HSSAM-Net: hyper-scale shifted aggregation network for precise colorectal polyp segmentation in endoscopic images
Qing Feng, Shahzad Ahmed, Yueming Zhang, Lan He, Muhammad Yaqub

TL;DR
This paper introduces HSSAM-Net, a deep learning model that improves colorectal polyp detection in colonoscopy images with high accuracy and real-time performance.
Contribution
The novel HSSAM-Net framework combines a Hyper-Scale Shifted Aggregation Module and Max-Diagonal Pooling for efficient and accurate polyp segmentation.
Findings
HSSAM-Net achieves state-of-the-art accuracy (Dice: 0.949–0.952, mIoU: 0.924–0.930) on five benchmark datasets.
The model operates at 24.1 FPS with only 0.9 million parameters, making it suitable for real-time clinical use.
It outperforms existing methods while maintaining efficiency and boundary refinement.
Abstract
Colorectal cancer remains a leading cause of cancer-related mortality worldwide, emphasizing the importance of early detection through accurate polyp identification. However, colonoscopy relies heavily on precise polyp segmentation in endoscopic images, yet this task remains challenging due to morphological variability, low contrast, and imaging artifacts. In this study, we propose HSSAM-Net, a lightweight deep learning framework that integrates a Hyper-Scale Shifted Aggregation Module to capture multi-scale contextual information while preserving fine-grained details, Progressive Reuse Attention mechanism that strengthens feature propagation across the encoder-decoder pathway, and Max-Diagonal Pooling/Unpooling (MaxDP/MaxDUP) a novel dual-branch sampling scheme to improve texture representation, feature alignment to enhance feature aggregation, context learning, and boundary…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
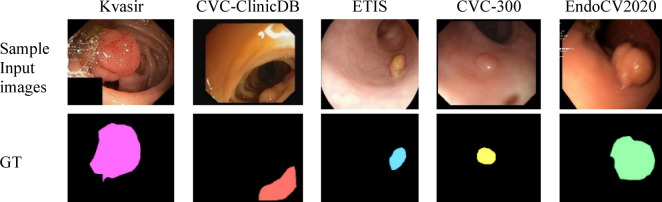 Figure 1
Figure 1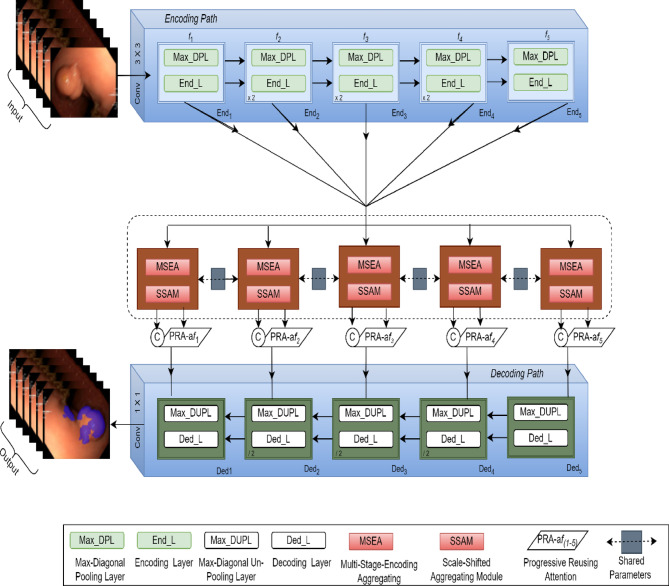 Figure 2
Figure 2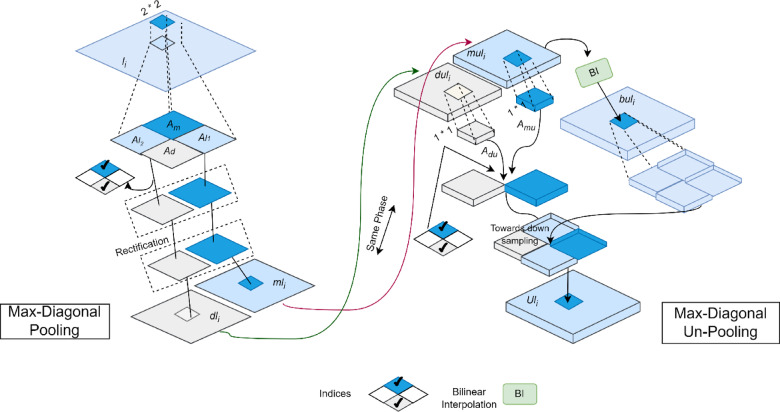 Figure 3
Figure 3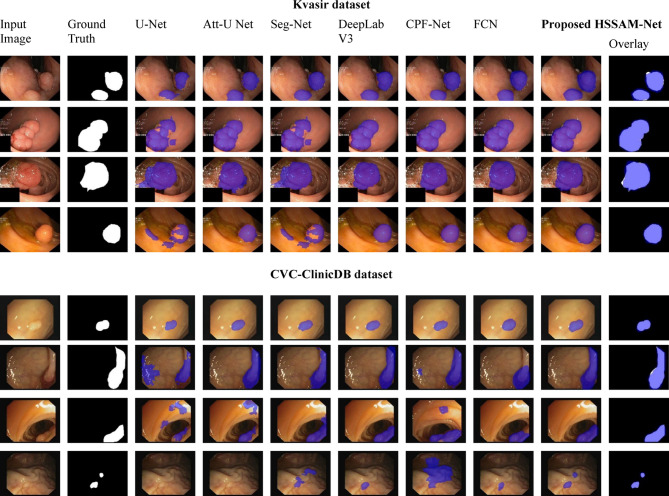 Figure 4
Figure 4 Figure 5
Figure 5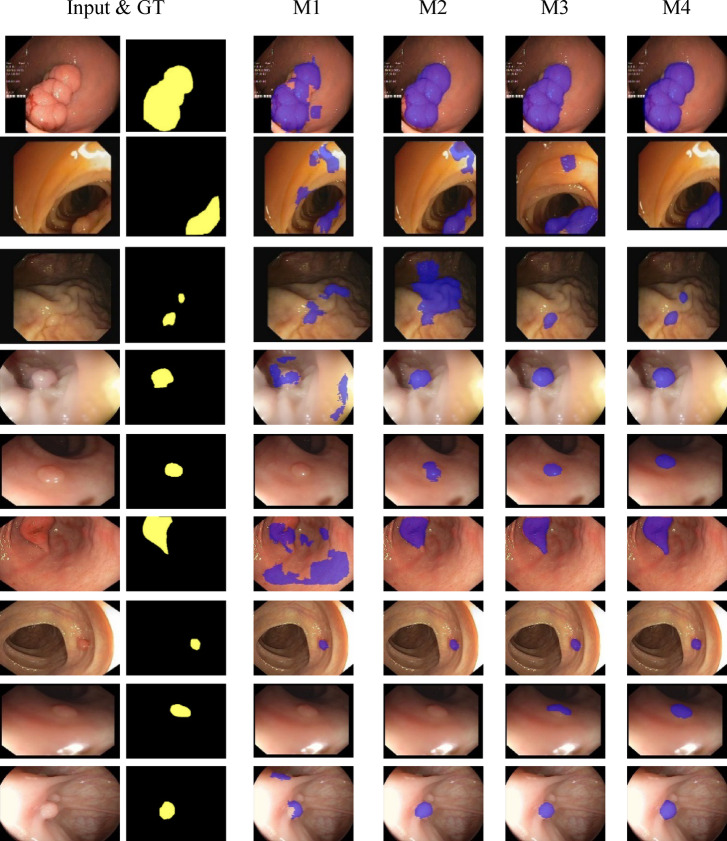 Figure 6
Figure 6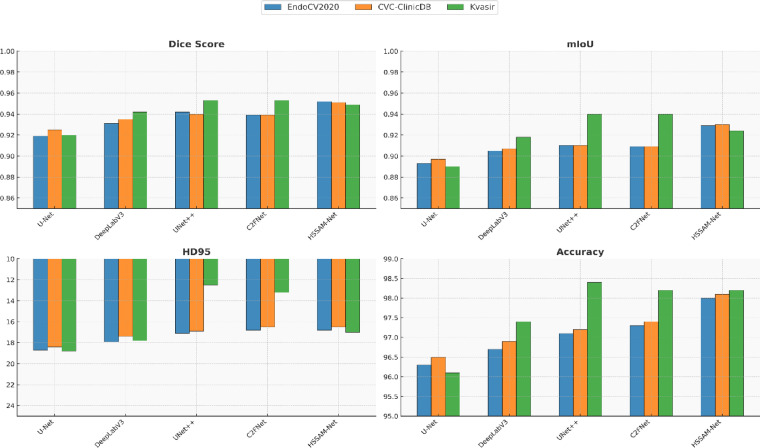 Figure 7
Figure 7- —Natural Science Foundation of Hunan Province of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsColorectal Cancer Screening and Detection · Advanced Neural Network Applications · COVID-19 diagnosis using AI
Introduction
CRC is one of the most prevalent malignancies worldwide, representing a major global health burden. According to the GLOBOCAN 2022 report, CRC ranks as the third most commonly diagnosed cancer and the second leading cause of cancer-related deaths globally, accounting for nearly 1.9 million new cases and 935,000 deaths annually^1–3^. Early detection and removal of precancerous polyps during colonoscopy is critical in reducing CRC incidence and mortality. However, the manual detection and delineation of polyps is highly challenging due to factors such as variable sizes, irregular shapes, poor contrast, occlusion, and the presence of artifacts like specular highlights and intestinal folds. Despite technological advancements in endoscopic imaging, significant challenges persist in reliably detecting polyps during routine examinations. Current miss rates for polyps range from 22–28% overall, climbing to nearly 40% for diminutive lesions measuring just 1–3 mm^4^. These missed detections have profound clinical consequences, as each 1% improvement in adenoma detection rate correlates with a 3% reduction in interval cancer incidence. Polyps are abnormal tissue growth that commonly develop in areas such as the colon, rectum, stomach, and throat. Given their potential to become cancerous, precise evaluation in clinical settings is essential this includes monitoring their size, location, and morphological characteristics. However, the wide variability in polyp shape, size, and appearance presents significant challenges during routine colonoscopy procedures. Even under similar imaging conditions, polyp lesion samples may differ in background contrast, number of lesions, and boundary clarity. Representative examples highlighting these variations are presented in Fig. 1.Fig. 1. Sample input images and their corresponding ground truth masks from all five datasets used in this study for polyp segmentation.
