Identification of Regions of Interest in Neuroimaging Data With Irregular Boundary Based on Semiparametric Transformation Models and Interval‐Censored Outcomes
Chun Yin Lee, Haolun Shi, Da Ma, Mirza Faisal Beg, Jiguo Cao

TL;DR
This paper introduces a new method to identify brain regions linked to Alzheimer's progression using irregular neuroimaging data and censored time outcomes.
Contribution
A novel semiparametric model using bivariate splines and an EM algorithm for irregular neuroimaging data with interval-censored outcomes is proposed.
Findings
Bivariate splines over triangulation effectively model irregular brain regions in neuroimages.
The proposed method identifies regions of interest associated with Alzheimer's progression.
Simulation studies and real data analysis confirm the method's effectiveness and efficiency.
Abstract
Alzheimer's disease (AD) is a progressive neurodegenerative disorder that leads to memory loss, cognitive decline, and behavioral changes, without a known cure. Neuroimages are often collected alongside the covariates at baseline to forecast the prognosis of the patients. Identifying regions of interest within the neuroimages associated with disease progression is thus of significant clinical importance. One major complication in such analysis is that the domain of the brain area in neuroimages is irregular. Another complication is that the time to AD is interval‐censored, as the event can only be observed between two revisit time points. To address these complications, we propose to model the imaging predictors via bivariate splines over triangulation and incorporate the imaging predictors in a flexible class of semiparametric transformation models. The regions of interest can then be…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
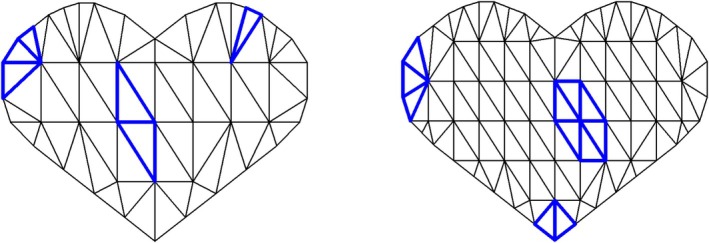 FIGURE 1
FIGURE 1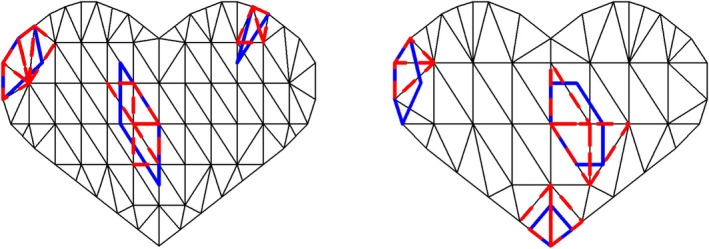 FIGURE 2
FIGURE 2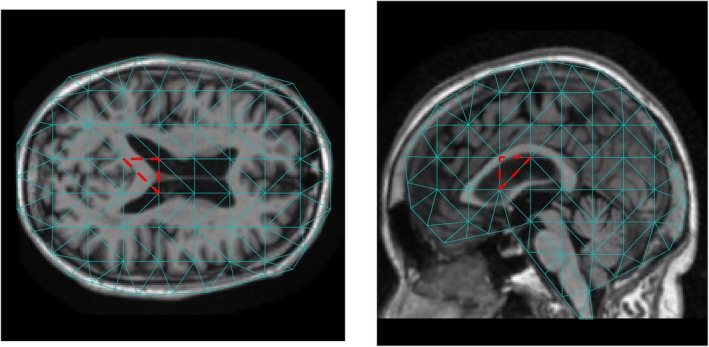 FIGURE 3
FIGURE 3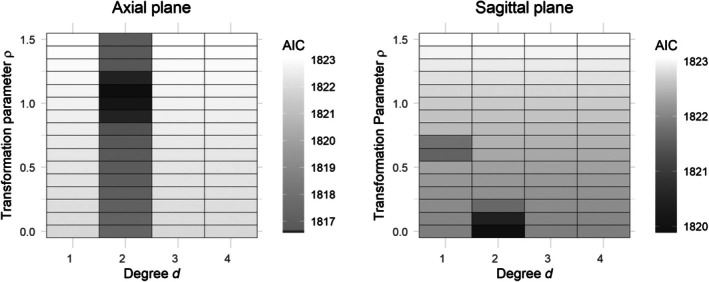 FIGURE 4
FIGURE 4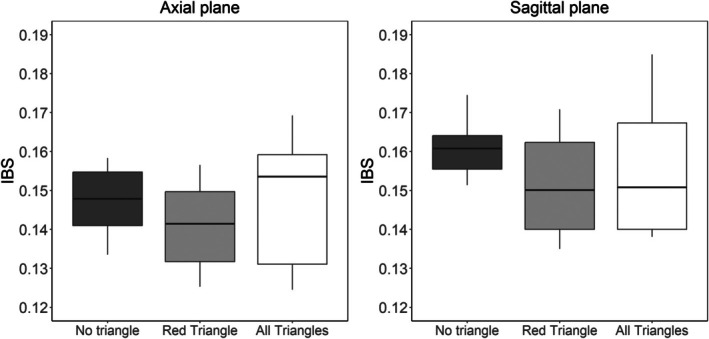 FIGURE 5
FIGURE 5| TP | FP | TP | FP | TP | FP | TP | FP | TP | FP | TP | FP | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100 | 1.000 | 0.003 | 0.847 | 0.007 | 0.597 | 0.022 | 0.995 | 0.002 | 0.816 | 0.014 | 0.143 | 0.003 |
| 200 | 1.000 | 0.004 | 1.000 | 0.012 | 0.963 | 0.040 | 1.000 | 0.002 | 0.998 | 0.016 | 0.645 | 0.032 | |
| 500 | 1.000 | 0.010 | 1.000 | 0.009 | 1.000 | 0.030 | 1.000 | 0.002 | 1.000 | 0.013 | 0.874 | 0.039 | |
| 1000 | 1.000 | 0.029 | 1.000 | 0.015 | 1.000 | 0.035 | 1.000 | 0.008 | 1.000 | 0.014 | 0.929 | 0.040 | |
| 0.5 | 100 | 0.990 | 0.003 | 0.850 | 0.008 | 0.578 | 0.018 | 0.995 | 0.003 | 0.730 | 0.012 | 0.122 | 0.004 |
| 200 | 1.000 | 0.004 | 1.000 | 0.013 | 0.970 | 0.037 | 1.000 | 0.002 | 1.000 | 0.019 | 0.650 | 0.030 | |
| 500 | 1.000 | 0.007 | 1.000 | 0.006 | 1.000 | 0.028 | 1.000 | 0.003 | 1.000 | 0.012 | 0.894 | 0.044 | |
