The LEADING guideline: Reporting standards for expert panel, best-estimate diagnosis, and longitudinal expert all data (LEAD) methods
Veerle C. Eijsbroek, Katarina Kjell, H. Andrew Schwartz, Jan R. Boehnke, Eiko I. Fried, Daniel N. Klein, Peik Gustafsson, Isabelle Augenstein, Patrick M.M. Bossuyt, Oscar N.E. Kjell

TL;DR
This paper introduces the LEADING guideline to improve reporting of expert-based diagnostic methods in health research.
Contribution
The novel contribution is the development of a structured reporting guideline called LEADING for expert-based diagnostic assessments.
Findings
The LEADING guideline includes 20 reporting standards grouped into four categories.
Testing revealed that 10–63% of standards were missing in existing published studies.
The guideline was developed through expert feedback and iterative refinement.
Abstract
Accurate assessments of symptoms and illnesses are essential for health research and clinical practice but face many challenges. The absence of a single error-free measure is currently addressed by assessment methods involving experts reviewing several sources of information to achieve a best-estimate assessment. This assessment method is called the Expert Panel method in medicine, and the Best-Estimate Diagnosis or Longitudinal Expert All Data (LEAD) method in psychiatry and psychology. However, due to poor reporting of the assessment methods, the quality of pro-claimed best-estimate assessments is typically difficult to evaluate, and when the method is reported, the reporting quality varies substantially. To tackle this gap, we have developed a reporting guideline following a four-stage approach: 1) drafting reporting standards accompanied by empirical evidence, which were further…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
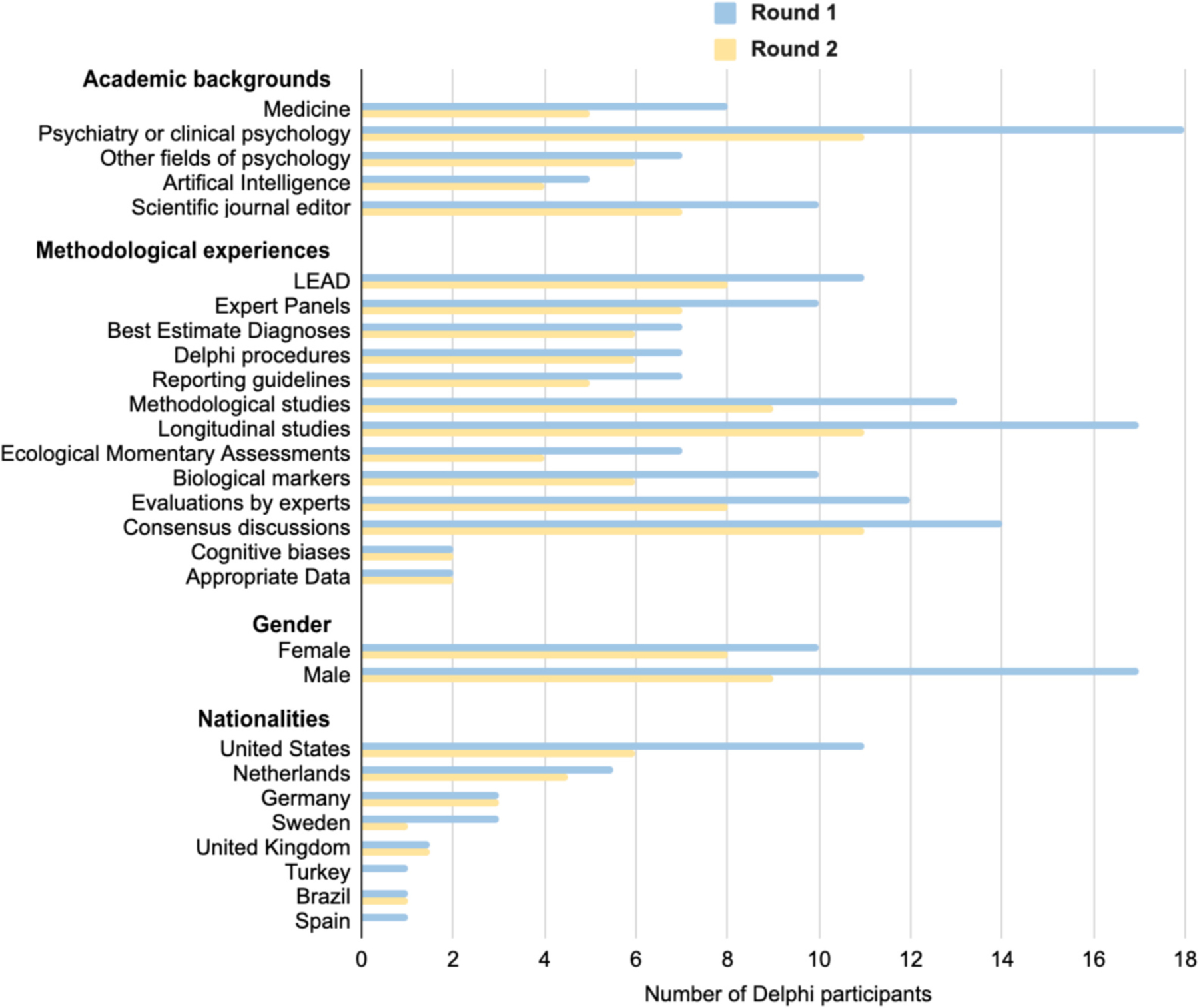 Figure 1
Figure 1 Figure 2
Figure 2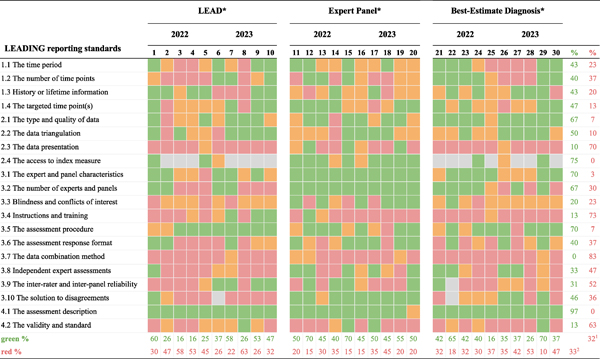 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMeta-analysis and systematic reviews · Delphi Technique in Research · Health Systems, Economic Evaluations, Quality of Life
Introduction
