Federated nnU-Net for privacy-preserving medical image segmentation
Grzegorz Skorupko, Fotios Avgoustidis, Carlos Martín-Isla, Lidia Garrucho, Dimitri A. Kessler, Esmeralda Ruiz Pujadas, Oliver Díaz, Maciej Bobowicz, Katarzyna Gwoździewicz, Xavier Bargalló, Paulius Jarus̆evic̆ius, Richard Osuala, Kaisar Kushibar, Karim Lekadir

TL;DR
This paper introduces FednnU-Net, a privacy-preserving framework for medical image segmentation using federated learning.
Contribution
The paper introduces two novel federated learning methodologies, FFE and AsymFedAvg, for decentralized training of the nnU-Net framework.
Findings
FednnU-Net achieves high and consistent performance for breast, cardiac, and fetal segmentation.
The framework is tested on a multi-modal collection of 6 datasets from 18 institutions.
The proposed methods enable decentralized training while preserving patient privacy.
Abstract
The nnU-Net framework has played a crucial role in medical image segmentation and has become the gold standard in multitudes of applications targeting different diseases, organs, and modalities. However, so far it has been used primarily in a centralized approach where the collected data is stored in the same location where nnU-Net is trained. This centralized approach has various limitations, such as potential leakage of sensitive patient information and violation of patient privacy. Federated learning has emerged as a key approach for training segmentation models in a decentralized manner, enabling collaborative development while prioritising patient privacy. In this paper, we propose FednnU-Net, a plug-and-play, federated learning extension of the nnU-Net framework. To this end, we contribute two federated methodologies to unlock decentralized training of nnU-Net, namely, Federated…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
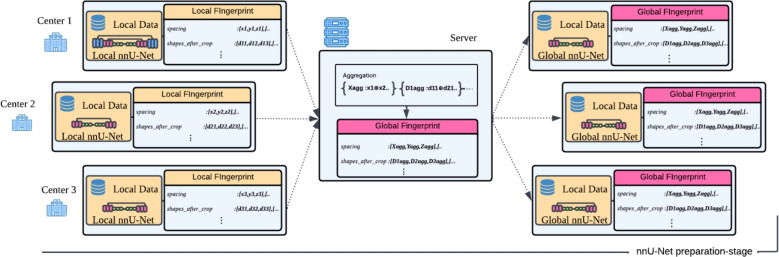 Figure 1
Figure 1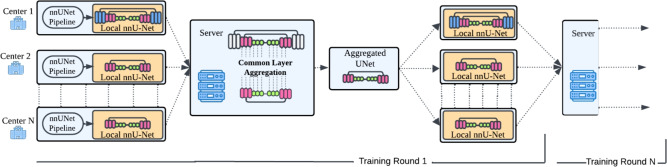 Figure 2
Figure 2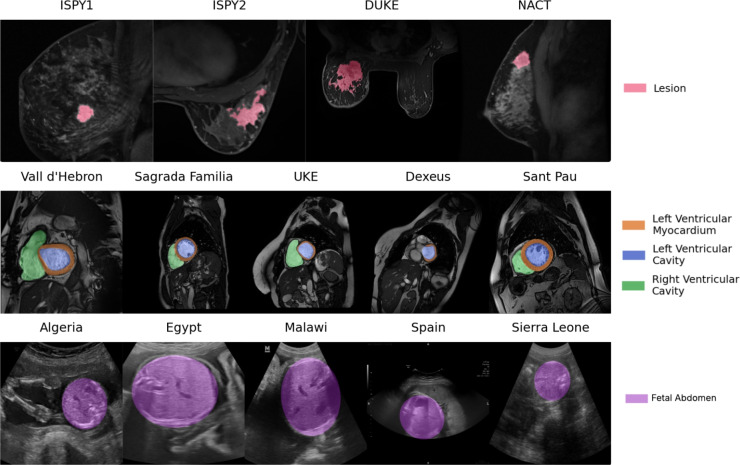 Figure 3
Figure 3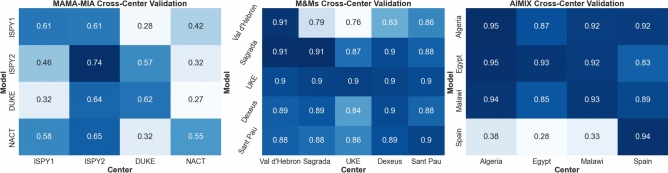 Figure 4
Figure 4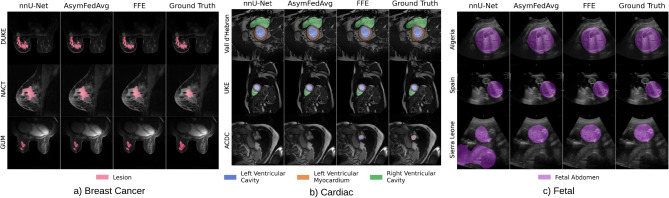 Figure 5
Figure 5 Figure 6
Figure 6| Method | ISPY1 | ISPY2 | DUKE | NACT | ||||
|---|---|---|---|---|---|---|---|---|
| Metrics | DSC | HD95 | DSC | HD95 | DSC | HD95 | DSC | HD95 |
| nnU-Net (local) | 0.612±0.058 | 17.60±3.07 | 0.739±0.012 | 19.03±2.66 | 0.616±0.030 | 33.56±5.22 | 0.551±0.059 | 23.24±7.27 |
| FednnU-Net AsymFedAvg | 0.636±0.054 | 16.81±2.44 | 0.744±0.010 | 18.78±1.67 | 0.642±0.029 |
| 0.606±0.093 | 21.76±4.81 |
| FednnU-Net AsymFedAvg EC | 0.634±0.058 | 16.69±2.16 | 0.739±0.010 | 18.15±1.85 | 0.621±0.024 | 28.70±5.03 | 0.620±0.071 | 21.79±3.05 |
| FednnU-Net FFE |
|
|
|
|
| 46.63±10.86 |
|
|
| FednnU-Net FFE EC | 0.644±0.063 | 16.20±1.68 | 0.742±0.012 | 17.48±0.52 | 0.653±0.031 | 39.54±6.21 | 0.660±0.078 | 17.49±3.87 |
| nnU-Net (centralized) | 0.654±0.062 | 17.28±2.09 | 0.750±0.011 | 19.84±2.93 | 0.657±0.026 | 58.99±11.42 | 0.675±0.077 | 17.35±3.43 |
| Method | Hospital Vall d’Hebron | Clinica Sagrada Familia | Universitätsklinikum Hamburg-Eppendorf | Hospital Dexeus | Hospital Sant Pau | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metrics | DSC | HD95 | DSC | HD95 | DSC | HD95 | DSC | HD95 | DSC | HD95 |
| nnU-Net (local) | 0.908±0.003 | 4.27±0.13 | 0.912±0.009 |
| 0.902±0.036 | 6.56±5.90 | 0.896±0.002 | 4.31±0.17 | 0.900±0.012 | 4.34±1.33 |
| FednnU-Net AsymFedAvg | 0.909±0.004 | 4.23±0.18 | 0.913±0.008 | 3.64±0.31 | 0.909±0.029 | 3.97±1.19 | 0.897±0.002 | 4.05±0.30 | 0.903±0.013 | 3.99±1.17 |
| FednnU-Net AsymFedAvg EC | 0.909±0.003 | 4.20±0.15 | 0.913±0.007 | 3.70±0.30 | 0.907±0.028 | 4.23±1.49 | 0.897±0.002 | 4.29±0.34 | 0.902±0.011 | 4.07±1.24 |
| FednnU-Net FFE |
|
