New Binary Reptile Search Algorithms for Binary Optimization Problems
Broderick Crawford, Benjamín López Cortés, Felipe Cisternas-Caneo, José Manuel Gómez-Pulido, Rodrigo Olivares, Ricardo Soto, José Barrera-Garcia, Cristóbal Brante-Aguilera, Giovanni Giachetti

TL;DR
This paper introduces a new binary version of the Reptile Search Algorithm to solve complex binary optimization problems like the Set Covering and Knapsack Problems.
Contribution
The paper proposes a two-step binarization framework for the Reptile Search Algorithm using transfer functions and binarization rules for binary optimization.
Findings
The Reptile Search Algorithm achieves competitive performance on benchmark binary optimization problems.
The Z4 transfer function consistently improves performance across all tested algorithms.
Appropriate binarization strategies are crucial for adapting continuous metaheuristics to binary domains.
Abstract
Binarizing continuous metaheuristics to solve challenging NP-hard binary optimization problems is a fundamental step in adapting continuous algorithms for discrete domains. Binary optimization problems, such as the Set Covering Problem and the 0–1 Knapsack Problem, demand tailored approaches to efficiently explore and exploit the solution space. The process of binarization often introduces complexities, as it requires balancing the transformation of continuous populations into binary solutions while preserving the algorithm’s capability to navigate the search space effectively. In this context, we explore the performance of the Reptile Search Algorithm (RSA), a continuous metaheuristic, applied to these two benchmark problems. To address the binary nature of the problems, a two-step binarization process is implemented, utilizing combinations of transfer functions with binarization…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
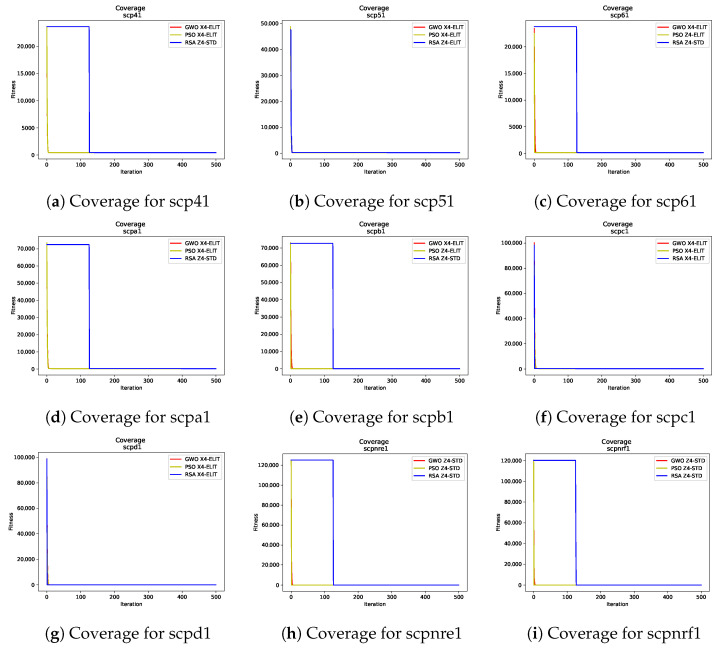 Figure 1
Figure 1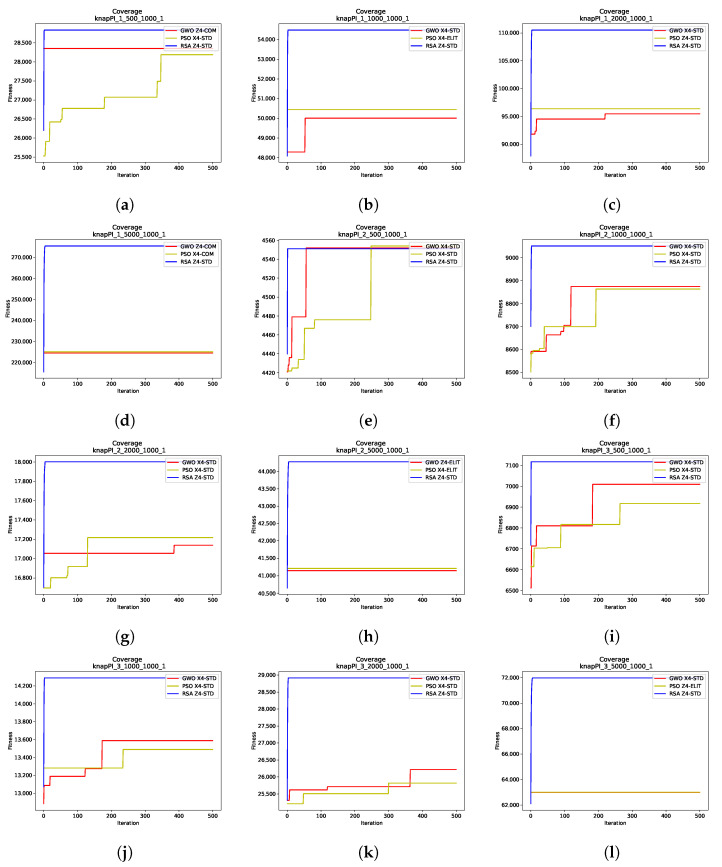 Figure 2
Figure 2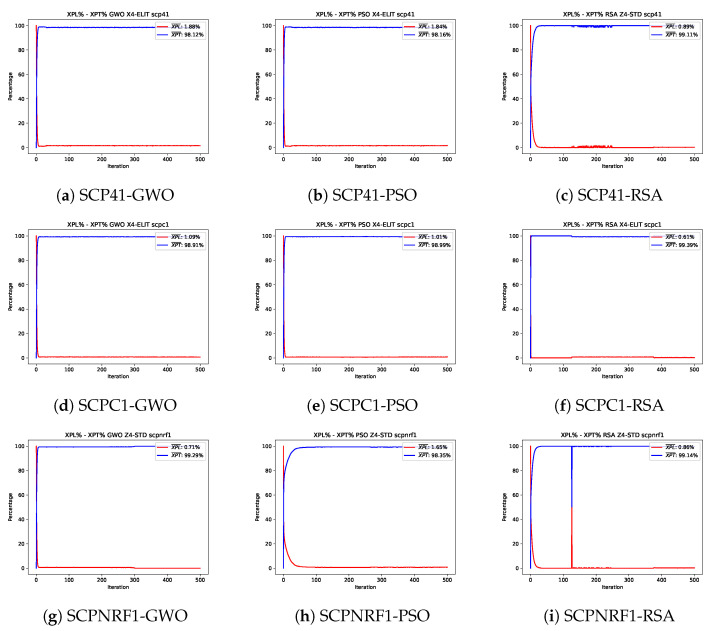 Figure 3
Figure 3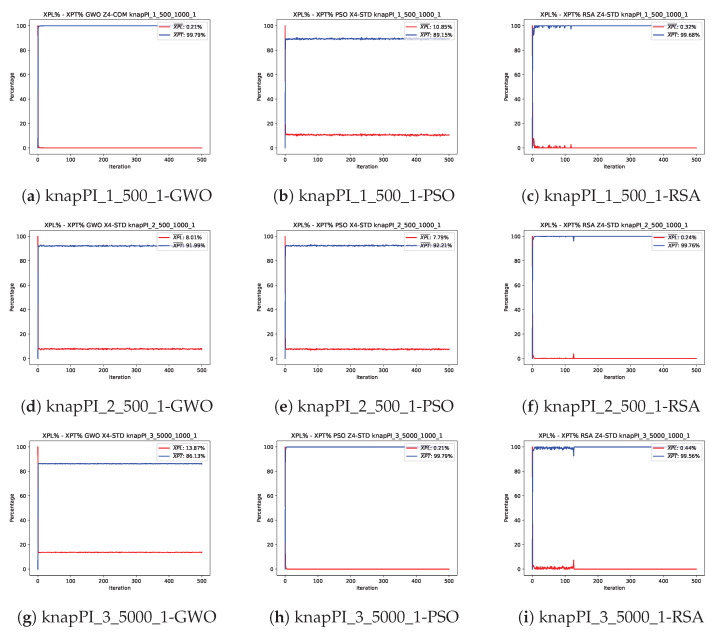 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMetaheuristic Optimization Algorithms Research · Vehicle Routing Optimization Methods · Optimization and Packing Problems
1. Introduction
In nearly every domain of human endeavor, resource scarcity poses a fundamental challenge. Whether the resources in question are physical—such as industrial materials, inventory, or energy—or abstract, like workforce availability, data, or time constraints, the demand for efficient allocation mechanisms remains ever-present. Optimization techniques play a crucial role in addressing these challenges by enabling us to maximize productivity and effectiveness in resource utilization.
Optimization problems can generally be categorized into two types: those involving discrete variables, where solutions are selected from a finite set (e.g., subsets of integers), and those with continuous variables, where solutions can take any real value. While continuous problems benefit from smoothness and mathematical properties like gradients to guide the search process, discrete problems are more challenging due to rugged search spaces. Despite this, discrete optimization has extensive applications in areas like load dispatch [1], dynamic vehicle routing [2], emergency humanitarian logistics [3], nurse scheduling [4], and vaccine distribution [5]. Exact methods, such as branch and cut [6] and branch and bound [7], offer robust solutions but often require significant computational resources for large-scale problems, making them impractical for time-sensitive applications.
