Predictive Model for Managing the Clinical Risk of Emergency Department Patients: A Systematic Review
Maria João Baptista Rente, Liliana Andreia Neves da Mota, Ana Lúcia da Silva João

TL;DR
This paper reviews predictive models for managing clinical risk in emergency departments, finding that they can improve decision-making and patient safety.
Contribution
The study evaluates the performance of predictive models in emergency departments, highlighting their potential when integrated with artificial intelligence.
Findings
Four studies were included, with participant ranges from 4,388 to 448,972.
Predictive models like the Older Persons' Emergency Risk Assessment score and machine learning models were identified.
Models were evaluated for outcomes like in-hospital mortality and clinical deterioration.
Abstract
Background/Objective: The growing volume and complexity of cases presented to emergency departments underline the urgent need for effective clinical-risk-management strategies. Increasing demands for quality and safety in healthcare highlight the importance of predictive tools in supporting timely and informed clinical decision-making. This study aims to evaluate the performance and usefulness of predictive models for managing the clinical risk of people who visit the emergency department. Methods: A systematic review was conducted, including primary observational studies involving people aged 18 and over, who were not pregnant, and who had visited the emergency department; the intervention was clinical-risk management in emergency departments; the comparison was of early warning scores; and the outcomes were predictive models. Searches were performed on 10 November 2024 across eight…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
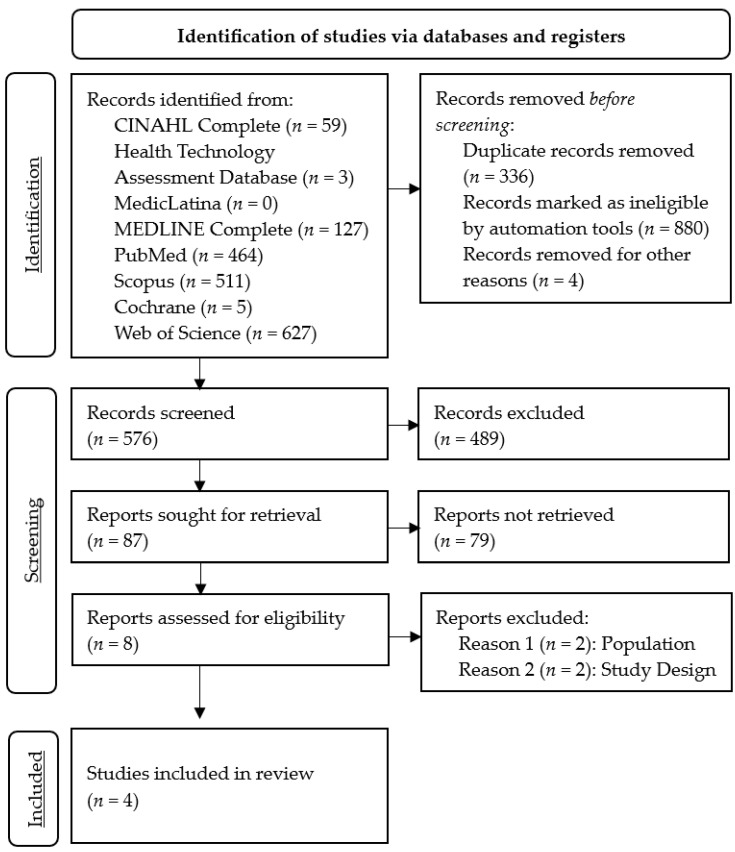 Figure 1
Figure 1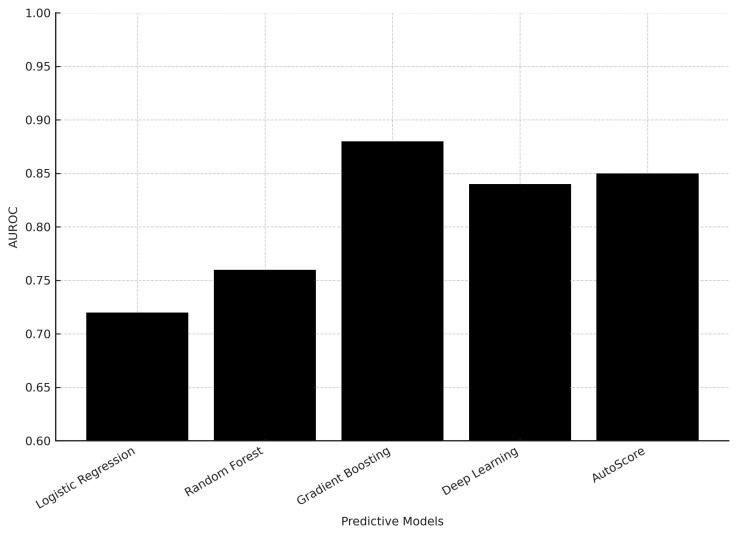 Figure 2
Figure 2- —Comprehensive Health Research Centre
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsEmergency and Acute Care Studies · Trauma and Emergency Care Studies · Healthcare cost, quality, practices
1. Introduction
The purpose of emergency departments (EDs) is to provide care to people at clinical risk of experiencing complex disease processes and/or organ failure [1,2,3,4,5,6].
