Contrast analysis for competing hypotheses: A tutorial using the R package cofad
Mirka Henninger, Simone Malejka, Johannes Titz

TL;DR
This paper introduces contrast analysis as a useful alternative to traditional methods in psychology for testing hypotheses between different groups or conditions.
Contribution
The paper introduces the use of competing-contrast analysis and demonstrates its implementation in R using the cofad package.
Findings
Contrast analysis is a valuable alternative to traditional ANOVA for directional hypothesis testing.
Competing-contrast analysis can be conducted using the R package cofad.
This method is flexible, powerful, and hypothesis-driven for psychological research.
Abstract
Researchers in psychology traditionally use analysis of variance to examine differences between multiple groups or conditions. A less well-known, but valuable alternative is contrast analysis — a simple statistical method for testing directional, theoretically motivated hypotheses that are defined prior to data collection. In this article, we review the core concepts of contrast analysis for testing hypotheses in between-subjects and within-subjects designs. We also outline and demonstrate the largely unknown possibility of directly testing two competing contrasts against each other. In the tutorial part of the article, we show how such competing-contrast analyses can be conducted in the free, open-source software R using the package cofad. Because competing-contrast analysis is a straightforward, flexible, highly powered, and hypothesis-driven approach, it is a valuable tool to extend…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
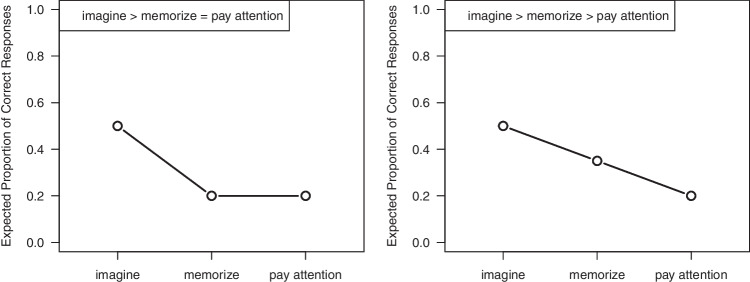 Figure 1
Figure 1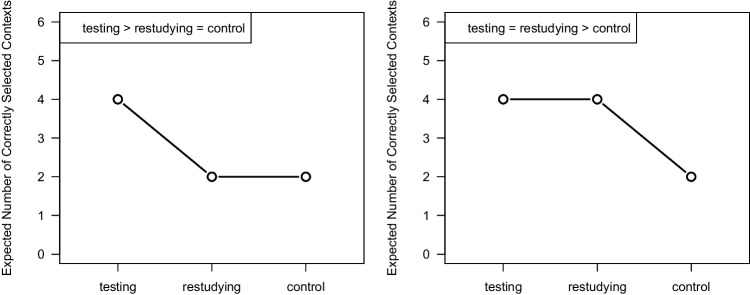 Figure 2
Figure 2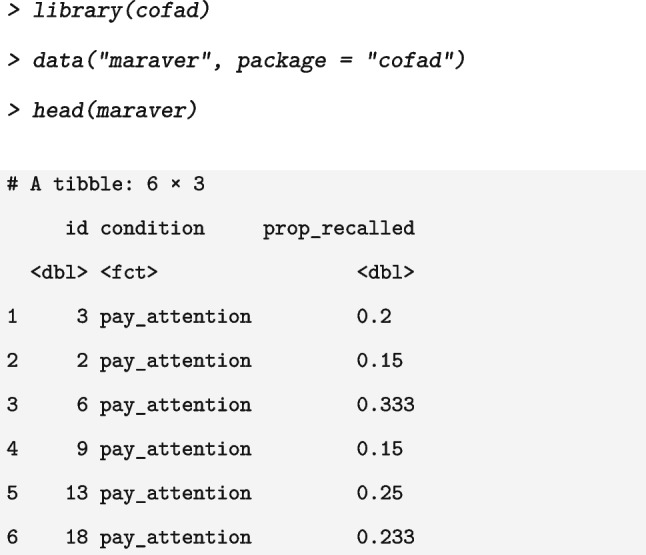 Figure 3
Figure 3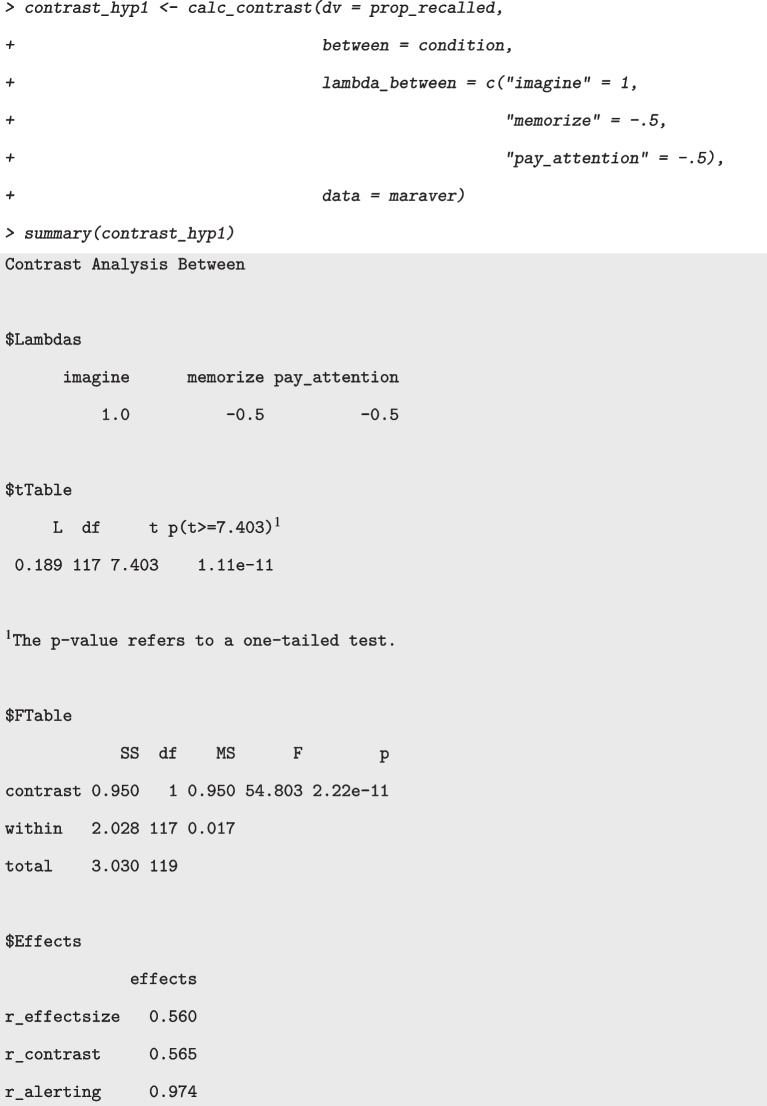 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9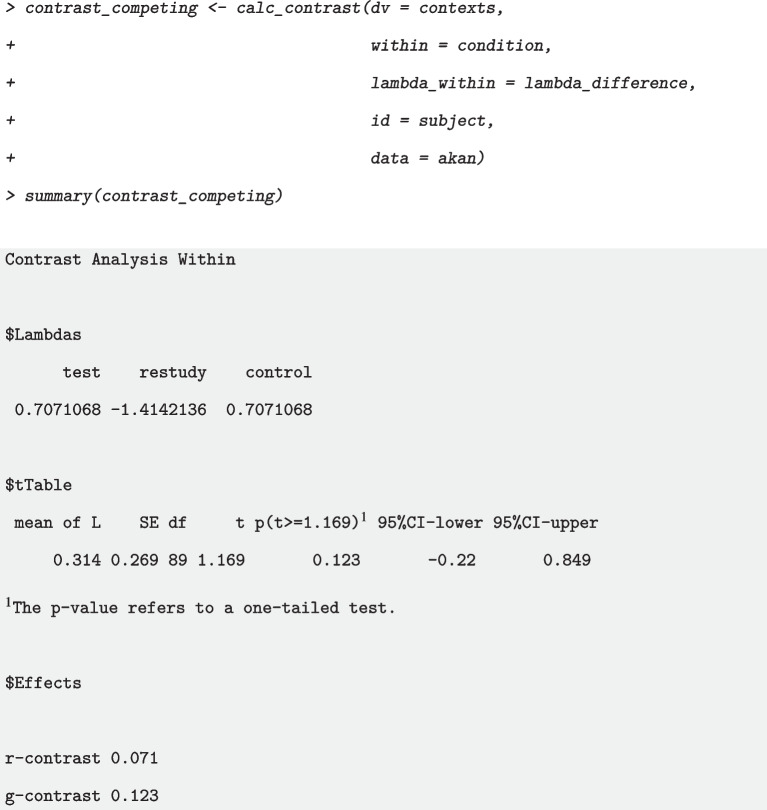 Figure 10
Figure 10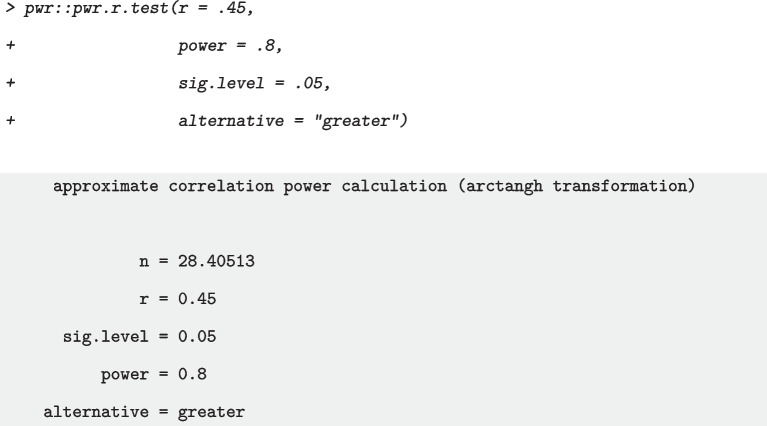 Figure 11
Figure 11- —University of Basel
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMental Health Research Topics · Meta-analysis and systematic reviews · Data Analysis with R
Psychological researchers traditionally analyze multi-group data using analysis of variance (ANOVA). ANOVAs allow researchers to test omnibus hypotheses about main and interaction effects of (quasi-)experimental factors. A less commonly used alternative is contrast analysis, which can be used to test specific, directional, a priori hypotheses about a specific pattern of group or condition means. This procedure yields several advantages, such as a higher statistical power when the predicted mean pattern is observed in empirical data. Furthermore, contrast analysis provides researchers with the possibility to directly compare two competing hypotheses.
To illustrate the value and the procedure of contrast analyses, we introduce an experiment by Maraver et al. (2021) investigating a false-memory effect as an example from cognitive psychology. The term false memory subsumes various phenomena in memory psychology relating to erroneously remembering an event or detail that the person believes to be true, but that did not actually happen or occurred differently than remembered Bernstein et al. (2018). One such memory error is remembering events that were implied or could be inferred from a sentence, but were not explicitly stated (Brewer, 1977). For example, after reading the sentence “The karate champion hit the cinder block” participants may recall that the karate champion broke the cinder block, even though the original sentence did not mention whether the block actually broke.
In their Experiment 1, Maraver et al. (2021) tested whether instructions to imagine the study material can protect against false memories. Participants were presented with everyday action sentences that could induce pragmatic inferences. The encoding instructions were to either imagine , to memorize , or to pay attention to the sentences. Finally, participants were asked to fill in the critical words in a sentence-completion task (e.g., ”The karate champion \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\_\_\_\_\_\_$$\end{document} the cinder block“). Memory performance was measured as the proportion of correctly completed sentences. The condition of interest was the imagine instruction, whereas the memorize and pay attention instructions served as control conditions.1