Establishing valid and reliable assessments of symptoms and diagnoses is the foundation of health and clinical sciences. Given that reliable biological markers or specific objective signs for most mental health problems are lacking and many medical conditions only show objective markers in late stages, accurate assessments are difficult [1,2]. Essentially, every single measure of a psychological construct has some potential source of bias (e.g., self-report and recall bias) or can be seen as fallible in some respect [3,4] – which can result in inaccurate assessments and delayed treatments.
The absence of a single error-free measure can be addressed by involving multiple experts reviewing several sources of information to form a best-estimate assessment or a reference standard [5–7]. To understand the quality of such an assessment, it is crucial to understand how it was reached (i.e., the quality of the specific assessment method used). However, the quality of best-estimate assessments is typically very difficult to evaluate due to poor reporting of the assessment method, and when the method is reported, the reporting quality varies substantially [7]. Here, we tackle this problem by developing a guideline for how to report assessment methods that aim to achieve such best-estimate assessments, i.e., where experts review several sources of (longitudinal) information to achieve a more accurate assessment than a single, error-prone measure.
Assessment
1.1.
Assessment includes the evaluation, integration, and interpretation of several sources of information (e.g., outcomes of different measures, tests, or scans) to derive a valid and reliable decision (e.g., a best-estimate diagnosis) [8]. Accurate assessments are crucial. In clinical practice, under- or over-estimation of illnesses can have severe negative impacts on people's lives. In research, inaccurate assessments threaten the validity of scientific results. For policy and implementation development, assessments are the basis for guideline development and the economic and societal evaluations of interventions. Furthermore, obtaining more accurate assessments has become increasingly important considering that high-accuracy assessments are needed in diverse fields such as Biological Psychiatry (e.g., to find reliable biomarkers linked to reference standard assessments [9–11]) and Artificial Intelligence (e.g., to train models to reference standard assessments [12–14]).
A methodological solution
1.2.
