Integrating clinical indications and patient demographics for multilabel abnormality classification and automated report generation in 3D chest CT scans
Theo Di Piazza, Carole Lazarus, Olivier Nempont, Loic Boussel

TL;DR
This paper introduces a deep learning model that combines 3D chest CT scans with patient demographics and clinical data to improve abnormality detection and report generation.
Contribution
A novel multimodal deep learning framework that integrates imaging and non-imaging data for enhanced CT scan analysis.
Findings
Incorporating clinical and demographic data improves multilabel classification F1 score by 6.13%.
Automated report generation benefits with F1 score increases of 14.78% and 6.69% for extended models.
The approach enhances radiological workflows and abnormality detection accuracy.
Abstract
The increasing number of computed tomography (CT) scan examinations and the time-intensive nature of manual analysis necessitate efficient automated methods to assist radiologists in managing their increasing workload. While deep learning approaches primarily classify abnormalities from three-dimensional (3D) CT images, radiologists also incorporate clinical indications and patient demographics, such as age and sex, for diagnosis. This study aims to enhance multilabel abnormality classification and automated report generation by integrating imaging and non-imaging data. We propose a multimodal deep learning model that combines 3D chest CT scans, clinical information reports, patient age, and sex to improve diagnostic accuracy. Our method extracts visual features from 3D volumes using a visual encoder, textual features from clinical indications via a pretrained language model, and…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
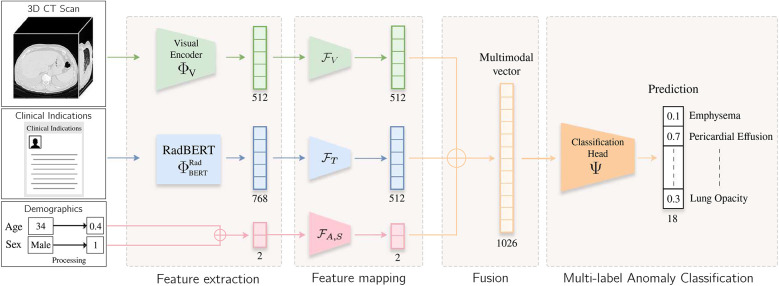 Figure 1
Figure 1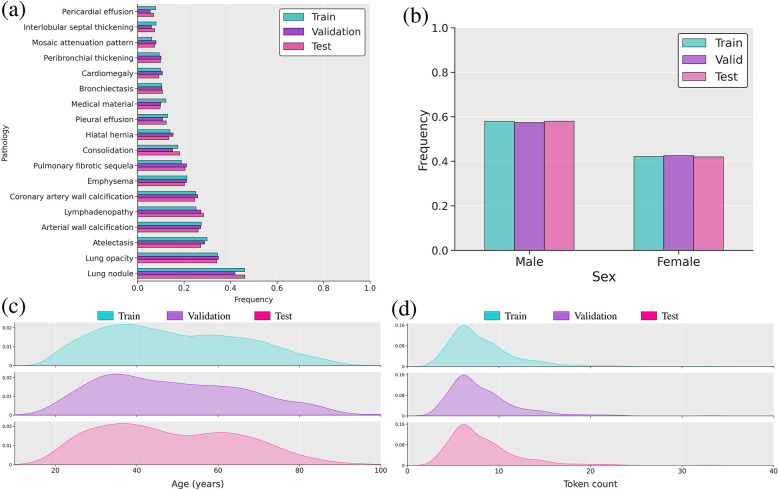 Figure 2
Figure 2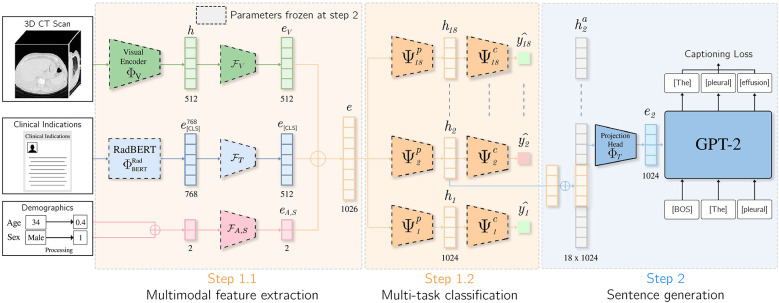 Figure 3
Figure 3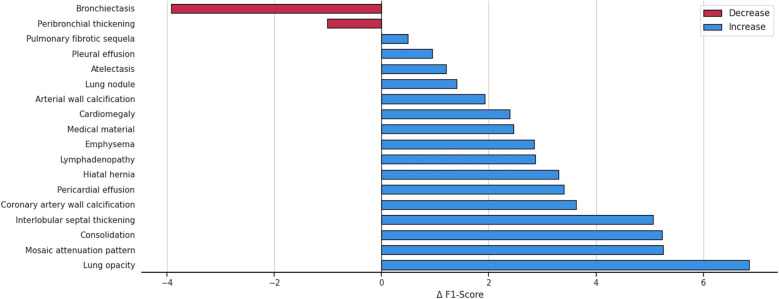 Figure 4
Figure 4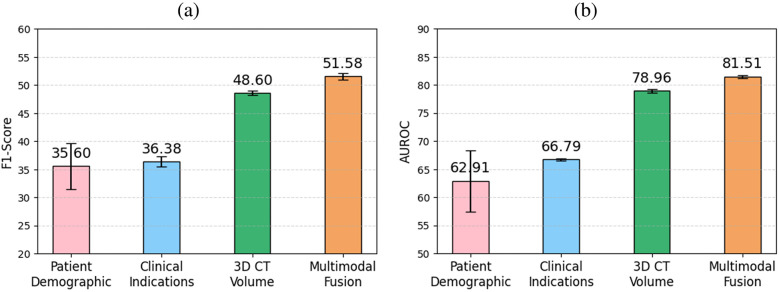 Figure 5
Figure 5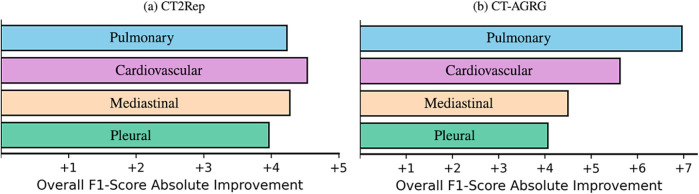 Figure 6
Figure 6 Figure 7
Figure 7| ID | Sex | Age | Clinical indications |
|---|---|---|---|
| Patient 1 | F | 64 | Shortness of breath |
| Patient 2 | F | 42 | Suspicion of lung cancer |
| Patient 3 | M | 50 | Hematological malignancy fever chest pain |
| Patient 4 | M | 37 | Patient with multiple myeloma, focus of infection |
| Method | AUROC | Accuracy | F1 score | W. F1 score | Precision | Recall |
|---|---|---|---|---|---|---|
| Random predictions | 49.93 | 50.11 | 27.18 | 33.02 | 20.24 | 49.68 |
| 75.14 | 73.52 | 44.38 | 49.56 | 35.35 | 62.42 | |
