Development and Validation of Prognostic Models for Treatment Response of Patients with B-Cell Lymphoma: Standard Statistical and Machine-Learning Approaches
Adugnaw Zeleke Alem, Itismita Mohanty, Nalini Pati, Cameron Wellard, Eliza Chung, Eliza A. Hawkes, Zoe K. McQuilten, Erica M. Wood, Stephen Opat, Theophile Niyonsenga

TL;DR
This study develops and validates a new model to predict treatment response in B-cell lymphoma patients, showing better performance than existing systems.
Contribution
A novel nomogram for predicting treatment response in B-cell lymphoma patients that outperforms existing prognostic indices like IPI.
Findings
The nomogram achieved an AUC of 0.70, outperforming IPI-based systems.
Decision curve analysis confirmed the nomogram's superior net benefit.
All models showed similar performance with AUC values between 0.69 and 0.70.
Abstract
Background: Achieving a complete response after therapy is an important predictor of long-term survival in lymphoma patients. However, previous predictive models have primarily focused on overall survival (OS) and progression-free survival (PFS), often overlooking treatment response. Predicting the likelihood of complete response before initiating therapy can provide more immediate and actionable insights. Thus, this study aims to develop and validate predictive models for treatment response to first-line therapy in patients with B-cell lymphomas. Methods: The study used 2763 patients from the Lymphoma and Related Diseases Registry (LaRDR). The data were randomly divided into training (n = 2221, 80%) and validation (n = 553, 20%) cohorts. Seven algorithms: logistic regression, K-nearest neighbor, support vector machine, random forest, Naïve Bayes, gradient boosting machine, and extreme…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
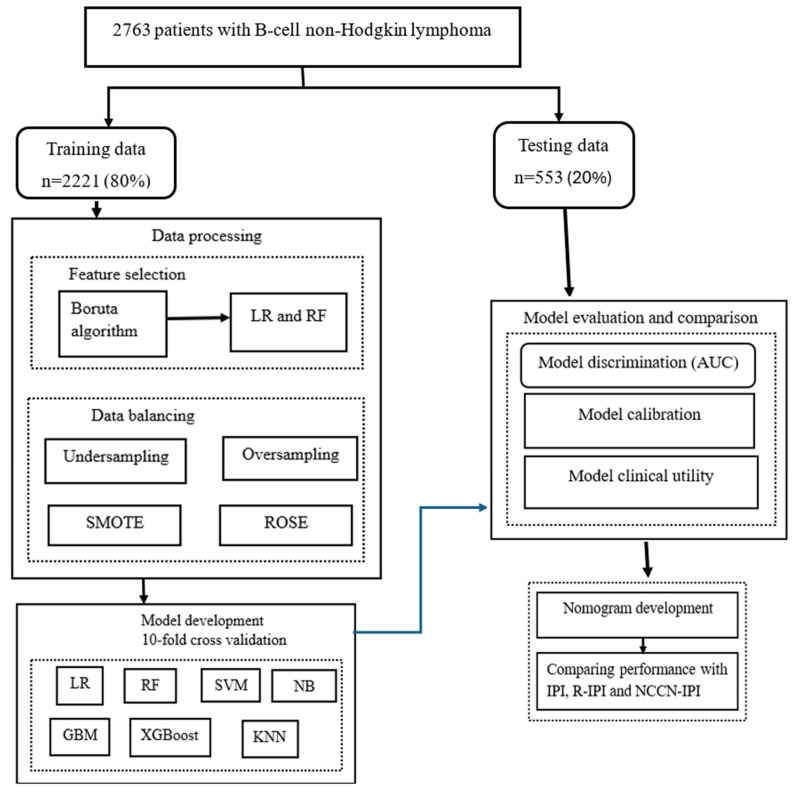 Figure 1
Figure 1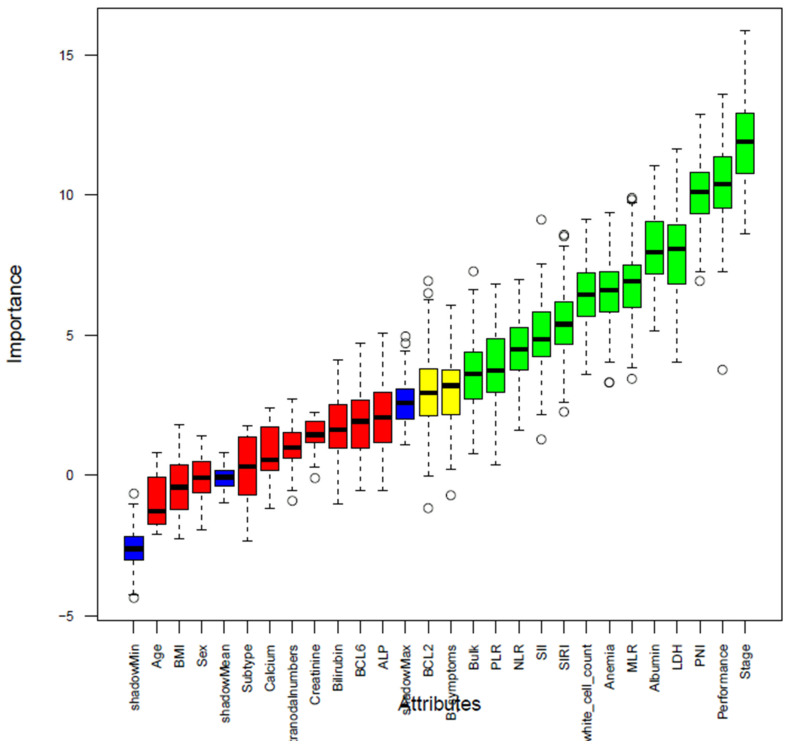 Figure 2
Figure 2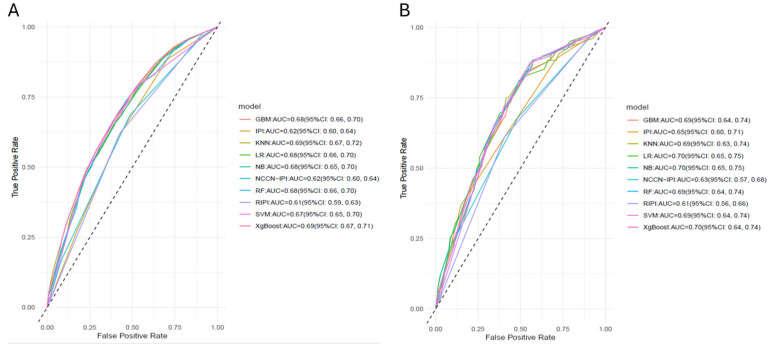 Figure 3
Figure 3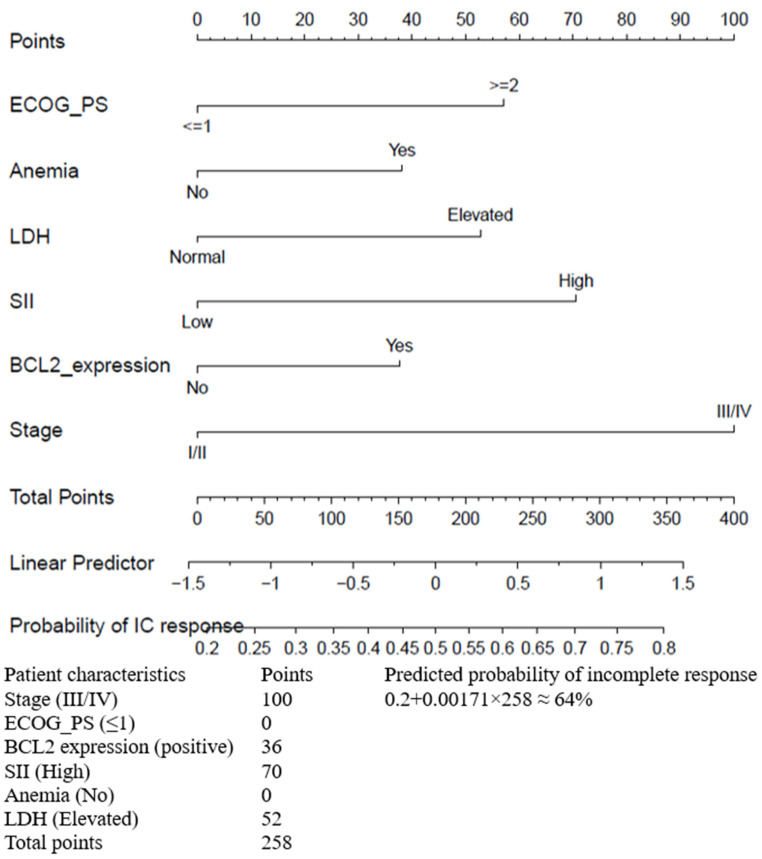 Figure 4
Figure 4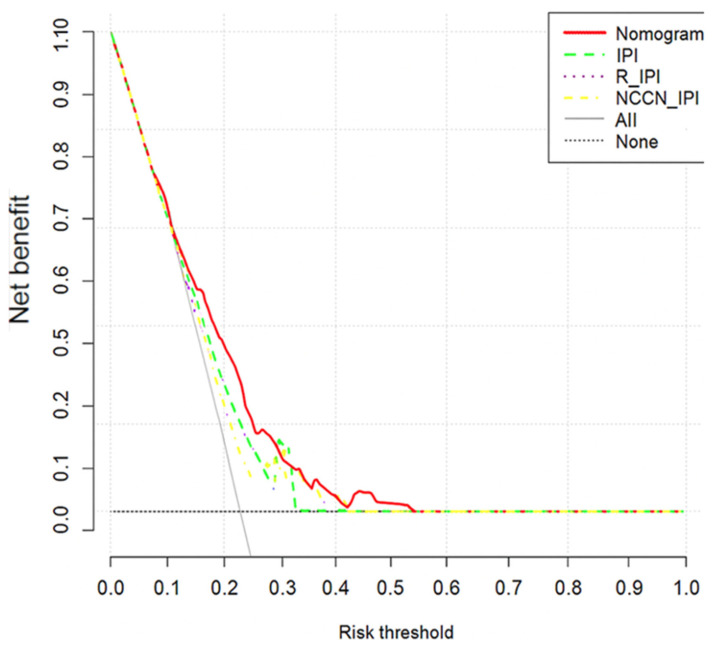 Figure 5
Figure 5- —University of Canberra higher degree by research stipend scholarship
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods in Clinical Trials
1. Introduction
Lymphoma is the most common type of hematological cancer, with non-Hodgkin lymphoma (NHL) accounting for approximately 90% of all lymphoma subtypes [1,2]. In 2020, an estimated 5.44 million people were diagnosed with NHL cases, and approximately 260,000 deaths were attributed to NHL globally [3]. Age-specific incidence rates of NHL are estimated to vary globally, with the most pronounced increasing trends observed in Australia and New Zealand [4]. Moreover, in 2019, NHL resulted in 8,650,352 age-standardized disability-adjusted life years (DALYs) globally [4].
