Studying Evolutionary Solution Adaption by Using a Flexibility Benchmark Based on a Metal Cutting Process
Léo Françoso Dal Piccol Sotto, Sebastian Mayer, Hemanth Janarthanam, Alexander Butz, Jochen Garcke

TL;DR
This paper introduces a benchmark for studying how evolutionary algorithms adapt to changing manufacturing optimization tasks, showing that adapted methods reduce computational effort.
Contribution
A new flexibility benchmark for evolutionary optimization in metal cutting, with two NSGA-II variants that improve adaptation efficiency.
Findings
Adaptation with standard NSGA-II reduces evaluations needed for optimization.
The proposed variants further halve the computational effort compared to non-adapted baselines.
More research is needed to apply these methods effectively in real-world scenarios.
Abstract
We consider optimization for different production requirements from the viewpoint of a bio-inspired framework for system flexibility that allows us to study the ability of an algorithm to transfer solutions from previous optimization tasks, which also relates to dynamic evolutionary optimization. Optimizing manufacturing process parameters is typically a multi-objective problem with often contradictory objectives, such as production quality and production time. If production requirements change, process parameters have to be optimized again. Since optimization usually requires costly simulations based on, for example, the Finite Element method, it is of great interest to have a means to reduce the number of evaluations needed for optimization. Based on the extended Oxley model for orthogonal metal cutting, we introduce a multi-objective optimization benchmark where different materials…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
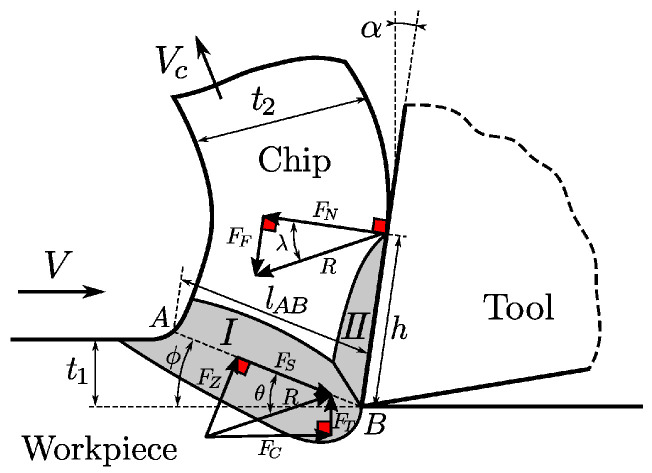 Figure 1
Figure 1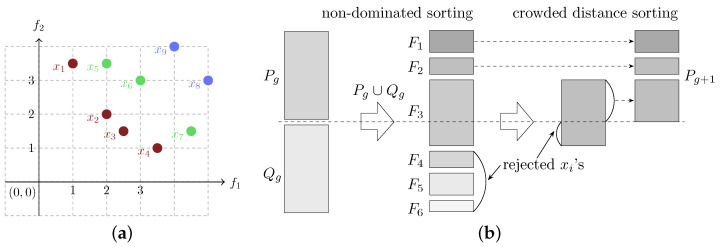 Figure 2
Figure 2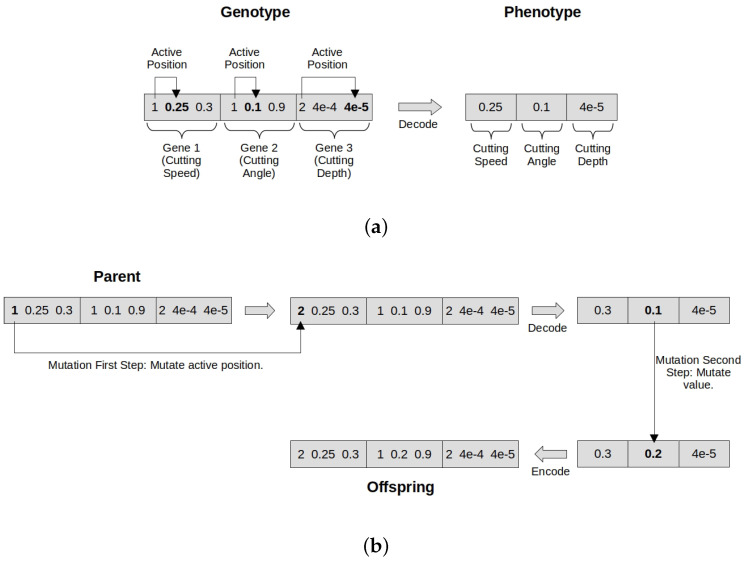 Figure 3
Figure 3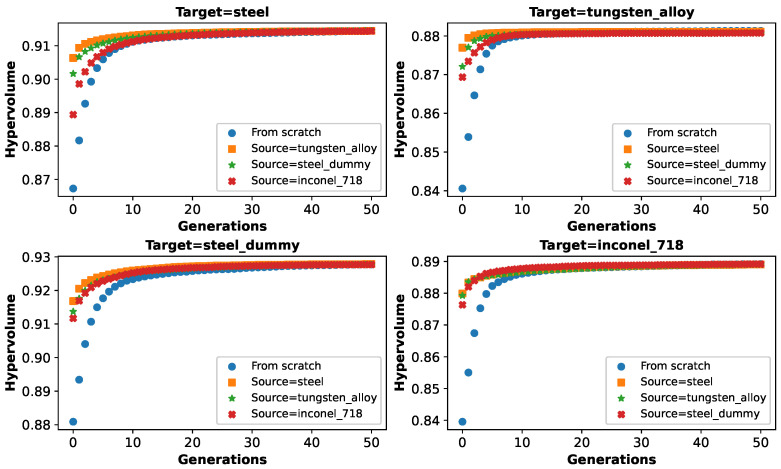 Figure 4
Figure 4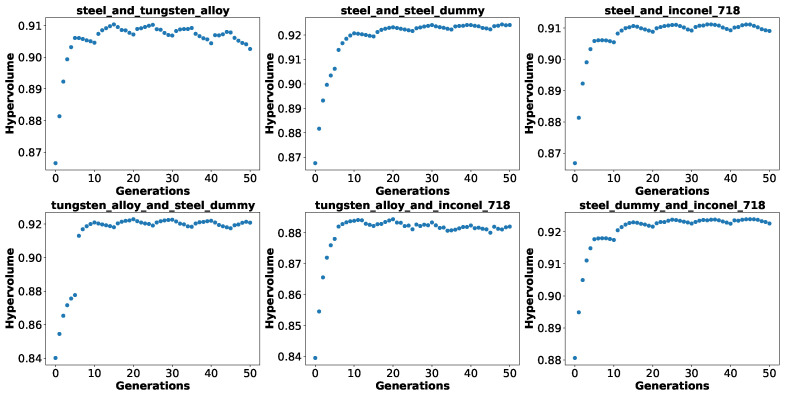 Figure 5
Figure 5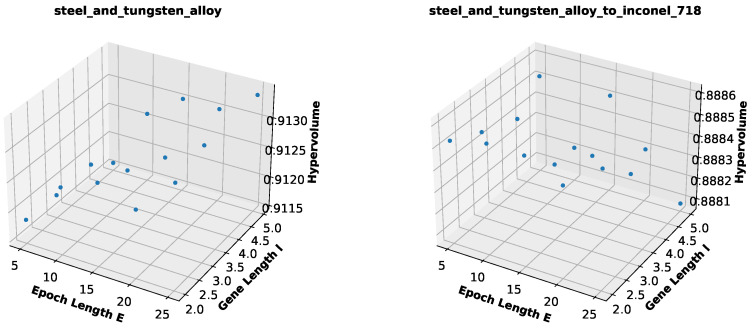 Figure 6
Figure 6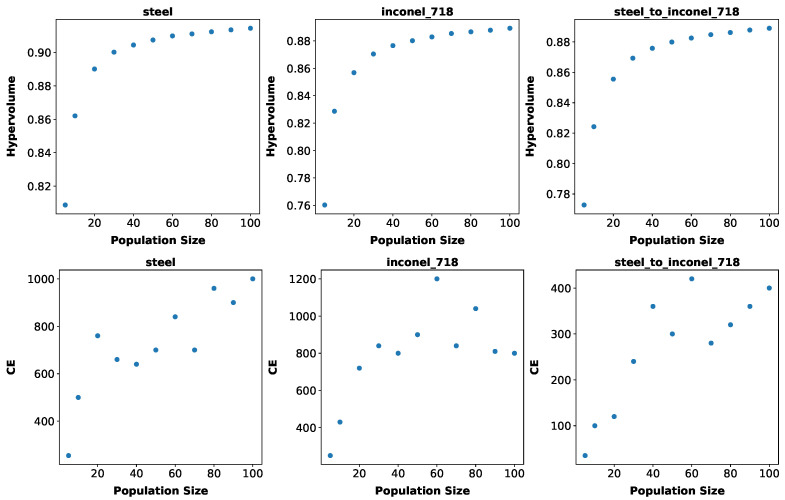 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsManufacturing Process and Optimization · Advanced machining processes and optimization · Engineering Technology and Methodologies
1. Introduction
A manufacturing process is a series of steps that transforms raw materials, components, or parts into finished products that meet specific requirements or specifications. Achieving optimal operations typically requires the multi-objective optimization of process parameters in terms of various aspects affecting material cost, product quality, and production time. Evolutionary multi-objective optimization of manufacturing process parameters has received considerable attention [1]. However, these works assume fixed production requirements. If the production requirements change, one has to compute optimal parameters from scratch again. This can be prohibitive if requirements change frequently, in particular, if costly numerical simulations are involved. For instance, in simulations based on the Finite Element (FE) method, it can easily take hours to even days for one simulation run [2]. Hence, it is of interest to have flexible evolutionary optimization methods that efficiently adapt solutions from previous optimization tasks to a new related optimization task by using only few additional evaluations of the objective functions.
To implement a flexibility benchmark that allows us to measure an evolutionary algorithm’s capacity to adapt solutions from previous to new related optimization tasks, we follow the approach used in [3], which is based on the general framework for system flexibility introduced in [4]. The bio-inspired framework for system flexibility [4] is based on design features of living systems that are known to promote flexibility, called “elements of flexibility”. It reflects research results from the study of living systems as natural examples of flexible, self-adapting task-performing systems. What makes living systems so flexible that they can react quickly and adapt easily to changing environments is of interest to computer scientists and engineers who seek inspiration from nature to increase the flexibility of manufacturing systems. The proposed benchmark allows for a systematic and quantitative study of the concept of bio-inspired system flexibility.