|
| 76.09 | 74.83 | 45.51 | 50.97 | 36.75 | 63.00 |
|
|
| Method | AUROC | Accuracy | F1 score | W. F1 score | Precision |
|---|---|---|---|---|---|
| Random predictions | 49.93 | 50.11 | 27.18 | 33.02 | 20.24 |
| Patient demographics | |||||
| Age + sex | 62.92 | 50.83 | 35.60 | 43.26 | 25.71 |
| Clinical indications | |||||
| Transformer encoder [ | 65.64 | 64.30 | 34.87 | 41.80 | 26.49 |
| BERT [ | 65.96 | 63.28 | 35.16 | 42.00 | 25.98 |
| RadBERT [ | 66.79 | 65.41 | 36.38 | 42.34 | 27.64 |
| 3D CT volumes | |||||
| CT-Net [ | |||||
| Multimodal fusion | |||||
| CT-Net | |||||
| 3D CT volumes | Patient demographics | Clinical indications | AUROC | F1 score | Paired | Training time | Inference time |
|---|---|---|---|---|---|---|---|
| ✓ | 78.96 | 48.60 | – | 15.09 | 4.16 | ||
| ✓ | ✓ | 80.51 | 49.79 |
| 16.05 | 4.11 | |
| ✓ | ✓ |
| 111.30 | 76.19 | |||
| ✓ | ✓ | ✓ |
| 112.96 | 76.76 |
| Method | AUROC | Accuracy | F1 score | W. F1 score | Precision |
|---|---|---|---|---|---|
| Random predictions | 49.93 | 50.11 | 27.18 | 33.02 | 20.24 |
| CT-Net [ | 78.96 | 78.49 | 48.60 | 54.18 | 42.56 |
| Methods below utilize clinical indications | |||||
| With self-attention | 80.35 | 78.67 | 49.21 | 55.35 | 42.23 |
| With cross-attention | 80.36 | 78.11 | 49.84 | 55.44 | 42.29 |
| With sum | |||||
| With concatenation | |||||
| Demographics and indications | Fusion strategy | AUROC | Accuracy | F1 score | W. F1 score | Recall |
|---|---|---|---|---|---|---|
| ✗ | 78.96 | 78.49 | 48.60 | 54.18 | 60.15 | |
| ✓ | Prompt-based | 80.66 | 51.12 | 56.78 | 63.50 | |
| ✓ | Modality-specific | 79.48 |
| Method | NLG metrics | CE metrics | ||||
|---|---|---|---|---|---|---|
| BLEU-1 | ROUGEL | BERT | CRG | Recall | F1 score | |
| Random predictions | – | – | – | 0.397 | 50.92 | 27.18 |
| CT2Rep [ | 0.318 | 0.236 | 0.863 | 0.417 | 32.56 | 31.86 |
|
| 0.342 | 0.259 | 0.430 | 36.22 | 36.57 | |
| CT-AGRG [ | 0.863 | |||||
|
| ||||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCOVID-19 diagnosis using AI · Radiomics and Machine Learning in Medical Imaging · Machine Learning in Healthcare
Introduction
1
Three-dimensional computed tomography (3D CT) scans have become essential tools in medical imaging [1], offering unparalleled insights into anatomical structures and pathological conditions. This type of medical image is critical for identifying diseases such as pleural effusion [2], lung cancer [3], and cardiomegaly [4]. Given the rapidly growing number of scans to analyze [5] and the increasing demand for specialized radiological expertise in many healthcare systems [6, 7], automating abnormality