Robust Occupant Behavior Recognition via Multimodal Sequence Modeling: A Comparative Study for In-Vehicle Monitoring Systems
Jisu Kim, Byoung-Keon D. Park

TL;DR
This paper compares different AI models for recognizing driver and passenger behaviors using body, gaze, and facial data, finding that attention-based models perform best.
Contribution
The study introduces a comprehensive comparison of temporal modeling approaches for multimodal occupant behavior recognition in vehicles.
Findings
Temporal models outperform static models in occupant behavior recognition.
The Transformer model achieves a state-of-the-art Macro F1 score of 0.9570.
Transformers offer a strong balance between performance and computational efficiency.
Abstract
Understanding occupant behavior is critical for enhancing safety and situational awareness in intelligent transportation systems. This study investigates multimodal occupant behavior recognition using sequential inputs extracted from 2D pose, 2D gaze, and facial movements. We conduct a comprehensive comparative study of three distinct architectural paradigms: a static Multi-Layer Perceptron (MLP), a recurrent Long Short-Term Memory (LSTM) network, and an attention-based Transformer encoder. All experiments are performed on the large-scale Occupant Behavior Classification (OBC) dataset, which contains approximately 2.1 million frames across 79 behavior classes collected in a controlled, simulated environment. Our results demonstrate that temporal models significantly outperform the static baseline. The Transformer model, in particular, emerges as the superior architecture, achieving a…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
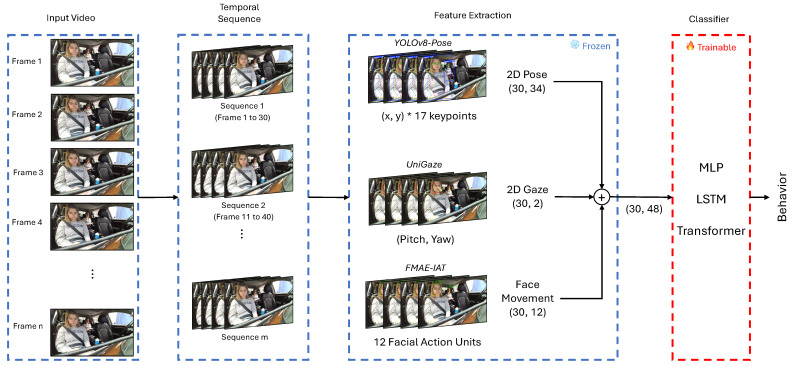 Figure 1
Figure 1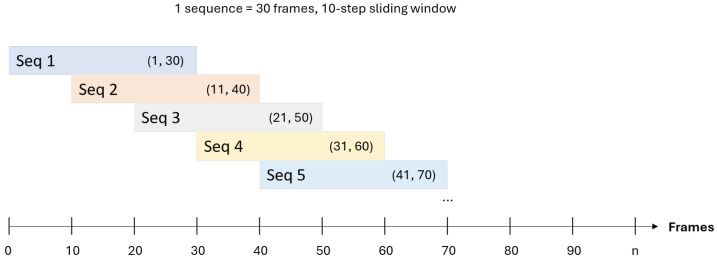 Figure 2
Figure 2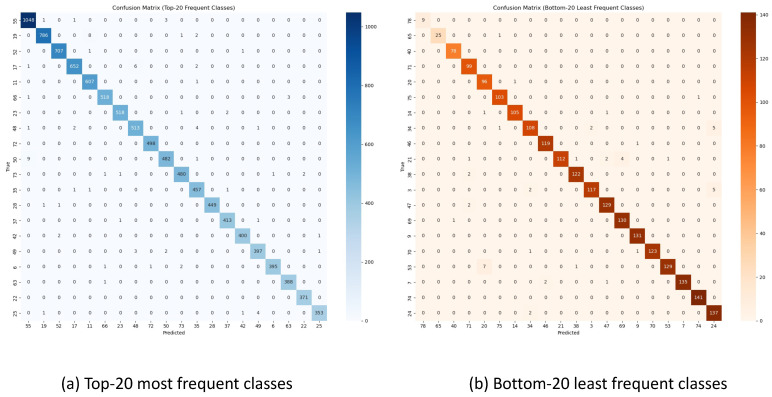 Figure 3
Figure 3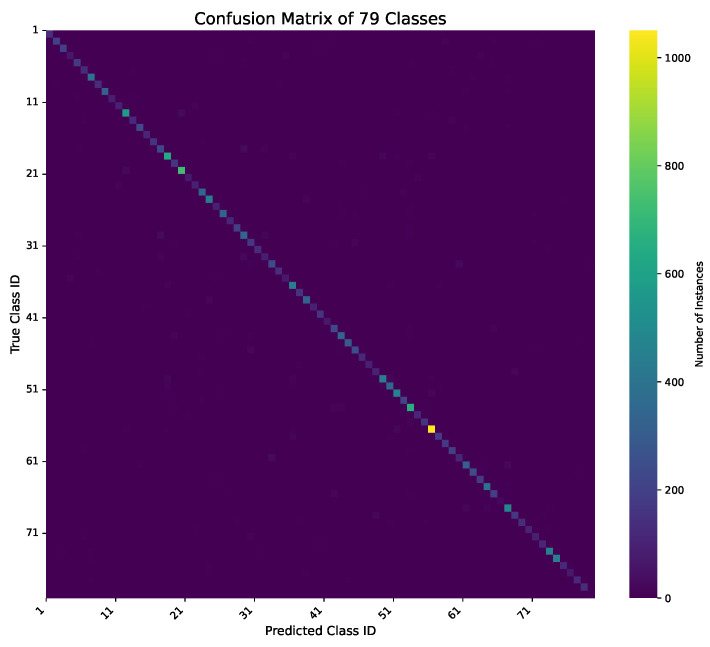 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsVideo Surveillance and Tracking Methods · Anomaly Detection Techniques and Applications · Human Pose and Action Recognition
1. Introduction
