A Fast Nonlinear Sparse Model for Blind Image Deblurring
Zirui Zhang, Zheng Guo, Zhenhua Xu, Huasong Chen, Chunyong Wang, Yang Song, Jiancheng Lai, Yunjing Ji, Zhenhua Li

TL;DR
This paper introduces a new nonlinear sparse model for blind image deblurring that improves performance and efficiency.
Contribution
The novel LN regularization and AGST algorithm offer stronger sparsity and better deblurring results.
Findings
LN regularization provides stronger sparsity than traditional L2, L1, and Lp regularizations.
The proposed model achieves superior deblurring performance on synthetic and real-world images.
AGST combined with HQS ensures efficient optimization and computational efficiency.
Abstract
Blind image deblurring, which requires simultaneous estimation of the latent image and blur kernel, constitutes a classic ill-posed problem. To address this, priors based on L2, L1, and Lp regularizations have been widely adopted. Based on this foundation and combining successful experiences of previous work, this paper introduces LN regularization, a novel nonlinear sparse regularization combining the Lp and L∞ norms via nonlinear coupling. Statistical probability analysis demonstrates that LN regularization achieves stronger sparsity than traditional regularizations like L2, L1, and Lp regularizations. Furthermore, building upon the LN regularization, we propose a novel nonlinear sparse model for blind image deblurring. To optimize the proposed LN regularization, we introduce an Adaptive Generalized Soft-Thresholding (AGST) algorithm and further develop an efficient optimization…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
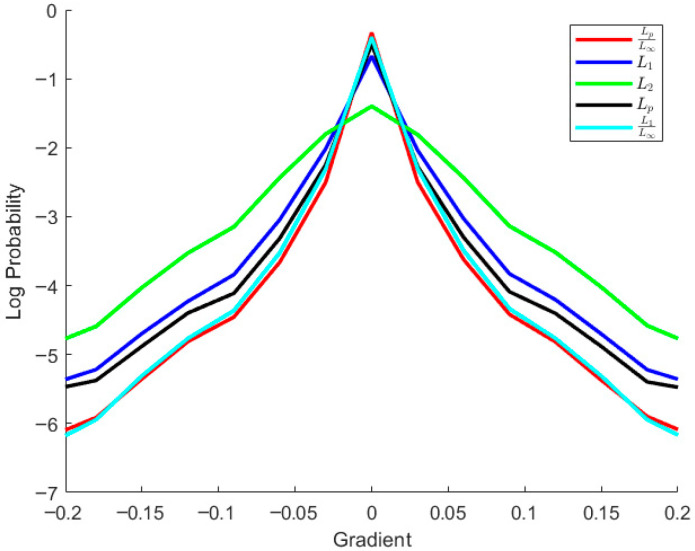 Figure 1