| 0.913±0.009 | 3.69±0.31 |
|
|
| 4.02±0.30 |
|
|
| FednnU-Net FFE EC |
| 4.05±0.24 |
|
| 0.922±0.007 | 3.30±0.56 |
|
| 0.904±0.012 | 3.87±1.30 |
| nnU-Net (centralized) | 0.910±0.004 | 4.20±0.27 | 0.914±0.008 | 3.53±0.25 | 0.923±0.008 | 3.26±0.67 | 0.905±0.003 | 3.87±0.16 | 0.907±0.014 | 3.81±1.43 |
| Method | Algeria | Egypt | Malawi | Spain | ||||
|---|---|---|---|---|---|---|---|---|
| Metrics | DSC | HD95 | DSC | HD95 | DSC | HD95 | DSC | HD95 |
| nnU-Net (local) | 0.952 ± 0.006 | 11.87 ± 2.85 | 0.931 ± 0.037 | 24.21 ± 11.46 | 0.926 ± 0.014 | 26.83 ± 10.21 | 0.942 ± 0.008 | 29.82 ± 8.53 |
| FednnU-Net AsymFedAvg | 0.951 ± 0.006 | 11.39 ± 2.06 | 0.937 ± 0.024 | 18.89 ± 5.10 | 0.934 ± 0.006 | 20.43 ± 7.75 |
| 26.20 ± 7.58 |
| FednnU-Net AsymFedAvg EC | 0.951 ± 0.006 | 11.16 ± 1.78 | 0.941 ± 0.021 | 18.29 ± 4.54 | 0.939 ± 0.007 | 16.20 ± 3.64 |
|
|
| FednnU-Net FFE | 0.954 ± 0.007 | 10.29± 1.82 | 0.953 ± 0.010 | 14.69 ± 2.27 |
|
| 0.937± 0.012 | 43.94 ± 22.21 |
| FednnU-Net FFE EC |
|
|
|
| 0.943 ± 0.010 | 15.64 ± 4.55 | 0.938 ± 0.013 | 47.58 ± 25.67 |
| nnU-Net (centralized) | 0.954 ± 0.007 | 10.23 ± 1.86 | 0.953 ± 0.008 | 14.50 ± 2.90 | 0.943 ± 0.007 | 15.55 ± 3.16 | 0.932 ± 0.014 | 55.76 ± 26.88 |
| Method | Breast MRI | Cardiac MRI | Fetal ultrasound | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| GUMED | KAUNO | HCB | ACDC | Sierra Leone | ||||||
| Metrics | DSC | HD95 | DSC | HD95 | DSC | HD95 | DSC | HD95 | DSC | HD95 |
| nnU-Net (local) | 0.579 | 35.64 | 0.636 |
| 0.544 | 46.30 | 0.887 | 4.79 | 0.831 | 53.20 |
| FednnU-Net AsymFedAvg | 0.574 | 35.82 | 0.644 | 34.17 | 0.554 | 49.93 | 0.892 | 4.25 | 0.850 | 45.17 |
| FednnU-Net AsymFedAvg EC | 0.557 | 51.43 | 0.637 | 32.43 | 0.551 | 49.10 | 0.889 | 4.58 |
|
|
| FednnU-Net FFE |
|
|
| 31.89 |
|
|
|
| 0.808 | 46.23 |
| FednnU-Net FFE EC | 0.582 | 28.83 | 0.645 | 33.52 | 0.565 | 40.41 | 0.897 | 3.87 | 0.809 | 46.57 |
| nnU-Net (centralized) | 0.582 | 52.44 | 0.644 | 41.17 | 0.569 | 57.98 | 0.898 | 3.89 | 0.804 | 54.34 |
- —https://doi.org/10.13039/100018693HORIZON EUROPE Framework Programme
- —https://doi.org/10.13039/100019180HORIZON EUROPE European Research Council
- —https://doi.org/10.13039/100010661Horizon 2020 Framework Programme
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPrivacy-Preserving Technologies in Data · AI in cancer detection · Advanced Neural Network Applications
Introduction
Medical image segmentation plays a key role in clinical workflows to accurately delineate anatomical structures and help with diagnosis, treatment planning, and disease monitoring^1–5^. Deep learning methods, especially convolutional neural networks (CNNs) ^6,7^, have shown great success in this field. One of the most effective approaches is the no-new-U-Net framework (nnU-Net) ^8^ which, over the years, has established itself as the go-to framework for medical image segmentation task, evidenced by its multiple first-place finishes on public leaderboards and its widespread adoption as the foundation for further model development across diverse segmentation challenges ^9,10^.
nnU-Net extends the widely adopted U-Net architecture^11^, which utilizes an encoder-decoder structure with skip connections to capture both semantic and localization information. Going beyond the original U-Net, nnU-Net automatically configures network architectures tailored to a given dataset, provides a robust training schedule and data augmentation strategy, as well as postprocessing methods to further improve the final performance. This “no-new” (nn) principle largely eliminates the manual effort associated with hyperparameter tuning and architectural engineering, rendering nnU-Net both powerful and highly convenient across a broad range of biomedical tasks^8,12–14^.
