Multicancer early detection in a cohort of patients with confirmed and suspected cancer by measuring plasma amino acid cross sections with the Enlighten test: MODERNISED protocol
Sam Wilding, Victoria Goss, Wesley Sukdao, Zaed Hamady, Joanne Lord, Adam Coleman, Catherine Pointer, Jocelyn Walters, Will Herbert, Katy Mclaughlin, Robert Waugh, Nicola Irvine, Tom Oliver, Irene Soulsby, Julie Hooper, Simon J Crabb, Gareth Griffiths, Emma Yates, Andrew Davies

TL;DR
The MODERNISED study aims to improve a blood test called Enlighten that detects multiple types of cancer early by analyzing amino acids in the blood.
Contribution
The study expands the Enlighten test to detect ten cancer types and evaluates its performance in a large, diverse cohort.
Findings
The Enlighten test detected 78% of early-stage cancers in an initial cohort with no false positives in healthy controls.
The study will assess cancer detection accuracy at high specificity thresholds (95%, 99%, 99.9%).
The test will be validated for predicting cancer type and stage using machine learning.
Abstract
Detecting cancer earlier improves treatment options and long-term survival. A multicancer early detection test that reliably picks up early-stage cancer would potentially save lives and reduce the cost of treating cancer. One promising candidate is the Enlighten test, which applies machine learning to plasma amino acid concentrations to detect cancer. In a cohort of 77 patients recently diagnosed with breast, colorectal, pancreatic or prostate cancer, 60 (78%) were detected by the test (sensitivity), with no false positives in 20 healthy controls. The MODERNISED study will further develop the Enlighten test to detect 10 different cancers by adding bladder, lung, melanoma, oesophageal, ovarian and renal cancer to the test. MODERNISED (ISRCTN17299125) is a multicentre prospective, non-interventional, case–control study. We aim to recruit 1000 adult participants with a recent cancer…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
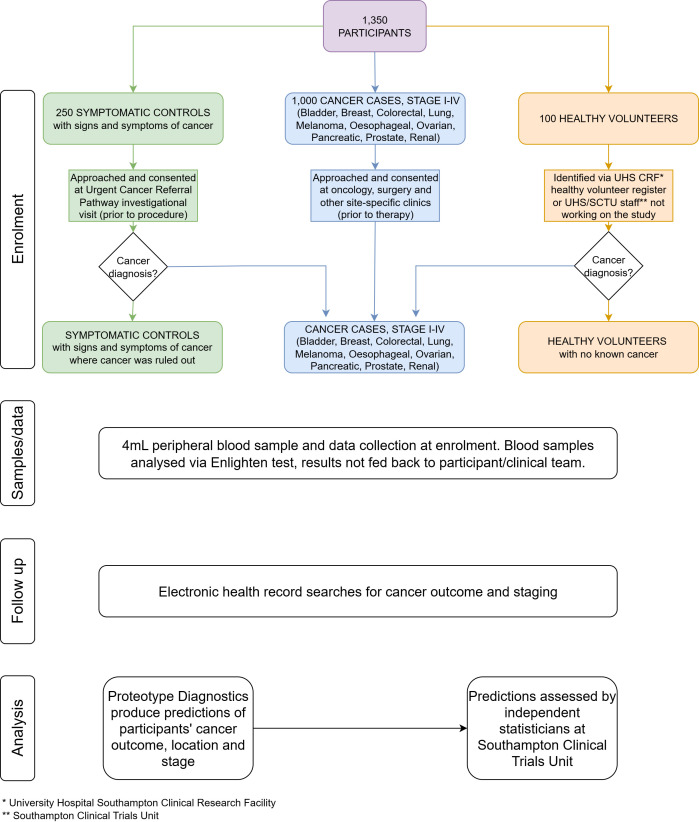 Figure 1
Figure 1| Entry arm | Inclusion criteria | Exclusion criteria |
|---|---|---|
| All | 1. Age 18 years or older. | 6. Pregnancy (by self-report of pregnancy status), or pregnancy within the last 12 months. |
| Cancer cases | 4. Have either of the following: Or | 15. Currently receiving, or ever received, any of the following therapies to treat their current cancer: surgical management of the cancer beyond that required to establish the cancer diagnosis; local, regional or systemic chemotherapy, including chemoembolisation; targeted therapy, immunotherapy, including cancer vaccines; hormone therapy or radiation therapy. |
| Symptomatic control | Or | 19. Known current or prior diagnosis of cancer, per guidance in protocol. |
| Asymptomatic control | 20. Known current or prior diagnosis of cancer, per guidance in protocol. |
- —National Institute for Health Research and the Office for Life Sciences
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMetabolomics and Mass Spectrometry Studies · Advanced Proteomics Techniques and Applications · Amino Acid Enzymes and Metabolism
Introduction
Cancer is one of the leading causes of death worldwide, with 149 022 deaths attributed to cancer in England and Wales across 2023.1 Detecting cancer earlier improves the number of treatment options available and long-term survival.2 In 2019, the National Health Service (NHS) in the UK committed to increasing the proportion of cancers that are diagnosed at stage I or II.3 There has been minimal change in the proportion between 2019 (53.4%) and 2022 (54.8%), despite an increasing number of people referred for cancer diagnostics.4 5 Additional tools are required to detect cancer at an early stage, which would improve the proportion of cancers diagnosed at an earlier stage, improve patient outcomes and reduce the cost burden on the system.