classification has emerged as an active research area [8–10] to enhance radiologist efficiency. The interpretation of 3D CT scans presents a time-intensive challenge, exacerbated by the heterogeneous nature of observed anomalies. Some anomalies, such as lung nodules [11], can be very small, requiring careful attention from radiologists to avoid missing them. Hence, depending on the patient demographics [12] and clinical indications [13], radiologists may dedicate more time to specific anatomical regions that could potentially present anomalies. As illustrated in Table 1, clinical indications consists of a brief paragraph written by the radiologist before the examination, describing the patient’s condition, reason for the visit, and any suspected pathologies that might be revealed during the examination.
Inspired by the workflow of radiologists, we propose a multimodal end-to-end model that integrate clinical indications, patient age, and sex to predict chest pathologies [14]. As shown in Figure 1, our approach extends state-of-the-art methods relying on 3D CT scans to the integration of textual data corresponding to clinical indications, along with utilizing structured data such as patient age and sex. These data have a significant impact on the prevalence of a pathology [15, 16]. We separate feature extraction from each modality using individual modules and then aggregate all these extracted features to predict anomalies. As illustrated in Figure 3, we extend our experimental results by leveraging this multimodal encoder to enhance existing automated report generation methods [17, 18]. Our contributions are as follows:
- •We introduce a supervised multimodal method for multilabel classification, capable of taking the 3D CT scan, clinical indications, age, and sex as input.
- •We evaluate the model on a public dataset and add an ablation study to demonstrate the importance of each module.
- •We extend our experimental results by integrating clinical indications and patient demographics into the automated report generation task.
Overview of the method. The input volume is processed by a visual extractor ΦV [either CT-Net [9] or CT-ViT [19]] and FV, which generates a visual embedding. Clinical indication is processed by RadBERT [20], yielding a token-level embedding. The [CLS] token is fed into a lightweight MLP FT to project textual and visual features into a common latent space. Patient age and sex information are processed by another lightweight MLP FA,S. These vectors are concatenated, and the resulting vector is passed to a classification head Ψ, which predicts an abnormality score for each label.
