Variable Selection via Fused Sparse‐Group Lasso Penalized Multi‐state Models Incorporating Molecular Data
Kaya Miah, Jelle J. Goeman, Hein Putter, Annette Kopp‐Schneider, Axel Benner

TL;DR
This paper introduces a new statistical method for analyzing complex disease progression data by combining molecular information with advanced regularization techniques.
Contribution
The novel fused sparse-group lasso method enables joint variable selection and effect estimation in multi-state models with high-dimensional molecular data.
Findings
The proposed FSGL method effectively selects relevant covariates while enforcing similar effects across disease transitions.
Simulation studies and AML data analysis demonstrate improved performance over global lasso regularization in sparse model selection.
The ADMM optimization algorithm successfully adapts to transition-specific hazards regression in multi-state frameworks.
Abstract
In multi‐state models based on high‐dimensional data, effective modeling strategies are required to determine an optimal, ideally parsimonious model. In particular, linking covariate effects across transitions is needed to conduct joint variable selection. A useful technique to reduce model complexity is to address homogeneous covariate effects for distinct transitions. We integrate this approach to data‐driven variable selection by extended regularization methods within multi‐state model building. We propose the fused sparse‐group lasso (FSGL) penalized Cox‐type regression in the framework of multi‐state models combining the penalization concepts of pairwise differences of covariate effects along with transition‐wise grouping. For optimization, we adapt the alternating direction method of multipliers (ADMM) algorithm to transition‐specific hazards regression in the multi‐state setting.…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
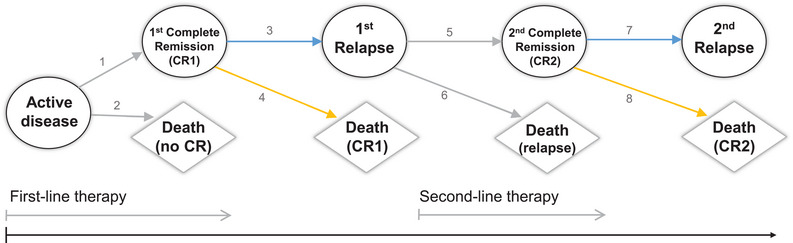 FIGURE 1
FIGURE 1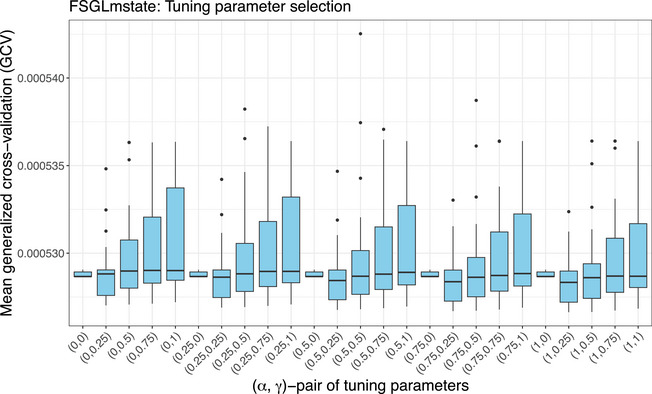 FIGURE 2
FIGURE 2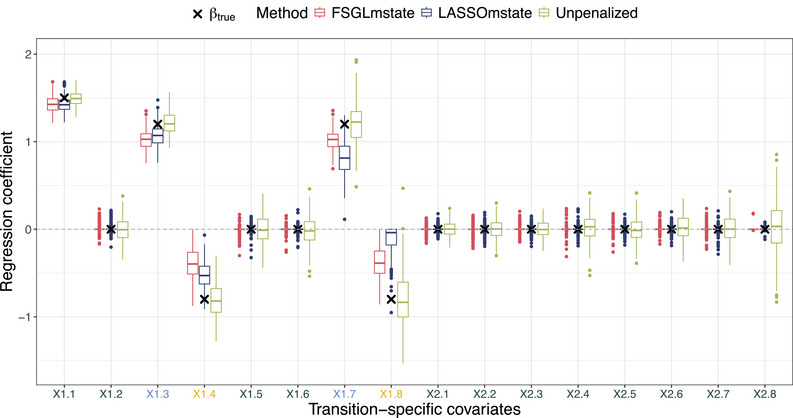 FIGURE 3
FIGURE 3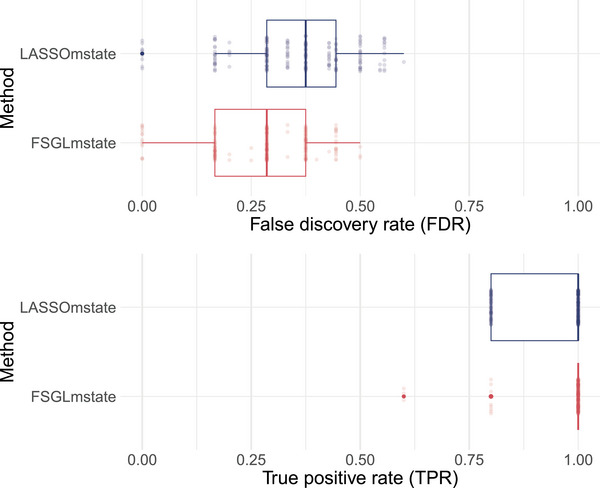 FIGURE 4
FIGURE 4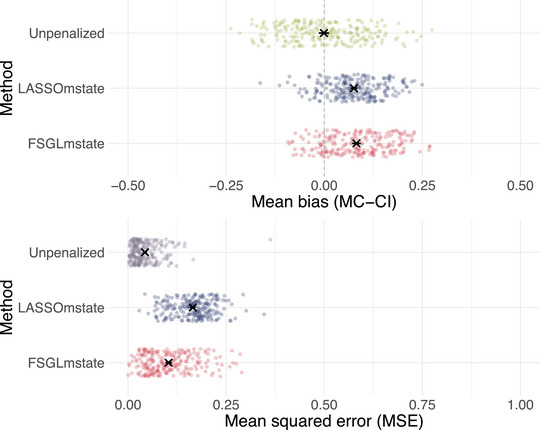 FIGURE 5
FIGURE 5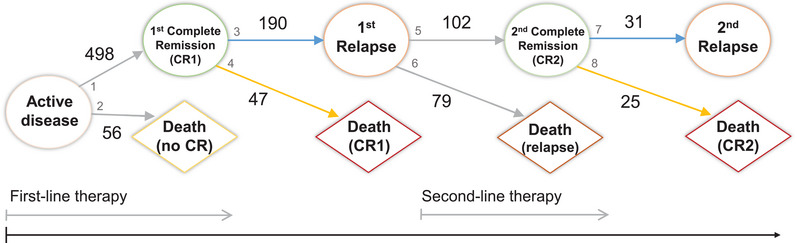 FIGURE 6
FIGURE 6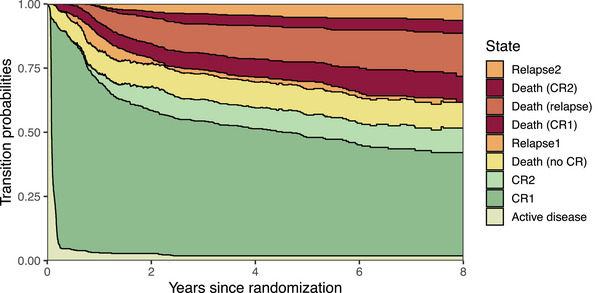 FIGURE 7
FIGURE 7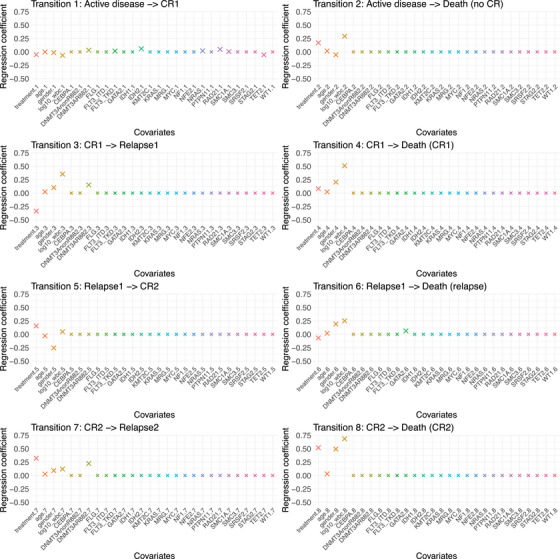 FIGURE 8
FIGURE 8| Penalization method | Penalty function | Parameters | Model type |
|---|---|---|---|
| Ridge | Linear (Hoerl and Kennard | ||
| Lasso | Linear (Tibshirani | ||
| Elastic net | Linear (Zou and Hastie | ||
| Fused lasso | Linear (Tibshirani et al. | ||
| Group lasso | , groups , group size | Linear (Yuan and Lin | |
| Sparse‐group lasso | Linear & Cox (Simon et al. | ||
| Fused sparse‐group lasso | , fusion matrix | Linear (Beer et al. | |
| Lasso mstate | Competing risks (Saadati et al. | ||
| Elastic net mstate | Multi‐state (Huang et al. | ||
| Fusion lasso mstate | Multi‐state (Sennhenn‐Reulen and Kneib |
| ADEMP criterion | Definition |
|---|---|
| Aim | Evaluation of sparse variable selection detecting relevant transition‐specific effects and equal cross‐transition effects |
| Data‐generating mechanism | Multi‐state model based on transition‐specific hazards models |
| Estimand/target | Regression coefficients |
| Methods | Unpenalized Cox‐type multi‐state estimation with ADMM optimization; |
| Lasso penalized multi‐state model with ADMM optimization (LASSOmstate); | |
| Fused sparse‐group lasso penalized multi‐state model with ADMM optimization (FSGLmstate) | |
| Performance measures | True positive rate (TPR); False discovery rate (FDR); |
| Bias; Mean squared error (MSE) |
- —Deutsche Forschungsgemeinschaft10.13039/501100001659
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Inference · Statistical Methods and Bayesian Inference · Bayesian Methods and Mixture Models
Introduction
1
