Vision-language model performance on the Japanese Nuclear Medicine Board Examination: high accuracy in text but challenges with image interpretation
Rintaro Ito, Keita Kato, Marina Higashi, Yumi Abe, Ryogo Minamimoto, Katsuhiko Kato, Toshiaki Taoka, Shinji Naganawa

TL;DR
Vision-language models perform well on text-based nuclear medicine questions but struggle with image interpretation, showing promise as assistants but not replacements for experts.
Contribution
First evaluation of state-of-the-art vision-language models on the Japanese Nuclear Medicine Board Examination, revealing performance trends and limitations.
Findings
ChatGPT o1 pro achieved the highest overall accuracy (83.3%) on the JNMBE questions.
All models performed significantly better on text-only questions than on image-based ones.
VLMs struggled with Japanese regulations and showed declining accuracy from 2022 to 2024.
Abstract
Vision language models (VLMs) allow visual input to Large Language Models. VLMs have been developing rapidly, and their accuracy is improving rapidly. Their performance in nuclear medicine compared to state-of-the-art models, including reasoning models, is not yet clear. We evaluated state-of-the-art VLMs using problems from the past Japan Nuclear Medicine Board Examination (JNMBE) and assessed their strengths and limitations. We collected 180 multiple-choice questions from JNMBE (2022–2024). About one-third included diagnostic images. We used eight latest VLMs. ChatGPT o1 pro, ChatGPT o1, ChatGPT o3-mini, ChatGPT-4.5, Claude 3.7, Gemini 2.0 Flash thinking, Llama 3.2, and Gemma 3 were tested. Each model answered every question three times in a deterministic setting, and the final answer was set by majority vote. Two board-certified nuclear medicine physicians independently provided…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
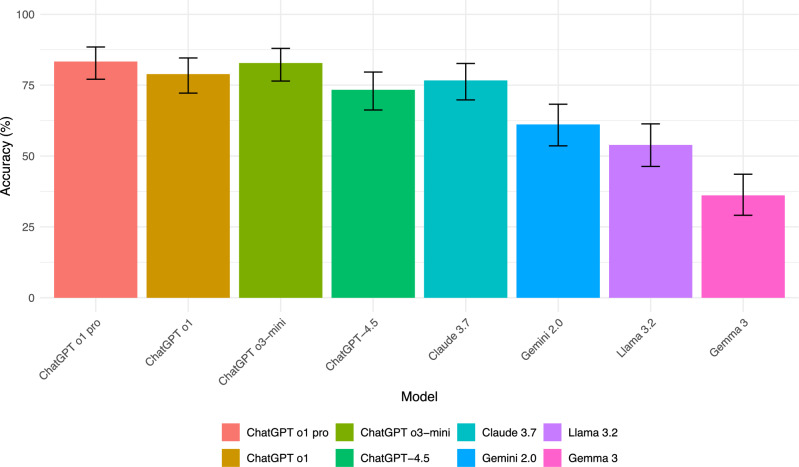 Figure 1
Figure 1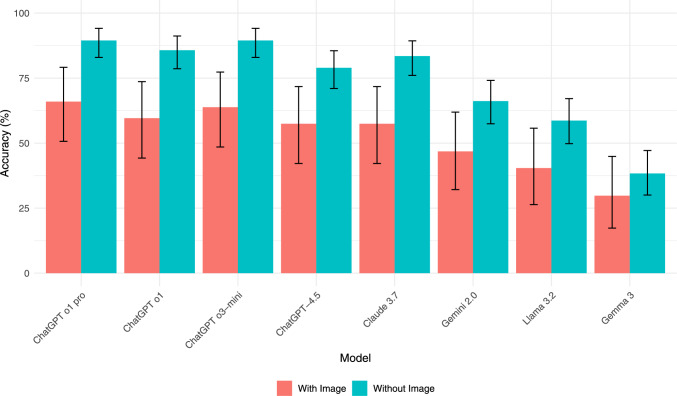 Figure 2
Figure 2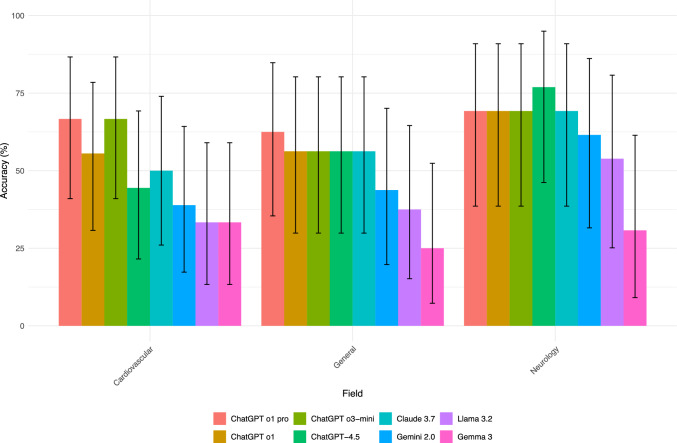 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Topic Modeling · Interpreting and Communication in Healthcare