Bayesian generalized method of moments applied to pseudo-observations in survival analysis
Léa Orsini, Caroline Brard, Emmanuel Lesaffre, Guosheng Yin, David Dejardin, Gwénaël Le Teuff

TL;DR
This paper introduces a new Bayesian method for survival analysis that avoids specifying the baseline hazard function by using pseudo-observations and generalized method of moments.
Contribution
The novelty is a Bayesian GMM approach for survival analysis using pseudo-observations without requiring baseline hazard specification.
Findings
Bayesian and frequentist GMMs provided valid inferences comparable to benchmark methods in most scenarios.
Performance was similar to Cox, GEE, and Bayesian piecewise exponential models except for small samples and high censoring.
Post-hoc analyses on Ewing Sarcoma trials confirmed the method's effectiveness in estimating hazard ratios.
Abstract
Bayesian inference for survival regression modeling offers numerous advantages, especially for decision-making and external data borrowing, but demands the specification of the baseline hazard function, which may be a challenging task. We propose an alternative approach that does not need the specification of this function. Our approach combines pseudo-observations to convert censored data into longitudinal data with the generalized method of moments (GMM) to estimate the parameters of interest from the survival function directly. GMM may be viewed as an extension of the generalized estimating equations (GEE) currently used for frequentist pseudo-observations analysis and can be extended to the Bayesian framework using a pseudo-likelihood function. We assessed the behavior of the frequentist and Bayesian GMM in the new context of analyzing pseudo-observations. We compared their…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
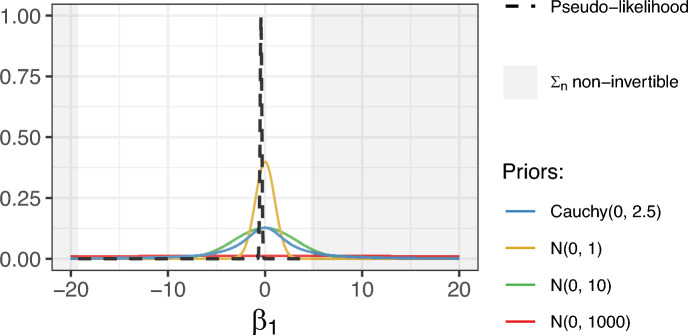 Figure 1
Figure 1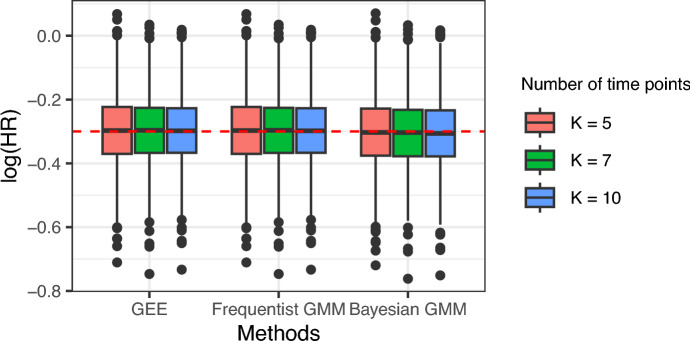 Figure 2
Figure 2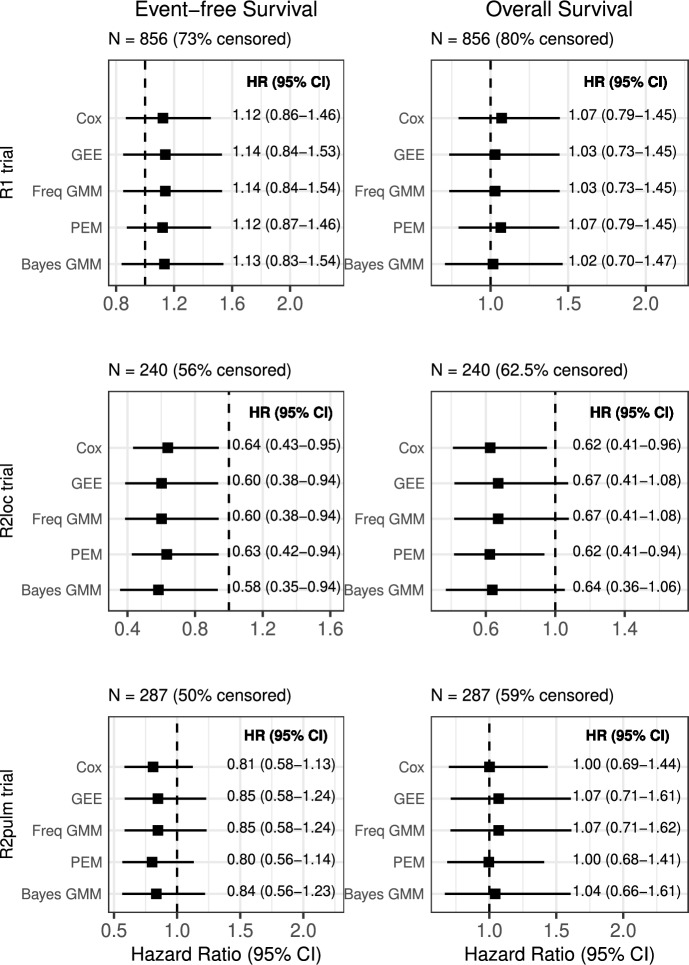 Figure 3
Figure 3- —Université Paris-Saclay
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Inference · Statistical Methods and Bayesian Inference · Advanced Causal Inference Techniques
Introduction
Bayesian analysis offers many benefits in pharmaceutical research for drug development and clinical trials. The Bayesian computation methods are flexible and allow for fitting every model by estimating the posterior distribution of the parameters through a sampling procedure, even when no closed-form formula is available for this particular problem. Consequently, it allows the estimation of the posterior tail probability for any given threshold that may be clinically relevant, which is particularly useful for decision-making (Held 2020). It also provides adaptive design methods for clinical trials that are naturally suited for interim analysis. In addition, Bayesian methods are advantageous in the context of rare diseases or precision medicine, where external information can be incorporated through the prior definition (Lesaffre et al. 2024).
Despite those advantages, Bayesian survival analysis is yet rarely used in survival analysis (Chevret 2011; Brard et al. 2017). One reason may be that contrary to the frequentist framework where the partial likelihood of the Cox proportional hazard model can be used to estimate the regression coefficients of covariates on the survival outcome from right censored data (Cox 1972), in Bayesian inference, the baseline hazard function is usually modeled and associated with priors (Biard et al. 2021), introducing nuisance parameters in this setting. Numerous Bayesian models have been proposed using parametric distributions (exponential or Weibull) and other functions (monotone or polynomials) referenced in Ibrahim et al. (2001), Chapters 2 and 3. According to the literature review of Fors and González (2020), the most common model in randomized clinical trials is the piecewise exponential model, which assumes the baseline hazard function to be constant on intervals. More complex models have been developed using splines, which allow more flexibility (Murray et al. 2016). Non-parametric alternatives exist but involve many parameters and are computationally intensive. The Gamma process is chosen in many applications, and Cox’s partial likelihood can be seen as the limiting case of this Bayesian process by allowing the prior precision to approach zero (Kalbfleisch 1978).