Emergency departments require transdisciplinary approaches [1,2,3,4,7,8] that combine diverse fields of expertise [4,9] to anticipate clinical risk and standardize assessment processes [2,3,5,6,10,11].
Risk stratification [1,2,6,10,12,13,14,15], supported by predictive models, can improve the anticipation of patient needs and enhance their safety and quality of care [2,6,9,10,12,13,14,16,17,18].
These approaches are aligned with current evidence highlighting the importance of proactive risk management in acute care settings [2,3,5,6,10,11].
A predictive model can support emergency professionals in systematizing decisions and organizing care in transdisciplinary teams [1,2,3,4,5,6,7,8,11,19,20,21,22,23,24,25].
Predictive models, typically grounded in algorithmic frameworks derived from machine learning or statistical methodologies, are designed to estimate risk and thereby inform decision-making processes in EDs [21,22,24,26,27,28].
Machine learning approaches, which include supervised and unsupervised techniques such as logistic regression, decision trees, ensemble learning, and neural networks, enable the identification of complex patterns in large clinical datasets. These models have shown increasing promise in predicting outcomes such as hospital admission, intensive care needs, and mortality, complementing or outperforming traditional scoring systems [29]. Their integration into emergency care may facilitate earlier recognition of deterioration and more targeted interventions.
The objective of this review is to evaluate the performance and usefulness of predictive models for managing the clinical risk of people who visit the ED.
2. Materials and Methods
This systematic review was conducted and reported according to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) [30,31] (Appendix A). We performed a systematic review on the use of predictive models for managing the clinical risk of ED patients.
Registration and protocol: This protocol was registered in PROSPERO under the name “Predictive model for managing the clinical risk of ED patients: A systematic review” and registration number CRD42024556926. No protocol was prepared, and no amendments have been made to the information provided at registration.
2.1. Eligibility Criteria
We aimed to identify all predictive models developed until 10 November 2024 for managing the clinical risk of ED patients. The articles needed to fulfill the following population, intervention, comparison, and outcome criteria to be considered for inclusion (Table 1).
2.2. Information Sources
The following databases were searched from inception until 10 November 2024: CINAHL^®^ Plus, the Health Technology Assessment Database, MedicLatina, MED-LINE^®^, PubMed, Scopus, the Cochrane Plus Collection, and Web of Science.
Information sources were restricted to peer-reviewed articles to ensure methodological rigor and reliability of the extracted data, and the gray literature and preprints were excluded.
The selection of electronic databases was informed by guidance from the Cochrane Handbook for Systematic Reviews of Interventions (Chapter 4: Searching for and selecting studies) [33]. MedicLatina was included due to its coverage of peer-reviewed scientific and medical journals from established Latin American and Spanish-language publishers, thereby enabling comprehensive retrieval of the relevant literature published in Spanish.
2.3. Search Strategy
Among the entry terms, we used the following keywords according to Medical Subject Headings: risk assessment (health risk assessment, risk analysis); risk management; risk adjustment (case-mix adjustment); risk factors; early warning score; emergency service; and hospital (emergency departments). The initial search strategy was developed in PubMed and subsequently adapted to meet the specific syntax and indexing requirements of each included database. The full search strategies for all databases are provided in Appendix B.
