Independent Increments and Group Sequential Tests
Anastasios A. Tsiatis, Marie Davidian

TL;DR
This paper introduces a new method to create test statistics for clinical trials that can be used with existing tools and are more powerful for specific treatment effect scenarios.
Contribution
The paper introduces a novel approach to derive linear combinations of test statistics with independent increments property for targeted alternative hypotheses.
Findings
Linear combinations of test statistics can be derived to have independent increments regardless of original covariance structure.
New test statistics have greater power against specific alternative hypotheses compared to original statistics.
The method is illustrated with two practical examples.
Abstract
Widely used methods and software for group sequential tests of a null hypothesis of no treatment difference that allow for early stopping of a clinical trial depend primarily on the fact that sequentially‐computed test statistics have the independent increments property. However, there are many practical situations where the sequentially‐computed test statistics do not possess this property. Key examples are in trials where the primary outcome is a time to an event but where the assumption of proportional hazards is likely violated, motivating consideration of treatment effects such as the difference in restricted mean survival time or the use of approaches that are alternatives to the familiar logrank test, in which case the associated test statistics may not possess independent increments. We show that, regardless of the covariance structure of sequentially‐computed test statistics,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
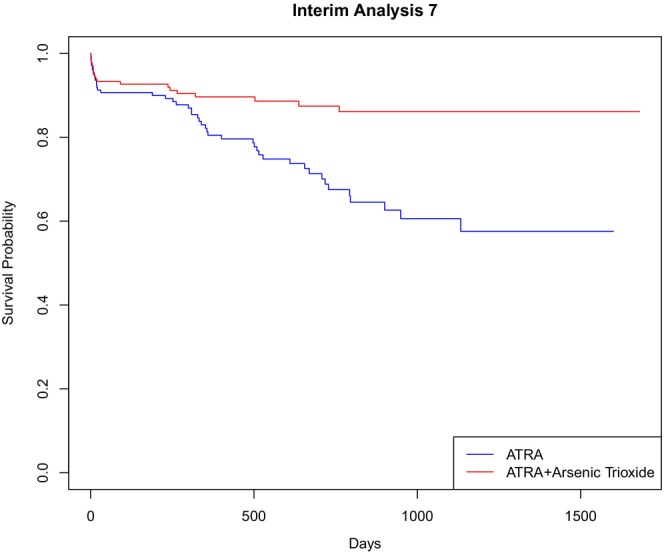 FIGURE 1
FIGURE 1| Test | Null | Prop‐haz | Log‐odds | Non‐prop‐haz |
|---|---|---|---|---|
| Wilcoxon (unadjusted) | 0.044 | 0.745 (3.62) | 0.779 (3.29) | 0.252 (4.83) |
| Wilcoxon (adjusted) | 0.050 | 0.763 (3.56) | 0.796 (3.23) | 0.270 (4.81) |
| Wilcoxon I | 0.049 | 0.740 (3.64) | 0.744 (3.34) | 0.372 (4.76) |
| Wilcoxon II | 0.050 | 0.773 (3.56) | 0.796 (3.23) | 0.316 (4.80) |
| Wilcoxon III | 0.049 | 0.787 (3.55) | 0.786 (3.23) | 0.489 (4.78) |
| Wilcoxon IV | 0.048 | 0.677 (3.72) | 0.658 (3.43) | 0.736 (4.71) |
| Logrank | 0.048 | 0.840 (3.25) | 0.771 (3.29) | 0.749 (4.17) |
| RMST | 0.047 | 0.833 (3.27) | 0.707 (3.43) | 0.822 (3.87) |
| RMST I | 0.050 | 0.824 (3.28) | 0.732 (3.39) | 0.736 (3.99) |
| RMST II | 0.049 | 0.835 (3.26) | 0.720 (3.41) | 0.806 (3.90) |
| RMST III | 0.050 | 0.802 (3.36) | 0.651 (3.54) | 0.858 (3.79) |
| Wilcoxon (adjusted) | Wilcoxon I | Wilcoxon II | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.271 | 0.321 | 0.371 | 0.405 | 0.408 | 0.231 | 0.228 | 0.227 | 0.226 | 0.227 | 0.591 | 0.587 | 0.586 | 0.586 | 0.587 | ||
| 0.321 | 0.450 | 0.521 | 0.572 | 0.575 | 0.228 | 0.431 | 0.429 | 0.427 | 0.427 | 0.587 | 0.708 | 0.707 | 0.706 | 0.706 | ||
| 0.371 | 0.521 | 0.701 | 0.771 | 0.776 | 0.227 | 0.429 | 0.711 | 0.709 | 0.708 | 0.586 | 0.707 | 0.831 | 0.830 | 0.829 | ||
| 0.405 | 0.572 | 0.771 | 0.962 | 0.972 | 0.226 | 0.427 | 0.709 | 0.976 | 0.973 | 0.586 | 0.706 | 0.830 | 0.972 | 0.970 | ||
| 0.408 | 0.575 | 0.776 | 0.972 | 1.000 | 0.227 | 0.427 | 0.708 | 0.973 | 1.000 | 0.587 | 0.706 | 0.829 | 0.970 | 1.000 | ||
| Interim analysis time (days) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 560 | 746 | 933 | 1120 | 1310 | 1490 | 1680 | 1870 | 2050 | 2240 | |
| RMST III | ||||||||||
| Statistic | 1.701 | 2.034 | 2.882 | 2.449 | 2.288 | 3.041 |
| 4.870 | 4.636 | 4.863 |
| Boundary | 5.367 | 4.607 | 4.109 | 3.750 | 3.445 | 3.258 |
| 2.923 | 2.767 | 2.621 |
| Logrank | ||||||||||
| Statistic | −1.639 | −1.820 | −2.660 | −2.483 | −2.103 | −2.609 |
| −3.913 | −3.736 | −4.050 |
| Boundary | 5.367 | 4.622 | 4.104 | 3.742 | 3.458 | 3.246 |
| 2.896 | 2.767 | 2.616 |
- —National Institutes of Health10.13039/100000002
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods in Clinical Trials · Advanced Causal Inference Techniques · Statistical Methods and Bayesian Inference
Introduction
1
Interim monitoring of clinical trials to allow for the possibility of early stopping for efficacy or futility is a critically important practice in health sciences and biopharmaceutical research and is ordinarily accomplished through the use of group sequential methods. Key to straightforward implementation of such methods is the property of independent increments of sequentially‐computed test statistics; see Kim and Tsiatis [1] for a comprehensive overview. Specifically, computation of sequential stopping boundaries to which the test statistic is compared at interim analyses requires multivariate integration with respect to the (usually asymptotic) joint distribution of the test statistic across monitoring times. However, if the increments between statistics used to construct the test statistics are independent, the computation simplifies to involve only simple univariate integration, which is the foundation for the widely used group sequential methods [2, 3, 4] that are available in standard software.
In many trials, inference focuses on a treatment effect that can be characterized by a single parameter in a relevant statistical model, for example, the difference of treatment means in the case of a continuous outcome or the risk difference, risk ratio, or odds ratio with a binary outcome, where the definition of the parameter is the same across all time. Under these conditions, it has been shown [5, 6] that efficient estimators of such treatment effect parameters, computed sequentially, have the independent increments property, so that standard group sequential methods are readily implemented. However, there are many situations where efficient test procedures may be unavailable or not straightforward to implement. For example, Van Lancker et al. [7] discuss use of a test statistic based on an estimator for the treatment effect parameter that incorporates covariate adjustment for prespecified baseline covariates thought to be prognostic for the outcome. Although covariate adjustment can enhance the precision of the final analysis, owing to the complexity of the efficient estimator, the estimator and thus statistic the authors adopt for practical use is not efficient and thus does not enjoy the independent increment structure, so that standard group sequential methods cannot be used.