The first major challenge lies in the inherent information loss that occurs during standard hierarchical feature extraction in deep neural networks. Conventional architecture employs repeated pooling operations sacrifice fine-scale details that are essential for detecting small polyps, preserving only about 61.8% of high-frequency edge information while introducing positional errors exceeding 2 pixels. This proves particularly problematic for sessile serrated polyps, which require sub-pixel boundary accuracy for reliable identification. The second limitation stems from inefficient feature aggregation strategies in current multi-scale architectures. Our analysis reveals that over 58% of skip connection features in popular U-Net variants contribute minimally to final segmentation accuracy, representing substantial computational redundancy while failing to adequately preserve long-range spatial relationships needed for detecting flat lesions. Attention mechanisms were introduced to address these shortcomings by dynamically weighting feature importance, but current implementations exhibit critical flaws. Most notably, nearly 90% of attention parameters are allocated to deep network layers where spatial resolution has already been irrecoverably degraded, while shallow layers containing crucial boundary information receive inadequate focus. Furthermore, existing attention gates struggle to distinguish true polyps from common endoscopic artifacts like mucosal folds and bubbles, with precision dropping below 43% for these confounding features. Compounding these issues, the computational overhead of typical attention modules introduces over 50 ms of latency a prohibitive cost for real-time clinical applications requiring sub-200 ms response times.
Recent studies have attempted to mitigate these issues through transformer-based architectures^5^, hybrid CNN-based frameworks^6^, and clinically focused polyp segmentation solutions^7^. While these methods have shown promise, they often rely on heavy models with millions of parameters, which hinders real-time applicability in resource-constrained clinical settings. A wide range of computer-aided diagnosis (CAD) systems have been developed, with deep learning-based methods emerging as the dominant approach. The introduction of fully convolutional networks, such as U-Net and its variants, revolutionized medical image segmentation by enabling end-to-end learning of pixel-wise representations^8^. Subsequent improvements, including UNet + + ^9^, PraNet^10^, and HarDNet-MSEG^11^, have demonstrated remarkable progress in polyp segmentation by incorporating dense skip connections, attention mechanisms, and boundary-aware learning. Despite these advances, many existing approaches suffer from limitations such as high computational cost, limited generalization to unseen datasets, or reduced ability to capture multi-scale contextual information effectively. In this study, we propose HSSAM-Net, a lightweight and efficient segmentation framework designed to overcome the above limitations. The network integrates a Hyper-Scale Shifted Aggregation Module (HSSAM), Progressive Reuse Attention (PRA), and Max-Diagonal Pooling/Unpooling (MaxDP/MaxDUP) to effectively capture both global context and fine-grained boundary details. Unlike prior works, our design emphasizes computational efficiency without sacrificing accuracy, enabling real-time performance while maintaining state-of-the-art segmentation quality across multiple benchmark datasets.
Objectives and contribution
This paper presents a novel and lightweight architecture named HSSAM-Net (Hyper-Scale Shifted Aggregation Network), specifically designed to address the key challenges in colorectal polyp segmentation from endoscopic images. The model integrates advanced multi-scale feature aggregation, boundary-aware enhancement, and parameter-efficient modules to improve precision and robustness in clinical settings.
Novelty HSSAM-Net introduces a hyper-scale shifted aggregation mechanism combined with a progressive reusing attention (PRA) strategy and a novel pair of parameter-free dual-branch sampling layers Max-Diagonal Pooling (MaxDP) and Max-Diagonal Unpooling (MaxDUP). These components work in synergy to retain fine-grained spatial features, reduce redundant aggregation, and achieve precise boundary alignment. The network also incorporates partial-to-global channel attention and multiscale reusing spatial attention to dynamically refine features and suppress noise across hierarchical layers.
Aim The primary aim of this study is to develop a computationally efficient, lightweight, and accurate deep learning model for colorectal polyp segmentation, capable of delivering real-time performance while maintaining state-of-the-art accuracy across diverse datasets.
Objectives The primary objective of this study is to evaluate the effectiveness and advantages of the proposed HSSAM-Net architecture in comparison to state-of-the-art models for colorectal polyp segmentation. Specifically, this work aims to design a robust segmentation framework that overcomes limitations such as spatial inconsistencies, loss of fine-grained details, and inefficient feature aggregation commonly found in existing models. By integrating a hyper-scale shifted aggregation module, progressive reusing attention mechanisms, and a dual-branch Max-DP/Max-DUP strategy, HSSAM-Net is designed to preserve structural detail, improve contextual understanding, and enhance boundary precision. Additionally, this study focuses on developing a lightweight and computationally efficient model that maintains high segmentation accuracy across diverse datasets while ensuring real-time inference capability. Through comprehensive validation on five benchmark datasets, the objective is to demonstrate the model’s generalization ability, adaptability to varying imaging conditions, and suitability for deployment in real-world clinical settings.
*Contribution *The main contributions of this study are summarized as follows:
- HSSAM-Net introduces a novel Hyper-Scale Shifted Aggregation Module and a dual-branch Max-DP/Max-DUP sampling strategy to enhance both high-level context and low-level boundary features. These additions allow the network to maintain fine segmentation detail while minimizing computational overhead.
- A PRA strategy is proposed to strengthen skip connections by adaptively reusing hierarchical features. This is further complemented by partial-to-global channel attention and reusing spatial attention mechanisms that refine the most informative features.
- Despite its strong performance, HSSAM-Net contains only ~ 0.9 million parameters and operates at 24.1 FPS, making it ideal for real-time and embedded clinical applications without sacrificing accuracy.
- We conduct comprehensive experiments on five public benchmark datasets (Kvasir, CVC-ClinicDB, ETIS, CVC-300, EndoCV2020), demonstrating the superior segmentation accuracy and generalization capability of our model compared with state-of-the-art methods.
The structure of this paper is organized as follows: Sect. “Methodology” outlines the methodology, detailing the overall architecture of the proposed model, with particular emphasis on the HSSAM, PRA, and the MDP and MDUP mechanisms. It also discusses the datasets utilized, implementation settings, and evaluation metrics employed in the study. Section “Experimental results and discussion” presents the experimental results, offering both quantitative and qualitative analyses that demonstrate the efficacy of the proposed model. Also provides a comparative analysis of HSSAM-Net against 11 SOTA models, accompanied by a discussion of its clinical implications, challenges and potential avenues for future research. Finally, Sect. “Conclusion” concludes the paper with a summary of the key findings.
Related work
Determining pixel attribution from native images has turned into the main avenue by which CNNs tackle this prickly issue of medical image segmentation, thanks to the continually improved new schemes and architectures. The main goal of their work is to accurately determine and clearly delineate the region of interest (ROI), usually defined as lesions that are important markers for diagnosis, pathological examination, surgery, and prognosis^12^. These deep networks depend less on expert knowledge by using self-learning techniques that better fit the true distribution of features and build precision in prediction. Replacement of more algorithms for manual diagnoses raises the need to explore innovative approaches to CNNs. This will save errors of distraction or fatigue resulting from lengthy, repetitive testing and allow doctors to attend to professional work. Besides, it may reduce technical errors and increase confidence in industrial implementation with a more solid and accurate model. Inspired by advanced network design ideas from nature, the image segmentation gave birth to a number of competitive CNN-based medical segmentation methods which are portable in both natural and medical domains. For example, FCN showed very competitive results in natural and medical image segmentation by just replacing the fully connected layers used in VGG-Net with deconvolution layers designed for pixel-wise tasks^13,14^. Of course, this can be realized in many ways; natural images, however, hold some consistent properties such as stable color and proportional size.
Medical image analysis is complicated by the inherent heterogeneity of biological tissues and variability in imaging parameters. For instance, brain tumor segmentation in MRI data (e.g. presents challenges due to low contrast and irregularly shaped lesions with distinct invasive patterns (e.g., GD-enhancing tumor, peritumoral edema, necrotic core^15–19^). Similarly, gastrointestinal polyp detection is hindered by subtle color variations at the mucosa boundaries between polyps and normal tissue. Addressing these issues requires methods with robust multi-scale adaptability, focused attention on critical features, and preservation of textural detail and consistency during sampling, particularly crucial for small lesions. The U-Net architecture, a prominent encoder-decoder network, has demonstrated effectiveness in microscopic cell segmentation, leveraging skip connections to mitigate spatial information loss at boundaries and improve gradient flow^20^. Its success has led to widespread adoption and adaptation across various medical imaging applications. Common improvements involve fusing multi-stage feature maps as skip connections, integrating both fine-grained (shallow) and coarse-grained (deep) scale information.
Several studies have explored multi-branch architectures with dilated convolutions or pyramid pooling to expand contextual perception for pixel-wise classification^21–24^. Furthermore, techniques such as the incorporation of high-level features with parallel partial decoding for refined feature generation (PraNet) and dynamic multi-scale information fusion through global pyramid guidance and scale-aware pyramid fusion modules (CPFNet) have been proposed^25–28^. Multi-stage, multi-scale architecture offers the advantage of integrating diverse perspectives for improved feature synthesis. However, existing approaches often neglect crucial considerations. Specifically, these methods may retain excessive detail and introduce irrelevant information. In U-Net architecture, the common practice of downsampling shallower feature maps to match the spatial dimensions of deeper layers for summation risks spatial discontinuity and scale degradation. This work prioritizes maximizing the benefits of scale adaptability and fine-grained detail through an improved aggregation operation that enhances multi-scale interaction within the skip connections. Attention mechanisms have proven beneficial for pixel-level segmentation tasks, mitigating the impact of irrelevant features and emphasizing target-relevant information. Attention U-Net, for example, employs an attention gate to modulate shallow features using deeper semantic information within skip connections^29^. Other research has explored the use of attention weights across multiple branches and dual-modal channel attention in skip connections to improve accuracy in attentional state analysis^30,31^. Recent work has integrated four-stage outputs using a two-step parallel position-channel attention module based on a ResNet-101 backbone^32,33^. CA-Net^34^ sequentially applies spatial and channel attention, leveraging both low-level and high-level features to calibrate spatial-channel responses^34^. Similar to attention gates, other methods have implemented additive channel-space attention, providing a more comprehensive attention score through dual-aspect guidance.
