Evolutionary bi-level neural architecture search with training: A framework for color classification
Mitchell Ángel Gómez-Ortega, Miguel Gabriel Villarreal-Cervantes, Mario Aldape-Pérez, Alam Gabriel Rojas-López, Daniel Molina-Pérez, Ramón Silva-Ortigoza

TL;DR
This paper introduces a new method for designing efficient neural networks that achieve high performance while using fewer resources.
Contribution
The novel EB-LNAST framework simultaneously optimizes architecture, weights, and biases using bi-level optimization.
Findings
EB-LNAST outperforms traditional machine learning algorithms and advanced models in predictive performance.
It achieves up to 99.66% reduction in model size compared to MLPs with hyperparameter tuning.
The method remains competitive with only a 0.99% performance reduction when compared to optimized MLPs.
Abstract
The design of Artificial Neural Networks (ANNs) for classification tasks has been a topic of interest. However, defining an optimal ANN architecture remains challenging, especially when considering resource constraints and the large number of design parameters. This paper proposes an Evolutionary Bi-Level Neural Architecture Search with Training (EB-LNAST) approach that simultaneously optimizes the architecture, weights, and biases of a neural network using a bi-level optimization strategy. The upper level focuses on minimizing the network complexity penalized by the lower level performance function, while the lower level optimizes training parameters to minimize the loss function and maximize the predictive performance. The proposal is evaluated on a real-world color classification task and the WDBC dataset, demonstrating statistically significant improvements over traditional machine…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
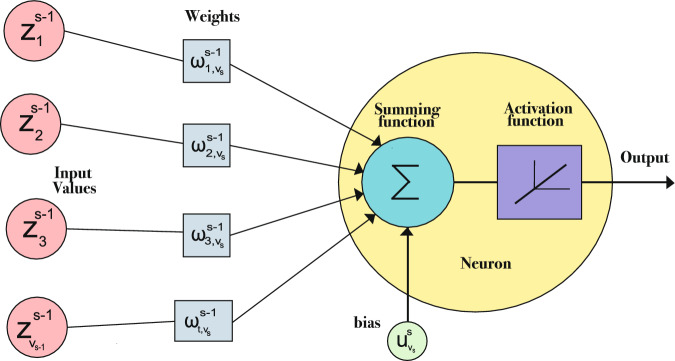 Figure 1
Figure 1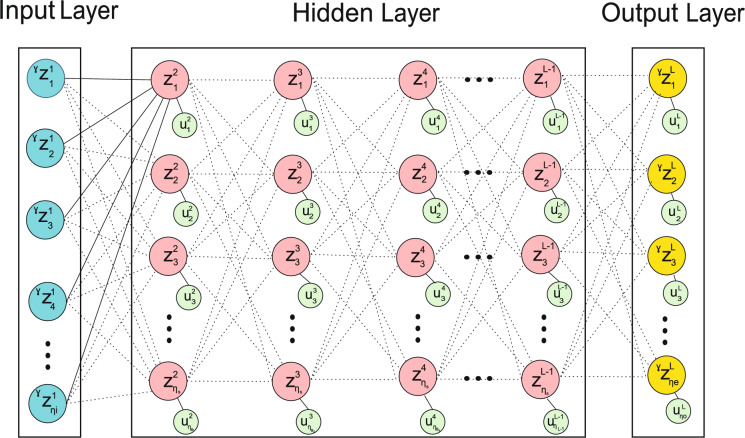 Figure 2
Figure 2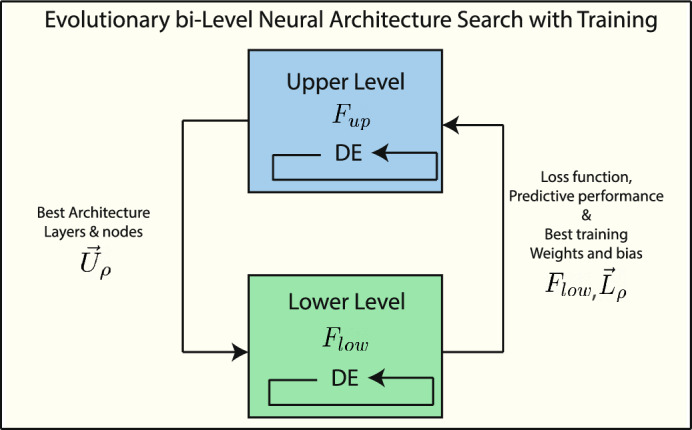 Figure 3
Figure 3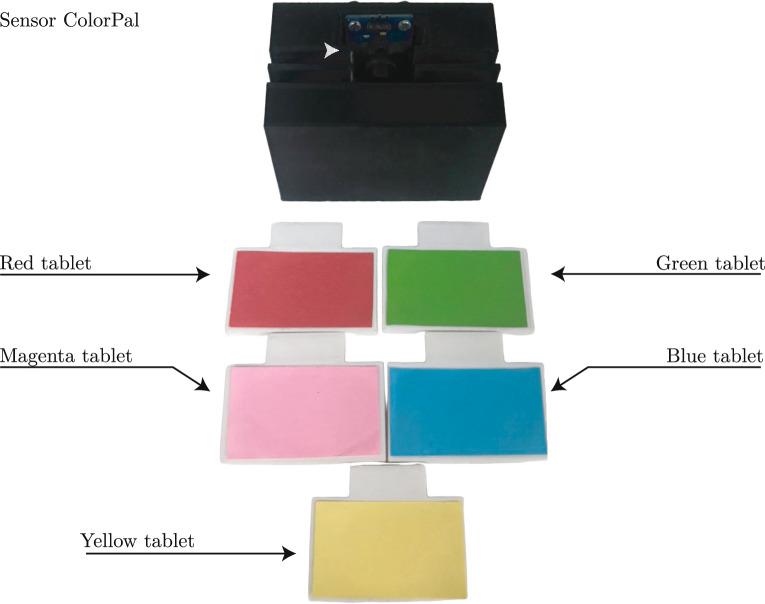 Figure 4
Figure 4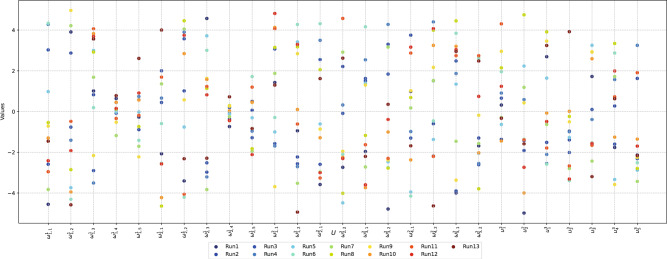 Figure 5
Figure 5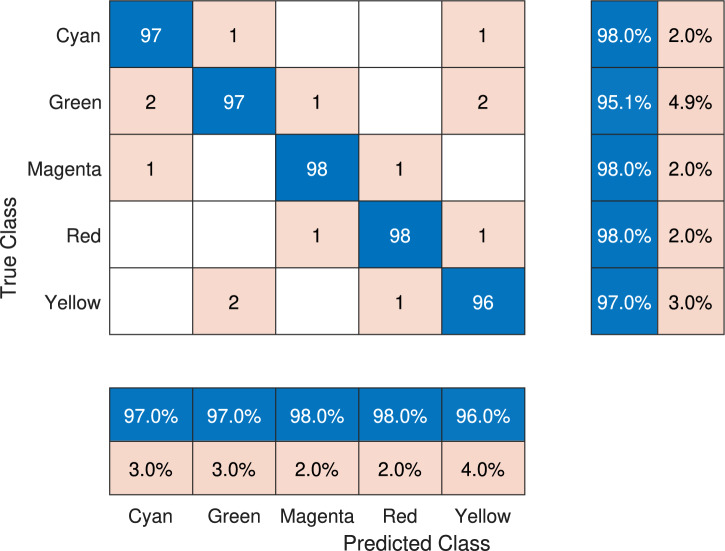 Figure 6
Figure 6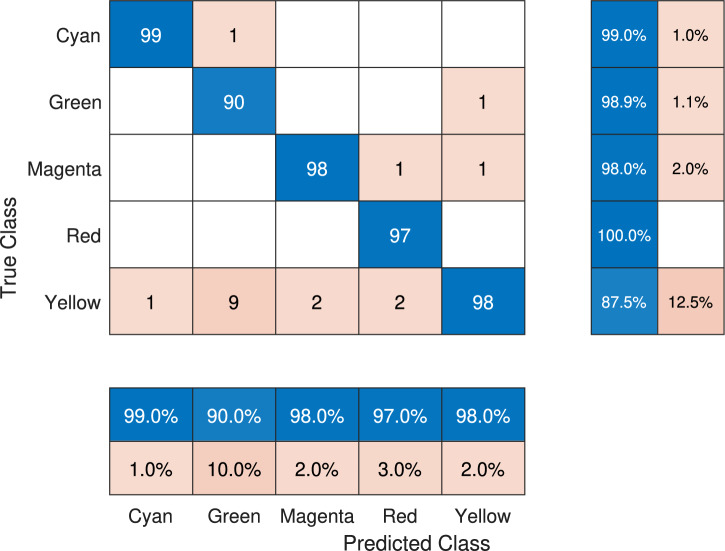 Figure 7
Figure 7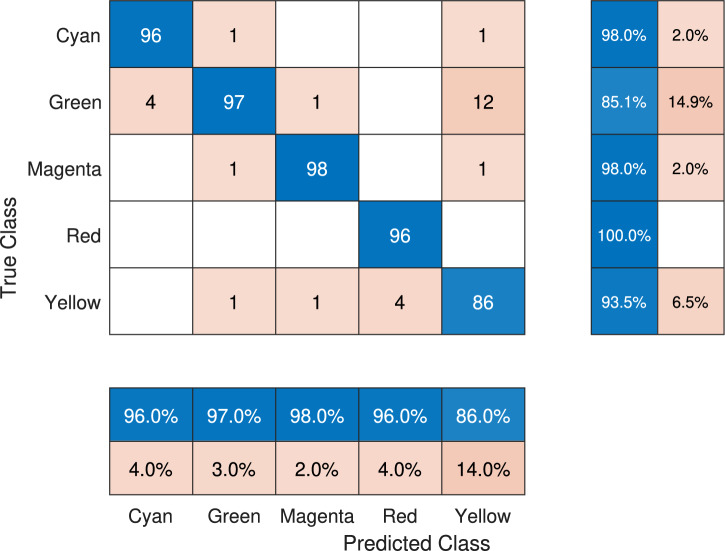 Figure 8
Figure 8 Figure 9
Figure 9- —Secretaría de Investigación y Posgrado (SIP) of the Instituto Politécnico Nacional
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMetaheuristic Optimization Algorithms Research · Evolutionary Algorithms and Applications · Machine Learning and Data Classification
Introduction
Background and motivation
Artificial Neural Networks (ANNs) are one of the most well-known techniques in artificial intelligence, with the primary goal of enabling machines to make decisions, perform analytical evaluations, and make comparative judgments, thereby simulating human behavior. ANNs are methods inspired by the biological functioning of the human brain^1^. During the past decades, ANNs have become popular for solving problems in various fields of knowledge, for instance, in color classification^2^, textile industry monitoring^3^, color classification in tempering processes^4^, air overpressure prediction^5^, and vibration analysis caused by mining explosions^6^. In the medical field, applications range from X-ray image analysis^7^ to energy-related applications^8^, as well as studies on Convolutional Neural Networks (CNNs).
