Curvature-Aware Point-Pair Signatures for Robust Unbalanced Point Cloud Registration
Xinhang Hu, Zhao Zeng, Jiwei Deng, Guangshuai Wang, Jiaqi Yang, Siwen Quan

TL;DR
This paper introduces a new method for registering unbalanced point cloud pairs by leveraging local cluster structures to improve accuracy and efficiency.
Contribution
A novel registration method using local point cluster structure features for unbalanced point cloud pairs with significant scale and density disparities.
Findings
The proposed method outperforms state-of-the-art approaches in registration success rate and computational efficiency on the KITTI-UPP benchmark.
It achieves competitive results on the real-world TIESY dataset, demonstrating its generalizability.
The Local Point Cluster Structure Feature effectively filters outliers in unbalanced point cloud registration.
Abstract
Existing point cloud registration methods can effectively handle large-scale and partially overlapping point cloud pairs. However, registering unbalanced point cloud pairs with significant disparities in spatial extent and point density remains a challenging problem that has received limited research attention. This challenge primarily arises from the difficulty in achieving accurate local registration when the point clouds exhibit substantial scale variations and uneven density distributions. This paper presents a novel registration method for unbalanced point cloud pairs that utilizes the local point cluster structure feature for effective outlier rejection. The fundamental principle underlying our method is that the internal structure of a local cluster comprising a point and its K-nearest neighbors maintains rigidity-preserved invariance across different point clouds. The proposed…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
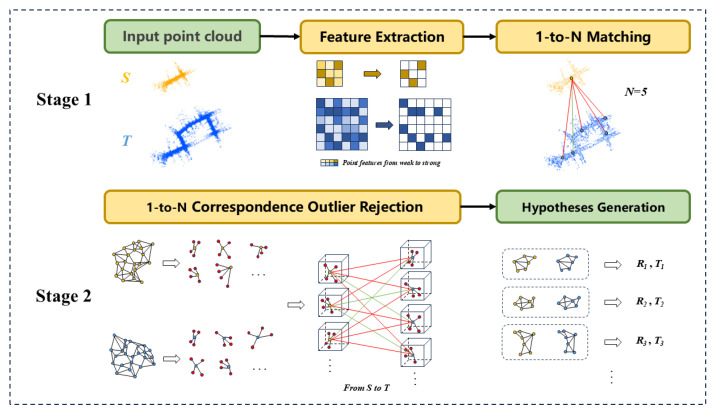 Figure 1
Figure 1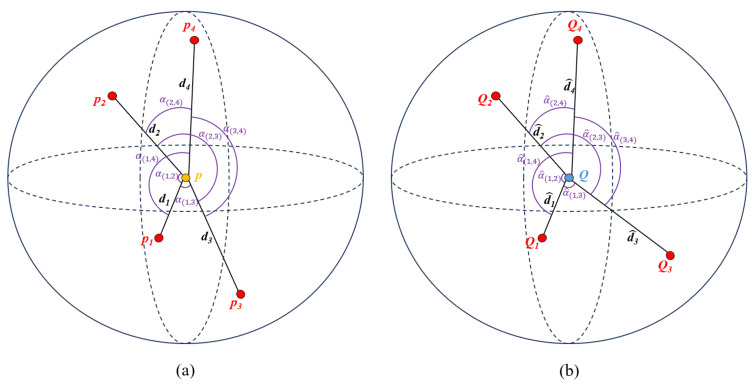 Figure 2
Figure 2 Figure 3
Figure 3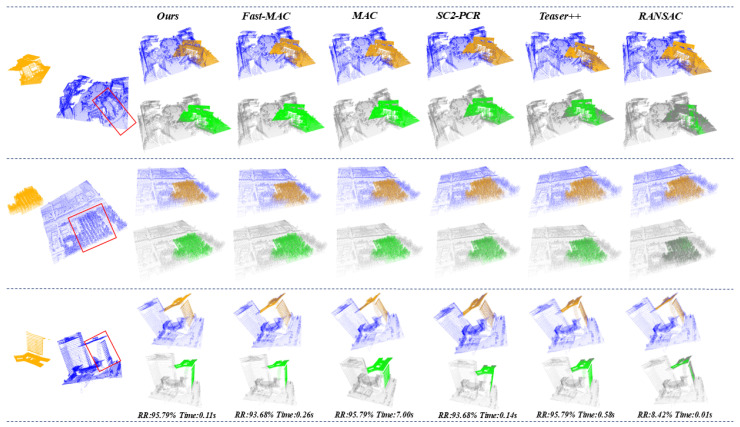 Figure 4
Figure 4- —Tianjin Key Laboratory of Rail Transit Navigation Positioning and Spatio-temporal Big Data Technology
- —the Natural Science Basic Research Plan in Shaanxi Province of China
- —Science and Technology Program of Tianjin
- —Science and Technology Research and Development Program of China State Railway Group Co., Ltd.
