Graph convolution network based on meta-paths and mutual information for drug-target interaction prediction
Shujuan Cao, Binying Cai, Zhejian Qiu, Tiantian Chang, Qiqige Wuyun, Fang-Xiang Wu

TL;DR
This paper introduces a new graph-based method for predicting drug-target interactions, which could help in drug repositioning and reduce experimental costs.
Contribution
GCNMM, a novel graph convolutional network using meta-paths and mutual information for improved DTI prediction.
Findings
GCNMM outperforms existing baseline models in predicting drug-target interactions.
Case studies confirm the practical effectiveness of GCNMM in drug repositioning.
Abstract
Predicting drug-target interactions (DTIs) plays a pivotal role in accelerating drug repositioning by prioritizing candidate drugs and reducing experimental costs. Despite advancements in deep learning, several challenges still require further exploration, including sparsity and inadequate representation of feature relationships. We propose GCNMM, a novel graph convolutional network based on meta-paths and mutual information, to predict latent DTIs in drug-target heterogeneous networks. Our approach begins by constructing a fused DTI network based on meta-paths and a graph attention network. We compute multiple similarity networks by using Jaccard coefficients and integrate them into the fused drug and target similarity networks through entropy-based fusion. These networks are then jointly processed by graph convolutional auto-encoder to generate low-dimensional feature…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 10
Figure 10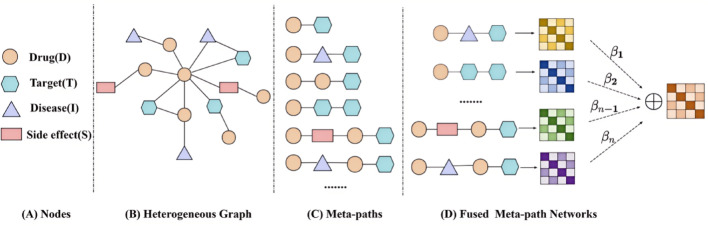 Figure 1
Figure 1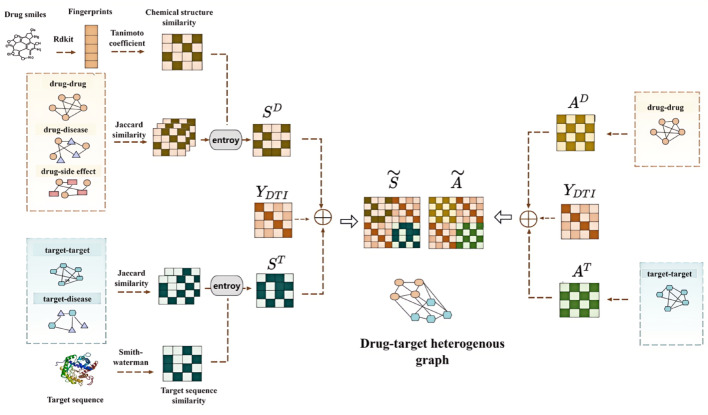 Figure 2
Figure 2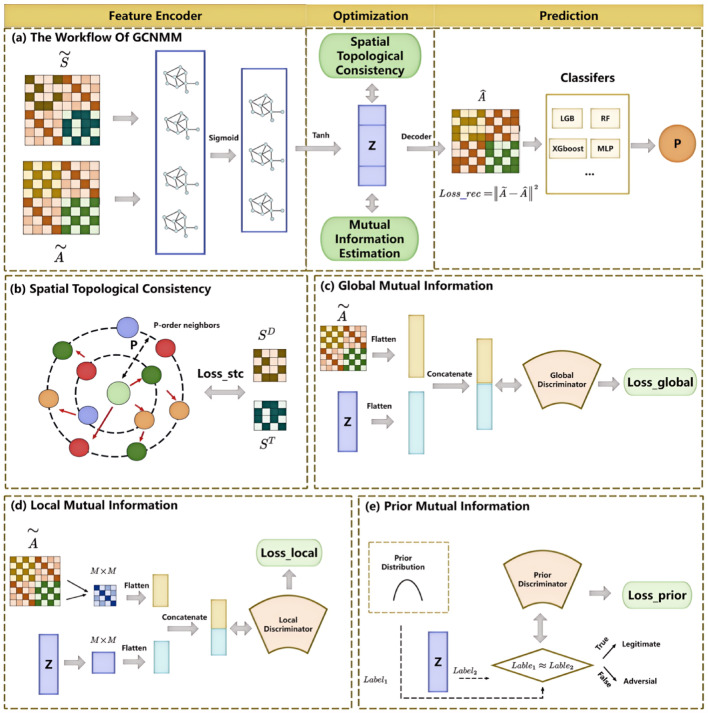 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7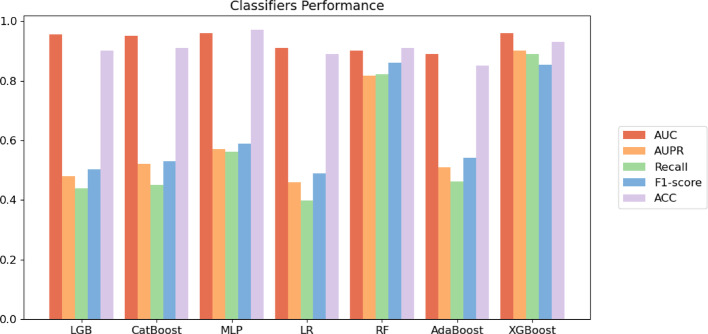 Figure 8
Figure 8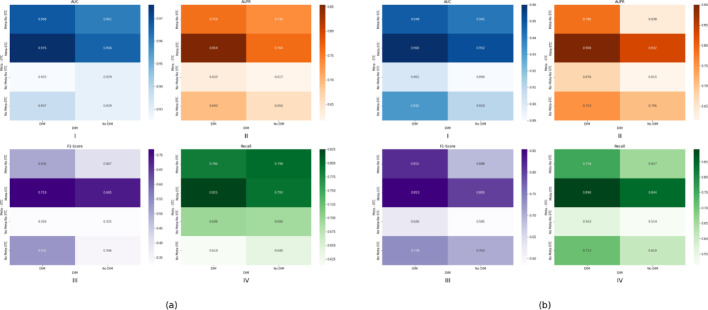 Figure 9
Figure 9- —Natural Science Foundation of Tianjin
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsComputational Drug Discovery Methods · Advanced Graph Neural Networks · Bioinformatics and Genomic Networks
Introduction
The drug discovery process is time-consuming and expensive, often accompanied by a high failure rate before the market approval. With the growing availability of biological databases and the advances in computational techniques, drug repositioning has emerged as an efficient strategy and a key research focus in pharmaceutical science [1, 2]. By leveraging public databases and bioinformatics methods, researchers can predict high-confidence drug-target interactions (DTIs), thereby narrowing the search space of potential drugs targeting specific diseases or uncovering candidate targets for existing drugs [3, 4].
