The Impact of Blame Attribution on Moral Contagion in Controversial Events
Hua Li, Qifang Wang, Renmeng Cao

TL;DR
This paper explores how blaming individuals or structures affects the spread of controversial events on social media, using data from Weibo.
Contribution
The study introduces blame attribution as a key factor in moral contagion and provides cross-issue evidence from Chinese social media.
Findings
Moral contagion is strongest in street-level bureaucracy events with individual blame attribution.
Unverified accounts amplify the spread of moral-emotional language in both individual and structural attribution contexts.
Fear-type moral-emotional words increase reposts in gender-based violence events.
Abstract
Controversial events are social incidents that trigger wide discussion and strong emotions, often touching on public interests, moral judgment, or social values. Their diffusion typically involves moral evaluations and affect-laden language. Prior work has mostly examined how the quantity of moral and emotional words shapes diffusion, while largely overlooking blame attribution—that is, whether audiences locate the cause of a controversial event in individual actions or in social structures, across different contexts. Using 189,872 original Weibo posts covering 105 events in three domains— street-level bureaucracy (SLB; individual attribution), education governance (EG; structural attribution), and gender-based violence (GBV; mixed attribution)—we estimate negative binomial models with an interaction between word type and account verification and report incidence rate ratios (IRR).…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
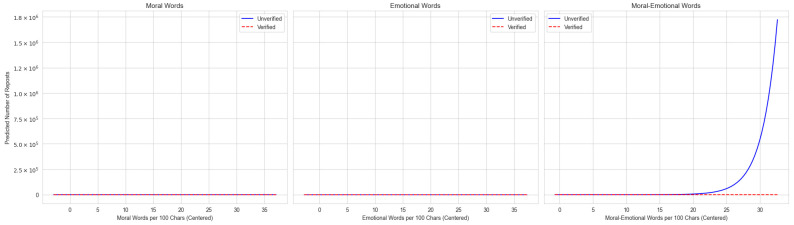 Figure 1
Figure 1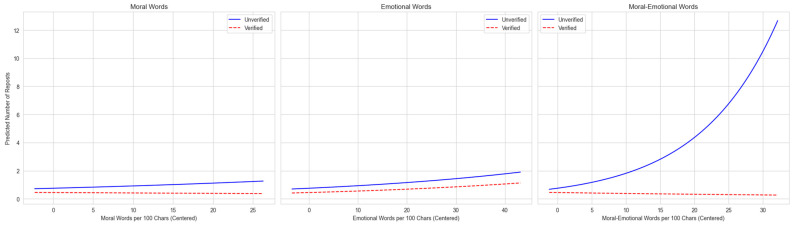 Figure 2
Figure 2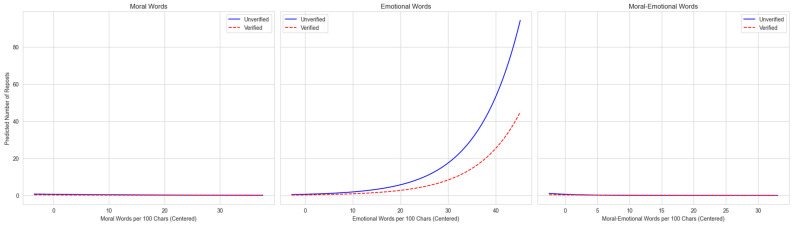 Figure 3
Figure 3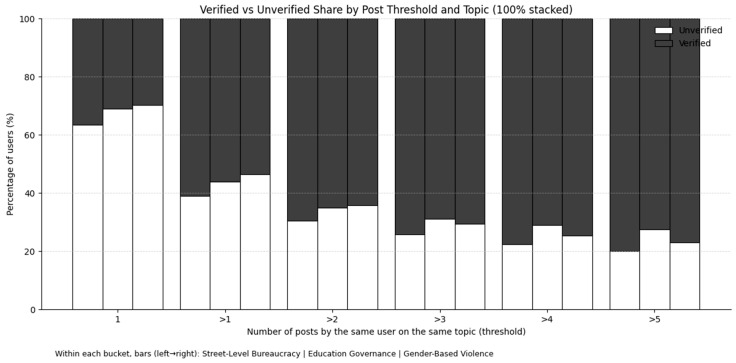 Figure 4
Figure 4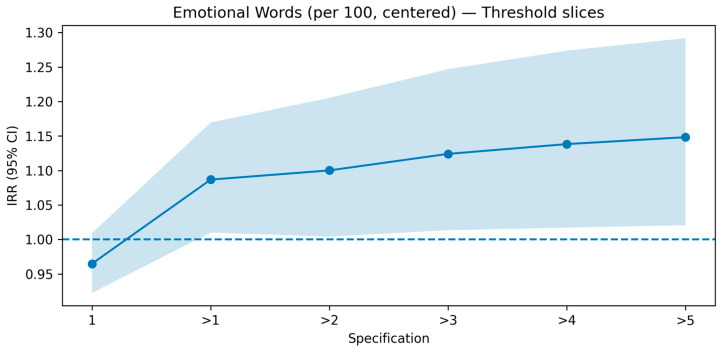 Figure 5
Figure 5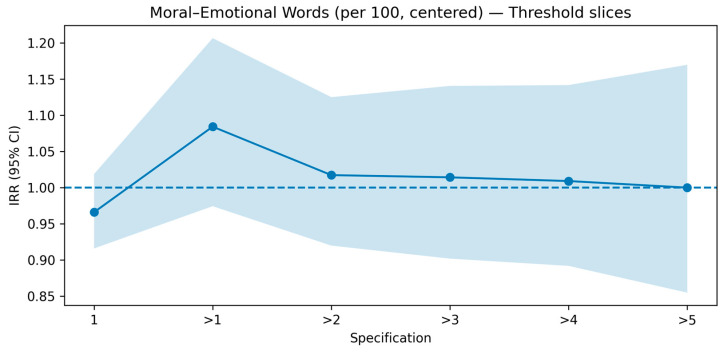 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9- —Fundamental Research Funds for the Central Universities
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPsychology of Moral and Emotional Judgment · Terrorism, Counterterrorism, and Political Violence · Social and Intergroup Psychology
1. Introduction
Public evaluations of controversial events on social media commonly express moral stances and emotional bias. Language that blends moral judgment with emotion can attract attention and influence public opinion [1,2]. Yet the same cue does not travel equally well across all issues [3]. Weibo is a Chinese social platform similar in functionality to Twitter. In settings like Weibo, where institutional actors and ordinary users interact under invisible moderation, how people assign blame—to individuals or to systems—can change diffusion dynamics and, by extension, the tone of public life [4,5]. These dynamics matter because they can amplify polarization in events that focus on individual deviant behavior while muting concern for system-level failures.
Prior work shows that moral-emotional wording can boost online diffusion [6], but effects are different across domains [3]. In events focusing on individual behavior, narratives highlight the actions of specific people, inviting individual blame; in governance disputes, coverage foregrounds abstract rules and institutions, inviting structural attributions [7] (p. 482). These contrasts should have an influence on how moral-emotional language performs. In the Weibo context, media accounts post more cautiously, whereas unverified users rely on affective appeals to spur peer reposting. This pattern is consistent with professional media’s credibility norms and with the platform’s reposting incentives [4,8].