- —Science and Technology Development Project of China Railway Design Group Co., Ltd.
- —China Railway Design Corporation Science and Technology Program Major Program
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobotics and Sensor-Based Localization · Remote Sensing and LiDAR Applications · 3D Surveying and Cultural Heritage
1. Introduction
Point cloud registration (PCR) is a fundamental task in 3D computer vision [1,2], which aims to estimate a six-degree-of-freedom (6-DoF) rigid transformation so that point clouds can be precisely aligned. This technique plays a critical role in various applications, including autonomous vehicle localization, 3D object detection [3,4], and large-scale scene reconstruction [5]. While existing methods assume scale-balanced inputs, practical scenarios frequently necessitate unbalanced registration, where a local partial scan (e.g., single LiDAR frame) must be aligned with a global environmental map (e.g., city-scale 3D model) [6,7]. This paradigm introduces substantial challenges primarily arising from extreme scale disparities that significantly amplify outlier ratios [8,9,10]. Non-uniform density distributions further suppress discriminative local structures during feature extraction [11,12], while performance degradation becomes particularly pronounced in low-overlap scenarios [12]. The presence of repetitive architectural patterns also contributes to matching ambiguities in large-scale environments [13].
Despite substantial progress in handling low-overlap and high-outlier scenarios [11,14], current point cloud registration methods exhibit critical limitations when faced with unbalanced inputs characterized by significant differences in spatial extent and point density [15,16]. Feature-based methods leveraging matchability detection [11] or hierarchical correspondence prediction [13] frequently succumb to descriptor indistinctiveness as sparse local structures interact with dense environmental regions, while deep learning-based registration networks optimized for balanced inputs demonstrate poor generalization to extreme scale variations [12,17]. Furthermore, global localization frameworks that discretize large-scale maps into fragmented components [18,19] introduce artificial segmentation artifacts, fundamentally compromising holistic alignment integrity. Crucially, all methods suffer from structural distractions that repetitive geometric patterns in expansive environments misguide feature matching [11], compounded by density-induced bias that drowns discriminative local features within high-density zones of global point clouds [12].
To address these challenges, we propose a point-pair signature method that is aware of curvature (CURV) and specifically designed for unbalanced point cloud registration. Our main contributions are summarized as follows:
- Curvature-optimized keypoint detection that significantly outperforms existing methods (e.g., ISS, H3D) [8,20,21,22,23] in repeatability under scale variations.
- Systematic investigation of one-to-N correspondence for unbalanced PCR, demonstrating its superiority over conventional one-to-one matching paradigms [24,25].
- By integrating curvature-aware signatures with geometric consistency validation, our rejection mechanism simultaneously improves inlier selection ratios, maintains registration accuracy, and ensures computational efficiency [9,26,27].
This paper is structured as follows: Section 2 reviews the existing literature on point cloud registration, covering both balanced and unbalanced scenarios. Section 3 details our method, including problem formulation, keypoint detection via voxel downsampling curvature estimation, one-to-many correspondences generation using feature similarity, and local cluster-based matching. Section 4 presents the experimental setup and evaluation results validating our method. Section 5 draws the conclusions and discusses future research directions.
2. Related Work
This section provides a brief overview of the existing point cloud registration methods, including balanced and unbalanced registration methods.
2.1. Balanced Point Cloud Registration
Recent advances in point cloud registration methodologies can be broadly categorized into two main methods: traditional geometric methods and deep learning-based methods.
For geometric methods, the classical RANSAC framework [8,20,21,25,26,28] remains fundamental for 6-DoF pose estimation. Several improved variants have been developed, including SAC-IA (utilizing spatial uniform sampling) [24], GC-RANSAC (employing graph-cut optimization) [8], and SAC-COT (based on compatibility graph sampling) [25]. Complementary global optimization methods such as GO-ICP [27] and GORE [9] have been proposed, implementing intelligent ICP [29] scheduling and precise boundary computation, respectively.
Deep learning-based methods have introduced various novel architectures for point cloud registration. Some methods, such as FCGF [30] and D3Feat [11], employ fully convolutional designs and joint learning frameworks for feature extraction. Architectures such as Predator [12] utilize attention mechanisms to address low-overlap scenarios, while SpinNet [1] incorporates rotation-invariant designs. Additionally, some methods like PointDSC [11] and RGM [31] apply deep learning and graph matching techniques for inlier/outlier differentiation. Recent detection-free methods [32], particularly CoFiNet [17] and GeoTransformer [33], focus on the transformation parameter estimation by an end-to-end manner.
