A shrinkage-based statistical method for testing group mean differences in quantitative bottom-up proteomics
Namgil Lee, Hojin Yoo, Juhyoung Kim, Heejung Yang

TL;DR
The paper introduces a new statistical method for analyzing proteomics data that improves accuracy in detecting changes in peptide quantities.
Contribution
A novel probabilistic graphical model and statistical method that uses shrinkage estimation and bootstrap techniques for better performance in small sample sizes.
Findings
The proposed method outperforms classical methods in specificity, sensitivity, and accuracy with simulated data resembling real MS data.
The method effectively identifies peptides with mean quantity changes in real DIA-MS data after treatment with Staurosporine.
The new approach is particularly effective under small sample size conditions.
Abstract
In bottom-up proteomics using data-independent acquisition mass spectrometry (DIA-MS), quantitative measurements are obtained following multiple steps of protein fragmentation and ionization, which introduces cumulative errors and impairs the effectiveness of classical statistical methods. This study proposes an alternative statistical approach for testing group mean differences at the peptide level in quantitative bottom-up proteomics. We present a novel probabilistic graphical model, that accounts for the non-normality of empirical distributions and the correlations between fragment ion quantities. Based on the model, we propose a new statistical method that improves upon the classical feature-based approach by incorporating distribution-free shrinkage estimation of covariance matrices and bootstrap-based estimation of degrees-of-freedom. Simulated experiments demonstrate that the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
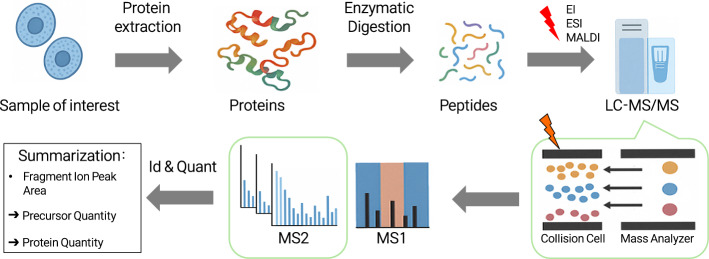 Figure 1
Figure 1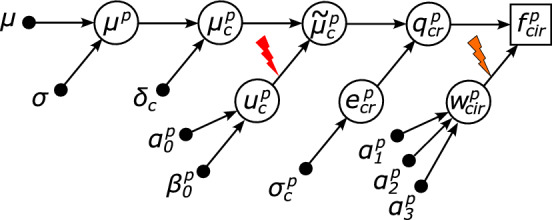 Figure 2
Figure 2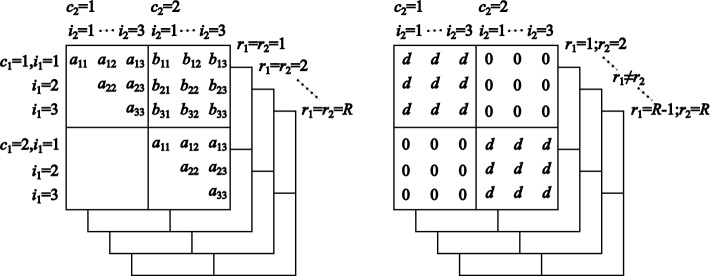 Figure 3
Figure 3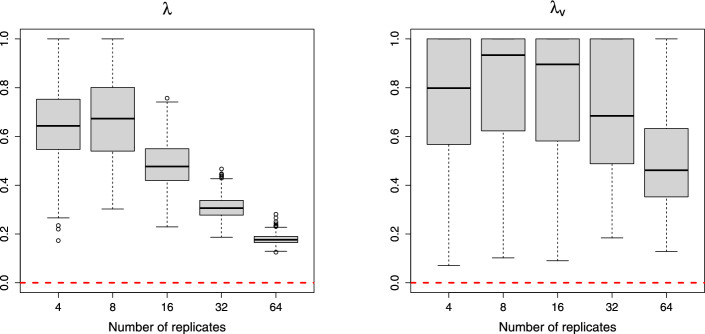 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7- —https://doi.org/10.13039/501100003725National Research Foundation of Korea
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Proteomics Techniques and Applications · Advanced Biosensing Techniques and Applications · Mass Spectrometry Techniques and Applications
Background
Due to technological advances in high-resolution mass spectrometry (MS), quantitative measurements of proteins and peptides across multiple conditions have increased [1]. Proteomic experiments are often conducted using complex experimental designs that involve numerous conditions and replicates, with the primary focus of the analysis being the detection of quantitative changes across conditions [2]. As the size and complexity of liquid chromatography coupled with tandem mass spectrometry (LC-MS/MS) data increase, there is a greater need for statistical methodologies to detect differentially abundant proteins and peptides [3].
Differential expression analysis workflows for proteomic data consist of multiple stages [4]. At the first stage, analysis software platforms such as Spectronaut [5], MaxQuant [6], and Skyline [7] perform peptide identification and quantification by their own complex workflows. The rest of the stages is often referred to as a downstream analysis or post-processing, and it includes the matrix representation stage, normalization stage, imputation stage, and statistical analysis stage [4]. For the final statistical analysis stage, classical statistical methodologies such as the analysis of variance (ANOVA) [8], t test [9], and linear mixed model [3, 10–12] have been widely used. But classical methodologies are often based on strong distributional assumptions, such as normality or independence, which are inconsistent with the characteristics of MS data acquisition techniques in recent bottom-up proteomics.
This study proposes an alternative statistical method for differential expression analysis at the peptide level, which post-processes quantification reports generated by analysis software platforms. Especially, the proposed method aims to analyze data-independent acquisition mass spectrometry (DIA-MS) data in bottom-up proteomics [13], where spectral features correspond to both precursor peptides and fragment ions.
In general, statistical methodologies for differential expression analysis can be categorized into two-step methods or feature-based methods [3]. In two-step methods, all feature intensities of each protein or peptide in a run are summarized, and then statistical analysis is performed on the summarized quantities. Feature-based methods conduct statistical analysis directly on the feature-level quantities. For example, ROTS [14] takes protein-level summarized quantities and selects an optimal test statistic among a family of modified t-statistics. MSqRob [11, 12] and MSstats [3] can perform both feature-based and two-step based analyses at the protein-level. For feature-based analysis, they take quantified features as input and use a linear mixed model for differential analysis. However, two-step methods tend to yield reduced sensitivity compared to feature-based methods, especially due to small sample sizes and bias [15]. On the other hand, feature-based methods are prone to underestimating between-sample variability and the correlation between features of the same protein (or peptide), which results in an inaccurate estimation of the degrees-of-freedom [12, 15].
In this study, we propose a novel hierarchical probabilistic graphical model to address the characteristics of real-world MS data distributions, including non-normality and the correlation among fragment ion quantities. The proposed model is a generative model that represents hierarchically structured LC-MS/MS data. In this model, two types of ionization efficiency are introduced as hidden variables for both the MS1 and MS2 spectra. Moreover, we propose a new t test statistic for detecting group mean differences. The proposed test statistic enhances a classical feature-based test statistic by addressing the random variation and correlation of ionization efficiencies. Specifically, covariances between fragment ion quantities are estimated using a James-Stein-type distribution-free shrinkage estimation method [16, 17], which can address the issue of reduced sensitivity due to small sample sizes. A bootstrap approach is suggested to accurately estimate the degrees-of-freedom of the proposed test statistic [18].