In most cases, ANNs are trained using the backpropagation method, which adjusts weights and biases to minimize prediction error through gradient descent^9^. In spite of backpropagation being widely used for weight optimization in feedforward neural networks (FNNs), it may present limitations in specific training scenarios, such as a tendency to become trapped in local minima. Various factors can hinder convergence and may lead to overfitting, including the initial network conditions, learning rate, and the inherent complexity of the problem, among others. To mitigate these issues, regularization techniques such as L2 (Ridge Regularization), L1 (Lasso Regularization), Dropout, and batch normalization are frequently employed to improve the generalization of the ANN performance by reducing error and increasing the likelihood of reaching a global minimum^10^.
Another issue that plays a vital role in network performance lies in the architecture design. The ANN architecture design is another critical and complex aspect that involves determining the number of layers, the number of neurons per layer, layer types, connection schemes, and other factors. As the ANN training requires a fixed and predefined architecture, the combined selection of the training and architecture parameters is neither intuitive nor systematic^11^, such that designers require extensive experience because improper selection of design parameters can lead to loss of ANN performance^12–16^.
On the other hand, metaheuristic algorithms have emerged as robust alternatives for training artificial neural networks (ANNs) and for finding optimal network architectures, addressing this challenge^17^. These algorithms are based on heuristic principles inspired by natural phenomena, physical processes, or collective intelligence strategies to strike a balance between the exploration of new solution space areas and the exploitation of known solutions to refine them^18^. Various metaheuristic algorithms inspired by biological evolution enhance the search for solutions, guiding convergence to the closest region of the global minimum and overcoming the previously mentioned limitations. The most commonly used methods include evolutionary algorithms (EAs), which optimize network structure and weights, as well as other parameters, by employing mutation and crossover operators to explore the solution space efficiently. In^19^, the Particle Swarm Optimization (PSO) algorithm is employed to optimize the training parameters, such as weights and biases of the ANN, thereby balancing the exploration and exploitation of the search space. Evolutionary programming is used to simultaneously combine the network architecture and connection weights to find optimal neural network configurations^20^.
The use of deep neural network architecture search techniques has also been explored to improve the output of the neural network. For instance, the medical image segmentation is improved by optimizing convolutional neural network architectures using the genetic algorithm^21^. On the other hand, an auto-adaptive approach is used for architecture search employing the metaheuristic Teaching-Learning-Based Optimization (TLBO)^22^. Architecture search is also addressed through an evolutionary multiobjective approach based on supernets^23^. Evolutionary search for monocular depth estimation and image classification is also addressed in^24^, and the Warm-Start Multiobjective Evolutionary Algorithm is employed for graph neural networks in^25^. Alternatively, other techniques for Neural Architecture Search (NAS) include Random Search, Q-Learning, and Bayesian Optimization, which are used to explore and optimize the architecture of Deep Neural Networks in drug response prediction^26^. The use of regularization techniques aids in preventing overfitting and improving model generalization. Reinforcement learning in graph assembly^27^ is another strategy, as well as the use of Differentiable Architecture Search (DARTS) to reduce the spatial redundancy of features in computer vision techniques that facilitate feature learning^28^. These examples illustrate active research in the field of searching for efficient architectures for deep learning, where optimization is not limited to training parameters but extends to the very design of the network. The diversity of the search approaches underscores the importance of finding optimal architectures as a fundamental step towards improving the performance in specific applications, which in turn influences the need for appropriate parameter optimization for each architecture found.
Every parameter that affects the performance of an ANN is considered a HyperParameter (HP). These hyperparameters can be categorized into five main categories depending on the aspect of the network they impact. The first group is related to the architecture parameters, which define the network structure relating to the layer numbers, activation functions, network type, etc. The second group includes training parameters that adjust the learning process, such as the learning rate, batch size, epoch number, and optimizers. The regulation parameters involve the third group, which aims to prevent overfitting and includes L1/L2 weight penalties, dropout, and other methods. The fourth group is related to the preprocessing parameters that influence the input data quality, such as normalization and augmentation strategies. The fifth group is directly related to the particular characteristics of each type of neural network. For instance, in convolutional neural networks, the hyperparameters could be related to the filter size, stride, and padding; in both recurrent neural networks like Long Short-Term Memory (LSTM) and Bidirectional Long Short-Term Memory (Bi-LSTM) those parameters are related to the number of memory units, the recurrent dropout rate; in Transformer networks the HPs include the number of attention heads, the number of encoder and decoder layers, among others. Defining the appropriate values is a challenge, which is why the process of determining suitable parameters is referred to as Hyperparameter Optimization (HO)^29^.
Regarding optimization techniques^30^, presents an analysis of HO techniques in deep learning applications, addressing challenges in applying these techniques and comparing different algorithms. This analysis covers key hyperparameters related to model training and structure, such as learning rate, batch size, optimizer, number of hidden layers, and layer width, discussing their importance and methods for defining their value ranges. The study evaluates the efficiency and accuracy of gradient-based optimization algorithms, including Stochastic Gradient Descent (SGD) and its variants, such as AdaGrad, RMSProp, and Adam, particularly in the context of deep learning networks. While the review provides a comprehensive overview of HO algorithms, tools, and applications, it acknowledges limitations, such as the performance of classical search algorithms for large hyperparameter spaces and the computational expense of evaluating complex deep learning models. Similar studies on hyperparameter optimization^31–34^ focus on tuning parameters, such as learning rate, number of hidden layer nodes, number of filters, LSTM network dimensions, number of training epochs, L2 regularization technique, dropout rate, and entropy coefficient, among others, with the use of gradient-based algorithms.
According to the aforementioned works, hyperparameter optimization is a critical factor. In^35^, the Robust and Efficient Hyperparameter Optimization at Scale (BOHB) approach is utilized. This method combines Bayesian Optimization (BO) with bandit-based evaluation strategies, such as Hyperband (HB), to achieve a balance between performance and rapid convergence toward optimal configurations for various types of Artificial Neural Networks (ANNs). The considered hyperparameters (HPs) are learning rate, momentum, batch size, and regularization techniques such as Weight Decay and Dropout rates.
The application of metaheuristic algorithms in the Deep Learning framework includes implementations of PSO, Ant Colony Optimization (ACO), Firefly Algorithm (FFA)^36^, the Dragonfly Algorithm^37^, Sparrow Search Algorithm (SSA)^38^, and multiobjective Swarm Algorithm (MSA)^39^ to address kernel size, layers, convolutional layers, pooling layers, among others.
Beyond the optimization of hyperparameters, the architecture of a neural network itself plays a fundamental role in its performance. A case study addressing ANN architecture optimization is presented in^40^, where a Convolutional Neural Network (CNN) is optimized regarding convolutional layers, the number of nodes per layer, and filter size using Differential Evolution (DE) to identify hyperparameters that compete with state-of-the-art CNNs. Other studies, such as those presented in^41^ and^42^, also address the optimization of ANN architectures, considering aspects such as the number of layers, the number of hidden nodes, and the number of hidden layers. To simultaneously optimize multiple hyperparameters, bi-level optimization^43^ can be considered a solution. This hierarchical problem-solving technique operates with two independent optimization levels. The upper level controls decisions that condition those of the lower level, which resolves a subordinate problem based on upper level decisions. By addressing the optimization problem in a bi-level manner, the possibility arises to define and optimize a much broader set of hyperparameters jointly. In^44^, the authors explored neural architecture search (NAS) for graph neural networks (GNNs) using a framework called Adaptive Bayesian Genetic Neural Architecture Search (ABG-NAS). This approach extends evolutionary methods by incorporating a comprehensive search space of propagation and transformation operations, specifically designed for learning graph representations. Another relevant method is DDS-NAS, proposed in^45^, which integrates dynamic data selection (DDS) into the NAS process. By combining hard example mining with curriculum learning, DDS-NAS constructs balanced training subsets that are dynamically updated as the model masters simpler examples, replacing them with increasingly challenging and diverse samples from the same class. A further contribution is DEEP Q-NAS, presented in^46^, which introduces a reinforcement learning–based NAS scheme employing Deep Q-Networks (DQNs). Those works focus on NAS as a means to overcome the labor-intensive nature of manual architecture design and the dependence on specialized expertise. Nevertheless, in the context of automatic architecture search, those recent approaches share a scheme to direct attention to the search of architecture parameters (dimension size, topology, and so on) that maximizes of the model predictive performance on a validation set, either through metrics such as F1-scores, accuracy, or precision, while adjusting the training parameters (weights, biases, optimizer setting, and so on) by minimizing the loss function as the objective function, either through metrics such as cross-entropy, Mean Square Error (MSE). So, those approaches focus exclusively on improving predictive performance, which may lead the search process to unnecessarily complex architectures because they can not penalize overparameterized models, resulting in computationally expensive architectures and impractical for execution in systems with limited computing resources.