2.4. Selection Process
Duplicate articles were removed using Rayyan. Two authors (M.R. and L.M.) independently screened titles and abstracts, and conflicting results were discussed in consensus meetings. After screening the titles and abstracts, the full text of each article was assessed for eligibility by the same authors to decide whether or not they should be included in the systematic review.
2.5. Data Collection Process
The method used to collect data from the included articles followed the guidelines of the Cochrane Handbook for Systematic Reviews of Interventions [33]. One author (M.R.) collected data from each article, and a random check was conducted by another author (L.M.). This check showed no discrepancies.
2.6. Data Items
The following data were extracted from every included article: study details (authors, publication year, language, country where the study was carried out, study aim/research question, design, recruitment source, inclusion and exclusion criteria, type of allocation, stratification, and sample size); characteristics of participants (age, gender, ethnicity, and multimorbidities); intervention details (intervention content, intervention setting, delivery of intervention, and number of participants assessed at follow-up); comparison/control characteristics (type of control program/intervention); and outcomes (primary and secondary outcomes, where between-group differences, total scores/means, and standard deviations in each group were extracted from the study results; methods of outcome measurement, including blinding procedures; and time of outcome measurements).
2.7. Risk-of-Bias Assessment in Included Studies
The methods used to assess risk of bias in the included studies were assessed with the Critical Appraisal and Data Extraction for Systematic Reviews of Prediction Modeling Studies (CHARMS) checklist and Prediction Model Risk-of-Bias Assessment Tool (PROBAST) [34]. Two review authors (M.R. and L.M.) independently assessed the risk of bias in the included studies, and disagreements were resolved by consensus.
2.8. Effect Measures
The effect measures that we evaluated for the outcomes of predictive models for clinical-risk management were discrimination and calibration.
2.9. Synthesis Methods
We visually displayed the results of individual studies and syntheses in a table, which groups the characteristics of the included studies, including the authors, year, sample, objectives, assessment tools, interventions, results, and conclusions.
The method used to synthesize the results and our rationale for choosing this method are reported in the text.
Owing to the anticipated methodological and clinical heterogeneity, a meta-analysis was not performed. Instead, a narrative synthesis was undertaken to address heterogeneity across model types, with particular emphasis on identifying and interpreting inconsistencies in the findings—such as divergent effect directions or substantial variations in effect magnitudes—across the included studies.
2.10. Reporting Bias Assessment
To assess potential reporting biases, selective outcome reporting within studies was evaluated by comparing the reported results with those outlined in the study protocols, where available. Although a formal meta-analysis was not conducted, the potential for publication bias was considered by documenting the presence or absence of non-significant findings and assessing whether studies were prospectively registered (e.g., in clinical trial registries). Any discrepancies between registered protocols and final publications will be critically appraised and discussed.
2.11. Certainty Assessment
The methods used in the included studies to assess confidence in the body of evidence for an outcome were herein assessed using the GRADE (Grading of Recommendations Assessment, Development, and Evaluation) approach [35,36,37], which evaluates the quality of evidence based on factors such as risk of bias, consistency, directness, precision, and publication bias.
3. Results
3.1. Study Selection
The search process identified 1796 records, of which 576 remained after the removal of records before screening. The exclusion of studies based on titles and abstracts resulted in the retention of eight full-text articles eligible for assessment. Of these, four articles were excluded because the studies did not address the population criteria (n = 2) or the study design criteria (n = 2). Finally, we included four articles in this systematic review, with full details of the study selection summarized in Figure 1.
3.2. Study Characteristics
The study characteristics are summarized in Table 2. The four studies utilized different models: the Older Persons' Emergency Risk Assessment (OPERA) score, which is a risk prediction model developed and validated by the authors to predict in-hospital mortality and other outcomes in older adults admitted to the ED [38]; the new situation awareness (SA) model, which was introduced in an intervention group and consisted of the existing regional early warning score (EWS) system plus five additional subjective parameters (skin observations, dyspnea reported by the patient, pain, clinical intuition or concern, and patients' or relatives' concerns) [39]; benchmarking ED prediction models, which refer to various machine learning and deep learning models (including logistic regression, random forest, gradient boosting, multilayer perception, Med2Vec, and long short-term memory) that were developed and evaluated for predicting three different ED outcomes [40]; and the Vital-Sign Scoring (VSS) system, which is based on the presence of seven potential vital-sign abnormalities that were used to predict hospital mortality [41].