Existing methods for predicting DTIs mainly include ligand-based methods, structure-based methods, and machine learning methods. However, the first two approaches face significant limitations. Ligand-based methods fail to provide a deep understanding of the mechanisms underlying DTIs [5]. The applicability of structure-based methods is strictly limited to cases where detailed structural information of both drugs and proteins is available [6].
Machine learning approaches have recently gained attention as promising techniques for candidate DTI prediction. These methods are generally partitioned into feature-based methods and network-based methods [7]. For the feature-based methods, Wang et al. integrated pharmacological information, therapeutic effects, molecular structures of drugs, and genomic data of proteins through kernel functions in support vector machine (SVM) to characterize DTIs [8]. Lan et al. developed PUDT that using Random walk with restarts, KNN and heat kernel diffusion to predict DTIs [9]. Yan et al. constructed comprehensive similarity correction matrices for drugs and targets by combining multiple kernel learning with clustering techniques, and subsequently applied a bi-random walk algorithm to infer candidate DTIs [10]. Yu et al. developed FPSC-DTI, a model that combined feature projection fuzzy classification with super cluster classification for the prediction of DTIs [11]. Additionally, a matrix tri-factorization method named NMTF-DTI, employed multiple kernels as similarity metrics and incorporated Laplacian-based regularization to improve DTI prediction accuracy [12]. However, these methods often required substantial prior knowledge and struggled to capture the deeper associations between drugs and targets. By comparison, network-based methods utilized principles of network theory to build heterogeneous networks by incorporating multimodal biological entities. The method NRWRH imported the random walk with restart on a heterogeneous network to predict candidate DTIs [13]. The DTI prediction was framed as a link prediction issue in some studies [14–16]. DTiGEMS + constructed a heterogeneous network by using similarity fusion algorithm, and built a link prediction model of DTIs based on the graph embedded method node2vec and graph mining [14]. Shao et al. introduced DTI-HETA, the model combined Graph Convolutional Neural Network (GCN) with the Graph Attention Mechanism (GAT) to obtain the embedded representations from a heterogeneous network [15]. Fu et al. developed MVGCN, a multi-view link prediction framework that constructed a heterogeneous network and designed an embedding layer with neighborhood information aggregation to enhance the node embedding updates [16]. Wang et al. proposed DTI-BGCGCN which employs a bipartite attribute graph and ClusterGCN to predict DTIs for modern and traditional medicine [17].
Meta-paths are critical constructs in heterogeneous networks, describing composite relationships and capturing underlying semantic information among different nodes. Distinct meta-paths enable the identification of diverse and meaningful relationships among nodes [18]. For instance, Wang et al. [19] applied attention mechanisms at both the node and semantic level to evaluate the influence of nodes and their neighbors defined by meta-paths, as well as the significance of the meta-paths themselves. A new graph neural network framework, MHGNN [20], was developed to capture the complex graph structure and higher-order semantic information by leveraging meta-paths to predict DTIs. Qiao et al. presented DMHGNN [21], which leveraged a graph encoder based on meta-paths combined with a denoising auto-encoder to learn heterogeneous network features, and captured the latent representation of drug-protein pairs (DPPs) via a multi-channel graph convolutional network for predicting DTIs.
Moreover, mutual information (MI) was used to quantify the statistical dependence between two random variables. It has been widely applied in tasks such as feature selection and data fusion. However, traditional techniques for calculating MI encountered substantial difficulties when handling high-dimensional data, including high computational complexity and sensitivity to data distribution [22]. To overcome these limitations, Mutual Information Neural Estimation (MINE) [23] was proposed, offering linear scalability with respect to both dimensionality and sample size. MINE transforms the mutual information estimation problem into an optimization task for neural networks by leveraging gradient descent. Furthermore, Hjelm et al. [24] proposed an unsupervised framework called Deep InfoMax (DIM) that enhanced the representation learning through the joint maximization of mutual information at both the global and local aspects between input data and encoder outputs, while adversarial learning constrains the representations to match a prior distribution.
In this study, a Graph Convolution Network framework based on Meta-paths and Mutual Information, named GCNMM, is proposed to predict potential DTIs by leveraging structural and semantic information in a heterogeneous network. First, indirect DTI networks are constructed through meta-paths, and a fused DTI network is obtained based on meta-path networks and GAT. This process aims to reduce the sparsity of the original DTI network. Similarity networks for drugs and targets are constructed by calculating Jaccard coefficients from multiple aspects, and then fused based on entropy. Second, based on the fused similarity networks and the fused DTI network, the low-dimensional feature vectors are learned with a graph convolutional auto-encoder. During the encoding process, the spatial topological consistency is integrated to ensure the preservation of node topology relationships between the embedding space and the original space as much as possible. Additionally, the MI estimation using global–local-prior discriminators is introduced to further enhance the dependence between the input and outputs of the self-encoder. Finally, an XGBoost classifier is leveraged to predict unobserved DTIs.
The core contributions of GCNMM include the following:
- The fused DTI network based on meta-paths is proposed to reduce the sparsity of the original DTI network and alleviate the imbalance between positive and negative samples.
- Spatial topological consistency is applied to ensure that the nearest-neighbor relationships in the embedded space remain close to the original space as much as possible.
- Estimations of global, local, and prior mutual information are incorporated to strengthen the correlations between the fused DTI network and the feature vectors.
- Experimental results show that GCNMM consistently superior to the baseline methods for DTI prediction. Furthermore, the effectiveness and robustness of the model are thoroughly validated through ablation experiments and case studies.
Preliminaries
This part provides formal definitions relevant to heterogeneous networks.
Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G=\left(V,E\right)$$\end{document} denote a graph, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V$$\end{document} represents the node set, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E$$\end{document} denotes the edge set. A heterogeneous graph [18] is also linked to a node category mapping function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ A' \to A $$\end{document} , and an edge category mapping function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ B' \to B $$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B$$\end{document} represent the quantities of node and edge categories, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left|A\right|+\left|B\right|>2$$\end{document} .
In our model, a heterogeneous graph is built to depict correlations among bio-entities, including Target (T), Drug (D), Disease (I), and Side effect (S). Edges represent the interactions among bio-entities, such as D-T, D-D, T-I, T-T, shows in Fig. 1(A)-(B).Fig. 1. An illustration of a fused DTI network. (A) Node types (i.e., drug, target, disease, side effect). (B) A heterogeneous graph. (C) Meta-paths extracted from a heterogeneous graph. (D) A fused meta-path network based on GAT
The meta-path [18] \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M$$\end{document} can be described as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{1}\stackrel{{B}_{1}}{\to }{A}_{2}\stackrel{{B}_{2}}{\to }\cdots \stackrel{{B}_{l}}{\to }{A}_{l+1}$$\end{document} , where node categories \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{1},{A}_{2},\cdots ,{A}_{l+1}\in A$$\end{document} , edge categories \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${B}_{1},{B}_{2},\cdots ,{B}_{l+1}\in B$$\end{document} . Nodes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{1}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{l+1}$$\end{document} are connected by a composite relation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${B}_{1}\circ {B}_{2}\circ \cdots \circ {B}_{l}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\circ $$\end{document} denotes a composite operator on the connection relation.