In medical research, prediction models still predominantly make use of composite endpoints such as progression‐ or event‐free survival (EFS). However, these time‐to‐first‐event endpoints do not take into account important aspects of the individual disease pathway and therapy course. Multi‐state models are a natural framework to assess the effect of prognostic factors and treatment on the event history of a patient and to separate risks for the occurrence of distinct events. These extend competing risks analyses of event time endpoints such as time to progression, relapse, remission or death, by modeling the sequence of competing consecutive events on a macro level. In survival analysis, the multi‐state model class is used for event history data where individuals experience a sequence of events over time. Each event is defined by an entry and exit time along with transition types. This paper is motivated by an application to the acute myeloid leukemia (AML) disease pathway. Figure 1 illustrates the event history for AML patients in the form of a state chart of a multi‐state model with nine states and eight transitions. Distinct states are treated as nodes and possible transitions are represented by directed arrows.
State chart of the multi‐state model for acute myeloid leukemia (AML) with nine states and eight possible transitions represented by arrows. Numbers denote the corresponding transition.
To assess how intensities of going from state to state depend on covariates, multi‐state proportional hazards regression models can be used. In the era of precision medicine with increasingly high‐dimensional information on molecular biomarkers, such a holistic analysis of a multi‐state model is of essential interest. For our motivating AML application, we will investigate the effect of biomarkers along with established clinical covariates on the different transitions of the multi‐state model depicted in Figure 1. In particular, incorporating biomarker effects on similar transitions from complete remission (CR) to death or relapse marked by yellow and blue arrows in Figure 1 is of interest. Further, no biomarker effect is expected on, for example, transition 2, i.e., from active disease to early death, since this might rather be related to the initiation of intensive chemotherapy. Thus, effective variable selection strategies for multi‐state models incorporating high‐dimensional molecular data are required to obtain a sparse model and mitigate overfitting. Such data‐driven model building strategies will contribute to a deeper understanding of the individual disease progression and its therapeutic concepts as well as improved personalized prognoses.
This paper focuses on data‐driven variable selection via penalized multi‐state models to capture pathogenic processes and underlying etiologies more accurately. The goal is to select a sparse model based on high‐dimensional molecular data by extended regularization methods. We want to use a priori knowledge about the multi‐state model structure to help simplify it. First, we assume that most biomarkers might have no effect on specific disease transitions, and if they have an effect on one transition, they might have an effect on many. Second, we presume that effect parameters of similar transitions are often of a similar direction and magnitude. Third, biomarker effects might only be relevant for specific transitions. Thus, the parameter space dimensionality should be decreased by setting non‐relevant biomarker effects to zero (i.e., sparsity), identifying similar biomarker effects across distinct transitions (i.e., similarity) and detecting only relevant biomarker effects for specific transitions of interest (i.e., transition‐wise grouping). Furthermore, we want to combine molecular and clinical data by incorporating established clinical predictors into the model that remain unpenalized.