| 1000 | 1.000 | 0.019 | 1.000 | 0.014 | 1.000 | 0.031 | 1.000 | 0.004 | 1.000 | 0.013 | 0.940 | 0.050 | |
| 1.0 | 100 | 0.980 | 0.002 | 0.877 | 0.009 | 0.575 | 0.019 | 0.980 | 0.002 | 0.798 | 0.012 | 0.097 | 0.003 |
| 200 | 1.000 | 0.003 | 0.997 | 0.010 | 0.960 | 0.041 | 1.000 | 0.002 | 0.994 | 0.015 | 0.564 | 0.020 | |
| 500 | 1.000 | 0.006 | 1.000 | 0.009 | 0.998 | 0.030 | 1.000 | 0.003 | 1.000 | 0.011 | 0.878 | 0.041 | |
| 1000 | 1.000 | 0.012 | 1.000 | 0.008 | 1.000 | 0.031 | 1.000 | 0.003 | 1.000 | 0.009 | 0.935 | 0.049 | |
| True grid | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| True prop | |||||||||||||
| Adopted grid | |||||||||||||
| Surrogate prop | |||||||||||||
| TP | FP | TP | FP | TP | FP | TP | FP | TP | FP | TP | FP | ||
| 0 | 100 | 0.470 | 0.006 | 0.370 | 0.007 | 0.241 | 0.006 | 0.985 | 0.008 | 0.772 | 0.034 | 0.324 | 0.021 |
| 200 | 0.505 | 0.009 | 0.677 | 0.016 | 0.590 | 0.024 | 1.000 | 0.007 | 0.973 | 0.041 | 0.713 | 0.057 | |
| 500 | 0.505 | 0.010 | 0.808 | 0.022 | 0.770 | 0.048 | 1.000 | 0.020 | 0.995 | 0.042 | 0.856 | 0.083 | |
| 1000 | 0.500 | 0.012 | 0.830 | 0.023 | 0.819 | 0.050 | 1.000 | 0.051 | 1.000 | 0.050 | 0.899 | 0.096 | |
| 0.5 | 100 | 0.375 | 0.005 | 0.370 | 0.006 | 0.187 | 0.006 | 0.985 | 0.005 | 0.807 | 0.031 | 0.303 | 0.021 |
| 200 | 0.550 | 0.009 | 0.708 | 0.018 | 0.599 | 0.026 | 1.000 | 0.006 | 0.948 | 0.036 | 0.659 | 0.058 | |
| 500 | 0.500 | 0.010 | 0.830 | 0.023 | 0.782 | 0.043 | 1.000 | 0.015 | 1.000 | 0.039 | 0.846 | 0.084 | |
| 1000 | 0.500 | 0.010 | 0.847 | 0.022 | 0.840 | 0.055 | 1.000 | 0.035 | 1.000 | 0.047 | 0.876 | 0.095 | |
| 1.0 | 100 | 0.340 | 0.004 | 0.308 | 0.006 | 0.148 | 0.004 | 0.980 | 0.006 | 0.760 | 0.031 | 0.244 | 0.017 |
| 200 | 0.530 | 0.008 | 0.723 | 0.018 | 0.593 | 0.024 | 1.000 | 0.007 | 0.948 | 0.036 | 0.687 | 0.060 | |
| 500 | 0.515 | 0.010 | 0.832 | 0.022 | 0.778 | 0.040 | 1.000 | 0.014 | 0.998 | 0.034 | 0.850 | 0.092 | |
| 1000 | 0.500 | 0.010 | 0.847 | 0.022 | 0.823 | 0.051 | 1.000 | 0.029 | 1.000 | 0.044 | 0.877 | 0.097 | |
- —Natural Sciences and Engineering Research Council of Canada10.13039/501100000038
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Inference · Functional Brain Connectivity Studies · Dementia and Cognitive Impairment Research
Introduction
1
Alzheimer's disease (AD) is a condition that affects a large number of individuals globally. A report from Alzheimer's Disease International in 2018 indicated that over 50 million people globally are currently living with dementia, a number projected to triple by 2050. In the meantime, structural magnetic resonance imaging (MRI) has been widely used to gain insights into the underlying processes of AD in individual patients. Identifying the brain regions linked to the disease progression from MRI scans has become an area of crucial research interest, essential for developing targeted treatments and interventions.