In principle, given a sample covariance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_{ij}$$\end{document} between two random variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_j$$\end{document} (e.g., representing fragment ion quantities), a James-Stein type shrinkage estimator of the covariance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_{ij}^*$$\end{document} can be expressed as a linear combination:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} S_{ij}^* = (1 - \lambda ) S_{ij} + \lambda T_{ij}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0\le \lambda \le 1$$\end{document} denotes the shrinkage intensity and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{ij}$$\end{document} is the shrinkage target. When \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda = 1$$\end{document} , the shrinkage estimator reduces to the target \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{ij}$$\end{document} , and when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda = 0$$\end{document} , it coincides with the sample covariance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_{ij}$$\end{document} . Although the sample covariance is unbiased, it suffers from high variance for small sample sizes or high dimensionality, resulting in low estimation accuracy. By contrast, the shrinkage target \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{ij}$$\end{document} is typically set to have low variance, such as a constant value. By selecting an optimal shrinkage intensity, the shrinkage estimator achieves improved accuracy through a balance between bias and variance.
Through the analysis of real MS data, we show that the proposed model effectively captures the actual data distribution, especially the variability and correlations in ionization efficiency. We also provide estimated hyperparameter values based on this real MS data. Simulated experiments confirm that the proposed test statistic is asymptotically consistent, following a Student’s t-distribution with accurately estimated degrees-of-freedom. Numerical experiments using both simulated and real DIA-MS data demonstrate that the proposed method outperforms two classical statistical methods, paired t test and independent samples t test, and two modern statistical methods, ROTS [14] and MSstatsLiP [19], in terms of specificity, sensitivity, accuracy, and area under the receiver operating characteristic curve (AUC), particularly when the hyperparameter values closely match the real MS data distribution.
The remainder of this paper is organized as follows. Section 2 describes the proposed hierarchical graphical model and the shrinkage-based statistical test method. Section 3 presents numerical experiments that compare the performance of the shrinkage-based statistical test method and the other classical methods by using simulated data. In addition, we analyze real DIA-MS data from HeLa cells treated with the kinase inhibitor Staurosporine at multiple doses to identify peptides with significant changes in mean quantity. Discussion and conclusions are provided in Sect. 4.
Methods
Hierarchical probabilistic graphical model for bottom-up proteomics
Consider an experiment with multiple conditions, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c=1,2,\ldots ,C$$\end{document} , and a few technical replicates, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r=1,2,\ldots ,R_c$$\end{document} , for each condition c. In bottom-up proteomics, peptides can be represented in three different forms: stripped sequences, modified sequences, and precursors. Among these, a precursor is the most specific representation, defined by an amino acid sequence with possible modifications and a specific charge state. A modified sequence retains the amino acid sequence and its modifications but ignores the charge state. A stripped sequence includes only the amino acid sequence, ignoring both modifications and charge state. In this study, each peptide, denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p = 1, 2, \ldots , P$$\end{document} , refers to a precursor-level peptide, i.e., the most detailed form of representation. As a result, peptides with the same amino acid sequence but different modifications or charge states are treated as distinct precursors. Table 1 summarizes the mathematical notations used in this paper.Table 1. Mathematical notationsNotationDescription \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c=1,2,\ldots ,C$$\end{document} Condition \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r=1,2,\ldots ,R_c$$\end{document} Replicate at condition c \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=1,2,\ldots ,P$$\end{document} Precursor peptide \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i=1,2,\ldots ,I$$\end{document} Fragment ion \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{cir}^p$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{cir}^p$$\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$= \log _{10} f_{cir}^p$$\end{document} )Quantity of fragment ion i, and its \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log _{10}$$\end{document} -transformation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q_{cr}^p$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{cr}^p$$\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$= \log _{10} q_{cr}^p$$\end{document} )Peptide quantity of precursor p, and its \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log _{10}$$\end{document} -transformation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w_{cir}^p$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\xi _{cir}^p$$\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$= \log _{10} w_{cir}^p$$\end{document} )Ionization efficiency for fragment ion i, and its \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log _{10}$$\end{document} -transformation. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_{c}^p$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\zeta _{c}^p$$\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$= \log _{10} u_{c}^p$$\end{document} )Data acquisition rate for peptide p, and its \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log _{10}$$\end{document} -transformation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Delta \xi _{ir}^p$$\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$= \xi _{1ir}^p - \xi _{2ir}^p$$\end{document} )Difference between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log _{10}$$\end{document} -transformed ionization efficiencies \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$e_{cr}^p$$\end{document} Sampling error
Figure 1 illustrates the workflow for peptide quantification in bottom-up proteomics using DIA-MS. In this approach, proteins are enzymatically digested into peptides and the resulting peptides are ionized with specific charge states as they are injected into the mass spectrometer. While the mass spectra of the precursors are first measured in a survey scan, known as the MS1 spectrum, the precursors are fragmented in a collision cell, producing fragment ions whose spectra are collected as MS2 spectra. In DIA-MS, these MS2 spectra are used to quantify fragment ions, which are then aggregated to quantify their corresponding precursors, and further summarized to infer protein-level abundances. Due to the hierarchical nature of the data acquisition process, MS2 spectra are often subject to data loss, non-normal distributions, and inter-run dependences.Fig. 1. Workflow for quantification in bottom-up proteomics using DIA-MS. The red lightning symbol represents peptide ionization by methods such as Electron Ionization (EI), Electrospray Ionization (ESI), or Matrix-Assisted Laser Desorption Ionization (MALDI). The orange lightning symbol with a black outline indicates the fragmentation of these ionized peptides (precursors) into fragment ions via Collision Induced Dissociation (CID) in the collision cell of the mass spectrometer. The fragment ions are then analyzed to obtain MS2 spectra, which are quantified based on their peak area
We suggest a hierarchical probabilistic graphical model for simulating quantitative bottom-up proteomics, which is graphically illustrated in Fig. 2. In sequential window acquisition of all theoretical mass spectra (SWATH-MS) DIA, quantification is usually performed based on MS2 spectra [13, 20]. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{cir}^p$$\end{document} denote the measured quantity of fragment ion i of peptide p under condition c and replicate r. A standard method for summarizing fragment ion quantities for a peptide is to sum the best I fragment ion quantities of the highest ranks, where typically \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$I\approx 3$$\end{document} [21]. That is, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ q_{cr}^p = \sum _{i=1}^I f_{cir}^p. $$\end{document} The proportion of a selected fragment ion quantity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{cir}^p$$\end{document} to the peptide quantity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q_{cr}^p$$\end{document} can be parameterized as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w_{cir}^p = f_{cir}^p / q_{cr}^p$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i=1,2,\ldots ,I$$\end{document} , or equivalently,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} f_{cir}^p = q_{cr}^p \cdot w_{cir}^p. \end{aligned}$$\end{document}The parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w_{cir}^p$$\end{document} represents the probability that fragment ion i is detected and quantified, and it is referred to as the ionization efficiency.Fig. 2. Graphical illustration of the hierarchical probabilistic graphical model for quantitative bottom-up proteomics. The squared node, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{cir}^p$$\end{document} , represents the quantity of a fragment ion, which is an observed variable. The circled nodes represent latent variables, and the black dots represent hyperparameters of the distributions that generate the latent variables. The red lightning symbol indicates peptide ionization and the orange lightning symbol with a black outline indicates the fragmentation of the ionized peptides; see Fig. 1. Mathematical notations and their descriptions are summarized in Table 1
The log-transformed peptide quantities, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log _{10} q_{cr}^p$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r=1,2,\ldots ,R_c$$\end{document} , are assumed to be independently and normally distributed with a mean of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{\mu }}_c^p$$\end{document} and a standard deviation of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma _c^p$$\end{document} , as expressed by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \log _{10} q_{cr}^p = {\tilde{\mu }}_c^p + e_{cr}^p, \quad e_{cr}^p \sim \text {N}(0, (\sigma _c^p )^2). \end{aligned}$$\end{document}We assume that the mean of the peptide quantity, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{\mu }}_c^p$$\end{document} , is a biased esimate of the true mean value, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _c^p$$\end{document} , as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} {\tilde{\mu }}_c^p = \mu _c^p + \log _{10} u_c^p. \end{aligned}$$\end{document}The random variable \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_c^p$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0 < u_c^p \le 1$$\end{document} , denotes the proportion of the estimated mean peptide quantity to the true mean quantity as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} 10^{{\tilde{\mu }}_c^p} = 10^{\mu _c^p} \cdot u_c^p. \end{aligned}$$\end{document}We note that the relative total amount of missing fragment ions can be expressed by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(10^{\mu _c^p} - 10^{{\tilde{\mu }}_c^p}) / 10^{\mu _c^p} = 1 - u_c^p$$\end{document} . This implies that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_c^p$$\end{document} corresponds to the ionization efficiency of the precursors, or in other words, the proportion of total measured fragment ion quantities. We will refer to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_c^p$$\end{document} as the data acquisition rate to distinguish it from the ionization efficiency \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w_{cir}^p$$\end{document} .
