Threshold Adaptation for Improved Wrapper-Based Evolutionary Feature Selection
Uroš Mlakar, Iztok Fister, Iztok Fister

TL;DR
This paper shows that adjusting a threshold parameter during feature selection improves performance in evolutionary algorithms for classification tasks.
Contribution
The first large-scale evaluation of threshold adaptation in wrapper-based evolutionary feature selection.
Findings
Adaptive threshold mechanisms significantly outperform static threshold control in classification accuracy and subset size.
Adaptive methods provide better trade-offs between accuracy and feature subset size compared to static approaches.
Threshold adaptation surpasses state-of-the-art feature selection methods on multiple benchmarks.
Abstract
Feature selection is essential for enhancing classification accuracy, reducing overfitting, and improving interpretability in high-dimensional datasets. Evolutionary Feature Selection (EFS) methods employ a threshold parameter θ to decide feature inclusion, yet the widely used static setting θ=0.5 may not yield optimal results. This paper presents the first large-scale, systematic evaluation of threshold adaptation mechanisms in wrapper-based EFS across a diverse number of benchmark datasets. We examine deterministic, adaptive, and self-adaptive threshold parameter control under a unified framework, which can be used in an arbitrary bio-inspired algorithm. Extensive experiments and statistical analyses of classification accuracy, feature subset size, and convergence properties demonstrate that adaptive mechanisms outperform the static threshold parameter control significantly. In…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
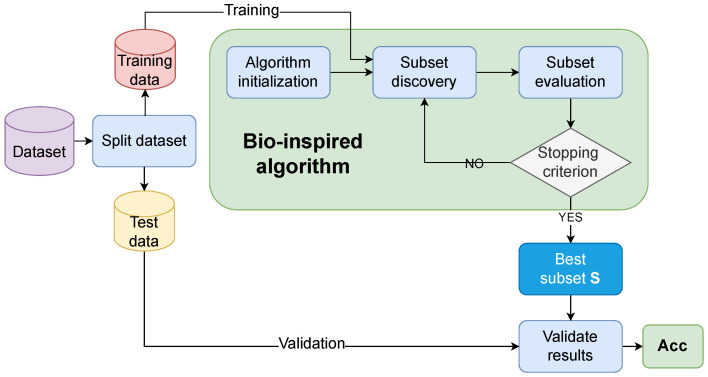 Figure 1
Figure 1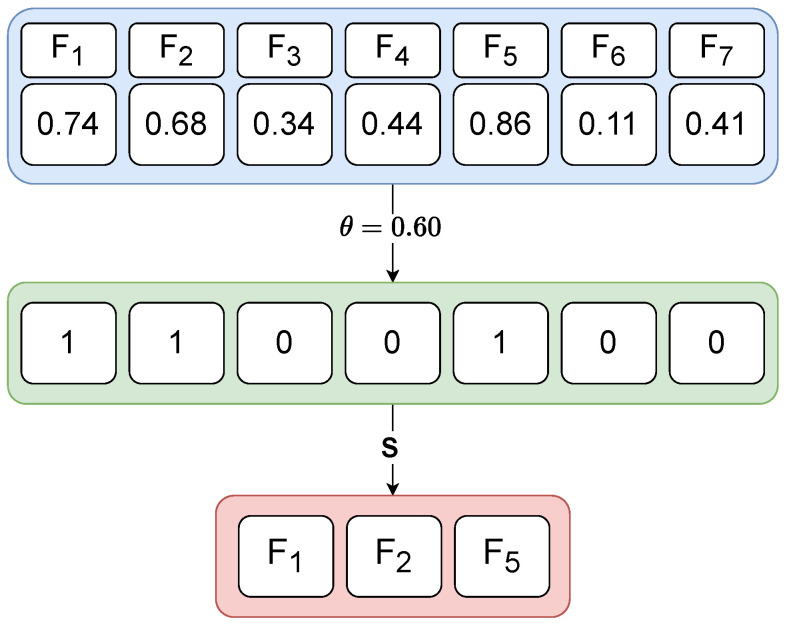 Figure 2
Figure 2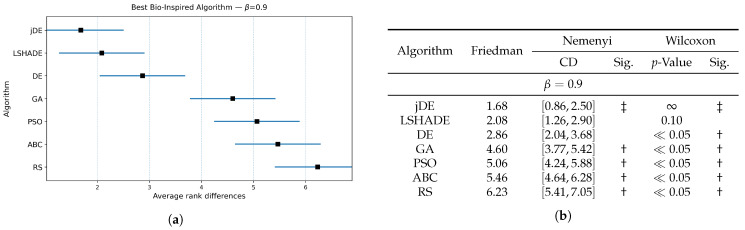 Figure 3
Figure 3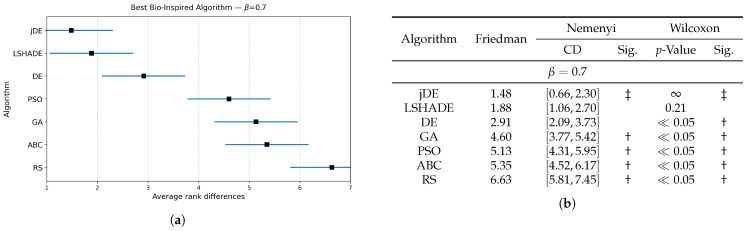 Figure 4
Figure 4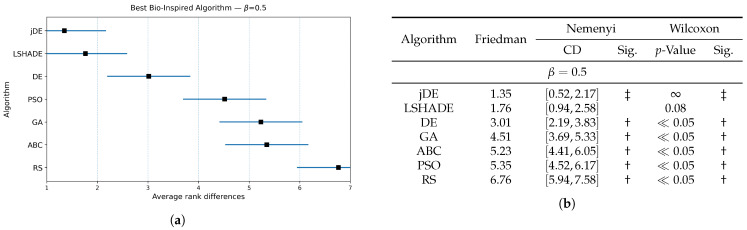 Figure 5
Figure 5 Figure 6
Figure 6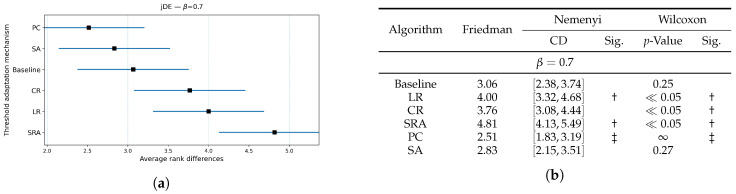 Figure 7
Figure 7 Figure 8
Figure 8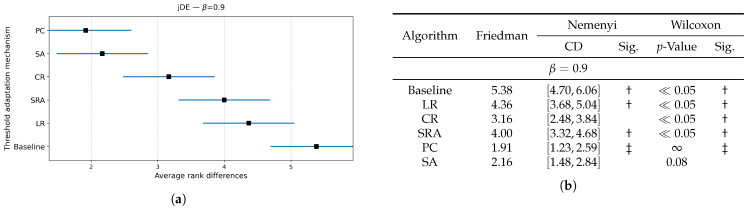 Figure 9
Figure 9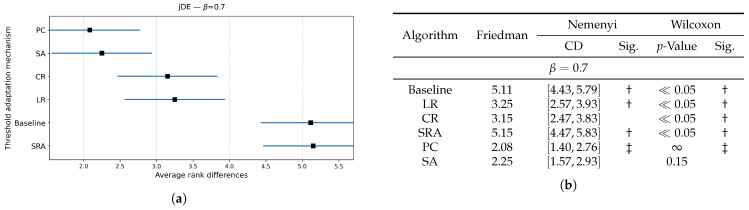 Figure 10
Figure 10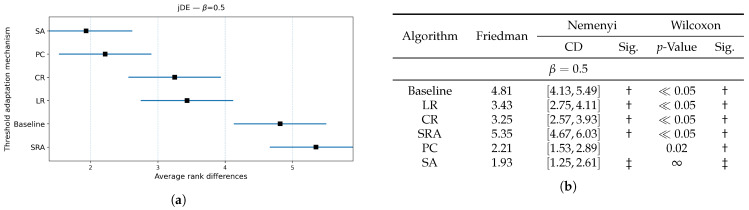 Figure 11
Figure 11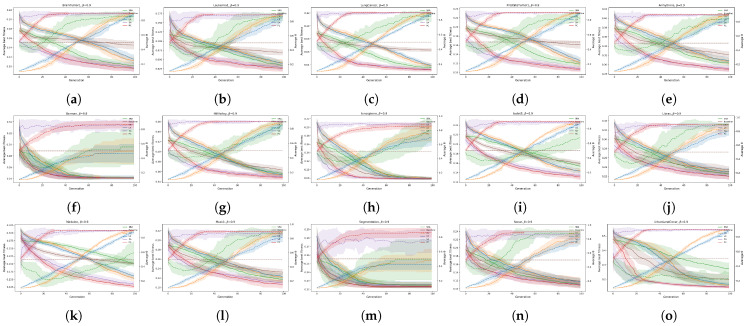 Figure 12
Figure 12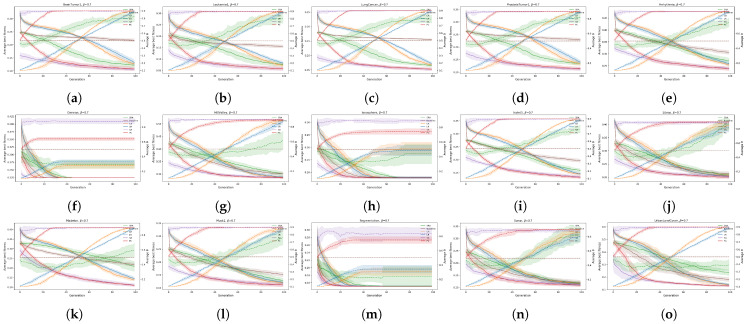 Figure 13
Figure 13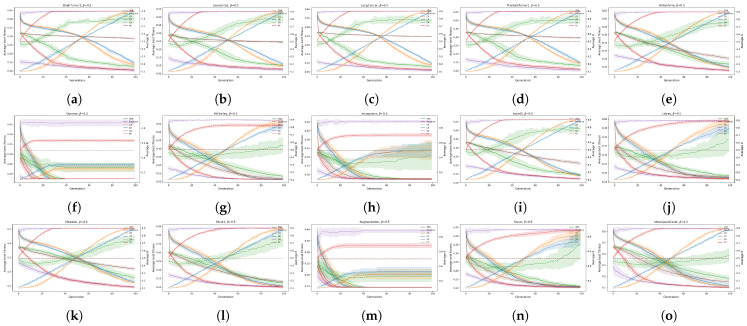 Figure 14
Figure 14- —Slovenian Research Agency
- —Slovenian Research and Innovation Agency
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsEvolutionary Algorithms and Applications
1. Introduction
Feature selection is a critical step in data preprocessing, especially in high-dimensional datasets often encountered in fields such as bioinformatics [1] and data mining [2]. The goal of feature selection is to identify a subset of relevant features that contribute the most to the predictive power of a model, thereby enhancing performance, reducing overfitting, and improving interpretability. Among the various feature selection methods, bio-inspired algorithms have gained significant attention due to their ability to search large and complex spaces efficiently. Additionally, hybrid approaches have been developed by combining evolutionary algorithms with other simpler optimization techniques, such as Simulated Annealing [3] or traditional filter methods [4], to balance exploration and exploitation more effectively. These hybrid methods often result in faster convergence and improved accuracy, as they capitalize on the strengths of each individual algorithm.
