Assessment of cyclists yielding to pedestrians at an unsignalized zebra crossing in Germany using drone video
Hiba Nassereddine

TL;DR
This study uses drone footage to analyze how cyclists in Germany yield to pedestrians at unsignalized crossings, identifying factors that influence their behavior.
Contribution
The study introduces a proactive framework for analyzing cyclist-pedestrian interactions without relying on crash data.
Findings
Cyclist yielding behavior is influenced by speed, trajectory changes, pedestrian time-to-conflict-point, and interaction proximity.
Speed reduction and pedestrian presence on the zebra crossing improve yielding rates.
Clustering analysis identified two distinct cyclist behavior groups based on yielding compliance.
Abstract
Previous research has examined vehicle-pedestrian and vehicle-cyclist interactions, but there have been few studies that examined cyclist-pedestrian interactions at intersections. This study addresses this gap by analyzing cyclist-pedestrian interactions at an unsignalized intersection in Germany using publicly available drone data. The study presents a framework and proof of concept for analyzing cyclist behavior proactively, without relying on crash data. The primary objectives are to identify the variables influencing cyclist yielding behavior and obstructed travel time (OTT) within a predefined zone at a zebra crossing and to classify cyclist behaviors. Using logistic and linear regression models, several key predictors were identified, including cyclist speed, trajectory changes, pedestrian time-to-conflict-point, and interaction proximity, which significantly impacted yielding…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
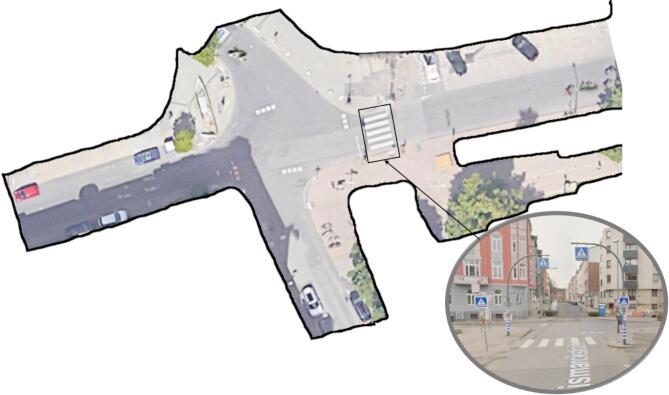 Figure 1
Figure 1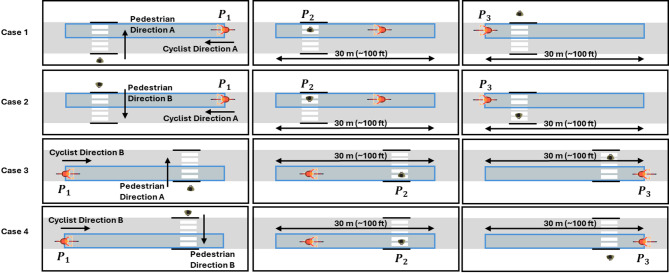 Figure 2
Figure 2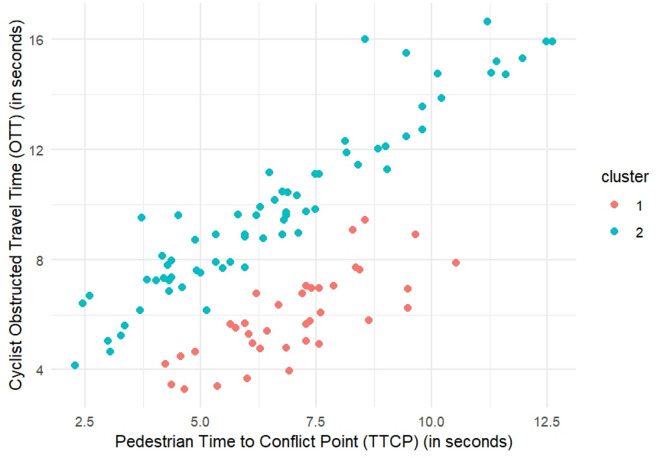 Figure 3
Figure 3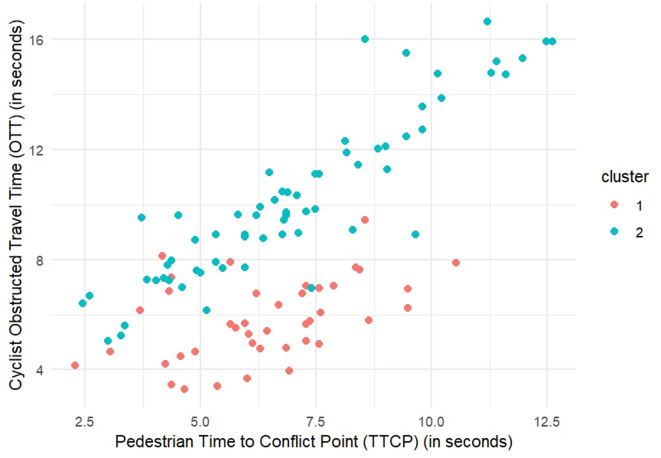 Figure 4
Figure 4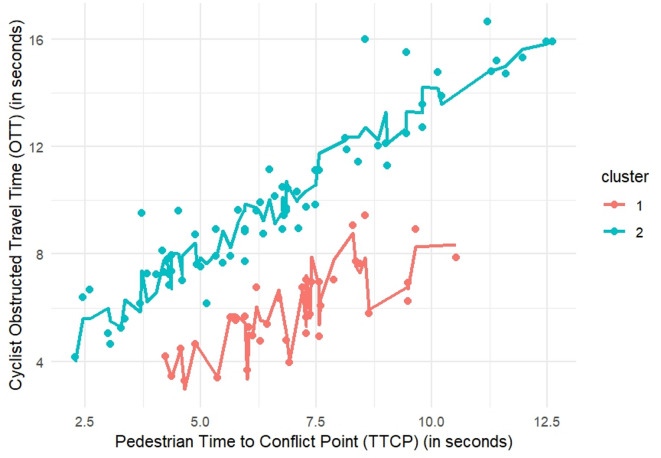 Figure 5
Figure 5- —Universität der Bundeswehr München (3147)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTraffic and Road Safety · Autonomous Vehicle Technology and Safety · Human-Automation Interaction and Safety
Introduction
Walking and cycling are popular modes for short-distance trips, promoting both sustainable transport systems and healthy lifestyles. Many national and local governments worldwide advocate for cycling to enhance sustainability^1–4^. Creating walkable and cyclable road networks aids in reducing private vehicle usage, addressing energy and environmental concerns^5^. However, the rise in urban cycling and walking has increased interactions between pedestrians and cyclists, which are critical to study due to their impact on safety, comfort, and urban transportation efficiency. Because the two groups move at comparable speeds, share sight lines, and have similar reaction times, conventional right-of-way cues become blurred, generating many near misses that do not appear in crash statistics. Understanding these interactions is therefore essential for increasing perceived pedestrian safety and for achieving Vision Zero goals that cover all road users, not only motorized traffic.
Cyclist-pedestrian interactions occur in various urban settings, including intersections, shared paths, and pedestrian crossings. These interactions range from simple co-presence to more complex scenarios involving yielding, stopping, or altering paths to avoid collisions. The nature of these interactions is influenced by infrastructure, road user behavior, and contextual elements such as traffic volume and environmental conditions. Traffic conflicts are defined as situations where two or more road users come so close in time and space that a collision is likely if neither altered course. Interactions broaden this definition to include less severe events, such as when a pedestrian and cyclist are on the road simultaneously and adjust their movements in advance to prevent a conflict, ensuring smooth movement for both^6^. Although these interactions increasingly affect urban comfort and safety, they have received less attention than vehicle-related interactions. Many reports document interactions between pedestrians and cyclists, but due to a lack of data, little is known about the frequency and nature of cyclist-pedestrian collisions, conflicts, and interactions. Collisions resulting in injury between pedestrians and cyclists are relatively rare^7–9^, making them difficult to study and often an insufficient data source for predicting new collisions.