Maraver et al. (2021) expected that imaginal encoding protects against false memories, because generating images improves memory (imagination facilitation; Foley et al., 2006), whereas the two control conditions should not affect memory performance. This hypothesis could be formalized as the following predicted mean pattern \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _{\textit{imagine} } > \mu _{\textit{memorize} } = \mu _{\textit{pay attention} }$$\end{document} .
As an alternative to the research question investigated by Maraver et al. (2021), one could formulate a hypothesis regarding the control conditions that may suggest different forms of learning when participants are asked to memorize versus to pay attention to the sentences. When explicitly instructed to memorize, participants expect a memory test and thus intentionally encode the sentences (Bereiter & Scardamalia, 1989). This in turn could motivate them to select encoding strategies that involve deeper cognitive processing according to the levels-of-processing theory (Craik & Lockhart, 1972). Deeper processing (e.g., thinking about meaning) leads to better memory than shallow processing (i.e., attending to surface features). Hence, the competing hypothesis could be formalized as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _{\textit{imagine} }> \mu _{\textit{memorize} } > \mu _{\textit{pay attention} }$$\end{document} .
In the study conducted by Maraver et al. (2021), a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1\times 3$$\end{document} between-subjects ANOVA showed significant main effects of the encoding instructions on the proportion of correct responses, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F(2,117) = 28.89, p <.01, \eta _p^2 =.33$$\end{document} . This result indicates that the type of encoding instructions plays a role in memory performance. The post-hoc Bonferroni adjusted comparisons reported by Maraver et al. (2021) showed better memory performance in the imagine condition than in the memorize or the pay attention condition.
Omnibus versus specific hypothesis tests
As many researchers in experimental psychology, Maraver et al. (2021) used ANOVA and post-hoc tests to analyze their data. In ANOVA, the null hypothesis states that the means in all conditions are equal. This null hypothesis is tested against the alternative hypothesis, stating that at least two conditions have different means. Unfortunately, ANOVAs do not allow researchers to test specific differences between conditions, and post-hoc pairwise comparisons often lack sufficient power. We demonstrate in this tutorial article how specific hypotheses can be tested using contrast analysis and how researchers can assess which of two competing hypotheses is more strongly supported by the data (Steiger, 2004).
Many textbooks emphasize that contrast analysis can serve as a substitute for traditional ANOVA (e.g., Saville & Wood, 1991; Draper & Smith, 1998). For instance, a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$2 \times 2$$\end{document} factorial ANOVA can be reformulated using a set of orthogonal contrasts representing the two main effects and their interaction. Analogously to ANOVA, this approach accounts for the total between-group variance with the advantage of conducting directional tests for each factor and their interaction2 (see Appendix A for the contrast weights). Similarly, in one-factor designs with more than two conditions, contrast analysis enables the testing of specific directional hypotheses regarding the expected pattern of condition means. For example, Helmert contrasts can be used to test whether the mean in a control group is lower than the average of two intervention groups, and whether one intervention group outperforms the other (see Appendix A for different sets of contrast vectors). Finally, a single contrast can be used to test whether the observed group means covary with a pattern predicted from theory. In such cases, beyond the general advantages of contrast analysis, this approach avoids a potential type-I error inflation in multiple testing by relying on a single, theory-based test, and offers greater statistical power than post-hoc tests when the observed means align with the hypothesized pattern (Furr, 2008; Langenberg et al., 2023).
We would like to note that contrast analysis is not new. In fact, it has already been promoted in the 1980s and 1990s (e.g., Abelson & Prentice, 1997; Rosenthal & Rosnow, 1985), and is statistically simple and, in principle, can be conducted by hand. Even though some tutorial-style articles are available (e.g., Furr, 2008; Haans, 2018) and contrast analysis is a regular topic in psychological curricula (Sternkopf et al., 2025), the full potential of contrast analysis has not yet been exploited in psychological research (but see de Melo & Terada, 2020; Lachner et al., 2019; Vorauer et al., 2020, for recent applications).