Evolutionary Feature Selection (EFS) methods, which apply bio-inspired algorithms, like evolutionary algorithms (EAs) [5] and Swarm Intelligence (SI)-based algorithms [6], to the task of selecting the optimal subset of features have shown great promise in handling high-dimensional data. These methods rely on the models of biology (like natural selection, the behavior of bird swarms, flocks of fishes, etc.) to evolve feature subsets iteratively, balancing between exploration and exploitation to avoid the local optima. The balancing depends crucially on a parameter threshold that determines the inclusion/exclusion of the particular feature in the solution subset. Indeed, this parameter influences the tradeoff between model complexity and generalization capability. The higher threshold might result in a smaller subset, potentially leading to underfitting if relevant features are discarded. Conversely, the lower threshold might retain too many features, increasing the risk of overfitting and computational cost. Therefore, finding the optimal threshold is essential for maximizing the effectiveness of EFS methods.
Recent works have explored various aspects of EFS, such as the development of new crossover and mutation strategies, hybrid approaches combining EFS with other optimization techniques, and the application of EFS in different domains. Wang et al. [1] introduced a PSO-based feature selection algorithm with a dynamic adjustment mechanism for the inertia weight, enhancing convergence speed and solution quality. Many studies highlight the potential of EFS methods in feature selection, but often overlook the impact of the threshold parameter, focusing primarily on algorithmic innovations. Moreover, some recent studies have recognized the need to optimize feature selection thresholds but have approached it from a heuristic or domain-specific angle. Deng et al. [7] proposed a novel approach for high-dimensional feature selection, named the Feature-Thresholds-Guided Genetic Algorithm (FTGGA). Traditional genetic algorithms suffer from unguided crossover and mutation operations, leading to slow convergence and suboptimal features. To address these challenges, FTGGA introduces a multi-objective feature scoring mechanism that updates feature thresholds during the evolutionary process, allowing for a more targeted crossover and mutation. However, the algorithm integrates the ReliefF [8] technique to filter out most of the redundant features initially, followed by a genetic algorithm guided by continuously updated feature thresholds. Li et al. [9] proposed an Improved Sticky Binary Particle Swarm Optimization (ISBPSO) algorithm for feature selection in high-dimensional classification tasks. The method enhances the standard SBPSO by integrating three key mechanisms: a feature-weighted initialization using mutual information, a dynamic bit masking strategy that reduces the search space progressively by freezing unpromising features, and a genetic refinement process applied to the particles’ personal bests to prevent premature convergence. A notable distinction of ISBPSO is the use of a feature selection threshold of 0.6 instead of the typical 0.5, in order to retain only strongly activated features. Fister et al. [10] introduced a novel Self-Adaptive Differential Evolution Algorithm for feature selection, enhanced by a threshold mechanism. Their approach improved feature selection by updating feature presence thresholds dynamically by means of complex adaptation during the evolutionary process.