Here, we connect three bodies of literature that have proposed similar assessment methods: The Expert Panel method in medicine [7,15,16] – as well as the Best-Estimate Diagnosis [6,17] and the Longitudinal Expert All Data (LEAD [5]) methods in clinical psychology and psychiatry. The three methods share the same goal of attaining best-estimate assessments through similar methodological approaches: All three methods use expert panels or consensus teams (e.g., clinical psychologists or medical doctors) to review several sources of information (e.g., clinical questionnaires and medical tests) to establish a more accurate assessment (e.g., a best-estimate diagnosis).
The Best-Estimate Diagnosis method was introduced by Leckman et al. [6] as a strategy to set accurate lifetime psychiatric diagnoses. The method focuses on two components, namely 1) using all data (e.g., information from medical records and relatives in addition to interviews) that is 2) evaluated by expert clinicians (who review all data and then reach a consensus [17]). Consequently, Spitzer [5] proposed the Longitudinal Expert All Data (LEAD) method to obtain a criterion or reference standard to validate the Diagnostic Interview Schedule [18] for setting psychiatric diagnoses. LEAD extends the Best-Estimate Diagnosis method and involves three essential components, namely Longitudinal data collection (i.e., not limited to a single examination at one point in time), Expert evaluation (i.e., the diagnoses are set by expert clinicians), and All Data (i.e., the experts have access to multiple data sources). A similar approach was proposed in medicine, where the Expert Panel method was developed as a solution for diagnostic accuracy studies with an imperfect or missing reference standard [16,19,20]. Here, a panel of experts decides on a medical condition based on all relevant information. A review of expert panel studies [7] identified four critical components of the expert panel design, namely 1) the panel constitution, 2) the information presented to the panel, 3) the decision process of the panel, and 4) the validity of the panel diagnosis.
So, all three methods employ a similar approach to obtain best-estimate assessments (e.g., for diagnostic purposes or as a reference standard) while accentuating parts of it: The Best-Estimate Diagnosis method accentuates the use of informants and objective tests next to self-reported data [6,17]; the Expert Panel method focuses on the characteristics, constitution, and procedure of the panel [7,15] and only the LEAD method requires a longitudinal design [5], although longitudinal data are also used in some Expert Panel designs (≈27 % of studies [7]). Herein, we collectively refer to these three approaches as the assessment methods.
The result of the assessment methods is a consensually derived criterion (e.g., a best-estimate assessment) that has been used for many different applications where there is no single error-free measure. It has, for example, been used to i) evaluate the accuracy of a measurement tool or marker through comparison to a best-estimate assessment [21–26]; ii) establish the prevalence of symptoms and disorders [27–29]; iii) establish the temporal stability or development of symptoms and disorders [30–32]; iv) improve (earlier) detection or screening of symptoms or disorders [33–35]; v) study genetics and family history [36–38]; and vi) examine classification systems or diagnostic criteria [39–41]. The applications span diverse fields, including medicine, psychiatry, clinical psychology, public health/epidemiology, and artificial intelligence. Box 1 provides more examples of how the best-estimate assessments have been applied in different types of studies across fields.
Reporting issues
1.3.
The assessment methods possess a high potential for achieving best-estimate reference standards in many situations. However, the quality of such proclaimed best-estimate assessments varies substantially and is typically very difficult to evaluate due to poor reporting of the method how they were achieved (e.g., see reviews of expert panels [7,15]). A systematic review of assessment methods and reporting of expert panels [7] has demonstrated that the methods used for panel or consensus diagnoses vary substantially across studies and that many aspects of the procedure are often unclear or not reported at all (i.e., in 83 % of the reviewed studies). Many recent studies fail to report central aspects of the assessment procedures, including the quality, structure, or presentation of the data [43], the training and qualifications of the experts [44], the method for avoiding biases and achieving consensus [45], and the time span of the longitudinal design-component [46]. The poor operationalization of the assessment methods jeopardizes the goal of achieving best-estimate assessments – where a vaguely described method makes it difficult to evaluate the research. Referring to an assessment as a best-estimate (and sometimes even as a gold standard) while vaguely describing or poorly operationalizing the method for achieving the assessment is alarming [47,48].