Figure 1 Figure 2
Figure 2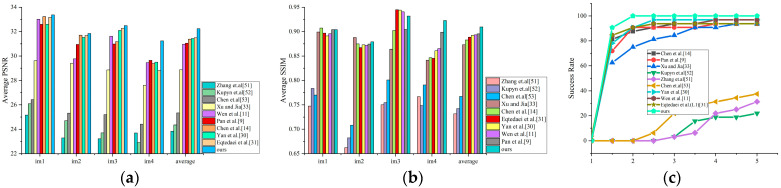 Figure 3
Figure 3 Figure 4
Figure 4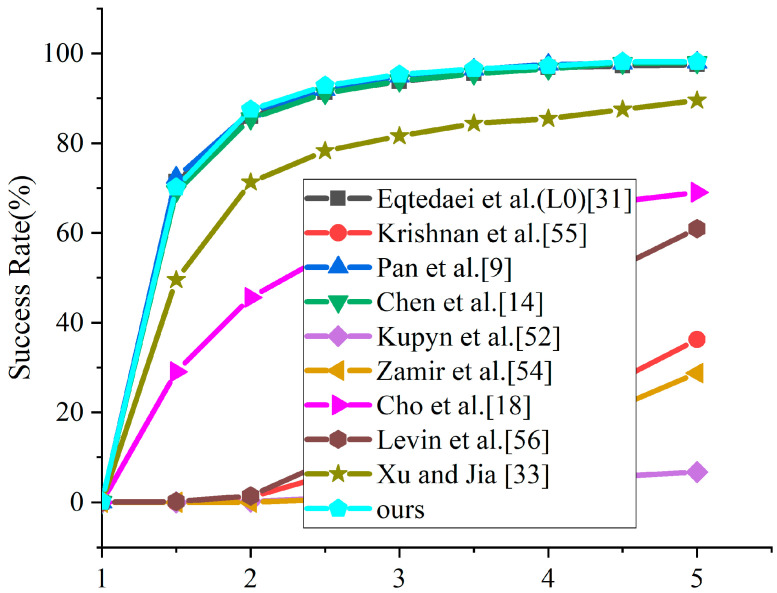 Figure 5
Figure 5 Figure 6
Figure 6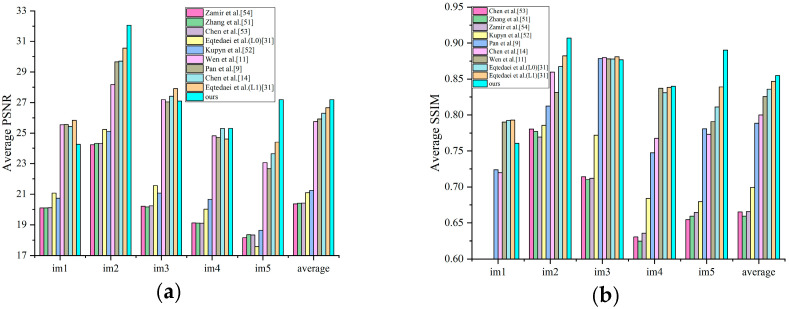 Figure 7
Figure 7 Figure 8
Figure 8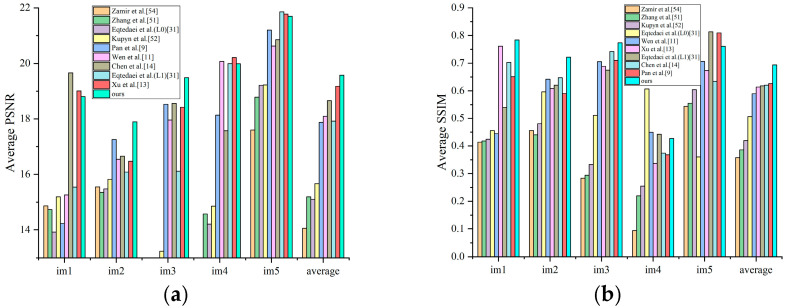 Figure 9
Figure 9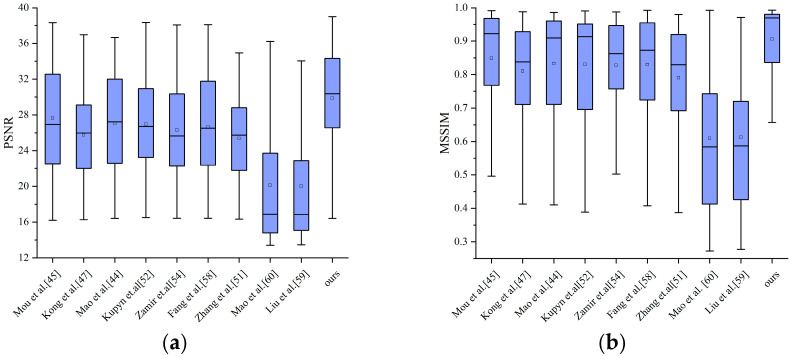 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12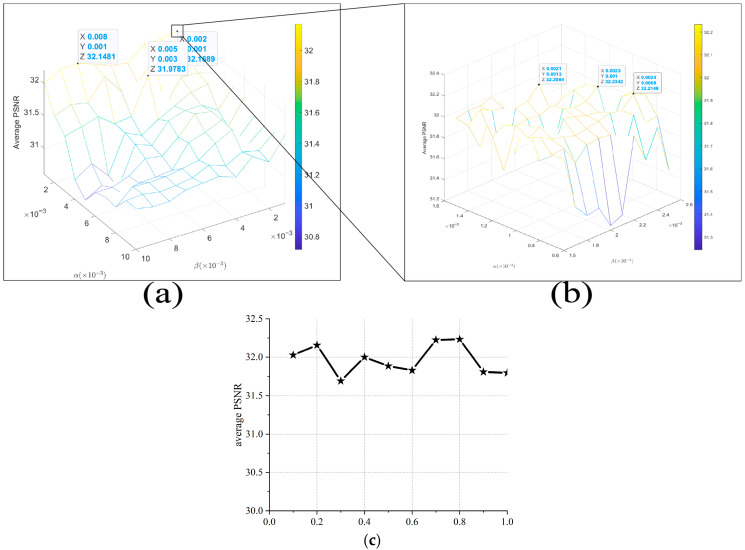 Figure 13
Figure 13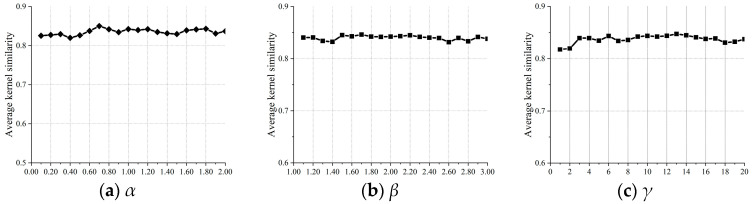 Figure 14
Figure 14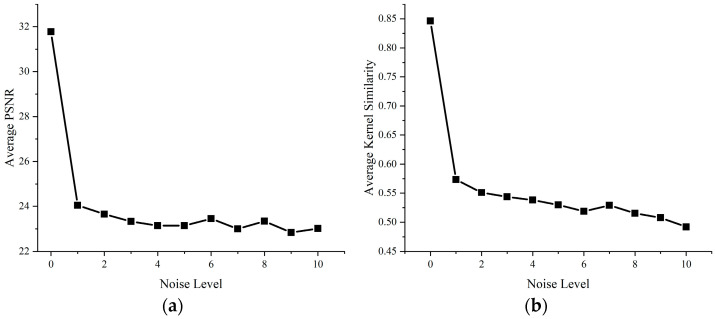 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18- —National Natural Science Foundation of China
- —Nanjing University of Science and Technology
- —Humanities and Social Science Project of the Ministry of Education of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Image Processing Techniques · Image and Signal Denoising Methods · Advanced Image Fusion Techniques
1. Introduction
Recent advances in computer vision have intensified the research focus on image processing, particularly through significant contribution to the development of image deblurring, a fundamental component of low-level image processing. In the context of space-invariant blur kernel modeling, a blurred image y can be mathematically represented as:
here B denotes the blurred image, denotes the sharp image corresponding to B, ⊗ denotes the convolution operator, denotes the blur kernel, and denotes the inevitable additional noise. Image deblurring encompasses two distinct categories: non-blind deblurring, where the kernel is known, and blind deblurring, where the kernel is unknown. This research addresses the latter.