In contrast to these method-specific designs, our study tests various threshold parameter control mechanisms systematically under a unified, optimizer-agnostic framework. According to Eiben and Smith [5], the parameter control techniques in evolutionary computation can be classified into one of the following three categories: (1) deterministic, (2) adaptive, and (3) self-adaptive. The algorithm’s parameters are altered according to some deterministic rule by the deterministic parameter control. The adaptive parameter control means that there is some feedback from the search process, which determines the direction or magnitude of the change by the control parameters. In the last parameter control mechanism, the parameters are included into the representation of individuals, and, together with the problem variables, they suffer the effects of the variation operators. In this sense, we benchmark deterministic schedules, population-level feedback mechanisms, and self-adaptive per-individual threshold adaptations across multiple bio-inspired optimizers and datasets, using a common interface and evaluation protocol. This isolates the mechanism effect of threshold adaptation from confounding factors (e.g., prefiltering or operator choice) and yields generalizable guidance on when and how adaptive thresholding improves the quality of the selected feature subsets. In order to present a picture as comprehensively as possible, the random search deterministic algorithm with no parameter control is included into the comparative study.
To the best of our knowledge, this study represents the first large-scale systematic investigation of several mechanisms for feature selection threshold adaptation across a wide range of bio-inspired algorithms and datasets. This allows us to uncover generalizable insights about threshold behavior that are independent of the underlying evolutionary operator. The obtained results suggest that using a higher static threshold already achieves significant improvements in classification accuracy and subset compactness, highlighting the importance of tuning the feature threshold. To summarize, the proposed paper introduces the following key novelties:
- Proposing a threshold adaptation mechanism, which can be used in an arbitrary bio-inspired algorithm for EFS;
- Comparing different feature threshold adaptation mechanisms to the baseline method ( = 0.5);
- Investigating the balance of classification accuracy and feature subset size in the fitness function by using five different threshold mechanisms in bio-inspired algorithms;
- A large-scale study of five feature threshold adaptation mechanisms in bio-inspired algorithms and their influence on the quality of the selected feature subset;
- A large-scale study of five feature threshold adaptation mechanisms in bio-inspired algorithms and their influence on the size of the selected feature subset;
- Investigating the convergence properties of the bio-inspired algorithm in regard to using different feature threshold adaptation mechanisms;
- Comparing the best adaptation mechanism (according to the obtained results) to the state of the art.
The rest of the paper is organized as follows: In Section 2, the foundation of EFS is explained in detail. Section 3 illustrates the design and implementation of the proposed method. The experimental work and the analysis of the obtained results are the subjects of Section 4. Finally, the paper is concluded with Section 5, where we explain the potential directions of future work.
2. Materials and Methods
This section introduces the foundational knowledge necessary for potential readers to grasp to understand the concepts that follow. Firstly, the feature selection problem is defined, which is presented as an optimization problem. Then, the idea of wrapper-based feature selection is introduced. Finally, the application of a wrapper-based feature selection is defined using an arbitrary evolutionary algorithm.
2.1. Feature Selection
Feature selection is a preprocessing mechanism, which involves identifying the most relevant subset of features from a given dataset, thereby reducing the dimension of the problem and improving the learning algorithm efficiency and performance. Mathematically, the feature selection problem can be formulated as follows: Let represent the set of all n features in a dataset, and let Y denote the corresponding target class variable. The goal of feature selection is to find a subset of features , such that a model trained on S achieves optimal performance in terms of an evaluation metric . Formally, the feature selection is expressed as follows:
where represents the performance of the trained model on the selected feature subset S and depends on the selected feature selection method.
2.2. Evolutionary Feature Selection
EFS is a bio-inspired optimization approach in order to identify the most relevant subset of features. Unlike traditional methods, which often rely on deterministic algorithms, bio-inspired computation comprises a class of stochastic nature-inspired population-based search algorithms suitable for solving the hardest optimization problems. These algorithms evolve a population of candidate feature subsets iteratively, by selecting, combining, and mutating them to explore the search space effectively. This process not only enhances model performance by reducing overfitting, but also improves interpretability and computational efficiency by eliminating irrelevant or redundant features. EFS is particularly useful in high-dimensional datasets where the feature space is vast, making an exhaustive search impractical.
During the optimization, a bio-inspired algorithm maintains a population of solutions , for , where denotes the population size. Each solution is a vector of j values, where j corresponds to the number of all features in the dataset. Each element of the vector represents a feature from the dataset. All of the reviewed bio-inspired algorithms for feature selection use a threshold mechanism internally for selecting the relevant features in the search space of the algorithm. This can be expressed mathematically as follows:
where the variable S denotes the feature subset, which will be used for training the selected machine learning algorithm, and the parameter is a threshold determining if the specific feature will be included in the feature subset or not. Let us mention that the value of the threshold is typically set to 0.5 in most of the reviewed literature.
2.3. Wrapper-Based Feature Selection
Wrapper-based methods evaluate the usefulness of feature subsets by using the predictive model as a black box to assess their performance directly. By iterative searching and selecting subsets of features that optimize a given performance metric, wrapper-based approaches can identify the most relevant features for the model effectively. This method is computationally intensive but often yields superior results compared to filter-based methods, as it considers feature dependencies and interactions within the context of the specific predictive algorithm. The wrapper-based feature selection process in our study is implemented using a bio-inspired algorithm, which evolves a population of feature subsets iteratively towards optimal solutions inspired by models which have arisen in biology.
The fitness function for evaluating a solution in a wrapper-based method is defined as follows:
where the variable C designates the selected classifier and the variable S is the feature subset. The variable denotes the classification accuracy of the observed feature subset S.
Since the feature subset size also plays an important role, the following fitness function was adapted in this study:
where is the length function, which counts the number of features in a subset S, and is the weighing factor for balancing the importance between the classification accuracy and the number of selected features.
3. The Proposed Evolutionary Feature Selection and Threshold Adaptation Mechanisms
This section describes the complete EFS framework used throughout our experiments. The framework builds upon a generic bio-inspired optimization algorithm using a threshold-based genotype–phenotype mapping to control feature subset generation. It is implemented as a wrapper-based approach and is compatible with an arbitrary population-based bio-inspired algorithm (Figure 1).
As is evident from Figure 1, a general feature selection process is divided into the following four key steps:
- Dataset splitting;
- Subset discovery;
- Subset evaluation;
- Validation of results.
