Preprocessing Large-Scale Conversational Datasets: A Framework and Its Application to Behavioral Health Transcripts
Paz Mor Naim, Shiri Sadeh-Sharvit, Samuel Jefroykin, Eddie Silber, Dennis P Morrison, Ariel Goldstein

TL;DR
This paper introduces a framework for preprocessing noisy conversational datasets, especially in behavioral health, using a mix of statistical analysis, human annotation, and large language models.
Contribution
The novel contribution is a hybrid framework combining feature extraction, human input, and LLMs to filter non-session transcripts in behavioral health data.
Findings
Approximately one-third of transcripts had transcription errors like incomprehensible segments or speaker misattribution.
Zero-shot LLM prompting achieved moderate agreement with expert annotations (κ=0.71) in classifying sessions vs non-sessions.
High speaking rate and short duration were indicators of non-therapy conversations like answering machine messages.
Abstract
The rise of artificial intelligence and accessible audio equipment has led to a proliferation of recorded conversation transcripts datasets across various fields. However, automatic mass recording and transcription often produce noisy, unstructured data that contain unintended recordings such as hallway conversations, media (eg, TV, radio), or transcription inaccuracies as speaker misattribution or misidentified words. As a result, large conversational transcript datasets require careful preprocessing and filtering to ensure their research utility. This challenge is particularly relevant in behavioral health contexts (eg, therapy, counseling) where deriving meaningful insights, specifically dynamic processes, depends on accurate conversation representation. We present a framework for preprocessing large datasets of conversational transcripts and filtering out non-sessions—transcripts…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1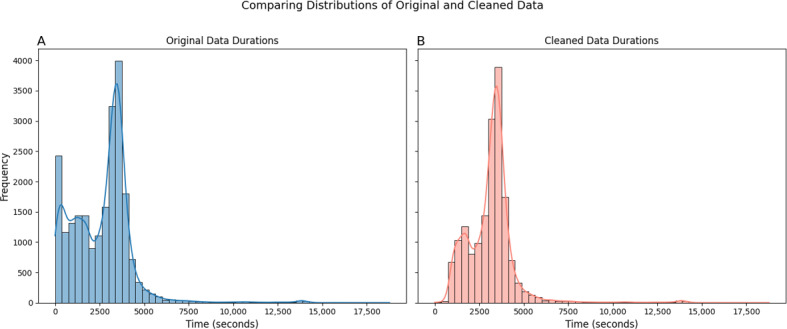 Figure 2
Figure 2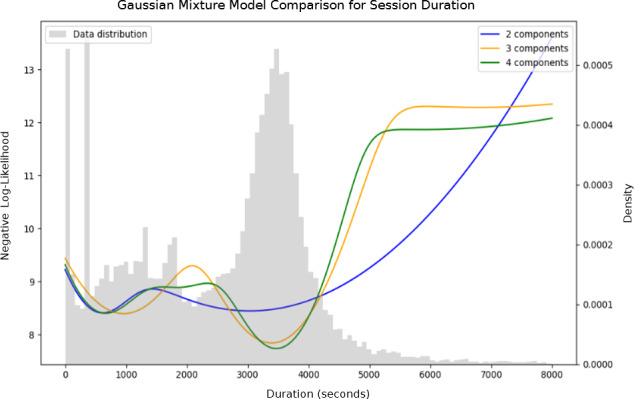 Figure 3
Figure 3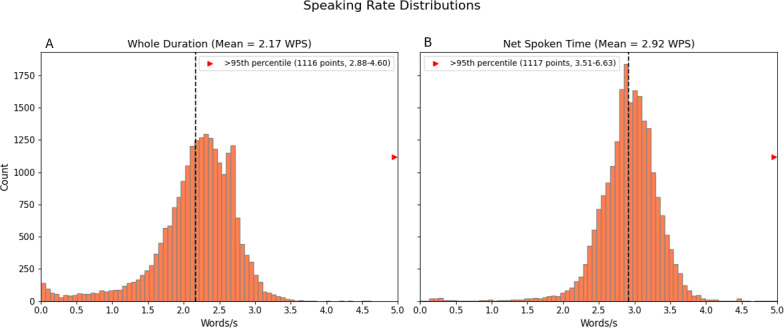 Figure 4
Figure 4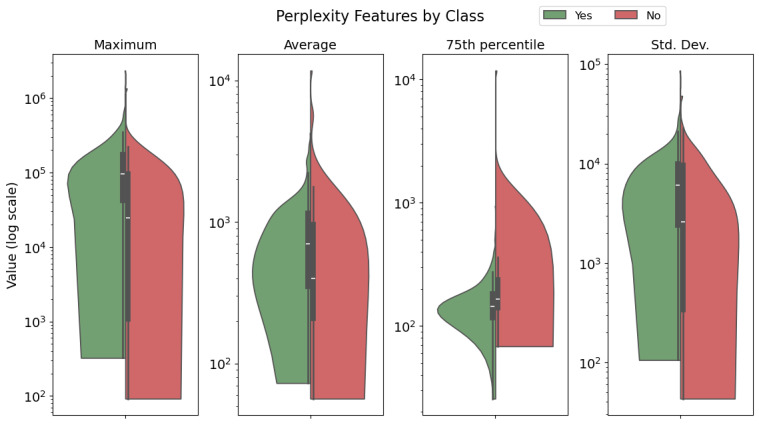 Figure 5
Figure 5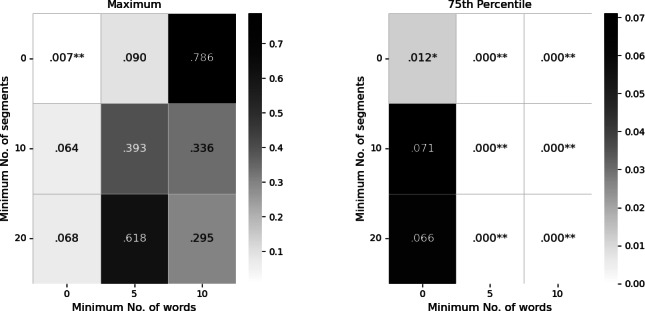 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Text Analysis Techniques · Topic Modeling · Misinformation and Its Impacts