The manufacturing process that we consider in this paper is orthogonal metal cutting. Cutting is a process in which a material is cut to a desired final shape and size by a controlled material-removal process. We consider a so-called task context, which is a set of related parameter optimization tasks for the orthogonal cutting process that arises from considering different materials as the production requirement changes. In other words, different materials constitute different but related optimization tasks. As a performance indicator for successful solution adaption, we evaluate the overall cost that an evolutionary optimization algorithm has for adapting solutions from a source to a target task. To simulate the cutting process, we use the extended Oxley model [5]. This is an analytic model that is inexpensive to evaluate. We chose to use this model as a substitute for costly but more accurate FE simulations to provide a benchmark that allows for extensive experimentation with a high number of repetitions that guarantee stable results. Moreover, an easy-to-evaluate benchmark makes it easier to test many different optimization methods. The downside is that without further validation using realistic simulations, the provided benchmark allows only for negative conclusions; these are, nevertheless, useful. Optimization methods that already need many evaluations to adapt process parameters for the Oxley model do not even have to be considered in more realistic setups. Optimization methods that show good adaption capabilities in the benchmark only yield a first proof of concept that requires further validation with more realistic simulations. This validation is beyond the scope of this paper.
The flexibility setup described above shares similarities with dynamic (multi-objective) optimization [6,7], which studies optimization problems that change over time. Indeed, one can consider the material changes as discrete events in time that change aspects of the underlying optimization problem. However, in our setup there is no need to detect the changes algorithmically, which is an important aspect of dynamic optimization. The optimization problems usually considered in dynamic optimization are intrinsically dynamic, such as the moving peaks benchmark, the dynamic knapsack problem, or the dynamic traveling salesman problem [8]. We are aware of only one work that overlaps with simulation-based multi-objective optimization for manufacturing, in which the turning of material with continuously changing properties, such as gradient materials, is studied [9]. Nevertheless, adaption and transfer of solution is an important aspect of dynamic (multi-objective) optimization that has been intensively studied and which we can build upon.
Using the new flexibility benchmark, this paper provides an exemplary investigation of the potential of dynamic variants of the well-known NSGA-II algorithm [10] for the adaption of manufacturing process parameters. We study two variants: optimizing for two tasks at the same time (varying goals) and using a genotype with active and inactive positions that can accommodate different solutions in one chromosome (active–inactive genotype). Furthermore, instead of adapting a solution to solve each problem in an optimal or near-optimal way as the goals change over time, we aim at providing a good starting point for adaption that is not necessarily optimal for the problems it was trained on. Our results show the following: (1) For the defined problem, the cost of adapting solutions from source materials is much lower than the cost of searching from scratch for each material. (2) The proposed variants are able to further reduce this cost by optimizing source solutions that are in-between solutions for different tasks and that accommodate different values for the process parameters that can be activated or deactivated. However, for any optimization method to be really interesting for industrial use cases, it should need a number of evaluations for adaption that is a magnitude lower than what we could achieve in our experiments even in the best-case scenario. Hence, there is clearly a need for further research.