One of the potentials of contrast analysis lies in the possibility to directly test two competing hypotheses against each other (Rosenthal et al., 2000). While competing hypotheses involving only two conditions can be compared in a two-sample or paired t-test, testing competing hypotheses across more than two conditions, as in the study by Maraver et al. (2021), is more challenging. Herein, we focus on this potential of contrast analysis and demonstrate how researchers can compare competing contrasts to determine whether one favored hypothesis aligns more closely with the observed data compared to a rival hypothesis. We refer to this procedure as competing-contrast analysis.Fig. 1. Visualization of the expected proportion of correct responses in the experiment by Maraver et al. (2021). Note. Left panel: Visualization of Hypothesis 1. The expected proportion of correct responses is highest in the imagine condition and the memorize as well as the pay attention are proper baseline conditions. Right panel: Visualization of Hypothesis 2. The expected proportion of correct responses is highest in the imagine condition; the memorize condition outperforms the pay attention condition because it induces a deeper level of processing at encoding. The expected proportions of correct responses are selected based on performances in a typical memory experiment and this relative pattern of condition means helps to determine the contrast weights
This tutorial is organized as follows. We first review the principles of standard contrast analysis for multi-group comparisons with a priori hypotheses using an example with one experimental factor and three conditions. We then demonstrate the largely unknown advantage of contrast analysis to directly compare two competing hypotheses about the expected mean pattern across these conditions. Finally, using data by Maraver et al. (2021) and Akan et al. (2018), we show how researchers can conduct contrast analyses for independent (between-subjects designs) and dependent samples (within-subjects designs; repeated measurements), and competing hypotheses by hand and using the R package cofad (Titz & Burkhardt, 2021, 2024). An accompanying R script is available on the Open Science Framework (OSF) at https://osf.io/ny5b6/. Throughout the article, we use a nominal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha $$\end{document} -level of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$5\%$$\end{document} .
Contrast analysis
The main idea behind contrast analysis is that a specific, predicted mean pattern across conditions (e.g., based on an a priori hypothesis) is tested against the observed mean pattern across conditions in empirical data. This may include main and interaction effects as in standard ANOVA, but with directional statistical tests, as well as more specific hypotheses. Depending on the type of hypothesis to be tested, researchers have to specify so-called contrast weights for one or multiple contrasts. Researchers can then examine whether the specified contrast weights covary with the mean pattern observed in the data (Rosenthal et al., 2000; Maxwell et al., 2004; Sedlmeier & Renkewitz, 2008). The contrast weights can be directly determined from the to-be-tested hypothesis as described next.
Determining contrast weights
The contrast vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda }$$\end{document} of one contrast is composed of K contrast weights, one for each experimental condition i with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i \in (1,...,K)$$\end{document} . Apart from that, the only formal requirement for contrast weights is that they sum to zero for a given contrast:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \sum _{i = 1}^K\lambda _{i} = 0. \end{aligned}$$\end{document}The contrast vector should reflect the relative predicted mean pattern in the K groups. Sedlmeier and Renkewitz (2008) propose to determine the contrast weights as follows:
- derive the relative predicted mean pattern for all experimental conditions from the theory,
- subtract the average of the expected group means from the mean pattern, and
- optionally multiply each contrast weight by a constant to obtain more manageable and interpretable values. These three steps may not sound very intuitive when researchers first come into contact with contrast analysis. At the same time, deriving contrast weights from one’s hypothesis may be a major strength of this statistical method. It encourages researchers to think about the predicted mean pattern at an early stage of the research project. In the light of open science practices and preregistered reports, specifying the expected results as detailed as possible can improve the quality of psychological research (see Lakens, 2019).Table 1. Illustration of how to determine the contrast weights for the predicted mean pattern of Hypothesis 1 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _{\textit{imagine} } > \mu _{\textit{memorize} } = \mu _{\textit{pay attention} }$$\end{document} ) based on the experiment by Maraver et al. (2021)imaginememorizepay attentionPredicted mean pattern0.50.20.2Subtract average \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.5-0.3 = 0.2$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.2 - 0.3 = -0.1$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.2 - 0.3 = -0.1$$\end{document} Multiply by constant \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.2 \cdot 5 = 1.0$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.1 \cdot 5 = -0.5$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.1\cdot 5 = -0.5$$\end{document} Note. The expected mean values are based on the visualization in Fig. 1Table 2. Contrast weights specified for Hypothesis 1 and Hypothesis 2 derived for the experiment by Maraver et al. (2021)imaginememorizepay attention \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _1$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _2$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _3$$\end{document} Hypothesis 1: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _{\textit{imagine} } > \mu _{\textit{memorize} } = \mu _{\textit{pay attention} }$$\end{document} 1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.5$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.5$$\end{document} Hypothesis 2: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _{\textit{imagine} }> \mu _{\textit{memorize} } > \mu _{\textit{pay attention} }$$\end{document} 10 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-1$$\end{document}
One way to determine the contrast weights for a given hypothesis is to visualize the expected group means. Each predicted mean pattern can then be translated into a set of contrast weights. Using the study by Maraver et al. (2021) as an example, two contrasting hypotheses can be derived (e.g., Thapar & McDermott, 2001): While imaginal encoding is always expected to protect against false memories and thus should lead to the best memory performance, two different hypotheses for the control conditions can be formulated. On the one hand, the memorize and the pay attention instruction can be understood as proper control conditions, leading to the same memory performance as illustrated in the left panel of Fig. 1 (Hypothesis 1). On the other hand, according to levels-of-processing theory, memorize instructions should lead to deeper encoding and thus better memory performance than pay attention instructions as illustrated in the right panel of Fig. 1 (Hypothesis 2).
Once the predicted mean pattern (i.e., the relative differences between the group means) is established, the researcher can determine the contrast weights that reflect this mean pattern and that meet the requirement that the sum of the contrast weights of each contrast is equal to zero. Table 1 illustrates this procedure. For Hypothesis 1, the average of the expected group means is subtracted from the predicted mean pattern and then the result is multiplied by 5 for convenience, to obtain the following vector of contrast weights: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda }_{\text {Hyp1}} = (1.0, -0.5,-0.5)$$\end{document} . We can now use these contrast weights to test whether postulating this specific mean pattern makes a good prediction on observed data. Under the null hypothesis, the contrast weights are unrelated to the observed data. Under the alternative hypothesis, the contrast weights covary with the group means in the observed data.
Note that only the relative pattern of contrast weights, not the absolute value of the contrast weights, plays a role in the significance test of the contrast. Some researchers recommend using integer values as weights, others recommend values between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$+1$$\end{document} because the contrast weights reflect the relative weighting of the observed means. In our example, we use the latter approach in which imagine is contrasted with the memorize and pay attention conditions. This is indicated by the absolute weight of 0.5 (i.e., “half” or “average”) for the memorize and the pay attention condition.
In contrast analysis, researchers often use multiple contrast vectors to test distinct components of a single, a priori hypothesis about the pattern of condition means. In the example by Maraver et al. (2021) with three experimental conditions, the contrast vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda }_{\text {Hyp}1} = (1, -0.5, -0.5)$$\end{document} derived above tests whether the mean of the first group differs from the average of the second and third group means. Additionally, a second contrast vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda }_{\text {Hyp}2} = (0, 1, -1)$$\end{document} can be used to test whether the second and third group means differ. Together, these two contrast vectors form a Helmert contrast set, which exhausts the between-group degrees of freedom ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K - 1$$\end{document} for K groups) by specifying two orthogonal contrasts. This analytic strategy — first testing whether the first group differs from the remaining groups and then examining whether the remaining groups differ from one another — is commonly used in contrast analysis (Draper & Smith, 1998; Kaltenbach, 2021; Saville & Wood, 1991). For further details and examples of contrast sets, see Appendix A.