Meta-paths are capable of capturing specific semantic information within a heterogeneous graph, as distinct meta-paths convey different semantics. Particularly, as shown in Fig. 1(C), there are multiple meta-paths, D-T shows the known drug-target interactions, D-I-T indicates a drug-target pair interconnected through the common disease, D-D-T represents a drug-target pair connected with the same drug.
A given meta-path instance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M}_{i,j}$$\end{document} is a chain of nodes in the heterogeneous graph that follows the definition of the meta-path, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j$$\end{document} correspond to the initial and terminal nodes of the meta-path, respectively. For example, D_1_-I_1_-T_1_, D_1_-I_2_-T_1_, D_2_-I_2_-T_1_ and D_2_-I_2_-T_2_ are four distinct instances that satisfy the meta-path D-I-T.
Method
In this section, we present an innovative GCN-based approach (GCNMM) to predict candidate DTIs. As depicted in Figs. 2 and 3, the overall workflow of GCNMM consists of feature encoder module, optimization module, and prediction module.Fig. 2. The scheme of Network Fusion. The fused similarity network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widetilde{S}$$\end{document} are obtained by concatenating the drug fused similarity network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${S}^{D}$$\end{document} , the target fused similarity network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${S}^{T}$$\end{document} and the fused meta-path network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Y}_{DTI}$$\end{document} . The fused interaction heterogeneous network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widetilde{A}$$\end{document} are obtained by concatenating the drug-drug interaction network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}^{D}$$\end{document} , the target-target interaction network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}^{T}$$\end{document} and the fused meta-path network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Y}_{DTI}$$\end{document} Fig. 3. Illustration of GCNMM. (a) The workflow of GCNMM includes feature encoder, optimization and prediction module. (b) Architecture of spatial topological consistency. (c)-(d) Architecture of global, local and prior mutual information
Meta-path networks
Based on previous studies [25–27], we obtain six networks: Drug-drug interaction network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{drug-drug}$$\end{document} , drug-target interaction network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{drug-target}$$\end{document} , drug-disease interaction network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{drug-disease}$$\end{document} , drug-side effect interaction network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{drug-side effect}$$\end{document} ,
,target-target interaction network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{target-target}$$\end{document} , and target-disease interaction network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{target-disease}$$\end{document} , if a node \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} and a node \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j$$\end{document} have a known association, the item \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{i,j}=1$$\end{document} , otherwise, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{i,j}=0$$\end{document} .
In the original dataset, just a minor proportion of drug-target pairs exhibit known interactions, while the majority remain unexplored. As a result, many isolated nodes appear in the networks, making it difficult for GCN-based models to effectively capture their characteristics [28]. To address this limitation, we introduce meta-paths to uncover latent interactions between disconnected nodes. Each meta-path is constrained to start from a drug and end at a target, and its length is limited to no more than 5 [29], which is sufficient to retain meaningful semantic and structural information.
We obtain nine distinct meta-paths {DT, DDT, DIT, DTT, DIDT, DITT, DSDT, DDIT, DTDT}, the corresponding networks are denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left\{{A}_{1},{A}_{2},\cdots ,{A}_{9}\right\}$$\end{document} . For example, the indirect DT association matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{DIDT}$$\end{document} can be obtained by integrating drug-disease association information and direct drug-target association information, the formula is below: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{DIDT}={A}_{DI}*{A}_{DI}^{T}*{A}_{DT}$$\end{document} .
Fused meta-path network based on GAT
The meta-path D-T denotes the direct drug-target interaction, how to effectively fuse different indirect drug-target interactions is a core issue to be addressed. The GAT [30] is introduced to capture latent semantic significance and efficiently aggregate the information encapsulated within the meta-paths of indirect drug-target interactions, as shown in Fig. 1(D).
To effectively learn the features, a linear transformation is applied to project the network into a uniform embedding space, then we employ GAT to compute attention weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${w}_{i}$$\end{document} and obtain fused meta-path network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{pat{h}_{-}fusion}$$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${z}_{i}={f}_{\theta }\left({A}_{i}\right)={W}_{1}\cdot {A}_{i}+{b}_{1}, i=2,3,\cdots ,9.$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${w}_{i}=q\cdot \text{tanh}\left({W}_{2}\cdot {z}_{i}+{b}_{2}\right),$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{pat{h}_{-}fusion}=\sum_{i=2}^{9}{A}_{i}\cdot soft\text{max}\left({w}_{i}\right).$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${f}_{\theta }\left(\cdot \right)$$\end{document} denotes the linear projection function, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${z}_{i}$$\end{document} denotes the projected feature, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q$$\end{document} refers to the learnable attention vector, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${W}_{j}$$\end{document} refer to the learnable weight matrices, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${b}_{j}$$\end{document} refer to the learnable bias vectors, respectively. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$soft\text{max}\left(\cdot \right)$$\end{document} is a softmax activation function for normalizing attention weights.
The elements in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{pat{h}_{-}fusion}$$\end{document} represent the magnitude of interactions, the higher values indicate stronger indirect DTIs. A threshold value is applied to discretize the network:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ Y_{{DTI}}^{{meta}} = ~\left\{ {\begin{array}{*{20}c} {0, A_{{ij}} < \tau ,} \\ {1, A_{{ij}} \tau .} \\ \end{array} } \right. $$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau $$\end{document} is a predefined threshold value.
The final fused meta-path network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Y}_{DTI}$$\end{document} is obtained as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Y}_{DTI}=\text{max}\left({A}_{1},{Y}_{DTI}^{meta}\right).$$\end{document}Multiple similarities fusion
Drug chemical similarity
RDKit is used to convert Simplified Molecular Input Line Entry Specification (SMILES) [31] sequences of drugs into corresponding Morgan fingerprints [32], subsequently the chemical similarity between drug molecules is quantified by means of the Tanimoto coefficient:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T\left({r}_{i},{r}_{j}\right)=\frac{{f}_{{r}_{i}}{f}_{{r}_{j}}}{{\Vert {f}_{{r}_{i}}\Vert }^{2}+{\Vert {f}_{{r}_{j}}\Vert }^{2}-{f}_{{r}_{i}}{f}_{{r}_{j}}}.$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${f}_{{r}_{i}}$$\end{document} refers to the Morgan fingerprints of drug \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${r}_{i}$$\end{document} . The drug chemical similarity network is constructed, denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${S}_{chemical}^{D}$$\end{document} .
Target sequence similarity
For target sequence, the Smith-Waterman algorithm [33] is applied to compute pairwise similarity, followed by a normalization process:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${S}_{sequence}^{T}\left(i,j\right)=\frac{sw\left(i,j\right)-\text{min}\left(s{w}_{i}\right)}{\text{max}\left(s{w}_{i}\right)-\text{min}\left(s{w}_{i}\right)}.$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$sw\left(i,j\right)$$\end{document} is the sequence similarity score between targets \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s{w}_{i}$$\end{document} indicates the sequence similarity score between target \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} and other targets, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text{max}\left(s{w}_{i}\right)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text{min}\left(s{w}_{i}\right)$$\end{document} indicate the highest and lowest sequence similarity values between the target \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} and other targets, respectively. The target sequence similarity network is designated as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${S}_{sequence}^{T}$$\end{document} .