Blind deblurring algorithms aim to direct the optimization process toward the desired solution, with traditional optimization approaches employing regularization terms to enhance constraints on both the latent image and blur kernel , facilitating convergence to the appropriate blur kernel and sharp latent image. The standard formulation of blind deblurring is expressed as:
where denotes the data fidelity term; and denote the regularization terms for the latent image and blur kernel , respectively.
Regarding the regularization term , researchers have developed numerous effective image priors, with gradient sparsity-based priors receiving extensive attention and implementation. For instance, Xu et al. [1] introduced an norm-based image smoothing algorithm and subsequently expanded regularization to the field of image deblurring [2], revealing that optimizing regularization presents a Nondeterministic Polynomial (NP)-hard problem, rendering direct solutions impractical. To address this limitation, Xu et al. [2] developed an unnatural distribution to approximate the regularization solution. Concurrently, the compressed sensing community typically addressed this challenge by relaxing the norm to one of convex optimization. Earlier approaches commonly replaced the norm with that of [3,4]; however, the limited sparsity of the norm results in performance that fails to match that of regularization in image processing applications.
To address this issue, Wang et al. [3,4,5,6] introduced a series of norm-ratio-based regularizations, e.g., and , establishing that could effectively approximate the L0 norm [7]. Given that the L1 norm represents a special case of norm where p = 1, we extend Wang et al.’s work by generalizing regularization into a broader framework: (0 < p < 1) regularization (termed nonlinear sparse regularization, denoted as regularization). To evaluate the effectiveness of regularization, we perform a sparsity analysis of various regularizations using gradient distribution statistics, as presented in Figure 1. The results indicate that the proposed regularization achieves superior sparsity, offering preliminary evidence of its advantage over regularization.
Due to its high sparsity, the gradient prior exhibits strong filtering capabilities against harmful artifacts in blurred images, although this restricts its performance when processing detail-rich images. To overcome this limitation, researchers have developed an deblurring prior framework that combines the gradient prior with complementary prior terms, a hybrid approach which aims to filter detrimental artifacts effectively while preserving fine image structures. Current X-prior terms frequently incorporate various patch-based image priors [9,10,11,12,13]; however, these methods encounter challenges due to their high computational complexity, excessive resource consumption, and low operational efficiency. In response, Chen et al. [14] introduced an enhanced sparse model utilizing the gradient prior as the X-term, substantially improving computational speed. Building on this work, we incorporate the proposed regularized gradient prior as the X-term and combine it with the gradient prior, developing a novel fast nonlinear sparse model.
The main contributions of this paper are as follows:
We propose a novel nonlinear sparse regularization ( ) that nonlinearly couples the norm with the norm.An Adaptive Generalized Soft-Thresholding (AGST) algorithm is developed to optimize the regularization problem.Building upon -regularization, we design a novel nonlinear sparse model for blind deblurring and develop an efficient optimization algorithm based on AGST and HQS.
The rest of this paper is organized as follows: Section 2 provides a comprehensive review of existing deblurring methods; Section 3 introduces the proposed nonlinear sparse regularization and the corresponding fast nonlinear sparse model; Section 4 experimentally evaluates the model on synthetic datasets and real-world blurred images; Section 5 analyzes ablation studies in order to validate the components of our fast nonlinear sparse model, including runtime performance tests; and Section 6 gives our conclusion.
2. Related Work
Generally, all existing methods can be classified into two categories: optimization-based and deep-learning-based methods. This section provides an overview of these distinct methodologies.
