A Hybrid SAO and RIME Optimizer for Global Optimization and Cloud Task Scheduling
Ming Zhu, Jing Li, Xiao Yang

TL;DR
This paper introduces a new hybrid optimization algorithm for cloud task scheduling, combining SAO and RIME to improve performance and efficiency.
Contribution
The novel hybrid SAO-RIME optimizer improves global optimization and cloud task scheduling through ecological niche initialization and enhanced escape from local optima.
Findings
The HSAO algorithm outperformed 11 other algorithms on the IEEE CEC2017 test set.
HSAO successfully improved cloud computing task scheduling with excellent practical results.
Abstract
In a global industrial landscape where the digital economy accounts for over 40% of total output, cloud computing technology is reshaping business models at a compound annual growth rate of 19%. This trend has led to an increasing number of cloud computing tasks requiring timely processing. However, most computational tasks are latency-sensitive and cannot tolerate significant delays. This has led to the urgent need for researchers to address the challenge of effectively scheduling cloud computing tasks. This paper proposes a hybrid SAO and RIME optimizer (HSAO) for global optimization and cloud task scheduling problems. First, population initialization based on ecological niche differentiation is proposed to enhance the initial population quality of SAO, enabling it to better explore the solution space. Then, the introduction of the soft frost search strategy and hard frost piercing…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
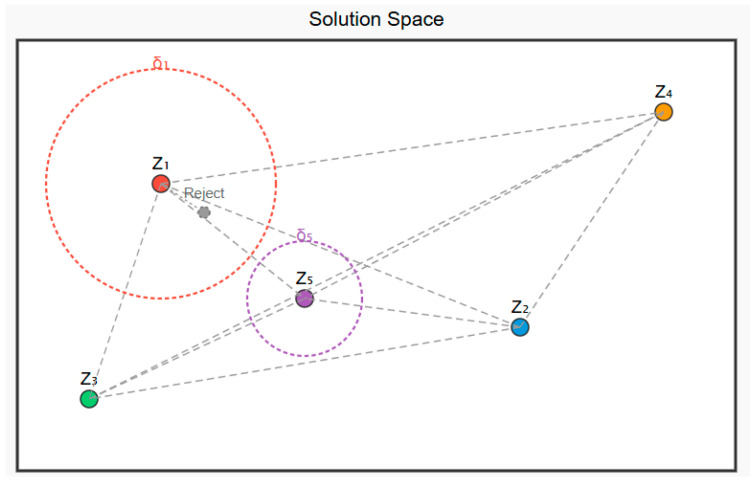 Figure 1
Figure 1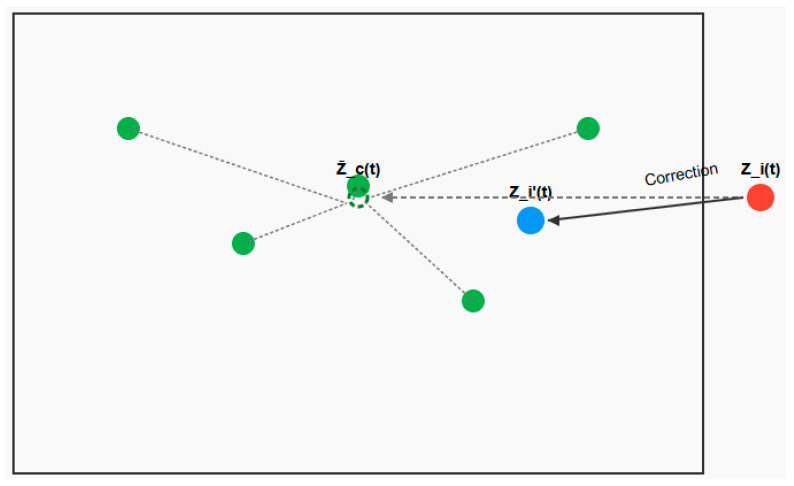 Figure 2
Figure 2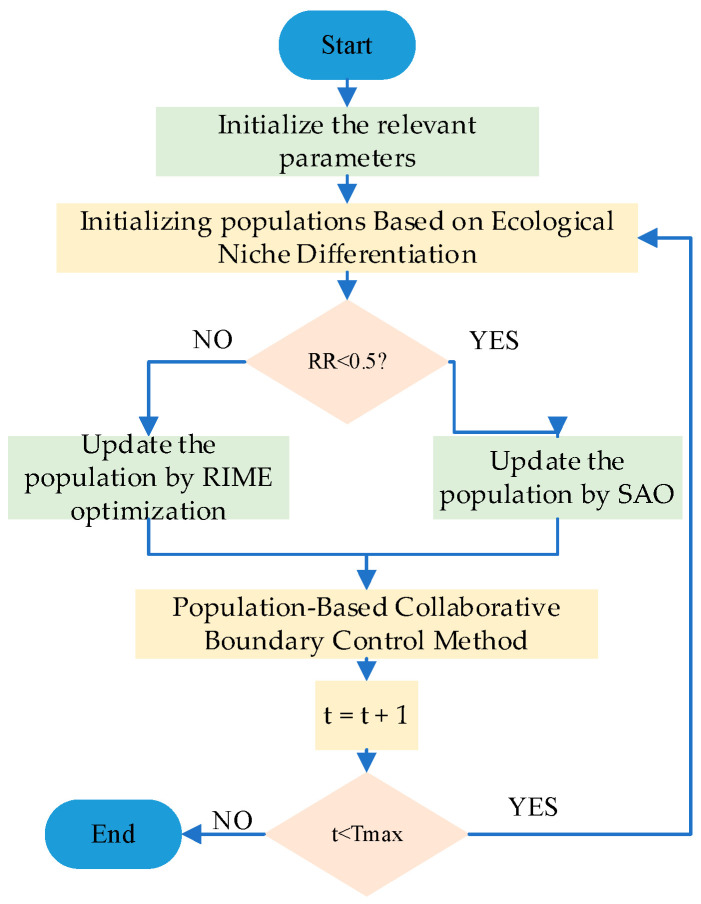 Figure 3
Figure 3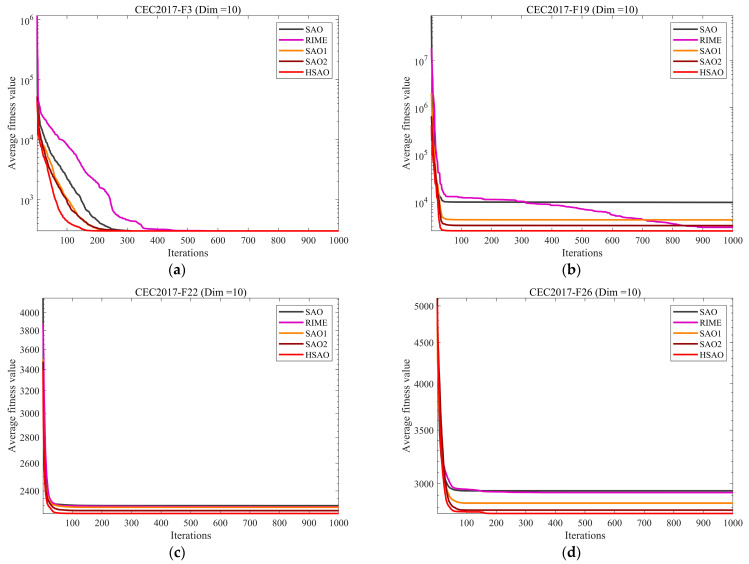 Figure 4
Figure 4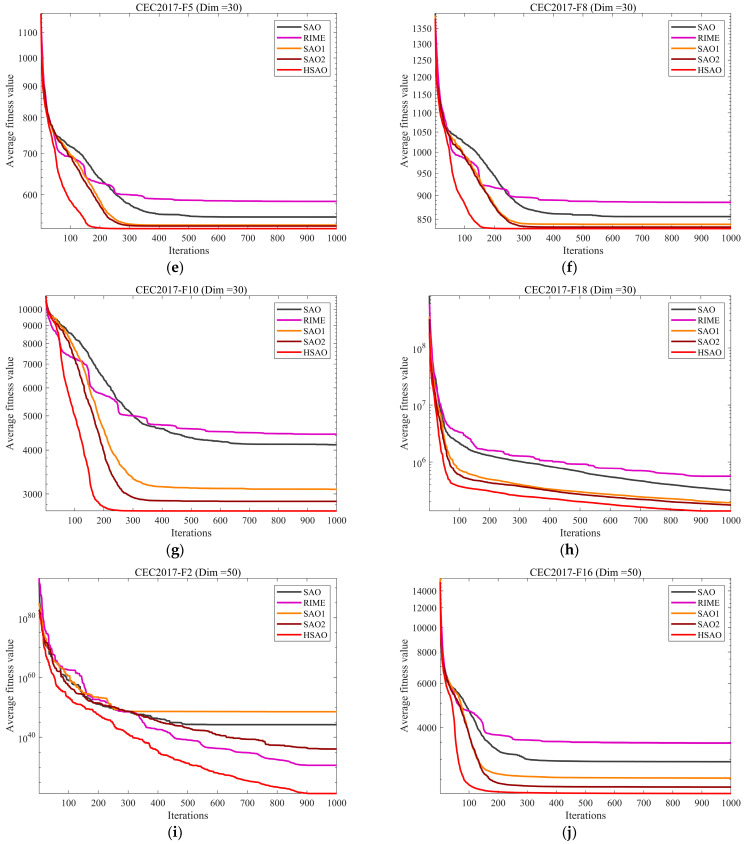 Figure 5
Figure 5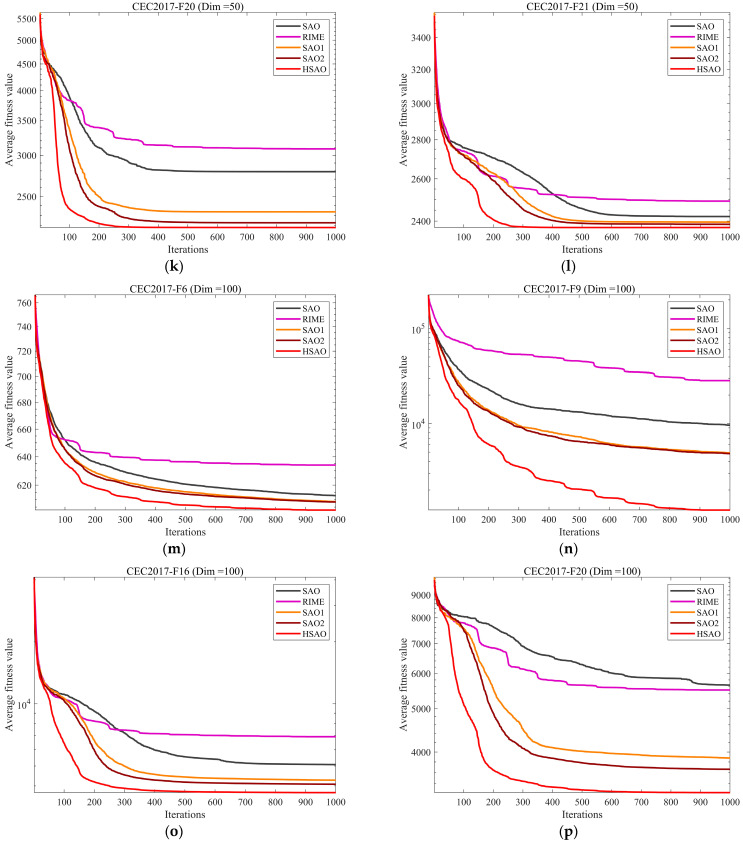 Figure 6
Figure 6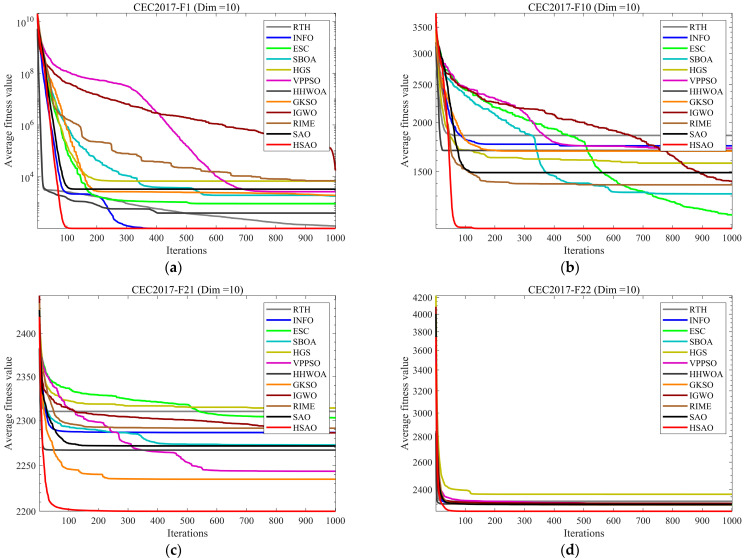 Figure 7
Figure 7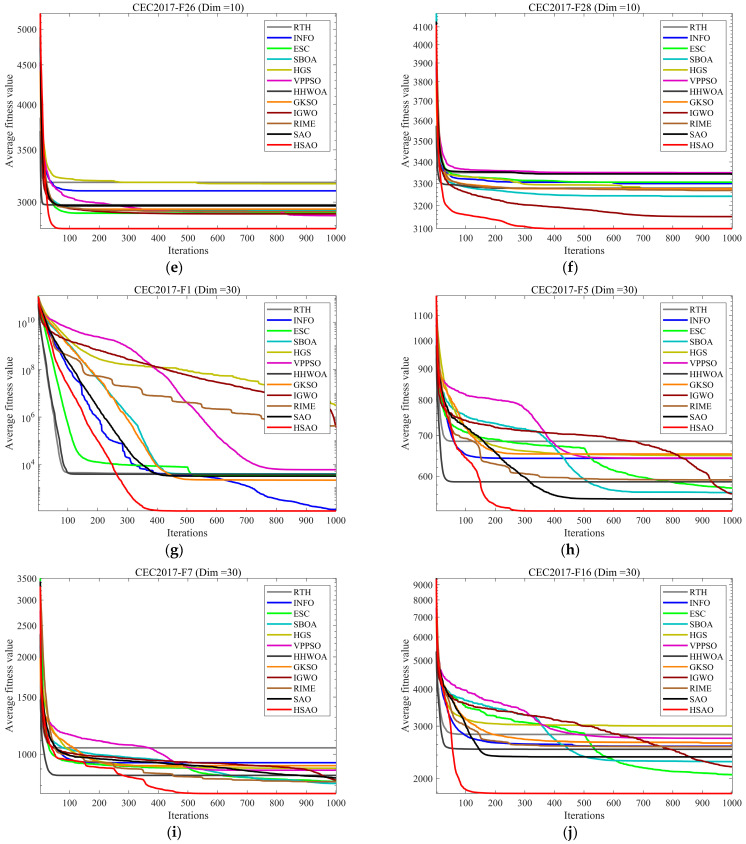 Figure 8
Figure 8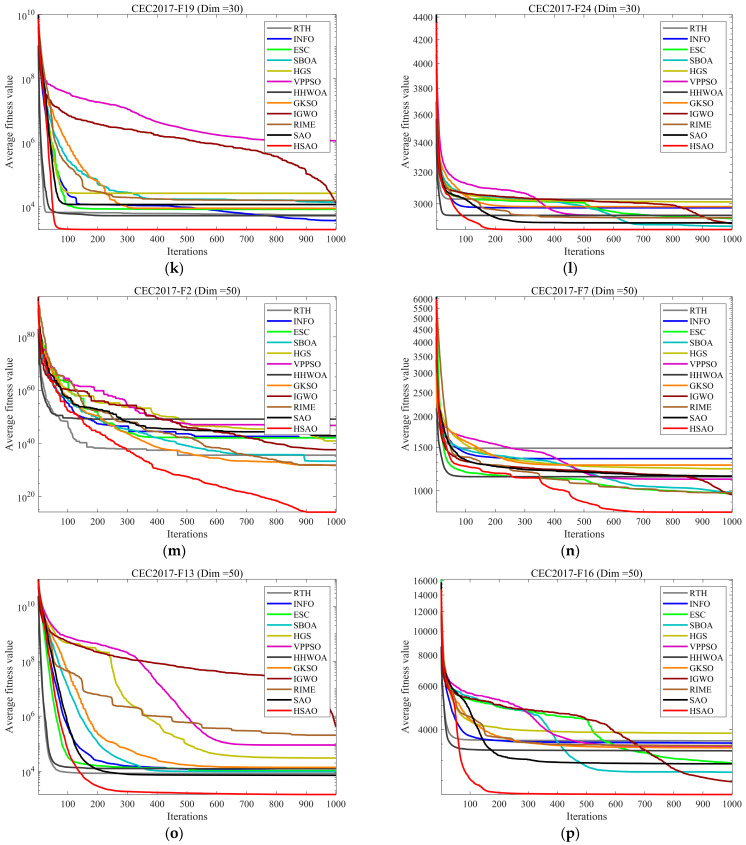 Figure 9
Figure 9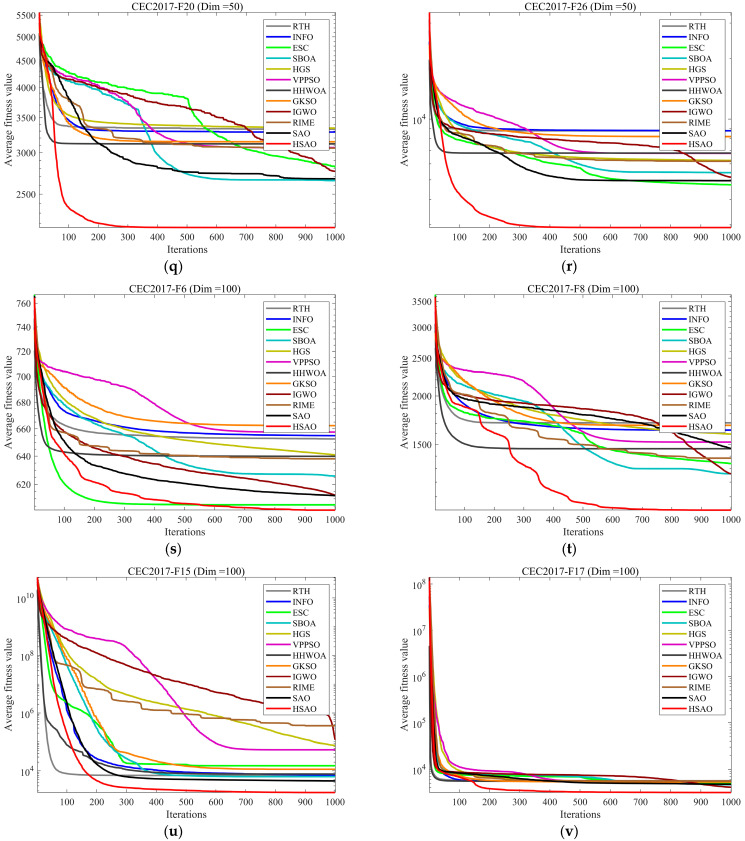 Figure 10
Figure 10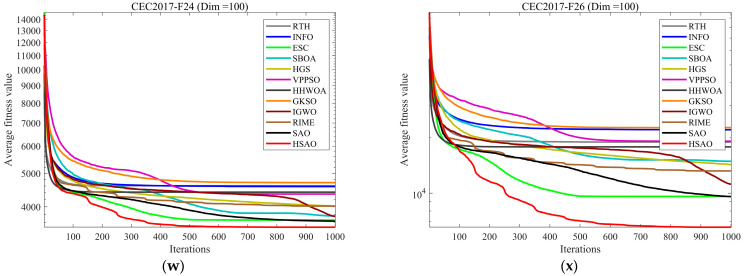 Figure 11
Figure 11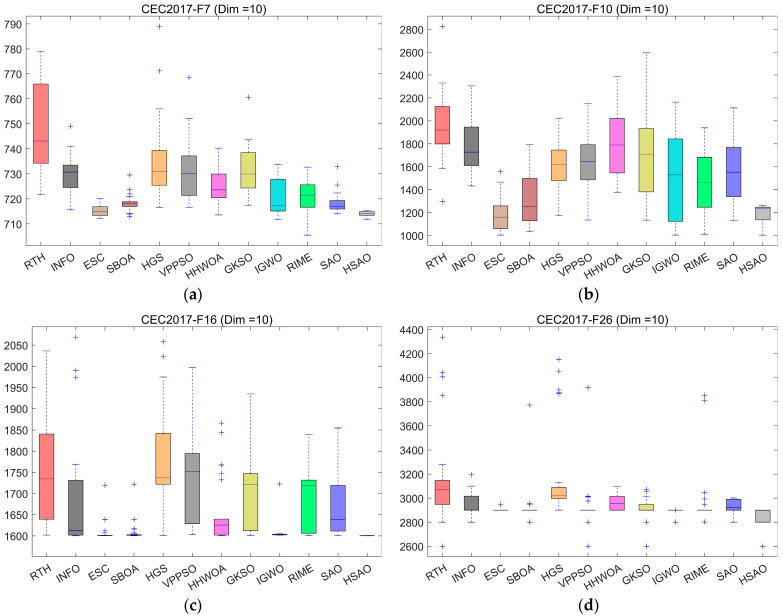 Figure 12
Figure 12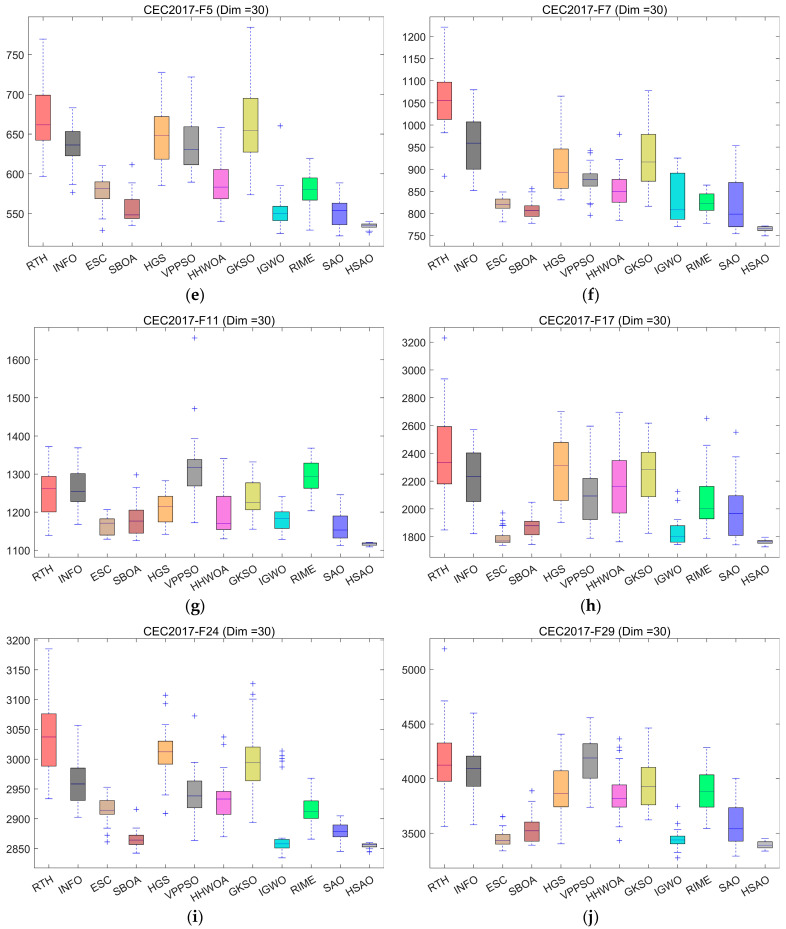 Figure 13