Interaction similarity
To accurately capture the structural attributes of the network and thoroughly investigate the latent correlations among nodes, the similarity of interaction network is assessed by using Jaccard similarity.
Jaccard Similarity is an index employed to quantify the degree of similarity between two sets. Given two elements \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${x}_{i}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${x}_{j}$$\end{document} in an interaction network, their Jaccard similarity coefficients are calculated in the following:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Sim\left(i,j\right)=\frac{\left|N\left({x}_{i}\right)\cap N\left({x}_{j}\right)\right|}{\left|N\left({x}_{i}\right)\cup N\left({x}_{j}\right)\right|},$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left|N\left({x}_{i}\right)\cap N\left({x}_{j}\right)\right|$$\end{document} refers to the count of shared neighbors of the two elements, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left|N\left({x}_{i}\right)\cup N\left({x}_{j}\right)\right|$$\end{document} represents the total count of neighbors connected to either element \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${x}_{i}$$\end{document} or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${x}_{j}$$\end{document} . The Jaccard similarity coefficient ranges within the interval [0,1], with values proximal to 1 indicating a strong similarity between the elements, and values proximal to 0 indicating a weak similarity.
For D-D network, D-I network, and D-S network, the corresponding three drug-drug similarity networks is obtained: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${S}_{interaction}^{D}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${S}_{disease}^{D}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${S}_{sider}^{D}$$\end{document} . Similarly, for T-T network and T-I network, their corresponding target-target similarity networks are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${S}_{interaction}^{T}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${S}_{disease}^{T}$$\end{document} .
Similarity network fusion
Subsequently, we integrate above similarity networks by leveraging information entropy [34]. Taking drug similarity network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${S}_{sider}^{D}$$\end{document} as an example, we calculate the entropy of each row in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${S}_{sider}^{D}$$\end{document} and calculate their average value:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${E}_{sider}^{i}=-\sum_{j=1}^{k}\frac{{S}_{sider}^{D}\left(i,j\right)}{\sum_{j=1}^{k}{S}_{sider}^{D}\left(i,j\right)}\text{log}\left(\frac{{S}_{sider}^{D}\left(i,j\right)}{\sum_{j=1}^{k}{S}_{sider}^{D}\left(i,j\right)}\right),$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${E}_{sider}^{mean}=\sum_{i=1}^{k}\frac{{E}_{sider}^{i}}{k}.$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${S}_{sider}^{D}\left(i,j\right)$$\end{document} denotes the drug-side effect similarity coefficient, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k$$\end{document} denotes the count of rows in a similarity network.
The average entropy of the similarity network is a crucial factor in similarity measures. A similarity network with lower average entropy means the less random information and has a greater weight in a comprehensive similarity network. The weight \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\omega }_{m}$$\end{document} of drug similarity network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m$$\end{document} is specified as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\omega }_{m}=\frac{\raisebox{1ex}{$1$}\!\left/ \!\raisebox{-1ex}{${E}_{m}^{\text{mean}}$}\right.}{\sum_{m=1}^{n}\raisebox{1ex}{$1$}\!\left/ \!\raisebox{-1ex}{${E}_{m}^{mean}$}\right.},$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n$$\end{document} denotes the number of drug similarity networks.
Finally, the drug fused similarity network is constructed:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${S}^{D}={\omega }_{1}{S}_{\text{interaction}}^{D}+{\omega }_{2}{S}_{\text{disease}}^{D}+{\omega }_{3}{S}_{\text{s}ider}^{D}+{\omega }_{4}{S}_{chemical}^{D}.$$\end{document}Similarly, the target fused similarity network is obtained:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${S}^{T}={\eta }_{1}{S}_{\text{interaction}}^{T}+{\eta }_{2}{S}_{\text{disease}}^{T}+{\eta }_{3}{S}_{sequence}^{T},$$\end{document}where, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\eta }_{i}$$\end{document} is the weight of target similarity network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} =1,2,3).
Heterogeneous network construction
The set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D=\left\{{d}_{i}\left|i=1,...{N}_{d}\right.\right\}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${N}_{d}$$\end{document} denotes the count of drugs, while another set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T=\left\{{t}_{j}\left|j=1,...{N}_{t}\right.\right\}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${N}_{t}$$\end{document} denotes the count of targets. The fused meta-path network denotes as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Y}_{DTI}\in {R}^{{N}_{d}\times {N}_{t}}$$\end{document} , if drugs and targets have interactions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Y}_{DTI}\left(i,j\right)=1$$\end{document} , and otherwise \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Y}_{DTI}\left(i,j\right)=0$$\end{document} . To deeper capture the intrinsic associations and attributes of drugs and targets, two heterogeneous networks are constructed. One is the fused interaction heterogeneous network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widetilde{A}$$\end{document} , which comprises the drug-drug interaction network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}^{D}$$\end{document} , the target-target interaction network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}^{T}$$\end{document} and the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Y}_{DTI}$$\end{document} , the other is fused similarity network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widetilde{S}$$\end{document} , which is composed of drug fused similarity network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${S}^{D}$$\end{document} , target fused similarity network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${S}^{T}$$\end{document} and the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Y}_{DTI}$$\end{document} . The specific workflow is shown in Fig. 2. The two heterogeneous networks are as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widetilde{A}=\left(\begin{array}{cc}{A}^{D}& {Y}_{DTI}\\ {Y}_{DTI}^{T}& {A}^{T}\end{array}\right) \widetilde{S}=\left(\begin{array}{cc}{S}^{D}& {Y}_{DTI}\\ {Y}_{DTI}^{T}& {S}^{T}\end{array}\right)$$\end{document}Network representation learning
GCN encoder
The feature representations of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widetilde{A}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widetilde{S}$$\end{document} are obtained through GCN, as shown in Fig. 3. Specifically, to incorporate the self-information of each node within the network, we set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}^{{^{\prime}}}=\widetilde{A}+I$$\end{document} , then \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}^{{^{\prime}}}$$\end{document} is normalized to obtain the Laplace matrix. The GCN encoding process for heterogeneous networks is specified as follow:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}^{\left(1\right)}=f\left(\widetilde{S},\widetilde{A}\right)={\sigma }_{1}\left({D}^{-\frac{1}{2}}{A}^{{^{\prime}}}{D}^{-\frac{1}{2}}\widetilde{S}{W}_{\left(1\right)}\right),$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}^{\left(2\right)}=f\left({H}^{\left(1\right)},\widetilde{A}\right)={\sigma }_{2}\left({D}^{-\frac{1}{2}}{A}^{{^{\prime}}}{D}^{-\frac{1}{2}}{H}^{\left(1\right)}{W}_{\left(2\right)}\right),$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D=\text{diag}\left\{{D}_{1},\cdots ,{D}_{\left({N}_{d}+{N}_{t}\right)}\right\},{ D}_{i}=\sum_{j}{A}^{{^{\prime}}}\left(i,j\right).$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D$$\end{document} is a diagonal matrix, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}^{\left(l\right)}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\sigma }_{l}$$\end{document} are the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$l$$\end{document} -layer embedding of nodes and nonlinear activation function, respectively, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$l=1,2$$\end{document} . Additionally, we set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\sigma }_{1}=sigmoid\left(t\right)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\sigma }_{2}=\text{tanh}\left(t\right)$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${W}_{\left(l\right)}$$\end{document} represents the weight matrix of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$l$$\end{document} -layer embedding, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${W}_{\left(1\right)}\in {R}^{\left({N}_{d}+{N}_{t}\right)\times m}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${W}_{\left(2\right)}\in {R}^{m\times k}$$\end{document} . After two layers of encoder training, we derive a low-dimensional feature vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z\in {R}^{\left({N}_{d}+{N}_{t}\right)\times k}$$\end{document} .