In the first step (i.e., dataset splitting), a dataset is divided into training and validation sets with respect to some predefined ratio. Thus, the former set is used for the training phase, while the latter is used for the validation phase of the EFS. The second step (i.e., subset discovery) involves generating candidate subsets of features from the full feature space. In the context of evolutionary algorithms, this corresponds to evolving a population of individuals where each individual encodes a potential feature subset. The third step (i.e., the subset evaluation) is achieved by applying a fitness function to assess the quality of each feature subset. The last step (i.e., validation of results) evaluates the selected subset on a separate testing set to assess its generalization performance. This step is crucial to avoid overfitting and to ensure the robustness of the selected features across different data splits. The result of the process is the best subset S according to the fitness value, as proposed by the definite bio-inspired algorithm and its accuracy Acc.
Let us mention that the second and third steps are entrusted to a particular bio-inspired algorithm by the framework. Although the concept of bio-inspired algorithms captures two classes of nature-inspired algorithms (EAs and SI-based), they share common characteristics that enable us to deal with them similarly. Moreover, some efforts were made by Fister et al. in defining the universal framework of these stochastic nature-inspired population-based algorithms [11]. As a result, the generic bio-inspired algorithm can be defined as illustrated in the pseudo-code of Algorithm 1. Algorithm 1 The pseudo-code of a generic bio-inspired algorithm.
- 1:INITIALIZE_population_randomly
- 2:EVALUATE_each_individual
- 3:while Termination_condition_not_met do
- 4: MODIFY_each_individual
- 5: EVALUATE_each_trial
- 6: SELECT_individuals_for_the_next_generation
- 7: FIND_global_best_individual
- 8:end while
Indeed, these algorithms follow a common evolutionary paradigm and differ only in their specific update/modification mechanisms (i.e., function ‘MODIFY_each_individual’). In summary, the function in EAs consists of the following three functions [5]:
- SELECT_parents;
- RECOMBINE_pairs_of_parents;
- MUTATE_the_resulting_offspring.
However, in SI-based algorithms, this function represents the implementation of some biological model that serves as an inspiration for the search process design captured in the ‘MODIFY_each_individual’ function. Therefore, our main effort in the design was to adapt the specific bio-inspired algorithm to be capable of solving the feature selection problem as an optimization. Indeed, the adaptation demands two modifications of the bio-inspired algorithm, namely the following:
- genotype–phenotype mapping;
- fitness function evaluation.
The genotype–phenotype mapping decodes the representation of an encoded solution in the search space to the solution in the problem space. The solution of the EFS in the genotype search space is represented as a real-valued vector of length equal to the number of features, while, in the phenotype space, this is decoded as a binary feature mask derived by applying a threshold to the genotype vector. Specifically, features with values above the threshold are included in the selected subset, while others are excluded (see Equation (2) and Figure 2).
In our study, a wrapper-based approach is used, where the fitness function considers the classification accuracy and the number of selected features jointly (see Equation (4)).
Threshold Parameter Control
To study the control of the threshold parameter systematically, we grouped the different parameter control mechanisms into three classes that can be applied to an arbitrary bio-inspired algorithm:
- Deterministic schedules, varying the threshold over time according to a preset curriculum (e.g., linear ramps, cosine cycles), shaping feature selection pressure without using any feedback from the population;
- Population-level feedback mechanisms updating a single global threshold by regulating the measurable metrics, such as improvement/success rate or diversity, thereby tightening or relaxing selection as the search progresses;
- Self-adaptive per-individual thresholds treating the threshold as a gene, which is co-evolved with the features, allowing different individuals to investigate the search space on their own.
All the used mechanisms exposed the same interface, which consumes population summaries and then outputs the global threshold parameter or the local, i.e., per-individual-based threshold parameter , so they can be compared fairly and used across all bio-inspired methods under the common objective.
Two deterministic threshold parameter control mechanisms were used, namely, Linear Ramp (LR) and Cosine Ramp (CR). The LR increases the threshold linearly over generations as follows:
while the CR increases the threshold by following a half-cosine curve, thus ensuring a slow increase at the beginning and end, with a faster transition in the middle; in other words,
where t denotes the current generation, T the maximum number of generations, and and are the minimum and the maximum values of the threshold parameter.
We implemented two adaptive threshold parameter control mechanisms: The first mechanism, called Proportional Control (PC), regulates the threshold parameter toward a target feature subset size. It uses a target selection rate , which represents the desired fraction of selected features. At each generation t, we compute the realized selection rate from the population and form the error rate . The threshold is then updated with a learning rate . The larger positive error rate leads to the larger increase in the threshold, which yields the smaller feature subset in the next generation, while the negative error rate produces the opposite effect. The projection operator keeps the threshold parameter within the desired interval , i.e.,
The second mechanism, called Success Rate Adaptation (SRA), adjusts the threshold parameter using the fraction of individuals improving their fitness in the current generation. For instance, let denote the success rate and be the target success rate, which is determined empirically. When the observed success rate falls below the target one, the threshold is increased by 15%, to promote smaller subsets and stronger exploitation. When the observed success rate exceeds the target, the threshold is decreased by 15%, to promote larger subsets and additional exploration; in other words,
where and are constants which control the value of the threshold in the new generation.
The final parameter control mechanism, called Self-Adaptation (SA), assigns each individual its own threshold parameter . This parameter is encoded in the genome and updated by the variation operators of the evolutionary search process together with the problem variables. Each individual therefore operates with its own selection rate and can adjust it over time. Different solutions explore different areas of the search space at the same time, which increases population diversity and allows each individual to progress at its own pace without relying on a single global controller. Thus, the threshold control parameter becomes a part of solution; in other words,
where for denote the problem variables, and N is the number of elements. Thus, each individual produces the feature subset using their own threshold, as follows:
4. Experiments and Results
This section describes the results of the experimental work which was conducted in this study. The main goal of the experimental work was to check whether the threshold value of the feature selection process in the search space of the algorithm has any implications on the quality of the feature selection process. In line with this, the following experiments were conducted:
- Determining the best baseline bio-inspired algorithm;
- Investigating the impact of different threshold parameter control mechanisms on the classification accuracy;
- Investigating the impact of different threshold parameter control mechanisms on the feature subset size;
- Analyzing the algorithm’s convergence;
- Comparing the best parameter control mechanism with state-of-the-art algorithms.
Although various evolutionary algorithms have been proposed and refined to address the challenges of feature selection, we selected a broad set of both classical and state-of-the-art bio-inspired algorithms for our experimental work. Specifically, we considered Differential Evolution (DE) [12], Particle Swarm Optimization (PSO) [13], Self-Adaptive Differential Evolution (jDE) [14], Linear Population Reduction Success History Adaptive Differential Evolution (LSHADE) [15], genetic algorithm (GA) [7], and Artificial Bee Colony algorithm (ABC) [16]. These algorithms were chosen because they represent the most widely used methods in Evolutionary Feature Selection, as reported in recent surveys [17,18,19], and have also been shown to perform well in related studies (e.g., LSHADE in the CEC competition). To provide a baseline and to cover fixed parameter strategies, we further included random search (RS) [20]. In line with the majority of the literature, all algorithms operate in a continuous search space, with candidate solutions mapped to the binary feature space using the standard threshold .