In these studies, while adaptations of Squeeze-and-Excitation (SE) and Convolutional Block Attention Modules (CBAM) attention mechanisms have yielded promising results in various medical imaging tasks, their application within U-Net architectures reveals limitations. The inherent variability in feature map dimensions across different network depths presents a significant challenge for many existing attention methods, which often lack the necessary adaptability. Moreover, effectively synthesizing multi-level channel interactions remains problematic using solely global or local attention strategies. A multi-scale approach offers a potential solution by enabling more precise attention focusing on specific spatial dimensions. Successive spatial downsampling in multi-stage architectures can lead to a loss of information and the gradual disappearance of ROIs, particularly due to the information reduction inherent in max-pooling layers. Various strategies have been proposed to address this issue, focusing on preserving high-fidelity feature representations during downsampling. These include methods that: (1) calculate feature selection probabilities; (2) randomly switch between max-pooling and average pooling; (3) employ trainable parameters for pooling weight calculation; (4) utilize a softmax-like approach to maintain differentiability; and (5) leverage hard attention masks from previous predictions to guide subsequent layers^35–39^. Some approaches also incorporate auxiliary data; for example^40^, combines average pooling with double-tree wavelet transforms. CE-Net explores multiple fields of view to mitigate spatial damage and improve multi-scale object identification^41^. Modifications to max-pooling have also been explored, such as the local adaptive module which incorporates a bypass using a 1 × 1 convolution, batch normalization, ReLU activation, and average pooling. Furthermore, dual-path samplers have been used in architectures like MShNet^42,43^.
While many existing methods focus on improving either downsampling or upsampling, they often lack a holistic approach. In contrast, the symmetrical structure of U-Net architecture allows for paired sampling layers that provide consistent guidance for aligning encoded and decoded features, including both feature alignment and texture trends. For ROIs with small pixel proportions, continuous max-pooling is not an optimal downsampling method, as it can lead to excessive information loss and hinder decoder correction. The BI approach utilizes an approximate dense-filling strategy based on neighboring features, a so-called “more-to-more” procedure for upsampling^44,45^. In contrast, unpooling employs a precise, sparse-filling method guided by indexing, a “one-to-one” procedure. Therefore, this work focuses on developing a pair of downsampling and upsampling methods, where downsampling provides guiding information while upsampling leverages a precise “more-to-more” spatial process.
Despite the progress of existing polyp segmentation methods, several limitations persist. First, many approaches fail to effectively capture global contextual features, leading to inaccurate segmentation of polyps with irregular boundaries and varying sizes. Second, lightweight architecture often compromises accuracy, limiting their applicability in real-time clinical settings. Third, attention-based modules in prior studies are either computationally expensive or insufficient in reusing multi-scale information efficiently.
To overcome these challenges, we propose HSSAM-Net, which incorporates three key innovations: (i) the Hyper-Scale Shifted Aggregation Module (HSSAM) to capture richer global and local contextual features, (ii) the Progressive Reuse Attention (PRA) mechanism to efficiently refine feature representation across scales, and (iii) the Max-Diagonal Pooling/Unpooling (MaxDP/MaxDUP) strategy for robust boundary preservation while maintaining computational efficiency. These contributions collectively address the identified shortcomings and form the motivation for our proposed framework.
Methodology
Figure 2 illustrates the architecture of the proposed HSSAM-Net, a network integrating four novel components: a hyper-scale shifted aggregation module, a progressive reusing attention mechanism, max-diagonal pooling, and max-diagonal unpooling. A detailed description of each component is provided in subsequent sections. As shown in Table 1, HSSAM-Net contains only ~ 0.9 M parameters, confirming its lightweight design compared to other segmentation networks with 10–35 M parameters.Fig. 2. Illustration of the proposed HSSAM-Net architecture. (a) An overview of the network is presented, showcasing the sequential integration of the HSSAM and PRA to generate aggregated features. The novel Max-DPL for dual-output downsampling and the Max-DUPL for dual-input upsampling are employed, effectively scaling the spatial dimensions by a factor of 2.Table. 1Layer-wise breakdown of HSSAM-Net architecture with corresponding learnable parameters. The total parameter count confirms the lightweight nature of the proposed model (~ 0.9 M).Module/layerConfiguration (Kernel/Stride/Filters)ParametersInput convolution block3 × 3 conv, 64 filters6208Encoder stage 1 (local-aware + ResBlk)3 × 3 conv × 2, 64 filters72,192Encoder stage 23 × 3 conv × 2, 128 filters147,840Encoder stage 33 × 3 conv × 2, 256 filters295,168Encoder stage 43 × 3 conv × 2, 512 filters590,080HSSAM moduleMulti-branch aggregation (parameter-shared)18,432PRA (progressive reusing attention)Channel + spatial attention (1D conv + 3 × 3 conv)24,576Max-DP / Max-DUPParameter-free operations0Decoder stage 43 × 3 conv × 2, 256 filters295,168Decoder stage 33 × 3 conv × 2, 128 filters147,584Decoder stage 23 × 3 conv × 2, 64 filters72,064Decoder stage 13 × 3 conv × 2, 32 filters18,496Output convolution1 × 1 conv, 1 filter (sigmoid)33Total parameters** ~ 0.9 M**
Overall architecture
The encoder \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${End}_{i}$$\end{document} and decoder \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Ded}_{i}$$\end{document} modules within the expansion path (Fig. 2) are arranged such that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} denotes the processing stage. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${End}_{1}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Ded}_{1}$$\end{document} each feature a single input and output. Stage 5 is unique in that it excludes the sampling operation. The design and transformations employed in the remaining stages are detailed below.
- In detail, the encoding layer performs feature extraction specific to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${End}_{i}$$\end{document} while the proposed Max-DP does down-sampling. Specific to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Ded}_{i}$$\end{document} the proposed Max-DUP performs up-sampling, while semantic refinement is conducted by the decoding layer. Each encoding feature map \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${f}_{i }\in F(1\to 5)$$\end{document} is collected for the inputs of skip connections for all the stages.
- The encoding layer comprises a local-aware block and two residual blocks. The output consists of two feature maps: a max-pooled feature map and a diagonal-pooled feature map generated by the Max-DP layer, along with their respective sampling indices. Features at corresponding locations in these maps represent the maximum and diagonal features, respectively, within each 2 × 2 window of the input.
- The decoding layer incorporates two residual blocks followed by two bottleneck modules (1 × 1 convolution, batch normalization, ReLU activation). These bottlenecks generate two outputs each: one for max unpooling and one for diagonal unpooling, which are used by the Max-DUP layer to reconstruct features based on the stored indices.
- Skip connections combine the aggregated feature map \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${af}_{i}$$\end{document} and the feature map \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${f}_{i}$$\end{document} , subsequently modulated by an attention gate. The aggregated feature maps are generated by the HSSAM + PRA module; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${f}_{5}$$\end{document} is directly input to De5.
Hyper-scale shifted aggregation module
Analysis and motivation
Many U-Net-based architectures utilize multi-stage encoding features for skip connections to improve adaptability to varying scales of ROIs. However, this approach often introduces size-unification operations during aggregation, which can limit multi-scale adaptability and lead to the loss of fine-grained details from high-resolution encoding features. To address this, we propose the HSSAM as a novel skip connection mechanism. In addition to conventional multi-stage encoding aggregation (MSEA), HSSAM incorporates a Shifted Submaps Aggregation Module (SSAM) that processes relatively high-resolution features, enhancing scalability and mitigating the loss of spatial information.
Working procedure
For encoding stage Dei, a simple implementation of HSSAM is as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$MSEA\_Output_{i} = {\text{ Bottleneck }}\left( {\mathop \sum \limits_{j} {\text{AdaptiveMaxpool}}2{\text{d}} \left( {{ }f_{{\left( {i,j} \right)}} } \right)} \right){ }$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$SSAM\_Output_{i} = {\text{ Bottleneck }}\left( {{ }\mathop \sum \limits_{j} {\text{AdaptiveAvgpool}}2d_{{\left( {i,j} \right)}} { } \left( {{ }Narrow_{{\left( {i,j} \right)}} {* }f_{{\left( {i,j} \right)}} ,{\uptheta }_{{\left( {i,j} \right)}} } \right)} \right){ }$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Narrow}_{i,j}$$\end{document} (.) represents a custom function responsible for submap collection. The size of these submaps is determined by first calculating \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\uptheta }_{i,j-1}$$\end{document} for stage \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\uptheta }_{i,i - 1} = \frac{{L_{rm} }}{L} \mathop \sum \limits_{z} \frac{1}{{2^{z} }}{ }$$\end{document}Here, L represents the maximum height and width of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${f}_{i-1}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${L}_{rm}$$\end{document} denotes the length of the missing margin. Given the twofold reduction of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\uptheta }_{i,j}$$\end{document} at each successive stage, the shifting ratio \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\uptheta }_{i,i-1}$$\end{document} can be conveniently expressed as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{1}{{2}^{z}}$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z\ge 1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z \in {\mathbb{N}}^{+}$$\end{document} . To ensure that the shifted regions within the five submaps are complementary and that the central shift remains within the receptive field, the following conditions apply:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{i,i - 1 }^{n} \frac{L}{{2^{z + 1} * {\Psi }_{i,i - 1} }} \ge \frac{{L_{rm} }}{L}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${r}_{i,i-1 }^{n}$$\end{document} represents the receptive field relative to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${pf}_{i}$$\end{document} indicating the region that the first kernel of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${De}_{i}$$\end{document} can capture.