The degree of validity
1.4.
These assessment methods aim to achieve high validity (i.e., the degree to which the assessment captures what it aims to measure). Typically, the assessment methods aim to achieve as high validity as possible (i.e., a “leading” assessment) or, depending on resources, at least more accurate than a single error-prone measure. Despite this central aim, research often fails to clearly describe the degree of validity of the attained assessment. Using these assessment methods does not automatically guarantee high validity – it depends on how well the method is executed.
In addition, the derived assessments are often described with different terms: reference standard is often used in medicine, and criterion standard or best-estimate diagnosis is often used in psychology. We propose that the reporting of these assessment methods benefit from more explicitly describing what was measured and how well it measures up to different standards – whether and how they relate to a state-of-the-art assessment. Whereas reference and criterion standards fail to convey an intention of “nearing” a state-of-the-art assessment, the best-estimate diagnosis narrowly focuses on the classification of a diagnosis and not on symptom severity. Therefore, we here use the term best-estimate assessment in the context of describing a “leading”, state-of-the-art assessment.
Reporting standards
1.5.
Previous well-established guidelines have focused on the complete reporting of specific study designs, such as the STrengthening the Reporting of OBservational studies in Epidemiology (STROBE [49]) for observational studies; the Statement for Reporting for Diagnostic Accuracy (STARD [50]) for diagnostic accuracy studies; the Consolidated Standards of Reporting Trials (CONSORT [51]) for randomized trials, and the Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD+AI [52]) for prediction model studies (see the supplementary material [SM] for other relevant guidelines). The STARD guidance is most closely related to the reporting of the assessment methods since best-estimate assessments are often used to evaluate a measure's (diagnostic) accuracy. However, none of the guidelines are sufficient for complete reporting of the assessment methods, where (multiple) experts review several sources of (longitudinal) information to form a best-estimate assessment. Although an earlier systematic review identified and structured the various choices involved in Expert Panel procedures [7], no attempt was made to develop a formal guideline for the reporting of Expert Panel assessments.
Aim
1.6.
Our aim is to develop reporting standards for comprehensive reporting of Expert Panel, Best-Estimate Diagnosis, and LEAD methods – which can help researchers plan and report studies employing these assessment methods, as well as help readers evaluate them. We call the reporting guideline the LEADING guideline, emphasizing the methodological components and the importance of describing what is assessed and how well (i.e., how it relates to a “leading” assessment). The individual reporting standards are divided into four groups according to the components of LEAD (Longitudinal, Expert, All Data [5]), from which we revised the original meanings to Longitudinal, Evaluation – experts, materials and procedures, Appropriate Data, and Validity. In short, the LEADING guideline aims to guide the reporting of assessment method to improve evaluations of the assessment standard.
Methods
We developed the reporting guideline over four stages: 1) drafting reporting standards, 2) incorporating expert feedback, 3) refining the final guideline, and 4) testing the guideline. The development method largely followed Moher and colleagues' guidance for developing reporting guidelines [53] (See Table S1 for elaborations on each recommended step). For organizational purposes, a working group (V.E., K. K., & O.K.) was set up, and a steering group (H.A.S., J.B., E.F., D.K., P.G., I.A., & P.B.) was formed to provide a wide range of expertise. The steering group included seven experts and was selected to cover diverse expertise and fields related to the assessment methods (e.g., psychiatry/clinical psychology, medicine, epidemiology/public health, and Artificial Intelligence). Information regarding ethics is presented after the discussion.
Drafting reporting standards
2.1.
The working group, with the support of the steering group members, identified relevant research using or describing the assessment methods, including the three bodies of literature: Expert Panel [7], Best-Estimate Diagnosis [6], and LEAD [5]. In addition, articles using any of the three assessment methods were identified through a literature search using Google Scholar with the following search terms: [“expert panel diagnosis” OR “expert panel assessment” OR “expert panel consensus” OR “expert panel methodology” OR “expert panel standard” OR “expert panel reference”] for Expert Panel studies; [“best-estimate diagnosis” OR “best-estimate diagnostic” OR “best-estimate standard” OR “best-estimate assessment” OR “best-estimate methodology” OR “best-estimate reference”] for Best-Estimate Diagnosis studies; and [“longitudinal expert all data” OR “longitudinal evaluation all data”] for LEAD studies. Articles that clearly stated using one of the three assessment methods were selected. Articles stating another purpose than assessment (e.g. when an expert panel was used to reach a consensus about a treatment strategy) were excluded.