Figure 13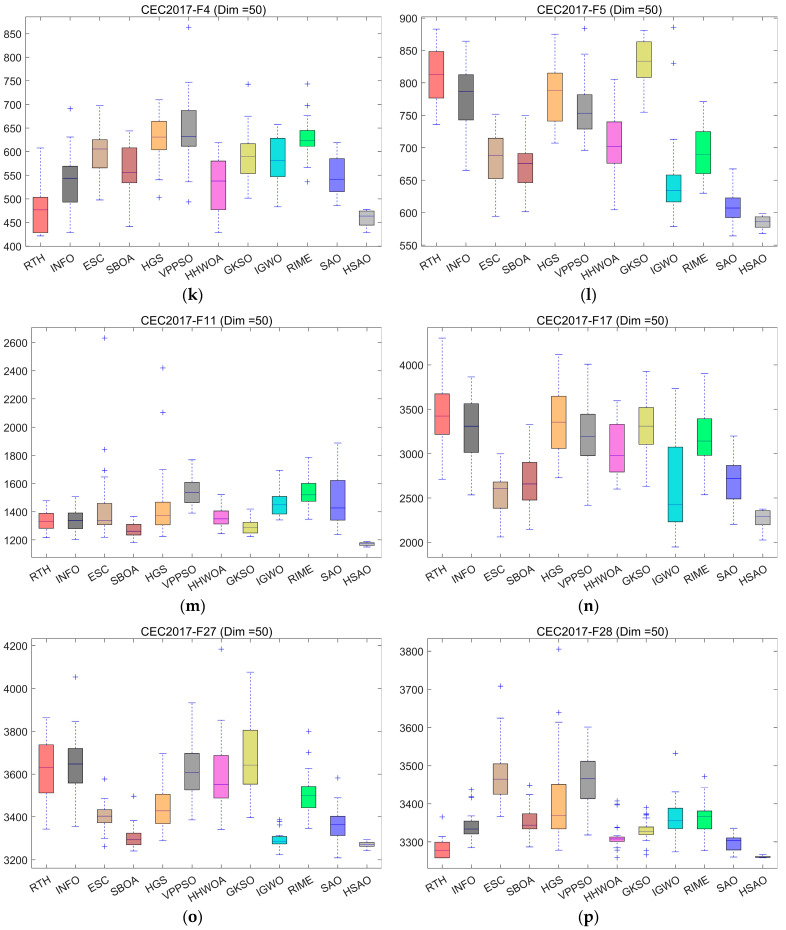 Figure 14
Figure 14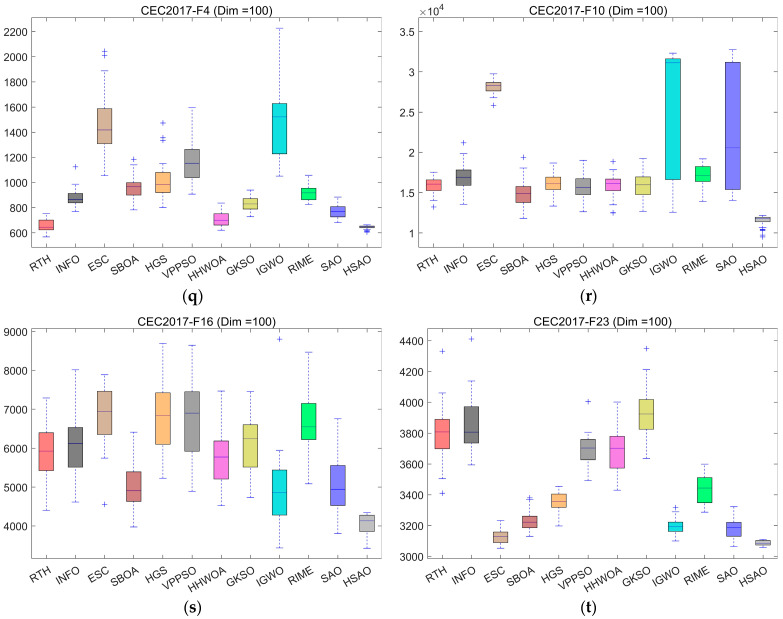 Figure 15
Figure 15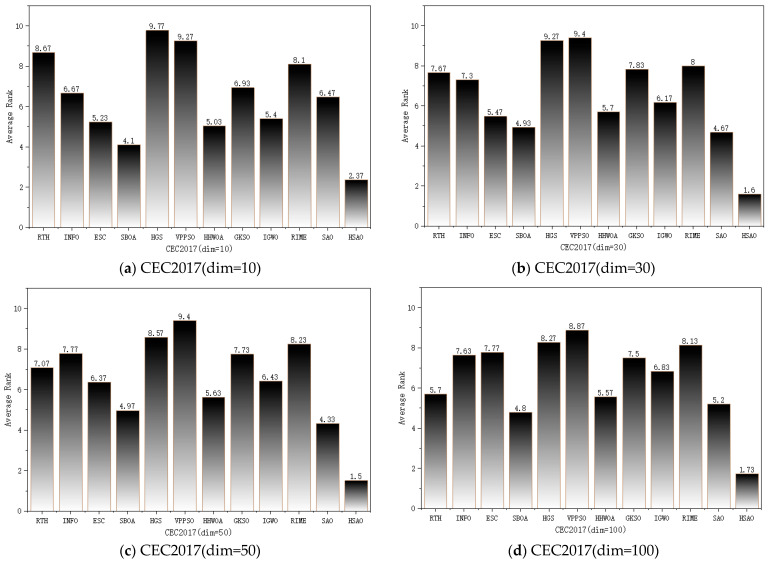 Figure 16
Figure 16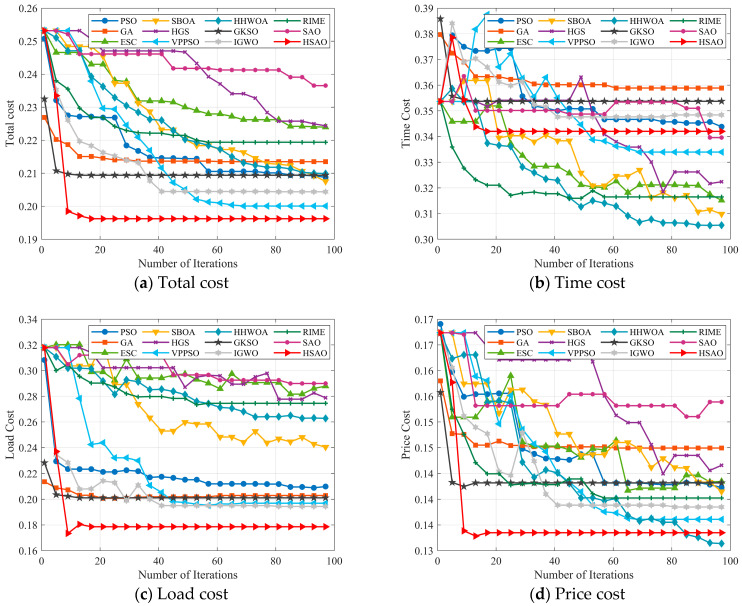 Figure 17
Figure 17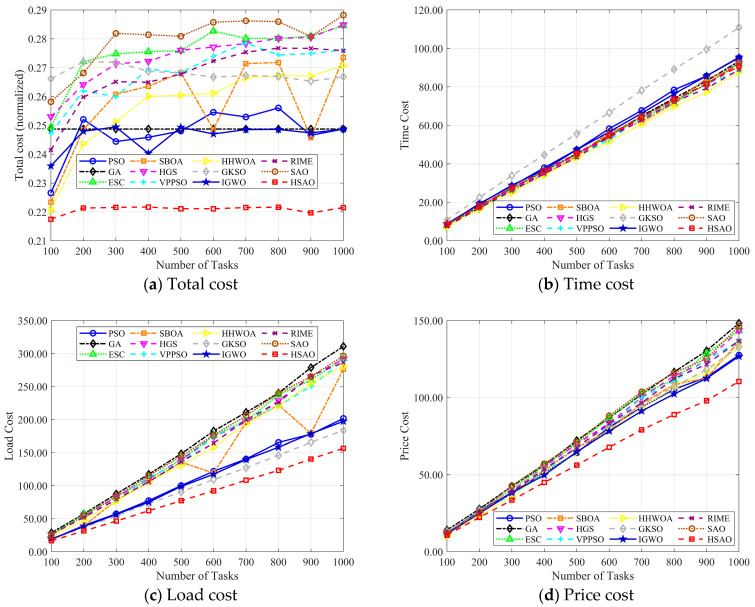 Figure 18
Figure 18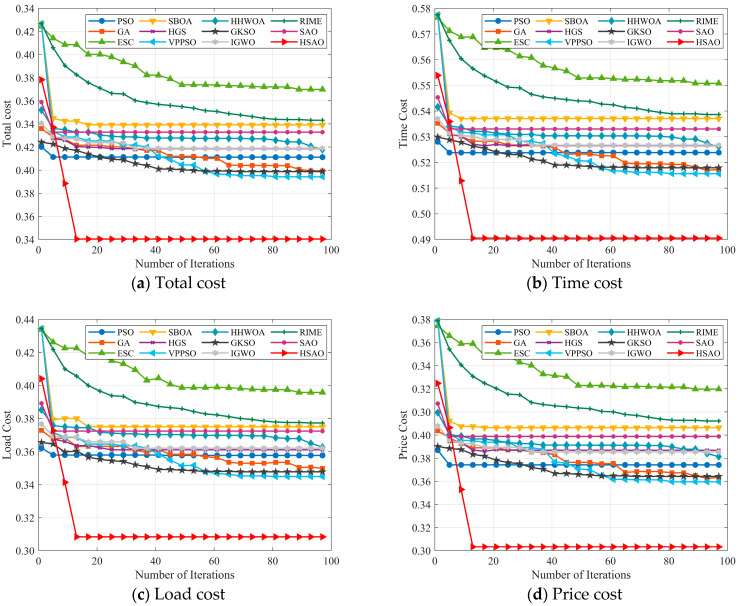 Figure 19
Figure 19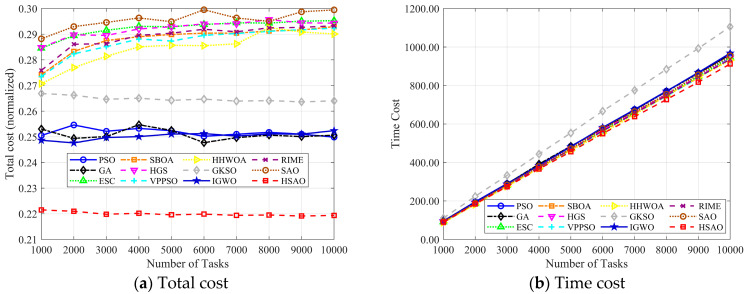 Figure 20
Figure 20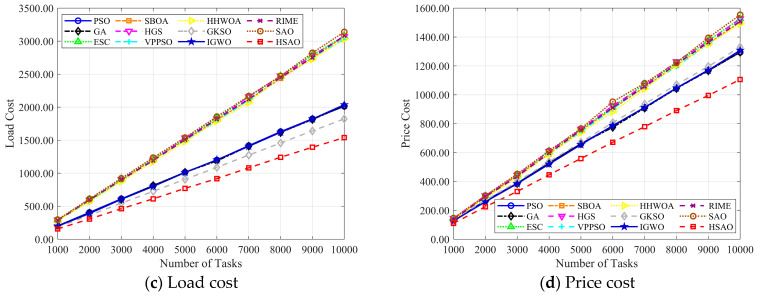 Figure 21
Figure 21Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCloud Computing and Resource Management · Distributed and Parallel Computing Systems · Metaheuristic Optimization Algorithms Research
1. Introduction
In today’s era of surging digital transformation, cloud computing has become a critical technological pillar driving progress across all industries. As cloud computing applications continue to expand—from the financial sector’s stringent demands for data security and compliance, to the manufacturing industry’s urgent need for enhanced data processing capabilities during digital transformation, to the software testing sector leveraging cloud testing platforms to reduce costs and boost efficiency—the workload and complexity borne by cloud platforms are growing exponentially. Against this backdrop, cloud task scheduling emerges as a core component determining the performance of cloud computing systems; its importance is becoming increasingly prominent.
Reasonable cloud task scheduling enables balanced resource allocation, preventing situations where some resources are overloaded while others remain idle and underutilized. This significantly improves resource utilization and reduces operational costs for businesses. To deliver high-quality services for IoT artificial intelligence devices, cloud computing can strike a balance between the limited computational resources at the network edge and the high latency caused by geographical distance to the cloud [1]. In the financial sector, through precise task scheduling, financial institutions can efficiently allocate tasks to public cloud resources during peak business periods to ensure smooth transactions [2]. During off-peak periods, core tasks are securely placed on private clouds to safeguard data security and effectively control costs. For the manufacturing sector, leveraging intelligent task scheduling enables real-time production data to be securely stored in private clouds while non-core analytical tasks are offloaded to public clouds for enhanced efficiency [3]. This approach significantly advances both production efficiency and innovation capabilities.