Despite rich theorizing, we lack comparative, cross-issue evidence from non-Western platforms that identifies when moral contagion strengthens, weakens, or reverses. We also know little about how user identity moderates these effects in practice. Without such evidence, people may overgeneralize from highly polarizing cases, and platforms may unintentionally give more visibility to incendiary content through their curation. Our results preview the stakes: moral-emotional language is far more impactful in SLB than in EG, while in GBV, fear-type moral-emotional language drives diffusion; moreover, unverified users benefit most from affect-heavy wording, while verified accounts see muted or even negative returns. Understanding these contingencies is essential for responsible amplification and for designing guardrails that do not simply reward the loudest voices.
This study asks when moral-emotional language increases sharing and for whom. We focus on attribution framing—whether audiences read a problem as caused by individual misconduct or by structural conditions—and on user identity (verified vs. unverified) [9] (p. 16). Our goal is to identify the boundary conditions of “moral contagion” on social media and to translate them into actionable guidance for communicators and platforms. Concretely, we compare three issue contexts that naturally differ in attribution: street-level bureaucracy (SLB, individual blame) [10], education governance (EG, structural blame) [11], and gender-based violence (GBV, mixed attribution) [12,13], and test whether moral emotional language is affected by topic attributes and user identity.
To this end, we test a model of moral contagion that centers attribution framing and user identity, asking when moral-emotional language boosts reposts and when it fails to do so.
Our contributions are fourfold. (1) We describe the contextual boundary conditions of moral contagion, showing it is conditional rather than universal—robust in individual-attribution settings (SLB), attenuated or null in structural frames (EG), and reversed in mixed contexts (GBV) where fear-type moral-emotional language predominates. (2) We demonstrate that user identity influences the effect of moral contagion: unverified accounts capture the largest gains from moral-emotional language, whereas verified or institutional actors do not. (3) Methodologically, we introduce a transparent, replicable workflow that integrates length-normalized linguistic measures with topic classification and moderation analysis, tailored to short-text platforms. (4) We distill practical implications for platform design and public communication under Chinese platform norms. Taken together, these contributions shift the research agenda from asking whether moral contagion exists to specifying when it occurs—and for whom.
2. Literature Review
2.1. Contextual Boundaries of Moral-Emotional Diffusion
Moral contagion theory [6] posits that language combining moral and emotional content diffuses more widely than language containing either element alone. The words that intersect the emotional dictionary and the moral dictionary are moral-emotional words. That is to say, when posting comments on controversial events on social platforms, compared with purely moral words and purely emotional words, words that contain both moral values and emotional signals are more likely to promote the forwarding of the post. The theory holds that moral language signals group identity and norms, while emotional language provides the motivation to share. Together, these elements produce a synergistic effect. Analyzing Twitter debates on contentious topics, Brady et al. [6] found that each moral-emotional word in a tweet increased its expected retweet count by approximately 20%.