Three of the included studies had a prospective design, and all four studies prospectively assessed the performance of the models.
3.3. Risk of Bias in Studies
The results of the risk-of-bias assessment for each included study are presented in Table 3 and Supplementary Materials, for which we used the CHARMS checklist and PROBAST [34].
In [38], selection bias may have occurred due to the exclusion of patients without NEWS2 or CFS data, as well as patients with a short length of stay, and there was potential information bias due to missing data, which the authors addressed through multiple imputations. In general, the study design and methods aimed to help to reduce the risk of bias, but there are still potential sources of bias that could affect the validity of the results.
In [39], seasonal variation in the case mix and imbalance in the baseline characteristics between the intervention and control groups may have influenced the results. In addition, there was a lack of fidelity monitoring to ensure that the intervention was implemented as planned.
In [40], selection bias due to the single-center nature of the dataset may have limited the generalizability of the results, and measurement bias and residual confounding may have occurred due to the lack of certain potentially important risk factors in the dataset. In addition, bias could have been introduced by the simple imputation method used to handle missing data, which can hide the underlying data structure.
Based on the information provided in [41], the primary sources of bias in this study are likely selection bias due to the exclusion of outpatient cases, and information bias due to the need to extract data from patient records in some cases. However, the authors recognize these limitations and provide evidence that they are unlikely to have had a significant impact on the results. Overall, the risk of bias in this study appears to be moderate.
3.4. Results of Individual Studies
The OPERA risk score was derived and validated using data of 8974 and 8391 patients, respectively. The OPERA model included the NEWS2, CFS, acute kidney injury, age, sex, and the Malnutrition Universal Screening Tool (MUST). The OPERA model demonstrated superior performance for predicting in-hospital mortality, with an area under the curve (AUC) of 0.79, compared to NEWS2 (AUC = 0.65) and CFS (AUC = 0.76). The OPERA risk groups were able to predict prolonged hospital stay, with the highest-risk group having an odds ratio of 9.7 for staying more than 30 days. The OPERA model maintained good performance even when excluding the variable requiring a laboratory result (creatinine for acute kidney injury) [38].
The new SA model reduced the odds of CD by 21% compared to the control group, but there was no significant impact on mortality, ICU admissions, or readmissions [39].
The gradient boosting machine learning model achieved high performance in predicting critical outcomes (Area Under the Receiver Operating Characteristic—AUROC: 0.880) and hospitalization (AUROC: 0.819), but lower performance in predicting 72-h ED reattendance, and deep learning models did not outperform the gradient boosting model. Traditional clinical scoring systems had poor discriminatory performance, but the interpretable AutoScore model achieved better performance in predicting critical outcomes (AUROC 0.846) and hospitalization (AUROC 0.793) using a small number of variables [40].
Figure 2 illustrates the comparison of AUROC performance across predictive models, highlighting the superior performance of gradient boosting.
Most individual vital-sign abnormalities, except seizures and abnormal respiratory rate, were independent predictors of hospital mortality. Higher initial and maximum VSS values were significantly associated with increased hospital mortality. VSS values had a higher predictive power for hospital mortality when collected in the first 15 min after ED admission, compared to the maximum score over the entire stay [41].
3.5. Results of Syntheses
The OPERA model performed even better at predicting in-hospital mortality when excluding patients already receiving care or palliative care, with an AUC of 0.80 in the validation cohort [38].
Machine learning models, particularly gradient boosting, outperformed other methods in predicting hospitalization and critical outcomes, but struggled with predicting 72-h ED reattendance. While traditional clinical scoring systems performed poorly, the interpretable AutoScore model achieved reasonably good performance on the critical outcome and hospitalization prediction tasks [40].
3.6. Reporting Biases
None of the studies explicitly discuss any communication biases.