The independent increments property also may not hold because of the nature of the treatment effect. In clinical trials in chronic disease and especially in cancer, the primary outcome is a time to an event, and the most common characterization of treatment effect is through the hazard ratio under the assumption of proportional hazards, with the primary analysis typically based on the logrank test or Cox model. However, the proportional hazards assumption is often violated, which has led to interest in representing the treatment effect through the difference in restricted mean survival time (RMST), the mean time to the event restricted to a specified time L [8]. As discussed by Murray and Tsiatis [9] and Lu and Tian [10], because of limited follow up, at the jth interim analysis at time tj, say, the parameter of interest is the difference in RMST to a time Lj≤tj; thus, the parameter of interest changes over time, and it can be shown that the independent increments property does not hold for the corresponding statistic.
Test statistics that are motivated by intuitive considerations may or may not possess the independent increments property. For example, an alternative approach when violation of the proportional hazards assumption is thought to be due to differences that manifest early in time is to base the analysis on Gehan's Wilcoxon test [11], which gives more weight to events at early time points. Here, the null hypothesis of a difference in event time distributions cannot be expressed in terms of a single parameter, and the statistic on which this test is based has been shown to not possess the independent increments property [12]. In contrast, that for the logrank test, which can also be motivated from an intuitive perspective, does have independent increments.
In this article, we show that, regardless of the covariance structure of sequentially‐computed statistics, and thus regardless of whether or not they possess the independent increments property, it is always possible to derive sequential linear combinations of these statistics that do possess this property. Thus, for a given statistic, a group sequential test procedure based on these linear combinations can be implemented using standard methods and software. If the original statistics are not efficient, our formulation shows that linear combinations of them leading to independent increments can be chosen judiciously to also result in more efficient tests. As a result, depending on the alternative of interest, basing interim monitoring on tests involving such linear combinations of statistics may yield stronger evidence for early stopping, even if the original statistics possess the independent increments property. In Section 2, we present the general statistical framework and the main result. In Section 3, we show how the result is used to choose linear combinations to yield independent increments and increase efficiency. We consider two examples in Section 4: interim monitoring based on Gehan's Wilcoxon test when the treatment effect is the difference in treatment‐specific survival distributions, and interim monitoring when the treatment effect is the difference in treatment‐specific RMST. We discuss practical implementation in Section 5 and demonstrate the methods by retroactive application to a completed cancer clinical trial in Section 6.
Statistical Framework and Main Result
2
The property of independent increments can be characterized as follows. Consider a normally distributed random vector Z=(Z1,…,ZK)T with (K×K) covariance matrix 𝒱Z. Then Z has the independent increments property if 𝒱Z(j,k)=𝒱Z(j,j), j≤k, j,k=1,…,K, where 𝒱Z(j,k) denotes the (j,k)th element of 𝒱Z.
We now state and prove the general result that serves as the foundation for the methodology. To this end, let X1,…,XK denote time ordered, sequentially‐computed random variables. Later, these variables will be (suitably normalized) statistics computed at K possible interim analyses of a clinical trial using all the available data through each interim analysis. Often, such statistics are asymptotically normally distributed and constructed so that they have mean zero under the relevant null hypothesis of no treatment effect. Let X=(X1,…,XK)T be the K random variables collected into a vector, and, for j=1,…,K, define the (K×1) vector X_j=(X1,…,Xj,0,…,0)T; that is, the K‐dimensional vector leading with (X1,…,Xj)T followed by (K−j) zeros. Denote the (K×K) covariance matrix of X by 𝒱 and the covariance matrix of X_j by 𝒱j, the (K×K) matrix with upper left (j×j) submatrix equal to the covariance matrix of (X1,…,Xj)T and all remaining elements equal to zero.
For j=1,…,K, let aj=(aj1,…,ajj,0,…,0)T be a K‐dimensional vector, where the first j components aj1,…,ajj are constants followed by (K−j) zeros. Then denote the sequentially‐computed linear combinations of X by
Henceforth, assume that the covariance matrix 𝒱 has full rank and thus a unique inverse 𝒱−1 and that the linear combinations in (1) are nontrivial in the sense that Yj=aj1X1+…+ajjXj, which in the context of interim monitoring would be the linear combination computed at the jth interim analysis, must include Xj; that is, ajj≠0, j=1,…,K. This condition guarantees that the covariance matrix of Y also has full rank. The key result, that these sequentially‐computed linear combinations of X have the independent increments property, follows from Theorem 1, the proof of which is presented in the Supporting Information.
Theorem 1 Under the above conditions, with 𝒱 of full rank and 𝒱j, j=1,…,K, defined as above, the vector of nontrivial, sequentially‐computed linear combinations Y=(Y1,…,YK)T has the independent increments property if and only if there exists a vector of constants b=(b1,…,bK)T such that aj=𝒱j−b_j, where b_j=(b1,…,bj,0,…,0)T, j=1,…,K, and 𝒱j− is the (K×K) matrix with upper left hand (j×j) submatrix the inverse of the covariance matrix of (X1,…,Xj)T and all remaining elements of the matrix equal to zero; that is, 𝒱j− is the Moore‐Penrose generalized inverse of 𝒱j.
Derivation of Test Procedures
3
Choice of Linear Combination
3.1
Theorem 1 is a very general result, demonstrating that linear combinations of time ordered random variables X=(X1,…,XK)T with covariance matrix 𝒱 will have the independent increments property if the coefficients of the linear combination satisfy
for some arbitrary vector b=(b1,…,bK)T. Consequently, to construct a linear combination of elements of X with independent increments, one can choose any arbitrary K‐dimensional vector of constants b. However, depending on the objective, judicious choices of b can be identified.
We now discuss considerations for the choice of b when interest focuses on a null hypothesis H0 of no treatment effect to be tested in a clinical trial potentially involving n subjects at up to K interim analyses. Let Xn=(X1,n,…,XK,n)T be the vector of suitably normalized statistics used to form the test statistic for this hypothesis, to be computed sequentially over time. For example, if the test statistic is the score test statistic based on a suitable log likelihood, Xj,n is equal to n−1/2 times the score. We emphasize that the test statistic computed in practice at the jth interim analysis at time tj is based only on the data accumulated through tj and does not involve n; we discuss this further below. We consider normalized statistics Xj,n solely for the theoretical developments that support how b should be chosen. Here, taking n to grow large (n→∞) can be viewed as allowing the staggered entry times at which subjects enroll in the trial to become more and more dense. The statistics can be based on parametric, semiparametric, or nonparametric models and, under H0, generally satisfy Xn→DN(0,𝒱) as n→∞; that is, Xn converges in distribution to a normal random vector with mean zero and covariance matrix 𝒱, so that, for n large,
Letting 𝒱^n be a consistent estimator for 𝒱, typically, at the jth interim analysis, one computes the standardized test statistic
which thus has an approximate N(0,1) distribution under H0, and H0 is rejected if the test statistic (or absolute value thereof) exceeds some critical value. The standard approach to identifying the critical value is through a specified α‐spending function [4] that, for chosen level of significance α, determines how α is to be “spent” over the potential K analyses. More precisely, the α‐spending function is a sequence α1<⋯<αK=α such that the probability of rejecting H0 at or before the jth interim analysis is αj. The corresponding critical values are referred to as the stopping boundaries. In general, Xn may or may not have the independent increments property (asymptotically).