Despite these advancements, the development of robust segmentation models often requires aggregating extensive datasets from multiple institutions to capture diverse patient populations and imaging protocols. However, the consolidation of such data is frequently impeded by stringent data privacy regulations, ethical considerations, and logistical challenges associated with data sharing. Federated learning (FL) ^15^ was introduced as a promising solution to these challenges by facilitating collaborative model training across multiple institutions without the need to exchange raw data.
Although nnU-Net has become a standard for medical image segmentation in centralized settings, its use in FL is challenging due to its dataset-specific customization which involves preprocessing, normalization, model choice, and training schedules based on the underlying data ^8^. The model architecture itself includes design decisions regarding the size and stride of convolutional kernels, as well as the number of network blocks. Such level of customization fundamentally conflicts with standard FL methods like FedAvg ^15^ that require uniform model architectures and training procedures across clients.
To solve these limitations, we introduce FednnU-Net–the first fully federated privacy-preserving implementation of nnU-Net. FednnU-Net is specifically designed to maintain the automated and out-of-the-box nature of nnU-Net while overcoming the challenges associated with decentralized, heterogeneous data.
To this end, we propose two methods—Federated Fingerprint Extraction (FFE) and Asymmetric Federated Averaging (AsymFedAvg) to unlock distributed training of nnU-Net. These methods address the challenges posed by variations in dataset properties across different centers, ensuring that each institution maximizes the benefit from shared knowledge training. Our experiments demonstrate that both methods consistently outperform local, non-collaborative training setups for 2D and 3D segmentation tasks across six public and non-public datasets.
By extending nnU-Net’s automated pipeline to FL and introducing methods to handle data heterogeneity, this work advances the development of robust, scalable, and privacy-preserving medical image segmentation solutions. Furthermore, its modular design also unlocks access to bringing a wide range of nnU-Net extensions to the federated settings, including improved training efficiency through e.g. curriculum learning ^16^, enhanced model explainability ^17^, continual learning ^18^, or uncertainty estimation ^19–21^.
Related work
Federated learning in medical imaging
FL has been widely adopted in medical imaging for tasks such as disease classification, lesion detection, and organ segmentation across multiple institutions ^22–24^. A range of federated segmentation methods have been introduced to tackle key challenges such as data heterogeneity, communication inefficiency, and limited generalization across sites. Notable examples include FedEvi ^25^, which employs evidence-based aggregation to account for uncertainty in model updates; FedGS ^26^, which utilizes gradient statistics to enhance robustness; and Fed-MENU ^27^, which integrates model ensembling with uncertainty-aware learning to improve stability. Transformer-based ^28^ methods leverage self-attention mechanisms and have shown high performance in distributed training for positron emission tomography (PET) and computed tomography (CT) segmentation ^29^. However, standard Transformers are data and memory intensive, which can limit their use in low-resource environments. While their lightweight variants ^30,31^, reduce memory usage at a small performance cost, they are still relatively recent and not yet extensively tested on modest in size medical datasets. Additionally, recent approaches like FedFMS ^32^ incorporate foundation models like SAM ^33^ and MedSAM ^34^ into FL through fine-tuning, aiming to harness large-scale pretrained representations for downstream segmentation tasks in a privacy-preserving context.
Despite the overall progress, these methods present limitations in terms of practical applicability. Many rely on highly customized architectures, complex aggregation strategies, or specialized pretraining, which can pose significant barriers for researchers without profound expertise in machine learning. In contrast to the nnU-Net framework, Transformer- and foundation model-based approaches often offer less flexibility for adaptation to varied training conditions, making them harder to deploy in typical clinical environments.
These constraints limit their out-of-the-box usability and, as a result, chances of clinical application. There remains a strong need for universal FL methods that are robust across datasets, computationally efficient, and readily applicable by a broad range of users—including those with limited resources or domain-specific requirements.
Heterogeneous model aggregation
Conventional FL assumes identical models and similarly distributed data across clients. However, real-world deployments often involve heterogeneous datasets and varying compute capacities. To address this, HeteroFL ^35^ allows training subnetworks of different widths from a shared supernetwork. While effective for standard CNNs, it is incompatible with nnU-Net, which adapts model depth, resolution, and preprocessing to dataset-specific features. FjORD ^36^ introduces Ordered Dropout for training nested submodels, enabling dynamic scaling. Yet, it relies on a fixed architecture, limiting its applicability to nnU-Net’s dataset-driven design. FedRolex ^37^ improves fairness by cyclically training submodels from a global network. However, it still assumes all client models are subsets of a shared template—an assumption that nnU-Net’s self-configuring framework violates. Since none of the existing methods accommodates the flexible and adaptive nature of nnU-Net, we develop a new federated approach tailored specifically to nnU-Net’s architecture and requirements.
Methods
We propose two tailored methods to federate nnU-Net’s pipeline for image segmentation, namely, FFE and AsymFedAvg. These two approaches are tailored towards addressing the challenges of decentralized, heterogeneous data in model training while simultaneously allowing to maintain nnU-Net’s self-configuring advantages.
nnU-Net vs FednnU-Net
nnU-Net is a multi-stage segmentation pipeline initiated by a preparation stage, where dataset fingerprint extraction is performed and a customized training plan is generated, which includes a tailored segmentation network architecture. This is followed by a training stage before concluding with a post-training stage that selects the best-performing models alongside optimal image post-processing techniques. To extend nnU-Net into a FL framework, we integrate our proposed methods in the respectively corresponding components of this pipeline. The first method, FFE, is incorporated into the preparation stage, ensuring that data characteristics from all participating institutions are captured and considered when generating the training plan. The second method, AsymFedAvg, operates during the training stage and facilitates the aggregation of model weight updates across nodes with heterogeneous network architectures. With the following sections providing detailed descriptions of each method, we use the terms “node” and “client” interchangeably to refer to each institution participating in the decentralized training process. We further denote the term “server” as the coordinating agent responsible for communication and aggregation of inputs from the nodes.
