A hierarchical dataset on multiple energy consumption and PV generation with emissions and weather information
Hanjiang Dong, Jizhong Zhu, Chi-yung Chung, Zipeng Liang, Haosen Yang, Xiyu Wen

TL;DR
This paper introduces a comprehensive dataset combining energy consumption, solar power generation, emissions, and weather data for 147 buildings and communities.
Contribution
The novel contribution is a hierarchical, multi-source dataset with detailed energy, emissions, and weather data for benchmarking and analysis.
Findings
The dataset includes 11,987,328 records spanning 2014-2022 with 13 hourly variables.
A two-stage data cleaning process ensures data quality and provides artificial ground truth for benchmarking.
The dataset is publicly available for tasks like forecasting and optimization.
Abstract
This study constructs a multi-source and hierarchical dataset of energy consumption, photovoltaic (PV) power generation, greenhouse gas (GHG) emissions, and weather information, dubbed Hierarchical Energy, Emissions, and Weather (HEEW). This dataset contains 11,987,328 records for 147 individual buildings, four aggregated communities, and the entire region, which is structured as time-series tables indexed by building ID and timestamps from 1 January 2014 to 31 December 2022. It includes 13 hourly variables as follows. Energy records involve PV output and total energy consumption of electricity, heat, and cooling loads. Weather involves temperature, dew point, humidity, wind speed, wind gust, pressure, and precipitation. GHG emissions are estimated as the net values between the emissions from energy consumption and the offset by PV output. To ensure the feasibility, we develop a…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
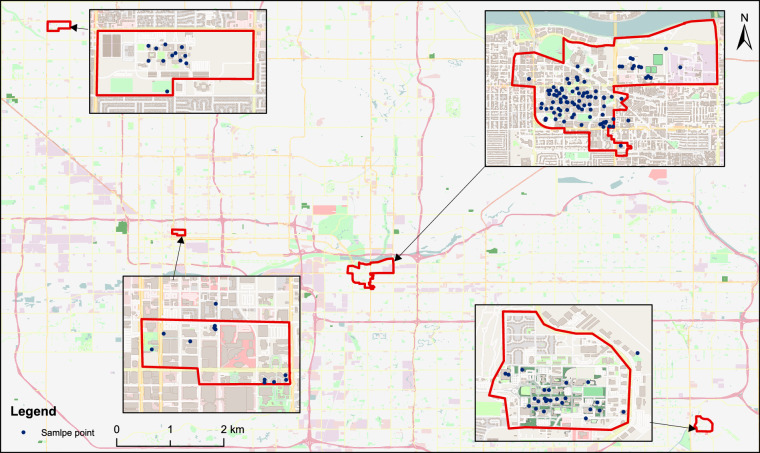 Figure 1
Figure 1 Figure 2
Figure 2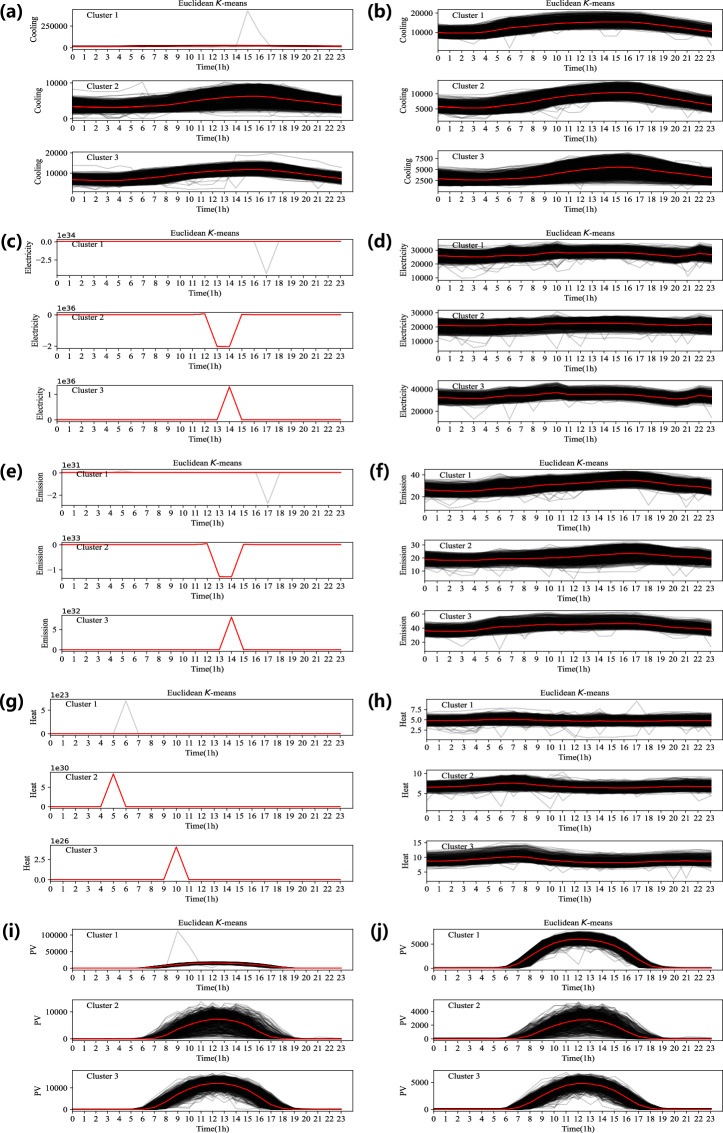 Figure 3
Figure 3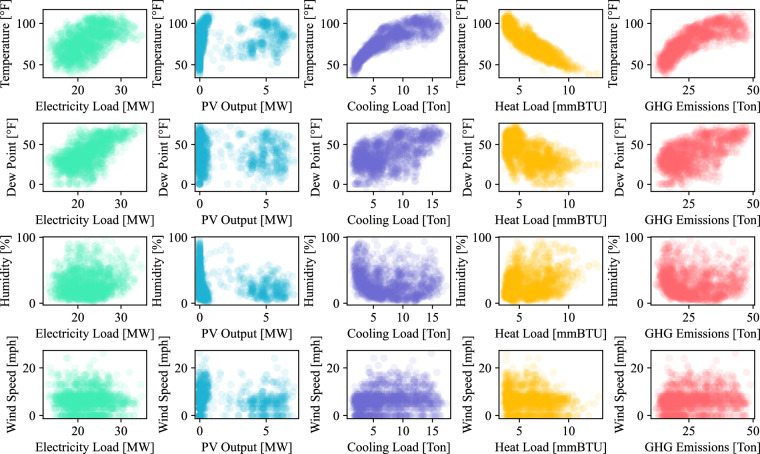 Figure 4
Figure 4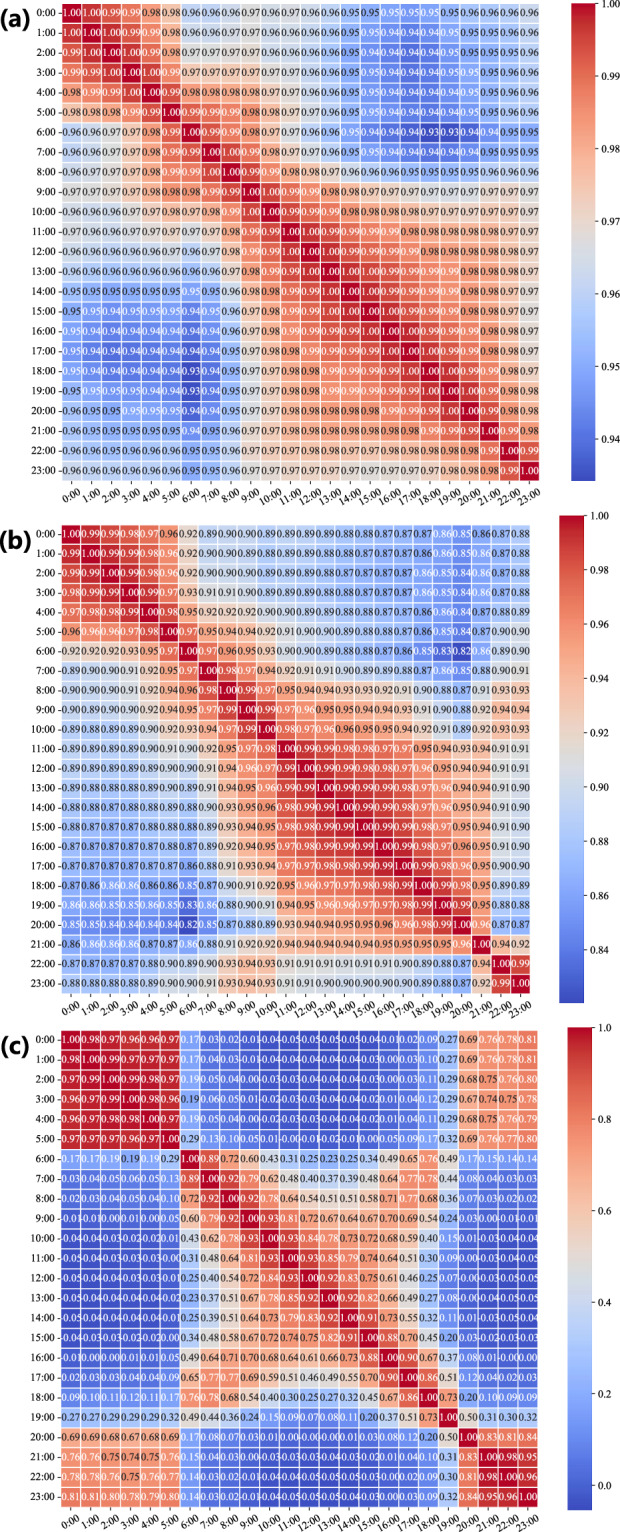 Figure 5
Figure 5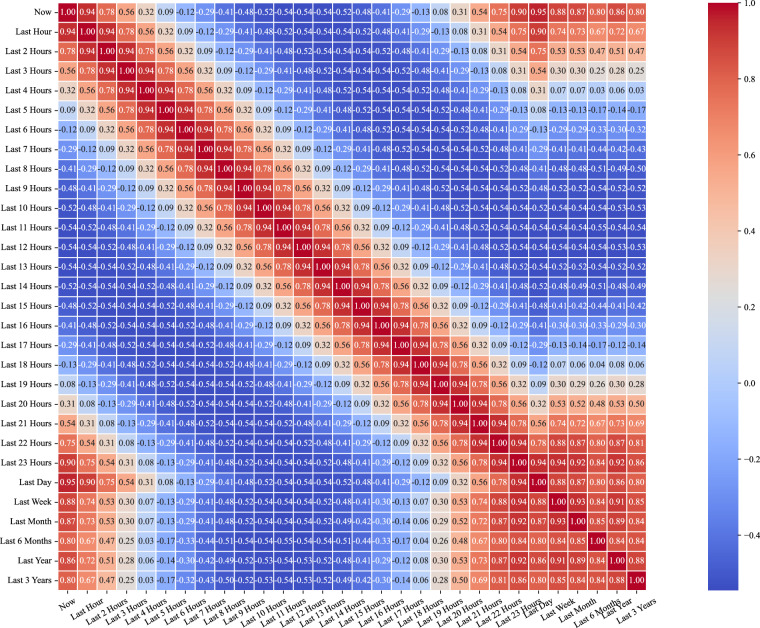 Figure 6
Figure 6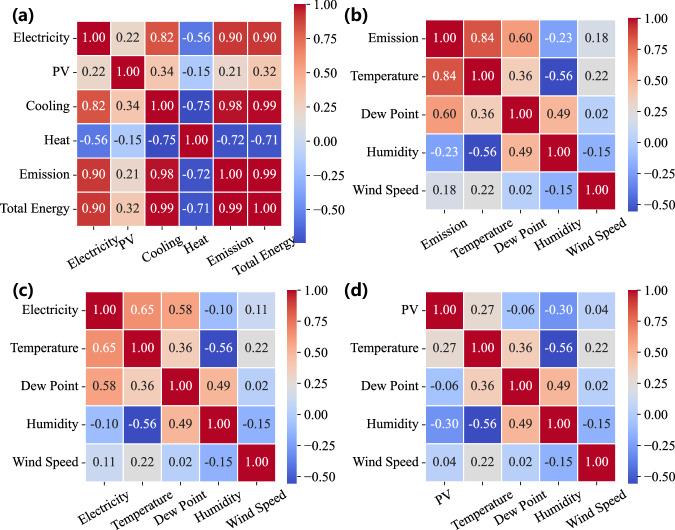 Figure 7
Figure 7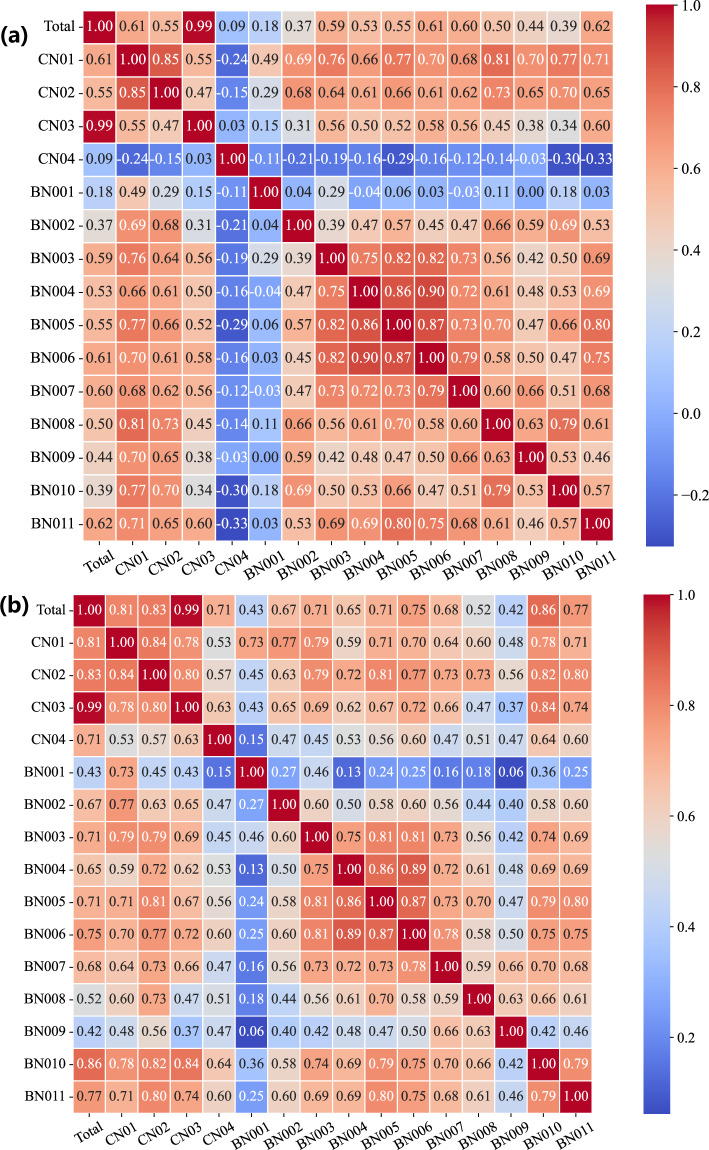 Figure 8
Figure 8- —https://doi.org/10.13039/501100001809National Natural Science Foundation of China (National Science Foundation of China)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSolar Radiation and Photovoltaics · Energy Load and Power Forecasting · Smart Grid Energy Management
Background & Summary
Utilities such as power systems, information internet infrastructures, transportation networks, natural gas pipelines, and district heating systems are generally operated in an autonomous manner. The concepts of Energy Internet and Integrated Energy Systems, which facilitate the coordination of myriad systems or networks, represent promising approaches for penetrating renewable power generation and promoting net-zero greenhouse gas (GHG) emissions^1^. Through the increasing deployment of smart meters and