Previous research has examined vehicle-pedestrian and vehicle-cyclist interactions, but there has been less studies on cyclist-pedestrian interactions^10^. The studies that have focused on cyclist-pedestrian interactions have identified various individual and environmental factors influencing these interactions, such as pedestrian gender, speed, distraction (e.g., cell phone use), pedestrian density, two-way roads, speed limits, and ground markings for cyclists^10–15^. Most of the existing research has concentrated on shared paths, with very little attention given to interactions at intersections. The limited studies that have examined interactions at intersections were conducted at non-signalized intersections on university campuses^11,14^, where behaviors may differ from those at various intersection types throughout a city. In support of this, the 2023 edition of the Cycling Monitor in Germany^16^ surveyed 4003 citizens aged 14 to 69 about their mobility preferences and habits. The survey revealed that 60% of respondents believe that many cyclists contribute to road traffic insecurity due to their driving behavior, with 53% identifying as cyclists. In the 2021 edition, 43% of respondents felt that other road users do not show enough respect and consideration for pedestrians. Among the 77% who identified as cyclists, 34% admitted to only following traffic rules they deemed appropriate.
Expectations that cyclists will yield to pedestrians at crossings are not always met, leading to potential safety issues. Cyclists often swerve or alter speed to avoid yielding, which can surprise pedestrians and lead to unsafe situations. In a Vancouver and Montreal study, cyclists yielded more consistently in well-designed environments with clear expectations and signals. Key factors influencing interactions included pedestrian gender, speed, and the presence of pedestrian ground markings^17^. Another study showed that 47.5% of interactions at pedestrian crossings occur between a conflicting pedestrian and a cyclist passing through, with both parties traveling perpendicular to each other. The study also reported that the most common issue concerning cyclists is the failure to give way to pedestrians at pedestrian crossings^18^.
Traditional methods for assessing intersection safety typically rely on historical crash data^19^. However, this approach has notable limitations, especially at unsignalized intersections where such data is often sparse, incomplete, or unavailable, necessitating alternative evaluation methods^20^. An alternative is the use of surrogate safety measures (SSMs), which indicate potential collision risks based on observable interactions rather than actual crashes^21^. Rather than relying on rare crashes, SSMs quantify the likelihood and severity of potential conflicts by analyzing observable interactions, such as relative timing, spacing, and evasive actions. SSMs use trajectories from video or sensors to enable proactive safety evaluations at sites where crash records are sparse or unrepresentative. SSMs also facilitate comparisons across locations and designs before harm occurs. Utilizing video analysis and advanced detection technologies, detailed data on pedestrian and cyclist movements can be captured to compute these SSMs^22^. Some studies have analyzed the time needed to complete a right turn based on a pedestrian’s position in the crosswalk to understand how drivers respond to pedestrians at signalized intersections. The time taken to complete a right turn was considered an effective safety indicator, reflecting the level of “respect” drivers have for pedestrians and serving as a surrogate safety measure to rank intersections by safety based on driver behavior, independent of crash data^23,24^. Another study of vehicle-pedestrian interactions at unsignalized intersections clustered driver behavior by using the obstructed travel time of through-moving vehicles in a predefined zone; it revealed two distinct groups, one with high driver-yielding compliance, and another with low compliance^25^. A pattern-based approach using SSMs has been proposed to enhance safety by educating drivers about proper behavior. This approach categorizes pedestrian-vehicle interactions based on road user behavior, particularly distinguishing between evasive and non-evasive behaviors of pedestrians and vehicles at unsignalized intersections^26^. These methods used to investigate vehicle-pedestrian interactions could also be applied to study cyclist-pedestrian interactions.
Cyclist-pedestrian interactions at unsignalized intersections remain understudied because reliable data are limited. Crash report capture only the rare events that end in injury or fatality, while systematic video recording is difficult, especially in Germany, where strict privacy rules and lengthy approval processes limit recording. Even when cameras are installed, footage suffers from occlusion, limited viewing angles, and the observer effect: road users modify their behavior when they notice conspicuous equipment. Consequently, although several studies have documented driver compliance at zebra crossings, reporting yielding rates that span from as low as 4% to as high as 45% in different national contexts^27–31^; by contrast, the yielding behavior of cyclists at comparable crossings has received far less scholarly attention.
To address these gaps, this study presents a framework and proof of concept for using drone video data from a top-down view, sourced from a publicly available dataset, as an alternative method for studying road user behavior proactively, without the need for crash data. The study leverages high-resolution drone footage shot from more than 60 m above the carriageway. The bird’s-eye perspective eliminates occlusions, delivers high positional accuracy in both longitudinal and lateral axes, and remains effectively invisible to people on the ground, preserving naturalistic behavior while masking personal identities. This approach provides a more dynamic understanding of cyclist-pedestrian interactions, facilitating safety improvements before crashes occur. By classifying and categorizing cyclist behavior during interactions with pedestrians at a zebra crossing within a predefined zone, this study aims to inform targeted interventions to improve safety and compliance with traffic laws. The specific objectives are:
- to identify and understand the factors influencing cyclist yielding behavior and cyclist travel time when pedestrians are present, and.
- to apply clustering techniques to categorize cyclists based on their interaction patterns, providing insights into different behaviors to pedestrians.
Methodology
Model-based clustering32
Model-based clustering is a statistical approach to partitioning data into clusters, where each cluster is assumed to be generated by a particular probabilistic model. This methodology offers a principled framework for clustering by formally defining clusters through statistical models, often Gaussian mixtures.
In model-based clustering, the data is assumed to come from a mixture of underlying probability distributions, where each component of the mixture corresponds to a cluster. The clustering problem is therefore transformed into a density estimation problem. Mathematically, if we denote the data by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X=\left\{{x}_{1},{x}_{2},\dots\:,{x}_{n}\right\}$$\end{document} , the density of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{i}$$\end{document} is modeled as in Eq. (1).
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:f\left({x}_{i}|\varTheta\:\right)=\sum\limits_{k=1}^{K}{\pi\:}_{k}{f}_{k}\left({x}_{i}\right|{\theta\:}_{k})$$\end{document}where:
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} is the number of clusters,
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\pi\:}_{k}$$\end{document} is the mixing proportion for cluster k (with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\sum\:}_{k=1}^{K}{\pi\:}_{k}=1\:$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\pi\:}_{k}>0$$\end{document} for all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:k$$\end{document} ),
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{f}_{k}\left({x}_{i}\right|{\theta\:}_{k})$$\end{document} is the component density of the k^th^ component,
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varTheta\:={\left\{{\pi\:}_{k},{\theta\:}_{k}\right\}}_{k=1}^{K}$$\end{document} represents the parameters of the mixture model.
For example, in a dataset with two clusters, each cluster might be represented by a different Gaussian distribution, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{f}_{k}\left({x}_{i}\right|{\theta\:}_{k})$$\end{document} could be the probability density function of a Gaussian distribution with parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\theta\:}_{k}$$\end{document} (mean and covariance). The goal is to estimate these parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varTheta\:$$\end{document} , which involves determining the mixing proportions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\pi\:}_{k}$$\end{document} and the parameters of the component densities \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\theta\:}_{k}$$\end{document} .
The data point \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{i}$$\end{document} represents an individual observation, that has data on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:d$$\end{document} variables, in the dataset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X$$\end{document} , which is assumed to be generated from one of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:K$$\end{document} clusters according to the probabilities \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\pi\:}_{k}$$\end{document} . The challenge is to infer which cluster each data point belongs to and to estimate the parameters that best describe the data’s underlying distribution.
Model-based clustering for mixed data33
Model-based clustering for mixed data extends these principles to datasets containing both continuous and categorical variables. For mixed data, each observation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{i}=({x}_{ic},\:{x}_{id})$$\end{document} consists of continuous variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{ic},\:$$\end{document} and discrete variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{id}$$\end{document} . The mixture model will include different types of distributions for continuous and categorical variables. One approach is to use a latent class model for categorical data and a Gaussian model for continuous data, with joint density specified as in Eq. (2):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:f\left({x}_{i}|\varTheta\:\right)=\sum\limits_{k=1}^{K}{\pi\:}_{k}{f}_{kc}\left({x}_{ic}\right|{\theta\:}_{kc}\left){f}_{kd}\right({x}_{id}\left|{\theta\:}_{kd}\right)$$\end{document}where:
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{f}_{kc}$$\end{document} is the probability density function (pdf) of the continuous variables for cluster k,
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{f}_{kd}$$\end{document} is the probability mass function (pmf) of the discrete variables for cluster k,
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\theta\:}_{k}=({\theta\:}_{kc},\:{\theta\:}_{kd})$$\end{document} are the parameters for the continuous and discrete parts of cluster k.