Over the past twenty years, the use of pseudo-observations in the frequentist framework has become an attractive research field in survival analysis since it offers a flexible and unique framework to directly estimate quantities of interest such as the survival probability, the cumulative incidence, the transition and state-occupation probabilities in multi-states models, or the restricted mean survival time (Andersen and Pohar-Perme 2010). Pseudo-observations are computed for a specific quantity of interest, and a straightforward regression model, with pseudo-observations as outcome, is used to directly estimate the association between the covariates and this quantity. Initially, pseudo-observations were introduced in multistate models to describe the association between covariates and transition probabilities (Andersen et al. 2003). They were later extended to situations where the Markov assumption is not verified (Andersen et al. 2022) or when the data are interval-censored instead of right-censored (Sabathé et al. 2020). Pseudo-observations have also been used to estimate cumulative incidence in competing risks settings (Klein and Andersen 2005; Parner, et al. 2020) or to estimate restricted mean survival time, over one time window (Andersen et al. 2004) and several time windows (Ambrogi et al. 2022). Although other approaches exist to model these different quantities, covariate adjustment is difficult with non-parametric estimators, while the assumption of fully parametric estimators may be challenged by the data (Sachs and Gabriel 2022). Pseudo-observations are also used in relative survival, where they provide an alternative that is easier to implement in software than the existing estimator (Pavlič and Pohar-Perme 2019). Pseudo-observations also offer graphical tools for checking hazard regression model assumptions (Pohar-Perme and Andersen 2008). In summary, by transforming (right or interval) censored data into pseudo-observations, survival analysis turns into a standard regression problem.
When traditional Bayesian survival methods involve the formulation of the full likelihood, including the specification of the baseline hazard function in the setting of regression coefficient estimation, which may be challenging due to censoring, the transformation of censored data into pseudo-observations may be advantageous in overcoming this issue. This paper presents a methodology to analyze pseudo-observations in the Bayesian framework, creating an alternative approach for Bayesian survival analysis, which does not require specifying the baseline hazard function. Currently, pseudo-observations are usually analyzed as an outcome of a generalized linear model using the generalized estimating equations (GEE), introduced in Liang and Zeger (1986). This marginal approach does not involve a likelihood function and is consequently not easily translatable to the Bayesian framework. Our approach relies on the generalized methods of moments (GMM) for which a Bayesian version based on a pseudo-likelihood function has been developed by Yin (2009). The GMM, originally proposed by Hansen (1982), is widely used in econometrics. GMM is defined by specifying multiple moments from the data. GMM estimates are obtained by minimizing a quadratic inference function that combines these moments.
In this paper, we assess the usefulness of the frequentist and Bayesian GMMs in the particular context of estimating hazard ratios with pseudo-observations. The rest of the paper is organized as follows. Section 2 presents the theoretical aspects of pseudo-observations analysis using GEE and the innovative application of GMM to analyze pseudo-observations, comparisons of the GMM models to benchmark methods are presented through simulations in Sect. 3, and illustrations through real-data examples in Sect. 4. We conclude with some final remarks and future extensions of the proposed approach in Sect. 5.
Methods
Pseudo-observations computation to estimate hazard ratios
As previously stated, pseudo-observations have been used in many applications in survival analysis. Suppose that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_1, \ldots , T_n$$\end{document} are n independent and identically distributed time to event variables and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{\theta }$$\end{document} is an unbiased estimator of a quantity of interest \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta = \mathbb {E}(h(T_i))$$\end{document} , where h is a known function. For individual i, the pseudo-observation is calculated as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \widehat{\theta }_{i} = n\widehat{\theta } - (n-1)\widehat{\theta }^{-i} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{\theta }^{-i}$$\end{document} is the value of the estimator when the i-th individual is removed from the data set. From this definition, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{\theta }_i$$\end{document} is an approximately unbiased estimator of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} . Pseudo-observations can be interpreted as an individual contribution to the overall estimate of the quantity of interest.
Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_k$$\end{document} be a specific time. In the case of estimating hazard ratios from a proportional hazard model, the pseudo-observation of the i-th individual at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_k$$\end{document} is defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} y_{ik} = n\widehat{S}(t_k) - (n-1)\widehat{S}^{-i}(t_k) \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{S}(t_k)$$\end{document} is the Kaplan-Meier estimator of the survival probability at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_k$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{S}^{-i}(t_k)$$\end{document} is the Kaplan-Meier estimator of the survival probability at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_k$$\end{document} after removing the i-th individual from the data set.
From this definition, pseudo-observations can take values around 0 and 1 that vary over the follow-up time depending on the status (censored/uncensored) of each patient. For all the individuals at risk at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_k$$\end{document} , their pseudo-observation is greater than one. If one individual experiences an event, the corresponding pseudo-observations will be negative for all times after this event. If one individual is censored, the pseudo-observations will always be positive and will decrease towards 0 for all times after the last event time of the data set which has occurred before its censoring time (Andersen and Pohar-Perme 2010). These pseudo-observations are then analyzed as an outcome variable in a generalized linear model with a complementary log-log link function to interpret the estimated regression coefficients as log hazard ratios from a Cox model. Below is the justification for choosing this particular link function.
Since the Cox proportional hazard model with a P-dimensional covariate vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{X}_i$$\end{document} can be written at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_k$$\end{document} as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S(t_k|\textbf{X}_i) = S_0(t_k)^{\exp ( \textbf{X}^\top _i\varvec{\beta })}$$\end{document} , applying the complementary log-log link function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g(x) = \log (-\log (x))$$\end{document} to the previous equation results in
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} g(S(t_k|\textbf{X}_i)) = \log (H_0(t_k)) + \textbf{X}^\top _i\varvec{\beta } \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_0(t_k) = -\log (S_0(t_k))$$\end{document} is the cumulative baseline hazard. Assuming that the censoring does not depend on covariates and the event times, Graw et al. (2009) developed theoretical justifications to prove the approximate unbiasedness of pseudo-observations given the covariates (i.e. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E(y_{ik}|\textbf{X}_i) \approx S(t_k|\textbf{X}_i))$$\end{document} . For additional information on the theoretical properties of pseudo-observations, refer to the discussion in Andersen and Pohar-Perme (2010) and to Overgaard et al. (2017). Consequently, pseudo-observations can be analyzed as an outcome variable in the generalized linear model,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} g(E(y_{ik}|\textbf{X}_i)) = \log (H_0(t_k)) + \textbf{X}^\top _i\varvec{\beta }. \end{aligned}$$\end{document}We can compute the pseudo-observations not only at one time point \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_k$$\end{document} but at different time points ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_k, k=1,\ldots ,K$$\end{document} ) for each individual. A multivariate model for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S(t_1|\textbf{X}_i), \ldots , S(t_K|\textbf{X}_i)$$\end{document} can be analyzed similarly, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}_i$$\end{document} is now a K-dimensional vector since several pseudo-observations are defined for each individual. This model, extended for multiple time points, corresponds to a Cox model where the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta $$\end{document} ’s can be interpreted as log hazard ratios.
