Continuous Rating Scale Analytics (CoRSA): A tool for analyzing continuous and discrete data with item response theory
Yeh-Tai Chou, Yao-Ting Sung, Wei-Hung Yang

TL;DR
This paper introduces CoRSA, a new tool for analyzing continuous and discrete rating scale data using item response theory, making it easier to work with continuous scales like the VAS.
Contribution
The paper introduces CoRSA, a validated analytical tool for continuous rating scales with a user-friendly interface.
Findings
CoRSA showed superior parameter recovery for continuous data compared to existing tools like pcIRT.
CoRSA demonstrated good model-data fit when applied to real-world career interest and work value assessments.
Integration of CoRSA into the VAS-RRP 2.0 platform improved accessibility for researchers unfamiliar with statistical methods.
Abstract
The use of continuous rating scales such as the visual analogue scale (VAS) in research has increased, yet they are less popular than discrete scales like the Likert scale. The non-popularity of continuous scales is primarily due to the lack of validated analytical tools and user-friendly interfaces, which have also jointly resulted in a lack of sufficient theoretical and empirical research supporting confidence in using continuous rating formats. This research aims to address these gaps through four studies. The first study proposed an algorithm and developed the Continuous Rating Scale Analytics (CoRSA) to estimate parameters for the continuous rating scale model (Müller, Psychometrika, 52, 165–181, 1987). The second study evaluated CoRSA’s efficacy in analyzing continuous scores compared to pcIRT (Hohensinn, Journal of Statistical Software, 84, 1–14, 2018) and discrete scores against…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
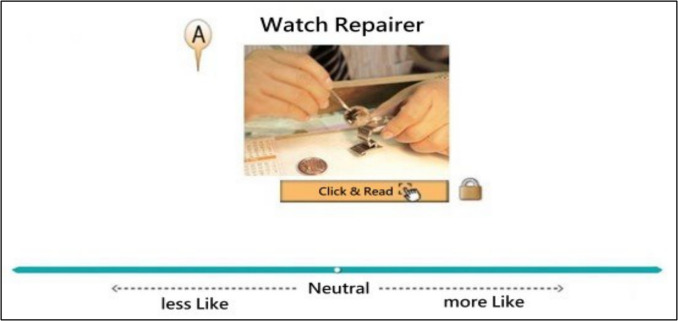 Figure 1
Figure 1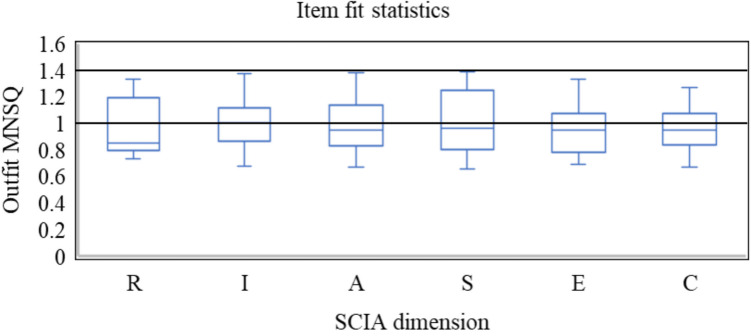 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8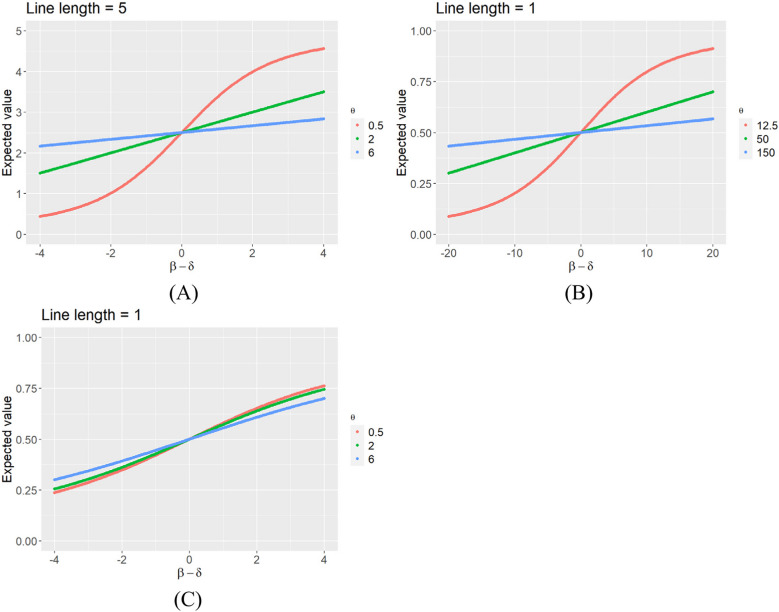 Figure 9
Figure 9- —National Taiwan Normal University
- —The Higher Education Sprout Project of Ministry of Education
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPsychometric Methodologies and Testing · Mental Health Research Topics · Personality Traits and Psychology
Introduction
Item response theory
Continuous response formats
Continuous response formats, in which the respondent’s item responses on a scale are recorded as continuous scores, have received increasing interest in recent years for measuring various psychological (e.g., pain perception) and educational latent traits (e.g., career interest). The most well-known example of continuous response formats is the visual analogue scale (VAS; Hayes & Patterson, 1921), where respondents make a mark along a horizontal or vertical line to express their level of agreement or preference for a latent construct (Couper et al., 2006). The item response is then scored by measuring the distance between the mark and the left endpoint (Reips & Funke, 2008). For example, a respondent may make a mark at the midpoint of the line, and this response might be recorded as 0.50 on a scale ranging from 0 to 1. Continuous response formats can be viewed as an extension of graded response formats, where the number of categories approaches infinity (Mellenbergh, 1994; Müller, 1987; Samejima, 1973). These formats offer more fine-grained measurements (Chimi & Russell, 2009), as well as obtaining test scores with higher variability, enhancing their reliability (Cook et al., 2001; Krieg, 1999) and responsiveness in measuring changes (Pfennings et al., 1995). Recently, the use of continuous response formats has become increasingly prevalent in clinical, educational, and psychological assessments, including domains such as career interest (Sung et al., 2017), depression (May & Pridmore, 2020), mood (Barrows & Thomas, 2018), pain perception (Kersten et al., 2014), personality (Kuhlmann et al., 2017), and quality of life (Feng et al., 2014; Hauser & Walsh, 2008).
Item response theory models for continuous responses
Within the item response theory (IRT) framework, several models have been proposed for analyzing continuous responses. These models describe the relationship between the probability density of a specific item response and parameters such as a person's trait level or an item's difficulty. Examples include the continuous response model (CRM; Samejima, 1973), continuous rating scale model (CoRSM; Müller, 1987), linear response model (Mellenbergh, 1994), nonlinear congeneric model (Ferrando, 2001), beta response model (BRM; Noel & Dauvier, 2007), and the zero-and-one inflated models (Molenaar et al., 2022). Molenaar et al. (2022) provided a comprehensive review of these models, with a particular focus on the conditional distributions of responses and the response situations. In the CRM (Samejima, 1973), for instance, it is assumed that an individual's response follows the S_B_ distribution, and individuals can mark any position along a continuous line, except at the endpoints, which is called the open response situation (Samejima, 1973). Consequently, transformations are needed to prevent scores on the scale’s boundaries (Molenaar et al., 2022). A notable feature of the CRM is that the item information is constant across all ability levels (García-Pérez, 2024), implying that the precision of ability estimates remains uniform. The EstCRM R package (Zopluoglu, 2012) is available for conducting parameter estimations using the CRM. In the CoRSM (Müller, 1987), it is assumed that an individual's response follows a truncated normal distribution. Unlike the CRM, the CoRSM allows item information to vary with ability level, enabling differential estimation precision along the ability continuum. In the BRM (Noel & Dauvier, 2007), responses are modeled to follow a beta distribution. BRM focuses on responses in the open interval (0, 1). To compute the log-likelihood effectively, responses at the endpoints of a scale—originally scored as 0 or 1—are typically adjusted to.0001 or.9999, respectively (Noel & Dauvier, 2007). Parameter estimation for the BRM can be performed using either the authors' original software or the sirt R package (Robitzsch, 2024).
Among these three IRT models, the CoRSM offers several distinctive features that make it particularly suitable for applied research. First, the CoRSM permits respondents to mark any point along a continuum, including the endpoints—referred to as the closed response situation (Samejima, 1973). This feature is advantageous because it eliminates the need for data transformations that are required to prevent scores at the scale's boundaries. In contrast, such transformations are required in both the CRM and the BRM when applied to closed response situations, in order to prevent biased parameter estimates (Molenaar et al., 2022). Second, the CoRSM is highly flexible with respect to data types. It extends the rating scale model (RSM; Andrich, 1978), making it capable of accommodating both continuous responses (e.g., markings on a VAS) and discrete responses (e.g., ratings on a Likert-type scale). Müller (1987) demonstrated that the model could analyze four-point discrete responses by approximating the response probability for each category with the corresponding area under a smooth curve (see Fig. 2 in Müller’s original publication). Additionally, as a member of the Rasch model family (Noel & Dauvier, 2007), the CoRSM can transform ordinal item responses into interval-level scores. This transformation is essential for conducting parametric statistical analyses (Embretson, 1996; Harwell & Gatti, 2001; Iramaneerat et al., 2008; see also Wright & Mok, 2004 for an overview of Rasch models). These features are summarized in Table 1, which compares the features of CoRSM with those of the CRM and BRM. Table 1. Comparisons of the features for three continuous IRT modelsModelResponsesituationResponse distributionIteminformationContinuous response model (CRM; Samejima, 1973)Open response situationS_B_ distributionRemains uniform across different ability levelsContinuous rating scale model (CoRSM; Müller, 1987)Closed response situationTruncated normal distributionVaries with the ability levelsBeta response model (BRM; Noel & Dauvier, 2007)Open response situationBeta distributionVaries with the ability levels
In our view, these features make CoRSM particularly advantageous for researchers and practitioners in applied settings. Accordingly, this study focused on evaluating the performance of the CoRSM—specifically in terms of parameter recovery—across various testing conditions, rather than conducting empirical comparisons with the BRM and CRM. Our goal was to provide practical guidance for researchers who work with both continuous and discrete data formats and who seek to derive interval-level scores suitable for parametric statistical analyses.
Barriers to expanding the use of continuous response formats in research and practice
The development of computer-based interfaces has significantly reduced the efforts required for manually processing continuous ratings on paper-based forms—a procedure that is both time-consuming and labor-intensive (Reips & Funke, 2008; Sung & Wu, 2018). Despite this advancement, the adoption of continuous response formats in research and practice still lags far behind that of discrete scales, such as the Likert scale. At least two critical issues need to be addressed to facilitate the broader adoption of continuous response formats.
