ni≤N0<∞, compare Brunner et al. (2019) for details (Section 3, Assumptions 3.17 and 3.19).
The construction of tests for H0:θ=1/2 requires knowledge about the variance σN2=Var(θ^N) or γN2=Var(Nθ^N)=NσN2 of the estimator θ^N. Many papers address the estimation of σN2. For example, Fligner and Policello (1981) proposed an estimator valid only for continuous distribution functions. In contrast, Bamber (1975) provided an unbiased estimator that remains valid in the presence of ties but did not consider a rank‐based representation of the estimator (for details, we refer to Brunner and Konietschke 2025). The following section introduces the variance estimators used for the tests in this paper. Specifically, we present the estimator proposed by DeLong et al. (1988), which is used in the Brunner–Munzel test, as well as the rank‐based representation of the Bamber (1975) estimator provided by Brunner and Konietschke (2025), which is used in our proposed test. It is worth noting that alternative variance estimators, including the Perme–Manevski estimator (Perme and Manevski 2019) and the Hanley–McNeil estimator (Hanley and McNeil 1982), are available and have been discussed in detail by Brunner and Konietschke (2025).
Variance Estimation
3.2
Estimator by DeLong et al. (1988)
3.2.1
For the derivation of this variance estimator, Brunner and Munzel (2000) used the asymptotic variance
based on the asymptotic equivalence theorem, as discussed in Brunner et al. (2019) (Section 7, Theorem 7.16) or Brunner and Munzel (2000). Here, σ12=Var(F2(X1i)) and σ22=Var(F1(X2j)) are generally unknown and need to be estimated from the data. With Rik(i) denoting the internal rank of observation Xik within sample i and
the so‐called placement of Xik in the respective other sample i′≠i (Orban and Wolfe 1982), replacing Fi with the corresponding empirical distribution function F^i leads to the L2‐consistent estimator
of σi2. The corresponding estimator for vN2 is obtained by the plug‐in estimator
Since the estimator provided by Brunner and Munzel (2000) is identical to that of DeLong et al. (1988), we refer to it as the DeLong estimator for the remainder of the paper. Note that this estimator is positively biased for continuous underlying distributions, as discussed by Brunner and Konietschke (2025).
Estimator by Brunner and Konietschke (2025)
3.2.2
The true variance σN2 of the Mann–Whitney estimator θ^N in Equation (2) can be expressed as
where again σ12=Var(F2(X1i)) and σ22=Var(F1(X2j)) and τ denotes the probability of ties in the overlap region of F1 and F2. This representation of σN2 can be found already in Bamber (1975), where an unbiased estimator of σN2 based on different U‐statistics is suggested without further discussion. In a recent paper, Brunner and Konietschke (2025) introduced a rank‐based version of Bamber's variance estimator by considering the U‐statistic representation of θ^N instead of the rank‐based form in Equation (2). They derived the following unbiased rank‐based estimator
where dN=n1(n1−1)n2(n2−1) and R¯i·∗=1n1∑i=1niRik∗ represents the mean of the placements Rik∗ defined in Equation (3). The probability of ties in the overlap region of F1 and F2, namely τ=P(X1j=X2i), can be estimated by
where R¯2·+ and R¯2·+ represent the means of the maximum and minimum ranks R2k+ and R2k− among all N observations and R¯2·(2)+ and R¯2·(2)− denote the means of the maximum and minimum internal ranks R2k(2)+ and R2k(2)− among all n2 observations in the second sample, respectively. For details, see Brunner and Konietschke (2025).
In contrast to the DeLong estimator v^DL2, this estimator is unbiased and non‐negative for all sample sizes ni≥2. Moreover, Brunner and Konietschke (2025) showed that σ^N2 is bounded by θ^N(1−θ^N)/(m−1), where m=min{n1,n2}. This sharp upper bound can be considered an empirical version of the Birnbaum–Klose inequality (1957). Given these preferable properties, we will use this variance estimator in the new test procedure.
Tests for the Nonparametric Behrens–Fisher Problem
4
The Brunner–Munzel–Test (2000)
4.1
To derive tests for the nonparametric Behrens–Fisher Problem H0:θ=1/2, first consider the quantity TN=N(θ^N−1/2)/γN, where γN2=VarNθ^N and note that, asymptotically, TN has a standard normal distribution, i.e., P(|TN|>z1−α/2)=α for N→∞ if γN>0 and N/ni≤N0<∞, i=1,2. Let γ^N2 denote some consistent estimator of γN2, then by Slutsky's theorem,
In particular, if γ^N2=v^DL2 as given in Equation (5), then, under H0,
is the test statistic of the Brunner–Munzel test, which, asymptotically, follows a standard normal distribution. Simulation studies have demonstrated that large‐sample sizes are required for a satisfactory approximation. In many medical and biological applications, however, the number of available observations may be quite small. Consequently, Brunner and Munzel (2000) proposed to approximate the distribution of TNBM by a tf‐distribution, where the degrees of freedom are estimated through
and σ^i2, i=1,2, is given in Equation (4). The estimated degrees of freedom f^ are obtained by replacing the variance estimators in the parametric Satterthwaite–Smith–Welch approximation by σ^i2 in Equation (4). Finally, the hypothesis H0:θ=1/2 is rejected at a two‐sided significance level α if
where tf^,1−α/2 denotes the 1−α/2‐quantile of a central t‐distribution with f^ degrees of freedom.