Furthermore, relevant reporting guidelines and systematic reviews were identified, including a review of expert panel applications [7], the STROBE statement [54], and the STARD guidance [50]. Other complementary reporting guidelines and systematic reviews are presented in the SM. The aim was for the reporting standards in the LEADING guideline to complement rather than repeat them (i.e., new standards should extend or complement existing standards rather than repeat them [53]). For example, when reporting a randomized trial that includes best-estimate assessments, one may use CONSORT [55] to report the trial design and main results, the LEADING guideline for describing the specifics for reaching the best-estimate assessments, and the Consolidated Health Economic Evaluation Reporting Standards (CHEERS) [56] for reporting the economic evaluations and comparisons.
Potential standards were drafted by the working group with the objective of encompassing a comprehensive reporting of the assessment methods. The reporting standards were grouped into four groups: Longitudinal design, Appropriate data, Evaluation – experts, materials and procedures, and Validity. Empirical and theoretical inclusion rationales were stated for the groups and the individual standards (i.e., explanations and elaborations). Lastly, the standards with inclusion rationales were further developed through a workshop with a patient organization for depression, followed by feedback from the steering group members to receive a wide range of perspectives early in the process.
Incorporating expert feedback
2.2.
To systematically collect expert feedback from different perspectives, we used a consensus-building procedure called the Delphi technique [57]. We used an iterative process based on two rounds of questionnaires (i.e., Delphi surveys), enabling feedback from round 1 to feed into round 2. Delphi participants received relevant background research, the reporting guideline aims, and the reporting standards with their inclusion rationales. They provided feedback through open- and closed-ended response formats. Through open-ended responses in Round 1, experts could propose new standards and provide feedback on the formulations of existing standards and their inclusion rationales. In addition, two closed-ended questions [58] about standard inclusion (This item should be included in the reporting checklist) and perception of study quality (Whether this information is present or not would influence my perceptions of the quality of a study) were answered with rating scales ranging from 1 = Strongly disagree to 7 = Strongly agree. In Round 2, the experts were asked to rate the updated reporting standards using the same two closed-ended questions as in Round 1 and to provide feedback on the clarifications and reformulations through open-ended responses.
To recruit Delphi participants, the first and/or last authors of articles since 2013 using any of the three assessment methods were identified using the search terms described above (n = 87 articles, n = 124 authors; see the SM for more details). These authors and the seven steering group members were invited via email to participate in the Delphi Round 1 (n = 131 participants emailed). In total, 27 participants completed the survey (response rate 21 %). Only participants from Round 1 who provided their contact details were invited to Round 2 (n = 25). In total, 20 participants completed the survey (response rate 80 %). All participants provided their informed consent. Fig. 1 presents the research experiences and demographics of the Delphi participants. Participants reported a wide range of academic backgrounds (e.g., Clinical Psychology, Psychiatry, Medicine, Artificial Intelligence, Journal Editors) and an extensive variety of relevant methodological experiences (e.g., Ecological Momentary Assessments, Biological Markers, and Expert Panels; Fig. 1), with an age range of 30–70 years (M = 51.54, SD = 12.40).
Delphi survey results
2.2.1.
The criteria for including a reporting standard was that the median of Delphi expert responses was at least 6 = Agree on the question about its inclusion. In Round 1, the mean ratings for the item inclusion scale ranged from 5.37 to 6.67 (M = 6.06; SD = 0.31; Table S2) with a median agreement ranging from 6 = Agree to 7 = Strongly Agree. No new standards were suggested. The feedback resulted in the removal of one reporting standard and the clarification and reformulation of 20 standards. The standard on Transparency and replicability was rated as relevant but removed because it is achieved by reporting the other reporting standards. Standard 4.2 Validity and Standard needed a major clarification about the meaning of validity as well as standard. Minor clarifications and reformations, such as grammar or word changes, were made for 19 standards (see open material). The mean ratings in Round 2 ranged from 5.47 to 6.70 (M = 6.20; SD = 0.37; Table S3), with open feedback resulting in minor clarifications and reformulations of nine standards.