Federated fingerprint extraction
The proposed FFE method enables the analysis of the federated datasets and the configuration of nnU-Net, allowing to determine a unified, one-fits-all training strategy for all data centers in the federated setup. This approach effectively approximates the configuration behavior in a centralized environment. The dataset’s fingerprint is a crucial component of the nnU-Net’s adaptive configuration, summarizing the key dataset characteristics that are used to determine the model configuration and preprocessing strategies. The FFE approach comprises two key steps:
- Local fingerprint extraction: Each participating node generates their dataset fingerprint by invoking the extraction process of nnU-Net. This local fingerprint encloses the local dataset’s spatial characteristics such as spacing and voxel size.
- Global fingerprint aggregation: The nodes share their local fingerprint with the server, where these get aggregated to form a global federated fingerprint z. Specifically, new lists of shapes_after_crop and spacings are created by the concatenation of their local representations. Fig. 1. The Federated Fingerprint Extraction (FFE) process. Each node computes a local fingerprint from its dataset and shares it with the server, which then aggregates them into a global fingerprint. Finally, the server redistributes this global fingerprint to all nodes for local nnU-Net configuration. This process happens once at the beginning of the training stage.
Figure 1 showcases an overview of the FFE process pipeline. As a final step, each node calculates its own nnU-Net training plan based on the combination of the received global fingerprint and the local hardware characteristics. This process ensures that all nodes will be optimizing either highly compatible or, in the case of nodes with sufficiently similar local memory and hardware constraints, identical network architectures.
Asymmetric federated averaging
In scenarios where nnU-Net is deployed across federated nodes, variations in model architecture can arise due to differences in data characteristics or computational capabilities. In classical FedAvg, all nodes are required to use an identical model architecture, since aggregation is performed by averaging parameters across all clients. Even a small architectural discrepancy, such as a different number of network blocks, convolution kernel sizes, or channel counts, will cause parameter tensors to become incompatible, making direct aggregation mathematically impossible. To address this inherent heterogeneity, we extend the classical FedAvg approach by developing a novel Asymmetric Federated Averaging strategy (AsymFedAvg). In contrast to other heterogeneous aggregation methods mentioned in Heterogeneous model aggregation, our method allows the aggregation of models with different lengths and layer configurations. AsymFedAvg enables nodes to share only the parts of the model that are common across the rest of the federation, effectively eliminating the need to constrain all nodes to a single, identical architecture.
At each participating node, we initialize nnU-Net’s adaptive configuration pipeline to generate node-specific U-Net architectures based on the aforementioned locally extracted dataset fingerprints of the centers. For illustration, a set of example configurations obtained from each data center is presented in Table 1.
To ensure semantic consistency of layer identifiers across participating nodes, AsymFedAvg aggregates only layers with identical name identifiers and matching parameter shapes. nnU-Net’s self-configuring pipeline uses a fixed internal naming schema (e.g., encoder.stages.0.0.convs.0.all_modules.1.weight), ensuring that running the same nnU-Net framework version across sites guarantees naming alignment. This rule forms the basis of the layer compatibility function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {C}$$\end{document} defined below(Eq. 2).Fig. 2. Overview of the asymmetric federated averaging (AsymFedAvg) training pipeline. The nodes of the federated setup generate a local nnU-Net from the nnU-Net pipeline. During training, the server receives the local nnU-Net weights of each node and aggregates them utilizing the Aggregation Function of AsymFedAvg. At the end of each training round, the server distributes the aggregated layers of the network back into the nodes. This process is respectively repeated throughout the entire model training process.
Table 1. Default nnU-Net training configurations for each center in MAMA-MIA dataset.ParameterISPY1ISPY2DUKENACT2D configurationBatch size49321249Patch size[256,256][320,320][512,512][256,256]Spacing[0.78,0.78][0.68,0.68][0.70,0.70][0.70,0.70]U-Net stages7787Features/stage[32–512][32–512][32–512][32–512]
Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {K} = {1,\dots , K}$$\end{document} be the set of participating nodes in the federation. For each node \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k \in \mathcal {K}$$\end{document} we define a local model state dictionary as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} S^k = {(l_i^k, \theta _i^k) | i \in \mathcal {L}^k}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$l_i^k$$\end{document} represents the layer identifier, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta _i^k$$\end{document} denotes the corresponding parameters for node k, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}^k$$\end{document} is the set of layers in node k’s model.
We define a layer matching function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {C}$$\end{document} which identifies the common layers of the models participating in the federation as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {C}({S^k}_{k=1}^K) = {l | \forall k,j \in \mathcal {K}: l \in \mathcal {L}^k \cap \mathcal {L}^j \wedge \text {dim}(\theta _l^k) = \text {dim} (\theta _l^j)}. \end{aligned}$$\end{document}For each compatible layer \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$l \in \mathcal {C}({S^k}_{k=1}^K)$$\end{document} , the aggregated parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\theta }_l$$\end{document} are computed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \hat{\theta }_l = \frac{1}{|\mathcal {K}l|} \sum {k \in \mathcal {K}_l} \theta _l^k , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {K}_l$$\end{document} is the set of nodes that contain layers l.
The aggregated model state dictionary \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{S}$$\end{document} is then constructed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \hat{S} = {(l, \hat{\theta }l) | l \in \mathcal {C}({S^k}{k=1}^K)}. \end{aligned}$$\end{document}During each federation round t, the update process goes as presented in Algorithm 1. Algorithm 1Asymmetric model aggregation.