In this tutorial, we pursue a different focus in contrast analysis: We aim to compare competing hypotheses directly by evaluating which of two predicted mean patterns aligns more closely – in terms of their covariation – with the observed mean pattern in the data, which we refer to as competing-contrast analysis. This approach evaluates whether both predicted mean patterns covary equally with the observed mean pattern, or whether the observed pattern shows a stronger covariance with the prediction from Hypothesis 1 than with the prediction from Hypothesis 2. In other words, competing-contrast-analysis tests the statistical null hypothesis that the predicted mean pattern based on Hypothesis 1 covaries with the observed mean pattern to the same extent as the predicted mean pattern based on the rival Hypothesis 2. Therefore, it can be understood as a test of theory-based differences between the two predicted mean patterns (Rosenthal et al., 2000; Sedlmeier & Renkewitz, 2008).
Competing-contrast analysis
Imagine a researcher wants to challenge the hypothesis that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _{\textit{imagine} } > \mu _{\textit{memorize} } = \mu _{\textit{pay attention} }$$\end{document} and favors the rival hypothesis that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _{\textit{imagine} }> \mu _{\textit{memorize} } > \mu _{\textit{pay attention} }$$\end{document} wherein the memorizing instructions should lead to deeper processing and is thus more beneficial to memory than paying attention. The resulting contrast weight vector for the second hypothesis is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda }_{\text {Hyp2}} = (1,0,-1)$$\end{document} . Table 2 summarizes the contrast vectors for both competing hypotheses.
When using competing-contrast analysis, the contrast vectors representing two competing hypotheses can be directly compared. This is done by calculating the difference between the two contrast vectors. Before computing this difference, the contrast weights must be standardized, such that the resulting weights do not unfairly favor the contrast with higher absolute weights. The result is a new contrast vector describing the standardized difference between the original vectors. The standardized contrast vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _i^*$$\end{document} is given by:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \lambda _{i}^* = \frac{\lambda _i}{s_{\lambda }} \end{aligned}$$\end{document}with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s_{\lambda }$$\end{document} being the standard deviation of the contrast weights, which is defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} s_{\lambda } = \sqrt{\frac{\sum _{i=1}^K\lambda _i^2}{K}}. \end{aligned}$$\end{document}The difference between the two standardized contrast vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{i,\text {Hyp1}}^*$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{i,\text {Hyp2}}^*$$\end{document} can then be used as the contrast vector to test whether Hypothesis 1 fits the data better than Hypothesis 2 :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \lambda _{i,\text {difference}} = \lambda _{i,\text {Hyp1}}^* - \lambda _{i,\text {Hyp2}}^* . \end{aligned}$$\end{document}More specifically, if we want to compare the two competing hypotheses in the experiment by Maraver et al. (2021), we first have to standardize their contrast weights depicted in Table 2. The standard deviation of the contrast weights in each contrast is given by:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} s_{\lambda _{\text {Hyp1}}} = \sqrt{\frac{1^2 + (-0.5) ^2 + (-0.5)^2 }{3}} = \sqrt{0.5} \end{aligned}$$\end{document}and
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} s_{\lambda _{\text {Hyp2}}} = \sqrt{\frac{1^2 + 0 ^2 + (-1)^2 }{3}} = \sqrt{0.667}. \end{aligned}$$\end{document}The standardized contrast weights are:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \boldsymbol{\lambda }_{\text {Hyp1}}^* = \Big ( \frac{1}{\sqrt{0.5}}, \frac{-0.5}{\sqrt{0.5}}, \frac{-0.5}{\sqrt{0.5}} \Big ) = ( 1.41, -0.71, -0.71 ) \end{aligned}$$\end{document}and
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \boldsymbol{\lambda }_{\text {Hyp2}}^* \!=\! \Big ( \frac{1}{\sqrt{0.667}}, \frac{0}{\sqrt{0.667}}, \frac{-1}{\sqrt{0.667}} \Big ) \!=\! ( 1.22, 0, -1.22). \end{aligned}$$\end{document}The resulting contrast vector to test the two competing hypotheses is obtained by subtracting the contrast vectors for each hypothesis as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \boldsymbol{\lambda }_{\text {difference}} = \boldsymbol{\lambda }_{\text {Hyp1}}^* - \boldsymbol{\lambda }_{\text {Hyp2}}^* = ( 0.19, -0.71, 0.51 ). \end{aligned}$$\end{document}If a directional test of this contrast is significant, it indicates that Hypothesis 1 corresponds more closely to the observed mean pattern than Hypothesis 2. In other words, we can test theoretically derived differences between two predicted mean patterns to assess whether the observed mean pattern covaries more strongly with Hypothesis 1 compared to Hypothesis 2.
Contrast analysis for independent samples
Contrast analysis for independent samples (between-subjects designs) can be conducted using the F-statistic or the t-statistic. Both variants are demonstrated below. The F-statistic of contrast analysis is closely related to the F-statistic in ANOVAs and may therefore be intuitive for researchers familiar with ANOVA. Note that the degrees of freedom in the numerator of the F-value for one contrast are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ df =1$$\end{document} , such that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F = t^2$$\end{document} or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sqrt{F} = |t|$$\end{document} . Thus, the t-test can conveniently be used instead of the F-test, with the advantage of allowing directional (one-tailed) tests. Also note that contrast analysis for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K=2$$\end{document} independent groups (e.g., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _1 = -1$$\end{document} ; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _2 = 1$$\end{document} ) is formally equivalent to a t-test for independent samples (Fitts, 2010; Sedlmeier & Renkewitz, 2008; Maxwell et al., 2004; Wahlsten, 1991; Steiger, 2004).
Statistical tests
F-test
Researchers familiar with ANOVA may find contrast analysis easily accessible due to their similarities. At its core, the premise remains unchanged: It is evaluated whether two ways of estimating the population variance yield similar outcomes, which corresponds to an F-value close to 1 under the null hypothesis. However, contrast analysis diverges from ANOVA in how it estimates the population variance for the numerator. Because \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum _{i = 1}^K\lambda _{i} = 0$$\end{document} , the population variance can be written as follows (see Rosenthal et al., 2000):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \hat{\sigma }_{\text {contrast}}^2= \frac{\big (\sum _{i=1}^K\lambda _i\bar{x}_i\big )^2}{\sum _{i=1}^K\frac{\lambda _i^2}{n_i}} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n_i$$\end{document} is the sample size in group i.
For the case that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda }$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\bar{x}}$$\end{document} are independent (as expected under the null hypothesis), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\sigma }_{\text {contrast}}^2$$\end{document} provides a reliable estimate for the population variance. However, if they are related in the manner the researcher hypothesizes (as expected under the alternative hypothesis), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\sigma }_{\text {contrast}}^2$$\end{document} will be substantially larger. This stems from the fact that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum _{i=1}^K\lambda _i\bar{x}_i$$\end{document} represents the covariation between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda }$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\bar{x}}$$\end{document} (Rosenthal et al., 2000; Maxwell et al., 2004; Sedlmeier & Renkewitz, 2008).3 When \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda }$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\bar{x}}$$\end{document} covary, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\sigma }_{\text {contrast}}^2$$\end{document} increases, which in turn leads to an increase in the F-statistic:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} F = \frac{\hat{\sigma }_{\text {contrast}}^2}{\hat{\sigma }_{\text {within}}^2} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\sigma }_{\text {within}}^2$$\end{document} represents the mean squared error (MSE) within the groups, serving as an alternative method to estimate the population variance:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \hat{\sigma }^2_{\text {within}} = \frac{\sum _{i = 1}^K\hat{\sigma }_i^2}{K}. \end{aligned}$$\end{document}The more accurately the researcher can predict \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\bar{x}}$$\end{document} through \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda }$$\end{document} , the higher both \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\sigma }_{\text {contrast}}^2$$\end{document} and F-value will become. The logic behind ANOVA is retained in contrast analysis, and its results can be presented in a typical ANOVA table. It is important to note that a scenario, in which \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda }$$\end{document} covary negatively with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\bar{x}}$$\end{document} , would also result in an F-value larger than 1. To evaluate the direction of the covariation between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda }$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\bar{x}}$$\end{document} , and to explicitly conduct a directional test with higher power, the t-statistic can be used.
t-test
In order to obtain the test statistic for a t-test, we compute the contrast estimate L, defined as the sum of the observed means weighted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _i$$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L = \sum _{i=1}^K\lambda _i\bar{x}_i. \end{aligned}$$\end{document}The L-value indicates whether the predicted mean pattern, as described by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda }$$\end{document} , covaries with the observed mean pattern \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\bar{x}}$$\end{document} in the dataset.