Meanwhile, efficient cloud task scheduling can significantly reduce task execution time, enabling rapid response to dynamic changes in business demands and effectively safeguarding business continuity and competitiveness. To address the challenge of generating delay-sensitive and energy-intensive tasks from AIoT devices within enterprise management systems, Dai et al. proposed a cloud-assisted fog computing framework featuring task offloading and service caching [4]. This framework minimizes task latency and energy consumption by leveraging dynamic service caching. To maximize the quality of experience for resource-constrained users, since each user focuses on maximizing their own QoE, Chen et al. defined the problem as a multi-user task offloading game. They proposed a game-based decentralized task offloading (GDTO) method to obtain Nash equilibrium offloading strategies, ensuring system performance guarantees under worst-case scenarios [5]. For IoT devices handling numerous computation tasks with stringent latency requirements, cloud computing can offload complex computations from IoT devices to mobile edge computing. Wu et al. employed the energy-efficient dynamic task offloading (EEDTO) algorithm using Lyapunov optimization techniques to jointly reduce energy consumption and task response time [6].
Moreover, with the deep integration of emerging technologies such as big data, artificial intelligence, and the Internet of Things with cloud computing, the types of tasks in cloud environments are becoming increasingly diverse. Challenges like data migration and security privacy continue to emerge, placing higher demands on the intelligence, flexibility, and security of cloud task scheduling. Therefore, in-depth research into cloud task scheduling mechanisms is not only a theoretical necessity for optimizing cloud computing system performance but also an urgent practical requirement for driving digital transformation across industries and achieving efficient development. It holds