Ordinarily, the goal is for a test procedure to have adequate power to detect some alternative hypothesis of interest. Typically, under a fixed alternative HA, common test procedures have the property that power converges to one as n→∞, so that usual asymptotic theory yields no insight into practical performance. Thus, to achieve nontrivial results reflecting the large sample properties of a test, rather than consider a fixed alternative, a standard approach is to consider performance of the test under a sequence of so‐called local alternatives HA,n, which are such that the alternative hypothesis HA,n approaches the null H0 as n→∞. As ordinarily the case in such local power analysis, with fixed alternatives characterized by a quantity δ that equals zero under H0, as in the examples we consider later in Section 4, the alternative under HA,n is δn, say, where n1/2δn→τ as n→∞. Under such local alternatives, it can be shown that Xn→DN(μ,𝒱) for some K‐dimensional vector μ=(μ1,…,μK)T depending on τ, where 𝒱 is the same covariance matrix as under H0, so that
Thus, to derive the optimal linear combination of X1,n,…,Xj,n yielding the greatest power to detect the alternative HA,n at the jth interim analysis, consider the standardized test statistic
where c_j=(cj1,…,cjj,0,…,0)T. The optimal such linear combination is that maximizing the noncentrality parameter
Maximizing the noncentrality parameter (2) can be accomplished using the Cauchy‐Schwartz inequality, analogous to Li and Lagakos [13], leading to the optimal choice of c_j maximizing power given by c_jopt∝𝒱j−μ_j. This result suggests sequentially computing the optimal statistics
Letting b∝μ, Theorem 1 can be used to show that Ynopt=(Y1,nopt,…,YK,nopt)T has the independent increments property.
Taking linear combinations in this way leads not only to statistics that yield powerful tests at each tj for detecting the alternative hypothesis HA,n, but also results in test statistics that have the desired independent increments property under H0; that is, Ynopt=(Y1,nopt,…,YK,nopt)T˜·N(0,𝒱Yopt), where 𝒱Yopt(j,j)=μ_jT𝒱j−μ_j, and 𝒱Yopt(j,k)=𝒱Yopt(j,j) for j≤k. The test at the jth interim analysis is based on the standardized test statistic
Because of the independent increments property, level α sequential tests and boundaries can be computed readily using standard methods and existing software. Note that, for standardized test statistics, dependence on n in the numerator and denominator cancels, so that all necessary calculations depend only on the data that have accumulated at each interim analysis.
The above rationale for choosing b to achieve high power at each interim analysis, given an alternative of interest, has intuitive appeal. In fact, it can be shown that choosing b in this way leads to the most powerful test that can be constructed for a specified level of significance α and α‐spending function, including relative to tests that are not based on linear combinations of X1,n,…,XK,n. A proof is presented in the Supporting Information.
The foregoing development assumes that a specific type of alternative to the null hypothesis is of interest, and the test statistic (4) with b chosen proportional to μ is derived to have high power against that type of alternative. If in truth the distribution away from the null hypothesis is not consistent with such alternatives, then the test statistics derived above will not necessarily be optimal, but they will still have the independent increment property under H0 because Theorem 1 guarantees that this property will hold for any arbitrary b. Thus, group sequential methods applied to them will preserve the type I error.
Considerations for Efficient Tests
3.2
If the original statistics X1,n,…,XK,n are indeed efficient for the alternative HA,n, for example, as for a score test for treatment effect parameters in a relevant parametric or semiparametric model, then it is well known that Xn has the independent increments property, so that the covariance matrix 𝒱 satisfies 𝒱(j,k)=𝒱(j,j), j≤k, and the mean under the alternative hypothesis is proportional to the variance; that is, μj=γ𝒱(j,j). Then, from (3),
However, under independent increments, the row vector {𝒱(1,1),…,𝒱(j,j),0,…,0} is the same as the jth row of 𝒱j. Thus,
a row vector with jth element γ and zeros otherwise, so that Yj,nopt=γXj,n, j=1,…,K, and the standardized test statistic as in (4) based on Yj,nopt is the same as the standardized test statistic based on Xj,n. That is, if we start with efficient tests, then the linear transformation for improvement leads us back to the same set of tests.
In some settings, the treatment effect can be characterized in terms of a scalar parameter θ in a parametric or semiparametric model, with null hypothesis H0:θ=0, and a consistent and asymptotically normal estimator for θ is available that can be used to form a test statistic for H0. Let θ^j be the estimator for θ based on all the available data through interim time tj, j=1,…,K, and define ϑ^=(θ^1,…,θ^K)T. These estimators may or may not be efficient estimators for θ in the sense of achieving the Fisher information bound. First consider the case where the estimators are indeed efficient, under which Scharfstein et al. [5] and Jennison and Turnbull [6] have shown that Xn=n1/2ϑ^ has the independent increments property under H0. Importantly, in the case of sequentially‐computed estimators, with 𝒱θ the (asymptotic) covariance matrix of Xn, the independent increments property takes the form
where 𝒱θ(j,k) is the (j,k)th element of 𝒱θ. Here, the variances 𝒱θ(j,j) of Xj,n=n1/2θ^j, j=1,…,K, decrease with j as more data accrue, and the covariance between n1/2θ^j and n1/2θ^k is equal to the variance of the latter.
Under a local alternative HA,n:θ=θn, where n1/2θn→τ, Xn=n1/2ϑ^_ converges in distribution to a normal random vector with mean τ1K and covariance matrix 𝒱θ, where 1K=(1,…,1)T is a K‐dimensional vector of ones. Thus, the optimal choice bopt for the vector b is proportional to 1K; and, defining 𝒱θ,j and 𝒱θ,j− analogously to 𝒱j and 𝒱j−, respectively, the optimal choice for Yj,nopt is given by
where 1j=(1,…,1,0,…,0)T is the K‐dimensional vector with j ones followed by (K−j) zeros, and ϑ^_j=(θ^1,…,θ^j,0,…,0)T. Under the independent increments structure (5) for estimators, the jth row of 𝒱θ,j is equal to 𝒱θ,j(j,j)1jT. Consequently, 𝒱θ,j(j,j)1jT𝒱θ,j−=(0,…,0,1,0,…,0) defined above, so that 1jT𝒱θ,j−=(0,…,0,1/𝒱θ,j(j,j),0,…,0), and
That is, the optimal linear combination of θ^1,…,θ^j leading to Yj,nopt involves only θ^j. Thus, for j≤k
demonstrating independent increments. Moreover, the mean of Yj,nopt is equal to τ/𝒱θ,j(j,j)=τvar(Yj,nopt), and it is straightforward that the standardized test statistic Yj,nopt/{var(Yj,nopt)}1/2 is the same as the standardized test statistic n1/2θ^j/{𝒱θ,j(j,j)}1/2=θ^j/{var(θ^j)}1/2. That is, using efficient linear combinations of efficient estimators resulting in the independent increments property to construct a test statistic for H0:θ=0 leads to the same result as that using the efficient estimators alone. In practice, an estimator for var(θ^j) would be substituted.