To test whether the contrast estimate significantly differs from zero, a t-test with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N-K$$\end{document} degrees of freedom can be conducted, where N represents the total sample size across all groups. The test statistic is then calculated as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} t = \frac{L}{\hat{\sigma }_{L}} \end{aligned}$$\end{document}with
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \hat{\sigma }_{L} = \sqrt{\hat{\sigma }^2_{\text {within}}\sum _{i=1}^K\frac{\lambda ^2_i}{n_i}}. \end{aligned}$$\end{document}This closely corresponds to the equation for the F-statistic for contrast analysis mentioned above.
Example of contrast analysis for independent samples
In the following, we reanalyze the data by Maraver et al. (2021) using contrast analysis with a t-statistic. Table 3 shows the contrast weights, means, variances, and sample sizes for the three experimental groups.Table 3. Contrast weights of Hypothesis 1, means and variances of the memory performance variable, as well as sample sizes in the three experimental groups in the experiment reported by Maraver et al. (2021)imaginememorizepay attention \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {Hyp1}}$$\end{document} 1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.5$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.5$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{x}_i$$\end{document} 0.4140.2000.250 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\sigma }^2_i$$\end{document} 0.0250.0120.015 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n_i$$\end{document} 404040Note: Means and variances are rounded to three decimals
To test Hypothesis 1, the contrast estimate and resulting empirical t-value are computed as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_{\text {Hyp1}}\approx & 1 \cdot 0.414 + (-0.5) \cdot 0.2 + (-0.5) \cdot 0.25 \approx 0.189,\nonumber \\ \hat{\sigma }^2_{\text {within}}\approx & \frac{0.025 + 0.012 + 0.015}{3} \approx 0.017,\nonumber \\ \hat{\sigma }_{L_{\text {Hyp1}}}= & \sqrt{\hat{\sigma }^2_{\text {within}}\sum _{i=1}^K\frac{\lambda ^2_i}{n_i}}\nonumber \\\approx & \sqrt{0.017\Big ( \frac{1^2}{40} + \frac{(-0.5)^2}{40} + \frac{(-0.5)^2}{40} \Big )}\nonumber \\\approx & \sqrt{0.017 \cdot 0.038} \approx 0.025, \end{aligned}$$\end{document}and
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \ \ t_{\text {Hyp1}} = \frac{L_{\text {Hyp1}}}{\hat{\sigma }_{L_{\text {Hyp1}}}} \approx \frac{0.189}{0.025} \approx 7.55. \end{aligned}$$\end{document}The empirical t-value can then be compared to the critical t-value from a t-distribution with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N-K$$\end{document} degrees of freedom and a predefined \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha $$\end{document} -level. For \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha =.05$$\end{document} and a one-tailed test, the critical value is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_{\text {crit}} = 1.65$$\end{document} . As \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.65 < 7.55$$\end{document} , we reject the null hypothesis. This result indicates that the contrast for Hypothesis 1, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda }_{\text {Hyp1}} = (1.0, -0.5,-0.5)$$\end{document} , positively covaries with the observed mean pattern.
Example of a competing-contrast analysis for independent samples
Performing a competing-contrast analysis works analogously to the general procedure of contrast analysis described above. However, for competing-contrast analysis the standardized difference contrast weights are used.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_{\text {difference}} \approx 0.19 \cdot 0.414 + (-0.71) \cdot 0.2 + 0.51 \cdot 0.25 \approx 0.064. \end{aligned}$$\end{document}Let us conduct a directional test assessing whether Hypothesis 1 aligns more closely to the observed data compared to Hypothesis 2. If both contrast vectors covary equally with the observed mean pattern or the contrast vector for Hypothesis 2 covaries stronger with the observed mean pattern, the contrast comparison value is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L \le 0$$\end{document} . If the contrast vector for Hypothesis 1 shows a stronger covariance with the observed mean pattern than Hypothesis 2, then \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L > 0$$\end{document} .
To obtain the corresponding t-test statistic, we need to compute the standard error for the contrast estimate:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \hat{\sigma }_{L_{\text {difference}}}= & \sqrt{\hat{\sigma }^2_{\text {within}}\sum _{i=1}^K \frac{\lambda ^2_i}{n_i}} \approx \sqrt{0.017\Big ( \frac{0.19^2}{40} + \frac{(-0.71)^2}{40} + \frac{0.51^2}{40} \Big )}\nonumber \\\approx & \sqrt{0.017 \cdot 0.02} \approx 0.019, \end{aligned}$$\end{document}and thus
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} t_{\text {difference}} = \frac{L_{\text {difference}}}{\hat{\sigma }_{L_{\text {difference}}}} \approx \frac{0.064}{0.019} \approx 3.377. \end{aligned}$$\end{document}The resulting t-value is compared to the critical t-value from a t-distribution with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N-K$$\end{document} degrees of freedom and a predefined \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha $$\end{document} -level of .05, which is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_{\text {crit}} = 1.65$$\end{document} . We thus reject the null hypothesis of the competing-contrast analysis and conclude that the predicted mean pattern derived from Hypothesis 1 covaries more strongly with the observed mean pattern than the predicted mean pattern derived from Hypothesis 2. Using competing-contrast analysis, we were able to compare the two competing hypotheses using only one statistical test. In the original study, using a classic ANOVA approach, three post-hoc tests were necessary.
Contrast analysis for independent samples in R
In this section, we demonstrate how the cofad package can be used to perform contrast analyses in R. We assume that users are familiar with using R for statistical analyses. First, we show how to run a contrast analysis for independent samples using the data from the experiment by Maraver et al. (2021). The dataset is contained in the cofad package, and we encourage the reader to load the data and follow the steps using the accompanying R script.
We first load the cofad package and inspect the data.
We see the data for several participants. The variable condition is a factor with three levels (imagine, memorize, pay attention). Each participant was assigned to one of these three conditions. The variable prop_recalled is the dependent variable. It gives the proportion of correctly recalled items for each participant. The hypothesis that we want to test is given by the following contrast vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda }_{\text {Hyp1}} = (1.0, -0.5, -0.5)$$\end{document} , as outlined above.
We can now call the calc_contrast function to run the analysis for the first contrast. The function takes four arguments: dv is used to specify the dependent variable, between is used to indicate the between-subjects factor, lambda_between is used to indicate the contrast weights for each level of the factor, and data is used to specify the dataset.
The output shows the contrast weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda }$$\end{document} associated with each condition, the t-table, the F-table, and several measures of effect sizes. The t-table contains the contrast estimate L, the degrees of freedom (df) for the contrast, which is always 1, the t-value and the p-value. Note that the p-value is for a directional test, meaning the t-test is one-tailed.4 Directional hypotheses are frequently employed in contrast analyses, which is why this is the default setting in the cofad package. The F-table shows the sums of squares of the contrast (SS), the degrees of freedom for the contrast, the mean sums of squares, the F-value, and the non-directional p-value.
The output also shows several commonly used measures of effect size for contrast analysis, such as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{\text {effectsize}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{\text {alerting}}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{\text {contrast}}$$\end{document} (Maxwell et al., 2004). Each effect size measure can be understood as the degree to which the observed mean pattern aligns with the predicted mean pattern. More precisely, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{\text {effectsize}}$$\end{document} reflects the correlation between participants’ values on the dependent variable and the specified contrast weights. It is straightforward to calculate and interpret, and it provides a direct assessment of how well the participants’ values are described by the contrast. From an ANOVA perspective, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{\text {effectsize}}^2$$\end{document} denotes the proportion of total variance that is explained by the contrast, similar in interpretation to the commonly used \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta ^2$$\end{document} .