The rest of this paper is organized as follows: Section 2 presents some background concepts important for this work: the notion of system flexibility (Section 2.1), the extended Oxley model (Section 2.2), and the NSGA-II algorithm (Section 2.3). Section 3 presents the proposed benchmark using the extended Oxley model. How we integrate some ideas from facilitated variation into NSGA-II is given in Section 4. We then present the experimental setup for evaluating the proposed methodology and the results obtained in Section 5. Section 6 presents some concluding remarks and possibilities of future work.
2. Background
2.1. System Flexibility
System flexibility refers to a system’s ability (i) to easily adapt from being good at one task to being good at a related task and (ii) to cope with a diversity of related tasks. The paper [4] introduces a general formalism for system flexibility that allows both aspects (i) and (ii) to be defined rigorously. In this paper, we focus on aspect (i). In preparation for the benchmark defined in Section 3, we introduce some terminology and cost notions in this section. We follow [3], which has studied an evolutionary algorithm from the viewpoint of system flexibility for the pole balancing problem.
We denote the system configuration space by X and a concrete system configuration by . As our application example we consider an orthogonal cutting process and the problem of adapting process parameters when a material change occurs. A cutting machine with the cutting tool forms a system that can perform the cutting process. The input of the cutting process is a workpiece of some metal, and the output is the workpiece with the desired amount of material removed. Here, the system configuration space is given by the vector space of all possible values for the process parameters.
We further consider the system to be equipped with an evolutionary algorithm A that the system uses to optimize process parameters. Since evolutionary algorithm A and how it operates on system configuration space X are the main concerns in this paper, we formally denote the system by a tuple . In our example, the task T that the system has to perform, for a specific type of metal, is to optimally cut the workpiece according to some feasibility criteria and multiple objectives. For our purposes, we can consider this to be equivalent to A solving the associated multi-objective optimization problem. The cost in terms of objective function evaluations to solve this problem from scratch is denoted by .
To measure the ability of evolutionary algorithm A to adapt process parameters when a material change occurs, we consider a task context of n multi-objective optimization problems, each associated to a different type of metal. For each pair , where , the adaption cost denotes the cost in terms of objective function evaluations to solve given that the algorithm has previously solved . To measure the adaption capability of A with regard to the task context, we can consider the worst-case adaption cost given by
the average-case adaption cost given by
or the best-case adaption cost given by
The lower the adaption cost, the better the considered algorithm is at exploiting information gained on a previous optimization task for a new optimization task. As reference values, we also consider the cost to solve the optimization task from scratch in the worst, average, or best case.
Note that the above definitions are not specific to evolutionary algorithms but can be used for any optimization algorithm. We only have to provide measures for and that are suitable for the considered optimization algorithm. The specific cost measures considered in this paper are discussed in Section 5.
2.2. Orthogonal Metal Cutting and the Extended Oxley Model
Orthogonal metal cutting is a machining operation where the cutting edge of the tool is perpendicular to the direction of relative motion between the tool and the workpiece surface. The process involves the removal of material from the workpiece by the cutting tool in a series of small, discrete steps, as the tool chips away at the workpiece material through plastic deformation. The process is known for producing high-quality, precise cuts but is also challenging to optimize due to the complex interactions among the cutting tool, the workpiece material, and the machining environment.
Predictive models are extensively developed and used in the process planning phase in order to enhance the product quality and to optimize the process parameters with respect to tool life, surface finish, part accuracy and beyond. Predictive models are divided into analytical models, which describe an idealized underlying physics; empirical models, which are derived from experimental observations; and numerical models, such as the Finite Element method (FEM), which take into account the precise multiphysical phenomena involved in the cutting process [11]. Due to the high costs involved in experimentally determining the empirical models and high computational power required for numerical methods, they are seldom used in an industrial context. On the contrary, analytical models including [12] are fast and assists in developing practical tools for the industry, albeit with the drawback of not capturing the multidimensional physics. The recent advancements in analytical models have, however, enhanced the predictions to make the latter more realistic. Due to its simplicity and negligible numerical costs, the analytical model initially proposed by [12] and the extension from [5] is used in this study. The work of [5] was implemented as a Python package and made available on GitHub (https://github.com/pantale/OxleyPython accessed on 30 September 2024) by the authors [13].
Oxley’s theory exploits the slip line field theory coupled with thermal phenomena to predict the cutting forces, temperatures, and stresses and strains in the workpiece. The flow stress in the workpiece, which depends on the magnitude of plastic deformation , rate of plastic deformation , and current temperature of the material, plays a central role in the prediction model. To account for a wide range of materials, a Johnson–Cook material flow rule (Equation (4)) that multiplicatively accounts for each of the influencing phenomena is used. A material is then fully defined by the following material parameters: plastic hardening parameters A, B, and n; plastic deformation rate sensitive parameters C and ; thermal softening exponent m; and the material’s melting point :
Figure 1 describes the analytical orthogonal cutting model. The material in the vicinity of the tool tip is divided into a primary shear zone (I) of length , where the material experiences compressive forces and initiates the plastic deformation along the line AB leading to chip formation, and a secondary shear zone (II), where further plastic deformation is induced due to the friction of the chip and tool contact. The workpiece is fed at a velocity of V against the tool to remove a layer of thickness resulting in a chip of thickness at a velocity of . The primary task of Oxley’s theory is to identify three internal variables that depend on the shear angle , the ratio of to the thickness of the primary shear zone, and the ratio of chip thickness to the thickness of the secondary zone, by solving a system of 3 nonlinear equations. The cutting force , the advancing force , and the rise in temperature in the individual zones are then computed from the internal variables. The readers are referred to [13] for a detailed description of the algorithm. We stress once more that due to the simplicity of the model, one clearly has to expect a gap between the extended Oxley model and realistic simulations. Nevertheless, a benchmark based on the extended Oxley model can provide valuable insights for adapting process parameters in manufacturing contexts, as optimization methods that already need many evaluation methods to adapt parameters for the Oxley model do not even need to be considered in more realistic settings.
The benchmark in Section 3 is an implementation of the formalism for the orthogonal cutting process and the problem of adapting process parameters when a material change occurs based on the extended Oxley model. In the formulation of Section 2.1, system configuration space X is given by the vector space of all possible values for process parameter tool speed V, tool rake angle , and the cutting depth in one step (see Figure 1).
2.3. NSGA-II: Non-Dominated Sorting Genetic Algorithm II
Many real-world problems require the optimization of two or more objectives at the same time, resulting in the class of multi-objective optimization problems [10,14]. Different objectives are often contradictory. Therefore, instead of searching for one solution that optimizes all objectives, multi-objective optimization methods search for a set of non-dominated solutions, the Pareto front.