Decoder
The vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z$$\end{document} is obtained by performing the encoding process, the reconstructed network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{A}$$\end{document} is calculated below:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{A}=sigmoid\left(Z\cdot {Z}^{T}\right).$$\end{document}The elements of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{A}$$\end{document} are the predicted scores of the DTIs. The higher scores correspond to increased association probability.
Next, the Mean Squared Error (MSE) is utilized to measure the deviation between the reconstructed network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{A}$$\end{document} and the original heterogeneous network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widetilde{A}$$\end{document} . The reconstitution loss function takes the following form:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Los{s}_{reconstitution}={\Vert \widetilde{A}-\widehat{A}\Vert }^{2}={\sum_{i}\sum_{j}\left(\widetilde{A}\left(i,j\right)-\widehat{A}\left(i,j\right)\right)}^{2}.$$\end{document}Optimization
Spatial topological consistency
Many potential drug-target interactions remain undiscovered within the network. Relying solely on low-dimensional feature vectors may disrupt their nearest-neighbor relationships in the embedding space, thereby negatively impact on the accuracy of the DTI prediction.
Spatial topological consistency (STC) [35] is mainly to constrain the p-order neighbors of nodes, that is, for any nodes in the original domain, its p neighbors should maintain a close distance in the embedded domain. Therefore, we construct p-nearest neighbor networks for drugs and targets separately. Considering the drug as a case, its p-nearest neighbor network can be obtained by the following formula:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N\left(i,j\right)=\left\{\begin{array}{c}1,j\in {\mathcal{N}}_{p}\left(i\right),i\in {\mathcal{N}}_{p}\left(j\right),\\ 0,j\notin {\mathcal{N}}_{p}\left(i\right),i\notin {\mathcal{N}}_{p}\left(j\right),\\ 0.5,otherwise.\end{array}\right.$$\end{document}We get the drug sparse similarity network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{S}}^{D}\left(i,j\right)\in {R}^{{N}_{d}\times {N}_{d}}$$\end{document} containing the neighbor information as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{S}}^{D}\left(i,j\right)=N\left(i,j\right)\cdot {S}^{D}\left(i,j\right).$$\end{document}Similarly, after the same steps we get the target sparse similarity network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{S}}^{T}\left(i,j\right)\in {R}^{{N}_{t}\times {N}_{t}}$$\end{document} .
Then, the spatial topological consistency loss is delineated by the following expression:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Los{s}_{STC}={\lambda }_{1}\left({\Vert {Z}^{D}\Vert }_{F}^{2}+{\Vert {Z}^{T}\Vert }_{F}^{2}\right)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${+\lambda }_{2}\sum_{i,r=1}^{{N}_{d}}{\widehat{S}}^{D}\left(i,r\right){\Vert {Z}_{i}^{D}-{Z}_{r}^{D}\Vert }^{2}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$+{\lambda }_{3}\sum_{i,r=1}^{{N}_{t}}{\widehat{S}}^{T}\left(j,q\right){\Vert {Z}_{j}^{T}-{Z}_{q}^{T}\Vert }^{2}.$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\Vert \cdot \Vert }_{F}$$\end{document} is Frobenius norms, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\lambda }_{1}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\lambda }_{2}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\lambda }_{3}$$\end{document} are nonnegative hyperparameters that determine the relative importance of the three terms. Specifically, the first term serves as a regularization to prevent overfitting. The second term measures the distances among drugs in the embedding space, ensuring that drugs which are close to each other in the original network maintain a similar proximity in the embedding space. Similarly, the third item guarantees that the neighbor information among targets is preserved.
Mutual information estimation
MI [22] enables to precisely quantify the degree of associations between variables grounded in Shannon entropy. For example, the MI between variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z$$\end{document} can be regarded as the reduction in the uncertainty of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X$$\end{document} given \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z$$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$I\left(X,Z\right)=H\left(X\right)-H\left(X\left|Z\right.\right),$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H$$\end{document} denotes the Shannon entropy, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H\left(X\left|Z\right.\right)$$\end{document} denotes the conditional entropy of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X$$\end{document} given \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z$$\end{document} .
Similarly, MI can be articulated in light of the Kullback–Leibler (KL) divergence. It is calculated by the KL divergence of the joint probability distributions of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\left(x\left|z\right.\right)p\left(z\right)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\left(z\right)p\left(x\right)$$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${D}_{KL}\left(p\left(x,z\right)\Vert p\left(x\right)p\left(z\right)\right)=\iint p\left(x,z\right)\text{log}\frac{p\left(x,z\right)}{p\left(x\right)p\left(z\right)}dxdz$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$=\iint p\left(x\left|z\right.\right)p\left(z\right)\text{log}\frac{p\left(x\left|z\right.\right)}{p\left(x\right)}dzdx$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$=I\left(X,Z\right),$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\left(x\right)$$\end{document} denotes the input distribution, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\left(z\right)$$\end{document} denotes the distribution of the output features, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\left(x,z\right)$$\end{document} refers to the joint distribution of the input and the output features. Obviously, the greater the discrepancy between the joint probability distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\left(x,z\right)$$\end{document} and marginal probability distributions' product \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\left(z\right)p\left(x\right)$$\end{document} , the stronger the dependence between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z$$\end{document} . When the divergence is 0, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z$$\end{document} are independent of each other.
Furthermore, we conduct mutual information estimation through global, local and prior mutual information estimation to optimize the encoder's performance by leveraging diverse objectives and features.