2.1. Optimization-Based Methods
Optimization-based image deblurring algorithms originated from the Richardson-Lucy method [15,16]. Subsequently, various approaches emerged, including the Gaussian mixture model (Fergus et al. [17]) and a fast norm-based deblurring method (Cho et al. [18]). However, regularization demonstrates limited effectiveness in blur kernel estimation due to its insufficient sparsity; therefore, a sparse regularized prior is urgently needed to meet the performance requirements of image deblurring. Yang et al. [19] and Candes et al. [20] proposed several -norm methods; however, these approaches failed to satisfy the sparsity requirements of the deblurring prior term.
To obtain superior restoration performance, Daniele et al. [21] tried an (0 < p < 1) gradient prior. Since the kernel estimation based on sparse regularization is a non-convex problem, this leads to a hard solution of optimization. To address this problem, Daniele et al. [21] transformed the non-convex optimization problem into a quadratic optimization problem by taking the log function of the regularization term. Gasso et al. [22] and Zou et al. [23] extended Iteratively Reweighted minimization (IRL1) [20] to the non-convex problem domain of minimization. Rao and Kreutz-Delgado [24] proposed an Iteratively Reweighted Least Squares (IRLS) approach to minimization; and She et al. [25] proposed the Iteratively Thresholding Method (ITM), which was only suitable for unconstrained problems. In 2013, Zuo et al. [26] proposed a GST operator to solve the minimization problem, and following this, Zuo et al. [27] applied regularization to the field of image deblurring.
In pursuit of enhanced norm sparsity during the deblurring process, research focus shifted toward the L0 norm. Xu et al. [1] introduced an image smoothing method in 2011, and building upon this, Xu et al. [2] developed an gradient prior by applying norm constraints to image gradients, enhancing kernel estimation and large-scale optimization. Extensive research has demonstrated that the generalized sparse gradient prior can effectively extract strong edges, and Xu et al.’s [2] groundbreaking work inspired numerous deblurring methods based on regularization: Pan et al. [28] implemented regularized intensity and gradient prior for text image deblurring, and Li et al. [29] applied norm to constrain the blur kernel intensity.
Despite the -regularization prior’s proven effectiveness in removing harmful artifacts from images and widespread adoption in blind deblurring, it often underperforms when processing images with complex structural details. To address this limitation, researchers developed the paradigm, combining the gradient prior with supplementary image priors. A representative example is the Dark Channel Prior (DCP) developed by Pan et al. [9], who discovered that sharp images exhibited sparser dark channels compared to blurred ones, combining the DCP with the gradient prior and achieving good results. Similarly, Yan et al. [30] extended the applicability of the DCP by combining it with the bright channel prior. Additionally, Eqtedaei et al. [31] developed a deblurring prior based on the difference between local maximum and minimum pixel values within an image region, developing two distinct deblurring algorithms utilizing and regularization, respectively.
The aforementioned image patch-based priors rely on overlapping patches, which substantially increases their computational complexity. To address this limitation, researchers have explored non-overlapping patches as an alternative approach. Notable examples include the Patch-wise Minimum Pixel (PMP) prior proposed by Wen et al. [11] and the Patch-wise Maximum Gradient (PMG) prior developed by Xu et al. [13]. These non-overlapping patch priors demonstrate significant computational acceleration while maintaining restoration accuracy; however, despite their improved efficiency, these methods still require individual path processing. Additionally, many patch-based priors necessitate the introduction of large, sparse matrices during optimization, consuming considerable computational resources and reducing algorithmic efficiency.
On the other hand, edge detection-based deblurring algorithms have emerged as a viable technical approach. Joshi et al. [32] implemented direct detection and prediction of latent sharp edges to enhance blur kernel estimation; Cho et al. [18] integrated bilateral filtering, shock filtering, and edge gradient thresholding for salient edges prediction; Xu et al. [33] developed a two-phase robust kernel estimation framework with an effective edge selection strategy; and Pan et al. [34] proposed a self-adaptive edge selection algorithm, while Liu et al. [35] implemented a surface-aware approach. Although explicit edge prediction methods demonstrate validity in blind deblurring, they remain dependent on heuristic filters. These methods therefore tend to amplify noise, potentially compromising the deblurring process and producing over-sharpened images as, furthermore, natural images do not consistently contain salient edges. Additionally, some scholars have begun exploring the integration of learning mechanisms with traditional optimization frameworks [36,37,38].
2.2. Learning-Based Methods
In the last decade, the rapid advancement of deep learning technology has prompted researchers to investigate its applications in image deblurring tasks.
In 2015, Sun et al. [39] pioneered the application of Convolutional Neural Networks (CNNs) to non-uniform image deblurring, marking an early successful integration of deep learning techniques. Subsequently, numerous CNN-based methods have emerged. For instance, Chakrabarti et al. [40] modified initial network layer connectivity using multi-frequency decomposition; Gong et al. [41] proposed a CNN-based approach for direct motion flow estimation from blur kernels; Ren et al. [42] designed a Maximum a Posteriori (MAP) deep learning hybrid framework, utilizing dual-branch networks for the alternating optimization of latent sharp images and blur kernels. Feng et al. [43] proposed Ghost-UNet, incorporating lightweight sub-networks for enhanced computational efficiency while preserving feature representation capacity; Mao et al. [44] developed a Residual Fast Fourier Transform with Convolution Block (ResFFT-Conv) module; and Mou et al. [45] transformed the Proximal Gradient Descent algorithm into a learnable deep architecture.