Exemplary results of the type‐I error rate of the test are presented in Figure 1, considering the case of heteroscedastic normal samples F1=N(0,1) and F2=N(0,9) with sample sizes n1=2n2, such that the larger variance corresponds to the smaller group. The results demonstrate that the Brunner–Munzel test may become slightly liberal for small‐sample sizes at a significance level of α=0.05. Notably, the test exhibits a clear liberal tendency at a lower α‐level of 0.5%, consistent with the findings of Noguchi et al. (2021). This behavior suggests that the t‐approximation may be inadequate in certain scenarios and motivates the exploration of alternative methods.
Simulated type‐I error rate of the Brunner–Munzel test TNBM for normal distributions F1=N(0,1) and F2=N(0,9) based on 100,000 replications at a two‐sided nominal significance level for α=0.05 (left) and α=0.005 (right). The sample sizes are chosen such that n1=2n2, resulting in a so‐called negative pairing of the variances and sample sizes. The dashed gray line represents the nominal significance level.
The 100(1−α)%‐confidence interval most naturally associated with this test can be obtained by inverting the test in Equation (11) leading to the confidence interval
Although this confidence interval is, by construction, compatible to the test decision from the test in Equation (11), it suffers from a poor coverage probability for larger effects θ (Pauly et al. 2016). Additionally, the confidence interval is not range‐preserving. To illustrate this drawback, consider the artificial dataset in Table 2. Using these data, we obtain a Mann–Whitney effect estimate of θ^N=0.8 and a p‐value of 0.0239, indicating the rejection of H0:θ=1/2 at a two‐sided significance level of α=0.05. The corresponding compatible 95%‐confidence interval calculated based on Equation (12) is [0.55,1.05], demonstrating a non‐range preserving confidence interval since 1.05>1. Alternatively, a range‐preserving logit‐transformation based confidence interval (see, e.g., Pauly et al., 2016; Kaufmann et al., 2005; Pepe, 2003) could be used.
This, however, is not compatible with the decision of the Brunner–Munzel test, which can be shown by simple counterexamples.
The Neubert and Brunner (2007) Test
4.2
To address the liberal behavior of the Brunner–Munzel test for small‐sample sizes and α∈{0.005,0.01}, Neubert and Brunner (2007) proposed a studentized permutation test, see also Pauly et al. (2016). The first step in conducting the test is to calculate the test statistic TNBM from Equation (9). Afterward, their approach involves collecting all data into a vector
randomly permute the observed data np times and compute the Brunner–Munzel test statistic TN,hBM for each permuted dataset. All test statistics are stored in a vector TpermBM=(TN,1BM,…,TN,npBM) and the two‐sided p‐value is computed as
Finally, the null hypothesis is rejected if the p‐value obtained from the empirical permutation distribution of TpermBM is smaller than the nominal significance level of α. Remarks 4.1Note that this computation may yield a p‐value of 0, even though the actual value cannot be zero considering the full permutation space. An alternative computation strategy is to include the identity permutation, resulting in (U+1)/(np+1), where U denotes one of the sums in Equation (13) (Phipson and Smyth, 2010; Hemerik and Goeman, 2018). For a large number of permutations np, however, the difference between the two methods becomes negligible.
Based on the approximation of the test statistic using the permutation distribution, a 100(1−α)%‐confidence interval can be constructed as
where c1 and c2 denote the empirical 1−α/2 and α/2‐quantile of TpermBM.
Pauly et al. (2016) provided a rigorous proof stating that the conditional permutation distribution of the studentized test statistics is approximately standard normal for any value of θ, justifying the construction of compatible confidence intervals. By simulation, Neubert and Brunner (2007) already demonstrated that this test adequately controls the type‐I error rate especially in small‐sample sizes, indicating that the distribution of the permuted test statistics approximates the null distribution of TNBM quite well. Noguchi et al. (2021) illustrated that the studentized permutation test robustly controls the type‐I error rate also for a nominal significance level as small as α=0.005. Therefore, we include this test in this paper for comparison. This test is a well‐known alternative to the standard Brunner–Munzel test, referring to it as studentized permutation test in the following.
Since the test relies on iteratively permuting the data and re‐computing the ranks and the statistic for each permutation, it tends to be computationally intensive. While this is not an issue when analyzing a single dataset, simulation‐based power evaluations and trial designs may involve quite long run times. In this context, analytical solutions would offer an advantage. Moreover, the corresponding confidence interval tends to be liberal for larger effects, as noted by Pauly et al. (2016).