Definition 1. Given a set of solutions X, a Pareto front P is the set of non-dominated solutions from X. A solution is non-dominated if and only if, , with , is better than in at least one objective.
The Pareto front is thus the set of trade-off solutions whose objectives cannot be improved without negatively impacting one or more of the other objectives. Given an optimized Pareto front, the decision-making process for choosing the solution to use will depend on each specific application.
As evolutionary algorithms work with populations of solutions, they are often employed for this class of problems [10,14]. Among them, the Non-Dominated Sorting Genetic Algorithm (NSGA-II), proposed by [15], is a popular multi-objective optimization algorithm. The NSGA-II algorithm has an overall functionality similar to that of a standard genetic algorithm. An initial population of candidate solutions (individuals) is randomly initialized. Individual chromosomes are represented as a vector of either integers or floats. Each generation, individuals are evaluated and attributed a fitness score. Tournaments are performed to select individuals based on this score, and these selected individuals are subject to the crossover and mutation operators, until a new population is formed. The search continues for a maximum number of generations or until a desired solution is found. The difference in NSGA-II lies mainly on the selection mechanism, which is supported by two other mechanisms: non-dominated sorting and crowding sorting.
Definition 2. The non-dominated sorting of a population P corresponds to sorting each individual into a non-domination class. The first domination class is composed of the non-dominated individuals of P, the second non-domination class is composed of the non-dominated individuals of P without the individuals in , and so on, until no individual is left in P.
Figure 2a illustrates the concepts of Pareto front and non-domination classes.
Definition 3. The crowded sorting of a non-domination class is the sorting of individuals in descending order of the crowding distance. The crowding distance of an individual is the volume in the objective space around it that is not covered by any other solution, calculated as the perimeter of the cuboid that has the nearest neighbors in the objective space as vertices.
Definition 4. Given two individuals and , with non-domination classes and and crowding distances and , respectively, the crowded comparison operator defines the partial order if and only if ( ) or ( and ).
By considering both non-dominated sorting and crowded sorting in the crowded comparison operator, NSGA-II balances elitism and preservation of diversity of individuals inside a Pareto front. More detailed explanations of these metrics can be found in Deb et al. [15]. With these definitions, the NSGA-II algorithm differs from a standard genetic algorithm in the following aspects: (1) The crowded comparison operator is used when comparing individuals for selection in the tournament. (2) Given a population P, at each generation, a set Q of offspring is generated via selection and application of genetic operators. The union of P and Q is then sorted in non-domination classes, and each class is internally sorted according to the crowding distances. The non-domination classes are then added to the next population until the population size is reached. If including the last non-dominated class before reaching the population size exceeds the population size, then individuals are chosen according to their crowding distance, in decreasing order. The process is illustrated in Figure 2b. Algorithm 1 summarizes the optimization procedure of NSGA-II. Algorithm 1: Pseudocode for NSGA-II.
3. Definition of the Flexibility Benchmark
Following Section 2.1, we now describe the details of the flexibility benchmark for the multi-objective optimization of process parameters based on the extended Oxley model presented in Section 2.2. The task context consists of four related multi-objective metal cutting process optimization tasks , where each task is associated to a different type of metal to be cut. We consider four different materials: steel, tungsten alloy, steel dummy, and inconel-718. In the extended Oxley model, a material is characterized by the material parameters described in Table 1. The specific material parameters for each of the four considered metal types is shown in Table 2.
In each task, we assume that a certain total length (in m) and a certain total depth (in mm) of material have to removed. We keep the total length and total depth fixed across all tasks. The process parametersthat span the solution space X are cutting speed, cutting angle, and cutting depth. Table 3 provides a description of these parameters as well as a suggested range, based on preliminary experimentation with the extended Oxley model. Given a specification of process parameters, the model outputs the values shown in Table 4. We use a combination of the process parameters and the output values to define a feasibility criterionand a performance measurefor candidate solutions. A solution is feasible if the cutting speed is below 50 m/s and the output forces and are both below 500 N. The performance of a solution is measured by four objectives that should be minimized: production time, tool wear, and the absolute output forces and . The production time, measured in seconds, is the time needed for removing the material, and is defined as
Tool wear measures how much the tool is affected by the operation and is defined as
As minimizing these four objectives can be contradictory at times, the optimization consists of finding a Pareto front of solutions, from which a domain expert can choose the most suitable solution at a given time. Based on the ranges for the input process parameters (Table 3), the maximum threshold for the output forces and , and Equations (5) and (6), we present, in Table 5, the ranges that the four objectives can achieve.
4. NSGA-II as a Baseline for Evolutionary Adaption of Solutions
As a baseline method for finding solutions for optimizing the objectives defined in Section 3, we have chosen NSGA-II, which is an established algorithm for finding a Pareto front for multi-objective optimization problems. We represent solutions as a real-valued vector, where each position refers to one process parameter being evolved (cutting speed, cutting angle, and cutting depth, as in Table 3). In the context of adaption of solutions from source to target tasks, we performed the following modifications to standard NSGA-II:
- We run the algorithm for a given task for a fixed number of generations and save the best Pareto front found. For assessing the quality of a Pareto front, we measure its hypervolume, although other measures can also be used for that [17,18,19].
- For adaption, we take the stored Pareto front from a source task as the initial population for optimizing for the target task. If the loaded Pareto front is lower than the population size, we complete the initial population with randomly generated individuals. However, the stored Pareto front was always as large as the population size in our experiments. In principle, adaption stops when a Pareto front with the same hypervolume as that found from scratch for the target task is found.
In a preliminary analysis, where we sampled 10,000 random solutions for each material (details for material parameters and process parameter ranges from which to sample in Section 3 and Section 4.3, respectively), we observed that the approximated Pareto front of different materials lie in the same region of the search space, although they differ in shape and exact location. Based on this, we hypothesize that a Pareto front more between two such approximated Pareto fronts would be a better starting point for adaptation to a target material, although it might not be the best solution for a particular material. Here, we took inspiration from the works by Parter et al. [20] and Kashtan et al. [21], where concepts of facilitated variation are applied to a genetic algorithm that evolves circuits for goals that vary over time and as a result produces solutions that can be much more easily adapted to a target circuit that uses the same modules as the ones used for training. Further, we also extend the genotype used for accommodating two or more values for each process parameter, from which only one is active at a time. Although we take inspiration from the work by Parter et al. [20], these two proposed variants for adaption are also related to existing algorithms from the field of dynamic (multi-objective) evolutionary optimization [6,7,8]. We present these two extensions to NSGA-II in the next two sections.
