Incremental 2D self-labelling for effective 3D medical volume segmentation with minimal annotations
Matthew Anderson, Maged Habib, David H. Steel, Boguslaw Obara

TL;DR
This paper introduces a method to train 2D models for 3D medical image segmentation using minimal annotations, significantly improving performance and reducing annotation costs.
Contribution
The novel incremental 2D self-labelling framework enables robust 3D segmentation with only one annotated slice per volume.
Findings
The self-labelling approach improved Dice Similarity Coefficient and Intersection over Union by up to 15.95% and 26.75%.
3D continuity improved, reducing the 95th percentile Hausdorff Distance from 69.88 mm to 36.46 mm.
Gradual propagation of high-confidence pseudo-labels was found to be most effective.
Abstract
The development and application of deep learning-based models have seen significant success in medical image segmentation, transforming diagnostic and treatment processes. However, these advancements often rely on large, fully annotated datasets, which are challenging to obtain due to the labour-intensive and costly nature of expert annotation. Therefore, we sought to explore the feasibility and efficacy of training 2D models under severe annotation constraints, aiming to optimise segmentation performance while minimising annotation costs. We propose an incremental 2D self-labelling framework for segmenting 3D medical volumes from a single annotated slice per volume. A 2D U-Net is first trained on these central slices. The model then iteratively generates and filters pseudo-labels for adjacent slices, progressively fine-tuning itself on an expanding dataset. This process is repeated…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2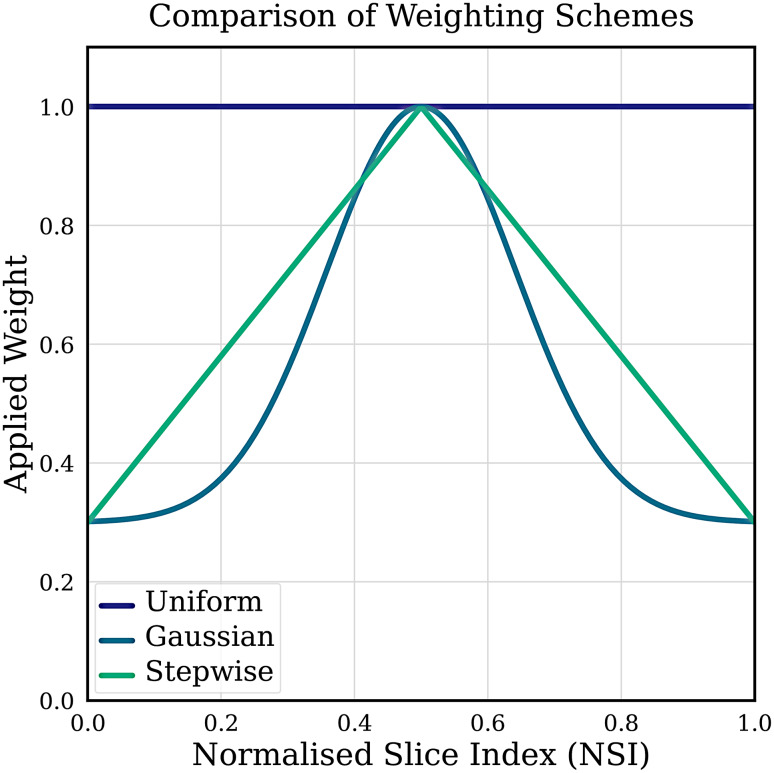 Figure 3