Refining the guideline through expert consensus
2.3.
The authors finalized the guidelines in an expert consensus meeting. The meeting was held online with nine working and steering group members. The content and structure of the consensus meeting were prepared by the working group, and the meeting was led by the last author (O.K.). Participants had access to the guidelines, inclusion rationales (i.e., elaboration and explanation), and the drafted paper before the meeting, where they also had the option to provide comments and feedback in writing. The meeting included reviewing the Delphi Rounds 1 and 2 findings and discussing the paper draft, including the individual reporting standards and groups. We decided not to carry out another Delphi round since i) the median agreement for each reporting standard in both Delphi Rounds 1 and 2 ranged from 6 = Agree to 7 = Strongly Agree, ii) no new standards were suggested, and iii) only minor changes were needed after Round 2, which taken together suggest consensus.
Testing the guideline
2.4.
To test the applicability of the guideline, the guideline was tested i) by independent researchers with experience of each method piloting the reporting of each standard and ii) by the authors (V.E., K.K.) applying it to published articles. The two test procedures resulted in adding minor clarifications to three standards (2.4 The access to the index measure, 3.3 Blindness and conflict of interest, and 3.4 Instructions and training). Also, a concrete example of how to report the items was added to the guideline instructions.
Incorporating test-user feedback
2.4.1.
Two test users (PhD, with experience using the LEAD and Expert Panel method) who had not been involved in the development of the guideline (e.g., in the Delphi procedure) were recruited to pilot the guideline (see the SM for more details). They were asked to report each standard based on a finished, ongoing or planned study using one of the assessment methods and/or provide feedback about the formulation of the standards.
Applying the standards to published studies
2.4.2.
Three separate targeted searches (LEAD, Expert-panel, Best-estimate) were conducted using the search terms described above. The first author (V.E.) examined which standards were reported in 30 randomly selected articles applying the assessment methods in 2022 and 2023 (i. e., five from each method from each year; see the SM for the selection process). Each reporting standard was rated using four categories: standard not reported; standard reported vaguely or insufficiently; standard (minimally) sufficiently reported; or standard not applicable to the study. Out of the 30 articles, six were randomly selected (i.e., one from each method from each year) and examined by the second author (K.K.) to get insight into the accuracy of the ratings of the first author. Discussing their disagreements to reach consensus resulted in changing 23 ratings (19 %) of the first author. This testing procedure also provided information about the strengths and shortcomings of contemporary reporting of published articles using the assessment methods (see Results section).
Results
The reporting guideline is presented in Table 1 (see Fig. 2 for an overview). It comprises 20 standards for comprehensive reporting of the assessment methods divided into four groups: 1. The Longitudinal design group (4 standards), 2. The Appropriate data group (4 standards), 3. The Evaluation – experts, materials, and procedures group (10 standards), and 4. The Validity group (2 standards). The reporting standards encourage researchers to elaborate on what was done and why – whilst avoiding normative standards, such as a minimum number of experts. Each standard description in Table 1 is accompanied by an example. Further Explanations and Elaborations regarding the individual reporting standards and the four groups are presented in the SM, including Tables S4 and S5. A reporting template for providing an overview of the standard reports can be found on www.leading-guideline.org.
Applying the LEADING guideline to published studies
3.1.
Applying the guideline to a random selection of 30 articles indicated severe heterogeneity in what of the methods is reported and how (Table 2; see the SM for the search strategy). Across the 30 studies, 10 to 63 % (Mean = 33 %) of the standards were not reported. Regarding the reporting standards, the type and quality of the data (2.1), the access to the index measure (2.4), the expert and panel characteristics (3.1), the number of experts and panels (3.2), the assessment procedure (3.5), and the assessment description (4.1) were mostly reported (i.e., green in more than 50 % of the studies). However, the data presentation (2.3), the instructions and training (3.4), the data combination method (3.7), the inter-rater and inter-panel reliability (3.9), and the validity and standard (4.2) were not reported at all in the majority of the studies (i.e., red in more than 50 % of the studies). Considering that most changes that resulted from discussing disagreements between the raters (V.E. and K.K.) were from green to orange, and that green refers to a (minimally) sufficiently reported and orange to insufficiently reported, this suggests that the table is conservative in regards to the severity of the current state of poor reporting (i.e., potentially showing a more positive picture; for more information see the SM).