Contributions
In contrast to previous approaches, this work introduces a synergetic neural architecture search framework based on evolutionary bi-level optimization where in the upper level, the method implements an optimization strategy that explicitly balances predictive accuracy with architectural simplicity by minimizing structural complexity (i.e., number of layers and neurons) while penalizing inadequate validation performance, as quantified by the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta }$$\end{document} metric, and jointly integrating the training MSE given in the lower lever. In this way, the upper-level objective is designed not only to achieve high predictive performance but also to enforce compactness and stability in the resulting model. At the lower level, the optimization process simultaneously considers validation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta }$$\end{document} and training MSE for updating weights and biases, thereby ensuring that the evaluation metrics are consistently aligned with the optimization objectives. Unlike most studies reported, which often emphasize only predictive performance or rely on a single optimization criterion, the proposed framework explicitly integrates both predictive and architectural efficiency in a unified bi-level formulation. This dual focus constitutes a key novelty of the present work and differentiates it from existing approaches in the field.
To the best of the author’s knowledge, this is the first work that simultaneously optimizes the architecture, weights, and biases of ANNs in a general context using a bi-level optimization strategy with the aim of reducing the complexity of the network while achieving predictive performance comparable to, or better than, more complex models. As the case study, the proposed approach is applied to a color classification problem and to a complex dataset.
Then, the main contributions of this work are threefold. First, it introduces a novel approach called Evolutionary Bi-Level Neural Architecture Search with Training (EB-LNAST), which simultaneously searches for both the optimal model architecture and its parameters. This bi-level optimization framework leads to a more efficient search process, mitigates overfitting to specific configurations, and results in models that are not only more compact but also demonstrate improved generalization performance compared to traditional methods. Second, the effectiveness and robustness of the proposed method are demonstrated through its application to a real-world problem and a widely used complex benchmark dataset, providing empirical evidence of its practical utility. Third, a comparative performance analysis is conducted against several state-of-the-art machine learning algorithms, with statistical validation confirming that EB-LNAST consistently outperforms or remains competitive with existing methods and offers measurable advantages in terms of both accuracy and model efficiency.
The remaining structure of this work is organized as follows: The first Section details the proposed bi-level Optimization approach applied to the design and optimization of neural network architectures. The second Section presents the specific case study of color classification, detailing the problem addressed and the system used for experimentation. In the third Section, the results obtained by applying the proposed approach are presented and analyzed, including the initial conditions of the optimizers, a performance analysis of the bi-level method, and its comparison with other machine learning approaches and another well-known dataset. The final Section presents the main conclusions derived from the research, highlighting the key findings and contributions of the work. This final section also outlines possible future research directions and limitations identified in the present work. (Fig. 1)
Bi-level optimization approach in neural network architecture
The Evolutionary Bi-Level Neural Architecture Search with Training (EB-LNAST) approach addresses two common problems in ANNs: architecture search, training, and validation, with a focus on different architecture sizes. In the EB-LNAST approach, it is assumed that the ANN architecture takes the structure of a multi-layer perceptron (MLP), as shown in Figure 2. The MLP is a type of artificial neural network composed of multiple layers of neurons, with additional hidden layers between the input and output, each containing nodes^47^. The characteristic equation representing a node is given in (1) and shown in Figure 1. The overall MLP architecture is displayed in Figure 2.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} z^s_{v_s} = f \left( \sum _{t=1}^{|v_{s-1}|} \omega ^{s-1}_{t,v_s} \cdot z^{s-1}_{v_{s-1}} + u^s_{v_s}\right) \end{aligned}$$\end{document}where
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s = \{1, 2, \dots , L\} \in \mathbb {Z}^+$$\end{document} : Represents the index of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s$$\end{document} -th layer of the neural network, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L$$\end{document} is the total number of layers.
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$v_s \in \mathbb {Z}^+$$\end{document} : Represents the index of a neuron (node) within the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s$$\end{document} -th layer. The general relation is described in (2).
The value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s$$\end{document} depends on the layer:
- For the input layer ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s = 1$$\end{document} ): \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$v_s = v_r = \{1, 2, \dots , \eta _i\}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta _i$$\end{document} is the maximum number of neurons in the input layer.
- For the hidden layers ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s = \{2, \dots , L-1\}$$\end{document} ): \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$v_s = v_m = \{1, 2, \dots , \eta _{h_s}\}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta _{h_s}$$\end{document} is the maximum number of neurons in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s$$\end{document} -th hidden layer.
- For the output layer ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s = L$$\end{document} ): \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$v_s = v_q = \{1, 2, \dots , \eta _o\}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta _o$$\end{document} is the maximum number of neurons in the output layer.
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z^s_{v_s} \in \mathbb {R}:$$\end{document} Represents the output of the neuron \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$v_s$$\end{document} in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s$$\end{document} -th layer, including the activation function:
- For the input layer ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s = 1$$\end{document} ), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${}^{\gamma } z^1_{v_r}$$\end{document} corresponds to the input data of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$v_r$$\end{document} -th neuron. The term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} represents the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} -th input of the neuron \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$v_r$$\end{document} .
- For the hidden layers ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s \in \{2, \dots , L-1\}$$\end{document} ), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z^s_{v_m}$$\end{document} is the output of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$v_m$$\end{document} -th neuron in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s$$\end{document} -th hidden layer.
- For the output layer ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s = L$$\end{document} ), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${}^{\gamma } z^L_{v_q}$$\end{document} is the output of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$v_q$$\end{document} -th neuron. The term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} represents the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} -th output of the neuron \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$v_q$$\end{document} in the output layer \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L$$\end{document} for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} -th input vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${}^{\gamma } z^{1}_{v_r}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\forall$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$v_r$$\end{document} .
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u^s_{v_s} \in \mathbb {R}$$\end{document} : Represents the bias of the neuron \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$v_s$$\end{document} in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s$$\end{document} -th layer. It is worth mentioning that for the input layer, no bias is included ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u^1_{v_s} = 0$$\end{document} ).
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega ^{s-1}_{t, v_s} \in \mathbb {R}$$\end{document} : Expresses the synaptic weight that connects the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t$$\end{document} -th neuron in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s-1$$\end{document} -th layer with the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$v_s$$\end{document} -th neuron in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s$$\end{document} -th layer (for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s> 1$$\end{document} ).
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f(z^{s-1}_{v_{s-1}}, \omega ^{s-1}_{t, v_s}, u^s_{v_s})$$\end{document} : Represents the activation function, which defines the transformation applied to the output of the neuron \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z^{s}_{v_s}$$\end{document} . Fig. 1. Detail of the node in the MLP from Figure 2.Fig. 2. Multi-layer neural network.
For the EB-LNAST approach, two interdependent decision-making levels are considered, i.e., with two levels of upper and lower optimization. Fig. 3 displays a graphical representation of the proposed approach with the corresponding interactions between layers. In the upper level, the goal is to find the minimal MLP architecture. In the lower level, the goal is to optimize the weights and biases of the architecture from the upper level using a simultaneous training and validation strategy. If the architecture size is modified, the number of weights and biases could increase or decrease.Fig. 3. Graphical representation of the upper and lower levels in the proposed EB-LNAST approach.
Upper level: architecture design
In terms of architecture, it is known that the input \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\gamma }z_{v_r}^{1}$$\end{document} is defined by the data provided by the user to the MLP. Similarly, the output data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\gamma }z_{v_q}^{L}$$\end{document} is also set from the beginning. Therefore, the variables to be determined in the upper level are the total number of hidden layers, defined as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_L$$\end{document} , and the number of neurons (nodes) corresponding to each hidden layer. Thus, the total number of layers L is given by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L=h_L + 2 \in \mathbb {Z^+}$$\end{document} .
The upper optimization problem consists of determining the minimal architecture, which includes the number of hidden layers \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_L$$\end{document} and the number of nodes in each hidden layer, described as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta _{h_s}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\forall$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s=\{2,...,L-1\}$$\end{document} , that generate the maximum validation of the input data of the MLP performance. Therefore, the variables mentioned above are considered as the upper level design variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\vec {U}_\rho =[\vec {U}_{\rho _{1}},\vec {U}_{\rho _{2}}]^T \in \mathbb {N}^{1 + \eta _{{h_2}}+ \ldots +\eta _{h_{L-1}}}$$\end{document} , which are grouped in (3), where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\vec {U}_{\rho _{1}}$$\end{document} relates the hidden layer numbers and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\vec {U}_{\rho _{2}}$$\end{document} includes the node number of each hidden layer.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \vec {U}_\rho = [h_L, \eta _{h_2}, \ldots ,\eta _{h_{L-1}}]^T \end{aligned}$$\end{document}Once the upper-level design variables are defined, the first term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{{up}_{1}}( \vec {U}_{\rho })$$\end{document} of the objective function for the upper level \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{up}$$\end{document} , represented in (4), is formulated. This level examines the MLP architecture in terms of its hidden layers and the nodes within each hidden layer.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} J_{{up}_{1}}( \vec {U}_{\rho }, \vec {L}_\rho )= h_{L} + \sum _{s=2}^{L-1} \eta _{h_s} \end{aligned}$$\end{document}At this upper level, a constraint is established such that the design variables from the lower level, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\vec {L}_\rho$$\end{document} , solve an optimization problem related to the training and validation of the MLP, resulting in the MLP’s weights and biases. Therefore, at this upper level, the lower-level design vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\vec {L}_\rho$$\end{document} is considered constant.