The implementations of all the considered algorithms were taken from the Niapy framework [21]. To ensure a fair comparison, the population size of all the algorithms was set to 30, along with 3000 maximum function evaluations. Due to the stochastic nature of evolutionary algorithms, each experiment was executed 30 times for each dataset and algorithm. Let us emphasize that the default values of the other algorithm’s parameters, as proposed in the corresponding literature, were employed for the specific algorithms during the experimental work. Because the selected feature selection approach was wrapper-based, the KNN machine learning algorithm was adopted with a value of . This classifier was selected due to its simplicity, computational efficiency, and robustness, which make it particularly suitable for wrapper-based feature selection. KNN has no explicit training phase, allowing for rapid evaluation of candidate feature subsets across many iterations, which is essential in large-scale experimental setups like ours. Furthermore, KNN is used commonly in the literature [22]. By focusing only on the KNN classifier, we ensured that variability in results comes primarily from the threshold adaptation mechanisms and evolutionary algorithms in the study, rather than from differences in classifier behavior. While the threshold adaptation mechanisms may behave differently with classifiers such as Support Vector Machines (SVMs) or Random Forest (RF), the present work deliberately isolates the effect of threshold adaptation. Consequently, all results should be understood as classifier-dependent. In all the described mechanisms, the parameters were set as follows: was set to , was set to , and target success rate was set to , while the learning rate was set to . The choice of fixed bounds ensured comparability across datasets, even though these values may have different implications in lower- and higher-dimensional feature spaces.
For evaluating the quality of the feature selection process, the considered metric in Equation (4) was applied using the final feature subset size variable , and the classification accuracy of the selected feature subset parameter was weighted by parameter . In this study, we tested three values of the weighting factor , namely, . The value is a commonly adopted setting in wrapper-based EFS methods [9] and ensures that classification accuracy has a dominant influence in the evaluation of feature subsets, while maintaining a lower weight for subset size. The lower values and were tested, to check whether the lower classification weight (and a higher feature weight) has any significant effect on selecting the final feature subsets. Lower values of were not considered, as placing a higher weight on the feature subset size can severely degrade algorithm performance by driving the search toward extreme solutions (i.e., selecting almost no features; consequently, the trained classifier fails to capture relevant patterns and achieves low accuracy). Similarly, excessively high values were avoided to ensure that feature subset size retained at least some influence in the fitness evaluation.
Although we agree that accuracy has limitations, especially in imbalanced or multi-class datasets, the majority of state-of-the-art feature selection studies report accuracy as the primary evaluation metric, which allows us to make a direct comparison with existing works. For consistency and comparability, we therefore adopted accuracy as our main performance measure. Accuracy was computed as the overall classification accuracy across all samples. While alternative metrics such as balanced accuracy, F1-score, or AUC could provide additional insights, incorporating them is beyond the scope of this study and represents an interesting direction for future work.
All the experiments were performed on a desktop computer, with the following configuration:
- Intel(R) Core(TM) i9-10900KF CPU @ 3.70 GHz;
- RAM: 65 GB;
- Operating system: Linux Ubuntu 22.04 Jammy Jellyfish.
To evaluate the impact of a threshold in EFS, the datasets listed in Table 1 were used during the experimental work. The characteristics of each dataset are presented in terms of the number of instances, features, and number of classes. All the datasets contain diverse classification problems, as they contain a different number of instances and features [23]. These datasets are used commonly in the research literature [24].
Each dataset was split randomly into training and testing sets, with 70% of the samples going to the training and 30% to the testing set. When dividing, we paid attention to the equal division of classes between the two sets. One algorithm run consists of selecting the relevant features from the training set and then evaluating the performance of the selected features on the test set. During the training phase, a 5-fold cross-validation scheme was employed on the training set to ensure the robustness and generalizability of the selected feature subsets. Cross-validation is widely recognized as the standard approach to mitigate classifier overfitting in EFS, although it cannot fully eliminate the risk. The test set remained completely unseen throughout the training and feature selection process, and was only used for the final evaluation of the selected features. Let us notice that the datasets were normalized so that no feature with a larger range disproportionately influenced the KNN classifier.
To assess the statistically significant difference between the algorithms in the test, we used the non-parametric Friedman test, which is used for comparing multiple algorithms over multiple datasets by ranks [25,26]. For each dataset, the algorithms were ranked according to their performance. The Friedman statistic was then computed from these ranks and used to test the null hypothesis assuming that all algorithms are equivalent. This means that they have the same expected rank. We performed post hoc analysis only when the Friedman null hypothesis was rejected.
Following Demšar [25], we applied the Nemenyi post hoc test to obtain pairwise comparisons based on average ranks, and to visualize the results with critical difference diagrams, which show which average ranks differ significantly [27]. The Nemenyi procedure is conservative, especially when many algorithms are compared, or when the number of datasets is modest, so its statistical power can be limited, and some pairs may remain indistinguishable [27].
To increase sensitivity, we identified a control method, defined as the algorithm with the lowest average rank, and then applied the Wilcoxon signed-rank test for paired comparisons between each algorithm and the control [26]. This choice follows the recommendation of Benavoli et al., who advocate paired distribution free tests over procedures that rely only on mean ranks, because they offer greater power and a clearer interpretation [28]. In our reporting, the Nemenyi test provides graphical summaries through critical difference diagrams, while the Wilcoxon test provides the primary significance assessment. All the tests were conducted using a significance level .
The pairwise observations used in the tests were constructed as follows: For each of the 15 datasets, we considered two summary statistics of the experimental outcomes, namely, the mean and the median. This yielded pairwise measurements (also classifiers) for each algorithmic comparison and defined the effective sample size for the Wilcoxon analyses reported in the paper.
In the remainder of this section, we illustrate the detailed results of the statistical tests obtained after the conducted experiments.
4.1. Determining the Best Baseline Bio-Inspired Algorithm
The purpose of the first experiment was to recognize the best-performing bio-inspired algorithm using the fixed value of the threshold control parameter, which will later be used as a baseline algorithm for comparing against other bio-inspired algorithms using different adaptation mechanisms. The control algorithm will be recognized in terms of the fitness function (Equation (4)), which considers the threshold control parameter to be static throughout the whole evolutionary run of the algorithm that was set to . Given the large number of results, only the aggregated statistical results, considering all datasets, are reported in the corresponding tables.