Over the past two decades, the prognosis of lymphoma patients has been significantly improved due to advances in diagnostic tools and targeted therapies, including immunotherapy, and cellular therapies [5,6]. Developing accurate prognostic predictions to categorize patients and inform clinical decisions is essential for enhancing patient outcomes. Currently, the International Prognostic Index (IPI), its updated versions, such as the Revised-IPI (R-IPI) and the National Comprehensive Cancer Network-IPI (NCCN-IPI), are widely used for risk stratification in diffuse large B-cell lymphoma (DLBCL) patients [7,8,9]. Moreover, the Follicular Lymphoma IPI (FLIPI) and the Mantle Cell Lymphoma IPI (M-IPI) are also valuable prognostic tools for risk stratification in follicular lymphoma (FL) and mantle cell lymphoma (MCL) [10,11]. However, these prognostic tools have primarily focused on overall survival (OS) and progression-free survival (PFS) as endpoints [8,9,12,13]. While 5-year OS and PFS are important predominating endpoints for measuring treatment efficacy [14], predicting treatment response before initiating therapy can provide more immediate and actionable insights for effective management and may facilitate the development and evaluation of novel therapies [15,16]. Recent evidence has demonstrated that early treatment response is a validated surrogate endpoint for long-term survival outcomes in lymphoma [16]. This underscores the need for prognostic models that incorporate treatment response as a primary endpoint.
Achieving a complete response (CR) after the course of therapy is an important predictor of long-term survival in lymphoma patients [16,17,18,19]. Although the cure rate of lymphoma patients has improved, patients’ response to therapy varies widely depending on the types of lymphoma and patient characteristics, ranging from progressive disease to CR [5,20]. The IPI scores of 0–1, 2, 3, and 4–5, developed in the pre-rituximab era using CT and bone marrow assessments, correspond to CR rates of 87%, 67%, 55%, and 44%, respectively [7]. However, its predictive accuracy and clinical utility for treatment response have not been thoroughly assessed in the context of modern therapeutic and imaging approaches. Moreover, while revised indices such as R-IPI and NCCN-IPI improve survival prediction, they did not estimate response rates across risk groups [8,9]. Furthermore, the IPI tool fails to capture the wide range of clinical factors and biomarkers. More importantly, addition of molecular abnormality adds significant value to the prognostication of lymphomas [21]; however, most exiting tools do not have this incorporated necessitating further updated tools which again needs to be tested in bigger cohorts. Hence, an updated risk stratification model incorporating routinely collected clinical variables and biomarkers is needed.
Several studies have demonstrated that inflammatory and nutritional indicators are closely related to the prognosis of cancer patients [12,13,22,23,24,25,26,27,28,29]. Systemic inflammation and inadequate diet promote the proliferation of tumor cells, provide nutrition for tumor cells, stimulate cell growth, and disrupt the immune system, which in turn leads to poor prognosis [30]. Body mass index (BMI), serum albumin, and the prognostic nutritional index (PNI) are often used to assess nutritional status in cancer patients. Traditional inflammatory parameters such as the platelet-to-lymphocyte ratio (PLR), neutrophil-to-lymphocyte ratio (NLR), and lymphocyte-to-monocyte ratio (LMR), along with novel indicators like the systemic immune-inflammation index (SII) and systemic inflammation response index (SIRI) are simple measures to assess systemic inflammation. An increasing amount of research indicates that these inflammation and nutritional indicators are independent predictors of lymphoma prognosis [13,26,27,28]. For example, Liu et al., [12] demonstrated that a nomogram incorporating inflammatory-nutritional markers (SII and PNI) exhibited superior discriminative ability compared to the IPI and NCCN-IPI in predicting OS for DLBCL. Moreover, other studies showed that PNI and SII were significantly associated with complete remission rate [26,28]. However, these studies have only drawn associations between these inflammatory-nutritional indicators and treatment response, without demonstrating whether combining these markers with other prognostic factors enhances predictive accuracy and clinical utility. Although inflammation-nutritional indicators are routinely collected, and relatively inexpensive, their prognostic value in predicting treatment response has been limited in patients with lymphoma.
The pretreatment prediction of therapy response is essential for stratifying patients by their likelihood of achieving a CR and the delivery of precise treatment [31]. However, current clinical prediction tools for forecasting treatment response in lymphoma remain limited. Wang et al. developed a nomogram that integrates imaging features with clinico-pathological factors to assess the CR to chemotherapy in patients with gastric DLBCL [20]. However, this model is not applicable for predicting treatment response before starting therapy, as it was constructed based on post-treatment indicators. Therefore, this study aims to develop and validate a novel prognostic model incorporating pretreatment inflammation-nutritional indicators and using machine learning (ML) for treatment response in B-cell NHL. Additionally, the study evaluated the predictive performance of the IPI, R-IPI, and NCCN-IPI in stratifying patients based on treatment response.
2. Methods
2.1. Data Source and Study Population
The study utilized data from the prospective binational Lymphoma and Related Diseases Registry (LaRDR; https://lardr.org/), a multicentre registry established in 2016 across Australia and New Zealand. Adult patients (≥18 years) with a new diagnosis of lymphoma, chronic lymphocytic leukemia (CLL), or related diseases in accordance with the World Health Organization (WHO) classification (WHO-HAEM3 or WHO-HAEM4, depending on the time of registration) were included in the registry [32,33]. The methodology of the LaRDR has been described in detail elsewhere [34]. In this study, patients diagnosed with B-cell NHL, namely, DLCBL, FL, MCL and Burkitt lymphoma (BL), who had been treated with chemotherapy/immunotherapy were included.