In addition, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{\text {alerting}}$$\end{document} indicates the correlation between the observed group means and the contrast weights, and can be interpreted as a group-level correlation. In ANOVA terminology, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{\text {alerting}}^2$$\end{document} corresponds to the proportion of between-group variance explained by the contrast weights. For instance, in datasets with high within-group variance that complicates the detection of group differences in a traditional omnibus ANOVA, a high \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{\text {alerting}}$$\end{document} can alert researchers that potentially meaningful differences in group means, aligned with the specified contrast, may be present. Importantly, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{\text {alerting}}$$\end{document} serves as an upper boundary for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{\text {effectsize}}$$\end{document} .
Finally, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{\text {contrast}}$$\end{document} represents the partial correlation between participants’ values on the dependent variable and the contrast weights, while partialing out the group differences not captured by the contrast. This measure is similar to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta _p^2$$\end{document} in ANOVA. Although \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{\text {contrast}}$$\end{document} may be more complex to interpret than the other effect size measures in the R output, it has a direct connection to the significance test, making it valuable for power analysis. Researchers can use \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{\text {contrast}}$$\end{document} in power calculations and sample size planning, for example using the pwr.r.test function in the pwr package (Champely, 2020) or comparable functions in the pwrss package (Bulus, 2023) or the WebPower package (Zhang & Mai, 2023) in R as we discuss further below. At the same time, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{\text {contrast}}$$\end{document} can be valuable for meta-analyses, particularly in cases in which different experiments involve different numbers of factors, while \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{\text {effectsize}}$$\end{document} would not allow for such comparisons (Furr, 2004). For additional information on the effect size measures, we recommend the works by Rosenthal et al. (2000), Furr (2004), Haans (2018), Rosnow et al. (2000), and Sedlmeier and Renkewitz (2008). Power analysis for contrasts using G*Power Faul et al. (2007, 2009) is discussed by Perugini et al. (2018).
In line with the results that we calculated by hand, the results from the cofad package suggest that the contrast for Hypothesis 1 describes the observed mean pattern in the data well. The imagine condition showed the highest memory performance compared to the average of the memorize condition and the pay attention conditions. Regarding the effect sizes, we can conclude that the contrast reflects the condition means closely (r_alerting), but the correlation between participants’ values on the dependent variable and the contrast weights (r_effectsize) is much smaller. The two effect size measures, hence, indicate that there remains unexplained interindividual heterogeneity within the experimental conditions.
Competing-contrast analysis for independent samples in R
We now demonstrate how competing-contrast analysis can be conducted using the cofad package. This approach allows us to directly compare Hypothesis 1 to Hypothesis 2. To test whether Hypothesis 1 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _{\textit{imagine} } > \mu _{\textit{memorize} } = \mu _{\textit{pay attention} }$$\end{document} ) aligns more closely with the observed data in comparison to Hypothesis 2 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _{\textit{imagine} }> \mu _{\textit{memorize} } > \mu _{\textit{pay attention} }$$\end{document} ), we first compute the standardized difference between the two contrast vectors. For this purpose, we can use the lambda_diff function in the cofad package. The researcher passes the two contrast vectors and a vector containing the labels of the factor levels. The function then computes the standardized difference between the contrast vectors, where lambda_favored is the contrast vector reflecting the favored hypothesis and lambda_rival is the contrast vector reflecting the rival hypothesis.
We can now use the standardized difference in contrast weights as a new contrast vector in the calc_contrast function from the cofad package:
The results show that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p<\alpha $$\end{document} and that all effect size measures deviate substantially from zero. Hence, we reject the null hypothesis and conclude that the predicted mean pattern derived from Hypothesis 1 covaries more strongly with the observed mean pattern in the data compared to the predicted mean pattern derived from Hypothesis 2. The effect size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{\text {alerting}}$$\end{document} describes the correlation between the group means and the contrast weights of the difference contrast vector. The effect size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{\text {effectsize}}$$\end{document} quantifies how strongly the predicted mean pattern based on Hypothesis 1 correlates with the participants’ observed values on the dependent variable when compared to Hypothesis 2. The effect sizes thus quantify the strength of the relationship between the observed data and the theory-based differences between the two hypotheses.
Contrast analysis for dependent samples
Contrast analysis and competing-contrast analysis can also be used for dependent samples (within-subjects designs). Data from dependent samples are typically obtained in experiments with repeated measurements. Examples include testing the same participants at multiple time points (e.g., before a treatment, directly after a treatment, and a follow-up) or across multiple conditions (e.g., shallow, moderate, and deep encoding, or positive, negative, and neutral stimuli). The resulting measurements within one participant are not independent, which the statistical test needs to take into account.
When applied to dependent samples instead of independent samples, the main principle of contrast analysis remains the same. However, the test statistic and effect size measures are calculated differently. To illustrate the method of contrast analysis for dependent samples, we selected data from an experiment by Akan et al. (2018, Experiment 2B). The authors were interested in whether taking a memory test during the learning phase can improve or harm memory for contextual information.Fig. 2. Visualization of the expected number of correctly selected contexts in the experiment by Akan et al. (2018). Note. Left panel: Visualization of Hypothesis 1, according to which testing leads to better context memory. Right panel: Visualization of Hypothesis 2, according to which testing does not lead to better context memory than restudying
The testing effect (also retrieval-practice effect) is defined as better memory performance after taking an initial test (i.e., practicing retrieval) compared to restudying the same material (Roediger & Karpicke, 2006). One popular explanation of the testing effect is the episodic-context account (Karpicke et al., 2014), which assumes that contextual information from the initial test is encoded alongside the central to-be-learned information. The contextual information may later act as retrieval cues and help to retrieve the central information during the final test. The original episodic-context account states that the relevant contextual information is temporal, whereas a more recent interpretation states that it can also be environmental (e.g., background scenes; Schwoebel et al., 2018).
To decide whether the episodic-context account can be extended from temporal to environmental cues, Akan et al. (2018) asked participants to study cue–target word pairs presented across different screen locations. The within-subjects factor was the type of practice each word pair received before the final test: cued-recall testing of the target given the cue (testing ), additional presentation (restudying ), and no additional exposure (control). The final test two days later included a cued-recall test (item test), followed by an alternative forced-choice test of the original item location (context test) that will be the focus of our reanalysis.
In the experiment by Akan et al. (2018), context memory measured as the proportion of correctly selected contexts was significantly higher for tested than restudied pairs, significantly higher for tested than control pairs, and did not differ significantly between restudied and control pairs. These results required three pairwise comparisons. However, the hypotheses can also be examined in a single test using competing-contrast analysis.
The hypothesis favored by Akan et al. (2018) and its rival hypothesis can be expressed using contrast weights for the three experimental conditions. For Hypothesis 1 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _{\textit{testing} } > \mu _{\textit{restudying} } = \mu _{\textit{control} }$$\end{document} ), the contrast vector is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda }_{\text {Hyp1}} = (1, -0.5, -0.5)$$\end{document} , which compares the testing condition to the average of restudying and control conditions. Alternatively, Hypothesis 2 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _{\textit{testing} } = \mu _{\textit{restudying} } > \mu _{\textit{control} }$$\end{document} ) can be represented by the contrast vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda }_{\text {Hyp2}} = (0.5, 0.5, -1)$$\end{document} , contrasting the control condition with the average of the testing and restudying conditions. Figure 2 illustrates the predicted mean patterns for the two competing hypotheses, and Table 4 summarizes their contrast weights.Table 4. Contrast weights specified for Hypothesis 1 and Hypothesis 2 of the experiment by Akan et al. (2018)testingrestudyingcontrol \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _1$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _2$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _3$$\end{document} Hypothesis 1: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _{\textit{testing} } > \mu _{\textit{restudying} } = \mu _{\textit{control} }$$\end{document} 1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.5$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.5$$\end{document} Hypothesis 2: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _{\textit{testing} } = \mu _{\textit{restudying} } > \mu _{\textit{control} }$$\end{document} 0.50.5 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-1$$\end{document}
Statistical tests
In contrast analysis for dependent samples, the L-statistic reflects a measure of association between the contrast weights and the observed values of each person on the dependent variable for the different within-subjects conditions.
