Comparison of GPT-4o With Human Performance in the Polish Vascular Surgery Specialty Examination
Michalina Loson-Kawalec, Anna Kowalczyk, Aleksander Tabor, Patrycja Dadynska, Aleksandra Wielochowska, Dawid Boczkowski, Tomasz Dolata, Weronika Majchrowicz, Piotr Sawina, Dominika Radej, Maja Kruplewicz, Dawid Bartosik, Marta Zerek, Alicja Szalach, Gracjan Sitarek, Ada Latkowska

TL;DR
This study compares the performance of the ChatGPT-4o AI model with human standards on a Polish vascular surgery exam, finding that it passes but has limitations in self-assessment.
Contribution
The study evaluates ChatGPT-4o's performance on a real Polish medical exam in vascular surgery, comparing its accuracy and confidence with human benchmarks.
Findings
ChatGPT-4o answered 73.3% of questions correctly, surpassing the minimum passing score.
The model's confidence levels did not reliably predict its accuracy in answers.
Performance was similar for clinical and non-clinical questions.
Abstract
Background Artificial intelligence (AI) offers many possibilities by using language models such as ChatGPT, also known as a synthetic generative intelligence chatbot advanced by OpenAI (OpenAI, Inc., San Francisco, USA). Using the potential of AI in medicine can provide a crucial tool to assess medical expertise and create a promising future in the field of medical education. Prior investigations have documented the progressive advancing performance of AI systems in addressing medical situations. These studies were also conducted in the evaluation of Polish medical examinations, comprising the State Specialization Examination (PES) as discussed in this article. These findings have stimulated scholarly debate regarding the potential of such technologies to serve as instruments for enhancing postgraduate specialist education and training. Objective This study aimed to evaluate the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
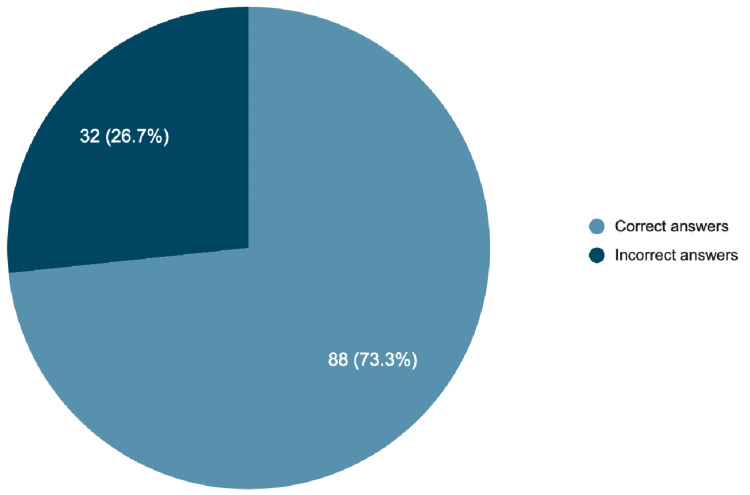 Figure 1
Figure 1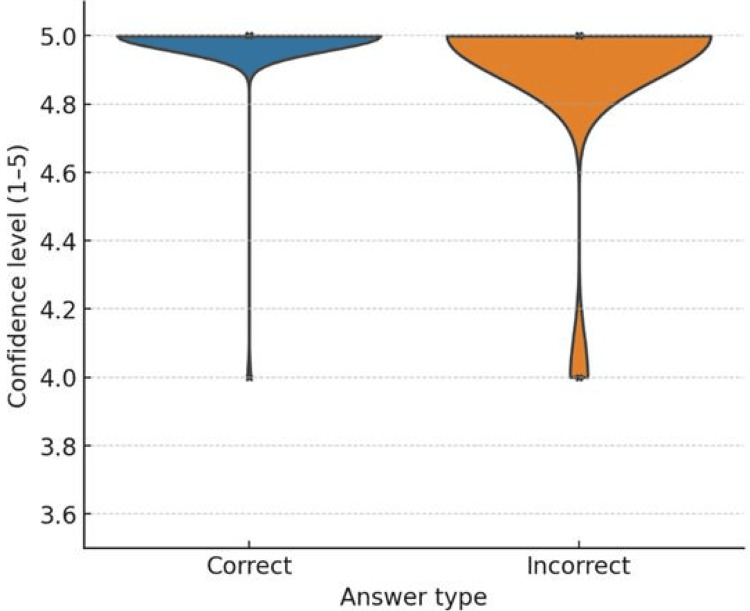 Figure 2
Figure 2| Question number | Official answer | ChatGPT answer | ChatGPT confidence level (1-5) |
| 1 | C | B | 5 |
| 2 | E | E | 4 |
| 3 | A | A | 5 |
| 4 | B | B | 5 |
| 5 | E | E | 5 |
| 6 | D | A | 5 |
| 7 | E | E | 5 |
| 8 | A | A | 5 |
| 9 | D | E | 5 |
| 10 | A | D | 5 |
| 11 | A | A | 5 |
| 12 | C | C | 5 |
| 13 | A | A | 5 |
| 14 | D | D | 5 |
| 15 | D | D | 5 |
| 16 | B | B | 5 |
| 17 | D | B | 5 |
| 18 | E | B | 5 |
| 19 | C | C | 5 |
| 20 | A | A | 5 |
| 21 | B | D | 5 |
| 22 | C | C | 5 |
| 23 | E | B | 5 |
| 24 | D | D | 5 |
| 25 | A | A | 5 |
| 26 | C | C | 5 |
| 27 | B | B | 5 |
| 28 | C | C | 5 |
| 29 | C | C | 5 |
| 30 | C | C | 5 |
| 31 | D | D | 5 |
| 32 | E | E | 5 |
| 33 | A | A | 5 |
| 34 | D | B | 4 |
| 35 | C | C | 5 |