Occupant behavior recognition has emerged as a crucial component of intelligent transportation systems, enabling real-time monitoring to enhance road safety and situational awareness. Traditional approaches often rely on single-modality visual cues and static frame-level classifiers, which struggle with the subtle, temporally dependent patterns found in complex, simulated driving environments. Moreover, a single feature type is often insufficient to capture the diverse range of behaviors, from gross body movements to fine-grained facial expressions.
Recent advancements in multimodal learning and temporal modeling have shown promise in addressing these limitations. By combining complementary cues such as body pose, gaze, and facial movements, a more holistic understanding of occupant behavior can be achieved. Temporal models, like LSTMs, can further exploit sequential dependencies to distinguish between visually similar yet temporally distinct actions. More recently, attention-based architectures such as the Transformer have demonstrated state-of-the-art performance in various sequence modeling tasks, offering an alternative approach to capturing long-range dependencies.
To address these challenges, this paper presents a lightweight and modular framework for occupant behavior recognition that leverages temporal modeling of multi-feature inputs. Our approach fuses three complementary modalities—2D pose, 2D gaze, and facial movement (FM)—into fixed-length sequences, which are then classified using three distinct architectures: a static Multi-Layer Perceptron (MLP), a recurrent Long Short-Term Memory (LSTM) network, and an attention-based Transformer encoder. We conduct a comprehensive evaluation on the large-scale Occupant Behavior Classification (OBC) dataset, and our main contributions are as follows:
- A multimodal occupant behavior recognition pipeline that integrates 2D pose, 2D gaze, and facial movement (FM) features using an early fusion strategy.
- A comparative analysis of static (MLP), recurrent (LSTM), and attention-based (Transformer) classification models, highlighting the benefits of temporal modeling for complex behavior recognition.