Beyond CNNs, other neural network architectures, including Recurrent Neural Networks (RNNs), Generative Adversarial Networks (GANs), and Feed-Forward Networks (FNNs), have demonstrated success in image deblurring. Zhang et al. [46] developed a Hybrid Deblur Net incorporating RNNs for non-uniform deblurring; Wang et al. [5] proposed a real-time deblurring algorithm utilizing GANs; and Kong et al. [47] developed a Frequency domain-based Self-Attention Solver (FSAS) to address the limitations of FFNs in image deblurring.
Despite their superior deblurring capabilities, neural networks face two significant limitations: (1) Their substantial data dependency means they require extensive training samples for optimal performance, resulting in generalization failures with distributionally shifted data. (2) Computational requirements are significant during both training and inference phases, particularly for architectures with numerous parameters.
3. Proposed Method
In this section, we present our improved sparse regularization and develop an effective deblurring algorithm based on this model.
3.1. Definition of Nonlinear Sparse Regularization
The nonlinear sparse regularization ( ) is defined as:
Given a corrupted signal , we assume the latent sharp signal is sparse. With a basic quadratic penalty, the objective energy function can be written as:
where denotes the regularization parameter, and denotes the iteration level. Connecting to the definition of in (Equation (3)), Equation (4) can be rewritten as:
where denotes the result after this iteration level, while denotes the result of the previous iteration level. The notation represents the infinity norm, which is mathematically defined as the maximum absolute value of a matrix, expressed as . Building on previous successful practices [3,4,6,7], we utilize the infinity norm ( ) of the signal from the previous iteration as a weighting factor to adjust the regularization parameter. To facilitate the solution of our model, we decompose the signals and into a series of independent subproblems:
where denotes the location of an element. The nonlinear sparse regularization term in Equation (6) presents a non-convex optimization problem, and following successful experiments, we are able to transform optimization into optimization with an adaptively adjustable regularization parameter. Based on the GST algorithm widely employed for norm optimization, we further develop an AGST algorithm. To illustrate the nonlinear sparse regularization, we abstract the -related component in Equation (6) as a function:
The curves of function under different values of variable are displayed in the following figure:
The curves in Figure 2 illustrate the existence of a threshold : when falls below this threshold, the minimum value of the function in Equation (7) occurs at ; when exceeds this threshold, the function reaches its minimum at a non-zero value. These properties indicate that the threshold satisfies the following condition:
Here, denotes the variable when the function in Equation (7) achieves its non-zero minimum, and denotes the first-order derivative of . These conditions yield the following solutions:
As shown in Equation (11), since varies with the optimization target , which directly relates to the threshold , the proposed AGST algorithm adapts its thresholding dynamically according to the intrinsic characteristics of input variables. The solution is expressed as:
The workflow of AGST is outlined in Algorithm 1. Algorithm 1: The Adaptive Generalized Soft-Thresholding algorithminput: , , , p, J if else for t = 1, 2, …, J end end****Output:
3.2. Deblurring Model and Optimization
This subsection describes the proposed deblurring model and its optimization procedure. In our formulation, we employ the -norm, commonly utilized in traditional algorithms, to regularize the fidelity term and the blur kernel term. For image-related regularization terms, building upon previous successful approaches [9,10,11,13,14], we combine the gradient prior with the widely adopted gradient prior, thereby constructing a novel fast nonlinear sparse model. The complete model is expressed as:
where ∇ denotes the gradient operators in vertical and horizontal dimensions (i.e., ); , , and denote the weight parameters. We solve Equation (13) by alternatively updating and with the other one held fixed. The sub-problems referring to and are given by:
3.2.1. Updating Latent Image I
The latent image is updated while keeping the kernel fixed. Since Equation (14) presents a highly non-convex problem, the HQS method is employed. Two auxiliary variables, and , are introduced to represent in the second and third terms of Equation (14), respectively, transforming Equation (14) into:
where and denote the penalty parameters. Similarly to Equation (13), Equation (16) is decomposed into three subproblems associated with , , and :
Solving . Equation (17) represents a classical quadratic optimization problem solvable via Fast Fourier Transform (FFT), with its closed-form solution expressed as:
Solving . Based on the definition in Equation (3), Equation (18) is reformulated as:
where denotes the obtained from the previous iteration level. Adopting the AGST algorithm, the solution for variable is expressed as:
Solving . The objective function for the auxiliary variable in Equation (19) represents an gradient prior [2]. The solution employs the unnatural distribution method, yielding the closed-form solution for g:
The principal steps for estimating the latent image are summarized in Algorithm 2. Algorithm 2: Latent image estimationInput Blurred image , initialized from the coarser level. , , repeat Calculating using Equation (22) Calculating using Equation (23) Calculating using Equation (20) λ1←2λ1λ2←2λ2 until λ1 >α_max_Output Intermediate latent image .