2.2. Study Variables Measurement
Treatment response to first-line chemotherapy/immunotherapy was the primary outcome variable of this study. According to the Lugano 2014 criteria [35], treatment response is categorized as complete response (Deauville score 1–3/disappearance of all evidence of disease), partial response (Deauville score reduction from 4–5 to 1–3/decrease in the size of previously abnormal lesions by at least 50%), no response/stable disease (insufficient reduction to qualify for partial response, but also not meeting criteria for progressive disease), and progressive disease (appearance of new lesions or increase in the size of measurable disease by at least 50% of previously involved sites). In this study, treatment response to first-line therapy was dichotomized into CR and incomplete response (partial response, no response/stable disease, or progressive disease).
Pretreatment factors covering sociodemographic characteristics, clinical features, biomarkers, and inflammatory-nutritional indicators, including age, sex, lymphoma subtype, number of extranodal disease sites, ECOG performance status, B-symptoms, presence of bulk disease (>5 cm), lactate dehydrogenase (LDH), albumin, bilirubin, BMI, C-reactive protein, serum β2 microglobulin, creatinine, alkaline phosphatase (ALP), calcium, hemoglobin, white blood cell count, NLR, MLR, PLR, PNI, SII, SIRI, BCL6 expression and BCL2 expression were considered as potential prognostic factors.
Performance status was measured according to the ECOG (Eastern Cooperative Oncology Group) scale based on four criteria which has been found to be highly correlated with survival and may help predictability to tolerate therapy. BMI is categorized based on WHO cutoff points [36]: underweight (BMI < 18.5 kg/m^2^), normal weight (BMI between 18.5–24.9 kg/m^2^), overweight (BMI between 25–29.9 kg/m^2^), and obese (BMI ≥ 30 kg/m^2^). Patients with anemia and hypoalbuminemia were categorized as per local values and criteria. NLR, MLR and PLR were determined by dividing the absolute counts of neutrophils, monocytes, and platelets by the absolute lymphocyte count, respectively. PNI was expressed as (Albumin (g/L) + 5) × total lymphocyte count × 10^9^/L [26]. SII was calculated as neutrophil counts × platelet counts/lymphocyte counts [37]. SIRI was calculated as monocyte count (10^9^/L) × neutrophil count (10^9^/L)/lymphocyte count (10^9^/L) [38].
2.3. Statistical Analysis
Patients characteristics were summarized using frequencies and percentages, according to treatment responses (complete versus incomplete), and the Pearson chi-square (χ^2^) test was employed. Receiver operating characteristic (ROC) curve analysis was used to determine the optimal predictive cutoff values for quantitative variables, including ALP, creatinine, bilirubin, NLR, PLR, MLR, PNI, SII, and SIRI. Since missingness in the dataset ranged from 0.07% to 62.4% (Supplementary Table S1), complete case analyses were utilised on variables with less than 5% missing values, while variables with 5% to 40% missing values were handled by multiple imputations using the mice R package. Variables with more than 40% missing values, including C-reactive protein (CRP) and beta-2 microglobulin (B2M), were excluded. All data management and statistical analyses were performed using R version 4.4.2.
2.4. Model Development
The data were randomly divided into a training cohort (n = 2221) for tuning model parameters and a validation cohort (n = 553) for predicting model performance metrics (for internal validation) at a 4:1 ratio. The chi-square test was applied to compare the differences in characteristics of patients in the training and validation sets. Six widely used ML algorithms, such as gradient boosting (GBM), K-nearest neighbor (KNN), random forest (RF), support vector machine (SVM), Naïve Bayes (NB), and extreme gradient boosting (XgBoost), along with logistic regression (LR) were employed to predict treatment response of patients with B-cell NHL. The R packages gbm, caret, randomForest, e1071, glmnet, and xgboost were utilized to implement these models. To mitigate the risk of overfitting, a 10-fold cross-validation method was employed in the model training process. In this procedure, the dataset is randomly partitioned into 10 equal folds. Then, the model is trained 10 times, with each iteration using 9 folds for training and the remaining fold for validation and the model performance is averaged across the folds. This approach provides a more reliable estimate of out-of-sample performance compared with a single train test split.
2.5. Feature Selection
To select relevant features and achieve efficient data reduction, we employed two stages of variable selection. First, a Boruta algorithm [39,40] was employed to examine the multivariable relationships among the variables, considering all features relevant to the outcome variable. It is a wrapper method built around Random Forests that identifies all features relevant to an outcome rather than only a minimal optimal subset. It works by creating shadow variables (randomly permuted copies of the original features) and then comparing the importance of each real variable to these shadow features. Then, it classifies variables as confirmed (those that outperform the best shadow feature), tentative (those with intermediate performance), or rejected (those that perform worse than the best random shadow feature). Tentative variables whose importance scores are too close to those of shadow features were further evaluated using importance scores to determine inclusion. Secondly, multivariable LR and RF algorithm were employed for variables retained by the Boruta algorithm. The LR model helps identify potential relationships and key variables influencing the outcome [41]. The RF algorithm aids in feature selection by evaluating the importance of variables. To evaluate variable importance, the mean decrease in the Gini index was used. It is a measure of node impurity used in decision trees and Random Forests. It reflects the probability that a randomly chosen observation from a dataset would be incorrectly classified if it were labelled according to the distribution of classes in that node. A Gini index of 0 indicates perfect purity (all cases in the node belong to a single class), while higher values indicate greater heterogeneity. In Random Forests, variable importance is estimated by averaging the reduction in the Gini index each time a variable is used to split the data across all trees in the forest. Variables that achieve larger decreases in impurity are considered more important for prediction [41,42].