immeasurable significance for enhancing societal operational efficiency and promoting high-quality economic development. The existing methods for solving scheduling problems primarily encompass six major categories: dynamic programming, probabilistic algorithms, heuristic methods, metaheuristic algorithms, hybrid algorithms, and machine learning (ML) [7]. Among the six major solution approaches for cloud task scheduling problems, heuristic methods demonstrate significant advantages in addressing the dynamic and complex challenges of tasks and resources in cloud environments due to their unique design logic. They have thus become one of the most widely applied scheduling strategies in practical scenarios. For instance, to address energy losses caused by transmission delays and multi-hop forwarding in cloud computing, Wen et al. proposed a cloud-edge-device collaborative task offloading strategy based on genetic algorithms and particle swarm optimization [8]. This approach optimizes both task response time and execution energy consumption under resource-constrained environments, reducing the objective function value by approximately 6–12%. To reduce operational costs and enhance user experience in cloud environments, Qin et al. proposed an enhanced red-tailed hawk algorithm (ERTH) based on multiple elite strategies and chaotic mapping to optimize task scheduling efficiency in cloud computing [9]. Experiments demonstrated that for tasks of varying scales, the ERTH algorithm reduced total system costs by 34.8% and 36.4%, respectively, compared to traditional algorithms. Additionally, Hosny et al. also proposed an enhanced whale optimization algorithm to optimize dependency task offloading in multi-edge cloud computing environments [10]. In summary, heuristic methods serve as a pivotal bridge connecting theoretical research in cloud task scheduling with industrial practice, leveraging three key advantages: efficient adaptation to dynamic environments, balanced efficiency and quality, and flexible handling of heterogeneous demands. Particularly in medium-to-large-scale, dynamically evolving cloud scenarios, their value far surpasses algorithms solely pursuing “theoretical optimality,” making them one of the preferred solutions for enterprises addressing practical scheduling challenges today.