- An extensive ablation study on the effects of feature combinations, sequence lengths, and frame sampling strategies, providing insights into optimal design choices for in-vehicle monitoring systems.
- A lightweight and computationally efficient design suitable for practical deployment, supported by performance and inference cost evaluations.
Through these contributions, this work underscores the importance of multimodal fusion and temporal modeling for occupant behavior recognition, offering practical guidelines for the development of robust occupant monitoring systems for in-vehicle applications.
2. Related Work
2.1. Pose Estimation for Occupant Behavior
Accurate pose estimation is essential for capturing body dynamics during driving. Recent YOLO-based frameworks have demonstrated real-time, high-accuracy keypoint detection by integrating object detection and pose estimation into a unified pipeline. YOLO-Pose extends the YOLO architecture for multi-person 2D pose estimation, jointly predicting bounding boxes and keypoints in a single stage, achieving state-of-the-art performance on large-scale benchmarks [1]. Building on this, YOLOv8-PoseBoost incorporates channel attention modules, multi-scale detection heads, and cross-level feature fusion to improve small-target detection in complex environments [2]. These advances provide a robust foundation for extracting spatial cues in occupant monitoring systems.
2.2. Gaze Estimation
Gaze estimation is a key indicator of occupant attention and situational awareness. UniGaze [3] proposes a universal gaze estimation framework trained on large-scale, in-the-wild face datasets using masked autoencoder (MAE) [4] pre-training with a Vision Transformer backbone. This approach improves cross-domain generalization under both leave-one-dataset-out and joint-dataset evaluation protocols, making it suitable for deployment in diverse and unconstrained driving scenarios.
2.3. Facial Movement Modeling
Subtle facial movements can provide critical clues for identifying occupant states, such as Inattention or drowsiness. The FMAE-IAT framework [5] leverages MAE pre-training on the large-scale Face9M dataset, combined with identity adversarial training to avoid identity-dependent biases. It achieves state-of-the-art performance on action unit detection benchmarks such as BP4D [6], BP4D+ [7], and DISFA [8], highlighting its capacity to capture fine-grained facial behavior.
2.4. AI-Based In-Vehicle Occupant Behavior Recognition
AI-based behavior recognition is a cornerstone of modern in-vehicle occupant monitoring systems. A significant body of research has focused on driver-centric applications, leveraging machine learning and deep learning to enhance safety. Convolutional Neural Networks (CNNs), in particular, have been widely adopted for detecting driver distraction. For instance, Xing et al. (2019) [9] utilized models like AlexNet and GoogLeNet to classify seven driver activities, achieving up to 91.4% accuracy in distinguishing distracted from normal driving. Similarly, Valeriano et al. (2018) [10] recognized 10 types of distracted behaviors with 97% accuracy using a ResNet-based model. Beyond deep learning, traditional methods like Support Vector Machines (SVMs) and Decision Trees have also proven effective. Costa et al. (2019) [11] reached 89–93% accuracy in detecting driver fatigue and distraction, while Kumar and Patra (2018) [12] achieved 95.58% sensitivity in drowsiness detection using SVMs with facial features.
More recent works have adopted multimodal approaches, integrating data from RGB, depth, and infrared sensors to capture a richer representation of behavior. Ortega et al. (2020) [13] demonstrated a system that monitors distraction, drowsiness, gaze, and hand–wheel interactions, reporting performance exceeding 90%. While these foundational studies primarily target the driver for safety-critical alerts, their methodologies are broadly applicable to understanding the behaviors of all vehicle occupants, paving the way for more holistic in-cabin monitoring systems. Alongside these, attention-based models like the Transformer [14], originally developed for natural language processing, are increasingly being adapted for time-series and sequence modeling tasks due to their proficiency in capturing long-range dependencies.
2.5. Summary and Positioning
Previous studies have successfully established methodologies for classifying specific, often safety-critical, occupant behaviors within a limited range of 7–10 categories using techniques like CNNs and SVMs [9,10,11]. However, this focus on the driver often overlooks the broader spectrum of general occupant behaviors, and many studies do not systematically compare different feature sets and temporal modeling configurations.