Based on the aforementioned limitations, it is our intention to develop a novel analytical test procedure that remains valid even at smaller nominal significance levels, such as 0.001≤α≤0.05. The motivation for focusing on smaller nominal α‐levels stems from recent recommendations advocating for more stringent significance thresholds, such as 0.5% (see, e.g., Johnson, 2013; Benjamin et al., 2018; Held, 2019). Furthermore, in the context of multiple testing, commonly used correction procedures often yield adjusted α‐levels that are substantially smaller than the conventional threshold of α=0.05. A second key requirement for the new test procedure is the availability of confidence intervals for the Mann–Whitney effect θ that are compatible with the test decision and range‐preserving, unlike those derived from directly inverting the Brunner–Munzel test—as illustrated in Table 2. Additionally, the proposed procedure must remain well‐defined and stable even in extreme cases, such as complete sample separation, where the estimated variance σ^N2=0.
In the next section, we will introduce a new test procedure that follows a different strategy, rather than merely replacing the unknown variance σN2 of θ^N with a consistent estimator and then providing an approximation of the asymptotic normal distribution. The test will then be compared to the Brunner–Munzel test and the corresponding studentized permutation test by means of a simulation study.
A New Test for H0:θ=1/2
4.3
To derive the proposed test of the hypothesis H0:θ=1/2, we again start by noting that for large‐sample sizes,
since θ^N is asymptotically normally distributed. Various options to approximate the unknown variance σN2 in Equation (15) are available. The most straightforward solution directly replaces σN2 with a suitable consistent variance estimator. For instance, replacing σN2 with the estimator v^DL2 in Equation (5), one obtains the Brunner–Munzel statistic as presented earlier. Alternatively, one could replace the unknown variance σN2 by the theoretical upper bound of σN2 which is given by σN,max2=θ(1−θ)/m according to the Birnbaum–Klose inequality (Birnbaum and Klose 1957). Here, m=min{n1,n2} denotes the smaller sample size in both groups. By using the theoretical upper bound of the variance, this approach does not require estimating the variance and the resulting test will, unsurprisingly, be quite conservative.
The key idea of the new approach is to estimate the ratio between the true variance σN2 and its maximum value σN,max2 by an appropriate estimator. Here, we simply estimate both the numerator and the denominator of
by plugging in the estimators θ^N and σ^N2 from Equations (2) and (6) and we obtain
By approximating r with r^, the true variance σN2 can be expressed as a quadratic function of θ and of the quantity
which can be computed from the data. More concretely, setting r≈r^ yields the following approximation of the true variance:
Inserting this relation in Equation (15), one obtains
where c1−α=z1−α/22 denotes the (1−α)‐quantile of the χ12‐distribution. The last expression in Equation (19) is used (1) to construct a test for the null hypothesis H0:θ=1/2 and (2) to derive a compatible confidence interval for the Mann–Whitney effect θ by using Wilson's idea (Wilson 1927).
An asymptotic test for H0:θ=1/2 is obtained by substituting θ=1/2 into Equation (19), yielding
and the hypothesis H0:θ=1/2 is rejected at the significance level α if C2>c1−α. The corresponding p‐value is computed as p‐value =1−Fχ12(C2), where Fχ12 denotes the cumulative distribution function of the central χ12‐distribution. For the remainder of the paper, we will refer to this test as C2‐test. Remarks 4.2
-
- As discussed by Brunner and Konietschke (2025) (Section 4.4), the DeLong estimator can be biased in either direction in general. For continuous distributions the bias is positive. Thus, the DeLong estimator overestimates the variance in case of no ties which counteracts the otherwise more liberal behavior of the Brunner–Munzel test. Consequently, simply replacing the biased DeLong estimator of the asymptotic variance with the unbiased estimator σ^N2 in Equation (6) would result in an even more liberal test in this case which can be demonstrated by simulations. We therefore decided not to pursue this approach further.
-
- In Equation (17), an alternative approximation is given by r^∗=θ^N(1−θ^N)/[(m−1)σ^N2] since Brunner and Konietschke (2025) showed that σ^N2≤θ^N(1−θ^N)/(m−1) which may be regarded as an “empirical Birnbaum–Klose” inequality. Then, letting r≈r^∗ leads to the approximation σN2≈m−1mq^θ(1−θ), thereby inducing a slight dependency on the smaller sample size by the factor (m−1)/m where m=min{n1,n2}. For the sake of simplicity we will set this factor (which converges to 1 for m→∞) equal to 1 also for small‐sample sizes since simulations suggest that the resulting test does not demonstrate significant improvements.
-
- The C2‐statistic in Equation (20) can also be expressed as C2=(θ^N−1/2)2/σ∼N2, where
This formulation shows that deriving a test based on the ratio of the true variance σN2 to the maximum variance σN,max2 results in a testing procedure using the unbiased variance estimator σ^N2, scaled by the inflation factor 1/[4θ^N(1−θ^N)]≥1. Hence, this approach yields a compromise between the true variance σN2 and its theoretical upper bound 1/(4m) under the null hypothesis H0:θ=1/2, as σN2≤θ(1−θ)/m=H01/(4m).