2.6. Class Imbalance Management
In classification models, ML algorithms often achieve high accuracy for the majority class but assign less importance to the minority class. This imbalance can significantly affect the performance of classifiers. To address class imbalance, we used oversampling, undersampling, and two hybrid methods, such as the Random oversampling of examples (ROSE) and Synthetic minority oversampling (SMOTE) techniques in the training dataset. SMOTE and ROSE are a widely used method to address class imbalance in classification tasks. SMOTE generates synthetic examples of the minority class by interpolating between existing minority instances and their nearest neighbours [43]. ROSE generates synthetic balanced samples by drawing new examples from a smoothed bootstrap distribution of both classes, improving classifier performance in binary imbalanced learning [44].
2.7. Model Performance Evaluation
Model discrimination metrics such as the area under the curve (AUC) and classification metrics, including accuracy, sensitivity, specificity, positive and negative predictive values were calculated for each algorithm. The AUC is a discriminating performance indicator that indicates how well a model can distinguish event individuals (i.e., with incomplete response) from non-event individuals (i.e., CR). It ranges from 0 to 1, where values of 0, 0.5 and 1, indicate perfect anti-discrimination, no discrimination, and perfect discrimination, respectively. Brier scores were also used to evaluate the overall agreement between predicted and actual treatment response probabilities, with lower values indicating better calibration and accuracy [45]. In addition, to evaluate and compare developed prediction models in the context of clinical decision-making, a decision curve analysis (DCA) was employed. Based on selected variables, a nomogram for predicting the treatment response of B-cell NHL patients was constructed. This nomogram is a visual tool derived from a statistical model that enables clinicians to estimate the likelihood of a particular clinical outcome. It displays variables separately and assigns to each variable a specific score based on its impact on the probability of the event of interest. By assigning different weights to each risk factor, the nomogram provides a more individualized and accurate risk assessment. The overall score is obtained by summing up the individual variables’ scores [46,47]. Furthermore, the predictive ability of our model, IPI, R-IPI, and NCCN-IPI was compared by AUC, Brier score, and DCA (Figure 1). The R packages pROC, pec, rmda, and rms were used to calculate the AUC, compute the Brier score, perform the DCA, and construct a nomogram, respectively.
3. Results
3.1. Determination of Cut-Off Values for Inflammatory Nutritional Indicators
A total of 2763 patients with B-cell NHL were included in this study. Using ROC curve, the optimal cut-off points for PLR, MLR, NLR, PNI, SII, and SIRI were 274.773, 0.611, 5.123, 40.93, 1686.985, and 3.529, respectively, with corresponding AUC values of 0.555, 0.563, 0.574, 0.572, 0.570, and 0.574 (Supplementary Table S2). According to the ROC cut-off value, creatinine, bilirubin, ALP, NLR, MLR, PLR, PNI, SII and SIRI were divided into a low and high group.
3.2. Background Characteristics
Incomplete response to first-line therapy was more common in patients with adverse clinical features, including stage III/IV, ECOG performance status > 1, elevated LDH, anemia, multiple extranodal sites involvement, and low albumin. Regarding inflammatory nutritional indicators, an incomplete response was more common in patients with low PNI and high SIRI, PLR, NLR, and MLR (Table 1). Additionally, univariable logistic regression identified several factors significantly associated with incomplete response, including advanced stage, poor performance status, elevated LDH, anemia, and inflammatory markers (PNI, SII, SIRI, MLR, PLR, and NLR) (Supplementary Table S3). The training and validation sets were comparable in terms of key characteristics (Supplementary Table S4).
3.3. Features Selection
In the first step, based on the Boruta algorithm, out of 25 attributes, 10 were rejected (red boxplots), 13 were confirmed (green boxplots), and 2 were designated as tentative (yellow boxplots) (Figure 2). Both tentative variables were retained (considered as important variables) based on importance scores (Supplementary Table S5). Of the 15 variables retained by the Boruta algorithm, multivariable LR identified six significant independent prognostic factors: performance status, stage, LDH, BCL2 expression, anemia and SII (Supplementary Table S6). The top six important variables from the RF algorithm, including absolute white cell count, bulk, stage, LDH, performance status and BCL2 expression, were identified to compare with the LR model results (Supplementary Figure S1). The combined methods selected eight variables: six significant variables from the LR model, plus additional two factors (bulk disease and white blood cell counts) from RF ranking.
3.4. Model Development and Performance
In our study, we conducted a comparative analysis of seven algorithms using two distinct predictor sets: variables identified as statistically significant through multivariable LR, and a combination of top six variables based on RF importance with those statistically significant in multivariable LR. Additionally, we employed four methods for managing data imbalance as disproportion in treatment response was encountered, with 75.6% of patients achieving a complete response and 24.4% not achieving a CR. Data balancing improved the performance of only the SVM and RF algorithms, and there was no superior data balancing method, as the performance was consistent across the four data balancing methods (Supplementary Table S7). The inclusion of top variables based on RF importance, alongside those statistically significant in multivariable LR, did not yield a significant enhancement in the predictive performance of the models (Supplementary Figure S2). Consequently, we used six prognostic factors identified as significant through multivariable LR, namely, ECOG performance status, stage, LDH, BCL2 expression, anemia and SII to predict treatment response. The AUCs of all ML in the validation cohort were similar, ranging from 0.69 to 0.70 (Table 2 and Figure 3). The AUC values for all algorithms in both the training and validation sets exhibit minimal differences, indicating that the models were not overfitted and could generalize effectively to unseen data. Moreover, the Brier score ranged from 0.223 for NB to 0.298 for RF, with a score of 1 indicating the poorest calibration and a score of 0 representing perfect calibration (Table 2).