A scoping literature review on model selection methods for multi‐state models was conducted using the PubMed database (http://www.ncbi.nlm.nih.gov/pubmed/advanced). This review identified a variety of approaches addressing model selection in this context. However, to the best of our knowledge, the integration of a priori information regarding structural dependencies between transitions in a multi‐state model remains limited. In the following, we provide a brief overview of current strategies for model selection in multi‐state survival analysis.
Model selection in survival analysis frequently relies on regularization techniques aimed at avoiding to include covariates with negligible effects. In the context of competing risks, Saadati et al. (2018) proposed a lasso‐penalized cause‐specific hazards model for high‐dimensional data, linking separately penalized models by selecting the tuning parameter combination that yields optimal predictive accuracy. Within the multi‐state framework, Sennhenn‐Reulen and Kneib (2016) introduced the structured fusion lasso penalty to enable sparse modeling by considering cross‐transition effects, defined as equal covariate effects across different transitions. Their approach penalizes both the L1‐norm of the regression coefficients as well as of all pairwise differences between transitions. Further penalization approaches include the one‐step coordinate descent algorithm for L1‐penalization by Dang et al. (2021), and an elastic net‐penalized Markov model by Huang et al. (2018). Beyond penalization, boosting algorithms provide flexible model selection techniques in high‐dimensional settings. Reulen and Kneib (2016) developed a component‐wise functional gradient descent boosting approach for simultaneous variable selection and model specification in multi‐state models, accounting for non‐linear and cross‐transition effects. Complementary work by Edelmann et al. (2020) extended the global test framework to assess equality of regression coefficients across transitions under the Markov assumption. In related efforts to reduce model complexity in terms of dimension reduction, Fiocco et al. (2005, 2008) developed reduced rank regression in proportional hazards models for competing risks and multi‐state data. Alternative frameworks outside the hazard‐based approach also exist, such as direct modeling using accelerated failure time (AFT) models or pseudo‐observations. However, variable selection methods tailored specifically to high‐dimensional multi‐state models within these frameworks have not yet been developed. In this work, we focus on the well‐established Cox‐type framework for multi‐state models, emphasizing hazard‐based model specification. Consequently, alternative direct modeling strategies such as AFT or pseudo‐observation approaches are not pursued further. While the aforementioned approaches provide effective variable selection tools, they often do not fully exploit known structural information inherent to the multi‐state model. For example, general lasso, elastic net, and boosting methods treat transition‐specific effects largely independently or rely on limited assumptions about cross‐transition similarities. Although the structured fusion lasso penalty introduces pairwise constraints on covariate effects across transitions, it does not account for further a priori information on the model structure. Furthermore, flexible variable selection strategies for more complex multi‐state models, that is, moving beyond the illness–death model, have not been sufficiently developed nor implemented, even in low‐dimensional settings. To address these limitations, we propose the fused sparse‐group lasso (FSGL) framework to multi‐state models, which integrates overall sparsity, grouping, and fusion penalties. This approach enables both covariate selection and model structuring informed by a priori knowledge, making it especially suitable for multi‐state models with partially shared effects across transitions or a focus on specific clinically relevant transitions.
In this paper, we introduce the FSGL penalty for multi‐state models combining the concepts of general sparsity, fusion of covariate effects, and transition grouping. To fit such a penalized model, we adapt the alternating direction method of multipliers (ADMM) algorithm to multi‐state Cox‐type hazards regression, leveraging its ability to decompose complex objective functions. Our current implementation focuses on continuous‐time Markov chains with time‐constant covariates and constant baseline hazards.
The remainder of the paper is structured as follows: The methodological background of multi‐state models needed for the proposed adaptation is given in Section 2. Section 3 introduces the FSGL penalty extended to the multi‐state setting. Section 4 describes the general ADMM optimization algorithm for parameter estimation in Subsection 4.1 along with the derived ADMM update steps to fit FSGL penalized multi‐state models in Subsection 4.2. Section 5 shows the results of a proof‐of‐concept simulation study to investigate the regularization performance of the derived algorithm and Section 6 illustrates a real data application to AML patients.
Methods for Multi‐state Modeling
2
The following section provides a brief introduction to the multi‐state model class in survival analysis needed for our adapted FSGL penalty to the multi‐state setting. A holistic framework to multi‐state modeling theory can be found in Andersen et al. (1993). Subsection 2.1 introduces the general multi‐state process and defines the concept of transition‐specific Cox proportional hazards regression for multi‐state models. Furthermore, Subsection 2.2 denotes the explicit likelihood formulation in the multi‐state setting along with its derivatives needed for model fitting.
Multi‐state Proportional Hazards Regression Model
2.1
Following Andersen and Keiding (2002) and Putter et al. (2007), a multi‐state process is a stochastic process {Z(t),t∈T} with times in T=[0,tmax],0<tmax<∞, and a finite state space K={1,⋯,K}. The transition probabilities are given as
for transition q=[k.k′] from state k to k′,k,k′∈K,s,t∈T,s≤t, and q∈Q={1,⋯,Q} the set of observable transitions. We assume a continuous‐time Markovian model, that is, the probability for a transition only depends on the current state of the multi‐state process at the current time. The transition intensities are defined as the corresponding derivatives
To assess the dependence on covariates, these transition‐specific hazard rates can be modeled by separate Cox proportional hazards models for each transition as
for an individual with covariate vector x=(x1,⋯,xP)T∈RP, where h0,q(t) denotes the baseline hazard rate of transition q at time t and βq=(β1,q,⋯,βP,q)T∈RP the vector of transition‐specific regression coefficients. Thus, Cox‐type regression analysis for multi‐state data enables simultaneous modeling of the relationship between covariates and all relevant transitions (Le‐Rademacher et al. 2022).
Multi‐state Likelihood Formulation
2.2
In the multi‐state framework, the generalized partial likelihood can be written in terms of a stratified formulation as a product of Cox partial likelihoods for each transition, that is,
where xi=(x1;i,⋯,xP;i)T∈RP denotes the covariate vector of individual i,i=1,⋯,N, βq∈RP the transition‐specific regression vector, and δi,q the event indicator for transition q (Putter et al. 2007, 2006). Ri,q denotes the risk set for individual i with transition q at time ti,q. This set includes all individuals who are at risk of experiencing a transition of type q at time ti,q. The transition‐specific Cox partial likelihood lq(βq) compares the hazard of the individual with an event at time ti,q to the hazard of all individuals under risk at ti,q.