In the case where the estimators for θ are not efficient and thus do not necessarily have the independent increments property, it is advantageous to take such linear combinations. Specifically, taking b=1K, compute (Y1,nopt,…,YK,nopt)T, where Yj,nopt=n1/21jT𝒱θ,j−ϑ^_j, and reject the null hypothesis whenever the standardized test statistic
exceeds some boundary value. In practice, an estimator for 𝒱θ,j would be substituted. By construction, these tests have the independent increments property, so that standard group sequential software can be used to compute the boundary values, and will have higher power than the usual test based on the statistic θ^j/{var(θ^j)}1/2. This approach is used by Van Lancker et al. [7] in the situation described in Section 1. Namely, by taking linear combinations of sequentially‐computed, potentially inefficient covariate adjusted estimators θ^j, j=1,…,K, that do not have the independent increments property, these authors derived a test enjoying this property that is potentially more efficient.
Examples
4
Preliminaries
4.1
We now consider two settings involving a time to event outcome where an existing test procedure for a relevant null hypothesis H0 of no treatment effect is based on statistics without the independent increments property. For each, we demonstrate how the foregoing developments can be used to obtain modified statistics that have this property and target specific types of alternatives of interest. As is the case in many such formulations, the derivation is based on identifying the influence function [14] associated with the original test statistic under H0 by representing the statistic as asymptotically equivalent to a sum of independent and identically distributed (iid) quantities, from which obtaining the covariance matrix of sequentially‐computed statistics is straightforward.
Consider a clinical trial comparing two treatments coded as 0 and 1, where up to n individuals enter in a staggered fashion at iid times E1≤⋯≤En measured from the start of the trial at time t=0. For definiteness, suppose that interim analyses potentially are to be conducted at times t1<⋯<tK, with t1>0. Let Z∈{0,1} indicate randomized treatment assignment, and denote the event time for an arbitrary individual, measured from study entry, by T. Define the treatment‐specific time to event/survival distributions as Sz(u)=P(T≥u|Z=z), with corresponding hazard functions λz(u), z=0,1. The event time T may be right censored, for example, due to loss to follow up. As is standard, letting C denote potential censoring time, U=min(T,C), Δ=I(T≤C) are observed, where I(·) is the indicator function, and we assume censoring is noninformative in the sense that T⊥C|Z, where “⊥” denotes “independent of.” Under these conditions, it is well known that the cause‐specific hazard functions λzU(u)=limdu→0(du)−1P(u≤U<u+du,Δ=1|U≥u,Z=z), which are identifiable from the data, are the same as λz(u), z=0,1. Assuming that subjects enter the trial according to a completely random process, E⊥(U,Δ,Z), and, indexing subjects by i, we take (Ei,Zi,Ui,Δi), i=1,…,n, to be iid. At interim analysis time t, we observe data only for individuals i already enrolled in the trial, for whom Ei≤t; and further administrative censoring is induced: for these individuals, we observe (Ui,Δi) if Ui≤t−Ei; otherwise, Ui is censored at time t−Ei.
Interim Monitoring Based on Gehan's Wilcoxon Test
4.2
In the setting of time to event outcome, a null hypothesis of central interest is that of equality of the treatment‐specific survival distributions; that is, H0:S1(u)=S0(u) for all u≥0, which is equivalent to that of equality of the corresponding hazard functions, H0:λ1(u)=λ0(u). As in Section 1, when the assumption of proportional hazards is likely to be violated, analysts may wish to base a test of H0 on a test statistic other than that for the standard logrank test. When differences in survival are anticipated to occur early in time, Gehan's Wilcoxon test, which may be more sensitive to such differences, is an attractive alternative; for example, Jiang et al. [15] demonstrate this advantage in analyses of data from the National Institute on Aging Interventions Testing Program, where the interventions compared are expected to influence mortality prior to middle age but not afterward.
Slud and Wei [12] have shown that the statistics on which Gehan's Wilcoxon test is based with censored survival data, computed sequentially, do not have the independent increments property, complicating the test's use in the context of interim monitoring. These authors demonstrate how group sequential tests that preserve the desired significance level can be constructed using an α‐spending function and recursively computing multivariate normal integrals to obtain stopping boundaries based on the asymptotic joint distribution of the statistics under the null hypothesis. However, given the appeal of using standard software for this purpose, we show how Theorem 1 can be used to obtain modified statistics that do have the independent increments property by identifying appropriate linear combinations of the sequentially‐computed statistics while not sacrificing power.
Under H0, S0(u)=S1(u)=S(u) and λ1(u)=λ0(u)=λ(u), say. Define the event time counting process 𝒩(u)=I(U≤u,Δ=1) and at risk process 𝒴(u)=I(U≥u), and let dℳ(u)=d𝒩(u)−λ(u)𝒴(u)du denote the associated martingale increment. Tarone and Ware [16] have shown that Gehan's Wilcoxon test statistic with censored data can be written equivalently as a weighted logrank test; namely, at time t, the (normalized) statistic on which the test is based is given by
and
By an algebraic identity, under H0,
and it can be shown that
where
is the ith influence function of Gn(t), oP(1) is a term that converges to zero as n→∞, and
where “→p” denotes convergence in probability. Thus,
and {Gn(s),Gn(t)}, s<t, converges in distribution under H0 to a bivariate normal random vector with mean zero and covariance matrix
We show in the Supporting Information that
and, for s≤t,
From (7) and (8), in general, cov{IF(s),IF(t)}≠var{IF(s)} for s≤t, and thus the statistic Gn(t) does not have the independent increments property.
Let Xj,n=Gn(tj), j=1,…,K, denote the original sequential statistics, and let 𝒱IF be the (K×K) asymptotic covariance matrix of (X1,n,…,XK,n)T, obtained from (7) and (8). Gehan's Wilcoxon test statistic at the jth interim analysis would be computed as
where 𝒱^IF is an estimator for 𝒱IF obtained by estimating (7) and (8). Namely, using standard counting process methods, var{IF(t)} in (7) can be estimated by
where N(u,t)=∑i=1nI(Ui≤u,Δi=1,Ui≤t−Ei), and, similarly, a consistent estimator for cov{IF(s),IF(t)} in (8) is given by
We now describe several approaches to choosing linear combinations of the sequentially‐computed statistics Xj,n that result in statistics that do have the independent increments property, which involve choice of the vector of constants b=(b1,…,bK)T. In the first two approaches, we choose b to target specific alternative hypotheses as in Section 3.1. It is well known that the Wilcoxon test in the case of no censoring has high power to detect log‐odds alternatives; that is, where
and δ denotes the treatment effect parameter. We show in the Supporting Information that, under local log‐odds alternatives with treatment effect parameters δn such that n1/2δn→τ, the resulting Gehan's Wilcoxon statistic Gn(t) converges in distribution to a normal random variable with variance var{IF(t)} (same as under the null hypothesis) but with mean
A consistent estimator for μ(t) in (12) is given by
where S^(u,t) is the Kaplan–Meier estimator of the survival distribution under H0 using all the available censored survival data combined over both treatments through time t. The proposed test statistic at the jth interim analysis is then
where, with μ^(t) as in (13), μ^_j={μ^(t1),…,μ^(tj),0,…,0}T, and 𝒱^IF,j is the (K×K) matrix with upper left hand (j×j) submatrix that of 𝒱^IF and the remainder of the matrix zeros. The Yj,n, j=1,…,K, have the independent increments property, and the test should be more powerful against the log‐odds alternative than that based on the original Wilcoxon statistics X1,n,…,Xj,n.