The objective of global mutual information estimation is concentrating on the entire input and output features. At a macroscopic level, it assesses the model's retention of the input network structure information and its ability to effectively transform information into output features. Based on the concept of MINE, we use discriminators to distinguish between the joint probability distribution and the marginal probability distribution. Specifically, we adopt the Donsker-Varadhan formulation of the KL-divergence to provide a lower-bound of MI:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \left( {X,Z} \right)\hat{I}_{{DV}} \left( {X,Z} \right) = E_{{\left( {x,z} \right)\sim p\left( {zx} \right)p\left( x \right)}} \left[ {T_{\omega } \left( {x,z} \right)} \right] - {\text{log}}E_{{\left( {x,z} \right)\sim p\left( z \right)p\left( x \right)}} \left[ {e^{{T_{\omega } \left( {x,z} \right)}} } \right],$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${T}_{\omega }$$\end{document} is the neural network discriminator parameterized by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega $$\end{document} . Then, we refine the encoder \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E$$\end{document} by approximating and maximizing the mutual information. The loss function for global mutual information estimation is:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Los{s}_{G}=arg\text{max}{\widehat{I}}_{DV}\left(X,Z\right),$$\end{document}since our primary objective is to maximize MI rather than obtain specific values, we adopt an alternative estimation approach, such as the Jensen-Shannon (JS) divergence [35], whose advantage over the KL-divergence is the symmetry and the existence of an upper bound, the formulation is:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{I}}_{JS}\left(X,Z\right)={E}_{\left(x,z\right)\sim p\left(z\left|x\right.\right)p\left(x\right)}\text{log}\left[{T}_{\omega }\left(x,z\right)\right]+{E}_{\left(x,z\right)\sim p\left(z\right)p\left(x\right)}\text{log}\left[1-{T}_{\omega }\left(x,z\right)\right].$$\end{document}For local mutual information estimation, we focus on the local substructures of the input and their matching local output features. First, we encode the input as a feature mapping: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${C}_{\psi }\left(x\right)={\left\{{C}_{\psi }^{\left(i\right)}\right\}}_{i=1}^{M\times M}$$\end{document} , which denotes the local structure of the input, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M\times M$$\end{document} denote the number of local regions. The ultimate goal is to enhance the average mutual information shared by these local structures and their respective local features. There are average local MI estimation and loss function:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{I}}_{L}\left({X}^{\left(i\right)},{Z}^{\left(i\right)}\right)={E}_{\left({x}_{i},{z}_{i}\right)\sim p\left({z}_{i}\left|{x}_{i}\right.\right)p\left({x}_{i}\right)}\text{log}\left[{T}_{\omega }^{L}\left({C}_{\psi }^{\left(i\right)}\left(x\right),{z}_{i}\right)\right]+{E}_{\left({x}_{i},{z}_{i}\right)\sim p\left({z}_{i}\right)p\left({x}_{i}\right)}\text{log}\left[1-{T}_{\omega }^{L}\left({C}_{\psi }^{\left(i\right)}\left(x\right),{z}_{i}\right)\right],$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Los{s}_{L}=\underset{\omega ,\psi }{arg\text{max}}\frac{1}{{M}^{2}}\sum_{i=1}^{M}{\widehat{I}}_{L}\left({X}^{\left(i\right)},{Z}^{\left(i\right)}\right).$$\end{document}A prior mutual information estimation is employed to assess the relationship between the output feature distribution and the prior distribution. For desirable latent representations, it is essential to not only retain the maximum amount of original information but also to ensure that the representation distribution closely approximates a specific prior distribution. In our study, we specify the latent distribution to follow Gaussian distribution. First, under the assumption that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q\left(z\right)$$\end{document} adheres to Gaussian distribution, we estimate the divergence \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D\left(q\left(z\right)\Vert p\left(z\left|x\right.\right)\right)$$\end{document} by training a discriminator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${D}_{\phi }$$\end{document} , then train the encoder to make \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\left(z\left|x\right.\right)$$\end{document} approximate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q\left(z\right)$$\end{document} so as to minimize this estimate. The loss function for prior mutual information estimation is as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Los{s}_{P}=\underset{\psi }{arg\text{min}}\underset{\phi }{arg\text{max}{\widehat{D}}_{\phi }}\left(q\left(z\right)\Vert p\left(z\left|x\right.\right)\right)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$={E}_{z\sim q\left(z\right)}\text{log}\left[{D}_{\phi }\left(z\right)\right]+{E}_{x\sim p\left(x\right)}\text{log}\left[1-{D}_{\phi }\left({E}_{\psi }\left(x\right)\right)\right].$$\end{document}The above three loss functions of mutual information estimation impose constraints on the encoder from global, local and prior perspectives, respectively. By integrating these functions, we obtain the final loss function for mutual information estimation as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Los{s}_{MI}=\underset{{\omega }_{1},\psi }{arg\text{max}}\alpha {\widehat{I}}_{JS}\left(\widetilde{A},Z\right)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$+\underset{{\omega }_{2},\psi }{arg\text{max}}\frac{\beta }{{M}^{2}}\sum_{i=1}^{M}{\widehat{I}}_{L}\left({\widetilde{A}}^{\left(i\right)},{Z}^{\left(i\right)}\right)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$+\underset{\psi }{arg\text{min}}\underset{\phi }{arg\text{max}\gamma {\widehat{D}}_{\phi }}\left(q\left(z\right)\Vert p\left(z\left|a\right.\right)\right).$$\end{document}where the input is flattened and denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widetilde{A}$$\end{document} , the output feature is represented in a flattened form \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha $$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta $$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma $$\end{document} are hyperparameters to balance the loss.
Overall loss function
The overall loss function comprises the reconstitution loss, spatial topological consistency loss function and mutual information estimation loss function, as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Los{s}_{total}=Los{s}_{reconstitution}+Los{s}_{STC}+Los{s}_{MI}.$$\end{document}Generally, a lower value of the loss function indicates a better-performing model.
Experiments
Datasets
We adopt the two heterogeneous biological datasets by Luo et al. [36] and Li et al. [20] in this study. These datasets comprise four node categories and six association types, statistical details are provided in Table 1. In addition, the drug chemical similarity derived from drug chemical structure is quantified with the Tanimoto coefficient, the target sequence similarity is constructed via the Smith-Waterman algorithm.Table 1. Statistics information of Luo’s dataset and Li’s datasetTypeItemsLuo’s datasetLi’s datasetNumbersResourcesNumbersResourcesNodeDrug (D)708DrugBank (3.0) [37]2214DrugBank (5.1.8) * MERGEFORMAT [41]Target (T)1512HPRD (Release 9) [38]1968UniProtKB (2021) * MERGEFORMAT [42]Disease (I)5603CTD (2013) [39]7205CTD (2021) * MERGEFORMAT [43]Side effect (S)4192SIDER (Version 2) [40]3935SIDER (Version 4) * MERGEFORMAT [44]EdgeDrug-Target1923DrugBank (3.0) [37]8750DrugBank (5.1.8) * MERGEFORMAT [41]Drug-Drug10,036DrugBank (3.0) [37]1,091,870DrugBank (5.1.8) * MERGEFORMAT [41]Drug-Disease199,214CTD (2013) [39]542,970CTD (2021) * MERGEFORMAT [43]Drug-Side effect80,164SIDER (Version 2) [40]104,629SIDER (Version 4) * MERGEFORMAT [41]Target-Target7363HPRD (Release 9) [38]456,592STRING (11.0) [45]Target-Disease1,596,745CTD (2013) [39]2,922,064CTD (2021) [43]
Evaluation metrics
The five-fold cross-validation is adopted to appraise the efficacy of GCNMM. The fundamental principle is to partition the dataset into disjoint subsets, which are alternately utilized as training and test sets. Specifically, all known DTIs are designated as positive samples and split into five equal disjoint subsets through a randomization process. Meanwhile, unknown DTIs are considered as negative samples and undergo the same operation. In each fold, each subset is rotated as the test set while the remaining four subsets are utilized for training.