| 36 | A | A | 5 |
| 37 | E | E | 5 |
| 38 | E | E | 5 |
| 39 | C | C | 5 |
| 40 | C | C | 5 |
| 41 | A | A | 5 |
| 42 | C | C | 5 |
| 43 | A | A | 5 |
| 44 | C | C | 5 |
| 45 | D | D | 5 |
| 46 | E | E | 5 |
| 47 | B | B | 5 |
| 48 | B | A | 5 |
| 49 | C | C | 5 |
| 50 | B | D | 5 |
| 51 | B | B | 5 |
| 52 | B | B | 5 |
| 53 | A | C | 5 |
| 54 | B | B | 5 |
| 55 | C | C | 5 |
| 56 | B | B | 5 |
| 57 | D | D | 5 |
| 58 | B | B | 5 |
| 59 | C | C | 5 |
| 60 | C | C | 5 |
| 61 | B | B | 5 |
| 62 | E | C | 4 |
| 63 | B | B | 5 |
| 64 | D | D | 5 |
| 65 | B | B | 5 |
| 66 | D | A | 5 |
| 67 | B | B | 5 |
| 68 | A | E | 5 |
| 69 | A | A | 5 |
| 70 | B | A | 5 |
| 71 | D | D | 5 |
| 72 | A | B | 5 |
| 73 | E | D | 5 |
| 74 | B | C | 5 |
| 75 | C | C | 5 |
| 76 | B | B | 5 |
| 77 | B | B | 5 |
| 78 | E | E | 5 |
| 79 | D | D | 5 |
| 80 | D | C | 5 |
| 81 | A | E | 5 |
| 82 | B | B | 5 |
| 83 | E | E | 5 |
| 84 | E | E | 5 |
| 85 | C | C | 5 |
| 86 | D | D | 5 |
| 87 | D | C | 5 |
| 88 | D | D | 5 |
| 89 | C | D | 5 |
| 90 | C | C | 5 |
| 91 | A | A | 5 |
| 92 | D | D | 5 |
| 93 | B | B | 5 |
| 94 | C | E | 5 |
| 95 | C | C | 5 |
| 96 | B | A | 5 |
| 97 | A | A | 5 |
| 98 | B | E | 5 |
| 99 | A | A | 5 |
| 100 | C | B | 5 |
| 101 | B | B | 5 |
| 102 | D | D | 5 |
| 103 | D | D | 5 |
| 104 | E | B | 5 |
| 105 | B | D | 5 |
| 106 | C | C | 5 |
| 107 | A | A | 5 |
| 108 | C | C | 5 |
| 109 | B | B | 5 |
| 110 | C | C | 5 |
| 111 | D | D | 5 |
| 112 | B | A | 5 |
| 113 | D | D | 5 |
| 114 | E | D | 5 |
| 115 | B | B | 5 |
| 116 | A | A | 5 |
| 117 | D | B | 5 |
| 118 | E | C | 5 |
| 119 | D | D | 5 |
| 120 | E | E | 5 |
| Type of question | Correct answers, n (%) | Incorrect answers, n (%) | p-Value χ² Value |
| Clinical cases | 47 (39.17) | 19 (15.83) | p = 0.561 χ² = 0.337 |
| Other | 41 (34.17) | 13 (10.83) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCardiac, Anesthesia and Surgical Outcomes · Artificial Intelligence in Healthcare and Education · Hemodynamic Monitoring and Therapy
Introduction
Artificial intelligence (AI), when combined with relevant tools and knowledge, has a profound impact on the advancement of medicine. This solution offers numerous benefits and has the potential to yield substantial improvements in healthcare. The introduction of AI is set to transform both medical education content and improve patient care, medical research, and health systems [1]. The integration of AI into medicine is generating widespread fascination. AI's ability to process and analyze enormous volumes of data, quickly identify patterns and signals, and precisely predict results is superior to that of humans. Hopes are high that AI-driven healthcare will lead to greater precision and efficiency while also reducing costs for both patients and health systems.
