Memory-efficient, accelerated protein interaction inference with blocked, multi-GPU D-SCRIPT
Daniel E Schäffer, Samuel Sledzieski, Lenore Cowen, Bonnie Berger

TL;DR
This paper introduces a memory-efficient and accelerated version of D-SCRIPT for predicting protein interactions at scale using multiple GPUs.
Contribution
The novel contribution is blocked multi-GPU parallel inference, which significantly reduces memory usage and enables large-scale PPI analysis.
Findings
Blocked multi-GPU inference reduces memory usage by 13.8× for large proteomes.
The new method enables multi-GPU parallelism for PPI inference.
The updated D-SCRIPT is publicly available with these improvements.
Abstract
D-SCRIPT is a powerful tool for high-throughput inference of protein–protein interactions (PPIs), but it is expensive in time and memory to infer all PPIs for network-/proteome-level analyses. We introduce D-SCRIPT with blocked multi-GPU parallel inference, which substantially reduces memory usage across tasks and computational systems (13.8× for a representative large proteome) and enables multi-GPU parallelism. Blocked multi-GPU parallel inference has been integrated into the main D-SCRIPT package, available at https://github.com/samsledje/D-SCRIPT. An archived version of the code at time of submission can be found at https://doi.org/10.5281/zenodo.16325182.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
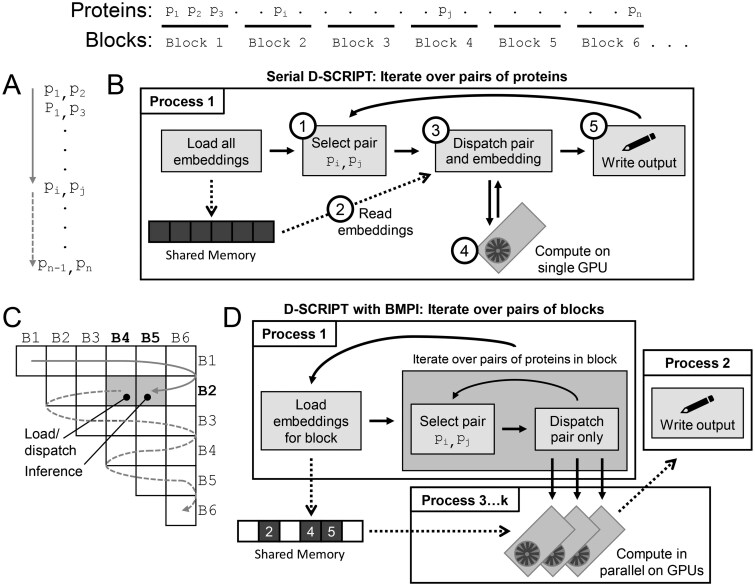 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBioinformatics and Genomic Networks · Protein Structure and Dynamics · Advanced Proteomics Techniques and Applications