Related work
2
Supervised abnormality classification
2.1
In the domain of abnormality classification in medical imaging [21], significant research has been conducted on 2D imaging [22, 23] across various modalities such as magnetic resonance imaging (MRI) [24, 25], x-rays [26–29], and skin images [30]. In the field of x-ray imaging, the publicly available MIMIC-CXR dataset [31], comprising 2D radiographs and associated clinical reports, has facilitated the development of various supervised approaches for abnormality detection [32–35] and classification [36]. While some methods focus on a single abnormality or a specific anatomical region [37, 38], others adopt a more comprehensive approach by aiming to simultaneously detect or classify multiple anomalies [39–41] using deep learning models. However, new challenges emerged with 3D imaging and the use of CT or 3D MRI. These modalities introduce novel challenges stemming from the scarcity of publicly available datasets in this domain [10], the high-dimensional nature of the data, and the significant computational demands. Prior work [9, 42] adopted traditional convolutional neural network (CNN) architectures. Recent advances have adopted transformer-based architectures [43] for volumetric data analysis. ViViT [44], an extension of the Vision Transformer [45] originally designed for video understanding [46], has demonstrated strong representational capacity and has since been adapted for a range of CT-based tasks, including radiology report generation [18] and synthetic volume generation [19], with the introduction of CT-ViT [19], which has already demonstrated its effectiveness for various tasks such as report generation [18] and abnormality classification [10].
Multimodal fusion
2.2
In machine learning, multimodal fusion [47] has played a pivotal role in advancing classification tasks across various research domains [48–51]. By integrating information from multiple data sources or modalities [52–54], such as combining images from different imaging techniques (e.g., MRI, CT, PET) or fusing imaging data with clinical records [55] or biological information [56], multimodal approaches offer significant advantages. They not only enhance the discriminative capability of classification models but also provide resilience against the inherent variability in single-modal datasets [47, 57, 58]. Feature extraction from each modality is typically performed using a module per modality [59] and then aggregated with a fusion module [60, 61]. The fusion of features across modalities can be achieved through simple concatenation [48], by leveraging self-attention mechanisms [59], or via cross-modality attention modules[62]. Regarding specific work on 3D CT scans, CT2RepLong [18] automatically generates a medical report from the volume and imaging report of the previous medical report of the same patient. This fusion between visual and textual features is achieved through a cross-attention module.
Report generation
2.3
Image captioning [63] refers to generating textual descriptions from input images, with significant progress made across various application domains [64–66]. In medical imaging, early generation methods [67] were introduced for 2D modalities using public datasets, such as x-rays [31]. The initial approaches, based on encoder–decoder architectures [68], extract a vector representation using a visual encoder (typically a CNN or attention-based model) and then pass it to a decoder module, often relying on attention mechanisms, to generate the report. Recently, the incorporation of relational memory [69], prior knowledge [70], large language models (LLMs) [71], reinforcement learning [72], and guidance-based methods [73] has enhanced the quality of generated reports. Existing methods for x-ray report generation [74] incorporate medical knowledge or prior information, often in the form of textual modalities, to enhance the quality of the generated reports [75–77]. For 3D CT volumes, the CT-RATE public dataset [10] enabled the development of CT2Rep [18], the first end-to-end method for report generation that extracts vector representations from CT-ViT [19] and passes them to a decoder to generate the report. Similar to 2D imaging, integrating LLMs [78] or multiview encoders [79] has shown improvements in report quality. In the 2D x-ray imaging domain, prior works have explored the integration of clinical indications for report generation. For example, SEI and MLRG employ cross-attention mechanisms to combine indication features with multiview or historical case information [80, 81], while Pragmatic LLaMA introduces indications as additional input to a large language model for guiding report generation [82]. These approaches share with our work the idea of leveraging clinical indications to enrich textual output. However, they are designed for 2D chest radiographs, whereas our method targets volumetric 3D CT scans, which present unique challenges in terms of data dimensionality, abnormality diversity, and multimodal fusion. Regarding guided methods for 3D CT scans, CT-AGRG [17] decomposes the task into two steps: first, a visual encoder performs feature extraction and abnormality classification, and second, a GPT-2 model [83] fine-tuned on a medical corpus [84] generates a description for each detected abnormality. In our work, we extend these approaches by integrating clinical indications and patient demographics into CT2Rep (an end-to-end method) and CT-AGRG (a guided method) to improve performance on the report generation task.