sensors, practitioners collect more refined observations to offer better energy supply services. For instance, customized services are available for residential, industrial, commercial, and other types of consumers; flexible loads, such as heating, ventilation, and air conditioning, can actively participate in integrated demand responses for penetrating renewables^2,3^. Machine learning, deep learning, and data-driven optimization approaches require data sources to estimate the states of energy systems^4,5^, predict their future conditions^6–8^, and optimize energy generation, distribution, and utilization^2,3,9^. Hence, it is imperative to underscore the criticality of data sources to energy system management.
Due to privacy and information security, data sources are not always accessible, especially in a deregulated market. Presently, complete datasets on energy systems mainly involve electricity consumption^10–12^, renewable energy generation^10,11^, and meteorological information (widely accepted as influential factors for energy system operations)^10–12^, structured in a multi-source manner^10,12^ and hierarchical fashion^12^. Multi-source datasets that involve multiple loads, photovoltaic (PV) panels, or other components are desirable for managing decentralized energy systems such as microgrids. Hierarchical datasets contribute to the interactions between microgrids and centralized energy systems such as power distribution systems. However, the lack of heat and cooling energy consumption may make these datasets unsuitable for analyzing the interactions among multiple energy sectors.
In the context of energy systems penetrated with renewables, many studies prefer a sufficient, complete dataset of multiple energy consumption, renewable power generation, GHG emissions, and weather information. In practice, the number of suitable multiple energy datasets is relatively limited compared to those targeted at power systems, which may constrain further investigations^1^. Generally, only a few types of multiple energy consumption of individuals are provided in the multiple energy dataset, in which the record of renewable power generation is not considered, thus limiting the implementation of the dataset. For instance, the electricity and thermal energy consumption of 38 houses in Germany is contained in the dataset without other data sources^13^. The reality is that multiple energy datasets incorporating multi-source information are significantly less common than those focusing solely on electricity. Furthermore, the record of GHG emissions has not yet been included in current multiple energy datasets. On the other hand, the length of multiple energy datasets is often within a year or several months. It is far from sufficient for leveraging the power of deep learning methods compared with electricity-only datasets^1,6^. There is still a conspicuous absence of multi-source energy datasets with a hierarchical structure (see Fig. 2), from individuals to aggregations and up to the top level, despite the fact that many raw data sources remain messy and insufficiently prepared for reproducibility, customization, and further development.