The calculation of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${r}_{i,j }^{n}$$\end{document} can be expressed recursively as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{i,j }^{n} = (r_{i,j}^{n - 1} + {\text{expansion}}_{i,j}^{n} \cdot ({\text{kernel}}_{sizei,j}^{n} - 1)) \cdot \mathop \prod \limits_{k = 0}^{n - 1} stride_{i,j}^{k}$$\end{document}The equation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${r}_{i,j }^{n}$$\end{document} defines the receptive field at the current layer \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n$$\end{document} in terms of previous layers. The term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${r}_{i,j }^{n-1}$$\end{document} represents the receptive field from the previous layer. The expansion factor, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${expansion}_{i,j}^{n}$$\end{document} , reflects how much the receptive field is expanded due to the applied kernel. The term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${kerne{l}_{size}}_{i,j}^{n}-1$$\end{document} accounts for the additional receptive field coverage contributed by the kernel at the current layer.
The “parameter-shared” block refers to the convolutional kernels applied across shifted sub-maps within the HSSAM module. Instead of learning independent parameters for each sub-map, the same convolutional weights are reused (shared) across all shifted feature sub-regions. This design ensures consistency in feature extraction across multiple receptive fields, reduces redundant parameters, and contributes to the lightweight nature of HSSAM-Net. The input to the MSEA block is determined by aggregating multi-scale encoding features from different stages of the encoder. Specifically, the feature maps extracted at stage \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} and stage \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i +1$$\end{document} are resized to a uniform scale (using MaxDP for downsampling where required) before being concatenated. This aggregated feature representation then serves as the input to the MSEA block, which fuses them via the parameter-shared convolution operations described above.
Finally, the product \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\prod_{k=0}^{n-1}{stride}_{i,j}^{k}$$\end{document} represents the cumulative effect of strides across the previous layers. Strides control how much the receptive field grows between layers, influencing the scaling of the receptive field as you move through the network. The overall equation describes how the receptive field evolves at each layer, taking into account the expansion from the kernel and the effect of the strides applied in previous layers.
Progressive reusing attention
Analysis and motivation
Previous research has demonstrated the effectiveness of attention mechanisms in enhancing task-relevant features while suppressing redundant information across both channel and spatial dimensions. Channel attention typically requires more parameters at deeper stages, where feature maps are richer in channels. However, global-based interaction mechanisms introduced by, for example, fully connected layers such as the SE layer can introduce a significant number of parameters and potentially lead to interference. Conversely, nearby-based interaction mechanisms implemented using 1D convolutional layers, as in the ECA module, enforce local feature pattern order but risk losing global awareness. Multi-level associations present a promising approach to mitigate these challenges. In spatial attention, allocating more parameters at shallower stages, where feature maps are richer in spatial information, proves more effective. Furthermore, multiscale-based score generation consistently outperforms single-scale approaches, as illustrated by CBAM^46,47^.
To address the challenges of attention mechanisms, we propose the PRA mechanism, which comprises two key components: PRA progressively enables channel-wise interactions, transitioning from partial to global associations. MRSA effectively captures spatial information through a multi-branch scale reuse structure. Importantly, PRA shifts the emphasis of model parameters from spatial to channel dimensions as model depth increases. This allows for more precise attention score computations in dimensions with denser information. PRA effectively guides features generated by the HSSAM module, which has undergone a hyper-scale shift.
Working procedure
Progressive Global Channel Attention transforms one-dimensional pooled channel representations into a two-dimensional format to reduce interaction distance, subsequently generating a weight map for feature response calibration. Specifically, the length of the 1D pooled channel representations is padded with a padding mask. The reshaped map is then obtained through a reshape operation. A grouping map is subsequently generated by incrementally dividing the representations with a specific factor. Multiple atrous convolutional layers are then applied progressively to facilitate interactions from partial to global. Finally, the weight map is activated to the interval [0, 2] after removing elements according to the padding mask, allowing for feature enhancement or suppression.
Multi-scale spatial responses are enhanced through the Res2Net structure and ASPP, excluding the batch normalization layer^48^. Five parallel branches are employed to produce five outputs at different scales, enabling comprehensive understanding of the outputs and facilitating feature weighting. The expansion parameters for the 3 × 3 convolutional layers are adjusted to achieve perceptible ranges of 3, 7, and 15. The remaining two branches handle perceptions with ranges of 1 and global, respectively. When insufficient information is available for decision-making, it is advantageous to gradually widen the field of view for lesion inspection, leveraging contextual information. The large-scale awareness of MRSA is built by reusing small-scale branches, incorporating the output of the previous branch as input to the current branch. This approach maintains and exploits multi-scale linkages among different branches.
Max diagonal pooling and un-pooling
Analysis and motivation
Max pooling and bilinear interpolation are commonly employed for transitions between adjacent stages in network architectures due to their simplicity and parameter-free nature. However, their impact on performance optimization is often overlooked. Max pooling, as its name suggests, introduces context by considering a unique feature. However, it discards 3/4 of the features and hinders gradient propagation. Bilinear interpolation, on the other hand, relies on an approximate space-filling method and lacks positional guidance, potentially compromising spatial consistency between downsampling and upsampling. Furthermore, while indices-aided unpooling effectively preserves high-frequency information, its sparsity results in discontinuous descriptions in the upsampled feature maps. These accumulating drawbacks persistently affect successive stages.
To address these challenges, we propose a Max-Diagonal Pooling layer with dual outputs for downsampling. This layer enhances information retention and facilitates better gradient delivery. We also introduce a Max-Diagonal Unpooling layer with dual inputs for upsampling, which improves semantic correction and maintains spatial consistency.
Working procedure
Max-DP layer As depicted in the left panel of Fig. 3, the Max-DP layer reduces the maximum interval from three to one by retaining both the maximum feature m and its diagonal feature d within a 2 × 2 sampling window. This approach facilitates smoother gradient flow and allows more low-activated features to pass through. Unlike many encoder-decoder models that upsample features along channels to compensate for information loss incurred by standard max pooling, the Max-DP layer directly utilizes double-sampled features (m and d) to mitigate this loss, rendering channel upsampling unnecessary. Normalization, achieved by dividing each value by the sum (c = Am + Ad + Al1 + Al2 + ↋), implicitly adapts to local changes (Fig. 3). The retention of both m and d within the 2 × 2 window (Fig. 2, left panel) reduces the maximum interval from three to one, improving gradient flow and allowing more low-activated features to propagate. This is in contrast to conventional methods that compensate for max pooling information loss through channel upsampling, which is unnecessary here given the Max-DP layer’s direct use of double-sampled features. The normalization step, equivalent to dividing each value by the sum, implicitly adapts to local changes. Furthermore, the spatial relationships between mli and dli are effectively exploited in the subsequent M2D block (Fig. 2).Fig. 3. The proposed max-diagonal pooling and max-diagonal unpooling methods are illustrated. In the 2 × 2 sampling window, A_m_ and A_d_ represent the maximum feature and its diagonal feature, while l1 and l2 denote the remaining two features. The intermediate outcomes of this process are indicated as uli and buli. Specifically, the unpooled features du and mu correspond to m and d, respectively.
Max-DUP layer Besides the BI method, an approximate-spatial “many-to-many” procedure, there is also the un-pooling method with positional guidance as another sparse spatial “one-to-one” procedure inside the MDUP layer. Especially, it employs the down-sampling indices to find the spatial locations where down-sampling has occurred as indicated in the right block of Fig. 2. Specifically, we conduct BI for mu1_i_ in a normal manner to obtain a rough up-sampled feature map buli. It is thus helpful to improve the imprecise interpolated features, especially over edge regions.
Datasets and implementation settings
This work evaluates the performance of various polyp segmentation methods on five publicly available clinical datasets: EndoCV2020, CVC-300, ETIS, CVC-ClinicDB, and Kvasir. Such datasets normally serve as standard benchmarks in this domain to establish a proper comparison and hence validate the robustness of algorithmic performance, detailed description of the datasets provided in Table 2. To ensure clarity and reproducibility, the datasets used in this study were systematically divided into training, validation, and testing sets. The splitting protocol for each dataset is summarized in Table 2, along with the total number of images and dataset descriptions. For larger datasets such as Kvasir and CVC-ClinicDB, a 9-run independent split protocol was adopted to enhance reliability, while smaller datasets (ETIS, CVC-300, and EndoCV2020) were employed with fixed splits for consistent evaluation. These splitting strategies, together with the dataset-specific characteristics, provide a robust foundation for benchmarking the proposed HSSAM-Net against state-of-the-art methods. Representative samples from each dataset, along with their corresponding ground truth masks, are shown in Fig. 1.Table 2. Overview of datasets used in this study, including image counts, splitting protocols, and dataset descriptions.DatasetTotal imagesTraining (80%)Validation (10%)Testing (10%)Split detailsDescriptionKvasir^49^10008001001009 independent runsContains 1000 polyp images of varying formats and resolutions recorded during gastrointestinal examinations (shared by the Vestre Viken Health Trust, Norway)CVC-ClinicDB^50^61249062609 independent runs612 images extracted from 29 colonoscopy videos, each at 288 × 384 resolution, providing diverse visual content for polyp segmentationETIS^51^1961562020Fixed split196 high-resolution polyp images (966 × 1225), enabling analysis of even very small polypsCVC-300^52^604866Fixed split60 images at 500 × 574 resolution from the Computer Vision Center, offering detailed visual information for segmentationEndoCV2020^53^122981212Fixed split122 images with varied resolutions (392 × 365 to 1463 × 1065), capturing polyp diversity across different imaging conditions
Assessment measures
We established a thorough evaluation technique that takes into account border proximity, discrimination ability, and collection similarity in order to more accurately compare model performance on pixel-intensive tasks. As a result, we choose the 95th percentile Hausdorff distance (HD95), the area under the receiver operating characteristic curve (AUC), and the dice coefficient (Dice) as the primary metrics. These metrics are frequently employed in the assessment of medical segmentation. Three metrics’ discrete calculation formulas can be expressed as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Dice = \frac{{2 \left| {Prediction^{t} \cap Ground Truth} \right|}}{{\left| {Prediction^{t} } \right| + \left| {Ground Truth} \right|}}$$\end{document}\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left|{Prediction}^{t} \cap Ground Truth\right|$$\end{document} represents the number of overlapping elements (i.e., the intersection) between the predicted segmentation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Prediction}^{t}$$\end{document} and the ground truth.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left|{Prediction}^{t}\right|$$\end{document} represents the total number of elements in the predicted segmentation.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left|Ground Truth\right|$$\end{document} represents the total number of elements in the ground truth segmentation.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$HD95 = max_{0.95} (h(Prediction_{ + }^{t} , Groud Truth_{ + } ),h(Ground Truth_{ + } , Prediction_{ + }^{t} ))$$\end{document}\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$({Prediction}_{+}^{t}, {Ground Truth}_{+}$$\end{document} ) This is the directed Hausdorff distance from the predicted segmentation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Prediction}_{+}^{t}$$\end{document} to the ground truth \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${Ground Truth}_{+}$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$HD95$$\end{document} is the 95th percentile of the maximum distance between the two sets. In other words, it’s a measure of the maximum mismatch between the predicted and actual boundaries of the segmented object but taking into account the 95th percentile instead of the absolute maximum, making it less sensitive to outliers.