The AsymFedAvg allows nodes to maintain their unique architectural components while sharing knowledge via their common space of compatible layers, handling the diverse nature of medical imaging data across different centers. Figure 2 depicts an overview of the AsymFedAvg pipeline and illustrates the process of updating the heterogeneous architectures in each training round.
Implementation
Federated learning environment
For the federated communication, we select the Flower framework ^38^, which is an open-source library designed to streamline FL tasks on a cluster of machines. Flower’s high-level application programming interface (API) eliminates the need for delving into complex and time-consuming processes such as network communication between nodes and model aggregation, as it supports multiple FL optimization algorithms such as Federated Averaging (FedAvg), FedProx^39^ and Federated SGD (FedSGD)^15^. Additionally, Flower’s client-server architecture is well-suited for our multi-center setup, facilitating seamless integration of local models while maintaining centralized coordination on the server.
FednnU-Net framework
Our framework maintains full functionality of the original nnU-Net while offering a federated extension that allows experimentation in both real-world and simulated environments. Focusing on usability, its modular structure enables seamless integration not only with the original nnU-Net but also with respective customized versions, allowing researchers to adapt their traditional centralized training methods to a federated setup. Key features include:
- Custom architecture selection: users can select from nnUNet’s built-in architecture presets, including configurations optimized for high performance (e.g., residual encoder variants), even if they require more memory or compute.
- Per-client resource configuration: GPU memory constraints can be individually defined for each client, enabling heterogeneous resource allocation scenarios such as in AsymFedAvg.
- Training hyperparameter control: users can configure learning rate schedules, loss functions, optimizer settings, and number of training epochs through the native nnUNetTrainer class.
- Support for pretrained weights: initialization from pretrained weights is supported, allowing faster convergence or domain adaptation across clients.
- Simulated and real-world federation: the same codebase supports both simulated federated setups (single machine, multi-client emulation) and deployment across physically distributed clients. This design ensures both high flexibility for research experimentation and practicality for real-world deployment across diverse clinical environments.
Distributed setup
Our experimental framework consists of 4 computational nodes with varying hardware and system specifications (Table 2), resembling real-world clinical scenarios in low-resource countries. In particular, the availability of GPU device with 8GB of memory, is the requirement for each node in order to run the default nnU-Net training setup. The proposed framework was deployed and tested independently across all nodes, although the final model training is done on a single, multi-GPU cluster to simplify experimental control.Table 2. Hardware specifications of the computational nodes.NodeCPU (cores/GHz)GPU (memory)OSNode 1Intel i7-8700K (12/3.20)NVIDIA GTX 1080 (8GB)Ubuntu 22.04Node 2Intel i7-8700K (12/3.20)NVIDIA GTX 1080 (8GB)Windows 10Node 3Intel i7-9700K (8/3.60)NVIDIA RTX 2080S (8GB)Ubuntu 22.04Node 4Intel i7-9700 (8/3.00)NVIDIA RTX 2080S (8GB)Ubuntu 22.04 CPU central processing unit, GPU graphics processing unit, OS operating system.
Datasets
We evaluate our proposed methods on three distinct clinical applications (i.e., breast, cardiac, fetal), using datasets that serve as valuable testbeds due to their multi-institutional and heterogeneous cohorts; representative samples from each modality are shown in Fig. 3. The following sections provide a detailed description of the datasets employed in each use case.
Fig. 3. Example images with annotations from each data center used in this work. From the top: breast MRI, cardiac MRI, fetal US.
Breast MRI
MAMA-MIA
The MAMA-MIA dataset ^40^ is the largest publicly available collection of breast dynamic contrast-enhanced MRI (DCE-MRI) cases with expert primary tumor segmentations, providing an essential resource for advancing and benchmarking artificial intelligence (AI) algorithms in breast cancer imaging. It comprises 1,506 cases acquired between 1995 and 2016 from four cohorts within The Cancer Imaging Archive (TCIA): ISPY-1 (n=171), ISPY-2 (n=980), Duke (n=291), and NACT (n=64). The annotation process focused on delineating primary tumors and non-mass-enhanced lesions within a single breast, using the first post-contrast phase as the reference—a phase typically associated with maximum enhancement of cancerous tissues that offers superior contrast between lesions and surrounding healthy tissue compared to later phases. However, significant imaging differences among these cohorts (Table 3) pose challenges for training robust models. For example, the NACT cohort predominantly features scans with a 2 mm slice thickness and an average of 60 slices per case, whereas Duke’s samples are mostly acquired with 1 mm thickness and include an average of 169 slices per case. Moreover, the centers used different scanner models and field strengths, further contributing to the variability in imaging protocols.Table 3. Summary of MRI acquisition parameters across the four centers (ISPY1, ISPY2, DUKE, and NACT) in the MAMA-MIA breast cancer dataset^40^.CenterVendorScanner modelSlice thickness (mm)Number of slicesField strength (T)Number of studiesISPY1GE (67.3%)Siemens (25.7%)Philips (7.0%)Signa Genesis (60.2%)Other (39.8%)2.4 [1.5, 4.0]64 [44, 256]1.5 (100.0%)3.0 (0.0%)171ISPY2GE (62.3%)Siemens (25.7%)Philips (11.9%)Signa HDxt (54.7%)Avanto (12.6%)Other (32.7%)2.0 [0.8, 3.0]106 [52, 256]1.5 (73.0%)3.0 (27.0%)980DUKEGE (60.5%)Siemens (39.5%)Other (55.7%)Avanto (24.1%)Signa HDxt (20.3%)1.1 [1.0, 2.5]169 [60, 256]1.5 (46.7%)3.0 (53.3%)291NACTGE (100%)Signa Genesis (100%)2.0 [2.0, 2.4]60 [46, 64]1.5 (100.0%)3.0 (0.0%)64
EuCanImage