3.2.2. Updating Blur Kernel k
The objective function for the blur kernel presents a quadratic optimization problem similar to Equation (15). While Equation (15) emphasizes image intensity information, previous advanced methods [9,13,18,28] demonstrate that blur kernel estimation achieves higher accuracy when based on image gradient. Therefore, Equation (15) is modified into a gradient-based form:
and can be effectively solved through FFT:
The essential steps of blur kernel estimation are summarized in Algorithm 3. Algorithm 3: Blur kernel estimationInput Blurred image Initialized from the previous level of the image pyramid. while do Estimate using Algorithm 2 Estimate using Equation (25)Output Blur kernel
4. Experimental Results
This section presents an evaluation of the proposed method using natural image datasets [8,48,49], real-world images, and a specific domain dataset [50], comparing it with several state-of-the-art methods, including traditional methods and deep learning methods. For all uniform image deblurring experiments, the parameters are set as , , , , , and , and for fair comparison, the other algorithms utilize the default settings from the authors’ codes. Throughout the experiments, blur kernel estimation employed different blind deblurring methods, followed by the same non-blind deblurring method as the final step, and the model implementation used MATLAB R2022a with efficiency assessment conducted on an Intel Core i7-11800H CPU with 16GB RAM (Intel Corporation, Santa Clara, CA, USA).
4.1. Natural Images
This subsection demonstrates our method’s performance on two synthetic datasets from Levin et al. [8] and Sun et al. [49]. The restoration results undergo quantitative evaluation using three standard metrics: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), and cumulative error ratio. The mathematical definitions of each evaluation metric are expressed as follows:
where denotes the restored image, denotes the reference ground truth image used for quality assessment, and denotes the deblurred image using the real blur kernel. In Equation (26), and denote the size of an image, indicates the maximum pixel value of image , and means the mean squared error. In Equation (27), and denote the mean values of images and , and denote their standard deviation, denotes the covariance between the two images, and and are two constants.
4.1.1. Levin’s Dataset
The initial evaluation utilizes the dataset reported by Levin et al. [8], comprising 32 blurred images generated from 4 images filtered with eight blur kernels, each maintaining a uniform resolution of 255 × 255 pixels. The PSNR, SSIM, and cumulative error ratio metrics of our method is compared with several state-of-the-art methods [9,11,14,30,31,33,51,52,53], with the results presented in Figure 3. As demonstrated in Figure 3a,b, the proposed model achieves superior average PSNR and SSIM metrics (32.234 dB in PSNR and 0.909 in SSIM), surpassing the model by 0.866 dB in PSNR and 0.024 in SSIM, respectively. Additionally, Figure 3c displays the cumulative error ratio curves of the comparative methods, with the results demonstrating that the proposed method consistently outperforms competing approaches, achieving a 90.625% success rate when the error ratio is ≤1.5, and a 100% success rate when the error ratio is ≤2.0.
Figure 4 presents a particularly challenging image—exhibiting a large blur kernel and complex texture details, posing significant difficulties for deblurring algorithms—alongside the restoration results of the compared methods, with corresponding PSNR and SSIM values annotated in the upper-left corner. The proposed method achieves superior kernel estimation accuracy and visual quality, producing the highest PSNR (30.046 dB).
4.1.2. Sun’s Dataset
To expand the comparative analysis, evaluation was conducted on Sun’s dataset [49], containing 640 high-resolution blurred images, using the cumulative error ratio as the comparison metric. Our method was evaluated against several established deblurring methods [9,14,18,31,33,52,54,55,56], with the quantitative results presented in Figure 5. For equitable comparison, an identical non-blind deblurring approach [57] was applied for all competing methods. As the figure illustrates, the proposed method achieves an 87.500% success rate when the error ratio is ≤2, exceeding Chen et al.’s [14] enhanced sparse model, which achieves an 85.469% success rate.
Following an established protocol, a representative case is presented in Figure 6 to illustrate the advantages of the proposed method over comparative approaches, with quantitative metrics annotated in the upper-left corner. The selected example features an interior architectural space with intricate structural details, and the results demonstrate that the proposed method has superior blur kernel accuracy compared to alternative approaches. Notably, the method achieves a 0.489 dB PSNR improvement and 0.011 SSIM gain over the model proposed by Chen et al. [14].
4.2. Specific Images
With Section 4.1 having demonstrated the superior performance of the proposed method on natural images, this subsection presents the results of targeted experiments using representative scenarios from the dataset in [50], specifically evaluating performance on two distinct scenarios: human face images and text images.