Hence, this study develops a sufficient multi-source and hierarchical dataset by integrating diverse data sources of multiple energy consumption (e.g., electricity, heat energy, and cooling energy), PV power generation, GHG emissions, and weather information (temperature, dew point, humidity, wind speed, pressure, and precipitation), dubbed Hierarchical Energy, Emissions, and Weather (HEEW). The dataset ranges from 1 January, 2014, to 31 December, 2022, providing information on 147 individual buildings in the entire region. The multi-source data records originating from these buildings can be aggregated to form the combined datasets of the four communities. Then, the aggregated records from these communities can be synthesized to produce a hierarchical dataset representative of the entire region. The dataset can be used for investigations on imputation, anomaly detection, clustering, decomposition, classification, forecasting, and optimization. For reproductivity, customization, and development, we believe this real-world dataset can serve as the benchmark of time series sequence or tabular data to improve the management of multiple energy systems and decentralized systems.
In HEEW, the data source of multiple energy consumption has been widely used in energy demand forecasting, energy trade optimization, energy system simulation, system sustainability assessment, and other topics. Specifically, existing studies identify the complicated, influential factors, such as the nonlinear synergy between different types of demand^14^, and simultaneously generate the multiple energy predictions (including probabilistic ones^15^), where the data source is leveraged through support vector regression^16^, random forecast^17^, convolutional neural networks^18^, recurrent neural networks^18^, graph neural networks^19^, Transformer sequence-to-sequence networks^15,20^, and multi-task learning strategy^21^. Existing studies also assess the metabolic sustainability and the multiple energy interaction of universities as small-scale urban energy systems, where the data source is used for case studies^22,23^. In addition, a multi-objective optimization model that considers the interests of interconnected end-users in peer-to-peer energy trades is tested using the data source^24^. Numerous works demonstrate the wide range of research interests in multiple energy management. As current works mainly focus on the data source of multiple energy consumption of the entire region or several buildings, we contend that the scope for research and practical applications will not be fully realized unless we integrate comprehensive data sources, including meteorological information, PV power generation, and GHG emissions, to construct a complete, multi-source, and hierarchical dataset.