The second term of the upper-level objective function is presented in (5). This second term includes the training and validation of the ANN through the Mean Squared Error (MSE) and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_\beta$$\end{document} ^48^ metrics, which are provided by the objective function of the lower level \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{low}(\vec {U}_{\rho }, \vec {L}_\rho )$$\end{document} . Therefore, these metrics incorporate a constant penalty for the upper-level objective function, which is proportional to the training and validation error obtained at the lower level. This second term is explained in detail in Section 2.2.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} J_{{up}_{2}}(\vec {U}_{\rho },\vec {L}_\rho ) = F_{low}(\vec {U}_{\rho },\vec {L}_\rho ) \end{aligned}$$\end{document}Therefore, to define the upper-level objective function (6), it is necessary to combine (4) and (5) using the weighting coefficients \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{s_1}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{s_2}$$\end{document} , which determine the importance of each element within the objective function during the optimization process.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} F_{up}(\vec {U}_{\rho },\vec {L}_{\rho })=a_{s_1} J_{{up}_{1}}( \vec {U}_{\rho },\vec {L}_{\rho }) + a_{s_2}J_{{up}_{2}}(\vec {U}_{\rho },\vec {L}_{\rho }) \end{aligned}$$\end{document}Lower level
The design variables associated with the lower level modify the training and validation of the MLP. Therefore, the weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega ^{s-1}_{t,v_{s}}$$\end{document} and biases \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u^{s}_{v_s}$$\end{document} are considered variables to be determined at the lower level. These variables are grouped in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\vec {L}_\rho =[\vec {L}_{\rho _1},\vec {L}_{\rho _2}]^T \in \mathbb {R}^{(\eta _i \times \eta _{h_i}) + \sum ^{L-2}_{s=1} (\eta _{h_s} \times \eta _{h_{s-1}}) + (\eta _{h_{L-1}} \times \eta _o) + \sum ^{L-1}_{s=2} (\eta _{h_s}) + \eta _o}$$\end{document} , as shown in (7). \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\vec {L}_{\rho _1}$$\end{document} includes the weight values and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\vec {L}_{\rho _2}$$\end{document} denotates the bias values.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \vec {L}_\rho =[\omega ^{s-1}_{t, v_s},u^{s}_{v_s}]^T \forall s=\{2,...,L\} \end{aligned}$$\end{document}The first term of the lower-level objective function is associated with the MSE of the MLP training, as shown in (8). The MSE minimizes the error between the target output \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\gamma }\hat{z}^{o}_{v_q}$$\end{document} and the output obtained \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\gamma }z^{L}_{v_q}$$\end{document} by the MLP during the optimization process, considering the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_t$$\end{document} input vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${}^{\gamma } z^{1}_{v_r}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\forall$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{v_r,\gamma \}$$\end{document} .
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} J_{{low}_{1}}(\vec {U}_{\rho },\vec {L_\rho })= \frac{1}{|v_q|} \sum _{\gamma =1}^{N_t} \sum _{v_q} ( ^{\gamma }z^{L}_{v_q}-^{\gamma }\hat{z}^{o}_{v_q} )^2 \end{aligned}$$\end{document}The second term of the lower-level objective function considers the MLP validation. For this, a set of inputs provided to the MLP must be regarded. This set can be divided into \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_t$$\end{document} training data and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_v$$\end{document} validation data, as reducing the MSE during MLP training does not guarantee suitable generalization. In fact, the MLP may fail to perform appropriately on unknown data during the test phase. For this reason, the second objective function is established as the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta }$$\end{document} metric, described in (9). This metric enables the evaluation of MLP performance, particularly in binary classification problems, as it combines Precision and Recall through a factor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} that adjusts the balance between the two measures when assessing the network’s performance. Precision provides information about the model’s ability to identify positive cases, while Recall quantifies the proportion of true positive cases correctly identified. Combining them reduces false positives and, simultaneously, decreases false negatives^49^. Furthermore, the values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_\beta$$\end{document} lie within the range [0, 1], where a value of 1 indicates \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$100\%$$\end{document} prediction accuracy, while a value of 0 corresponds to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0\%$$\end{document} prediction accuracy.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} J_{{low}_{2}}(\vec {U}_{\rho },\vec {L\rho })&=F_{\beta } \\&= (1+ \beta ) \frac{(Precision)(Recall)}{(\beta ^2 (Precision)+Recall)} \end{aligned} \end{aligned}$$\end{document}In expression (9), Precision and Recall are defined in equations (10) and (11), respectively. True Positives (TP) refer to cases where the model correctly predicts a positive instance when it is indeed positive in the data. False Positives (FP) are cases where the model incorrectly predicts a positive instance when it is negative. True Negatives (TN) refer to instances that are correctly predicted as negative, while False Negatives (FN) occur when the model incorrectly predicts a negative outcome for a truly positive instance. To better visualize the distribution of correct and incorrect predictions across multiple classes, a multiclass confusion matrix is employed in the proposed approach^50,51^.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & Precision = \frac{TP}{TP + FP} \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & Recall = \frac{TP}{TP + FN} \end{aligned}$$\end{document}To formulate the lower-level objective function (12), it is necessary to unify the terms associated with training (8) and validation (9) using a weighted sum approach. The weighted sum approach assigns the weighting coefficients \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{1_{low}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{2_{low}}$$\end{document} to each term. At this lower level, the goal is to minimize the MSE ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{{low}_{1}}(\vec {L}_\rho )$$\end{document} ) and maximize the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_\beta$$\end{document} metric ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{{low}_{2}}(\vec {L}_\rho )$$\end{document} ), so the negative sign is assigned to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{{low}_{2}}(\vec {L}_\rho )$$\end{document} to formulate the optimization problem as a minimization one.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} F_{low}(\vec {U}_\rho ,\vec {L_{\rho }})= a_{1_{low}} J_{{low}_1}(\vec {L_{\rho }}) - a_{2_{low}} J_{{low}_2}(\vec {L_{\rho }}) \end{aligned}$$\end{document}General formulation of the EB-LNAST optimization problem
Once the design variables, objective functions, and constraints of the EB-LNAST approach are defined, the optimization problem is formulated to find the optimal trained architecture that considers the input and output data, thereby achieving a suitable trade-off between training and validation of the MLP. Therefore, the general formulation of the proposed optimization problem is shown in (13).
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned}&\min _{\vec {U}_\rho , \vec {L}_{\rho }} F_{up}(\vec {U}_{p},\vec {L}_{\rho }) \\&\text {s.t.} \\&\quad \vec {U}_\rho \in \underset{\vec {L}_\rho }{\operatorname {argmin}} \left\{ \begin{array}{ll} F_{low}(\vec {U}_{\rho },\vec {L_{\rho }}) \\ s.t. \\ \vec {L}_{\rho _{min}} \le \vec {L}_{\rho } \le \vec {L}_{\rho _{{max}}} \end{array} \right. \\&\quad \vec {U}_{\rho _{min}} \le \vec {U}_{\rho } \le \vec {U}_{\rho _{max}} \end{aligned} \end{aligned}$$\end{document}Optimization technique
Traditionally, neural network training is performed using the backpropagation algorithm^9^, a widely used method due to its simplicity and efficiency. However, its main drawback is the possibility of getting trapped in local optima without guaranteeing convergence to the global optimal solution, which can negatively impact the model’s performance.
To address the optimization problem using the EB-LNAST approach, a bi-level model is proposed to overcome the limitations of the backpropagation algorithm. Since the upper-level objective functions involve discrete variables, multiple solutions must be generated instead of relying on gradient-based methods. In this work, DE, a global optimization algorithm inspired by biological evolution, is employed. DE enables a broader exploration of the solution space, facilitating the search for optimal architectures and ensuring the reproducibility of experiments. Additionally, it reduces the risk of getting trapped in local optima, offering a more versatile alternative for training artificial neural networks^52^.
To implement the EB-LNAST approach with DE, the variable \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\textbf {X}}_{sup}=[h_L, \eta _{h_2}, \ldots ,\eta _{h_{L-1}}]^T$$\end{document} is assigned for the upper level, noting that at this level the variables are handled as positive integers. Consequently, for the lower level, the variable \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\textbf {X}}_{low}=[\omega ^{s-1}_{t, v_s}, u^{s}_{v_s}]^T$$\end{document} is assigned with real values. The structure of the DE algorithm for the EB-LNAST approach is presented in Algorithm 1, specifically using the best/1/bin variant^53^.
Algorithm 1Differential evolution algorithm for bi-level optimization
In the related literature, many approaches to optimizing hyperparameters and neural network architectures rely on deterministic methods for training. However, when simultaneously searching for both network architectures and optimizing weights and biases, DE provides a robust framework by exploring multiple architectural solutions. This approach mitigates the issue of repetitive training, allowing for a more comprehensive exploration of potential solutions.
Case study: color classification
As a case study for the EB-LNAST approach, the color classification through the ColorPal device from Parallax is included. The device features a compact TSL13T sensor that detects the intensity of light reflected by the object in millivolts. This voltage provides information about the light spectrum in which the object’s color is located. However, ambient light can introduce values that do not correspond to the actual light spectrum, making color identification a complex task.