The multi‐state partial likelihood formulation for the stacked regression vector β=(β1,1,⋯,β1,Q,β2,1,⋯,βP,Q)T∈RPQ and corresponding extended covariate vector x∼i=(x1.1;i,⋯,x1.Q;i,x2.1;i,⋯,xP.Q;i)T∈RPQ, where xp.q;i denotes the observation of covariate Xp for transition q of individual i, is then derived as
where R∼i denotes the corresponding risk set formulation based on long format data according to de Wreede et al. (2010) with row lines i,j from a total number of n rows of the long format data set. In this format, each individual has a row for each transition for which they are at risk. The negative logarithm of the multi‐state partial likelihood is
The regression parameters are then estimated by minimizing this negative partial log‐likelihood. The estimate β^ is plugged‐in in Breslow's estimate of the cumulative baseline hazard (Putter et al. 2007)
For estimation, we need the first and second derivatives of the Cox partial log‐likelihood function. The score vector is given as
where X∈Rn×PQ denotes the design matrix, δ=(δ1,⋯,δn)T the vector of event indicators and μ^=(μ^1,⋯,μ^n)T the estimated cumulative hazards with elements μ^i=Λ^0(t)exp{x∼iTβ^}, and estimated cumulative baseline hazard Λ^0(t) based on long format data. The Hessian matrix is
with W∈Rn×n the weight matrix of the estimated cumulative hazards μ^ (Goeman 2010; van Houwelingen et al. 2006).
Fused Sparse‐Group Lasso Penalty
3
This section describes our adapted fused sparse‐group lasso (FSGL) penalty to multi‐state models as key variable selection strategy for high‐dimensional multi‐state modeling.
For data‐driven model selection, established methods incorporate regularization in the fitting process in order to conduct variable selection (Benner et al. 2010; Heinze et al. 2018). Especially in applications with the number of predictors exceeding numbers of events, regularization is needed in order to obtain a unique and more stable solution of the regression parameters (Salerno and Li 2023). Several regularization methods that perform covariate selection beyond the least absolute shrinkage and selection operator (lasso) (Tibshirani 1996) have been developed. These include elastic net (Zou and Hastie 2005), fused lasso (Tibshirani et al. 2005), sparse‐group lasso (Simon et al. 2013), and FSGL (Zhou et al. 2012) penalization. In the multi‐state framework, adapted regularization approaches incorporate the lasso (Saadati et al. 2018; Dang et al. 2021), elastic net (Huang et al. 2018), and structured fusion lasso (Sennhenn‐Reulen and Kneib 2016) for penalized multi‐state modeling. Table 1 gives an overview of existing penalization methods along with their penalty functions as well as their original publications for linear regression models and adaptations to Cox models for survival outcomes.
The fused sparse‐group lasso penalty, introduced by Zhou et al. (2012) and adapted by Beer et al. (2019) for linear models, provides a combination of lasso, fused, and grouped regularization. Thus, prior information of spatial and group structure can be incorporated into the prediction model. The global lasso penalty fosters overall sparsity. The fusion penalty regularizes absolute pairwise differences of regression coefficients. The group penalty allows variables within the same group to be jointly selected or shrunk to zero.
We propose to transfer this combined penalty to the multi‐state framework based on transition‐specific hazards regression models in order to obtain overall sparsity, link covariate effects across transitions, and incorporate transition grouping. Thus, we advocate the FSGL penalty that provide estimates with three properties:
Sparsity: The resulting estimator automatically zeros out small estimated coefficients to achieve variable selection and simplify the model (Fan and Li 2002).
- 2. Similarity: The resulting estimator penalizes absolute differences of covariate effects across similar transitions, thus addressing homogeneous cross‐transition effects.
-
Transition‐wise grouping: The resulting estimator allows variables within the same transition to be jointly selected or shrunk to zero, thus incorporating transition grouping.
We consider the same set of P (time‐fixed) covariates, for example, biomarkers, for each transition q∈{1,⋯,Q}=Q. Furthermore, we presume a subset S of pairs of similar transitions {(q,q′):q≠q′,q,q′∈Q}, of which we assume that covariate effects across these transitions are of a similar magnitude, i.e., we consider potential cross‐transition effects (Sennhenn‐Reulen and Kneib 2016). The FSGL penalty function is then defined as
with transition‐specific regression coefficients βp,q of covariate xp,p=1,⋯,P, for transition q, transition‐specific regression vector βq∈RP, and tuning parameters λ,α,γ. The tuning parameter λ>0 controls the overall level of regularization, α∈[0,1] balances between global lasso and group lasso and γ∈[0,1] balances between sparse penalties and the fusion penalty (Beer et al. 2019). Thus, the optimal tuning parameter λopt is chosen at preselected values of α and γ via a model selection criterion (see Section 4.3). For (α,γ)=(1,1), the estimator reduces to the global lasso, for (α,γ)=(0,1) to the group penalty and for (α,γ)=(1,0) or (α,γ)=(0,0) to the fusion penalty. The regression parameter β is estimated by minimizing the penalized negative partial log‐likelihood function, i.e.,
Optimization Algorithm
4
To effectively fit FSGL‐penalized multi‐state models, it is necessary to employ numerical optimization techniques. Therefore, this section introduces the general concept of the ADMM optimization algorithm in Subsection 4.1 and provides the novel explicitly derived ADMM updating steps specifically tailored for fitting general FSGL penalized multi‐state models in Subsection 4.2. The criterion of selecting optimal penalty parameters is described in Subsection 4.3.
For penalized Cox‐type regression, several numerical optimization algorithms exist for parameter estimation by minimizing the penalized negative likelihood function. Simon et al. (2013) utilize an accelerated generalized gradient algorithm for the sparse‐group lasso penalty. However, the accelerated gradient method depends on the separability of the penalty term across groups of β, so that the fusion penalty can only be applied within groups. For the structured fusion lasso penalty, Sennhenn‐Reulen and Kneib (2016) make use of a penalized iteratively reweighted least squares algorithm. This second‐order optimization has high computation cost and potential convergence problems (Dang et al. 2021). Furthermore, coordinate descent algorithms do not work for the fused lasso penalty due to its non‐separability into a sum of functions of the elements of β that is also not continuously differentiable. Thus, we chose the ADMM optimization algorithm to fit FSGL penalized multi‐state models due to the decomposability of the objective function as well as superior convergence properties.