Numerous retrospective studies have investigated patients with AD to explore how different brain regions contribute to its onset and advancement. The hippocampus is widely recognized as the key region associated with early‐stage disease development due to its involvement in forming long‐term memories. Additionally, given the network of interconnected brain regions, it is likely that the onset and progression of AD may involve regions beyond the hippocampus. For example, the entorhinal cortex has been shown to associate with the preclinical stage of AD progression, whose posterior‐lateral subfields are most susceptible to early neurofibrillary tangle [1]. Presubiculum and subiculum subfields have been found to exhibit the earliest atrophy and are predictive of memory performance in the progression of the disease [2]. Recent studies have also shown from a gradient pattern of pathological markers that the amygdala serves as a hub for propagating AD pathology through its connections with other brain regions [3]. Other key regions related to the disease progression include, for example, ventricle, basal forebrain, cingulate cortex, and white matter tracts [4, 5, 6, 7].
Among the brain regions considered in various retrospective studies, to reliably identify the most crucial one that is statistically associated with the progression of AD, we propose a data‐driven approach for the survival analysis of the large MRI datasets from the Alzheimer's Disease Neuroimaging Initiative (ADNI) study. Such a method can help corroborate or challenge existing hypotheses about the role of the various brain regions in the disease progression and may find patterns that may not be apparent through traditional retrospective research methods.
Our objective is to develop a reliable model for detecting regions of interest within brain MRI scans that are associated with the onset of AD. There exist a few statistical challenges to this objective. First, in the ADNI study, the regularly followed‐up patients were clinically assessed only at each revisit time point to ascertain the onset or progression of the disease. Therefore, the exact time for the conversion of AD was unknown but only observed to fall between two revisit time points, hence interval‐censored [8, 9, 10]. The standard estimation procedure, such as the partial likelihood, cannot be directly applied to interval‐censored data. Second, since the brain area within MRI scans is confined within an irregular region with noise elsewhere, using existing methods for rectangular (regular) boundaries on such images would result in boundary leakage issues [11]. A direct consequence of the boundary leakage is that the background information would be incorrectly included in the analysis due to the dominance of sharp transitions between the image and background, as demonstrated in several examples in Ramsay [12].
To address these challenges, we propose a novel model for identifying key areas in brain MRI scans that are statistically associated with the progression of AD. Our method specifically addresses the difficulties related to the irregular contours found in MRI images and the interval‐censored data based on a flexible class of semiparametric transformation models. We propose to approximate the image with irregular boundaries via bivariate polynomial splines constructed on triangulation grids as proposed in Lai and Schumaker [13] and Lai and Wang [14]. By utilizing piecewise polynomial functions on a triangulated surface, the brain scans can be smoothly incorporated into a survival model. This allows for the precise location of the area of interest within a regression framework. Moreover, to incorporate the interval‐censored data, we develop a Poisson data augmentation approach, which is shown to be computationally efficient and powered by the Expectation Maximization (EM) algorithm. Finally, as some but not all regions of the brain are of interest, we propose to incorporate group penalty terms on the imaging predictors, selectively emphasizing areas implicated in disease onset. The regions of interest can then be identified by maximizing a penalized likelihood. The R codes for implementing our method in this paper are publicly available on GitHub: https://github.com/lcyjames/Roiico.
Incorporating high‐dimensional images for survival models has received considerable attention recently, with a majority of the research work focused on functional principal component analysis (FPCA). Zipunnikov et al. [15] established a linkage between the FPCA and singular value decomposition, which allows for computationally efficient estimation of the single‐level FPCA for vectorized images. To retain the spatial structure of the image, Reiss and Ogden [16] studied the functional generalized linear models regressing scalar outcomes on two‐dimensional image predictors, approximated via the radial B‐spline function. Zhou et al. [17] later extended the generalized linear regression model to incorporate tensor‐structured predictors. They assumed a rank‐R decomposition for the tensor such that the number of parameters to be estimated is substantially reduced. Wang et al. [18] proposed a minimum penalized total variation approach, based on the scalar‐on‐image regression model, that yields piecewise‐smooth regression coefficients. Jiang et al. [19] studied the supervised FPCA to analyze two‐dimensional imaging data and performed risk prediction by incorporating the estimated FPC scores into the Cox model for right‐censored outcomes. Bayesian nonparametric methods have also been developed to estimate scalar‐on‐image regression models; for instance, see Goldsmith et al. [20], Kang et al. [21], and Feng et al. [22]. However, the aforementioned work typically assumes that the image is bounded within a rectangular domain, and the outcome variable is often noncensored or right‐censored. Mattos et al. [23] introduced an estimation approach for the tuning parameter in a semiparametric linear mixed effects model, which incorporates a roughness penalty on the unknown smooth function. A scant amount of work has paid attention to the association between image predictors and interval‐censored outcome variables.
The rest of the paper is structured as follows. Section 2 first introduces the notations, the models for image predictor and survival outcome, and the likelihood. A flexible class of semiparametric transformation models incorporating imaging predictors is proposed for the survival outcomes. A sieve maximum likelihood approach for interval‐censored data with group penalties is proposed for identifying the regions of interest. In Section 3, we discuss the computation algorithms of the penalized estimator. Extensive simulation studies are conducted in Section 4, investigating the finite‐sample performance of the proposed methods. We illustrate the methods based on the ADNI dataset in Section 5. Some concluding remarks are provided in Section 6.