Despite these advancements, both methodological categories present certain limitations. Traditional geometric methods face computational challenges in high-outlier scenarios [10] and demonstrate sensitivity to point cloud scale variations [9,27]. Deep learning-based methods remain constrained by their dependence on extensive training data and exhibit limited generalization capabilities [12,13,34]. Emerging hybrid methods such as MAC [14,35] attempt to address these limitations by integrating geometric- and learning-based advantages. Future research should focus on developing more efficient and robust registration algorithms capable of handling complex 3D scenarios in practical applications.
2.2. Unbalanced Point Cloud Registration
Unbalanced registration addresses scenarios characterized by extreme disparities in spatial scale or point density, exemplified by the alignment of large-scale reconstructed maps with local scans [7,15,36,37]. Existing methods can be broadly categorized into two paradigms.
The first is the localization paradigm, which adopts a two-stage “retrieval + local registration” framework: global descriptors like NetVLAD [7] first retrieve the most relevant reference frame from a prebuilt map, followed by balanced pairwise registration. Although some methods such as Du [16] attempt joint optimization of local and global features, this framework suffers from fundamental limitations [38]. Significant computational and memory overhead arises from storing numerous overlapping reference frames [18,19], leading to memory explosion. The method also fails to handle domain differences; for instance, severe density gaps between sparse SfM point clouds and dense LiDAR scans cause feature matching to collapse [39]. Crucially, errors from the retrieval stage propagate irreversibly—if coarse alignment fails, subsequent registration cannot recover [38].
The second is the registration paradigm, where existing robust estimators catastrophically fail under unbalanced conditions. RANSAC assumes uniform point distributions [8,20], causing ineffective minimal set sampling in density-variant regions. BnB methods [9,10,27] rely on spatial consistency for bound computation, but scale discrepancies induce overly loose bounds that nullify optimality guarantees. Spatial compatibility-based outlier filters [35] misclassify correspondences in non-overlapping areas due to geometric asymmetry. Although specialized pipelines such as Lu [11] target niche challenges (e.g., large-scale LiDAR registration), no unified framework addresses unbalanced registration holistically [13,40]. The core conflict lies in the inherent “equilibrium assumption” of traditional methods clashing with the geometric heterogeneity of unbalanced scenarios, demanding fundamentally adaptive mechanisms for scale and density variations.
3. Method
Our method is illustrated in Figure 1, registering a partial-scanned source point cloud to a large-scale target under a significant scale difference. First, keypoints are extracted from two point clouds based on curvature information. Second, initially dense correspondences are generated via the FPFH [24] descriptor and feature matching method for both point clouds. Finally, a novel point-pair signature is introduced to remove outliers from the initial correspondences, and then the 6-DoF transformation is estimated through robust hypothesis evaluation.
3.1. Problem Formulation
Given source point cloud and target point cloud , which are downsampled from the original partial-view source point cloud and the complete target point cloud , respectively, with indicating a substantial scale difference. A correspondence pair represents a feature matching from a point p in and a point q in . The goal of registration is to find a 6-DoF rigid transformation, composed of a rotation matrix R and a translation vector t, that optimally aligns to Q such that holds for corresponding points.
3.2. Keypoint Detection
The critical innovations introduced by our curvature-aware detection module are fundamentally different from the traditional keypoint detectors like ISS [22]. While ISS [22] typically employs fixed threshold and uniform neighborhood processing, our method utilizes a normalized eigenvalue ratio that prioritizes subtle geometric features through the smallest eigenvalue, significantly enhancing sensitivity to scale variations. Furthermore, our integrated pipeline combines adaptive threshold with hysteresis-based NMS using a dynamic radius ( ), ensuring robust keypoint selection across non-uniform point densities and reducing noise sensitivity through second-order differential properties. The unique combination of density invariance, noise robustness, and geometric discriminability specifically addresses the inherent challenges of unbalanced scenarios, including extreme scale disparities and heterogeneous density distributions.
The practical implementation of our strategy relies on the strategic configuration of two core parameters: the voxel size and curvature threshold . The voxel size functions as a physical-scale normalizer, with its selection guided by the characteristic scale of salient geometric features in the target environment, providing inherent adaptability to different scene scales and point densities. Complementarily, the curvature threshold governs the essential trade-off between keypoint repeatability and distinctiveness, configurable through analysis of curvature value distributions in representative data samples. The principled yet flexible parameter selection strategy underpins the method’s consistent performance across diverse datasets and sensing conditions, as evidenced by our results on both KITTI-UPP and TIESY benchmarks, representing a key strength for handling the inherent variations in unbalanced point cloud registration.