3.7. Certainty of Evidence
Based on the study design, methods, and statistical analysis, the certainty of evidence in [39] is moderate. The quasi-experimental controlled pre- and post-intervention design, large sample size, and appropriate statistical analysis provide a reasonable level of confidence in the findings, but the inherent limitations of a non-randomized study design prevent this study from achieving higher certainty.
Based on the details provided in [41], the certainty of evidence appears to be high. This study was a large, prospective cohort study with a comprehensive set of relevant patient data, conducted ethically and with appropriate oversight. The methodological details suggest a high-quality study with a high degree of certainty in its findings.
The methods used in the included studies to assess confidence in the body of evidence for an outcome were herein assessed using the GRADE (Grading of Recommendations Assessment, Development, and Evaluation) approach [35,36,37] (Table 4).
We are moderately confident that an estimate of the effect (or association) is correct (i.e., the certainty of the evidence from the included studies is moderate). Our confidence in the effect estimate is limited by the small number of included studies, and the true effect may be substantially different from the effect estimate.
4. Discussion
4.1. Current Research Status
The first study derived and validated the OPERA score, which can help clinicians stratify older patients by risk of mortality and prolonged hospital stay. The model demonstrated good discrimination and calibration, with a small over-prediction of mortality risk, which was addressed. Excluding patients without a documented frailty score limited the sample size, as this assessment may not have been conducted for patients in relatively good health. OPERA performed better for short-term mortality compared to longer-term outcomes, likely due to its focus on acute-illness severity. OPERA provided useful odds ratios for extended hospital stay, which could support discharge planning and resource allocation [38,42].
The new SA model reduced the odds of CD compared to the existing EWS system, but did not impact secondary outcomes like mortality, ICU admission, or readmissions. The SA model’s wider approach to increasing situational awareness and identifying early signs of deterioration was supported by these findings. The lack of impact on mortality is consistent with previous studies on EWS systems. There was a trend towards reduced ICU admissions in the intervention group, but this was likely due to differences in case mix. A higher EWS at ED entry was associated with increased risk of CD, as seen in other studies [28,39,43,44].
Machine learning models demonstrated higher predictive accuracy than traditional scoring systems, but complex deep learning models did not outperform simpler models on the relatively low-dimensional ED data. While machine learning models had higher predictive accuracy, their black-box nature makes them less suitable for clinical decision-making in emergency care, where explainability is important. Traditional scoring systems had lower predictive accuracy, but the interpretable AutoScore system achieved higher accuracy while maintaining the advantages of transparent, point-based scoring systems [19,40].
VSS, which measures the presence, onset, or worsening of vital-sign instability, is highly predictive of hospital mortality. Both the initial VSS value and its change during the ED stay is relevant, with patients who exhibit an increase in VSS having higher mortality. The individual components of VSS, such as impaired consciousness, hypotension, hypoxemia, and abnormal heart rate, were the strongest predictors of mortality. Its lack of independent predictive value for seizures and respiratory rate may be due to their co-occurrence with other VSS components. These results suggest that using VSS for the rapid identification and treatment of at-risk patients in EDs has the potential to improve outcomes for critically ill patients [41,45].
4.2. Trends
Gradient boosting methods demonstrated superior AUROC values (0.819–0.880) compared to logistic regression and random forest, while deep learning models did not outperform simpler methods. This suggests that moderately complex models may provide the best balance between predictive accuracy and interpretability in emergency settings. Clinical integration requires models that are not only accurate but also interpretable at the bedside. Tools such as AutoScore provide transparent, point-based frameworks that maintain predictive accuracy while allowing clinicians to understand and trust the decision-making process—an essential factor for adoption in high-pressure emergency settings.
Table 5 provides a schematic overview summarizing the strengths and limitations of traditional scoring systems, machine learning, and deep learning approaches.
4.3. Limitations
The limitations of the evidence obtained in this study are related to the scarcity of existing studies on predictive models for managing the clinical risk of ED patients. Furthermore, the number of included studies was small, which might be because we only included studies in English, Portuguese, and Spanish. Importantly, the small number of studies included significantly limits the generalizability of our findings.
In practice, predictive models represent objective methods to identify clinical risk or deterioration, supporting timely decision-making and interventions to improve patient outcomes.