Model and Likelihood
2
Let X(s) be a random two‐dimensional stochastic process modeling the spatially correlated pixels of an image, where location s≡s1,s2∈Ω⊂ℛ2, and Ω is a bounded two‐dimensional domain of possibly irregular shape. Without loss of generality, we assume that X(.) has mean 0. Suppose that there are n realizations of the random process, where each realization pertains to a two‐dimensional surface. Furthermore, we observe Ni sets of noisy samples from the ith surface, i=1,…,n. The observed data point Yij is given by
for i=1,…,n and j=1,…,Ni where Eϵij=0, Eϵij,ϵij′=Ij=j′σ2, ϵij is independent of sij, and I(.) is the indicator function. Note that Xi(.) is intrinsically an infinite‐dimensional function measured on a two‐dimensional space with an irregular boundary, which refers to a circular region along the axial plane in the study of neuroimaging data. We approximate Xi(.) via the bivariate polynomial splines constructed on the partitions over a two‐dimensional triangulated domain [13, 14]. Compared with other polygon shapes, triangulation offers the advantage that any polygonal domain of arbitrary shape can be partitioned into finitely many triangles, thus providing greater flexibility. Let Δ=τ1,…,τM be the collection of triangles that forms a triangulation of Ω=∪l=1Mτl, where each τl is the convex hull of three points that are not colinear, and any nonempty intersection between τl and τl′ (l≠l′) is either a common vertex or a common edge. The spline space of a degree d and smoothness r over triangulation Δ can be defined as Tdr(Δ)={u∈Cr(Ω):uτ∈ℙd,τ∈Δ} where r≥0, Cr(Ω) denote the collection of all r‐th continuously differentiable functions over Ω, and ℙd denotes the space of all polynomials with degree not greater than d.
Specifically, we adopt the Bernstein polynomials, with each polynomial tailored to a specific triangle in Ω. Suppose that τ∈Δ is a nondegenerate triangle (with a nonzero area) with vertices v1,v2, and v3. Then, an arbitrary point s∈Ω can be uniquely represented by s=b1v1+b2v2+b3v3, where b1,b2,b3 are known as the barycentric coordinates of the point s relative to triangle τ, and b1+b2+b3=1. We define a set of Bernstein polynomial basis functions of degree d for s relative to τ by Bτ,d(s)T=Bijkτ,d(s),i+j+k=d, with dimension Kd=d+22, where Bijkτ,d(s)=d!(i!j!k!)−1b1ib2jb3k. Therefore, the polynomial piece of spline u restricted to τ is given by u|τ=ατTBτ,d, where ατT=αijkτ,i+j+k=d is a Kd‐dimensional vector of coefficients of the basis functions. In the sequel, we assume that d is common to all triangles, and we drop the subscript d in K and superscript d in B for notational simplicity. The Bernstein polynomial based approximation of Xi(s) is given by
The estimates of αi=αiτ1T,…,αiτMTT can be obtained by minimizing the least squares criterion with the thin‐plate spline penalty [24, 25]:
where ςi>0 pertains to the roughness penalty parameter, and ∇s1p pertains to the pth‐order derivative in the direction s1 at the point s=s1,s2. In addition, we require Hα=0 to meet the smoothness condition of the splines, where H is a matrix that enforces smoothness across shared edges of triangles; some examples on the construction of H can be found in Zhou and Pan [26].
In addition to the image data, let T be the failure time, and Z be a vector of demographic covariates. We propose a flexible class of semiparametric transformation models for T with the conditional cumulative hazard function
where G is a prespecified strictly increasing transformation function indexed by parameter ρ, Λ is an unspecified increasing function with Λ(0)=0, β is a vector of regression parameters, and γ(s) is an imaging parameter which characterizes the effects of imaging data on the hazard function. The transformation model in Equation (3) reduces to the Cox proportional hazards (PH) model when G(x;ρ)=x, and the proportional odds (PO) model when G(x;ρ)=log(1+x), respectively. Hence, it is reminiscent of the logarithmic or the Box‐Cox transformation functions. In this paper, we assume the logarithmic transformation function G(x;ρ)=log(1+ρx)/ρ with ρ≥0, where ρ=0 and ρ=1 correspond to the Cox PH and PO models, respectively. Equation (3) equipped with the logarithmic transformation function is also known as the generalized odds rate model [27] in the literature. For mathematical tractability, we approximate Xi(s) in Equation (3) by X˜i(s) in Equation (1), and suppose that γ(s) can also be expanded on the set of bivariate Bernstein polynomial basis functions, that is γ(s)=∑l=1MγτlTBτl(s), where γτl is a K‐dimensional vector of coefficients of the basis functions restricted to the lth triangle, l=1,…,M. Then, we can rewrite Equation (3) as
where Wτl=Bτl,BτlT is a K×K dimensional matrix, and ⟨⋅,⋅⟩ denotes the inner product of functions. The second last line of Equation (4) is obtained based on the fact that Bτl,Bτl′T=0 for any l′≠l. Let W=diagWτ1,…,WτM be a block diagonal and positive definite matrix, and ξi=Wαi. Then, Equation (4) becomes
where γ=γτ1T,…,γτMTT.