The Motivation–Attention–Design (MAD) model [1] further explains this amplification. It posits that users are motivated to share moral-emotional content to reinforce group identity. This content naturally captures attention due to its salience, and platform design (e.g., likes, algorithms) amplifies these motivational and attentional biases [14]. This mechanism motivates our first hypothesis:
H1: Posts containing moral-emotional language will be reposted more than posts containing only moral or only emotional language.
However, scholars have recently questioned whether “moral contagion” generalizes across topics and contexts [3]. Much of the strongest evidence to date comes from polarized issues (e.g., gun control) on Western platforms [6], where what counts as a “polarizing topic” can be subjective, and effect sizes vary by domain. In some polarizing topics, moral-emotional words even predict reduced sharing, indicating that moral contagion does not apply universally [3]. These results do not undermine moral contagion; they point to its boundary conditions. Guided by the MAD framework [1], we treat user sharing motivations, context-driven selective attention, and platform design as the key boundary conditions of moral contagion. Our study examines these conditions in a non-Western setting and offers an exploratory test of when moral-emotional language amplifies—and when it fails to amplify—sharing.
China’s content-moderation system permits some criticism but seeks to deter large-scale collective expression [4]; this institutional context partly shapes how discussions of controversial events spread on Chinese social media. In this moderated space, institutional and official accounts play an outsized agenda-setting role and frequently function as opinion hubs [5,15]. Because verified accounts generally reach larger audiences, they tend to show higher baseline diffusion in routine contexts [16]. However, audiences often read low-arousal or neutral language as more credible [8]. For verified professional or institutional accounts, using moral-emotional language can therefore backfire—prompting doubts about credibility and reducing willingness to repost, especially on controversial events. By contrast, for unverified users, moral-emotional language can signal in-group alignment and mobilize like-minded audiences [6], consistent with the echo-chamber dynamics observed on Weibo [17]. Additionally, posts by conservative-leaning users that employ moral-emotional language are more likely to spread [18], suggesting that moral contagion resonates more readily with broad, non-elite audiences. In such cases, emotionally charged moral claims from grassroots accounts can diffuse rapidly on Weibo, at least prior to the full salience of any collective-action risks.
We therefore hypothesize the following:
H2: For posts containing moral-emotional language, unverified user status will predict more reposts than verified user status.
2.2. Arousal-Driven Mechanisms of Emotional Sharing
Emotional contagion is a fundamental mechanism of social cohesion [19]. Emotional tweets are shared more often and faster than neutral ones [20], and emotional interaction can become part of a society’s social beliefs and reshape relational structures, thereby shaping how we see and judge social problems [2].
Finer-grained evidence shows that emotional valence does not have a uniform impact across settings. In news, positive content tends to spread more virally [21]; in rumor diffusion, false rumors go viral when they contain more positive-emotion words [22]. By event type, positive emotion builds up for highly-anticipated events, whereas unexpected events are marked by negative emotion; correspondingly, positive information reaches broader audiences, while negative information spreads faster [23]. In political contexts, negative affect more reliably boosts sharing [24]. Together, these patterns indicate that the effects of emotional valence are context-dependent rather than universal.
Compared with valence, physiological arousal provides a clearer framework for explaining why different emotions spread to different degrees. High-arousal states—positive (e.g., awe) or negative (e.g., anger, anxiety)—promote viral diffusion, whereas low-arousal emotions (e.g., sadness) suppress it [21]. Studies of discrete emotions further show that anger is more contagious than joy, an effect amplified by weak social ties [25]. This perspective motivates our first research question:
RQ1: Across different valences and categories, which specific moral-emotional language best predicts reposts?
2.3. Attribution Frames and Issue Types
According to attribution theory, different emotional responses are evoked depending on where blame is placed. When individuals are held responsible (internal attribution), the common emotional reaction is anger [26]. When the cause is seen as structural (external attribution), the response is more likely to be sympathy [26].
“Attribution in terms of impersonal and personal causes, and with the latter, in terms of intent, are everyday occurrences that determine much of our understanding of and reaction to our surroundings” [9] (p. 16). When observing others, people tend to underestimate situational factors and overestimate dispositional ones. This cognitive bias, known as the fundamental attribution error, is a robust phenomenon observed even in trained psychologists [27] and is likely widespread in the general public.
Attributing social problems is inherently political. While the sociological imagination encourages linking individual biographies to broader social structures [28] (pp. 10–11), the dominant tendency is often to “blame the victim” [29] (pp. 11, 17). This ideology individualizes systemic issues, framing them as personal failings that require exceptional, case-by-case solutions rather than universal reforms. This focus on personal deficits over structural causes ultimately reinforces the existing social order [29] (p. 19).
Media narratives shape public attribution by framing the causes of social problems [7] (pp. 477, 493). News coverage that focuses on individual actions and choices encourages internal attributions. Conversely, coverage that examines systemic or social causes promotes external, situational attributions [7] (p. 482). Therefore, person-centric event narratives are more likely to lead to individual blame, while abstract, institution-focused narratives are more likely to lead to structural blame.
To operationalize these framing effects in our study, we next define three issue categories that map media narratives to attributional logics: attributable to individual actions, attributable to social structures, and attributable to a mix of the two.