-
4.While it is theoretically possible to replace the unbiased variance estimator in Equation (17) with the DeLong estimator v^DL2/N, thereby yielding a C2‐test involving the DeLong variance estimator, we do not intend to pursue this option further. This decision is motivated by two considerations:
-
a. The use of σ^N2 is naturally justified by the fact that this estimator has the sharp upper bound θ^N(1−θ^N)/(m−1)≈θ^N(1−θ^N)/m as noted in the previous item. Note also that the ratio r^∗ in Item 2 requires an upper bound of the variance estimator which is not known for the DeLong variance estimator.
-
b. Simulation studies suggest that substituting the DeLong estimator yields no considerable improvement in performance.
Confidence intervals compatible with the C2‐test can also be derived directly from Equation (19),
Applying the ideas of Wilson (1927) for binomial proportions, an approximate 100(1−α)% confidence interval for θ is obtained by solving the quadratic inequality (θ^N−θ)2<q^c1−αθ(1−θ) for θ, leading to the confidence bounds
Here, the index r refers to the fact that we consider the ratio in Equation (16). By construction, the confidence interval θL,Ur is compatible with the decision derived from the C2‐test since both procedures are derived from Equation (19) and it follows that C2>c1−α if 1/2∉[θLr,θUr] and vice versa. Remarks 4.3
-
- Note that, similar as the confidence intervals for binomial proportions by Wilson (1927), the confidence intervals in Equation (21) are asymmetric with respect to θ^N. This may be advantageous when the asymptotic normality of the estimator is questionable, e.g., in small samples and extreme effects. For details on the derivation, we refer to Appendix A.1.
-
- The confidence interval θL,Ur in Equation (21) is range‐preserving by construction. The corresponding proof can be found in Appendix A.2. To illustrate this property, we revisit the data example in Table 2. Applying the C2‐test to analyze the data, we obtain a p‐value of 0.0282 and the 95% confidence interval [0.53,0.93], which is both range‐preserving and compatible with the test decision.
-
- The conclusion from the C2‐test in Equation (20) is not compatible with the confidence interval derived from the Brunner–Munzel test or corresponding range‐preserving transformations, such as the logit‐ or probit‐transformation. Hence, the C2‐test result should always be reported alongside the confidence interval in Equation (21).
In case of completely separated samples, we have θ^N∈{0,1} and σ^N2=0, resulting in undefined values of the C2‐test statistic. Although of limited practical relevance, this scenario may occasionally occur in simulations with small‐sample sizes, even for moderate deviations of θ from 1/2. Therefore, it is necessary to address this situation separately. To ensure that no distribution is excluded, we propose setting σN2=σN,max2=θ(1−θ)/m, as the Birnbaum–Klose inequality is sharp. Consequently, there exist distributions for which the equality σN2=θ(1−θ)/m holds exactly. In this case, q^ in Equation (19) is replaced with the sharp upper bound of its theoretical counterpart q=σN2/[θ(1−θ)]≤1/m. As a result, variance estimation is no longer required, leading to the simplified test statistic
By plugging in θ^N∈{0,1}, this statistic becomes CσN,max2=m which only depends on the minimum sample size m. The p‐value of this test would then be given by p-value=1−Fχ12(m). Hence for, a significance level of α=0.05 or α=0.01, this test will consistently reject the null hypothesis H0:θ=1/2 if m≥4 or m≥7, respectively. This result seems reasonable, as the criterion for rejecting the null hypothesis is expected to be comparatively liberal when observing effects as extreme as θ^∈{0,1}.
To obtain compatible confidence intervals also in these extreme cases, we again approximate the true variance through the upper bound σN,max2 and solve the quadratic inequality (θ^N−θ)2≤c1−αθ(1−θ)/m for θ, leading to the confidence interval
analogously to the confidence interval in Equation (21). Here, the index BK refers to the fact that we use the bound of the Birnbaum–Klose inequality to replace the unknown variance (Birnbaum and Klose 1957). With θ^N∈{0,1}, those boundaries further simplify to
and
hence turning into one‐sided confidence intervals for the extreme values of θ^N. Note that the confidence interval in Equation (23) does not require estimation of the variance σN2. It remains conservative for all distributions provided that the normal approximation of θ^N can be considered as sufficiently accurate.
A more detailed investigation of the confidence interval in Equation (21) is beyond the scope of this paper and is considered as a separate research question requiring particular considerations for ‘larger’ values of θ or if the estimator θ^N is ‘close’ or equal to the boundaries 0 or 1.
Simulation Study
5
Neubert and Brunner (2007) conducted extensive simulations demonstrating that the studentized permutation test effectively controls the preassigned type‐I error level α under the null hypothesis, even for very small‐sample sizes, outperforming the Brunner–Munzel test in this regard. Additionally, they provided some power simulation results. In this section, we compare both approaches to the C2‐test by examining the type‐I error rate and assessing the power of all three methods. Furthermore, we evaluate the coverage of the corresponding confidence intervals.
