Intercept Estimation of Semi‐Parametric Joint Models in the Context of Longitudinal Data Subject to Irregular Observations
Luis Ledesma, Eleanor Pullenayegum

TL;DR
This paper improves a statistical model for analyzing irregular longitudinal data by estimating an intercept term, leading to better accuracy and efficiency in predicting outcomes.
Contribution
The paper introduces an extended Sun estimator that estimates the intercept term in semi-parametric joint models, improving bias and standard error.
Findings
The extended estimator outperforms the original Sun estimator in bias and standard error in simulations.
The new estimator allows estimation of mean outcome trajectories, which the original model could not.
The extended model is computationally more efficient and recommended for longitudinal data analysis when intercepts are modeled with splines.
Abstract
Longitudinal data are often subject to irregular visiting times, with outcomes and visit times influenced by a latent variable. Semi‐parametric joint models that account for this dependence have been proposed; among these, the Sun model is the most suitable for count data as it employs a multiplicative link function. Semi‐parametric joint models define an intercept function as the mean outcome when all covariates are set to zero; this is differenced out in the course of estimation and is consequently not estimated. The Sun estimator thus provides estimates of relative covariate effects, but is unable to provide estimates of absolute effects or of longitudinal prognosis in the absence of covariates. We extend the Sun model by additionally estimating the intercept term, showing that our extended estimator is consistent and asymptotically Normal. In simulations, our estimator outperforms…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
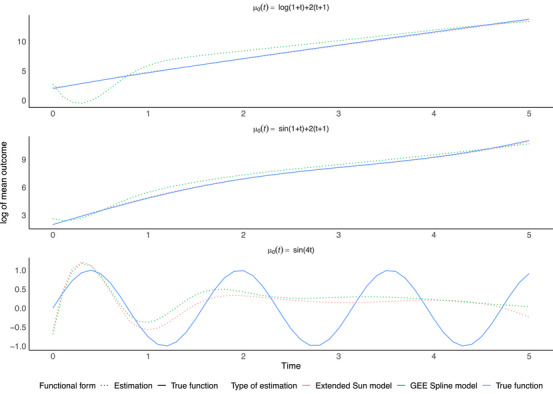 FIGURE 1
FIGURE 1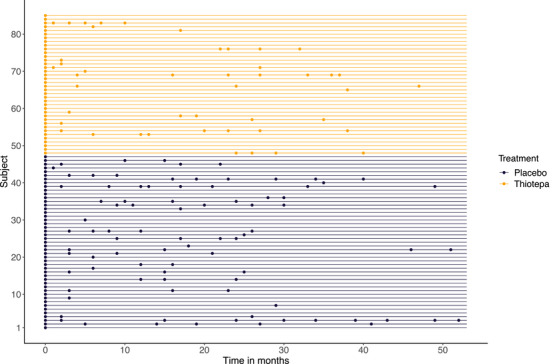 FIGURE 2
FIGURE 2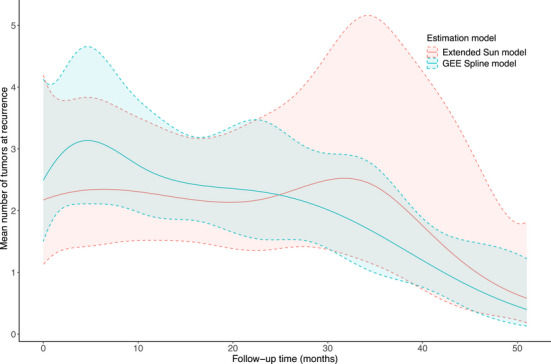 FIGURE 3
FIGURE 3| Simulation scenario | |||||
|---|---|---|---|---|---|
| 1 | 1 | 5 | |||
| 2 | 200 | 1 | |||
| 3 | 200 | 5 | |||
| 4 | 200 | 5 | |||
| Bias | ESE | Bias | ESE | Bias | ESE | Bias | ESE | |
|---|---|---|---|---|---|---|---|---|
| GEE spline model | 0.029 | 0.24 | 0.035 | 0.17 | 0.026 | 0.13 | 0.037 | 0.10 |
| Sun model | 0.013 | 0.52 | 0.019 | 0.36 | 0.049 | 0.27 | 0.046 | 0.23 |
| Extended Sun model | −0.0054 | 0.11 | −0.0068 | 0.078 | −0.0044 | 0.058 | −0.0056 | 0.049 |
| Bias | ESE | Bias | ESE | Bias | ESE | |
|---|---|---|---|---|---|---|
| GEE spline model | −0.10 | 0.11 | −0.013 | 0.13 | 0.035 | 0.16 |
| Sun model | 0.11 | 0.26 | −0.0050 | 0.29 | 0.019 | 0.36 |
| Extended Sun model | 0.063 | 0.18 | −0.00062 | 0.11 | −0.0068 | 0.078 |