Alternating Direction Method of Multipliers Algorithm
4.1
The alternating direction method of multipliers (ADMM) algorithm provides a very general framework for numerical optimization of convex functions. It originates from the 1950s and was developed in the 1970s (Gabay and Mercier 1976; Glowinski and Marroco 1975), but was holistically examined later by Boyd et al. (2011) for a broader conceptuality. The algorithm combines the decomposability of the objective function with superior convergence properties of the method of multipliers (Boyd et al. 2011). Consider the following general optimization problem with respect to a variable β∈RP
where f,g denote convex functions. In the ADMM framework, the generic constrained optimization problem introducing an auxiliary variable θ∈RP is given as
Thus, the objective function becomes additively separable, which simplifies the subsequent optimization steps. As in the method of multipliers, the augmented Lagrangian function adding an L2‐term to enhance optimization stability (Parka and Shin 2022) is given as
with Lagrangian multiplier ϕ∈RP, augmented Lagrangian parameter ρ>0 (i.e., the ADMM step size), and scaled dual variable ν=ϕρ∈RP. The general ADMM iterations consist of the following alternating update steps at iteration r+1:
The algorithm comprises a β‐minimization step, a θ‐minimization step, and a dual variable ν‐update. Thus, the usual joint minimization is separated across the decomposition of the objective function over parameters β (e.g., likelihood) and θ (e.g., penalty) into two steps.
As a stopping criterion, Boyd et al. (2010) propose sufficiently small primal and dual residuals, that is,
with absolute and relative tolerances εabs=10−4 and εrel=10−2.
ADMM for Penalized Multi‐state Models
4.2
In the FSGL penalized multi‐state framework, the constrained optimization problem for the stacked regression parameter β∈RPQ is given as
where f(β)=L(β) is the negative multi‐state partial log‐likelihood function as in (1) and g(θ)=pλ,FSGL(θ) is the FSGL penalty function (4) with auxiliary variable θ=(θ1,⋯,θM)T∈RM, M=PQ+s+PQ, such that θm=Kmβ. The penalty structure matrix is defined as K=(K1|⋯|KM)T∈RM×PQ, with elements kij∈{−1,0,1}, such that
where um denotes the unit vector of the identity matrix IPQ∈RPQ×PQ corresponding to the global lasso penalty. The contrast vector dm denotes the (m−PQ)th row vector of the fusion matrix D∈Rs×PQ consisting of s pairs of similar transitions with elements dij∈{−1,1} at the corresponding positions of covariates of such similar transitions. These contrast vectors correspond to the fusion penalty, for example, d1=(1,−1,0,⋯,0)T for the regression coefficients of covariates X1.1 and X1.2 of transitions 1 and 2. Gm−PQ−s∈RP×PQ are the group matrices of the Q transitions consisting of unit vectors, for example, g1=(1,0,⋯,0)T, that indicate the group allocation of a variable to a specific transition, corresponding to the group penalty. For instance, the group matrix for transition 1 of a total of Q=2 transitions and P=2 covariates, such that β=(β1,1,β1,2,β2,1,β2,2)T, is given as
indicating that the regression coefficients of covariates X1.1 and X2.1 are considered for transition 1 with respect to the group penalty. The penalty structure matrix K is then given as
Thus, the total number of rows of the penalty structure matix K∈RM×PQ is M=PQ+s+PQ. Optimization of the likelihood and penalty terms are separated and therefore simplified.
For the β‐updating step, Cox estimation of the regression parameter β is performed by numerical algorithms. The gradient descent update is given as βGDr+1=βr+εGDU(βr) using the score vector U(βr) at iteration r as in (2) and step size εGD. The Newton–Raphson update is
using both the gradient U(βr) and Hessian matrix J(βr) at iteration r as in (3). The estimation tolerance for the convergence criterion based on the partial log‐likelihood is denoted as tolNR or tolGD, respectively. A hybrid algorithm as proposed by Goeman (2010) combines adaptive gradient descent and Newton–Raphson to derive β‐estimates in a Cox model. It starts with a single gradient descent step and then switches to Newton–Raphson updating steps. To enable an efficient update of the parameter vector θ, we utilize the proximity operator associated with the L2‐norm. Specifically, we employ the vector soft‐thresholding operator defined for a∈Rm as
with Sκ(0)=0 and (·)+=max{0,·}. This operator performs shrinkage toward zero and yields a closed‐form solution to the proximal mapping of the L2‐norm regularizer. As such, it enables a computationally efficient update of θ in each iteration. For a detailed derivation, see Boyd et al. ().
We derive the augmented Lagrangian function along with its first and second derivatives with respect to β as
with step size ρ>0, scaled dual variable ν=(ν1,⋯,νM)T∈RM, score vector U(β) as in (2), and Hessian matrix J(β) as in (3). Thus, by plugging‐in both derivatives to the Newton–Raphson β‐updating step, our ADMM algorithm for the stacked regression parameter β∈RPQ in a multi‐state model consists of the following steps:
- 1.Initialize β0,θ0, and ν0.
- 2.Update until stopping criterion met:
where parameter dimensions are θ,ν∈RM. λm denotes the regularization parameters for the global lasso, fusion, and group penalties, respectively, and wm=P the group weights incorporating the group sizes corresponding to the group penalty. For the stopping criterion, we follow Boyd et al. (2010) adapted for FSGL by Beer et al. (2019) (cf. their Appendix Section 2.2) as
with ε1=PQεabs+εrelmax{∥Kβr+1∥2,∥θr+1∥2}, ε2=Mεabs+εrel∥KTνr+1∥2 and tolerances εabs,εrel as in Subsection 4.1. Regarding the ADMM step size ρ>0, we follow Beer et al. (2019) by implementing an adaptive step size proposed by He et al. (2000) to accelerate the convergence of the ADMM algorithm, that is,
where we set τ=2, η=10, and initialize ρ0=1. Algorithm 1 provides a summary of the adapted ADMM algorithm to FSGL penalized multi‐state models (FSGLmstate).
ALGORITHM 1ADMM for fused sparse‐group lasso penalized multi‐state models (FSGLmstate). 1:Set K∈RM×PQ, α,γ∈[0,1], ρ0=1, and tolGD=10−6 or tolNR=10−6.2: initialize β0=0PQ,θ0=0M,ν0=0M.3: repeat 4:Update βr+1=argminβL(β,θr,νr),5:Update θmr+1=Sλmwmρr(Kmβr+1+νmr/ρr),m=1,…,M,6:Update νr+1=νr+ρr(θr+1−Kβr+1),7: until ∥θr+1−Kβr+1∥2<ε1 and ∥ρrKT(θr+1−θr)∥2<ε2 for sufficiently small ε1 and ε2.8: obtain β^=θ^.John Wiley & Sons, Ltd.