Using the ColorPal device, a system is integrated with five 3D-printed tablets of different colors. The device is placed in a semi-enclosed base at a distance of 1 cm from the position where the tablets are located, aiming to measure light reflection in millivolts. The light reflections of the onboard RGB Light Emitting Diode (LED) are used as a distinctive feature (attribute) for color classification. Then, the device sequentially illuminates the tablet with red, green, blue, and white lights to form the input instance of the MLP network. The ambient light is also included in the input instance when the lights of the RGB LED are turned off. The sensitivity of ambient light is reduced by taking samples in different locations and times of the day.
The ColorPal system, as shown in Figure 4, is designed to provide information about the input features related to the light reflections using five different light intensities. The EB-LNAST approach determines the optimal ANN architecture for identifying the color class to which an input instance belongs. The following section presents the particularities of the EB-LNAST approach in this case study.Fig. 4. ColorPal system for measuring light reflection.
Optimization problem formulation for color classification
Input data
A total of 570 measurements (reflected light intensity-related voltages) are collected from 3D-printed tablets with colors cyan, red, yellow, green, and magenta under varying ambient light conditions. In this work, a sample consists of five different voltages related to the reflected light intensities on a specific color tablet. Fourteen samples using a color tablet with different ambient light are averaged to serve as an input instance (input data in the ANN). In total, seventy measurements are used to provide five instances or samples (five input data related to each color tablet) in the training of the EB-LNAST approach delivering a balanced data set. The mean reflected light intensities, in millivolts, corresponding to the five input instances are presented in Table 1.Table 1. Input instances (input data) from the average of 14 measurements in mV obtain by ColorPal system.Color tabletsCyan ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma =1$$\end{document} )Red ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma =2$$\end{document} )Yellow ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma =3$$\end{document} )Green ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma =4$$\end{document} )Magenta ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma =5$$\end{document} )LightintensitiesRed \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${}^{\gamma } z^{1}_{1}$$\end{document} 1358.071956.002716.50785.362649.29Green \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${}^{\gamma } z^{1}_{2}$$\end{document} 1643.64493.932052.711152.361304.79Blue \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${}^{\gamma } z^{1}_{3}$$\end{document} 3131.14653.572219.36897.212548.50White \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${}^{\gamma } z^{1}_{4}$$\end{document} 1893.21461.711325.93753.001201.14Ambient \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${}^{\gamma } z^{1}_{5}$$\end{document} 644.00272.71405.86323.21384.64
The input vector for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} -th color tablet is presented as a vector in (14).
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} {}^{\gamma } z^{1}_{v_r} = [{}^{\gamma } z^{1}_{1}, {}^{\gamma } z^{1}_{2}, {}^{\gamma } z^{1}_{3}, {}^{\gamma } z^{1}_{4}, {}^{\gamma } z^{1}_{5}]^T \end{aligned}$$\end{document}For the validation process in the proposed approach, the previously mentioned 70 measurements (i.e., 14 samples) are used. The remaining 500 measurements (100 samples) are then employed to test the optimal architecture obtained.
Output data
The output is encoded using One-Hot Encoding, representing the target color in the tablet to be identified. Therefore, the MLP output for this case study is represented as a vector as in (15), where the corresponding MLP output vectors to each color tablet are presented in Table 2.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} {}^{\gamma } \hat{z}^{o}_{v_q} = [{}^{\gamma } \hat{z}^{o}_{1}, {}^{\gamma } \hat{z}^{o}_{2}, {}^{\gamma } \hat{z}^{o}_{3}, {}^{\gamma } \hat{z}^{o}_{4}, {}^{\gamma } \hat{z}^{o}_{5}]^T \end{aligned}$$\end{document}Table 2. One-Hot Encoding for MLP Outputs.OutputColor tabletsCyan ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma =1$$\end{document} )Red ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma =2$$\end{document} )Yellow ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma =3$$\end{document} )Green ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma =4$$\end{document} )Magenta ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma =5$$\end{document} ) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${}^{\gamma } \hat{z}^{o}_{1}$$\end{document} 10000 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${}^{\gamma } \hat{z}^{o}_{2}$$\end{document} 01000 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${}^{\gamma } \hat{z}^{o}_{3}$$\end{document} 00100 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${}^{\gamma } \hat{z}^{o}_{4}$$\end{document} 00010 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${}^{\gamma } \hat{z}^{o}_{5}$$\end{document} 00001
Activation functions for neurons
In the proposed approach, the purelin and softmax activation functions are implemented for each hidden layer and output layer, respectively.
Problem formulation for the case study
Once the inputs and outputs of the case study are defined for the training and validation processes, the initial conditions for the optimization problem in the proposal are established.
The upper-level design variable vector limits for the number of MLP hidden layers are defined as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$2\le \vec {U}_{\rho _1}\le 5$$\end{document} . The number of nodes in the hidden layer is bounded by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1\le \vec {U}_{\rho _2}\le 5$$\end{document} . For the lower level, the limits associated with the MLP weights and biases are set as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-5\le \vec {L}_{\rho _1}\le 5$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-5\le \vec {L}_{\rho _2}\le 5$$\end{document} , respectively.
On the other hand, regarding the weighting values for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{up}$$\end{document} , a value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{s_{1}} = 0.1$$\end{document} is assigned to reflect the importance level attributed to the size of the neural network architecture. In contrast, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{s_{2}} = 0.9$$\end{document} corresponds to the error and validation obtained from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{low}$$\end{document} . For \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{low}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{low_{1}} = 0.01$$\end{document} is used to indicate the relevance of the MSE, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{low_{2}} = 0.99$$\end{document} is assigned to the validation of the proposed approach for each generated architecture.
Then, the optimization problem of the proposed EB-LNAST approach in (13) is solved by DE, as is described in the previous in Algorithm 1. It is important to note that once the model derived from the EB-LNAST approach is obtained, the resulting optimal network is fully specified and does not require the use of differential evolution (DE), as it already includes the trained weights and biases necessary for evaluation on unseen data. However, the bi-level training phase based on DE requires a considerable computational cost. To alleviate this limitation, the use of graphics processing units (GPUs), together with parallel and distributed computing strategies, can substantially reduce execution time while preserving the quality of the obtained solution.
Experimental results
This section presents the analysis of the results obtained using the EB-LNAST approach in color identification through the ColorPal system. The first section discusses the conditions required for the optimizer to solve the EB-LNAST approach. The second section presents the performance analysis of the EB-LNAST approach, and the final section validates the proposal by comparing it with two fixed neural network architectures: one trained using DE and the other using GD.
Optimizer conditions
To solve the optimization problem using the EB-LNAST approach, the initial conditions shown in Table 3 are used. The values of the scaling factor F and the crossover factor CR are proposed based on the suggestion provided in^53^. The population size (NP) and the maximum number of generations ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G_{Max}$$\end{document} ) are determined through an empirical trial-and-error process, where different values are systematically tested to identify those yielding the best overall performance.Table 3. Initial conditions of the DE algorithm for the EB-LNAST approach.ParameterUpper levelLower LevelNP2010 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G_{Max}$$\end{document} 1050F0.9[0.3, 0.9]CR0.90.9
To verify and evaluate the behavior of the EB-LNAST approach, this study performs thirty independent executions. The corresponding performance analysis of the proposed approach appears in the following section.
Performance analysis of the EB-LNAST approach
The complete set of thirty executions of the proposed approach using DE is provided in Table 18 of the appendix. The best executions of such a table are shown in Table 4. The first column indicates the execution number followed by the value of the upper-level objective function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{up}$$\end{document} , the first term of the upper level \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{up_1}$$\end{document} , the lower-level objective function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{low}$$\end{document} , the lower level’s first term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{{low_1}}$$\end{document} , the lower level’s second term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{{low_2}}$$\end{document} , and the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta _{test}}$$\end{document} metric. The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta _{test}}$$\end{document} metric considers one hundred test data points (100 samples), as is described in Section 3.1. It is worth noting that, in all executions of the proposed approach, the generated architecture results in a single hidden layer ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_{L}=1$$\end{document} ) with two nodes ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta _{h_1}=2$$\end{document} ).Table 4. Results of the fourteen best executions from the EB-LNAST approach.Executions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{up}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{up_1}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{low}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{{low_1}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{{low_2}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta \, \text {test}}$$\end{document} 2−0.5913−0.99010.913−0.5913−0.99010.9286−0.5913−0.99010.9567−0.5913−0.99010.9310−0.5913−0.99010.95711−0.5913−0.99010.9312−0.5913−0.99010.97214−0.5913−0.99010.90615−0.5913−0.99010.95419−0.5913−0.99010.93822−0.5913−0.99010.96423−0.5913−0.99010.94624−0.5913−0.99010.92629−0.5913−0.99010.92
The obtained results of the proposed approach yield the same value for the higher-level objective function ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{up} = -0.591$$\end{document} ) and the lower-level objective function ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{low} = -0.99$$\end{document} ). The value \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{low}$$\end{document} implies that the terms corresponding to the MSE converge to zero ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{{low_1}}=0$$\end{document} ). The validation metric \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta _{val}}$$\end{document} associated with the other term reaches a maximum value ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{{low_2}}=1$$\end{document} ). This means that no errors are generated during the model’s validation with the proposed approach, implying that the MLP correctly generalizes each pattern from the case study without error, which reflects the outstanding performance of the obtained model. However, despite all executions having the same validation, the difference lies in the trained parameters. The resulting weights and biases show differences, as displayed in Figure 5. So, although the executions converge to the same value for both the higher- and lower-level objective functions, the parameters obtained by the proposed approach exhibit differences. Therefore, the generated architecture has a complex topology with multiple optimal solutions, which confirms the multimodality of the problem.Fig. 5. The parallel coordinate plot of the design variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\vec {U}_\rho$$\end{document} corresponding to the fourteen best executions with higher-level objective function values \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{up}=-0.591$$\end{document} and lower-level objective function value \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{low}=-0.99$$\end{document} .