Methods
Raw data collection
The constructed dataset, HEEW, contains 11,987,328 records, involving diverse data sources. On the one hand, energy and GHG records derive from campus buildings of Arizona State University through the Campus Metabolism Project (http://cm.asu.edu/), a sensor-based system. These sensors are installed within the utility rooms of the buildings, in close proximity to the existing utility meters and circuit breakers, facilitating the immediate capture and logging of energy data. The accumulated data is then relayed to a central server machine, organized, and stored within a Structured Query Language (SQL) database. The server infrastructure is anchored by the Energy Information System, a system deployed in 2004 and maintained by the Arizona State University Facilities Management with aid from Ameresco. Upon being stored within the SQL database, a web-based tool can retrieve the data based on the user-defined viewing parameters and display it on-screen. It is worth noting that the sensor data is timestamped and reported to the central server, with data kept in onboard memory as a buffer to mitigate potential outages. In line with the project’s stated goal to support research and education, the original data was made publicly available by the Campus Metabolism, and has been widely used in the literature^14–24^. However, the original release had several limitations, including data gaps, minimal documentation, and a lack of integration with relevant environmental variables such as meteorological data. Specifically, 795,852 missing points occur in the data source of energy consumption, 12,625 in PV power generation, and 50364 in GHG emissions, which may affect the quality of raw data sources derived from the Campus Metabolism Project. The data for this study were downloaded on 23 September 2023. At the time of this writing, the project’s original website was inaccessible, and its availability has been noted to be intermittent. Since the real-world missing values have no ground truth, we develop a two-stage data cleaning scheme, as detailed in the following sections, which performs imputation and correction to generate artificial ground truth. The missing patterns structured by the proposed scheme can serve as a baseline for further investigations.
On the other hand, weather information is collected through the National Weather Service (https://www.weather.gov/), an agency of the United States federal government responsible for delivering weather-related products to organizations and the public. The equipment at the station records and reports a range of meteorological parameters, including temperature, humidity, wind speed, wind direction, atmospheric pressure, and precipitation. Similarly, there are 8356 missing points in the raw data source provided by the National Weather Service. Despite the inevitable occurrence of missing points in practical conditions, we believe in the application potential of integrating weather information into the multiple energy dataset. Hence, this study curates a comprehensive and user-ready version of the dataset and constructs the HEEW dataset. More specifically, we (1) conduct missing data imputation and abnormal data correction for missing or inconsistent records; (2) integrate publicly accessible meteorological records from the U.S. National Weather Service and other relevant data sources; and (3) apply standardized quality control procedures and harmonizing metadata for broader usability. All data processing, integration, and validation steps in this study have been completed using institutional computing resources and infrastructure.
Buildings and end-use types
The data sources derive from the observations of sensors and meters installed in 147 individual buildings, four aggregated communities, and the entire region of Arizona State University. Figure 1 shows the spatial distribution of 147 individual buildings scattered in four communities of the entire region of Arizona State University. The individual buildings involve academic buildings (e.g., lecture halls, classrooms, and seminar rooms), research facilities (laboratories, research centers, and institutes), administrative offices (executive, financial, and administrative), student residences (dormitories, apartments, and residential colleges), recreational centers (fitness gyms, swimming pools, and sports arenas), performing arts venues (theaters, concert halls, and dance studios), libraries (scholarly resources, digital archives, and study spaces), dining halls and cafeterias (nutritional services and social spaces), the student union (a hub for student governance, organizations, and social interaction), health services (medical facilities, counseling centers, and wellness programs), conference centers (professional gatherings, symposia, and academic conferences), visitor accommodations (guest houses or hotels for visiting scholars, parents, and prospective students), and auxiliary services (bookstores, retail outlets, and other commercial services). The records cover all of the buildings in the Downtown Campus, the Polytechnic Campus, the Tempe Campus, and the West Valley Campus. These campuses in the entire region of Arizona State University are located in diverse areas and present varying patterns of energy demand. For instance, the Tempe Campus, located in Phoenix, Arizona, has a large demand for cooling energy because Phoenix, known for its torrid desert, has the highest average annual temperature in America. Overall, the end-use types include air conditioning, refrigeration, cooking, experimental processes or equipment, hot water, lighting, office equipment, and many other types. Both the chilled water and heating consumed in buildings are produced by either central plants or by the electricity that is already metered within a building.Fig. 1. The distribution of individual buildings in four communities.
First-stage missing data imputation
Missing data, or the absence of data values in a dataset, refers to information that is not recorded or lost in practical conditions. The missing points can arise from a multitude of factors that are often contextually dependent on data acquisition from sensors or smart meters (e.g., sensor malfunctions, manual reporting errors, and environmental interferences), transmission via communication networks (communication failures, cybersecurity breaches, and protocol incompatibilities), storage in databases or data warehouses (database integrity issues, data archival practices, and access control errors), and even system-wide considerations (data integration complexities and resource constraints). To ensure the feasibility of the constructed dataset, HEEW, we develop a two-stage data cleaning scheme, which serves as a baseline to compare, as both the original raw data and the cleaned data processed by this scheme are made available to encourage comparative studies.
In the first stage, an empirical Threshold-Based Contextual Cleaning Algorithm (TCCA) is constructed as follows, considering the time-series characteristic of continuity and periodicity. Without loss of generality, the ratio μ is set as 5 to obtain the volatile threshold θ based on the upper quartile (UQ) of each column of the data sources (in the form of vectors x), thus deleting the abnormal values as Not a Number (NaN). Let AVERAGE be the function that returns the arithmetic mean of two input values, and RANDOM be the function that returns a random value within a specified range, where the left input denotes the lower bound and the right input denotes the upper bound. In instances where the absence of data is attributed to the original lack of sensor deployment, for instance, scenarios where PV panels have not been installed, such missing data is considered negligible. In other words, if the missing points occur in the whole column or a numeric value occurs from the first i + 1 rows, we assume these missing points are set to −1 for no installment situations. Importantly, energy data (including load and PV generation), GHG emissions, and weather conditions (such as temperature and humidity) are assumed to exhibit both temporal continuity, which means values change gradually over time, and periodicity, which reflects regular patterns over daily, weekly, or seasonal cycles^25^. Specifically, we expand linear interpolation into multiple correlation conditions^26–28^ and supplement each missing point by simultaneously searching the values from the last and following single timestamp and periods (e.g., day, week, and month), respectively, thus averaging both values that are not NaN values. For insurance, a random number within the interval between the minimum and maximum values of the column will be assigned to the missing value if both values that are not NaN values can not be found. Then, initial assignments from the first-stage missing data imputation will be improved based on the second-stage abnormal data correction.
Algorithm 1
Threshold-Based Contextual Cleaning (TCCA) Algorithm.
Second-stage abnormal data correction
The noise is inevitably introduced to the actual observations during the processes of measurement, transmission, and storage, thereby impairing the quality of the data source. Specifically, noise manifests as minor spikes within raw data due to human-induced errors (such as recording by hand), discrepancies due to differing statistical methods, and the presence of outlier data. Human errors are particularly prevalent in sensors or smart meters that operate at high collection frequencies, have extended operational durations, or have lower levels of aggregation. Discrepancies in statistical methods may arise from differences in the types, manufacturers, and production standards of electrical equipment, sensors, or smart meters. In other words, human-induced errors and methodological discrepancies contribute to a portion of the data noise observed. Outlier data refers to statistical data affected by sudden events or specific causes, which can introduce significant random disturbances into standard time series, thereby influencing the accuracy of the values. If raw data is directly used as input for a model without any correction, the model’s output is assumed to deviate from the true values severely.
