Beyond Conventional Meta-Analysis: A Meta-Learning Model to Predict Cohort-Level Mortality After Transcatheter Aortic Valve Replacement (TAVR)
Yamil Liscano, Darly Martinez Guevara, Gustavo Andrés Urriago-Osorio, John Quintana

TL;DR
This study uses machine learning to better predict mortality after a heart procedure, finding that factors like patient risk and time trends explain much of the variation.
Contribution
Introduces a meta-learning model that outperforms traditional methods in predicting TAVR mortality and identifying key determinants.
Findings
Meta-learning explained 65.3% of variability in TAVR mortality, a 46 percentage-point improvement over traditional methods.
Key predictors included patient risk scores, procedure year, and diabetes prevalence, showing a strong temporal trend.
The model highlights how medical practice evolution impacts outcomes, beyond patient-level factors.
Abstract
Context and Objective: Post-Transcatheter Aortic Valve Replacement (TAVR) mortality exhibits extreme heterogeneity that conventional meta-analyses fail to explain, limiting the clinical utility of evidence synthesis and hindering accurate prognostic assessment. This study evaluated whether meta-learning, using aggregate data from the literature, can predict cohort-level mortality and identify its determinants, overcoming the limitations of traditional methods to provide a clearer understanding of the factors driving TAVR outcomes. Methods: A systematic review following PRISMA guidelines was conducted across five databases. Methodological quality was assessed with standardized tools (Risk of Bias 2, Newcastle-Ottawa Scale, Risk of Bias in Non-randomized Studies of Exposure). After performing conventional meta-analyses and meta-regressions, multiple machine learning models were trained…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
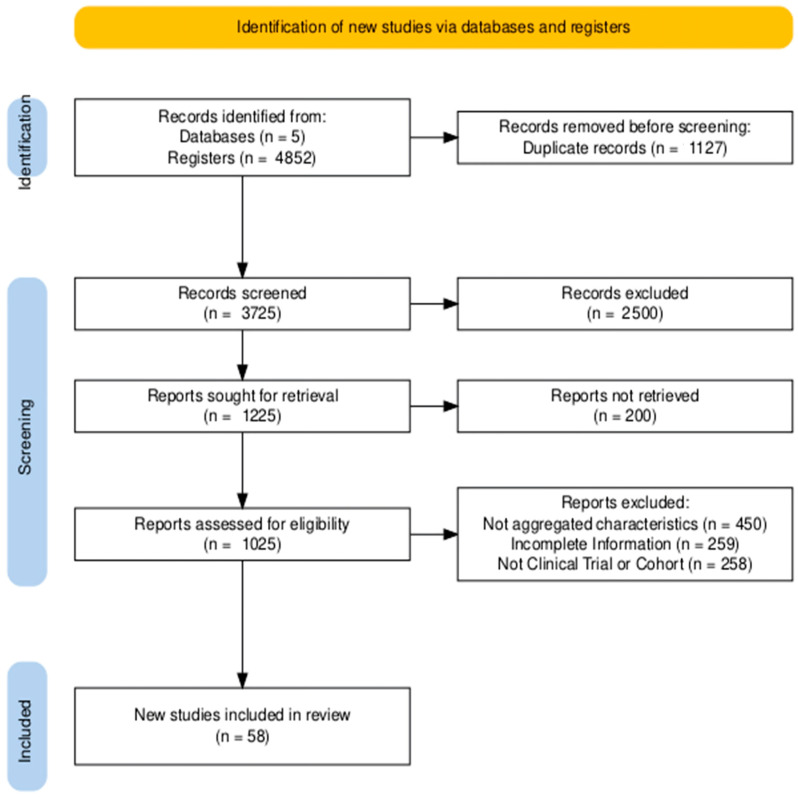 Figure 1
Figure 1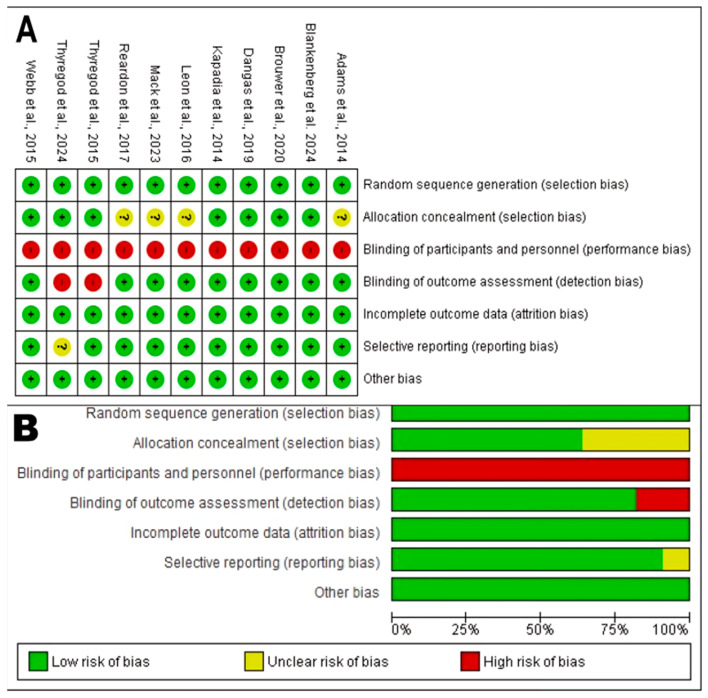 Figure 2
Figure 2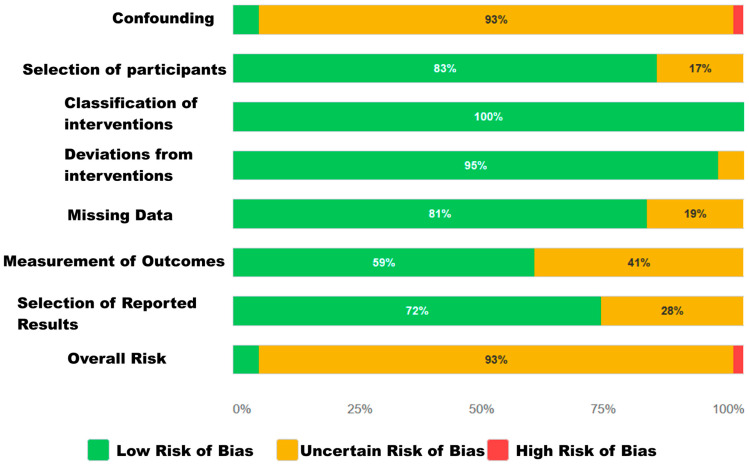 Figure 3
Figure 3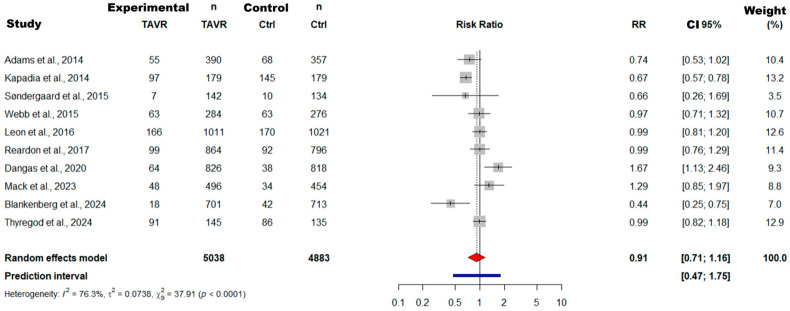 Figure 4
Figure 4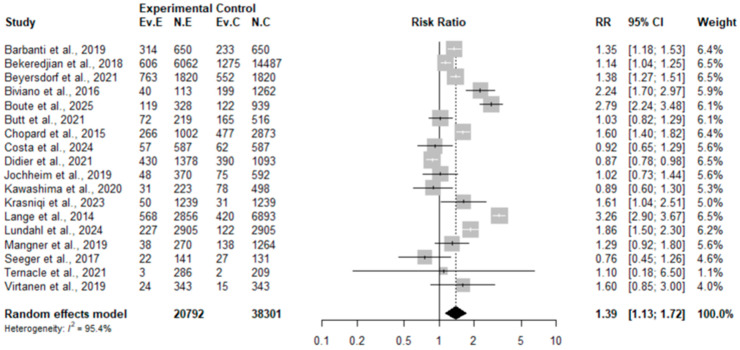 Figure 5
Figure 5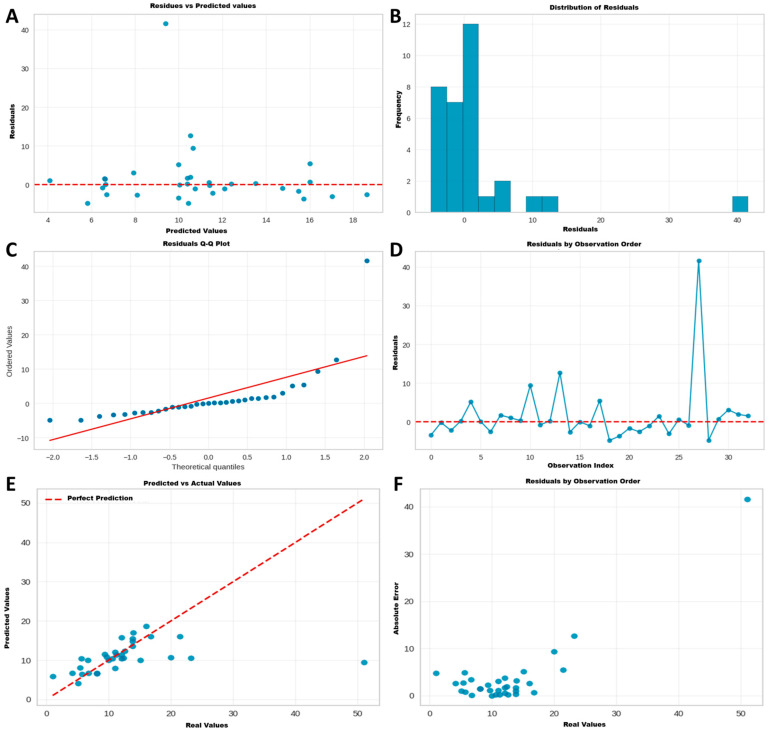 Figure 6
Figure 6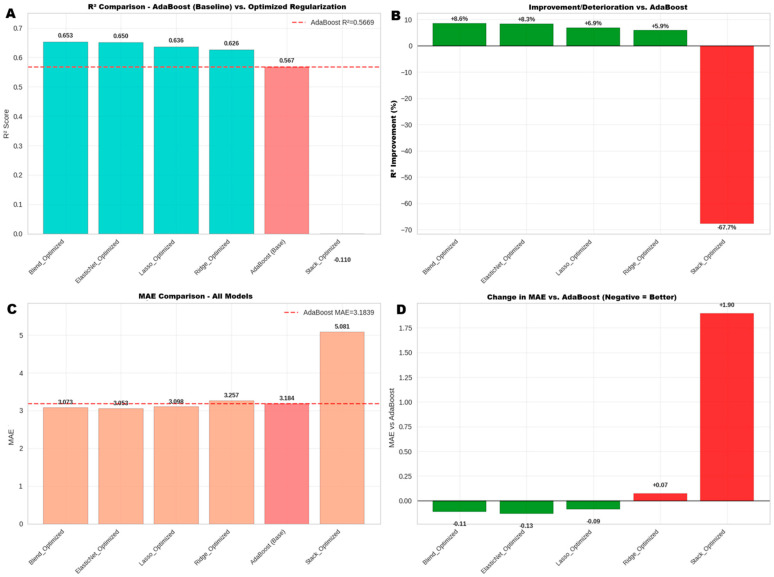 Figure 7
Figure 7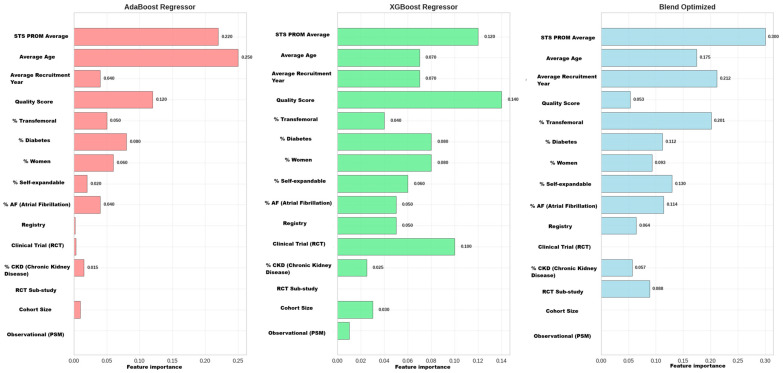 Figure 8
Figure 8- —Dirección General de Investigaciones of Universidad Santiago de Cali
- —Fortalecimiento de grupo GISI
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCardiac Valve Diseases and Treatments · Infective Endocarditis Diagnosis and Management · Orthopaedic implants and arthroplasty
1. Introduction