Suppose Ti is censored by a random interval Li,Ri, i=1,…,n. In the framework, we set Li=0 and Ri=∞ to accommodate left‐ and right‐censored observations. Under the paradigm of noninformative censoring, and for given ξi's, the observed likelihood of (Λ,β,γ) is proportional to
Since Λ is modeled nonparametrically, we propose a sieve maximum likelihood approach for parameter estimation. We approximate Λ(t) via Λ˜(t)=∑j=1JωjIj(t), where I1,…,IJ are the I‐spline basis functions [28] constructed over 0,tmax, and ω=ω1,…,ωJ are nonnegative coefficients ensuring that Λ˜ is a monotone function. In practice, tmax is set to be the largest finite value of the combined vector of Li's and Ri's. The observed likelihood of θ≡(ω,β,γ) under sieve approximation is given by
In general, not all regions of the image are of clinical interest, and we wish to identify some useful regions for disease prognosis. We adopt the group lasso [29, 30] to penalize the parameters associated with each of the M triangles. Specifically, we propose to maximize the following objective function:
where ∥.∥2 denotes the Euclidean norm, K1=⋯=KM=K, s(.) is a function used to rescale the penalty corresponding to the dimensionality of γτl, and λ≥0 is a tuning parameter that controls the size of the penalty. As is customary, we set sKl=K pertaining to a normalizing constant for l=1,…,M, and we normalize each element in ξi before carrying out the estimation procedure. The demographic variables Zi are not penalized in this setting. The group lasso penalty acts as an intermediate between the l1‐ and l2‐type penalties, selecting variables at the group level. Consequently, if the lth triangle is not penalized, then all values in γτl remain nonzero, retaining all the basis functions restricted to that triangle.
Computational Details
3
We propose a two‐step estimation procedure for computational efficiency. The estimation in Equation (2) can be handled easily via some existing software, such as the BPST package in R. Given the estimates of ξi's, we then approximate θ by maximizing the penalized likelihood in Equation (7) with the detailed procedures as follows.
To simplify the computation, we adopt a class of frailty‐induced transformation models [31]. Let G(x;ρ)=−logΦζ(x;ρ) where Φζ(x;ρ)=∫0∞exp(−ζx)fζ(ζ;ρ)dζ is the Laplace transform of a positive‐valued frailty ζ, and fζ(.;ρ) is the density function of ζ. We obtain the logarithmic transformation G(x;ρ)=log(1+ρx)/ρ when ζ follows a gamma distribution with mean 1 and variance ρ. Furthermore, let ΔLi, ΔRi, and ΔIi≡1−ΔLi−ΔRi be the indicators for left‐, right‐, and interval‐censored observations, respectively. Then, Equation (6) can be written as
where fζ(.;ρ) is the density of a gamma distribution with both shape and rate parameters equal to ρ−1. The maximization of Equation (8) is challenging due to the lack of analytical expressions for ω1,…,ωJ. To address this issue and accommodate the latent variable ζi, we propose a data augmentation approach and develop an EM algorithm for obtaining the sieve maximum likelihood estimate (MLE). For i=1,…,n and j=1,…,J, let Aij and Bij be two latent Poisson variables that are independent given ζi, with conditional means ζiμij and ζiηij respectively, where μij≡ωjΔLiIjRi+ΔIiIjLieβTZi+γTξi and ηij≡ωjΔIiIjRi−IjLi+ΔRiIjLieβTZi+γTξi. Furthermore, let Ai≡∑j=1JAij, Bi≡∑j=1JBij, and
One can see that the observed likelihood in Equation (8) is equivalent to that obtained from the data O1,…,On where Oi≡Li,Ri,Zi,ξi,O˜iT, treating Aij, Bij, and ζi as missing data. Therefore, the maximizer of Equation (8) can be computed based on the EM algorithm with the augmented data. It suffices to write down the complete data log‐likelihood
omitting the terms which do not depend on θ.
Let θ(d) denote the current estimates of θ in the dth iteration (d=0,1,…) of the EM algorithm. In the E‐step, we evaluate E^Aij, E^Bij, and E^ζi where E^(⋅) denotes the conditional expectation given O1,…,On evaluated at θ(d). The analytical expressions of these conditional expectations are relegated to the Appendix A, where we show that only conditional expectations of functions of ζi are required in the E‐step. In particular, those integrals have closed‐form expressions, thus, the computationally intensive numerical approximation is not required in the proposed method.
In the M‐step, we obtain θ(d+1) by maximizing the penalized Q‐function Qθ,θ(d)≡E^ℓC(θ)−λ∑l=1MsKl∥γτl∥2. Taking the partial derivative of Qθ,θ(d) with respect to ω and setting it to zero yields a closed‐form solution for ω, in terms of β and γ, as
By replacing ωj with ωj*(β,γ) in Qθ,θ(d), the revised penalized Q‐function is
where E^ℓCω*,β,γ is given by
Based on Equation (9), β(d+1) is obtained via a one‐step Newton–Raphson algorithm. Then, we update γ via the block coordinate descent algorithm [30, 32]. Specifically, we fix the values of γτl′ for any l′≠l, and (ω,β) at ω(d),β(d+1), while updating γτl. Based on the direct consequence of the Karush–Kuhn–Tucker conditions, we have γτl(d+1)=0 if ∥Gl∥2≤λsKl where Gl=∂∂γτlE^ℓCω*,β,γγτl=0, and γτl(d+1) is obtained via minimizing the negative penalized‐Q function in Equation (9) otherwise, for l=1,…,M. Then, we obtain ωj(d+1)=ωj*β(d+1),γ(d+1) for j=1,…,J. We iterate between the E‐ and M‐steps until convergence, where the maximum absolute difference between two consecutive estimates is smaller than a certain threshold.
Determination of the tuning parameter λ is a crucial task in the estimation procedure. We propose to implement a data‐adaptive Akaike information criterion (AIC):
where θ^λ is the estimator obtained in Equation (7) under a prespecified λ, and the degree of freedom dfλ is taken as the total number of nonzero estimates in θ^λ. In practice, we consider a grid of values for λ and choose the model with a minimum value of AICλ. This criterion performs well as indicated in our simulation studies. Other model selection methods, such as the Bayesian information criterion [33] or cross‐validation, can also be considered.