Type‐I Error Rate Simulation
5.1
The distributions used for generating data considered in the type‐I error simulation study are summarized in Table 3. These settings encompass metric (discrete and continuous) and ordinal data. Additionally, equal and unequal variances, along with symmetric and skewed distributions, are considered. The Laplace distribution is included to also investigate heavy‐tailed distributions. The settings involving heteroscedastic distributions are depicted in the Supporting information, Section 1. For details on simulating ordered categorical data, we refer to Appendix A.3. We consider balanced as well as unbalanced designs involving the following combinations of sample sizes.
That is, we consider the sample size ratios n1/n2∈{0.5,1,2}, covering both positive pairing (larger variance in the larger group) and negative pairing (larger variance in the smaller group) for normal, beta, and Laplace distributions in case of heteroscedastic distributions. Note that, to accommodate the asymptotic nature of the proposed method, we opted not to go below ni<15 in our simulation study. The nominal α‐level is set to α∈{0.001,0.005,0.01,0.05}. This approach is motivated by recent recommendations advocating for the use of more stringent significance levels α<0.05 which are also used in α‐adjusting methods for multiple comparisons. We use niter=100,000 for all settings, giving rise to a Monte Carlo error of about 0.0001 to 0.0007 for α=0.001 to α=0.05. Finally, we estimate the type‐I error rate as 1niter∑i=1niter1{ϕg(Xi)=1} where represents one of the statistical tests g={C2,TNBM,TpermBM} considered throughout this manuscript. For the studentized permutation test, we set np=10,000 as the number of permutations.
For all analyses, we used our implementations in the software package R (Version 4.1.2) in conjunction with the RStudio IDE (Version 2022.07.1) (R Core Team 2021). In the case of separate samples, the variance estimator v^DL2 used for the Brunner–Munzel and the corresponding permutation test becomes zero such that corresponding tests and confidence intervals are undefined. Details on handling this singularity can be found in Appendix A.4. All code necessary to reproduce the presented results is included in the Supporting information and publicly available on GitHub at https://github.com/SteSchueuerhuis/C2‐Test‐Code.
Exemplary results from the type‐I error rate simulations for settings 1, 2, and 7–10 in Table 3 are illustrated in Figures 2 and 3 for α=0.005. Additional simulation results are provided in the Supporting information. Here, we briefly summarize and discuss the findings for all tests included in the simulation study, beginning with a description of the plot setup. The columns of the plot represent different sample size settings. For homoscedastic settings, the balanced case is shown in the left column and the unbalanced case in the right column. For heteroscedastic samples, the left column corresponds to n2=2n1, the center column to n1=n2, and the right column to n1=2n2. The rows correspond to different parameter settings for the respective distributions. For example, in the lower row of Figure 2, F1=N(0,1) and F2=N(0,9). Here, the lower right plot illustrates the case of negatively paired variances, while the lower left plot represents positive pairing. In all figures, the x‐axis shows the total sample size N=n1+n2, and the y‐axis displays the simulated type‐I error rate. The gray dashed line indicates the target nominal α‐level. Based on the presented figures and the comprehensive simulation study detailed in the Supporting information, the simulation results can be summarized as follows:
- The Brunner–Munzel test (TNBM), represented by the orange lines with crosses, demonstrates liberal behavior for small‐sample sizes across most examined scenarios, regardless of the underlying distribution. This tendency becomes more pronounced as the significance level decreases. However, as the sample size increases, the type‐I error rate converges to the nominal α‐level. These findings align with previous research, such as Noguchi et al. (2021) and Pauly et al. (2016), which similarly observed that the test exhibits a liberal tendency, particularly at smaller significance levels.
- The studentized permutation test (TpermBM), represented by the blue line with triangles, exhibits improved type‐I error rate control across nearly all underlying distributions, particularly for small‐sample sizes. This suggests that the studentized permutation distribution effectively approximates the null distribution of the Brunner–Munzel test statistic, aligning with the theoretical foundation established by Pauly et al. (2016), who also demonstrated that the permutation test can robustly control the type‐I error rate for even smaller sample sizes. However, it is important to note that when variances are either negatively (larger variance in smaller group) or positively paired (larger variance in larger group), the studentized permutation test appears to inherit the behavior of the original Brunner–Munzel test, exhibiting liberal or conservative tendencies, respectively. This pattern is evident, for instance, in the lower row of Figure 2, as well as in cases involving heteroscedastic Beta distributions and corresponding 5‐point Likert scales.
- The C2 ‐test (green line with squares) demonstrates improved type‐I error rate control compared to the Brunner–Munzel test. This improvement generally holds across different underlying distributions and significance levels α, suggesting that the χ12‐approximation used in Equation (20) is valid. The only exception arises in small‐sample scenarios involving highly skewed 5‐point Likert‐scale data, as illustrated in Figure 3, where the underlying distribution is Fi=B(2,5),i=1,2. Here, the test slightly exceeds the target α‐level. This behavior may be attributed to the extreme skewness of the simulated data, where the discretization causes most values to fall into a low number of categories. As a result, the data may be close to an empirical one‐point distribution, causing variance estimation to degenerate and leading to liberal type‐I error rates. Note also that for α=0.05, the C2‐test may tend to be slightly conservative compared to the Brunner–Munzel test, in particular in setting 2 and setting 5 of Table 3 (see Supporting information).