Attributable to individual actions: Events framed mainly as the choices, intentions, or misconduct of specific people (e.g., a police officer, a teacher, a local official). The problem is treated as a discrete event caused by identifiable actors, and solutions focus on disciplining, rewarding, or replacing those individuals.Attributable to social structures: Events framed as the result of rules, incentives, institutions, or broad social conditions (e.g., laws, hiring systems, cultural norms). The problem is treated as systemic and persistent across cases, and solutions emphasize policy or organizational reform.Attributable to a mix of individual actions and social structures: Events where narratives link specific actors’ behaviors to the larger systems that enable or constrain them. Both personal agency and structural conditions are presented as necessary parts of the explanation, and solutions combine accountability for individuals with reforms to rules or contexts.
We compare three types of issues that naturally encourage different attributions. For individual attribution, we selected street-level bureaucracy, which involves the concrete actions of specific people. We then selected education governance as a case of structural attribution, as it involves abstract institutions. To further examine how issues that combine individual and structural attributions unfold, we analyze gender-based violence as a mixed case. By analyzing the moral-emotional content and repost counts of posts within these domains, we can examine the boundary conditions of the theory.
The concept of street-level bureaucracy, introduced by Lipsky [10,30], refers to frontline public service personnel who exercise discretion under conditions of limited resources and ambiguous goals, effectively shaping how policies are implemented. In China, such cases often involve urban management officers or police. Media narratives of these incidents usually highlight the actions of individual officials (e.g., “a police officer kicked a student”), which encourages the public to attribute the problem to personal misconduct rather than broader structural factors.
Education governance refers to controversies over the structural arrangements, rules, and policies within the education system. In contrast to the concrete actions of SLB, EG is an abstract, multi-level system where actors are often faceless institutions [11]. Media coverage of EG issues therefore focuses on macro-level rules, guiding the public toward situational or structural attributions.
Although Weibo shares the core microblogging affordances of Twitter/X, the cultural and institutional environment in which those affordances operate is distinct. While platforms like Weibo possess an open structure capable of empowering users to spread information publicly [31], the same moral-emotional cue can have weaker or stronger effects depending on whether the public reads a problem as structural (stable, systemic) or personal (discrete, individual-level). Structural frames implicitly raise the perceived potential for wide-scale collective expression—making such content more likely to be constrained under moderation rules [4]. —whereas person-centric incidents pose less threat to institutional stability and thus allow moral-emotional content to travel farther.
We therefore predict the following:
H3: Moral-emotional language will have a weaker effect on reposts in the context of education governance compared to street-level bureaucracy.
Then, we follow the United Nations High Commissioner for Refugees (UNHCR) [12] and World Health Organization (WHO) [13] to define gender-based violence as violence, discrimination, or coercion directed at individuals—especially women and gender minorities—on the basis of gender, gender identity, or socially constructed gender roles. Manifestations include physical and sexual violence, verbal abuse and harassment, humiliating or stigmatizing speech (including online), and institutional or systemic inequities; these harms can occur in both private and public settings and carry severe, sometimes lifelong, consequences.
“Violence, Peace and Peace Research” [32] distinguishes personal (direct) from structural (indirect, system-level) violence and argues they are intertwined rather than separable: individual actions are patterned by institutional arrangements and social norms. Building on this, ecological models of violence against women conceptualize GBV as arising from the interaction across levels—individual traits and relationships (micro), situational and organizational contexts (meso), and cultural, legal, and economic structures (macro) [33]. Taken together, these frameworks justify treating GBV as a mixed attribution domain in which personal agency and structural conditions jointly shape expression and diffusion.
3. Materials and Methods
3.1. Data Collection and Issue Classification
Our data is drawn from the Sina Weibo Online Emergency Public Opinion Dissemination Dataset provided by the 2025 Micro Hotspot Big Data Research Institute, which contains 349 trending events from 2024 onward. The provider clustered Weibo posts to events by lexical similarity and assigned unique IDs to all events. We then collected the original Weibo posts for these events, extracting the full text, user verification status, follower count, media type and repost count for analysis.
We employed a human–Artificial Intelligence (AI) collaborative approach for issue classification, leveraging the ability of Large Language Models (LLMs) to replicate expert annotations while maintaining human supervision for accuracy [34,35]. Our process adapts the workflow from Chew et al. [36] to classify the event titles.
From the universe, we drew two random subsets for calibration. In each subset, two trained coders independently labeled the event titles into four mutually exclusive categories— street-level bureaucracy (SLB), education governance (EG), gender-based violence (GBV), and other—using short operational definitions. We then prompted Gemini 2.5 Pro to code the same events (full prompt in Appendix C.2). Human labels and model outputs were compared; both calibration rounds showed high agreement, leading us to proceed with model-assisted coding of the full corpus while keeping human oversight for flagged or ambiguous cases. This “calibrate → audit → scale” design follows recent guidance on LLM-assisted deductive coding and on integrating LLMs into workflows that emphasize human oversight and triangulation [36,37].
After the two audits confirmed stable agreement, we applied the same instructions and settings to all 349 events and retained human spot-checks for any low-confidence determinations. Following data quality screening, we excluded events with missing critical fields (e.g., user IDs) required for downstream analyses. The resulting research sample comprised 42 SLB events, 46 EG events, and 17 GBV events; the remainder were labeled “other” and not analyzed as focal categories. Our procedure mirrors the recommended final step in LLM-assisted content analysis—using the model to create the final coded dataset once non-inferiority to human coding has been demonstrated—while documenting prompts, model name, and run parameters for replicability [36,37] (see Appendix C).