Generalized Estimating Equations (GEE)
Andersen et al. (2003) suggested analyzing pseudo-observations as an outcome variable in a regression model using the generalized estimated equations from Liang and Zeger (1986). This marginal approach is based on quasi-likelihood functions where only the moments are defined (McCullagh and Nelder 1991). Suppose that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{X}_i$$\end{document} = \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\textbf{X}^{(1)}_{i}, \ldots , \textbf{X}^{(P)}_{i})^\top $$\end{document} is the covariate matrix for the i-th individual. Since we are in a longitudinal setting with K repeated measures, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{X}_i$$\end{document} is now of dimension \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P \times K$$\end{document} where P is the number of explanatory variables, including an intercept vector, and K is the number of time points. For the sake of clarity, only a treatment variable is considered here ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P = 2$$\end{document} ). \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{X}_i$$\end{document} has then two rows of dimension K: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{X}^{(1)}_i = (1, \ldots , 1)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{X}^{(2)}_{i} = (X^{(2)}_{i1}, \ldots , X^{(2)}_{iK})$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{X^{(2)}_{ik} \}^K_{k = 1}$$\end{document} is the treatment indicator. More covariates may be added to account for other explanatory features, as illustrated in the real-data examples (see Sect. 4). In addition, the time is considered as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K-1$$\end{document} dummy variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\textbf{I}_{2}, \ldots , \textbf{I}_{K})$$\end{document} , derived from the indicator of the time at which the pseudo-observation is defined, i.e. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{I}_{k}$$\end{document} is a K-dimensional vector with 1 for the k-th coefficient and 0 elsewhere. Finally, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}_i = (y_{i1}, \ldots , y_{iK})^\top $$\end{document} is the outcome vector composed of the K pseudo-observations of the i-th individual, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\mu }_i = (\mu _{i1}, \ldots , \mu _{iK})^\top $$\end{document} is the mean vector for the i-th individual specified as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \varvec{\mu }_i = E(\textbf{y}_{i}|\textbf{X}_i) = \textrm{cloglog}^{-1}(\beta _0\textbf{X}^{(1)\top }_{i} + \beta _1\textbf{X}^{(2)\top }_{i} + \beta _2\textbf{I}_{2} + \cdots + \beta _{L-1}\textbf{I}_{K})\end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta } = (\beta _0,\ldots ,\beta _{L-1})^\top $$\end{document} is the L-dimensional vector of parameters to estimate. Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L = K+1$$\end{document} , with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _0$$\end{document} the intercept, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1$$\end{document} the treatment effect, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _2,\ldots ,\beta _L$$\end{document} the time effects of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K-1$$\end{document} dummy variables. The coefficient of interest in this model is the treatment effect ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1$$\end{document} ) since the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K-1$$\end{document} dummy time variables only serve as adjustment variables. More generally, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L=P+K-1$$\end{document} , thus L increases if one decides to include more explanatory variables in the model (increasing P) or to account for more time points (increasing K). In practice, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K = 5$$\end{document} time points equally spaced on the event time scale are sufficient to capture all the information from the Kaplan-Meier curve (Klein et al. 2014). The vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }$$\end{document} is estimated by solving the score equations,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \textbf{U}_n(\varvec{\beta )}= \frac{1}{n}\sum ^n_{i = 1} \textbf{u}_i(\varvec{\beta )}=\frac{1}{n}\sum ^n_{i = 1} \textbf{D}_i^\top \textbf{R}^{-1}(\alpha )(\textbf{y}_i - \varvec{\mu }_i)=0,\end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{D}_i = \partial \varvec{\mu }_i/\partial \varvec{\beta }^\top $$\end{document} is a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K \times L$$\end{document} matrix and the working correlation matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{R}(\alpha )$$\end{document} is assumed to be of a specific form: the two common ones are the independence form where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{R}(\alpha )$$\end{document} equals the identity matrix and the exchangeable matrix defined as 1 on the diagonal and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha $$\end{document} elsewhere. The nuisance parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha $$\end{document} is estimated alternatively with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }$$\end{document} , switching between estimating \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }$$\end{document} for fixed values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{\alpha }$$\end{document} , and estimating \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha $$\end{document} for fixed values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{\varvec{\beta }}$$\end{document} . Using a consistent estimator of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha $$\end{document} suggested in Liang and Zeger (1986), the GEE estimator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{\varvec{\beta }}$$\end{document} is also consistent, even if the working correlation matrix is misspecified. When applying GEE to pseudo-observations, the working correlation matrix is usually assumed to be independent, even if pseudo-observations are correlated by definition (Klein et al. 2008). The GEE estimator converges in distribution to a normal distribution,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \sqrt{n}(\widehat{\varvec{\beta }} - \varvec{\beta }) \overset{d}{\rightarrow }\ N(0, \varvec{\varGamma }),\end{aligned}$$\end{document}with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\varGamma } = \underset{n\rightarrow +\infty }{\lim }\ \varvec{\varGamma }_0^{-1}\varvec{\varGamma }_1\varvec{\varGamma }_0^{-1}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\varGamma }_0 = \frac{1}{n}\sum _{i=1}^n \textbf{D}_i^\top \textbf{R}^{-1}(\alpha ) \textbf{D}_i$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\varGamma }_1 = \frac{1}{n}\sum _{i=1}^n \textbf{D}_i^\top \textbf{R}^{-1}(\alpha ) (\textbf{y}_i - \varvec{\mu }_i)(\textbf{y}_i - \varvec{\mu }_i)^\top \textbf{R}^{-1}(\alpha )\textbf{D}_i$$\end{document} . The estimator of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\varGamma }$$\end{document} matrix, referred to as the sandwich or robust variance estimator, is obtained by evaluating the matrices \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\varGamma }_0$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\varGamma }_1$$\end{document} at their empirical estimates. Jacobsen and Martinussen (2016) have shown that this estimator is slightly conservative, but the correction of the variance proposed by the authors is numerically small. Therefore, the sandwich estimator is still commonly used (Bouaziz 2023).
Frequentist generalized method of moments
The generalized method of moments (GMM) is defined by Hansen (1982) and is widely used in econometrics, contrary to biostatistics. Ziegler (1995) showed that the GMM and the GEE approaches give asymptotically equivalent estimators. The principle of GMM is to combine multiple moments through score equations. The system of equations becomes over-identified as the number of equations exceeds the number of unknown parameters. Therefore, the exact solution cannot be found anymore. The estimates are then found by minimizing an objective function defined using the score vector and a weight matrix that gives more weight to the equations with less variability.
Qu et al. (2000) proposed a GMM approach for longitudinal data with a theoretical efficiency improvement under correlation misspecification. In this particular case, only the first moment (ie. the mean model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\mu }_i$$\end{document} ) is specified identically to GEE. This approach can be viewed as an extension of GEE since the general idea is to express the inverse of the working correlation matrix, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{R}$$\end{document} , as a linear combination of J basis matrices, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{R}^{-1} \approx \sum ^J_{j = 1} a_j\textbf{M}_j$$\end{document} . The inverses of the different working correlation matrices specified in the GEE approach can be expressed as a sum of the basis matrices. For example, the inverse of the independence matrix is expressed as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{R}^{-1} = a_1\textbf{M}_1$$\end{document} , the inverse of the exchangeable matrix as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{R}^{-1} = a_1\textbf{M}_1 + a_2\textbf{M}_2$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{M}_1$$\end{document} is the identity matrix and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{M}_2$$\end{document} is the matrix with 0 on the diagonal and 1 elsewhere. The first-order auto-regressive (AR-1) working correlation matrix is defined with coefficients \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{ij} = \alpha ^{|i-j|}$$\end{document} , with i the line and j the column number. Its inverse \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{R}^{-1}$$\end{document} can be approximated by two working correlation matrices: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{M}_1$$\end{document} is the identity, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{M}_2$$\end{document} is the matrix with 1 on the two diagonals on both sides of the main diagonal and 0 elsewhere.