Given source point cloud and target point cloud , we perform keypoint detection through curvature analysis as follows:
3.2.1. Voxel Downsampling
Both point clouds undergo voxel grid filtering for computational efficiency:
where is the voxel edge length controlling the downsampling resolution. This operation preserves geometric features larger than while reducing point density.
3.2.2. Local Curvature Estimation
For each point and , compute the covariance matrix over its -radius neighborhood:
Through the eigen decomposition ( ), the curvature is as follows:
where encode the local surface variation. The same process is applied to to obtain .
3.2.3. Candidate Keypoint Selection
Select geometrically salient points from both clouds:
where the is a corresponding threshold set for keypoint selection.
3.2.4. Non-Maximum Suppression
The refined keypoints are selected through spatial competition:
where , ( ), and introduce hysteresis.
3.3. One-to-Many Correspondances
The proposed one-to-many matching strategy provides an effective solution to the feature asymmetry challenge inherent in unbalanced point cloud registration. Building upon the detected keypoints and from Section 3.2, our method establishes multiple potential correspondences for each source keypoint, creating a redundant yet discriminative matching space. This design offers two key benefits: (1) the increased correspondence candidates significantly improve inlier counts for final registration; (2) the adaptive feature extraction pipeline maintains geometric consistency while accommodating density variations.
The core innovation of our method lies in its integrated handling of two critical aspects: local feature representation and correspondence validation. For feature representation, we employ FPFH descriptor with adaptive radius scaling to dynamically adjust to non-uniform point distributions. For correspondence validation, the reciprocal -norm similarity metric provides robust constraints in feature space, effectively suppressing mismatches from non-overlapping regions. This combination ensures both the quantity and quality of matches, addressing the fundamental challenges in unbalanced registration.
3.3.1. Feature Extraction
The FPFH features are computed from source and target keypoints:
where denotes the FPFH descriptor, computed with adaptive radius search:
Here represents the keypoint set ( for source, for target), d is the average spacing between keypoints, and is a scale factor. The nearest neighbor is searched within the same keypoint set.
3.3.2. Similarity Metric
This curvature-aware similarity metric facilitates robust correspondence establishment by quantifying the geometric affinity between locally salient points across different point clouds. The feature similarity is defined using -norm reciprocal:
3.3.3. One-to-Many Correspondence Generation
For each source keypoint , find the target keypoints with the highest similarity:
where selects the N points with maximum similarity. The initial correspondence set is generated as follows:
This strategy generates up to keypoint-level correspondences. The redundant design boosts inlier quantity while feature similarity constraints ( ) filter interference from non-overlapping regions.
3.4. Local Geometric Verification
The local geometric verification module establishes robust correspondences by examining the structural consistency between keypoints and their k-nearest neighborhoods (illustrated using ), as visualized in Figure 2. For each candidate pair , ordered neighbor sets and (sorted by Euclidean distance ) are extracted to calculate two complementary geometric descriptors: (1) relative distance features and , and (2) angular consistency measures and . The binary agreement indicators and are then derived by adaptive thresholds and , with the final similarity score calculated as a normalized consensus of matched characteristics.
This dual feature paradigm addresses a critical limitation of conventional methods, which often solely rely on distance metrics, by introducing angular coherence as an orthogonal validation signal. Furthermore, the adaptive thresholding mechanism dynamically adjusts to local point density variations, ensuring reliable performance even under significant noise. In particular, the neighborhood-preserving design guarantees that local structures from sparser point clouds remain identifiable within denser counterparts, overcoming a key challenge in unbalanced registration scenarios.
Building upon the initial correspondences in Section 3.3, geometric verification is performed through local structure matching. Each candidate is evaluated by comparing its k-NN geometric constellation, achieving computational efficiency via feature evaluation while outperforming global verification methods in outlier rejection. The balance of precision and scalability makes the method particularly suitable for real-time applications where structural fidelity must be preserved without compromising processing speed.
3.4.1. Local Structure Construction
For each keypoint and , its local geometric structure is constructed using its k nearest neighbors:
where the neighbors are ordered by the Euclidean distance from the central point.
3.4.2. Local Structure Similarity Matching
The geometric features and their matching criteria are defined as follows:
The and are the distance features. The and are the angle features. For each feature, a binary match indicator is defined based on the threshold conditions:
where the is a distance difference threshold, and the is an angle difference threshold.