For \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j \in (1,...,J)$$\end{document} measurements (i.e., experimental conditions) and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i \in (1,...,N)$$\end{document} participants, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_i$$\end{document} for person i is defined as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_i = \sum _{j = 1}^J(\lambda _j x_{ij}). \end{aligned}$$\end{document}To obtain the test statistic, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_i$$\end{document} is calculated for all participants in the dataset. Then, the average L across participants is taken to derive the contrast estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{L}$$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \bar{L} = \frac{\sum _{i=1}^N (L_i)}{N}. \end{aligned}$$\end{document}Under the assumption that all participants provide data for all measurements (i.e., a balanced design, which is most often the case in repeated measures designs), one can test whether the contrast estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{L}$$\end{document} is significantly larger than zero using a t-test with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N-1$$\end{document} degrees of freedom. The test statistic is calculated as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} t = \frac{\bar{L}}{\sqrt{\frac{\hat{\sigma }_L^2}{N}}} \end{aligned}$$\end{document}Note that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\sigma }_L^2$$\end{document} is calculated as the sample variance of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_i$$\end{document} values and provides an estimate for the population variance:5
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \hat{\sigma }_L^2 = \frac{\sum _{i=1}^{N} (L_i - \bar{L})^2}{N-1}. \end{aligned}$$\end{document}Example of contrast analysis for dependent samples
We illustrate the procedure of contrast analysis for dependent samples using the data from the three conditions(testing, restudying, and control) in Experiment 2B reported by Akan et al. (2018). For illustrative purposes, we only calculate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{L}$$\end{document} and the t-statistic for the first four participants and Hypothesis 1 (but of course these statistics will need to be calculated for all participants as is done using R further below).
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {Hyp1}}$$\end{document} for Participant 1 is calculated as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_{\text {Hyp1}} = 1 \cdot 1 + (-0.5) \cdot 5 + (-0.5) \cdot 3 = -3. \end{aligned}$$\end{document}The resulting \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {Hyp1}}$$\end{document} values for the four participants are shown in Table 5 together with the average \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{L}$$\end{document} values calculated across the four participants. From the L values, the estimate of the population variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\sigma }^2_{L}$$\end{document} can be computed.Table 5. Values of the dependent variable and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {Hyp1}}$$\end{document} for four participants and corresponding \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{L}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\sigma }^2_{L}$$\end{document} for Hypothesis 1testingrestudyingcontrol \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {Hyp1}}$$\end{document} Participant 1153 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-3$$\end{document} Participant 2143 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-2.5$$\end{document} Participant 33211.5Participant 4475 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-2$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{L}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-1.5$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\sigma }^2_{L}$$\end{document} 4.17
Using \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{L}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\sigma }^2_{L}$$\end{document} , we can then calculate the t-value of the four participants. The test statistic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_{\text {Hyp1}}$$\end{document} for these four participants is given by:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} t_{\text {Hyp1}} = \frac{\bar{L}_{\text {Hyp1}}}{\sqrt{\frac{\hat{\sigma }^2_{L_{\text {Hyp1}}}}{N}}} = \frac{-1.5}{\sqrt{\frac{4.17}{4}}} = -1.47. \end{aligned}$$\end{document}This observed t-value can then be compared to the critical t-value from a t-distribution with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N-1$$\end{document} degrees of freedom and a predefined \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha $$\end{document} -level. For \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha =.05$$\end{document} , we obtain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_{\text {crit}}(3) = 2.35$$\end{document} and retain the null hypothesis. Next, we conduct the contrast analysis using the cofad package, but this time for all 90 participants.
Contrast analysis for dependent samples in R
The R syntax for dependent sample contrast analysis in the cofad package is similar to the R syntax for independent samples. However, the data are structured in a different format because the data set contains multiple observations per participant. First, we load the data from Experiment 2B by Akan et al. (2018) with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N=90$$\end{document} participants providing values in each of the three experimental conditions (testing, restudying, control).
The dataset shows the participant id (subject), the within-subjects condition (condition), and the number of correctly selected contexts of each participant (contexts). This data format is also called the long format (as opposed to the wide format).
To conduct the contrast analysis for the dependent sample, we again apply the calc_contrast function from the cofad package, but this time with within, lambda_within, and id as arguments. The latter indicates each participant. We use the calc_contrast function to test the contrast reflecting Hypothesis 1 with the contrast vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda }_{\text {Hyp1}} = (1, -0.5, -0.5)$$\end{document} .
In the resulting output, the contrast estimate, standard error, degrees of freedom (df \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$=N-1),\,t$$\end{document} -value, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p$$\end{document} -value are shown in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t$$\end{document} -table. For within-subjects designs, the effect sizes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_\text {contrast} { and}g_\text {contrast} $$\end{document} are reported. The latter demonstrates how well the relative differences in the observed means between the conditions are reflected by the contrast weights, and it can serve as an estimate of Cohen’s \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d$$\end{document} in the population. For more details on effect sizes for dependent samples, we refer the interested reader to Rosenthal et al. (2000), Sedlmeier and Renkewitz (2008), Steiger (2004), and Wiens and Nilsson (2017).
The results in the R output suggest that the contrast for Hypothesis 1 describes the observed mean pattern well. In the testing condition, the number of correctly selected contexts seems to be higher compared to the average of the restudying and control conditions.
Competing-contrast analysis for dependent samples in R
We now conduct a competing-contrast analysis to test Hypothesis 1 against Hypothesis 2 (see Fig. 2 for the predicted mean patterns of the two hypotheses). Following the case of independent samples, we first calculate the standardized differences between both vectors of contrast weights.
We can now conduct the competing-contrast analysis for dependent samples using the vector of contrast weight differences:
As for independent samples, the default t-test in the cofad package is directional such that a positive value of the t-statistic indicates that the favored contrast vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda } = (1, -0.5, -0.5)$$\end{document} covaries more strongly with the observed mean pattern compared to the rival contrast vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{\lambda } = (0.5, 0.5, -1)$$\end{document} . The t-test is not significant and we retain the null hypothesis. Note that Akan et al. (2018) reached a similar conclusion, but had to run three t-tests.
Power calculation in contrast analysis
For between-subjects designs, sample size planning and power analysis can be conducted using the effect size measure \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_\text {contrast}$$\end{document} in combination with one of the many available power analysis packages in R. For example, using the pwr package, the required sample size for a between-subjects contrast analysis based on a t-test can be obtained by using the pwr.r.test function as follows:
To achieve a minimum power of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$80\%$$\end{document} in the case of four conditions and a balanced design, 32 participants in total (due to rounding up) and eight participants per condition would be required. For the same parameters, Perugini et al. (2018) uses the non-directional F-test for contrast analysis, resulting in a recommendation to test nine participants per condition. Hence, as expected, a directional test is more powerful. This power calculation shows that contrast analysis allows researchers to test the predicted mean pattern in an efficient way. If the predicted mean pattern closely aligns with the observed mean pattern, as is the case in this example with an effect size of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r =.45$$\end{document} , a higher statistical power is achieved using contrast analysis compared to an omnibus ANOVA or post-hoc tests, which reduces the required sample size.
For within-subjects designs, the power analysis is based on a dependent-samples t-test. The output of cofad provides \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g_\text {contrast}$$\end{document} , which can serve as an estimate of d in the population. In turn, d can be used for power analysis using the pwr.t.test function as follows:
The power analysis results in a required sample size of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N=19$$\end{document} participants to detect an effect of size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d = 0.8$$\end{document} with a power of .95 in a within-subjects experiment. As with between-subjects designs, the t-test for dependent samples requires fewer participants when conducted as a one-tailed test.