Dataset
3
We used the CT-RATE public dataset [10], containing 50,188 reconstructed non-contrast 3D chest CT volumes, to train and evaluate our method. For each scan, we had access to age, sex, and 18 distinct types of abnormalities. The pseudo-labels were extracted from radiology reports using a RadBERT classifier [10, 20]. We only retained samples containing clinical indications, resulting in a dataset comprising 16,009 unique patients (24,085 volumes) for the train set, 792 patients (1,551 volumes) for the validation set, and 792 patients (1,531 volumes) for the test set. We ensured there was no overlap of patients between the training, validation, and test sets. Following Draelos et al. and Hamamci et al. (author?) [9, 10], all volumes were either center-cropped or padded to achieve a resolution of with in-slice spacings of 0.75 mm and 1.5 mm on the -axis. Hounsfield unit (HU) [85] values were clipped between and . Subsequently, we normalized the clipped HU values to the range [ ] to facilitate network training. The input age was min–max-normalized [86] to the range [0, 1] to ensure proper handling by the neural network. Sex was encoded as a binary variable, with 0 representing female and 1 representing male. Figure 2 illustrates the distribution of patient age and sex, along with the 18 abnormalities.
Overview of the multimodal dataset. (a) Bar plot of label frequency. (b) Bar plot of sex frequency. (c) Distribution of age in years. (d) Distribution plot of reports’ lengths based on token count using the RadBERT tokenizer.
Methods
4
As illustrated in Figure 1, our feature extraction module consists of three key components. First, low-level feature extraction is performed independently for each modality, producing modality-specific vector representations. These embeddings are then mapped into a shared feature space using lightweight feedforward networks. Finally, the transformed representations are aggregated via summation to obtain a unified vector representation.
Visual feature extraction
4.1
The model receives an input volume . This volume is passed to a visual extractor , which is either CT-Net [9] or ViViT [19]. To demonstrate the flexibility and generality of our framework across different visual encoders, we conducted experiments using both CT-Net and ViViT. CT-Net consists of 2D ResNet [87] modules followed by a lightweight 3D convolutional network that aggregates the features maps into a compact vector representation [88]. ViViT [44] is a Vision Transformer [45] based on the attention mechanism [43] computed from 3D patches extracted from the initial volume. To ensure a fair evaluation across methods, ViViT is initialized via weight inflation [89] from a 2D ViT [45] pretrained on ImageNet [90], while the 2D ResNet module in CT-Net is directly initialized from a 2D ResNet pretrained on ImageNet. While our contribution focuses on integrating modalities such as clinical indications and demographic information into a visual encoder, we leveraged pretrained weights to facilitate network training, ensuring that model parameters are initialized under comparable conditions. Exploring alternative initialization or pretraining strategies is left for future work. From the initial volume , both CT-Net and CT-ViT yield a vector representation . Subsequently, this embedding is passed to a projection head [91] to obtain , as defined in Equation 1 such that:
Clinical indication feature extraction
4.2
To extract embedded tokens from the textual clinical indication report, a pretrained RadBERT [20] model is used. It is a bi-directional neural network, trained on a large radiology report database on a masked language modeling task. From tokens of the clinical indications report, a single vector representation is extracted from the Classification [CLS] token [92, 93] outputted by the language model. Working exclusively with the [CLS]-embedded token enables easy projection of textual and visual embeddings into the same-dimensional latent space. Next, is passed through a lightweight multilayer perceptron (MLP) to project the vector representation from textual latent space of dimension to a latent space of dimension . The resulting vector is obtained as defined by Equation 2:
Age and sex feature extraction
4.3
To handle the normalized age feature and the sex feature , a lightweight MLP , implemented as a linear projection followed by a ReLU activation function, is used to obtain a vector representation , as defined by Equation 3:
Multimodal fusion
4.4
The three vector representations associated with different modalities are concatenated [54, 94] into a single vector , such that . A normalization layer [95] is incorporated to ensure stability during training and that the resulting vector is properly scaled and balanced across its dimensions.
Multilabel classification
4.4.1
In the context of abnormality prediction from CT scans, leveraging clinical indications and patient demographics, vector is given a traditional classification head to obtain . As commonly practiced, the model is trained on a multilabel classification task using a binary cross-entropy loss function [96].