The snow ablation optimizer (SAO) [11], as a physics-based metaheuristic algorithm, has demonstrated excellent performance and is widely applied in drone path planning [12], mobile robot path planning [13], power system optimization for generation scheduling [14], and photovoltaic power forecasting optimization problems [15]. However, due to the No Free Lunch theorem, SAO is prone to getting stuck in local optima when tackling cloud resource scheduling and complex multimodal function problems, resulting in suboptimal performance. This paper aims to propose targeted improvements for the cloud computing task scheduling problem we need to address. The RIME optimization algorithm is also a physics-based approach. By simulating the growth processes of rime ice—soft rime and hard rime—it constructs a soft rime search strategy and a hard rime pruning mechanism to achieve exploration and exploitation behaviors in the optimization method. It is widely applied in problems such as feature selection [16], training of extreme learning machines [17], and operational optimization of microgrid hybrid energy storage systems [18].
Based on the above research, this paper proposes a hybrid SAO and RIME optimizer for cloud task scheduling problems. The specific contributions are as follows.
Population initialization based on ecological niche differentiation is proposed to enhance the initial population quality of SAO, enabling it to better explore the solution space.The introduction of the soft frost search strategy and hard frost piercing mechanism from the RIME optimization algorithm enables the algorithm to better escape local optima and accelerate its convergence.A population-based collaborative boundary control method is proposed to handle outlier individuals, preventing them from clustering at the boundary and enabling more effective exploration of the solution space.The algorithms were qualitatively analyzed using 30 test functions from the IEEE CEC2017 test set and compared with 11 other algorithms to obtain competitive results. Most importantly, the algorithms were statistically analyzed to fully analyze the superior performance of HSAO.HSAO was applied to solve cloud computing task scheduling problems to prove its engineering applicability.
The next part of this paper is organized as follows: Section 2 gives a brief introduction of SAO and RIME; Section 3 gives a detailed introduction of the hybrid strategy in this paper; in Section 4, we apply the HSAO in global optimization experiments and analyze the experimental results in detail; in Section 5, we apply the algorithm to cloud computing task scheduling problems and provide a comprehensive analysis of its advantages and disadvantages; in Section 6, we summarize and provide an outlook of the work in this paper to clarify the direction of future work.
2. Snow Ablation Optimizer (SAO)
Since the HSAO proposed in this paper is an improvement upon SAO, this subsection provides a brief introduction to SAO. SAO is a nature-inspired algorithm that primarily simulates the sublimation and melting behavior of snow to explore and develop the solution space. Its robust performance has been demonstrated through the extraction of core parameters for photovoltaic systems.
2.1. Initialization Stage
In SAO, the initial population is generated randomly by modeling the entire population as an rows, Dim columns matrix, specifically represented by Equation (1).
where and represent the upper and lower bounds of the problem, respectively. represents a random number between 0 and 1. represents the population size, and represents the problem dimension.
2.2. Exploration Stage
This section details the exploration strategy within SAO. When snow or liquid water vaporizing into steam is present, the search agents exhibit highly dispersed behavior due to irregular motion. Brownian motion is employed to simulate this scenario, with the corresponding mathematical model expressed as Equation (2).
By employing dynamic and uniform stride lengths, Brownian motion can explore certain potential regions within the search space. Consequently, it effectively reflects the diffusion behavior of steam throughout the search domain. Position updates during exploration are implemented via Equation (3).
where denotes the -th individual in the -th iteration; refers to individuals randomly selected from a group of several elite members within a population, and it can be expressed through Equation (4). is a Gaussian-distributed random Brownian motion. represents a random number between 0 and 1. indicates the current optimal solution. represents the position of the center of mass for the entire population, and it can be calculated through Equation (5).
where and represent the second-best and third-best individuals in the population, respectively. denotes the centroid position of individuals ranked in the top 50% by fitness value and can be calculated through Equation (6).
where represents the number of leaders, which in SAO is set to half the population size.
2.3. Exploitation Stage
In this phase, the author uses the melting behavior of snow to simulate the algorithm development stage. The degree-day method, as one of the most classic snowmelt models, is employed to reflect the snowmelt process. Specifically, it can be expressed as Equation (7).
where represents the snowmelt rate, a key parameter for simulating snowmelt behavior during the development phase. denotes the daily average temperature and represents the base temperature, while 111 denotes the degree-day factor within the range of 0.35 to 0.6. In each iteration, the updated value of the can be expressed as Equation (8).
where indicates the current iteration count and indicates the maximum iteration count. In SAO, an adaptive parameter is used to represent the average daily temperature, so the snowmelt rate can be expressed as Equation (9).
Therefore, during the development phase, the position update formula for individuals in the population can be expressed as Equation (10).
where represents a random number between −1 and 1. This parameter facilitates communication between individuals.
2.4. Dual-Population Mechanism
In genetic heuristic algorithms, achieving a balance between exploration and exploitation is crucial. In SAO, the authors employ a dual-population mechanism to reflect this balance and maintain both exploitation and exploration. During the early stages of iteration, the entire population is randomly split into two subpopulations of equal size. Subsequently, in later iterations, the number of individuals in the exploration-focused population gradually increases, while the number in the exploitation-focused population gradually decreases. The specific details can be represented by Algorithm 1. Algorithm 1: Dual-population mechanism1: Initialize: , , , where denotes the population size. 2: While do 3: if then 4: , 5: End if 6: 7: End While
In summary, the position update of SAO can be expressed using Equation (11). The pseudocode for the SAO algorithm can be represented as Algorithm 2.
where denotes the population used for exploration, while denotes the population used for exploitation.Algorithm 2: Pseudo-code of SAO1: Initialize: The relevant parameters and population 2: Fitness evaluation 3: Record the current best individual 4: While do 5: Calculate the snowmelt rate 6: Randomly divide the population into two subpopulations7: for each individual do8: Update each individual’s position9: end for10: Fitness evaluation 11: Update 12: 13: end while 14: Return
3. Proposed HSAO
The original SAO algorithm exhibits excellent performance and a simple structure, demonstrating strong capabilities in solving unconstrained benchmarks and real-world constrained optimization problems and extracting core parameters from photovoltaic models. However, when tackling complex cloud task scheduling problems, it tends to get stuck in local optima, resulting in lower convergence accuracy. To address these issues, we propose a novel hybrid algorithm (HSAO) by combining it with the RIME optimization algorithm. The specific details are as follows.
3.1. Population Initialization Based on Ecological Niche Differentiation
The niche differentiation-based population initialization method is a strategy inspired by the biological phenomenon of “niche partitioning.” Its core principle involves simulating the natural mechanism by which species avoid competition through occupying distinct resource spaces (niches), ensuring the initial population is uniformly distributed across the solution space and covering more potential areas. In this subsection, we control the minimum distance between individuals through the “niche width threshold” to ensure each occupies a unique ecological niche. The niche threshold for the i-th individual can be expressed as Equation (12). Initially, the first individual in the population is generated randomly. When subsequent individuals are generated, their proximity to all existing individuals is first calculated. If all distances are greater than or equal to the threshold, the new individual is deemed to occupy a novel ecological niche and is accepted into the population. Otherwise, it is rejected and regenerated. The distance between two individuals within a population can be calculated using Equation (14).
where is the initial threshold, calculated using Equation (13); is the decay coefficient, which is a constant value of 2; is the generation progress of the population.
Repeat this process until the final initial population is generated. Figure 1 illustrates a schematic diagram of the population initialization strategy based on niche differentiation.
3.2. Frost Growth Mechanism Based on the RIME Optimization Algorithm
RIME is an optimization algorithm inspired by the growth mechanisms of frost and ice in nature [19]. It leverages the randomness of soft frost and the regularity of hard frost for search, enhancing algorithmic performance through soft frost search strategies and hard frost pruning mechanisms. Extensive experiments on test sets and PVD problems demonstrate RIME’s high efficiency. In this subsection, we address the issue that SAO tends to get stuck in local optima in complex problems, resulting in lower convergence accuracy. We enhance the SAO algorithm by incorporating RIME’s soft frost search and hard frost piercing mechanisms.
Soft Frost Search Strategy: In a gentle breeze environment, soft frost exhibits highly random growth patterns which allow frost particles to freely cover object surfaces while growing slowly in the same direction. Drawing inspiration from these growth characteristics, a soft frost search strategy is proposed. By leveraging the strong randomness and coverage properties of frost particles, the algorithm rapidly covers the entire search space, avoiding local optima. Its mathematical model can be expressed as Equation (15).
where and are random numbers between 0 and 1 used to introduce strong randomness into the algorithm, enabling it to better escape local optima. represents the wind angle, which can be calculated using Equation (16); is the step function in mathematical modeling, and it can be calculated using Equation (17).
where is the current iteration count, is the maximum iteration count, and w is a default constant with a value of 5. is the adhesion coefficient, which influences the probability of condensation and can be calculated using Equation (18).
Hard Frost Puncture Mechanism: Under these conditions, in strong wind environments, hard frost growth becomes simpler and more regular, while soft frost growth becomes more random. Hard frost agents grow in a snowball-like manner along the same direction and are prone to penetration phenomena. Therefore, simulating this mechanism accelerates algorithm convergence. It can be expressed by Equation (19).
where represents a random number between 0 and 1, while denotes the normalized fitness value of individual .