Multicancer early detection (MCED) tests
MCEDs, tests that analyse a ‘liquid-biopsy’ such as blood, urine, saliva or stool and test for the presence of multiple cancers in a singular sample, are being proposed as a complement to traditional cancer diagnosis pathways to improve early detection.6 A 2024 systematic review found 36 studies evaluating six different MCEDs, with most having a high risk of bias.7 There are no randomised studies demonstrating that using MCEDs leads to an increase in the proportion of cancers diagnosed at stage I or II. The majority of MCEDs that have published data available are using cell-free DNA (cfDNA) or circulating-tumour DNA (ctDNA), which are fragments of DNA released into the bloodstream that may possess alterations indicative of cancer.8
The degree of mutations present within cfDNA and ctDNA increases as cancer progresses, so this approach may not be successful if the aim is to detect cancers at stage I or II, where the amount of material shed into the bloodstream is below the limit of detection.9 The largest evaluation of an MCED in the UK, the SYMPLIFY study, used the GRAIL test on 5461 symptomatic patients referred for urgent investigation for a possible gynaecological, lung or gastrointestinal cancer. The sensitivity for cancer detection was much lower at stage I (24.2%) than at stage IV (95.3%).10 This is a common trend among cfDNA MCEDs. One meta-analysis found a pooled sensitivity of 50.3% for stage I or II versus 77.4% for stage III or IV.11 To increase early cancer detection, alternative techniques are required.
The Proteotype Diagnostics Enlighten test
Proteotype Diagnostics (PD) have developed an alternative approach to MCED testing. Instead of measuring material released from tumours (cfDNA or ctDNA), amino acid concentrations are measured in plasma in the Enlighten test, which are affected by the immune response. Immune responses are stronger during the early stages of cancer12 and therefore may be used to improve the detection of stage I and II cancers. Machine learning (an ensemble subspace discriminant classifier) was applied to classify tested samples to cancer or non-cancer in a retrospective observational study of 77 cancer patients (breast, colorectal, pancreatic and prostate) and 20 healthy volunteers. A sensitivity of 78% at 100% specificity was achieved using Enlighten, and concentrations were further differentiated in early-stage cases.13
Southampton Experimental Cancer Medicine Centre (ECMC) responded to an open call for partnerships with PD to develop a study further evaluating the Enlighten test. Southampton Clinical Trials Unit (SCTU) then developed a research proposal with PD and ECMC as partners, which is academically sponsored by University Hospital Southampton Trust and jointly funded by the National Institute for Health and Care Research and the Office for Life Sciences (ref NIHR207538).
The primary aim of this study is to train a machine learning classifier to use amino acid concentrations from the Enlighten test to detect cancer (bladder, breast, colorectal, lung, melanoma, oesophageal, ovarian, pancreatic, prostate and renal) in comparison to adult participants with symptoms of cancer where a cancer diagnosis was ruled out and healthy volunteers. Participants will be randomised, with 75% used to train the classifier and 25% used to validate the classifier. Secondary aims include:
Training and validating a classifier to distinguish cancer patients from adult participants with symptoms of cancer, where a cancer diagnosis was ruled out.Training and validating a classifier to distinguish cancer patients from healthy controls.Evaluating discrimination and sensitivity by tissue of origin (ToO), stage, age, sex at birth and availability of a UK cancer screening programme.Training and validating a classifier to predict ToO.Training and validating a classifier to predict cancer stage.