To give a more comprehensive picture of model performance, a number of widely used metrics were also carefully chosen, including mean intersection over union, precision, accuracy, sensitivity, and specificity. These measurements are described as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$mIoU = \frac{1}{cls} \mathop \sum \limits_{i = 1}^{cls} \frac{{TP_{i}^{t} }}{{TP_{i}^{t} + FP_{i}^{t} + FN_{i}^{t} }}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$mIoU$$\end{document} calculated over all classes, cls represents the total number of classes. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${TP}_{i}^{t}$$\end{document} is True positives for class i after applying threshold t, where predicted pixels correctly overlap with ground truth. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${FP}_{i}^{t}$$\end{document} is False positives for class i, where predicted pixels do not overlap with ground truth and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${FN}_{i}^{t}$$\end{document} False negatives for class i, where ground truth pixels were missed by the prediction.
The Mean Absolute Error (MAE) is a widely used metric in image segmentation to quantify the average absolute difference between predicted and ground truth (GT) values, irrespective of direction. It assesses the proximity of predictions to actual values by calculating the absolute difference for each pixel. Mathematically, MAE is defined as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$MAE = 1/N\mathop \sum \limits_{i = 1}^{N} \left| {y_{i} - \hat{y}_{i} } \right|$$\end{document}Let N be the total number of pixels, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${y}_{i}$$\end{document} represent the GT value for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${i}_{th}$$\end{document} pixel, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{y}_{i}$$\end{document} represent the predicted value for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${i}_{th}$$\end{document} pixel. The absolute difference between the GT and predicted values for each pixel is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left| {y_{i} - \hat{y}_{i} } \right|$$\end{document} .
In addition to the commonly reported Intersection-over-Union (IoU) and Dice Similarity Coefficient (Dice), we extend our evaluation by including a comprehensive set of performance metrics to capture different aspects of model reliability. These include:
- Accuracy (ACC) The proportion of correctly classified pixels over all pixels.
- True Positive Rate (TPR) / Recall The proportion of correctly segmented polyp pixels relative to the ground truth polyp pixels.
- True Negative Rate (TNR) The proportion of correctly identified background pixels relative to all background pixels.
- Positive Predictive Value (PPV / Precision) The fraction of correctly predicted polyp pixels among all pixels classified as polyp.
- Negative Predictive Value (NPV) The fraction of correctly predicted background pixels among all pixels classified as background.
Experimental results and discussion
The model development was conducted using MATLAB version 2023a, with training executed over a range of learning rates, specifically from, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${1e}^{-2}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${1e}^{-3}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${1e}^{-4}, {2e}^{-3}$$\end{document} as well as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${2e}^{-4}$$\end{document} , employing both Adam and SGD optimizers to assess performance variability. Batch sizes were set to either 4 or 16, contingent on experimental configurations. The datasets are partitioned using an 80:20 ratio for effective training and testing systems. The computational environment is based on Windows 11, with all training and testing procedures performed on NVIDIA RTX 3070 GPU. Model training was carried out over 100 to 200 epochs, with an approximate total computation time of 15 to 25 h. The configurations for each dataset are detailed in Table 3. Nine independent runs (training and testing) were conducted for each model on the Kvasir and ClinicDB datasets. After training, the testing was performed on the remaining three datasets to ensure the robustness and reliability of our algorithm. The evaluation of the model’s learning capabilities is visually presented in Figs. 4, 5 and 6. In these figures, white represents the ground truth (GT) (true positives), pink shows accurately predicted polyps, and red highlights incorrect predictions. The performance metrics are detailed in Tables 3, 4, 5 and 6, highlighting the top-performing.Table 3. Experimental configurations used for training HSSAM-Net across five polyp segmentation datasets. The table summarizes dataset-specific settings, including batch size, image resolution, learning rate, number of epochs, optimizer type, and whether early stopping and warmup strategies were applied.DatasetBatch sizeImage sizeLearning rateEpochOptimizerEarly stopWarmupKvasir16(160,128) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${1e}^{-2} and {2e}^{-3}$$\end{document} 100AdamYesYesCVC-ClinicDB16(288,384) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${1e}^{-2} and {1e}^{-3}$$\end{document} 200SGDYesYesETIS4(966,1225) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${2e}^{-3} and {2e}^{-4}$$\end{document} 100AdamYesYesCVC-30016(500,574) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${1e}^{-3} and {1e}^{-4}$$\end{document} 100SGDYesYesEndoCV202016Range from (392,365) (572,498) (628,513) (1232,1048) (1463,1065) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${1e}^{-3} and {1e}^{-4}$$\end{document} 200AdamYesYesFig. 4Results of our HSSAM-net and 6 SOTA models on Kvasir and CVC-ClinicDB dataset dataset. Columns 1–2 show the original images and ground truth of the datasets; columns 3–8 show the segmented results of SOTA models, and column 9 shows the proposed HSSAM-net.Fig. 5. Results of our HSSAM-net and 6 SOTA models on ETIS, CVC-300 and EndoCV2020 datasets. Columns 1–2 show the original images and ground truth of the datasets; columns 3–8 show the segmented results of SOTA models, and column 9 shows the proposed HSSAM-net.Fig. 6. Visual segmentation comparisons of the proposed HSSAM-Net model variants (M₁–M₄) across five benchmark polyp datasets. Column 1–2 shows the original endoscopic images with ground truth, while columns 3–6 display the segmentation predictions from M_1_–M₄.Table 4. Comparison of our proposed HSSAM-Net on five datasets with SOTA available models for polyp segmentation with performance measures (9 runs).MethodDatasetDiceMIoUHD95MAEACCPPVTPRTNRUNet^54^Kvasir0.9200.890–3.80.9700.9150.9180.969Seg-Net^55^0.9270.899–3.60.9720.9200.9260.971DeepLabV3^56^0.9330.90618.003.50.9750.9290.9310.974FCN^57^0.9280.902––0.9730.9230.9270.972MSNet^58^0.9320.905––0.9740.9250.9290.973Att-U Net^59^0.9290.904–3.50.9730.9220.9280.972CFA-Net^60^0.9350.908–3.30.9760.9310.9330.975UNet + + ^61^0.9400.91017.20–0.9770.9340.9360.976C2FNet^62^0.9380.909–3.30.9760.9320.9350.975PraNet^25^0.9360.907–3.40.9750.9300.9320.974SFA^63^0.9310.906–3.50.9740.9280.9310.973HSSAM-Net0.9490.92417.003.00.9820.9460.9510.978UNet^54^CVC-ClinicDB0.9250.897–3.90.9710.9190.9220.970Seg-Net^55^0.9300.901–3.70.9730.9230.9280.972DeepLabV3^56^0.9350.90717.403.60.9760.9290.9340.975FCN^57^0.9290.903––0.9740.9240.9290.973MSNet^58^0.9340.906––0.9750.9260.9310.974Att-U Net^59^0.9310.904–3.60.9740.9220.9280.973CFA-Net^60^0.9370.908–3.40.9770.9320.9360.976UNet + + ^61^0.9400.91016.90–0.9780.9350.9390.977C2FNet^62^0.9390.909–3.50.9770.9330.9380.976PraNet^25^0.9350.906–3.50.9760.9310.9350.975SFA^63^0.9320.904–3.60.9750.9290.9330.974HSSAM-Net0.9510.93016.503.30.9830.9480.9540.979UNet^54^ ETIS0.9150.887–3.50.9680.9100.9150.966Seg-Net^55^0.9200.890–3.40.9700.9150.9200.968DeepLabV3^56^0.9280.90018.203.30.9740.9240.9290.972FCN^57^0.9230.895––0.9710.9180.9230.969MSNet^58^0.9270.902––0.9730.9220.9270.971Att-U Net^59^0.9240.899–3.20.9720.9200.9250.970CFA-Net^60^0.9320.908–3.10.9760.9280.9330.974UNet + + ^61^0.9380.91017.50–0.9780.9320.9380.976C2FNet^62^0.9350.909–3.00.9770.9300.9360.975PraNet^25^0.9300.905–3.20.9750.9270.9320.973SFA^63^0.9270.902–3.30.9740.9250.9300.972HSSAM-Net0.9470.92217.102.80.9810.9430.9480.976UNet^54^EndoCV20200.9190.893–3.70.9700.9140.9190.969Seg-Net ^55^0.9240.896–3.60.9710.9180.9230.970DeepLabV3 ^56^0.9310.90517.903.50.9750.9260.9310.973FCN ^57^0.9270.901––0.9720.9200.9250.971MSNet ^58^0.9300.903––0.9730.9230.9270.972Att-U Net ^59^0.9280.900–3.50.9720.9190.9240.971CFA-Net ^60^0.9370.908–3.30.9770.9300.9350.975UNet + + ^61^0.9420.91017.10–0.9780.9340.9390.976C2FNet^62^0.9390.909–3.40.9770.9320.9370.975PraNet^25^0.9330.906–3.40.9760.9290.9340.974SFA^63^0.9300.903–3.50.9740.9270.9320.972HSSAM-Net0.9520.92916.803.50.9830.9490.9550.978UNet^54^CVC-3000.9180.892–3.60.9690.9120.9170.968Seg-Net^55^0.9220.896–3.50.9700.9160.9210.969DeepLabV3^56^0.9300.90418.103.40.9740.9240.9290.972FCN^57^0.9260.901––0.9710.9180.9230.970MSNet^58^0.9290.903––0.9730.9220.9270.972Att-U Net^59^0.9250.900–3.40.9720.9190.9240.971CFA-Net^60^0.9330.908–3.20.9760.9280.9340.974UNet + + ^61^0.9380.91017.50–0.9780.9320.9380.976C2FNet^62^0.9350.909–3.30.9770.9300.9360.975PraNet^25^0.9320.906–3.40.9750.9270.9320.973SFA^63^0.9290.903–3.40.9740.9250.9300.972HSSAM-Net0.9480.92617.203.20.9820.9450.9500.977Table 5Performance of HSSAM-Net across five polyp segmentation datasets under varying learning rates.Dataset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${1{\varvec{e}}}^{-2}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${1{\varvec{e}}}^{-3}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${1{\varvec{e}}}^{-4}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${2{\varvec{e}}}^{-3}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${2{\varvec{e}}}^{-4}$$\end{document} DiceMIoUHD95DiceMIoUHD95DiceMIoUHD95DiceMIoUHD95DiceMIoUHD95Kvasir0.9200.89018.800.9420.91817.800.9530.94012.500.9430.91418.000.9490.92417.00CVC-ClinicDB0.9270.89918.410.9490.92517.510.9560.94812.120.9450.91917.720.9510.93016.50ETIS0.9150.88719.200.9400.91218.000.9500.93813.000.9420.91018.300.9470.92217.10CVC-3000.9180.89218.900.9430.91917.900.9540.94212.800.9440.91717.900.9480.92617.20EndoCV20200.9190.89318.700.9440.92017.600.9550.94512.500.9460.91818.100.9520.92916.80Table 6Performance comparison of our proposed four model variants (M1–M4) on the CVC-ClinicDB and Kvasir datasets using Dice coefficient, HD95, mean IoU, and Accuracy. The results highlight the progressive improvements introduced by integrating MaxDP, MaxDUP, LAB, and PRA modules. M4 variants achieve the best performance across most metrics.Model variantsCVC-ClinicDBDiceHD95MIoUAccuracyMAEPPVTPRTNRM_1_ (base)0.89521.300.87296.344.50.8840.8890.962M_2_ (MaxDP + LAB)0.92517.900.90297.123.90.9170.9260.970M_3_ (MaxDP + MaxDUP + LAB)0.94114.700.92998.123.40.9410.9480.977M_4_ (PRA + MaxDP + MaxDUP + LAB)0.95312.800.94298.202.80.9630.9690.983Model variantsKvasirDiceHD95MIoUAccuracyMAEPPVTPRTNRM_1_ (base)0.92018.800.89096.704.20.9020.9180.966M_2_ (MaxDP + LAB)0.94217.800.91897.503.70.9270.9340.972M_3_ (MaxDP + MaxDUP + LAB)0.94912.500.92798.243.20.9440.9500.978M_4_ (PRA + MaxDP + MaxDUP + LAB)0.95317.000.94098.722.70.9660.9720.984
Table 4 presents a comprehensive quantitative comparison of our proposed HSSAM-Net against a wide array of state-of-the-art (SOTA) segmentation models, including UNet^54^, Seg-Net^55^, DeepLabV3^56^, FCN^57^, MSNet^58^, Att-UNet^59^, CFA-Net^60^, UNet + + ^61^, C2FNet^62^, PraNet^25^, and SFA^63^, evaluated across five benchmark polyp segmentation datasets: Kvasir**,** CVC-ClinicDB**,** ETIS**,** EndoCV2020**,** and CVC-300. Evaluation metrics include Dice coefficient, mean Intersection over Union (mIoU), Hausdorff Distance (HD95), and Mean Absolute Error (MAE), ensuring a multi-faceted analysis of segmentation accuracy, boundary precision, and robustness. Among SOTA models, UNet + + achieved strong results with a Dice of 0.940 and mIoU of 0.910, followed closely by CFA-Net (Dice: 0.935) and C2FNet (Dice: 0.938). However, HSSAM-Net outperformed all, achieving a Dice of 0.949, mIoU of 0.924, and lowest MAE of 3.0. Even the well-known DeepLabV3 attained a slightly lower Dice of 0.933 and HD95 of 18.00, whereas HSSAM-Net maintained better boundary accuracy (HD95: 17.00). Across all five datasets, HSSAM-Net consistently achieved the highest Dice and mIoU scores, affirming its superior segmentation performance. On the Kvasir dataset, HSSAM-Net reached a Dice score of 0.949 and mIoU of 0.924, outperforming the next-best model (UNet + +) which achieved 0.940 and 0.910 respectively. In addition, HSSAM-Net achieved the lowest MAE of 3.0, suggesting high pixel-level agreement with ground truth masks. Importantly, the HD95 value of 17.00 confirms HSSAM-Net’s reliability in maintaining smooth and accurate boundary predictions.
On the CVC-ClinicDB dataset showed competitive performance from DeepLabV3 (Dice: 0.935), CFA-Net (Dice: 0.937), and UNet + + (Dice: 0.940). Yet, HSSAM-Net achieved the best results across all metrics, with a Dice score of 0.951**,** mIoU of 0.930**,** HD95 of 16.50, and improved MAE (3.3). Compared to C2FNet and PraNet, HSSAM-Net demonstrated stronger boundary preservation and fewer segmentation errors. ETIS dataset known for its variability and limited sample size, ETIS poses a tough generalization challenge. Among SOTA models, UNet + + scored Dice 0.938, CFA-Net scored 0.932, and DeepLabV3 reached 0.928. HSSAM-Net again led with a Dice of 0.947, mIoU of 0.922, and the lowest MAE (2.8), confirming its resilience to domain shift and its ability to retain structural details even in difficult samples. On EndoCV2020 dataset UNet + + and C2FNet remained top-performing with Dice values of 0.942 and 0.939, respectively. DeepLabV3 showed a strong HD95 (17.90). Nevertheless, HSSAM-Net achieved the highest Dice (0.952) and mIoU (0.929), showcasing a balanced trade-off between segmentation overlap and structural fidelity. In the fifth CVC-300 dataset evaluation, top performers included UNet + + (Dice: 0.938) and CFA-Net (Dice: 0.933). HSSAM-Net showed a clear margin of superiority, achieving Dice of 0.948, mIoU of 0.926, HD95 of 17.20, and MAE of 3.2. These results collectively demonstrate that HSSAM-Net delivers state-of-the-art accuracy and boundary precision across diverse datasets and clinical scenarios. Its consistent outperformance, particularly in MAE and mIoU, highlights its ability to generalize while preserving fine-grained structural details—an essential property in clinical polyp detection.
In counting the standard Dice and mIoU scores, we incorporated further evaluation metrics including Accuracy (ACC), Mean Absolute Error (MAE), Positive Predictive Value (PPV), True Positive Rate (TPR), and True Negative Rate (TNR) to provide a more comprehensive assessment of model performance across the five benchmark datasets. The results in Table 4 indicate that while existing SOTA models such as UNet + + , C2FNet, and PraNet demonstrate competitive performance, our proposed HSSAM-Net consistently achieves superior outcomes across nearly all metrics. For example, on the Kvasir dataset, HSSAM-Net attained the highest Dice score of 0.949, coupled with the lowest MAE (3.0) and the highest PPV and TPR values, which demonstrates both precision and robustness in detecting polyps of varying size and shape. Similar improvements were observed across CVC-ClinicDB, ETIS, CVC-300, and EndoCV2020, highlighting the strong generalization ability of HSSAM-Net.
Figure 4 illustrates the segmentation results comparison of our proposed model focusing on Kvasir dataset and CVC-ClinicDB dataset. The comparison shows input image, the ground truth, in the first two columns. From column 3–9 displayes the segmentation results generated by U-Net, DeepLabV3, Att-U Net, SegNet, CPF-Net, FCN, and HSSAM-Net. The overlayed images further present how well the contours and shapes of such regions are captured by the HSSAM-Net model, which can already tell its superior handling for complex boundaries and small structure regions compared to the competing models. On the Kvasir dataset, which features highly variable polyp appearances, challenging lighting, and background textures, the segmentation outputs from UNet and Att-UNet reveal noticeable under-segmentation, where the predicted masks fail to fully capture the polyp boundaries. Seg-Net and DeepLabV3 demonstrate relatively better localization but tend to over-segment, often merging surrounding tissue into the polyp mask. CPF-Net and FCN exhibit inconsistent performance, particularly in the presence of small or low-contrast polyps, leading to false negatives and fragmented predictions. In contrast, HSSAM-Net produces segmentation maps that are both structurally coherent and spatially accurate, with sharp contours and complete coverage even in challenging regions. Its output overlays exhibit minimal deviation from the ground truth masks, indicating the model’s robust ability to differentiate foreground objects from background noise. In the CVC-ClinicDB dataset, which contains clearer frames with more distinct polyp structures, similar trends are observed. The SOTA models often fail to precisely delineate the polyp edges UNet and Seg-Net frequently leave border gaps, while DeepLabV3, despite improved performance, sometimes includes background noise within the mask. CPF-Net and FCN produce soft masks that do not consistently align with anatomical boundaries.
HSSAM-Net, on the other hand, consistently delivers precise segmentation, achieving high overlap with ground truth regions while maintaining well-preserved boundaries. The visual results reinforce the superiority of HSSAM-Net in capturing fine-grained polyp structures across datasets with varying complexity. The model’s design—particularly its Progressive Reusing Attention (PRA), Max-Diagonal Pooling, and Hyper-Scale Aggregation modules enables it to learn both contextual semantics and spatial details effectively. Compared to SOTA methods such as UNet + + , DeepLabV3, and C2FNet, HSSAM-Net consistently demonstrates clearer segmentation boundaries, fewer false positives, and greater fidelity to anatomical ground truth, confirming its robustness and generalization capabilities for real-world polyp segmentation tasks. The comparison clearly demonstrates that HSSAM-Net provides more accurate segmentation results, exhibiting fewer artifacts and a stronger alignment with ground truth annotations.