After initial cleaning (de-duplication, removal of missing values, and trimming repost outliers at the 0.1% level), the final analytic samples comprised 23,730 posts for SLB (42 events), 97,731 posts for EG (46 events), and, with the addition of the GBV topic, 68,411 posts for GBV (17 events).
3.2. Operationalization of Variables
Our dependent variable is the repost count, a key indicator of information diffusion [6]. Because repost counts are over-dispersed count data (i.e., the variance is much larger than the mean), we selected a statistical model appropriate for this distribution.
Our core independent variables measure the language used in each Weibo post. We constructed these variables using two Chinese lexicons: the Chinese Moral Foundation Dictionary (C-MFD) 2.0 moral lexicon [38] and the Information Retrieval Laboratory of Dalian University of Technology (DUTIR) emotional lexicon [39]. From these, we created three mutually exclusive categories:
- Moral-Emotional Words: Words present in both lexicons (n = 1957);
- Distinctly Moral Words: Words unique to the moral lexicon (n = 3747);
- Distinctly Emotional Words: Words unique to the affective lexicon (n = 25,358).
To control for post length, we normalized the count of each word type using the following formula:
The normalized metric represents the number of words of a given type per 100 characters, which improves the interpretability and stability of the model coefficients. Our analysis also includes the following moderator and control variables:
- User Verification (Moderator): Effects-coded as ordinary user (−1) or verified user (+1);
- Follower Count (Control): To control for user influence, we use the log-transformed number of followers due to the variable’s right-skewed distribution;
- Media Type (Control): Effects-coded as text-only (−1) or multimedia (e.g., images, video) (+1);
- Post Length (Control): The character count of the post is included as an additional control in our robustness checks.
To address RQ1, we created fine-grained sentiment intensity scores for each post. These scores were calculated using a standard Chinese sentiment formula [40] that integrates several components:
- Core Lexicons: The DUTIR lexicon [39] provided word polarity (positive/negative) and discrete emotion categories (e.g., joy, sadness).
- Modifier Lexicons: We incorporated established negation [41] and degree-adverb [42] lexicons.
- Scoring Logic: The formula accounts for a word’s polarity (+1 or −1), its strength (on a 5-point scale), the multiplicative effect of negators, and the weighting of degree adverbs.
This process generated our final exploratory variables: scores for positive/negative emotion, positive/negative moral-emotion, and each discrete moral-emotion category. The formula is as follows:
3.3. Analytic Strategy
We used negative binomial regression to model the repost counts. This method was chosen because our dependent variable is an over-dispersed count, meaning its variance is much larger than its mean. Unlike Poisson regression, which assumes equal mean and variance, the negative binomial model accounts for this over-dispersion and is therefore more appropriate for our data [43].
To test our hypotheses, we modeled repost counts using negative binomial regression. The models included interaction terms to assess the main effects of language type and the moderating effect of user verification. The resulting coefficients are interpreted as incident rate ratios (IRRs):
where
i is indexes the i-th post; is the expected repost count for post i; is the intercept;X_j,i_ is the value of the j-th predictor (main effect) for post i; is the coefficient for the j-th predictor; is the value of the k-th interaction term for post i; is the coefficient for the k-th interaction term.
To investigate RQ1, we specified two exploratory models. The first model tests the effect of emotion valence, classifying emotions as positive (joy, good, surprise) or negative (anger, sadness, fear, disgust) based on the DUTIR lexicon while holding all controls constant [39]. Second, we created variables for five discrete moral-emotion categories, excluding two due to low frequency (surprise and anger). In both models, intensity is measured as a normalized frequency per 100 characters. The models are specified as follows:
4. Results
4.1. Main Effects of Language on Reposts and Cross-Issue Differences (Model 1)
Table 1, Table 2 and Table 3 present the negative binomial regression results for the SLB, EG, and GBV topics, respectively.
The results do not support H1 across all issues. In SLB, moral-emotional language has the strongest effect (IRR = 1.337), exceeding distinctly moral (IRR = 1.067) and distinctly emotional (IRR = 1.061) language. In EG, the pattern is similar but smaller: moral-emotional (IRR = 1.037) exceeds distinctly emotional (IRR = 1.022). However, in GBV, the pattern reverses: distinctly emotional language increases sharing (IRR = 1.118), whereas moral-emotional decreases it (IRR = 0.844), and distinctly moral language also decreases it (IRR = 0.952). These findings indicate that moral contagion effects vary by topic and message type.
The data support H3, revealing the context-dependent effectiveness of language strategies. Moral-emotional language was significantly more impactful in SLB (IRR = 1.337) than in EG (IRR = 1.037). These findings suggest that moral contagion is strongest when the media narrative highlights a direct conflict and blames the problem on individual misconduct.
4.2. The Moderating Role of User Identity
The analysis supports H2, showing that user verification status acts as a moderator for the diffusion effect of language. Given the complexity of interpreting interaction coefficients directly, we plotted the predicted marginal effects. This graphical analysis demonstrates how the relationship between language and post diffusion differs significantly for verified versus unverified users within each topic.