To model uncertainty in data acquisition rate, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_c^p$$\end{document} is assumed to follow a beta distribution:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} u_c^p \sim \text {Beta}(\alpha _0^p, \beta _0^p), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha _0 > 0$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _0 > 0$$\end{document} are the shape parameters. We assume that the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_c^p$$\end{document} are independent across conditions. Additionally, the ionization efficiencies \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w_{cir}^p$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i=1,2,\ldots ,I$$\end{document} , are assumed to follow a Dirichlet distribution:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} (w_{c1r}^p, \ldots , w_{cIr}^p) \sim \text {Dirichlet}(\alpha _1^p, \ldots , \alpha _I^p), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha _1^p, \alpha _2^p, \ldots , \alpha _I^p > 0$$\end{document} are the shape parameters. We assume that the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w_{cir}^p$$\end{document} may be correlated across conditions with a correlation coefficient of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0 \le \rho ^p \le 1$$\end{document} , e.g., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Corr}(w_{1ir}^p, w_{2ir}^p) = \rho ^p$$\end{document} . The assumption of a nonnegative correlation suggests that the ionization of the same fragment ion will be similar across conditions.
Each peptide is allowed to have a distinct mean quantity, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _c^p$$\end{document} , and it is assumed that the mean quantities differ by a fixed constant between conditions, expressed as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _c^p = \mu ^p + \delta _c$$\end{document} . We do not assume a specific probability distribution for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu ^p$$\end{document} for theoretical analysis. However, for numerical simulation, the mean quantities are generated from a normal distribution with a mean of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu $$\end{document} and a standard deviation of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma $$\end{document} as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mu ^p \sim \text {N}(\mu , \sigma ^2). \end{aligned}$$\end{document}Shrinkage-based statistical test
Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _c^p$$\end{document} denote the bias-corrected means of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log _{10}$$\end{document} -transformed peptide quantities for conditions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c=1,2$$\end{document} , respectively; that is, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _c^p = {\tilde{\mu }}_c^p - \log _{10} u_c^p$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c=1,2.$$\end{document} For comparing the mean values, the mean difference between the two groups can be written as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L = \mu _1^p - \mu _2^p. \end{aligned}$$\end{document}Equation (9) can be extended to a linear combination of multiple mean values to address group comparisons involving two or more expected values, expressed as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L = \sum _c a_c \mu _c^p$$\end{document} for any contrast coefficients \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_c,\ c=1,\ldots ,C,$$\end{document} satisfying \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum _c a_c = 0$$\end{document} . In general, a test statistic for testing group differences, e.g., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_0: \mu _1^p = \mu _2^p \ \ \text {versus} \ \ H_A: \mu _1^p \ne \mu _2^p,$$\end{document} can be expressed in the following form [3]: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ t = {\hat{L}} / \text {SE}({\hat{L}}), $$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{L}}$$\end{document} is an estimate of L and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SE}({\hat{L}})$$\end{document} is the standard error of the estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{L}}$$\end{document} .
We propose an alternative test statistic and a bootstrap method for determining appropriate degrees-of-freedom. The alternative method is referred to as the shrinkage t test in this paper. The proposed statistical method is developed using fragment ion quantities, making it a feature-based methodology similar to the paired t test. However, the assumption of independence among fragment ions in the paired t test does not hold in real MS experiments. The hierarchical probabilistic graphical model described in Sect. 2.1 addresses this through the Dirichlet distribution in (7). The proposed method also tackles this issue by estimating the correlations directly.
The proposed test statistic can be expressed as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} t_\text {shrink} = \frac{{\hat{L}}_\text {shrink}}{\text {SE}({\hat{L}}_\text {shrink})}, \end{aligned}$$\end{document}where the numerator is an estimate of the group mean difference, defined by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} {\hat{L}}_\text {shrink} = \sum _{i=1}^I \left( {\bar{x}}_{1i}^p - {\bar{x}}_{2i}^p \right) , \end{aligned}$$\end{document}with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\bar{x}}_{1i}^p$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\bar{x}}_{2i}^p$$\end{document} representing the sample means of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{1ir}^p$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{2ir}^p$$\end{document} , respectively. We note that the numerator is directly related to that of the paired t test statistic by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{L}}_\text {shrink} = I {\hat{L}}_\text {paired}$$\end{document} , where I denotes the number of fragment ions, in the case of an equal number of replicates, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R \equiv R_1 = R_2$$\end{document} . The denominator can be written as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {SE}({\hat{L}}_\text {shrink}) = ( \text {Var}({\hat{L}}_\text {shrink}) )^{1/2} $$\end{document} by the definition of the standard error. Using (11) and the bilinearity of covariance, the variance term can be expanded as a sum of covariance terms: assuming that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R_1 = R_2 \equiv R$$\end{document} ,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \begin{aligned} {\text{Var}}(\hat{L}_{{{\text{shrink}}}} ) = & \frac{1}{{R^{2} }}\sum\limits_{{i = 1}}^{I} {\sum\limits_{{j = 1}}^{I} {\left( {\sum\limits_{{c = 1}}^{2} {\sum\limits_{{r = 1}}^{R} {\sum\limits_{{r^{\prime} = 1}}^{R} {{\text{Cov}}} } } (x_{{cir}}^{p} ,x_{{cjr^{\prime}}}^{p} ) + } \right.} } \\ & \left. { - \sum\limits_{{r_{1} = 1}}^{R} {\sum\limits_{{r_{2} = 1}}^{R} {{\text{Cov}}} } (x_{{1ir_{1} }}^{p} ,x_{{2jr_{2} }}^{p} ) - \sum\limits_{{r_{1} = 1}}^{{R_{1} }} {\sum\limits_{{r_{2} = 1}}^{{R_{2} }} {{\text{Cov}}} } (x_{{2ir_{2} }}^{p} ,x_{{1jr_{1} }}^{p} )} \right). \\ \end{aligned} $$\end{document}Equation (12) is further elaborated in the next section.