| Bias | ESE | Bias | ESE | Bias | ESE | Bias | ESE | Bias | ESE | Bias | ESE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GEE spline model | ||||||||||||
| −0.5 | 0.039 | 0.16 | 0.034 | 0.11 | 0.0062 | 0.060 | 0.046 | 0.20 | 0.022 | 0.13 | 0.011 | 0.065 |
| 0.024 | 0.16 | 0.035 | 0.11 | 0.0079 | 0.057 | 0.052 | 0.17 | 0.038 | 0.12 | −0.0037 | 0.068 | |
| 0.035 | 0.16 | 0.029 | 0.12 | 0.013 | 0.059 | 0.043 | 0.19 | 0.039 | 0.13 | −0.0082 | 0.074 | |
| Sun model | ||||||||||||
| −0.5 | 0.058 | 0.36 | 0.023 | 0.22 | −0.0033 | 0.090 | 0.085 | 0.43 | 0.035 | 0.27 | 0.014 | 0.12 |
| 0.022 | 0.35 | 0.026 | 0.23 | −0.0069 | 0.090 | 0.038 | 0.42 | 0.014 | 0.26 | −0.018 | 0.11 | |
| 0.019 | 0.36 | 0.014 | 0.24 | −0.0079 | 0.093 | −0.016 | 0.42 | −0.015 | 0.28 | −0.0054 | 0.12 | |
| Extended Sun model | ||||||||||||
| −0.0053 | 0.081 | −0.0038 | 0.082 | −0.0041 | 0.085 | −0.000010 | 0.093 | −0.0063 | 0.092 | −0.00071 | 0.10 | |
| −0.0083 | 0.080 | −0.0028 | 0.075 | −0.0065 | 0.089 | 0.00020 | 0.091 | −0.0022 | 0.085 | −0.010 | 0.10 | |
| −0.0068 | 0.078 | −0.0054 | 0.078 | −0.0042 | 0.086 | −0.014 | 0.089 | −0.011 | 0.090 | 0.0058 | 0.098 | |
| Parameter estimates (Bootstrap SE) | Mean outcome ratios | |||
|---|---|---|---|---|
| (SE) | (SE) | Treatment (95% CI) | Initial number of tumors (95% CI) | |
| GEE spline model | −0.66 (0.19) | 0.16 (0.045) | 0.53 (0.37, 0.77) | 1.17 (1.08 1.28) |
| Sun model | −0.84 (0.39) | 0.20 (0.12) | 0.45 (0.21, 0.95) | 1.20 (1.05, 1.51) |
| Extended Sun model | −0.72 (0.32) | 0.15 (0.067) | 0.48 (0.25, 0.90) | 1.16 (1.01, 1.32) |
- —Natural Sciences and Engineering Research Council of Canada10.13039/501100000038
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Inference · Statistical Methods and Bayesian Inference · Advanced Causal Inference Techniques
Introduction
1
Longitudinal studies allow us to study the progression of a disease and risk factors associated with disease progression. However, often measurements are not obtained uniformly through time, with the timing of visits varying across patients; in some scenarios, no two subjects share an observation time. Furthermore, the visit times can be informative, that is, the response variable of interest is related to the visit intensity of a particular subject. For example, visits could be patient‐driven, where a patient being unwell could result in either more visits (due to concerns related to their illness) or fewer visits (due to them being unable to visit the medical center). Failing to account for the times at which measurements are recorded and their relationship with the outcome of interest may result in biased estimation (Buzkova et al. 2010) of the disease process.