At the same time, AI is a source of concern. Key ethical issues include questions of trust, privacy, bias, accountability, and responsibility. To address these challenges, various efforts are underway to create ethical frameworks aimed at preventing AI from unleashing unforeseen negative consequences. Both national and international initiatives are working to establish principles and safeguards to ensure the responsible use of AI [2]. The artificial intelligence behind ChatGPT is transforming a wide range of industries. According to the Financial Times, OpenAI’s tools are used by around 500 million people each week [3].
It has been four years since OpenAI (San Francisco, USA) launched the first version of ChatGPT. During this time, the company has introduced five major releases, along with numerous updates and sub-versions. These analyses included a series of models spanning recent releases: GPT-3.5 (2022), GPT-4 (2023), GPT-4 with tool integration (2023), GPT-4 Turbo (2023), and the GPT-4o, launched in May 2024. This model acquires any combination of text, audio, and image as input and generates any of their combinations. GPT-4o is capable of processing speech, sound, images, and text in real time, while being faster and more cost-efficient than GPT-4 Turbo. It also provides improved multimodal context understanding, emotion recognition, interpretation of images and charts, and supports voice-based interaction.
With the advancement of AI, there is a growing global interest in applying modern AI models in various areas of medicine. In a 2023 study, Kufel et al. found that a previous version of ChatGPT failed to pass the Polish State Specialization Exam (PES) in radiology [4]. Jaworski et al. in May 2024 showed that, after being acquainted with the examination regulations, ChatGPT-4o could reach a passing score on the Medical-Dental Final Examination [5]. A similar occurrence was reported later, in July 2025, when B. Sławinska et al. achieved high effectiveness on the PES ophthalmology examination [6].
The dynamic evolution of AI, illustrated by OpenAI’s models, highlights the need for continuous monitoring. Responding to rapid changes requires systematic research that captures and reports progress in their development and adaptation into the realities of healthcare operations.
The objective of this study was to assess the performance of the ChatGPT-4o language model on questions from the PES vascular surgery examination, with emphasis on the accuracy of its answers and its self-reported confidence levels. The evaluation was conducted using the official correct answers database of the Medical Examination Center (CEM) in Łódź and by comparing it with the answers generated by ChatGPT [7].
Materials and methods
This study used the GPT-4o model and was performed from the 12th of August to the 18th of August 2025. The study focused on one vascular surgery specialized test from the Spring 2025 that was selected at random from the CEM in Łódź's archive database. The examination questions and their official answers are publicly accessible and readily available. The chosen test had 120 questions with five distractions, each of which had only one right response. The Examination Board did not rule out any of the 120 questions, indicating that they were all in line with what was currently known.
For analysis, the examination questions were grouped into two types: those based on clinical cases and those addressing non-clinical topics. Clinical case questions described patient scenarios and required responses based on clinical reasoning, symptom analysis, test result interpretation, and decisions regarding diagnostic and therapeutic procedures. The questions in the non-clinical group assessed theoretical understanding, treatment recommendations, or factual data unrelated to a particular patient case. Question classification was conducted independently by two researchers, with any disagreements resolved by a third, independent reviewer. Before encountering the exam questions, ChatGPT was briefed on the exam format, including the total questions, answer choices, and correct answers.