The results of the Friedman and Wilcoxon tests are presented in Figure 3, Figure 4 and Figure 5 for values of weighting factor , , and , respectively. Thus, each figure is divided into two parts, i.e., the table for presenting the results numerically and the diagram for illustrating the same graphically. The table contains the results of the Friedman tests, together with corresponding Nemenyi and Wilcoxon post hoc tests, while the figure presents the calculated Friedman ranks. The results of the Nemenyi post hoc test are represented as critical difference intervals, where the results of two algorithms are statistically significant if their critical difference intervals do not overlap. The Friedman tests’ ranks of particular baseline bio-inspired algorithms were compared with the ranks obtained by the control algorithm, to identify the best bio-inspired algorithm. The results of the Wilcoxon non-parametric test are depicted through corresponding p-values, where a significant difference between two algorithms is indicated when . In Figure 3b, Figure 4b and Figure 5b, the best baseline algorithm identified by the Nemenyi post hoc test becomes a control algorithm for the Wilcoxon test. The control algorithm serves as a basis for comparison with the other baseline bio-inspired algorithm and is therefore denoted with the symbol ‡ in the table. Moreover, the presence of a significant difference between the control algorithm and the corresponding bio-inspired algorithm is represented by the symbol †.
The Nemenyi post hoc test results are presented graphically through corresponding diagrams in Figure 3a, Figure 4a and Figure 5a. Each diagram displays the average ranks represented by squares, while lines indicate the confidence intervals (critical differences) for the algorithms being compared. Thus, the lower rank values signify better-performing algorithms.
In summary, the jDE baseline bio-inspired algorithm attained the lowest average rank and was taken as the control algorithm. LSHADE was consistently the closest competitor, followed by DE, GA, PSO, ABC, and RS trailing behind. Under the Nemenyi test, the confidence intervals of jDE overlapped with those of LSHADE (and marginally with DE) by using the weighting factors and , so these algorithms were not significantly distinguished from the control one, whereas GA, PSO, ABC, and RS were significantly worse. When , DE’s interval no longer overlapped with that of jDE; therefore, DE performed significantly worse. LSHADE remained statistically indistinguishable from the control across all three weighting factor values. The Wilcoxon signed-rank test, which has higher power than Nemenyi, corroborated the finding with a stronger separation. For each , the pairwise Wilcoxon tests indicated significant differences between jDE and the other methods (all ), while the differences between jDE and LSHADE were not significant.
Overall, these results suggest a stable two-tier structure, where jDE and LSHADE form the top tier, tied statistically under both post hoc procedures across the tested values, while DE occupies a borderline position that becomes clearly inferior when the objective places more weight on feature subset size ( ). The algorithms GA, PSO, ABC, and RS constituted the lower tier, being consistently worse than the control under both post hoc analyses. For selecting a baseline optimizer, jDE is therefore a reasonable default, with LSHADE as an equally competitive alternative, depending on the implementation or runtime preferences.
4.2. Impact of Different Threshold Parameter Control Mechanisms on the Classification Accuracy
The purpose of this study was to analyze how different threshold parameter control mechanisms influence the classification accuracy. Since the jDE algorithm obtained the best results in the first experiment, it was used as the basic algorithm, whose results should be improved using various threshold parameter controls. Therefore, the jDE algorithm was executed 30 times for each evaluation dataset using five different threshold parameter control mechanisms: LR, CR, SRA, PC, and SA. The obtained classification accuracies and final thresholds are presented in Table 2 for all observed weighting factor values . In the table, the row marked “# best” indicates the number of datasets on which each mechanism obtained the best results at a specific value.
Table 2 shows that within jDE, threshold parameter control is most beneficial when accuracy dominates the weighting factor value . In line with this, the SA threshold parameter control achieves the most wins (5), while the same algorithm using PC parameter control follows (4), with many best runs converging to higher thresholds (often ). The jDE algorithm incorporating the deterministic parameter control wins only sporadically and the fixed baseline ( ) tops just a few datasets. As the objective gives more weight to the size of the feature subset ( ), the fixed-baseline algorithm regains ground (6 wins), while the jDE employing the PC parameter control remains a strong, stable second (5). The same algorithm with SA threshold parameter control stays competitive (3), indicating that regulating a target selection rate is often sufficient. At , where accuracy and subset size are balanced, results diversify, where the baseline algorithm again leads (6), the algorithm with SA threshold parameter control remains effective on several problems (4), and the same using more reactive mechanisms (SRA and CR) register isolated wins (two each), consistent with scenarios where mid or lower thresholds are preferable. Overall, the jDE applying the SA threshold parameter control offers the highest upside across datasets, while the PC parameter control is the safest default for . We can conclude that deterministic threshold parameter control is inconsistent, while the SRA threshold parameter control is dataset-sensitive.
We can also observe a clear trend that on high-dimensional datasets, the SA and PC threshold parameter controls tend to achieve the best results.
Figure 6, Figure 7 and Figure 8 extend the jDE analysis by comparing threshold control parameter mechanisms at three weighting factor values . The Friedman test determined the SA threshold parameter control as the best method at and , and PC threshold parameter control at . By using the weighting factor value , the Friedman test did not declare other threshold parameter control mechanisms significantly different from SA, while Wilcoxon detected that the LR, CR, and SRA threshold parameter control mechanisms were significantly worse (all ), whereas the Baseline and PC threshold parameter control mechanisms were not ( and ). At , the PC threshold parameter control mechanism clearly leads, since the Friedman and Wilcoxon tests both separated it from the LR, CR, and SRA threshold parameter control mechanisms (all significant), and the SA threshold parameter control mechanism remained statistically comparable (Wilcoxon ). At , the SA threshold parameter control mechanism again attained the best rank, where the post hoc Nemenyi test marked the SRA threshold parameter control mechanism as significantly worse. Additionally, the results of the Wilcoxon pairwise non-parametric statistical tests reported the PC, SRA, LR, and CR threshold parameter control mechanisms as worse ( ), while the Baseline remained indistinguishable ( ). Overall, the SA per-individual threshold parameter control mechanism was the most reliable choice, when accuracy dominates, or is balanced with feature subset size in the fitness function, while the PC threshold parameter control mechanism was preferred at the intermediate setting ( ).
4.3. Impact of the Feature Threshold Parameter Control Mechanisms on the Feature Subset Size
The purpose of this study was to analyze the effect of different feature threshold parameter control mechanisms on the size of the final feature subset. The obtained feature subset sizes, along with final thresholds, are presented in Table 3 for all values.