Approaches that account for irregularly observed data include methods involving inverse‐intensity weighting and semi‐parametric joint modeling (Pullenayegum and Lim 2016). The main difference between the two methods lies in the assumptions placed on the associations between the outcome and visit time processes. In particular, inverse‐intensity weighting assumes that the outcome and visit time processes are conditionally independent given previously observed outcomes, covariates, and visit times. In contrast, semi‐parametric joint models assume that conditional independence holds given baseline covariates and random effects. Semi‐parametric joint models have been developed for both additive and multiplicative link functions for the conditional mean outcome given covariates and random effects (Pullenayegum and Lim 2016). A multiplicative specification for the outcome model, the Sun model (Sun et al. 2011), is of particular interest when dealing with count data.
Semi‐parametric joint models typically use a nonparametric intercept, where the intercept is the mean outcome as a function of time when all the covariates are set to zero. While the nonparametric formulation of the intercept in semi‐parametric joint models avoids misspecification, it leaves these models unable to estimate disease trajectories over time, and in the case of the Sun model only allows for the interpretation of relative covariate effects. While this could be useful when assessing how the different covariates relate to the outcome of interest, estimating prognosis and absolute effects is often of interest. The Liang additive semi‐parametric joint model (Liang et al. 2009) was recently extended to permit intercept estimation and exhibited smaller standard errors and reduced computation time compared to the original Liang model (Pullenayegum et al. 2023).
In this paper, we propose to extend the Sun semi‐parametric joint model to include the estimation of a parametric functional form for the intercept. We examine the large‐sample properties of this extended estimator and assess its finite sample performance through simulation. Finally, we illustrate the methods developed through application to a randomized trial of tumor recurrence.
Methods
2
Notation
2.1
For subjects i={1,⋯,n}, let Yi(t) correspond to a longitudinal outcome at a given time t for t∈[0,τ), where τ is the maximum observation time. Moreover, define Xi as a vector of time‐invariant covariates.
Let Ni(t) be a counting process for individual i’s observation times, with associated intensity function λ. Let Ci be the censoring time for subject i, and we also define Δi(t)=I(Ci≥t) as the at‐risk indicator function at time t for subject i.
If β is a parameter of interest in the model, then define β0 as the true value of the parameter.
The Sun Model
2.2
The Sun model considers a multiplicative model for the longitudinal outcome. For a random effect νi for subject i with E(νi|Xi)=1 (for identifiability), under the Sun model, the outcome and visit intensity models are given by
where λ0(t) is a nonparametric baseline intensity function for the intensity model, γ0 is a regression parameter for the intensity model, μ0(t) is a nonparametric intercept term for the outcome model, and β0, the regression coefficients corresponding to covariates Xi for the mean outcome model under a log link, is the parameter of interest. We assume that the outcome and visit processes are conditionally independent given the random effects and covariates.
Estimation of β0 proceeds as follows. We define a process Mi(t) for arbitrary β and γ by
and note that dMi(t)(β0,γ0) is zero mean conditional on Xi and νi. We can thus estimate β0 by solving the following system of equations:
yielding the following estimating equation for β^ (Sun et al. 2011):
where
The random effect νi is unobserved, but νi2 can be estimated through a method of moments by Ω^i, where
for mi being the number of assessments for subject i and Λ0(t)=∫0tλ0(u)du. If the censoring is assumed to be non‐informative, we can use estimates Λ^0 of Λ0 and γ^ of γ from a root‐n consistent estimator γ^ of γ0, such as the Andersen–Gill estimator (Andersen and Gill 1982).