In contrast, our work addresses these gaps by proposing a lightweight pipeline designed for comprehensive occupant behavior recognition. We leverage state-of-the-art pre-trained models—YOLOv8-Pose, UniGaze, and FMAE-IAT—as efficient feature extractors for three complementary cues: 2D pose, 2D gaze, and facial movement. Crucially, our work is distinguished by its validation on the large-scale Occupant Behavior Classification (OBC) dataset, which encompasses 79 diverse occupant behavior classes, moving far beyond driver-specific tasks. We conduct an extensive ablation study to systematically compare three distinct architectural paradigms, a static model (MLP), a recurrent model (LSTM), and an attention-based model (Transformer), and analyze the impact of sequence length and frame sampling strategies. This positions our work at the intersection of multimodal fusion and temporal modeling, providing a robust framework and practical insights for developing next-generation in-vehicle occupant monitoring systems.
3. Methodology
To address the challenges of recognizing complex, temporally dependent occupant behaviors, we designed a lightweight and modular recognition pipeline. Our approach prioritizes both high accuracy through multimodal fusion and computational efficiency by freezing feature extractors. As illustrated in Figure 1, the pipeline is divided into three main stages:
- Feature Extraction: For each input frame, we extract three types of features—2D pose, 2D gaze, and facial movement (FM). Pre-trained models are used to extract these features, and to improve computational efficiency, the feature extractors are frozen during training.
- Fusion and Sequence Construction: The extracted features from each modality are concatenated to form a unified feature vector per frame. Then, consecutive frames are grouped into sequences based on a specified number of frames and step size.
- Temporal Classification: The constructed sequences are fed into a lightweight classifier. We compare three distinct architectures: a static MLP, a recurrent LSTM, and an attention-based Transformer. Only the classifier is trainable, keeping the rest of the pipeline fixed.
This modular design allows easy experimentation with different combinations of input features, sequence lengths, and model architectures, facilitating both ablation and computational cost analysis.
3.1. Multi-Feature Fusion
To construct a comprehensive representation of occupant behavior, we fuse three complementary modalities: 2D pose, 2D gaze, and facial movement (FM). Each feature type captures a different aspect of occupant behavior: pose encodes gross body movement, gaze reflects visual attention, and FM captures subtle expressions related to the occupant’s state (e.g., drowsiness or inattention). Each modality is processed by a specialized, pre-trained feature extractor chosen for its state-of-the-art performance and efficiency, as discussed in Section 2.
Two-dimensional Pose: We employ YOLOv8-Pose [15], selected for its high accuracy and real-time keypoint detection capabilities crucial for in-vehicle monitoring.Two-dimensional Gaze: We use UniGaze [3], which offers robust cross-domain generalization, making it suitable for diverse and unconstrained driving scenarios.Facial Movement: We utilize FMAE-IAT [5] to extract a 12-dimensional vector of Facial Action Units (AUs). The process involves detecting and cropping the occupant’s face, resizing it, and feeding it into the frozen FMAE-IAT feature extractor, which directly outputs the 12-dimensional AU intensity vector.
Once extracted, the features from each modality are concatenated along the channel axis for each frame. This early fusion strategy allows the temporal model to learn from a unified representation that incorporates information across all modalities. By design, these feature extraction modules are frozen during training to maintain a lightweight pipeline and ensure computational efficiency.
3.2. Temporal Sequence Modeling
Occupant behaviors are inherently temporal phenomena. To effectively model these dynamics while managing computational load, we transform the continuous video data into discrete sequences using a two-stage sampling process governed by three key hyperparameters, as illustrated in Figure 2.
First, we define a sequence span ( ), which is the total duration of the temporal window from the raw video. Second, from within this span, we downsample a fixed number of frame samples ( ). These frames are selected at a uniform interval to form the final input sequence.