For the SLB topic (Figure 1), a stark divergence emerges between user types. A higher density of moral-emotional language predicts an exponential increase in reposts for unverified users, indicating it can trigger virality. Conversely, this language has no discernible impact on the engagement of verified users, whose repost counts remain low regardless of its use.
In the EG topic (Figure 2), the engagement pattern differs. Overall engagement is lower, with predicted reposts for unverified users peaking at approximately 12. For these accounts, the positive relationship between moral-emotional language and reposts is weaker and linear, not exponential.
For the GBV topic (Figure 3), diffusion is driven primarily by emotional language. As the density of emotional words increases, predicted reposts for unverified accounts rise steeply while verified accounts also gain but plateau at a lower level, indicating that verification attenuates the payoff from emotional language. By contrast, moral-emotional language does not fuel sharing: predicted reposts stay low and even edge downward across the range for both user types, with only minor separation between the lines. Distinctly moral language shows a similarly flat-to-negative pattern near zero.
Taken together, the results show clear moderation by user verification. Unverified users gain most from affective cues: in SLB, moral-emotional language turns viral; in EG, it helps modestly; in GBV, emotion drives the gains. Verified users see little benefit from moral-emotional language and a muted return to emotion in GBV, consistent with credibility-preserving strategies [8]. In short, weaker actors lean on affect to mobilize sharing, while institutional actors keep tone restrained to protect trust.
4.3. Robustness Checks
We conducted several robustness checks which confirmed that our core findings are stable. The effect of moral-emotional language and its moderation by user type were unaffected by the following changes:
- Model Simplification: The results held when retaining only moral-emotional words, their interactions, and controls;
- Control Variables: The results were consistent when adding post length or removing media type as controls (except EG);
- Interaction Terms: The results were unchanged when retaining only interactions involving moral-emotional words.
Finally, a bootstrap analysis (1000 resamples) confirmed that the effects are not artifacts of user-level clustering (except EG). Therefore, the findings are robust to alternative model specifications and data structures (see Appendix A for details).
Only the education governance checks raised reliability concerns, likely because this structurally framed topic is disproportionately influenced by users who post multiple times. When the chance of adopting or sharing a message rises with repeated exposure, and cluster size (the number of posts per user) is related to outcomes conditional on covariates, an “informative cluster size” (ICS) problem can arise.
In our data, about 27% of authors contributed more than one post, introducing non-independence. As Table 4 shows, most of these multi-post authors contributed exactly two posts, while authors with five or more posts were rare. Cluster sizes were also highly heterogeneous across topics (ranges in Table 4): SLB: 1–76; EG: 1–380; GBV: 1–466.
Moreover, within each topic the share of verified accounts increases as the number of posts per author rises, indicating that highly active users are disproportionately verified. Compositional differences across user types likely account for the observed interaction (see Figure 4).
We conducted two checks on the education governance topic. First, a cluster-aware bootstrap (1000 resamples; one post drawn per multi-post user in each resample) showed that, when the influence of highly active users is muted, the effects of distinctly emotional and moral-emotional language on reposts become small and often trend below unity, indicating weak or even negative associations (see Appendix A.5 Figure A2). Second, we implemented a threshold-slices analysis that incrementally re-introduces multi-post users by estimating separate negative-binomial models on six nested subsets: users with exactly one post (=1), and users with ≥2, ≥3, ≥4, ≥5, and ≥6 posts (notated “>1” through “>5”). The resulting IRR trajectories (Figures “Emotional Words—Threshold slices” and “Moral-Emotional Words—Threshold slices”) reveal a clear pattern: for distinctly emotional language, the IRR crosses the 1.00 line precisely when moving from the single-post slice to “>1” (≈0.97 → ≈1.09) and then creeps upward with wider CIs as more high-activity users are included (see Figure 5); for moral-emotional language, the IRR similarly jumps above 1.00 at “>1” (≈0.97 → ≈1.08) but then flattens back toward ≈1.00 as thresholds increase, with broadening uncertainty bands (see Figure 6). Taken together, these visuals show that the apparent promotive effects in the EG main model are largely induced by a small set of highly active accounts; once we control for this ICS bias, the effects attenuate or reverse.
4.4. Exploratory Analysis: Effects of Emotion Valence and Categories
Negative emotions show a diffusion advantage. In SLB (IRR = 1.028) and EG (IRR = 1.03) topics, posts containing negative emotional language were significantly more likely to be reposted, whereas those with positive emotional language were not. But in the GBV topic, positive emotional language reliably increases reposts (IRR = 1.041), whereas negative emotion is not significant.
The effects of polarity are more complex for moral-emotional language. In the SLB topic, both positive (IRR = 1.084) and negative (IRR = 1.055) moral-emotional language significantly promoted reposts. In the EG topic, however, only negative moral-emotional language had an effect of suppressing reposts (IRR = 0.988). Similarly, in the GBV topic, negative moral-emotional language slightly reduces reposts (IRR = 0.993).