Both proposed mechanisms are in principle applicable to any problem that can be encoded as an NSGA-II solution. In the case of the concrete cutting problem considered, we know as discussed that the Pareto fronts from related tasks are in similar regions, which makes the varying goals mechanism suitable. Further, the active–inactive genotype mechanism allows two configurations for different materials to be stored in only one genotype and to be easily activated, deactivated, or combined.
4.1. Varying Goals
The varying goals evolution strategy consists of optimizing for two or more goals at the same time in one run. The goal is varied according to a parameter that we here call epoch length E; the goal is changed each E generations. Thus, a same population is optimized for different goals that change each E generations, which defines an epoch. Given n goals and an epoch length E, the goal index in generation i, when the generation begins with 1, is calculated as
Optimizing for different goals raises the question of which Pareto front to store for further adaption. We store the best hypervolume found for each goal and update the best Pareto front so far each time that this best value for the current goal improves. That is, the stored Pareto front is not necessarily the one that achieved the best global quality but the one that last improved on the best value of a given current goal. We chose to do so because the hypervolume achieved for each material is different (see Section 5.1.1). If we stored the Pareto front with the best global hypervolume, we would risk favoring one goal over the others. By storing the one that last improves the best value of the current goal, we also ensure that the stored Pareto front has gone through more iterations of optimization.
Parter et al. [20] propose the varying goals strategy in the biology context in order to study the mechanisms of facilitated variation, specifically the elements of modularity and weak regulatory linkage (see Section 2.1). They show that when optimizing under different but modular goals, the solutions can be quickly adapted to one or the other goal or to other goals composed of different combinations of the same module by mutations that change the connections between learned modules. For the problem we consider, the genotype is a vector of three real-valued numbers that represent process parameters, so it is difficult to imagine modules in there, although one could still argue that solutions to different goals could share building blocks that can be swapped through crossover. In order to go beyond just making solutions stay among the optimal regions for different materials, we also propose a way to accommodate different possibilities in one solution, using a representation model we call active–inactive genotype, which we discuss in the next section.
The varying goals strategy relates to the actual task of dynamic optimization, although in the context of having better starting points for manufacturing optimization, where the topic of reducing the number of necessary evaluations is still open and recent approaches deal more with surrogate models for the simulations [14].
4.2. Active–Inactive Genotype
What we call an active–inactive genotype refers to a genotype with both active and inactive positions, where only active positions appear in the phenotype and positions can be both activated or deactivated via mutations. In the context of evolutionary computation, the concept of inactive genes or nodes appears in specific representations for genetic programming [22,23]. In these representations, the interest for such mechanism lies mostly in neutral search, where solutions can escape local optima via neutral mutations, while some works also examine the hypothesis that evolved information that can be deactivated and further reactivated influences search [24]. Although this does not seem to always be the case when evolving for a fixed goal, we consider the hypothesis that under varying goals, information evolved for one goal can be deactivated when the goals change but can be further activated for different goals or for adaption. That is, we propose studying the interplay between active and inactive positions as a way for the genotype to be able to store information about different goals and thus using this for improving adaption to a target goal.
In the proposed representation model, given a gene length l, each gene, associated to a process parameter, is composed of positions. The first position tells us which of the next l positions is active; the next l positions each encode a possible value for the given process parameter. A phenotype is derived by taking the active position of each gene, resulting in the real-valued vector given as input to the simulation for evaluation. Figure 3a shows an example solution and the decoded phenotype. Algorithm 2 shows a pseudocode for decoding a solution.
We have also adapted the genetic operators to work with the proposed genotype. Crossover acts on the decoded phenotype as a regular crossover, then the result is encoded into the genotype. Mutation works with two steps. First, the first position of each gene can be mutated to activate or deactivate with a probability of , where is the number of process parameters, so that one position is activated/deactivated on average. Next, the decoded phenotype is mutated as in a regular mutation, and the result is encoded in the genotype. A pseudocode for encoding a phenotype into a genotype is shown in Algorithm 3, and Algorithm 4 shows the pseudocode of the two-step mutation operator. Although shown separately in the algorithms, the decoded phenotype is always stored together with the encoded genotype, to avoid having to decode it again for evaluation. Figure 3b shows an example of the application of the modified two-step mutation operator. Algorithm 2: Pseudocode for obtaining a decoded phenotype from a genotype with active and inactive positions. Algorithm 3: Pseudocode for encoding a phenotype given a genotype with active and inactive positions. Algorithm 4: Pseudocode for the two-step mutation on the genotype with active and inactive positions.
The active–inactive genotype relates to the concept of memory, which, in the dynamic evolutionary optimization literature, stores and reuses useful information from previous goals and works well in cyclic environments [7,8]. More specifically, the approach is related to the strategy of implicit memory, which uses redundant representations to store information, like in the diploid genetic algorithm from Uyar and Harmanci [25]. In the context of NSGA-II or memory for multi-objective dynamic problems, Deb et al. [26] introduce a dynamic NSGA-II algorithm using a diversity promotion strategy, Goh and Tan [27] propose an algorithm with memory using coevolution of subpopulations, and Wang and Li [28] propose NSGA-II with memory. However, the way we build an implicit memory via the active–inactive genotype differs from these previous works; moreover, we apply the strategy to train a solution that will be adapted to solve a previously unseen problem in the context of static manufacturing optimization, as opposed to a cyclic environment.
4.3. Parameters and Implementation Details
The base implementation used for the extended Oxley model was the one provided by Pantalé et al. [13] (https://github.com/pantale/OxleyPython, 30 September 2024). For the implementation of the NSGA-II algorithm, we used the DEAP library in Python [29]. For tournament and selection of the next population, we used the provided NSGA-II selection method (https://deap.readthedocs.io/en/master/api/tools.html#deap.tools.selNSGA2, 28 August 2025). As genetic operators, we used simulated binary bounded crossover (https://deap.readthedocs.io/en/master/api/tools.html#deap.tools.cxSimulatedBinaryBounded, 28 August 2025) and polynomial bounded mutation (https://deap.readthedocs.io/en/master/api/tools.html#deap.tools.mutPolynomialBounded, 28 August 2025). Simulated binary bounded crossover swaps genes between two parent chromosomes and may apply a perturbation to some genes. Polynomial bounded mutation applies a perturbation to each gene with probability , where is the number of process parameters being optimized and thus the chromosome length. Both operators respect lower and upper bounds for each gene, which are the lower and upper bounds for the process parameters provided in Table 3. The extended algorithms with varying goals and active–inactive genotype were implemented on top of the baseline algorithm according to the explanations and pseudocodes from Section 4.