Metaheuristic algorithms offer a compelling alternative. These algorithms are designed to balance exploration and exploitation within the solution space, making them well-suited for finding high-quality solutions efficiently, even for large and complex problems. Unlike exact methods, metaheuristics do not guarantee globally optimal solutions, but they provide approximate solutions of sufficient quality within acceptable computational timeframes. Furthermore, the no-free-lunch theorem mentioned in [8] emphasizes that no single optimization algorithm is universally superior, thereby fostering a continual stream of innovative metaheuristic designs tailored to specific problem characteristics. Recent examples of such algorithms include the Grey Wolf Optimizer [9], Honey Badger Algorithm [10], Eurasian Oystercatcher Optimizer [11], Sea-Horse Optimizer [12], and Fox Optimizer [13]. Classic algorithms such as Particle Swarm Optimization (PSO) [14] remain relevant and continue to perform well in many scenarios.
However, most of these metaheuristics are inherently designed for continuous domains. To adapt them for discrete optimization, a binarization process is required to transform the continuous solution space into a discrete one. This process enables continuous metaheuristics to tackle combinatorial problems by converting their continuous population representation into a format suitable for discrete problem spaces. Consequently, the effective design and evaluation of binarization schemes play a crucial role in determining the success of these algorithms in discrete applications.
In this work, we focus on evaluating the performance of the Reptile Search Algorithm (RSA) [15], a novel continuous metaheuristic, in solving binary combinatorial optimization problems. We explore its behavior under various binarization schemes and compare its performance to both contemporary and classic metaheuristics under identical conditions. By investigating the interplay between the binarization process and algorithmic performance, we aim to contribute valuable insights into the broader field of discrete metaheuristics.
The structure of this paper is as follows: Section 2 provides an overview of related work, including a detailed discussion of binarization techniques and the metaheuristics considered in this study. Section 3 describes the preliminaries, focusing on the mathematical foundations of the algorithms and the techniques used to adapt continuous metaheuristics to binary search spaces, such as transfer functions and binarization rules. Section 4 outlines the experimental design and methodological framework. Section 5 presents and analyzes the computational results obtained from the experiments. Finally, Section 6 concludes the paper by summarizing key findings and proposing directions for future research.
2. Related Work
Binarization strategies play a pivotal role in adapting continuous metaheuristics for solving binary optimization problems [16]. Numerous studies have explored innovative techniques to enhance the efficiency and effectiveness of these strategies [17]. Below, we summarize some of the key contributions in this domain.
One of the first proposals for the binarization of metaheuristics is the one by Kennedy and Eberhart in 1997 [18], where they propose a binarization for PSO. This binarization consists of binarizing the velocity of the particles, a key process for movement in the PSO search space.
Doe and Smith in [19] introduced a Binary Ant Lion Optimizer applied to the Knapsack problem, demonstrating how binarization can significantly improve the algorithm’s capability to address discrete optimization challenges. Similarly, Brown and White in [20] proposed a Binary Electric Eel Foraging Optimization Algorithm for the 0–1 Knapsack Problem, focusing on refining representation techniques and search mechanisms in the binary domain.
Xiong et al. in [21] developed a generalized method for binary optimization, offering convergence analysis and applications to various discrete problems. This study underscores how advancements in binarization methodologies contribute to enhancing algorithmic robustness and solution quality. Complementing this, Tian et al. in [22] presented a recommender system for metaheuristic algorithms based on deep recurrent neural networks. While not directly focused on binarization, the work indirectly supports binary optimization by tailoring algorithm selection to problem-specific characteristics.