Report generation
4.4.2
To integrate clinical indications and patient demographics into the report generation task, we extended the CT2Rep [18] and CT-AGRG [17] models by replacing their original visual encoder with our proposed module, which fuses multiple modalities. As illustrated in Figure 3, the decoder responsible for generating the report takes the vector representation as input. In CT2Rep, the decoder generates the entire report in a single pass from . In contrast, CT-AGRG follows a two-step process: the encoder first predicts the set of abnormalities, and the decoder then generates a detailed description for each predicted abnormality. The models are trained using a next-token prediction objective with binary cross-entropy loss [96]. During inference, the decoder receives only the vector representation of the input volume and a Beginning Of Sentence [BOS] token to signal the start of the sequence [92]. The report is then generated iteratively, token by token [83].
Integration of clinical indications and patients demographics for the CT-AGRG method. Features derived from the 3D CT volume, clinical indications, patient age, and sex are aggregated to form vector e. This vector is fed into 18 classification heads (one per abnormality). If a classification head predicts an abnormality, the corresponding vector representation is passed to a pretrained GPT-2 model, which generates a textual description of the detected abnormality.
Experimental setup
5
Training details
5.1
For the multilabel classification task, the model was trained on 40 epochs on a GPU with 48GB of memory. We used Adam Optimizer [97] with a learning rate of and a batch size of . For the report generation experiments, we adopted the same setup as used for CT2Rep [18] and CT-AGRG [17].
Language model
5.2
We limited the maximum number of tokens to , which is typically found in clinical indication reports [98]. During training, we only fine-tuned the last three layers of RadBERT, with the rest frozen [99].
Experimental results
6
This section is organized as follows: we first present quantitative results on the multilabel abnormality classification task with the integration of clinical indications and patient demographics; we then conduct an ablation study to assess the contribution of each module; and finally, we extend our analysis to automatic report generation.
Multilabel classification task
6.1
We evaluated the model’s performance using commonly used metrics: AUROC, F1 score, precision, recall, and accuracy. We also reported the weighted F1 score, computed by averaging the F1 score of each abnormality, weighted by its occurrence frequency. Because the dataset is dominated by normal findings for most labels (Figure 2), we determined label-specific thresholds on the validation set by maximizing the F1 score [100], as it balances precision and recall [21, 101]. On the test set, we then computed the average of each metric across all labels.
Table 2 demonstrates that incorporating clinical indications and patient demographics significantly improves upon state-of-the-art single-modality methods. Specifically, our model achieves an AUROC of ( over CT-Net) and the highest accuracy of . However, in an imbalanced multilabel setting, accuracy is primarily driven by correct predictions on abundant classes (especially the normal class) and therefore tends to overestimate overall performance. This also explains why precision ( ) and recall ( ) are lower despite high accuracy: even a small number of false positives can markedly reduce precision for rare classes. For this reason, we emphasize the F1 score as a more informative indicator of abnormality detection. Specifically, we achieved an average F1 score of [improvements of and over CT-Net [9] and CT-ViT [10], respectively]. CT-Net with demographics and clinical indications outperforms baseline CT-Net and CT-ViT (paired -test, ) for all metrics, indicating that incorporating clinical and demographic information enhances classification performance.
Figure 4 details the impact on F1 score for each abnormality when integrating patient demographics and clinical indications, demonstrating that this additional contextual information improves performance for 16 out of 18 anomalies. The largest gains, observed for interlobular septal thickening, consolidation, mosaic attenuation, and lung opacity, suggest that these findings are particularly context-dependent and strongly correlated with clinical factors. While most anomalies benefit from the auxiliary information, a minority, such as bronchiectasis, shows slight performance decreases, possibly because the added inputs may introduce noise for anomalies that already possess distinctive visual signatures. A promising future direction is to develop adaptive integration strategies that selectively incorporate contextual information when it is beneficial.
Variation in the F1 score across anomalies, highlighting the impact of integrating patient demographics and clinical indications into the multilabel abnormality classification task.
Ablation study
6.2
We conducted a comprehensive ablation study to assess the contributions of the clinical indication feature extractor, each auxiliary input modality, and the fusion module to overall performance.