Table 6 shows the parameter specifications for NSGA-II and the two proposed variants. In our preliminary analysis, where we sampled 10,000 random solutions to estimate the Pareto front for each material, Pareto fronts had approximately 100 to 300 solutions. We thus set the population size to 100 and the number of generations to 50. We used a standard tournament size of 2 based on preliminary runs. The and parameters for crossover and mutation, respectively, define the magnitude of the perturbation to the chromosome values—high values produce offspring more similar to the parents, whereas low values produce more different offspring. We performed 50 runs using different value combinations (20, 40, 80, 120, 140, 180) for optimizing for steel, inconel-718, and from steel to inconel-718. We observed that low values produced Pareto fronts with higher hypervolumes and thus used the suggested values from the DEAP documentation. We set the epoch length E to 5 to allow for some optimization without staying too long on the same goal, and the gene length l was set to 2 because we optimized for two goals at the same time. Preliminary runs showed that these values achieved good results.
5. Results and Discussion
Using the benchmark described in Section 3, our analysis consists of comparing the best-, average-, and worst-case adaption costs with the costs from scratch as obtained for each target material and also comparing the adaption costs for baseline NSGA-II, NSGA-II with varying goals, and NSGA-II with varying goals and active–inactive genotype (Section 5.1). To measure the quality of a Pareto front, we use the hypervolume, which is a measure of the volume in the objective space that is covered by the solutions in the Pareto front, given a reference point which is a vector of the worst objective values [17,18,19]. Thus, greater values stand for better Pareto fronts. To calculate the hypervolume, we take the objective values, with ranges described in Table 5, and first apply a natural logarithmic scale to production time and tool wear. We then normalize the values between 0 and 1. For normalization, we use as reference for lower and upper bounds for each objective the ranges provided in Table 5. We then take as the reference point representing the worst possible solution in the range from 0 to 1.
The objective and contribution of this paper are demonstrating the potential of the proposed benchmark to measure the flexibility of a learning system and showing that certain mechanisms can make a method more flexible. Therefore, a comparison with other methods from the literature of dynamic evolutionary optimization in order to find the best performing method is out of the scope of the work and not performed here.
Besides comparing this measure of flexibility of different optimization algorithms, we also perform a study on the introduced parameters epoch length E and gene length l, repeating a reduced flexibility experiment as the one described above for NSGA-II with varying goals and active–inactive genotype, in order to assess the influence of these parameters on optimization from scratch and adaption (Section 5.2). Finally, we also repeat the flexibility experiment with different population sizes to study if the adaption cost can be reduced in situations where smaller populations are sufficient for finding a solution with the desired quality (Section 5.3).
5.1. Flexibility Experiment
5.1.1. Obtained Hypervolumes
For reference, Table 7 shows the average maximum hypervolume obtained for each material over 100 runs when using the baseline NSGA-II with 100 individuals and 50 generations. As seen from the standard deviations, values are stable and vary only in the third or fourth decimal digit. The value achieved also depends on the material, ranging from 0.8813 for tungsten alloy to 0.9277 for steel dummy, which probably reflects properties of each task. These values found from scratch by the baseline NSGA-II algorithm are used as reference for adaption. That is, when adapting from steel to tungsten alloy, for example, the objective is to find a hypervolume for tungsten alloy similar to the one in Table 7.
Although some values may seem close to each other, as we take the logarithm of two objectives (production time and tool wear) and normalize all objectives between 0 and 1, a small difference in the hypervolume of a Pareto front may reflect a great difference in practice for the objective values. In this work, we chose to work with the hypervolume as an indicator of quality of a Pareto front and reference for adaption, but in more concrete problems, it should be possible for domain experts to define more concrete goals.
5.1.2. Hypervolumes Across Generations
In Figure 4, we show the hypervolume of the best Pareto front found so far across the generations averaged over 100 runs for each material, both for searching from scratch with the baseline NSGA-II algorithm and for adapting from different source materials also with the baseline NSGA-II algorithm. For all cases, there is rapid improvement in the first 10 generations followed by phases of smaller improvements. Based on a visual inspection of the plots, when adapting from different source materials, the quality of the source Pareto front evaluated on the target task is already superior to a random initial population and achieves higher values much quicker in comparison with the search from scratch for more or less 10 generations, beyond which the hypervolumes become very similar both for the search from scratch and for adaption. This enables us to state the following:
- Solutions from a source material work better than random solutions in a target material;
- Adapting solutions from a source material enables faster optimization towards a threshold quality.
We also show in Figure 5 how the hypervolume develops across generations when using NSGA-II with varying goals, only for the search from scratch, in order to visualize the effect of changing the goals each E generations. Differently from Figure 4, here, we show the hypervolume at each generation for the current goal, not the best hypervolume found so far. As in the plots for the baseline NSGA-II algorithm, we observe a rapid increase in hypervolume in the first 10 generations. After that, although they remain more stable than in the beginning, we observe a different pattern each time the goal changes. Note that the plots for NSGA-II with varying goals and active–inactive genotype present the same pattern, while the plots for baseline NSGA-II with the current hypervolume of each generation instead of the best so far present frequent decreases in hypervolume only for tungsten alloy. Interestingly, in almost all cases, the hypervolume for one goal always increases while it decreases for the other goal. This may be an effect of the solutions moving from one goal to another, but it warrants further analysis. As already observed by Parter et al. [20], the quality of the solutions found under varying goals is not necessarily the best for a given goal, as what we aim at here is having an optimized population that lies between goals and is, thus, more adaptable, as we show next.
5.1.3. Learning and Adaption Costs
The hypervolumes found in Table 7 require a very high number of evaluations, which can be prohibitive in real scenarios that rely on costly computational simulations. In such a scenario, a domain expert would define criteria for stopping the search when a good enough solution is found, which will not have the best possible hypervolume. Furthermore, we observed in preliminary experiments that the exact reference hypervolume is more often found from scratch, as there is a higher initial diversity in the population, and the advantage of adapting solutions is more visible when looking for a value close to it, which, as argued, is also more reasonable from a practical perspective. Therefore, for the assessment in this section, we define the stopping criterion as finding a solution with a hypervolume that has 99% of the reference hypervolume for each material. When comparing adaption against the search from scratch, we compare against the cost of finding 99% of the reference hypervolume both for the search from scratch and for adaption in each run, in order to highlight the differences in performance when aiming at the same threshold.
In our analysis in Table 8, we compare the cost of finding 99% of the reference hypervolume from scratch against the cost of adapting from different source materials. We show the Minimum Computational Effort (CE), which is a statistic that, given the number of evaluations needed for finding the solution in each run, estimates the minimum number of evaluations needed for finding the solution with a probability of 99% [30]. As we are using a population size of 100 individuals, the minimum cost here is 100, when the loaded population already works.