3.3. Population-Based Collaborative Boundary Control Method
In intelligent optimization algorithms, boundary control serves as the core technique for addressing the issue of individuals exceeding boundaries during the optimization process. SAO employs the clipping method for boundary control, primarily focusing on passive corrections at the “individual level.” This approach only isolates individuals that have already crossed boundaries, potentially leading to reduced population diversity and local optima traps.
Population collaborative boundary control is an active boundary regulation strategy based on the “population level.” Its core concept is to avoid treating individual boundary-violating entities in isolation. Instead, it establishes collaborative mechanisms among individuals within the population. Through information exchange, resource sharing, or coordinated correction, boundary-violating entities interact with other members of the population to achieve boundary compliance and performance optimization through “collective intelligence.” This approach breaks away from traditional “isolated individual correction” models by deeply integrating boundary control with population evolution and information transmission. It is particularly well-suited for high-dimensional, multi-modal, and complex-constrained optimization problems. Based on the above concept, outlier individuals can be corrected using Equation (20).
where represents the weight for retaining outlier individual information, set to 0.3. represents the average of all high-quality individuals in the collaboration, it can be expressed by Equation (21). represents the random disturbance coefficient, preventing excessive convergence among individuals after correction. represents a uniformly distributed random number between −1 and 1, used to enhance population diversity.
where indicates the number of high-quality individuals. Figure 2 illustrates a schematic diagram of the population-based collaborative boundary control method. Figure 3 illustrates the execution flow of the HSAO algorithm.
3.4. Time Complexity of HSAO
Time complexity analysis serves as the “bridge” connecting the theoretical design of intelligent optimization algorithms to their practical application, and it is a major criterion for evaluating algorithm performance. In this subsection, we analyze the time complexity of HSAO. Its time complexity primarily consists of the following components: initialization, individual position update, fitness evaluation, and fitness sorting. During the initialization phase, each dimension of every individual must be initialized, resulting in a time complexity of , The time complexity of updating individual positions is . The time complexity of fitness evaluation and fitness sorting is and , respectively. denotes the population size. denotes the dimension of the problem. In summary, the time complexity of HSAO is .
4. Experimental Results and Detailed Analyses
In this section, with the aim of assessing the performance of the HSAO algorithm proposed in this study, a global optimization experiment is carried out using the CEC2017 test suite. Firstly, a concise overview of the test suite functions is presented, and the configuration details of comparative algorithms and parameters are elaborated; secondly, experiments are conducted to perform a comparative analysis of the HSAO algorithm and 11 other competing algorithms; finally, statistical analysis is implemented to fully verify the superior performance of the HSAO algorithm. To guarantee the fairness of the experiments, the population size of all comparative algorithms is uniformly set to 50, and the maximum number of iterations is fixed at 1000 in the experimental analysis. All experiments are conducted using the MATLAB 2023a platform with a 2.90 GHz Intel Core i7-10700F CPU and 8 GB of RAM.
4.1. Benchmark Test Functions
The CEC2017 test suite is a widely recognized and extensively used benchmark for evaluating the performance of global optimization algorithms, developed by the IEEE Computational Intelligence Society (CIS) Evolutionary Computation Technical Committee (ECTC) [20]. It comprises 30 diverse test functions, systematically categorized into four types to comprehensively assess different algorithm capabilities: unimodal functions (10) that test convergence speed and local search precision by lacking local optima, basic multimodal functions (10) that examine global exploration ability through multiple local optima, hybrid functions (5) that combine characteristics of basic functions to simulate complex real-world scenarios, and composition functions (5) that integrate transformed basic functions to challenge algorithms’ adaptability to non-uniform landscapes and multi-scale optima. With standardized parameter settings, clear evaluation metrics (e.g., error value, success rate), and strong representativeness of real-world optimization problems (such as engineering design, resource allocation), CEC2017 has become a core tool in the field of evolutionary computation and swarm intelligence, enabling fair and rigorous comparative analysis of newly proposed algorithms (e.g., heuristic, metaheuristic methods) against classical or state-of-the-art counterparts. Therefore, this paper selects CEC2017 as the test set for global optimization.
4.2. Competitor Algorithms and Parameter Setting
In this section, we compare the algorithm proposed in this paper with 11 other optimization algorithms to evaluate the performance of HSAO. To conduct a comprehensive comparison, we selected algorithms based on group behavior, including the red-tailed hawk algorithm (RTH), weighted mean of vectors (INFO), secretary bird optimization algorithm (SBOA), Hunger Games Search (HGS), and Genghis Khan shark optimizer (GKSO); algorithms based on physical phenomena including the escape optimization algorithm (ESC), RIME optimization algorithm (RIME), and snow ablation optimizer (SAO); and hybrid and improved algorithms including velocity pause particle swarm optimization (VPPSO), HHWOA, and the Improved Grey Wolf Optimizer (IGWO). Table 1 summarizes the parameter settings of these algorithms for easier reading.
4.3. Strategy Effectiveness Analysis
Erasure experiments constitute an indispensable core component within algorithm verification frameworks. Their fundamental purpose lies in systematically removing individual modules and comparing algorithmic performance before and after each removal, thereby precisely identifying the actual contribution and necessity of each component. This approach serves to validate the efficacy of each strategy and determine whether redundant design elements exist within the algorithmic architecture.
Therefore, in this subsection, we conduct a policy effectiveness analysis of HSAO. By comparing the policy effectiveness of SAO, RIME, the algorithm incorporating the first policy (designated as SAO1), the algorithm incorporating the second policy (designated as SAO2), and the proposed HSAO, the convergence curves for each algorithm are presented in Figure 4. The experimental results demonstrate that in 10-dimensional scenarios, the algorithms frequently locate the global optimum. However, HSAO converges more rapidly than SAO, SAO1, and SAO2. When confronting high-dimensional complex function problems where algorithms struggle to identify the global optimum, HSAO achieves higher convergence accuracy than the other comparison algorithms. Considering the four dimensions collectively, HSAO demonstrates a superior performance. Furthermore, ablation experiments indicate no redundant design elements across each strategy, confirming that every strategy constitutes an effective innovation.
4.4. Compare Using CEC2017 Test Functions
In this section, we assess the performance of the HSAO algorithm via the CEC2017 test suite and conduct a comparative analysis between it and 11 other competing algorithms. The outcomes of the experiments are tabulated in Table 2, Table 3, Table 4 and Table 5. Among these, mean and Std represent the mean and standard deviation, respectively, obtained by running the algorithm independently 30 times. To intuitively exhibit the speed fluctuations throughout the convergence process, Figure 5 depicts the convergence velocities of the 12 algorithms in a three-dimensional space. For the purpose of further evaluating the stability of the algorithms across multiple runs, Figure 6 presents boxplots of the 12 algorithms following 30 iterations.
The experimental results show that in the 10-dimensional case, for unimodal function F1 (a), which emphasizes convergence speed, HSAO demonstrates a rapid decline in average fitness value from the initial stage, swiftly approaching the optimal solution and maintaining a stable lead throughout the iterations, outperforming counterparts like RTH and INFO. In dealing with multimodal function F10 (b), where escaping local optima is crucial, HSAO’s curve not only decreases steeply at the beginning but also avoids stagnation in local optima, showcasing superior global exploration capability compared to algorithms such as SBOA and HGS. Overall, in the 10-dimensional setting, HSAO shows remarkable advantages in convergence speed, global exploration, and adaptability to complex problem spaces compared with the other algorithms. In the case of hybrid function F7 (i) and composition function F16 (j), which integrate multiple function traits to mimic intricate real-world scenarios, HSAO consistently shows a smooth and rapid descent in average fitness value, reflecting its strong adaptability to non-uniform and complex landscapes. Even for the highly challenging F19 (k) and F24 (l), HSAO’s average fitness value decreases swiftly and stabilizes at a relatively low level, indicating its robustness in handling multi-scale optima and maintaining solution quality in diverse problem settings. In a 50-dimensional scenario, in the case of hybrid function F13 (m) and composition function F16 (n), which combine multiple function characteristics to simulate complex real-world scenarios, HSAO consistently exhibits a smooth and fast-descending trend in average fitness value, reflecting its strong adaptability to non-uniform landscapes. Even for the highly challenging F20 (o) and F26 (p), HSAO’s average fitness value decreases swiftly and stabilizes at a relatively low level, indicating its robustness in handling multi-scale optima and maintaining solution quality in various problem settings.
The boxplots in the figure present the performance of the HSAO algorithm and other comparative algorithms (such as RTH, INFO, ESC, etc.) on different CEC2017 test functions under 10-dimensional, 30-dimensional, 50-dimensional, and 100-dimensional settings. In the 10-dimensional scenarios Figure 6a–d, for functions F7, F10, F16, and F26, the boxplot of HSAO consistently shows several notable advantages: the median (the line inside the box) is at a significantly lower position compared to most other algorithms, indicating that the average fitness value of HSAO is better. The box itself is relatively narrow, which implies that the algorithm has good stability in multiple runs, with small fluctuations in results. Moreover, there are few or no outlier points (marked by “+”), suggesting that HSAO rarely produces extreme values in the optimization process, further reflecting its robustness. When transitioning to the 30-dimensional setting Figure 6e–f for functions F5 and F7, HSAO still maintains these superior characteristics. Its boxplot remains at a lower fitness value level, the box is compact, and there are almost no outliers. This demonstrates that even as the problem dimension increases (from 10 to 30, which greatly increases the complexity of the optimization problem), HSAO can still achieve excellent optimization results with high stability, fully showcasing its strong adaptability and competitiveness in solving high-dimensional complex optimization problems. In the 50-dimensional scenarios Figure 6m–p, for functions F11, F17, F27, and F28, the boxplot of HSAO exhibits remarkable advantages: the median (the line within the box) is positioned at a much lower level compared to most other algorithms, signifying that the average fitness value of HSAO is superior. The box is relatively narrow, indicating that the algorithm has good stability in multiple runs with small result fluctuations. Additionally, there are few or no outlier points (marked by “+”), which reflects the robustness of HSAO as it rarely generates extreme values during the optimization process. When moving to the 100-dimensional setting Figure 6q–t for functions F4, F10, F16, and F23, HSAO still maintains these excellent features. Its boxplot remains at a lower fitness value level, the box is compact, and there are almost no outliers. This shows that even when the problem dimension increases significantly (from 50 to 100, which greatly enhances the complexity of the optimization problem), HSAO can still achieve outstanding optimization results with high stability, fully demonstrating its strong adaptability and competitiveness in addressing high-dimensional complex optimization problems.