Severe aortic stenosis stands as the most prevalent valvular heart disease in developed countries, with a growing epidemiological burden due to population aging. Without intervention, the prognosis for symptomatic patients is grim. In this context, Transcatheter Aortic Valve Replacement (TAVR) has transformed the therapeutic landscape. Initially conceived as an alternative for inoperable or high-risk patients, its indication has expanded exponentially to intermediate- and low-risk cohorts, consolidating its position as a cornerstone in disease management. However, this rapid expansion, and the inclusion of increasingly diverse patient populations, have highlighted a fundamental clinical challenge: the notable variability in long-term outcomes [1,2,3,4]. Five-year follow-up findings from the Placement of Aortic Transcatheter Valves Trial and Evolut-Low-Risk trials confirm that, even in low-risk patients, survival and prosthetic durability show divergent patterns compared to conventional surgery [5].
Clinical outcomes after TAVR, especially all-cause mortality, show considerable heterogeneity in the literature. Conventional meta-analyses frequently report extremely high statistical variability, often with an I^2^ greater than 75%. In fact, recent studies confirm that this heterogeneity reaches extreme levels (overall I^2^ = 99.06%), attributing it to fundamental differences in populations, procedures, and the data used to train predictive models. This inconsistency has direct clinical implications: it hinders clinicians’ ability to communicate an accurate prognosis, personalize therapeutic decisions, and, importantly, identify high-risk patients who would benefit from more intensive postoperative surveillance [6,7,8].
Part of this challenge stems from the limitations of current risk stratification tools. Scores such as the Society of Thoracic Surgeons Predicted Risk of Mortality (STS-PROM) or European System for Cardiac Operative Risk Evaluation II, while essential, were designed for open-heart surgery and not specifically for TAVR. Even traditional models developed specifically for TAVR have shown, at best, modest or incremental improvements. This inadequacy has been conclusively quantified, demonstrating that machine learning algorithms consistently outperform traditional scores with an average difference in C-statistic of 0.11 (p < 0.00001). This highlights the need for approaches that capture the unique complexity of this population, as factors not included in traditional scores, such as frailty or patient functional status (measured by scales like American Society of Anesthesiologists and Clinical Frailty Scale), have been shown to be more potent predictors of mortality than EuroSCORE II itself [4,9,10].
In addition to the limitations of risk scales, traditional analytical methods have also proven insufficient. Meta-regression, a standard tool for exploring heterogeneity, typically analyzes variables in isolation and linearly, unable to model the complex and non-linear interactions that likely determine outcomes. This perpetuates a knowledge gap, where high variability in mortality remains unexplained, and findings from randomized controlled trials (RCTs) often contrast with those from large population registries and real-world practice studies [11,12,13]. The ESC/EACTS 2021 guidelines and the ACC/AHA 2023 update also point to the need to incorporate functional variables and biomarkers not included in classic scores to improve stratification [5,14].