Effects differ across discrete emotion categories. An analysis of specific categories (restricted to good, sadness, fear, disgust, and joy due to data sparsity) revealed further distinctions. Moral-emotional language related to good promoted reposts across the SLB topic (IRR = 1.022), while language related to disgust significantly suppressed them in the EG topic (IRR = 0.988). But in the GBV topic, discrete ME categories reveal sharper contrasts: While good-related moral-emotional language is associated with a modest increase in reposts (IRR = 1.069), fear-type moral-emotional words shows a large promotive effect (IRR = 1.314).
These results suggest that future research could benefit from using finer-grained emotional taxonomies to capture how specific emotions influence diffusion (see Appendix B for details).
5. Discussion
5.1. Summary of Findings
Our exploratory attribution analysis shows that moral contagion is not uniform across issues. When problems are framed at the individual level (SLB), moral-emotional language strongly boosts diffusion; when framed as structural (EG), the effect weakens or reverses once we address high-activity users and cluster bias. In the mixed case (GBV), purely emotional cues increase sharing while moral-emotional cues reduce it, echoing evidence from #MeToo contexts that moralized appeals can backfire in mixed-attribution debates [3]. These patterns suggest that attribution—not emotion alone—conditions when moral language spreads.
User type also matters. Unverified accounts gain most from affect-heavy messaging, consistent with discursive empowerment of non-elite actors. Verified and institutional accounts see muted returns, likely because credibility norms favor a neutral tone [8] and because platform dynamics around public-affairs topics penalize overt moralization [4]. Together, these results point to distinct audience–disseminator fit.
Emotion structure further clarifies the boundary conditions. In GBV, both fear-related and good-related moral-emotional language are associated with increased reposting, whereas sadness-related language is not. High-arousal signals travel; low-arousal signals do not. The implication is both practical and theoretical: amplifying high-arousal moral language can heighten visibility through diffusion, but it may intensify polarization and reduce space for reasoned debate.
These findings advance a conditional view of moral contagion: attribution framing, user type, and emotion structure jointly determine diffusion. We show strong effects for individual-level issues, attenuation or reversal for structural issues, and fear-type moral-emotional language driven diffusion in GBV. We therefore shift the question from “does moral contagion exist?” to “when does it occur?”.
5.2. Theoretical and Methodological Implications
This study advances moral-contagion theory on three fronts. First, using large-scale Weibo data, we show that moral contagion is not confined to a single cultural context—consistent with cross-lingual evidence that emotion–virality relationships generalize across languages when modeled via valence, arousal, and dominance (VAD) [44]. Its impact varies by topic and disseminator identity, supporting a contextual, rather than universal, model. Second, by linking contagion to arousal theory, we clarify mechanism: in contentious debates, high-arousal cues—especially negative ones—do most of the work. Arousal, not valence alone, appears to translate moralized content into sharing [21].
Our findings also suggest a social-psychological bridge between attribution and polarization. When issues are framed at the individual level, audiences can more easily locate a responsible agent, often outside their in-group [45]. Prior work shows that perceived out-group hostility is over-detected online and that such perceptions spur reposting [46]. This points to a testable hypothesis: individual-level attribution may heighten out-group antagonism, which in turn amplifies moral contagion. If supported, interventions could target early attribution framing (e.g., encouraging structural explanations) to slow polarization.
Methodologically, we contribute three tools for computational text analysis. We introduce a relative density metric that normalizes word use by text length, improving sensitivity for short posts. We develop a human–AI coding pipeline that combines researcher rules with LLM validation to classify large volumes of social media data at low cost. Following prior work on Chinese sentiment scoring [40], which integrates polarity, intensity, negation, and degree adverbs, we repurpose that formula to analyze moral-emotional valence and discrete emotions in Chinese moral contagion.
Finally, we provide a replicable framework for studying moral and emotional discourse in Chinese social media: custom lexicons, a transparent human–AI workflow, and statistical models that handle clustering and heterogeneity. The framework is portable and can be adapted across platforms and contexts to test when individual-, structural-, or mixed-attribution amplifies or attenuates moral contagion.
5.3. Practical Implications
Our findings that moral-emotional language generally boosts diffusion on Weibo, but with sizable heterogeneity by issue domain and user identity (e.g., ≈33.7% in SLB vs. ≈3.7% in EG; identity moderation strongest for unverified users), align with and extend platform-agnostic theories of affective amplification.
This pattern resonates with evidence from Facebook that highly engaged participation within like-minded communities can tilt collective sentiment toward negativity and shape group dynamics—an “echo-chamber” mechanism that helps explain why strong moralized emotion travels farther in conflict-laden, individually attributable topics (SLB) than in structurally framed governance discussions (EG) [47].
At the same time, our topic- and identity-specific contingencies complement recent modeling work that tracks user and community sentiments over time and introduces “cross-contamination” between communities and their neighborhoods; our results suggest that such community-level sentiment dynamics are likely to differ by issue attribution and actor status on Weibo, and they motivate future analyses that couple our diffusion estimates with network-based sentiment evolution frameworks [48].
For platform governance, our findings highlight a tension between maximizing user engagement and maintaining social responsibility. Algorithms designed for engagement may unintentionally amplify the most incendiary and emotionally negative content, increasing exposure to polarizing material and potentially worsening social divisions [1]. This suggests a need to integrate principles of social responsibility directly into the design of content curation and distribution algorithms.