The assessment metrics include the area under the receiver operating characteristic curve (AUC), the area under the precision-recall curve (AUPR), Recall, F1-score, and Accuracy (ACC).
Parameter settings
The GCNMM model was developed with Pytorch 2.1.2 and trained on a Tesla P40 24 GB*4 GPU. The hyperparameters configuration is as follows:
In the fused meta-path network block, the threshold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau $$\end{document} impacts the model performance significantly, as shown in Fig. 4, Luo’s dataset obtains optimal performance at threshold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau =17$$\end{document} , while Li’s dataset performs best at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau =15$$\end{document} after tuning the hyperparameters to optimize performance.Fig. 4(a) The evaluation of different thresholds of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{pat{h}_{-}fusion}$$\end{document} on Luo’s dataset. (b) The evaluation of different thresholds of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${A}_{pat{h}_{-}fusion}$$\end{document} on Li’s dataset
In the GCN encoder block, a set of parameters is configured to optimize the model performance, as shown in Figs. 5 and 6. After experiments and comparisons of GCN layer \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$l\in \left\{1,2,3,4\right\}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$learning rate\in \left\{0.00001,0.0001,0.001,0.01\right\}$$\end{document} , hidden sizes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m\in \left\{128,256,512,1024\right\}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$epochs\in \left\{1000,3000,5000,6000\right\}$$\end{document} , ultimately, the learning rate is configured at 0.001, the dimensions of the hidden layer and output are set to 512, 256, respectively. The training batch size is determined to be 64, and the process is conducted over 5000 epochs.Fig. 5. The impact of layer numbers, learning rates, hidden sizes and epochs on Luo’s datasetFig. 6The impact of layer numbers, learning rates, hidden sizes and epochs on Li’s dataset
The selection of hyperparameters for the subsequent modules is guided by the ranges suggested in the literature [24, 35]. In the loss function of spatial topological consistency, we set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\lambda }_{1}$$\end{document} =0.001, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\lambda }_{2}$$\end{document} =0.001 and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\lambda }_{3}$$\end{document} =0.01. In the loss function of mutual information estimation, the parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha $$\end{document} =0.001, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta $$\end{document} =0.001 and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma $$\end{document} =0.0001.
The hyperparameters of classifiers are determined through grid-search, detailed hyperparameters are provided in Supplementary Materials.
Classifier comparison
The feature vectors are obtained after network representation learning and optimization. Several widely used classification algorithms are adopted to make predictions and evaluate performance, including LightGBM (LGB), Categorical Boosting (CatBoost), Multilayer Perceptron (MLP), Logistic Regression (LR), Adaptive Boosting (AdaBoost), Random Forest (RF), and eXtreme Gradient Boosting (XGBoost).
Each classifier performs five-fold cross-validation. Figures 7–8 display the average metrics of the aforementioned classifiers, which indicate that the XGBoost classifier surpasses the other classifiers. Although the MLP classifier has a marginally higher AUC value than the XGBoost classifier, the XGBoost classifier demonstrates superior overall performance. Consequently, we select the XGBoost classifier for predicting DTIs.Fig. 7. Comparison of different classifiers on Luo’s datasetFig. 8Comparison of different classifiers on Li’s dataset
Baseline models
To highlight the capability of GCNMM, we select various baseline models for comparison, including GADTI [46], VGAEDTI [47], SDGAE [35], SMGCN [48], MFADTI [49] and NEODTI [50].
- GADTI is a graph autoencoder approach that combines GCN with random walk to acquire node embedding, DistMult is utilized as a decoder for the DTI prediction.
- VGAEDTI is a DTI prediction approach that integrates variational inference and graph auto-encoder to acquire deep features of drugs and targets, then random forest algorithm is to make prediction.
- SDGAE is a GCN encoder that trains the model by using spatial consistency constraint and adversarial model, then predicts DTIs based on LightGBM classifier.
- SMGCN fuses multi-similarity and employs GCN to derive multi-layer low-dimensional embedded vector, then incorporates multiple kernel learning to integrate embedding features. Afterwards, the Dual Laplace Regularized Least Squares approach is utilized for DTI prediction.
- MFADTI applies graph learning from interaction graph, then a chemical structure learning mechanism is utilized to derive structures features. A multi-head self-attention mechanism as fusion module to combine feature vectors for prediction.
- NEODTI is a DTI prediction approach based on convolutional neural networks, it aggregates neighborhood information and conducts topological learning for automatic feature extraction pertinent to drugs and targets in heterogeneous networks.
The outcomes of the comparison experiments with these baseline models on two datasets are shown in Figs. S1-S2 and Table 2, with the best values highlighted in bold. Specifically, GCNMM demonstrates overwhelmingly superior performances across all five evaluation metrics compared to all baseline models on Luo’s dataset, with an AUC of 0.976, an AUPR of 0.854, a Recall of 0.825, an F1-score of 0.719 and an ACC of 0.995. On Li’s dataset, GCNMM achieves the best performances in four out of five evaluation metrics over all baseline models, with notable improvements of 3.78%, 18.43%,11.67%, 25.44% over metrics of AUC, AUPR, Recall and F1-score compared to the best-performing baseline model. While the ACC value of GCNMM is higher than the five baseline models, it is slightly lower than one baseline model (VGAEDTI) on Li’s dataset. Evidently, the GCNMM significantly outperforms the other comparison models in DTI prediction.Table 2. The outcomes of the baseline models on two datasetsDatasetModelAUCAUPRRecallF1-scoreACCLuo’s datasetVGAEDTI0.9250.6830.6880.0600.961SMGCN0.7980.4690.6000.6400.957MFADTI0.7690.8420.7290.6640.497SDGAE0.9500.6100.6790.6410.995GADTI0.8810.5190.7850.1820.195NEODTI0.9170.7440.5000.5970.972GCNMM0.9760.8540.8250.7190.995Li’s datasetVGAEDTI0.9160.6630.6690.0510.956SMGCN0.7820.4720.5890.5880.947MFADTI0.6790.7650.6900.6650.499SDGAE0.9250.6080.6890.3760.951GADTI0.8410.3540.7970.3490.221NEODTI0.7580.3590.4260.6800.840GCNMM0.9600.9060.890****0.8530.951
We attribute the outstanding performance of GCNMM to these several modules. First, we introduce meta-path-based networks, which help alleviate the sparsity of the original DTI network. Second, spatial topological consistency ensures that nodes remain close to their neighbors in the embedding space. Third, mutual information estimation strengthens the correlation between the input network and the learned feature representations. Overall, the integration of these modules leads to improved model performance on both datasets.
Ablation analysis
To demonstrate the rationale of the model components, a series of ablation studies on GCNMM were performed with the following settings:
- GCNMM: the complete proposed model.