To address these methodological limitations, we propose meta-learning as an innovative approach. Its main strength is that it learns directly from the aggregate and heterogeneous data of a systematic review, thus overcoming the frequent obstacle of unavailable individual patient data. The novelty of this work lies in applying this capability to solve a classic problem in evidence synthesis: using published data to model the complex non-linear interactions that cause clinical heterogeneity. TAVR serves here as a case study for a methodological challenge common throughout cardiology. Therefore, validating a method that can extract meaningful clinical signals from aggregate data represents an important step toward more reliable evidence-based medicine. With this, our research becomes one of the first applications of this technique to unravel the determinants of post-TAVR mortality [4,15,16].
To answer the central question of this work, a multiphase methodological approach was designed. First, a comprehensive systematic review was conducted to consolidate all published evidence. Next, traditional meta-analyses and meta-regressions were applied to quantify global effects and to explore sources of heterogeneity using conventional statistical methods. Finally, and in direct response to the unexplained variability limitations identified in previous analyses, the objective of the final phase was to use the aggregate data to develop a meta-learning model that could accurately predict the 1-year cohort-level mortality rate and identify the complex combinations of predictors that traditional methods failed to capture.
2. Materials and Methods
2.1. Study Protocol
A systematic review was conducted following the guidelines of the Cochrane Collaboration Handbook, where applicable for observational studies, and the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) recommendations [17]. The protocol was registered in the PROSPERO database (CRD420251103208). The study will be formulated according to the Population, Exposure/Intervention, Comparison, and Outcomes (PICO) strategy, focusing on aggregate study-level data for predictive modeling.
2.2. Research Question
For a population of (P) cohorts of studies on patients with severe aortic stenosis undergoing TAVR, we seek to determine whether the (I) application of a meta-learning model, which uses aggregate characteristics (demographic, clinical, and methodological), is superior to the (C) conventional meta-analysis and meta-regression approach for (O) accurately predicting the 1-year all-cause mortality rate at the cohort level and identifying its most influential predictors.
2.3. Eligibility Criteria
2.3.1. Inclusion Criteria
Study Design: RCTs, cohort studies (prospective or retrospective), and analyses of national or multicenter registries.Population: Cohorts of adult patients (>18 years) undergoing TAVR for severe aortic stenosis.Required Data: Studies that reported the following:
- Baseline and procedural characteristics of the cohort in aggregate format (mean, median, or percentage).
- The 1-year all-cause mortality rate in extractable form. This endpoint was chosen due to its consistent reporting across the widest range of study designs and publication eras, maximizing the available data for robust model training. Cohort Size: Predominantly studies with a cohort size greater than 100 patients to ensure stability of estimates.
2.3.2. Exclusion Criteria
Articles without original data (narrative reviews, editorials, letters, meta-analyses).Case reports or small case series (generally N < 100).Studies that did not allow extraction of aggregate baseline characteristics or 1-year mortality.Duplicate publications of the same cohort (in which case, the most complete or recent report was selected).Data published only as conference abstracts or pre-prints without a complete manuscript available.
2.4. Data Sources and Search Strategy
Searches were conducted in the following databases: PubMed/MEDLINE, Embase, Cochrane Library, Web of Science, and Scopus. Language filters (English and Spanish) and publication dates were applied as appropriate.
The search strategy was designed and executed by at least two independent researchers using keywords and MeSH/Emtree terms related to (“Transcatheter Aortic Valve Replacement”[Mesh] OR “Transcatheter Aortic Valve Implantation”[tiab] OR TAVR[tiab] OR TAVI[tiab]) AND (“Mortality”[Mesh] OR “mortality”[tiab] OR “death”[tiab] OR “survival”[tiab] OR “prognosis”[tiab] OR “outcome*”[tiab] OR “Major Adverse Cardiac Events”[tiab] OR MACE[tiab] OR “Stroke”[Mesh] OR “stroke”[tiab] OR “Myocardial Infarction”[Mesh] OR “myocardial infarction”[tiab] OR “Heart Failure”[Mesh] OR “heart failure”[tiab] OR “rehospitalization”[tiab]) AND (“Clinical Trial”[ptyp] OR “Randomized Controlled Trial”[ptyp] OR “Observational Study”[ptyp] OR “Cohort Studies”[Mesh] OR “cohort stud*”[tiab] OR “Registry”[ptyp] OR “registries”[tiab]).
Adjustments will be made as necessary for each database. Additionally, reference lists of relevant articles and systematic reviews were manually reviewed to identify any studies not captured in the initial search. Zotero (version 6.0; accessed 20 May 2025) was used for citation management and duplicate removal. Remaining records were then uploaded to Rayyan (Rayyan Systems Inc., Cambridge, MA, USA; accessed 20 May 2025, https://www.rayyan.ai/), a web application designed to facilitate collaborative screening.
2.5. Information Selection and Extraction
Two independent reviewers (Y.L. and D.M.G.) screened the titles and abstracts of the identified studies to determine eligibility. Pre-selected articles then underwent full-text review to confirm compliance with inclusion and exclusion criteria. Disagreements were resolved by consensus or through consultation with a third reviewer. The degree of agreement between reviewers for study selection was assessed using Cohen’s Kappa statistic.
To meet the objective of mapping evidence and feeding meta-learning models, a structured form was developed for the detailed extraction of a wide range of variables. The goal was to capture heterogeneity in study designs, cohort characteristics, and reported outcomes. The form collected the following variables:
- Study Identifiers: First author, publication year, study design (RCT, registry, cohort), and country/geographic region.
- Cohort Baseline Characteristics: Size of the analyzed cohort, average age, percentage of women, and prevalence of key comorbidities (% of diabetes mellitus, % of atrial fibrillation, % of chronic kidney disease).
- Risk Scores and Hemodynamic Data: Average STS-PROM score, average EuroSCORE II, and average Left Ventricular Ejection Fraction (LVEF).
- Procedural Characteristics: Percentage of transfemoral approach and percentage of self-expanding valve use.
- Methodological Variables: Follow-up duration, Valve Academic Research Consortium criteria used, and study quality score (derived from NOS/Jadad scales).
- Outcome Variables (Endpoints): All-cause mortality rate (at 1 year and other follow-ups), myocardial infarction (%), stroke (%), rehospitalization for heart failure (%), and composite Major Adverse Cardiovascular Events (%).
The PRISMA flow diagram summarizing the study selection process is presented in Figure 1. The diagram was generated using the R online package PRISMA2020 (https://estech.shinyapps.io/prisma_flowdiagram/; accessed 20 May 2025).
2.6. Risk of Bias Assessment
The risk of bias was independently assessed by two reviewers (Y.L. and D.M.G.), using standardized tools specific to each study design. Discrepancies were resolved by discussion until consensus was reached.
2.6.1. Randomized Controlled Trials (RCTs)
For RCTs, the risk of bias was assessed using the Cochrane Risk of Bias (RoB 2) tool. Information was recorded and managed in Review Manager software (RevMan version 5.4; accessed 25 May 2025). The domains assessed were (a) random sequence generation, (b) allocation concealment, (c) blinding of participants and personnel, (d) blinding of outcome assessment, (e) incomplete outcome data handling, and (f) selective reporting of results. For each domain, studies were rated with “low,” “unclear,” or “high” risk of bias. Additionally, methodological quality was quantified with the Jadad scale, which assigns a score from 0 to 5 (5 being maximum quality) based on randomization, blinding, and handling of withdrawals and dropouts. A score of 3 or more was considered indicative of adequate quality.
2.6.2. Observational Studies
For cohort studies and registries, methodological quality was assessed with the Newcastle–Ottawa Scale (NOS). This tool scores studies from 0 to 9 stars, evaluating three key domains: (a) cohort selection, (b) comparability between exposed and unexposed groups, and (c) outcome assessment. Complementarily, the ROBINS-E (Risk of Bias in Non-Randomized Studies—of Exposures) tool was used for a deeper assessment of bias domains specific to non-randomized studies, such as confounding bias.
2.7. Descriptive Analysis and Traditional Meta-Analysis/Meta-Regression
Descriptive statistics weighted by cohort size were generated. For each clinical outcome, a random-effects meta-analysis was performed using the DerSimonian–Laird estimator; heterogeneity was interpreted with I^2^ and the Q test. When I^2^ ≥ 50%, univariable and multivariable meta-regressions (method of moments) were undertaken to explore the influence of STS-PROM, age, publication year, and other covariates. Publication bias was investigated with funnel plots and Egger’s and Begg’s tests.