Simulation Study
4
We study the finite‐sample performance of the proposed methods to identify the regions of interest. To mimic the practical situation in which images are observed with an irregular boundary, we confine the images to a rectangular grid of size 40 × 40, where 1036 of them are situated within a heart‐shaped boundary region. We construct the sets of bivariate Bernstein polynomials based on two settings on the fineness of the triangulation, namely M=62 triangles with 47 vertices, and M=118 triangles with 80 vertices. The triangulation grids used in these two settings are depicted in Figure 1. Specifically, the jth pixel of the image surface observed for the ith subject is given by
for i=1,…,n; j=1,…,Ni, and Ni=1036 for all i. Specifically, we set the degree of the Bernstein polynomial d=2 (i.e., K=6) and ϵij's are generated from a normal distribution with mean 0 and variance 0.12. We generate αi from a zero‐mean multivariate normal distribution with covariance matrix ∑ where the diagonal elements of ∑ are equal to 1, and the within‐triangle and between‐triangle correlations are equal to 0.4 and 0.1, respectively. Subsequently, we generate the survival time Ti based on the model:
where Sl is a set of indices of the triangles that are assigned to be associated with the survival outcomes. We set the basis coefficient γτl=(0.1,0.2,0.3,0.5,0.6,0.4) for all l∈Sl, and γτl=0 otherwise. We set Λ(t)=t2/4, and the transformation parameter ρ to be 0,0.5 and 1. The interarrival times follow a uniform distribution with support (0.1,0.5). We assume that there is an administrative censoring time, such that observations are right‐censored beyond this time point. The average right‐censoring proportion varies from 30% to 45% across the scenarios. We set β=(0.5,−0.5) and Zi=Zi1,Zi2 where Zi1 follows a Bernoulli distribution with probability 0.5 and Zi2 follows the standard normal distribution. We consider n=100,200,500, and 1000, and the number of selected triangles ∣Sl∣ to be ⌊aM⌋, the largest integer value smaller than or equal to aM, where a=0.025,0.05, and 0.1.
Illustration of the triangulation grids used in the simulation study. The left and right panels displayed grids of 62 and 118 triangles, respectively. The triangles with thickened boundaries illustrate the mechanism by which a certain proportion of the triangles is selected to be associated with the survival outcome.
We adopt the I‐splines basis functions with degree 3 and 4 interior knots (i.e., J=7) to approximate Λ. The knots were positioned at the empirical quantiles of the endpoints of the observed intervals. For implementing the EM algorithm, we set the initial parameter values as follows: ωj(0)=0.1 for j=1,…,J, β(0)=0, and γ(0)=0. The tolerance level for the convergence criterion is set to be 10−3. The optimal value of λ is selected by AIC, as discussed in Section 3.
Table 1 presents the simulation results for two different triangulation grid settings, with 100 replicates in each scenario. The performance of the proposed methods is assessed based on the true positive rate and false positive rate. The true positive rate is defined as the proportion of triangles in Sl being correctly identified, while the false positive rate is the proportion of triangles which does not belong to Sl but are identified. The two rates are computed for each replicate, and the average rates are reported. The empirical results demonstrate that the proposed method performs satisfactorily under the transformation models in general, except when the sample size is as small as n=100 and when the number of triangles in Sl is relatively large, such as when a=0.1, as expected. This indicates that the proposed method can effectively identify all the regions of interest that are truly associated with survival time. Also, the false positive rates remain consistently low across all scenarios, suggesting that the proposed method often accurately excludes regions without any impact during the variable selection process.
To assess the potential impact of an incorrectly specified triangulation grid on the performance of the proposed methods, we conduct a simulation where the grid used for data generation differs from the grid used for identifying regions of interest. Specifically, data are generated using a (true) grid with M=62 triangles, with those associated with survival outcomes depicted in the left panel of Figure 1. We then fit the model using a (misspecified) triangulation grid with M*=118 triangles, and vice versa. All other parameter settings remain unchanged as above. As our main objective is to evaluate the precision of the identification methods, it necessitates a surrogate measurement for determining true and false positive rates under the conditions of misspecified grids. To achieve this, we examine each triangle within the misspecified grid and classify it as associated with the outcome if its centroid falls within the region defined by the true grid. Note that varying triangle proportions a in the true grid yield different numbers of (associated) surrogate triangles in the misspecified grid, leading to different surrogate proportions a*. Figure 2 illustrates the surrogate triangles, marked with red dashed lines, which are utilized to assess the surrogate performance of the methods, alongside the true region of interest bounded with blue solid lines. The results, along with the values of M, M*, a, and a* in the settings, are summarized in Table 2.
Illustration of the surrogate triangles to facilitate the definition of true and false positive rates under a misspecified triangulation grid in the simulation. In the left (right) panel, the blue solid lines indicate the triangles associated with the survival outcome with triangulation grids M=62 (M=118), and the red dashed lines indicate the surrogate triangles associated with the survival outcome under a misspecified grid where M=118 (M*=62).*
When an overly refined grid is erroneously applied to the data, specifically when the true grid size is M=62 but a grid size of M*=118 is applied, the true positive rates tend to diminish. This decline is likely attributable to the discordance between the true and misspecified grids, as well as a decrease in the sparsity of the associated triangles, given that the number of surrogate triangles exceeds that of the true triangles. Conversely, when a coarser grid is mistakenly applied, where the true grid size is M=118 but a grid size of M*=62 is used, the true positive rates remain satisfactory. This result may be due to an increase in the sparsity of the associated triangles. Overall, the false positive rates exhibit a moderate increase, particularly when the adopted grid is coarser than the true grid, compared to scenarios where the triangulation grids are correctly specified. The results demonstrate that the proposed methods still manage to provide reasonable performance, although careful selection of the triangulation grid can enhance precision. In practice, the optimal choice of M is unknown. Adopting a balanced triangulation grid guided by practitioners, that is both clinically meaningful and tailored to the specific context of the study, is recommended to enhance the performance of the identification methods. Some guidelines for the choice of triangulation can be found in Wang et al. [25].