Finally, the step size (S) determines the offset by which this entire sequence span window is moved to create the next overlapping sequence. A single ground-truth label is assigned to each final sequence by taking the majority vote of the frame-level labels within its span.
3.3. Classifier Architectures
For classifying the fused feature sequences, we implemented and compared three architectures representing different modeling paradigms: a static model (MLP), a recurrent model (LSTM), and an attention-based model (Transformer). Our design focuses on keeping these classifiers lightweight while freezing the upstream feature extractors, which is critical for practical deployment. The detailed architectural parameters for each model are summarized in Table 1.
3.3.1. Multi-Layer Perceptron (MLP)
The MLP serves as our static baseline. It processes a sequence by flattening all temporal features into a single large vector, thus ignoring explicit temporal ordering. Our implementation consists of four fully connected layers with ReLU activations and batch normalization, which progressively reduce the feature dimension before a final classification layer.
3.3.2. Long Short-Term Memory (LSTM)
As a representative recurrent model, the LSTM is chosen for its ability to model temporal dependencies by processing sequences step by step and maintaining an internal memory state. We use a three-layer unidirectional LSTM, where the mean-pooled output of the final time step’s hidden state is passed through a layer normalization step before being used for classification.
3.3.3. Transformer
To represent attention-based models, we use a Transformer encoder architecture. The model first projects the input features into a higher-dimensional space and adds sinusoidal positional encodings to retain sequence order. The data is then processed by a stack of four multi-head self-attention layers, which allows the model to weigh the importance of all frames in the sequence simultaneously. The final classification is made from the mean-pooled and layer-normalized output of the encoder.
4. Experiments
In this section, we describe the dataset used in our study, the evaluation metrics employed, and the implementation and training details and provide a comprehensive analysis of our results, including an ablation study to examine the contribution of each component.
4.1. Dataset
For this study, we utilized the Occupant Behavior Classification (OBC) dataset. This dataset was originally collected at the University of Michigan Transportation Research Institute (UMTRI) to investigate occupant behaviors across different levels of simulated vehicle automation (protocol approved by the UMTRI Institutional Review Board: HUM00162942). The dataset is not publicly available due to privacy protection considerations. The data collection included 42 licensed drivers (21 men and 21 women) with a broad range of anthropometric characteristics and ages from 18 to 59 years. All participants were recorded in a stationary 2018 Hyundai Genesis G90 sedan equipped with two Microsoft Azure Kinect sensors mounted near the A-pillars to capture both front seats.
The dataset contains approximately 2.1 million frames captured at 10 frames per second with a resolution of . It covers 79 distinct occupant behavior classes, which were elicited by asking participants to perform a series of scripted tasks. To elicit naturalistic-style behavior, participants were instructed to perform these tasks as they normally would in a real moving vehicle and to find postures they would consider comfortable for a long ride. These tasks were performed under three simulated automation levels: Manual (MN), Fully Automated (FA), and Semi-Automated (SA). For the MN and SA sessions, the participant was seated in the driver’s seat, while for the FA session, they were moved to the passenger’s seat to reflect a non-driving role. The data includes synchronized video from two front-facing camera views, one positioned in front of the driver seat and the other in front of the passenger seat. The OBC dataset captures a variety of controlled driving conditions, including scenarios with a single driver as well as those with passengers seated in the back. Each frame is annotated with a single occupant behavior class.
For our experiments, the dataset was split into training (80%, 1.68 M frames), validation (10%, 210 K frames), and testing (10%, 210 K frames) subsets. The full list of behavior classes is provided in Appendix A. It is important to note the constraints of the data collection environment. The experiments were conducted in a stationary vehicle with a locked steering wheel, and some seat adjustment controls were deactivated to standardize conditions. Behaviors were elicited via scripted prompts from an investigator, which may differ from fully spontaneous actions in an on-road driving context.