More valid tools for analyzing continuous scores need to be developed for researchers and practitioners
There are abundant on-shelf tools available for conducting IRT analyses, such as ConQuest (Adams et al., 2020), Winsteps (Linacre, 2023), IRTPRO (Cai et al., 2011), and WinBUGS (Spiegelhalter et al., 2003), along with various freely available R packages (Choi & Asilkalkan, 2019). However, it is notable that most of these computer programs are designed for the analysis of discrete data. Only a few, such as WinBUGS, EstCRM (Zopluoglu, 2012), and pcIRT (Hohensinn, 2018), are capable of handling continuous data formats. This scarcity of valid tools for continuous data analysis may hinder the broader adoption of continuous response formats and models. Taking the CoRSM (Müller, 1987) as an example, despite its several distinctive features, the model is not well known by researchers, nor is it commonly used by practitioners. One major factor hampering its adoption is the lack of efficient algorithms and valid analytical tools for parameter estimation. As a member of the Rasch model family, the CoRSM theoretically permits item parameter estimation via the conditional maximum likelihood (CML; Andersen, 1970). However, in practice, this method is hindered by intensive computational demands. Verhelst (2019) discussed these technical challenges in detail, noting that the computational burden of the CML approach renders it largely impractical. Currently, the primary tool available for estimating parameters of the CoRSM is the pcIRT R package (Hohensinn, 2018). This package employs the pairwise conditional likelihood (PAIR; Choppin, 1985; Müller, 1999) method, which has been shown to provide accurate estimates of overall item difficulty in both dichotomous and polytomous Rasch models (Garner & Engelhard, 2002). The robustness of the PAIR approach for CoRSM under diverse testing conditions has not been fully validated. Additionally, pcIRT uses maximum likelihood estimation (MLE) to obtain person parameters. However, because the MLE method yields estimates of negative or positive infinity for examinees who obtain either zero or perfect raw scores, pcIRT does not provide MLE estimates for these two extreme cases.
Another barrier to the broader adoption of the CoRSM is the lack of user-friendly tools accessible to general users, particularly those who require data analysis tools but are not proficient in R programming. Although the pcIRT package implements CoRSM in R, it still requires users to interact with R scripts. For users unfamiliar with the R environment, even basic syntax can present a hurdle to conducting CoRSM analyses. Similarly, while using WinBUGS, another tool that can handle continuous data analyses, users must have knowledge of Bayesian statistical methods and Markov chain Monte Carlo (MCMC) algorithms (Johnson, 2017). These requirements pose a considerable challenge for users without an extensive mathematical background, making the parameter estimation process quite daunting. To enhance the accessibility and utilization of the CoRSM, there is a need to develop more intuitive and user-friendly tools that lower the entry barrier for CoRSM analysis. These tools are specifically designed to support users who either do not use R or lack training in advanced statistical modeling. Simplifying the interface and automating estimation procedures would make analytical tools more accessible to general users in the social sciences and could potentially facilitate the adoption and application of the CoRSM across various fields.
More theoretical and empirical research is needed to uncover the psychometric nature of continuous scales
Due to the lack of user-friendly interfaces and easily accessible analytical tools, there is currently limited research investigating the psychometric properties of continuous scales. The first issue of concern revolves around determining the optimal granularity of measurement scales. Researchers are interested in comparing the reliability or measurement errors of fine- and coarse-grained scales, and they hold differing views on the advantages of scales with varying levels of coarseness. For example, some researchers found that coarse-grained measuring scales offer sufficient reliability and that an excessive number of points would create distractions that instead lower the reliability of the test (e.g., Cox, 1980; Tourangeau et al., 2000). However, other researchers hold the view that fine-grained measuring scales provide more options and flexibility, which can subsequently maximize the accuracy of a test (e.g., Cook et al., 2001; Reips & Funke, 2008; Russell & Bobko, 1992). It is noteworthy that, since the continuous scale can be considered as a special case of the discrete scale (Samejima, 1973), comparing the differences between discrete scales with various points as well as continuous scales with infinite points is important to fully answer the above questions. However, instead of collecting truly continuous scores and analyzing the data with appropriate tools for continuous data, all of the research either collected discrete scores or analyzed their data with tools for discrete scores. For instance, Simms et al. (2019) and Flynn et al. (2004) compared the VAS with Likert scales that have response options ranging from 2 to 11 points. In these two studies, the VAS scores were divided into 1000 or seven discrete points. Then the reliability was calculated using the divided scores with a summation function instead of an integration function, which may result in the loss of information provided by continuous response formats and would not accurately reflect the statistical properties of continuous scales.
The second issue of concern is the intervalness of continuous scales. Researchers advocate employing interval scores instead of ordinal scores to avoid the issue of inappropriate use of parametric statistics for ordinal data (Harwell & Gatti, 2001; Iramaneerat et al., 2008; Wright & Mok, 2004) and to improve the responsiveness of change scores (Kersten et al., 2014). Although there is plenty of research and tools addressing the issue of transforming discrete ordinal scores into interval scores (see de Leeuw & Mair, 2007, for the special volume titled ‘Psychometrics in R’), much less research investigates the intervalness of continuous scores. Taking the VAS as an example, some researchers claimed that VAS scores exhibit interval-level measurement properties (Price et al., 1983; Hofmans & Theuns, 2008; Reips & Funke, 2008), while others argue that VAS scores do not behave linearly and lack the property of equal intervals between scores (Kersten et al., 2014). It is interesting to note that none of the research employed methods specifically designed for analyzing continuous scores to substantiate their claims. For instance, Kersten et al. (2014) attempted to compare the intervalness of Likert and VAS scales. In their study, participants marked their pain level on a 10-cm line, which was divided into 50 equal parts. Each mark was scored from 0 to 50. Moreover, the scores were analyzed using a summation function rather than an integration function, which does not correspond with the continuous nature of the scores, potentially compromising the accuracy of reliability calculations. As a member of the family of Rasch models (Müller, 1987; Noel & Dauvier, 2007), the CoRSM can transform ordinal item responses into interval scores. These interval measurements are more suitable for conducting parametric statistical procedures and revealing the intervalness of data derived from continuous scores.
The third issue of interest concerns the relationship between continuous scales and ipsative scores. Researchers have explored the plausibility of integrating ipsative and normative scales using at least two approaches. The first approach is combining the formats of ipsative and normative scales. For example, Chiu and Alliger (1990) proposed the quantitative ranking scale (QRS), which integrates a ranking scale requiring seven items to be ranked and a Likert scale with ten points. Participants can rank the items at any point on the scale, obtaining both ipsative (ranking) and normative (Likert) scores simultaneously. Chiu and Alliger (1990) found that this method performed well in comparison to other scales. Another approach is using statistical methods to transform ipsative scores into normative scores. For example, Brown & Maydeu-Olivares (2011) developed the Thurstonian item response theory (TIRT) model, providing new methods for transforming ipsative ranking data into normative scores. It is notable that when continuous VAS scales are combined with ranking or paired-comparison methods to form the VAS-RRP scales (Sung & Wu, 2018), they become a general case of rating, ranking, and pairwise comparison. This newly proposed technique allows for the simultaneous acquisition of normative scores (rating with continuous scores), ipsative scores (rankings), and partially ipsative/normative scores (rankings with continuous scores). The normative and partially ipsative/normative scores gathered from VAS-RRP scales can be analyzed using continuous IRT models such as the CoRSM mentioned earlier, and the results can be compared with other approaches from Chiu and Alliger (1990) and Brown and Maydeu-Olivares (2011).
The research issues mentioned above represent just a part of the possible issues that need to be addressed by researchers. However, researchers and practitioners need to be empowered by more user-friendly interfaces and valid analytical tools, as well as more research examples, to gain deeper insights and explore the diverse potential usages of continuous scales.
Purposes of the present article
To address the aforementioned technical and practical issues associated with analyzing continuous rating data within the IRT framework, this research conducted four studies, each with a specific research goal. The first study aims to propose an estimation algorithm for the CoRSM, referred to as Al-CoRSM, utilizing the marginal maximum likelihood (MML; Bock & Aitkin, 1981) and the maximum a posteriori (MAP) methods. In conjunction with this algorithm, we developed a user-friendly analytical tool named Continuous Rating Scale Analytics (CoRSA) to implement Al-CoRSM and support parameter estimation for both researchers and practitioners. The second study aims to verify the capability of CoRSA in analyzing continuous and discrete scores through a series of simulations and to evaluate whether person and item parameters of the CoRSM can be accurately estimated under various measurement conditions. The estimation performances of CoRSA were compared with those obtained using pcIRT (Hohensinn, 2018) and ConQuest (Adams et al., 2020). The third study aims to verify the capability of CoRSA in analyzing two empirical datasets involving continuous and discrete scores and to examine model-data fit for each dataset. This study focuses on demonstrating the applicability of CoRSA in practical applications. The datasets analyzed in this study are available in the Open Science Framework repository at https://osf.io/c3jzy/?view_only=0314d5f0cbef4627812ac0bf5d54d271. The fourth study integrated CoRSA into the VAS-RRP 2.0 platform (Sung & Wu, 2018; http://vasrrp.net/vasrrp2), and focused on introducing its user-friendly interface and functionality. This web-based implementation was developed to serve users who either do not use R or lack training in advanced statistical modeling, enabling them to conduct CoRSM analyses with both continuous and discrete data through an accessible, code-free environment.
Study 1: Proposing the algorithm for estimating the parameters of the CoRSM
This study proposed an algorithm called Al-CoRSM to estimate the item and person parameters for the CoRSM. Detailed derivations of the MML and the MAP methods as implemented by the Al-CoRSM are then provided, respectively.
The Continuous Rating Scale Model (CoRSM)
For modeling item responses on a continuous rating scale, Müller (1987) derived a unidimensional IRT model by extending the formulation of the rating scale model (RSM; Andrich, 1978) based on the following assumptions:
- The rating scale comprises a line of length L with midpoint c, and
- The respondent can mark any point along the line in the closed response situation, where the random variable X can take any value within the closed interval \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x\in \left[c-L/2,c+L/2\right]$$\end{document} .
Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${x}_{ni}$$\end{document} refer to the observed response of person n responding to item i with n = 1, 2, …, N and i = 1, 2, …, I. The probability density of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${x}_{ni}$$\end{document} is given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left(X=x_{ni}\vert\beta_n,\delta_i,\theta\right)=\frac1{\gamma_1}exp\left[x_{ni}\left(\beta_n-\delta_i\right)+x_{ni}\left(2c-x_{ni}\right)\theta\right]$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\beta}_{n}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\delta}_{i}$$\end{document} denote the locations of person n and item i on a latent continuum, θ is the dispersion parameter, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\gamma}_{1}={\int\nolimits_{c-L/2}^{c+L/2}}exp\left[t\left({\beta}_{n}-{\delta}_{i}\right)+t\left(2c-t\right)\theta \right]dt$$\end{document} is a normalizing factor. When assuming that the person’s rating conforms to a doubly truncated normal distribution, Eq. (1) can be written as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left(X=x_{ni}\vert\beta_n,\delta_i,\theta\right)=\frac{exp\left[-\theta\left(x_{ni}-c-\frac{\beta_n-\delta_i}{2\theta}\right)^2\right]}{\int_{c-L/2}^{c+L/2}exp\left[-\theta\left(t-c-\frac{\beta_n-\delta_i}{2\theta}\right)^2\right]dt}$$\end{document}The parameter θ reflects the shape of the rating distribution (Andrich, 1982). A smaller θ indicates that examinees’ item responses are distributed over a wide interval and thus have a larger variance of the item responses, which leads to higher discrimination (Verhelst, 2019). The item characteristic curves of the CoRSM for three θ values (e.g., 0.5, 2.0, and 6.0) were presented in Appendix 1. Because the length of the line in the response format can be expressed in arbitrary units and with an arbitrary reference point (Müller, 1987), so that we can assume without loss of generality that c = 0 and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x\in \left[-L/2,L/2\right]$$\end{document} .
Item parameters
Al-CoRSM used the MML method (Bock & Aitkin, 1981) to estimate the item parameters of the CoRSM. Under the assumption of local independence, the conditional probability density, as a function of the whole set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Theta$$\end{document} of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\beta}_{n}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\delta}_{i}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} parameters, given the observed response vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{X}}_{n}$$\end{document} is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P\left({\mathbf X}_n\vert\Theta\right)=\prod\limits_{i=1}^If\left(x_{ni}\vert\beta_n,\delta_i,\theta\right)=\prod\limits_{i=1}^I\frac{exp\left[-\theta\left(x_{ni}-\frac{\beta_n-\delta_i}{2\theta}\right)^2\right]}{\int_{-L/2}^{L/2}exp\left[-\theta\left(t-\frac{\beta_n-\delta_i}{2\theta}\right)^2\right]dt}$$\end{document}If persons are randomly sampled from a population where the latent trait is distributed according to a density function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g\left(\beta \right)$$\end{document} , the marginal probability density of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{X}}_{n}$$\end{document} is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P\left({\mathbf{X}}_{n}\right)={\int\nolimits}_{-\infty }^{+\infty}\prod\limits_{i=1}^{I}f\left({x}_{ni}|\Theta \right)g\left(\beta \right)d\beta$$\end{document}Then the likelihood function is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L=\prod\limits_{n=1}^{N}P\left({\mathbf{X}}_{n}\right)=\prod\limits_{n=1}^{N}{\int\nolimits}_{-\infty }^{+\infty}\prod\limits_{i=1}^{I}f\left({x}_{ni}|\Theta \right)g\left(\beta \right)d\beta$$\end{document}And the log-likelihood function is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ln\left(L\right)=\sum\limits_{n=1}^{N}ln\left[P\left({\mathbf{X}}_{n}\right)\right]$$\end{document}The first partial derivative of Eq. (6) with respect to parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\delta}_{i}$$\end{document} is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{\partial ln\left(L\right)}{\partial {\delta }_{i}}=\sum\limits_{n=1}^{N}\frac{1}{P\left({\mathbf{X}}_{n}\right)}\int\nolimits_{-\infty }^{+\infty}\frac{\partial f\left({x}_{ni}\vert\Theta \right)}{\partial {\delta}_{i}}\frac{P\left({\mathbf{X}}_{n}|\Theta \right)}{f\left({x}_{ni}\vert\Theta \right)}g\left(\beta\right)d\beta$$\end{document}Equation (7) can be approximated using the Gauss quadrature as follows (see Appendix 2):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{\partial ln\left(L\right)}{\partial\delta_i}=\sum\limits_{n=1}^N\sum\limits_{q=1}^Q\left(\frac{L_n\left(V_g\right)A\left(V_g\right)}{\sum_{q=1}^{\mathrm Q}L_n\left(V_g\right)A\left(V_g\right)}\frac{\partial f\left(x_{ni}\vert V_g,\delta_i,\theta\right)}{\partial\delta_i}\frac1{f\left(x_{ni}\vert V_g,\delta_i,\theta\right)}\right)$$\end{document}An algorithm similar to that described by Roberts et al. (2000) is used to solve these likelihood equations. The values that solve Eqs. (7) and (8) are the MML estimates ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{\delta }}_{i}$$\end{document} ). The Newton–Raphson procedure is used to compute the most likely item parameter estimates for all items. The second partial derivatives needed are as follows (see Appendix 2):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{{\partial}^{2}ln\left(L\right)}{\partial {\delta}_{i}^{2}}=\sum\limits_{n=1}^{N}\frac{1}{P{\left({\mathbf{X}}_{n}\right)}^{2}}\left[\frac{{\partial}^{2}P\left({\mathbf{X}}_{n}\right)}{\partial {\delta}_{i}^{2}}P\left({\mathbf{X}}_{n}\right)-{\left(\frac{\partial P\left({\mathbf{X}}_{n}\right)}{\partial {\delta}_{i}}\right)}^{2}\right]$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{{\partial}^{2}ln\left(L\right)}{\partial {\delta}_{i}\partial {\delta}_{j}}=\sum\limits_{n=1}^{N}\frac{1}{P{\left({\mathbf{X}}_{n}\right)}^{2}}\left(\frac{{\partial}^{2}P\left({\mathbf{X}}_{n}\right)}{\partial {\delta}_{i}\partial {\delta}_{j}}P\left({\mathbf{X}}_{n}\right)-\frac{\partial P\left({\mathbf{X}}_{n}\right)}{\partial {\delta}_{i}}\frac{\partial P\left({\mathbf{X}}_{n}\right)}{\partial {\delta}_{j}}\right)$$\end{document}The procedure terminates when the largest change in any \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{\delta}}_{i}$$\end{document} from one cycle to the next is less than.001, or until some maximum limit of iterations has been reached (e.g., 25). The initial values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{\delta}}_{i}$$\end{document} are set to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-\left(\sum\nolimits_{n=1}^{N}{x}_{ni}/N\right)/\!{~}_{{2}\theta}$$\end{document} , which are found to be appropriate to obtain rapid convergence of the estimates of item parameter. Because there is no natural origin in the measurement scale, the mean of all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{\delta}}_{i}$$\end{document} is arbitrarily set to zero.
Person parameters
Al-CoRSM adopted the MAP method to estimate the person parameters of the CoRSM. The posterior density function of observing a response vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbf{X}}_{n}$$\end{document} is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${f}^{\ast}\left({\beta}_{n}\vert{\mathbf{X}}_{n}\right)=\frac{P\left({\mathbf{X}}_{n}\vert{\beta}_{n}\right)g\left(\beta \right)}{P\left({\mathbf{X}}_{n}\right)}$$\end{document}The log posterior function is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ln{f}^{\ast}\left({\beta}_{n}\vert{\mathbf{X}}_{n}\right)=ln\left[P\left({\mathbf{X}}_{n}\vert{\beta}_{n}\right)\right]+ln\left[g\left(\beta \right)\right]+{\mathrm{constant}}$$\end{document}The MAP estimates of person parameters ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{\beta }}_{n}$$\end{document} ) are obtained by setting the first partial derivative of Eq. (12) to zero and solving the equations. The first and second partial derivatives needed for the Newton–Raphson procedure are as follows (see Appendix 2):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{\partial ln{f}^{\ast}\left({\beta}_{n}\vert{\mathbf{X}}_{n}\right)}{\partial {\beta}_{n}}=\sum\limits_{\mathrm{i}=1}^{\mathrm{I}}\frac{\partial}{\partial {\beta}_{n}}lnf\left({x}_{ni}\vert\Theta \right)-\left(\frac{{\beta}_{n}-\mu}{{\sigma}^{2}}\right)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{{\partial }^{2}ln{f}^{\ast}\left({\beta}_{n}\vert{\mathbf{X}}_{n}\right)}{\partial {\beta}_{n}^{2}}=\sum\limits_{\mathrm{i}=1}^{\mathrm{I}}\frac{{\partial}^{2}}{\partial {\beta}_{n}^{2}}lnf\left({x}_{ni}\vert\Theta \right)-\frac{1}{{\sigma}^{2}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{{\partial }^{2}ln{f}^{\ast}\left({\beta}_{n}\vert{\mathbf{X}}_{n}\right)}{\partial {\beta}_{n}\partial {\beta}_{m}}=\sum\limits_{\mathrm{i}=1}^{\mathrm{I}}\frac{{\partial}^{2}}{\partial {\beta}_{n}\partial {\beta}_{m}}lnf\left({x}_{ni}\vert\Theta \right)+\frac{\partial}{\partial {\beta}_{m}}\left(-\frac{{\beta}_{n}-\mu}{{\sigma}^{2}}\right)$$\end{document}The initial values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{\beta}}_{n}$$\end{document} were set to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left({\sum\nolimits}_{i=1}^{I}{x}_{ni}/I\right)/\!{~}_{{2}\theta}$$\end{document} to obtain rapid convergence.
Dispersion parameters
Al-CoRSM used the MLE approach to estimate the dispersion parameter. The probability of observing a response matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf{X}$$\end{document} given \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\boldsymbol{\beta}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\boldsymbol{\delta}}$$\end{document} is equal to
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P\left(\mathbf{X}|\Theta \right)=\prod\limits_{n=1}^{N}\prod\limits_{i=1}^{I}f\left({x}_{ni}|\Theta \right)$$\end{document}The log-likelihood function is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ln\left[P\left(\mathbf{X}|\Theta \right)\right]=\sum\limits_{n=1}^{N}\sum\limits_{i=1}^{I}lnf\left({x}_{ni}|\Theta \right)$$\end{document}The MLE estimate of the dispersion parameter ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{\theta}$$\end{document} ) is obtained by using the Newton–Raphson procedure. The MML estimates of item parameters and the MAP estimates of person parameters are used in conjunction with the observed responses to derive \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{\theta }$$\end{document} . The first and second partial derivatives needed are as follows (see Appendix 2):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{\partial lnP\left(\mathbf{X}|\Theta \right)}{\partial \theta }=\sum\limits_{n=1}^{N}\sum\limits_{i=1}^{I}\frac{\partial}{\partial \theta }lnf\left({x}_{ni}|\Theta \right)=\sum\limits_{n=1}^{N}\sum\limits_{i=1}^{I}\left({A}_{\theta}^{^\prime}-\frac{{\gamma}_{\theta}^{^\prime}}{\gamma}\right)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{{\partial}^{2}lnP\left(\mathbf{X}|\Theta \right)}{\partial {\theta}^{2}}=\sum\limits_{n=1}^{N}\sum\limits_{i=1}^{I}\frac{{\partial }^{2}}{\partial {\theta}^{2}}lnf\left({x}_{ni}|\Theta \right)=\sum\limits_{n=1}^{N}\sum\limits_{i=1}^{I}\left({A}_{\theta}^{^{\prime\prime} }-\frac{{\gamma}_{\theta}^{^{\prime\prime} }\gamma -{{\gamma}^{\prime}}_{\theta }^{2}}{{\gamma}^{2}}\right)$$\end{document}Study 2A: A simulation study with continuous data
The accuracy of parameter estimation is crucial for reliable IRT modeling. Study 2A aimed to evaluate the accuracy of estimation for the CoRSA, which implemented the Al-CoRSM for researchers and practitioners to conduct parameter estimation. The performance of CoRSA was compared to that of pcIRT (Version 0.2.4; Hohensinn, 2019) under different measurement conditions.