Hence, a Clustering-Based Ratio Algorithm for Correction (CRAC) is constructed as follows to double-check the abnormal values and improve the quality of the constructed dataset, HEEW. Let MIN be the function that returns the smaller value of two input numbers. The hourly resolution time series (e.g., electricity consumption) of each column is divided into daily curves. On the one hand, this study employs K-means clustering to extract typical daily curves and categorize all daily curves. Specifically, after pre-experiments, without loss of generality, the number of clusters is set at three, i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\boldsymbol{c}}}_{1},{{\boldsymbol{c}}}_{2},{{\boldsymbol{c}}}_{3}$$\end{document} . Three days are selected from all the daily curves as the initial clustering centers by empirical pre-trials. The Euclidean distance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\rm{DISTANCE}}\left({\boldsymbol{x}},{{\bf{X}}}_{{c}_{i}}\right)$$\end{document} between a curve x and the typical curve \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\bf{X}}}_{{c}_{i}}$$\end{document} is calculated as follows, according to which the curve is put into the nearest cluster with the minimum distance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\rm{MIN}}\left({\boldsymbol{d}}\right)$$\end{document} .
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\rm{DISTANCE}}\left({\boldsymbol{x}},{{\bf{X}}}_{{c}_{i}}\right)=\sqrt{\mathop{\sum }\limits_{t=1}^{{\rm{LEN}}\left({\boldsymbol{x}}\right)}{\left({x}_{t}-{{\rm{X}}}_{{c}_{i},t}\right)}^{2}}$$\end{document}After each epoch, the typical curve is recalculated for each new cluster, which is repeated until the typical curves of all clusters remain unchanged. On the other hand, we assume the data points at the same moment in each cluster fluctuate in a certain (e.g., nearby) region composed of all the curves in the cluster. Thus, the abnormal values can be identified by setting the iteration ratio ε, which in this study is set to 3000, regarding the discrepancy between a single point \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\boldsymbol{x}}}_{j}$$\end{document} and the mean of all the points of the curves at the same moment, i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left({\sum }_{t}^{{\rm{LEN}}\left({\bf{Y}}\right)}{{\bf{Y}}}_{t,j}\right)/{\rm{LEN}}\left({\bf{Y}}\right)$$\end{document} . For variations exceeding the threshold ratio, the data points are assumed and identified as abnormal values, which will be corrected using the ratio method, considering the similarity assumption between adjacent time points as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${x}_{j}={y}_{j}\times \left(\frac{{x}_{j-1}}{{y}_{j-1}}+\frac{{x}_{j+1}}{{y}_{j+1}}\right)/2,i=p,\cdots ,q$$\end{document}In Eq. (2), the correction of the abnormal data can be realized by utilizing the normal data from the baseline central curve within the same cluster^29^. By exploiting the local similarity of the curves^30^, values from the corresponding position on the baseline curve within the same cluster can be transposed onto the curve in need of correction using the ratio method, thereby correcting the abnormal data. Hence, the abnormal data within initial assignments from the first-stage missing data imputation have been identified and corrected while avoiding the improper alteration of normal data. The improved assignments from the second-stage abnormal data correction ensure the quality of the dataset, HEEW.
Algorithm 2
Clustering-based Ratio Algorithm for Correction (CRAC).
Refined data estimation
GHG emissions are not directly collected in the constructed HEEW dataset. Instead, they are estimated as the difference between the emissions caused by the demand-side total energy consumption in each building and the emissions offset by solar energy production, which is evenly distributed across all metered buildings based on the total solar generation in the region. Specifically, the total energy consumption in mmBTU is calculated as the sum of electricity, cooling, and heat energy consumption. However, since these loads are expressed in different units, electricity in kilowatts (kW), cooling in refrigeration tons (Ton), and heat directly in mmBTU, they cannot be added directly. To ensure consistency, the electrical and cooling loads must first be converted to mmBTU/hr. For electricity, the conversion follows: kW to BTU/hr (using 1 kW ≈ 3,412 BTU/hr), then BTU/hr to mmBTU/hr (by dividing by 1,000,000). For cooling load, the process is: Ton to kW (1 Ton ≈ 3.51685 kW), then kW to BTU/hr to mmBTU/hr as above. The heating load, originally given in mmBTU, is interpreted as mmBTU/hr by assuming a 1-hour time resolution. Once all loads are expressed as mmBTU/hr, they can be summed to obtain the total energy consumption in a consistent unit.
Then, a distribution percentage is determined by calculating a building’s consumption against the total energy consumption and then using this same percentage against the total solar production value. The resulting amount of GHG is calculated by applying weighted emission factors to the building’s electric, chilled water, and heating loads separately and subtracting that allocation from the building based on the distribution percentage. In HEEW, the value of GHG is summed as follows based on the 2009 eGrid emission factors and corresponding multipliers. Since the energy consumed is initially measured in mmBTU, it is first converted to megawatt-hours (MWh) to facilitate the calculation of GHG emissions. Specifically, for every megawatt-hour (MWh) of energy consumed, the associated emissions are: 1191.35 lbs of carbon dioxide (CO₂), 0.01913 lbs of methane (CH₄), and 0.01558 lbs of nitrous oxide (N₂O). These are then converted to metric tons using a conversion factor of 2204.62 lbs per metric ton. The CH₄ and N₂O emissions are further multiplied by their respective global warming potential (GWP) factors, 21 for CH₄ and 310 for N₂O, to obtain their CO₂-equivalent impact.