Estimation and model selection
The Expectation-Maximization (EM) algorithm is a widely used method for estimating the parameters of mixture models. During the E-step, the algorithm calculates the expected value of the log-likelihood based on the current estimates of the distribution over cluster assignments. In the M-step, it maximizes this expected log-likelihood to update the parameter estimates.
In practice, the EM algorithm starts with initial parameter guesses and alternates between the E-step and M-step. This iterative process continues until the parameters converge to stable values, indicating that the mixture model has been adequately fitted to the data. Due to its flexibility, the EM algorithm is applicable to a broad range of clustering problems, from simple Gaussian mixtures to more complex scenarios involving different data types and distributions^32^.
The combination of EM for parameter estimation and criteria like the Bayesian Information Criterion (BIC) for model selection makes this methodology robust and efficient for uncovering the underlying structure in data. This ensures that the most appropriate model is chosen for representing the given dataset.
Linear regression34
Linear regression is a fundamental statistical method used to model the relationship between a dependent variable and one or more independent variables. The goal is to find a linear equation that best predicts the dependent variable based on the independent variables. The simplest form is simple linear regression, where there is one independent variable. The model is expressed as in Eq. (3).
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Y={\beta\:}_{0}+{\beta\:}_{1}X+\epsilon$$\end{document}where:
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Y$$\end{document} is the dependent variable,
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X$$\end{document} is the independent variable,
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\beta\:}_{0}$$\end{document} is the y-intercept,
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\beta\:}_{1}$$\end{document} is the slope of the line, and.
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\epsilon$$\end{document} represents the error term, accounting for the variation in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Y$$\end{document} not explained by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X$$\end{document} .
The coefficients \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\beta\:}_{0}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\beta\:}_{1}$$\end{document} are estimated using the method of least squares, which minimizes the sum of the squared differences between the observed values and the values predicted by the model. The least squares estimates are given by Eqs. (4) and (5).
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\widehat{{\beta\:}_{1}}=\frac{{\sum\:}_{i=1}^{n}\left({X}_{i}-\bar{X}\right)\left({Y}_{i}-\bar{Y}\right)}{{\sum\:}_{i=1}^{n}{\left({X}_{i}-\bar{X}\right)}^{2}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\widehat{{\beta\:}_{0}}=\bar{Y}-\widehat{{\beta\:}_{1}}\bar{X}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\bar{X}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\bar{Y}$$\end{document} are the means of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Y$$\end{document} , respectively.
Multiple linear regression extends this to multiple independent variables. The model is given by Eq. (6).
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Y={\beta\:}_{0}+{\beta\:}_{1}{X}_{1}+{\beta\:}_{2}{X}_{2}+\cdots\:+{\beta\:}_{p}{X}_{p}+ϵ$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\beta\:}_{j}$$\end{document} (for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:j=1,\dots\:,p$$\end{document} ) are the coefficients for the independent variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{X}_{j}$$\end{document} .
Logistic regression35
Logistic regression is used for modeling binary outcome variables, where the dependent variable can take on only two possible outcomes (often coded as 0 and 1). Unlike linear regression, logistic regression models the probability that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Y$$\end{document} belongs to a particular category. The logistic regression model is formulated as in Eq. (7).
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:logit\left(P\left(Y=1|X\right)\right)=ln\left(\frac{P\left(Y=1|X\right)}{1-P\left(Y=1|X\right)}\right)={\beta\:}_{0}+{\beta\:}_{1}{X}_{1}+{\beta\:}_{2}{X}_{2}+\dots\:+{\beta\:}_{p}{X}_{p}$$\end{document}The left-hand side, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:logit\left(P\left(Y=1|X\right)\right)$$\end{document} , is the log-odds of the probability that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Y=1$$\end{document} . The model ensures that the predicted probabilities lie between 0 and 1. The probability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:P\left(Y=1|X\right)$$\end{document} can be derived by applying the logistic function given by Eq. (8).
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:P\left(Y=1|X\right)=\frac{1}{1+{e}^{-\left({\beta\:}_{0}+{\beta\:}_{1}{X}_{1}+{\beta\:}_{2}{X}_{2}+\dots\:+{\beta\:}_{p}{X}_{p}\right)}}$$\end{document}The coefficients \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\beta\:}_{0},\:{\beta\:}_{1},{\beta\:}_{2},\dots\:,{\beta\:}_{p}$$\end{document} are typically estimated using maximum likelihood estimation (MLE), which finds the parameter values that maximize the likelihood function given by Eq. (9).
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:L\left(\beta\:\right)=\prod\limits_{i=1}^{n}{P\left({Y}_{i}|{X}_{i}\right)}^{{Y}_{i}}{\left[1-P\left({Y}_{i}|{X}_{i}\right)\right]}^{1-{Y}_{i}}$$\end{document}Incorporating regression in clustering36
To enhance the analysis, regression models can be incorporated within the clusters identified by a clustering algorithm. Initially, the data is clustered based solely on specific key variables using a clustering algorithm, such as Mclust^37^. This initial clustering identifies distinct clusters within the dataset. Following this, separate regression models are fitted within each cluster to understand the relationship between multiple predictors and the response variable. The predictors used in the multiple linear regression include significant predictors identified from prior analysis.
This advanced approach integrates a regression model within each cluster, fitting a unique regression model for each cluster to predict the response variable based on the predictor variables. The combined methodology provides deeper insights and more precise data partitioning, allowing for the identification of distinct subgroups within the data, each characterized by its specific relationship between the response and predictor variables.
By leveraging the combined strengths of clustering and regression, this methodology offers a robust framework for analyzing complex datasets with mixed data types and inherent relationships between variables. It improves the interpretability of the clusters by providing clear mathematical relationships within each cluster, facilitating better decision-making and predictive analytics. This approach enhances the analytical power and applicability of clustering techniques, making it a valuable tool for researchers and practitioners alike.
Data collection
Germany’s strict data-privacy laws mean that any video recording containing identifiable information, such as faces or license plates, requires explicit permission from local authorities. This process not only takes significant time but also requires full compliance with various data protection guidelines under the General Data Protection Regulation (GDPR). Given these challenges and the time-consuming nature of obtaining these permissions, for the purpose of this paper as a framework and proof of concept, the study relies on a publicly available dataset based on top-view drone video footage. The top-view perspective ensures that individuals are not directly identifiable, thus minimizing privacy concerns while still providing valuable data for analyzing cyclist-pedestrian interactions.
This study leverages a publicly available dataset^38^ to analyze and cluster cyclist behavior at an unsignalized intersection in Germany. The drone videos, captured in 4 K resolution (4096 × 2160 pixels) at 25 frames per second, each last about 20 min and cover an area of 80 × 40 m. A total of 242.6 min were recorded. Pedestrian and cyclist trajectories were provided by the dataset, which extracted and processed the trajectories from the drone video recordings at four intersections. This study focused on the intersection of Bismarck Str. and Schloss Str. (Recording ID 18 to 29), specifically examining the interactions between cyclists and pedestrians at a zebra crossing as shown in Fig. 1. The crossing at the intersection is 5 m long and 3.5 m wide, with zebra stripes marking the pedestrian crossing area. Pedestrian crossing signs are placed on both sides of the road, and a dotted line is present after the crossing to indicate a yield for vehicles entering the intersection. However, this yield line is intended for vehicles, not specifically for pedestrian right-of-way. The speed limit at this intersection was 50 km/h (30 mph).
While the raw video data was not provided, a Python source code was made available by the dataset provider to visualize the trajectories. The visualizer imports the trajectory data and displays it on an image of the recording site. Users can visualize specific frames or playback the recorded tracks, with the option to display information such as track IDs. Each road user class is represented by a specific shape: vehicles are displayed as rectangles, while cyclists and pedestrians are represented by dots for each frame they are visible.