Method
A series of Monte Carlo simulations was conducted to evaluate the accuracy of estimation for person ability, item difficulty, and dispersion parameters under different measurement conditions. The estimated values were compared with the true values of these parameters for simulated continuous data sets. Model parameters were manipulated as described below, using self-written functions and codes in R statistical software (Version 4.1.2) by the authors.
Design
Three independent variables were manipulated in this study: sample size (200, 500, and 1000 subjects, indicating small, medium-sized, and large samples, respectively), test length (20, 40, and 60 items, representing short, medium-length, and long tests, respectively), and dispersion parameters (0.5 and 2.0, indicating high and moderate discriminations). We expected that a longer test would improve the person parameter recovery, while a larger sample or a smaller dispersion parameter would improve the item parameter recovery.
Because the pcIRT implicitly rescales the observed data to the unit interval, this leads to the line length changing. Verhelst (2019) demonstrated that rescaling the observed data changes the unit of the latent continuum. An instance of this effect is that halving the observed data will double the values of the person estimates, thereby doubling the mean and standard deviation (SD) of the ability distribution (Verhelst, 2019). Furthermore, since both the MML and MAP methods are usually implemented with the assumption of a normal distribution, it is worthwhile to examine the robustness of these methods when they are applied in the continuous IRT models by comparing the estimation accuracies for normal and nonnormal distributions.
In order to investigate the effect of rescaling the observed variables without modifying the unit of the scale and violating the assumption of a normal ability distribution on parameter recovery, this study took the line length and the form of ability distributions into account jointly in three combinations: (i) the ability distribution being the unit normal N(0, 1) and the length of the response scale set as one (denoted as L = 1), and thus the lower and upper bounds of the observed variable are defined as 0 and 1, respectively; (ii) the ability distribution being the unit normal and L = 5, which means the two bounds are defined as 0 and 5, respectively; and (iii) the ability distribution being nonnormal and L = 5. This study focused on examining whether the CoRSA accommodates the unit of the latent scale when rescaling the observed data by comparing the estimation accuracies for normal distributions with different line lengths. There were \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3\times 3\times 2\times 3=54$$\end{document} conditions with 100 replications each.
Data generation
To compare the parameter recoveries of the CoRSA and pcIRT, all data sets were simulated using the simCRSM function of the pcIRT (Hohensinn, 2019; retrieved from https://github.com/christinehohensinn/pcIRT/tree/master/R), which generated continuous item responses according to the CoRSM (Müller, 1987). The simCRSM function has five arguments: The first is a vector of item parameters. All generated item difficulties were uniformly distributed within the interval [–2, 2]. The second argument is the value of the dispersion parameter, which was set as 0.5, and 2.0, respectively, for high, and moderate discriminations. The third argument is a vector of person parameters. For the normal distribution, person parameters were randomly sampled from the unit normal distribution N(0, 1). For the nonnormal distribution, a polynomial transformation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta =a+bx+{cx}^{2}+{dx}^{3}$$\end{document} was used to transform the person abilities, which leads to the generation of nonnormal ability distributions (Fleishman, 1978). The values of coefficients* a*, b, c, and d were set as – 0.22, 0.78, 0.22, and 0.06, respectively, which resulted in a nonnormal distribution with a mean, SD, kurtosis, and skewness of around 0.04, 1.06, 1.63, and 4.01, respectively. The fourth and fifth arguments of the simCRSM function are the midpoint and length of the response scale, which were set as 0.5 and 1, respectively, for L = 1, and as 2.5 and 5 for L = 5. The above-described steps were then applied to generate simulated responses for all items answered by all subjects.
All of the simulated data were rescaled to the unit interval and then calibrated using the CoRSA and pcIRT, respectively. The performance in parameter recovery was evaluated by computing the mean absolute deviation (MAD) and root mean square error (RMSE) values for the parameter estimates across 100 replications in each condition. The MAD value was defined as the averaged absolute difference between the estimated and true values of the parameters across all persons or items. The RMSE value was computed by taking the square root of the mean of squared differences between the estimated and true values of the parameter across all persons or items.
Because the unit of the latent trait scale is related to the line length (Müller, 1987), it should be noted that the MAD and RMSE can be compared only when the distributions of true abilities and their corresponding estimated abilities have the same SD. Suppose that simulated continuous item responses were distributed within the interval [0, 5], with the true person abilities following a normal distribution with a mean of zero and a variance of one. Recall that when the item responses are rescaled to the unit interval, which is the implicit procedure implemented by the pcIRT, it can be expected that the estimated person abilities will follow a normal distribution with a mean of zero and a variance of 25. Thus, the estimated person ability estimates need to be divided by 5 to make the SD identical to that for the true person abilities.
Results
Tables 2, 3, and 4 present the MAD and RMSE values for person ability, item difficulty, and dispersion parameters, respectively, under various testing conditions. A summary of the results is provided below. Table 2. Parameter recovery for person parametersUnit normal distribution with line length = 1Unit normal distribution with line length = 5Nonnormal distribution with line length = 5Independent variablesMADRMSEMADRMSEMADRMSEDispersionTest lengthSample sizeCoRSApcIRTCoRSApcIRTCoRSApcIRTCoRSApcIRTCoRSApcIRTCoRSApcIRT0.5202000.500.660.630.840.210.630.260.810.210.610.260.795000.500.660.630.840.210.660.260.840.220.630.280.8710000.500.660.630.830.210.680.260.870.220.650.290.90402000.390.470.490.590.150.670.190.840.150.590.190.765000.400.470.500.590.150.710.190.900.150.610.200.8410000.400.470.500.590.150.660.190.830.160.630.210.87602000.340.380.420.480.120.690.160.870.120.580.150.755000.340.380.430.480.120.670.150.830.130.600.160.8310000.340.380.430.480.120.670.150.840.130.620.170.862.0202000.510.690.640.880.320.720.400.900.320.680.400.875000.510.690.650.870.320.740.400.920.320.700.410.9310000.520.690.650.870.320.730.400.910.330.710.420.95402000.410.500.510.630.240.730.300.880.240.630.300.805000.410.490.520.610.240.680.300.850.240.650.300.8810000.410.480.520.610.240.680.300.860.240.660.300.90602000.350.400.440.500.200.650.250.830.200.610.250.785000.350.400.440.500.200.680.250.850.200.630.250.8510000.350.400.440.500.200.680.250.850.200.650.250.88Table 3Parameter recovery for item parametersUnit normal distribution with line length = 1Unit normal distribution with line length = 5Nonnormal distribution with line length = 5Independent variablesMADRMSEMADRMSEMADRMSEDispersionTest lengthSample sizeCoRSApcIRTCoRSApcIRTCoRSApcIRTCoRSApcIRTCoRSApcIRTCoRSApcIRT0.5202000.210.210.260.260.070.850.090.990.070.860.091.005000.130.130.160.170.050.850.060.980.050.850.060.9810000.090.100.120.120.040.840.050.980.040.850.050.98402000.210.210.260.270.070.840.090.970.070.840.090.975000.130.130.170.170.040.830.060.960.040.830.060.9610000.090.090.120.120.030.820.040.950.040.820.040.95602000.210.210.260.270.070.830.090.970.070.830.090.975000.130.140.170.170.040.820.060.950.040.820.050.9510000.090.100.120.120.030.820.040.950.030.820.040.942.0202000.210.220.270.280.110.860.141.000.110.860.141.005000.140.140.170.180.080.850.100.980.080.850.100.9810000.100.100.120.130.060.840.080.970.060.850.080.98402000.220.220.270.270.110.840.140.980.120.840.140.985000.140.140.170.170.070.830.090.960.070.830.090.9610000.100.100.120.120.050.820.070.950.050.830.070.95602000.220.220.270.280.110.830.140.970.110.830.140.975000.140.140.170.180.070.820.090.950.070.820.090.9510000.100.100.120.120.050.820.060.950.050.820.070.95Table 4Parameter recovery for dispersion parametersUnit normal distributionwith line length = 1Unit normal distributionwith line length = 5Nonnormal distributionwith line length = 5Independent variablesMADRMSEMADRMSEMADRMSEDispersionTest lengthSample sizeCoRSApcIRTCoRSApcIRTCoRSApcIRTCoRSApcIRTCoRSApcIRTCoRSApcIRT0.5202000.180.180.230.230.020.490.020.490.010.490.020.495000.170.100.200.130.020.480.020.480.020.480.020.4810000.170.090.200.110.020.480.020.480.020.480.020.48402000.120.140.150.170.010.490.010.490.010.490.010.495000.120.080.150.100.010.490.010.490.010.480.010.4810000.110.060.130.080.010.480.010.480.010.480.010.48602000.120.110.140.140.010.490.010.490.010.490.010.495000.090.070.110.090.010.480.010.480.010.480.010.4810000.080.050.090.060.010.480.010.480.010.480.010.482.0202000.210.180.250.230.061.950.071.950.051.950.061.955000.180.130.220.150.071.930.071.930.071.930.081.9310000.190.080.210.100.071.920.071.920.081.930.091.93402000.150.150.170.180.031.950.041.950.031.950.041.955000.120.070.150.090.041.930.041.930.041.930.041.9310000.120.060.140.080.041.930.041.930.051.930.051.93602000.110.120.140.150.021.950.031.950.021.950.031.955000.100.070.120.080.031.930.031.930.031.930.031.9310000.090.050.110.060.031.930.031.930.031.930.031.93
Effect of sample size
For item parameters, the MAD and RMSE values obtained from CoRSA decreased as the sample size increased, while holding the dispersion parameter constant. This indicates that CoRSA achieved better estimation precision with larger samples. In contrast, the MAD and RMSE values from pcIRT remained relatively unchanged across different sample sizes when line length = 5, suggesting limited sensitivity to sample size in item parameter estimation. Moreover, the effect of sample size on the estimation accuracy of ability and dispersion parameters was negligible for both CoRSA and pcIRT.