2.8. Meta-Learning: Development, Validation, and Interpretation of Predictive Models
Definition: In the context of clinical evidence synthesis, meta-learning is defined as an advanced methodological approach that applies machine learning algorithms to an aggregate dataset, where each row represents an individual study extracted from a systematic review. Unlike traditional meta-analysis, whose primary objective is to estimate a single combined effect (e.g., an average Risk Ratio), the goal of meta-learning is to build a robust predictive model that operates exclusively at the cohort level, with no applicability for individual risk prediction. This model uses study-level characteristics (demographic, clinical, procedural, and methodological variables) as predictors to estimate a cohort-level outcomes (in this case, the 1-year mortality rate). Meta-learning therefore allows for modeling complex, non-linear interactions among multiple factors simultaneously, seeking to explain outcome heterogeneity that conventional meta-regression methods fail to capture.
2.8.1. Methodology for Calculating the Normalized Quality Score for Studies Used in Meta-Learning
To create a quality variable comparable across different study types, the scores from each scale were converted to a unified 10-point scale to generate the Final Score.
For Observational Studies (Cohort): The total score from the Newcastle–Ottawa Scale (NOS), which has a maximum of 9 stars (★), was used. Normalization formula:
For RCTs: The Jadad Scale score, which has a maximum of 5 points, was used.
Normalization formula:
2.8.2. Analytical Dataset and Preprocessing for Modelling
Of the 58 studies included in the systematic review, the final dataset for meta-learning modelling was constructed. A preprocessing pipeline was applied to this dataset, which included the following stages: data cleaning and standardization, logit transformation of the target variable, handling of missing values by predictor exclusion and median imputation, categorical variable encoding (one-hot encoding), and continuous feature normalization (Z-score).
2.8.3. Phase 1: Initial Algorithm Training and Comparison
The PyCaret platform version 3.1.0 was used to automate setup, preprocessing, and 10-fold stratified cross-validation. In an initial screening phase, 18 regressors, from penalized linear models to gradient machines, were evaluated, optimizing hyperparameters with grid search. The objective of this phase was to identify a set of high-performing models and to establish a robust baseline model. Key metrics were Mean Absolute Error, Root Mean Squared Error, and R^2^, all recalculated on the original percentage scale.
2.8.4. Phase 2: Advanced Optimization and Final Model Selection
After identifying the limitations of the initial approach, and based on the screening results, a second phase of exhaustive optimization was implemented. Recognizing that regularization models and ensembles are particularly sensitive to their hyperparameter configurations, a systematic and manual search was performed to maximize their performance:
- Regularization Models: Ridge, Lasso, and Elastic Net models were individually optimized through extended searches in the parameter space (e.g., logarithmic search for α, two-dimensional search for α and l1_ratio).
- Ensemble Model (Blending): A Blend_Optimized meta-model was constructed that weighted and combined the predictions of the already optimized regularization models.
- Stacking Model: Additionally, a Stack_Optimized model was evaluated to compare its performance against the blending approach.
The selection of the final model was based on a comparative evaluation of performance (R^2^ and MAE) between the reference model (AdaBoost) and the new optimized models, with the aim of identifying the architecture with the highest explanatory power and predictive accuracy. Model robustness was verified through cross-validation analyses and evaluation on an internal test set.
2.8.5. Comparative Model Interpretability Analysis
To understand not only which model performed best, but why, a comparative interpretability analysis was conducted. Instead of analyzing only the final model, the feature importance hierarchy of three key models was compared: the baseline (AdaBoost), a powerful black-box alternative (XGBoost), and the best-performing final model (Blend_Optimized).
The following techniques were used for this analysis:
- Global Feature Importance: The ranking of the global influence of variables from each model was extracted to understand their predictive priorities.
- Comparative Visualization: Results were visualized both in separate bar charts for each model and in a consolidated heatmap. This visual matrix allowed for a direct comparison of how each algorithm weighted the same features, facilitating the identification of robust predictors (important across all models), model-dependent predictors, and synergies or the unique findings of the ensemble model.
2.8.6. Considerations on Ecological Fallacy and Model Limitations
It is fundamental to recognize that the models developed in this study operate under the inherent limitations of the ecological fallacy. Associations identified at the cohort level cannot be directly extrapolated to individual risk predictions. The model identifies which study characteristics are associated with higher reported mortality, but it does not replace personalized clinical assessment or existing individual risk stratification tools.
2.9. Ethical Considerations and Software Used for Meta-Analysis, Meta-Regression, and Meta-Learning
Given that all data are derived from previously published studies and no intervention was performed on participants’ demographic or physiological variables, the present research was classified as minimal risk in accordance with the principles of the Declaration of Helsinki and Resolution No. 8430 of 1993 of Colombian legislation. Therefore, no additional ethics committee approval was required for its execution.
Conventional statistical analyses were performed in R (version 4.3.1; accessed 20 May 2025) with the meta and metafor packages, while meta-learning was implemented in Python (version 3.11.5; accessed 20 May 2025) with an ecosystem of specialized libraries. Analytical dataset loading, manipulation, and preparation were carried out with Pandas (version 2.2.2; accessed 20 May 2025) and NumPy (version 1.26.4; accessed 20 May 2025). The machine learning workflow was primarily managed with the high-level PyCaret framework (version 3.3.2; accessed 20 May 2025) to automate preprocessing, comparative model training, and initial visualization. This operates on Scikit-learn (version 1.4.2; accessed 20 May 2025), which served as the base library for algorithms and for building manual validation pipelines. The advanced optimization phase, training of the final models (including Blend_Optimized and Stack_Optimized), and manual validation were performed directly with Scikit-learn. The XGBoost library (version 2.0.3; accessed 20 May 2025) was used for implementing the specific Extreme Gradient Boosting model, while advanced model interpretability was achieved with SHAP (version 0.45.0; accessed 20 May 2025) to explain predictions using Shapley values. Finally, custom graph and visualization generation was performed with Matplotlib (version 3.8.4; accessed 20 May 2025) and Seaborn (version 0.13.2; accessed 20 May 2025).
3. Results
3.1. Studies Identified for Review
The search for studies was conducted in four databases, from which 4852 records were identified. After removing 1127 duplicates, a total of 3725 records proceeded to the screening phase. During title and abstract screening, 2500 records were excluded. Of the remaining 1225 reports sought for more detailed review, full text could not be retrieved for 200. This left 1025 reports to be fully evaluated for eligibility. At this stage, 964 reports were excluded for the following reasons:
- n = 450 for not presenting aggregate characteristics.
- n = 259 for being preprints or other incomplete studies.
- n = 258 for not being RCTs or cohort studies.
Finally, 58 studies met all inclusion criteria and were selected for systematic review. Reviewer agreement (measured with Cohen’s Kappa statistic) was 0.90 during the record screening phase and 0.95 in the eligibility assessment of reports (see Figure 1).
3.2. Characteristics of Studies Included in the Review
The present systematic review comprises 58 clinical studies, collectively providing data from over 533,000 patients. The chronology of included publications shows a remarkable acceleration in evidence generation on TAVR. While only one study (1.7%) was published before 2015, substantial growth is observed between 2015 and 2020, a period encompassing 48.3% of the works (n = 28). Field consolidation is evident from 2021 onwards, with a majority of 50% of publications (n = 29). Geographically, research is predominantly concentrated in cohorts from Europe and North America.
Study populations were characterized by marked diversity, spanning the full spectrum of surgical risk. This heterogeneity is reflected in an STS-PROM score range that varied between 1.8% and 14.1% across studies. The baseline profile of the analyzed population reveals an elderly cohort, with a mean age of 80.9 years and 49.4% female participation. The comorbidity burden was significant, highlighting a mean hypertension prevalence of 85.0%, coronary artery disease of 47.6%, and atrial fibrillation of 35.7%. Additionally, the mean for diabetes mellitus was 32.8% and, for chronic kidney disease, 39.5%. Baseline surgical risk, as measured by the STS-PROM score, presented a mean of 6.2%, while pre-procedure left ventricular function, assessed by LVEF, averaged 55.3%.