It is notable that classical statistical methods, such as the independent samples t test and the paired t test, rely on strong independence assumptions between measurements. Specifically, the independent samples t test assumes that two quantities originating from different biological samples are uncorrelated, i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Cov}(x_{c_1i_1r_1}^p, x_{c_2i_2r_2}^p) = 0$$\end{document} whenever \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c_1 \ne c_2$$\end{document} or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_1 \ne r_2$$\end{document} ÿ. Similarly, the paired t test assumes that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Cov}(x_{c_1i_1r_1}^p, x_{c_2i_2r_2}^p) = 0$$\end{document} whenever the two quantities come from different replicates or fragment ions ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i_1 \ne i_2$$\end{document} or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_1 \ne r_2$$\end{document} ). By contrast, the proposed method does not impose such restrictive assumptions; instead, it estimates the covariance terms directly through the hierarchical graphical model introduced in the previous section in combination with shrinkage estimation.
Structure of covariance matrix
To determine which of the covariance terms, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Cov}(x_{c_1i_1r_1}^p, x_{c_2i_2r_2}^p)$$\end{document} , are nonzero, we use the hierarchical graphical model presented in (2) to (7). We note that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{cir}^p = \mu ^p + \delta _c + \zeta _c^p + e_{cr}^p + \xi _{cir}^p$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\zeta _c^p = \log _{10} u_c^p$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\xi _{cir}^p = \log _{10} w_{cir}^p$$\end{document} . It follows that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {Cov}(x_{c_1i_1r_1}^p, x_{c_2i_2r_2}^p) = \text {Cov}(\zeta _{c_1}^p, \zeta _{c_2}^p) + \text {Cov}(e_{c_1r_1}^p, e_{c_2r_2}^p) + \text {Cov}(\xi _{c_1i_1r_1}^p, \xi _{c_2i_2r_2}^p), $$\end{document} while the peptide p is fixed. The nonzero covariance terms are determined as described below.
- In the case that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c_1 = c_2 \equiv c$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_1 = r_2 \equiv r$$\end{document} , then,
for all c, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i_1$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i_2$$\end{document} , and r. 2. In the case that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c_1 \ne c_2$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_1 = r_2 \equiv r$$\end{document} , then,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} b_{i_1i_2} \equiv \text {Cov}(x_{c_1i_1r}^p, x_{c_2i_2r}^p) = \text {Cov}(\xi _{c_1i_1r}^p, \xi _{c_2i_2r}^p), \end{aligned}$$\end{document}for all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c_1 \ne c_2$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i_1$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i_2$$\end{document} , and r. 3. In the case that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c_1 = c_2 \equiv c$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_1 \ne r_2$$\end{document} , then,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} d \equiv \text {Cov}(x_{ci_1r_1}^p, x_{ci_2r_2}^p) = \text {Var}(\zeta _{c}^p), \end{aligned}$$\end{document}for all c, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i_1$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i_2$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_1 \ne r_2$$\end{document} . Figure 3 illustrates the structure of the covariance matrix, which consists of the elements \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Cov}(x_{c_1i_1r_1}^p, x_{c_2i_2r_2}^p)$$\end{document} for the proposed hierarchical graphical model. The entries \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{i_1i_2}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b_{i_1i_2}$$\end{document} , and d are defined as described above. Notably, the log-transformed fragment ion quantities are correlated even in cases where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c_1 \ne c_2$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_1 = r_2$$\end{document} , due to the entries \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b_{i_1i_2}$$\end{document} , and in cases where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_1 \ne r_2$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c_1 = c_2$$\end{document} due to the entry d.Fig. 3. Structure of the covariance matrix comprising the elements \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Cov}(x_{c_1i_1r_1}^p, x_{c_2i_2r_2}^p)$$\end{document} . The slices on the left represent cases where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_1 = r_2$$\end{document} , and those on the right represent cases where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_1 \ne r_2$$\end{document} . Each slice in the left and right panels takes the form of a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$2I \times 2I$$\end{document} matrix, since there are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C=2$$\end{document} conditions and I fragment ions, while \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_2$$\end{document} are fixed
The variance term in (12) can be re-written in a simpler form as follows: assuming that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R_1 = R_2 \equiv R$$\end{document} ,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text {Var}({\hat{L}}_\text {shrink}) = \frac{2}{R} \sum _{i=1}^I \sum _{j=1}^I a_{ij} - \frac{2}{R} \sum _{i=1}^I \sum _{j=1}^I b_{ij} + \frac{2I^2(R-1)}{R} d. \end{aligned}$$\end{document}Estimation of covariance terms where \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r_1 = r_2$$\end{document}
For the estimation of the covariance terms, we separate the case of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_1 = r_2$$\end{document} and the case of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_1 \ne r_2$$\end{document} . To simplify the notation, we will omit the superscript p in the following paragraph where it is unlikely to cause confusion.