Application to AD Study
5
We demonstrate the proposed methods using the ADNI dataset [34]. This is a longitudinal study in which the cognitive status of the subjects was reassessed approximately every 6 months in the first 2 years, followed by annual evaluations beyond 2 years. The maximum number of visit time points was 13, and the maximum follow‐up period was 120 months. At each visit time point, the subjects underwent brain MRI scans and were clinically classified into one of the three stages of AD, namely cognitive normal (CN), mild cognitive impairment (MCI), and AD. We treat the onset of AD as the event of interest, which was interval‐censored due to the study design. The main objective of this analysis is to identify the region of interest in the brain MRI scan associated with the survival time of the patients. We focus on a subset of subjects initially diagnosed as CN or MCI (i.e., AD‐free) at baseline. This yields a sample size of n=674 subjects of which 286 have been diagnosed with AD by the end of the study. Apart from the volumetric images at baseline, other covariates, including gender and age at baseline, are available for each subject. Before the statistical analysis, the MRI scans are preprocessed to ensure that they are approximately transformed into the same stereotaxic space, based on the registration procedure in Ma et al. [35]. We proceed to extract the middle slice from both the axial and sagittal axes of the processed image and store the pixel intensities of the slices in the format of a 200×200 matrix.
As illustrated in Figure 3, we construct boundaries to envelop the brain regions on the axial and sagittal planes in the MRI scans and partition the regions into M=118 and M=103 triangles, respectively. For i=1,…,674, a total number of Ni=21,393 data points fall inside the boundary of the axial plane, constituting Yij's, whereas there are Ni=16,078 data points inside the boundary for the sagittal plane. We let gender and age‐at‐baseline be the unpenalized covariates Z. We adopt the I‐splines basis functions with degree 3 and 4 interior knots. We adopt the same set of initial parameter values for the EM algorithm as in the simulation study. The tolerance level for the convergence of the EM algorithm is set to be 10−4. The degree of the Bernstein polynomial d and the transformation parameter ρ are typically unknown in practice. To achieve a parsimonious fit, we perform a two‐dimensional grid search over the parameters (d,ρ). Specifically, we vary ρ from 0 to 1.5 in increments of 0.1, and we consider d values from the set {1,2,3,4}. For each pair (d,ρ), we compute the minimum value of AICλ, where AICλ is defined in Equation (10) based on a grid of λ values ranging from 101 to 102.5. The interval (1,2.5) is divided into 500 uniformly spaced partitions, serving as exponents with base 10. We then identify the optimal model by selecting the pair (d,ρ) that yields the smallest AIC value among all evaluated combinations. In terms of computational burden, the EM algorithm takes approximately 30 min for computing the 500 AICλ values for d=2 and a given value of ρ in each of the planes using a standard desktop (2.4GHz, 16GB RAM) without parallel programming.
The triangulation over the region of the brain. Left panel: Axial plane with M=118 triangles. Right panel: Sagittal plane with M=103 triangles.
The results are illustrated in Figure 4. One can observe that the model with d=2 and ρ=1.1 achieves the lowest AIC value for the axial plane, while the model with d=2 and ρ=0 achieves the lowest AIC value for the sagittal plane. This suggests that the PO and PH models should be applied to the data for axial and sagittal planes, respectively. The selected model identifies only one triangle associated with survival time in both planes. The selected triangles are marked by red dotted lines in the two panels of Figure 3, and they roughly correspond to the lateral ventricle region of the brain. The change in the size of the ventricle is known to be highly associated with impairment in cognitive function and dementia. Enlargement of the ventricle region has been identified as a reliable predictor for AD progression [4, 36].
The minimum value of AICλ achieved in each given pair of (d,ρ) for the axial and sagittal planes.
To assess the model predictive performance of the proposed method, we use a 10‐fold internal cross‐validation procedure based on the integrated Brier score (IBS). The IBS, introduced by Graf et al. [37], is a prominent and widely adopted tool for gauging prediction error for right‐censored data. Tsouprou et al. [38] later extended this method to accommodate interval‐censored data. Specifically, it takes the form:
where S^it|X˜i,Zi is the estimated survival function of the ith subject evaluated at time t. Clearly, ITi>t=1 for t≤Li and ITi>t=0 for t>Ri. When Li<t≤Ri, ITi>t is unknown and is estimated by
It is remarked that IBS ranges between 0 and 1, and a smaller value of this metric reflects a higher model predictive accuracy. In all models used for comparison, we always include the unpenalized covariates Zi. For the axial plane, we fit the following three PO models (i) without any triangles, setting γ=0 in Equation (5); (ii) with the selected triangle highlighted in red in Figure 3, based on a second‐stage model, by allowing only γτl to be nonzero for that specific triangle in Equation (4); and (iii) with all triangles, permitting all elements in γ to be nonzero in Equation (5). We perform an analogous model comparison for the sagittal plane based on the PH model. The results of the cross‐validation are summarized by box plots in Figure 5. For the axial plane, the average IBS values for models (i), (ii), and (iii) are 0.147, 0.141, and 0.148, respectively. For the sagittal plane, the average IBS values for the three models are 0.161, 0.152, and 0.156, respectively. These results underscore the superior predictive performance of the proposed model with the selected triangle in red over the two planes, as evidenced by its minimal average IBS.