A novel metaheuristic algorithm tailored for binary optimization was introduced by Von Dollen et al. in [23]. This study highlighted the importance of customized binarization techniques in achieving superior results for combinatorial optimization problems. Additionally, Jiang et al. in [24] proposed an enhanced Binary Grey Wolf Optimizer for dependent task scheduling in edge computing. This work illustrated how binarization strategies tailored to specific problem requirements can boost performance in real-world applications.
The work published by Thaher et al. in [25] explored the integration of evolutionary binarization techniques with Teaching–Learning-Based Optimization for feature selection. Their approach demonstrated the potential of hybrid strategies to balance exploration and exploitation effectively, addressing the challenges of binary optimization problems.
The authors in [26,27,28,29,30,31] explored advanced binarization strategies in metaheuristics for feature selection, emphasizing enhanced exploration–exploitation balance and efficient dimensionality reduction. Techniques like hybrid algorithms, novel transfer functions, and evolutionary approaches demonstrate significant improvements in classification accuracy and feature subset optimization. Collectively, these studies highlight the critical role of binarization in solving complex feature selection challenges across diverse datasets.
The advancement of machine learning has allowed the development of hybridizations with continuous metaheuristics. García et al. in [32] use unsupervised learning based on clustering for the binarization process of swarm intelligence algorithms. Crawford et al. in [33] propose the incorporation of reinforcement learning for the binarization process. Specifically, this learning technique aims to determine the best combinations of the transfer function and binarization rule that allow exploring and exploiting the search space.
Another interesting binarization approach is the quantum method, where the q-bit concept is used to perform the binarization process [34]. The authors in [35,36,37] highlight the use of this quantum approach to binarize continuous metaheuristics for the multidimensional knapsack problem, ordering problem, and feature selection problem.
These works collectively underline the importance of binarization in solving discrete optimization problems, demonstrating diverse approaches ranging from novel algorithms to advanced applications in specific domains. Our work, motivated by the no-free-lunch theorem [38,39], builds upon these foundational studies by exploring a two-step binarization process within the RSA, comparing its effectiveness against established methods.
3. Preliminaries
In this section, main topics will be addressed. First, metaheuristic algorithms will be discussed, including a detailed explanation of the Reptile Search Algorithm and the metaheuristics used for comparison: the Grey Wolf Optimizer and Particle Swarm Optimization. Then, the two-step technique will be introduced as a method for applying continuous metaheuristics to binary problems.
3.1. Reptile Search Algorithm
The Reptile Search Algorithm is a metaheuristic proposed by Laith Abualigah et al. [15], inspired by the encircling and hunting behaviors observed in crocodiles, along with their social dynamics. This algorithm balances exploration and exploitation of the search space using four distinct equations, alternating through iterations. Two key parameters are used to control the exploration accuracy, defined as the variation between candidate solutions.
The exploration phase, referred to as the Encircling Phase, encompasses two movement equations inspired by the high-walking and belly-walking behaviors of crocodiles while encircling their prey. These movements create disturbances that prevent the crocodiles from approaching their target directly, leading this phase to prioritize wide search space exploration.
In contrast, the exploitation phase, known as the Hunting Phase, also includes two movement equations derived from crocodile hunting strategies: hunting coordination and hunting cooperation. These strategies allow crocodiles to intensify their efforts and effectively approach their target. Consequently, this phase emphasizes discovering near-optimal solutions through focused exploitation of the search space.
The algorithm alternates between exploration and exploitation phases based on the number of iterations. Each equation operates during a specific quarter of the total iterations, transitioning from exploration to exploitation at the midpoint of the search process. The equations for exploration (1) and exploitation (2) are defined as follows:
Encircling Phase: The equations for high-walking and belly-walking are
Hunting Phase: The equations for hunting coordination and hunting cooperation are
In these formulas, represents the jth position in the best solution found so far, while is a random number between 0 and 1. The variable t denotes the current iteration, and T is the total number of iterations. The parameter takes a value between 0 and 1. The variables and are random integers between 1 and N, where N is the number of candidate solutions. Additionally, , , , and are computed as follows:
where is a small constant to prevent division by zero, is a random integer between −1 and 1, and and represent the upper and lower bounds of the jth position, respectively. The parameter takes a value between 0 and 1. Additionally, , the average position of the ith solution, is calculated as
This study evaluates the Reptile Search Algorithm’s performance, including its exploration and exploitation dynamics and the diversity of solutions it generates. Two other metaheuristics will also be tested for comparative purposes, ensuring a comprehensive analysis.
3.2. Particle Swarm Optimization
Particle Swarm Optimization is a foundational metaheuristic algorithm introduced by Kennedy and Eberhart in [14]. It draws inspiration from sociobiological theories, particularly the observation that groups of animals, such as schools of fish or flocks of birds, benefit from sharing discoveries and leveraging the prior experiences of individual members during their collective search for resources [40]. This behavioral analogy forms the core principle of PSO, which enables optimization by mimicking the way these groups collaborate and adapt in dynamic environments.
One of the primary advantages of PSO is its simplicity. The algorithm requires only basic mathematical operations and is computationally efficient, both in terms of memory usage and processing speed. This makes PSO highly accessible and applicable to a wide variety of optimization problems, ranging from engineering design to machine learning and beyond.
The PSO algorithm operates by maintaining a swarm of P particles, where each particle represents a candidate solution in the search space. Each particle is characterized by its position and velocity, which are iteratively updated based on its own experience and the experiences of others in the swarm. The update rules for position and velocity are as follows:
where denotes the position of the ith particle at iteration t, and represents the velocity of the ith particle at iteration . The velocity update equation is given by
where and are acceleration coefficients that determine the influence of the personal best and global best positions, respectively; and are random numbers uniformly distributed between 0 and 1, introducing stochasticity into the search process; is the personal best position found by the ith particle in the jth dimension; and is the global best position found by the entire swarm in the jth dimension. w is the inertia weight, which balances exploration and exploitation by controlling the influence of the previous speed, which is calculated as indicated in Equation (10).
where and are the limits of the inertia weight, which is defined as 0.9 and 0.1, respectively; indicates the current iteration and indicates the maximum iterations of the algorithm, therefore, the inertia weight (w) starts at 0.9 and gradually decreases to 0.1 as the iterations progress.
The algorithm proceeds by iteratively updating the positions and velocities of all particles in the swarm. Each particle is influenced by its own best position ( ) and the swarm’s best-known position ( ), promoting both individual and collective learning. The inertia weight (w) plays a critical role in balancing exploration and exploitation. Higher values of w encourage exploration of the search space, while lower values promote convergence by focusing on exploitation of the known promising regions.