Discussion
Our objective was to develop a guideline that supports comprehensive reporting of assessment methods collecting longitudinal, appropriate data that experts evaluate to achieve an assessment that is more accurate than a single error-prone measure. This assessment method is known as Expert Panel in medicine, and Best-Estimate Diagnosis or LEAD in psychiatry and clinical psychology. Given that reliable biological markers or specific objective signs are lacking not only in mental health but also in some medical conditions, the assessment approach—and this guideline—have wide applicability across diverse clinical domains (see Box 1). The aim of the LEADING guideline is to help researchers plan, conduct, report, and evaluate the assessment method-related elements of this study design.
The LEADING reporting standards were established through an open process, incorporating relevant empirical evidence and methodological work, complementary reporting guidelines, and comprehensive iterations of expert feedback and patients' perspectives. As this guideline focuses on the assessment methods, we recommend that researchers also rely on established guidelines for other parts of their research, such as sampling and other epidemiological aspects (e.g., STROBE, CONSORT, and STARD).
Limitations
4.1.
We have connected three assessment methods with similar approaches from related fields and drafted applicable reporting standards. We presented the rationale for these three methods and each reporting standard with supporting evidence in the Delphi survey for review, which did not bring up additional methods or reporting standards. As we did not carry out a systematic literature review, we cannot exclude the existence of other assessment methods with similar approaches. We welcome any suggestions about similar methods to which the guideline is applicable.
The Delphi survey participants and the author group had a wide range of experiences and backgrounds; however, geographically, Europe and North America were the most common, whereas several areas were not represented. The Delphi participants were the first or last authors of studies employing the assessment methods. The quality of the articles and the education or experience of the authors were not taken into account as selection criteria (although it was self-reported, as presented in Fig. 1). The number of Delphi participants (27 in Round 1, 20 in Round 2) is relatively small compared to some other standard developments (e. g., 73 in the development of STARD [88]) but comparable to others (e.g., 24 for the development of the TRIPOD statement [89]). Even though the response rate in Round 1 (21 %) can be considered low, the number of participants was sufficient to cover a broad range of academic backgrounds, methodological experiences, and demographics (Fig. 1). The same limitation is applicable to the size of the steering group (n = 7) and the current test-user group (n = 2).
Implementation, adherence, and evolvement
4.2.
Implementation
4.2.1.
We encourage implementation of and adherence to the LEADING guideline via www.leading-guideline.org, scientific journals, editorials, commentaries, and the Enhancing the QUAlity and Transparency Of health Research (EQUATOR) Network (www.equator-network.org). The LEADING guideline aims to support authors in writing their research reports, editors and peer reviewers in reviewing submitted reports, and readers in critically evaluating published reports. We encourage editors and publishers to support adherence to the LEADING guideline by referring to it in author guidelines. We recommend that authors submit the guideline as an appendix to their manuscripts (see www.leading-guideline.org for a reporting template). We also encourage dissemination of the guideline via inclusion in research seminars and method courses in clinical studies. Teaching early career researchers about the benefits of comprehensive reporting can promote adoption and adherence, for example, by requiring students to write theses in accordance with the applicable guideline. Further dissemination is encouraged by welcoming translations of the guideline into different languages.
Adherence
4.2.2.
Reporting guidelines have become widely available for different study designs, especially in medicine. However, it is important to measure adherence to the guidelines, including identifying barriers and opportunities, and evaluate their impact on reporting quality [90,91]. Potential adherence barriers include prolonged reporting time, especially when multiple guidelines are needed for the report of the complete study design. However, standardized templates, as well as training and repeated practice, can increase efficiency and facilitate adherence [90,91]. We plan to measure adherence to the LEADING guideline via, for example, standardized adherence assessment forms [92] or AI-based tools that are currently being developed for determining reporting guideline compliance [93,94].