To tackle the dependency of the penalized estimation solution on relative variable scales, standardization is performed for continuous covariates before applying penalization, that is, xp.q∗=xp.qσ^xp.q, where σ^xp.q denotes the empirical standard deviation of xp.q. For interpretation, the regression coefficients have to be scaled back after estimation.
The algorithm can be easily amended to situations in which certain covariates should not be penalized (e.g., established clinical predictors). Therefore, we introduce an individual penalty scaling factor ζm≥0,m=1,⋯,PQ, which allows different penalties for each variable, that is, λm=λζm (Friedman et al. 2010). Unpenalized parameters get a penalty scaling factor set to zero, that is, ζm=0 for m∈{1,⋯,PQ}.
Furthermore, it is important to note that the ADMM algorithm does not generate exact zeros for the β^‐solution (Andrade et al. 2021; Parka and Shin 2022). However, the estimated auxiliary variable θ^ is sparse, so that variable selection results are based on the derived estimate θ^. Thus, we get the final estimated penalized regression vector as β^=θ^.
Selection of Tuning Parameters
4.3
For tuning parameter selection, we focus on the approximate generalized cross‐validation (GCV) statistic (Craven and Wahba 1978). This selection criterion was used by Tibshirani et al. (2005) for the fused lasso and Fan and Li (2002) for variable selection in penalized Cox models. GCV is an estimator of the predictive ability of a model (Jansen 2015), which is defined as
where λ is a general tuning parameter. The effective number of model parameters for the Cox proportional hazards model in the last step of the Newton–Raphson algorithm iteration (Fan and Li 2002) is approximated as
with
and p′(·) denoting the first derivative of the locally quadratic approximated penalty function. The optimal tuning parameter is then selected as λopt=argminλ{GCV(λ)}. For the selection of an optimal combination of multiple tuning parameters, grid search (Tibshirani et al. 2005) along with the Brent optimization algorithm (Brent 1973) is utilized.
Simulation Study
5
This section describes the design of a proof‐of‐concept simulation study for evaluating FSGL penalized multi‐state models in terms of variable selection in Subsection 5.1 and illustrates corresponding results in Subsection 5.2. Additional higher‐dimensional simulation results can be found in Appendix A.
Simulation Design
5.1
The aim of the following proof‐of‐concept simulation study is to evaluate the variable selection procedure based on FSGL penalized multi‐state models in terms of its ability to select a sparse model distinguishing between relevant transition‐specific effects and equal cross‐transition effects. As a methodological phase II simulation study, it offers empirical evidence to demonstrate validity in finite samples across a limited range of scenarios (Heinze et al. 2024). The corresponding ADEMP criteria (i.e., acronym for Aim, Data‐generating mechanism, Estimand, Methods and Performance measures) according to Morris et al. (2019) of the simulation study are summarized in Table 2. A detailed simulation study plan according to ADEMP‐PreReg (Siepe et al. 2023) can be found in the Supporting Information.
Data‐Generating Mechanism
5.1.1
In each simulation run, we generate multi‐state data with a sample size of N=1000 from the AML nine‐state model displayed in Figure 1 based on transition‐specific hazards regression as a nested series of competing risks experiments according to Beyersmann et al. (2009). Thus, data have been generated by the following data‐generating process: Waiting times in state l are generated from an exponential distribution with hazards hl·=∑k=1,k≠l9h[lk], l=1,⋯,9. Transition‐specific baseline hazards are set constant to h0,q(t)=0.05 for all transitions q=1,⋯,8. We synthesize two independent biomarkers as binary covariates Xp,i∼B(0.5),p=1,2,i=1,⋯,1000. The true regression parameters for biomarker X1 are set to β1,1=1.5 for transition 1, β1,3=β1,7=1.2 for transitions 3 and 7, β1,4=β1,8=−0.8 for transitions 4 and 8, and β1,2=β1,5=β1,6=0 for transitions 2, 5, and 6. Similar transitions are 3 and 7, that is, from first complete remission (CR1) to first relapse and from second complete remission (CR2) to second relapse, as well as 4 and 8, that is, CR1 to death in CR1 and CR2 to death in CR2. Thus, covariate X1 has equal effects on these two pairs of similar transitions. Covariate X2 has no effect on any transition, that is, β2,1=⋯=β2,8=0.
Target
5.1.2
Our primary target focuses on the true non‐zero regression coefficients βp.q from the penalized multi‐state Cox‐type proportional hazards models
where h0,q(t) denotes the baseline hazard rate of transition q at time t, x=(x1,⋯,xP)T∈RP the vector of covariates, and βq∈RP the vector of transition‐specific regression coefficients for P covariates, chosen as described in the data‐generating mechanism.
Methods
5.1.3
We aim to compare the FSGLmstate algorithm to unpenalized multi‐state Cox‐type estimation and lasso penalized estimation (LASSOmstate) based on ADMM optimization. For fitting Cox‐type multi‐state models by ADMM optimization as described in Section 4.2, we chose the following parameter settings: The ADMM variables are initialized as β0=θ0=ν0=0 and the adaptive ADMM step size as ρ0=1. The step size in gradient descent is set to εGD=0.01, the tolerance of the stopping criterion for Cox estimation tolGD=10−6, the relative and absolute tolerance for the ADMM stopping criterion εrel=10−2 and εabs=10−4, and the maximum number of iterations to maxiter=500. For each combination of tuning parameters α,γ∈{0,0.25,0.5,0.75,1}, the optimal overall penalty parameter λ^opt>0 is selected by minimal GCV over a grid of 20 values of λ∈{0.01,0.023,⋯,362.38,500}, equally spaced on a logarithmic scale.
Performance Measures
5.1.4
Regularization performance is assessed by true positive rates (TPRs) and false discovery rates (FDRs) of variable selection. Median counts of true positives (TPs), true negatives (TNs), false positives (FPs), and false negatives (FNs) of variables over all simulations are calculated. Based on these absolute counts, TPR is calculated as TPR=TPTP+FN. Furthermore, FDR is defined as the number of unrelated variables selected (i.e., FPs) divided by the total number of selected variables, that is, FDR=FPTP+FP.
For quantifying the estimation bias, Bias(β^)=β^−β, for the non‐zero covariates, the mean squared error (MSE) over all simulation iterations is used. The MSE for the non‐zero covariates is defined as
where d denotes the number of non‐zero covariates with βp,q≠0 of the true model. The mean bias and mean MSE averaged over the non‐zero predictors over all simulation runs along with Monte Carlo standard errors (MCSEs) are calculated according to Morris et al. (2019).