The primary outcome, 1-year all-cause mortality, had a mean of 13.5% across studies. However, this value must be interpreted in the context of considerable heterogeneity, with reported rates ranging from 1.0% to 35.7%. This dispersion is largely attributable to variability in follow-up duration, which, in some cases, extended up to 10 years, and to methodological differences between investigations, such as a lack of standardization in outcome definitions. A detailed summary of each study’s characteristics is presented in Table 1.
3.3. Results of Risk of Bias Assessment
3.3.1. Risk of Bias in RCTs
The methodological quality and risk of bias for the 11 RCTs included in this review were assessed. The evaluation was based on the Jadad scale criteria, supplemented by a domain-based bias assessment (Figure 2). Results showed a notably uniform quality profile across the entire RCT cohort, as detailed below by domain:
- Random Sequence Generation (Selection Bias): The generation of an adequate random sequence was considered low risk in all 11 analyzed RCTs. All studies (e.g., Reardon et al., 2017 [58]; Dangas et al., 2019 [35]; Leon et al., 2016 [51]) described an appropriate randomization method, such as centralized or computer-generated systems, achieving the maximum score in this domain. This provides high confidence that group allocation was truly random.
- Allocation Concealment: The description of robust randomization methods in all trials suggests a low to unclear risk of bias. Most protocols for these large trials typically include adequate concealment mechanisms.
- Blinding of Participants and Personnel (Performance Bias): This domain represented the primary and universal source of bias risk. All 11 RCTs [18,27,30,35,44,51,54,58,61,67,73] were rated with high performance bias risk, receiving a score of 0 in the blinding item. This is an inherent and expected limitation in trials comparing device interventions like TAVR versus surgery, where the nature of the procedure prevents blinding of both patients and clinical personnel.
- Blinding of Outcome Assessment (Detection Bias): Despite the lack of participant blinding, the risk of bias in objective outcome assessment (such as mortality) is considered low. This is because hard endpoints are less susceptible to observer influence, and many of these pivotal trials use blinded clinical event adjudication committees.
- Handling of Incomplete Outcome Data (Attrition Bias): This was a domain of methodological strength. All 11 trials adequately described losses during follow-up and withdrawals; thus, they were classified with low attrition bias risk.
On the other hand, evaluation with the Jadad scale yielded a consistent score of 3 out of 5 for all RCTs. This indicates moderate–good methodological quality. The main limitation is the inevitable performance bias due to lack of blinding, a common characteristic in this research field (see Table 2).
3.3.2. Risk of Bias for Observational Studies
For the 47 non-randomized studies (observational cohorts and registries), the risk of bias was assessed using the ROBINS-E tool. The results, detailed in Table 3, indicate that the overall risk of bias in this sub-cohort was predominantly moderate.
Clear methodological strengths were identified in certain domains. The risk of bias due to intervention classification was consistently low across all studies, indicating that the definition of treatment groups (TAVR) was adequate. Similarly, participant selection in the studies and deviations from intended interventions presented a low risk of bias in the vast majority of cohorts.
However, the domain that primarily contributed to the overall risk was confounding bias, which was rated as moderate in the vast majority of studies. This finding is expected and is critical in observational studies, as unmeasured differences between treatment groups can distort the true relationship between the intervention and the outcome. Other domains, such as missing data handling and outcome measurement, also presented a moderate risk in a minority of the works.
Consequently, the overall risk of bias was rated as moderate for the vast majority of observational studies. This assessment underscores the importance of interpreting the results of these studies with caution and reinforces the methodological decision to include the Quality Score as a key predictor in the meta-learning model (see Figure 3).
The methodological quality of the 47 included observational studies was assessed using the Newcastle–Ottawa Scale (NOS), which evaluates cohort selection, comparability between groups, and outcome assessment, as detailed in Table 4.
Overall, the quality of evidence from observational studies was notably high. The vast majority of studies, 85.1% (n = 40), were rated as “Excellent” (9 stars) or “Very Good” (8 stars) quality. An additional 14.9% (n = 7) achieved “Good” quality (6–7 stars), and no study was considered “Fair” or “Poor” quality.
Analyzing the scale domains, it was observed that the main strength of the studies lay in cohort selection and outcome assessment. Most articles obtained maximum scores in these sections, indicating that populations were representative and follow-up for mortality determination was adequate and complete.
However, the main methodological limitation identified was the “Comparability” domain. A proportion of studies (approximately 6.4%, or 3 of 47) obtained only one of the two possible stars in this section. This finding is crucial, as a low comparability score indicates insufficient control of key confounding factors in the study design or analysis. This lack of adjustment is a potential source of bias that could influence reported results and, once again, justifies the inclusion of the Quality Score as an essential predictive variable in the meta-learning model.
3.4. Results of Meta-Analysis and Meta-Regression
3.4.1. Results of Meta-Analysis and Meta-Regression for the RCT Subgroup
The meta-analysis of the subgroup of 11 RCTs, which included 5638 patients in the TAVR arm and 4883 in the control group, found no statistically significant difference in all-cause mortality (see Figure 4). The pooled Risk Ratio (RR) was 0.91 (95% CI: 0.71 to 1.16), suggesting a non-significant trend in favor of TAVR. A fundamental finding was the presence of very high and statistically significant heterogeneity among studies (I^2^ = 76.7%; p < 0.0001), implying that underlying moderating factors influence the results. Publication bias assessment using Egger’s (p = 0.63) and Begg’s (p = 0.86) tests yielded no evidence of significant bias, which reinforces the validity of the pooled effect by suggesting that results are unlikely to be distorted by the absence of studies with unfavorable or inconclusive results.
To explore sources of heterogeneity, meta-regression analysis demonstrated that none of the analyzed covariates, including Mean Age (p = 0.93), percentage of Women (p = 0.72), and STS-PROM (p = 0.53), was a statistically significant effect modifier. This suggests that the variability is likely due to other unmeasured factors, such as differences in trial protocols or patient characteristics not captured by the variables studied.
3.4.2. Results of Meta-Analysis and Meta-Regression for the Observational Study Subgroup
The analysis of the subgroup of 18 comparative observational studies yielded a significantly different result from that of the RCTs. In this context, TAVR was associated with a statistically significant 32% increase in mortality, with a pooled Risk Ratio (RR) of 1.32 (95% CI: 1.10 to 1.58) (see Figure 5).
This overall effect, derived from the conventional meta-analysis, must be interpreted with extreme caution due to the massive heterogeneity detected among studies (I^2^ = 96.8%). Variability of this magnitude indicates that the studies do not measure a homogeneous effect and that simple risk aggregation using this traditional method is insufficient to guide clinical practice. Despite this dispersion, publication bias assessment using Egger’s (p = 0.985) and Begg’s (p = 1.00) tests did not suggest that the results were due to missing studies.
In an attempt to explain the heterogeneity, meta-regression evaluated five study-level covariates. However, none of these variables proved to be a significant effect moderator (all p > 0.13), and almost none managed to explain a portion of the variance between studies (R^2^ = 0%), with the exception of STS-PROM, which explained 6.8% of the variability. The absence of a clear signal in meta-regression suggests that the variability is due to other unmeasured factors, such as differences in selection criteria or residual confounding.
The apparent contrast between increased mortality in observational studies and the neutral effect seen in RCTs points to a fundamental methodological explanation: confounding by indication bias. It is very likely that, in real clinical practice, patients referred for TAVR were more frail and had a higher comorbidity burden than those assigned to surgical control arms. Therefore, although the signal from these studies is important, evidence from RCTs should remain the primary reference for therapeutic decision making.