Effect of test length
For ability and dispersion parameters, the MAD and RMSE values from CoRSA decreased as test length increased when the dispersion parameter was held constant. In contrast, the pcIRT was less sensitive to changes in test length when line length = 5, with minimal or no change in MAD and RMSE values for ability and dispersion parameters. The effect of test length on item difficulty parameter estimation was negligible for both the CoRSA and pcIRT.
Effect of dispersion parameter
For the ability, item, and dispersion parameters, the MAD and RMSE values from CoRSA increased as the true dispersion parameter increased. In contrast, the pcIRT was less sensitive to changes in dispersion, with noticeable increases in MAD and RMSE values only for higher dispersion in the estimation of dispersion parameters when line length = 5. For ability and item parameters, the changes were minimal.
Effect of data transformation (L = 1 vs. L = 5)
The value of L had opposite effects on CoRSA and pcIRT. For all three types of parameters, CoRSA showed lower MAD and RMSE values when L = 5 compared to L = 1. This was because item responses were concentrated within a narrow interval at L = 1 (as shown in subplot C of Fig. 9 in Appendix 1), resulting in lower discrimination and reduced estimation precision. In contrast, pcIRT yielded lower MAD and RMSE values when L = 1 compared to L = 5, which was particularly evident for item and dispersion parameters. This was primarily due to the pcIRT routinely rescaling the input data to the unit interval without modifying the unit of the trait scale, leading to discrepancies between the estimated and true parameters when L = 5.
Effect of ability distribution (normal vs. nonnormal)
For all three types of parameters, the estimation accuracy of CoRSA and pcIRT remained robust when the ability distribution deviated from normality. For L = 5, the MAD and RMSE values for ability, item difficulty, and dispersion parameters under a nonnormal distribution were comparable to those under a normal distribution. However, pcIRT consistently exhibited higher MAD and RMSE values than CoRSA across all parameter types, regardless of distributional form.
In general, CoRSA provided higher estimation accuracy than pcIRT for all three types of parameters, particularly under conditions where no transformation was applied (e.g., L = 5). The accuracy advantage of CoRSA was most pronounced in scenarios with longer tests and larger samples. Conversely, when transformation was applied (e.g., L = 1), pcIRT delivered comparable performance to CoRSA for item parameters and slightly outperformed CoRSA in estimating dispersion parameters.
For researchers and practitioners who seek better model–data fit rather than interval-level parameter estimates, a slight extension of Müller’s model proposed by Verhelst (2019) can be used to analyze data. Verhelst’s model incorporates both item difficulty and item-level dispersion for each item. To address this need, we derived the estimation algorithm for Verhelst’s model and conducted simulations under the same testing conditions identical to Study 2A, with one exception: the dispersion parameters for each item were randomly sampled from the interval [0.3, 2.0], thereby mimicking items with moderate and high discrimination. The MAD and RMSE values under each condition are presented in Appendix 3. The patterns of parameter recovery were similar to those reported in Tables 2, 3, and 4. Overall, the algorithm for Verhelst’s model demonstrated satisfactory accuracy in estimating person abilities, item difficulties, and item-level dispersions. However, performance declined under the conditions where the ability distribution was normal and the line length = 1.
Estimation efficiency of the CoRSA and pcIRT
Table 5 presents the computation time (in seconds) required to complete the parameter estimation procedures for both CoRSA and pcIRT. For example, under the condition with a dispersion of 0.5, a test length of 60, and a sample size of 200, CoRSA completed the estimation in 12.4 s, whereas pcIRT required 74.8 s, which was approximately six times longer. This pattern was consistent across most conditions, except for two cases involving a dispersion value of 2.0, a test length of 20, and a sample size of 1000. Overall, these results indicate that CoRSA is more computationally efficient than pcIRT for parameter estimation. All analyses were conducted on a desktop computer with an Intel Core i5-14500 processor (2.60 GHz), 32 GB of RAM, running Windows 10. Table 5. Estimation efficiency of the CoRSA and pcIRTIndependent variablesUnit normal distribution with line length = 1Unit normal distribution with line length = 5Non-normal distribution with line length = 5DispersionTest lengthSample sizeCoRSApcIRTCoRSApcIRTCoRSApcIRT0.5202003.19.05.512.94.712.95005.516.712.523.913.024.4100011.423.425.333.425.434.1402006.734.512.151.19.850.850013.363.624.593.624.994.3100023.186.745.2128.349.6129.56020012.474.819.7114.820.6113.850023.7136.739.3209.639.3209.9100040.8187.179.4284.986.5285.62.0202004.39.09.215.220.734.05008.416.618.922.725.030.0100015.123.335.127.937.331.9402009.835.120.861.021.163.250018.664.341.290.243.397.7100033.788.076.6108.881.4116.86020017.778.537.9137.538.5145.550034.0143.373.8202.679.4216.0100060.6194.7137.9242.4354.3554.2
Study 2B: A simulation study with discrete data
Since continuous item responses can be regarded as a limiting case of discrete item responses in which the number of response categories becomes infinitely large (Mellenbergh, 1994; Samejima, 1973), the present study postulated that the CoRSA can also be used to perform parameter estimations for discrete data when the distances between two adjacent step difficulty parameters are equal (this is the case 3 of the rating scale model, Andrich, 1978). This study aimed to recover the parameters using the CoRSA by comparing the estimated values with the generated true values of the ability, overall difficulty, and step difficulty parameters for simulated discrete data sets. Parameter recovery in ConQuest (Adams et al., 2020) was used for comparison purposes as appropriate.
Method
Monte Carlo simulations were used to evaluate parameter recovery under different measurement conditions. To simulate 100 data sets under each condition, discrete item responses were generated according to the RSM (Andrich, 1978). The probability function of the discrete response is given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${P}_{nik}=\frac{exp\left[\sum\limits_{j=0}^{k}\left[{\beta}_{n}-\left({\delta}_{i}+{\tau}_{j}\right)\right]\right]}{\sum\limits_{k=0}^{m}exp\left[\sum\limits_{j=0}^{k}\left[{\beta}_{n}-\left({\delta }_{i}+{\tau}_{j}\right)\right]\right]},{\mathrm{where}}\sum\limits_{j=0}^{0}\left[{\beta}_{n}-\left({\delta}_{i}+{\tau}_{j}\right)\right]\equiv 0$$\end{document}where Pnik is the response probability of scoring k on item i for subject n, βn is the location of the nth person on the continuum, δi is the overall difficulty of the ith item on the continuum, τj is the step difficulty of the jth threshold on the continuum, and* m* is the number of response categories in each item. Model parameters were manipulated as described below, using self-written functions and codes in R statistics software (Version 4.1.2).
Design
The sample size was fixed at 500 subjects to ensure a sufficient number of subjects for parameter estimation. The number of response categories was set at three levels (five, seven, and nine, which represented three types of commonly used items in discrete rating scales). The test length was set at four levels (5, 10, 20, and 30, which were considered very short, short, medium, and long tests, respectively). Two analytical tools (CoRSA and ConQuest) were used to calibrate the simulated data. In summary, this simulation experiment had 24 (3 × 4 × 2) unique conditions, and 100 replications were carried out under each condition. We expected that the parameter recoveries of the CoRSA would be accurate and similar to those obtained using ConQuest.
Data generation
The data generation process in each condition consisted of the following steps: First, ability parameters were randomly generated from the unit normal distribution. Second, overall difficulty parameters for all items were set to range uniformly from – 2.0 to 2.0. Third, the step parameters were set to range from – 2.3 to 2.5. The step parameters were set to the four values of – 2.3, – 0.9, 0.7, and 2.5 when there were five response categories, to – 2.3, – 1.3, – 0.5, 0.2, 1.4, and 2.5 when there were seven response categories, and to – 2.3, – 1.6, – 0.8, – 0.3, 0.1, 0.9, 1.5, and 2.5 when there were nine response categories. Fourth, these generated parameters (abilities, overall difficulties, and step difficulties) were used to compute the corresponding category and cumulative probabilities using the RSM (Andrich, 1978), which is demonstrated in Eq. (20). Fifth, the cumulative probability values were compared with a random number sampled from the uniform distribution (0, 1). The simulated discrete item response was defined as the category with the highest score at which the random number was less than or equal to the corresponding cumulative probability. The above-mentioned steps were performed to generate simulation data for the responses by all subjects on all the items.
Each simulated data set was calibrated using the CoRSA and ConQuest. To evaluate the parameter recovery, the MAD and RMSE values of all estimates for the ability, overall difficulty, and step difficulty parameters were computed, respectively, and were averaged across replications within each condition. This study represented the comparison of the means of the MAD and RMSE values for person, overall difficulty, and step difficulty parameters between conditions.
Results
Table 6 presents the MAD and RMSE values for person ability, overall item difficulty, and step difficulty parameters under various testing conditions. Table 6. Parameter recovery of the CoRSA and ConQuestResponse categoryTest lengthAnalytical toolPerson parameterOverall difficulty parameterStep difficulty parameterMADRMSEMADRMSEMADRMSE55CoRSA0.4700.5630.2070.2140.1710.176ConQuest0.4760.5740.2010.2120.1090.12710CoRSA0.3710.4480.2020.2090.1270.130ConQuest0.3820.4610.2010.2100.0990.11020CoRSA0.3000.3630.2000.2090.1010.104ConQuest0.3120.3750.2000.2090.0850.09330CoRSA0.2760.3310.2000.2090.1000.102ConQuest0.2870.3430.2000.2090.0770.08375CoRSA0.3990.4810.2030.2080.2020.182ConQuest0.4080.4950.2010.2100.2020.20210CoRSA0.3180.3840.2000.2060.1410.145ConQuest0.3290.3950.2010.2080.1110.12520CoRSA0.2730.3240.2000.2050.1320.135ConQuest0.2820.3330.2000.2070.1160.12530CoRSA0.2530.2980.2000.2050.1080.111ConQuest0.2660.3100.2000.2060.0750.08395CoRSA0.3330.4050.2010.2060.1470.151ConQuest0.3440.4160.2030.2120.1220.14510CoRSA0.2630.3190.2000.2050.1430.146ConQuest0.2750.3300.2020.2080.1250.14020CoRSA0.2200.2640.2000.2040.1210.124ConQuest0.2330.2760.2000.2050.0760.08730CoRSA0.2000.2370.2000.2040.1210.123ConQuest0.2160.2540.2000.2050.0370.045
Effect of response categories
For ability parameters, the MAD and RMSE values obtained from CoRSA decreased as the number of response categories increased when the test length was held constant. This indicates that CoRSA achieved better estimation precision for person ability with more response categories. In contrast, the MAD and RMSE values for the step difficulty parameters slightly increased with more response categories. For example, with a test length of 20, the RMSE increased from 0.104 with five response categories to 0.135 with seven. This suggested that CoRSA provided slightly lower estimation precision for step parameters when tests involved a greater number of response categories. The effect of response category on overall difficulty parameter estimation was negligible, as the MAD and RMSE values remained relatively stable across conditions. ConQuest demonstrated similar patterns to CoRSA across all testing conditions.