PSO’s simplicity and flexibility have contributed to its widespread adoption in solving both continuous and discrete optimization problems. However, it is important to note that the algorithm is highly sensitive to parameter tuning. Improper selection of w, , and can lead to premature convergence or slow exploration. Various adaptive and hybrid approaches have been proposed in the literature to address these challenges and enhance PSO’s performance across diverse applications.
3.3. Grey Wolf Optimizer
The Grey Wolf Optimizer was proposed by Mirjalili et al. in [9] and is inspired by the social hierarchy and hunting behavior of grey wolves. Wolves in a pack are organized into a social structure comprising four roles: alpha ( ), beta ( ), delta ( ), and omega ( ). The alpha wolf is the leader and the most dominant individual, responsible for making decisions and guiding the pack. The beta wolf serves as an advisor and enforcer of the alpha’s commands while maintaining discipline within the pack. The delta wolves take on roles such as scouts, sentinels, or hunters, supporting the leadership. Finally, the omega wolves are the lowest-ranking members, often subordinate but playing supportive roles such as caretakers.
In the context of optimization, the GWO models this hierarchy by assigning the best candidate solution as the alpha ( ), the second best as the beta ( ), and the third best as the delta ( ). All other solutions are considered omegas ( ), which follow the guidance of the three top-ranked wolves during the optimization process. This dynamic allows the algorithm to simulate the hunting behavior of wolves, leveraging both exploration and exploitation in the search space.
The position of each wolf in the search space is updated using the following equations:
Here, t is the current iteration, represents the position vector of the prey (optimal solution), and is the position vector of a grey wolf. The vectors and are coefficient vectors, defined as:
The components of linearly decrease from 2 to 0 over the iterations, and are random vectors uniformly distributed in [0, 1]. The parameter manages the balance between exploration (searching new regions) and exploitation (intensifying search around known good solutions), while introduces randomness to help the algorithm escape local optima.
To simulate the hunting process in an unknown search space, the positions of wolves are guided by the best solutions obtained so far. The following equations model this behavior:
Here, , , and are the positions of the alpha, beta, and delta wolves, respectively. is the current position of the wolf, and is the updated position. By averaging the contributions of the three leading wolves, the algorithm ensures a balanced search behavior that progressively converges to the optimal solution.
The Grey Wolf Optimizer stands out due to its simplicity, lack of extensive hyperparameter tuning, and ability to achieve competitive results in diverse optimization scenarios. Its biologically inspired structure provides a flexible framework for solving both continuous and discrete optimization problems when adapted appropriately.
3.4. Two-Step Technique
To adapt continuous metaheuristics for discrete optimization problems, a binarization framework is applied. This framework consists of two steps: first, transfer functions convert continuous values into probabilities; second, binarization rules use these probabilities to produce binary solutions [16]. Additionally, population diversity plays a critical role in evaluating the balance between exploration and exploitation, which is essential for the algorithm’s efficiency. The following subsections detail transfer functions, binarization rules, and the role of diversity in guiding optimization processes.
3.4.1. Transfer Functions
The transfer function provides a probabilistic mapping for continuous population values, offering a computationally inexpensive approach to binarization. Numerous transfer functions exist, with no universally superior option, as their performance depends on the specific problem. Table 1 presents S-shaped, V-shaped, X-shaped, and Z-shaped transfer functions [41,42,43,44]. These functions calculate probabilities based on the continuous values of the dimensions of candidate solutions.
3.4.2. Binarization Rules
Once probabilities are calculated using transfer functions, binarization rules convert these probabilities into binary values. Table 2 lists commonly used binarization rules [16,17]. The choice of rule impacts performance and must align with the problem’s requirements to achieve optimal results.
3.4.3. Diversity
Population diversity provides insights into the exploration and exploitation dynamics of an algorithm. It measures the variation among candidate solutions and helps identify whether the algorithm is exploring new areas or exploiting known promising regions. Hussain et al. in [45] formalized diversity as follows:
where is the diversity value, is the mean of all individuals in the dth dimension, is the value of the ith individual in the dth dimension, n is the population size, and l is the dimension size.
Using diversity, the exploration percentage ( ) and exploitation percentage ( ) are calculated as proposed by Morales–Castañeda et al. in [46]:
where is the maximum diversity value observed during the optimization process. This information will be used to analyze the behavior of the algorithms during the optimization process in terms of exploration-exploitation.
4. Experimental Setup
This section describes the experimental setup designed to evaluate the performance of three continuous metaheuristics—the Reptile Search Algorithm, the Grey Wolf Optimizer, and Particle Swarm Optimization—on two classical combinatorial optimization problems: the Set Covering Problem (SCP) and the Knapsack Problem (KP). The choice of Particle Swarm Optimization and Grey Wolf Optimizer is based on a recent literature review indicating the relevance of both in the field [47].
Given the combinatorial nature of these problems, the continuous populations generated by the metaheuristics must be converted into binary solutions. This is achieved through a two-step binarization process, which first applies transfer functions to transform continuous values into probabilities, followed by binarization rules that map these probabilities into binary solutions. This methodology enables continuous metaheuristics to effectively address discrete optimization problems, as discussed in previous sections.
To comprehensively evaluate the performance of the metaheuristics under diverse scenarios, the experiments combine two transfer functions (X-shaped and Z-shaped) with three binarization rules (Standard, Complement, and Elitist). Each metaheuristic was tested across all possible configurations of these transfer functions and binarization rules. For example, the Reptile Search Algorithm paired with the Z-shaped transfer function and the Elitist binarization rule emphasized intensification, focusing on exploiting promising regions of the search space. In contrast, Particle Swarm Optimization combined with the X-shaped transfer function and the Complement binarization rule aimed to enhance exploration by introducing greater variability in the binarization process. These setups ensured a thorough exploration of the algorithms’ capabilities in balancing exploration and exploitation.
4.1. Set Covering Problem
The SCP is a well-known NP-hard combinatorial optimization problem with applications in resource allocation, logistics, and scheduling. The SCP involves finding a subset of sets that covers all elements in a universal set while minimizing the total cost. The problem can be formulated mathematically as follows:
subject to:
where is an binary matrix, with if set j covers element i, and otherwise. Each column j has an associated cost , and is a binary decision variable indicating whether set j is included in the solution.
In this study, instances from Beasley’s OR-Library are used [48]. Specifically, the first instances of sets 4 to are selected to evaluate algorithm performance across diverse problem sizes and complexities.