With the GMM approach, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{u}_i(\varvec{\beta })$$\end{document} is now a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(J\times L)$$\end{document} -dimensional score vector defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \textbf{u}_i(\varvec{\beta }) = \begin{Bmatrix} \textbf{D}_i^\top \textbf{M}_1(\textbf{y}_i - \varvec{\mu }_i)\\ \textbf{D}_i^\top \textbf{M}_2(\textbf{y}_i - \varvec{\mu }_i)\\ \vdots \\ \textbf{D}_i^\top \textbf{M}_J(\textbf{y}_i - \varvec{\mu }_i) \end{Bmatrix},\end{aligned}$$\end{document}and the objective function (quadratic inference function) is written as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} Q_n(\varvec{\beta }) = \textbf{U}_n^\top \mathbf {(\varvec{\beta })C}_n^{-1}\mathbf {(\varvec{\beta })U}_n(\varvec{\beta }),\end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{U}_n(\varvec{\beta }) = \frac{1}{n}\sum _{i = 1}^n \textbf{u}_i(\varvec{\beta })$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{C}_n(\varvec{\beta }) = \frac{1}{n^2}\sum _{i = 1}^n \textbf{u}_i(\varvec{\beta })\textbf{u}_i^\top (\varvec{\beta })$$\end{document} . Contrary to GEE, the vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{U}_n(\varvec{\beta })$$\end{document} now contains more equations than unknown parameters, and the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }$$\end{document} ’s are estimated by minimizing the quadratic inference function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{\varvec{\beta }} = \textrm{argmin}(Q_n(\varvec{\beta }))$$\end{document} . The Newton–Raphson algorithm can be used to minimize this function, with starting values usually chosen to be the least squared estimates. A consistent variance estimator can also be derived with a sandwich form,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathbf {\widehat{\textrm{cov}}(\widehat{\varvec{\beta }})} = \frac{1}{n} \left[ \{\partial \textbf{U}_n(\widehat{\varvec{\beta }})^\top /\partial \varvec{\beta }\}\textbf{C}_n^{-1}\{\partial \textbf{U}_n(\widehat{\varvec{\beta }})/\partial \varvec{\beta }^\top \}\right] ^{-1} .\end{aligned}$$\end{document}Under some regulatory conditions, Yu et al. (2020) have shown that this approach produces identical point estimates compared to GEE and robust covariances with an independence or exchangeable working matrix. Regarding the analysis of pseudo-observations with GMM, the mean model is identical to the one of the GEE approach, with a cloglog link function to interpret the regression coefficients as hazard ratios.
Bayesian generalized method of moments
Model
The formulation of the Bayesian generalized method of moments can be derived by considering that the minimization problem of the GMM can be converted to a Bayesian sampling problem. By applying the Central Limit Theorem,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \textbf{U}_n(\varvec{\beta }) \overset{d}{\longrightarrow }\ N(0,\varvec{\varSigma }(\varvec{\beta })), \text { as }n \rightarrow \infty \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\varSigma }(\varvec{\beta }) = \underset{n \rightarrow \infty }{\lim }\varvec{\varSigma }_n(\varvec{\beta }),$$\end{document} then
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} Q_n(\varvec{\beta }) \overset{d}{\longrightarrow }\ \chi _{(J-1) \times L}^2. \end{aligned}$$\end{document}A Chi-squared test can be derived, analogous to the usual likelihood ratio test, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_n(\varvec{\beta })$$\end{document} behaves like \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-2\log L(\varvec{\beta }|y)$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L(\varvec{\beta }|y)$$\end{document} being the likelihood function (Hansen 1982). Thus, the GMM approximates the likelihood for selected moments of the data without specifying the full likelihood (Chernozhukov and Hong 2003). Given these theoretical results, Yin (2009) presented a Bayesian version of GMM by defining a pseudo-likelihood function as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \tilde{L}(\varvec{\beta }|y) \propto \exp \left\{ -\frac{1}{2}\textbf{U}_n^\top (\varvec{\beta })\varvec{\varSigma }_n^{-1}(\varvec{\beta })\textbf{U}_n(\varvec{\beta })\right\} ,\end{aligned}$$\end{document}with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\varSigma }_n(\varvec{\beta }) = \frac{1}{n^2}\sum _{i = 1}^n \textbf{u}_i(\varvec{\beta })\textbf{u}_i^\top (\varvec{\beta }) - \frac{1}{n}\textbf{U}_n(\varvec{\beta })\textbf{U}_n^\top (\varvec{\beta })$$\end{document} . Note that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\varSigma }_n^{-1}(\varvec{\beta })$$\end{document} in the quasi-likelihood has an additional term compared to the empirical covariance matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{C}_n(\varvec{\beta })$$\end{document} in the quadratic inference function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q_n(\varvec{\beta })$$\end{document} .
Yin (2009) showed the validity of the posterior distribution resulting from this pseudo-likelihood. However, this pseudo-likelihood function, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{L}(\varvec{\beta }|y)$$\end{document} , is only defined on the support of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {R}^L$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\varSigma }_n$$\end{document} is invertible, which is restricted due to the cloglog link function used for pseudo-observations analysis. For example, Figure 1 represents the pseudo-likelihood function as a function of the treatment effect \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1$$\end{document} ; all other parameters are fixed at their GEE estimates. The gray zone indicates the values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1$$\end{document} for which the matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\varSigma }_n$$\end{document} is not invertible. Thus, convergence issues may occur when parameter values fall outside this local support. The inverse link function being \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x \rightarrow \exp (-\exp (x))$$\end{document} may result in extreme values of the parameters. In practice, when the Bayesian sampler draws a value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }$$\end{document} far from the true value, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\varSigma }_n$$\end{document} becomes non-invertible. Consequently, it is essential to calibrate the Bayesian algorithm well by choosing appropriate priors and starting values for each model parameter. Below, we specify (i) how to choose appropriate prior distributions and (ii) the algorithm to generate sensible starting values.
Choosing appropriate priors
Choosing appropriate priors for the cloglog scale partially resolves the convergence issue previously mentioned. Gelman et al. (2008) proposed to use Cauchy(0, 2.5) for all regression coefficients as default priors in generalized linear regression models after centering and re-scaling all the input variables. These weakly informative priors reflect the fact that large changes on the logit or cloglog scale are rare. Using weak Gaussian priors such as N(0, 10) or N(0, 1), as recommended by the Stan Development Team (2020), can provide an alternative to Cauchy priors. They may be more adapted to the pseudo-likelihood defined on a small support because they have lighter distribution tails (See Figure 1). We do not recommend using extremely vague priors, for example, N(0, 1000), as they correspond to unrealistic values on the probability scale. As we estimate hazard ratios, such large priors are unreasonable. Although weak priors are more informative than flat priors, they are vague enough compared to the pseudo-likelihood (Gelman et al. 2017).Fig. 1. Example of the pseudo-likelihood function (black dashed line) depending on the treatment effect ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1$$\end{document} ), all the other parameters are fixed to their GEE estimations. Solid lines represent different priors that have been investigated. Gray zone represents values \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\varSigma }_n$$\end{document} is non-invertible and thus, the likelihood function is not defined
Starting values
Setting starting values randomly is not optimal as they might fall outside the definition support of the pseudo-likelihood. Even if they are on the edge of the support, the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }$$\end{document} values may fall outside the support after a few iterations, especially during the warm-up period where the No-U-turn sampler (NUTS) chooses the step size adaptively (Hoffman and Gelman 2014). Consequently, the step size may be too large for some iterations, resulting in poor convergence. To overcome this issue, we propose to generate starting values of the NUTS in a similar manner to the one used for the frequentist GMM, which are based on the least square estimates, while taking into account the cloglog link function. The generation of these initial values includes three steps described as follows:
- Truncate the pseudo-observations to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$[\epsilon , 1-\epsilon ]$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon >0$$\end{document} takes a small value. Pseudo-observations above \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1-\epsilon $$\end{document} are set to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1-\epsilon $$\end{document} , and pseudo-observations below \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon $$\end{document} are set to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon $$\end{document} . This step is needed to apply the cloglog function to pseudo-observations as it is defined on ]0, 1[.