Replacing all these estimates of the intensity model into Equation (2), one derives the following modified estimating equation for β^:
for X¯ being X¯∗ but with the estimate Ω^i of νi2:
Estimating the Intercept Term
2.3
We now adapt the intercept estimation technique applied in Pullenayegum et al. (2023) to the estimation of the parameters of the Sun multiplicative model. Suppose we model the intercept as μ0(t)=exp(Bt(t)′α) for a known vector‐valued function Bt of time and parameter α of the same dimension as Bt(t), which is to be estimated. As in Pullenayegum et al. (2023), a spline basis can be used for Bt to maintain modeling flexibility.
Let η=(β,α), η0 be the true value of the parameter, and Zi(t)=(Xi,Bt(t)), and define
Both of these are mean zero for the true values of the parameters; to see that dMi∗(t)(η0,γ0) is mean zero, notice that Δi(t),Yi(t), and Ni(t) are conditionally independent given Xi and νi, which allows us to split the expectation of the product into
where we have used Equation (1) for the conditional expectation of the outcome and visit processes. It follows that
The motivation behind weighting by exp(−Zi(t)′η) is an inverse variance weighting under a Poisson model, which can improve efficiency.
Using the Andersen–Gill estimator γ^ of γ0, by considering Equation (3) and a generalized method of moments approach (Hall 2005), an estimator η^ of η0 can be found as the solution to the system of equations:
For ease of notation, we will use dMi∗∗(t) to indicate dMi∗∗(t)(γ^) and dMi∗(t) to indicate dMi∗(t)(η,γ^). Solving Equation (4) yields the usual estimate of the baseline intensity:
Plugging this into Equation (5), we have
Now, since Ni is a Poisson process,
Replacing the expectations with the observed quantities and solving for νi and νi2 using the estimator γ^, we propose the method of moments estimators for νi2 and νi, Ω^i and ω^i, respectively:
Plugging in the estimators λ^0(t), Ωi^, and ωi^ into Equation (6), one defines:
Compared to the original Sun estimation approach, this approach has the benefit that we do not need to estimate η in the inner sum, making estimation less complex.
Letting L(η)=L(η;γ^), an estimate η^ of η0=(β0,α0) can be obtained by solving L(η)=0, that is,
which we denote as the extended Sun estimator.
In the Supporting Information, we show that the extended Sun estimator is consistent and asymptotically Normal. We also derive an asymptotic variance estimator; however, we note that, as in Liang et al. (2009), this involves Taylor expansions of complex functions around the infinite‐dimensional parameter Λ0 and is thus likely to be unstable with small‐ to moderate‐sized samples. Consequently, as in Liang et al. (2009), we recommend the use of the bootstrap to obtain variance estimates.
Goodness‐of‐Fit Diagnostics
2.4
In this section, we propose some diagnostics to assess the goodness‐of‐fit for the marginal regression model E(Yi(t)∣Xi)=Zi(t)η. Similar to Sun et al. (2011), we define the residual function
where Λ^0(t) is the Breslow estimator of the integrated baseline hazard Λ0(t)=∫0uλ0(u)du. Sun et al. (2011) discuss assessments for the functional forms of each component of Xi, and so here we focus on the functional form of the intercept, that is, Bt(t). Since statistical tests often suffer from either over‐powering or under‐powering, we aim to provide diagnostics rather than tests. Let
In the Supporting Information, we show that Res(t) converges in probability to zero, and we thus suggest plotting Res(t) versus t as a diagnostic for the intercept function.