4.2. 0–1 Knapsack Problem
The 0–1 Knapsack Problem is another classic NP-hard problem that involves selecting a subset of items to maximize total value while ensuring that the total weight does not exceed the knapsack’s capacity. The problem is formulated as follows:
subject to
where is a binary decision variable indicating whether item i is included in the knapsack ( ) or not ( ). and represent the value and weight of item i, respectively, and C is the maximum capacity of the knapsack.
For this work, instances from Pisinger’s dataset are employed [49]. These include instances with 500, 1000, 2000, and 5000 items across uncorrelated, weakly correlated, and strongly correlated datasets, allowing for a robust comparison of algorithm performance under varying conditions.
4.3. Experimental Details
The algorithms were implemented in Python 3.11 and executed on a private server equipped with an AMD Ryzen 7 5800X processor (Advanced Micro Devices, Silicon Valley, CA, USA) and 32 GB of DDR4 RAM. Each metaheuristic algorithm employed a population of 20 individuals and a maximum of 500 iterations across all experiments. To ensure statistical reliability, 31 independent runs were performed for each instance. Table 3 shows the parameters of the three metaheuristics used in this work.
The evaluation focuses on three key aspects: (1) convergence plots to illustrate optimization progress, (2) analysis of exploration and exploitation behaviors to assess balance, and (3) statistical tests comparing performance across configurations. This comprehensive evaluation provides insights into the strengths and weaknesses of each algorithm in addressing complex combinatorial problems.
5. Computational Results
This section presents an analysis of the results obtained using the three metaheuristics discussed earlier. Table 4, Table 5, Table 6, Table 7, Table 8 and Table 9 display the best fitness achieved among all 31 experiments, the average value of all fitnesses across the 31 experiments, and the relative percentage deviation (RPD), grouped by each SCP or KP instance. Each row in these tables represents a specific combination of metaheuristic, transfer function, and binarization rule.
The calculation of the RPD varies depending on the optimization problem. For minimization optimization problems such as the Set Covering Problem, the RPD is calculated as indicated in Equation (27). On the other hand, for maximization optimization problems such as the Knapsack Problem, the RPD is calculated as indicated in Equation (28). Both measures provide a relative deviation from the optimal solution, indicating the performance of each configuration.
where corresponds to the optimum of the instance and corresponds to the best value obtained for the experiment.
For the Set Covering Problem results, as summarized in Table 4, Table 5 and Table 6, all algorithms demonstrated competitive performance when paired with appropriate combinations of transfer functions and binarization rules. A notable observation is that the Elitist binarization rule consistently delivered the best results across most scenarios, particularly when used with both the Z4 and X4 transfer functions. In contrast, the Standard and Complement binarization rules showed mixed performance. When paired with the Z4 function, these rules provided competitive results, occasionally rivaling the performance of the Elitist rule. However, when combined with the X4 function, the algorithms’ performance significantly declined. The worst performance was observed with the X4–Complement pairing, where the minimum RPD obtained was 752, recorded on the SCP41 instance using RSA.
Overall, the RSA emerged as the top performer. The RSA achieved the optimal solution in seven combinations, spanning instances such as scpnre1 (Z4–Standard, Z4–Complement, Z4–Elitist, and X4–Elitist) and scpnrf1 (Z4–Standard, Z4–Complement, and X4–Elitist). PSO followed, achieving the optimum in four combinations, including scpnre1 (Z4–Elitist and X4–Elitist) and scpnrf1 (Z4–Elitist and X4–Elitist). The GWO achieved the optimum in only two combinations (scpnrf1 with Z4–Standard and X4–Elitist). Even under the less effective binarization schemes (X4–Standard and X4–Complement), the RSA mitigated performance loss better than PSO and the GWO, consistently achieving lower RPD values.
Notably, there are only four cases where a metaheuristic achieved a lower RPD than the RSA, all of which involve PSO. Three of these cases are observed under the X4–Elitist scheme for the SCP51, SCPC1, and SCPD1 instances. The fourth case is under the Z4–Elitist scheme for the SCPNRF1 instance. It is worth emphasizing that, in all these instances, RSA’s fitness value was just one unit larger than PSO’s.
There are eleven instances where RSA matched the RPD achieved by other algorithms. With a total of 162 possible combinations (12 metaheuristic and binarization schemes across 9 SCP instances), the RSA either equaled or outperformed the other algorithms in 158 cases. Specifically, RSA matched performance in 11 cases, fell slightly behind PSO in 4 cases, and outperformed PSO and the GWO in the remaining 147 cases.
In the case of the 0–1 Knapsack Problem results, as summarized in Table 7, Table 8 and Table 9, all algorithms demonstrated competitive performance when paired with appropriate combinations of transfer functions and binarization rules. Among the binarization rules, the Standard rule emerged as the most effective, delivering consistent results when paired with both Z4 and X4 transfer functions in the PSO and GWO experiments. However, the Reptile Search Algorithm (RSA) showed a notable advantage when paired with the Z4 transfer function and the Standard binarization rule, significantly outperforming the other configurations.
Contrary to the trends observed in the Set Covering Problem, the Elitist binarization rule performed poorly in the KP experiments. This highlights the problem-dependent nature of binarization rules and transfer functions, as strategies that excel in one context may underperform in another.
The results across KP instances were generally more consistent, with performance values staying closer to the optimum. The worst-case RPD was 20%, observed with the GWO algorithm using the X4–Complement binarization scheme. Despite this, none of the algorithms delivered poor results overall. The average RPD across all experiments was , with a standard deviation of . These values are significantly better compared to the SCP results, which had a much higher average RPD of and a standard deviation of . This disparity can likely be attributed to the SCP experiments’ susceptibility to extreme values caused by the combination of the X4 transfer function with the Standard and Complement binarization rules across all algorithms.
The RSA consistently outperformed PSO and the GWO in the KP instances, achieving the only zero-valued RPD in the experiments (Instance knapPI_3_5000_1000_1 with the Z4–Standard binarization scheme). While the RSA’s performance was generally close to that of PSO and the GWO, the Z4–Standard binarization scheme provided a significant boost, achieving RPD values below 1% across all KP instances. This result underscores the importance of carefully selecting the binarization scheme, as it can unlock the full potential of an algorithm. The RSA paired with Z4-Standard consistently excelled, while other binarization schemes did not fully leverage RSA’s capabilities.