Since the MLP architecture presents different parameters with the same objective function value, the most appropriate architecture for the case study is selected based on the network’s performance with the test data, with the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta \, test}$$\end{document} metric. In Table 4, the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta \, test}$$\end{document} metric is shown, where a prediction greater than 0.90 is observed in all fourteen executions, confirming that these correctly classify the majority of the solutions found. In particular, the most promising solution (the best for practical purposes) has a value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta \, test}=0.9720$$\end{document} , whereas the worst one has \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta \, test}=0.9060$$\end{document} . Moreover, all executions present a standard deviation of 0.0195, indicating the variability of the fourteen optimal solutions obtained. In Table 5, the associated variables of the most promising solution with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta \, test}=0.9720$$\end{document} are shown.Table 5. Design variables (DVs) corresponding to the most promising solution with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta _{test}}$$\end{document} = 0.9720.DVsValueDVsValueDVsValue \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{1,1}^{1}$$\end{document} 4.336559165 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{1,2}^{1}$$\end{document} −4.308587149 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_{1}^{2}$$\end{document} 1.958767935 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{1,3}^{1}$$\end{document} 0.193691725 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{1,4}^{1}$$\end{document} 0.122280253 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_{1}^{3}$$\end{document} −2.583709719 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{1,5}^{1}$$\end{document} −1.415386565 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{2,1}^{1}$$\end{document} −0.589810735 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_{2}^{2}$$\end{document} −1.360421044 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{2,2}^{1}$$\end{document} −4.208863746 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{2,3}^{1}$$\end{document} 3.005774596 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_{2}^{3}$$\end{document} −3.38735932 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{2,4}^{1}$$\end{document} 0.262737489 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{2,5}^{1}$$\end{document} 1.718634339 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_{3}^{3}$$\end{document} −1.541036076 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{1,1}^{2}$$\end{document} −0.292894766 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{1,2}^{2}$$\end{document} 4.275509663 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_{4}^{3}$$\end{document} 2.872284614 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{2,1}^{2}$$\end{document} 4.312974947 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{2,2}^{2}$$\end{document} −2.100953911 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_{5}^{3}$$\end{document} −2.512897963 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{3,1}^{3}$$\end{document} 4.162213365 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{3,2}^{3}$$\end{document} −2.749309781 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{5,1}^{2}$$\end{document} 3.842026311 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{4,1}^{2}$$\end{document} −4.147006129 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{4,2}^{2}$$\end{document} −0.458866391 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\omega _{5,2}^{2}$$\end{document} 2.628829431
To analyze the behavior of the most promising solution in its architecture for the case study, a multiclass confusion matrix is shown in Figure 6. The main diagonal of the confusion matrix refers to the total number of correct predictions, i.e., the TPs. The values outside the diagonal represent incorrect predictions, including both FNs and FPs. A summary of such a prediction is presented in the bottom part of the confusion matrix, where the first row of the predicted class box shows the percentage of total TPs for each color, while the second row displays the percentage of errors (sum of FP and FN) obtained for each class. It can be seen that the percentages in the FPs and FNs indices are within the interval \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$[2, 4]\%$$\end{document} , confirming an acceptable error percentage in color classification within the test set. On the other hand, to the right of the confusion matrix, the prediction index corresponding to the true classes for the proposed approach is shown. It is observed that for each class, the prediction interval is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$[95.1, 98.0]\%$$\end{document} , indicating the high precision of the model in correctly classifying each class.Fig. 6. Confusion matrix generated by the EB-LNAST approach corresponding to the best execution with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta _{test}}=0.972$$\end{document} .
Comparative analysis with fixed architecture of a DNN
In this section, the proposed EB-LNAST approach is compared with a fixed architecture of a DNN, whose weights and biases are optimized using the DE and GD algorithms. The primary objective is to evaluate the performance of the proposed model against a DNN with multiple hidden layers. Subsequently, the results obtained with DE and GD are analyzed, and a direct comparison is made with the results achieved by the EB-LNAST approach.
Based on the results obtained from the proposed approach in section 4.2, it can be observed that the generated architecture consists of a total of twelve nodes, which are distributed across five nodes in the input and output layers, with one hidden layer ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_L=1$$\end{document} ) containing two nodes in that layer ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta _{h_1}=2$$\end{document} ). In practice, most neural network architectures are selected based on the designer’s experience and empirical experimentation, testing various configurations to solve the same problem, as in the case of pattern classification, image recognition, regression problems, and/or function approximation^54,55^.
Many of these studies suggest that with a greater number of parameters in the neural network architecture, better performance is likely to be obtained. However, this also comes with an increase in processing time, and many of these studies are exclusively focused on Deep Learning and do not follow an established metric or methodology for architecture selection. This results in the empirical selection of architectures that increase the experimentation time and reduce the repeatability of results due to the trial-and-error process.
Therefore, considering the architecture generated by the EB-LNAST approach, the comparative DNN is formed by a total of 25 nodes grouped among the input layer, output layer, and three hidden layers ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_L = 3$$\end{document} ), with five nodes in each hidden layer ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta _{h_1} = 5$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta _{h_2} = 5$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta _{h_3} = 5$$\end{document} ). The comparative DNN exhibits a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$108.33\%$$\end{document} increase in the number of nodes relative to the architecture obtained with the EB-LNAST approach. In other words, the EB-LNAST method achieves a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$52\%$$\end{document} reduction in architectural size compared to the DNN. For this comparison, this new configuration may provide better performance compared to the architecture generated by the proposed approach.
The comparative DNN architecture is optimized using both DE and GD. In the case of the GD algorithm, an increase in the depth of the network leads to problems of vanishing or exploding gradients^56^, especially if the initial conditions are not correctly set. On the other hand, when considering the search for solutions using DE, the increase in the complexity of the architecture implies a greater number of objective function evaluations are required to achieve convergence towards optimal architectures. It is worth mentioning that the same activation functions are employed in the DNN architecture as in the proposed method, namely the purelin function for the hidden layers and the softmax function for the output layer. This design choice ensures a fair comparison by maintaining consistent activation dynamics across models, thereby isolating the effect of other architectural and algorithmic differences. The parameters for GD and DE are shown in Table 6, and those are obtained through experimental observations. In the first and second columns of the table, the parameters used for the GD algorithm are presented, including a maximum number of training epochs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$200{,}000$$\end{document} , a Learning Rate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1 \times 10^{-3}$$\end{document} , and weight and bias initialization based on a normal distribution between the interval expressed in Table 6. The third and fourth columns present the parameters used for the DE algorithm. A total of thirty executions are performed for each optimizer (GD and DE).Table 6. Conditions for experiments in the training of the DNN with GD and DE.GDDEMax epochs200000NP30Learning Rate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1 \times 10^{-3}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G_{max}$$\end{document} 250Weight init.[−0.1, 0.1]CR0.6Bias init.[−0.1, 0.1]F[0.3, 0.9]
Table 19a in the Appendix section presents the total number of executions by using DE and GD in the training of the DNN. Tables 7 and 8 report the best executions in both cases. The test evaluation is also incorporated in the aforementioned tables. A similar presentation of results is provided as in Table 4. It is important to highlight that, during the experimental tests, it is observed that classifications performed using the GD method resulted in output probabilities from the MLP that consistently remained below 0.90. This behavior contrasts with the EB-LNAST and DE approaches applied to DNNs, which produced probabilities approaching 0.99999 and even reaching 1 in some cases. Such a discrepancy indicates a lower level of confidence in the predictions made by the DNN trained with GD. This does not necessarily imply incorrect predictions but rather suggests a reduced likelihood of correct classification according to the model’s internal confidence. To address this issue and accurately reflect the GD-trained model’s behavior on the test dataset, the predicted class is assigned based on the maximum probability output, following the methodology proposed in^57,58^. This allows for a more faithful evaluation of the actual performance of the DNN optimized using GD.Table 7. Performance of the best DE executions in the DNN training, incorporating test evaluation.Execution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{low}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{{low_1}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{{low_2}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta \, test}$$\end{document} 3−0.99010.955−0.99010.9369−0.99010.89413−0.99010.94216−0.99010.92221−0.99010.95423−0.99010.9525−0.99010.93626−0.99010.87627−0.99010.94828−0.99010.96229−0.99010.964Table 8. Performance of the best execution provided by GD in the DNN training, along with their respective performance on the testing dataset.Execution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{low}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{{low_1}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{{low_2}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta \, test}$$\end{document} 2−0.99 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.50\times 10^{-13}$$\end{document} 10.946
It is observed that in the case of GD results, only one best solution is found, which presents a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta \, test}$$\end{document} metric of 0.946. Meanwhile, in the case of DE results, twelve solutions with the same training performance are found. Therefore, test performance is used to select the most suitable solution in practice since all executions yield the same or very similar values for the lower-level performance metric \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{low}$$\end{document} .