Methods and analysis
Study design
MODERNISED (ISRCTN17299125) is a multicentre prospective, non-interventional, case–control study recruiting 1000 participants with known cancer, 250 under investigation for cancer where cancer was ruled out, and 100 healthy volunteers. Participants will be recruited from five secondary care sites and healthy volunteer register banks, or hospital or university staff in England. Recruitment began in January 2025. Recruitment is underway, and version 2 (01 April 2025) is the latest version of the study protocol at the time of submitting this manuscript. Important protocol modifications are reported to relevant parties as part of the SCTU’s standard operating procedures.
Study participants
The first cohort, ‘cancer cases’, will consist of 1000 adults recently diagnosed with one of the 10 cancers, recruited from secondary care sites prior to treatment. The second cohort, ‘symptomatic controls’, will consist of 250 adults either currently or previously under investigation for one of the 10 cancers, recruited from secondary care sites, who are found to be cancer-free following normal diagnostic pathways. Participants in this cohort who are found to have cancer during follow-up will be moved to the cancer cases cohort. These participants will be reached via screening of clinic lists and approached during routine hospital visits for symptom investigation, or by phone call to invite them to attend an enrolment visit. The third cohort, ‘healthy volunteers’, will consist of 100 adults with no known cancer and no active symptoms indicative of cancer, recruited from volunteer groups at secondary care sites, or University and hospital staff if recruitment is slower than anticipated. These participants will be reached by advertisement of the study in email newsletters and invited to attend recruitment clinics. Participants in this cohort who are found to have cancer during follow-up will be moved to the cancer cases cohort. Full inclusion and exclusion criteria can be found in table 1. The study workflow is outlined in figure 1.
MODERNISED study workflow. CRF, clinical research facility; SCTU, Southampton Clinical Trials Unit; UHS, University Hospital Southampton.
Baseline data collection
Clinic and MDT lists will be screened regularly (minimum two times per day) to identify cancer cases referred to relevant clinics. Clinic and 28-day faster diagnosis pathway lists will also be used to identify individuals referred to secondary care by their general practitioner for symptoms, which indicate that they may have one of the 10 cancers being investigated. Healthy volunteers are recruited from registers where they have consented to be approached for involvement in research and will be contacted by the research team. If recruitment of healthy volunteers is challenging, the protocol allows for members of staff at the University Hospital Southampton and the University of Southampton to be approached. Those providing informed consent will be invited to a baseline visit (T_0_).
At the baseline visit, eligibility will be confirmed with a trained and delegated healthcare professional, who will also collect medical history, concomitant medications, demographics and the Index of Multiple Deprivation. Pseudonymised data will then be entered into Medidata’s Rave Electronic Data Capture, which can then only be accessed by allocated staff at SCTU. Participants will then have 4 mL of blood drawn into an EDTA tube. Any adverse events related to blood collection will be reported to the SCTU and summarised in the final study publication. All blood samples will be posted overnight Monday to Thursday at ambient temperature using Royal Mail Safeboxes (or equivalent) to the University Hospital Southampton NHS Foundation Trust, Wessex Investigational Sciences Hub (WISH). The Enlighten assay will be performed by Southampton ECMC-trained laboratory personnel housed in the WISH laboratory, and pseudonymised assay results (participant identifier and amino acid readings) will be transferred securely to PD to be converted to amino acid concentrations.
Outcome measurement
Cancer outcome and staging will be retrieved from the Electronic Health Record (EHR) via local hospital research staff. This will be triggered for each participant once 3 months have passed since informed consent (T_1_), but data may be entered earlier where appropriate. Cancer diagnosis will be coded using ICD-10 to capture ToO, morphology and staging according to TNM (tumour, node, metastases) and cancer-specific staging system, as appropriate. Consent will be gained to collect further cancer diagnoses up to 2 years from participants’ enrolment.
Model training and validation
Participants will be randomised in a 3:1 ratio with varying permuted blocks, balanced by cancer ToO and stage, into a model training (75% of participants) or model validation (25% of participants) set. The randomisation list will be pregenerated by a statistician at SCTU. Those in the model training set will have their cohort (cancer case, symptomatic control and asymptomatic control), age and sex shared with PD to train machine learning algorithms in combination with amino acid concentrations. PD will be blinded to the diagnostic status of participants in the model validation set.