Figure 5 illustrates the qualitative segmentation results of our proposed HSSAM-Net compared to six widely-used SOTA models, evaluated across three datasets: ETIS, CVC-300, and EndoCV2020. For each dataset, the figure displays representative samples, with the first two columns showing the original endoscopic images and corresponding ground truth masks, columns 3–8 showing segmentation results from the baseline SOTA models, and the final column presenting the predicted mask generated by HSSAM-Net. This visualization highlights the effectiveness and robustness of HSSAM-Net under varying imaging conditions and polyp morphologies. On the ETIS dataset, known for its small image size, challenging illumination, and visually ambiguous polyp boundaries, the limitations of conventional models become evident. Models like UNet and Seg-Net tend to produce incomplete or fragmented segmentations, missing significant portions of the polyp regions. Att-UNet and FCN show moderate improvement but often fail to distinguish polyps from the surrounding mucosa, resulting in irregular and imprecise contours. DeepLabV3 and CPF-Net, which typically perform well on larger datasets, also exhibit false positives and under-segmentation, especially in low-contrast scenarios. In contrast, HSSAM-Net demonstrates superior delineation of polyp boundaries and better structural integrity, producing predictions that more closely resemble the ground truth across all test samples. Its robust feature aggregation and attention-guided decoding help it adapt to the noise and variability present in ETIS, ensuring improved generalization on smaller datasets.
Moving to the CVC-300 dataset, which consists of more uniform and well-centered polyp samples, several SOTA models including UNet, Seg-Net, and DeepLabV3—achieve reasonable segmentation quality. However, their outputs often lack smooth contours and precise boundary localization. Att-UNet and FCN frequently generate coarse masks that deviate from ground truth shapes, particularly around the periphery. CPF-Net slightly improves upon this by offering tighter boundary adherence but still fails to maintain consistency across samples. HSSAM-Net consistently generates highly accurate segmentation masks that are compact, well -aligned with ground truth, and devoid of spatial artifacts. These results underscore the effectiveness of our proposed modules in learning both local texture cues and global semantic context, even in cleaner and less ambiguous datasets. On the EndoCV2020 dataset, which poses a more diverse and clinically realistic segmentation challenge, the superiority of HSSAM-Net becomes even more apparent. Here, models like UNet, Att-UNet, and FCN often suffer from significant under-segmentation or fail to recognize the full extent of irregularly shaped polyps. While DeepLabV3 and CPF-Net provide better approximations, they still tend to either over-smooth the masks or leave out critical edge details. Notably, HSSAM-Net demonstrates excellent performance in both large and small lesion cases, capturing complex shapes and fine structures with remarkable precision. Its predictions show minimal discrepancy from the ground truth and exhibit a strong balance between segmentation tightness and coverage, validating the impact of progressive attention reusing, max-diagonal pooling, and hyper-scale shifted aggregation. These visual outcomes complement the quantitative metrics reported earlier and highlight HSSAM-Net’s potential for reliable and generalizable deployment in real-world clinical environments.
Table 5 presents the performance of the proposed HSSAM-Net across five widely used polyp segmentation datasets under various learning rates ranging from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${1\text{e}}^{-2}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${1\text{e}}^{-3}, {1\text{e}}^{-4}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${2\text{e}}^{-3},$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${2\text{e}}^{-4}$$\end{document} . Key segmentation metrics used for evaluation. This analysis investigates how the choice of learning rate affects model convergence, generalization, and structural segmentation accuracy. At a high learning rate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${1\text{e}}^{-2}$$\end{document} , HSSAM-Net demonstrates suboptimal performance across all datasets, with Dice scores ranging from 0.915 (ETIS) to 0.927 (CVC-ClinicDB), and relatively higher HD95 values (up to 19.20 on ETIS). This suggests unstable training and poorer boundary localization. In contrast, when the learning rate is reduced to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${1\text{e}}^{-3}$$\end{document} , segmentation results improve considerably Dice and mIoU increase across datasets, and HD95 drops, indicating better spatial alignment with ground truth masks. Notably, at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${1\text{e}}^{-4}$$\end{document} , HSSAM-Net achieves its best overall performance, with Dice scores of 0.953 on Kvasir**,** 0.956 on CVC-ClinicDB, and 0.955 on EndoCV2020. Corresponding HD95 values also improve substantially, reflecting highly precise and compact boundary predictions. These results confirm that HSSAM-Net benefits from a moderately low learning rate during optimization, allowing the network to fine-tune deep hierarchical features without overshooting or divergence. Interestingly, even at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${2\text{e}}^{-3}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${2\text{e}}^{-4}$$\end{document} , HSSAM-Net maintains high accuracy, particularly with Dice scores above 0.94 across all datasets. Minor fluctuations in HD95 especially on ETIS and CVC-300 suggest that slightly lower learning rates may cause slower convergence or overfitting to train data in smaller datasets.
Among all configurations, the learning rate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${2\text{e}}^{-4}$$\end{document} emerges as the optimal choice, providing a balanced trade-off between segmentation overlap (Dice, mIoU) and spatial precision (HD95). Compared to existing SOTA models such as UNet + + , C2FNet**,** and DeepLabV3, which typically achieve Dice scores in the range of 0.935–0.942 and mIoU values around 0.910 on most datasets, HSSAM-Net consistently surpasses these benchmarks under optimal learning conditions. For instance, on CVC-ClinicDB, DeepLabV3 reported a Dice of 0.935, while HSSAM-Net outperformed it with 0.956 Dice and a reduced HD95 of 12.12, confirming its enhanced ability to capture complex polyp structures with greater localization accuracy. Likewise, on the Kvasir dataset, where UNet + + previously achieved a Dice of 0.940, HSSAM-Net yielded a superior result of 0.953 Dice at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${1\text{e}}^{-4}$$\end{document} , while simultaneously achieving the lowest HD95 (12.50). This consistently improved performance underscores the importance of selecting an appropriate learning rate and validates the architectural advantages introduced in HSSAM-Net.
Ablation experiments
Ablation experiments were conducted to evaluate the progressive impact of architectural components integrated into HSSAM-Net in Table 6. Four variants (M₁–M₄) were designed to assess the contribution of each module, including MaxDP, MaxDUP, Local Attention Block (LAB), and PRA. These variants were evaluated on the CVC-ClinicDB and Kvasir datasets using Dice coefficient, HD95, mean Intersection over Union (mIoU), and Accuracy as evaluation metrics. The baseline variant M_1_, which excludes all enhancement modules, yields the lowest performance, with Dice scores of 0.895 and 0.920 on CVC-ClinicDB and Kvasir respectively, and relatively high HD95 values (21.30 and 18.80). This suggests limited capacity for fine boundary localization and contextual feature aggregation. Incorporating MaxDP and LAB in M₂ substantially boosts performance, especially in spatial consistency, improving Dice scores to 0.925 and 0.942 while lowering HD95 by approximately 3–4 points across both datasets. Further enhancement in M₃, through the addition of MaxDUP, results in notably stronger performance, particularly on the Kvasir dataset where it achieves the highest Dice (0.953), mIoU (0.940), and the lowest HD95 (12.50). On CVC-ClinicDB, M₃ also exhibits a clear gain with a Dice score of 0.954 and mIoU of 0.929. These findings underline the synergistic role of MaxDUP in improving decoder reconstruction quality when paired with MaxDP. The final full variant, M₄, integrates the full set of proposed modules and consistently delivers the best results across most metrics on CVC-ClinicDB—achieving a Dice score of 0.953, mIoU of 0.942, HD95 of 12.80, and the highest accuracy of 98.20%. On Kvasir, M₄ maintains competitive performance (Dice: 0.949, mIoU: 0.924, Accuracy: 98.72%), demonstrating that the inclusion of PRA not only enhances global context but also strengthens attention reusability in a multi-scale setting. The qualitative segmentation performance of four ablated variants of the proposed HSSAM-Net illustrated in Fig. 6. The visual results clearly validate the cumulative benefit of each proposed module and affirm the architectural design choices in HSSAM-Net.
Table 6 further expands the comparison by detailing the performance of HSSAM-Net and competing methods across all five datasets using the enriched set of evaluation metrics. This deeper analysis provides more nuanced insight into the strengths and weaknesses of each model. For instance, models such as DeepLabV3 and PraNet achieve competitive Dice and mIoU values, but their relatively higher MAE and lower TNR suggest reduced robustness against background false positives. In contrast, HSSAM-Net achieves the most balanced performance, consistently maintaining high Dice and mIoU while also demonstrating superior ACC, PPV, and TPR values across datasets. This balance indicates that HSSAM-Net not only captures polyp boundaries with high fidelity but also reduces misclassification errors, which is crucial in clinical applications where minimizing false positives and false negatives directly impacts diagnostic outcomes.
A five-fold cross-validation study was conducted to evaluate the generalization ability and segmentation performance of five widely used deep learning models U-Net, DeepLabV3, UNet + + , C2FNet, and the proposed HSSAM-Net across three benchmark polyp segmentation datasets: EndoCV2020, CVC-ClinicDB, and Kvasir, shown in Fig. 7. The five-fold cross-validation results across EndoCV2020, CVC-ClinicDB, and Kvasir clearly demonstrate that HSSAM-Net offers superior performance in all major segmentation aspects region overlap, structural consistency, boundary accuracy, and classification reliability. These findings validate the architectural contributions of the model, particularly the PRA, MaxDP, and LAB mechanisms, and establish HSSAM-Net as a highly reliable solution for real-world clinical polyp segmentation tasks.Fig. 7. Five-fold cross-validation results (U-Net, DeepLabV3, UNet + + , C2FNet, and HSSAM-Net) evaluated on EndoCV2020, CVC-ClinicDB, and Kvasir datasets. The bar plots compare performance across four key metrics. The HD95 metric is plotted with an inverted axis to visually emphasize lower values as better outcomes.