4.2.1. Human Face Images
Face image processing constitutes a fundamental research area in this field, with images of faces presenting unique challenges due to their frequent absence of dominant structural information, complicating blur kernel estimation. Figure 7 presents quantitative comparison results of face images from the dataset in [50]. The results indicate the superior PSNR and SSIM metrics (27.638 dB PSNR and 0.860 SSIM) of the proposed method, showing an improvement of 1.337 dB in PSNR and 0.030 in SSIM compared to Chen et al.’s model [14].
The first row of Figure 8 presents a challenging face image example from the dataset [50], while column (b) displays the ground-truth sharp image. This example demonstrates that our method reconstructs the most accurate blur kernel while producing results with minimal ringing artifacts. Following standard practice, the PSNR and SSIM metrics are displayed in the under-left corner, indicating the substantial improvement achieved by the proposed method over the model, obtaining a PSNR of 28.085 dB.
4.2.2. Text Images
Text image processing represents another significant application domain, different from other tasks in that these images predominantly contain two-tones that do not follow the heavy-tailed distribution of natural images, making text images particularly challenging for most deblurring methods. Figure 9 presents the average PSNR and SSIM for text images from the dataset in [50], indicating that our method achieves the highest quantitative evaluation metrics, surpassing the second-highest method by 0.533 dB in PSNR and 0.066 in SSIM. For visual comparison, the second row of Figure 8 illustrates an exemplar text image from the dataset [19], containing abundant image details. The comparative experimental results demonstrate that our method generates reconstructed results with superior detail preservation. The quantitative analysis metrics indicated in the upper-left corner reveal a PSNR improvement of 0.374 dB compared to other methods.
4.3. Comparison Against Deep Learning Methods
The recent decade has witnessed rapid advancement in deep learning, leading to numerous deep learning-based deblurring methods being proposed. To validate the effectiveness of our approach, we performed comparative experiments with several state-of-the-art deep learning models [44,45,47,51,52,54,58,59,60] on dataset proposed by Köhler et al. [48]. The quantitative analysis results, presented in Figure 10, demonstrate that our model achieves superior performance compared to several deep learning approaches in terms of both PSNR and Mean SSIM (MSSIM), surpassing the best-performing deep learning model [45] by 2.237 dB and 0.057, respectively.
For qualitative evaluation, we illustrate a challenging example from the dataset in Figure 11. The results indicate that most deep learning methods encounter difficulties in producing satisfactory restoration results when processing images with large blur kernels. Our method, however, maintains accurate reconstruction quality even in this challenging case, achieving a PSNR of 28.064 dB and an MSSIM of 0.907.
4.4. Real-World Images
Following evaluation on synthetic datasets, we tested our algorithm using real-world blurred images, inputs that present greater randomness and uncertainty compared to synthetic images, thus imposing higher requirements on algorithmic stability and adaptability. Figure 12 illustrates an example of a real-world blurred image, featuring rich structural details and exhibiting relatively complex blur kernel size and motion trajectory characteristics. To ensure fair comparison, we applied the same non-blind image deblurring algorithm [8] with identical parameter settings throughout all experiments, and the other methods’ restoration parameters for other methods were configured using the combinations published by their respective authors. The results demonstrate that our proposed fast nonlinear sparse model achieves the most accurate blur kernel estimation among all compared methods, producing a final restored image with superior detail preservation and minimal ringing artifacts.
5. Analysis and Discussion
In this section, we analyze a series of ablation experiments to systematically validate the effectiveness of our proposed fast nonlinear sparse model, accompanied by comprehensive discussions on key parameter influences and computational efficiency.
5.1. The Effectiveness of the Fast Nonlinear Sparse Model
This section presents a series of ablation experiments conducted to validate the effectiveness of the proposed fast nonlinear sparse model, evaluating various combinations of regularization norms commonly employed in deblurring methods, with quantitative results illustrated in Table 1. Specifically, columns 1–3 present the quantitative deblurring evaluations for three distinct regularization method– , , and ; column 4 presents the average PSNR and SSIM obtained by standalone -regularization; and columns 5–7 demonstrate the corresponding performance when these norm-ratio-based regularizations are coupled with the norm.
The comparative analysis reveals three significant findings: First, within columns 1–3, the proposed nonlinear sparse regularization ( ) exhibits substantial advantages over other norm-ratio-based regularizations. Compared to the prior, the proposed prior achieves an average PSNR improvement of 0.591 dB, indicating superior performance over other nonlinear coupled norm priors. Second, the coupled versions (columns 5–7) achieve markedly better performance than their standalone counterparts (columns 1–3). Incorporating the prior yields an average improvement of 1.629 dB in PSNR and 0.038 in SSIM, which demonstrates that the regularization prior significantly enhances algorithm performance. Third, the results in the last four columns indicate that combining nonlinear coupled norm priors with the prior enhances the deblurring algorithm’s performance more effectively than using the prior alone, achieving PSNR improvements of 0.184 dB, 0.091 dB, and 0.679 dB, respectively. Furthermore, the proposed fast nonlinear sparse model, integrating the prior with the prior, achieves optimal deblurring performance with a 32.234 dB PSNR and 0.909 SSIM.