Effect of test length
For both ability and step difficulty parameters, the MAD and RMSE values obtained from CoRSA decreased as the test length increased when the number of response categories was held constant. This indicates that CoRSA achieved better estimation precision with longer tests. In contrast, the test length had minimal impact on the estimation accuracy of the overall difficulty parameter. Again, ConQuest exhibited similar trends to those observed for CoRSA.
Overall, when CoRSA was used to analyze discrete data with five, seven, and nine response categories, the accuracy of parameter estimation was highly comparable to that achieved by ConQuest. Both tools demonstrated appropriate parameter recovery and were able to accurately estimate ability, overall difficulty, and step difficulty parameters.
Summary of Study 2 A and 2B
The simulation studies conducted in Study 2A and 2B provide robust evidence that CoRSA demonstrates effective parameter recovery across various testing conditions. It is observed that increasing the sample size leads to reduced estimation errors for item difficulties, while longer tests decrease estimation errors for person abilities. It is also observed that increasing dispersion parameters diminishes the accuracy of estimations for both person abilities and item difficulties. Additionally, the simulations also highlighted challenges with the pcIRT (Hohensinn, 2018), particularly its lower estimation accuracy when rescaling the observed variables without modifying the unit of the latent scale (e.g., L = 5). This limitation hinders the practical applicability of pcIRT. In contrast to pcIRT, CoRSA provided satisfactory parameter estimates even under conditions such as narrow response intervals (e.g., L = 1), showcasing its robustness. Finally, the results suggest that CoRSA performs comparably to ConQuest (Adams et al., 2020) when applied to discrete data, indicating its versatility and effectiveness across different types of data.
Study 3A: Applying the CoRSA to empirical continuous data from the career interest assessment
Studies 3 A and 3B were designed to employ the CoRSA to transform both ordinal continuous and discrete data into interval scores. The Rasch model and its extensions, such as the RSM (Andrich, 1978), are widely recognized for their ability to convert ordinal discrete data into interval scores when data adequately fit the model (Bond & Fox, 2015). As a member of the Rasch family models (Noel & Dauvier, 2007), the CoRSM is similarly expected to be capable of transforming not only ordinal continuous data but also ordinal discrete data into interval scores when data fit this model. Specifically, Study 3A utilized the CoRSA to estimate both person and item parameters, and to evaluate the fit between the CoRSM and the empirical continuous data from the career interest assessment using item fit statistics (Wright & Masters, 1982). When all items demonstrate acceptable fit statistics, it robustly indicates that the data fit the model well. Consequently, the resulting estimates of person abilities and item difficulties are regarded as being on an interval measurement scale (Bond & Fox, 2015; Smith, 2000; Wright & Mok, 2004). These interval-level measures fulfill the requirements of conducting parametric statistical analyses (Harwell & Gatti, 2001; Iramaneerat et al., 2008; Wright & Mok, 2004). It is inappropriate to directly compare the model-data fit of the CoRSA and pcIRT (Hohensinn, 2018) using the empirical dataset, as the true values of the person, item, and dispersion parameters are unknown. Therefore, pcIRT was not utilized in the analysis of the empirical data.
Method
Participants
For this study, the sample comprised 800 ninth graders from junior-high-schools in Taiwan, with a mean age of 13.71 years. Among them were 257 males (32.13%) and 543 females (67.88%). These students took the career interest assessment (see the next section) during career guidance classes, and the results would be used as one of the references for students’ career decisions when considering further streaming to vocational high schools.
Assessment tools
The Situation-Based Career Interest Assessment (SCIA) (Sung et al., 2016, 2017), which is a VAS-format scale, was used to collect participants’ continuous item responses. The SCIA is a computerized test of vocational interest that is designed to help students in grades 7 through 12 with their career choices and is based on the vocational interest theory of Holland (1997), in which vocational interests are categorized into six types: Realistic (R), Investigative (I), Artistic (A), Social (S), Enterprise (E), and Conventional (C). The SCIA included a total of 138 items, with 23 items in each of the six dimensions. Each VAS item comprised an 800-pixel continuous line along with an item describing a job title, a curriculum course, or an activity related to one of the six types of vocational interest (as shown in Fig. 1). Considering that high school students might not be familiar with all of the vocations presented, a picture and description were provided under the heading of each vocation. Students could also click on the icon next to each vocation to learn more about it. As each item appeared on the screen, the student dragged and dropped each vocational description onto the line continuum. Placing a vocational item further to the right of the line indicated that the student had a stronger preference for it. The student could place the item at any point along the line. The ratio of the distance (calculated in pixels) of the item from the left end of the line determined the student’s score for that vocation.Fig. 1A Screenshot of the Situation-Based Career Interest Assessment (SCIA) item. Note. Icon A represents the single description related with the Realistic type of vocational interest
Procedure
The test data were collected in April 2022. The purpose of the SCIA and the method of endorsing the item were explained to the participating students before the scale was administered to them. The administration of the SCIA lasted for around 20–25 min.
Analysis
To verify the model-data fit of each SCIA dimension, we used the CoRSA to analyze each dimension of the data individually. The raw continuous data were transformed into the unit interval. The outfit mean square error (MNSQ; Wright & Masters, 1982) values for each item in each dimension were calculated as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{MNSQ}}_{i}=\sum\limits_{n=1}^{N}{\left(\frac{{x}_{ni}-{p}_{ni}}{\sqrt{{V}_{ni}}}\right)}^{2}\bigg{/}{N=\sum\limits_{n=1}^{N}{z}_{ni}^{2}}\bigg{/}N$$\end{document}where xni, pni, Vni, and zni are the observed score, expected score, variance of the observed scores, and standardized residual on item i for subject n, respectively, and N is the sample size. The term V reflects the spread of the rating distribution. A larger value of V indicates that examinees’ item responses are distributed over a wide interval; conversely, a smaller value indicates a more concentrated response pattern. Wright and Linacre (1994) recommended that acceptable MNSQ values fall between 0.6 and 1.4. However, as noted in the same article, Linacre emphasized that low MNSQ values (i.e., overfit) are generally less problematic than high values (i.e., underfit). He advised that when analyzing data from an existing test, items with very low MNSQ values should not be removed, as they can still provide useful information. Therefore, in line with Linacre’s guidance, we retained items with MNSQ values below 0.6 and excluded only those exceeding 1.4. The data were considered to fit the CoRSM adequately if the outfit MNSQ values of all retained items were at or below 1.4 (Bond & Fox, 2015).
Results
There were 6, 2, 3, 0, 4, and 2 items excluded from the R, I, A, S, E, and C dimensions of the SCIA, respectively. To verify the stability of the model-data fit, we split the full sample into two random subsamples and refitted the model separately to each subsample. The procedures were repeated ten times, and we recorded the number of times each item was classified as fitting (e.g., MNSQ < = 1.4) or misfitting (e.g., MNSQ > 1.4). In the first subsample, for example, within the R dimension, six items (item 3, 7, 12, 19, 22, and 23) were identified as fitting in fewer than seven out of the ten replications. This result indicated that these items consistently misfit the model. Similarly, 2, 3, 0, 4, and 2 items were consistently identified as misfitting in the I, A, S, E, and C dimensions, respectively. Notably, the misfitting items in the first subsample matched those identified in the full sample. The second subsample produced comparable results, again identifying 6, 2, 3, 0, 4, and 2 misfitting items across the R, I, A, S, E, and C dimensions, respectively.
Figure 2 shows the distribution of MNSQ values for items retained in each dimension, where the MNSQ values ranged from 0.66 to 1.39. In addition, the mean MNSQ value ranged between 0.96 and 1.00 for each dimension. These results suggest that the subjects’ responses to the retained items fit the CoRSM well. The dispersion parameter for each dimension was 0.42, 0.41, 0.35, 0.37, 0.53, and 0.58, respectively. Estimates of item difficulty parameters of the remaining items are reported in Table 7. The values of item difficulties across all dimensions ranged from – 0.56 to 0.54. The standard errors of item difficulties ranged between 0.19 and 0.24. Fig. 2. Outfit MNSQ values for remaining items in each SCIA dimension. Note. Each box plot shows the median, first and third quartiles, and range. R = Realistic; I = Investigative; A = Artistic; S = Social; E = Enterprise; and C = ConventionalTable 7Results from a CoRSM analysis of the Situation-Based Career Interest Assessment (SCIA)Item No.Item difficulty parameter estimateRealisticInvestigativeArtisticSocialEnterpriseConventional10.23– 0.11– 0.270.10– 0.190.2120.150.08-0.380.480.543-– 0.05– 0.070.01– 0.37– 0.0140.03– 0.12– 0.110.08– 0.260.135– 0.180.020.10– 0.10– 0.06– 0.096– 0.560.020.23– 0.200.060.257-0.36-0.13– 0.230.2080.33-0.10– 0.120.030.159– 0.120.49– 0.08– 0.41-0.29100.03– 0.01– 0.25– 0.16– 0.07– 0.0911– 0.34– 0.150.130.220.26– 0.0512-0.31– 0.03– 0.04– 0.08-13– 0.08– 0.01– 0.320.210.04– 0.07140.19– 0.11– 0.050.200.14– 0.1815– 0.03– 0.010.040.03-– 0.4016– 0.03– 0.11– 0.230.07– 0.37– 0.3417– 0.17– 0.140.460.120.090.14180.300.050.27–0.28-– 0.0919-– 0.03-– 0.100.150.01200.24– 0.240.000.140.04–0.34210.01-– 0.15– 0.380.45– 0.0822-– 0.25– 0.010.16– 0.12– 0.1823-0.010.24– 0.06--M0.000.000.000.000.000.00SD0.230.190.200.200.240.23Note. “-” indicates that the item was removed and thus the estimate was not available
In summary, the results of the analyses demonstrated that after excluding the poorly fitting items, the remaining items fit the CoRSM well. Based on the well model-data fit, the CoRSA was capable of estimating the interest measures in each dimension for each subject. These estimates conform to the requirements of the interval-level measurement scale for applying parametric statistics (Bond & Fox, 2015; Harwell & Gatti, 2001; Iramaneerat et al., 2008; Wright & Mok, 2004), thereby facilitating more precise and reliable measurement of career interest.