First, for the cases of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_1 = r_2$$\end{document} , the corresponding covariance terms, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{i_1i_2}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b_{i_1i_2}$$\end{document} , are estimated using the James-Stein-type shrinkage estimation method [16, 17]. We note that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{cir}^p$$\end{document} can be expressed as the sum of its components: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{cir}^p = \mu ^p + \delta _c + \zeta _c^p + e_{cr}^p + \xi _{cir}^p$$\end{document} . Based on this representation, the deviation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{cir}^p - {\bar{x}}_{ci}^p$$\end{document} is equivalent to the deviation of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$e_{cr}^p + \xi _{cir}^p$$\end{document} with respect to its sample mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\bar{e}}_{c}^p + {\bar{\xi }}_{ci}^p$$\end{document} . Consequently, the sample covariance, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s_{c_1i_1, c_2i_2}$$\end{document} , provides an estimate of the covariance of the components, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Cov}(e_{c_1r}^p + \xi _{c_1i_1r}^p, e_{c_2r}^p + \xi _{c_2i_2r}^p)$$\end{document} , rather than the direct covariance term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Cov}(x_{c_1i_1r}^p, x_{c_2i_2r}^p)$$\end{document} . The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{i_1i_2}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b_{i_1i_2}$$\end{document} in (13) and (14) can be estimated by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} a_{i_1i_2}&\approx d + s_{ci_1,ci_2}^*,\\ b_{i_1i_2}&\approx s_{c_1i_1,c_2i_2}^*, \end{aligned} \end{aligned}$$\end{document}for all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c, c_1, c_2, i_1$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i_2$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s_{c_1i_1,c_2i_2}^*$$\end{document} represents a shrinkage estimate of the covariance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Cov}(e_{c_1r}^p + \xi _{c_1i_1r}^p, e_{c_2r}^p + \xi _{c_2i_2r}^p)$$\end{document} . The shrinkage estimate is written in terms of a correlation estimate and variance estimates as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} s_{c_1i_1,c_2i_2}^* = r_{c_1i_1,c_2i_2}^* \sqrt{s_{c_1i_1,c_1i_1}^* s_{c_2i_2,c_2i_2}^*}. \end{aligned}$$\end{document}The correlation estimate, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{c_1i_1,c_2i_2}^*$$\end{document} , is obtained by shrinking the sample correlation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{c_1i_1,c_2i_2}$$\end{document} , computed between the log-transformed fragment ion quantities \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{c_1i_1r}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{c_2i_2r}$$\end{document} , toward zero: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ r_{c_1i_1,c_2i_2}^* = (1 - {\hat{\lambda }}) \cdot r_{c_1i_1,c_2i_2}, $$\end{document} if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c_1\ne c_2$$\end{document} or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i_1 \ne i_2$$\end{document} ; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{c_1i_1,c_2i_2}^* = 1,$$\end{document} otherwise, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0\le {\hat{\lambda }} \le 1$$\end{document} is the shrinkage intensity parameter [17]. The variance estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s_{ci,ci}^*$$\end{document} is obtained by shrinking the sample variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s_{ci,ci}$$\end{document} of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{cir}$$\end{document} toward the median of all sample variances: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ s_{ci,ci}^* = (1 - {\hat{\lambda }}_\text {v}) \cdot s_{ci,ci} + {\hat{\lambda }}_\text {v} \cdot s_{\text {median}}, $$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s_{\text {median}}$$\end{document} denotes the median of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{ s_{11,11}, s_{12,12}, \ldots , s_{2I,2I} \}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0\le {\hat{\lambda }}_\text {v} \le 1$$\end{document} is the shrinkage intensity parameter [16].
Note that if the shrinkage parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\lambda }}$$\end{document} is set to one, the correlation estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r^*_{c_1i_1, c_2i_2}$$\end{document} is reduced to zero. Setting zero correlation coefficients as the shrinkage target reflects the strong assumption of independence across biological samples and fragment ions—an assumption imposed by classical statistical methods such as the independent samples t test and the paired t test.
In this paper, the shrinkage parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$({\hat{\lambda }}, {\hat{\lambda }}_\text {v})$$\end{document} are computed using the R package corpcor via the function cov.shrink [22]. In corpcor, the optimal values of the shrinkage parameters are obtained by minimizing the mean squared errors (MSEs) in the estimation of correlations and variances, respectively [16, 17].
Equal covariance assumption
We assume that the covariances are equal across conditions to reduce the number of parameters to estimate, i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Cov}(x_{1i_1r}^p, x_{1i_2r}^p) = \text {Cov}(x_{2i_1r}^p, x_{2i_2r}^p)$$\end{document} . From the estimated covariances in (18), the pooled covariance estimates can be computed by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ s_{\cdot i_1, \cdot i_2}^* \equiv (\cdot s_{1 i_1, 1 i_2}^* + \cdot s_{2 i_1, 2 i_2}^* ) / 2 , $$\end{document} for all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i_1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i_2$$\end{document} , which replace \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s_{ci_1, ci_2}^*$$\end{document} in the expression for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{i_1i_2}$$\end{document} in (17).
Estimation of covariance terms where \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r_1 \ne r_2$$\end{document}
Second, for the cases where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_1 \ne r_2$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c_1 = c_2 \equiv c$$\end{document} , we notice that the covariance terms are equal to the variance, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Var}(\zeta _c^p)$$\end{document} , for all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c, i_1, i_2$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_1 \ne r_2$$\end{document} , as presented in (15). From the hierarchical graphical model described in Sect. 2.1, the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log _{10}$$\end{document} -transformed peptide quantity is represented as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{cr}^p = \mu ^p + \delta _c + \zeta _c^p + e_{cr}^p$$\end{document} . We compute the normalized quantity as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_{cr}^p = y_{cr}^p - m_c^y + m^y$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m_c^y$$\end{document} represents the median of all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{cr}^p$$\end{document} values under condition c, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m^y$$\end{document} denotes the median of all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{cr}^p$$\end{document} values across all conditions. This normalization removes variability caused by the condition difference, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta _c$$\end{document} . Furthermore, we calculate the sample mean as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\bar{z}}_c^p = \sum _{r=1}^R z_{cr}^p / R$$\end{document} for all c and p. This sample mean can be considered an instance of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu ^p + \delta + \zeta _c^p$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta $$\end{document} is a fixed constant independent of c and p. Note that:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text {Var}(\mu ^p + \delta + \zeta _c^p) = \text {Var}(\mu ^p) + \text {Var}(\zeta _c^p). \end{aligned}$$\end{document}The variance, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Var}(\mu ^p + \delta + \zeta _c^p)$$\end{document} , is estimated by calculating the sample variance of all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\bar{z}}_{c}^p$$\end{document} values across all conditions and peptides. To estimate the variance of the mean quantity, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Var}(\mu ^p)$$\end{document} , we notice that the empirical distribution for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\bar{z}}_c^p$$\end{document} is typically skewed as illustrated in Figure S1(a) of the Additional file 1 in Supplementary Information, whereas the distribution for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu ^p$$\end{document} is symmetric as presented in (8). The variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Var}(\mu ^p)$$\end{document} is estimated through the following steps:
- The mode \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M^z$$\end{document} of the empirical distribution of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\bar{z}}_c^p$$\end{document} values is computed using the kernel density estimation method, implemented in the R package stats using the function density.
- The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\bar{z}}_{c}^p$$\end{document} values are then split into two parts, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z_1 = \{M^z - {\bar{z}}_c^p \,|\, {\bar{z}}_c^p \le M^z\}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z_2 = \{{\bar{z}}_c^p - M^z \,|\, {\bar{z}}_c^p > M^z\}$$\end{document} .
- An estimate of the standard deviation, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\text {Var}(\mu ^p))^{1/2}$$\end{document} , is computed using a quantile from one of the split parts, divided by the corresponding standard normal quantile. Specifically,
where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Phi (z) = P(Z\le z)$$\end{document} is the cumulative distribution function of a standard normal random variable Z. Finally, an estimate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Var}(\zeta _c^p)$$\end{document} is computed by subtracting the estimated variances as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} d \approx \widehat{\text {Var}}(\zeta _c^p) = \widehat{\text {Var}}(\mu ^p + \delta + \zeta _c^p) - \widehat{\text {Var}}(\mu ^p). \end{aligned}$$\end{document}Bootstrap estimation of degrees-of-freedom
The degrees-of-freedom for the proposed test statistic, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_\text {shrink}$$\end{document} , are determined using a bootstrap technique known as the additive method [18]. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal {X}}$$\end{document} denote the set of independent and identically distributed random variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal {X}} = \{z_r^p\}, r=1,\ldots ,R,$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_r^p = (x_{11r}^p, \ldots , x_{1Ir}^p, x_{21r}^p, \ldots , x_{2Ir}^p)$$\end{document} representing the list of fragment ion quantities for peptide p in the rth replicate. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal {X}}^*_1, \ldots , {\mathcal {X}}^*_B$$\end{document} be B random samples of size R, generated by independently sampling elements from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal {X}}$$\end{document} with replacement. For each sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal {X}}^*_b$$\end{document} , bootstrap shrinkage-based test statistics are computed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} t_{\text {shrink},b}^* = \frac{{\hat{L}}_{\text {shrink},b}^*}{\text {SE}({\hat{L}}_{\text {shrink},b}^*) + a_R}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_R > 0$$\end{document} is a fixed constant that prevents the denominator from approaching zero [18]. We remark that the number of replicates R is often as small as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R=4$$\end{document} , in which case the standard error term in the denominator may degenerate to zero because of duplicates in bootstrap samples, leading to unstable values. The value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_R$$\end{document} is determined at the minimum point of the coefficient of variation (see Sect. 3.1.1). Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s^{*2}$$\end{document} denote the sample variance of the B test statistics, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_{\text {shrink},1}^*,\ldots ,t_{\text {shrink},B}^*$$\end{document} . The degrees-of-freedom are determined based on the relationship between the variance and the degrees-of-freedom of Student’s t distribution:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \nu _\text {shrink} = \frac{ 2 s^{*2} }{ s^{*2} - 1 } \end{aligned}$$\end{document}for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s^{*2} > 1$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\nu _\text {shrink} = \infty $$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s^{*2} \le 1$$\end{document} .