Simulation Study
3
We proceed to study the finite‐sample performance and efficiency of this extended Sun estimator through simulation. Specifically, we seek to (a) verify that the bias and standard errors decrease with increasing sample size and maximum follow‐up time τ; (b) examine how the performance of the estimator varies across different functional forms for the intercept μ0(t); (c) examine whether the performance of the estimator varies for binary versus continuous covariates.
We follow a similar simulation setup as in Sun et al. (2011) and Wang et al. (2001). For given Xi and νi, observation times were generated with intensity λ(t)=νiexp(0.5Xi). At each simulated visit time, the response variable was generated as
where εi(t) is a measurement error generated from an independent N(−0.0625,0.1225) distribution for all t; thus E(exp(εi(t)))=1, and so we have
The censoring times were taken from the uniform distribution U(1,1.1τ), where this is independent of the covariates and outcome. In addition, administrative censoring was applied at the maximum follow‐up time τ.
Following Sun et al. (2011), when Xi was generated from a Bernoulli distribution with expectation 12, the latent variable νi was generated by letting
where νi∗ is generated from the density function:
When Xi was generated from a normal distribution N(0,0.25), νi is defined as
and νi∗ from the density function:
In both scenarios, E(νi|Xi)=1.
Parameters β0, n, τ, and μ0(t) were varied as shown in Table 1, as was the distribution of Xi. For each simulation scenario, 505 simulated datasets were generated.
After generating a simulated dataset, we generated a B‐spline basis with degree 3 and 4 knots (at the first to the fourth quintiles) on the simulated visit times. Then, we estimated β0 using the original Sun model, and η0 by augmenting the simulated dataset with the B‐spline basis and an intercept term and applying our extended Sun model, and a Generalized Estimating Equation (GEE) (Diggle et al. 2002) with a log link that included the B‐spline basis but ignored the correlation between visit and outcome processes induced by the random effect ν; we refer to this latter model as a GEE with splines model.
The spline basis was fixed across the simulation scenarios to allow for easier interpretability in the results. Estimates were compared in terms of their bias and empirical standard errors (ESE) for the relative effects β^. Moreover, we assessed how well the GEE with splines and extended Sun model approaches recover the intercept function term μ0(t), by examining the estimates B(t)′α^.
In addition, to assess the goodness of fit of the intercept term, we applied our residual diagnostic to one simulated dataset for each choice of μ0(t), taking n=200, τ=5, β0=1, and a binomial distribution of the covariates (see Supporting Information Section B).
Simulation Results
3.1
For all sample sizes, the extended Sun model results in a lower bias of the relative effects compared to the other estimation techniques; this bias decreases as sample size increases, as does the ESE (see Table 2). Moreover, the ESE for the extended Sun model is lower than the other two methods for all sample sizes considered. The variance estimates for increasing sample size have also been estimated by using a bootstrap approach (see Table S1).
The smaller bias of the extended Sun estimator over the original Sun and GEE estimator persists as the maximum follow‐up time τ is varied (Table 3). The ESE for the extended Sun model decreases as τ increases, while the ESEs for the other two models increase as τ increases. For the values of τ examined, the extended Sun model had a lower ESE than the regular Sun model.
The extended Sun model maintained a smaller bias than the original Sun and GEE models as the intercept was varied, with the exception of the case where μ0(t)=sin(4t), where the extended Sun and original Sun models had similar biases (see Table 4). For the extended Sun model, the ESE estimates do not appear to greatly change across the different specifications of the intercepts. In contrast, for the other two models, the ESE is reduced for the sinusoidal specification of the intercept. In fact, for this specification of the intercept, the ESE for the extended Sun estimator is higher than that of the GEE with splines and similar to that for the regular Sun estimator. Results were similar when the covariate was Normal rather than Bernoulli.