Figure 3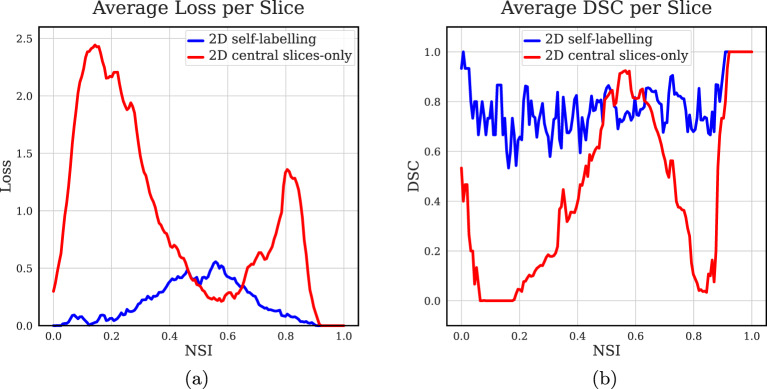 Figure 4
Figure 4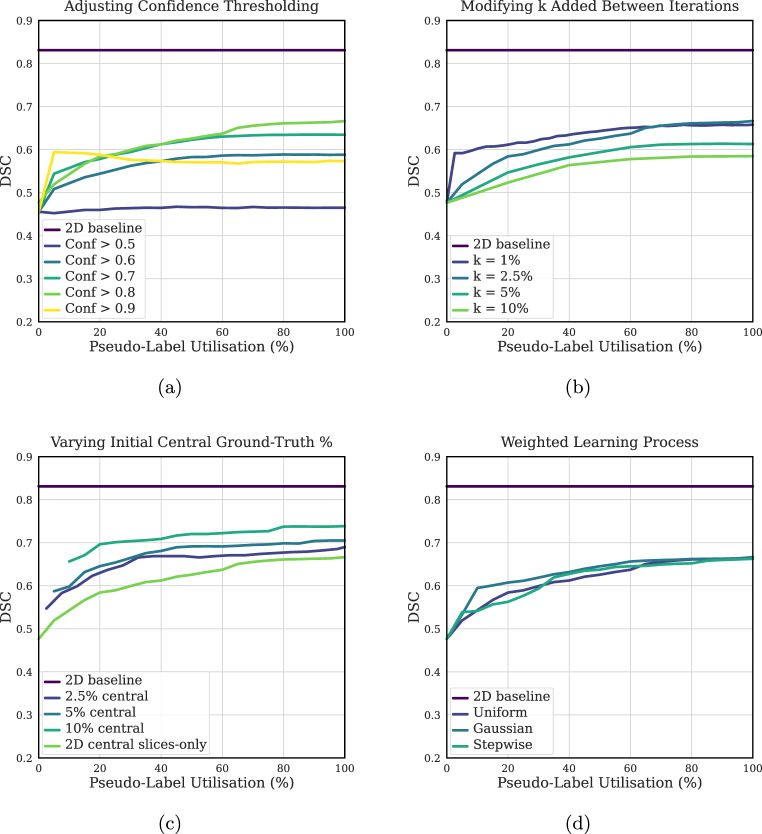 Figure 5
Figure 5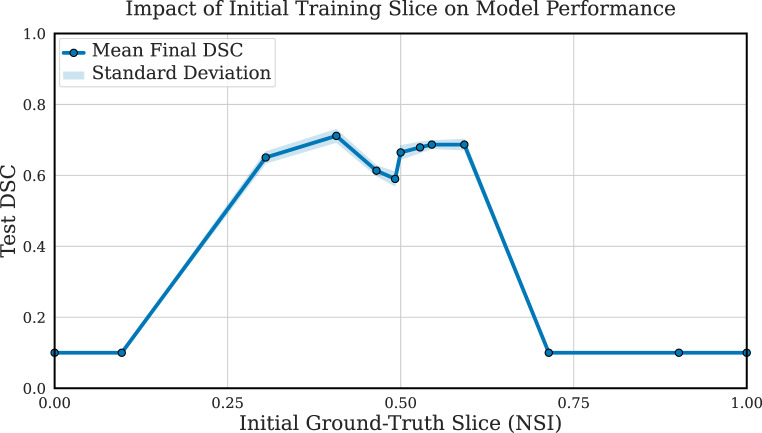 Figure 6
Figure 6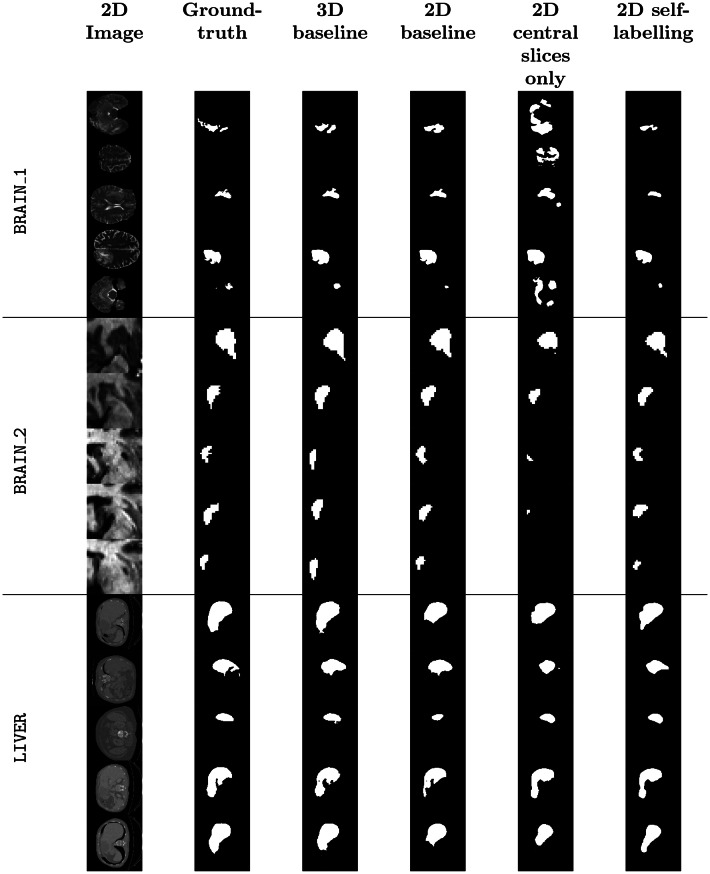 Figure 7
Figure 7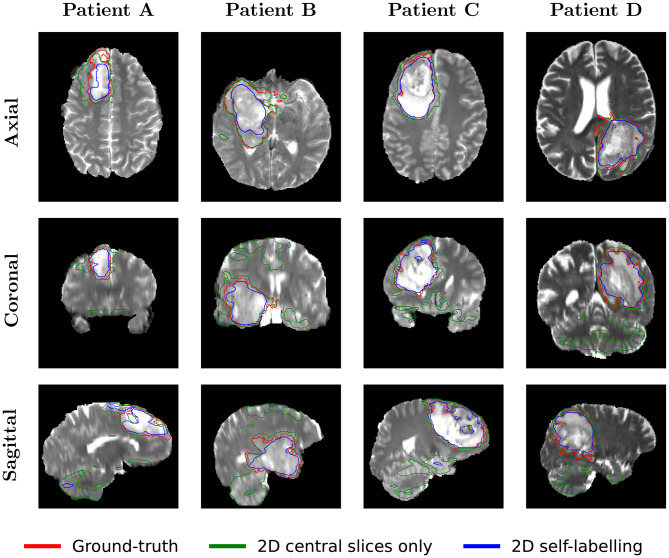 Figure 8
Figure 8 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
Topics3D Shape Modeling and Analysis · Medical Image Segmentation Techniques · Digital Image Processing Techniques
Introduction
Image segmentation falls within the domain of computer vision and digital image processing. The objective of image segmentation is to categorise comparable regions or segments within an image based on their respective class labels. This technique has been utilised in a wide range of applications such as robot vision [1], agricultural monitoring [2], and facial recognition [3]. A particularly impactful application has been medical image segmentation, where the goal is to identify and outline specific anatomical structures, such as organs and tumours, within medical images. This fundamental step is integral to various clinical applications, including computer-aided diagnosis [4], treatment planning [5], and radiation therapy [6]. Precise segmentation yields dependable volumetric and shape information, facilitating subsequent clinical tasks such as disease diagnosis, treatment guidance, and response prediction.