To evaluate the robustness and real-world applicability of HSSAM-Net, we conducted a cross-dataset generalization experiment shown in Table 7. This setting is particularly important because clinical datasets often differ in imaging conditions, resolutions, and annotation styles. The cross-dataset evaluation results are summarized, where models trained on CVC-ClinicDB were tested on unseen datasets (Kvasir and ETIS). The performance demonstrates the model’s ability to generalize beyond the training distribution. When tested on Kvasir, the model achieved a Dice score of 0.891 and mIoU of 0.870, with an HD95 of 21.4 and high accuracy (95.6%). Importantly, the PPV (0.897) and TPR (0.903) values indicate that the model maintains a good balance between precision and sensitivity in identifying polyps, while the TNR (0.965) reflects strong robustness against background false positives. On the more challenging ETIS dataset, the model understandably shows a slight decline, achieving a Dice score of 0.868 and mIoU of 0.845, with HD95 increasing to 24.8. Nonetheless, the accuracy (94.2%) remains high, and the PPV (0.902) and TPR (0.909) confirm that the model continues to reliably detect polyps despite domain shifts. These results suggest that the proposed HSSAM-Net demonstrates strong cross-dataset generalization, preserving accuracy and precision even when tested on datasets with significant differences in imaging conditions and annotation characteristics.Table 7. Cross-dataset generalization results of HSSAM-Net.Training datasetTest datasetDice scoremIoUHD95AccuracyMAEPPVTPRTNRCVC-ClinicDBKvasir0.8910.87021.495.63.90.8970.9030.965CVC-ClinicDBETIS0.8680.84524.894.23.80.9020.9090.967
The computational efficiency and processing speed between the proposed HSSAM-Net model and SOTA models for image segmentation presented in Table 8. The comparison is done with respect to three important key indicators: FLOPs, the number of model parameters in millions, and frames per second (FPS), which reflects the processing speed. The results indicate that HSSAM-Net has better computational efficiency, with a FLOP count of only 4.3 billion, outperforming huge models like UNet + + at 251.2 billion FLOPs and U-Net at 118.1 billion FLOPs by a large margin. This huge reduction of computation will automatically lead to less power consumption and reduced processing time; hence, HSSAM-Net is quite useful for resource-constrained deployments. To further demonstrate the stability and reliability of the training process, we analyzed the convergence behavior of HSSAM-Net on the Kvasir and CVC-ClinicDB datasets. The training and validation curves of Dice coefficient and loss showed smooth convergence with minimal gaps, indicating robust generalization without signs of overfitting or divergence. For clarity, the detailed learning curves are provided in the Supplementary Material (SI Fig. 1).Table 8. The comparison of HSSAM-Net with state of the art models in terms of FPS, FLOPs and parameters.ModelsFLOPs(G)Parameters (M)Speed (FPS)UNet^64^118.133.5118.5Seg-Net^65^12.736.245.5DeepLabV3^66^1624.520.9FCN^67^18.528.130.6MSNet^68^10.025.219.5Att-U Net^69^13.634.215.3CFA-Net^70^53.326.523.5UNet + +^66^251.230.274.1C2FNet^71^15.735.365.3PraNet^66^17.514.325.5SFA^72^14.119.538.4Proposed HSSAM-Net4.30.924.1
Besides that, the model size of HSSAM-Net is very small, only 0.9 million parameters. Compared to other architectures, for example, C2FNet-35.3 million and SegNet-36.2 million, the parameters of this proposed method are comparatively low. It leads to faster training with reduced memory requirements, increasing the suitability for resource-limited environments. It is impressive to note that despite the drastically reduced computational complexity and much smaller model size, the achieved competitive processing speed for HSSAM-Net is 24.1 FPS. It is rather decent compared with DeepLabV3’s 20.9 FPS and MSNet’s 19.5 FPS, thus suggesting that its efficiency gain does not come at the cost of real-time performance.
The HSSAM-Net dynamically adjusts the reception field, retaining the salient fine-grained features in both the downsampling and upsampling processes; thus, this brings significantly higher performance than traditionally designed U-Net Variants, which usually suffer due to the loss of the fine spatial details caused either by fixed-size receptive fields or by excessive loss from resampling. Not introducing redundancy while aggregating the features across different scales enriches the capability of a segmentation model to precisely catch large and small-size structures. This point especially becomes very important within the polyp segmentation context where size, shape, and contrast for a polyp may change fairly prominently. Equally important, the proposed Max-Diagonal Sampling allows more focused sampling concerning image features, being much more attentive to the most informative pixels with the view to enhancing segmentation accuracy. In this way, it allows the model to focus on areas of interest that, in the majority of cases, are underrepresented by classic uniform sampling. This helps in strengthening the robustness of the model, especially for images where polyps could appear in low-contrast or irregular regions.
Implications, challenges, and future research directions
The proposed HSSAM-Net has several important implications for clinical and real-world applications. First, by achieving accurate and real-time segmentation of colorectal polyps, the model can serve as a decision support tool for gastroenterologists during colonoscopy, thereby reducing miss rates and facilitating early detection of colorectal cancer. Second, owing to its lightweight design with only ~ 0.9 M parameters and low FLOPs, HSSAM-Net can be efficiently deployed in resource-constrained environments, including portable colonoscopy systems or embedded medical devices, broadening access to advanced diagnostic support. Third, the consistent and objective delineation of polyps across diverse datasets helps reduce inter-observer variability, contributing to more standardized diagnosis and documentation in clinical practice. Finally, the model’s robustness and efficiency make it suitable for integration into computer-aided detection and diagnosis (CADe/CADx) systems, providing real-time feedback to clinicians and enhancing workflow efficiency. Together, these practical implications underscore the clinical relevance of HSSAM-Net and its potential to support reliable, efficient, and widely deployable colorectal cancer screening solutions.
Despite its strong performance, several challenges remain. First, although the model generalizes well across multiple public datasets, its robustness under domain shifts caused by varying camera hardware, patient demographics, or procedural protocols in real-world clinical settings has yet to be comprehensively tested. Second, the model’s performance on extremely small or heavily occluded polyps cases that are particularly challenging and clinically significant could benefit from further enhancement. Additionally, the inference time and computational cost, while moderate, may still pose barriers to deployment on low-resource or real-time embedded systems without further optimization.
Looking ahead, several future research directions emerge. One promising avenue is the integration of semi-supervised or self-supervised learning, which can leverage large amounts of unlabeled endoscopic data to improve model generalization without reliance on extensive manual annotation. Incorporating temporal information from video frames rather than processing single frames independently may also improve detection consistency and reduce false positives in live procedures. Moreover, multi-modal fusion combining RGB images with depth, texture, or spectral data could further enhance boundary delineation in difficult cases. From a deployment perspective, efforts should be directed toward developing lightweight or quantized variants of HSSAM-Net for real-time use in resource-constrained environments such as portable colonoscopy units or mobile diagnostic platforms.
Conclusion
In this study, we proposed HSSAM-Net, a novel and lightweight U-Net-based architecture tailored for precise colorectal polyp segmentation in endoscopic images. The model integrates several key innovations, including the Hyper-Scale Shifted Aggregation Module for enriched multi-scale feature fusion, the Progressive Reusing Attention (PRA) mechanism for enhanced feature reusability, and the dual-branch Max-Diagonal Pooling/Unpooling (MaxDP/MaxDUP) strategy for improved geometric consistency. These components work synergistically to overcome common limitations of existing segmentation methods, such as loss of fine-grained details, inefficient feature aggregation, and high computational cost. Extensive experiments across five benchmark datasets (Kvasir, CVC-ClinicDB, ETIS, CVC-300, and EndoCV2020) demonstrated that HSSAM-Net consistently outperforms state-of-the-art models in both region-based and boundary-aware metrics. Notably, the network achieved superior Dice and mIoU scores while maintaining an extremely low parameter count (~ 0.9 M) and real-time inference speed (24.1 FPS). These results confirm that HSSAM-Net achieves an effective balance between segmentation accuracy and computational efficiency, making it suitable for integration into real-time computer-aided diagnosis systems. Beyond quantitative performance, qualitative evaluations highlighted the model’s robustness in capturing small, low-contrast, and irregularly shaped polyps, underscoring its potential clinical utility. The lightweight design also makes it adaptable for deployment in resource-constrained settings, such as portable colonoscopy systems or embedded medical devices, broadening access to advanced diagnostic support. At the same time, we acknowledge certain limitations of the present work, including the need for further validation under real-world domain shifts, challenges in extremely diminutive or occluded polyp cases, and the requirement of additional optimization for ultra-low-power embedded deployment. Future work will therefore focus on addressing these limitations by exploring semi-supervised or self-supervised learning, multi-modal data fusion, and prospective validation on multi-center clinical datasets. HSSAM-Net provides a powerful, efficient, and clinically relevant solution for automated colorectal polyp segmentation, advancing the state of the art while laying the groundwork for broader clinical translation.
Supplementary Information
Below is the link to the electronic supplementary material.
Supplementary Material 1
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Yue, G., et al., Progressive feature enhancement network for automated colorectal polyp segmentation. IEEE Trans. Autom. Sci. Eng. (2024).
- 2Αλεβίζος, Β. Novel Radiomics Interpretation Pipeline With Feature Extraction And Radiomics (2023).
- 3Wang, S. The Future Of Brain Tumor Diagnosis: CNN And Transfer Learning Innovations (2024).
- 4Huang, Y. and Y.J.a.p.a. Chen, Autonomous driving with deep learning: A survey of state-of-art technologies (2020).
- 5Fan, D.-P., et al. Pranet: Parallel reverse attention network for polyp segmentation. in International conference on medical image computing and computer-assisted intervention. 2020. Springer.
- 6Ji, G.P., et al. Automatic Polyp Segmentation via Parallel Reverse Attention Network. In Media Eval. 2020.
- 7Yaqub, M., et al., Gan-tl: Generative adversarial networks with transfer learning for mri reconstruction. 2022. 12(17): p. 8841.
- 8Xu, H., et al., Multimodal dual cross-attention fusion strategy for autonomous garbage classification system. IEEE Trans. Ind. Inform. (2024).