The number of simulation runs is based on the TPR as one of the primary performance measures of interest. Thus, we need nsim=225 simulation repetitions per scenario as we aim for TPR ≥0.9 and MCSE(TPR) ≤0.02 and assume MCSE(TPR^)≤0.15, resulting in nsim=0.9·0.10.022=225.
Simulation Results
5.2
This section summarizes the main simulation findings, with full results available in the R supplement within the Supporting Information. Tuning parameter selection by minimal GCV for FSGLmstate is illustrated in Figure 2. Boxplots depict mean GCV across combinations of tuning parameter pairs (α,γ) for a grid of penalty parameter λ∈{0.01,⋯,500} over all nsim=225 simulated data sets. For LASSOmstate corresponding to (α,γ)=(1,1), the most frequent lowest GCV is obtained for the optimal tuning parameter λ^opt,L=8.6 with mean GCV(λ^opt,L)·1000=0.52597 over all simulations. For FSGLmstate, the tuning parameter combination (α,γ)=(1,0.25) yields the most frequent lowest GCV for λ^opt,FSGL=38.1 with mean GCV(λ^opt,FSGL)·1000=0.52663 over all simulated data sets with the corresponding penalty parameter combination.
Tuning parameter selection results for FSGLmstate: Mean generalized cross‐validation (GCV) statistics across all preselected combinations of penalty parameters (α,γ) over nsim=225 simulation runs. The pair (α,γ)=(1,1) corresponds to the global lasso penalty.
The regularization performance of the FSGLmstate algorithm in comparison to unpenalized and lasso penalized multi‐state Cox‐type estimation is depicted in Figure 3. For our simulation setting with N=1000 observations and PQ=16 regression parameters, unpenalized Cox‐type estimation serves as a gold standard.
Boxplots of estimated regression coefficients based on simulated data of the nine‐state AML model with eight transitions and two binary covariates. X1.3 and X1.7 as well as X1.4 and X1.8 refer to transitions with true equal effects of covariate X1. Covariate X2 has no true effect on any transition. Dots depict estimated covariate effects based on λ^opt,L and λ^opt,FSGL of each simulated data set. True underlying covariate effects βtrue are denoted as crosses (×).
The boxplots illustrate the estimated regression coefficients of the binary covariates based on λ^opt,L and λ^opt,FSGL. Whereas LASSOmstate identifies the non‐zero effects of β1,1=1.5, β1,3=β1,7=1.2, and β1,4=−0.8, the negative effect of β1.8=−0.8 for the late transition 8 from CR2 to death in CR2 is set to zero on average. FSGLmstate recognizes the similarity structure of the covariate effect pairs β1,3=β1,7=1.2 as well as β1,4=β1.8=−0.8 while setting all other true negative covariate effects to zero. The unpenalized Cox‐type estimation based on ADMM optimization identifies all non‐zero effects, but inherently does not perform regularization, which results in larger variances for all true negative coefficients.
Figure 4 depicts variable selection results in terms of TPR and FDR for LASSOmstate and FSGLmstate. Whereas FSGLmstate more often detects all non‐zero regression effects, LASSOmstate's estimated TPR varies between 0.8 and 1.0 (left panel). With regard to FDR, FSGLmstate has a median estimated FDR of 0.29 and LASSOmstate of 0.38 (right panel).
Variable selection results in terms of true positive rates (TPRs) and false discovery rates (FDRs) for LASSOmstate and FSGLmstate. Dots illustrate TPR and FDR of each simulated data set.
Figure 5 illustrates the mean bias and MSE of estimating the non‐zero covariate effects along with MCSE. As expected, unpenalized Cox‐type estimation exhibits smallest mean bias and MSE of estimating the non‐zero covariate effects in our simulation setting with N=1000 observations. Notably, FSGLmstate provides smaller mean MSEs than LASSOmstate.
Mean bias and mean squared error (MSE) of estimating the non‐zero covariate effects along with 95% Monte Carlo confidence intervals (MC‐CI). Dots illustrate mean bias and mean MSE of a single simulated data set.
Application to Leukemia Data
6
The potential of FSGL penalized multi‐state models is further investigated in an illustrative application to leukemia data. The AMLSG 09‐09 study is a randomized phase III trial conducted between 2010 and 2017 at 56 study hospitals in Germany and Austria. The clinical trial evaluated intensive chemotherapy with or without gemtuzumab ozogamicin (GO) in patients with NPM1‐mutated AML. Final analysis results for the single and composite endpoints EFS, overall survival (OS), CR rates, and cumulative incidence of relapse (CIR) with long‐term follow‐up are published in Döhner et al. (2023). In conclusion, primary endpoints of the trial in terms of EFS and OS were not met. Additional gene mutation data are available for N=568 study patients.
Our motivating nine‐state model for AML along with event counts based on the 09‐09 trial data is illustrated in Figure 6. Late transitions 7 and 8 are rather rarely observed with few events (E7=31,E8=25). Derived from this multi‐state model, Figure 7 depicts the stacked transition probabilities to all states from randomization, calculated by the Aalen–Johansen estimator (de Wreede et al. 2011). The probability of being in an intermediate state can fluctuate over time, either increasing or decreasing, while the absorbing state probabilities can only increase over time.
Event counts of the multi‐state model for acute myeloid leukemia (AML) with nine states and eight transitions based on the AMLSG 09‐09 trial data. Gray numbers indicate the corresponding transition.
Stacked transition probabilities to all states from randomization derived from the multi‐state model for acute myeloid leukemia (AML) based on the AMLSG 09‐09 trial data. The distance between two adjacent curves represents the probability of being in the corresponding state. CR: Complete remission.
For our nine‐state model, we investigate covariate effects of P=24 gene mutations with a prevalence of >3% along with the Pc=4 established clinical predictors treatment (GO vs. standard), age (years), sex (male vs. female), and log10 transformed white blood cell count (109 cells/l). Considering these P=28 covariates and Q=8 transitions, we need to incorporate (P+Pc)Q=28·8=224 regression parameters. The clinical predictors should persist unpenalized, thus we apply the FSGL penalty to the remaining 192 mutation parameters. We assume similarity for transitions 3 and 7, that is, CR1 to first relapse and CR2 to second relapse, as well as transitions 4 and 8, that is, CR1 to death in CR1 and CR2 to death in CR2, so that we have s=2 pairs of similar transitions. With respect to a priori expert knowledge on similarity and grouping structures in AML mutations, tuning parameter combinations are investigated for α∈{0.5,0.75,1} with more weight on the global lasso and γ∈{0,0.25,0.5} putting more weight to the fusion penalty. Among all predefined pairs (α,γ), the optimal combination of regularization parameters (α^opt,FSGL,γ^opt,FSGL)=(0.75,0.5) and λ^opt,FSGL=20 is then selected by minimal GCV over the grid λ∈{0.01,⋯,500}. Figure 8 depicts all estimated regression coefficients of clinical and mutation variables by FSGLmstate separately for each transition.