Impact of the clinical indication encoding module
6.2.1
To evaluate the impact of different modules for encoding clinical indications into vector representations, we conducted an ablation study comparing three approaches: a transformer encoder trained from scratch, a BERT language model pretrained on a general corpus, and RadBERT, a BERT-based model pretrained specifically on radiology text. Table 3 and Figure 5 report the classification performance achieved when using only clinical indications as input for each of these modules. RadBERT achieved an F1 score of 36.38, representing a improvement over general-domain BERT and a improvement over the transformer encoder trained from scratch. These results suggest that leveraging a domain-specific pretrained language model facilitates the extraction of more meaningful features from clinical indications, ultimately enhancing classification performance.
Comparison of (a) F1 score and (b) AUROC across clinical indications, patient demographics, 3D CT volume, and multimodal fusion for multilabel abnormality classification. The highest performance is achieved when fusing all modalities, highlighting the benefit of multimodal integration.
Impact of auxiliary information
6.2.2
Table 4 presents the ablation study evaluating the incremental impact of incorporating patient demographics and clinical indications as auxiliary inputs alongside the 3D CT Volumes. Adding patient demographics yields an F1 score of 49.79, reflecting a improvement over the CT-Net baseline. Incorporating clinical indications results in an F1 score of 50.86, corresponding to a gain. For each auxiliary input configuration, a paired -test comparing the F1 score distributions against the baseline yields a -value , highlighting the statistical significance of the observed performance improvements. Removing CT features led to a consistent drop in performance, indicating that the model does not rely solely on clinical text or metadata.
Impact of the fusion module
6.2.3
Our ablation study results related to the fusion module, presented in Table 5, indicate that concatenating features yields the highest AUROC and F1 score increase seen through the integration of clinical indications. Specifically, we obtained an F1 score of 50.86, demonstrating a improvement over sum and a improvement over cross-modality attention. This suggests that, in our specific setting, direct concatenation provides a strong signal without the overhead of more complex interaction modeling where the modalities may have relatively low complexity. While more expressive mechanisms such as cross-attention mechanisms demonstrate robust performances in large-scale multimodal learning, we found that in our setting, where the dataset is relatively modest, a simpler fusion provides more robust performance, requiring fewer parameters to fully benefit from modalities effectively. We evaluated an alternative fusion strategy where clinical indications and demographic features are combined into a prompt for the BioMistral LLM [102]. As presented in Table 6, independent concatenation of modality-specific embeddings demonstrates a improvement in the F1 score and a improvement in AUROC over the LLM-based prompt fusion. We attribute this improvement to the robustness of simpler fusion in the context of our relatively small dataset. While prompt-based fusion offers more expressive modeling, it may require larger datasets to fully realize its benefits, highlighting the importance of matching fusion complexity to dataset scale.
Report generation task
6.3
We extend our experiments to the task of automated report generation by integrating clinical information for two methods: CT2Rep [18], which generates the entire report in a single pass, and CT-AGRG [17], which first predicts abnormalities and then generates a description for each detected abnormality. Once the report is generated, we evaluate its quality using two sets of metrics: natural language generation (NLG) metrics and clinical efficacy (CE) metrics [69, 73]. NLG metrics assess the similarity between the generated text and the ground truth. We used BLEU-1 [103], which compares the overlapping 1-grams between the reference and the prediction. ROUGE evaluates recall-oriented metrics, like overlap and precision, between -grams. BERTScore [104], an embedding-based metric, measures the cosine similarity of vector representations of the embedded tokens between the reference and the generated text. Clinical efficacy metrics evaluate the clinical accuracy of generated reports. We extracted abnormality mentions as one-hot vectors using a RadBERT language model classifier [20], which was originally used for CT-RATE [10] label annotation. These predictions are then compared to ground-truth labels using standard multilabel classification metrics, such as the F1 score. In addition, we report the CRG score [105], a recently proposed distribution-aware metric for radiology report generation. Unlike conventional metrics, CRG focuses exclusively on clinically relevant abnormalities explicitly described in the reference report, while also accounting for class imbalance.