Classical image segmentation, widely researched for decades, largely falls into three categories: boundary-based, region-based, and hybrid-based segmentation [7]. However, classical techniques can struggle when dealing with diverse and complex image content. AI-powered machine learning algorithms, particularly those employing deep learning frameworks, have demonstrated a remarkable capacity to learn intricate patterns and features within datasets. This proficiency equips them to effectively manage increasingly complex image data. In particular, the introduction of U-Net [8] has led to substantial advances in medical image segmentation tasks. However, training these deep learning models is challenging, as it often requires a large amount of accurately annotated data, a time-consuming and costly process for clinical experts [9]. Conversely, anonymised unlabelled medical data is often readily available, and effectively harnessing this resource has the potential to improve segmentation performance at a minimal cost. Various techniques have been introduced to tackle this problem, including a range of semi-supervised and weakly-supervised learning approaches [10–14]. Pseudo-labelling [15, 16] is a type of semi-supervised learning whereby pseudo-labels are created using predictions from a trained model. These pseudo-labelled data points are then included in the training set to improve model performance, and this process is repeated iteratively in a self-training cycle.
Incremental learning involves acquiring knowledge or skills step by step while building on existing knowledge and is a key feature of natural intelligence [17]. It is characterised by the gradual accumulation of information, allowing systems to refine their understanding of tasks and concepts over time. In particular, humans exhibit remarkable learning capabilities in dynamic environments. Through extensive neurophysiological evolution, the brain has developed the capacity to gradually accumulate and retain knowledge on successive sequential tasks [18]. Consequently, the principles governing knowledge processing in the brain, explored through biological methodologies, inspire the advancement of computational approaches. This area of machine learning research has been rapidly expanding, fuelled by the potential utility of deploying continual learning algorithms for applications such as recommender systems [19], autonomous driving [20] and aid in investment decisions [21].
This study considers a scenario where a medical image dataset comes with extremely minimal annotations. This situation is not uncommon given the scarcity of large volumes of expertly annotated medical image data, which can hinder the growth of deep learning in medical image diagnosis [22]. We investigate how using only a central-annotated slice from each training volume, we can slowly propagate pseudo-labels across the entire volume in an iterative self-labelling approach using a 2D deep learning segmentation model. Our exploration is rooted in the principle of building upon familiar information incrementally. Beginning with a small amount of ground-truth data, analogous to foundational knowledge, we aim to emulate a learning trajectory where understanding builds upon familiar concepts. This strategy responds to the challenges posed by the limited availability of annotated data in medical imaging. By gradually exposing the model to variations of data it has already encountered, we anticipate that this measured approach may unlock novel avenues for enhancing model performance in medical volume segmentation.
Experimental results with the proposed self-labelling method on multiple diverse datasets show that the approach is superior to that of a model using only a small amount of ground-truth annotated data. Our approach achieves substantial improvements across multiple segmentation metrics, with the Dice Similarity Coefficient DSC and Intersection over Union IoU increasing by an average of 15.95% and 26.75% respectively over the baseline, highlighting the potential to alleviate annotation constraints for medical volumes. The main contributions are:
- We introduce a simple and computationally efficient 2D self-labelling framework to improve 3D medical volume segmentation from extremely sparse annotations (Sect. 4).
- We demonstrate through comprehensive analysis that the incremental propagation of pseudo-labels significantly improves 3D segmentation continuity and boundary accuracy (HD95) from a single annotated slice (Sect. 5).
The remainder of this paper is structured as follows. We begin by reviewing related works in pseudo-labelling and semi-supervised learning in Sect. 2. Section 3 then details the datasets and model architectures used in our experiments. In Sect. 4, we present our incremental self-labelling framework and training methodology. We report our quantitative and qualitative results in Sect. 5, followed by a comprehensive discussion of their implications and limitations in Sect. 6. Finally, Sect. 7 concludes the paper and suggests directions for future research.
Related work
Our research is closely aligned with the general application of pseudo-labeling which has been an active area of research in semi-supervised learning over recent years [15, 23]. Consistency regularisation is a commonly employed technique in pseudo-label learning [24]. This method compels the model to produce consistent predictions for inputs subjected to varying degrees of perturbation, such as weakly and strongly augmented images. Another prevalent approach is the Mean Teacher framework [25], which operates as a teacher-student system. To address the issue of confirmation bias [26], where incorrect pseudo-labels may impact the model, some existing methods suggest refining predictions considering their confidence scores [27, 28], where only predictions with high confidence are utilised as pseudo-labels, while ambiguous ones are disregarded.
Cai et al. [29] introduced a notably relevant approach, the weakly supervised slice propagated segmentation (WSSS) method, using convolutional neural networks (CNNs) for the segmentation of volumetric lesion in CT images. The WSSS method utilises response evaluation criteria in solid tumours (RECIST) annotations as weak supervision, generating initial lesion segmentation on RECIST-marked slices, and extending the segmentation to achieve volumetric completeness. Addressing the challenges associated with manual 3D segmentation, this method shows performance comparable to that of fully supervised counterparts on annotated datasets. Bitarafan et al. [30] addressed segmentation from a single annotated 2D slice per volume using a self-training method named 3D-SegReg. Their framework is built on a hybrid architecture that iteratively combines a 3D segmentation network (3D-SegNet) with a separate 2D registration network (2D-RegNet). In their process, the 2D network propagates labels to adjacent slices via registration, and these predictions are then aggregated with the output of the main 3D network to generate pseudo-labels. By fusing 2D inter-slice registration with 3D volumetric processing, their work demonstrates a powerful method for learning from sparse annotations.
Despite the abundance of research on 3D AI segmentation techniques, strategies for enhancing 3D segmentation performance using solely 2D AI models with sparse annotations remain a less-explored area. The potential advantages of 2D models, namely their significantly reduced computational demands, make them a compelling but underutilised option in this context. This paper aims to fill this void by demonstrating how a computationally efficient 2D framework can be leveraged to achieve robust 3D segmentation results.