Each recording consists of an image from the drone’s perspective and three CSV files. Two CSV files contain metadata about road users and the recordings, including details such as recording number, track ID, class, frame rate, duration, location, and the number of pedestrians. The third CSV file provides trajectory information per frame, featuring variables such as ID, frame number, x and y positions, x and y velocities, heading, x and y accelerations, and lateral and longitudinal velocities and accelerations. The dataset covers the trajectories of various vehicles (cars, buses, trucks) and vulnerable road users (pedestrians and cyclists), with the focus of this study being on pedestrian and cyclist trajectories. The age and gender of the road users were not included in the provided dataset.
Fig. 1. Google Maps satellite view of the unsignalized intersection of Bismarck Str. and Schloss Str. with visual representation of road users and zebra crossing signage (Imagery ©2025 Airbus, Map data ©2025 GeoBasis-DE/BKG (©2009), Google).
The final dataset used for modeling cyclist-pedestrian interactions includes observations limited to leading cyclists passing through, i.e., the first rider in any approach stream, who encountered a single pedestrian or a pedestrian group crossing from one direction. Trailing cyclists, who might react to both the actions of the leading cyclist and the pedestrians, were excluded from the analysis. Likewise, if a motor-vehicle was present either directly ahead of or behind the cyclist, or pedestrians were crossing from both directions, these interactions were dropped so that the analysis isolates pure cyclist-pedestrian interactions. By excluding influences such as traffic volume, pedestrian density, and cyclist-cyclist interactions, this filtering approach confines the study to comparable one-to-one cyclist-pedestrian interactions allowing for a more focused analysis of the cyclist-pedestrian interaction at the crossing.
Interactions between cyclists passing through and conflicting pedestrians were documented within a predefined zone. The cyclist travel zone measures 30 m (approximately 100 ft) in length, starting 5 m (16.5 ft) before the pedestrian crossing and extending 25 m beyond it. The pedestrian crossing region was defined to include both the zebra crossing and areas outside of the crossing. A custom Python code was written to extract specific details, including the pedestrian’s start and end of crossing, the cyclist’s entry and exit from the predefined zone, and the direction of travel for both pedestrians and cyclists. Several other variables were also extracted and documented, including the number of conflicting pedestrians and whether the pedestrian(s) started crossing within the zebra crossing, among others.
An automated process was employed to identify interactions between cyclists and pedestrians. The automated Python script first flagged every potential cyclist-pedestrian interaction. Each candidate interaction was then visually checked frame-by-frame to confirm that one leading cyclist interacted with a single stream of pedestrians. Once an interaction was confirmed, the exact frames where the interaction occurred were analyzed.
To limit subjectivity, interaction confirmation followed two binary inclusion rules: (i) a single leading cyclist interacting with one pedestrian or a single pedestrian stream within the predefined zone, and (ii) no observable motor-vehicle influence on the cyclist-pedestrian interaction (e.g., no vehicle directly ahead/behind the cyclist within the zone or encroaching on the crossing). All machine-flagged candidates were reviewed frame-by-frame using the trajectory visualizer. Ambiguous cases, such as trailing cyclists, overtaking or side-by-side cyclists, simultaneous pedestrian streams approaching from both sides, partial occlusions around key timestamps, or any potential motor-vehicle influence, were excluded rather than resolved by judgment. No inferences about intent were made; decisions were based solely on observable criteria (leading status, single pedestrian stream, and absence of vehicle influence). A simple screening log was maintained to document decisions (candidate ID, keep or drop, and reason). To enhance reproducibility, future studies should include blinded duplicate screening of a sample of cases and report an inter-rater agreement statistic.
On two mid-weekdays in July 2019 (Tuesday and Wednesday), drones operated from 16:00 to 19:15 on day 1 and 16:00 to 18:00 on day 2; however, only 135 min and 104 min of footage, respectively, were recorded and provided for analysis. The weather was sunny/clear, and sunset has not yet occurred, so visibility and pavement conditions were stable. A total of 604 pedestrians crossing on the zebra crossing and 1,125 cyclists passing through were recorded during the 242.6 min of video data. Of these, 107 cyclist-pedestrian interactions of interest were identified. Table 1 summarizes the key characteristics of the video recordings used in the analysis, including the number of crossing pedestrians, passing cyclists, and identified interactions of interest during each recording session. Although the data was collected on different weekdays and times, the strict inclusion rules described above, together with the absence of darkness or adverse weather conditions, minimize the influence of time of day on the behavioral variables analyzed here. Residual temporal effects are acknowledged as a limitation and motivation for future multi-period data collection.
Table 1. Summary of video recordings and interactions of interest.DayDuration (min)Number of crossing pedestriansNumber of passing through cyclistsNumber of interactions of interestDay 1135.1633562054Day 2104.4026950553
Four cases of cyclist-pedestrian interactions were identified at the zebra crossing. These cases were defined by the direction of travel for both the cyclist and the pedestrian. The identified cases are:
- case 1: Cyclist traveling in direction A and pedestrian crossing in direction A,
- case 2: Cyclist traveling in direction A and pedestrian crossing in direction B,
- case 3: Cyclist traveling in direction B and pedestrian crossing in direction A, and
- case 4: Cyclist traveling in direction B and pedestrian crossing in direction B.
The frame numbers from the dataset were converted into timestamps to capture the key moments of the interactions. Figure 2 illustrates these four identified cases, showing the cyclist travel zone along with the timestamps corresponding to the two key positions of cyclists and one key position of conflicting pedestrians:
- the timestamp when the center of the bicycle entered the predefined zone, referred to as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{P}_{1}$$\end{document} ,
- the timestamp when a conflicting pedestrian arrived at the conflict point, referred to as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{P}_{2}$$\end{document} , and
- the timestamp when the center of the bicycle exited the predefined zone, referred to as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{P}_{3}$$\end{document} .
Fig. 2. Visual representation of cyclist-pedestrian interaction cases and key timestamps.
The four cases shown in Fig. 2 simply illustrate every geometric configuration that can occur when a single leading cyclist and a single pedestrian (or a pedestrian group) approach the zebra crossing from either side. Cases 1 and 4, as well as Cases 2 and 2, are mirror images that differ only in approach direction, but they are illustrated separately to show where the three reference timestamps \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{P}_{1}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{P}_{2}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{P}_{3}$$\end{document} are located. In the analysis, direction is captured by a single binary variable (A or B).
Data analysis and results
The Pedestrian Time to Conflict Point (TTCP) is defined as the time from when the cyclist enters the zone to when the pedestrian arrives at the conflict point ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:TTCP={P}_{2}-{P}_{1}$$\end{document} ), conceptually related to time-to-zebra (TTZ). The cyclist Obstructed Travel Time (OTT) is defined as the time it takes for a cyclist to traverse the zone ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:OTT={P}_{3}-{P}_{1}$$\end{document} ), adapted from Obstructed Right-Turn Time (ORTT)^23,24^. TTCP captures the temporal opportunity for interaction, and OTT reflects the cyclist’s behavior within that opportunity. These SSMs are used to indicate interaction dynamics and yield rather than to predict crash risk. To understand cyclist-pedestrian interactions, both logistic and linear regression models were applied to identify the key predictors of yielding behavior and obstructed travel time (OTT). The predictors considered in these models included pedestrian time-to-conflict-point (TTCP), cyclist speed upon entering the zone, cyclist deceleration, cyclist direction of travel, changes in path, speed reduction, the proximity of the interaction, whether the pedestrian was already on the zebra crossing, pedestrian speed, pedestrian direction of travel, whether the pedestrian started crossing within the zebra crossing, and whether the pedestrian was part of a group. A significance level of α = 0.05 was used to determine the inclusion of variables in the models.
Additionally, two clustering methods—Mclust and ClustMD—were applied to the dataset. These methods were chosen to capture different behavioral patterns due to the mixed nature of the data (continuous and categorical variables). Mclust assumes data follows a Gaussian distribution, while ClustMD incorporates a mixture of continuous and categorical variables. This approach ensured robustness in the clustering analysis, revealing distinct groups of cyclist behaviors based on interactions with pedestrians.