Simulated type‐I error rate for normal distributions F1=N(0,1) and F2=N(0,σ22) based on 100,000 replications at a two‐sided nominal significance level of α=0.005 for all considered tests. In the upper row of the graphs, the variances are equal σ12=σ22 while in the lower row, σ22=9σ12. The results for the so‐called positive pairing are displayed in the left graph of the bottom row and the results for the negative paring in the right graph of the bottom row. The dashed gray line represents the nominal significance level.
Simulated type‐I error rate for ordered categorical data settings 7–10 in Table 3 based on 100,000 replications at a two‐sided nominal significance level of α=0.005 for all considered tests. In the upper two rows of the graphs, the variances are equal while in the lower two rows the variances are unequal. In case of heteroscedastic samples, results for the positive pairing are displayed in the left graph and the results for the negative paring in the right graph. The dashed gray line represents the nominal significance level.
Power Simulation
5.2
In the previous section, we examined the type‐I error rate, illustrating that the proposed C2‐test has decent small‐sample size properties. In practice, we are additionally concerned with the statistical power of the tests. Table 4 summarizes the settings we consider for power simulation. The generate alternatives, we determine the distributional parameters μ,α, and λ such that they correspond to some target Mann–Whitney effect θ∼>0.5. Exemplary distributions are depicted in the Supporting information, Section 1. Regarding sample sizes, we consider (n1,n2)∈{(15,15),(15,30),(30,15)} to encompass both balanced and unbalanced sample sizes. We again used 100,000 iterations in the simulation study.
Since the results for the other distributions are virtually identical, we present only the power for settings 1 and 2 in the normal distribution case (see Table 4) in the main manuscript. The results for the other settings are provided in the Supporting information. The x‐axes represent the true Mann–Whitney effect θ, while the y‐axes display the simulated power. The gray dashed line indicates the conventionally chosen target power level of 80%. Note that power curves appeared to be largely overlapping.
Figure 4 illustrates that differences in power among the tests are minimal, regardless of the variances or sample size configurations. Overall, the Brunner–Munzel and the permutation tests exhibit slightly higher power than the C2‐test, although these differences are negligible. Notable discrepancies occur only when σ12<σ22 while n1>n2, as highlighted in the bottom‐right panel of Figure 4. However, it should be noted that the slightly higher power of the Brunner–Munzel and permutation test likely stems from their slight liberality in scenarios involving negatively paired variances and small‐sample sizes, as illustrated in the bottom‐right plots of Figure 2. These findings conclude that the C2‐test achieves satisfactory power while providing improved control of the type‐I error rate across the scenarios considered compared to the Brunner–Munzel test.
Power for normal distributions F1=N(0,1) and F2=N(μ,σ22) based on 100,000 replications at a two‐sided nominal significance level of α=0.05. In the upper row, σ22=1 while σ22=9 in the lower row. F1 and F2 are chosen such that θ∈[0.5,0.9]. The dashed gray lines indicate the target power of 80%.
Coverage Simulation
5.3
Lastly, we briefly address the coverage probabilities of the confidence intervals in Equations (12), (14), and (21), derived from the Brunner–Munzel test, the studentized permutation test, and the C2‐test. To this end, we simulated normally distributed data as outlined in Table 4, considering Mann–Whitney effects ranging from 0.5 to 0.95, ensuring consideration of rather extreme effects. Figure 5 presents the results for homoscedastic samples in the top row (left: n1=n2=15; right: (n1,n2)=(30,15)) and for heteroscedastic samples in the bottom row (left: (n1,n2)=(15,30); center: n1=n2=15; right: (n1,n2)=(30,15)).
Simulated coverage probability for normal distributions F1=N(0,1) and F2=N(0,σ22) based on 100,000 replications at a two‐sided nominal significance level of α=0.05 for all considered confidence intervals. In the upper row, σ22=1 while σ22=9 in the lower row. Gray dotted lines represent the robust Bradley (1978) limits [0.925,0.975].
In Figure 5, all methods show a reasonable coverage at small values of θ. However, as θ increases, all confidence intervals tend to become liberal at some point. Specifically, the confidence intervals derived from inverting the Brunner–Munzel test and the studentized permutation test show a decline in coverage, falling below 0.925 for approximately θ>0.8 in the homoscedastic case (upper row). In contrast, the confidence interval associated with the C2‐test maintains higher coverage over a broader range of θ. Notably, its coverage drops below 0.925 only at θ>0.9 in the unbalanced case and θ>0.85 in the balanced case. A similar trend is observed in the heteroscedastic scenario (lower row), where the C2‐test also extends the range of θ for which coverage remains adequate, outperforming the alternative methods. In conclusion, the C2‐test provides a compatible confidence interval with improved coverage across a wider range of θ while additionally being range‐preserving. Methods aimed at improving coverage specifically for extreme values of θ deserve particular attention, as emphasized by Perme and Manevski (2019). While the confidence interval based on the C2‐test already demonstrates an improvement over competing methods, addressing its behavior at the boundaries remains an open question for future research.