- Apply the cloglog function to the truncated pseudo-observations.
- Perform a linear regression model using these modified pseudo-observations as a continuous outcome and treatment factor and dummy time variables as covariates, then use the ordinary least square estimates as starting values. Different values of the truncation parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon $$\end{document} can be chosen, resulting in different starting values for each chain of the NUTS sampling. We emphasize the point that this process does not give correct estimation (1) the pseudo-observations have been truncated to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$[\epsilon , 1-\epsilon ]$$\end{document} which may induce a bias in the estimates, (2) the cloglog is applied to the pseudo-observations themselves and not to the mean vector, and (3) the correlation between pseudo-observations of the same individual is not taken into account using the least square estimation. So, this is only a generic and straightforward process to generate starting values in the definition support of the pseudo-likelihood to improve the convergence.
Simulation study
We performed a simulation study to assess the performance of the frequentist and Bayesian GMM applied to pseudo-observations in order to estimate the hazard ratio of the treatment effect. The purpose of this simulation study was (a) to assess the validity of the pseudo-observations analysis using the frequentist and Bayesian GMM; (b) to compare the performances of the GMM models to the three benchmark methods: the Cox proportional hazard model, and the GEE approach based on pseudo-observations in the frequentist framework, and to the piecewise exponential model in the Bayesian framework; and (c) to evaluate the impact on the estimation of the different choices made in the pseudo-observations based models, i.e., the number of time points and the form of the working correlation matrix.
Settings
Simulations were based on a two-arm randomized clinical trial with a time-to-event outcome. Event times were generated from a Weibull distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f(t|a,b) = (a/b)(t/b)^{a-1}\exp ((t/b)^a)$$\end{document} with shape parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a=0.6$$\end{document} and scale parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b = \exp (- (\beta _1X_1)/a)$$\end{document} depending on the treatment indicator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_1$$\end{document} coded 1 for the experimental arm and 0 for the control arm. This corresponds to a randomized controlled trial with a median survival time of approximately 6 months in the control arm for the core scenario (i.e., with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=500$$\end{document} , a censoring rate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$20\%$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log (\textrm{HR})=-0.3$$\end{document} ). No other explanatory variables were considered in the simulations. Censoring times were generated independently following a uniform distribution. The parameter of the uniform distribution was chosen according to the desired censoring rate, following Wan (2017). The simulation parameters were the sample size, varying from 50 to 1000, the censoring rate, ranging from 5% to 70%, and the true treatment effect varying from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.5 to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.1 (log scale) corresponding to a hazard ratio from 0.6 to 0.9, approximately. These specifications represent different scenarios of randomized clinical trials with different sizes of the treatment effect between the experimental and control arms. Bias, average standard error (ASE), average standard deviation (ASD), root-mean-square error (RMSE), and coverage rate from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$95\%$$\end{document} confidence intervals and equal-tailed intervals were calculated from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n_\mathrm{{sim}} = 1000$$\end{document} replications for each scenario.
All computations were performed using the R Language for Statistical Computing (R Core Team (2021), version 4.1.2). Pseudo-observations have been computed using the R package pseudo (Pohar-Perme et al. 2017), with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K = 5$$\end{document} time points selected to define an equal-spaced quantile partition of the event times, similarly to Rizopoulos (2010), meaning we selected time points such that there are as many observed events in each of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K+1$$\end{document} time intervals created \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$([0, t_1], [t_1, t_2], \ldots , [t_K, t_\text {max}])$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_\text {max} = \max (\left\{ T_i\right\} _{i = 1}^n) $$\end{document} is the maximum observed event time. Because the R package qif by Jiang et al. (2019) only allows the use of the canonical links (identity, log, logit, inverse), we developed an R script to implement the frequentist GMM with a cloglog link function.
We also developed a specific script to implement the Bayesian GMM using the Stan software (Carpenter et al. 2017). The model was then compiled via the rstan R package (Stan Development Team 2023). The NUTS sampling was performed with 3 chains of each 5000 iterations after a warm-up of 1000 iterations, and thinning of 5, yielding 3000 iterations overall. As mentioned in Sect. 2, weakly informative priors were specified for all parameters (intercept, treatment effect, and dummy time variables). In scenarios with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n = 50$$\end{document} or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n = 100$$\end{document} , a prior distribution of N(0, 1) was specified for all parameters; in all the other scenarios, N(0, 10) prior was specified. Initial parameters were set by fixing the truncation parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon \in (0.01, 0.05, 0.1)$$\end{document} for the three chains, respectively. The convergence diagnoses were performed through trace plots checking and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{R}$$\end{document} estimation (Vehtari 2021).
The R package geepack was used to implement the GEE approach on pseudo-observations (Hojsgaard et al. 2022), which provide multiple jackknife variance estimators in addition to the sandwich variance estimator. The approximate jackknife variance estimator was recommended to analyze pseudo-observations, following suggestions in Klein et al. (2008). All the estimators were found to be equivalent for large samples, as referenced in Yan and Fine (2004). We used the spBayesSurv R package by Zhou et al. (2020) to implement the Bayesian piecewise exponential model. The number of intervals for the time partition was chosen according to the number of events following the rule in Murray et al. (2014) (i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M = \max \{5, \min (r/8, 20)\}$$\end{document} ) where M is the total number of intervals, and r is the observed number of events in the trial data set. The baseline hazard is assumed constant within each interval: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_0(t) = \sum _{m=1}^M h_m I\{t \in I_m\}$$\end{document} . All the priors were kept as default, i.e., the priors for the baseline hazard were \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_m \sim \textrm{Gamma}(1, \widehat{h})$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{h}$$\end{document} the maximum likelihood estimate of the rate parameter from fitting an exponential proportional hazard model, and the priors for the log hazard ratio was \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1 \sim N(0,10^5)$$\end{document} .