The similarity score is then computed as the proportion of matched features:
where the k is the number of nearest neighbors and the .
3.4.3. Matched Point Pairs Generation
Final correspondences are established by selecting candidate pairs that satisfy the similarity threshold condition:
where is a similarity threshold that controls the matching strictness and ensures correspondence quality.
3.5. Hypothesis Generation and Evaluation
Based on the filtered correspondence set obtained from outlier rejection, the number of outliers in the point correspondence set is significantly reduced, thus we can directly employ the RANSAC algorithm for robust transformation estimation. We employ the RANSAC algorithm to robustly estimate the optimal 6-DoF rigid transformation . The algorithm iteratively performs the following procedure: in each iteration, three point correspondences are randomly selected to compute a rigid transformation hypothesis via SVD, followed by inlier counting with threshold (where ) [41,42,43]. After typically thousands of iterations, the hypothesis with the maximum inliers is selected and refined using its consensus set to obtain the final transformation estimate.
To quantitatively evaluate the registration accuracy, we computed the rotation error and translation error against the ground truth transformation . After multiple rounds of optimization, the best hypothesis is refined to obtain the final transformation. The registration result is evaluated using the following:
The rotation error (RE) is computed using the trace operator , which sums the diagonal elements of a matrix. Specifically, RE quantifies the angular deviation in degrees between the estimated and ground truth rotations. And the translation error (TE) measures the Euclidean distance between the estimated and ground truth translation vectors. These metrics provide complementary perspectives on registration quality, with RE quantifying rotational alignment and TE quantifying positional accuracy. Lower values for both metrics indicate better registration performance.
4. Experiments
4.1. Experimental Setup
Datasets. Our method is evaluated on two complementary datasets:
- Synthetic KITTI-UPP: Created from KITTI Odometry with fixed sampling interval (hop=10) to control unbalance ratios [44]:
- -Balanced (1:1): 150-frame query vs. 150-frame reference
- -Moderate Unbalance (1:4): 150-frame query vs. 600-frame reference
- -Severe Unbalance (1:10): 150-frame query vs. 1500-frame reference Each group contains 108 registration pairs with query frames strictly excluded from reference point clouds. The unbalanced ratios (1:1, 1:4, 1:10) precisely define the relative scale between source and target point clouds based on frame aggregation ranges. For example, the 1:10 ratio configuration involves registration between a source point cloud aggregated from frames 0–150 and a target point cloud aggregated from frames 0–1500, ensuring the source is entirely contained within the target. Some samples are visualized in Figure 3.
- Real-world TIESY dataset: Collected via mobile LiDAR scanning in diverse urban/rural environments by TIESY Survey Institute, featuring natural unbalance ratios of 1:4 to 1:6. This dataset comprises 95 registration pairs across 18 geographical areas, covering streets, buildings, vegetation, and infrastructure. Some samples of the dataset are visualized in Figure 4.
Evaluation Criteria. For both the KITTI-UPP dataset and the real-world TIESY dataset, we employ the RE and TE as the evaluation metrics. The registration is considered successful when RE ≤ 15° and TE ≤ 60 cm. A dataset’s registration accuracy of a method is defined as the ratio of successful cases to the total number of point cloud pairs.
Implementation Details. In our experiments which are designed to evaluate performance under varying unbalanced conditions, we adopt appropriate values of N (which determines the one-to-many matching pairs) for the three KITTI-UPP ratios: for the 1:1 ratio, for the 1:4 ratio, and for the 1:10 ratio. Furthermore, for the scenario involving large-scale point clouds aggregated by 3000 frames, we maintain the parameter N at 20. For the real-world TIESY dataset, all the results we selected are tested with the parameter N set to 12. Regarding the local point cluster structure that we utilize, the number of neighboring points k is set to four, while the angle and distance thresholds are configured as 5° and 0.1 m, respectively.
4.2. Results on KITTI-UPP Dataset
4.2.1. Evaluation on One-to-Many Correspondences
Building upon our evaluation framework, an evaluation of one-to-many correspondence generation is conducted using ISS [22] keypoints on the KITTI-UPP dataset with 1:4 ratio. The assessment examines two distinct registration scenarios: (1) Small-to-Large: registration from partial scans to the whole; (2) Large-to-Small: registration from the whole scans to the partial.
In the experiments, the parameter N is varied across the following discrete values:
Small-to-Large: ;
Large-to-Small: .