Materials
Datasets
To evaluate the proposed method, we perform experiments on three different well-documented segmentation datasets, as shown in Table 1. The datasets were chosen due to variations in imaging modalities, segmentation tasks, and clinical applications, thereby allowing for comprehensive analysis across a spectrum of medical imaging challenges. The Medical Segmentation Decathlon (MSD): Task01_BrainTumour (BRAIN_1) and MSD: Task04_Hippocampus (BRAIN_2) are two datasets from the Medical Segmentation Decathlon challenge [31], which was developed to test the generalisability of machine learning algorithms. The BRAIN_1 dataset includes multi-parametric magnetic resonance images mp-MRI from patients with either glioblastoma or lower-grade glioma. Ground-truth annotations of three tumour sub-regions (oedema, enhancing, and non-enhancing tumour) are provided. Collected from 19 different institutions, this dataset represents a subset of the data from the 2016 and 2017 Brain Tumor Segmentation (BraTS) challenges. The BRAIN_2 dataset consists of MRI images from healthy adults and adults with non-affective psychotic disorder, with annotations for the anterior and posterior of the hippocampus. Table 1. Summary of biomedical datasets used in our experimentAcronymDescriptionTargetModalityVolumesDimensions ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x$$\end{document} pixels, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y$$\end{document} pixels, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z$$\end{document} slices, channels)BRAIN_1MSD: Task01 [31]Brain tumormp-MRI100176x144x155x4BRAIN_2MSD: Task04 [31]Hippocampus locationMRI26032x32x24-47x1LIVERLiTS 17 [32]Liver and liver tumorCECT10096x96x74-986x1
The Liver Tumor Segmentation Benchmark 2017 (LIVER) is a dataset which includes contrast-enhanced computed tomography CECT scans of the abdomen from various institutions [32]. Each scan is annotated with pixel-wise segmentation masks for the liver and tumours. It was introduced as part of the LiTS challenge to encourage the development of automatic liver lesion segmentation algorithms.
Some sample 2D slices for each dataset can be seen in Fig. 1. Fig. 1. Sample 2D image slices from datasets: (a) BRAIN_1, (b) BRAIN_2, (c) LIVER
Preprocessing
Due to computational resource limitations, preprocessing varied by dataset. All images were resized using bilinear interpolation and binary masks with nearest-neighbour interpolation. Cropping was used to remove excess background. The specific changes for each dataset were as follows. For the BRAIN_1 dataset, we applied a central crop of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$176 \times 144$$\end{document} pixels and used a random subset of 100 volumes. For the BRAIN_2 dataset, volumes were resized from an average of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$50 \times 35$$\end{document} pixels to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$32 \times 32$$\end{document} pixels. For the LIVER dataset, volumes were resized from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$512 \times 512$$\end{document} pixels to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$96 \times 96$$\end{document} pixels, and a random subset of 100 volumes was used. All datasets were randomly split into 70% training, 15% validation, and 15% test sets.
Data was standardised to a mean of 0 and a standard deviation of 1. For single-channel data, each 2D slice was standardised independently; for multi-channel data, each channel within each slice was standardised independently.
The annotations for each dataset were also converted into binary segmentation tasks. This modification reduces annotation complexity and improves training stability, particularly with imbalanced classes. For the BRAIN_1 dataset, we combined the classes (1) oedema, (2) non-enhancing tumour, and (3) enhancing tumour into a single ‘tumour’ class. For the BRAIN_2 dataset, we merged the (1) anterior and (2) posterior hippocampus classes into a single ‘hippocampus’ class. For the LIVER dataset, we combined the (1) liver and (2) tumour classes into a single ‘region-of-interest’ class. While these modifications alter the original challenge intended by the dataset curators, they allowed us to assess the performance of our approach under simplified conditions.
Model architecture
While our proposed self-labelling method is model-agnostic, we implemented and tested it using a 2D U-Net. The network follows the original architecture defined by Ronneberger et al. [8], but with a reduced number of feature maps due to computational constraints; specifically, the number of convolutional filters starts at 8 in the first layer and doubles with each downsampling step to a maximum of 128 in the bottleneck.
To handle 3D and 4D datasets, 2D slices were extracted and processed independently. The same 2D U-Net architecture was used for all 2D model comparisons (the full 2D baseline, the central-slice-only model, and our self-labelling model) to ensure a fair comparison. The 3D baseline model used an analogous architecture but replacing 2D operations (e.g., convolutions, pooling) with 3D versions.
Methods
Incremental 2D self-labelling framework
To tackle the challenge of training segmentation models with minimal annotations, we propose a self-labelling framework for a 2D U-Net to iteratively generate labels and improve its performance on 3D medical volumes. The core problem addresses a scenario where only a single, central 2D slice of each 3D training image is annotated. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ I_{\mathrm{train}} = \{I_n\}_{n=1}^N $$\end{document} denote the training set of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N$$\end{document} 3D images, where each volume \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ I_n $$\end{document} has a depth of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ z_n $$\end{document} . Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M_{\mathrm{GT}} = \{M_n\}_{n=1}^N$$\end{document} be the corresponding set of ground-truth annotations, where each \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M_n$$\end{document} is the mask for the central slice of volume \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$I_n$$\end{document} . All slice indexing is zero-based; for a volume with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ z_n $$\end{document} slices, the central slice is at index \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \lfloor z_n / 2 \rfloor $$\end{document} .