Evolvement
4.2.3.
The LEADING guideline should be regarded as an evolving reporting guideline requiring ongoing evaluation, refinement, and revision. Methodological components of assessment methods evolve: The LEADING guideline will be periodically updated to correspond to the state-of-the-art of Expert Panel, Best-Estimate Diagnosis, and LEAD methods. We encourage readers to provide recommendations for improvements by emailing the corresponding author. Future modifications will be published on the website and aim to reflect feedback and new evidence, ultimately aiming to improve the reporting quality of the assessment methods.
Conclusions
4.3.
The LEADING guideline emphasizes the transparent reporting of the methodological components of Expert Panel, Best-Estimate Diagnosis, and LEAD designs and the importance of reporting what was assessed and how well. Considering the increasing need for high-accuracy assessments in diverse fields, we hope that the LEADING guideline will be useful in assisting researchers in planning, carrying out, reporting, and evaluating research that aims to achieve accurate assessments.
Supplementary Material
media-1.pdf
Appendix A. Supplementary data
The supplementary material includes 1) relevant and complementary reporting guidelines and systematic reviews, 2) elaboration on the steps for developing a health research reporting guideline (Table S1; Moher et al., 2010), 3) the search strategies for identifying articles using the assessments methods and for recruiting Delphi participants and test-users, 4) the closed-ended ratings for each reporting standard from the Delphi surveys (Tables S2 and S3), 5) the explanation and elaboration for the reporting standards, including inclusion rationales and empirical evidence (Table S4), and 6) the procedure for applying the reporting standards to studies published in 2022 and 2023. Supplementary data to this article can be found online at [https://doi.org/10.1016/j.comppsych.2025.152603].
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Hirschtritt ME, Insel TR. Digital technologies in psychiatry: present and future. Focus Am Psychiatr Publ 2018;16(3):251–8. Jul.31975919 10.1176/appi.focus.20180001 PMC 6493099 · doi ↗ · pubmed ↗
- 2Venkatasubramanian G, Keshavan MS. Biomarkers in psychiatry - a critique. Ann Neurosci 2016;23(1):3–5. Mar.27536015 10.1159/000443549 PMC 4934408 · doi ↗ · pubmed ↗
- 3Cronbach LJ, Meehl PE. Construct validity in psychological tests. Psychol Bull 1955;52(4):281–302. Jul.13245896 10.1037/h 0040957 · doi ↗ · pubmed ↗
- 4Lilienfeld Scott O, Katheryn Sauvigne, Jay Lynn Steven, Latzman Robert D, Robin Cautin, Waldman Irwin D. Fifty psychological and psychiatric terms to avoid: a list of inaccurate, misleading, misused, ambiguous, and logically confused words and phrases. Front Psychol 2015;6. Aug 1.10.3389/fpsyg.2015.01100 PMC 452260926284019 · doi ↗ · pubmed ↗
- 5Spitzer RL. Psychiatric diagnosis: are clinicians still necessary? Compr Psychiatry 1983;24(5):399–411. Sep.6354575 10.1016/0010-440x(83)90032-9 · doi ↗ · pubmed ↗
- 6Leckman JF, Sholomskas D, Thompson WD, Belanger A, Weissman MM. Best estimate of lifetime psychiatric diagnosis: a methodological study. Arch Gen Psychiatry 1982;39(8):879–83. Aug.7103676 10.1001/archpsyc.1982.04290080001001 · doi ↗ · pubmed ↗
- 7Bertens LCM, Broekhuizen BDL, Naaktgeboren CA, Rutten FH, Hoes AW, van Mourik Y, Use of expert panels to define the reference standard in diagnostic research: a systematic review of published methods and reporting. P Lo S Med 2013; 10(10). Oct 15. (e 1001531).10.1371/journal.pmed.1001531 PMC 379713924143138 · doi ↗ · pubmed ↗
- 8Hunsley J, Mash EJ. Evidence-based assessment. Annu Rev Clin Psychol 2007;3: 29–51.17716047 10.1146/annurev.clinpsy.3.022806.091419 · doi ↗ · pubmed ↗