Data Records
Data sources and content
The dataset is available at figshare^31^, and involves 147 individual buildings of Arizona State University in terms of multiple energy consumption, PV power generation, GHG emissions, and weather information. However, the record can be obtained after a certain time because the equipment was not installed in the building before, as mentioned in the section on Missing Data Imputation. Meanwhile, not all the dimensions can be provided for each building, as some equipment is not installed in the building. Table 1 summarizes the data sources available in HEEW.Table 1. Summary of data sources in HEEW.ECPVGEWECPVGEWECPVGEWTotalALL√√√BN048E√BN099E√√CN001ALL√√BN049E√BN100ALL√√BN001ALL√BN050E√√BN101ALL√BN002E&C√√BN051ALL√BN102ALL√BN003E√BN052ALL√√BN103ALL√BN004E√BN053E√BN104ALL√BN005E√BN054ALL√√BN105E&H√√BN006E√BN055E&H√√BN106ALL√BN007E√BN056ALL√√BN107E&C√BN008E√BN057ALL√√BN108E&C√BN009E√BN058ALL√BN109E&C√BN010E&C√BN059ALL√BN110E&H√BN011E√BN060ALL√BN111E&C√CN002ALL√√BN061ALL√BN112E&C√BN012E√BN062ALL√BN113E&C√BN013E√BN063ALL√√BN114ALL√√BN014E&C√BN064E√√BN115ALL√√BN015E√BN065E&C√BN116ALL√BN016E√BN066E√√BN117E√BN017E&C√BN067ALL√BN118ALL√BN018E&C√BN068E√BN119E&C√√BN019E√BN069ALL√√BN120ALL√BN020ALL√BN070ALL√√BN121E√BN021E&C√BN071ALL√√BN122E&C√BN022E√BN072E&C√√BN123E&C√BN023E√BN073E&C√BN124E&C√BN024E√BN074E&C√√BN125E√BN025E√BN075√√BN126E√√BN026E&C√BN076ALL√√BN127E√√BN027E√BN077E√BN128E&C√BN028E&C√BN078ALL√BN129E√√BN029E&C√BN079ALL√√BN130E√√BN030E√BN080ALL√BN131E√√BN031E√BN081ALL√BN132ALL√√BN032E&C√√BN082E√√BN133ALL√BN033E&C√BN083ALL√BN134E√BN034E&C√BN084ALL√BN135E√BN035E√BN085ALL√BN136E&C√√BN036E&C√BN086ALL√CN004E&C√√CN003ALL√BN087E&H√BN137E&C√BN037E√√BN088ALL√BN138E&C√BN038ALL√BN089E&C√√BN139E√BN039E√BN090ALL√BN140E&C√BN040ALL√√BN091E√√BN141E&C√BN041ALL√√BN092ALL√BN142E&C√BN042ALL√√BN093E&C√BN143E&C√BN043ALL√BN094ALL√√BN144E&C√√BN044E&C√BN095ALL√BN145E&C√BN045ALL√√BN096ALL√BN146E&C√BN046E&C√BN097E&C√√BN147E&C√BN047ALL√BN098E√√CN: Community No., Building No., EC: Energy Consumption, E: Electricity [kW], H: Heat [mmBTU], C: Cooling Energy [Ton], PV: PV Power Generation [kW], GE: Greenhouse Gas Emission [Ton], W: Weather, including Temperature [°F], Dew Point [°F], Humidity [%], Wind Speed [mph], Wind Gust [mph], Sea Level Pressure [in], Precipitation [in].
In Table 1, all electric loads in buildings come either from PV output or the utility grid. It is also shown that not all buildings are equipped with the district heating system and PV panels, and some buildings are only equipped with electric load or electric and cooling loads. The building dubbed BN075 is only installed with PV panels without any loads, and weather information is only available for area-level aggregated communities. In addition, net GHG emissions are calculated considering the gap between emission increase due to energy consumption and emission reduction due to PV power generation.
Data record glossary
Table 2 summarizes the data record glossary in the constructed dataset, HEEW. The calendar information involves year, month, day, hour, and weekday. The timestamp is composed of year, month, day, and hour, in which the year ranges from 2014 to 2022, and the month refers to January, February, March, April, May, June, July, August, September, October, November, and December. The weekday refers to Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, and Sunday.Table 2. Glossary of data records in HEEW.Column headerExplanation and unitYear, Month, Day, Hour, WeekdayYear, month, day, hour, and weekday are calendar information. The timestamp is composed of year, month, day, and hour, in which the year ranges from 2014 to 2022.ElectricityElectricity is the electrical energy used to energize lighting systems, electronic devices, and ventilation equipment. The unit used to denote the rate of electricity consumption is the kilowatt (kW).PVPV power generation is the electrical energy produced to supply electricity consumption. The unit used to denote the rate of PV power generation is also kW, which signifies the instantaneous electrical power output provided by the solar installation.CoolingCooling energy is the energy used to cool the water and air within buildings. The unit used to denote the rate of cooling energy consumption is the Ton.HeatHeat energy is the energy used to heat the water and air in the building. The unit used to quantify heat energy consumption is the British Thermal Unit (Btu), which in HEEW is expressed in the form of mmBtu (1,000,000 Btu).Total EnergyThe total energy is the sum of electricity consumption given in the form of mmBtu (1 kWh = 3.4 mBtu), cooling energy consumption in the form of mmBtu (1 Tonh = 11.972 mBtu), and heat energy consumption.EmissionGHG emission is calculated as the gap between emission increase due to energy consumption and emission reduction due to PV power generation. The unit used to denote the GHG emission is the Ton.TemperatureTemperature is a measure of the thermal energy present in a substance or object. The unit used to denote the measurement of temperature is the degree Fahrenheit (°F), which is a scale on which water freezes at 32 degrees and boils at 212 degrees under standard atmospheric conditions.Dew PointThe dew point is the temperature at which air becomes saturated with moisture, and water vapor begins to condense into dew. The unit used to denote the measurement of the dew point is also the degree Fahrenheit (°F).HumidityHumidity is the amount of water vapor present in the air. The unit used to denote the measurement of humidity is the percentage (%) to quantify the degree to which the air is saturated with moisture.Wind SpeedWind speed is the velocity at which air moves from areas of high pressure to areas of low pressure. The unit used to measure wind speed is miles per hour (mph), which indicates the number of miles the wind travels in one hour.Wind GustThe wind gust is a brief and sudden increase in wind speed that typically lasts for just a few seconds. The unit used to measure the wind gust is also miles per hour (mph), conveying the distance, in miles, that the gust travels within one hour.Sea Level PressureSea Level Pressure is a measure of the atmospheric pressure at sea level. The unit used to measure sea level pressure is inches of mercury (in). The standard sea level pressure is defined as 29.92 inches of mercury under standard gravitational conditions at a temperature of 32 degrees Fahrenheit (0 degrees Celsius).PrecipitationPrecipitation is various forms of moisture, such as rain, snow, sleet, and hail, that falls from clouds and reaches the ground. The unit used to denote the measurement of precipitation is inch (in).
Electricity is the electrical energy used to energize lighting systems, electronic devices, and ventilation equipment. The quantification of electricity consumption is gauged by a power meter, which is installed at the electrical ingress of the building.
Cooling energy is the energy used to cool the water and air within buildings. At Arizona State University, the central utility facility cools the water through electric chillers, and the cool water is then distributed to various buildings. The quantification of cooling energy consumption is calculated through the thermal increment and volumetric flow rate of the cool water that circulates into and out of the facility [14].
Heat energy is the energy used to heat the water and air in the building. Arizona State University is equipped with a central plant where natural gas-fired burners are employed to heat water, which is thereafter channeled to the various buildings across the campus [14]. The heat consumed by buildings primarily originates from such centralized sources, and heat pumps may also contribute to heating in some cases, depending on the mechanical system design and energy infrastructure. Moreover, the total energy consumption is also calculated as the sum of electricity, cooling energy, and heat energy consumption for generic purposes.