Symptomatic controls and healthy volunteers may later be diagnosed with cancer (and therefore move into the cancer cases cohort). Randomisation will therefore only occur on three occasions during the study to reduce the impact of imbalance between building and validation sets. All participants and care providers will remain blinded. Participants will not be randomised more than once. The occasions are as follows: (1) when the amino acid concentrations have been measured for the first batch of 20 participants’ samples with complete data (to stress test processes). (2) When the T_1_ visit has occurred for 50% of the target participants in the breast, colorectal, prostate and lung cancer cohorts. (3) When the T_1_ visit has occurred for all participants, and all data have been returned.
Machine learning training and validation
Machine learning techniques considered will include: random forests, support vector machines, ensemble subspace discriminant classifiers, XGBoost, neural networks and deep learning algorithms. The final modelling strategy will be informed by comparative predictive performance and computational cost. Triplicate values of the five amino acids (Cysteine, Reduced Cysteine, Lysine, Tryptophan and Tyrosine) will be used as input parameters (or combined as average readings), with potential additions of participant age and sex. Feature importance will be measured by Shapley values. Stratified cross-validation will be used to reduce overfitting.
One algorithm will predict diagnostic status (‘cancer’ or ‘no cancer’), a second will predict cancer ToO (bladder, breast, colorectal, lung, melanoma, oesophageal, ovarian, pancreatic, prostate and renal) and a third will predict cancer stage (I, II, III, IV). The trained algorithms will use amino acid concentrations (and potentially age and sex) to predict diagnostic status, ToO and cancer stage in the development and validation cohorts. These predictions will be provided to statisticians at SCTU to independently validate predictions against true status.
Sample size calculation
A prediction model for a binary outcome (cancer yes/no status, prevalence 74%), 15 prediction parameters (five amino acids Cysteine, Reduced Cysteine, Lysine, Tryptophan and Tyrosine, potentially age and sex, and allowing for additional interactions in models), Nagelkerke’s r-squared of 20% and target shrinkage of 10% requires a minimum sample size of 916 (678 events) to reduce overfitting.14 Rounded up to 750 events and allowing a random 3:1 split between data available for model building and validation, the total required sample size is 1000 events, with 250 symptomatic controls, and 100 healthy volunteers, a total of 1350.
Of the 1350, the total sample size for validation would be 337, with 250 cancer cases, 62 symptomatic controls and 25 healthy volunteers. Because the distribution of the linear predictor derived from the prediction model is not known in advance, the anticipated Area Under the Receiver Operator Curve (AUROC) can be used to determine the required sample size for validation.15 Using this simulation approach with a target CI width of 0.1, the prediction model’s AUROC must be at least 0.84 to validate the model with sufficient accuracy with 337 individuals. As the pilot data demonstrated an AUROC of 0.98, it seems reasonable to assume an AUROC of 0.84 or higher can be achieved within this study.
Analysis plan
Baseline medical history, concomitant medications, demographics and Index of Multiple Deprivation will be summarised using descriptive statistics by cohort. The number of symptomatic controls and healthy volunteers who are later diagnosed with cancer and moved into the cancer cases cohort will be presented.
PD will train machine learning algorithms for diagnostic status, ToO and cancer stage. The output for diagnostic status will be a continuous risk score. The output for ToO will be one of the 10 cancers involved in the study, and may include the percentage chance for each ToO. The output for cancer stage will be either stage I, stage II, stage III or stage IV, and may include the percentage chance for each stage. Statisticians at SCTU will produce an AUROC plot in the model training and validation groups for diagnostic status. The apparent c-statistic will be calculated and adjusted for optimism using bootstrapping16 with accompanying 95% CIs. Sensitivity will be calculated in each group at cut-offs of 95%, 99% and 99.9% specificity with accompanying 95% CIs. Accuracy of the ToO and cancer stage predictions will be calculated in the model training and validation groups with accompanying 95% CIs.
These analyses will be repeated, stratified by early stage (stage I or II) and late stage (stage III or IV) cancer; ToO; symptomatic controls and healthy volunteers; age band at recruitment; biological sex at birth; availability of screening programme for cancer (screening test available (breast, cervical, colorectal and lung) or not available). All analyses will be conducted in R V.4.4.2 (or higher) or STATA V.17 (or higher).
Ethics and dissemination
This study is sponsored by University Hospitals Southampton NHS Foundation Trust and has been approved by the Health Research Authority and Health and Care Research West Midlands (24/WM/0234). This study is funded jointly by the National Institute for Health Research and the Office for Life Sciences (ref NIHR207538). SCTU is committed to the responsible sharing of clinical study data and samples with the wider research community. Data and sample access are administered through the SCTU Data and Sample Release Committee, which will consider requests once the final analysis has been published.