The results of the coverage probability simulations can also be interpreted in the context of diagnostic testing. To this end, note that the Mann–Whitney effect θ is known to be equivalent to the area under the receiver operating characteristic (ROC) curve (AUC), a common measure of discriminatory accuracy in diagnostic testing (see, e.g., Bamber, 1975; Pauly et al., 2016). Although testing the null hypothesis of no discriminatory power, i.e., H0:θ=1/2, is primarily of interest, Pauly et al. (2016) emphasized that it may also be relevant to test hypotheses for arbitrary AUC values. This is particularly important when evaluating whether a new diagnostic test or biomarker shows improved accuracy over an existing one with an assumed AUC of θ0>1/2. To test the hypothesis H0:θ=θ0, a test statistic Cθ02 can be derived from Equation (19) by substituting θ with θ0 and the null hypothesis is rejected if Cθ02>c1−α. Since rejecting H0:θ=θ0 is equivalent to observing that θ0∉[θLr,θUr], the simulation results on coverage suggest that the test maintains the nominal α‐level for moderately large values of θ0. However, because the AUC is a composite measure that summarizes both sensitivity and specificity, evaluating diagnostic accuracy may require a more detailed analysis of these two components separately. Since the focus of this paper is on deriving a test for the nonparametric Behrens–Fisher problem, a detailed investigation of the confidence interval's coverage probability and the test for H0:θ=θ0≠1/2, respectively, is beyond the scope of this work.
Analysis of the Example
6
In this section, we revisit the data from the shoulder tip pain study in Section 2, which aimed to determine whether a specific suction procedure reduces pain in patients after laparoscopic surgery more effectively than the standard of care. In this context, values of θ>0.5 indicate a tendency toward lower pain scores in the treatment group, suggesting the procedure's effectiveness, while values of θ<0.5 favor the control group. The results are summarized in Table 5.
We observe that the DeLong variance estimate (used in the Brunner–Munzel test) and the unbiased variance estimate (used in the C2‐test) are quite close. Regarding the confidence intervals, we observe a slightly larger upper bound for the interval corresponding to the Brunner–Munzel test compared to a slightly smaller lower bound for the interval corresponding to the C2‐test. Despite these minor differences, all three tests consistently lead to the conclusion that the null hypothesis H0:θ=1/2 can be rejected at a nominal significance level of α=0.05 in favor of the treatment group, indicating that the specific suction procedure significantly reduced the pain scores in comparison to the control treatment.
Discussion and Outlook
7
The nonparametric Behrens–Fisher problem of testing H0:θ=1/2 addresses the comparison of two independent groups without relying on the assumption of equal variances or normality, where θ denotes the well‐known Mann–Whitney effect. Since θ is well‐defined even for discrete data, this hypothesis is especially useful when parametric assumptions are doubtful or when it is inappropriate to impose distributional assumptions. Consequently, the nonparametric Behrens–Fisher problem offers a flexible and broadly applicable framework. To date, the Brunner–Munzel test (Brunner and Munzel 2000) is the primarily recommended method for testing H0:θ=1/2. However, it faces important limitations: first, it tends to exceed the nominal type‐I error rate at small‐sample sizes and low‐significance levels, which limits its validity, particularly when adjustments for multiple testing are necessary. Second, compatible confidence intervals may become liberal for large effect sizes and are not range‐preserving by construction. On the other hand, range‐preserving confidence intervals obtained by the logit‐ or probit‐transformation are not compatible with the decisions from the Brunner–Munzel test. These limitations served as motivation to revisit the nonparametric Behrens–Fisher problem.
To address these drawbacks, we proposed a new closed‐form test based on considering the ratio of the true variance σN2 of θ^N to its theoretical upper bound σN,max2, as derived from the Birnbaum–Klose inequality (Birnbaum and Klose 1957). Additionally, we developed compatible, range‐preserving confidence intervals for this procedure. The performance of the proposed method was extensively evaluated through simulations by comparing it to the Brunner–Munzel test and the corresponding studentized permutation test (Neubert and Brunner, 2007; Pauly et al., 2016) across a wide range of scenarios, focusing on type‐I error rate control, statistical power, and the coverage probability of the corresponding confidence intervals.
In the simulation study, we observed that the C2‐test demonstrates improved type‐I error rate control in small‐sample sizes compared to the Brunner–Munzel test even at significance levels as small as α=0.005. Hence, the presented methods align with recent recommendations questioning the use of α=0.05 for hypothesis testing. Furthermore, the proposed test is comparable to the studentized permutation test by Neubert and Brunner (2007) regarding type‐I error control. While the studentized permutation test slightly exceeded the nominal α‐level in cases of negatively paired variances, the proposed test is slightly liberal under highly skewed ordered categorical data conditions. In terms of power, the observed differences were mainly negligible. Regarding coverage of the confidence intervals, we observed that the proposed confidence interval maintains adequate coverage over a broader range of θ compared to the competing methods. Finally, the proposed method has a closed‐form expression rather than relying on resampling. This improves runtime efficiency, which can be particularly beneficial for simulation‐based study planning. Based on the simulation results, we believe that the proposed method could serve as a useful alternative to both the Brunner–Munzel test and the studentized permutation test in practical applications.