The box plot for the IBS obtained in the 10‐fold internal cross‐validation based on the models (i) without any triangles; (ii) with the selected red triangle; and (iii) all triangles, over the axial and sagittal planes.
Conclusions and Discussion
6
Brain MRI is pivotal in prognostic assessments for AD, yet integrating it into statistical analyses presents complex challenges. This study introduces an innovative methodology for pinpointing regions of interest within brain MRI scans that are indicative of AD onset. Specifically, the proposed method tackles the challenges posed by irregular boundaries in the MRI scans and the interval‐censored nature of the data based on a flexible class of transformation models. By employing piecewise polynomial functions applied over triangulation, the brain images can be seamlessly integrated into the survival model and the region of interest can be subsequently identified within a regression‐based framework, enhancing the precision of AD prognosis. The efficacy of the proposed methodology is demonstrated using the ADNI dataset. A specific brain region has been identified as significantly associated with AD onset. In both axial and sagittal planes, the model with the selected region shows a smaller IBS (i.e., higher predictive accuracy) compared to the models without the imaging predictors and with all the imaging predictors. This finding offers valuable insights for clinical practitioners, especially in informing disease progression and risk stratification of patients.
The proposed method can be extended in the following ways. First, we utilize the brain MRI scans at baseline for risk prediction. However, the ADNI study has amassed longitudinal MRI scans with irregular revisiting time intervals, which presents an opportunity to enrich the predictive capability of the model. An advanced triangulation technique could be developed to capture features not only spatially across image pixels but also temporally across successive scans, potentially necessitating a three‐dimensional stochastic modeling framework for sparse functional data. Second, the proposed approach focuses on modeling two‐dimensional imaging data with irregular boundaries as predictors for survival outcomes. To further utilize the inherently three‐dimensional imaging data with irregular boundaries, the current method could be extended using, for example, the trivariate spline smoothing techniques recently proposed by Wang et al. [39]. Third, the proposed approach adopts a two‐stage estimation procedure. The initial stage involves approximating the image using Bernstein polynomials, followed by incorporating the approximated image into a survival model to perform group variable selection. While this method is computationally expedient, it is susceptible to the propagation of approximation errors from the first stage into the subsequent survival analysis. An alternative strategy could involve a joint modeling approach, wherein latent frailty terms are concurrently estimated, linking the imaging data directly with the latency component of the disease progression. Such methodological advancements would likely demand significantly increased computational resources.
Conflicts of Interest
The authors declare no conflicts of interest.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1J. Llamas‐Rodríguez , J. Oltmer , D. N. Greve , et al., “Entorhinal Subfield Vulnerability to Neurofibrillary Tangles in Aging and the Preclinical Stage of Alzheimer's Disease,” Journal of Alzheimer's Disease 87 (2022): 1379–1399.10.3233/JAD-215567 PMC 919875935491780 · doi ↗ · pubmed ↗
- 2G. A. Carlesimo , F. Piras , M. D. Orfei , M. Iorio , C. Caltagirone , and G. Spalletta , “Atrophy of Presubiculum and Subiculum Is the Earliest Hippocampal Anatomical Marker of Alzheimer's Disease,” Alzheimer's & Dementia: Diagnosis, Assessment & Disease Monitoring 1 (2015): 24–32.10.1016/j.dadm.2014.12.001PMC 487690127239489 · doi ↗ · pubmed ↗
- 3M. Gonzalez‐Rodriguez , S. Villar‐Conde , V. Astillero‐Lopez , et al., “Human Amygdala Involvement in Alzheimer's Disease Revealed by Stereological and Dia‐PASEF Analysis,” Brain Pathology 33 (2023): e 13180, 10.1111/bpa.13180.37331354 PMC 10467039 · doi ↗ · pubmed ↗
- 4S. M. Nestor , R. Rupsingh , M. Borrie , et al., “Ventricular Enlargement as a Possible Measure of Alzheimer's Disease Progression Validated Using the Alzheimer's Disease Neuroimaging Initiative Database,” Brain 131 (2008): 2443–2454, 10.1093/brain/awn 146.18669512 PMC 2724905 · doi ↗ · pubmed ↗
- 5R. Leech and D. J. Sharp , “The Role of the Posterior Cingulate Cortex in Cognition and Disease,” Brain 137 (2013): 12–32.23869106 10.1093/brain/awt 162PMC 3891440 · doi ↗ · pubmed ↗
- 6F. Rémy , N. Vayssière , L. Saint‐Aubert , E. Barbeau , and J. Pariente , “White Matter Disruption at the Prodromal Stage of Alzheimer's Disease: Relationships With Hippocampal Atrophy and Episodic Memory Performance,” Neuro Image 7 (2015): 482–492.25685715 10.1016/j.nicl.2015.01.014PMC 4326466 · doi ↗ · pubmed ↗
- 7T. W. Schmitz and S. R. Nathan , “Basal Forebrain Degeneration Precedes and Predicts the Cortical Spread of Alzheimer's Pathology,” Nature Communications 7 (2016): 13249.10.1038/ncomms 13249 PMC 509715727811848 · doi ↗ · pubmed ↗
- 8J. Huang and J. A. Wellner , “Asymptotic Normality of the NPMLE of Linear Functionals for Interval Censored Data, Case 1,” Statistica Neerlandica 49, no. 2 (1995): 153–163.