4.4. Future Prospects
Future research should focus on integrating explainable machine learning models into electronic health record systems to ensure real-time applicability in clinical workflows. Transparent frameworks, such as AutoScore, may balance predictive performance with interpretability, thereby increasing acceptance among healthcare professionals. Moreover, multicenter external validation studies are essential to confirm generalizability across diverse emergency department populations.
This study contributes to transforming the care model in health services, with re-percussions for health policies that will make it possible to reorganize EDs.
5. Conclusions
This systematic review highlights the potential of predictive models in managing clinical risk in EDs. Despite the limited number of studies included, our findings demonstrate that models such as OPERA, machine learning models, the situation awareness model, and the VSS system represent valuable solutions for predicting in-hospital mortality and clinical deterioration. Their implementation may support faster and more informed clinical decisions, as well as optimize resource allocation in high-pressure care settings. However, the strength of our conclusions is limited by the inclusion of only four studies, underscoring the need for more multicenter validation research.
The integration of predictive models with artificial intelligence tools represents an opportunity to significantly enhance patient safety and the quality of care they receive. However, the widespread adoption of such methods requires robust external validation, adaptation to the realities of different emergency services, and special attention to the clinical interpretability of models—an essential condition for their acceptance by healthcare professionals.
Therefore, future research should focus on the development and validation of transparent, efficient predictive models that are integrated into clinical information systems, contributing to a more proactive, safe, and person-centered care paradigm.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Administração Central do Sistema de Saúde, I.P. Termos de Referenciação Dos Episódios de Urgência Classificados Na Triagem de Prioridades Como Pouco Urgentes/Não Urgentes/Encaminhamento Inadequado Para o Serviço (Cor Verde, Azul Ou Branca, Respetivamente) Nos Serviços de Urgência Hospitalares Para Os Cuidados de Saúde Primários e Outras Respostas Hospitalares Programadas; Lisbon, Portugal 202216 Available online: https://www.acss.min-saude.pt/wp-content/uploads/2016/11/Circular_Normativa_11_2022.p
- 2Coimbra N. Teixeira A.C. Gomes A. Ferreira A. Nina A. Freitas A. Lucas A. Bouça B. Cardoso C.M. Esteves C. Enfermagem de Urgência e Emergência 1st ed. Coimbra N. Lidel—Edições Técnicas, Lda.Lisbon, Portugal 2021
- 3Ordem dos Enfermeiros Regulamento de Competências Específicas Do Enfermeiro Especialista Em Enfermagem Médico-Cirúrgica Na Área de Enfermagem à Pessoa Em Situação Crítica, Na Área de Enfermagem à Pessoa Em Situação Paliativa, Na Área de Enfermagem à Pessoa Em Situação Perioperatória e Na Área de Enfermagem à Pessoa Em Situação Crónica Diário da República n.o 135/2018, Série II Diário da República Lisbon, Portugal 20181935919370 Available online: https://www.ordemenfermeiros.pt/media/8732/m%C 3%A 9dico-
- 4Binnie V. Le Brocque R. Jessup M. Johnston A.N.B. Illustrating a Novel Methodology and Paradigm Applied to Emergency Department Research J. Adv. Nurs.2021774045405410.1111/jan.1501734462947 · doi ↗ · pubmed ↗
- 5Donaldson L. Ricciardi W. Sheridan S. Tartaglia R. Textbook of Patient Safety and Clinical Risk Management Springer International Publishing Cham, Switzerland 202110.1007/978-3-030-59403-936315660 · doi ↗ · pubmed ↗
- 6Barroso F. Sales L. Ramos S. Diniz A.M. Grilo A.M. Resendes A. Oliveira A.S. Coelho A. Correia A. Graça A. Guia Prático Para a Segurança Do Doente 1st ed.Lidel—Edições Técnicas, Lda.Lisbon, Portugal 2021
- 7Lawrence M.G. Williams S. Nanz P. Renn O. Characteristics, Potentials, and Challenges of Transdisciplinary Research One Earth 20225446110.1016/j.oneear.2021.12.010 · doi ↗
- 8Lawrence R. Handbook of Transdisciplinarity: Global Perspectives Edward Elgar Publishing Cheltenham, UK 202310.4337/9781802207835 · doi ↗