The answers provided were systematically evaluated according to the official database of the correct answers, which was released by CEM. For analysis, all questions and the corresponding answers were systematically compiled and documented. After each question was posed, ChatGPT was asked to assign a confidence score from 1 to 5, where 1 indicated no confidence, 2 low, 3 moderate, 4 high, and 5 complete confidence. This method provided a measure of the model’s self-evaluated certainty for each response.
ChatGPT was shown every exam question, and every exchange was methodically documented. To ensure consistency with the PES vascular surgery exam content, all communications with the model were conducted in Polish. Microsoft Excel (Microsoft® Corp., Redmond, USA) program and GraphPad Prism 10 (GraphPad Software Inc., Boston, USA) were used to conduct statistical analyses. To evaluate the model’s performance, differences in confidence ratings for correct versus incorrect responses were analyzed using the Mann-Whitney U test, while the chi-square test was applied to compare the frequency of correct and incorrect answers across clinical and non-clinical question categories. P-values below 0.05 were regarded as statistically significant.
Given the multicenter design of the study, collaboration among authors was conducted via remote communication platforms, including Microsoft Teams (Microsoft® Corp., Redmond, USA), email, and Google Docs (Google, Inc., Mountain View, USA). Contributions prepared by individual teams were reviewed by other authors, ensuring that all researchers were able to participate in and provide input on every section of the manuscript through these remote tools.
Results
ChatGPT-4o answered 88 questions correctly (73.3%) and 32 incorrectly (26.7%) (Figure 1, Table 1). No statistically significant difference in accuracy was observed between clinical and non-clinical questions (χ² = 0.337, p = 0.561) (Table 2, Figure 2). No strong association was observed between confidence ratings and the correctness of responses, indicating that, in this context, the model’s self-reported confidence was not a reliable predictor of answer accuracy (U = 1336; p > 0.001) (see Appendices).
General summary of GPT-4oThe results are reported as the number of responses (N) along with their corresponding percentage of the total questions (%), indicating the proportion of correct or incorrect answers.
Effectiveness of ChatGPT-4o depending on the question type: clinical cases vs. othersValues are presented individually for correct and incorrect responses. No significant association was found between confidence levels and correct answers. The connection between response accuracy and the confidence ratings provided by ChatGPT was assessed using the Mann–Whitney U test.
Discussion
The PES exam is a crucial step in qualifying a physician as a specialist in a specific medical specialty. The PES exam is considered passed when the physician achieves a score of at least 60% of the maximum possible score. It is known for being extremely challenging and requiring both theoretical understanding and real-world problem-solving abilities in clinical settings. This study focuses on the way the sophisticated ChatGPT-4o language model performs on tasks related to vascular surgical exams. In similar investigations in other medical domains, the model's pass score is higher than scores attained by previous iterations of ChatGPT models and surpasses the pass standards. Currently, no other studies in the literature have examined ChatGPT’s performance on the vascular surgery PES exam.
Recent advances in AI models, specifically the debut of ChatGPT-4o, have led to a notable improvement in performance, reflecting progress in the medical field’s understanding of such systems. In our investigation, the accuracy of the model’s replies was not largely correlated with its confidence level.
These results indicate that the model is, at least partially, capable of evaluating its own performance and expressing doubts. However, the model is not able to consistently predict performance, highlighting ongoing limitations in the model’s self-assessment capabilities. Importantly, these differences were not statistically significant according to the Mann-Whitney U test. While emphasizing the potential of AI as a valuable resource in medical education, the consistency of these conclusions across different examinations also emphasizes the need for careful application under the proper expert supervision. Additionally, our results might be comparable to a study on Japan's National Physical Therapist Examination [8]. Our study's findings also confirm the effectiveness and high efficiency of using GPT-4.0 for questions entered in a native language, suggesting its usefulness for healthcare professionals who do not speak English.
Crucially, when contrasting our current findings with the previously mentioned study [8], it becomes clear that ChatGPT-4o's frequent use of assertive language may be misleading, even if it is inaccurate, particularly in crucial industries, including healthcare. The success rate of ChatGPT-4.0 in this study was 73.4%, which is roughly comparable to the vascular surgery score of 73.3%. The model exceeded the 60% pass mark in both cases, indicating its educational applicability in advanced specialist examinations. A notable similarity between the two studies lies in the model’s accuracy in answering questions based on clinical expertise. Additionally, the authors of this study reported that GPT-4's performance on clinical cases with images and tables is lower, indicating areas for improvement.