Results
Table 1 represents the estimates of the hazard ratio (on a log scale) for different scenarios with a substantial treatment effect of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{HR}=0.74$$\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log (\textrm{HR})=-0.3$$\end{document} ), a censoring rate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$20\%$$\end{document} and different sample sizes. Overall, GMM approaches (frequentist and Bayesian) produce valid inferences with a bias that decreases toward zero as the sample size increases. From small and moderate sample sizes ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=50$$\end{document} , 100, and 200), Bayesian GMM results in slightly higher bias (varying from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.0852$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=50$$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.0155$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=200$$\end{document} ) compared to frequentist GMM (varying from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.0149$$\end{document} to 0.0004) and similar standard errors. Their ASE and ASD are comparable for all sample sizes and become almost equal as the sample size reaches \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n = 1000$$\end{document} . The coverage rates are close to the nominal coverage rate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$95\%$$\end{document} for large sample sizes ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n\ge 500$$\end{document} ). When comparing these performances with the ones of the three benchmark models: the Cox model, the pseudo-observations-based GEE model, and the piecewise exponential model, GMM gives similar results (bias close to zero, similar standard errors and RMSEs, coverage rate close to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$95\%)$$\end{document} . We note, however, a slight difference for the scenarios with small sample sizes ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n\le 100$$\end{document} ). For these scenarios, as expected, frequentist GMM and GEE give similar results with a higher variance than the estimates of the Cox and Bayesian exponential piecewise models. For example, the average standard error is 0.257 for frequentist GMM compared to 0.228 for the Cox model for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=100$$\end{document} . This result is consistent with Andersen et al. (2003). This results in a higher RMSE for pseudo-observations-based models. The estimates from Bayesian methods are more biased than the frequentist approaches, especially for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=50$$\end{document} , with a higher bias for the Bayesian GMM ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.0852$$\end{document} for Bayesian GMM, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.0574$$\end{document} for piecewise exponential model versus \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.0203$$\end{document} for Cox). Consequently, ASD and RMSE are approximately equal for all the frequentist approaches as we observe a negligible bias for all sample sizes, and similar results are observed for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n \ge 100$$\end{document} for the Bayesian approaches. In addition, this bias decreases when the treatment effect decreases (toward 0) for the piecewise exponential model, while it remains constant for the Bayesian GMM when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n\le 100$$\end{document} .Table 1. Performances of the frequentist and Bayesian GMM compared to the Cox, GEE, and piecewise exponential model (PEM) with a true log hazard ratio of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.3 (HR=0.74), a censoring rate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$20\%$$\end{document} and different sample sizesnMethodsBiasASEASDRMSECoverage50FrequentistCox \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.02030.3260.3320.33295.2GEE \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.01490.3550.3850.38592.6GMM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.01490.3670.3850.38593.5BayesianPEM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.05740.3320.3630.36792.7GMM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.08520.3540.3760.38691.9100FrequentistCox0.00540.2280.2450.24593.2GEE0.01000.2530.2700.27093.6GMM0.01000.2570.2700.27094.0BayesianPEM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.01780.2330.2640.26491.0GMM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.03410.2530.2710.27392.8200FrequentistCox0.00030.1600.1610.16194.1GEE0.00040.1800.1880.18893.5GMM0.00040.1810.1880.18893.5BayesianPEM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.02020.1630.1720.17493.4GMM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.01550.1890.1950.19593.1500FrequentistCox0.00280.1010.1000.10095.0GEE0.00320.1140.1120.11295.4GMM0.00320.1140.1120.11295.5BayesianPEM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00630.1020.1030.10494.0GMM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00280.1160.1130.11395.41000FrequentistCox0.00320.0710.0720.07294.8GEE0.00050.0810.0820.08295.2GMM0.00050.0810.0820.08295.2BayesianPEM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00170.0710.0730.07394.9GMM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00260.0820.0820.08295.2ASE: Average Standard Error, ASD: Average Standard DeviationRMSE: Root Mean Square Error
When varying the censoring rate for the core scenario ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log (\textrm{HR})=-0.3$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{HR}=0.74$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=500$$\end{document} ), the performances of GMM (frequentist and Bayesian) are similar to the three benchmark methods (Table 2). The more pronounced differences between these pseudo-observation-based approaches (GEE and GMM) and the Cox and Bayesian piecewise exponential methods occur with higher average standard error and RMSE for large censoring rates ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$30\%$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$70\%$$\end{document} ). For example, the average standard error of the Bayesian GMM is 0.194 compared to 0.166 for the Bayesian piecewise exponential model for a censoring rate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$70\%$$\end{document} .Table 2. Performances of the frequentist and Bayesian GMM compared to the Cox, GEE, and piecewise exponential model (PEM) with a true log hazard ratio of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.3 (HR=0.74), different censoring rates, and a sample size of 500CRMethodsBiasASEASDRMSECoverage5%FrequentistCox0.00160.0930.0940.09494.0GEE0.00320.1070.1050.10595.1GMM0.00320.1070.1050.10595.1BayesianPEM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00800.0940.0970.09793.6GMM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00360.1090.1080.10895.110%FrequentistCox0.00130.0950.0960.09694.4GEE0.00320.1090.1070.10795.5GMM0.00320.1090.1070.10795.5BayesianPEM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00800.0960.0980.09894.0GMM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00320.1110.1080.10895.320%FrequentistCox0.00280.1010.1000.10095.0GEE0.00320.1140.1120.11295.4GMM0.00320.1140.1120.11295.5BayesianPEM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00630.1020.1030.10494.0GMM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00280.1160.1130.11395.430%FrequentistCox0.00390.1080.1070.10794.8GEE0.00210.1210.1190.11995.0GMM0.00210.1210.1190.11995.2BayesianPEM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00550.1090.1100.11194.0GMM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00410.1230.1200.12095.170%FrequentistCox0.00180.1650.1650.16594.3GEE0.00060.1840.1850.18594.9GMM0.00060.1850.1850.18594.9BayesianPEM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00680.1660.1700.17093.9GMM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.01190.1940.1880.18895.0CR: Censoring Rate, ASE: Average Standard Error,ASD: Average Standard Deviation, RMSE: Root Mean Square Error
We evaluated the impact of different effect sizes from small to important (HR=0.90, 0.74, and 0.60) on the performances of the frequentist and Bayesian GMM approaches for the core scenario ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=500$$\end{document} , censoring rate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$=20\%$$\end{document} ). Performances are similar to the three benchmark methods (Table 3). The Online Resource Tables S1a, S1b, S2a, and S2b show the performances in all the other scenarios. For a given censoring rate and sample size, the size of the treatment effect did not affect the performances of all the models.Table 3. Performances of the frequentist and Bayesian GMM compared to the Cox, GEE, and piecewise exponential model (PEM) with different treatment effects (log hazard ratio of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.1 (HR=0.9), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.3 (HR=0.74), and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.5 (HR=0.60), a censoring rate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$20\%$$\end{document} and a sample size of 500HRMethodsBiasASEASDRMSECoverage0.9FrequentistCox0.00290.1000.1000.10094.1GEE0.00410.1140.1120.11294.9GMM0.00410.1140.1120.11295.0BayesianPEM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00060.1010.1030.10394.0GMM0.00120.1160.1130.11394.90.74FrequentistCox0.00280.1010.1000.10095.0GEE0.00320.1140.1120.11295.4GMM0.00320.1140.1120.11295.5BayesianPEM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00630.1020.1030.10494.0GMM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00280.1160.1130.11395.40.6FrequentistCox0.00340.1020.1010.10194.8GEE0.00200.1150.1120.11295.0GMM0.00200.1150.1120.11295.1BayesianPEM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.01070.1020.1040.10494.1GMM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00710.1180.1140.11495.6HR: Hazard ratio, ASE: Average Standard Error,ASD: Average Standard Deviation, RMSE: Root Mean SquareError
No convergence issue was observed through all scenarios and replicates, with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{R}$$\end{document} close to 1. The Bayesian GMM was run with a parallelized code using a server HPE DL385 (2.0 GHz) with 150 virtual cores. In the core scenario (with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n = 500$$\end{document} patients), the pseudo-observations computation took less than 1 s and the median running time of one chain was 12 minutes.
Sensitivity analysis on the number of time points
When computing pseudo-observations, the choice of the time points, K, remains arbitrary. Some authors (Klein and Andersen (2005), and Andersen et al. (2003)) suggested that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K=5$$\end{document} is sufficient to obtain asymptotically unbiased estimates and, therefore, this value has been considered as the default in the simulation study. To assess the impact of the number of time points, we transformed survival data generated from the core scenario (a true log hazard ratio of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.3$$\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{HR}=0.74$$\end{document} ), a censoring rate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$20\%$$\end{document} and a sample size of 500) into \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K=5$$\end{document} , 7, and 10 pseudo-observations separately. We analyzed the transformed data with the GEE, the frequentist GMM, and the Bayesian GMM models.