Estimated regression effects of clinical and mutation variables by FSGLmstate separately for each transition derived from the nine‐state model for acute myeloid leukemia (AML) based on the AMLSG 09‐09 trial data. Larger crosses (×) depict non‐zero effects.
In consistence with final analysis results for CIR, treatment has a negative regression effect on transition 3, that is, from CR1 to first relapse, suggesting an antileukaemic efficacy of intensive chemotherapy including GO (β^treatment.3=−0.34). With respect to molecular markers, mutations of the DNA methylation gene DNMT3A ^R882^ are selected for transition 3 from CR1 to first relapse, as well as for transition 7 from CR2 to second relapse. This result aligns with accompanying gene mutation analyses of Cocciardi et al. (2025), where DNMT3A ^R882^ mutations were associated with an increased CIR.
Discussion
7
In this paper, we propose FSGL penalized multi‐state models for data‐driven variable selection and dimension reduction in order to capture pathogenic disease processes more accurately while incorporating clinical and molecular data. The objective was to select a sparse model based on high‐dimensional molecular data by extended regularization methods. We adapted the ADMM algorithm to FSGL penalized multi‐state models combining the penalization concepts of general sparsity, pairwise differences of covariate effects along with transition grouping. Thus, FSGL penalized multi‐state models tackle sparse model building while incorporating a priori information about the covariate and transition structure into a prediction model. Furthermore, the ADMM algorithm can quite efficiently handle large‐scale problems due to the decomposability of the objective function as well as superior convergence properties.
The proof‐of‐concept simulation study evaluated the FSGLmstate algorithm's regularization performance to select a sparse model incorporating only relevant transition‐specific effects and similar cross‐transition effects. Compared to unpenalized and global lasso penalized estimation, FSGLmstate identifies similarity and grouping structures depending on the choices of the corresponding tuning parameters. Since the number of parameters in multi‐state models is generally large even when there are few covariates, our method requires a moderate to large sample size for effective estimation.
The data application on a phase III AML trial illustrated the utility of an FSGL penalized multi‐state model to reduce model complexity while combining clinical and molecular data. Whereas an unpenalized nine‐state model incorporating all established clinical predictors along with high‐dimensional mutation information based on the study data suffers from overfitting due to few events per variable, our FSGLmstate approach allows to fit a penalized nine‐state model combining clinical predictors and mutation variables.
Several improvements and extensions of the proposed FSGL penalty to multi‐state models offer further research directions. One limitation of our work is that time‐dependent covariates, for example, allogeneic stem cell transplantation, and time‐dependent effects are not yet incorporated. Beyond the current scope, future work could explore distributional baseline hazards. Furthermore, post‐selection inference requires to be investigated. Besides, the algorithm needs further adaptations to enhance computational speed and efficiently handle very high dimensions with P≫N. To this end, our implementation is computationally intensive given the multiple tuning parameter setting as well as the double optimization scheme. Thus, high‐dimensional simulation studies were limited by computation times and cloud computing resources. Furthermore, different tuning parameter selection criteria should be investigated and extensive phase III simulations for empirical method comparisons are required to evaluate the performance of our variable selection method across a wide range of settings.
Ethics Statement
The DFG project Mehrstadienmodellierung zur Prüfung prognostischer und prädiktiver Biomarker in der akuten myeloischen Leukämie (grant no. 514653984) was approved by the Ethics Committee of Ulm University (application no. 249/21). The AMLSG 09‐09 clinical trial was approved by the ethics committees at all sites.
Consent
Written informed consent was obtained from all patients involved in the study.
Conflicts of Interest
The authors declare no conflicts of interest.
Open Research Badges
This article has earned an Open Data badge for making publicly available the digitally‐shareable data necessary to reproduce the reported results. The data is available in the Supporting Information section.
This article has earned an open data badge “Reproducible Research” for making publicly available the code necessary to reproduce the reported results. The results reported in this article could fully be reproduced.
Supporting information
Supporting Information
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Andersen, P. K. , O. Borgan , R. D. Gill , and N. Keiding . 1993. Statistical Models Based on Counting Processes. Springer Science & Business Media.
- 2Andersen, P. K. , and N. Keiding . 2002. “Multi‐State Models for Event History Analysis.” Statistical Methods in Medical Research 11, no. 2: 91–115.12040698 10.1191/0962280202 SM 276ra · doi ↗ · pubmed ↗
- 3Andrade, D. , K. Fukumizu , and Y. Okajima . 2021. “Convex Covariate Clustering for Classification.” Pattern Recognition Letters 151: 193–199.
- 4Beer, J. C. , H. J. Aizenstein , S. J. Anderson , and R. T. Krafty . 2019. “Incorporating Prior Information With Fused Sparse Group Lasso: Application to Prediction of Clinical Measures From Neuroimages.” Biometrics 75, no. 4: 1299–1309.31022303 10.1111/biom.13075 PMC 6814453 · doi ↗ · pubmed ↗
- 5Benner, A. , M. Zucknick , T. Hielscher , C. Ittrich , and U. Mansmann . 2010. “High‐Dimensional Cox Models: The Choice of Penalty as Part of the Model Building Process.” Biometrical Journal 52, no. 1: 50–69.20166132 10.1002/bimj.200900064 · doi ↗ · pubmed ↗
- 6Beyersmann, J. , A. Latouche , A. Buchholz , and M. Schumacher . 2009. “Simulating Competing Risks Data in Survival Analysis.” Statistics in Medicine 28, no. 6: 956–971.19125387 10.1002/sim.3516 · doi ↗ · pubmed ↗
- 7Boyd, S. , N. Parikh , E. Chu , B. Peleato , and J. Eckstein . 2011. “Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers.” Foundations and Trends in Machine Learning 3, no. 1: 1–122.
- 8Brent, R. P. 1973. Algorithms for Minimization Without Derivatives. Prentice‐Hall.