Table 2, Table 3, Table 4 and Table 5 present the mean and standard deviation of fitness values for multiple algorithms (including HSAO, RTH, INFO, ESC, etc.) across all 30 functions of the CEC2017 test suite. HSAO demonstrates a superior performance: in terms of optimization accuracy, it achieves notably lower mean fitness values compared to most other algorithms across the majority of functions; regarding stability, its standard deviation values are relatively small for most functions, indicating high consistency in performance across multiple runs. In contrast, other algorithms like RTH and INFO often have much larger mean and standard deviation values, showing both lower optimization accuracy and poorer stability compared to HSAO. Overall, HSAO outperforms the other comparative algorithms in both optimization accuracy and stability across the vast majority of CEC2017 test functions.
4.5. Statistical Analysis
To ascertain if the performance disparities among different algorithms hold statistical significance, in this subsection, we carried out statistical analyses on HSAO. Specifically, we implemented the Wilcoxon rank-sum test and the Friedman mean rank test. The particulars are as follows.
4.5.1. Wilcoxon Rank Sum Test
In this subsection, we conducted the Wilcoxon rank sum test on HSAO. The Wilcoxon rank sum test, also called the Mann–Whitney U test, is a nonparametric statistical hypothesis test [30]. It aims to compare if two independent samples come from the same population or if there is a significant difference in their distributions, which is useful in scenarios like algorithm performance comparison. It assumes independence between the two samples and can handle ordinal data, as well as interval-scaled or ratio-scaled data that do not meet parametric test assumptions (e.g., normal distribution). The test process involves combining and ranking data from both samples (assigning average ranks to tied values), calculating the sum of ranks for one sample and then the test statistic using (where is the size of the first sample) and determining significance by comparing with critical values from a table based on sample sizes and a chosen significance level (set ). While it is flexible for unknown or non-normal data distributions and ordinal data, it has lower statistical power than parametric tests (like the two-sample t-test) when data meet parametric assumptions. When p < 0.05, the null hypothesis is rejected, indicating a significant difference between the two algorithms. Otherwise, the null hypothesis is accepted, indicating no significant difference between the two algorithms. The p-value statistics for the 11 algorithms across the four dimensions are presented in Table 6, Table 7, Table 8 and Table 9. The experimental results show that the HSAO proposed in this paper has significant advantages over other comparison algorithms.
Looking at the table, for most functions, the p-values when comparing HSAO with other algorithms are extremely small (many are on the order of where is a positive integer, far below 0.05). This suggests that HSAO demonstrates statistically significant superiority over most of the other algorithms across the majority of the CEC2017 test functions in the 10-dimensional, 30-dimensional, 50-dimensional, and 100-dimensional case, meaning the better performance of HSAO is not due to random chance but reflects its inherent advantages in solving high-dimensional optimization problems.
4.5.2. Friedman Mean Rank Test
The Friedman mean rank test is a nonparametric statistical method proposed by Milton Friedman in 1937 [31]. Its core application involves analyzing multiple related samples from repeated experiments to test whether the overall distributions across treatment groups exhibit significant differences. It serves as an alternative to two-way ANOVA when prerequisites such as normal distribution and homogeneity of variance are not met. The principle involves ranking observations by treatment within blocks according to their ranks, enabling effective differentiation of performance variations among algorithms. Therefore, in this subsection, we performed the Friedman mean rank test on HSAO. The experimental results are shown in Figure 7.
Figure 7 shows the ranking of HSAO and other algorithms across four dimensions on the CEC2017 test set. The values on the bar chart represent the average F-rank for each algorithm across 30 functions. Based on the average rankings across the four different dimensions, HSAO exhibits a significant and stable gap compared to other algorithms. Across all dimensions, HSAO consistently achieves the lowest average ranking among all algorithms. Meanwhile, both SAO and RIME algorithms maintain relatively high average rankings, indicating that HSAO represents an improvement over SAO and RIME while demonstrating exceptional stability.
5. HSAO for Cloud Task Scheduling
To overcome the challenges of cloud computing task scheduling, this section first sets up a multi-objective task scheduling model, and then performs simulation experiments with the adoption of the HSAO algorithm. The specific procedures are listed as follows:
5.1. Cloud Computing Task Scheduling Model
Cloud computing task scheduling is one of the core technologies in cloud resource management. Its essence lies in rationally allocating massive computational tasks across various resource nodes within the cloud computing environment based on predefined cost targets. This process aims to maximize resource utilization, optimize task execution efficiency, or achieve precise alignment with business requirements. In this subsection, we are given a set of tasks and assign them to available virtual machines, where represents computing resource nodes, represents computing tasks, and . Task scheduling under cloud computing can be represented by the following matrix.
In matrix , when , it indicates that task is executed on virtual machine . This section defines the attributes of each resource node, including processing capacity, initial memory, and resource bandwidth. Without loss of generality, the resources of a virtual machine can be represented as processing capacity , load capacity , and resource bandwidth . The computational requirements, size, and resource bandwidth requirements of each task can be expressed as .
Time Cost: In cloud computing task scheduling, time cost is a key metric for evaluating both system performance and user experience. For users, a lower time cost means that tasks can be completed more quickly, thereby meeting the requirements of real-time performance and Quality of Service (QoS). For service providers, optimizing time cost can improve resource utilization, reduce task congestion and delays, and ultimately enhance overall system throughput and economic efficiency. Therefore, the time cost in this model can be expressed by Equation (23).
Load Cost: In cloud computing task scheduling, load cost is one of the core factors affecting system efficiency and stability. For users, a reasonable load distribution can prevent tasks from being concentrated on specific nodes, thereby reducing performance degradation caused by resource contention and ensuring Quality of Service (QoS). For service providers, optimizing load cost can enhance the utilization of computing, storage, and network resources, avoid resource waste due to node overload or idleness, and ultimately improve overall system throughput and scalability. Therefore, the load cost in this model can be expressed by Equation (24).
Price Cost: In cloud computing task scheduling, price cost is one of the key factors influencing user decision-making and service provider profitability. For users, a reasonable price cost means completing tasks with lower expenses while meeting computing requirements and Quality of Service (QoS), thereby enhancing user experience and reducing financial burden. For service providers, optimizing price cost is not only related to the rationality of resource pricing strategies but also directly affects market competitiveness and profitability. By incorporating price cost into task scheduling, a balance between user expenses and resource utilization can be achieved to promote sustainable development and create a win–win situation in cloud computing environments. Therefore, the price cost in this model can be expressed by Equation (25).
where represents the value of the -th task, represents the value of the -th virtual machine, represents the value of the -th task, represents the value of the -th virtual machine, represents the value of the -th task, and represents the value of the -th virtual machine. Since the values of the three indicators vary greatly, they need to be normalized when used in the fitness function. The normalization of the above three objective functions can be expressed as follows:
In summary, the objective function in this section can be expressed as:
where , , and represent the weight values of , , and , respectively, and . Drawing upon the work of Qin et al., in our experiments we set the values of , , and to 0.33, 0.33, and 0.33, respectively. Therefore, is the optimal scheme for cloud computing task scheduling.
In the following experiments, we apply various optimization algorithms to cloud computing scheduling problems. Our cloud task scheduling problem involves M resource nodes and N tasks. The objective of the algorithms is to find an optimal mapping scheme between tasks and resources. Thus, each individual in the population represents a complete task scheduling plan. In each iteration, the actual scheduling method is selected by evaluating the fitness of each plan to determine the relative quality of scheduling solutions.
5.2. Analysis of Experimental Results
In this section, we assess the performance of HSAO and benchmark it against several existing approaches through a series of simulation experiments. The evaluation criteria employed to measure algorithm performance consist of three aspects: time cost, load cost, and price cost. Ultimately, the overall cost is derived from these three components. The specifics are outlined as follows.
5.2.1. Comparison with Small-Scale Tasks
In this section, we perform a comprehensive assessment of the algorithm’s performance on small-scale tasks, examining its convergence behavior and comparing the costs associated with dynamic variations in task numbers. The details are presented as follows:
Convergence behavior analysis: In this section, we investigate the convergence behavior of the algorithms. To maintain a fair comparison, the number of tasks is fixed at 100, and the maximum number of iterations is set to 100. Subsequently, the convergence of HSAO is compared with that of six other algorithms. The experimental results are illustrated in Figure 8.
Figure 8a–d shows the changes in total cost, time cost, load cost, and price cost as the number of iterations increases, with 100 tasks. As shown in Figure 7a, most of the compared algorithms gradually reduce the total cost during the iterations and eventually reach stability, whereas the proposed HSAO algorithm demonstrates the best performance in terms of both convergence speed and optimization accuracy. Specifically, HSAO rapidly decreases the total cost in the early iterations and converges to the lowest value (around 0.195) within relatively few iterations, while maintaining stability without noticeable oscillations. In contrast, although algorithms such as ESC and VPPSO also achieve relatively low costs, their overall performance is still inferior to HSAO, and methods like RIME and HGS converge more slowly with higher final costs. Overall, HSAO outperforms the other algorithms significantly in convergence efficiency, optimality, and stability.