Algorithm 1Incremental 2D self-labelling for 3D volume segmentation
The framework, detailed in Algorithm 1, consists of an initialisation phase followed by an iterative self-labelling and fine-tuning cycle. The entire process is also illustrated in Fig. 2. Fig. 2. Overview of the proposed incremental 2D self-labelling framework. The process has two main phases. (1) initialisation: a baseline model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ f_1 $$\end{document} is trained using only the central slice annotations from each 3D volume. (2) iterative self-labelling: In each iteration \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ i $$\end{document} , the current model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ f_i $$\end{document} predicts segmentation masks for neighbouring unlabelled slices. These predictions are thresholded to produce binary pseudo-labels, added to the training set, and used to fine-tune the model to obtain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ f_{i+1} $$\end{document} . This process repeats until all slices are labelled, resulting in the final model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ f_{\mathrm{final}} $$\end{document}
Step 1: Initialisation
The process begins by training an initial 2D U-Net model exclusively on the sparsely annotated dataset of central slices. To ensure robustness and select the best starting point, we employ a 5-fold cross-validation process and use the model weights that yield the highest Dice Similarity Coefficient (DSC) on the validation data. This initial phase enables the model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ f_1 $$\end{document} to learn the most representative features of the target structures, which are often best captured in the central part of a medical volume. Although the datasets used in this study have full 3D annotations, our method simulates a real-world scenario where only these central slices would be manually annotated.
Step 2: Iterative self-labelling and fine-tuning
Following initialisation, the model enters an iterative loop detailed in Algorithm 1. In each iteration, the model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ f_i $$\end{document} predicts pseudo-labels for a new set of adjacent, unlabelled slices. The number of slices to add is determined by the hyperparameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ k $$\end{document} (5% of each volume’s depth, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ z_n $$\end{document} , in our experiments as determined by parameter analysis). These are selected symmetrically above and below the currently labelled region. The predictions are filtered using a confidence threshold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \theta $$\end{document} to create partial masks, which are then added to the training set. The model is then fine-tuned on this expanded dataset to produce \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ f_{i+1} $$\end{document} . This process expands the labelled region outwards from the central slice until the entire volume is pseudo-labelled.
This cycle continues until a complete pseudo-label mask has been generated for every volume in the training set. The process terminates when the depth of each generated 3D pseudo-label volume matches the depth of its corresponding source image. It is important to note that slices are not skipped due to low confidence; if all pixels in a predicted slice fall below the confidence threshold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \theta $$\end{document} , the slice is treated as a background-only mask and is still added to the training set for the next fine-tuning iteration.
As pseudo-labels for slices further from the central ground-truth slice are expected to be less accurate, we explored applying different weighting schemes to the loss function during training. To standardise slice locations across datasets with varying depths, we define a Normalised Slice Index NSI. The NSI ranges from 0 (first slice) to 1 (last slice), with the central ground-truth slice positioned at an NSI of 0.5. We investigated three potential schemes (Uniform, Gaussian, and Stepwise), visualised in Fig. 3. The Uniform scheme weights all labels equally. The Gaussian and Stepwise schemes reduce the weight of slices far from the central slice. However, the final model presented in this study utilises the Uniform scheme (a weight of 1.0 for all slices), as our sensitivity analysis revealed that the more complex Gaussian and Stepwise schemes did not yield a significant performance improvement. Fig. 3A visual comparison of the three weighting schemes investigated: uniform, Gaussian, and stepwise. The weight applied to each pseudo-label is shown as a function of the slice’s normalised position within the volume (from 0 at the first slice to 1 at the last slice)
Parameter sensitivity analysis
We performed a sensitivity analysis on the BRAIN_1 dataset to evaluate how different hyperparameters affect the performance of the model. We investigated the impact of: (1) the confidence threshold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \theta $$\end{document} for pseudo-label filtering; (2) the percentage of new slices added per iteration with respect to the total volume depth, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ k $$\end{document} ; (3) the three proposed loss function weighting schemes (Uniform, Gaussian, and Stepwise); and (4) the amount of initial ground-truth data used for training.
3D boundary fidelity and smoothness analysis
To assess the boundary accuracy and fragmentation of the final 3D segmented volumes, a post-hoc analysis was performed on the test set predictions against their corresponding ground truth masks. For this, we calculated the HD95, a metric robust to small outliers that evaluates the distance between two surfaces and is widely used in evaluating medical image segmentation methods [33].
The symmetric HD between two point sets \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B$$\end{document} is defined as the maximum of the directed distances between them. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \partial M_{\mathrm{pred}} $$\end{document} be the set of surface voxels of a predicted volume and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \partial M_{\mathrm{GT}} $$\end{document} be the surface voxels of its ground truth. The distance from a point \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p$$\end{document} to a set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S$$\end{document} is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ d(p, S) = \min_{s \in S} \| p - s \| $$\end{document} . The set of all surface distances is the collection of minimum distances from every point on one surface to the other, and vice-versa:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal{D} = \{d(p, \partial M_{\mathrm{GT}}) \mid p \in \partial M_{\mathrm{pred}} \} \cup \{d(q, \partial M_{\mathrm{pred}}) \mid q \in \partial M_{\mathrm{GT}} \}$$\end{document}The HD95 is the 95th percentile of this combined set of distances \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal{D}$$\end{document} . Using the 95th percentile mitigates the impact of a few outlier voxel predictions, providing a more stable and clinically relevant measure of boundary deviation. A lower HD95 value indicates that the predicted segmentation boundary is a less fragmented prediction with boundaries that are more accurately aligned with the ground truth. This is clinically relevant, as accurate and continuous predictions are essential for reliable downstream analysis.
Training details
The experiments were conducted using the TensorFlow v2.10.1 framework, with distributed training across an NVIDIA RTX 4070 and RTX 3060 Ti, providing a combined 20 GB of VRAM. For our self-labelling approach, the initial model was trained exclusively on the central ground-truth slices using 5-fold cross-validation. Each fine-tuning round in our iterative framework consisted of training for up to 150 epochs using the RMSprop optimiser with an initial learning rate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ 1 \times 10^{-3} $$\end{document} . The learning rate was reduced by a factor of 0.1 if the validation loss plateaued, and training was subject to an early stopping condition with a patience of 6 epochs. The weights from the epoch with the best validation loss were saved and used as the starting point for the next iteration.