Greenhouse gas emissions result from greenhouse gases that contribute to the greenhouse effect by absorbing infrared radiation produced by solar warming of the Earth’s surface, including carbon dioxide (CO2), Methane (CH4), and nitrous oxide(NO2). Greenhouse gas emission is calculated as the gap between emission increase due to electricity consumption in each building and the emission reduction via solar production, equally distributed to each metered building.
PV power generation is the electrical energy produced to supply electricity consumption. At Arizona State University, PV panels are deployed atop certain buildings within the campus grounds. The capacity of these PV panels to generate electricity is also quantified in kW.
Weather information involves environmental factors, such as temperature, dew point, humidity, wind speed, wind gust, sea level pressure, and precipitation, provided by stations of the National Weather Service around the four communities. Specifically, temperature, a measure of the thermal energy present in a substance or object, serves as an indicator of the degree of heat or coldness as perceived by the sense of touch or determined by a thermometer.
The dew point is a precise measure of atmospheric moisture, indicating the temperature at which the air can no longer “hold” all of its water vapor, which then starts to condense into liquid water or dew, which is measured using a hygrometer or derived from other meteorological data through calculations involving temperature and relative humidity readings. A higher dew point signifies greater moisture content in the air, leading to a feeling of “mugginess” or “stickiness” as the moisture content approaches the saturation point. Conversely, a lower dew point means drier air and lower relative humidity, providing a more comfortable and less humid environment.
Humidity is commonly measured using instruments such as hygrometers, reflecting the current state of water vapor relative to the maximum amount that the air can hold at a given temperature, known as the saturation point. When the humidity level is expressed as 100%, the air is at full saturation, which often leads to the formation of dew, fog, or precipitation, as the air cannot hold any additional moisture. Conversely, lower humidity levels indicate drier air.
Wind speed is typically measured using an anemometer, a device specifically designed to gauge the speed of the wind with a high degree of accuracy. Wind gusts are short bursts of high-speed wind that are often associated with rapidly changing weather conditions, such as the approach of a storm front or convective activity within the atmosphere. To capture these transient events, anemometers, when measuring wind gusts, record the peak wind speed over a short interval, typically ranging from a few seconds to a minute, to ensure an accurate representation of the gust’s maximum force.
Sea level pressure indicates areas of high and low pressure, which is standardized to provide a reference that can be compared across various geographic locations, regardless of altitude, to ensure consistency in pressure readings. Barometric pressure sensors and mercury barometers are commonly used tools for measuring this atmospheric pressure parameter, with one inch of mercury representing the pressure exerted by a one-inch-high column of mercury at the Earth’s surface.
The amount of precipitation is recorded in terms of the depth of water that would accumulate on an impermeable, flat surface within a specified period. Precipitation is typically measured using a rain gauge, which collects falling water and allows for direct measurement of the depth, with an inch of precipitation meaning that a one-inch deep layer of water has fallen over a one-square-inch area.
To align with the Findable, Accessible, Interoperable, and Reusable (FAIR) data principles, we present a metadata summary of the 13 key variables, as shown in Table 3, including variable names, units, temporal resolution, data availability, and data sources. Based on Tables 1–4, researchers can quickly understand the structure of the HEEW dataset and efficiently leverage it for further investigation.Table 3. Metadata summary.VariableUnitFrequencyAvailabilitySourceElectricitykWHourly99.3% buildings and their aggregations in the entire region (2014–2022)Meters/sensorsPVkWHourly29.9% buildings and their aggregations in the entire region (2014–2022)Meters/sensorsCoolingTonHourly66.0% buildings and their aggregations in the entire region (2014–2022)Meters/sensorsHeatmmBTUHourly37.4% buildings and their aggregations in the entire region (2014–2022)Meters/sensorsTotal EnergymmBTUHourly99.3% buildings and their aggregations in the entire region (2014–2022)CalculationEmissionTonHourlyFull (2014–2022)EstimationTemperature°FHourlyThe entire region (2014–2022)Weather stationDew Point°FHourlyThe entire region (2014–2022)Weather stationHumidity%HourlyThe entire region (2014–2022)Weather stationWind SpeedmphHourlyThe entire region (2014–2022)Weather stationWind GustmphHourlyThe entire region (2014–2022)Weather stationSea Level PressureinHourlyThe entire region (2014–2022)Weather stationPrecipitationinHourlyThe entire region (2014–2022)Weather stationTable 4Summary of ranges, missing rates, and abnormal rates of the HEEW data.RangeMRARRangeMRARRangeMRARTotal20142200BN04820152200BN09920142200CN00120142200BN04920142200BN10020142200BN00120162200BN05020142200BN10120142200BN00220142200BN05120142200BN10220142200BN00320142200BN05220142200BN10320142200BN00420142200BN05320152200BN10420142200BN00520142200BN05420142200BN10520142200BN00620142200BN05520142200BN10620142200BN00720142200BN05620142200BN10720142200BN00820142200BN05720142200BN10820142200BN00920142200BN05820142200BN10920142200BN01020142200BN05920142200BN11020142200BN01120142200BN06020142200BN11120142200CN00220142200BN06120142200BN11220142200BN01220142200BN06220142200BN11320142200BN01320142200BN06320142200BN11420142200BN01420142200BN06420142200BN11520142200BN01520142200BN06520142200BN11620142200BN01620142200BN06620142200BN11720142200BN01720142200BN06720142200BN11820142200BN01820182200BN06820192200BN11920142200BN01920142200BN06920142200BN12020142200BN02020142200BN07020142200BN12120142200BN02120142200BN07120142200BN12220172200BN02220142200BN07220142200BN12320172200BN02320142200BN07320142200BN12420172200BN02420142200BN07420142200BN12520142200BN02520142200BN07520142200BN12620142200BN02620142200BN07620142200BN12720142200BN02720142200BN07720142200BN12820142200BN02820142200BN07820142200BN12920142200BN02920142200BN07920142200BN13020142200BN03020142200BN08020142200BN13120142200BN03120142200BN08120142200BN13220142200BN03220142200BN08220142200BN13320142200BN03320142200BN08320142200BN13420142200BN03420142200BN08420142200BN13520142200BN03520142200BN08520142200BN13620142200BN03620142200BN08620142200CN00420142200CN00320142200BN08720142200BN13720142200BN03720142200BN08820142200BN13820142200BN03820142200BN08920142200BN13920142200BN03920142200BN09020142200BN14020142200BN04020142200BN09120142200BN14120142200BN04120142200BN09220142200BN14220172200BN04220142200BN09320142200BN14320142200BN04320182200BN09420142200BN14420142200BN04420142200BN09520142200BN14520142200BN04520142200BN09620142200BN14620142200BN04620142200BN09720142200BN14720142200BN04720142200BN09820142200MR: Missing rate, AR: Abnormal rate [%].