3.5. Nomogram Development
The final six independent prognostic factors were integrated into the nomogram to predict treatment response. Variable scores can be obtained by where the vertical line intersects the point scale at the top of the chart for each variable (Figure 4), and these scores can then be summed up to get a total score. This total score provides predictive measures of treatment response for each patient. The bottom of the series shows the model’s estimated probability of incomplete response after chemotherapy/immunotherapy in patients with B-cell NHL. For example, a patient with performance status (≥2), anemia, elevated LDH, high SII, positive BCL2 expression, and stage III/IV could obtain 57 points, 37 points, 52 points, 70 points, 36 points, and 100 points, respectively, resulting in a total score of 352 points. For patients having all these six risk factors, their probability of having an incomplete response is 80%, compared to 20% for patients without these six risk factors (Figure 4). Generally, the probability of an incomplete (IC) response can be approximated using the formula:
Probability of IC response = 0.2 + 0.00171 × Total points, where 0.0017 is the slope (scaling factor).
The AUCs for the nomogram in the validation cohort was 0.70 (95% CI: 0.65, 0.75), indicating that our model had acceptable discriminating ability. The AUC of the nomogram outperformed the Revised IPI (AUC = 0.61, 95% CI: 0.56, 0.66), NCCN-IPI (AUC = 0.63, 95% CI: 0.57, 0.68), and IPI (AUC = 0.65, 95% CI: 0.60, 0.71). Calibration of the nomogram was superior, with a lower Brier score (0.227) compared to existing indices (Table 2). Furthermore, the decision curve analysis confirmed the clinical utility was better for nomogram (Figure 5).
Based on quantiles, the total score of the nomogram was categorized into four risk groups: low risk (<138 points), low intermediate (138–188 points), high intermediate (188–225 points) and high-risk (≥225 points). In the validation cohort, there were 218, 125, 93, and 117 patients in the low-risk, low intermediate, high intermediate, and high-risk groups, respectively, with corresponding incomplete response rates of 9.1%, 25.6%, 32.3%, and 39.3% (Table 3).
As the IPI, R-IPI, and NCCN-IPI were originally developed for prognostication in DLBCL, we evaluated their performance specifically within the DLBCL cohort to ensure a fair comparison and to further contextualize their utility. In the validation cohort, our unified model demonstrated slightly superior discriminative ability compared to IPI, R-IPI, and NCCN-IPI (AUC: 0.64 vs. 0.59, 0.57, and 0.60, respectively) (Supplementary Figure S3). These findings suggest that our model may offer slightly improved predictive accuracy, even within the subtype for which these existing clinical scores were originally designed.
4. Discussion
Here, we developed and internally validated a nomogram and machine learning algorithms using universally collected clinical features, biomarkers, and inflammatory-nutritional markers data from 33 hospitals to assess the predictability of treatment response. In this study, both LR and ML (RF) identified overlapping key predictors, including stage, LDH, ECOG performance status, and BCL2 expression. Overall, ML algorithms and LR analysis demonstrated comparable predictive ability in predicting treatment response. Notably, the nomogram showed significantly better discriminative ability compared to the R-IPI.
In this study, the comparable predictive performance observed between ML algorithms and LR can be attributed to several factors. First, although categorizing continuous variables are not a statistically recommended practice in predictive modelling [48,49], we categorized them based on predefined cutoff points or ROC curve analysis for simplicity in clinical use. Categorizing continuous variables may have influenced ML model performance. For example, categorization can lead to a loss of information and reduce their ability to capture complex, non-linear relationships, particularly in tree-based methods. Second, the number of predictors used in model development was limited. It is noted that standard regression methods perform well when applied to datasets with relatively few predictor variables and large sample sizes [50]. While no definitive threshold exists for the number of predictors required to enhance ML performance, incorporating more variables may have provided ML algorithms with a more significant advantage over LR.
Although the application of ML in predicting healthcare outcomes has been increasing in recent years, evidence regarding its superiority over traditional regression methods remains inconclusive [51,52,53,54,55]. Consistent with our findings, a registry-based study from the European Society for Blood and Marrow Transplantation reported that LR performed comparably to ML algorithms in predicting hematopoietic stem cell transplantation-related mortality in patients with acute leukemia [51]. Similarly, studies utilizing electronic health records (EHR) in China found no significant difference in the discriminatory ability of ML models and LR for predicting recurrence and mortality in patients with DLBCL [52,53]. Similar performances of LR and ML have also been reported for predicting solid tumors and non-oncologic outcomes, for example, predicting gastric cancer risk [55] and hypertension incidence [56]. In contrast, an EHR-based study from Shanxi Tumor Hospital demonstrated that ML outperformed LR in stratifying recurrence risk among DLBCL patients [54]. Moreover, a systematic review and meta-analysis demonstrated the superiority of ML in predicting overall survival in lung cancer [57] and treatment response in rectal cancer patients [58]. These inconclusive results suggest that further investigation is needed to understand the conditions under which ML models outperform traditional methods.