Mini-batches are formed by pooling all available 2D slices (both ground-truth and pseudo-labelled) from all 3D volumes in the training set. The data generator then creates batches by randomly sampling from this combined pool of 2D slices. This ensures that each batch contains a diverse mix of examples from different subjects and slice locations.
Basic image augmentation was applied exclusively during the initial training of model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ f_1 $$\end{document} on ground-truth central slices. Preliminary experiments showed that applying augmentation during the fine-tuning steps on pseudo-labelled slices resulted in reduced model performance, therefore were not applied on pseudo-labels. This is likely due to because pseudo-labels containing less certain boundaries and inherent noise from the model’s own predictions, and aggressive geometric augmentation may exacerbate this noise, forcing the model to learn incorrect or noisy spatial features. Augmentations included horizontal and vertical flips, and random rotations up to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ 90^\circ $$\end{document} .
Training used the binary cross-entropy (BCE) loss, defined below, which measures the pixel-wise discrepancy between predicted probabilities and ground-truth labels:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm{BCE} = -\frac{1}{P} \sum_{j=1}^{P} \left[ y_j \cdot \log(p_j) + (1 - y_j) \cdot \log(1 - p_j) \right],$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ P $$\end{document} is the total number of pixels in a batch, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ y_j $$\end{document} is the ground-truth label for pixel \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ j $$\end{document} (either 1 or 0), and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ p_j $$\end{document} is the predicted probability of pixel \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ j $$\end{document} belonging to the positive class. The final model used no slice-level weighting.
Results
Performance metrics
To measure the performance of our models, we use a combination of common segmentation metrics, including DSC, IoU, True Negative Rate TNR and True Positive Rate TPR, as shown in Eqs. 3, 4, 5 and 6, respectively.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ DSC = \frac{{2{TP}}}{{2TP+FP+FN}},$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ IoU = \frac{TP}{TP+FP+FN},$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$TNR = \frac{TN}{TN+FP},$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$TPR = \frac{TP}{TP+FN},$$\end{document}where TP, TN, FP and FN refer to true positive, true negative, false positive and false negative regions, respectively. Both the DSC and IoU, with a range of 0 to 1, assess the overlap between sets. However, unlike the DSC, the IoU penalises under- and over-segmentation more than the DSC.
Quantitative evaluation
In Table 2, we present the quantitative results for five different methods in the three datasets used in this study, with the 3D baseline and 2D baseline models trained on full ground-truth annotations for benchmark comparisons. To evaluate the effectiveness of our approach, we also provide the results of a 2D self-labelling U-Net which follows the same method previously detailed but instead randomly predicts data to then use for training/validation. The number of pseudo-labels incorporated into the dataset between iterations for both approaches is kept constant between both ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=5\%$$\end{document} ). The gradual expansion of 2D self-labelling consistently outperformed the 2D central slices only method across all datasets, where the greatest performance gains were on both the BRAIN_1 and BRAIN_2 datasets, with DSC and IoU increasing by an average of 15.95% and 26.75% between the 2D central slices only model, and 2D self-labelling model. Although the 2D self-labelling model did not outperform benchmarks with fully annotated ground-truth data, its competitive performance suggests its potential utility in scenarios with minimal annotated data. The 2D self-labelling (random expansion) model also showed improvements over the 2D central slices only model, which supports the efficacy of using pseudo-labels to improve performance; however, it did not achieve as good performance as the gradual expansion method. Table 2. Performance metrics for different models on the different datasets. The best-performing metrics for non-benchmark models are highlighted in boldModel typeMetricDatasetBRAIN_1BRAIN_2LIVER3D baselineDSC0.859 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0110.882 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0060.896 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.008IoU0.658 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0080.748 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0000.667 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.006TPR0.823 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0070.891 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0010.836 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.000TNR0.998 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0010.996 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0000.999 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0002D baselineDSC0.831 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0020.812 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0030.851 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.007IoU0.578 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0020.639 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0030.682 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.009TPR0.805 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0070.782 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0040.798 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.015TNR0.998 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0000.992 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0000.998 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0002D centralDSC0.476 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0110.484 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0020.667 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.007Slices onlyIoU0.215 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0040.292 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0020.178 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.004TPR0.892 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0050.443 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0010.666 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.013TNR0.960 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0010.979 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0020.992 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0012D self-labellingDSC0.664 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.010****0.615 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.003****0.675 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.012IoU0.621 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0080.421 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0030.506 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.020TPR0.568 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0030.578 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.003****0.670 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.024TNR0.999 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.000****0.984 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.000****0.992 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0012D self-labellingDSC0.593 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0110.564 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0020.473 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.015(random expansion)IoU0.480 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0060.438 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0030.433 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.019TPR0.620 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0050.570 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0020.665 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.023TNR0.968 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0010.975 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0010.992 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.001
Figure 4 shows the performance comparison between the 2D self-labelling, and the 2D central slices only models averaged across all 2D slices of the BRAIN_1 test data. As seen in Fig. 4a, the 2D self-labelling model has on average reduced loss throughout the volume. This is further validated in Fig. 4b, where average DSC is improved across the entire volume. However, it has a higher average loss and reduced average DSC closer to the central slice at an NSI of approximately 0.5 to 0.6. Fig. 42D self-labelling and 2D central slices only models applied to BRAIN_1 test data, with (a) loss and (b) DSC averaged across all slices
3D continuity analysis
The 3D boundary accuracy analysis for the BRAIN_1 dataset is summarised in Table 3. The fully supervised 3D baseline established the strongest performance with the lowest mean HD95 of 11.57 mm, indicating the most accurate boundary alignment to the ground-truth annotations. Table 33D boundary fidelity and smoothness analysis for the BRAIN_1 dataset, evaluated using HD95. Lower values indicate better performance. The proposed model is indicated in boldModel TypeMean HD95 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} Std. Dev. (mm)3D baseline11.57 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 13.292D baseline19.00 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 23.122D central slices only69.88 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 19.542D self-labelling****36.46 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\pm}$$\end{document} 32.54
In contrast, the 2D central slices only model was the least accurate, producing a mean HD95 of 69.88 mm, which highlights a significant deviation from the ground truth boundaries when trained on minimal data. The proposed 2D self-labelling model achieved a mean HD95 of 36.46 mm. While this did not surpass the fully supervised 2D baseline (19.00 mm), it demonstrates a substantial improvement, reducing the boundary error by nearly half compared to the 2D central slices only model. This finding shows that on average the self-labelling framework successfully improves the fragmentation and spatial accuracy of the final 3D prediction by propagating knowledge from the single annotated slice.