In some settings, a treatment may be expected to have a delayed effect. We thus consider the alternative hypothesis where
that is, the hazard function for treatment 1 is the same as that for treatment 0 through some delay time 𝒯delay and then is proportional to that for treatment 0 by a proportionality constant exp(δ). We refer to this as a non‐proportional hazards alternative, with the null hypothesis being δ=0. We show in the Supporting Information that, under local alternatives δn such that n1/2δn→τ, the Gehan's Wilcoxon statistic Gn(t) converges in distribution to a normal random variable with variance var{IF(t)}, but mean
A consistent estimator for μ(t) in (16) is given by
As above, the test statistic at the jth interim analysis is of the form (14), where now μ^_j={μ^(t1),…,μ^(tj),0,…,0}T with μ^(t) as in (17), and the Yj,n, j=1,…,K, have the independent increments property, so that the test should be more powerful against this alternative than that based on X1,n,…,Xj,n. Note that if 𝒯delay=0, then (15) reduces to a proportional hazards alternative.
An ad hoc approach to choosing b without specifying a targeted alternative is to proceed as if the statistics were efficient with independent increments, in which case the mean of the statistics would be (asymptotically) proportional to the variance; that is, μj=E(Xj,n)=E{Gn(tj)}∝var{Gn(tj)}=var{IF(tj)}, j=1,…,K. Then, as above, b would be chosen to be proportional to [var{IF(t1)},…,var{IF(tK)}]T. Although the Wilcoxon statistics are not efficient, this approach is simple to implement and leads to the modified statistics
where b_^j=[var^{IF(t1)},…,var^{IF(tj)},0,…,0]T, which have the independent increments property.
We demonstrate the performance of these tests in a suite of simulation studies, each involving 10 000 Monte Carlo group sequential trials. In all studies, S0(u) follows an exponential distribution with constant hazard rate equal to 1, S0(u)=exp(−u). We consider three sets of alternatives: proportional hazards, where S1(u)=S1(u,δ) is exponential with constant hazard rate exp(δ), S1(u)=S1(u,δ)=exp{−uexp(δ)}; log‐odds as in (11); and non‐proportional hazards as in (15) with 𝒯delay=0.5. In all three cases, δ=0 corresponds to the null hypothesis H0. In each trial, individuals enter according to a uniform U(0,2) distribution and are randomized to treatments 0 and 1 with equal probability, π=P(Z=1)=P(Z=0)=0.5. For each individual, with Z=z, T has distribution corresponding to Sz(u), z=0,1, C follows an exponential distribution with hazard rate equal to 0.25, and U=min(T,C) and Δ=I(T≤C). Each trial is monitored at K=5 interim analysis times t=(1.5,1.75,2.0,2.5,3.0), and in all cases the nominal significance level α=0.05.
We consider several group sequential test procedures based on Gehan's Wilcoxon test. The first, denoted as the unadjusted Wilcoxon test, does not take account of the fact that the usual Gehan's Wilcoxon statistics do not have the independent increments property and naively computes stopping boundaries using standard methods for tests based on independent increments. The second, referred to as the adjusted Wilcoxon test, is based on the usual Gehan's Wilcoxon statistics, with boundaries computed to preserve the desired significance level using an α‐spending function and recursive multivariate normal integration using the mvtnorm package in R [17] based on the asymptotic joint distribution of the sequentially‐computed statistics under the null hypothesis, as proposed by Slud and Wei [12]. Four additional tests based on the modified Wilcoxon statistics leading to independent increments are also evaluated: the ad hoc version with the constant vector b chosen to be proportional to the variance of the sequentially‐computed Wilcoxon statistic, denoted Wilcoxon I; that with b chosen to favor log‐odds alternatives according to (13), Wilcoxon II; that with b chosen to favor proportional hazards alternatives according to (17) with 𝒯delay=0, Wilcoxon III; and that with b chosen to favor non‐proportional hazards alternatives according to (17) with 𝒯delay=0.5, Wilcoxon IV. For comparison, we consider the logrank test, which has power targeted for proportional hazards alternatives.
In each study, the potential sample size n=1000, and we use an α‐spending function at each of the five interim analysis times of (0.05,0.1,0.4,0.7,1)×0.05. All tests are two‐sided, and H0 is rejected whenever the absolute value of the standardized test statistics exceeds the boundary values, which for the unadjusted Wilcoxon and Wilcoxon I‐IV are computed in all cases using the ldbounds package in R [18] and for the adjusted Wilcoxon are computed as above. For each simulation scenario, we compute the empirical level and power of each test as the proportion of the 10 000 trials for which the null hypothesis is rejected and also report the Monte Carlo average of the number of analyses conducted before stopping the trial.
Results are presented in Table 1. Under the null hypothesis, all tests except the unadjusted Wilcoxon have empirical type I error close to the nominal 0.05, which is not surprising given that incorrect stopping boundaries are used for the latter. As expected, the logrank test has greatest power to detect a proportional hazards alternative, followed by the Wilcoxon III, which targets this alternative. The Wilcoxon II test, which targets log‐odds alternatives, has the highest power in this scenario, along with the adjusted Wilcoxon test. The greatest difference in power across tests occurs under the non‐proportional hazards alternative, where the Wilcoxon IV test targeting such alternatives and the logrank test achieve considerably higher power than the other tests. The adjusted Wilcoxon test achieves similar power to Wilcoxon II across alternatives. The average number of analyses conducted is similar across tests but somewhat lower for those with higher power, as expected.
Table 2 shows the Monte Carlo average of the standardized covariance matrix of the statistics used in constructing each test under H0, obtained by dividing the empirical covariance matrix by the empirical variance of XK,n. As expected, the statistics associated with the logrank test and the Wilcoxon I, II, III, and IV tests all have empirical standardized covariance matrices consistent with independent increments; that associated with the adjusted Wilcoxon (usual Gehan's Wilcoxon) test does not.
Monitoring Using Restricted Mean Survival Time
4.3
Restricted mean survival time (RMST) is defined as R(L)=E{min(T,L)}, for some specified time L, mean survival time restricted to time L, which can also be computed as R(L)=∫0LS(u)du, the area under the survival distribution S(u) of T through time L. In many studies, because of limited follow up, it is not possible to estimate E(T) unless the support of T is contained in the interval from 0 to the maximum follow up time. Thus, of necessity, survival time must be restricted; for example, at an interim analysis at time t, survival time can be observed only through t. Given possibly censored observations on T, R(L) can be estimated nonparametrically by ∫0LS^(u)du, where S^(u) is the Kaplan–Meier estimator of S(u) based on these data. Consequently, the null hypothesis of equality of treatment‐specific survival distributions can be characterized in terms of the treatment effect parameter θ=R1(L)−R0(L)=∫0L{S1(u)−S0(u)}du, the difference in treatment‐specific RMST, as H0:θ=0. This parameter has intuitive appeal, as it can be viewed also as representing the expected years of life saved by using the better treatment over the restricted time interval (0,L). Moreover, θ can be estimated nonparametrically by
where S^z(u), z=0,1, are the treatment‐specific Kaplan–Meier estimators of Sz(u), z=0,1.