Figure 2 shows that increasing the number of time points had no impact on the median of the log hazard ratios estimated from 1000 replicates and a minor impact on the variability of these estimates, whatever the method. Online Resource Table S3 details the different performances of each model with different numbers of time points. Hence, our findings align with the previous sensitivity analysis from the literature. Thus, using \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K>5$$\end{document} time points is not recommended as the gain in efficiency is negligible compared to the complexity induced and the increase in the running time of the NUTS algorithm for the Bayesian GMM (data not shown).Fig. 2. Sensitivity analysis on the number of time points ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K=5$$\end{document} , 7, and 10) used for the computation of pseudo-observations. Box plots represent the hazard ratio (log scale) estimated from GEE, frequentist, and Bayesian GMM from 1000 replicates, with a true log hazard ratio of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.3$$\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{HR}=0.74$$\end{document} ), a censoring rate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$20\%$$\end{document} and a sample size of 500. The horizontal red line represents the true log hazard ratio
Sensitivity analysis on the choice of the working correlation matrix
The choice of the working correlation matrix is one of the assumptions required when applying GEE or GMM. Previous results from pseudo-observations-based approaches are obtained with the independent working correlation matrix. This structure is often chosen in practice when using GEE to analyze pseudo-observations because the GEE method yields unbiased estimates even when the working correlation matrix is misspecified. The frequentist GMM has been developed to produce more efficient estimates than GEE for longitudinal continuous data when the working correlation matrix is misspecified (Qu et al. 2000). Thus, we analyzed the impact of different correlation matrices on hazard ratio estimates for the GEE, frequentist, and Bayesian GMM based on pseudo-observations. We first limit this analysis to the core scenario (true log hazard ratio of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.3$$\end{document} , censoring rate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$20\%$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=500$$\end{document} ). Table 4 shows that GMM approaches produce unbiased estimates and comparable ASE and ASD, whatever the working matrix, and similar standard errors between the three structures. Similar results are obtained with different treatment effects (See Online Resource Tables S4a and S4b). In this context, the differences in the precision of the estimations between the GEE and GMM approaches were marginal. These results concur with Yu et al. (2020), who compared the GEE and the frequentist GMM approaches to analyze longitudinal outcomes in randomized clinical trials.Table 4. Comparison of the performances of GEE and GMM models with different working correlation matrices: Independence (IND), Exchangeable (EXCH) and first-order auto-regressive (AR-1) for a true log hazard ratio of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.3 (HR=0.74), a censoring rate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$20\%$$\end{document} and sample size of 500MethodsWCMBiasASEASDRMSECoverageFrequentistGEEIND0.00320.1140.1120.11295.4GEEEXCH0.00210.1130.1120.11295.1GEEAR-10.00240.1110.1100.11095.5GMMIND0.00320.1140.1120.11295.5GMMEXCH0.00010.1110.1110.11195.3GMMAR-1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00170.1110.1110.11295.3BayesianGMMIND \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00280.1160.1130.11395.4GMMEXCH \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00550.1130.1120.11395.0GMMAR-1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.00730.1130.1130.11394.7WCM: Working Correlation Matrix, ASE: Average Standard Error,ASD: Average Standard Deviation, RMSE: Root Mean Square Error
Illustration on real-data examples
For illustration, post-hoc efficacy analyses were performed on three randomized clinical trials ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{R1}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm {R2_{loc}}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm {R2_{pulm}}$$\end{document} ) involving patients with Ewing Sarcoma to evaluate different consolidation treatments. After receiving intensive induction chemotherapy and surgery, patients were included in one of these trials according to prognostic factors and the response after surgery. In all these trials, the main endpoint was the event-free survival (EFS), defined as the time from random assignment to the first occurrence of any of the following events: relapse, second malignancy, or death from any cause, and the secondary endpoint was overall survival (OS), considering all causes of death.
The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{R1}$$\end{document} trial was a phase III non-inferiority trial, which included standard-risk patients with small localized tumors or good histologic response to chemotherapy. The cyclophosphamide-based experimental arm was compared to the Ifosfamide-based control arm (Le Deley et al. 2014). This trial recruited 856 patients ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=431$$\end{document} received Vincristine-Actinomycine-Cyclophosphamide (VAC), and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=425$$\end{document} received Vincristine-Actinomycine-Ifosfamide (VAI)). The median follow-up was 5.9 years, and the censoring rate was \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$73\%$$\end{document} for the main endpoint. The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm {R2_{loc}}$$\end{document} trial, a phase III superiority trial, included high-risk patients with large localized tumors or poor histologic response. Busulfan and Melphalan (BuMel) were compared with the standard chemotherapy VAI (Whelan et al. 2018). This trial recruited 240 patients ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=122$$\end{document} received BuMel and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=118$$\end{document} received VAI). The median follow-up was 7.8 years, and the censoring rate was \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$56\%$$\end{document} for the main endpoint. The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm {R2_{pulm}}$$\end{document} trial, a phase III superiority trial, enrolled patients with only pulmonary or plural metastases and compared VAI + BuMel with VAI + pulmonary radiotherapy (RT) (Dirksen et al. 2019). This trial included 287 patients ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=144$$\end{document} receiving VAI+BuMel and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=134$$\end{document} received VAI+RT). The median follow-up was 8.1 years, and the censoring rate was \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$50\%$$\end{document} for the main endpoint.
The same methods and settings from the simulation study were used to analyze the EWING data. Online Resource Figure S1 shows the Kaplan-Meier curves for the three trials and the corresponding pseudo-observation profiles for all patients. Focusing on the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{R1}$$\end{document} trial, most of the events were observed between 0 and 3 years post-randomization. Consequently, the last time point to compute pseudo-observations is at 2.81 year. As most individuals are censored, we observed most of the pseudo-observations above 1 or between 0 and 1. Similar observations can be drawn from the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm {R2_{loc}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm {R2_{pulm}}$$\end{document} trials.Fig. 3. Hazard ratio estimates (and 95% confidence intervals) of treatment effect from the Cox proportional hazard, GEE, frequentist (Freq) GMM, piecewise exponential and Bayesian (Bayes) GMM models in the three EWING trials ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{R1}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm {R2_{loc}}$$\end{document} , or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm {R2_{pulm}}$$\end{document} ) for event-free survival (left part) and overall survival (right part). These analyses were performed with no adjustment on covariates. The independent working correlation matrix is used for GEE and GMM approaches. The vertical dashed line represents the null effect
Figure 3 depicts the estimates of the hazard ratios with their 95% confidence intervals for EFS and OS, produced by the frequentist and Bayesian GMM and the three benchmark methods (Cox, GEE, and piecewise exponential models) without adjustment for covariates, contrary to the published results. The results of the different methods are consistent, supporting the validity of the GMM approaches for analyzing pseudo-observations. Frequentist GMM and GEE give similar results with a higher variance, as expected, compared to the Cox proportional hazard model. The results from the Bayesian GMM and piecewise exponential model are also similar, with a slightly higher variance for the former. According to the trace plots of the NUTS sampling for the Bayesian GMM, the 3 chains mixed well and appeared stationary, suggesting no divergence issue (see Online Resource Figures S2a to S2f).