Parameter sensitivity analysis
Our parameter sensitivity analysis on the BRAIN_1 dataset revealed that adjusting the hyperparameters had a substantial impact on the resulting model performance. The confidence threshold for pseudo-label filtering was found to be optimal between 0.6 and 0.8 (Fig. 5a). While using high-confidence predictions helps minimise error propagation, an excessively high threshold of 0.9 reduced the final test DSC, likely due to the exclusion of too much useful information. Similarly, the amount of pseudo-labels added between each iteration, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k$$\end{document} , was optimal at 5% of the volume (Fig. 5b). A larger step size of 10% decreased the final test DSC by 5.1%, suggesting that a more gradual expansion is beneficial. Fig. 5. Parameter sensitivity analysis for the pseudo-labeling approach on the BRAIN_1 dataset. Each plot shows the model’s performance (DSC) on the test set as a function of the amount of pseudo-labelled data used in training. The 2D baseline, trained on all ground-truth volumes on a slice-by-slice basis, is included for reference. The parameters varied in each subplot are: (a) the confidence threshold for generating pseudo-labels; (b) the percentage of pseudo-labels added per iteration; (c) the size of the initial ground-truth training set; and (d) the weighting strategy applied to the pseudo-labels
The initial conditions for the training process were also found to be critical. As indicated by Fig. 6, commencing the initial model with ground-truth slices from the feature-rich central third of the volume proved effective. Initiating with a slice outside this region resulted in a notably poor final test performance, mainly due to the limited annotated area for the initial model to learn from. Furthermore, increasing the amount of initial ground-truth data yielded notable and persistent performance improvements throughout the self-labelling process (Fig. 5c). In contrast, all weighted-learning approaches yielded similar performance to the standard unweighted method, with less than a 1% variance in the final test DSC (Fig. 5d). Fig. 6. Final test DSC of the 2D self-labelling model when initial training is performed using different single-slice ground-truth annotations from varying positions within the training volumes on the BRAIN_1 dataset. Results show that starting from slices near the centre of the volume (NSI ≈ 0.3-0.7) yields better performance, while peripheral slices lead to significantly worse outcomes
Table 4 shows how different methods compare computational costs. For the 3D baseline, 2D baseline, and 2D central slices only, the times provided exclude 5 cross-fold validations, only showing the average time across all 5 splits. As expected, the 2D central slices only model is the quickest to train but performs poorly. Both 3D and 2D models take roughly the same time to train. However, the 2D self-labelling model takes the longest to train due to repeated cycles on augmented datasets, with an average training time 35.37 times greater than the 2D central slices only model. Table 4. Model parameters and training timeModel TypeDataset# ParametersTraining Time (minutes)3D baselineBRAIN_11,412,41757.49BRAIN_21,411,7691.88LIVER1,411,769226.152D baselineBRAIN_1485,88946.16BRAIN_2485,6732.58LIVER485,673224.012D central slices onlyBRAIN_1485,8896.47BRAIN_2485,6731.25LIVER485,67343.872D self-labellingBRAIN_1485,889336.72BRAIN_2485,67338.25LIVER485,6731444.052D self-labelling (random expansion)BRAIN_1485,889346.81BRAIN_2485,67337.12LIVER485,6731421.64
Qualitative evaluation
Figure 7 shows randomly selected segmentations from the test data of each dataset. Predictions from each model type are presented alongside the ground-truth. These images, drawn from thousands of slices, are intended solely for illustration and may not fully reflect overall segmentation performance. Nonetheless, some qualitative differences between the 2D central-slice and 2D self-labelling models align with the quantitative results in Table 2. Fig. 7. Qualitative comparative analysis of the segmentation performance. The source 2D image slice obtained from test volumes is shown alongside the ground-truth mask and subsequent predictions from each model type are detailed
For the BRAIN_1 dataset, the self-labelling model substantially reduces over-segmentation, particularly on slices farther from the centre that were not included in the training data. In the BRAIN_2 dataset, predicted boundaries and areas are closer to the ground-truth, consistent with a 13.5% improvement in TPR. Improvements on the LIVER dataset are less pronounced, likely due to the dataset’s large size and complexity, with volumes ranging from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z \in [74, 986]$$\end{document} . In some cases, using a single annotated slice represents only 0.001% of the total volume.
To provide a more comprehensive volumetric assessment, Fig. 8 presents orthogonal views of a representative BRAIN_1 segmentation. While Fig. 7 shows 2D slice performance, this cross-plane visualisation highlights the full 3D effect of our method. The baseline model trained only on central slices produces fragmented, incomplete predictions, with disjoint segments visible in the coronal and sagittal planes. In contrast, our incremental self-labelling approach generates a coherent 3D volume that closely matches the ground truth. This qualitative improvement corresponds to a significant reduction in mean HD95 from 69.88 mm to 36.46 mm (Table 3), demonstrating the framework’s ability to enforce 3D consistency from a single annotated slice. Fig. 8. Qualitative segmentation results for four representative cases (A-D) from the BRAIN_1 test dataset. Each row corresponds to a specific anatomical view (Axial, Coronal, Sagittal). The coloured contours represent the ground-truth (red), 2D central slices only model (green), and 2D self-labelling model (blue)
Discussion
Our approach addresses a complementary setting to mainstream semi-supervised learning, which typically assumes many unlabelled volumes and some fully annotated ones. By contrast, we focus on propagating labels from a single annotated slice, and therefore our evaluation emphasises baselines tailored to this sparse-annotation problem rather than direct competition with general semi-supervised methods.