Group sequential testing based on RMST has been discussed by several authors [9, 10]. At interim analysis times t1,…,tK, one considers ϑ_=(θ1,…,θK)T, where
Because of limited follow up at tj, the restricted time Lj must be less than tj, and Lj, j=1,…,K, may be taken to increase with increasing tj to reflect that additional data are accrued as the study progresses. The null hypothesis is then H0:θ1=⋯=θK=0, and monitoring the study and testing the null hypothesis entails estimating ϑ_ by some estimator ϑ^_=(θ^1,…,θ^K)T and rejecting H0 at the first time the estimated treatment effect parameter (or absolute value thereof), suitably normalized and standardized, exceeds some critical value. Letting S^z(u,t) denote the Kaplan–Meier estimator for Sz(u), z=0,1, based on all available data through time t, and defining R^z(t,L)=∫0LS^z(u,t)du, z=0,1, the obvious estimator for θj in (18) is
Taking Lj not to vary with tj, so that Lj=L for all j=1,…,K, implies that monitoring does not begin until after L, that is, t1>L, and that θj=θ, j=1,…,K. As demonstrated by Murray and Tsiatis [9], under these conditions, at each interim analysis, the common θ is estimated using the efficient Kaplan–Meier estimators for Sz(u), z=0,1, and the sequentially‐computed estimators ∫0L{S^1(u,tj)−S^0(u,tj)}du, suitably normalized, have the independent increments property, so that group sequential methods can be implemented readily with standard software. However, if Lj and thus θj do vary over time as above, then normalized versions of θ^j in (19) do not have this property. In this case, Murray and Tsiatis [9] and Lu and Tian [10] show that group sequential tests can be constructed that preserve the desired significance level by using an α‐spending function and recursively evaluating multivariate normal integrals to construct stopping boundaries based on the asymptotic joint distribution of suitably normalized θ^j under the null hypothesis. As in Section 4.2, to take advantage of standard software for computing stopping boundaries, we now describe how Theorem 1 can be used to derive modified statistics based on linear combinations of sequentially‐computed estimators that have the independent increments property.
Let nz=∑i=1nI(Zi=z) denote the potential number of individuals randomized to treatment z, z=0,1, with entry times Ez,i and event/censoring times and indicators (Uz,i,Δz,i), i=1,…,nz. Then n=n0+n1 is the total potential sample size, and, n1/n→π=P(Z=1) as n→∞. We proceed analogous to the previous section and derive the asymptotic covariance matrix 𝒱θ of n1/2ϑ_^=n1/2(θ^1,…,θ^K)T. Following previous authors [9, 10] and owing to the form θ^j in (19) as the difference of treatment‐specific terms, we first find the influence functions for R^z(t,L), z=0,1. The ith influence function IFR,z,i(t,L) for R^z(t,L) satisfies
We show in the Supporting Information that IFR,z,i(t,L) is given by
where Az(u,L)=∫uLSz(x)dx. Accordingly, at tj,
where (see the Supporting Information)
A consistent estimator for var{IFR,z(tj,Lj)} in (22) is given by, analogous to Nemes et al. [19],
where
Similarly, [nz1/2{R^z(tj,Lj)−Rz(Lj)},nz1/2{R^z(tk,Lk)−Rz(Lk)}]T,j≤k converges in distribution to a bivariate normal random vector with mean zero and covariance matrix with diagonal elements var{IFR,z(tj,Lj)} and var{IFR,z(tk,Lk)} and off‐diagonal elements cov{IFR,z(tj,Lj),IFR,z(tk,Lk)}. We show in the Supporting Information that
Inspection of (22) and (24) shows that the independent increments property (for estimators) does not hold unless Lk=Lj. A consistent estimator for (24) is given by
Note that in (25) we estimate both Az(u,Lj) and Az(u,Lk) using all the data through the larger time tk.
From these results, the asymptotic distribution of n1/2ϑ^_ under H0 and thus the form of 𝒱θ can be deduced; it suffices to derive the bivariate distribution of n1/2(θ^j,θ^k)T. Note that, under H0, R1(Lj)=R0(Lj), so that
using (21), Slutsky's theorem, and the fact that the treatment‐specific RMST estimators are from independent samples, and similarly for n1/2θ^k. Moreover, using (24),
Thus, n1/2(θ^j,θ^k)T converges in distribution to a normal random vector with mean zero and covariance matrix that follows from these results. An estimator 𝒱^θ for 𝒱θ follows by substitution of (23) and (25) in the foregoing expressions along with the estimator π^=n1/n. With these substitutions, the standardized test statistic n1/2θ^j/{𝒱^θ(j,j)}1/2 does not depend n, n1, or n0 and thus depends only on the data accrued through tj.
We are now in a position to define modified test statistics obtained by choosing linear combinations of the normalized, sequentially‐computed estimators that result in statistics with the independent increments property. We thus must choose the vector of constants b=(b1,…,bK)T accordingly. Let Xj,n=n1/2θ^j denote the original, sequentially‐computed statistics. Following Section 3.1, we demonstrate how to choose b to target the same specific alternatives as in Section 4.2. For a given such alternative S1(t,δ) as in (11) and (15), under local alternatives δn, such that n1/2δn→τ, Xj,n converges in distribution to a normal random variable with variance 𝒱θ(j,j) and mean given by the limit of n1/2∫0Lj{S1(u,δn)−S0(u)}du, which equals
For the log‐odds alternative (11), S˙1(u)=S0(u){1−S0(u)}, and the asymptotic mean can be estimated by
where as before S^(u,t) is the Kaplan–Meier estimator of the survival distribution under H0 using the data through time t combined over both treatments. For the non‐proportional hazards alternative (15), S1(u,δ)=exp{−Λ1(u,δ)}, where Λ1(u,δ) is the cumulative hazard function
and thus S˙1(u)=−S0(u){Λ0(u)−Λ0(𝒯delay)}I(u≥𝒯delay), and the asymptotic mean can be estimated by
where Λ^(u,t) is the Nelson‐Aalen estimator for the cumulative hazard function under H0 using the data through time t combined over both treatments. Proportional hazards alternatives can be targeted by taking 𝒯delay=0. As before, for the alternative of interest, the proposed test statistic at the jth interim analysis is
where μ^_j={μ^(t1,L1),…,μ^(tj,Lj),0,…,0}T, and 𝒱^θ,j is the (K×K) matrix where the upper left hand (j×j) submatrix is that of 𝒱^θ and the remainder of the matrix zeros. The Yj,n, j=1,…,K, have the independent increments property, and the test should be more powerful against the targeted alternative than that based on X1,n,…,Xj,n.
We study the performance of group sequential test procedures based on RMST and compare to that of the procedures based on the Gehan's Wilcoxon and logrank tests in simulations studies involving the same 10 000 Monte Carlo trial data sets with n=1000 for each of the generative scenarios in Section 4.2, with significance level α=0.05 and the same five interim analysis times and α‐spending function. For the procedures based on RMST, which require Lj≤tj, j=1,…,K, at each interim analysis, because of the potential instability of θ^j at the tail of the distribution, we considered choosing Lj=tj,tj−0.1, and tj−0.2. The latter two choices resulted in empirical type I error closest to the nominal 0.05 level with no discernible loss of power against any of the alternatives considered. We thus report results with Lj=tj−0.2, j=1,…,K.