4.2. Evaluation Metrics
To evaluate the performance of occupant behavior recognition models, we adopt five widely used metrics for multi-class classification: accuracy, Balanced Accuracy, Macro F1, Weighted F1, and the confusion matrix. Accuracy measures the overall proportion of correctly classified instances:
where N is the total number of instances, is the ground-truth label, is the predicted label, and is the indicator function. Balanced Accuracy computes the average recall over all C classes, mitigating the impact of class imbalance:
where and denote the true positives and false negatives for class c. Macro F1 is the unweighted average of per-class F1-scores:
Weighted F1 computes the F1-score per class and weights each score by the number of instances in that class:
where is the number of true instances of class c. A confusion matrix is a matrix M, where denotes the number of instances of class i predicted as class j. It provides a detailed visualization of misclassifications:
The full confusion matrix for all 79 classes is provided in Appendix B.
4.3. Experimental Setup
We trained and evaluated all three models—MLP, LSTM, and Transformer—under a consistent experimental framework to ensure a fair comparison. The architectural details of each model are described in Section 3.3. For the sequential models (LSTM and Transformer), we conducted an extensive ablation study on temporal configurations by varying the sequence span ( ), step size (S), and the number of frame samples ( ). Each sequence was assigned a single ground-truth label based on the majority vote of its constituent frames.
All models were trained using the Adam optimizer for up to 200 epochs, employing an early stopping mechanism with a patience of 10 epochs based on the validation loss. The key training hyperparameters, such as learning rate, batch size, and dropout, are summarized for each model in Table 2. All experiments were implemented in PyTorch (version 2.7.1+cu126) and executed on a high-performance computing cluster equipped with an NVIDIA Tesla V100 GPU (Santa Clara, CA, USA).
5. Results
This section presents a comprehensive evaluation of our proposed framework, comparing the performance of the MLP, LSTM, and Transformer models. We analyze the results from four perspectives: the impact of input feature modalities, the effect of temporal configurations on the Transformer model, a direct comparison of model performance versus computational efficiency, and an in-depth analysis of per-class performance.
5.1. Input Modality Ablation Study
To understand the contribution of each visual cue, we first evaluated all three models with various combinations of 2D pose, 2D gaze, and facial movement (FM) features, using a fixed sequence length of 30 frames. As shown in Table 3, several key trends emerge. First, 2D pose is consistently the most dominant modality, providing a strong performance baseline. Second, both LSTM and Transformer significantly outperform the static MLP model across all feature combinations, underscoring the importance of temporal modeling. Third, the Transformer model generally achieves the highest performance, particularly when modalities are fused. The best overall result is achieved when all three modalities (‘Pose + Gaze + FM’) are used with the Transformer, reaching a Macro F1 of 0.8970.
5.2. Temporal Configuration Analysis for the Transformer
Given the strong performance of the Transformer, we conducted an extensive ablation study to analyze its sensitivity to different temporal configurations, with detailed results presented in Table 4. The results indicate that a smaller, denser step size (S) consistently yields better performance. For instance, with a sequence span ( ) of 50, a step size of 10 achieves a Macro F1 of 0.9570, whereas a step size of 50 results in a score of only 0.3012. The number of frame samples ( ) also plays a crucial role. The highest performance was achieved with a 50-frame span and a step size of 10. Specifically, the configuration with yielded the best Macro F1 score of 0.9570, while the configuration with achieved the highest Balanced Accuracy of 0.9567.
5.3. Performance vs. Efficiency Comparison
A critical aspect for practical deployment is the trade-off between predictive performance and computational cost. We summarize this comparison in Table 5. As expected, the MLP is the most lightweight model but provides the lowest performance. While the LSTM model shows the highest peak performance (Macro F1 of 0.9931), this result stems from our initial experimental design using a frame-level data split. As detailed in our Discussion (Section 6), this approach can lead to performance inflation. In contrast, the Transformer model offers a compelling balance. Its best-performing configuration ( ) achieves a high and, crucially, more robust Macro F1 score of 0.9570. This positions the Transformer as the superior architecture, providing state-of-the-art performance within our revised framework. Furthermore, its most efficient configuration ( ) delivers a strong Macro F1 of 0.9395 with only 0.02 GFLOPs, highlighting its suitability for resource-constrained environments.