Through the European project EuCanImage ^41^, we access a non-public breast MRI collection comprising 574 samples from three different countries. The EuCanImage dataset represents a multi-institutional effort to create standardized imaging biobanks for cancer research and serves here as an external test set to validate our methodology on data acquired under protocols that differ markedly from those in MAMA-MIA. Detailed specifications of the acquisition parameters are provided in Table 4. Notably, while MAMA-MIA includes both axial and sagittal acquisitions, the EuCanImage collection consists exclusively of axial slices. In addition, images in EuCanImage are predominantly acquired from scanner models that differ from those represented in MAMA-MIA, and a significantly larger fraction of the scans are captured at 3T field strength. Although the spatial image characteristics are largely similar between the two datasets, these differences in scanner models, field strengths, and imaging orientations lead to distinct scan appearances, potentially challenging the robustness of segmentation algorithms.Table 4. Summary of MRI acquisition parameters across the three centers (GUMED, KAUNO, and HCB) in the EuCanImage breast MRI dataset.CenterVendorScanner modelSlice thickness (mm)Pixel Spacing (mm)FieldStrength (T)Number ofStudiesGUMED (Poland)SiemensAera (100%)1.00–1.491.00–1.491.5 (100%)30KAUNO (Lithuania)Philips (88.4%)Siemens (11.6%)Ingenia (88.4%)Avanto (11.6%)1.50–1.99 (84.5%)0.50–0.99 (96.6%)1.5 (11.6%)3.0 (88.4%)232HCB (Spain)GE (69.2%)Siemens (30.8%)Signa HDxt (63.8%)Aera (22.8%)Others (13.4%)2.00–2.49 (87.2%)0.50–0.99 (98.1%)1.5 (90.7%)3.0 (9.3%)312
Cardiac MRI
M&Ms
To further validate our approach, we leverage the Multi-center, Multi-vendor & Multi-disease (M&Ms) cardiac MRI datasets. As a part of our study, we curate a merged version of datasets that were used in the M&Ms challenges^42,43^ by excluding the overlapping samples based on anonymized patient IDs provided by each institution. This curation allows to reach the full potential of this data collection without the risk of replicated samples. The final, accumulated set consists of 543 unique, short-axis cardiac MRI scans with expert annotations from 5 distinct international institutions. We make this collection publicly available.
The M&Ms datasets are particularly valuable for validation due to their inherent heterogeneity (Table 5), they include images from four different vendors (Siemens, GE, Philips, Canon), various scanner models (from older systems like Symphony to newer ones like Vantage Orian), and different field strengths (1.5T and 3.0T). This multi-center, multi-vendor nature mirrors the real-world variability in clinical settings, making these datasets ideal for testing the generalizability of our approach.
The technical heterogeneity across centers is evident in variations of scanner models, field strengths and different acquisition protocols. This diversity presents similar challenges to those encountered in our MAMA-MIA analysis, particularly in terms of standardization and harmonization of imaging parameters.Table 5. Average specifications of images acquired in different centers across the merged collection of M&Ms 1^42^ and M&Ms 2^43^ challenge datasets.CenterVendorScanner modelSlice thickness (mm)Number of slicesField strength (T)Number of studiesHospital Vall d’HebronSiemensSymphony TIM (63.18%)Avanto Fit (15.48%)Other (21.34%)9.5131.5 (97.91%)3.0 (2.09%)239Clinica SagradaFamiliaPhilipsAchieva10131.598UniversitätsklinikumHamburg-EppendorfPhilipsAchieva10111.551Hospital Universitari DexeusGESigna Excite (75.24%)Signa HDxt (23.81%)Signa Explorer (0.95%)9.9121.5 (88.57%)3.0 (11.43%)105Hospital Sant PauCanonVantage Orian10131.550
ACDC
The Automated Cardiac Diagnosis Challenge (ACDC) dataset consists of 150 cardiac short-axis MRI examinations acquired at the University Hospital of Dijon (France)^3^. The dataset is evenly distributed across five groups (30 cases each): normal subjects (NOR), patients with myocardial infarction (MINF), dilated cardiomyopathy (DCM), hypertrophic cardiomyopathy (HCM), and abnormal right ventricle (RV). This dataset is particularly valuable for validation due to its well-defined pathological diversity and standardized acquisition protocols. It is used for external validation of models trained on M&Ms dataset.
Fetal ultrasound
AIMIX
With a focus on resource-constrained environments, the AIMIX ^44^ dataset was developed to advance inclusive image analysis in prenatal care. This dataset addresses critical challenges, including the scarcity of African medical data, limited computational resources, and a lack of clinical expertise. The dataset comprises pregnancy blind-sweeps 2D ultrasound scans, along with associated patient metadata such as age and ethnicity. The data span multiple international sites, including Algeria, Egypt, Malawi and Spain, reflecting diverse geographic and healthcare settings.
In this study, we focus on abdominal segmentation, a crucial step in prenatal ultrasound analysis. To enable the evaluation on this multi-center dataset, we provide a set of 308 standard-plane images with masks corresponding to the fetal abdomen. Our data processing workflow involved detecting the optimal abdominal plane from each blind-sweep and segmenting it using a 4-point ellipse-fitting algorithm^45^, utilizing a semi-automatic software by a researcher with more than five years of experience and reviewed by an expert clinician. Table 6 lists the number of samples and the mean resolution for each center.Table 6. Summary of the AIMIX and ACOUSLIC-AI datasets, including number of samples, mean resolution, nnU-Net patch size, and U-Net stages for each dataset.CenterMean resolution (h x w)Number of studiesAlgeria418 x 50025Egypt450 x 40020Malawi400 x 50025Spain1228 x 127660Sierra Leone (external)561 x 743178
ACOUSLIC-AI Sierra Leone
For the external validation, we utilize the publicly available samples from ACOUSLIC-AI Challenge dataset ^46^. We use a collection of 178 cases collected in Sierra Leone from three Public Health Units (PHUs). With a resolution of 744 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 562 pixels, the images from Sierra Leone sit between the low-end devices used in Algeria and Malawi and the high-end scanners employed in Spain. This intermediate imaging quality makes the dataset an ideal candidate for assessing model generalizability across varying image qualities and clinical environments, ensuring robust validation of AI performance.