Table 3 reports the selected feature subset sizes for jDE using different threshold parameter control mechanisms and three values of weighting factor values . Overall, the jDE using the adaptive parameter control mechanisms shrank the subset noticeably compared to the Baseline jDE algorithm, with the best count row # best indicating that the PC threshold parameter control dominated when accuracy was emphasized ( , 9 wins), while the SA threshold parameter control became progressively stronger as the feature subset size importance increased ( : 6 wins; : 8 wins). At weighting factor value , the jDE incorporating the PC threshold parameter control achieved large reductions on high-dimensional datasets (e.g., BrainTumor1: ; LungCancer: ), while the same algorithm with the SA threshold parameter control was close behind. The deterministic threshold parameter controls incorporated into the jDE algorithm reduce the feature subset size but less aggressively, while the SRA threshold parameter control was occasionally unstable, even inflating the subset (e.g., UrbanLandCover: ). Considering , the jDE using the SA threshold parameter control was best on most large feature datasets (for example, BrainTumor1: 877; LungCancer: 1609), while the PC threshold parameter control remained a strong second. The determinstic schedules (LR and CR) were best on a few smaller datasets (e.g., Musk1, HillValley). With the weighting factor value , the jDE employing the SA threshold parameter control was the clear winner by searching for the minimum subset size. It reached the smallest subset sizes on the majority of datasets (e.g., ProstateTumor1: 611 vs. baseline 2745; BrainTumor1: 681 vs. 2734), while PC still provided substantial reductions.
Across all weighting factor values , it was notable that datasets with fewer features (e.g., German, Segmentation, Ionosphere) naturally hit small absolute feature set sizes, sometimes matching the baseline floor, whereas on high-dimensional datasets the gains from adaptive threshold parameter control are both larger in magnitude and typically lower in variance (see, for instance, Isolet5 and Madelon). By using the jDE algorithm, the PC threshold parameter control was better suited when accuracy predominates, while the SA threshold parameter control produces better results as the fitness function places more weight on the number of selected features.
Figure 9, Figure 10 and Figure 11 compared threshold parameter control mechanisms built in the jDE algorithm with respect to the size of the selected feature subset for all observed weighting factor values . When accuracy dominated (when ), the PC threshold parameter control attained the best average rank, while the SA threshold parameter control was statistically indistinguishable from it according to the Wilcoxon non-parametric statistical test, whereas the Baseline jDE and the jDE using the LR, CR, and SRA threshold parameter controls yielded significantly larger subsets (all ). As the objective placed more weight on limiting the number of selected features (when ), the jDE incorporating the SA threshold parameter control became the best and delivered the smallest subsets consistently. The same algorithm using the PC threshold parameter control remained the closest competitor but produced significantly larger subset sizes according to the Wilcoxon non-parametric statistical test. Across all the weighting factor values , the jDE using deterministic threshold parameter controls (i.e., LR and CR) reduced the feature subset sizes relative to the Baseline jDE algorithm, but remained significantly worse than the jDE with the SA threshold parameter control. The SRA threshold parameter control was distinguished as the most unreliable, often producing the largest subsets. In short, a global target on the selection rate by the PC threshold parameter control is sufficient when accuracy is important, while by the SA per-individual threshold parameter control, it becomes decisively superior as the fitness function rewards smaller feature subsets increasingly.
4.4. Convergence Analysis
The mentioned experiment was reserved for comparing the convergence rates of different bio-inspired algorithms for wrapper-based feature selection considering different feature selection threshold parameter controls. The convergence rates are presented in terms of fitness convergence (see Figure 12, Figure 13 and Figure 14) and by using the Generation to Convergence Metric ( ), which is defined as the generation number at which the best fitness value was first obtained during the run of the evolutionary algorithm. This metric captures how quickly an algorithm is able to reach its “optimal” solution, providing additional insights into its convergence speed. The results of the metric are reported in Table 4.
Let us notice that mechanisms that previously delivered strong accuracy and smaller feature subsets also tended to converge in fewer generations, although the balance depends on the weighting factor . At the weighting factor value , the jDE armed with the SA threshold parameter control most often reached convergence earliest, for example, on BrainTumor1, Leukemia1, LungCancer, HillValley, Ionosphere, Sonar, and UrbanLandCover. This aligns with its accuracy gains and near-minimal subset sizes at this setting. The jDE using the PC threshold parameter control was close to the former and was best on some datasets, e.g., Musk1 and Madelon. When the fitness function placed more weight on limiting the number of selected features, that is , the same algorithm with the PC threshold parameter control frequently achieved the lowest GTC on high-dimensional datasets in the first block of datasets, while those using the CR threshold parameter control converged fastest on several medium-size datasets, e.g., Ionosphere, Isolet5, Libras, Musk1, Segmentation, and Sonar. This mirrors the earlier results, where the jDE using the SA threshold parameter control minimized subset size, but using the PC or the CR threshold parameter control often reached convergence earlier, which indicates a balance between speed and compactness. The selected algorithm incorporated with PC threshold parameter control was best on Leukemia1, ProstateTumor1, Libras, Madelon, Musk1, Segmentation, and UrbanLandCover, while the same using the SA threshold parameter control was best on BrainTumor1 and LungCancer. The CR threshold parameter control was distinguished as the fastest on a few datasets, such as Arrhythmia, HillValley, and Ionosphere.
Across all the observed weighted factor values , the jDE using the SRA threshold parameter control minimized the rarely. The Baseline jDE algorithm occasionally converged most quickly on very low-dimensional datasets, such as German and Segmentation at , which was consistent with the smaller search space. For early convergence with competitive accuracy, the jDE armed with the PC threshold parameter control is a safe default, especially when or . The SA threshold parameter control offers similar or better convergence speed at and remains attractive when the goal is fast convergence, strong accuracy, and small feature subsets. Deterministic threshold parameter controls can accelerate convergence on some datasets but they should be weighed against their subpar performance.
The fitness convergence rates are reported in Figure 12, Figure 13 and Figure 14 for all values of the weighting factors , where the solid lines present the average fitness, and the dotted lines represent the average for each dataset.
4.5. Comparison of the Best Threshold Parameter Control Mechanism with the State-of-the-Art Algorithms
To assess the effectiveness and external validity of the proposed threshold parameter control mechanisms, we compared our best-performing bio-inspired algorithm (i.e., the jDE using the SA threshold parameter control) with three representative state-of-the-art algorithms from the literature. We selected studies that reported average classification accuracy under wrapper-based settings and extracted the published mean classification accuracy and standard deviations. The comparison was restricted to datasets that overlap with ours, to ensure a like-for-like evaluation. One of the selected papers [9] departed from the conventional fixed threshold and used , with the same fitness function formulation and the weighting factor value . The other two papers [29,30] implemented method-specific procedures within PSO or DE, and used a fixed threshold value . For each study, we ran a paired Wilcoxon non-parametric signed-rank statistical test, with the null hypothesis that the results of the jDE with the SA threshold parameter control and the method taken from literature perform equally. The resulting p-values in Table 5 indicate statistically significant improvements in favor of the jDE using the SA threshold parameter control, including against the method increasing the fixed threshold to a value of . These findings suggest that modifying the threshold during the evolutionary run provides a measurable advantage over the fixed-threshold designs and over method-specific heuristics. We note that the original studies may differ in train and test data partitioning. Despite this heterogeneity, the direction and magnitude of the changes are consistent across the overlapping datasets, which supports the threshold parameter control as a default component in wrapper-based EFS.