Given the comparable performance of LR and ML, we developed an LR-based nomogram to aid in incorporating our model into clinical practice. It is important to note that although our nomogram’s AUC of 0.70 appear modest, it exceeds that of well-established prognostic indices, including the IPI (0.65), R-IPI (0.61), and NCCN-IPI (0.63). To our knowledge, only one previous study has developed a nomogram for predicting treatment response in lymphoma [20]. Although the nomogram demonstrated promising discrimination (AUC = 0.957) in gastric DLBCL, its application may be limited by a small sample size (n = 108 patients), a single-centre design, dependence on imaging features not routinely available in practice and reliance on post-treatment indicators, which restrict its use for pre-treatment risk stratification. Other studies have also investigated the prediction of treatment response in lymphoma subtypes, such as primary central nervous system lymphoma and bulky Hodgkin and non-Hodgkin lymphomas, using advanced imaging or radiomic features, with a small sample size from single-centre settings. In these studies, discrimination has ranged from AUC 0.618 to 0.868, with combined radiomics–clinical models often performing better than clinical models alone [59,60]. While such studies suggest potential value in incorporating radiomics, our recent meta-analysis demonstrated that models incorporating radiomic features performed similarly to models based on clinical features in hematological malignancies [61]. In our multilevel meta-analysis of 38 ML models developed for lymphoma outcomes, we observed a pooled AUC of 0.779, which was higher than the current study’s performance, with most studies predicting OS and PFS. Taken together, our nomogram derived from routinely collected pre-treatment variables across 33 hospitals enables early prediction before therapy initiation, offers substantial potential for generalizability, and remains feasible even in resource-limited settings.
Importantly, although the AUC is a fundamental metric for assessing model discrimination, it does not capture a model’s calibration or its clinical usefulness. Model’s clinical utility can be assessed using DCA by evaluating the net benefit across different threshold probabilities [62,63]. DCA demonstrated that the nomogram provided a better net benefit over IPI-based scoring systems across a range of threshold probabilities, showing better clinical utility for guiding treatment decisions. Moreover, the Brier score for our nomogram was lower than that of existing prognostic indices, suggesting better agreement between predicted and observed probabilities, thereby providing reliable risk estimation. In our study, four risk groups were categorized based on total nomogram scores derived from ROC curve analysis rather than assigning equal weight to all factors as used in IPI-based scoring systems. Assigning equal weight to all factors can lead to a loss of discrimination power and inaccurate stratification since not all risk factors have an equal impact on the occurrence of an outcome. Our approach addressed this methodological limitation by allowing for more precise and detailed individualized risk stratification. Additionally, our nomogram included BCL2 expression, anemia, and SII, which were not originally part of the IPI-based scoring systems. This demonstrates the slightly enhanced predictive power and clinical usefulness of our model in stratifying patients.
In contrast to disease-specific prognostic indices such as the IPI for DLBCL, FLIPI for FL, and M-IPI for MCL, our model offers a unified prognostic tool applicable across multiple B-cell lymphoma subtypes. Although these existing indices were developed within subtype-specific cohorts, they primarily rely on general clinical parameters such as LDH, age, performance status, stage, extranodal involvement, and blood counts, which are not disease-specific markers but rather indicators of overall tumor burden and patient condition. Our model includes some of the shared factors found across these existing indices namely LDH, stage, and ECOG performance status and incorporating hemoglobin, which is included in FLIPI but not in IPI or MIPI. We also evaluated white blood cell count, a component of MIPI, as an independent variable, though it did not retain significance in the final model. Importantly, our model extends beyond conventional clinical variables by integrating BCL2 expression, a marker of anti-apoptotic signaling and treatment resistance [64,65] and the SII, a composite biomarker reflecting the host’s immune and inflammatory status [66]. Notably, the lymphoma subtype was not a significant predictor of initial treatment response in our cohort, suggesting that the features included in our model may capture shared biological and clinical characteristics relevant to treatment response across subtypes despite their known heterogeneity. As such, our model may serve as a practical and unified tool to stratify treatment response in various B-cell lymphomas. To further ensure fair comparison and clinical relevance, we propose to evaluate the model’s performance within individual subtypes using larger cohorts and benchmarking it against established disease-specific indices such as the FLIPI, and MIPI.
The prognostic significance of variables incorporated in our nomogram, including stage, LDH, ECOG performance status, BCL2 expression, anemia, and SII, has been well-documented in cancer prognosis [7,8,9,67,68,69,70,71]. Apart from factors included in the IPI, increasingly more evidence suggests that inflammatory-nutritional markers play a significant role in lymphoma prognosis [12,13,26,27,28]. We comprehensively tested various inflammatory-nutritional markers and found that only the SII was a significant independent risk factor for treatment response. The SII, a comprehensive inflammatory biomarker that incorporates neutrophil, platelet, and lymphocyte counts, was developed in 2014 to predict poor outcomes in patients with hepatocellular carcinoma. It is linked to circulating tumor cells and reflects the balance of the body’s inflammatory and immune responses, with higher SII values linked to poorer patient outcomes [66]. Our study observed that high SII were associated with a higher rate of incomplete responses in B-cell lymphoma patients. Consistent with our findings, a prospective study by Waley et al. [28] demonstrated that patients with high SII was significantly associated with low CR rate in patients with DLBCL. The prognostic role of SII in predicting survival outcomes for patients with lymphoma has also been well-established [12,13]. In addition, numerous meta-analyses have confirmed that high SII is associated with worse prognoses in a variety of tumors [72,73], as well as poor cardiovascular outcomes and an increased risk of cardiovascular diseases [74,75].
Moreover, our study demonstrated that patients with pretreatment anemia were more likely to have incomplete responses to treatment. Notably, anemia is a key component of the FLIPI score and has been reaffirmed as a significant prognostic factor in a recent model, the FL Evaluation Index (FLEX) [10,76]. Moreover, studies have shown that pretreatment anemia provides additional predictive value to the IPI, R-IPI, and NCCN-IPI in predicting OS for patients with DLBCL [77,78]. This can be attributed to hypoxia induced by low levels of hemoglobin, which has been shown to contribute to tumor progression and therapy resistance by promoting angiogenesis, inducing genomic mutations, and increasing resistance to apoptosis and the cytotoxic effects of chemo/radiotherapy-generated free radicals [79,80]. Given that anemia is a common hematologic abnormality in cancer patients and can be further induced by chemotherapy [81,82], our study suggests that incorporating pretreatment anemia status into existing prognostic tools for lymphoma patients may enhance their accuracy. This could help tailor treatment strategies more effectively, thereby improving therapy response and overall prognosis.