Experiments
Experimental setups
We adopt the vanilla nnU-Net architecture in both local and centralized training setups as the primary baselines for evaluating the performance of our proposed FednnU-Net framework. This choice is grounded in the fact that nnU-Net has established itself as a strong, standardized, and adaptive baseline for medical image segmentation tasks across a wide range of datasets ^14^. By using the same framework and memory constraints in local (per-institution) and centralized (pooled data) settings, we ensure a fair and controlled comparison that isolates the effect of the federation process itself, without introducing variability due to methodological, architectural or computational resource differences.
This experimental setup allows for a clear evaluation of how well the federated setting bridges the gap between privacy preservation and segmentation accuracy, thus aligning with the core motivation of our study. To this end, the training process is conducted and empirically evaluated across four different setups:
- Local training: Each node independently trains its own nnU-Net model using only its local dataset. This setup serves as a baseline, reflecting the performance of a node/institution without participation in the federation.
- Centralized training: All data is aggregated into a single dataset, which is used to train a centralized nnU-Net model. This setup represents the theoretical upper bound of performance, though it is typically infeasible and often not recommended in real-world scenarios due to significant privacy risks and data-sharing constraints.
- Federated fingerprint training: Utilizing our FFE approach (see “Methods”), the local dataset fingerprints from all nodes are aggregated at the central node into one federated fingerprint and distributed back to each node. As a result, each training site obtains an identical network architecture during the nnU-Net’s self-configuration process and enables the utilization of a standard FedAvg aggregation method. Moreover, this approach approximates nnU-Net’s behavior in the centralized training setup.
- Asymmetric aggregation training: Implemented using our AsymFedAvg strategy, this allows nodes to maintain their original nnU-Net configured architectures while sharing compatible parts of their networks. In addition to the standard aggregation that uses dataset-size proportional weights, we also conduct federated training with Equal Center (EC) weights, where each client contributes equally to the global model regardless of dataset size. This allows us to investigate the effect of uniform averaging across clients and its influence on model performance.
For our experimentation, we maintain nnU-Net’s default configuration parameters as described in^8^. We test the 2D U-Net architecture on breast MRI and fetal ultrasound data and the 3D architecture on a cardiac MRI use case, consistently employing the default training length of 1000 epochs. Following the original nnU-Net’s established protocol, we use the final checkpoint for all evaluations across federated nodes, which represents its the default behavior. In federated scenarios, all models are aggregated after each epoch and sent back to the clients.
Following other recent works on medical image segmentation^8,47,48^, we evaluate the models with Dice Similarity Coefficient (DSC) and 95% Hausdorff distance (HD95). For internal validation, we report results as the average of a 5-fold cross-validation, with standard deviation values calculated across the folds to reflect the stability of training under different data splits. For external testing, we follow the original nnU-Net approach by generating ensemble predictions from all five folds. Since this produces a single prediction per case that combines all trained models, standard deviation values are not applicable in the external validation setting. Moreover, each experiment uses identical data splits—for example, the n-th fold in the centralized setup corresponds directly to the set of n-th folds from centers used in the local setup. To assess statistical significance between segmentation methods, we apply the two-tailed Wilcoxon signed-rank test on paired DSC scores with 5% significance threshold. By adhering to these protocols, we try to minimize the influence of other factors on the final results, ensuring that any observed performance variations are primarily due to our federated learning adaptations rather than modifications to the base framework (Table 8).
Results
Breast MRI
Table 7 summarizes segmentation performance on the MAMA-MIA dataset. Both FFE and AsymFedAvg outperform local training across all centers in DSC and HD95. FFE achieves average DSC improvements over local models on ISPY1 (8.2%, p<0.001), ISPY2 (1.3%, p=0.002), DUKE (7.6%, p<0.001), and NACT (23.4%, p<0.001), also closely matching centralized results in DSC and surpassing them in HD95. Notably, AsymFedAvg yields the best HD95 on DUKE, reflecting its advantage in handling heterogeneous data (DUKE’s pixel size is 2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} smaller; see Table 3). Fig. 4 highlights this heterogeneity, with ISPY2 models generalizing better to DUKE due to similar resolutions. Sample predictions (Fig. 5) show marked improvements for NACT and DUKE using federated methods. External validation on EuCanImage confirms FFE’s generalization, achieving DSC comparable to centralized training (Table 10). KAUNO center results are consistent with MAMA-MIA, while GUMED’s drop likely reflects annotation discrepancies which are illustrated in Fig. 5. Experiments with EC training did not prove more effective than standard dataset-size-based averaging, most likely because of the relatively minor differences between centers and the limited contribution of smaller datasets such as NACT, which did not provide substantial additional information to improve model robustness.
Cardiac MRI
For M&Ms, federated methods outperform local models on both metrics, except for Clinica Sagrada Familia, where HD95 is slightly better locally. FFE consistently achieves the best DSC scores across internal and external datasets (combined significance using Fischer’s method: p<0.001), while AsymFedAvg shows limited benefit—likely due to the dataset’s homogeneity, where unified architectures are more suitable. Cross-center results (Fig. 4) support this, with models generalizing well across unseen centers. Importantly, FFE matches centralized performance despite additional privacy constraints. Sample predictions (Fig. 5) show consistent results for central slices, with more variability at the apex (ACDC) and atria (Vall d’Hebron). EC training did not provide a substantial change in results, despite the heterogeneous nature of the M&Ms dataset. Both aggregation methods proved to be equally performing in both AsymFedAvg and FFE scenario.
Fetal ultrasound
In the fetal abdomen segmentation task, FFE and AsymFedAvg differ markedly (Table 9). Strong heterogeneity (capture devices, resolution; Table 6) impairs generalization from Algeria, Egypt, and Malawi to higher-resolution Spanish samples (Fig. 4). Unified architectures (FFE) are less optimal here: allowing Spain to retain its native architecture (AsymFedAvg) improves performance for external centers like Sierra Leone (Table 10), notably the DSC raised to 0.851 (p<0.001). Fig. 5 shows that local models often misidentify abdomen regions, especially for Sierra Leone, whereas federated approaches improve delineation. Interestingly, experiments with EC training improved results across all African datasets (Algeria, Egypt, Malawi, Sierra Leone), which were considerably smaller and different in terms of acquisition characteristics. The comparatively large-scale dataset from Spain noted a slight decrease of performance in this scenario, likely due to reduced influence on the training process.Fig. 4. Cross-center DSC scores for isolated model training predictions across multiple centers.Fig. 5. Sample predictions of each method for datasets used in the study.