5.2. Effect of Main Parameters
The proposed fast nonlinear sparse model incorporates four key parameters: , , , and . The parameter optimization process consists of two stages: first, a two-dimensional grid search for the key parameters, and , utilizing the average PSNR as the selection criterion, and second, a separate search grid for parameter , given its relative independence, as illustrated in Figure 13c.
First, based on existing empirical knowledge, we construct a grid search for parameters and over the interval [ , ] with a step size of , as illustrated in Figure 13a, where the boxed coordinate indicates the position yielding the maximum average PSNR. This primary grid serves to identify the approximate optimal ranges for and . Subsequently, we perform a secondary grid search within the identified optimal range from the initial screen, employing a refined step size of (Figure 13b), enabling the precise determination of the final parameter values.
Parameter stability is essential for robust optimization-based deblurring, and that of the fast nonlinear sparse model was evaluated using blur kernel similarity (Figure 14). Parameters and demonstrate stable performance across the refined grid range illustrated in Figure 13b, with kernel similarity variances of and , respectively. All three parameters show minimal fluctuations in their similarity curves, confirming stable performance within reasonable ranges. Parameter exhibits particularly low sensitivity, maintaining stable kernel similarity across its 3–20 operating range (Figure 14c).
5.3. Runtime Analysis
Computational efficiency serves as a crucial metric for evaluating deblurring algorithm performance, whit shorter durations indicating higher efficiency. In this experiment, we assess the computational time of our algorithm across three distinct image resolutions (255 × 255, 600 × 600, 800 × 800 pixels), with testing conditions controlled by maintaining a fixed blur kernel size of 27 × 27 throughout the trials. The comprehensive timing results are presented in Table 2.
We compared runtime results between our method and several classical patch-based deblurring approaches [9,10,11,13,31]. As demonstrated in Table 2, non-overlapping patch priors [11,13] show substantial efficiency improvements over overlapping patch design priors [9,10,31], with our method achieving an approximately 50% runtime reduction compared to standard non-overlapping patch-based methods. This enhancement results from its pixel-wise optimization strategy, which eliminates patch extraction requirements in each iteration.
5.4. Limitations
In the previous sections, we evaluated the superior performance and computational efficiency of our proposed nonlinear sparse model compared to existing state-of-the-art methods using both synthetic datasets and real-world images. However, our model still exhibits certain limitations. First, due to its pixel-wise computation approach during optimization, it demonstrates poor resistance to salt-and-pepper noise; as shown in Figure 15 and Figure 16, restoration performance deteriorates significantly when such noise is present. Additionally, our model performs weakly when handling locally blurred images, such as that in Figure 17.
6. Conclusions
This paper introduces a novel nonlinear sparse regularization ( -regularization) based on the nonlinear coupling of the and norms, and to facilitate effective optimization, an AGST algorithm is developed. Through the integration of the and regularization priors, this research establishes a fundamentally new fast nonlinear sparse model. Statistical analyses demonstrate that regularization achieves optimal sparsity. Comprehensive experiments on synthetic datasets and real-world blurred images validate that our fast nonlinear sparse model delivers superior deblurring performance. Quantitative results show that the proposed model achieves approximately 1 dB higher PSNR and 0.04 better SSIM values compared to state-of-the-art optimization-based deblurring methods, further reducing the computational time by 50% compared to conventional patch-based approaches due to its pixel-wise optimization strategy.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Xu L. Lu C. Xu Y. Jia J. Image smoothing via L 0 gradient minimization Proceedings of the 2011 SIGGRAPH Asia Conference Hong Kong, China 12–15 December 2011
- 2Xu L. Zheng S. Jia J. Unnatural L 0 Sparse Representation for Natural Image Deblurring Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)Portland, OR, USA 23–28 June 2013 IEEE Piscataway, NJ, USA 2013
- 3Wang J. Ma Q. The variant of the iterative shrinkage-thresholding algorithm for minimization of the 1 over ∞ norms Signal Process.202321110910410.1016/j.sigpro.2023.109104 · doi ↗
- 4Wang C. Yan M. Yu J. Sorted L 1/L 2 Minimization for Sparse Signal Recovery J. Sci. Comput.2023993210.1007/s 10915-024-02497-2 · doi ↗
- 5Wang H. Hu C. Qian W. Wang Q. RT-Deblur: Real-time image deblurring for object detection Vis. Comput.2023402873288710.1007/s 00371-023-02991-y · doi ↗
- 6Wang C. Tao M. Nagy J. Lou Y. Limited-angle CT reconstruction via the L 1/L 2 minimizationar Xiv 20202006.00601
- 7Wang J. A wonderful triangle in compressed sensing Inf. Sci.20226119510610.1016/j.ins.2022.08.055 · doi ↗
- 8Levin A. Weiss Y. Durand F. Freeman W.T. Understanding and evaluating blind deconvolution algorithms Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition Miami, FL, USA 20–25 June 200919641971