It is worth noting that RSA was surpassed in only one instance (knapPI_2_500_1000_1), where both PSO and GWO marginally outperformed RSA using the X4–Standard binarization scheme. However, even in this case, the performance gap was minimal, reaffirming the RSA’s overall robustness across the KP instances.
5.1. Convergence Analysis
To analyze the convergence behavior of the nine SCP instances and the twelve 0–1 KP instances across the three algorithms, Figure 1 and Figure 2 display the convergence curves for the best runs of each algorithm in the respective instances. These figures highlight the binarization schemes employed by the metaheuristics, providing context for the results previously analyzed.
For the Set Covering Problem, the convergence curves in Figure 1 reveal distinct patterns among the algorithms. PSO and GWO demonstrate rapid convergence, significantly reducing the fitness value within the first few iterations. In contrast, the RSA exhibits a delayed reduction in fitness during the first quarter of iterations, with the exception of Figure 1b,f. This delay can be attributed to the RSA High Walking, which appears less effective in the initial exploration phase for this specific problem. However, after the first quarter of iterations, the RSA’s other movement equations contribute significantly to its performance, resulting in competitive fitness values.
It is noteworthy that all algorithms begin with high fitness values, leading to a sharp initial decline in all curves. For RSA, this sharp decline occurs slightly later due to the transition to its second phase, which appears better suited for SCP resolution. The results indicate that the Elite binarization rule dominates among the best-performing configurations, with the X4 transfer function frequently appearing in Figure 1a,b,d,f,g. However, for the largest SCP instances (Figure 1h,i), all algorithms consistently rely on the Z4–Standard binarization scheme.
For the 0–1 Knapsack Problem, the convergence curves in Figure 2 present a markedly different pattern. Unlike in the SCP, the RSA demonstrates a sharp initial reduction in fitness, quickly achieving high fitness values and maintaining relative stability throughout the iterations. In comparison, both PSO and the GWO show gradual improvements, incrementally reaching stable fitness values. This gradual behavior is particularly evident in smaller KP instances, as seen in Figure 2a,e–g,i–k. In larger instances, such as those in Figure 2d,h,l, both PSO and the GWO struggle to surpass the initial solution fitness throughout the entire process.
The results highlight that the RSA achieves its best performance using the Z4–Standard binarization scheme. PSO and the GWO also deliver their best results with the Standard binarization rule, although some cases involving the Complement and Elitist rules (Figure 2d,h,k) show competitive results. These instances, however, likely reflect the challenges posed by the larger KP instances, where PSO and the GWO struggle to improve upon their initial solutions.
Finally, we can state that the convergence analysis underscores the importance of selecting appropriate binarization schemes and transfer functions for each problem. While the RSA demonstrates slower initial progress in the SCP, it compensates with strong performance in later stages, particularly when paired with the Z4–Standard binarization scheme. In the KP, the RSA’s rapid initial convergence and stability further highlight its robustness compared to PSO and the GWO. These findings reaffirm the critical role of algorithmic configurations in optimization problems.
5.2. Exploration and Exploitation Analysis
This section examines the exploration and exploitation behavior exhibited by the three selected algorithms. Figure 3 and Figure 4 depict the analysis for three selected instances of the Set Covering Problem (SCP) and the 0–1 Knapsack Problem (KP), respectively. These figures illustrate the behavior of the algorithms during their best runs.
For the SCP, the exploration and exploitation curves are relatively stable for all algorithms, with the exception of the Reptile Search Algorithm, which displays notable changes throughout the iterations. The abrupt shifts observed in the convergence curves of PSO and GWO for the scp41 and scpc1 instances (Figure 3e). These show that the initially high exploration value is quickly replaced by a high exploitation value within the first few iterations. This behavior persists until the end of the process, likely because these two algorithms reached a local optimum early in the execution.
The RSA follows a similar trend to PSO and the GWO, rapidly transitioning to high exploitation values shortly after the execution begins. However, it is worth noting that the RSA exhibits spikes in exploration behavior between the second and third quarters of the iterations. This aligns with the convergence graphs, where the RSA does not significantly reduce the fitness value of the population during the first quarter of the iterations. After this period, as a new movement equation is applied, the fitness value decreases sharply, suggesting that the subsequent equations are better suited for exploring the SCP search space.
In the case of the KP, the exploration and exploitation curves shown in Figure 4 exhibit different patterns compared to those observed for the SCP. The curves for the GWO (Figure 4a,d) and PSO (Figure 4e,h) remain in a nearly constant state of approximately 90% exploitation and 10% exploration. This behavior is likely due to the search capabilities of these algorithms within the solution space for this specific problem. In many instances, particularly the larger ones, both algorithms fail to identify higher-quality solutions throughout the process.
In contrast, the RSA exhibits a behavior similar to its performance in the SCP, with an abrupt shift towards higher exploitation percentages due to the rapid identification of high-quality solutions. However, all RSA graphs across the studied instances show spikes in exploration during the first quarter of the iterations, similar to the spikes observed in the SCP curves between the second and third quarters of the iterations. This suggests that the RSA’s first equation is better suited for the KP, enabling a rapid increase in fitness value within the initial iterations. Conversely, in the SCP, the algorithm requires the subsequent equations to achieve better fitness-valued solutions.
5.3. Statistical Test
To rigorously evaluate the significance of these observations, the Wilcoxon–Mann–Whitney test was applied to the obtained results. This is a non-parametric statistical test [50], particularly suitable for data that is not normally distributed and for comparing independent samples. These conditions align with the characteristics of our experimental setup, where the data from each experiment does not follow a normal distribution, and the runs are performed independently.
For the statistical analysis, 31 runs were conducted for each combination of algorithm and binarization scheme. The hypotheses tested for the SCP and KP cases were formulated to reflect the specific optimization goals of each problem:
Set Covering Problem
: Algorithm A produces results that are not better than Algorithm B. : Algorithm A produces results that are better than Algorithm B.
0–1 Knapsack Problem
: Algorithm A produces results that are not worse than Algorithm B. : Algorithm A produces results that are worse than Algorithm B.
The null hypothesis ( ) represents the assumption of no significant difference in performance between the algorithms under comparison. If the resulting p-value is less than , is rejected, indicating that Algorithm A either outperforms or underperforms Algorithm B, depending on the specific hypothesis tested.
To ensure a comprehensive analysis, each individual problem instance underwent its own statistical test. With nine SCP instances and 12 KP instances analyzed across three algorithms, a total of 63 statistical tests were conducted. Each test examined the influence of the binarization scheme and transfer function on the algorithm’s performance for a particular problem instance.