For the first two specifications of the intercept term (log‐linear and sine‐linear), the proposed model estimated the outcome trajectory with less bias than the GEE with splines (Figure 1). By contrast, for the sinusoidal intercept, neither model is able to recover the true mean outcome trajectory. Residual diagnostics plots may be found in the Supporting Information. Similar simulation results were observed with a Normal covariate specification.
Comparison of the GEE with splines and extended Sun estimation methods for the three specifications of the true intercept function μ0(t), with a binary covariate distribution.
Data Analysis
4
We apply our proposed model to a bladder cancer study conducted by the Veterans Administration Cooperative Urological Research Group (VACURG) (Byar 1980). Patients were randomized to one of three treatment arms: placebo, thiotepa, and pyridoxine; for this analysis, we focus on the placebo (n=47) and thiotepa (n=38) arms. At each visit, the number of new tumors was detected and removed. Other information, such as the number of initial tumors and the size of the largest initial tumor, was also recorded. The maximum follow‐up time in the study is 53 months. For the purposes of analysis, the target of inference in this study is the ratio of the mean number of tumors for the thiotepa versus placebo arms, adjusted for the number of initial tumors.
As we can see in Figure 2, visits were irregular. Moreover, subjects who underwent thiotepa treatment had a lower average number of visits, with a mean of 1.18 (standard deviation 1.77) compared to 1.85 (standard deviation 2.25) for those who had a placebo.
Event times in months for subjects in the veterans' bladder cancer study during the follow‐up period, by treatment arm.
We fit both the outcome and visit processes by using Equation (1), using the treatment arm and initial number of tumors as X1,X2, respectively. Then, the Sun model equations are
The initial number of tumors is centered at the mean to provide interpretability of the mean outcome trajectory, and the placebo is the reference category for treatment. For estimating the visit process, we use an Andersen–Gill model with a frailty effect, using the function coxph() from the package survival. We used a cubic B‐spline with 3 knots for the specification of B(t) by using the function bs() from the package splines to generate the spline basis. For comparison, we also used a GEE with spline basis and the original Sun model. Standard error estimates were computed via a nonparametric bootstrap (Efron and Tibshirani 1994), using 600 resamples.
Patients in the thiotepa group had 52% fewer tumors (95% CI 8–75% fewer) compared to patients in the placebo group (see Table 5). The GEE estimated a smaller reduction but with a smaller standard error, while the usual Sun model estimated a larger reduction, but with a larger standard error. The mean outcome trajectories for the number of tumors in the placebo group for both the extended Sun and the GEE models are shown in Figure 3. The residual diagnostic plot suggested no lack of fit of the extended Sun model for our chosen spline basis (see Supporting Information).
Estimation of the mean number of tumors over time for the veterans' bladder cancer study, along with confidence bands, for both GEE with splines and extended Sun models.
Discussion
5
In this work, we developed an intercept estimation technique for the multiplicative Sun model for longitudinal data subject to irregular and informative assessment times. We showed that the resulting regression coefficient estimates are consistent and asymptotically Normal. In simulations comparing our approach to the existing Sun model, our approach was able to estimate the outcome trajectory without compromising bias and ESE.
An interesting feature of the simulations was that when the maximum follow‐up time was increased the ESE for both the GEE and the original Sun estimator increased, despite having more data on which to estimate the models. For the GEE with splines model, this is likely due to the informative nature of the visit process not being considered. The increased ESEs for the original Sun estimator could be further examined by testing scenarios where (a) the maximum follow‐up time is fixed, but the rate of visits is increased; (b) the maximum follow‐up time and rate of visits are both increased. This would allow us to disentangle the effects of the number of visits per patient and the duration of follow‐up.
Parameterization of the intercept term through a multidimensional function allows for a spline basis approach in model fitting. In most cases, this performed well in simulations, but resulted in not being able to recover the mean outcome trajectory when the intercept term was sinusoidal. Our recommendation is thus similar to the estimation of another marginal model in the context of informative visits (Coulombe et al. 2021): if the intercept function does not fluctuate extensively through time, then using spline bases provides reasonable estimates; for extensive fluctuation, a nonparametric intercept term may be desirable to avoid misspecification.