Results will be presented at scientific meetings and published in international peer-reviewed journals. Lay summaries of study progress and findings will be published on SCTU’s website.
Patient and public involvement
This study benefits from two funded PPI coapplicants who have lived experience of cancer, have extensive experience in providing a patient’s perspective in cancer research and an interest in equality, diversity and inclusion. They have contributed to the conception and development of the study and will be advising on the content and tone of patient-facing materials. They will also lead the public dissemination strategy and participate in all regular study management group meetings.
Discussion
This study will determine the diagnostic accuracy of machine learning techniques using the Enlighten test to detect cancer. This will be achieved by running the assay in a group of recently diagnosed cancer patients, patients who are symptomatic but cancer was ruled out, and participants with no symptoms or cancer diagnosis. Utility in guiding cancer diagnosis will also be assessed by determining the accuracy of the predicted ToO and stage of cancer. Cancer diagnosis will be collected and updated via local EHRs across five secondary care sites in the south of England. The potential applicability of the machine learning algorithms in future research will be assessed through a held-out dataset.
While this study focuses on 10 sites of cancer (bladder, breast, colorectal, lung, melanoma, oesophageal, ovarian, pancreatic, prostate and renal), additional ToO may be added, which will require model retraining in future research. This will reduce the risk of false results where a tested individual has a cancer that is not covered by the algorithm, which can delay the time to diagnosis. To improve the proportion of cancers detected early, a substantial number of cancer patients diagnosed at stage I or II must be recruited into the study. The research team have reviewed the throughput of recruitment sites in previous years, and recruitment will be monitored and potentially tailored to ensure that these requirements are met.
Theoretically, amino acids will improve the sensitivity for MCEDs to detect early-stage cancers in comparison to the more commonly used cfDNA and ctDNA techniques. If the Enlighten test does perform in this regard, then it could be used as a triage tool prior to expensive diagnostic imaging for individuals suspected of cancer. A reliable rule-in tool for cancer detection would reduce the overall demand for diagnostic imaging. This would, in turn, allow for individuals with a lower pretest probability of cancer to be tested, therefore increasing the rate of cancers detected early.
If the results from this study are promising, then the aim of future research will be to demonstrate an improvement in early-stage cancer detection balanced against the harms of overdiagnosis and cost in a randomised controlled trial. The feasibility of progressing to this stage depends on the recruitment success for all combinations of cancer ToO and stages, and the clinical acceptability of a 10 cancer MCED versus developing the MCED across further cancer ToO.
Supplementary material
10.1136/bmjopen-2025-108220online supplemental file 1
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Office for National Statistics Deaths registered summary statistics, England and Wales Availablehttps://www.ons.gov.uk/peoplepopulationandcommunity/birthsdeathsandmarriages/deaths/datasets/deathsregisteredsummarystatisticsenglandandwales Accessed 16-Jan-2025
- 2Etzioni R Urban N Ramsey S et al The case for early detection Nat Rev Cancer 200332435210.1038/nrc 104112671663 · doi ↗ · pubmed ↗
- 3NHS The NHS long term plan 2019 Availablehttps://www.longtermplan.nhs.uk/wp-content/uploads/2019/08/nhs-long-term-plan-version-1.2.pdf Accessed 16-Jan-2025
- 4NHS England CWT CRS – national time series Oct 2009 – Nov 2024 with revisions Availablehttps://www.england.nhs.uk/statistics/statistical-work-areas/cancer-waiting-times/Accessed 16-Jan-2025
- 5Cancer Research UK Early cancer diagnosis data hub Availablehttps://crukcancerintelligence.shinyapps.io/Early Diagnosis/Accessed 16-Jan-2025
- 6Guerra CE Sharma PV Castillo BS Multi-cancer early detection: the new frontier in cancer early detection Annu Rev Med 202475678110.1146/ANNUREV-MED-050522-033624/137729031 · doi ↗ · pubmed ↗
- 7Wade R Nevitt S Liu Y et al Multi-cancer early detection tests for general population screening: a systematic literature review Oncology (Williston Park, NY)202410.1101/2024.02.14.24302576 PMC 1180844439898371 · doi ↗ · pubmed ↗
- 8Stejskal P Goodarzi H Srovnal J et al Circulating tumor nucleic acids: biology, release mechanisms, and clinical relevance Mol Cancer 20232212110.1186/s 12943-022-01710-w 36681803 PMC 9862574 · doi ↗ · pubmed ↗