5.4. Per-Class Performance and Error Analysis
To gain deeper insights into the Transformer model’s behavior, we analyzed its per-class performance using its best-performing configuration, as detailed in Table 6. A notable finding is the model’s exceptionally high performance even on what are predicted to be challenging classes. The Top-5 performing classes are distinct actions like ‘Tilting sun visor’ or ‘Using laptop on armrest’. More impressively, the Bottom-5 classes, which often involve subtle motions or have low sample counts (e.g., ‘Adjusting pelvis in seat’), still achieve F1 scores near or above 0.90. This demonstrates the Transformer’s strong ability to capture discriminative features even from limited data.
This high overall performance is also reflected in the confusion matrices shown in Figure 3. For the 20 most frequent classes, the matrix shows a strong diagonal, indicating few misclassifications. For instance, some notable confusion can be observed between similar fine-grained tasks, such as different types of phone use or subtle posture changes. While the bottom-20 classes show slightly more confusion, the overall performance remains robust, consistent with the findings in our per-class analysis.
6. Discussion
Our experimental results provide several key insights into multimodal temporal modeling for occupant behavior recognition. This section discusses the implications of our findings, focusing on the comparison between static, recurrent, and attention-based models, the role of multimodal fusion, the trade-off between performance and efficiency, and the surprising robustness of our best model.
First, our comparative analysis confirms the critical importance of temporal modeling. As shown in the input modality ablation study (Table 3), both the LSTM and Transformer architectures substantially outperform the static MLP across all feature combinations. This demonstrates that capturing the sequential nature of actions is fundamental to achieving high accuracy. Between the two temporal models, the Transformer consistently shows a competitive edge, especially with fused modalities like ‘Pose + FM’, suggesting that its self-attention mechanism is highly effective for this task.
Second, the analysis of temporal configurations for the Transformer (Table 4) reveals a clear pattern: denser, more overlapping sequences created with smaller step sizes yield superior results. However, this increased performance comes at a higher computational cost. The trade-off between performance and efficiency, summarized in Table 5, is central to our findings. The MLP is the most efficient but least accurate model. In contrast, the Transformer presents a compelling balance; it achieves high performance (Macro F1 of 0.9561) while being significantly more resource-efficient than the LSTM in terms of parameters and FLOPs. This positions the Transformer as a strong candidate for practical, resource-constrained in-vehicle systems.
Third, the per-class performance analysis of our best Transformer model (Table 6) offers further insights into its robustness. A key finding is the model’s exceptionally high F1 scores even for its “Bottom-5” classes, which remain near or above 0.90. These classes, such as ‘Adjusting pelvis in seat’, are characterized by low support counts and subtle motions. This suggests that the Transformer’s self-attention mechanism is highly effective at learning discriminative patterns even from limited examples. This is visually corroborated by the confusion matrices in Figure 3, which display a strong diagonal dominance.