As shown in Figure 8b, most algorithms gradually reduce the time cost during the iterations, but significant differences exist in their convergence speed and final results. HSAO rapidly decreases the time cost at the early stage and reaches a stable value within relatively few iterations, with a smooth curve and no oscillations, demonstrating superior convergence efficiency and stability. In contrast, algorithms such as ESC and VPPSO converge more slowly with fluctuations, while RIME and HGS achieve relatively poor final results. Figure 8c illustrates the trend of load cost. HSAO quickly reduces the load cost at the beginning and ultimately converges to the lowest value (around 0.17), maintaining stability throughout the iterations, which makes it the best-performing algorithm. Although ESC also shows a relatively fast reduction in the early stage, its final result remains higher than that of HSAO. Algorithms such as SBOA, HGS, and RIME converge more slowly with higher final values, indicating their limited ability in optimizing task load balancing. As shown in Figure 8d, HSAO also demonstrates significant advantages in price cost. It converges to the lowest value (around 0.13) within a few iterations and remains stable in subsequent iterations, highlighting its effectiveness in reducing user expenses and enhancing economic efficiency. In contrast, ESC and GKSO also achieve relatively good results in the later stages, but their overall performance is still inferior to HSAO, while algorithms such as RIME and HGS show much poorer convergence outcomes.
Comparing the costs of dynamic changes in the number of tasks: In this part, we carried out experiments by changing the quantity of tasks. Figure 9 shows how the four indicators of each algorithm change when the number of cloud computing tasks rises from 100 to 1000. Figure 9a demonstrates that the HSAO algorithm (marked by the red box) exhibits an outstanding performance in total cost. Its total cost curve consistently maintains the lowest position across all task quantities and shows minimal fluctuation as the number of tasks increases. This indicates that HSAO reliably achieves excellent cost efficiency regardless of task scale variations.
To comprehensively assess the performance of various algorithms under different task scales, we conducted experiments by varying the number of cloud computing tasks from 100 to 1000. Figure 9b–d, respectively, illustrate the changes in time cost, load cost, and price cost of each algorithm as the number of tasks increases. The time cost of most algorithms shows a rising trend with the increase in task quantity. Among them, the HSAO algorithm (marked by red squares) maintains a relatively low and stable time cost compared to other algorithms. For instance, algorithms like SAO (brown line) and GKSO (gray line) exhibit a steeper upward trend in time cost as tasks increase, indicating that HSAO has better efficiency in terms of time consumption when handling growing tasks. As the number of tasks expands, the load cost of all algorithms generally increases, which is reasonable as more tasks bring heavier loads. However, the HSAO algorithm still stands out: its load cost curve (red squares) rises at a slower rate and remains at a lower level compared to algorithms such as PSO (blue line) and SBOA (orange line). This suggests that HSAO can more effectively manage the load even when facing a large number of tasks. Similar to the previous metrics, the price cost also increases with the growth in task numbers. The HSAO algorithm demonstrates superior performance here as well—it has the lowest price cost throughout the task quantity range, and the increase in its price cost is more gradual compared to algorithms like ESC (green triangles) and IGWO (blue stars). This reflects that HSAO can better control the economic cost in addition to time and load aspects.
In summary, across time cost, load cost, and price cost, the HSAO algorithm consistently exhibits a better performance in terms of cost control and stability compared to other algorithms when dealing with an increasing number of cloud computing tasks.
5.2.2. Comparison with Large-Scale Tasks
In this section, we carry out a thorough evaluation of the algorithm’s performance on large-scale tasks, examining its convergence characteristics and comparing the costs associated with dynamic variations in task numbers. The details are provided as follows:
Convergence behavior analysis: In this section, we examine the convergence behavior of the algorithms. For a fair comparison, the number of tasks is fixed at 100, and the maximum number of iterations is set to 100. We then compare the convergence performance of HSAO with six other algorithms. The experimental results are presented in Figure 10.
As shown in Figure 10a, all algorithms exhibit a decreasing trend in total cost during the iterations, but significant differences exist in convergence speed and final performance. HSAO rapidly decreases at the early stage and stabilizes around 0.34 after approximately 10 iterations, achieving both the fastest convergence speed and the lowest total cost, making it the best among all compared algorithms. In contrast, RIME and HHWOA converge slowly and result in relatively high final costs, showing weaker performance, while algorithms such as ESC and VPPSO achieve some reduction but still remain higher than HSAO. Overall, HSAO demonstrates remarkable superiority in both convergence efficiency and solution accuracy. Figure 10b presents the variation in time cost with the number of iterations, Figure 10c shows the iterative change in load cost, and Figure 10d reflects the iterative situation of price cost. It can be seen from the figures that for each algorithm in different cost dimensions, as the number of iterations increases, the cost shows a downward trend to varying degrees. Moreover, the HSAO algorithm has a fast cost reduction speed and a low final cost in these three subfigures, showing better optimization performance and being able to reduce time, load, and price costs more efficiently.
Comparing the costs of dynamic changes in the number of tasks: In this part, we carried out experiments by changing the quantity of tasks. Figure 10 shows how the four indicators of each algorithm change when the number of cloud computing tasks rises from 1000 to 10,000. Figure 11a demonstrates that the HSAO algorithm (marked by the red box) exhibits an outstanding performance in total cost. Its total cost curve steadily stays at the lowest spot among all task amounts and has very little variation as the number of tasks increases. This shows that HSAO dependably attains remarkable cost efficiency no matter how the task scale changes.
To evaluate the performance of various algorithms under different task scales, we conducted experiments by adjusting the number of cloud computing tasks from 1000 to 10,000. Figure 11b–d depict the variations in time cost, load cost, and price cost for each algorithm as the task quantity increases.
Figure 11b—Time Cost: With the growth in task numbers, the time cost of most algorithms shows an upward trend. Notably, the HSAO algorithm (marked by red squares) has a time cost curve that is consistently lower than other algorithms. For example, algorithms like SAO (brown line) and GKSO (gray line) see their time costs rise more sharply as tasks increase, while HSAO maintains a relatively low and stable time cost, demonstrating better time efficiency when handling expanding tasks.
Figure 11c—Load Cost: As the number of tasks expands, the load cost of all algorithms generally increases, which is expected with more tasks bringing heavier loads. However, the HSAO algorithm still performs exceptionally in that its load cost curve (red squares) rises at a slower pace and stays at a lower level compared to algorithms such as PSO (blue line) and SBOA (orange line), indicating effective load management even with a large number of tasks.
Figure 11d—Price Cost: Similar to the previous metrics, the price cost also increases with the growth of task numbers. The HSAO algorithm stands out here too—it has the lowest price cost throughout the range of task quantities, and the increase in its price cost is more gradual compared to algorithms like ESC (green triangles) and IGWO (blue stars), reflecting better control over economic costs in addition to time and load aspects.
In conclusion, across time cost, load cost, and price cost, the HSAO algorithm consistently shows a superior performance in cost control and stability compared to other algorithms when dealing with an increasing number of cloud computing tasks.
Finally, Table 10 summarizes the full forms of abbreviations frequently used in this paper for the reader’s reference.
6. Conclusions
In this paper, we propose a hybrid SAO and RIME optimizer (HSAO) for global optimization and cloud task scheduling problems. First, population initialization based on ecological niche differentiation is proposed to enhance the initial population quality of SAO, enabling it to better explore the solution space. Then, the introduction of the soft frost search strategy and hard frost piercing mechanism from the RIME optimization algorithm enables the algorithm to better escape local optima and accelerate its convergence. Additionally, a population-based collaborative boundary control method is proposed to handle outlier individuals, preventing them from clustering at the boundary and enabling more effective exploration of the solution space. To evaluate the effectiveness of the proposed algorithm, we compared it with 11 other algorithms using the IEEE CEC2017 test set and assessed the differences through statistical analysis. Experimental data demonstrate that the HSAO algorithm exhibits significant advantages. Furthermore, to validate its practical applicability, we applied HSAO to real-world cloud computing task scheduling problems, achieving excellent results and successfully completing the scheduling planning of cloud computing tasks. In the future, based on HSAO’s outstanding performance, we plan to apply it to more fields, for example, the path planning problem for drones under low-altitude economy through integrated sensing, communication, and computing.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Zhou J. Pal S. Dong C. Wang K. Enhancing Quality of Service through Federated Learning in Edge-Cloud Architecture Ad Hoc Netw.202415610343010.1016/j.adhoc.2024.103430 · doi ↗
- 2Zhu X. Ma F. Ding F. Guo Z. Yang J. Yu K. A Low-Latency Edge Computation Offloading Scheme for Trust Evaluation in Finance-Level Artificial Intelligence of Things IEEE Internet Things J.20241111412410.1109/JIOT.2023.3297834 · doi ↗
- 3Zheng P. Wang H. Sang Z. Zhong R. Liu Y. Liu C. Mubarok K. Yu S. Xu X. Smart Manufacturing Systems for Industry 4.0: Conceptual Framework, Scenarios, and Future Perspectives Front. Mech. Eng.20181313715010.1007/s 11465-018-0499-5 · doi ↗
- 4Dai X. Xiao Z. Jiang H. Alazab M. Lui J. Min G. Dustdar S. Liu J. Task Offloading for Cloud-Assisted Fog Computing With Dynamic Service Caching in Enterprise Management Systems IEEE Trans. Ind. Inform.20231966267210.1109/TII.2022.3186641 · doi ↗
- 5Chen Y. Zhao J. Wu Y. Huang J. Shen X. Qo E-Aware Decentralized Task Offloading and Resource Allocation for End-Edge-Cloud Systems: A Game-Theoretical Approach IEEE Trans. Mob. Comput.20242376978410.1109/TMC.2022.3223119 · doi ↗
- 6Wu H. Wolter K. Jiao P. Deng Y. Zhao Y. Xu M. EEDTO: An Energy-Efficient Dynamic Task Offloading Algorithm for Blockchain-Enabled Io T-Edge-Cloud Orchestrated Computing IEEE Internet Things J.202182163217610.1109/JIOT.2020.3033521 · doi ↗
- 7Zhou G. Tian W. Buyya R. Xue R. Song L. Deep Reinforcement Learning-Based Methods for Resource Scheduling in Cloud Computing: A Review and Future Directions Artif. Intell. Rev.20245712410.1007/s 10462-024-10756-9 · doi ↗
- 8Wen W. Huang Y. Xiao Z. Tan L. Zhang P. GAPSO: Cloud-Edge-End Collaborative Task Offloading Based on Genetic Particle Swarm Optimization Symmetry 202517122510.3390/sym 17081225 · doi ↗