This work demonstrates that a simple incremental pseudo-labelling approach can improve segmentation performance under severe annotation constraints. The quantitative results demonstrate the effectiveness of the self-labelling strategy. Incrementally incorporating pseudo-labels alongside ground-truth data enables the model to learn relevant features in neighbouring slices, resulting in improved performance on unseen data. Analysis of loss and DSC across the entire volume shows consistent gains beyond the central slices, highlighting the benefit of exposing the model to a broader range of image contexts.
A key finding is the impact on 3D continuity, evidenced by the reduction in mean HD95 from 69.88 mm for the 2D central slices only model to 36.46 mm with our method. This shows successful propagation of spatial knowledge from a single annotated slice, allowing the model to learn a more continuous and morphologically plausible 3D structure.
The parameter sensitivity results highlight important considerations for designing an effective self-labelling pipeline. (i) Selecting a pixel confidence threshold in the 0.6–0.8 range strikes a practical balance: high enough to filter unreliable pseudo-labels, but not so strict that it excludes valuable training signals. (ii) Gradually introducing pseudo-labels between iterations, rather than in large steps, improves performance by maintaining stability and limiting the impact of early misclassifications. (iii) The quality and location of initial ground-truth slices are critical—central slices rich in features allow the model to extract more useful representations, improving downstream pseudo-labelling. (iv) Increasing the number of initial annotations consistently strengthens performance, reinforcing the value of a robust starting point in low-data regimes. These findings collectively underline that while the method is designed for minimal supervision, careful tuning of initial conditions and expansion strategy is essential to exploit its full benefit.
The similarity in performance among weighted-learning approaches likely results from slices farther from the centre containing mostly background pixels in the BRAIN_1 dataset. Consequently, reducing the impact of pseudo-labels on these outer slices has minimal effect, as informative content is concentrated near the centre on this dataset.
Efficiency comparisons show the self-labelling method requires longer training but offers improved performance without additional manual annotations, making it viable when time permits. Compared to the 3D benchmark, the 2D models use roughly one-third of the parameters, underscoring their computational efficiency.
Limitations
Our approach has several limitations that warrant consideration. The self-labelling model is prone to propagating errors, as it cannot reliably correct mistaken pseudo-labels once introduced. Although high-confidence thresholds mitigate this, early errors may still compound [34].
Being a 2D framework, the model lacks volumetric context. While computationally efficient, this limits its ability to capture depth-dependent features that can improve segmentation performance [35].
Structural continuity across neighbouring slices is assumed, which may not hold in anatomically heterogeneous datasets (e.g., abdominal CT or whole-body PET/CT) or in modalities with low through-plane resolution or sparse slice sampling. Effectiveness may degrade when foreground structures are sparse or spatially disjoint.
The approach also assumes that the target object appears, at least partially, in the initially annotated slices. Small or peripheral structures (e.g., small tumours) may be absent in central slices, leading to poor or absent pseudo-label propagation.
Segmentation of anisotropic structures aligned with the slice axis, such as tubular objects (e.g., the aorta or spinal cord), may be less reliable, as individual slices may poorly represent these features.
Experiments were performed on downsampled images due to computational constraints. While this allowed for a thorough evaluation of the framework’s logic, performance on full-resolution (e.g., 512x512) images, where finer contextual details are present, remains to be explored.
The choice of initial annotated slices is critical. If these do not adequately represent the target anatomy, subsequent pseudo-labels may be unreliable, limiting robustness in low-data or highly variable settings.
Based on these limitations, the framework is most suitable for segmenting anatomies that (i) span multiple contiguous slices, (ii) have substantial representation in central regions of the scan, and (iii) are not highly anisotropic along the slice axis. Applications involving small, sparse, or peripherally located targets may require modified sampling strategies or volumetric models.
Future work
Several extensions could enhance the robustness and generalisability of the method. Improved initialisation using multiple annotated slices across the volume, rather than a single central slice, may provide broader contextual coverage and reduce sensitivity to initial slice placement.
Adaptive expansion strategies, such as guiding pseudo-label propagation using model uncertainty, anatomical boundaries, or confidence maps, could prove more effective than fixed slice-wise progression, particularly in datasets with complex or variable spatial structure.
To improve label reliability and mitigate confirmation bias during iterative training, future work could incorporate teacher-student frameworks, soft pseudo-labels, or consistency regularisation. These mechanisms can help prevent the model from reinforcing its own errors, especially in low-confidence regions. Additional safeguards, including adaptive confidence thresholds or uncertainty-guided correction, may further reduce error accumulation over time.
Finally, incorporating shallow 3D or 2.5D architectures may provide a better balance between spatial context and computational efficiency. Similarly, applying the 2D framework across multiple anatomical planes (axial, coronal, and sagittal) and fusing the resulting predictions could yield more isotropic and robust 3D segmentations, particularly for anisotropic structures. Automated selection of initial annotated slices based on image content or model uncertainty could further reduce reliance on manual expertise and improve early pseudo-label quality.
Conclusion
This study presented a simple yet effective incremental pseudo-labelling approach to improve 3D segmentation performance using 2D models under severe annotation constraints. Evaluations across multiple datasets show that starting from a single central slice, the method can produce accurate and morphologically consistent segmentation across entire volumes. Gradual exposure to neighbouring slices enhances both standard performance metrics and 3D continuity, despite the limited supervision. While the method performs best on centrally located, isotropic structures, it offers a practical and efficient solution in low-data regimes. Key design factors, such as confidence thresholds, annotation placement, and expansion strategy, are critical to its success. Future work will explore extensions to multi-class segmentation, adaptive propagation strategies, and hybrid 2D–3D architectures to improve robustness across more complex anatomical settings.