The DNN trained with DE achieves the best value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta \, test} = 0.964$$\end{document} , and the rest of the solutions are in the interval \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta _{test}} \in [0.876, 0.964]$$\end{document} . It is worth noting that higher values closer to one indicate better classification performance. On the other hand, the proposed method yields an \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta _{test}}$$\end{document} interval of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$[0.9060,\ 0.9720]$$\end{document} . Table 9 presents the 95% confidence intervals for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta \, \text {test}}$$\end{document} metric achieved by the EB-LNAST and DNN-DE approaches. The obtained confidence intervals suggest that both approaches achieve high performance on the classification task. Nevertheless, the EB-LNAST attains a peak \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta \, \text {test}}$$\end{document} value (0.972) larger than DNN-DE (0.964). These outcomes indicate that EB-LNAST provides slightly better peak predictive capability. In addition, the EB-LNAST yields a narrower confidence interval ([0.9267, 0.9501]) than the DNN-DE interval ([0.9191, 0.9532]). This suggests that EB-LNAST not only achieves strong peak performance but also reveals greater consistency and reliability across multiple executions. As a consequence, the EB-LNAST outperforms DNN-DE in terms of both maximum test performance and overall stability, making the solution with the proposed EB-LNAST a more robust one in terms of classification accuracy.Table 9. The 95% confidence interval of the metric \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta \, test}$$\end{document} .Confidence intervalEB-LNAST[0.9267, 0.9501]DNN-DE[0.9191, 0.9532]
To observe the distribution of predictions using the DNN trained by GD and DE, the confusion matrices corresponding to those networks are shown in Figure 7 and Figure 8. In the case of DBB-GD, it is observed that there is an error of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$14.0\%$$\end{document} for the yellow class, followed by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$4.0\%$$\end{document} for the red and cyan ones, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.0\%$$\end{document} for the green one, and finally \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$2.0\%$$\end{document} for the magenta class. This value represents a substantial increase in the error range, which is between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$[0.2, 14.0]\%$$\end{document} . Additionally, the prediction index for each class, shown on the right side of the matrix, ranges between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$[85.1, 100]\%$$\end{document} . In contrast with DNN-DE, it is observed that the DNN has a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10.0\%$$\end{document} error when predicting the green class, followed by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.0\%$$\end{document} for yellow and red, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$2.0\%$$\end{document} for magenta, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.0\%$$\end{document} for the cyan class. The confusion matrix of DNN-DE shows a prediction error range between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$[1,10]\%$$\end{document} . On the other hand, when analyzing the right side of the matrix, it is observed that the correct prediction rate for each class is between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$[87.5, 99]\%$$\end{document} .Fig. 7. Confusion matrix generated by DE for the DNN architecture corresponding to the best execution with a test \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta _{test}}$$\end{document} score of 0.964.Fig. 8. Confusion matrix generated by GD for the DNN architecture corresponding to the best execution with the test \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta _{test}}$$\end{document} score of 0.9472.
On the other hand, the inferential statistical analysis is also shown to generalize the obtained conclusion. In particular, the nonparametric statistical analysis provided by the pairwise Wilcoxon signed-rank test is used with the thirty data ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta \, test}$$\end{document} ) obtained in Tables 18 and 19a, corresponding to the proposed EB-LNAST and the DNN trained by DE, and GD, respectively. Table 10 displays the Wilcoxon test, where two-sided hypothesis and the statistical significance of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho = 5\%$$\end{document} are selected. The columns \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R_{+}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R_{-}$$\end{document} correspond to the sums of ranks computed during the test. Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R_{-}$$\end{document} reflects the instances where samples from the first set outperform those from the second, while \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R_{+}$$\end{document} captures the contrary. The winner is shown in boldface when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\text {-value} \le \rho$$\end{document} . Based on the Table 10, it is statistically confirmed that EB-LNAST is the best option because it outperforms the results given by both DNN-DE and DNN-GD. The second option is provided by the DNN-DE. The worst result is given by DNN-GD.Table 10. Summary of the inferential statistics for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta test}$$\end{document} : EB-LNAST vs. DNNs (DE, GD).Comparison \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${R_{+}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${R_{-}}$$\end{document} p-valueEB-LNAST vs DNN-DE86.5378.50.0019EB-LNAST vs DNN-GD5.5459.5 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$2\times 10^{-8}$$\end{document} DNN-DE vs DNN-GD1283370.0305
The results obtained indicate that the DNN architectures optimized using DE and GD do not outperform the classification accuracy achieved by the EB-LNAST approach. These findings suggest that arbitrarily increasing the number of hidden layers and nodes in a neural network does not necessarily guarantee improved performance. As mentioned earlier, the designer’s experience can influence the generation of effective classification models. However, the EB-LNAST approach shows that it is possible to identify compact and efficient architectures capable of solving the problem both effectively and reliably. A representative video showing the color classification performed by the model obtained through the EB-LNAST approach is available at https://www.dropbox.com/scl/fo/8b5s6xeyxyd9eexpk761z.
Furthermore, the dataset plays a fundamental role in the design and evaluation of neural architectures. Particularly, due to the multimodal characteristic of the classification problem, it is observed that DE did not encounter difficulties in finding efficient solutions. In contrast, the GD optimizer exhibits lower predictive reliability, as the initial conditions and sensitivity to local minima significantly hinder its performance.
Comparative analysis with popular machine learning classification algorithms
To enhance the comparative analysis of the EB-LNAST approach in the color classification task, four widely used Machine Learning (ML) classification algorithms implemented using the Scikit-learn library in Python are incorporated: Multi-Layer Perceptron (MLP), K-Nearest Neighbors (KNN), Naive Bayes (NB), and Random Forest (RF). For each algorithm, a hyperparameter optimization process is conducted to assess the effectiveness of the proposed bilevel optimization approach. Then, the comparisons also undergo optimal hyperparameter tuning. For instance, in the case of the MLP, particular attention is given to a comprehensive set of hyperparameters, including not only architectural aspects (number of layers and neurons), weights and bias terms, but also other relevant hyperparameters, such as, activation functions, weight initialization strategies, regularization techniques, gradient-based optimizers, thereby enabling a more comprehensive and fine-grained tuning process.
The hyperparameters of such ML algorithms are tuned by using the hyperparameter optimization from the Scikit-learn tool called “RandomizedSearchCV”, where the general setting of the tool is shown in Table 11 and the hyperparameter search space defined for each model is displayed in Table 12.Table 11. General configuration of the ML algorithms performed in Python using the RandomizedSearchCV tool from the Scikit-learn library.ConfigurationValueAlgorithmsMLP/NB/KNN/RFIterations50Cross-validation5Metric \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta }$$\end{document} Re-trainingTrueParallelism−1SeedVariable per runTable 12Hyperparameter search space used in RandomizedSearchCV tool.Multi Layer Perceptron (MLP)Hidden layers1 or 2Hidden layer sizesInteger values between 2 and 150Activation functionRelu, tanh, logistic, identitySolverAdam, sgdL2 regularization alphaPositive continuous values (mean 0.1)Learning rate initValues between 0.1 and 0.2Early stoppingTrue, FalseEpochs (max_iter)Integer values between 100 and 500Random Forest (RF)Number of estimatorsInteger values between 100 and 600Max depthInteger values between 3 and 50Min samples splitInteger values between 2 and 20Min samples leafInteger values between 1 and 20Max featuresProportion between 0.3 and 0.7BootstrapTrue, FalseClass weightNone, balanced, balanced subsampleCriterionGini, cross entropyK-Nearest Neighbors (KNN)Number of neighborsInteger values between 1 and 60WeightsUniform, distanceMetricMinkowski, euclidean, manhattan, chebyshevp (for minkowski)Integer values between 1 and 3AlgorithmAuto, ball_tree, kd_tree, bruteLeaf sizeInteger values between 15 and 60Naive Bayes (NB)AlgorithmGaussian NBVar smoothingValues between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^{-12}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^{-6}$$\end{document}
The results of thirty independent executions of the comparative ML algorithms, optimized via hyperparameter tuning, are reported in Table 20 and Table 21 in the appendix. The former table provides the information on the MLP comparison, the latter one for the rest of the ML algorithms (KNN, RF and NB). In addition, to support a general conclusion, Table 14 presents the pairwise Wilcoxon signed-rank test results for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta \text { test}}$$\end{document} metric, using the same configuration and following the same table description as in previous sections. This table statistically confirms that the proposed EB-LNAST achieves an outstanding performance with respect to KNN, RF and NB, while in the case of MLP, the proposal exhibits a performance drop. In particular, the best \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta \text { test}}$$\end{document} scores obtained by KNN, RF, and NB are 0.9272, 0.9265, and 0.8792, respectively. These represent performance reductions of approximately \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$4.62\%$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$4.68\%$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$9.55\%$$\end{document} compared to the proposed method. In the comparative analysis with MLP, the statistical results indicate that the proposed EB-LNAST does not outperform the model based on MLP. Nevertheless, the best \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta \text { test}}$$\end{document} score achieved by EB-LNAST (0.972) is only \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.80\%$$\end{document} lower than the best result obtained by MLP (0.9799). On the other hand, the MLP exhibits architectures with up to two hidden layers (see \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_L$$\end{document} in Table 20) and variable layer sizes reaching up to 149 neurons per layer (see \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta _{h_1}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta _{h_2}$$\end{document} in Table 20), which increases the network’s effective complexity as measured by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{up_1}$$\end{document} (4). In contrast, EB-LNAST maintains a fixed and compact structure with a single hidden layer of only two neurons (see \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_L$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta _{h_1}$$\end{document} for EB-LNAST), significantly reducing architectural complexity. Then, considering that the proposed method achieves a substantial architectural reduction of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$98.51\%$$\end{document} , as indicated by the MLP architecture metric \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{up_1}$$\end{document} in Table 20, and that network performance is only marginally affected, the EB-LNAST approach offers a competitive model that significantly enhances the trade-off between architectural complexity and training efficiency by integrating a bi-level architecture search with training parameter optimization.Table 13. Summary of the inferential statistics for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{up_1}$$\end{document} : EB-LNAST vs MLP.Comparison \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {R_{+}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {R_{-}}$$\end{document} p-value****EB-LNAST vs MLP435.00.0 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.7 \times 10^{-9}$$\end{document} Table 14. Summary of the inferential statistics for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta test}$$\end{document} : EB-LNAST vs ML algorithms (MLP, KNN, RF and NB).Comparison \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${R_{+}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${R_{-}}$$\end{document} p-valueEB-LNAST vs MLP79.0386.0 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.59 \times 10^{-3}$$\end{document} EB-LNAST vs KNN420.045.0 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.05 \times 10^{-5}$$\end{document} EB-LNAST vs RF440.025.0 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.68 \times 10^{-6}$$\end{document} EB-LNAST vs NB450.015.0 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$7.62 \times 10^{-6}$$\end{document}
On the other hand, to provide a clearer perspective on the computational demands of the proposed approach, the execution times of EB-LNAST and the baseline algorithms are reported. This analysis allows us to contextualize the trade-off between model accuracy and runtime. Table 15 summarizes the average execution time of the evaluated algorithms. It is evident that EB-LNAST requires a substantially higher runtime (approximately 120.7 seconds) compared to conventional algorithms. Among the baselines, Random Forest shows an intermediate runtime (7.58 seconds), whereas MLP, KNN, and NB achieve very low execution times, all below one second. These findings reflect the additional computational effort of EB-LNAST, which results from its bi-level evolutionary optimization strategy. Nevertheless, this effort is strategically invested in obtaining architectures that are not only compact and high-performing but also stable and reproducible properties. Moreover, once trained, these minimal architectures drastically reduce inference time and resource consumption in practical applications with limited computational resources. In this way, the higher computational demand during optimization is balanced by the long-term benefits of efficiency, reproducibility, and practical applicability.