Data summary
The time difference between when cyclists entered and exited the predefined travel zone ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{P}_{3}-{P}_{1}$$\end{document} ) was calculated and referred to as the cyclist’s obstructed travel time (OTT), representing the duration a cyclist was impeded by a pedestrian. Similarly, the time difference between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{P}_{2}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{P}_{1}$$\end{document} was calculated as the pedestrian time-to-conflict-point (TTCP), which indicates how long it would take for a conflicting pedestrian to reach the conflict point when the cyclist was at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{P}_{1}$$\end{document} . In addition to OTT and TTCP, several other key variables were documented for each observation, including:
- the speed of cyclists entering the predefined zone ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{V}_{cyclis{t}_{entering}}$$\end{document} ),
- cyclist deceleration ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Dec}_{cyclist}$$\end{document} ),
- pedestrian speed ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{V}_{ped}$$\end{document} ),
- cyclist direction of travel ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Dir}_{cyclist}$$\end{document} ),
- pedestrian direction of travel ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Dir}_{ped}$$\end{document} ),
- whether the pedestrian started crossing within the zebra crossing ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Cross}_{inside}$$\end{document} ),
- whether a group of two or more pedestrians crossed together ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Group}_{ped}$$\end{document} ),
- whether the pedestrian was on the zebra crossing when the cyclist was 5 m (16.4 ft) away from the crossing ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:PedOnZebra$$\end{document} ),
- whether the cyclist changed their trajectory to avoid colliding with the conflicting pedestrian, that is a cyclist executed a swerve, either remaining on a curved path or returning to a straight line after the maneuver ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:TrajectoryChang{e}_{cyclist}$$\end{document} ),
- whether the cyclist reduced their speed when they were 5 m (16.4 ft) away from the crossing ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{SpeedReduction}_{cyclist}$$\end{document} ), and.
- the proximity of the interaction, classified as “close” (both road users were near the conflict point) or “far” (one user was distant from the conflict point) ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Interaction}_{Proximity}$$\end{document} ).
Tables 2 and 3 provides a summary of selected statistics for these variables. This comprehensive dataset serves as the basis for the regression analyses, offering valuable insights into cyclist and pedestrian behavior at the zebra crossing, which can inform future traffic management strategies and safety improvements.
Table 2. Summary of continuous variables used in cyclist-pedestrian interaction modeling.VariablesMinMaxMean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:OTT\:\left(sec\right)$$\end{document} 3.2816.648.48 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:TTCP\:\left(sec\right)$$\end{document} 2.2812.606.74 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{V}_{{cyclist}_{entering}}\:\left(m/s\right)$$\end{document} 2.219.005.20 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Dec}_{cyclist}\left(m/{s}^{2}\right)$$\end{document} –2.85–0.02–0.96 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{V}_{ped}\left(m/s\right)$$\end{document} 0.423.301.57Number of observations107
Table 3. Summary of categorical variables used in cyclist-pedestrian interaction modeling.VariableCategoryCountPercentage \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Dir}_{cyclist}$$\end{document} A4946%B5854% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Dir}_{ped}$$\end{document} A4643%B6157% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Cross}_{inside}$$\end{document} Yes9387%No1413% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Group}_{ped}$$\end{document} Yes2725%No8075% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:PedOnZebra$$\end{document} Yes6359%No116%Ped started crossing2725% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{TrajectoryChange}_{cyclist}$$\end{document} Yes2321%No8479% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{SpeedReduction}_{cyclist}$$\end{document} Yes6763%No4037% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Interactio{n}_{Proximity}$$\end{document} Close8176%Far2624% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Yield}_{cyclist}$$\end{document} Yes6359%No4441%
The dataset comprises 107 observations of cyclist-pedestrian interactions at a zebra crossing. Key metrics include the cyclist obstructed travel time (OTT), which averages 8.48 s, and the pedestrian time-to-conflict-point (TTCP), with a mean of 6.74 s. These metrics indicate the typical duration cyclists are impeded by pedestrians and the time pedestrians take to reach the conflict point, respectively. Cyclists entered the predefined zone at an average speed of 5.20 m/s and decelerated by an average of –0.96 m/s² when interacting with pedestrians. Pedestrian speeds varied, averaging 1.57 m/s, reflecting a range of pedestrian behavior. A notable finding is that 87% of pedestrians started crossing within the marked zone, and 25% were in groups, highlighting common pedestrian behaviors at zebra crossings. Additionally, 63% of cyclists reduced their speed, and 21% altered their trajectory during interactions, suggesting significant caution exercised by cyclists in the presence of pedestrians. However, 41% of cyclists did not yield to pedestrians, indicating a substantial portion of non-compliance with yielding behavior at zebra crossings. This lack of yielding behavior represents a significant safety concern and highlights the need for improved traffic management strategies and enhanced safety measures at unsignalized intersections. These insights underscore the importance of targeted interventions to increase cyclist compliance and protect pedestrian safety.
The video observations of the intersection revealed that among the cyclists who yielded to pedestrians, 29% did so when the pedestrians were still approaching the zebra crossing and had not yet started crossing. Furthermore, among the cyclists who yielded to pedestrians, 14% changed their trajectory path right before yielding. Among the cyclists who did not yield to pedestrians, 45% had close interactions with pedestrians. Additionally, among the cyclists who did not yield to pedestrians, 75% did not yield when the pedestrians were already on the zebra crossing.
Logistic regression analysis
The logistic regression analysis aimed to model the probability of cyclists yielding to pedestrians at a zebra crossing. Initially, all potential variables influencing a cyclist’s decision to yield to pedestrians at a zebra crossing were included in the logistic regression model. Following this, only the significant variables were retained for the final analysis. The structure of the logistic regression model is shown in equations (10). The details of the model are shown in Table 4.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}Yiel{d}_{cyclist}&=1.01-0.04\:{V}_{{cyclist}_{entering}}-0.15\:TrajectoryChang{e}_{cyclist}\\ &\quad+0.67\:SpeedReductio{n}_{cyclist}-0.23\:Interactio{n}_{Proximity}+0.07\:PedOnZebra\end{aligned}$$\end{document}Table 4. Logistic regression analysis results.EstimateStd. Errorst valuep-value95% CIOdd ratioIntercept1.010.254.004< 0.0011.68–4.522.76 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{{V}}_{{{c}{y}{c}{l}{i}{s}{t}}_{{e}{n}{t}{e}{r}{i}{n}{g}}}$$\end{document} –0.040.02–2.3430.0210.92–0.990.96 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{T}{r}{a}{j}{e}{c}{t}{o}{r}{y}{C}{h}{a}{n}{g}{{e}}_{{c}{y}{c}{l}{i}{s}{t}}$$\end{document} –0.150.06–2.4250.0170.76–0.970.86 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{S}{p}{e}{e}{d}{R}{e}{d}{u}{c}{t}{i}{o}{{n}}_{{c}{y}{c}{l}{i}{s}{t}}$$\end{document} 0.670.0610.360< 0.0011.72–2.221.96 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{I}{n}{t}{e}{r}{a}{c}{t}{i}{o}{{n}}_{{P}{r}{o}{x}{i}{m}{i}{t}{y}}$$\end{document} –0.230.07–3.2830.00140.69–0.910.79 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{P}{e}{d}{O}{n}{Z}{e}{b}{r}{a}$$\end{document} 0.070.032.0470.0431.00–1.141.07
The final logistic regression model retained several significant variables. Higher speeds of cyclists entering the zone were associated with a lower likelihood of yielding to pedestrians, indicating that faster cyclists are less inclined to yield. Cyclists who changed their path were also less likely to yield, suggesting that path changes correlate with non-yielding behavior. Conversely, cyclists who reduced their speed were significantly more likely to yield, implying that encouraging speed reduction could improve yielding behavior. Far interactions decreased the likelihood of yielding, indicating that cyclists are less likely to yield when pedestrians are not near the conflict point. Additionally, the presence of pedestrians already on the zebra crossing increased the likelihood of cyclists yielding, suggesting that visible pedestrian presence on the crossing prompts cyclists to yield.