3.4.3. Comparative Synthesis of RCTs and Observational Studies
Taken together, the traditional analysis of evidence reveals a complex picture with apparent contradictions regarding mortality. Higher quality evidence, from 11, points to a neutral effect of TAVR on mortality (RR 0.91; 95% CI: 0.71 to 1.16). In contrast, evidence from 18 observational studies suggests a statistically significant increase in mortality risk with TAVR (RR 1.32; 95% CI: 1.10 to 1.58). This scenario is dominated by two key methodological challenges. First, both subgroups of studies present very high heterogeneity (I^2^ > 76%), which could not be satisfactorily explained by univariate meta-regression analyses. Second, the adverse outcome in observational studies is likely influenced by confounding by indication bias, where patients selected for TAVR in real clinical practice may have been intrinsically frailer than surgical candidates.
The inability of traditional linear statistical models to disentangle the complex interactions causing this variability in outcomes establishes the fundamental justification for applying a meta-learning approach. It is hypothesized that machine learning algorithms, by being able to model non-linear interactions among multiple predictors simultaneously, will be able to identify more robust and consistent risk patterns, thus overcoming the limitations of conventional analysis and offering a clearer insight into the true drivers of cohort-level mortality.
3.5. Meta-Learning Model Results
After establishing the limitations of traditional statistical methods in explaining outcome heterogeneity, we proceeded with the meta-learning approach to explore complex relationships between study characteristics and 1-year mortality. The final analytical cohort, resulting from the systematic review, was formed by the 58 studies that met all inclusion criteria. All machine learning analyses were performed on this dataset. Table 5 details the complete data matrix for this cohort, presenting the predictor variables (demographic, clinical, procedural, and quality) and the outcome variable that served as input for the models evaluated below.
3.5.1. Phase 1 of Meta-Learning: Screening and Model Comparison
The initial phase of meta-learning consisted of an exhaustive screening of multiple regression algorithms to identify the model with the highest predictive power and to establish a performance baseline. A 10-fold cross-validation protocol was employed, and each model’s performance was evaluated with various metrics, whose results are presented in Table 6.
The analysis conclusively identified the AdaBoost Regressor as the best-performing model. This algorithm achieved the lowest Mean Absolute Error (MAE) of 41.84 and the lowest Root Mean Squared Error (RMSE) of 58.77. Crucially, it was the model with the highest explanatory power, achieving a coefficient of determination (R^2^) of 0.191.
The Extreme Gradient Boosting (XGBoost) model ranked second in performance, although with considerably less predictive power (R^2^ = 0.031). It is noteworthy that the rest of the evaluated algorithms did not achieve performance superior to a reference model, obtaining negative R^2^ values; thus, they were discarded for subsequent phases. Based on its clear superiority in key metrics, the AdaBoost Regressor was selected as the baseline model for the subsequent interpretation phase.
3.5.2. Phase 2: Validation of the Reference Model (AdaBoost)
The diagnostic analysis of the AdaBoost model, presented in Figure 6, allows for the evaluation of the quality and robustness of its predictions. The residual plots (Figure 6A,D) show no systematic patterns, suggesting that errors are random. The distribution of residuals (Figure 6B) approximates normality, a desirable characteristic confirmed in the Q–Q plot (Figure 6C), where points align closely to the theoretical diagonal.
The actual versus predicted values plot (Figure 6E) confirms a satisfactory global fit of the model, with most points close to the perfect prediction line. However, a greater dispersion of error is observed in cohorts with mortality greater than 15%, as complemented by the absolute error plot (Figure 6F).
As the main conclusion of this phase, the AdaBoost model is validated as a robust reference model with acceptable predictive performance. Its precision is higher in low-to-moderate risk scenarios, although it decreases in cohorts with extremely high mortality, likely due to their scarce representation in the training dataset.
3.5.3. Phase 3: Advanced Optimization and Final Model Selection
After validating the AdaBoost model as a baseline, an advanced optimization phase was implemented to determine if predictive power could be improved. This stage focused on the hyperparameter tuning of regularization models and the creation of complex ensembles. The results of this comparative analysis are presented in Figure 7.
Optimization demonstrated a substantial leap in performance. The Blend_Optimized model emerged as the superior architecture in terms of explanatory power, achieving an R^2^ of 0.653. This represents an 8.6% improvement over AdaBoost’s R^2^ = 0.567 and means the model is capable of explaining 65.3% of the variability in mortality rates among studies.
In terms of prediction error, although the Lasso_Optimized model achieved a marginally lower Mean Absolute Error (MAE) (3.018 vs. 3.021), this difference is practically insignificant. In marked contrast, the “stacking” type ensemble performed poorly (R^2^ = 0.110), suggesting problems in its implementation for this dataset.
As a conclusion of this phase, the Blend_Optimized model was selected as the final model. The substantial gain in its explanatory power (R^2^) was considered more relevant than the minimal difference in MAE, positioning it as the most robust and generalizable solution.
3.5.4. Phase 4: Comparative Model Interpretability Analysis
The analysis of the prediction models (Figure 8) allows us to identify which factors have the greatest impact on 1-year mortality after transcatheter aortic valve replacement (TAVR). By comparing different algorithms, especially the Optimized Blend model, we can understand how each variable contributes to patient risk and establish a clear hierarchy of prognostic importance.
The analysis reveals that four key factors are consistently important across all evaluated models. The Average STS PROM Score is established as the most important factor, functioning as the most potent predictor in the Optimized Blend model and appearing as a primary variable in all models. Its main function is to measure the patient’s baseline surgical risk, serving as a fundamental basis for classifying each individual’s risk.
Complementing this baseline assessment, the percentage of patients with Diabetes emerges as a high-impact covariate. This variable reflects the negative effect of this disease on long-term outcomes, confirming that systemic comorbidities significantly affect post-TAVR prognosis. The importance of this variable underscores the need to consider the patient’s metabolic status as an integral component of risk assessment.
In parallel, the percentage of Transfemoral approach is identified as a powerful surrogate variable that encapsulates two critical aspects: patient frailty and procedural invasiveness. Its importance confirms that the access route is itself a significant prognostic determinant, reflecting both the patient’s functional capacity and the technical complexity of the procedure.
Particularly revealing, the Average Recruitment Year represents an emergent temporal factor of considerable importance. This temporal gradient quantifies the progressive improvement in TAVR outcomes, with an estimated mortality reduction of approximately 0.8–1.2% per year from 2008 to 2022, reflecting technological evolution (new generation valves, improved delivery systems), optimization of institutional learning curves, and progressive refinement of patient selection criteria. Its position as the second most important variable in the Optimized Blend model indicates the existence of a significant temporal gradient that models the evolution of device technology, improvement in operator learning curves, and changes in patient selection criteria over time.
This multivariate approach is fundamental for robust and accurate risk stratification to guide clinical decisions in TAVR candidates. Predicting 1-year post-TAVR mortality requires integrating four essential domains: baseline patient risk quantified by STS-PROM, critical comorbidities primarily represented by diabetes, procedural characteristics (especially the transfemoral route), and the temporal factors reflecting technological evolution and accumulated experience. This integration allows for a comprehensive evaluation that considers both intrinsic patient factors and procedural and temporal variables, providing a comprehensive framework for informed clinical decision making.
Implications of the Temporal Gradient: This finding suggests that results from studies published before 2015 may have limited applicability for contemporary practice, and that clinical guidelines should consider adjustments for temporal factors when integrating historical evidence. The magnitude of the temporal effect (importance = 0.212) indicates that the recruitment year is as predictive as traditional clinical variables, which has profound implications for the interpretation of meta-analyses including studies from multiple eras.
4. Discussion
4.1. Main Findings
This systematic review and meta-analysis were designed to address a critical question in TAVR evidence synthesis: Can meta-learning, utilizing solely aggregate study-level characteristics, more accurately predict 1-year mortality and robustly identify the most influential predictors, thereby surpassing the limitations of traditional statistical methods? This question gains particular relevance in a field characterized by extreme unexplained heterogeneity (I^2^ > 75%) in conventional meta-analyses.