Study 3B: Applying the CoRSA to empirical discrete data of work value assessment
Study 3B aimed to employ the CoRSA to transform ordinal discrete data into interval scores. Specifically, this study utilized the CoRSA to estimate both person and item parameters, and to evaluate the fit between the CoRSM and the empirical discrete data from the work value assessment using item fit statistics (Wright & Masters, 1982). When all items fit the model well, the resulting estimates of person abilities and item difficulties are on an interval measurement scale (Bond & Fox, 2015; Smith, 2000; Wright & Mok, 2004).
Methods
Participants
For this study, the sample comprised 716 senior-high-school students in Taiwan, with a mean age of 16.92 years. Among them were 354 males (49.44%) and 362 females (50.56%). The results would be used as one of the references for students’ career decisions of entering departments of colleges.
Assessment tool
The Likert-type version of the Work Values Assembly (WVA, Sung et al., 2019) was adopted to collect participants’ discrete item responses. The WVA consists of seven dimensions: prosocial motivation (PS), interpersonal connections (IP), prestige (PR), comfort (CS), professional growth (GR), self-actualization (SA), and autonomy (AU). Each dimension consists of six items, for a total of 42 items on the scale. Respondents rated the 42 items on the following five-point Likert-type scale: “not important,” “somewhat important,” “important,” “very important,” and “extremely important” (as shown in Fig. 3). Sung et al. (2019) indicated that the WVA has good reliability and validity in measuring the work values of Taiwanese high-school students. Fig. 3. Screenshot of the Likert version of the Work Value Assembly (WVA) interface
Procedure
The test data were collected in March 2023. The purpose of the scale and the method of endorsing the item were explained to the participating students before the scale was administered to them. The administration of the WVA lasted for around 15–20 min.
Analysis
To verify the model-data fit of each WVA dimension, we utilized the CoRSA to analyze each dimension of the data independently. The outfit MNSQ values of each item in each dimension were computed using Eq. (21). In this study, the data were considered to fit the CoRSM adequately when the outfit MNSQ values of all retained items were at or below 1.4 (Bond & Fox, 2015; Wright & Linacre, 1994).
Results
Table 8 indicates that the outfit MNSQ values for all items ranged from 0.48 to 0.86, so no items were excluded from the WVA. This result suggested that the participant’ responses to the items fit the model well. To verify the stability of the model-data fit, we split the full sample into two random subsamples and refitted the model separately to each subsample. The procedures were repeated ten times. In the first subsample, all items from the PS, IP, PR, CS, GR, SA, and AU dimensions of the WVA were identified as fitting in all ten replications. This result indicated that these items consistently fit the model. The second subsample produced similar results, confirming that all items were consistently identified as fitting across all dimensions. Table 8. Results of the item parameter estimation for the Work Value Assembly (WVA)ItemOverall difficulty estimateSEOutfitStep difficulty estimateStep 1Step 2Step 3Step 4PS10.100.050.48− 3.03− 1.011.013.03PS20.080.050.59PS3− 0.160.050.58PS40.100.050.65PS50.130.050.61PS6− 0.250.050.55IP1− 0.050.050.57− 2.97− 0.990.992.97IP20.120.050.53IP30.180.050.61IP4− 0.180.050.68IP5− 0.050.050.62IP6− 0.010.050.59PR10.380.040.61− 2.25− 0.750.752.25PR20.310.040.61PR30.210.040.66PR4− 0.520.040.67PR5− 0.610.040.64PR60.230.040.73CS1− 0.320.060.61− 3.01− 1.001.003.01CS2− 0.310.060.54CS30.100.060.70CS40.200.060.79CS5− 0.090.060.58CS60.430.050.69GR1− 0.070.050.67− 3.31− 1.101.103.31GR2− 0.340.050.53GR30.050.050.65GR4− 0.600.060.66GR50.990.050.86GR6− 0.030.050.63SA1− 0.610.060.61− 3.30− 1.101.103.30SA20.040.060.65SA30.010.060.63SA40.250.060.63SA50.140.060.72SA60.180.060.65AU10.130.050.59− 3.52− 1.171.173.52AU20.340.050.61AU3− 0.030.050.64AU4− 0.150.050.58AU5− 0.060.050.59AU6− 0.230.050.68Note. PS = prosocial motivation; IP = interpersonal connections; PR = prestige; CS = comfort; GR = professional growth; SA = self-actualization; AU = autonomy
The SEs of all items ranged from 0.04 to 0.06, implying that the estimations of overall difficulty parameters were accurate. The four estimates of step difficulties for the PR dimension (– 2.25, – 0.75, 0.75, and 2.25) were more closely distributed than those for the AU dimension (– 3.52, – 1.17, 1.17, and 3.52). This indicated that respondents with low PR levels (e.g., – 3.00) had higher probabilities of choosing “not important,” and those with high levels (e.g., 3.00) had higher probabilities of choosing “extremely important.” In the AU dimension, respondents with low AU levels had higher probabilities of choosing “somewhat important” and those with high levels had higher probabilities of choosing “very important.”
Table 9 presents the means, SDs, and correlations among the seven measures in the ability estimates. The SA dimension had the highest mean estimate across the dimensions, which implied that respondents had a stronger preference for the job, enabling them to make use of their expertise. The PR dimension had the lowest mean estimate across the dimensions, which indicated that respondents had a weaker preference for the job enabling them to achieve a higher social status. The inter-trait correlation coefficient ranged from 0.23 to 0.65. The correlation was strongest between the GR and SA dimensions, which implied that when respondents had a stronger preference for gaining specialized skills while working at a job, they would also have a stronger preference for a job enabling them to make use of their expertise. Table 9. Descriptive statistics and correlations of the person parameters for the Work Value Assembly (WVA)DimensionM**SDPSIPPRCSGRSAPS0.971.12–IP1.561.060.48–PR0.231.010.310.48–CS2.330.910.230.340.47–GR1.650.980.590.490.360.33–SA2.470.920.460.440.370.390.65–AU1.541.070.330.420.450.400.500.60Note. PS = prosocial motivation; IP = interpersonal connections; PR = prestige; CS = comfort; GR = professional growth; SA = self-actualization; AU = autonomy
In summary, the results of the above analyses demonstrated that the WVA items fit the CoRSM well. Based on the well model-data fit, the CoRSA is capable of estimating work value scores in each dimension for each individual. These estimates meet the requirements for applying parametric statistics to interval scores (Bond & Fox, 2015; Harwell & Gatti, 2001; Iramaneerat et al., 2008; Wright & Mok, 2004), thereby facilitating more precise and reliable measurement of work values.
Summary of Study 3 A and 3B
We applied the CoRSA to both a continuous dataset and a discrete dataset, demonstrating how to assess the degree of fit between the empirical data and the model using item fit statistics. This process is crucial for validating the benefits of the Rasch family models, including the CoRSM. By verifying that the empirical data fit the CoRSM, CoRSA effectively transforms both continuous and discrete raw data into interval-level scores. This transformation is critical because it allows researchers and practitioners to have confidence that the data meet the requirements necessary for conducting parametric statistical analyses (Embretson, 1996; Harwell & Gatti, 2001; Iramaneerat et al., 2008; Wright & Mok, 2004).
Study 4: The implementation of the Continuous Rating Scale Analytics (CoRSA)
To assist researchers and practitioners in analyzing their own continuous and discrete data collected from rating scales, the fourth study aimed to integrate CoRSA into the VAS-RRP 2.0 platform (Sung & Wu, 2018; http://vasrrp.net/vasrrp2). Below, we explain how to implement CoRSA to rescale continuous or discrete data to interval scores.
Step 1: Designate the data properties of scale scores
Users must specify whether their dataset contains discrete or continuous scale scores and define the original score range of the scale used during data collection. For example, scores may originate from a five-point Likert scale or range from 0 to 800 (see Fig. 4). Additionally, users can choose to analyze continuous datasets using either Müller’s model or Verhelst's model.Fig. 4. Designating the data properties of scale scores
Step 2: Download the template for your data file
CoRSA provides a template file formatted according to its required data structure (see Fig. 5). Users must submit their response data in this specified format to ensure that CoRSA can correctly process information about participants and item features.Fig. 5. Downloading the template of the data file for your reference
Step 3: Upload the data file and obtain the result file
To perform the analysis, users should upload their completed data file by clicking the "Choose File" button and selecting the appropriate file. Then, click the "Submit and get the result file" button to start the estimation process. Upon completion, the system will generate and download a result file containing interval estimates of the ability, difficulty, and dispersion parameters (see Fig. 6).Fig. 6. Submitting and getting the result file
It is noteworthy that users who are interested in constructing a scale and collecting data using the VAS-RRP Generator may skip steps 1–3 and instead simply select their surveys and click the “Get interval scores” button to rescale their raw data (see Fig. 7). The functions and procedure of the VAS-RRP Generator have been described by Sung and Wu (2018).Fig. 7. Using the CoRSA to analyze the response data collected by the VAS-RRP generator
The results of the analysis were systematically organized and stored in a worksheet within a Microsoft Excel file. For example, the upper part of the worksheet displayed descriptive statistics for the ability estimates of the entire sample, along with the difficulty estimates for all items (see Fig. 8). Additionally, the worksheet included the individual estimates of person abilities, item difficulties, and a test-level dispersion parameter, providing a comprehensive summary of the parameter estimation results.Fig. 8. Screenshot of the CoRSA output file
For readers who require more detailed instructions on conducting CoRSM analysis, or who wish to perform differential item functioning (DIF) analysis to evaluate the measurement fairness of rating scales using CoRSA, a worked example is available at: https://osf.io/c3jzy/?view_only=0314d5f0cbef4627812ac0bf5d54d271.