Discussion
Key contributions and performance
This study introduces FednnU-Net, a federated learning framework for 2D and 3D medical image segmentation that combines privacy preservation with high performance through two key innovations: Federated Fingerprint Extraction for standardized architecture sharing, and AsymFedAvg for flexible aggregation across heterogeneous node-specific models. Our experiments across three diverse medical imaging clinical tasks in (i) breast MRI (MAMA-MIA), (ii) cardiac MRI (M&Ms) , and (iii) fetal ultrasound (AIMIX) - show that FednnU-Net reliably matches or surpasses the performance of centralized strategies across settings and modalities. These results add to a growing body of evidence illustrating that distributed model optimization can achieve comparable accuracy while simultaneously fulfilling the requirements of complex real-world clinical collaborations, including those related to data privacy and deviations in institution-specific protocols.
Towards trustworthy AI in healthcare
Moreover, our findings underscore the critical need for, and the potential of, methods that effectively handle data heterogeneity during federated model training. To this end, our framework supports site-specific model adaptation and evaluation in line with the FUTURE-AI guidelines for trustworthy AI in healthcare^49^, particularly the 4 Universality Recommendation, which calls for assessing local clinical validity amid variations in populations, equipment, workflows, and end users. FednnU-Net addresses this by enabling center-specific model customization, allowing institutions to tailor models to their local data characteristics. This approach ensures alignment with local workflows while maintaining strong performance across diverse populations, thereby promoting trust and robustness in decentralized clinical environments.
While some federated segmentation methods report high accuracy by tailoring solutions to narrow, task-specific settings, this work focuses on delivering an accessible, privacy-preserving framework that emphasizes ease of use and adaptability. By prioritizing broad applicability and real-world viability, the framework is positioned to support diverse research settings and facilitate widespread adoption.
Indeed, the ongoing shift towards privacy-preserving, decentralized deep learning solutions in healthcare is critical for protecting patient confidentiality^24^. In addition to this, the FUTURE-AI General 2 guideline states the necessity of implementing rigorous data protection throughout the AI lifecycle, including the use of privacy-enhancing technologies and secure data governance. In the context of FL with FednnU-Net, data protection is operationalized by ensuring that patient data never leaves its local institutions of provenance, reducing the risk of sensitive information leakage during collaborative model training. To this end, FednnU-Net addresses critical privacy and security concerns inherent in decentralized healthcare AI solutions, fostering trust among stakeholders and ensuring compliance with ethical and regulatory standards. While FednnU-Net addresses critical requirements for privacy and local adaptation in line with FUTURE-AI guidelines, several important aspects still warrant further investigation:
- Scalability and client diversity: future work is to assess FednnU-Net across an even larger, geographically dispersed federation with diverse patient populations^49^ to study convergence dynamics at international, multi-institutional scales.
- Heterogeneous computational resources: while our framework already supports diverse node capabilities, further systematic ablation studies under varied hardware conditions, including low-resource settings^50^, are motivated towards showing the versatility for clinical adoption of the framework.
- Enhanced privacy mechanisms: FL improves data privacy by design, but it still does not guarantee full security. Attacks such as model inversion ^51^ or membership inference ^52^ can still extract sensitive information from shared model updates. Integrating differential privacy ^53–56^, synthetic data generation^57–59^, and secure multiparty computation^60^ could further reduce the risk of data leakage, even in aggregated updates.
Conclusion
FednnU-Net fills a critical gap by balancing segmentation performance, ease of use, and privacy preservation. As FL gains adoption in healthcare^24^, our FednnU-Net framework is a key component in enabling the translation of high-performance deep learning into privacy-compliant, scalable clinical solutions. Our framework enables researchers and practitioners to easily integrate nnU-Net, along with other dedicated frameworks and innovations built upon it, such as for instance Bayesian uncertainty estimation^21^, continual learning^18^, and curriculum learning extensions^16^, into FL setups, thereby broadening their applicability under privacy constraints and supporting the increasingly prevalent multi-center collaborations. Continued evaluation, targeted enhancements, and the combination with such innovations is to further strengthen the versatility and robustness of the framework, paving the way for widespread, trustworthy deployment across diverse clinical environments.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Reza, A. et al. Medical image segmentation review: The success of u-net. In IEEE Transactions on Pattern Analysis and Machine Intelligence (2024).
- 2Yang, X. et al. A medical image segmentation method based on multi-dimensional statistical features. Front. Neurosci.16. 10.3389/fnins.2022.1009581 (2022).
- 3Ma, J. Cutting-edge 3d medical image segmentation methods in 2020: Are happy families all alike? (2021). ar Xiv:2101.00232.
- 4Isensee, F. et al. nn U-Net revisited: A call for rigorous validation in 3D medical image segmentation . In Proceedings of Medical Image Computing and Computer Assisted Intervention – MICCAI 2024. Vol. LNCS 15009 (Springer, 2024).
- 5Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III. Vol. 18. 234–241 (2015).
- 6Liang, B. et al. Automatic segmentation of 15 critical anatomical labels and measurements of cardiac axis and cardiothoracic ratio in fetal four chambers using nnu-netv 2. BMC Med. Inform. Decis. Mak.24. 10.1186/s 12911-024-02527-x (2024).
- 7Huang, L., Miron, A., Hone, K. & Li, Y. Segmenting Medical Images: From U Net to Res-U Net and nn U Net . In 2024 IEEE 37th International Symposium on Computer-Based Medical Systems (CBMS). 483–489. 10.1109/CBMS 61543.2024.00086 (IEEE Computer Society, 2024).
- 8Mc Mahan, H. B., Moore, E., Ramage, D., Hampson, S. & y Arcas, B. A. Communication-efficient learning of deep networks from decentralized data. In International Conference on Artificial Intelligence and Statistics (2016).