We consider several group sequential test procedures: that based on the RMST test statistic n1/2θ^j/{𝒱^θ(j,j)}1/2, j=1,…,K; the modified RMST test as in (28) constructed using (26) to favor log odds alternatives, which we refer to as RMST I; the modified RMST test as in (28) constructed using (27) with 𝒯delay=0 to favor proportional hazards alternatives, RMST II; and the modified RMST test as in (28) constructed using (27) with 𝒯delay=0.5 to favor non‐proportional hazards alternatives, RMST III. Because the statistic for the usual RMST test does not have the independent increments property, boundaries are obtained using the above α‐spending function with multivariate normal integration accomplished using the mvtnorm package in R [17], analogous to the construction of boundaries for the adjusted Wilcoxon test in Section 4.2. For the modified tests RMST I–III, we used the ldbounds package in R [18] to compute the boundaries.
Empirical type I error and power under the alternatives are shown in Table 1. All tests based on RMST achieve the nominal level of 0.05, and, as expected, RMST I has the greatest power to detect the log‐odds alternative among them, somewhat less than that for Wilcoxon II, which also targets this alternative. RMST III has substantially greater power for detecting the non‐proportional hazards alternative than all other tests. Interestingly, RMST II has power approaching that of the logrank test for the proportional hazards alternative. Although our focus here is not on the relative performance of these test procedures, the results suggest that basing monitoring of treatment differences on RMST statistics as an omnibus approach may have good properties under a range of alternatives of interest. The Monte Carlo averages of the standardized empirical covariance matrices for the statistics involved in each RMST method under the null hypothesis are shown in Table 2. As expected, that for the unmodified RMST statistic is not consistent with the independent increments property while those for RMST I‐III are. The average number of analyses conducted shows a similar pattern as that for the Wilcoxon tests.
Practical Implementation
5
We present the steps an analyst would take to implement the methods in the analysis of a clinical trial in practice. We assume that the analyst has defined the null hypothesis of interest, for example, H0:S1(u)=S0(u), u≥0, or, if expected years of life saved is the treatment effect measure, H0:θ=0, where the RMST difference θ=R1(L)−R0(L)=∫0L{S1(u)−S0(u)}du, along with the clinically important alternative to be targeted. The alternative may be chosen based on the particular features of the treatments, as demonstrated in the application in Section 6 or on prior experience, expert knowledge, or convention. These specifications dictate upon which of the methods in Sections 4.2 or 4.3 to base interim analyses. For example, if H0 corresponding to RMST is the focus, one would identify the RMST‐based statistic favoring the chosen alternative. The analyst would then specify the number K and times t1,…,tK of potential interim analyses (often based on logistical considerations), the level of significance α, and the α‐spending function characterized by (α1,…,αK), α1<⋯<αK=α. As is common in practice, the potential sample size n might be determined based on the desired power to detect the chosen alternative at the final (Kth) analysis using standard methods, for example, for RMST [20, 21], taking into account resource and other constraints. Alternatively, the analyst might employ simulations, conducting Monte Carlo trials involving interim analyses using the chosen method under generative scenarios representative of candidate design expectations for the trial, implementing the steps we now present in each simulated trial to determine n based on empirical power.
Given a trial design embodying the above considerations, we outline the steps an analyst would take to implement interim monitoring as the trial progresses, focusing for definiteness on stopping for efficacy as in the simulations in Sections 4.2 and 4.3. The data available at interim analysis time t can be expressed as {Ei,Zi,Ui(t),Δi(t)} for all subjects i for whom Ei≤t, where Ui(t)=Ui,Δi(t)=Δi if Ui≤t−Ei, and Ui(t)=t−Ei, Δi(t)=0 if Ui has not yet been observed; that is, Ui(t)=min(Ui,t−Ei),Δi(t)=ΔiI(Ui≤t−Ei). If the methods based on Gehan's Wilcoxon statistics in Section 4.2 are to be used, define
and, with S^(u,t) the Kaplan–Meier estimator of S(u) under H0 based on the available data from both treatments through time t,
corresponding to the log odds, proportional hazards, and non‐proportional hazards alternatives, where 𝒯delay is as defined previously. Likewise, if the methods based on RMST in Section 4.3 are to be used, define the treatment‐specific quantities
and define
where L(t) is the restricted time corresponding to t, S^z(u,t) the Kaplan–Meier estimator of Sz(u) based on the available data through time t, and
Further, with Λ^(u,t) the Nelson‐Aalen estimator for the cumulative hazard function under H0 using the available data from both treatments through time t and L(t) the corresponding restricted time, define analogous to (29)
Given these definitions, the steps are as follows.
- At the first interim analysis time t1, based on the available data at t1, if methods based on Gehan's Wilcoxon statistic are being used, calculate X1=G(t1), ∑^1=𝒱^(t1,t1), and μ^1=μ^(t1), where μ^(t) is the appropriate choice in (29) for the targeted alternative of interest. If methods based on RMST are being used, calculate X1=θ^{t1,L(t1)}; ∑^1=𝒱^θ(t1,t1); and μ^1=μ^{t1,L1(t1)}, where μ^{t,L(t)} is the appropriate choice in (30) for the targeted alternative, and L1=L(t1). Then form the standardized test statistic 𝕋1=X1/∑^11/2 and reject H0 if 𝕋1 or |𝕋1| exceeds the boundary value ζ1=zα1 or zα1/2, respectively, where zηis the (1−η)th quantile of the standard normal distribution. If H0 is rejected, stop; otherwise calculate v^1=μ^12∑^1−1 and continue to step 2.
- At the second interim analysis time t2, based on the available data at t2, if methods based on Gehan's Wilcoxon statistics are being used, calculate X2=G(t2),
and μ^_2={μ^(t1),μ^(t2)}T, where μ^(t) is the appropriate choice in (29) for the targeted alternative of interest. If methods based on RMST are being used, calculate X2=θ^{t2,L(t2)}, with
and , where μ^{t,L(t)} is the appropriate choice in (30) for the targeted alternative, and L2=L(t2). Form X_2=(X1,X2)T, calculate Y2=μ^_2T∑^2−1X_2, v^2=μ^_2T∑^2−1μ^_2, and form the standardized test statistic 𝕋2=Y2/v^21/2. Calculate the proportion of information achieved at t1 and t2 as ℐ1=v^1/v^2 and ℐ2=v^2/v^2, respectively, and, using standard software, for example, the R package ldbounds, based on (ℐ1,ℐ2), obtain the boundary ζ2 for a one‐ or two‐sided test as appropriate, where the α‐spending function is characterized by (α1,α2). Reject H0 if 𝕋2 or |𝕋2| exceeds the boundary value ζ2. If H0 is rejected, stop; otherwise continue to Step 3. 3. For j=3,…,K, if the procedure failed to reject H0at tj−1, based on the available data at tj, if methods based on Gehan's Wilcoxon statistics are being used, calculate Xj=G(tj),
and μ^_j={μ^(t1),…,μ^(tj)}T, where μ^(t) is the appropriate choice in (29) for the targeted alternative of interest. If methods based on RMST are being used, and calculate Xj=θ^{tj,L(tj)},
and μ^_j=[μ^{t1,L(t1)},…,μ^{tj,L(tj)}]T, where μ^{t,L(t)} is the appropriate choice in (30) for the targeted alternative, and Lj=L(tj). Form X_j=(X1,…,Xj)T, calculate Yj=μ^_jT∑^j−1X_j, v^j=μ^_jT∑^j−1μ^_j, and form the standardized test statistic 𝕋j=Yj/v^j1/2. Calculate the proportion of information achieved at t1,t2,…,tj as ℐ1=v^1/v^j, ℐ2=v^2/v^j, …,ℐj=v^j/v^j, respectively, and, using standard software, for example, the R package ldbounds, based on (ℐ1,…,ℐj), obtain the boundary ζj for a one‐ or two‐sided test as appropriate, where the α‐spending function is characterized by (α1,α2,…,αj). Reject H0 if 𝕋j or |𝕋j| exceeds the boundary value ζj. If H0 is rejected, stop; otherwise, if j<K, let j=j+1 and repeat Step 3; if j=K and H0 is not rejected, conclude that there is not sufficient evidence from the trial to reject H0.