4.6. Discussion
The results support feature threshold parameter control consistently as a key design choice in wrapper-based EFS. In the algorithm-level comparison, the jDE algorithm emerged as the stronger baseline, the LSHADE was statistically indistinguishable from it in several settings, and the DE, GA, PSO, ABC, and RS algorithms ranked lower according to both the Nemenyi and Wilcoxon non-parametric statistical tests. Built in jDE, the obtained accuracies show that the SA threshold parameter control attained the largest number of per-dataset wins at a weighting factor value of , while the same one using the PC threshold parameter control was a close second. As the weight factor on the feature subset size was modified to and , the jDE using the PC threshold parameter control remained competitive, while the same algorithm armed with the SA threshold parameter control continued to produce the best results. Deterministic threshold parameter control in jDE can be useful but rarely dominated, while the SRA threshold parameter control was the most sensitive to short-term improvement.
The subset size analysis aligned with these trends. When accuracy dominated at the weighting factor value , the jDE using the PC threshold parameter control produced the smallest sets on most high-dimensional datasets, while the SA threshold parameter control was not statistically different from it. When the fitness function placed more emphasis on limiting the number of selected features, the jDE using the SA threshold parameter control became the best choice and won most frequently at the weighting factor . The deterministic threshold parameter controls reduced the feature subsets relative to the baseline jDE algorithm but remained significantly worse than the best mechanism, while the SRA threshold parameter control often yielded the largest feature subsets. These patterns confirm that a global target on the selection rate is effective when accuracy is the priority, whereas the SA per-individual threshold parameter control becomes advantageous once feature subset size is more important.
The results also show that the obtained accuracies tend to vary only slightly across independent runs, whereas the size of the selected feature subsets exhibits greater variability. This difference can be attributed to the stochastic initialization of the algorithms, which encourages exploration of diverse regions of the search space. Importantly, despite fluctuations in the subset size, classification accuracy remained stable, suggesting that different subsets found can yield comparably good performance.
The convergence analysis results are consistent with the accuracy and feature subset size findings. At the weighting factor value , the jDE using the SA threshold parameter control most often converged in fewer generations and did so while maintaining better accuracy and smaller feature subsets. At the weighting factor values and , the jDE with built-in PC threshold parameter control frequently converged fastest on large datasets, while the same one using the CR threshold parameter control can be the fastest on some medium-size datasets. The fixed-baseline jDE algorithm can converge quickly on very low-dimensional datasets, which was expected given the small search space. The jDE using the SRA threshold parameter control rarely minimized the number of generations and can be unstable in terms of convergence.
A comparison with the state-of-the-art algorithm results also confirms these conclusions. Using the overlapping datasets and the reported means and standard deviations from three representative studies, the Wilcoxon non-parametric statistical test shows that the jDE with the SA threshold parameter control mechanism achieved significantly higher accuracy than all three references at the weighting factor value . This includes a method that had already improved over the conventional setting by fixing . The direction of the differences was consistent across the shared datasets, despite minor differences in the evaluation protocols.
While the results demonstrate the effectiveness of threshold parameter control in wrapper-based EFS, several limitations of the present study should be noted. First, although cross-validation was employed to mitigate classifier overfitting, wrapper-based approaches remain vulnerable in extremely high-dimensional datasets with limited samples, where the risk of overfitting cannot be fully eliminated. Second, certain datasets exhibit substantial class imbalance, which may bias the KNN classifier toward majority classes and affect reported accuracy. Cross-validation reduces but does not remove these biases completely. Finally, it is important to note that the obtained results may not generalize directly to more complex classifiers.
5. Conclusions
This study examined different threshold adaptation mechanisms in wrapper-based EFS for classification. We evaluated five referenced bio-inspired algorithms and a random search method on widely used benchmark datasets. The analysis covered three aspects of performance, namely, classification accuracy, the size of the selected feature subset, and the number of generations to convergence. By holding the objective and the evaluation protocol fixed, we isolated the effect of threshold control from other algorithmic factors.
The results show that threshold adaptation in feature selection should be considered a default design choice. Within jDE, which emerged as a strong baseline with LSHADE as a close alternative, SA achieved the highest classification accuracy, most often when classification accuracy had a higher weight in the fitness function. As the fitness function placed more weight on limiting the number of selected features, SA also produced the smallest subsets most frequently. The algorithm also converged faster when using the SA mechanism and a higher weight on classification in the fitness function, whereas PC often converged earlier on larger datasets when the feature subset size gained more importance.
A comparison with representative state-of-the-art methods on overlapping datasets supports these conclusions further. By using statistical tests on the reported results, SA obtained statistically significant better results. This held even when the literature already improved the fixed threshold by moving from the default value to a larger constant. The combination of internal benchmarks and external comparisons therefore indicates that adapting the threshold during the evolutionary run provides measurable benefits over fixed-threshold designs.
For future research, we want to test more recent bio-inspired algorithms and use even larger datasets. It would also be interesting to investigate hybrid adaptation mechanisms that combine a global target with per-individual threshold mechanisms, and to study per-feature threshold adaptation. Another priority is a multi-objective formulation of the problem that treats accuracy and feature subset size as separate objectives. In addition, extending the study beyond the KNN classifier would strengthen the generalizability of the findings and reveal whether threshold adaptation interacts differently with classifiers of varying complexity. Finally, theoretical analysis of the stability of threshold dynamics and their interaction with population diversity would deepen the understanding of when and why adaptation is useful.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Wang L. Wang Y. Chang Q. Feature selection methods for big data bioinformatics: A survey from the search perspective Methods 2016111213110.1016/j.ymeth.2016.08.01427592382 · doi ↗ · pubmed ↗
- 2Nguyen B.H. Xue B. Zhang M. A survey on swarm intelligence approaches to feature selection in data mining Swarm Evol. Comput.20205410066310.1016/j.swevo.2020.100663 · doi ↗
- 3Kirkpatrick S. Gelatt C.D. Vecchi M.P. Optimization by Simulated Annealing Science 198322067168010.1126/science.220.4598.67117813860 · doi ↗ · pubmed ↗
- 4Hoque N. Bhattacharyya D.K. Kalita J.K. MIFS-ND: A mutual information-based feature selection method Expert Syst. Appl.2014416371638510.1016/j.eswa.2014.04.019 · doi ↗
- 5Eiben A.E. Smith J.E. Introduction to Evolutionary Computing 2nd ed.Springer Publishing Company Berlin/Heidelberg, Germany 2015
- 6Blum C. Merkle D. Swarm Intelligence: Introduction and Applications Springer Berlin/Heidelberg, Germany 200810.1007/978-3-540-74089-6 · doi ↗
- 7Deng S. Li Y. Wang J. Cao R. Li M. A feature-thresholds guided genetic algorithm based on a multi-objective feature scoring method for high-dimensional feature selection Appl. Soft Comput.202314811076510.1016/j.asoc.2023.110765 · doi ↗
- 8Kononenko I. Estimating attributes: Analysis and extensions of RELIEF Proceedings of the European Conference on Machine Learning Catania, Italy 6–8 April 1994171182