Finally, our study has several key limitations. The frame-level splitting of the dataset introduces potential data leakage from two perspectives. First, it does not guarantee that the training, validation, and test sets are subject-disjoint, which presents a risk of the model learning subject-specific mannerisms (identity leakage). Second, it preserves temporal continuity across the split boundaries, meaning a sequence at the beginning of the validation set can be a direct continuation of a sequence from the training set. Both factors can inflate performance and limit conclusions about generalization. Furthermore, the OBC dataset was gathered in a stationary vehicle with scripted tasks, not in an actual on-road driving context. Generalizing these findings to unconstrained scenarios requires further validation. The model was also not evaluated under challenging conditions common in on-road driving, such as poor illumination, partial occlusions, or unscripted, extreme postures. Additionally, while our analysis provides efficiency metrics on a high-performance GPU (Table 5), we did not benchmark the model on embedded hardware, such as the NVIDIA Jetson series, which is more typical for in-vehicle applications. Although our lightweight design with frozen feature extractors is a strong candidate for such resource-constrained environments, formal validation of its real-time performance on such hardware remains a critical task for future work. Lastly, this study did not include a fairness analysis to assess potential performance biases related to demographic factors such as gender or age. Future work should investigate the model’s performance across these groups to ensure the system is equitable and reliable for all occupants. We contend that these risks are partially mitigated by our feature-based approach. Nonetheless, future research must validate this framework using a strict subject-disjoint split on datasets captured in more naturalistic on-road conditions to confirm its real-world applicability.
7. Conclusions
In this paper, we presented and evaluated a lightweight, modular framework for occupant behavior recognition using multimodal visual features. Our approach effectively fused 2D pose, 2D gaze, and facial movement features and utilized three distinct classifier architectures—a static MLP, a recurrent LSTM, and an attention-based Transformer—to model the temporal dynamics of 79 distinct behaviors from the OBC dataset.
Our comprehensive experiments demonstrated several key findings: (1) temporal models (LSTM and Transformer) significantly outperform static, frame-based MLP classification, confirming the importance of sequential context; (2) fusing all three modalities consistently yields the best performance for the temporal models, validating the benefits of a multimodal approach; and (3) the Transformer model achieved the best overall performance, reaching a Macro F1 score of 0.9570 with a configuration of a 50-frame span, a step size of 10, and 25 sampled frames. Furthermore, our analysis revealed that the Transformer offers a superior balance between high accuracy and computational efficiency, positioning it as a strong candidate for practical, resource-constrained systems.
Overall, this work underscores the critical importance of integrating temporal context and complementary multimodal features for robust occupant behavior recognition. The findings provide a strong foundation and practical guidelines for the development of next-generation, computationally efficient in-vehicle occupant monitoring systems, with the Transformer architecture emerging as a particularly promising solution.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Maji D. Nagori S. Mathew M. Poddar D. YOLO-Pose: Enhancing YOLO for Multi-Person Pose Estimationar Xiv 20222204.06806
- 2Wang F. Wang G. Lu B. YOL Ov 8-Pose Boost: Advancements in Multimodal Robot Pose Keypoint Detection Electronics 202413104610.3390/electronics 13061046 · doi ↗
- 3Qin J. Zhang X. Sugano Y. Uni Gaze: Towards Universal Gaze Estimation via Large-scale Pre-Trainingar Xiv 20252502.02307
- 4He K. Chen X. Xie S. Li Y. Dollár P. Girshick R. Masked Autoencoders Are Scalable Vision Learners Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)New Orleans, LA, USA 19–24 June 20221600016009
- 5Ning M. Salah A.A. Ertugrul I.O. Representation Learning and Identity Adversarial Training for Facial Behavior Understanding Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition (FG)Clearwater, FL, USA 26–30 May 2025
- 6Zhang X. Yin L. Cohn J.F. Canavan S. Reale M. Horowitz A. Liu P. Girard J.M. BP 4D-Spontaneous: A High-Resolution Spontaneous 3D Dynamic Facial Expression Database Image Vis. Comput.20153269270610.1016/j.imavis.2014.06.002 · doi ↗
- 7Zhang X. Yin L. Cohn J.F. Canavan S. Reale M. Horowitz A. Liu P. Girard J.M. BP 4D+: A Spontaneous 3D Dynamic Facial Expression Database with Depth Data Image Vis. Comput.201655169179
- 8Mavadati S.M. Mahoor M.H. Bartlett K. Trinh P. Cohn J.F. DISFA: A Spontaneous Facial Action Intensity Database IEEE Trans. Affect. Comput.2013415116010.1109/T-AFFC.2013.4 · doi ↗