While the previous results are obtained with an independent working correlation matrix for GEE and GMM approaches (which is used by default for pseudo-observations analysis), our analysis was firstly extended using different correlation assumptions, as the generalized methods of moments also allow the definition of complex working correlation structures using multiple base matrices. We implemented the exchangeable (EXCH) and the first-order auto-regressive (AR-1) correlation matrices so that the results remain comparable with the GEE approach. However, the choice is not limited to these cases. Only one of the three chains did not converge for the Bayesian GMM with an exchangeable matrix for EFS. This issue was resolved by changing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon $$\end{document} from 0.05 to 0.03 for generating initial values of the NUTS algorithm. Overall, the results using different working correlation matrices are similar within each approach and between approaches, except for the exchangeable matrix for situations where the treatment effect \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1$$\end{document} is close to 0 (log scale). The results reported in Table 5 for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{R1}$$\end{document} trial (Online Resource Tables S5a and S5b for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm {R2_{loc}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm {R2_{pulm}}$$\end{document} ) suggest that increasing the complexity of the working correlation matrix gives a negligible increase in precision.Table 5. Log hazard ratio and standard error of treatment effect estimated by GEE and GMM with different correlation matrices: Independence (IND), Exchangeable (EXCH), and first-order auto-regressive (AR-1) in R1 trial for event-free survival and overall survivalMethodsWCMlog(HR)SEEvent-free survivalFrequentistGEEIND0.13090.150GEEEXCH0.10150.148GEEAR-10.12680.148GMMIND0.13090.150GMMEXCH0.08190.149GMMAR-10.12230.146BayesianGMMIND0.12530.156GMMEXCH0.07580.140GMMAR-10.12000.156Overall survivalFrequentistGEEIND0.02910.173GEEEXCH0.01640.170GEEAR-10.02510.171GMMIND0.02910.173GMMEXCH0.00680.171GMMAR-10.01100.168BayesianGMMIND0.01550.184GMMEXCH \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.01240.181GMMAR-10.01440.184WCM: Working Correlation Matrix,SE: Standard Error
To further illustrate the versatility of our approach, the analysis of the three trials was secondly extended by including age as a covariate. Age was a stratification variable, reported as a binary variable ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$<25$$\end{document} or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ge 25$$\end{document} ) years in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{R1}$$\end{document} trial and as a four-categorical variable (<12, 12-18, 18-25, and >25) years in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm {R2_{loc}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm {R2_{pulm}}$$\end{document} trials. The age-adjusted treatment effect is similar across the methods within a trial, with a larger variance for the Bayesian GMM in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm {R2_{pulm}}$$\end{document} trial (Online Resource Figure S3). One relevant advantage of the Bayesian inference over the frequentist approach is that one can better characterize the treatment effect through its posterior distribution, estimated with the piecewise exponential model and the Bayesian GMM based on pseudo-observations (Online Resource Figure S4 for EFS endpoint). For example, in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{R1}$$\end{document} trial, the posterior probability of the log(HR) to be below the noninferiority margin ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log ( 1.43)$$\end{document} ) is 0.973 (SE=0.002) and 0.906 (SE=0.005) for piecewise exponential and GMM models, respectively. In \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm {R2_{loc}}$$\end{document} , the posterior probability of a log(HR) to be below the log(HR) under \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_1$$\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log (0.60)$$\end{document} ) is 0.365 (SE=0.005) and 0.552 (SE=0.009) for piecewise exponential and GMM models, respectively. In \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm {R2_{pulm}}$$\end{document} , the posterior probability of a log(HR) to be below the log(HR) under \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_1$$\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log (0.65)$$\end{document} ) is 0.091 (SE=0.003) and 0.148 (SE=0.006) for piecewise exponential and GMM models, respectively.
Discussion
In this paper, we propose a new and practical approach for Bayesian survival regression modeling based on pseudo-observations. This method does not require specifying the full likelihood, contrary to the usual Bayesian parametric and semi-parametric regression models, where nuisance parameters are specified to model the baseline hazard function. With this new approach, we bypass this specification by transforming time-to-event data into pseudo-observations, then analyzed by the generalized method of moments. The generalized method of moments applied to pseudo-observations was evaluated for estimating the hazard ratio from a two-arm randomized clinical trial in a frequentist and Bayesian framework. This approach results in valid inferences and comparable results to those produced by the Cox, GEE, and piecewise exponential models. In the frequentist framework, GMM and GEE have similar results regardless of the treatment effects, censoring rates, and sample sizes. More interestingly, in the Bayesian framework, the GMM gives unbiased results when a reasonable number of events is observed. The hazard ratio estimations are, as expected, less efficient compared to the piecewise exponential model, but remain acceptable given that the model does not require any assumption on the full likelihood contrary to the piecewise exponential model. The effect size of the treatment did not influence these results, and there was no inflation of the standard errors estimated by the Bayesian GMM compared to the frequentist GMM. Under the exchangeable or the first-order auto-regressive assumption, the GMM approach gave results similar to the GEE’s.
Although our approach makes valid inferences, special care is needed in setting adequate priors and starting values of the regression coefficients to avoid convergence problems during the sampling. These convergence issues occur when one value of a regression coefficient falls outside the support of the pseudo-likelihood function. Priors have to be appropriately chosen according to a range of reasonable values that can be taken by the regression coefficient. In our simulation study of two-arm randomized clinical trials, we built a procedure as a preliminary step to specify the initial values of the regression coefficients carefully. So, both adequate priors and well-chosen initial values ensure the robustness of the Bayesian results. Although no additional covariate was included in the simulation study, the possibility of performing Bayesian inference with multiple covariates was reported in the real-data applications. As our approach was based on a pseudo-likelihood, it does not allow us to make predictions, while Bayesian deep learning algorithms using pseudo-observations have been proposed for this purpose (Zhao and Feng 2020).
In conclusion, this paper proposes the first Bayesian modeling of pseudo-observations using the generalized method of moments, combining the advantages of pseudo-observations with those of Bayesian inference. The Bayesian generalized method of moments was based on pseudo-observations to estimate hazard ratios, one of the most straightforward applications of pseudo-observations. Although this application is not complex and classical Bayesian survival models may also be used, the aim of this work is to be a proof of concept that pseudo-observations can be analyzed in the Bayesian framework. It serves as a starting point before its extension to other applications where pseudo-observations are useful, such as the restricted mean survival time estimation, the estimation of transition and state probabilities derived from multi-state models, or the analysis for interval-censored data in a Bayesian framework, and unlocks various options not available with traditional proportional hazard models. Compared to the frequentist methods, this approach offers not only new insights on interpretation via the estimated posterior distribution but may also overcome their limitations in some situations, especially in randomized clinical trials for rare diseases where it allows enriching the analysis by incorporating external data.
Additional Information
The R code to analyze pseudo-observations using frequentist and Bayesian GMM is available on GitHub https://github.com/Oncostat/pseudo_GMM.
Supplementary Information
Below is the link to the electronic supplementary material.Supplementary file 1 (pdf 764 KB)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Højsgaard S, Halekoh U, Yan J, Ekstrøm CT (2022) geepack R package version 1.3.9, https://cran.r-project.org/web/packages/geepack/ (accessed on October 2022)
- 2Jiang Z, Song P, Kleinsasser M (2019) qif: Quadratic Inference Function R package version 1.5, https://CRAN.R-project.org/package=qif (Accessed on April 2023)
- 3Pohar-Perme M, Gerster M, Rodrigues K (2017) pseudo: Computes Pseudo-Observations for Modeling R package version 1.4.3 URL: https://cran.r-project.org/web/packages/pseudo/
- 4R Core Team (2021). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. URL https://www.R-project.org/
- 5Stan Development Team (2020) Prior Choice Recommendations. Available online https://github.com/stan-dev/stan/wiki/Prior-Choice-Recommendations (accessed on April 2023)
- 6Stan Development Team (2023) R Stan: the R interface to Stan, R package version 2.21.7, https://mc-stan.org/ (accessed on October 2022)
- 7Whelan J, Le Deley M-C, Dirksen U, Le Teuff G, Brennan B, Gaspar N, et al (2018) High-dose chemotherapy and blood autologous stem-cell rescue compared With standard chemotherapy in localized high-risk Ewing sarcoma: results of Euro-E.W.I.N.G.99 and Ewing-2008. Journal of Clinical Oncology, 36(31)10.1200/JCO.2018.78.2516 PMC 620909030188789 · doi ↗ · pubmed ↗