All predictors exhibit very low variance-inflation factors (VIF ≈ 1.1–1.8), far below the commonly cited cautionary threshold of 2.5–5. This indicates that none of the variables is strongly linearly correlated with the others, so multicollinearity is negligible. Consequently, the standard errors and odds-ratio estimates in the logistic model should be stable and reliable. The model fits the data well. Residual deviance falls from 25.91 in the null model to 6.06 with the predictors included, so about 77% of the deviance is explained. A very small AIC of 10.5 further indicates a parsimonious yet informative fit, suggesting that the model provides a good overall description of the factors that influence whether cyclists yield at the crossing. The WebPower^39^ analysis indicates that a minimum of 55 observations is required to achieve the conventional 80% statistical power. With the actual sample of 107 cyclist-pedestrian interactions, the model exceeds this minimum threshold.
Linear regression analysis
The linear regression analysis aimed to understand the relationship between cyclist obstructed travel time (OTT) and various predictors. Initially, all potential variables influencing cyclist OTT were included in the linear regression model. After identifying the significant predictors, the model was refined to retain only those variables. The structure of the linear regression model is shown in equations (11). The details of the model are shown in Table 5.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}OTT&=4.20+0.92\:TTCP-0.44\:{V}_{{cyclist}_{entering}}-0.71\:De{c}_{cyclist}-0.49\:Di{r}_{cyclist}\\ & \quad +1.83\:SpeedReductio{n}_{cyclist}-2.02\:Interactio{n}_{Proximity}\end{aligned}$$\end{document}Table 5. Linear regression analysis results.EstimateStd. errorst valuep-value95% CIIntercept4.201.103.816< 0.0012.02 to 6.38 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{T}{T}{C}{P}$$\end{document} 0.920.0614.045< 0.0010.79 to 1.05 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{{V}}_{{{c}{y}{c}{l}{i}{s}{t}}_{{e}{n}{t}{e}{r}{i}{n}{g}}}$$\end{document} –0.440.10–4.426< 0.001–0.64 to –0.24 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{D}{e}{{c}}_{{c}{y}{c}{l}{i}{s}{t}}$$\end{document} –0.710.26–2.7150.0078–1.24 to –0.19 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{D}{i}{{r}}_{{c}{y}{c}{l}{i}{s}{t}}$$\end{document} –0.490.23–2.1290.0357–0.95 to –0.03 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{S}{p}{e}{e}{d}{R}{e}{d}{u}{c}{t}{i}{o}{{n}}_{{c}{y}{c}{l}{i}{s}{t}}$$\end{document} 1.830.384.756< 0.0011.07 to 2.60 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{I}{n}{t}{e}{r}{a}{c}{t}{i}{o}{{n}}_{{P}{r}{o}{x}{i}{m}{i}{t}{y}}$$\end{document} –2.020.36–5.622< 0.001–2.73 to –1.30Residual standard error: 1.177 on 100 degrees of freedom.Multiple R-squared: 0.8786, Adjusted R-squared: 0.8713.F-statistic: 120.7 on 6 and 100 DF, p-value: < 2.2e-16.
The final linear regression model retained several significant variables. Pedestrian Time to Conflict Point (TTCP) is positively associated with OTT, indicating that as the time it takes for a pedestrian to reach the conflict point increases, the obstructed travel time for cyclists also increases. A larger OTT can suggest that cyclists are yielding to pedestrians, as they should by law. Higher speeds of cyclists entering the zone are associated with a decrease in OTT, suggesting that faster cyclists are less likely to yield and instead opt to pass quickly through the crossing, reducing their obstructed travel time. Greater deceleration by cyclists is associated with a reduction in OTT, indicating that cyclists who decelerate more abruptly tend to clear the crossing faster, potentially not yielding to pedestrians. The direction of travel of the cyclist is a significant predictor, with a negative estimate, suggesting that certain directions might influence cyclists’ likelihood of yielding. Cyclists who reduce their speed have significantly longer obstructed travel times, indicating that cyclists who slow down are yielding to pedestrians, resulting in increased OTT. The proximity of the interaction has a significant negative impact on OTT, with more far interactions leading to shorter obstructed travel times, possibly due to more decisive actions taken by cyclists to navigate through the conflict zone without yielding.
Pair-wise correlations among the three continuous predictors are modest (|r| ≤ 0.44), and all variance-inflation factors lie between 1.0 and 2.7, well below the usual cautionary threshold of 5. Hence multicollinearity is negligible, and each variable contributes largely unique information to the model. The regression model explains almost 88% of the variance in OTT (R^2^ = 0.879, adjusted R^2^ = 0.871) and the F-test is highly significant. Residuals have a standard error of 1.18 s and an AIC of 347, indicating a parsimonious yet powerful specification. With the observed effect size (f^2^ = 7.24) the current sample of 107 interactions yields virtually 100% statistical power. Even for a more conservative, medium effect (f^2^ = 0.15), the model would require 98 observations; the study exceeds this a-priori threshold, confirming that the sample is more than adequate for detecting meaningful relationships.
Clustering
Model selection was considered for K = 1–5 under several covariance structures. Both BIC and ICL consistently selected K = 2 as the most parsimonious solution. Solutions with K ≥ 3 did not significantly improve the fit. These solutions tended to create a small third cluster composed primarily of observations close to the decision boundary in the TTCP-OTT space. This reduced interpretability without providing clear behavioral separation. Posterior assignment probabilities were generally high, indicating good separation for the two-group solution given the available data. For clarity and consistency in the remainder of this section, cyclists who yielded are referred to as “yielder” ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Yield}_{cyclist}=Yes$$\end{document} ), while those who did not yield are referred to as “non-yielders” ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Yield}_{cyclist}=No$$\end{document} ). Cluster 1 is referred to as non-yielders and Cluster 2 as yielders.
Using the Mclust method^37^, the Gaussian finite mixture model with ellipsoidal, equal orientation (VVE) was fitted, resulting in two optimal clusters. The model’s log-likelihood was − 456.4157, with a BIC of –959.5596 and an ICL of –964.0836. The clustering table shows that Cluster 1 contains 37 observations, while Cluster 2 contains 70 observations. The scatter plot generated from the Mclust clustering results displays two distinct clusters based on TTCP and OTT, as shown in Fig. 3. Cluster 1, non-yielder, (red in Fig. 3) primarily consists of data points with shorter TTCP and OTT values, indicating quicker interactions between cyclists and pedestrians. In contrast, Cluster 2, yielders, (blue in Fig. 3) consists of data points with longer TTCP and OTT values, suggesting more extended interactions where cyclists are more likely to yield to pedestrians. Tables 6 and 7 present the summary statistics for continuous and categorical variables, respectively, in each cluster.
Fig. 3. Clustering results for Mclust.
Table 6. Summary of continuous variables per cluster.VariablesCluster 1Cluster 2MinMaxMeanMinMaxMean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:OTT\:\left(sec\right)$$\end{document} 3.289.445.894.1616.649.85 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:TTCP\:\left(sec\right)$$\end{document} 4.2410.526.992.2812.66.61 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{V}_{{cyclist}_{entering}}\:\left(m/s\right)$$\end{document} 2.129.015.672.627.624.96 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Dec}_{cyclist}\left(m/{s}^{2}\right)$$\end{document} –1.83–0.02–0.46–2.85–0.19–1.22 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{V}_{ped}\left(m/s\right)$$\end{document} 0.893.301.80.423.301.56Number of observations3770
Table 7. Summary of categorical variables per cluster.VariableCluster 1Cluster 2CategoryCountPercentageCountPercentage \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Dir}_{cyclist}$$\end{document} A1746%3246%B2054%3854% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Dir}_{ped}$$\end{document} A1951%2739%B1849%4361% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Cross}_{inside}$$\end{document} Yes411%6086%No3389%1014% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Group}_{ped}$$\end{document} Yes924%1826%No2876%5274% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:PedOnZebra$$\end{document} Yes1130%5274%No1130%69%Ped started crossing1540%1217% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{TrajectoryChange}_{cyclist}$$\end{document} Yes924%1420%No2876%5680% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{SpeedReduction}_{cyclist}$$\end{document} Yes411%6390%No3389%710% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Interactio{n}_{Proximity}$$\end{document} Close1335%6897%Far2465%23% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Yield}_{cyclist}$$\end{document} Yes00%710%No37100%6390%
The ClustMD method^33^ was also used to cluster the data, employing an EVI model with two components. The estimated BIC for this model is -2940.229. The clustering table for ClustMD indicates that Cluster 1 (non-yielders) contains 37 observations, while cluster 2 (yielders) contains 70 observations. Similar to the Mclust results, the scatter plot from the ClustMD clustering shows two distinct clusters based on TTCP and OTT as shown in Fig. 4. Cluster 1, non-yielders, (red in Fig. 4) includes data points with shorter TTCP and OTT values, suggesting faster interactions and less likelihood of yielding. In contrast, Cluster 2, yielders, (blue in Fig. 4) includes data points with longer TTCP and OTT values, indicating more time spent in the interaction, implying a more extended interaction, likely due to cyclists yielding more frequently to pedestrians.