Discussion
Advances in computer technology have addressed practical challenges in collecting and scoring continuous data, facilitating the use of VASs (Reips & Funke, 2008). Within the framework of IRT, several models have been proposed to use the VAS-typed continuous responses as indicators of person-level abilities and to model an examinee’s expected rating as a function of person ability and item difficulty parameters. Samejima (1973) developed the CRM by treating continuous responses as a limiting case of graded responses, where the number of categories is infinitely large. Samejima’s study also explored open and closed response situations, inspiring subsequent development of models for continuous data. To manage more complex data structures, Noel and Dauvier (2007) proposed the BRM to address complexities of response distributions such as asymmetry of bounded continuous data, by assuming the item response follows a beta distribution. Recent advancements have led to the creation of accessible tools like the EstCRM (Zopluoglu, 2012) and the sirt (Robitzsch, 2024) R packages, designed to conduct parameter estimation for CRM and BRM. These developments have broadened the applicability of IRT modeling to continuous data. Nevertheless, several challenges persist in employing these models and tools for continuous data analysis. Primarily, the CRM does not address the issue of measurement scale levels, raising concerns about its capability to produce interval-level estimates for person and item parameters—crucial for conducting parametric statistical analyses (Harwell & Gatti, 2001; Iramaneerat et al., 2008; Wright & Mok, 2004). Furthermore, the mathematical complexity underlying the BRM and the implementation of the sirt R package may be difficult for general users in the social sciences to master, potentially limiting its use and popularity.
Among the various continuous IRT models, the CoRSM developed by Müller (1987) offers several advantageous features for practical applications. Firstly, it allows examinees to mark any point along a continuum, which eliminates the need for data transformations that prevent scores at scale boundaries (Molenaar et al., 2022). Secondly, the CoRSM is an extension of the rating scale model (Andrich, 1978), enabling it to accommodate not only continuous responses (e.g., markings on a VAS) but also discrete responses (e.g., ratings on a Likert-type scale). Most importantly, as a member of the Rasch model family (Noel & Dauvier, 2007), the CoRSM theoretically provides interval-level estimates for both persons and items, which are crucial for conducting parametric statistical procedures (Harwell & Gatti, 2001; Iramaneerat et al., 2008; Wright & Mok, 2004). However, the widespread adoption of the CoRSM may be hindered by the lack of efficient algorithms and validated analytical tools for parameter estimation. To date, the pcIRT R package (Hohensinn, 2018) appears to be the only available tool for estimating item and person parameters for the CoRSM. Nevertheless, the use of pcIRT comes with significant limitations. Firstly, the parameter recovery of pcIRT has not been thoroughly validated, which casts doubt on its accuracy for estimating person and item parameters for the CoRSM. Secondly, pcIRT does not address the issue of line length being related to the unit of the latent continuum. Consequently, pcIRT struggles to obtain accurate estimates because it uses algorithms that rescale the observed scale scores to a specified interval without modifying the unit of the latent trait scale. Additionally, implementing pcIRT requires users to engage with R programming, making it challenging for those unfamiliar with the R environment, which could limit its utility and popularity.
In this article, we conducted four studies to address the technical challenges associated with estimating parameters of the CoRSM. These studies provide more convincing evidence for the effectiveness of using the algorithms of continuous scores in both simulation and empirical data. Additionally, we offer a user-friendly interface for researchers and practitioners interested in collecting and analyzing continuous data. The first study proposed the Al-CoRSM algorithm, which utilized MML and MAP methods to estimate person and item parameters of the CoRSM. This study also developed the analytical tool CoRSA by implementing Al-CoRSM for researchers and practitioners to conduct parameter estimation. CoRSA boasts several notable advantages. Firstly, simulation studies show that CoRSA achieves effective parameter recovery across various testing conditions. It is observed that increasing the sample size leads to reduced estimation errors for item difficulties, while longer tests decrease estimation error for person abilities. These results align with previous research findings (Noel & Dauvier, 2007; Wang & Zeng, 1998). Furthermore, it is also noted that increasing dispersion parameters reduces the accuracy of estimations for both person abilities and item difficulties. Moreover, the MML and MAP methods implemented by CoRSA exhibit robustness, as evidenced by similar estimation accuracy for non-normal ability distributions compared to normal distributions.
The second study examined the capability of CoRSA to analyze continuous and discrete data. We verified the second key advantage of the CoRSA algorithm, which is its ability to adjust the unit of the trait scale when rescaling observed data to a specified interval, thus maintaining constant response probabilities. This critical feature, absent in pcIRT, allows for more accurate parameter estimation, especially when observed data are rescaled to the unit interval. This capability is particularly crucial in practical applications where data transformation is routinely required. Simulation studies have shown that rescaling data in pcIRT without adjusting the unit of the latent scale leads to parameter estimates that significantly diverge from the true values. In contrast, CoRSA is adept at providing satisfactory parameter estimates under these conditions, making it a more reliable tool for practical applications. These findings provide compelling evidence to support the superior performance of CoRSA. Furthermore, the capability of CoRSA to analyze discrete data was also verified. Given that continuous response formats can be viewed as an extension of graded response formats (Mellenbergh, 1994; Samejima, 1973), it theoretically suggests that the CoRSM is applicable to discrete data, such as those collected from Likert-type scales. Simulation studies tested the parameter recovery of CoRSA on discrete data with five, seven, and nine categories, and the results have shown that its performance is very comparable to that of ConQuest, a well-known software in IRT modeling. This finding not only supports the theoretical postulate that the CoRSM can effectively handle discrete data but also highlights the utility of CoRSA in providing accurate parameter estimates for such data. This versatility is particularly beneficial for researchers who deal with both continuous and discrete data formats, allowing them to utilize a single, robust methodological approach for diverse data types.
In the third study, we verified CoRSA’s capability to transform continuous raw data into interval scores. This transformation ensures that both person abilities and item difficulties estimated by CoRSA conform to an interval scale of measurement, provided that the data fit the CoRSM. This feature is particularly valuable as it aligns with the standards required for applying parametric statistical procedures. For discrete data, the benefits of transforming ordinal discrete responses into interval Rasch scores are well documented, yet these benefits are contingent on the data fitting the requirements of the Rasch family models (Bond & Fox, 2015; Wright & Mok, 2004). Given that the CoRSM is an extension of the RSM (Andrich, 1978), it inherits similar properties. Therefore, when the data fit the CoRSM, the ordinal continuous item responses can be rescaled using CoRSA to produce interval estimates for persons and items. This rescaling meets the requirements for conducting rigorous parametric statistics (Dumenci & Achenbach, 2008; Embretson, 1996; Harwell & Gatti, 2001; Iramaneerat et al., 2008; Li, 2016; Wright & Mok, 2004). The rescaling of scores from ordinal to interval levels is critical because using parametric statistics (e.g., t tests and ANOVA) on ordinal scores can lead to several statistical issues. CoRSA addresses these issues by enabling the application of parametric statistical procedures to interval-level scores derived from continuous scales, thereby avoiding the drawbacks associated with ordinal data analysis.
The fourth study addressed the issue of enhancing the accessibility and usability of psychometric tools for analyzing continuous data, which has long been a challenge for researchers who may not be familiar with the detailed theories and methods of psychometric measurement. The fourth study integrated CoRSA into the VAS-RRP 2.0 website, significantly simplifying the process for researchers to collect and rescale their continuous and discrete data sets to interval scores. This integration into a user-friendly web-based platform is poised to have a substantial impact on the field of educational and psychological assessment. By streamlining the rescaling process, CoRSA enables researchers, regardless of their background in psychometrics, to achieve more precise and accurate measurements. The availability of CoRSA on a platform like VAS-RRP 2.0 allows a broader range of professionals to employ advanced psychometric analyses in their work, and it fills the gap of lacking valid tools for analyzing continuous data compared to the abundance of tools for analyzing discrete data.
The CoRSA estimates item parameters using the MML method proposed by Bock and Aitkin (1981), which offers several advantages. It provides consistent item parameter estimates and is applicable across various IRT models (Baker & Kim, 2004; Bock & Aitkin, 1981). However, an important limitation of the MML framework lies in its reliance on an assumed latent trait distribution—typically the standard normal distribution. If this distributional assumption is violated, parameter estimates may become biased. Nonetheless, Embretson and Reise (2000) indicated that MML-based estimates are generally robust to moderate deviations from normality. The findings from Study 2A corroborate this, showing that even when the true ability distribution was non-normal, the CoRSA still yielded accurate item parameter estimates, as reflected in the MAD and RMSE values. In addition, it is notable to acknowledge that the computational burden of MML increases exponentially with the number of latent dimensions in multidimensional models. This is due to the need for multidimensional integration over the latent trait distribution (Cui et al., 2024; Rijmen, 2009). Future development of the CoRSA may therefore consider incorporating alternative estimation strategies to address issues in high-dimensional applications.
The present findings indicate several implications for future research, particularly regarding the scope and capabilities of the analytical tool CoRSA developed in this study. In addition to demonstrating the validity and efficacy of Al-CoRSM and CoRSA, this research also provides researchers/practitioners with persuasive examples of using continuous scales to collect data on psychological traits. Researchers/practitioners who are interested in issues such as comparing the measurement errors of scales with various levels of coarseness, investigating the intervalness of continuous scales, and exploring the possibility of creating partially ipsative scales through continuous scales would be empowered to obtain more solid evidence by using valid and easily accessible tools such as CoRSA. Furthermore, based on the CoRSM, CoRSA currently supports only unidimensional analysis of continuous data. This restriction becomes particularly limiting when analyzing multidimensional data, such as when assessing multiple psychological traits simultaneously. In cases where test data are multidimensional, it is necessary to perform analyses on each dimension independently. This approach not only increases the time required for analysis as the number of dimensions grows, but also fails to consider the intercorrelations among these dimensions. Consequently, this method allows only partial extraction of information from the test data, potentially leading to less accurate estimations of the subjects' latent traits. To address these limitations, future research should focus on the development of multidimensional models for continuous data. These models would enable the estimation of person abilities and item difficulties across multiple dimensions in a single analytical framework. By accounting for the correlations between dimensions, such models would enhance the capability of CoRSA to extract more comprehensive information regarding the exact levels of the subjects’ latent traits. This would not only improve the accuracy of the measurements but also reduce measurement errors, thereby providing a more accurate assessment of the latent traits.
Electronic supplementary material
Below is the link to the electronic supplementary material.Supplementary file1 (ZIP 1608 KB)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Baker, F. B., & Kim, S.-H. (2004). Item response theory: Parameter estimation techniques (2nd ed.). Marcel Dekker.
- 2Bond, T. G., & Fox, C. M. (2015). Applying the Raschmodel: Fundamental measurement in the human sciences (3rd ed.). Routledge. 10.4324/9781315814698
- 3Hohensinn, C. (2019). pc IRT: IRT models for polytomous and continuous item responses. (R package Version 0.2.4). Retrieved from https://cran.r-project.org/web/packages/pc IRT/index.html. Accessed 17 Feb 2021
- 4Linacre, J. M. (2023). Winsteps Rasch measurement computer program (Version 5.6.0) [Computer software]. Winsteps.com. https://www.winsteps.com/
- 5Robitzsch, A. (2024). sirt: Supplementary item response theory models (R package Version 4.1-15). Retrieved from https://cran.r-project.org/web/packages/sirt/index.html