Six methods including Fast-MAC [43], MAC [41], SC2-PCR [42], Teaser++ [45], FGR [46], and RANSAC [28] are rigorously evaluated under both configurations. Comprehensive performance results, including registration rates and error metrics, are provided in Table 1. Cases where Fast-MAC [43], MAC [41], and Teaser++ [45] fail to process due to excessive correspondence pairs or memory overflow are treated as registration failures and reflected in the registration success rate. Specifically, this occurs for MAC and Fast-MAC at N = 16, 20, and 24 in the small-to-large scenario and at N = 4, and 6 in the large-to-small scenario, while Teaser++ encounters similar limitations at N = 24 in the small-to-large scenario and at N = 4, and 6 in the large-to-small scenario.
As evidenced by the results in Table 1, our method consistently achieves superior performance under all experimental configurations. (1) A key observation is the significant performance improvement across nearly all methods as N increases. For instance, when N is increased from 1 to 12, the RR of methods such as Fast-MAC [43], MAC [41], and SC2-PCR [42] significantly improves from 51.85% to 97.22%, strongly validating the effectiveness of the one-to-many correspondence strategy. (2) While Fast-MAC [43], MAC [41], and Teaser++ [45] exhibit improved accuracy with larger N values, they often incur substantial computational overhead or even fail to process dense correspondence sets efficiently, resulting in performance degradation. When N is increased from 12 to 24, the registration time of methods such as Fast-MAC [43] and MAC [41] increases significantly, while the registration rate drops markedly from 97.22% to 26.85%. In contrast, our method not only attains the highest registration accuracy but also maintains the lowest computational time, demonstrating remarkable efficiency even at . (3) Our method retains competitive performance under large value of N when the keypoint detection module is substituted with ISS [22] method.
4.2.2. Experiments with Different Keypoint Modules
We conduct extensive experiments on the KITTI-UPP dataset under three unbalanced registration scenarios at ratios of 1:1, 1:4, and 1:10. Our evaluation framework incorporates multiple keypoint detection methods, including ISS [22], H3D [23], and our curvature-based method. As shown in Table 2, we report comprehensive comparisons with both traditional methods, including Fast-MAC [43], MAC [41], SC2-PCR [42], Teaser++ [45], FGR [46], and RANSAC [28], as well as deep learning-based methods, specifically GeoTransformer [33] and PARENet [47].
The comprehensive comparison demonstrates that our method achieves superior performance when utilizing curvature-based keypoints, particularly in severely unbalanced scenarios. Under the “CURV + FPFH“ configuration, our method not only attains the highest registration success rates across all imbalance ratios (100.00%, 99.07%, and 95.37%, respectively) but also maintains exceptional computational efficiency with consistently low time consumption (0.11 s, 0.10 s, and 0.10 s, respectively). This performance advantage becomes particularly evident in the most challenging 1:10 ratio scenario where our method outperforms all competing methods by achieving the highest registration success rate while simultaneously maintaining significantly superior computational efficiency compared to other high-performance methods. By contrast, deep learning-based methods that GeoTransformer [33] and PARENet [47] utilize their official KITTI pre-trained weights with uniformly downsampled inputs exhibit suboptimal performance, achieving only 38.89% and 71.30% success rates, respectively, under the 1:10 ratio. This progressive performance degradation is caused by the scale unbalance increasing. This limitation stems from their inability to handle the extreme point density variation and heterogeneous geometric information in unbalanced scenarios, a fundamental challenge that current learning-based architectures struggle to address. Our method outperforms all competing methods by achieving the highest registration success rate while simultaneously maintaining significantly superior computational efficiency compared with other high-performance methods. The comparative visualization of registration results for all methods is presented in Figure 3, featuring three representative scenarios from the KITTI-UPP dataset.
To further investigate performance boundaries under extreme unbalanced conditions, we conducted an additional experiment with an unprecedented unbalanced ratio of 1:20, which registers a 150-frame query point cloud against a 3000-frame reference point cloud. The scenario presents substantial challenges due to the massive scale disparity and significantly amplified outlier ratios. We selectively compared our method with the most competitive methods, including Fast-MAC [43], MAC [41], SC2-PCR [42], and Teaser++ [45], which had demonstrated superior performance in prior experiments. As evidenced in Table 3, our method achieves the highest registration success rate of 94.44% with exceptional computational efficiency of 0.11 s. Our method demonstrates a 2.77% point improvement in registration accuracy over SC2-PCR [42], which achieved 91.67% accuracy with 0.16 s computation time. Similarly, our method outperforms Teaser++ [45], MAC [41], and Fast-MAC [43] by 8.33%, 11.11%, and 14.81% points in registration success rate, respectively, while maintaining substantially lower computational requirements. These compelling results conclusively demonstrate notable competitiveness and exceptional robustness even in the ultra-extreme scenario of our method, underscoring the effectiveness of our curvature-aware method in handling severe scale disparities while ensuring computational efficiency.