As in power analyses for ANOVAs and other traditional statistical procedures, the technical aspects of power analysis for contrast analysis and competing-contrast analysis are relatively straightforward. However, selecting theoretically meaningful estimates for the effect size measure \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_\text {contrast}$$\end{document} remains a key challenge.
Because \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_\text {effectsize}$$\end{document} is easier to estimate, one possibility is to assume that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_\text {alerting}$$\end{document} is equal to one, which implies \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_\text {contrast} = r_\text {effectsize}$$\end{document} . In case that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_\text {alerting}$$\end{document} is smaller than one in reality, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_\text {effectsize}$$\end{document} serves as a lower bound for the true effect size and the power analysis will be conservative. Another possibility is to estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_\text {contrast}$$\end{document} directly, which requires knowing the sums of squares of the contrast under investigation and the sums of squares within groups. The size of these properties can be determined using data from previous studies or by conducting a pilot study. Alternatively, one could use a simulation approach (see Strobl et al., 2024) to generate plausible simulated data and calculate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_\text {contrast}$$\end{document} from this data.
Discussion
This tutorial article provided a tutorial to conduct contrast analysis using the R package cofad and outlined a rarely used method to compare two competing predictions via competing-contrast analysis. Contrast analysis offers a theory-driven, flexible, and powerful framework for testing directional, a priori hypotheses about mean patterns across experimental conditions or measurement points. Rather than relying on omnibus tests like ANOVA, contrast analysis allows researchers to directly evaluate the extent to which observed mean patterns align with predicted ones. Competing-contrast analysis extends this framework by enabling direct comparisons between two predicted patterns of condition means derived from competing theories, offering a structured statistical approach to theory testing.
A central element of contrast analysis is the specification of contrast weights, which translate theoretical predictions into testable statistical hypotheses (see Abelson & Prentice, 1997; Rosenthal et al., 2000; Rosnow & Rosenthal, 1996; Furr, 2008). For researchers unfamiliar with contrast analysis, deriving these weights may seem daunting at first. However, as demonstrated in our practical examples, this process often clarifies theoretical expectations and the interpretation of study results, and is thus a valuable step in the research process that deserves more attention. Pre-registering both the predicted mean patterns and the corresponding contrast weights can improve transparency, prevent post-hoc adjustments, and help maintain the confirmatory nature of hypothesis testing (e.g., Lakens, 2019; Maier & Lakens, 2022; Francis, 2012b; Francis, 2012a, for discussions). At the same time, the utility of pre-registration depends on how well the contrasts are theoretically derived. Reviewers should therefore examine whether the contrast weights are grounded in theoretical considerations.
While standard contrast analysis evaluates the degree to which a predicted pattern fits the data, competing-contrast analysis serves a different purpose: It assesses which of two competing, theory-driven predictions is more strongly supported by the observed results. This approach is especially valuable when different theoretical accounts lead to different expectations about mean patterns across conditions. In such cases, the research question shifts from asking whether a particular pattern fits to asking which of two competing hypotheses provides a better account of the data. Importantly, competing-contrast analysis does not test the absolute fit of either prediction, but rather their relative alignment with the observed pattern.
The fact that opposing hypotheses can be compared may make competing-contrast analysis a suitable statistical complement to so-called experimentum crucis designs in psychology. In the tradition of experimental science, an experimentum crucis can be understood as a critical experiment that favors one hypothesis and rules out the other (Platt, 1964; Lohne, 1968; Malejka et al., 2022; Sinico, 2018). Although psychological theories are often underspecified and empirical data tend to be noisy, researchers can often derive distinct predictions from competing theories. Competing-contrast analysis may thus offer a statistically rigorous way to evaluate such predictions, making it a promising tool in contexts in which theory comparison is the primary objective.
Another consideration when applying contrast analysis, especially when testing multiple contrasts as part of a contrast set, is how to handle the issue of multiple testing. The literature remains divided on whether adjustments to the significance level \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha $$\end{document} are required when conducting multiple hypothesis tests (e.g., Bennett et al., 2009; O’Keefe, 2003; Sinclair et al., 2013; Wilson, 1962). Rubin (2021) and Weber (2007) have highlighted that the type of multiple testing matters, that is, whether the goal is to evaluate a disjunction (e.g., at least one effect is present), a conjunction (e.g., all effects must be present), or whether individual hypotheses are tested independently. In contrast analysis, these considerations may imply that multiple individual directional hypotheses (e.g., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _1 > \text {mean}(\mu _2, \mu _3)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _2 = \mu _3$$\end{document} ) can be tested separately without necessarily requiring adjustments to the significance level \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha $$\end{document} – provided that each hypothesis is interpreted independently and not as part of a single, overarching hypothesis about the entire mean pattern. Because competing-contrast analysis involves a single, planned comparison between two competing predictions, it constitutes a planned test of one hypothesis and thus does not raise concerns about inflated type-I error rates due to multiple testing.
Despite its advantages, contrast analysis remains underutilized in published psychological research. This is somewhat surprising given that it is widely taught as part of psychological study programs. A recent survey of professors teaching methods and statistics at German universities found that 28 out of 34 B.Sc. and M.Sc. psychology programs teach contrast analysis (Sternkopf et al., 2025), suggesting a gap between educational standards and research practices. We believe that user-friendly R packages, accessible code scripts, and hands-on tutorials can help bridge this gap. In addition to the functions presented in this tutorial, the cofad package includes an integrated Shiny app that allows users to interactively select variables and define contrast weights. While scripted code is generally preferable for reproducibility and sharing, the app’s graphical interface may serve as a useful teaching aid in statistics education.
In sum, contrast analysis provides a more targeted and theoretically informative alternative to omnibus ANOVAs, particularly when researchers have clear predictions about expected patterns. In the light of the replication crisis and calls to increase statistical power in psychology, adopting contrast analysis for confirmatory research is a valuable approach. As an extension to standard contrast analysis, competing-contrast analysis adds further value by enabling researchers to directly test two competing hypotheses against each other, supporting stronger, theory-based inferences. In the future, we hope that contrast analysis, and in particular competing-contrast analysis, will become a standard method in the statistical toolbox of psychological researchers.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bulus, M. (2023). pwrss: Statistical power and sample size calculation tools [R package version 0.3.1]. https://CRAN.R-project.org/package=pwrss
- 2Champely, S. (2020). pwr: Basic functions for power analysis [R package version 1.3-0]. https://CRAN.R-project.org/package=pwr
- 3Draper, N. R., & Smith, H. (1998). Applied regression analysis. Wiley Series in Probability and Statistics. 10.1002/9781118625590
- 4Kaltenbach, H.-M. (2021). Comparing treatment groups with linear contrasts. In H.-M. Kaltenbach (Ed.), Statistical design and analysis of biological experiments (pp. 97–120). Springer International Publishing. 10.1007/978-3-030-69641-2_5
- 5Karpicke, J. D., Lehman, M., & Aue, W. R. (2014). Retrieval-based practice: An episodic context account. In B. H. Ross (Ed.), Psychology of learning and motivation (pp. 237–284). Elsevier Academic Press. 10.1016/b 978-0-12-800283-4.00007-1
- 6Lenth, R. V. (2016). Least-squares means: The R package lsmeans. Journal of Statistical Software, 69(1). 10.18637/jss.v 069.i 01
- 7Lohne, J. A. (1968). Experimentum crucis. Notes and Records of the Royal Society of London, 23(2), 169–199. https://www.jstor.org/stable/530985
- 8Malejka, S., Heck, D. W., & Erdfelder, E. (2022). Recognition-memory models and ranking tasks: The importance of auxiliary assumptions for tests of the two-high-threshold model. Journal of Memory and Language,127, 104356 . 10.1016/j.jml.2022.104356