Hierarchical data record benchmarking
The records of 147 buildings within the entire region aggregate to constitute four records of the four distinct communities, and the records of the four communities aggregate to generate the record of the entire region. This integrative process begets a comprehensive compilation of records, which, upon subsequent synthesis, culminates in the hierarchical dataset, HEEW. Figure 2 illustrates the three-level hierarchy of the HEEW data from individual buildings to four communities to the entire region, where the buildings belong to varying communities based on geographic locations and administrative boundaries, as shown in Fig. 1. In HEEW, the values in the record of each community are derived by the element-wise summation of values in the records of its buildings. For instance, the electricity consumption of the CN01 record on 15 September, 2022, is the sum of the electricity consumption of the records from BN001 to BN011 on 15 September, 2022.Fig. 2. Hierarchical illustration of the HEEW data. (a) Hierarchical illustration from individual buildings to aggregated communities to the entire region. (b) Hierarchy of the HEEW data, where the numbers at the bottom level indicate the number of buildings.
File organization
The HEEW dataset contains 152 files, each cataloging pertinent data on energy and climatic conditions. These files are systematically named and categorized based on the type of data they contain and the location from which the data were collected. The Total_energy.csv file encapsulates the aggregate energy consumption for the entire dataset, serving as a comprehensive summary of energy data across all buildings. Following this, there is a meteorological data file named Total_weather.csv, covering the entire region. These files furnish climate information relevant to energy consumption and production, such as temperature, humidity, and solar radiation, corresponding to various geographic regions or meteorological stations.
In addition, files named CN01_energy.csv through CN04_energy.csv contain energy consumption records of individual buildings within specific communities, with the numbers in the filenames designating different regions or building clusters. The prefix CN stands for Community Number, indicating the code for the respective area or cluster of buildings. The remaining files, prefixed with BN and enumerated from BN001_energy.csv to BN147_energy.csv, include the energy consumption data for individual buildings. In these filenames, BN denotes Building Number, with the subsequent three digits uniquely identifying each building. This systematic approach to file naming and organization enables clear identification of the content and source of each file, laying a solid foundation for in-depth analysis of energy consumption and weather data. Such an organizational structure also facilitates efficient data retrieval and processing by researchers according to their specific needs.
Technical Validation
In this section, we validate the quality and feasibility of our constructed dataset, HEEW, by checking data gaps and consistency. Table 4 summarizes the timestamp ranges, missing rates, and abnormal rates of each multi-source data source in HEEW.
Data gap check
In this part, the data gap, the degree of data completeness, is represented as the missing rate of the HEEW data, which can be obtained by checking the missing points. As the 152 data sources vary in the dynamic range of timestamps, the missing points have been set to 0 for the situations in which some equipment was not installed until a certain time or has never been installed in the past. Through the Threshold-Based Contextual Cleaning Algorithm (TCCA) for imputation, we have comprehensively addressed the issue of the missing entries, achieving a missing rate of zero percent within the constructed HEEW dataset. Thus, the data gap has been double-checked to guarantee the completeness of HEEW to a high level of confidence.
Data consistency check
In this part, we, on the one hand, evaluate the internal consistency in terms of the time-series characteristic of data sources from Arizona State University and, on the other hand, validate the integration consistency of multiple data sources from Arizona State University and those from the National Weather Service. For internal consistency, the abnormal rate of multiple energy consumption, PV power generation, and GHG emissions in the HEEW data is obtained by testing the abnormal points. Using the TCCA and CRAC, we have comprehensively addressed the issue of the abnormal entries on the fully reconstructed dataset with missing values already imputed, validating the developed algorithms for the HEEW dataset. Figure 3 shows the K-Means clustering results of the raw and cleaned data (e.g., multiple energy consumption, PV power generation, and GHG emissions) at the top level within HEEW as an instance. For integration consistency, the correlation between energy records and weather records (temperature, dew point, humidity, and wind speed) of the entire region for 2014 is exhibited as an instance, as shown in Fig. 4.Fig. 3. The K-means clustering results on the raw and cleaned data at the top level of the proposed dataset’s hierarchical structure. (a) PV output before correction. (b) PV output after correction. (c) Electric load before correction. (d) Electric load after correction. (e) Heat load before correction. (f) Heat load after correction. (g) Cooling load before correction. (h) Cooling load after correction. (i) Greenhouse gas emissions before correction. (j) Greenhouse gas emissions after correction.Fig. 4. Correlation scatter plot between energy and weather records.
Furthermore, we test the temporal-spatial summation consistency of multiple data sources from aggregated communities and those from individual buildings. Firstly, for each entry in the community records, we meticulously matched and reviewed the corresponding records of all buildings at the same time point. Taking the record of CN03 on 15 September, 2021, as an example, we checked the data of all buildings from BN037 to BN136 on that day. By summing up the records of these buildings, we verify that the recorded total for the community matches the sum of the records from buildings, and the discrepancy points are then obtained. Then, as programmatic scripts are developed to automate the aggregation process, we examine each community record to ensure that each is indeed the sum of the records of its constituent buildings. In addition, to rule out potential errors or discrepancies during the aggregation process, we implement multiple rounds of data cross-checking mechanisms. If any deviation between the aggregated data and the sum of the building data is detected, we reorganize and recalculate the data until the records of all communities are consistent. Through this data verification process, we can confidently assert that every community record in the HEEW dataset precisely represents the sum of the records from the buildings within it. Figures 5–8 show three correlation coefficient matrices of electricity consumption, PV power output, and GHG emissions, respectively, from varying aspects. Thus, the data consistency has been double-checked to guarantee the feasibility and quality of HEEW to a high level of confidence.Fig. 5. Correlation coefficient matrices from previous hours. (a) Electricity consumption. (b) PV power output. (c) Greenhouse gas emissions.Fig. 6. Correlation coefficient matrices of PV output from the past year.Fig. 7. Correlation coefficient matrices between various variables. (a) Energy consumption, PV output, and emissions. (b) Electricity consumption and weather. (c) PV power output and weather. (d) GHG emissions and weather.Fig. 8. Correlation coefficient matrices of the hierarchical components. (a) Electricity consumption. (b) GHG emissions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Dong, H. et al Dynamic load forecasting with adversarial domain adaptation based LSTM neural networks. 2023 IEEE IAS I&CPS Asia (2023).
- 2Dong, H. et al Ultra-short-term load forecasting based on convolutional-LSTM hybrid networks. 2022 IEEE ISIE (2022).
- 3Wang, C., Wang, Y., Ding, Z. & Zhang, K. Probabilistic multi-energy load forecasting for integrated energy system based on Bayesian transformer network. IEEE Trans. Smart Grid (2023).
- 4Zhuang, W., Fan, J., Xia, M. & Zhu, K. A multi-scale spatial-temporal graph neural network-based method of multienergy load forecasting in integrated energy system. IEEE Trans. Smart Grid (2023).
- 5Zhao, P. et al. Geometric loss-enabled complex neural network for multi-energy load forecasting in integrated energy systems. IEEE Trans. Power Syst. (2023).
- 6Dong, H. et al Feature-Driven Microgrid Economic Dispatch via Solar-Induced Contingent Balancing Satisficing. IEEE Trans. on Sustain. Energy. (2025).