4.3. Results on TIESY Dataset
4.3.1. Evaluation on One-to-Many Correspondences
Building upon our evaluation framework, this study conducts an evaluation of one-to-many correspondence generation using ISS [22] keypoints on the real-world TIESY Dataset with ratios ranging from 1:4 to 1:6. The assessment examines two distinct registration scenarios: (1) Small-to-Large: registration from the partial scans to the whole; (2) Large-to-Small: registration from the whole scans to the partial;
In the experiments, the parameter N is varied across the following discrete values:
Small-to-Large: ;
Large-to-Small: .
Six point cloud registration methods, including Fast-MAC [43], MAC [41], SC2-PCR [42], Teaser++ [45], FGR [46] and RANSAC [28] are rigorously evaluated under both configurations. Comprehensive performance results, including registration success rates and error metrics, are provided in Table 4.
While the RR of Fast-MAC [43], MAC [41], and Teaser++ [45] exhibited a positive correlation with increasing N, though with commensurate computational time escalation—for instance, in the partial-to-whole registration scenario, as N increased from 1 to 12, the RR improved significantly from 68.42% to 86.32%. Conversely, FGR [46] and SC2-PCR [42] maintained stable performance across all N configurations, while RANSAC [28] demonstrated progressive performance degradation as correspondence quantities expanded. In contrast, our method consistently achieves the highest registration success rate with the fastest computational speed, highlighting its superior efficiency and robustness under varying correspondence densities.
The following conclusions can be drawn: As N increases, the inlier count of correspondences increases, while the inlier ratio decreases. In practical registration, this effectively improves the registration success rate, but this comes at the cost of significantly increased computation time.
4.3.2. Robust Experiments
We conducted extensive experiments on the real-world TIESY dataset under both noiseless and noisy conditions, evaluating three unbalanced registration scenarios. Our evaluation framework is built on the CURV-based keypoint detection. For comprehensive comparison, we evaluate both traditional methods: Fast-MAC [43], MAC [41], SC2-PCR [42], Teaser++ [45], FGR [46], and RANSAC [28], and deep learning-based methods including GeoTransformer [33] and PARENet [47], and the results are represented in Table 5. Notably, the deep learning-based methods are evaluated using their official KITTI pre-trained weights, as TIESY is also an outdoor dataset. However, as shown in Table 5, these learning-based methods demonstrate significantly inferior performance, achieving only 39.80% and 33.67% registration success rates, respectively, substantially lower than traditional high-performance methods. The performance gap can be attributed to two primary factors: The TIESY dataset features substantial environmental complexity, comprising a wide range of real-world scenarios from buildings to vegetation. This diversity reveals the limited generalization capacity of deep learning-based methods when faced with challenging and varied conditions.
We quantitatively evaluate the noise robustness of our method by testing with different levels of Gaussian noise. The results presented in Table 6 demonstrate that our method maintains competitive performance across various noise conditions while consistently achieving low computational time. As indicated, while our method maintains strong performance at lower noise levels with a registration rate of 93.68% at noise level 0.01, a noticeable degradation occurs at higher noise intensities where the registration rate drops to 88.42% at noise level 0.03. This performance decline can be attributed to several factors inherent in the local geometric verification process. Firstly, the curvature-based keypoint detection, while robust under moderate noise, becomes less stable when significant Gaussian noise distorts local surface geometries, leading to inconsistent keypoint repeatability. Secondly, the FPFH descriptors, though efficient, are sensitive to neighborhood perturbations caused by noise, which amplifies feature mismatching in the one-to-many correspondence generation stage. Finally, the local structure similarity matching, which relies on precise distance and angular relationships, suffers from threshold misalignment when noise exceeds the adaptive tolerance of the geometric verification module.
4.4. Ablation Study
4.4.1. Keypoint Detection Comparison
We conduct experimental analyses on the KITTI-UPP and real-world TIESY datasets, specifically evaluating the performance of the keypoint detection methods proposed in Section 3—namely ISS [22], H3D [23], and curvature-based detection—combined with FPFH for generating various correspondences. The results of our tests on the KITTI-UPP dataset are summarized in Table 7, where the values of N for the small-to-large and large-to-small sequences are set to {1, 2, 4, 8, 12, 24} and {1, 2, 3, 4, 5, 6}, respectively. It can be observed that the curvature-based method, when combined with FPFH, significantly outperforms the other two methods in terms of correspondence quality and overall registration accuracy. As presented in Table 8, the inlier statistics of curvature-based feature matching on the real-world TIESY dataset are summarized. For this dataset, the values of N for the small-to-large and large-to-small sequences are set to {1, 2, 4, 8, 12, 16, 22, 26} and {1, 2, 3, 4}, respectively. Although the inlier ratio naturally decreases as the value of N increases, the absolute number of inliers demonstrates a consistent growing trend. This observation indicates that the feature correspondences derived from CURV keypoint detection exhibit high quality, enabling the algorithm to effectively distill a substantial number of correct correspondences from a large pool of candidate matches. These reliable correspondences form a solid foundation for subsequent high-precision registration tasks.