For social actors such as government agencies, media, and non-governmental organizations (NGOs), these findings highlight the critical role of language in communication strategy. The results show that while moral-emotional language can maximize a message’s reach, it also risks oversimplifying complex issues and inflaming conflict. This presents a key ethical dilemma: social actors must balance the strategic goal of effective dissemination against the responsibility to foster reasoned public discourse.
5.4. Study Limitations and Future Research
First, our operationalization of attribution by issue category relies on theoretically informed—but ultimately conceptual—distinctions rather than a direct, respondent-level measure of how audiences assign blame. Future work should incorporate more fine-grained, quantitative indicators of attribution—for example, employing a BERT-based feature set and human–AI collaborative coding to classify attributions in comments on polarizing events, then comparing moral-contagion effects across attribution types.
Second, our analyses of heterogeneity by user verification status and by moral-emotional polarity/category are exploratory. While we document systematic differences, we do not fully unpack the mechanisms that generate these patterns. Future studies should move beyond descriptive moderation to probe causal pathways.
Finally, we analyze moral contagion on Weibo to compare attribution effects, not to localize the phenomenon to China. Replications across platforms and across cultural/moderation contexts are needed to validate how attribution shapes moral contagion beyond this setting. Taken together, these limitations point to a clear agenda: pair audience-level attribution measures with mechanism-focused designs, and test the theory across diverse platforms and cultural–institutional contexts.
6. Conclusions
This study shows that moral contagion is conditional, not universal. Whether moral-emotional language spreads depends on three levers: attribution framing, user identity, and arousal profile. When issues are framed at the individual level (SLB), moral-emotional cues travel widely; for structural governance topics (EG), the effect weakens or can reverse once we account for highly active users and clustering. In mixed-attribution debates (GBV), diffusion is driven by high-arousal fear, while moral-emotional wording can backfire. Unverified users benefit most from affect-heavy language, whereas verified and institutional accounts see muted returns, consistent with credibility norms and public-affairs dynamics [8].
Theoretically, we shift the question from whether moral contagion exists to when it occurs. A conditional model—anchored in attribution and arousal—better explains variation across topics than emotion alone [6]. Methodologically, we provide a replicable toolkit for Chinese social media: a length-normalized density metric, a transparent human–AI coding workflow, and the adoption of an existing affect-scoring formula (polarity, intensity, negation, degree adverbs).
Practically, the findings highlight a tension for platforms and communicators. Engagement-optimized ranking can over-amplify high-arousal, incendiary content; responsible design should account for attribution cues and user type to avoid amplifying polarization. For public agencies, media, and NGOs, moralized appeals mobilize grassroots supporters yet have limited traction with policy audiences and can oversimplify complex problems.
Our evidence is bounded by conceptual attribution categories and exploratory heterogeneity analyses. Future work should measure audience attributions directly and test these mechanisms across platforms and cultural-institutional settings. A more precise, evidence-based account of how moral contagion operates can clarify why polarizing events escalate on social media, how they can be interrupted, and how online signals reshape offline collective beliefs [2].
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Brady W.J. Crockett M.J. Bavel J.J.V. The MAD Model of Moral Contagion: The Role of Motivation, Attention, and Design in the Spread of Moralized Content Online Perspect. Psychol. Sci.202015978101010.1177/174569162091733632511060 · doi ↗ · pubmed ↗
- 2Peters K. Kashima Y. Clark A. Talking about Others: Emotionality and the Dissemination of Social Information Eur. J. Soc. Psychol.20093920722210.1002/ejsp.523 · doi ↗
- 3Burton J.W. Cruz N. Hahn U. Reconsidering Evidence of Moral Contagion in Online Social Networks Nat. Hum. Behav.202151629163510.1038/s 41562-021-01133-534112981 · doi ↗ · pubmed ↗
- 4King G. Pan J. Roberts M.E. How Censorship in China Allows Government Criticism but Silences Collective Expression Am. Polit. Sci. Rev.201310732634310.1017/S 0003055413000014 · doi ↗
- 5Yang Z. Vicari S. The Pandemic across Platform Societies: Weibo and Twitter at the Outbreak of the COVID-19 Epidemic in China and the West Howard J. Commun.20213249350610.1080/10646175.2021.1945510 · doi ↗
- 6Brady W.J. Wills J.A. Jost J.T. Tucker J.A. Bavel J.J.V. Emotion Shapes the Diffusion of Moralized Content in Social Networks Proc. Natl. Acad. Sci. USA 20171147313731810.1073/pnas.161892311428652356 PMC 5514704 · doi ↗ · pubmed ↗
- 7Hoynes W. Media and the Construction of Social Problems The Cambridge Handbook of Social Problems Treviño A.J. Cambridge University Press Cambridge, UK 2018477496978-1-108-42616-9
- 8Giachanou A. Rosso P. Crestani F. The Impact of Emotional Signals on Credibility Assessment J. Assoc. Inf. Sci. Technol.2021721117113210.1002/asi.2448034589557 PMC 8453501 · doi ↗ · pubmed ↗