Given the volume of statistical tests performed, the results are summarized for clarity. Instead of presenting 63 individual tables, the outcomes were aggregated into six summary tables—one for each algorithm across both SCP and KP cases. These tables count the number of times a specific binarization scheme achieved a p-value below 0.05 in the tests. This aggregation provides a concise overview of the statistical significance of each binarization scheme’s contribution to the algorithms’ performance.
The statistical analysis revealed distinct patterns in algorithm performance.
Set Covering Problem: The Elitist binarization rule frequently achieved the most significant results, particularly when paired with the Z4 and X4 transfer functions. This observation aligns with the findings, where these combinations consistently delivered the best solutions across SCP instances.The 0–1 Knapsack Problem: The Standard binarization rule paired with the Z4 transfer function demonstrated superior performance, achieving statistically significant results in most KP instances. This reflects the algorithm’s ability to effectively balance exploration and exploitation under this configuration.Across both problems, the Reptile Search Algorithm emerged as the most consistent performer, showing a higher count of statistically significant outcomes compared to PSO and the GWO. This underscores the robustness of RSA, particularly when paired with the Z4–Standard binarization scheme.
The statistical tests reinforce the importance of selecting appropriate binarization schemes and transfer functions tailored to the problem at hand. While some configurations yielded universally strong results, others were more problem-specific. By systematically analyzing the p-values, we were able to identify the configurations that consistently enhanced algorithm performance. These findings provide valuable insights into the design and tuning of metaheuristic algorithms for combinatorial optimization problems.
Table 10 provides a comprehensive analysis of the Wilcoxon–Mann–Whitney statistical test results, comparing the performance of six binarization experiments—Z4-STD, Z4-COM, Z4-ELIT, X4-STD, X4-COM, and X4–ELIT—across three algorithms: RSA, PSO, and GWO. This analysis spans both the Set Covering Problem and the 0–1 Knapsack Problem, offering insights into the effectiveness of these combinations in optimizing each problem.
In the SCP context, the RSA algorithm demonstrates the most consistent and statistically significant results across all binarization schemes. Specifically, the RSA achieves p-values ranging from 0.00 to 0.03, indicating its superior performance in identifying better solutions compared to other algorithms. Notably, the RSA’s adaptability is evident in its significant performance across both the Z4 and X4 transfer functions, with consistently low p-values for Z4-STD ( ) and X4-ELIT ( ). These results highlight the RSA’s ability to balance exploration and exploitation effectively, leading to robust optimization outcomes.
PSO also performs well in the SCP domain, particularly with binarization schemes such as Z4-ELIT ( ) and X4-STD ( ). However, it falls short in distinguishing performance for X4-COM ( ), suggesting that this specific combination does not capitalize on PSO’s inherent strengths. The algorithm exhibits a broader range of p-values compared to the RSA, indicating some variability in its effectiveness depending on the choice of binarization scheme.
The GWO’s performance in the SCP is less consistent than the RSA but still exhibits notable strengths with schemes like Z4-STD ( ) and Z4-ELIT ( ). However, the non-significant results for Z4-COM ( ) and X4-COM ( ) suggest that the GWO struggles to leverage these schemes effectively. This variability underscores the GWO’s sensitivity to binarization schemes, where specific configurations significantly influence its optimization capability.
In the KP context, the RSA continues to outperform its counterparts with all p-values falling below 0.02. This consistency highlights the RSA’s adaptability to different problem structures and its capability to maintain strong performance regardless of the chosen binarization scheme. The significant results for Z4-STD ( ) and X4-STD ( ) demonstrate the RSA’s ability to harness the strengths of both Z4 and X4 transfer functions effectively.
The GWO also delivers significant results across all binarization schemes in the KP context, with p-values ranging from 0.01 to 0.03. This consistency across schemes and transfer functions reflects the GWO’s robustness in tackling KP instances. However, compared to RSA, GWO’s p-values are slightly higher, suggesting a marginally lower overall performance.
PSO exhibits mixed results in the KP context, with significant p-values for Z4-ELIT ( ) and X4-ELIT ( ), indicating its effectiveness in exploiting these schemes. However, non-significant results for Z4-COM ( ) and X4-COM ( ) suggest that PSO’s performance is less consistent and depends heavily on the specific binarization scheme employed.
Across both SCP and KP, Z4-ELIT and X4-ELIT emerge as the most reliable and effective binarization schemes. These schemes consistently deliver significant results across all three algorithms, highlighting their ability to enhance the algorithms’ optimization processes. On the other hand, Z4-COM and X4-COM frequently show non-significant differences, suggesting limited utility in distinguishing between algorithmic performances.
Finally, we can state that the RSA is the most versatile and effective algorithm across both problem contexts, consistently outperforming the GWO and PSO with statistically significant results for all binarization schemes. GWO demonstrates robustness but with slightly less consistent results compared to RSA, while PSO shows variability depending on the scheme and problem context. These findings emphasize the importance of aligning the choice of algorithm and binarization scheme to the specific problem characteristics to achieve optimal performance. The observed significant differences underscore the role of tailored configurations in leveraging problem-specific features, paving the way for superior optimization outcomes.
5.4. Summary of the Analysis
The analysis presented in this work reveals consistent patterns across the different evaluation dimensions, highlighting the critical role of binarization rules in determining algorithm performance, often outweighing the impact of the accompanying transfer function. While variations in performance are observed, certain trends emerge that provide valuable insights into the behavior of the algorithms and their configurations.
In the case of the SCP, the Elitist binarization rule consistently outperforms the other two across most instances and algorithms. While the Complement binarization rule occasionally demonstrates superior performance compared to the Standard rule, this behavior is not consistent across all statistical tests. Consequently, the Standard binarization rule emerges as the least effective choice for the SCP, failing to match the performance of the Elitist and Complement rules in most scenarios.
In contrast, the 0–1 Knapsack Problem reveals an inverse pattern. Here, the Standard binarization rule consistently delivers the best performance, while the Elitist rule is frequently the worst performer. The Complement rule, though occasionally surpassing the Elitist rule, does not consistently outperform the Standard rule. Among the algorithms, the GWO showcases three instances where the Complement rule achieves better results than the Elitist rule. Similarly, the PSO algorithm demonstrates a clear advantage only when using the Standard rule, with no consistent pattern of strong performance across the other binarization schemes.