Our initial analyses confirmed the inadequacy of traditional approaches in addressing this complexity. The meta-analysis of 11 RCTs (5638 TAVR patients vs. 4883 controls) not only yielded an inconclusive result for mortality (RR = 0.91, 95% CI: 0.71–1.16), but also exhibited significant heterogeneity (I^2^ = 76.7%, p < 0.0001) that could not be explained by meta-regression with variables such as STS-PROM, age, or publication year. Even more revealingly, the 18 observational studies presented an opposite but equally heterogeneous pattern (I^2^ = 96.8%), with a significant association between TAVR and increased mortality (RR = 1.32, 95% CI: 1.10–1.58), highlighting the influence of confounding by indication and the need for models capable of capturing non-linear relationships and complex interactions.
In this context, meta-learning achieved substantial and progressive methodological advances. An initial AdaBoost Regressor model demonstrated the viability of the approach, reaching a coefficient of determination (R^2^) of 0.191 through 10-fold cross-validation, significantly outperforming 17 alternative algorithms that yielded negative R^2^ values. However, the decisive breakthrough occurred through the optimization of regularization architectures. The development of a Blend_Optimized model, which weighted and combined the predictions of optimized Ridge, Lasso, and Elastic Net models, significantly elevated performance, explaining 65.3% of the variability in 1-year mortality rates (R^2^ = 0.653). This leap of over 46 percentage points compared to the baseline model represents a key methodological advance, demonstrating that a more sophisticated meta-learning architecture can capture a substantial portion of the predictive signal contained exclusively in aggregate data.
The interpretability analysis of the Blend_Optimized model revealed a hierarchy of predictors with transformative findings for understanding post-TAVR mortality. The Average STS-PROM consistently consolidated as the most influential factor (importance = 0.300), confirming its value as a quantifier of baseline surgical risk. However, the most disruptive finding was the emergence of Average Recruitment Year as the second most important predictor (importance = 0.212), suggesting the existence of a powerful temporal gradient that reflects technological evolution, operator learning curves, and changes in patient selection criteria. The percentage of Transfemoral approach positioned as the third predictor (importance = 0.201), encapsulating both patient frailty and procedural invasiveness.
This finding was strengthened by the comparative interpretability analysis, which showed that each model possesses a distinct predictive “personality.” While AdaBoost focused on the STS-PROM and average age, and XGBoost distributed the weight more evenly, including variables such as Quality Score, the Blend_Optimized model achieved its superior performance precisely by identifying and amplifying these synergistic signals. The consistency of the STS-PROM as a primary predictor across all models validated its clinical importance, but it was the temporal and procedural variables “discovered” by the Blend model that made the difference in predictive power.
In summary, this approach suggests that a substantial portion of the heterogeneity, seemingly unexplained in previous meta-analyses, is not solely due to random noise but to systematic and complex interactions among baseline patient clinical risk (STS-PROM), the temporal evolution of medical practice (Recruitment Year), procedural decisions (% Transfemoral), and systemic comorbidities (% Diabetes). The ability of meta-learning to model and unravel these multivariate relationships positions this methodology as a valuable complementary tool, though not a substitute for, traditional methods for the evaluation of complex clinical literature such as that of TAVR.
4.2. Contextualization of Findings in Current Literature
Our findings align remarkably well with the emerging literature documenting the fundamental limitations of traditional statistical methods in addressing heterogeneity in TAVR evidence. The superiority of machine learning that we documented, and the presence of extreme heterogeneity that we identified, find solid support in recent studies. Zaka et al. (2025) [4] provided definitive evidence by demonstrating that ML models achieved an average C-statistic of 0.79 (95% CI: 0.71–0.86) versus 0.68 (95% CI: 0.61–0.76) for traditional methods, with a statistically significant difference of 0.11 (p < 0.00001), in their analysis of nine studies (29,608 patients). This difference is consistent with our finding that meta-learning can capture predictive patterns that escape conventional methods. Sazzad et al. (2024) [8] complemented this evidence by documenting extreme heterogeneity (I^2^ = 99.06%) in 10 studies (22,933 patients), which persisted even after refined subgroup analyses, reaching I^2^ = 88.29% for in-hospital mortality and I^2^ = 91.97% for 1-year mortality. The authors attributed this heterogeneity to “significant differences in the datasets used to train AI models” and “great variability in the amount and type of data,” fully validating our premise that heterogeneity contains systematic signals extractable through advanced techniques.
The discovery of the temporal factor as an emerging predictor finds precedents in the literature on TAVR evolution. Recent studies have documented substantial improvements in outcomes over time, attributable to multiple factors consistent with our findings. Carroll et al. (2020) [32] documented a significant reduction in 30-day mortality from 4.6% in 2012 to 2.5% in 2019 (p < 0.001) in the STS/ACC TVT registry, while Vekstein et al. (2025) [70] reported a decrease in 1-year mortality from 24.1% in 2012 to 15.2% in 2019 in low-risk patients. These findings corroborate our discovery that the recruitment year captures a significant temporal gradient in TAVR outcomes. The specific limitations of traditional scores that we identified have been consistently documented in the contemporary literature. Siddiqi et al. (2020) [75], in their comprehensive meta-analysis of 68,215 patients, evaluating 11 risk stratification models for TAVR, found that all traditional models showed poor discrimination: STS-PROM reached only 0.60 (95% CI: 0.58–0.64), EuroSCORE II 0.61 (95% CI: 0.58–0.64), and Logistic EuroSCORE 0.59 (95% CI: 0.56–0.62). The authors concluded that “the discriminative capacity of currently available models is limited,” reinforcing our finding that traditional tools capture only a fraction of the complexity inherent in TAVR outcomes.
Of particular relevance is how our discovery regarding methodological quality as a systematic predictor finds antecedents in the literature on methodological bias. Barili et al. (2023) [76] documented substantial heterogeneity (I^2^ = 86%) in RCTs comparing TAVR versus surgery, identifying through meta-regression a significant association between follow-up time and patient loss (slope = 0.042, 95% CI: 0.017–0.066, p < 0.001), suggesting that “selective loss to follow-up is even more critical than total loss, as it is not random and can potentially lead to informative censoring.” Zaka et al. (2025) [4] and Sazzad et al. (2024) [8] consistently highlighted that “all analysed publications presented a high risk of methodological bias” due to poor handling of missing data and lack of external validations. Our study not only confirms these observations, but quantitatively demonstrates that these methodological differences constitute systematic predictors of outcomes, not random noise.
4.3. Study Limitations
Our study has inherent limitations that require explicit recognition for an appropriate interpretation of the findings. The primary conceptual limitation is the ecological fallacy inherent in the design: Our model predicts mortality at the cohort level based on aggregate characteristics, so the results must not be extrapolated for individual risk predictions. The model identifies which types of studies report higher mortality, but it cannot replace personalized risk assessment in clinical practice. This distinction is fundamental to avoid misinterpretations of the findings.
Geographical and demographic homogeneity represents a significant limitation for generalizability. With 56.7% of the studies originating from Europe and 14.9% from North America, while populations from Asia, South America, and other regions remain underrepresented, the findings may not be applicable globally. This geographical concentration particularly limits generalizability, considering the differences in healthcare systems, patient selection criteria, and procedural techniques that vary substantially between regions [77,78].
Methodological limitations include heterogeneity in data reporting, which constituted a constant challenge. The absence of key variables such as EuroSCORE II in a significant proportion of studies limited their inclusion as predictors, while the duration of follow-up varied considerably between studies. Although we focused on 1-year mortality to standardize the outcome, this temporal variability introduces unavoidable methodological noise. Furthermore, we acknowledge that, while necessary for methodological robustness, focusing on 1-year mortality does not capture the long-term outcomes that are increasingly crucial in contemporary TAVR practice.
The relatively limited sample size for machine learning modelling (58 studies) may constrain the statistical power to detect more subtle patterns and increase the risk of overfitting [9,79]. It is important to highlight that, although our best model (Blend_Optimized) explained 65.3% of the variability in mortality rates, a substantial proportion remains unexplained. This suggests that factors not systematically captured in study reports, such as patient frailty, specific anatomical details, institutional experience, or local sociodemographic characteristics, contribute significantly to the observed variability. This limitation underscores the need for standardization in data reporting and potentially the conduct of meta-analyses with individual patient data to validate these findings.