While we derived a closed‐form variance estimator, the standard error estimates performed poorly in simulations. Similar behavior has been noted in other semi‐parametric estimation procedures (Liang et al. 2009). As in Liang et al. (2009), we recommend standard error estimates be computed using a nonparametric bootstrap.
The Sun model assumes time‐invariant covariates, and an extension to time dependency could be of interest in certain applications (Sun et al. 2011). Indeed, Equations (1) and (8) can be easily adapted to time‐varying covariates, but one would need to know the value of the covariate process Xi(t) at every point in time, even at points when there are no visits. This limitation was also observed in the original estimation of the Liang model (Liang et al. 2009).
Our proposed estimation procedure allows for the estimation of the outcome trajectory for an outcome measured irregularly over time with observation times linked to the outcome via observed baseline covariates and a random effect. This is helpful in describing prognosis and in quantifying absolute treatment effects. Given that our approach achieves smaller standard errors and is computationally less intensive than the standard Sun model, we suggest that analysts consider using it in place of the standard Sun model when the intercept is not expected to fluctuate drastically over time.
Author Contributions
EP proposed the topic; LL developed the estimator, conducted the simulations, and analyzed the data with input from EP; LL drafted the manuscript; and EP reviewed the manuscript. Both authors approved the final submitted version.
Conflicts of Interest
The authors declare no conflicts of interest.
Open Research Badges
This article has earned an Open Data badge for making publicly available the digitally‐shareable data necessary to reproduce the reported results. The data is available in the Supporting Information section.
This article has earned an open data badge “Reproducible Research” for making publicly available the code necessary to reproduce the reported results. The results reported in this article could fully be reproduced.
Supporting information
Supporting file 1: bimj70088‐sup‐0001‐SuppMat.pdf
Supporting file 2: bimj70088‐sup‐0002‐DataCode.zip
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Andersen, P. K. , and R. D. Gill . 1982. “Cox's Regression Model for Counting Processes: a Large Sample Study.” The Annals of Statistics 10, no. 4: 1100–1120.
- 2Buzkova, P. , E. R. Brown , and G. C. John‐Stewart . 2010. “Longitudinal Data Analysis for Generalized Linear Models Under Participant‐Driven Informative Follow‐Up: an Application in Maternal Health Epidemiology.” American Journal of Epidemiology 171, no. 2: 189–197.20007201 10.1093/aje/kwp 353PMC 2878101 · doi ↗ · pubmed ↗
- 3Byar, D. 1980. “The Veterans Administration Study of Chemoprophylaxis for Recurrent Stage i Bladder Tumours: Comparisons of Placebo, Pyridoxine and Topical Thiotepa.” In Bladder Tumors and Other Topics in Urological Oncology, 363–370. Springer.
- 4Coulombe, J. , E. E. Moodie , and R. W. Platt . 2021. “Weighted Regression Analysis to Correct for Informative Monitoring Times and Confounders in Longitudinal Studies.” Biometrics 77, no. 1: 162–174.32333384 10.1111/biom.13285 · doi ↗ · pubmed ↗
- 5Diggle, P. J. , P. Heagerty , K.‐Y. Liang , and S. L. Zeger . 2002. Analysis of Longitudinal Data. Oxford University Press.
- 6Efron, B. , and R. J. Tibshirani . 1994. An Introduction to the Bootstrap. Chapman and Hall/CRC.
- 7Hall, A. 2005. Generalized Method of Moments. Oxford University Press.
- 8Liang, Y. , W. Lu , and Z. Ying . 2009. “Joint Modeling and Analysis of Longitudinal Data With Informative Observation Times.” Biometrics 65, no. 2: 377–384.18759841 10.1111/j.1541-0420.2008.01104.x · doi ↗ · pubmed ↗