From Table 8, in general, already with the baseline NSGA-II algorithm, the adaptive scheme reduces the cost of finding the threshold solution, with the exception of adaption from inconel-718 to steel, which has a cost of 1,000 in comparison to 900 for the search from scratch. For NSGA-II with varying goals, we used pairs of goals to produce a source population, and the costs for adaption further decrease. Now there is one case (adaption from steel dummy and inconel 718 to steel) where the cost is the same (900). Finally, NSGA-II with varying goals and active–inactive genotype obtains lower costs for adaption in comparison to the search from scratch in all cases, including adaption from steel dummy and inconel-718 to steel, which now costs 600 evaluations.
Table 9 offers a more summarized view of these results, presenting the worst, average, and best cases for the search from scratch and adaptation with baseline NSGA-II, NSGA-II with varying goals, and NSGA-II with varying goals and active–inactive genotype. All costs decrease incrementally as we add features to the standard algorithm. These results confirm that optimization under varying goals generates solutions that are more adaptable and that adding further structures to a genotype that allow it to store more information about different goals/options in a more complex way further enhances this effect. This happens because solutions for different materials, in this case, share some properties, like lying in a similar region of the search space.
We present the results of an analysis with non-parametric statistical tests as suggested by Demšar [31]. We first applied the Friedman test for multiple algorithms on multiple data on the CE values from Table 8. The Friedman test ranks the algorithms and calculates a p-value which, if less than 0.05 (significance level of 95%), means that there is a statistical difference between at least one pair of methods [32]. We obtain a p-value of 1 × 10 . The post hoc Nemenyi test then provides p-values for each pair of methods [33]. The p-values point to a difference between the baseline NSGA-II algorithm and the three variants for adaption, with incrementally lower values (0.036 when compared with baseline adaption, 0.004 for varying goals, and 0.001 for active–inactive genotype).
5.2. Influence of Epoch and Gene Lengths
As stated in Section 4.3, we find it reasonable to use an epoch length that is not so large in order to allow for enough variation in goals and a gene length that is compatible with the fact that we considered only pairs or tasks as sources for adaption. In order to have a better understanding of how these two introduced parameters influence both optimization from scratch as well as adaption, we performed a reduced flexibility experiment with different combinations of E in and l in . The experiments were performed for the pair of tasks steel and tungsten alloy and for adaption to inconel-718, using again the hypervolumes in Table 7 as reference for the threshold to be achieved (99%).
Figure 6 shows how the average best hypervolumes achieved over 50 runs vary in accordance to the parameters E and l for both considered tasks. We observe that the hypervolumes vary only slightly for the search from scratch and even less for adaption, which makes sense, as in adaption, we stop the search once the threshold hypervolume is achieved. Nonetheless, we can still discern two opposite behaviors. In the search from scratch, optimization is better with longer epochs, which is expected, as it gives more time for optimizing for a single goal. It is also interesting to notice that with shorter epochs, a small gene size is preferred, whereas a larger gene size works better in combination with longer epochs. One possible explanation for that is that a larger gene size introduces more diversity, which can be better explored in longer epochs for a fixed goal. Conversely, adaption works slightly better when the search from scratch is worse (shorter epochs and smaller gene size) and slightly worse when the search from scratch is better (longer epochs and larger gene size). By forcing more variation in goals, shorter epochs avoid over-optimization for a fixed goal. As for the gene size, we believe that the results could differ when optimizing for more than two goals at the same time, but the fact that larger gene sizes combined with longer epochs allow for better optimization for one goal may also influence adaption negatively in the case under study.
5.3. Experimenting with Lower Population Sizes
Although the proposed adaptive scheme and variants for NSGA-II were able to reduce the cost of finding a threshold Pareto front, as shown in Section 5.1.3, the number of simulations reported is still high in the context of manufacturing optimization that requires the execution of costly simulations for evaluation of candidate solutions. Therefore, we explore in this section how the adaptive scheme and the proposed variants of NSGA-II behave when we use lower population sizes, both for the search from scratch and adaption.
First, we ran a reduced flexibility experiment with population sizes of 5 and 10 to 100 with a step of 10 and kept the same number of generations as before (50) where we optimized from scratch for steel and inconel-718 and then adapted from steel to inconel-718, having as threshold 99% of the hypervolume obtained from scratch for inconel-718, repeated 50 times. Figure 7 shows the best hypervolumes and costs obtained. The CE shown both for adaption and for the search from scratch was calculated considering the threshold of 99% of the best hypervolume found in each run.
From Figure 7, there is a decrease in the best hypervolume obtained with every decrease in population size, with the value decreasing much more for population sizes of 10 and 5. Accordingly, the cost of finding 99% of this obtained hypervolume increases more or less linearly with the population size. There is an exception for inconel-718, where the cost remains more or less stable after the population size of 30. It could be that higher population sizes in some cases lead to better Pareto fronts more quickly, with less need for further generations, something which we also observe in the results below. The cost of adaption also decreases with the population size, which makes sense, as we are aiming at a lower target hypervolume. These results initially support the idea that when a lower population size is enough for finding a desired solution, adaption would still help to reduce the computational cost.
Next, we repeat the same flexibility experiment as in Section 5.1 with all materials and algorithms and 100 runs, but with population sizes of 50 and 20, first with 50 generations and then with 100 generations for the population size of 50 and 250 generations for the population size of 20, in order to have the same number of evaluations (5000) as with the population size of 100 and 50 generations from Section 5.1. The motivation for having the same number of evaluations is to asses if starting from a source that was optimized for more generations leads to better adaption as a trade-off for the longer training phase. The best hypervolumes obtained by standard NSGA-II from scratch for each setup of population size and maximum generations are presented in Table 10, as averages over 100 runs. For all materials, one can observe that (1) the obtained hypervolume is lower with lower population sizes and (2) optimizing for more generations leads to a slight increase in hypervolume.
Table 11 shows a summary of the worst, average, and best cases for the computational costs obtained for the search from scratch and adaption via NSGA-II, NSGA-II with varying goals, and NSGA-II with varying goals and active–inactive genotype, for the different setups of population size and maximum generations. One can observe that there is a sustained decrease in adaption cost for NSGA-II with varying goals and active–inactive genotype, as observed previously in Section 5.1.3, for the population size of 100. One exception is the population size of 20 with 50 generations, where the average- and worst-case costs are a bit higher in comparison with adaption with baseline NSGA-II.
We present the results of Friedman and post hoc Nemenyi tests for each of the four groups in Table 11, calculated with the CEs used to generate the summarized table. For all groups, the Friedman p-value is lower than 0.01, which points to a difference between at least one pair of methods in each group. For the population size of 50 and 50 generations, the Nemenyi p-values between baseline NSGA-II and the three adaption variants are also incrementally significant (0.044 in comparison with baseline adaption, 0.006 for varying goals, and 0.001 for active–inactive genotype). For the population size of 20 and 50 generations, they are also significant but higher for the varying goals variant (0.001 in comparison with baseline adaption, 0.014 for varying goals, and 0.001 for active–inactive genotype). For the population size of 50 and 100 generations, the p-value is only significant between baseline NSGA-II and NSGA-II with varying goals and active–inactive genotype (0.002). For the population size of 20 and 250 generations, the baseline NSGA-II algorithm is different from baseline adaption and active–inactive genotype (both p-values of 0.001) but not from varying goals. These results show that baseline adaption and NSGA-II with varying goals may face some difficulties in certain setups, but the addition of the active–inactive genotype could overcome this.