4.4.2. Parameter Sensitivity Analysis
We conducted an ablation study on the KITTI-UPP(1:4) dataset to evaluate the robustness of our method under different parameter settings. With fixed thresholds (distance difference m, angular difference , and matching score in Section 4, we systematically varied the number of neighboring points k around each target point. As shown in Table 9, with our parameter N set to 24, the method demonstrates strong robustness across different k values, maintaining high registration rates above 95% while keeping rotation errors below 0.007 rad in all cases. The consistent performance across parameter variations confirms the stability of our method.
To validate our core innovative components and assess the generalization capability of our method, we conduct ablation studies on KITTI-UPP(1:4) with parameter . We examine individual and combined contributions of angle and distance constraints across FPFH and PARENet descriptors using 1-to-24 correspondence pairs. As shown in Table 10, the combined constraints achieve optimal performance for both descriptors. FPFH with combined constraints reaches 100.00% RR, significantly outperforming angle-only (92.59%) and distance-only (25.00%) configurations. PARENet similarly benefits from combination (93.52%) versus angle-only (77.78%) and distance-only (85.19%). The complementary nature of constraints is evident from their varying effectiveness across descriptors. These results demonstrate that our method, through its combined use of angle and distance, is not only effective across different descriptors but also crucial for delivering superior registration accuracy in unbalanced point clouds.
5. Conclusions
We proposed a curvature-aware outlier rejection method for unbalanced point cloud registration. Our method employs a one-to-many correspondence strategy to increase inlier counts using geometric redundancy while preserving structural invariance. Based on local geometric consistency, we developed a robust outlier removal mechanism for dense correspondence sets. Experiments on synthetic KITTI-UPP and real-world TIESY datasets demonstrated that the proposed method achieved inherent resilience to partial overlaps through probabilistic correspondence expansion and improved registration stability via geometrically verified candidate pooling. The results confirmed that our correspondence generation strategy successfully balanced match quantity and precision in unbalanced registration. However, the proposed method exhibited relatively weak robustness in keypoint detection due to its reliance on curvature-based features. The future work will focus on enhancing keypoint stability, algorithmic acceleration for ultra-dense scenarios, integrating multi-scale or global features to handle large-scale inconsistencies, reducing sensitivity to parameters via adaptive- or learning-based optimization, and improving computational efficiency through hierarchical pruning and optimized feature extraction.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ao S. Hu Q. Yang B. Markham A. Guo Y. Spinnet: Learning a general surface descriptor for 3d point cloud registration Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Nashville, TN, USA 20–25 June 20211175311762
- 2Wang T. Fu Y. Zhang Z. Cheng X. Li L. He Z. Wang H. Gong K. Research on Ground Point Cloud Segmentation Algorithm Based on Local Density Plane Fitting in Road Scene Sensors 202525478110.3390/s 2515478140807946 PMC 12349206 · doi ↗ · pubmed ↗
- 3Aoki Y. Goforth H. Srivatsan R.A. Lucey S. Pointnetlk: Robust & efficient point cloud registration using pointnet Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Long Beach, CA, USA 15–20 June 201971637172
- 4Guo Y. Bennamoun M. Sohel F. Lu M. Wan J. 3D object recognition in cluttered scenes with local surface features: A survey IEEE Trans. Pattern Anal. Mach. Intell.2014362270228710.1109/TPAMI.2014.231682826353066 · doi ↗ · pubmed ↗
- 5Mian A.S. Bennamoun M. Owens R.A. Automatic correspondence for 3D modeling: An extensive review Int. J. Shape Model.20051125329110.1142/S 0218654305000797 · doi ↗
- 6Geiger A. Lenz P. Urtasun R. Are we ready for autonomous driving? The kitti vision benchmark suite Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Providence, RI, USA 16–21 June 201233543361
- 7Uy M.A. Lee G.H. Pointnetvlad: Deep point cloud based retrieval for large-scale place recognition Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Salt Lake City, UT, USA 18–23 June 201844704479
- 8Barath D. Matas J. Graph-cut RANSAC Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Salt Lake City, UT, USA 18–23 June 201867336741