The bi-level optimization stage can be significantly accelerated through parallel and distributed computing strategies, such as GPU-based implementations, which would effectively mitigate the runtime overhead. However, this remains an open direction for future work.Table 15. Average execution time (in seconds) of the compared algorithms.**Algorithm****Average Time (s)**EB-LNAST120.7074MLP0.3376RF7.5807KNN0.3644NB0.0964
Comparative analysis with a large dataset
To evaluate the performance of EB-LNAST on a larger and more complex dataset, the Breast Cancer Wisconsin (Diagnostic) Dataset (WDBC) is employed^59^. This dataset consists of 569 samples of digitized images of fine needle aspiration of breast masses classified as either benign (with 357 cases) or malignant (with 212 cases) in an imbalanced class distribution. In the WBDC dataset, ten morphological features of the cell nuclei were extracted: radius, texture, perimeter, area, smoothness, compactness, concavity, concave points, symmetry, and fractal dimension. For each of these base features, three descriptive statistics were computed: the mean, the standard error, and the worst value (defined as the mean of the three largest values). This results in thirty real-valued predictive attributes per sample, in addition to a unique identifier and the diagnostic class label.
Table 22 in appendix presents the results from thirty independent runs of the EB-LNAST approach in the WBDC dataset, using the same DE configuration for color identification, and the dataset is split into 70% for training and 30% for validation and testing to make a fair comparison with the reported results in the literature. Table 16 presents the report summary described by descriptive statistics in the metrics \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta test}$$\end{document} and accuracy. It is observed that the proposal achieves the best \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta test}$$\end{document} value of 0.9879, with a mean value of 0.9830 and a reduced standard deviation of 0.0031. In addition, the accuracy metric reaches values of 0.9883, 0.9709, and 0.0235, following the same order of comparison. Although of the EB-LNAST approach is formulated to improve the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta test}$$\end{document} , the accuracy metric presents a similar value.Table 16. Descriptive statistics of EB-LNAST for the WDBC dataset.Statistic (Accuracy)ValueStatistic ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{\beta test}$$\end{document} )ValueBest0.9883Best0.9879Worst0.9006Worst0.9758Mean0.9709Mean0.9830Std. Dev.0.0235Std. Dev.0.0031
With the purpose of evaluating the effectiveness of the proposed approach on a larger dataset, the best results reported in^60^ with different Machine Learning (ML) algorithms on the WBDC dataset are provided for comparison. The Gated Recurrent Unit-Support Vector Machine (GRU-SVM), Linear Regression (LR), MLP, L1 Nearest Neighbor regularization (L1-NN), L2 Nearest Neighbor regularization (L2-NN), Softmax Regression (SR), and Support Vector Machine (SVM) were the reported ML algorithms in^60^. Table 17 reports the accuracy obtained in the work. It is observed that the proposed EB-LNAST with an accuracy metric of 0.9883 outperforms six of the seven ML algorithms compared with^60^. The best reported results are given by MLP, which obtained an accuracy of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.9903\%$$\end{document} , slightly superior to the EB-LNAST, with a difference of 0.0021. Nevertheless, this small difference is offset by the remarkably compact architecture obtained with the proposal (a single hidden layer with only five neurons). In particular, the MLP used in^60^ relies on an architecture that is approximately 30000 times larger than the EB-LNAST approach (the obtained model with the proposal approach achieves a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$99.66\%$$\end{document} reduction w.r.t. the MLP in^60^), which requires three hidden layers with five hundred neurons each and uses the ReLU activation function. The results of the proposed approach reflect the particular trade-off defined by the weights assigned to the terms of the upper-level objective function. Alternative weight configurations could emphasize different performance aspects, highlighting the flexibility and competitiveness of the method in adapting to diverse optimization goals, particularly reinforcing its significance for medical data classification tasks.Table 17. Reported results from^60^ on WDBC dataset.MetricGRU-SVMLRMLPL1-NNL2-NNSRSVMAccuracy93.75%96.0937%99.0384%93.5672%94.7368%97.6562%96.0937%
Conclusions
This work presents an Evolutionary Bi-Level Neural Architecture Search with Training (EB-LNAST) approach for simultaneously optimizing the architecture, weights, and biases of a Multi-Layer Perceptron (MLP) through a bi-level optimization strategy. At the upper level, EB-LNAST generates candidate MLP architectures, while at the lower level, it tunes their weights and biases based on the dataset. The proposed approach is evaluated on a color classification task using a custom experimental setup, as well as on the Wisconsin Diagnostic Breast Cancer (WDBC) dataset.
The results show that the EB-LNAST approach statistically outperforms the evaluation of classification performance in the traditional machine learning algorithms KNN, NB, and RF in the color identification task, as well as advanced models such as GRU-SVM, LR, L1-NN, L2-NN, and SR-SVM on the WDBC dataset.
In the comparison with MLP-based approaches, the proposal achieves a superior predictive performance when the network architecture is excluded in the optimization process, and remains competitive (with a maximum performance decrement of up to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.99\%$$\end{document} ) when hyperparameter optimization extends beyond weights, and bias terms, to include additional factors such as architectural aspects (number of layers and neurons), activation functions, weight initialization strategies, regularization techniques, and gradient-based optimizers. In addition, the model obtained with the proposed approach achieves up to a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$99.66\%$$\end{document} reduction compared to MLP-based methods.
The results show that the EB-LNAST approach consistently identifies compact architectures while achieving competitive or superior predictive performance compared with machine learning classification algorithms for the color classification task, and the results obtained in the reported literature for the WDBC dataset.
By effectively exploring the architecture space and the training parameters in a bi-level framework, EB-LNAST identifies minimal yet high-performing networks, offering a robust alternative to traditional empirical design strategies. It also eliminates the need for exhaustive experimentation, resulting in significant time savings and more consistent outcomes.
Future work involves the application extension of EB-LNAST to other neural network architectures (e.g., convolutional neural networks or recurrent neural networks) and application domains with experimental evidence beyond color classification, for instance, optimal neural architectures for interpreting movement intention in a robotic platform, where the goal is to characterize and classify surface electromyographic (sEMG) signals from human upper limbs, enabling accurate translation of intended movements into robotic actions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Parameswaran, A., Kumar, K., Valsalam, S., Harikrishnan, G. & Muralidharan, V. An intelligent reflective colour sensor system for paper and textile industries. In 2012 IEEE International Conference on Sensors, 481–485, 10.1109/IC Sens T.2012.6461726 (2012).
- 2Remeseiro, B. & Bolon-Canedo, V. A review of feature selection methods in medical applications. Comput. Biol. Medicine 112, 10.1016/j.compbiomed.2019.103375 (2019).10.1016/j.compbiomed.2019.10337531382212 · doi ↗ · pubmed ↗
- 3Vijayalakshmi, K., Vijayakumar, K. & Nandhakumar, K. Prediction of virtual energy storage capacity of the air-conditioner using a stochastic gradient descent based artificial neural network. Electr. Power Syst. Res.208, 10.1016/j.epsr.2022.107879 (2022).
- 4Bishop, C. M. & Bishop, H. Deep Learning: Foundations and Concepts (Springer Cham, 2023), 1 edn. Published: Hardcover - 02 November 2023, e Book - 01 November 2023; Includes 200 b/w and 400 color illustrations.
- 5Aggarwal, C. C. Neural Networks and Deep Learning: A Textbook (Springer Cham, 2023), 2 edn. Published: Hardcover - 30 June 2023, Softcover - 01 July 2024, e Book - 29 June 2023; Includes 128 b/w and 22 color illustrations.
- 6Wang, S. Y. & Soo, V. W. A neural network architecture for the general problem solver. In 1991 IEEE International Joint Conference on Neural Networks, 1681–1686 vol.2, 10.1109/IJCNN.1991.170658 (1991).
- 7Andersen, T., Rimer, M. & Martinez, T. Optimal artificial neural network architecture selection for bagging. In IJCNN’01. International Joint Conference on Neural Networks. Proceedings (Cat. No.01CH 37222), 790–795 vol.2, 10.1109/IJCNN.2001.939460 (Washington, DC, USA, 2001).
- 8Pavićević, M. & Popović, T. Forecasting day-ahead electricity price with artificial neural networks: a comparison of architectures. In 2021 11th IEEE International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), 1083–1088, 10.1109/IDAACS 53288.2021.9660955 (Cracow, Poland, 2021).