Another observation is that although the population sizes are lower, the costs for finding 99% of the best hypervolume are of the same magnitude as with the population size of 100 (see Table 9). One possible reason is that as the reduced population produces a Pareto front with a lower hypervolume and more generations are needed for optimization, even though the final hypervolume obtained is still worse than when using 100 individuals (see Table 7). Therefore, when more generations are available (100 and 250), some costs can be even higher. Concretely, the population size and number of generations used will depend on a trade-off between the cost of simulations and the desired quality for a specific application. In general, we can conclude based on our results with smaller populations that both the adaptive scheme and the extension with varying goals and active–inactive genotype are able to reduce the cost of finding a threshold solution with different population sizes, given that a population was already trained on a source task.
6. Conclusions and Future Work
We have addressed the issue of reducing the number of computations necessary for manufacturing process optimization, which usually requires costly simulations, in the context of changing product specifications. For this purpose, we have considered optimization algorithms from the viewpoint of system flexibility, which is related to dynamic optimization. We have studied the ability of an optimization algorithm to adapt a solution to a target task that has previously been found for a source task, thus reducing the cost of finding a new solution.
In order to be able to systematically experiment within this framework, we have used the extended Oxley model, which simulates the process of orthogonal metal cutting. We introduced a new benchmark in the form of a multi-objective problem based on the extended Oxley model. We used the NSGA-II algorithm to optimize the process parameters for different tasks defined by different material parameters and experimented with adapting solutions for pairs of source and target tasks, in order to assess the potential of adaption in comparison with a search from scratch. Additionally, we extended NSGA-II with two features inspired by facilitated variation and that relate to dynamic optimization: varying goals, where a population is evolved for two goals at the same time, and active–inactive genotype, where each gene contains different possible values and only one is active at a time.
Given that the model used for the proposed benchmark problem is simpler than a numerical simulation, our results are a starting point and can be further extended by considering extensions to this model. However, it already enabled us to perform a more comprehensive analysis of the proposed methods and to show that they are able to reduce the adaption cost in a context of manufacturing optimization. Specifically, we could draw the following main conclusions:
- When problems are related and one can expect that solutions lie in a similar region of the search space, adapting solutions from source to target greatly reduces the number of evaluations needed for finding a threshold solution. The extensions with the varying goals strategy and active–inactive genotype can further reduce this cost by generating solutions that are in-betweens with respect to the original solutions and accommodating different possibilities/structures in one genotype.
- If a lower population size is enough for finding a desired solution for a given problem, the adaptive scheme and proposed variants will still most likely provide an advantage over the search from scratch, given that a solution for one or more related tasks has already been found.
As outlined in Section 1, the introduced benchmark allows only for negative conclusions due to the gap in accuracy between the extended Oxley model and realistic FEM simulations. For further research and in particular for practical applications, a validation with more realistic simulations is strongly recommended. Therefore, the benchmark itself should currently be considered a proof of concept. Its usefulness for identifying flexible optimization methods for manufacturing is only proven once an optimization method developed on the basis of the benchmark has been positively validated with more realistic simulations. Furthermore, although the computational effort to find solutions is on average more than halved, it would usually be still too high for practical applications, in particular if costly realistic simulations are involved.
Some interesting possibilities of future work that could follow from the work presented in this paper are the following:
- A more concrete definition of the multi-objective problem based on the Oxley model. Although we have used the hypervolume as a measure of the quality of the Pareto fronts, a more concrete definition of a goal would make the gains that a given algorithm can bring more understandable in practice. Furthermore, the Oxley model could be extended to reflect more the properties of real simulations, which could make the defined problem a candidate benchmark for manufacturing optimization.
- The defined multi-objective problem enables fast evaluation of different algorithm setups. A natural next step is the validation of the best setups found in a scenario based on, for example, FE simulations.
- Although the presented results show an improvement in the cost of adaption, the values obtained are still high if considered in a practical setting. Given the interdisciplinary flexibility framework used, one could consider extending the ideas of this work based on ideas for adapting and transferring data-driven models from other areas, such as meta-learning [34], transfer learning [35], few-shot learning [36], as well as efforts to combine transfer learning and dynamic multi-objective optimization [37].
- The proposed extensions to NSGA-II can also be incorporated in other optimizers that are based on iterations. One interesting possibility is integrating the varying goals and active–inactive genotype strategy into a Bayesian optimizer, which is a popular method for manufacturing optimization.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Pereira J.L.J. Oliver G.A. Francisco M.B. Cunha S.S. Gomes G.F. A review of multi-objective optimization: Methods and algorithms in mechanical engineering problems Arch. Comput. Methods Eng.2021292285230810.1007/s 11831-021-09663-x · doi ↗
- 2Pfrommer J. Zimmerling C. Liu J. Kärger L. Henning F. Beyerer J. Optimisation of manufacturing process parameters using deep neural networks as surrogate models Procedia Ci RP 20187242643110.1016/j.procir.2018.03.046 · doi ↗
- 3Sotto L.F.D.P. Mayer S. Garcke J. The pole balancing problem from the viewpoint of system flexibility Proceedings of the Genetic and Evolutionary Computation Conference Companion Boston, MA, USA 9–13 July 2022427430
- 4Mayer S. Sotto L.F.D.P. Garcke J. The Elements of Flexibility for Task-Performing Systems IEEE Access 2023118029805610.1109/ACCESS.2023.3238872 · doi ↗
- 5Kaoutoing M.D. Contributions à la Modélisation et la Simulation de la Coupe des Métaux: Vers un Outil d’aide à la Surveillance par Apprentissage Ph.D. Thesis Génie Mécanique Mécanique des Matériaux, INPT, Toulouse, France 2020
- 6Branke J. Evolutionary Optimization in Dynamic Environments Springer Science & Business Media New York, NY, USA 2012 Volume 3
- 7Azzouz R. Bechikh S. Ben Said L. Dynamic multi-objective optimization using evolutionary algorithms: A survey Recent Adv. Evol. Multi-Object. Optim.201723170
- 8Yang S. Evolutionary Computation for Dynamic Optimization Problems Proceedings of the Companion Publication of the 2015 Annual Conference on Genetic and Evolutionary Computation Madrid Spain 111–15 July 201562964910.1145/2739482.2756589 · doi ↗