Results
The proposed method was compared with two classical statistical methods–paired t test and independent samples t test–and two modern statistical methods–ROTS [14] and MSstatsLiP [19]–using simulated data sets and real MS data sets. Among the compared methods, the independent samples t test and ROTS are two-step methods, whereas the paired t test and MSstatsLiP are feature-based methods. Notably, the proposed method is designed for differential analysis of DIA-MS data at the precursor peptide-level, rather than at the protein-level. Other widely used statistical methods such as MSqRob and MSstats were not included in the comparison, as they are designed for protein-level analysis. The limma [23] will be integrated and evaluated for future work. All statistical methods numerically evaluated in this study are conveniently accessible via the R package MDstatsDIAMS (https://github.com/namgillee/MDstatsDIAMS).
Simulation experiments
Simulated data sets were generated using the hierarchical graphical model described in Sect. 2.1 to compare the performance of the proposed shrinkage-based method with two other classical statistical methods. The model parameters were chosen to ensure that the generated data distributions closely match the sampling distributions presented in Sect. S2 of the Additional file 1 in Supplementary Information. By default, the number of fragment ions was set to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$I=3$$\end{document} , the number of peptides to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P=500$$\end{document} , and the number of replicates to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R=4$$\end{document} . Default values for hyperparameters were set as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma _c^p = 0.2$$\end{document} for (3), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha _0^p = 2$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _0^p = 10$$\end{document} for a beta distribution in (6), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\alpha _1^p,\alpha _2^p,\alpha _3^p) = (2, 2, 2)$$\end{document} for (7), and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu = 5.0$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma = 1.0$$\end{document} for (8). The correlation, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho ^p$$\end{document} , between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w_{1ir}^p$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w_{2ir}^p$$\end{document} was set to 0.89 by default unless otherwise specified.
For the evaluation of hypothesis testing methods, we generated simulated data sets under two conditions with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _1^p = \mu ^p$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _2^p = \mu _1^p + \delta $$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta \ge 0$$\end{document} was varied as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta = 0$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log _{10} (2) \approx 0.3$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log _{10} (4) \approx 0.6$$\end{document} . After evaluating the results on P peptides, we computed the specificity for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta =0$$\end{document} and the sensitivity for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta > 0$$\end{document} . The accuracy was then calculated based on a contingency table, which included 95% of the cases with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta = 0.0$$\end{document} and 5% with a specific value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta > 0$$\end{document} .
Estimation of degrees-of-freedom
To determine an appropriate value for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_R$$\end{document} in (22), we generated \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B=100$$\end{document} bootstrap samples under the conditions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _1^p = \mu ^p$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _2^p = \mu _1^p + \delta $$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta =0, 0.3, 0.6$$\end{document} , and calculated the coefficient of variation (CV) for the bootstrap shrinkage-based test statistics \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_{\text {shrink},b}^*$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b=1,\ldots ,B$$\end{document} . Figure S6 of the Additional file 1 in Supplementary Information displays the CV values across different \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_R$$\end{document} values. The figure reveals that the curve is nearly flat, while fluctuation is relatively large for small \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_R$$\end{document} values. We selected \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_R$$\end{document} as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_4 = 0.3$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R=4$$\end{document} based on Figure S6 of the Additional file 1 in Supplementary Information, where the change in the CV is less than 10% of its maximum value. To ensure the asymptotic consistency of the proposed test statistics for larger R values, we set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_R$$\end{document} as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_R = a_4 \times (R / 4)^{-3/2} = 2.4 R^{-3/2}$$\end{document} [18].
Consistency of estimation
The proposed method estimates the covariance terms, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Cov}(x_{c_1i_1r_1}^p, x_{c_2i_2r_2}^p)$$\end{document} , as analyzed in Sect. 2.2.1 Using simulated data sets generated with the default parameter values, equal mean quantities \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _1^p = \mu _2^p = 5.0$$\end{document} , and increasing numbers of replicates ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R=4$$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R=64$$\end{document} ), we compared the estimated values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{ij}, b_{ij},$$\end{document} and d with their true theoretical values. Fig. 4 shows the estimated shrinkage intensity parameter values, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\lambda }}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\lambda }}_\text {v}$$\end{document} . The results clearly indicate that the shrinkage intensities decrease toward zero as the number of replicates increases.Fig. 4. Convergence of the estimated shrinkage intensity parameter values, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\lambda }}$$\end{document} (left) and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\lambda }}_\text {v}$$\end{document} (right). The red dotted line indicates the zero value
Figure 5 compares the estimated covariance terms with their corresponding true values as the number of replicates increases. From the theoretical results in Proposition S1 of the Additional file 1 in Supplementary Information, we can derive that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {Var}(\zeta _c^p) = (\psi '(2) - \psi '(12)) / (\log (10))^2 = 0.1053, $$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {Var}(e_{cr}^p) = (\sigma _c^p)^2 = 0.04, $$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {Var}(\xi _{cir}^p) = (\psi '(2) - \psi '(6)) / (\log (10))^2 = 0.0874. $$\end{document} Additionally, the covariances \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Cov}(\xi _{c_1i_1r}^p, \xi _{c_2i_2r}^p)$$\end{document} , involved in (13) and (14), were calculated using Monte Carlo simulations with Dirichlet distributions. Using these results, the true values for the covariance terms based on (13) to (15) are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{ii} - d = 0.04 + 0.0874 = 0.1274$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{i_1i_2} - d = 0.04 - 0.0342 = 0.0058$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i_1 \ne i_2$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b_{ii} = 0.0487$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b_{i_1i_2} = -0.0212$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i_1 \ne i_2$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d = 0.1053$$\end{document} .