Furthermore, building on the NCCN-IPI recommendation that the inclusion of biological markers such as BCL2 expression may enhance prognostic accuracy [9], we tested the significance of BCL2 expression and found that positive BCL2 expression was significantly associated with a higher rate of incomplete treatment responses. Similarly, in previous studies, positive BCL2 expression has been associated with an increased risk of recurrence, poor treatment response, and shorter PFS and OS in lymphoma patients [83,84,85,86], as well as poor therapy response in acute leukemia [87]. This finding aligns with the general understanding that overexpression of BCL2 can lead to the survival of abnormal cells that should otherwise undergo apoptosis, thereby contributing to tumor growth and resistance to therapy [64,65]. On the contrary, a recent study has shown that patients with BCL2 dependence in chronic lymphocytic leukemia (CLL) tend to respond favorably to therapy [88]. While BCL2 overexpression generally indicates poor prognosis due to enhanced cell survival and resistance to apoptosis, these findings underscore the complex role of BCL2 in cancer prognosis and warrant further investigation.
This study has some strengths and limitations. To the best of our knowledge, this is the first comprehensive comparison of various machine learning algorithms alongside standard regression techniques, as well as the validation of existing tools for predicting treatment response in B-cell lymphomas. Additionally, the utilization of multicenter data enhances the diversity and representativeness of the patient cohort. Although the model was developed using a multi-institutional dataset, and treatment response did not significantly differ across subtypes, the predominance of DLBCL cases may still influence our unified model’s performance. While we validated the model specifically in DLBCL, comparing its performance with IPI, R-IPI, and NCCN-IPI, further validation in rarer subtypes is needed to confirm broader applicability. Moreover, the study’s reliance on internal validation limits its generalizability, underscoring the need for external validation. In addition, although ROC curve analysis was employed to determine optimal predictive cutoff values for inflammatory-nutritional markers, an advantageous method for evaluating model performance across different thresholds, these cutoff points may not be universally applicable across diverse populations or clinical settings. Therefore, future research should prioritize the validation of these cutoff points to ensure their generalizability and reliability in varied clinical settings.
5. Conclusions
In conclusion, our study developed and internally validated predictive models for treatment response in lymphoma patients, demonstrating that machine learning models and standard regression have comparable performance. Although our nomogram, which incorporates clinical (stage, LDH, anemia and ECOG performance status), inflammatory (SII), and molecular (BCL2 expression) features, demonstrated slightly improved discriminative ability and clinical utility compared to existing tools, the overall discriminatory power remains limited. To advance prognostic accuracy and better reflect the evolving landscape of lymphoma care, future work will focus on integrating additional molecular parameters and transcriptomic signatures. Moreover, as our model is only internally validated, external validation is warranted to confirm its generalizability. This supports its potential use in risk stratification and decision-making for tailored treatment strategies in managing lymphoma patients.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Thandra K.C. Barsouk A. Saginala K. Padala S.A. Barsouk A. Rawla P. Epidemiology of Non-Hodgkin’s Lymphoma Med. Sci.20219510.3390/medsci 9010005 PMC 793098033573146 · doi ↗ · pubmed ↗
- 2Cancer Research Institute Immunotherapy: For Lymphoma. What Makes Immunotherapy for Lymphoma a Promising Treatment?Available online: https://www.cancerresearch.org/immunotherapy-by-cancer-type/lymphoma(accessed on 23 July 2025)
- 3Mafra A. Laversanne M. Gospodarowicz M. Klinger P. De Paula Silva N. Piñeros M. Steliarova-Foucher E. Bray F. Znaor A. Global patterns of non-Hodgkin lymphoma in 2020 Int. J. Cancer 20221511474148110.1002/ijc.3416335695282 · doi ↗ · pubmed ↗
- 4Chu Y. Liu Y. Fang X. Jiang Y. Ding M. Ge X. Yuan D. Lu K. Li P. Li Y. The epidemiological patterns of non-Hodgkin lymphoma: Global estimates of disease burden, risk factors, and temporal trends Front. Oncol.202313105991410.3389/fonc.2023.105991437333805 PMC 10272809 · doi ↗ · pubmed ↗
- 5Chao M.P. Treatment challenges in the management of relapsed or refractory non-Hodgkin’s lymphoma—Novel and emerging therapies Cancer Manag. Res.2013525126910.2147/CMAR.S 3427324049458 PMC 3775637 · doi ↗ · pubmed ↗
- 6Patrício A. Costa R.S. Henriques R. On the challenges of predicting treatment response in Hodgkin’s Lymphoma using transcriptomic data BMC Med. Genom.202316(Suppl. S 1)17010.1186/s 12920-023-01508-9PMC 1036023037474945 · doi ↗ · pubmed ↗
- 7International Non-Hodgkin’s Lymphoma Prognostic Factors Project A predictive model for aggressive non-Hodgkin’s lymphoma N. Engl. J. Med.199332998799410.1056/NEJM 1993093032914028141877 · doi ↗ · pubmed ↗
- 8Sehn L.H. Berry B. Chhanabhai M. Fitzgerald C. Gill K. Hoskins P. Klasa R. Savage K.J. Shenkier T. Sutherland J. The revised International Prognostic Index (R-IPI) is a better predictor of outcome than the standard IPI for patients with diffuse large B-cell lymphoma treated with R-CHOP Blood 20071091857186110.1182/blood-2006-08-03825717105812 · doi ↗ · pubmed ↗