Finally, while meta-learning proved to be a powerful tool, it does not supersede individual patient data (IPD) meta-analysis, which remains the gold standard. An IPD analysis would enable modelling of patient-level interactions and validation of our findings with superior granularity. The performance of the final model (R^2^ = 0.191), while robust and superior to traditional methods, indicates that a substantial proportion of the variability remains unexplained, likely due to factors not systematically reported, such as patient frailty, specific anatomical details, or institutional experience [80,81].
4.4. Implications for Research and Clinical Practice
The findings of this study carry important implications for cardiovascular research and, more directly, for how clinicians interpret the vast body of evidence on TAVR. From an epidemiological perspective, the application of meta-learning models represents a significant methodological advance that allows for detecting complex and non-obvious relationships between clinical, procedural, and temporal variables from aggregate data. For the practicing cardiologist, this means that much of the confusing variability seen in the literature is not random noise but can be explained by systematic factors, such as the era in which a study was conducted.
The identification of the temporal factor as an emerging predictor has profound implications for the interpretation of historical evidence in TAVR. Our findings suggest that results from older studies may not be entirely applicable to contemporary practice, owing to technological evolution, institutional learning curves, and changes in patient selection criteria. This necessitates a re-evaluation of how evidence is weighted in clinical guidelines, potentially favoring more recent studies or incorporating adjustments for temporal factors.
The confirmation that STS-PROM maintains its relevance as a primary predictor, even in complex models, reinforces its clinical utility for risk stratification. However, the emergence of the transfemoral approach as an independent predictor suggests that decisions regarding the access route not only affect immediate procedural complications, but also bear long-term prognostic implications. This could influence patient selection algorithms and recommendations for procedural techniques.
4.5. Recommendations for Future Research
This study establishes meta-learning as a transformative and valuable complementary methodological approach for complex evidence synthesis in interventional cardiology, demonstrating that systematic and clinically relevant signals can be extracted from heterogeneous literature using advanced analytical techniques. The findings regarding the temporal factor and the complex interactions between clinical and procedural variables represent significant conceptual advances for the interpretation of scientific evidence.
To fully leverage the potential of these advanced analytical techniques, we recommend coordinated efforts on multiple fronts:
Standardization of Data and Methods:
- Implement consistent reporting of a minimum set of variables (STS-PROM, EuroSCORE II, exact follow-up duration).
- Adopt standardized definitions based on more recent VARC criteria.
- Develop specific protocols for implementing meta-learning in cardiovascular evidence synthesis.
- Establish international collaborative registries that facilitate future analyses with standardized data.
- Diversity Expansion and Validation:
- Prioritize high-quality studies from underrepresented regions (Asia, Latin America, Africa) to evaluate the generalizability of the findings.
- Validate the identified associations using registries with individual patient data.
- Confirm whether cohort-level relationships remain consistent at the individual level through IPD analysis.
- Explore the applicability of the methodology in other complex cardiovascular procedures.
- Advanced Methodological Development:
- Incorporate new study-level variables (institutional volume, operator experience, specific quality metrics).
- Develop algorithms specifically designed for systematic review data that better handle heterogeneity.
- Explore deep learning techniques that can capture even more complex interactions.
- Investigate methods to integrate unstructured text data from original articles.
- Impact and Utility Assessment:
- Conduct economic evaluations comparing the efficiency of meta-learning versus traditional methods.
- Measure the impact on clinical decision making and the development of clinical practice guidelines.
- Establish standard metrics to evaluate the reduction of unexplained heterogeneity.
- Develop implementation tools that allow clinicians to apply these models in practice.
5. Conclusions
This work demonstrates that meta-learning is a viable and valuable complementary methodological approach for addressing some limitations of conventional meta-analysis in contexts of high heterogeneity, as is the case with TAVR. By achieving an increase of over 46 percentage points in explanatory power (from R^2^ = 0.191 to R^2^ = 0.653), our study not only identified robust predictors of baseline risk and procedural characteristics but, more importantly, discovered the existence of a powerful temporal gradient that reflects the evolution of medical practice. The ability of meta-learning to transform seemingly unexplained heterogeneity into systematic and clinically interpretable patterns suggests that this methodology can be a useful complementary tool for evidence synthesis in interventional cardiology. The findings suggest that much of the variability among studies does not constitute random noise but, rather, reflects complex yet systematic interactions between multiple clinical, procedural, and temporal factors.
To fully harness the potential of these advanced analytical techniques, it is imperative that the scientific community commits to standardizing data reporting, expanding the geographic diversity in research, and to developing specific methodological standards for meta-learning in medicine. This research opens new avenues for applying meta-learning in other fields of cardiovascular medicine, establishing a methodological precedent that can contribute to improving how we interpret and synthesize scientific evidence, always within its specific methodological limitations in contexts of high clinical complexity. Only then can we advance towards a more precise and clinically relevant evidence synthesis that ultimately improves outcomes for patients undergoing TAVR and other complex cardiovascular procedures.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Mas-Peiro S. Fichtlscherer S. Walther C. Vasa-Nicotera M. Current Issues in Transcatheter Aortic Valve Replacement J. Thorac. Dis.2020121665168010.21037/jtd.2020.01.1032395310 PMC 7212163 · doi ↗ · pubmed ↗
- 2Montenegro-Palacios J.F. Vidal-Cañas S. Murillo-Benítez N.E. Quintana-Ospina J. Cardona-Murillo C.A. Liscano Y. Common Risk Factors for Atrial Fibrillation After Transcatheter Aortic Valve Implantation: A Systematic Review from 2009 to 2024 J. Cardiovasc. Dev. Dis.2025129010.3390/jcdd 1203009040137088 PMC 11942775 · doi ↗ · pubmed ↗
- 3Witberg G. Patterson T. Redwood S.R. Prendergast B.D. Future Directions. Transcatheter Aortic Valve Implantation for Low-Risk Patients: Inevitable Evolution or a Step Too Far?Rev. Esp. Cardiol.2019866467110.1016/j.recesp.2019.02.01030930254 · doi ↗ · pubmed ↗
- 4Zaka A. Mustafiz C. Mutahar D. Sinhal S. Gorcilov J. Muston B. Evans S. Gupta A. Stretton B. Kovoor J. Machine-Learning versus Traditional Methods for Prediction of All-Cause Mortality after Transcatheter Aortic Valve Implantation: A Systematic Review and Meta-Analysis Open Heart 202512 e 00277910.1136/openhrt-2024-00277939842939 PMC 11784135 · doi ↗ · pubmed ↗
- 5Forrest J.K. Deeb G.M. Yakubov S.J. Gada H. Mumtaz M.A. Ramlawi B. Bajwa T. Teirstein P.S. De Frain M. Muppala M. 3-Year Outcomes After Transcatheter or Surgical Aortic Valve Replacement in Low-Risk Patients with Aortic Stenosis J. Am. Coll. Cardiol.2023811663167410.1016/j.jacc.2023.02.01736882136 · doi ↗ · pubmed ↗
- 6Migliavaca C.B. Stein C. Colpani V. Barker T.H. Ziegelmann P.K. Munn Z. Falavigna M. Meta-analysis of Prevalence: I 2 Statistic and How to Deal with Heterogeneity Res. Synth. Methods 20221336336710.1002/jrsm.154735088937 · doi ↗ · pubmed ↗
- 7Sattar Y. Song D. Riasat M. Singh G. Shah R.P. Elgendy I.Y. Mehmood A. Mir T. Zghouzi M. Ullah W. Quality Assessment of Transcatheter Aortic Valve Replacement Meta Analysis: Is It Worth Reading?Circulation 2021144(Suppl. S 1)A 1444510.1161/circ.144.suppl_1.14445 · doi ↗
- 8Sazzad F. Ler A.A.L. Furqan M.S. Tan L.K.Z. Leo H.L. Kuntjoro I. Tay E. Kofidis T. Harnessing the Power of Artificial Intelligence in Predicting All-Cause Mortality in Transcatheter Aortic Valve Replacement: A Systematic Review and Meta-Analysis Front. Cardiovasc. Med.202411134321010.3389/fcvm.2024.134321038883982 PMC 11176615 · doi ↗ · pubmed ↗