The effectiveness of different ChatGPT versions in medical examinations has also been investigated, particularly in the fields of infectious diseases [9], dermatology [10], and allergology [11]. Our findings reveal a comparable trend: the model’s confidence level did not show significant differences between correct or incorrect answers, similar to performance on clinical questions, which do not differ significantly from other question types. In reference to these results, the use of language models in medical education still presents certain limitations. In medical contexts, such models may generate responses that appear plausible but are, in fact, inaccurate, potentially leading to undesirable conclusions. Therefore, with appropriate academic supervision, their role in case studies, training, and education should be regarded as supportive rather than definitive.
There are several significant limitations to this study. Due to the absence of previous research examining the application of language models in this field, it is based solely on a single Polish specialist examination in vascular surgery. The generalizability of these results to other countries or international specialist exams may be limited by variations in exam format, language, and regional medical practices. Opportunities for comparison with the existing literature are inherently limited. The probabilistic nature of the model's responses, which can produce variable results across multiple trials, limits the study's reproducibility. Furthermore, if ChatGPT-4o's training data included material overlapping with the examination content, performance scores may have been artificially inflated.
Conclusions
The ChatGPT-4o model resulted in a positive pass rate and demonstrated successful performance in addressing PES vascular surgery exam questions from the Spring 2025 session, achieving results above the passing threshold. These findings indicate that advanced AI models may serve as valuable tools in specialist education, particularly for self-assessment, exam simulation, and knowledge testing under realistic conditions. Despite exceeding the pass mark, the GPT-4o chat model failed to demonstrate reliability, as it overestimated its capabilities in incorrect answers. This suggests that artificial intelligence cannot currently be relied upon as a sole source of information or as an assistance in medical practice.
ChatGPT-4o may also function as an interactive teaching assistant, facilitating education by recognizing learning deficiencies and supplying customized feedback, due to its capacity to generate human-like responses and self-assess confidence. Although early findings suggest that language models can be of assistance in diagnostic testing and exam preparation, long-term comparative studies across various medical professions remain in short supply. The integration of such systems into medical education necessitates further investigation, both to validate their effectiveness across different medical specialties and to establish safe, ethical, and practical implementation frameworks. Moreover, the development of clear standards for expert oversight and the definition of boundaries for AI-assisted learning are essential to ensure that these technologies enhance education without supplanting critical thinking or professional judgment.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1A scoping review of artificial intelligence in medical education: BEME Guide No. 84Med Teach Gordon M Daniel M Ajiboye A 4464704620243842312710.1080/0142159 X.2024.2314198 · doi ↗ · pubmed ↗
- 2Artificial intelligence in medicine: a caution about good intentions and where it may lead Otolaryngol Head Neck Surg Lee WT 1605160617020243827027010.1002/ohn.658PMC 11141720 · doi ↗ · pubmed ↗
- 3Can artificial intelligence predict COVID-19 mortality?Eur Rev Med Pharmacol Sci Genc AC Cekic D Issever K 986698712720233791635310.26355/eurrev_202310_34163 · doi ↗ · pubmed ↗
- 4Will Chat GPT pass the Polish specialty exam in radiology and diagnostic imaging? Insights into strengths and limitations Pol J Radiol Kufel J Paszkiewicz I Bielówka M 0488202310.5114/pjr.2023.131215 PMC 1055173437808173 · doi ↗ · pubmed ↗
- 5GPT-4o vs. human candidates: performance analysis in the Polish final dentistry examination Cureus Jaworski A Jasiński D Sławińska B 016202410.7759/cureus.68813 PMC 1145632439371744 · doi ↗ · pubmed ↗
- 6Performance of the Chat GPT-4o language model in solving the ophthalmology specialization exam Cureus Sławińska B Jasiński D Jaworski A 017202510.7759/cureus.88908 PMC 1239204840895978 · doi ↗ · pubmed ↗
- 7The database of the medical examination center in Łódź 9 2025 2025 https://www.cem.edu.pl/pytcem/eula_pes.php
- 8Performance of Chat GPT 4.0 on Japan's National Physical Therapist Examination: a comprehensive analysis of text and visual question handling Cureus Sawamura S Kohiyama K Takenaka T Sera T Inoue T Nagai T 016202410.7759/cureus.67347 PMC 1141347139310431 · doi ↗ · pubmed ↗