As shown in Table 7, the integration of clinical indications and patient demographics significantly enhances both NLG and CE metrics. For the CT2Rep model, incorporating these additional data results in a BLEU-1 score of 0.342, reflecting a increase compared to the baseline model, and an F1 score of 36.57, which corresponds to a improvement over the baseline. Similarly, for the CT-AGRG guided method, the inclusion of clinical indication and patient demographic information leads to a performance boost, achieving a recall of ( increase) and an F1 score of ( increase) over the original model. For each method, we performed a paired -test comparing the F1 score obtained with and without the integration of clinical indications and patient demographics. The resulting -values are all strictly below 0.01, indicating statistically significant improvements in the quality of the generated reports. In addition, Figure 6 allows us to identify which anomalies benefit most from richer multimodal inputs, making performance gains more clinically interpretable and highlighting where report generation is most reliable. Figure 7 illustrates two examples of report generation compared to the ground truth, emphasizing that our method produces reports with a structure and terminology closely resembling those written by radiologists.
F1 score improvements across four abnormality groups, when incorporating demographic and clinical indication information into 3D CT volume report generation.
Comparison of ground-truth labels with the report generated by the CT-AGRG model with and without the integration of clinical indications and patient demographics. For each of the two CT-RATE test set examples, we present an axial slice, clinical indications, demographic information, ground truth, and the generated report. Clinical relevance is highlighted using color-coded annotations.
Conclusion and discussion
7
In this paper, we present a simple and effective method capable of integrating various sources of information to classify multiple anomalies from chest 3D CT scans, available clinical indications, and age and sex features. We also integrate these information sources for report generation, demonstrating their ability to enhance model performance across various tasks related to 3D CT scans. Furthermore, our experiments validate the effectiveness of each module and the use of a pretrained language model for clinical indication feature extraction. Due to the limited availability of multimodal publicly accessible 3D chest CT datasets, our findings are based solely on the CT-RATE dataset. While this provides a solid foundation for initial validation, reliance on a single dataset may introduce biases related to language patterns, labeling conventions, or demographic representations. Moreover, the demographic features considered in this study (age and sex) remain limited. Future work should therefore aim to include external validation on independent datasets and explore richer metadata to better assess model generalizability and robustness. To enhance multimodal representation of a patient, future work could incorporate additional modalities, such as longitudinal patient data, richer demographic features, or similarity-based retrieval of reports and volumes, to further strengthen multimodal fusion.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Singh SP Wang L Gupta S Goli H Padmanabhan P Gulyás B. 3D deep learning on medical images: a review. Sensors (Basel). (2020) 20:5097. 10.3390/s 2018509732906819 PMC 7570704 · doi ↗ · pubmed ↗
- 2Jany B Welte T. Pleural effusion in adults—etiology, diagnosis, and treatment. Deutsches Ärzteblatt Int. (2019) 116:377–86. 10.3238/arztebl.2019.0377 PMC 664781931315808 · doi ↗ · pubmed ↗
- 3Dela Cruz CS Tanoue LT Matthay RA. Lung cancer: epidemiology, etiology, and prevention. Clin Chest Med. (2011) 32:605–44. 10.1016/j.ccm.2011.09.00122054876 PMC 3864624 · doi ↗ · pubmed ↗
- 4Amin H Siddiqui WJ. Cardiomegaly. In: Stat Pearls. Treasure Island, FL: Stat Pearls Publishing (2024). Available online at: https://www.ncbi.nlm.nih.gov/books/NBK 542296/ (Accessed June 25, 2024).
- 5Goergen SK Pool FJ Turner TJ Grimm JE Appleyard MN Crock C Evidence-based guideline for the written radiology report: methods, recommendations and implementation challenges. J Med Imaging Radiat Oncol. (2013) 57:1–7. 10.1111/jmiro.2013.57.issue-123374546 · doi ↗ · pubmed ↗
- 6Bastawrous S Carney B. Improving patient safety: avoiding unread imaging exams in the national VA enterprise electronic health record. J Digit Imaging. (2017) 30:309–13. 10.1007/s 10278-016-9937-228050717 PMC 5422229 · doi ↗ · pubmed ↗
- 7Rimmer A. Radiologist shortage leaves patient care at risk, warns royal college. BMJ (Clin Res Ed.). (2017) 359:j 4683. 10.1136/bmj.j 468329021184 · doi ↗ · pubmed ↗
- 8Djahnine A Jupin-Delevaux E Nempont O Si-Mohamed SA Craighero F Cottin V Weakly-supervised learning-based pathology detection and localization in 3D chest CT scans. Med Phys. (2024) 51:8272–82. 10.1002/mp.v 51.1139140793 · doi ↗ · pubmed ↗