Despite its advantages, the proposed method also has some limitations that warrant consideration. First, it relies on the asymptotic normality of θ^N, which may be questionable for smaller sample sizes (ni<15) per group. In those cases, we recommend computing p‐values and confidence intervals using studentized permutations, which are also appropriate for small‐sample sizes as small as ni=10 (Pauly et al. 2016). Second, similar to the competitor methods, the proposed confidence interval tends to exhibit liberal coverage when effect sizes approach the boundaries. Hence, confidence intervals under small‐sample sizes and large effects should be interpreted cautiously. Addressing this issue in the presence of extreme effects remains an open question for future research.
Alongside investigating properties under extreme effects, the new method provides a basis for numerous further research directions. First, it distinguishes itself from established approaches by incorporating the unbiased variance estimator used by Brunner and Konietschke (2025). When combined with range‐preserving transformations, such as logit‐ or probit‐transformations, this estimator could be integrated into modified studentized permutation procedures to potentially enhance the performance of the tests and confidence intervals proposed in Pauly et al. (2016), particularly for very small‐sample sizes. However, this paper intends to focus on tests that can be expressed through explicit formulas. Additionally, incorporating the Birnbaum–Klose inequality to improve adherence to type‐I error rate control could be leveraged to refine methods in other fields of application. For example, in diagnostic testing, a common research question is to compare biomarkers with respect to their ability to distinguish between diseased and non‐diseased individuals, i.e., to test H0:θ1=θ2, where θ1 and θ2 represent Mann–Whitney effects referring to the two biomarkers. A straightforward adaptation could replace the variance estimator in the commonly used DeLong test with that of Brunner and Konietschke (2025). In contrast, techniques similar to those used for the C2‐test could be developed to investigate alternative methods, particularly for small‐sample sizes. Another promising research area involves generalized pairwise comparisons (GPC), as introduced by Buyse (2010), which extend standard nonparametric methods to multivariate prioritized outcomes using U‐statistics. Adapting the proposals to the GPC framework might be possible as estimators such as θ^N and σ^N2 should remain valid when derived from U‐statistics with count functions rather than empirical distribution functions and ranks. However, establishing the theoretical underpinnings of this approach remains an open challenge. Finally, practical considerations such as sample size planning for the C2‐test or the extension to several samples and paired data represent important areas of research.
Author Contributions
St.S. contributed to developing the methods, wrote the manuscript, coded, and created the tables and figures. F.K. provided critical review of the manuscript. E.B. proposed the paper project and suggested to evaluate the ratio method, contributed to the development of the methods and provided supervision of the project. All authors read and approved the final manuscript.
Funding
This work was supported by the German Research Foundation (Grants KO 4680/4‐2 and 4680/6‐1).
Conflicts of Interest
The authors declare no conflicts of interest.
Open Research Badges
This article has earned an Open Data badge for making publicly available the digitally‐shareable data necessary to reproduce the reported results. The data is available in the Supporting Information section.
This article has earned an open data badge “Reproducible Research” for making publicly available the code necessary to reproduce the reported results. The results reported in this article could fully be reproduced.
Supporting information
Supporting information
Supporting Information
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ara, T. 2022. brunnermunzel: (Permuted) Brunner–Munzel Test . https://cran.r‐project.org/web/packages/brunnermunzel/index.html.
- 2Bamber, D. 1975. “The Area Above the Ordinal Dominance Graph and the Area Below the Receiver Operating Characteristic Graph.” Journal of Mathematical Psychology 12, no. 4: 387–415.
- 3Benjamin, D. J. , J. O. Berger , M. Johannesson , et al. 2018. “Redefine Statistical Significance.” Nature Human Behaviour 2, no. 1: 6–10.10.1038/s 41562-017-0189-z 30980045 · doi ↗ · pubmed ↗
- 4Birnbaum, Z. W. , and O. M. Klose . 1957. “Bounds for the Variance of the Mann–Whitney Statistic.” The Annals of Mathematical Statistics 28: 933–945.
- 5Bradley, J. V. 1978. “Robustness?” British Journal of Mathematical and Statistical Psychology 31, no. 2: 144–152.
- 6Brunner, E. , A. C. Bathke , and F. Konietschke . 2019. Rank and Pseudo‐Rank Procedures for Independent Observations in Factorial Designs, Using R and SAS. Springer.
- 7Brunner, E. , and F. Konietschke . 2025. “An Unbiased Rank‐Based Estimator of the Mann–Whitney Variance Including the Case of Ties.” Statistical Papers 66, no. 1: 20.
- 8Brunner, E. , and U. Munzel . 2000. “The Nonparametric Behrens–Fisher Problem: Asymptotic Theory and a Small‐Sample Approximation.” Biometrical Journal: Journal of Mathematical Methods in Biosciences 42, no. 1: 17–25.