Fig. 4. Clustering results for ClustMD.
To deepen the analysis, the data was first clustered using the Mclust algorithm using only TTCP, which revealed two distinct groups. Within each cluster, a separate multiple linear regression model was fitted to explain the cyclist obstructed travel time (OTT) from TTCP and the additional predictors that were significant in the prior model summarized in equations (11). The predictions from these regression models are visualized in Fig. 5, illustrating how the relationships between predictors and OTT differ between the two clusters. The colored lines are the fitted values obtained from those cluster-specific regression models. Each line is drawn by ordering the observations in a cluster by TTCP and joining their model-predicted OTT, so it represents the trend predicted by the full multivariable model rather than a simple univariate smoothing.
The clustering table shows that cluster 1, non-yielders, consists of data points with shorter OTT, while cluster 2, yielders, include data points with longer OTT values. The regression model for Cluster 1, non-yielders, reveals that cyclists in this group generally have lower OTT values, suggesting they are less likely to yield or are obstructed by pedestrians for a shorter time. The variability in the regression line within Cluster 1, non-yielders, indicates that other factors, such as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{V}_{{cyclist}_{entering}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:De{c}_{cyclist}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Interaction}_{Proximity}$$\end{document} also influence the OTT within this cluster. On the other hand, the regression model for Cluster 2, yielders, demonstrates a significant positive relationship between TTCP and OTT. This suggests that even when TTCP increases, OTT also increases. This indicates that cyclists in this cluster are more likely to wait and yield to pedestrians, resulting in longer OTT values.
Fig. 5. Results of mclust with separate regression models.
Discussion
The joint regression results highlight speed-related variables as the most significant predictor of cyclist behavior at the zebra crossing. Cyclists who reduced their speed in advance were more likely to yield, whereas higher entry speed, far cyclist-pedestrian interaction proximity, and any lateral swerve reduced the odds of yielding and shortened OTT. These findings align with previous research showing that lower speeds give road users more time to react to pedestrians, and thus lead to safer interactions^40^, and that cyclists often swerve to avoid yielding or colliding with pedestrians^41^.
Clustering methods offer a way to move beyond mean effects and uncover discrete behavioral groups in the data. Both Mclust and ClustMD independently converged on the same two behavioral groups, showing that unsupervised learning can reliably extract distinct profiles from trajectory data. Non-yielders (Cluster 1) cleared the crossing rapidly, exhibiting short OTT, high entry speed, and minimal deceleration, and suggesting that they are less likely to yield to pedestrians, possibly attempting to pass quickly before the pedestrians fully engage the crossing. Yielders (Cluster 2), on the other hand, included cyclists with longer OTT, greater speed reductions and deceleration, indicating deliberate yielding and greater respect for pedestrians’ right of way.
Although clustering yields useful behavioral groupings, the labels describe observed interaction patterns rather than fixed cyclist types. Posterior assignment probabilities were generally high, indicating good separation, but a small subset of observations lies near the decision boundary in the TTCP-OTT space. These borderline cases suggest locally continuous behavior between non-yielders and yielders and should be interpreted with caution.
Despite both clustering methods identifying two distinct clusters, the exact assignment of data points to clusters differs slightly between Mclust and ClustMD. Several factors could explain these differences. Mclust assumes data points are generated from a Gaussian mixture model and fits ellipsoidal clusters with equal orientation, capturing certain types of variability in the data. ClustMD incorporates continuous and categorical variables, using a mixture of Gaussian and discrete distributions. The EVI model allows for varying volume and equal shape, fitting data with different underlying distributions more effectively. Mclust treats all variables as continuous and applies Gaussian mixtures directly to the data, while ClustMD differentiates between continuous, ordinal, and categorical variables, leading to different clustering structures, especially if the data contains a mix of variable types. The initialization strategies and convergence criteria differ between the two methods, with Mclust using the EM algorithm for Gaussian mixtures, and ClustMD possibly using hierarchical clustering for initialization and a different approach to convergence, leading to different local optima. Differences in how the two methods handle scaling and normalization of variables can also affect the clustering outcome, with ClustMD applying different scaling strategies for continuous versus categorical data.
The Bayesian Information Criterion (BIC) indicated that two clusters best fit the data, neatly separating cyclists into yield and no-yield groups. However, this result may be influenced by the size of the dataset, the specific characteristics of the zebra crossing studied, or unobserved influences. For instance, pedestrian behavior such as assertiveness or distraction by mobile phones, and environmental conditions such as glare, rain on the pavement, or background vehicle noise may push a cyclist toward either cluster without being captured in the model. Because such confounding factors varied only narrowly in the current recordings, their influence cannot be separated from the core variables that drive the classification. With a larger dataset or data collected from other sites that exhibit wider ranges of pedestrian and cyclist behavior and environmental conditions, additional classifications might emerge, such as consistent yielders, opportunistic yielders, and non-yielders. This potential differentiation could offer a more detailed understanding of cyclist behavior and help guide the design of more targeted interventions.
Although yielding by cyclists likely exists along a continuum, the information-criterion analysis of this dataset supports two dominant behavioral modes: non-yielders, who approach faster with minimal deceleration, and yielders, who approach more slowly with a significant reduction in speed. Three-cluster exploratory solutions primarily separated a small borderline group near the boundary between these modes but did not improve model fit or interpretability. With larger, multi-site samples and broader variation in conditions, additional stable subgroups may emerge.
By revealing two distinct behavioral patterns, the clustering approach underscores the need for targeted interventions aimed at ensuring cyclist compliance with yielding laws at zebra crossings. The presence of a significant group of cyclists who do not yield poses safety risks to pedestrians. Interventions such as enhanced signage, speed reduction measures (e.g., bike-friendly speed bumps), improved intersection design, public awareness campaigns, and stricter enforcement of traffic laws could be effective in promoting safer behaviors. By focusing on the factors that influence whether cyclists yield to pedestrians, traffic management strategies can be more effectively designed to enhance pedestrian safety at unsignalized intersections.
Translating these findings into practice requires context-sensitive selection and piloting of measures rather than a one-size-fits-all approach. Enhanced signage is inexpensive and quick to deploy, but it is often less effective without physical speed management. Speed reduction measures for cyclists, such as bike-friendly speed bumps, can lower approach speeds. However, careful design is required to avoid discomfort or evasive swerving, and maintenance needs may constrain them. Improved intersection designs, such as narrowed approaches, better sight lines, and raised elements, tend to be more durable, but they require space, funding, and coordination with access needs. Public awareness campaigns are both scalable and visible. However, their impact typically fades without periodic repetition. Stricter enforcement can raise short-term compliance, but it requires sustained resources and consistent application. Overall, selecting and combining measures should reflect local site conditions and operational constraints. Despite the challenges, these measures can yield meaningful benefits, including lower approach speeds, higher yielding rates, improved pedestrian comfort, and clearer right-of-way expectations, especially when combined and periodically monitored.
Although the present dataset is limited to a single zebra crossing in Germany, the methodology is transferable to other urban settings and to different types of road user interactions. Drone footage or video for fixed pole-mounted cameras can be collected at signalized or unsignalized intersections, shared-space, and mid-block crossings. From these videos, key road user points can be extracted from trajectory data, local predictors can be identified, and behavior can be clustered like this study. Because the workflow is modular and data-driven, cities can generate comparable evidence even where crash records are sparse, enabling context-specific yet methodologically consistent safety interventions.