- GCNMM w./o. Meta: the model without meta-path fusion.
- GCNMM w./o. STC: the model without spatial topological consistency.
- GCNMM w./o. MI: the model without mutual information estimation (DIM).
- GCNMM w./o. Meta STC: the model without meta-path fusion and spatial topological consistency.
- GCNMM w./o. Meta MI: the model without meta-path fusion and mutual information estimation (DIM).
- GCNMM w./o. STC MI: the model without spatial topological consistency and mutual information estimation (DIM).
- GCNMM w./o. Meta STC MI: the model only with GCN module.
The model performance metrics (AUC, AUPR, F1-score, Recall) on two datasets are visually summarized through a heatmap representation, where color intensity corresponds to metric superiority, as shown in Fig. 9, the detailed experimental results are shown in Table S1. Specifically, on Luo’s dataset, the AUC, AUPR, Recall and F1-score of the GCNMM w./o. Meta show obvious reductions of 3.99%, 18.74%, 25.58% and 26.15% compared with the original model GCNMM, while on Li’s dataset, the reductions are 2.92%, 16.89%, 20% and 13.95%, indicating that meta-path fusion is crucial in GCNMM. Similarly, spatial topological consistency is essential for model performance. Compared to GCNMM, the AUC, AUPR, Recall and F1-score of the GCNMM w./o. STC on Luo’s dataset show decreases of 0.82%, 13.8%, 4.73% and 30.2%. While on the Li’s, the decreases are 1.25%, 13.25%, 15.28% and 4.45%. Additionally, compared to GCNMM, the results of the GCNMM w./o. MI on Luo’s dataset exhibits reductions of 1.02%, 10.54%, 8.7% and 10.43% in AUC, AUPR, Recall and F1-score, respectively. On Li’s dataset, the reductions are 0.83%, 8.16%, 10.11% and 1.06%, respectively. The ablation analysis results demonstrate that each component contributes significantly to the model GCNMM, underscoring the synergistic efficacy of meta-path fusion, spatial topological consistency, and mutual information estimation.Fig. 9(a) The performance of GCNMM and its variants on Luo’s dataset. (b) The performance of GCNMM and its variants on Li’s dataset
Case studies
To additionally assess and verify the predictive capability of GCNMM, three cases are implemented, including two drugs and one target. The two drugs are Methysergide (DrugBank ID: DB00247) and Epinephrine (DrugBank ID: DB00668), and the target is SLC6A4 (UniProt ID: P31645). Methysergide is a drug used for migraine headaches by effectively regulating the diastolic function of cerebral blood vessels, and also for the treatment of carcinoid syndrome. Epinephrine is an endogenous catecholamine used for cardiac arrest, anaphylactic shock, acute bronchial asthma, etc. SLC6A4 is a solute carrier gene mainly involved in the transport regulation of the neurotransmitter serotonin and plays a key role in psychiatric and neurological conditions such as depression, anxiety, and gastrointestinal diseases.
We estimate the likelihood of binding interactions for each selected drug and target across all entries in the dataset and rank them according to their prediction scores. Tables S2–S3 show the top 15 predicted items. Fourteen out of fifteen predicted targets of Methysergide are confirmed, where five predicted targets are the true targets of Methysergide by Luo’s dataset, and the other nine predicted targets are bona fide targets of the drug, as demonstrated in recent studies and public databases. Twelve out of fifteen predicted targets of Epinephrine are confirmed, where seven predicted targets are the true targets of Epinephrine by Luo’s dataset, and the other five predicted targets are known targets of the drug, as demonstrated in recent studies and public databases.
Similarly, the top 40 predicted drugs of SLC6A4 are presented in Table S4. Thirty-seven out of forty predicted drugs are confirmed, where thirty predicted drugs are known drugs of SLC6A4 by Luo’s dataset, and the other seven predicted drugs are bona fide drugs of the target, as demonstrated in recent studies and public databases.
Coach-D server is a molecular docking approach that reflects the binding ability of targets and ligands [51]. Pose^u^ Docking energy and C-Score by Coach-D server are applied to quantify the binding affinity of drugs for targets. Lower Pose^u^ Docking energy values correlate with a more potent binding capacity, reflecting a more stable and favorable interaction. The C-score is used to assess the quality and dependability of molecular docking outcomes, with higher values signifying greater confidence in the ligand’s binding conformation.
Docking energy and C-score values for the selected drugs are obtained from the Coach-D server, and their boxplots are shown in Fig. 10. The median docking energy and C-score values between Methysergide and the top 15 predicted targets are -8.45 and 0.755, respectively. The corresponding median values between Methysergide and known targets in DrugBank are -8.5 and 0.59, respectively. The highest docking energy between Methysergide and known targets is -7.7, indicating that Methysergide can bind to nearly all of the top 15 predicted targets. Similarly, Epinephrine exhibits analogous binding characteristics. The median docking energy and C-score values between Epinephrine and the top 15 predicted targets are -6.4 and 0.77, respectively. The corresponding values between Epinephrine and known targets in DrugBank are -6.3 and 0.77, respectively. The highest docking energy between Epinephrine and known targets is -3.9, indicating that Epinephrine can also bind to nearly all of the top 15 predicted targets.Fig. 10. The box plots of molecular docking’s results of selected drugs
Discussion
The exploration of DTIs plays a crucial role in advancing drug discovery. In this study, we propose a new framework called GCNMM. Meta-path networks are fused by using GAT to effectively address the issue of matrix sparsity. The incorporation of spatial topological consistency and mutual information estimation into the GCN encoding process ensures the preservation of topological integrity while strengthening the correlation between input and output features. Comparative evaluations show that GCNMM achieves superior performance over baseline models on two datasets. Ablation studies further confirm the importance of each component—meta-path fusion, spatial topological consistency, and mutual information estimation. Moreover, case studies validate the practical utility of GCNMM in DTI prediction.
Despite these promising results, GCNMM has certain limitations. It relies only on lower-dimensional structural information to obtain direct similarity between items. Additionally, the inclusion of mutual information estimation introduces matrix expansion operations during training, which not only prolongs training time but also increases computational resource demands. Future studies could incorporate three-dimensional structural characteristics of drugs and targets to further enhance model performance. Our subsequent work would focus on optimizing the model architecture, reducing computational complexity, and minimizing resource consumption.
Conclusion
In this research, we propose a novel graph convolutional network model, called GCNMM, which integrates meta-paths, similarity networks, and dual optimization based on spatial topological consistency and mutual information, to predict novel DTIs from heterogeneous networks. Two datasets were introduced to evaluate the effectiveness of GCNMM. The results of comparative experiments demonstrate that GCNMM achieves superior performance compared to six baseline models across AUC, AUPR, Recall, F1-score, and ACC metrics. In addition, the ablation analysis confirms the rationality of each module. Furthermore, case studies validate the efficacy of GCNMM for DTI prediction, highlighting its potential for drug discovery development.
Supplementary Information
Below is the link to the electronic supplementary material.
Supplementary Material 1
The reference list from the paper itself. Each links out to its DOI / PubMed record.