Attention to detail: A conditional multi-head transformer for traffic sign recognition
Isra Naz, Jamal Hussain Shah, Ali Tahir, Mahatma Reddy Marri, Rabia Saleem, Mutaz Elradi S. Saeed, Mudassir Khan, Mudassir Khan, Mudassir Khan, Mudassir Khan

TL;DR
This paper introduces a new Vision Transformer model that dynamically adapts to improve traffic sign recognition in autonomous vehicles.
Contribution
The novel Conditional Visual Transformer (CViT) dynamically adjusts attention mechanisms based on input sign type.
Findings
CViT achieved 99.87% overall accuracy in traffic sign recognition.
The model showed high performance with a Macro F1 Score of 99.07%.
Adaptive gating improved projection matrix adjustments across different signs.
Abstract
The challenge of traffic sign detection and recognition for driving vehicles has become more critical with recent advances in autonomous and assisted driving technologies. Although object recognition problems, particularly traffic sign recognition, have been extensively studied, most Vision Transformer (ViT) models still rely on static attention mechanisms with fixed projection matrices (Q, K, and V). Using this mechanism limits the ViTs to handle real-world problems such as object detection and traffic sign recognition, etc. Problems, such as partially or fully obscured signs, changes in illumination, and weather conditions, result in subpar feature extraction, which compounds the misclassification problem. To overcome this challenge, a Conditional Visual Transformer (CViT) is proposed in this research, which dynamically adapts feature aggregation, Q, K, and V projections, as well as…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8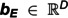 Figure 9
Figure 9 Figure 10
Figure 10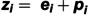 Figure 11
Figure 11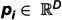 Figure 12
Figure 12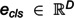 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40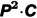 Figure 41
Figure 41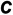 Figure 42
Figure 42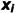 Figure 43
Figure 43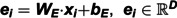 Figure 44
Figure 44 Figure 45
Figure 45 Figure 46
Figure 46 Figure 47
Figure 47 Figure 48
Figure 48 Figure 49
Figure 49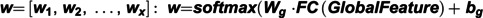 Figure 50
Figure 50Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Hand Gesture Recognition Systems · Handwritten Text Recognition Techniques