In the Supporting Information, we demonstrate how we specified the α‐spending function and obtained stopping boundaries using the R package ldbounds in the simulations in Sections 4.2 and 4.3 and in the application discussed in the next section.
Application: North American Leukemia Intergroup Study C9710
6
We demonstrate use of the methods in practice by applying them retroactively to data from North American Leukemia Intergroup Study C9710, coordinated by the Cancer and Leukemia Group B, now part of the Alliance for Clinical Trials in Oncology, in patients with acute promyelocytic leukemia (APL) [22], for which the primary outcome was (possibly censored) event‐free survival (EFS) time, a composite of time to failure to achieve complete remission (CR), relapse after CR, or death, whichever comes first. APL patients were randomized to receive standard induction chemotherapy, all‐trans‐retinoic acid (ATRA), followed by ATRA consolidation therapy with or without addition of arsenic trioxide (As_2_O_3_) if CR was achieved during/after induction. Patients remaining in CR after completion of consolidation were re‐randomized to one of two maintenance regimens; we focus here on the first randomization only. Thus, all patients received up to 90 days of the same ATRA induction therapy followed by assigned consolidation (ATRA or ATRA+As_2_O_3_) if CR was achieved. Consequently, it is natural to expect a delayed treatment effect (comparison of EFS distributions for ATRA with ATRA versus ATRA+As_2_O_3_ consolidation) of up to 90 days.
The analysis reported by Powell et al. [22] was completed on December 1, 2008 (day 3360 from the start of enrollment). Because the data provided to us have more extensive follow up, we created an illustrative analysis data set by censoring EFS outcomes at this date and eliminating seven patients with missing or anomalous values (e.g., enrollment date missing or after induction therapy start date), leaving data on 474 patients, of whom 234 (240) were randomized to ATRA (ATRA+As_2_O_3_) consolidation following ATRA induction, who enrolled in the trial starting in 1999. About 90% of patients in each group achieved CR. Powell et al. state that interim analyses of EFS were conducted semiannually using the logrank test; accordingly, we consider possible interim analyses every 3360/18 ≈187 days through day 3360. Owing to the paucity of events early in the trial, for illustration, we commence formal interim analyses at the third time (day 560 from start of enrollment), with 15 additional planned analyses. Given the expected delayed treatment effect, we chose a priori to base analyses on the modified RMST test statistic as in (28) constructed using (27) with 𝒯delay=90 favoring non‐proportional hazards alternatives, denoted as RMST III in Section 4.3, consistent with current interest in RMST as an alternative to the logrank test under such conditions. At each interim time tj, we take Lj=tj−5 days. For both RMST III and the logrank test, which have the independent increments property, for two‐sided tests with level of significance α=0.05, we used the R package ldbounds [18] to obtain the O'Brien‐Fleming α‐spending function corresponding to the time since start of enrollment for each of the K=16 planned analysis times; that is, (t1,…,t16)/t16 in the ldBounds() function; see the Supporting Information. We then obtained the stopping boundaries as in Steps 1–3 of the Section 5.
Table 3 presents the values of the standardized test statistics and the associated stopping boundaries to which their absolute values are compared at the first 10 potential interim analyses. Both standardized test statistics in absolute value exceed the stopping boundary for the first time at the seventh interim analysis at day 1680, at which point 66 events had occurred, 20 and 46 in the ATRA and ATRA+As_2_O_3_ groups, respectively. Notably, the modified RMST test statistic is consistently larger than the logrank statistic at all analyses and achieves an impressively large value relative to its corresponding boundary at the seventh analysis (and subsequently) and comes close to crossing the boundary at the sixth analysis, presumably reflecting that it is designed to target non‐proportional hazards alternatives. Figure 1 shows the Kaplan–Meier estimates of EFS distributions at interim analysis 7, which are consistent with both a treatment effect delay and evolving strong evidence of a treatment difference, aligned with the ultimate finding of Powell et al.
Treatment‐specific Kaplan–Meier estimates of EFS distributions at interim analysis 7.
Discussion
7
There is a vast literature on monitoring treatment differences in randomized clinical trials using group sequential tests. Much of the methodology is based on the premise that the associated statistics have the independent increments property, which allows standard algorithms and software to be used to compute stopping boundaries. However, this property may not hold for some tests of interest in practice. We have demonstrated that, regardless of whether or not the covariance matrix of the relevant statistics has the independent increments structure, it is always possible to find linear combinations of them that do have this structure. Moreover, we show how the linear combinations can be chosen judiciously to result in tests with high power to detect specific alternatives of interest. Thus, modified test statistics that can be derived from our results will have improved power, and monitoring based on them can be implemented readily using existing group sequential software.
Conflicts of Interest
The authors declare no conflicts of interest.
Supporting information
Data S1. Supporting Information.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1K. M. Kim and A. A. Tsiatis , “Independent Increments in Group Sequential Tests: A Review,” SORT ‐ Statistics and Operations Research Transactions 44 (2020): 223–264.
- 2S. J. Pocock , “Group Sequential Methods in the Design and Analysis of Clinical Trials,” Biometrika 64 (1977): 191–199.
- 3P. C. O'Brien and T. R. Fleming , “A Multiple Testing Procedure for Clinical Trials,” Biometrics 35 (1979): 549–556.497341 · pubmed ↗
- 4K. K. G. Lan and D. L. De Mets , “Discrete Sequential Boundaries for Clinical Trials,” Biometrika 70 (1983): 659–663.
- 5D. O. Scharfstein , A. A. Tsiatis , and J. M. Robins , “Semiparametric Efficiency and Its Implication on the Design and Analysis of Group Sequential Studies,” Journal of the American Statistical Association 92 (1997): 1342–1350.
- 6C. Jennison and B. W. Turnbull , “Group‐Sequential Analysis Incorporating Covariate Information,” Journal of the American Statistical Association 92 (1997): 1330–1341.
- 7K. Van Lancker , J. Betz , and M. Rosenblum , “Combining Covariate Adjustment With Group‐Sequential Information Adaptive Designs to Increase Randomized Trial Efficiency,” Biometrics 81 (2025): ujaf 020.40063405 10.1093/biomtc/ujaf 020 · doi ↗ · pubmed ↗
- 8L. Han , “Breaking Free From the Hazard Ratio: Embracing Restricted Mean Survival Time in Clinical Trials,” NEJM Evidence 2 (2023): EVI De 2300142.38320152 10.1056/EVI De 2300142 · doi ↗ · pubmed ↗