The top panels of Fig. 5 show that the estimates of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{ii} - d$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{ij} - d$$\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i\ne j$$\end{document} ) approach the true values as the number of replicates increases. Specifically, the variances of the estimates decrease, with small biases, leading to more accurate estimations. The middle panels illustrate that the estimates of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b_{ii}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b_{ij}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(i\ne j)$$\end{document} converge toward their true values as the number of replicates increases. Finally, the bottom panel demonstrates that the estimate for d is unbiased, although it shows relatively high variance.Fig. 5. Convergence of the estimated covariance terms: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{ii} - d$$\end{document} (top left), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_{ij} - d$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i\ne j$$\end{document} (top right), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b_{ii}$$\end{document} (middle left), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b_{ij}$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i \ne j$$\end{document} (middle right), and d (bottom). The red dotted line indicates the true values corresponding to the estimates
Figure S7 of the Additional file 1 in Supplementary Information shows the empirical distribution of the shrinkage-based test statistic for cases with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R=4$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R=64$$\end{document} replicates. In both cases, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P=500$$\end{document} test statistics and degrees-of-freedom were calculated, and the median of the calculated degrees-of-freedom was \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\infty $$\end{document} in both cases. The figure demonstrates that the empirical distribution of the test statistic closely aligns with the t-distribution.
Numerical evaluation
To compare the performance of the proposed shrinkage-based method with the four other classical methods, simulated data sets were generated under various model parameters including the number of replicates \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R=4,8,\ldots ,64$$\end{document} , the hyperparameters for the Beta distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\alpha _0^p, \beta _0^p) = (2,10), (4, 28), (11, 91)$$\end{document} , and the noise standard deviation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma _c^p = 0.05, 0.1,\ldots , 0.8$$\end{document} , while the rest of the parameters remained fixed.
Specificit
Using a significance level of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha =0.05$$\end{document} , specificity was calculated as the proportion of correctly classified peptides among those satisfying the true null hypothesis \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_0: \mu _1^p = \mu _2^p$$\end{document} . Fig. 6 illustrates the specificities produced by the five statistical methods under various model parameters. In cases of small noise standard deviations ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma _c^p = 0.05, 0.1$$\end{document} ), the shrinkage method achieved the highest specificities in most cases. For large noise standard deviations ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma _c^p = 0.8$$\end{document} ), the MSstatsLiP yielded the highest specificities for small R values, while the shrinkage method performed well for large R values.
In contrast, the paired t test consistently produced lower specificities under medium and high noise standard deviations. This result suggests that the paired t test rejects null hypotheses more frequently than the other methods due to the underestimation of standard errors and the overestimation of degrees-of-freedom. On the other hand, the shrinkage t test, which is also a feature-based method like the paired t test, improves performance by employing shrinkage-based covariance estimation to more accurately compute the standard errors used in the test statistic.Fig. 6. Specificity obtained using the five statistical testing methods: the MSstatsLiP, ROTS, paired t test, independent samples t test, and shrinkage t test. The model parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\alpha _0^p, \beta _0^p)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma _c^p$$\end{document} are specified below each figure panel
Sensitivity
Sensitivity was calculated as the proportion of correctly classified peptides among those with different mean log-quantities between conditions ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _1^p \ne \mu _2^p$$\end{document} ). Figure S8 of the Additional file 1 in Supplementary Information illustrates the sensitivities produced by the five statistical methods when the mean difference was set to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta = \log _{10}(2)$$\end{document} . In the figure, the paired t test consistently achieved higher sensitivity values compared to the other methods. This result is due to its tendency to reject the null hypothesis more frequently, as verified by its low specificities observed in the previous section. Although the other methods exhibited lower sensitivities than the paired t test, the performance reduction was minimal in cases with small noise standard deviations ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma _c^p = 0.05, 0.1$$\end{document} ), which better reflect the characteristics of real MS data distributions, as shown in Figure S1(b) of the Additional file 1 in Supplementary Information.
Accuracy
Accuracy was calculated as the proportion of correctly classified peptides from a mixture of those satisfying the null hypothesis and those not. For this calculation, we assumed that 95% of the peptides satisfied the null hypothesis, while the remaining 5% did not. The proportion reflects the realistic scenario where the number of drug targets showing drug-induced modulation in peptide quantities is much smaller than the number of non-targets.
Figure S9 of the Additional file 1 in Supplementary Information shows the accuracy of the five statistical methods in cases where the mean log-quantities of peptides differed between conditions by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta = \log _{10}(2)$$\end{document} . The figure demonstrates that the shrinkage t test achieved the highest accuracy among the five methods in almost all cases. This result suggests that the shrinkage t test performs best when the data distribution closely resembles real MS data distributions, while maintaining low false positives, as indicated by the high specificities shown in Fig. 6.
Mass spectrometry data analysis
The original MS raw files are publicly available through the ProteomeXchange Consortium via the PRIDE repository, with the dataset identifier PXD015446 [24]. We selected raw files from HeLa cell lysates treated with the kinase inhibitor Staurosporine, along with control samples processed under similar conditions. The DIA raw files were analyzed using Spectronaut 17, MaxQuant 2.4.10, and Skyline 25.1 with their respective default settings, except that the digest type was set to semi-specific. For further details on raw MS data processing, see Sect. S1 of the Additional file 1 in Supplementary Information.
The real MS datasets were further analyzed using five statistical methods: the MSstatsLiP, ROTS, paired t test, independent samples t test, and shrinkage t test. Each peptide was tested for differences in the mean log-quantities between two conditions, dimethyl sulfoxide (DMSO) and the drug-treatment condition, where the drug concentration varied from 100 pM to 100 µM.
The shrinkage t test method estimated the parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d = \text {Var}(\zeta _{c}^p)$$\end{document} for each comparison of two conditions, as described in Sect. 2.2.4. Table S2 of the Additional file 1 in Supplementary Information summarizes the estimated values of d. The table shows that the estimates are consistent across different comparisons, likely due to the large number of peptides involved in each comparison. This consistency indicates that the estimated values are reliable for real data analysis.