Conclusions
This study established a drone-based, crash independent framework and proof of concept for analyzing cyclist-pedestrian interactions at an unsignalized zebra crossing. By using high-resolution footage captured from more than 60 m above the carriageway, the method eliminates the occlusion, observer-effect, and privacy hurdles that hinder camera video data, while still preserving naturalistic behavior and high positional accuracy. This approach is particularly valuable for locations where crash data is sparse, underreported, or difficult to obtain, such as unsignalized intersections. The surrogate safety measures, regression models, and behavior-based clusters presented here provide an alternative method for assessing safety at intersections, enabling proactive safety measures in areas where crash data is unavailable. Although pedestrian fatalities involving cyclists are rare, the discomfort and hesitation many pedestrians experience when cyclists fail to yield underline the need for such forward-looking approaches.
Only 59% of cyclists yielded to pedestrians at the zebra crossing, 29% of them did so before pedestrians had started crossing, while 41% of cyclists did not yield at all, highlighting a significant level of non-compliance. Of those who failed to yield, 45% had close interactions with pedestrians, and 75% did not yield when pedestrians were already on the zebra crossing. Regression analysis showed that speed-related variables are the primary predictors of cyclist-pedestrian interactions. Logistic regression showed that cyclists traveling at higher speeds or those who changed their trajectory were less likely to yield, whereas speed reduction and pedestrian presence on the crossing increased the likelihood of yielding. Linear regression further showed this pattern: faster cyclists and abrupt deceleration were associated with shorter OTT, indicating less yielding, while speed reduction was positively associated with longer OTT, suggesting that encouraging cyclists to reduce speed could promote yielding behavior. Clustering analysis using Mclust and ClustMD revealed two optimal and distinct groups of cyclist behavior. Non-yielders (Cluster 1) exhibited shorter OTT, reflecting lower levels of yielding, while yielders (Cluster 2) had longer OTT, indicating a higher likelihood of yielding. This framework situates TTCP and OTT within the broader family of surrogate safety measures, highlighting how SSMs enable proactive safety assessment when crash data is limited. Hence, the findings should be interpreted as proactive screening evidence to guide design and operational choices rather than as direct estimates of crash risk.
This differentiation suggests that targeted interventions are needed to ensure compliance with yielding laws, particularly for non-yielders (Cluster 1), who are less likely to yield. By focusing on the significant predictors identified, traffic management strategies can be more effectively designed to protect pedestrians and enhance safety at unsignalized intersections. Interventions encouraging cyclists to slow down – such as “Yield to Pedestrian” markings or gentle speed cushions – and ensuring pedestrian visibility could enhance safety at zebra crossings. Clearer crossing designs may also help cyclists anticipate pedestrian presence and react appropriately. Educating cyclists about the importance of yielding and the potential consequences of not doing so could also be beneficial, especially targeting non-yielders (Cluster 1).
While this study provides valuable insights into cyclist-pedestrian interactions at an unsignalized intersection, several limitations should be acknowledged. First, the focus on a single German intersection, influenced by the availability of high-quality data, limits the transferability of the findings to other intersections with different environmental or design characteristics. In particular, the studied site is an unsignalized zebra crossing on a two-way street with one lane in each direction. The design and operational features of the intersection, such as the approach geometry and sight distance, the crosswalk length and marking style, as well as pedestrian and cyclist volumes, can influence cyclist yielding behavior and perceived risk. Moreover, local cultural context and enforcement norms may influence yielding expectations. While cyclists may perceive non-yielding as low risk when acceptable gaps exist, pedestrians may still experience discomfort, hesitation, or reduced perceived safety. The findings should be interpreted with caution when applied to settings that are different from those in which they were observed. Second, although an a-priori power check indicated that 107 interactions are sufficient to detect medium effect sizes in the regression models, this is still a modest sample. A larger sample size is therefore essential for testing the stability of the regression models and cluster boundaries. Third, the dataset.
lacks demographic information such as age, gender and socioeconomic status. Because different user groups exhibit systematic differences, the absence of these variables can bias effect estimates and further limit generalizability. Fourth, key contextual factors, such as sun position/glare, surface condition, ambient noise, and distraction indicators (e.g., phone use), were unavailable. These unmeasured variables may confound observed associations and influence cluster assignment. Due to the privacy constraints inherent to top-view video, direct measurement of these attributes is limited, which limits interpretability. Fifth, although the trajectories supplied by the source dataset were refined with Bayesian smoothing and claim pixel-level positional accuracy, residual noise and the interpolation of occluded frames can still shift the key timestamps ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{P}_{1}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{P}_{2}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{P}_{3}$$\end{document} ) by a few tenths of a second, injecting random error into OTT and TTCP. Finally, this study relies on trajectory-derived surrogate safety measures (TTCP and OTT). Although SSMs allow for a proactive assessment in areas with limited crash data, they are proxies rather than direct measures of crash risk. Their values depend on the zone definitions, timestamp estimations, and site context. Accordingly, the results should be interpreted as indicators of interaction dynamics and compliance rather than as calibrated crash predictions. Future work should examine transportability across sites and, where feasible, validate the results against independent conflict logs or multi-site datasets.
Future research should expand the scope to include data from multiple intersections with varying widths and flow levels, larger sample sizes, and demographic information to provide a broader understanding of cyclist-pedestrian interactions. To improve generalizability, future research should explicitly sample intersections with varied lane configurations, including multi-lane approaches, as well as different facility types and cultural contexts. Additionally, it should pair trajectory-based outcomes with pedestrian-reported measures of comfort and perceived safety. To address measurement gaps under privacy constraints, future work should explore alternative video modalities and viewpoints. For example, infrared or thermal imagery, as well as oblique or multi-camera angles, could be employed to detect the use of mobility aids and group composition without identifying faces. Additionally, future work should use time of day, solar position, and local weather data as proxies for glare and surface conditions. Additionally, combining trajectories with open environmental datasets (e.g., land use, facility type) would provide a better context for behavior. Additionally, the influence of vehicles and the impact of different infrastructure designs, such as bike lanes, mid-block crossings, and pedestrian islands, should be explored to assess their effectiveness in improving safety at unsignalized intersections. Examining cyclist behavior during right and left turns, as well as the role of advanced technologies like intelligent traffic signals and real-time warning systems, could offer new ways to manage cyclist behavior and enhance safety. Furthermore, it is important to consider the dynamics of following cyclists, not just leading ones, to fully capture cyclist-pedestrian interactions at zebra crossings.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Blitz, A., Busch-Geertsema, A. & Lanzendorf, M. More Cycling Less Driving? Findings of a Cycle Street Intervention Study in the Rhine-Main Metropolitan Region, Germany. Sustainability 12, 805 (2020).
- 2Bundesministerium für Digitales und Verkehr (BMDV). Cycling Monitor. (2023). https://bmdv.bund.de/Shared Docs/EN/Articles/St V/Cycling/cycling-monitor.html
- 3Abdulhafedh, A. Road traffic crash data: an overview on sources, problems, and collection methods. JT Ts. 07, 206–219 (2017).
- 4Saunier, N. & Sayed, T. A feature-based tracking algorithm for vehicles in intersections. in The 3rd Canadian Conference on Computer and Robot Vision (CRV’06) 59–59IEEE, Quebec, Canada, (2006). 10.1109/CRV.2006.3
- 5Nassereddine, H. Modeling vehicle-pedestrian interactions at unsignalized intersections. J. Transp. Saf. Secur.1–1910.1080/19439962.2024.2447989 (2025).
- 6Danielsson, S., Gustafsson, S., Hageback, C., Johansson, U. & Olsson, C. Korsningen Radhusgatan-Storgatan, seminarieuppgift i Trafikanalys. Tekniska Hogskolan I Lulea Sweden (1993).
- 7Hydén, C., Odelid, K. & Varhelyi, A. Effekten av generell hastighetsdämpning i tätort. Resultat av ett storskaligt försök i Växjö. I. Huvudrapport. 3109/3000 (1995).
- 8Kutner, M. H., Nachtsheim, C. J., Neter, J. & Li, W. Applied Linear Statistical Models (Mc Graw-hill, 2005).