There are significant differences among artificial intelligence large language models when answering scientific questions
Francisco Javier Álvarez-Martínez, Luis Esteban, Lucas Frungillo, Estefanía Butassi, Alessandro Zambon, María Herranz-López, Mario Aranda, Federica Pollastro, Anne Sylvie Tixier, Jose V. Garcia-Perez, David Arráez-Román, Andrew Ross, Pedro Mena, Ru Angelie Edrada-Ebel

TL;DR
This study compares how well different AI language models answer scientific questions and finds that some perform better than others.
Contribution
The study provides a comparative evaluation of five LLMs for scientific accuracy and highlights the need for ethical frameworks in AI use.
Findings
Claude 3.5 Sonnet scored highest in depth, accuracy, and clarity among the evaluated models.
RAG techniques and refined prompts improved LLM performance, but some models still require development.
Reviewers' trust in AI increased after evaluation, though ethical concerns about transparency remained.
Abstract
This study investigates the efficacy of large language models (LLMs) for generating accurate scientific responses through a comparative evaluation of five prominent free models: Claude 3.5 Sonnet, Gemini, ChatGPT 4o, Mistral Large 2, and Llama 3.1 70B. Sixteen expert scientific reviewers assessed these models in terms of depth, accuracy, relevance, and clarity. Claude 3.5 Sonnet emerged as the highest scoring model, followed by Gemini, with notable variability among the other models. Additionally, retrieval-augmented generation (RAG) techniques were applied to improve LLM performance, and prompts were refined to improve answers. The results indicate that although LLMs such as Claude 3.5 Sonnet have potential for scientific tasks, other models may require more development or additional prompt engineering to reach comparable accuracy. Reviewers’ perceptions of artificial intelligence…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
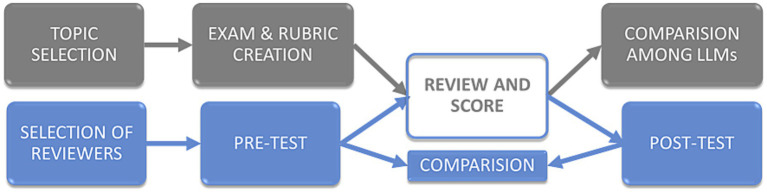 Figure 1
Figure 1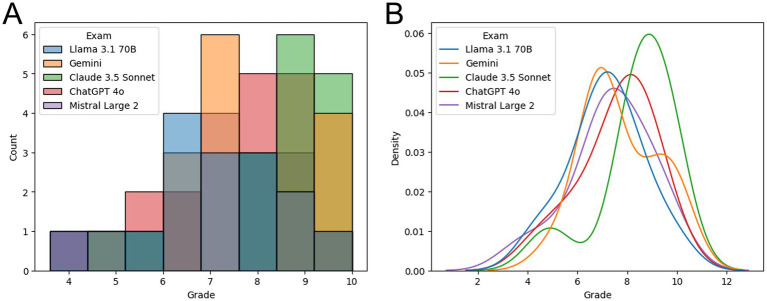 Figure 2
Figure 2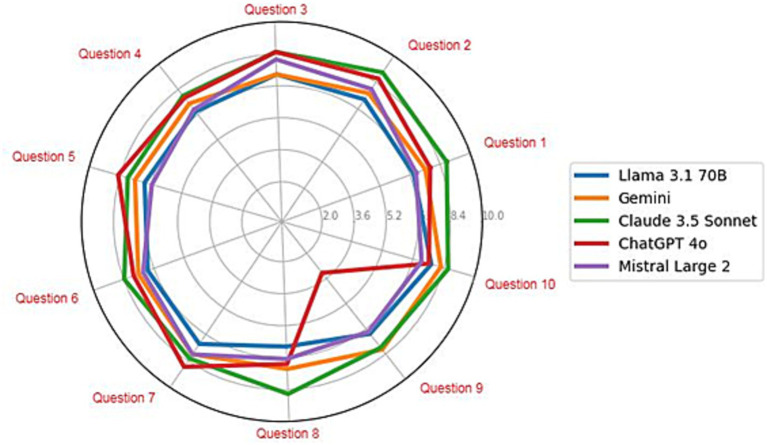 Figure 3
Figure 3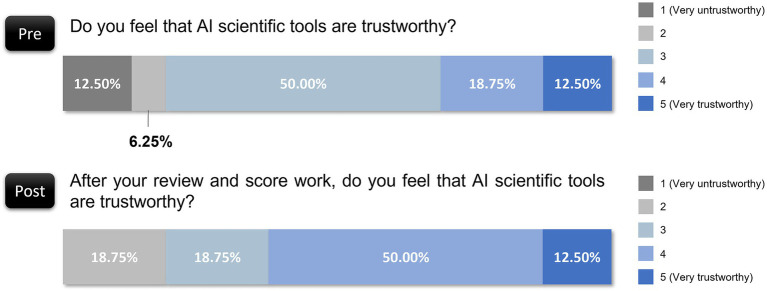 Figure 4
Figure 4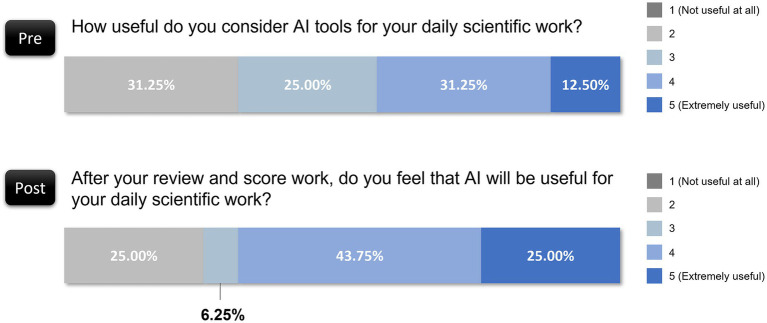 Figure 5
Figure 5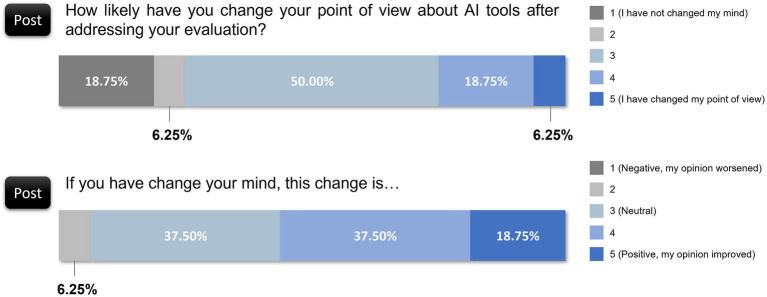 Figure 6
Figure 6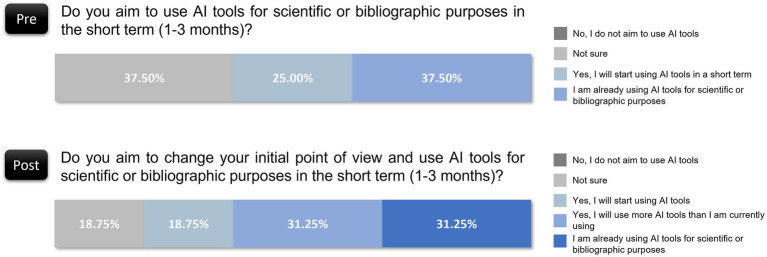 Figure 7
Figure 7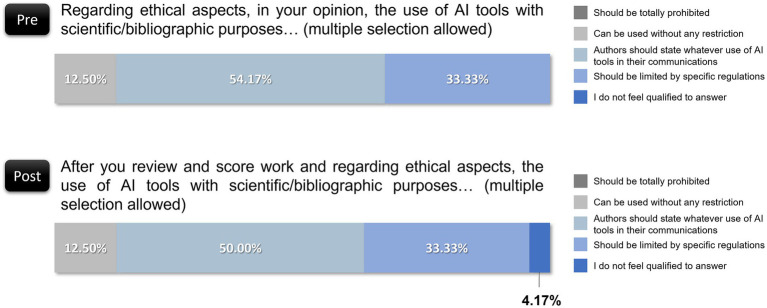 Figure 8
Figure 8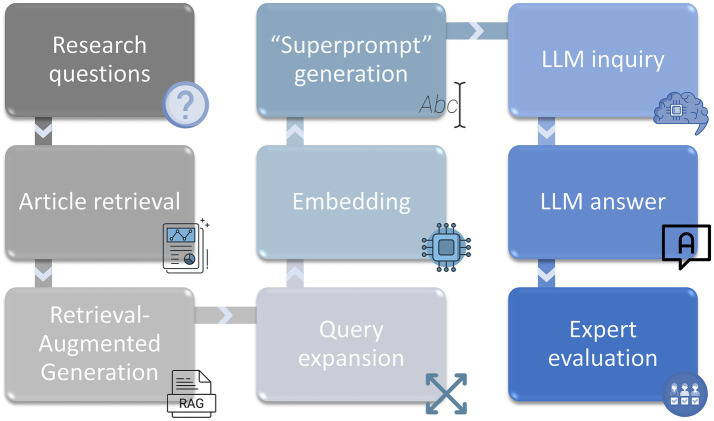 Figure 9
Figure 9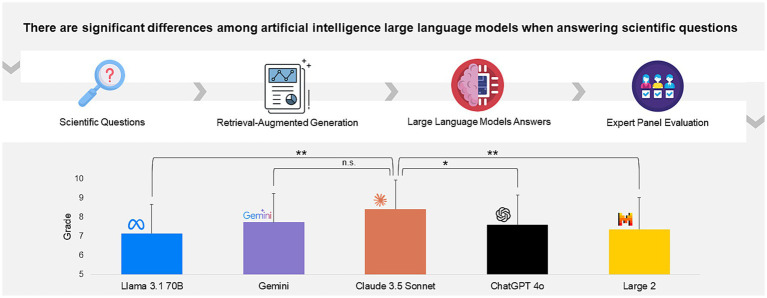 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsExplainable Artificial Intelligence (XAI) · Artificial Intelligence in Healthcare and Education