Reply to Koplenig and Wolfer: Global language analyses must account for relationships, location, and unbalanced binary data
Xia Hua, Lindell Bromham

Abstract
Click any figure to enlarge with its caption.
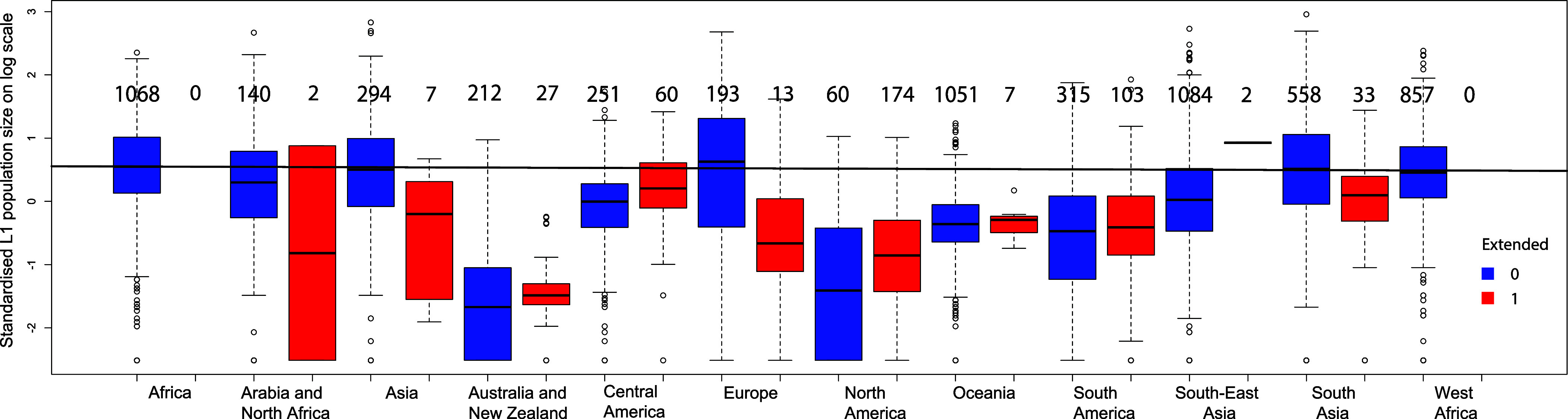 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpatial and Panel Data Analysis · Data-Driven Disease Surveillance · Statistical Methods and Inference
Koplenig and Wolfer (KW) (1) fail to account for important features of language data: i) Typological data (e.g., grammatical features) are often binary, unbalanced (far fewer languages with feature than without), and unevenly distributed (clustered in languages and regions); ii) autocorrelation due to relationships and distance cannot be captured in family or regional-level analyses. We show that aspects of our analysis (2) designed to deal with i) do not alter the conclusions, but failure to account for ii) explains KW’s results.
All statistical methods have assumptions, but some are more clearly violated than others. Bayesian (BIC)’s assumption of Gaussian posterior parameter distribution is violated for unbalanced binary variables like Polysynthesis. Using a numerical method that does not make assumptions about data distribution (reversible-jump-MCMC, rjMCMC) (3), which increases computational time by orders of magnitude, strengthens our conclusions (Table 1). RjMCMC estimates larger posterior inclusion probability (PIP) for Small_Family than BIC but similar PIP to maximum likelihood approximation. We use PIP only to rank the importance of predictors (2). Setting an arbitrary PIP threshold (e.g., PIP > 0.5) is inappropriate because PIP is underestimated for unbalanced binary predictors correlated with important continuous predictors. Small_Family correlates with altitude and L1_population, which require smaller sample sizes to achieve similar statistical power (4).
Moran’s coefficient (MC) (5) with unjustified normalization factor (1) performs well for nonnormal distributions (6), selecting the same eigenvector with similar values to the formula KW suggested (1), and is computationally efficient for ~2 × 10^4^ eigenvectors. Residual from ref. 7 was used for ordinal probit model only for endangerment, because spfilteR does not have residual for categorical variables. MC-based selection is recommended for binary regression for Eigenvector Spatial Filtering (ESF) (8), used as an exemplar in spfilteR (9) and proven to be the best approach for linear models (10). To show why selection based on model-fit is inappropriate, we rerun ESF as KW suggest. Akaike information criterion (AIC)-based selection (9) selects 55 eigenvectors, yet residual autocorrelation remains significant. The large number of eigenvectors gives a high chance of separating the rare polysynthetic languages from others simply by chance. This separation problem in binary regression is evident in unreliable estimates, unrealistically high model fit and failure to converge (1).
KW’s counterintuitive results (1) are due to failure to account for autocorrelation. Using families and subregions (1) does not account for languages’ shared history and environments (e.g., assumes neighboring Polynesian languages are no more similar than they are to distantly related Taiwanese languages from the same family). The logistic mixed model violates the assumption that heterogeneity among groups is independent of predictors (Fig. 1): Subregions with predominantly nonpolysynthetic languages have larger populations, so subregion random effect separates the information carried by 69% nonpolysynthetic languages on the effect of L1_population. Adding family random effect worsens the separation problem: 35 families are all polysynthetic and 179 families have no polysynthetic languages, so the variance of family random effect is unrealistically large (~936) and model fit is unrealistically high (r^2^ > 99%) (1). The large contribution of random effects in ref. 1 is due to the separation problem, not because it better corrects for autocorrelation than ESF.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1A. Koplenig, S. Wolfer, Statistical errors undermine claims about the evolution of polysynthetic languages. Proc. Natl. Acad. Sci. U.S.A. 122, e 2518416122 (2025).41060765 10.1073/pnas.2518416122 · doi ↗ · pubmed ↗
- 2L. Bromham, K. Yaxley, O. Wilson, X. Hua, Macroevolutionary analysis of polysynthesis shows that language complexity is more likely to evolve in small, isolated populations. Proc. Natl. Acad. Sci. U.S.A. 122, e 2504483122 (2025).40504149 10.1073/pnas.2504483122 PMC 12184492 · doi ↗ · pubmed ↗
- 3R. J. Lucchetti, L. Pedini, Par MA: Parallelized Bayesian model averaging for generalized linear models. J. Stat. Softw. 104, 1–39 (2022).
- 4O. L. Olvera Astivia, A. Gadermann, M. Guhn, The relationship between statistical power and predictor distribution in multilevel logistic regression: A simulation-based approach. BMC Med. Res. Methodol. 19, 97 (2019).31072299 10.1186/s 12874-019-0742-8PMC 6507150 · doi ↗ · pubmed ↗
- 5A. Cliff, J. Ord, Spatial Processes, Models and Applications (Pion, London, 1981).
- 6D. M. Drukker, I. R. Prucha, On the I 2(q) test statistic for spatial dependence: Finite sample standardization and properties. Spat. Econ. Anal. 8, 271–292 (2013).
- 7H. H. Kelejian, I. R. Prucha, On the asymptotic distribution of the Moran I test statistic with applications. J. Econom. 104, 219–257 (2001).
- 8M. Tiefelsdorf, D. A. Griffith, Semiparametric filtering of spatial autocorrelation: The eigenvector approach. Environ. Plan. A 39, 1193–1221 (2007).