Table 2 summarizes sensitivities of the five statistical methods at different specificity levels. The methods tested differences in mean log-quantities between the control vehicle (DMSO) and the drug-treatment condition at 100 µM, because proteins were labeled as positive if their binding affinity (dissociation constant, Kd) was reported to be lass than 10 µM in the literature [25], and as negative otherwise. After computing the * p* values for comparing two conditions using each statistical method, we applied the local false discovery rate (lfdr) approach [26] to calculate fdr scores for multiple hypothesis testing. Then, we assigned the minimum fdr score among the peptides originating from a given protein as the fdr score for that protein [27]. The fdr scores aggregated at the protein level were used to determine statistical significance. The table shows that the proposed shrinkage t test method achieved the highest sensitivity values of 0.69 and 0.84 at specificity levels of 0.4 and 0.2, respectively, indicating its enhanced effectiveness in detecting peptides with changes in mean log-quantities.Table 2. Sensitivities obtained using the five statistical methods were evaluated for different specificity values in testing differences in mean log-quantities between the control vehicle (DMSO) and the drug-treatment condition at 100 µMSensitivtySpecificitySpectronaut0.80.60.40.2MSstatsLiP0.26****0.440.630.81ROTS0.260.420.600.80Paired0.190.410.600.80Independent0.26****0.440.630.81Shrinkage0.200.410.69****0.84MaxQuant0.80.60.40.2MSstatsLiP0.210.380.570.78ROTS0.200.400.590.80Paired0.190.400.600.80Independent0.200.400.610.80Shrinkage0.200.400.620.81Skyline0.80.60.40.2MSstatsLiP0.200.400.600.80ROTS0.200.410.600.80Paired0.140.360.580.79Independent0.200.400.600.80Shrinkage0.200.400.600.80Boldface emphasizes the highest sensitivity value across all five methods and three software platforms
On the other hand, pairwise comparison results between every pair of drug conditions were aggregated for each peptide to evaluate its significance in the dose-response relationship. The statistical significance of a peptide’s dose-response relationship was determined by combining * p* values from consecutive pairwise comparisons, DMSO/10 nM, 10 nM/100 nM, and 100 nM/100 µM, as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} {\tilde{p}}_\text {drc} = \prod _{i: s_i = s_m} {\tilde{p}}_i \prod _{j: s_j \ne s_m} (1 - 0.5 {\tilde{p}}_j), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{p}}_i$$\end{document} is the p-value of the i-th comparison, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{p}}_m$$\end{document} is the minimum p-value among the comparisons, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s_i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s_m$$\end{document} are the signs of the estimates corresponding to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{p}}_i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{p}}_m$$\end{document} , respectively. The significance value, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{p}}_\text {drc}$$\end{document} , was further summarized at the protein level by taking the minimum value across peptides for each protein. The area under the receiver operating characteristic curve (AUC) was then evaluated based on the significance of each protein. Table 3 presents the AUCs for each method, showing that the proposed shrinkage method achieved the highest AUC score.Table 3AUC values obtained using the five statistical methods. The AUCs were computed based on the statistical significance described in (24), derived from a sequence of consecutive pairwise comparisons: DMSO/10 nM, 10 nM/100 nM, 100 nM/100 µMAUC valuesSpectronautMaxQuantSkylineMSstatsLiP0.4890.5450.502ROTS0.5390.5060.500Paired0.5320.5510.511Independent0.5310.5570.516Shrinkage0.5370.5990.521Boldface emphasizes the highest AUC value across all five methods and three software platforms
We further investigated the analysis results of the proposed method using the Spectronaut report. Since the results are peptide-specific, it is possible to detect precursor peptides exhibiting significant quantitative changes between drug treatment conditions. These peptides can be used to infer the location of drug-binding pockets on target proteins, as illustrated below.
Figure 7a shows a protein-level volcano plot comparing the DMSO and 100 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu $$\end{document} M conditions. The vertical axis represents the negative \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {log}_{10}$$\end{document} -transformed local false discovery rate (lfdr) scores, aggregated at the protein-level, and the horizontal axis shows the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {log}_2$$\end{document} fold change. The lfdr score allows for effective control of false positive rates. Based on the volcano plot, we selected three target kinase proteins that satisfied the criteria of lfdr \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\le 0.01$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$| \log _2(\text {fold change}) | \ge 1.$$\end{document} For each selected protein, we identified peptides with significant changes in abundance. Fig. 7b visualizes the 3D structure of the kinase protein NEK9. Four peptides with significant quantitative changes were detected: AEQEELHYIPIR, AGGGAAEQEELHYIPIR, GAFGEATLYR, and VTLLNAPTK. These peptides are highlighted in red, magenta, yellow, and blue, respectively. Based on their spatial positions in the 3D structure, it is possible to approximately localize the drug-binding pocket.
These structural analysis results highlight the utility of peptide-level differential expression analysis. Additional 3D structures of the other two kinase proteins, AKT2 and PKN1, with the detected peptides highlighted in red, are shown in Figure S10 in Additional file 1 of the Supplementary Information.Fig. 7a Volcano plot comparing the DMSO and 100 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu $$\end{document} M conditions. The lfdr scores were aggregated at the protein-level. Three kinase proteins, NEK9, AKT2, and PKN1, are selected and illustrated in the figure. b 3D structure of the kinase protein NEK9, with the four detected peptides highlighted in colors. The 3D structure was obtained from AlphaFold (https://alphafold.ebi.ac.uk/entry/[Q8TD19](Q8TD19))
Discussion and conclusions
In quantitative bottom-up proteomics, the instrument’s quantification performance depends on the loss or detection efficiency of the measured ions [28]. The total ion loss and its variability significantly affect peptide identification, and quantification performance, and throughput. In this study, we introduced a hierarchical graphical model for simulating tandem MS data in quantitative bottom-up proteomics using DIA-MS, in which ionization efficiency and data acquisition rate are incorporated as latent variables. Our results suggest that variations in ionization efficiency and data acquisition rates affect the performance of statistical methods. To address this, we developed a new statistical method using a shrinkage approach that incorporates these variations into the analysis, resulting in a more noise-robust and accurate test statistic. Simulated experiments and real data analyses demonstrated the effectiveness of the proposed method in handling hierarchically generated data with small sample sizes and biases.
This study proposes a statistical method for differential downstream analysis at the peptide-level. In contrast, traditional downstream analyses have mostly focused on protein-level inference, such as MSstats [3]. More recently, peptide-centric approaches have gained increasing attention, particularly in chemical proteomics, where the goal is to identify specific binding sites for drug candidates. For example, the MSstatsLiP [19] extends MSstats to investigate peptide-level quantitative changes in limited proteolysis mass spectrometry (LiP-MS) data. Other recent software tools for peptide-level chemical proteomics include LiPAnalyzeR [29], Flippr [30], and PELSA-Decipher [31].
For future work, the proposed hierarchical graphical model could be extended to incorporate strategies for handling missing data. Missing value imputation may be applied as a preprocessing step, as in MSstats, or embedded within the model itself, as in Triqler [32]. Triqler, a hierarchical Bayesian framework for protein-level differential analysis, offers the advantages of Bayesian approaches, which simplify model parameter estimation while improving robustness to noise and limited sample sizes. Alternatively, non-Bayesian approaches have also emerged. For example, the tree-based quantification method AlphaQuant [33] addresses missing values using counting statistics rather than direct imputation. These developments highlight the need for integrated methodologies that jointly address quantification and missing value handling within the hierarchical structure of bottom-up proteomics data.
Additional file
Additional file 1
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Rozanova, S., Barkovits, K., Nikolov, M., Schmidt, C., Urlaub, H., Marcus, K.: Quantitative mass spectrometry-based proteomics: An overview. In: Marcus, K., Eisenacher, M., Sitek, B. (eds.) Quantitative Methods in Proteomics, pp. 85–116. Springer, New York, (2021). 10.1007/978-1-0716-1024-4_810.1007/978-1-0716-1024-4_833950486 · doi ↗ · pubmed ↗
- 2Schafer, J., Opgen-Rhein, R., Zuber, V., Ahdesmaki, M., Duarte Silva, A.P., Strimmer, K.: Corpcor: Efficient Estimation of Covariance and (Partial) Correlation. (2021). R package version 1.6.10. https://CRAN.R-project.org/package=corpcor
- 3Zhu, H., Wang, K., Li, K., Fang, Z., Zhou, J., Xue, L., Ye, M.: PELSA-Decipher: A software tool for the processing and interpretation of ligand–protein interaction data sets acquired by PELSA. Journal of Proteome Research 10.1021/acs.jproteome.5c 0036510.1021/acs.jproteome.5c 0036540804637 · doi ↗ · pubmed ↗