The RSA demonstrates a distinct behavior compared to the GWO and PSO. The RSA delivers consistently strong results with both the Standard and Complement binarization rules, with the Standard rule being the best performer in the KP context. This finding aligns with the RSA’s demonstrated versatility across different optimization problems, suggesting that it maintains robust performance even with binarization rules that may be suboptimal for specific problems. This adaptability sets the RSA apart, reinforcing its suitability for a broader range of optimization tasks.
The statistical tests conducted provide further clarity on these patterns. While the tests do not measure raw performance directly, they highlight statistically significant differences between the performance of various binarization rule and transfer function combinations. The results underscore the critical role of binarization rules in driving algorithm performance, with the Elitist rule dominating SCP performance and the Standard rule leading in the KP context. However, examining the SCP results table reveals that the Z4 transfer function performs competently across a variety of binarization rules and algorithms. This consistency suggests that while binarization rules are the primary determinant of performance, the Z4 transfer function remains a reliable choice across the evaluated tests.
Summarizing, the analysis underscores the importance of selecting the appropriate binarization rule and transfer function for a given problem. The Elitist and Standard rules emerge as the strongest performers for SCP and KP, respectively, with the RSA demonstrating exceptional versatility across both problems. These findings emphasize the need for tailored algorithm configurations to optimize performance, providing a robust foundation for future work in algorithmic optimization.
6. Conclusions and Future Work
The objectives of this work, as outlined in the introduction, were successfully achieved. The Reptile Search Algorithm was rigorously evaluated on the Set Covering Problem and the 0–1 Knapsack Problem using various combinations of transfer functions and binarization rules. Its performance was compared against two established metaheuristics, Particle Swarm Optimization and the Grey Wolf Optimizer, providing valuable insights into the effectiveness of the RSA under diverse problem scenarios. Additionally, the binarization process was thoroughly analyzed, shedding light on its pivotal role in influencing algorithmic outcomes.
The RSA has demonstrated a consistently competitive performance against PSO and GWO, excelling across both tested problems. This versatility underscores its adaptability to different optimization contexts. In the SCP, the RSA particularly excelled in larger problem instances, where multiple combinations of transfer functions and binarization rules produced low RPD values. In the KP, the RSA consistently outperformed the other algorithms, achieving its best results when paired with the Z4-STD binarization experiment.
The convergence curves and exploration–exploitation results provide a detailed view of the RSA’s behavior, showcasing the flexibility afforded by its multiple movement equations. These equations allow the RSA to dynamically adapt its search strategy, with some equations proving more effective for specific problem characteristics. This adaptability underpins the RSA’s strong performance across both maximization and minimization problems.
The statistical analysis highlights the critical role of binarization rules in the binarization process. For SCP, the Elitist rule consistently delivered the best performance across all algorithms, regardless of the transfer function. For KP, the Standard rule emerged as the most effective, though RSA demonstrated strong results with the Complement rule as well. Notably, the Z4 transfer function mitigated performance losses when paired with less effective binarization rules, delivering competent results across all combinations. In contrast, the X4 transfer function showed significant performance degradation when not paired with the Elitist rule.
These findings emphasize the importance of tailoring algorithmic configurations to specific problem characteristics, aligning with the no-free-lunch theorem. The varying performances across transfer functions and binarization rules underscore the necessity of thoroughly understanding the problem at hand to select the most effective optimization strategy. While no universal algorithm guarantees optimal solutions across all scenarios, the RSA’s demonstrated flexibility and robustness make it a reliable choice for tackling a wide range of optimization problems.
The results also underscore the potential of the Z4 transfer function, which, while not universally optimal, significantly boosts performance with suboptimal binarization rules. This finding opens avenues for further research into the Z4 family and its potential to enhance two-step binarization methods for continuous metaheuristics applied to discrete problems.
Therefore, we can conclude that the RSA has proven to be a versatile and robust algorithm, capable of delivering strong performance across diverse problem domains. Its ability to adapt to both minimization and maximization problems makes it a valuable tool for addressing complex optimization challenges. Future work should focus on further exploring the RSA’s capabilities, particularly its flexibility and adaptability, while investigating the Z4 transfer function and its variants to improve the two-step binarization process and optimize results in discrete optimization problems. These insights lay a strong foundation for advancing metaheuristic design and application in complex problem-solving scenarios.
As future work, we propose to continue exploring the RSA’s performance across a broader range of optimization problems, including dynamic and large-scale scenarios, to further validate its flexibility and robustness. Additionally, an in-depth study of the Z4 transfer function and its family is suggested to enhance the effectiveness of the binarization process, particularly in cases where optimal binarization rules are not applied. Finally, the development of hybrid approaches that integrate RSA with other metaheuristics or machine learning techniques could open new avenues for tackling highly complex combinatorial optimization problems with improved precision and efficiency.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Apostolopoulos T. Vlachos A. Application of the Firefly Algorithm for Solving the Economic Emissions Load Dispatch Problem Int. J. Comb.2011201112310.1155/2011/523806 · doi ↗
- 2Xiang X. Qiu J. Xiao J. Zhang X. Demand coverage diversity based ant colony optimization for dynamic vehicle routing problems Eng. Appl. Artif. Intell.20209110358210.1016/j.engappai.2020.103582 · doi ↗
- 3Alizadeh R. Nishi T. Hybrid Set Covering and Dynamic Modular Covering Location Problem: Application to an Emergency Humanitarian Logistics Problem Appl. Sci.202010711010.3390/app 10207110 · doi ↗
- 4Tsai C.C. Li S.H.A. A two-stage modeling with genetic algorithms for the nurse scheduling problem Expert Syst. Appl.2009369506951210.1016/j.eswa.2008.11.049 · doi ↗
- 5Ab. Aziz N.A. Ab. Aziz K. Pendulum Search Algorithm: An Optimization Algorithm Based on Simple Harmonic Motion and Its Application for a Vaccine Distribution Problem Algorithms 20221521410.3390/a 15060214 · doi ↗
- 6Mitchell J. Branch-and-Cut Algorithms for Combinatorial Optimization Problems Handbook of Applied Optimization Oxford University Press Oxford, UK 2002
- 7Coniglio S. Furini F. San Segundo P. A new combinatorial branch-and-bound algorithm for the Knapsack Problem with Conflicts Eur. J. Oper. Res.202128943545510.1016/j.ejor.2020.07.023 · doi ↗
- 8Ho Y.C. Pepyne D.L. Simple Explanation of the No-Free-Lunch Theorem and Its Implications J. Optim. Theory Appl.200211554957010.1023/A:1021251113462 · doi ↗