Isometric representations in neural networks improve robustness
Kosio Beshkov, Jonas Verhellen, Mikkel Elle Lepperød

TL;DR
This paper shows that making neural networks preserve distances in data improves their robustness and accuracy, especially against adversarial attacks.
Contribution
The paper introduces an isometric regularization method that enhances neural network robustness by preserving input distances within classes.
Findings
Isometric regularization improves robustness to adversarial attacks on MNIST and CIFAR10.
Learned representations are isometric except near decision boundaries.
Hierarchical manipulation of representations helps maintain metric structure during classification.
Abstract
Artificial and biological agents are unable to learn given completely random and unstructured data. The structure of data is encoded in the distance or similarity relationships between data points. In the context of neural networks, the neuronal activity within a layer forms a representation reflecting the transformation that the layer implements on its inputs. In order to utilize the structure in the data in a truthful manner, such representations should reflect the input distances and thus be continuous and isometric. Supporting this statement, findings in neuroscience propose that generalization and robustness are tied to neural representations being continuously differentiable. Furthermore, representations of objects have the capacity of being hierarchical. Combined together, these two conditions imply that neural networks need to both preserve the distances between inputs as well…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
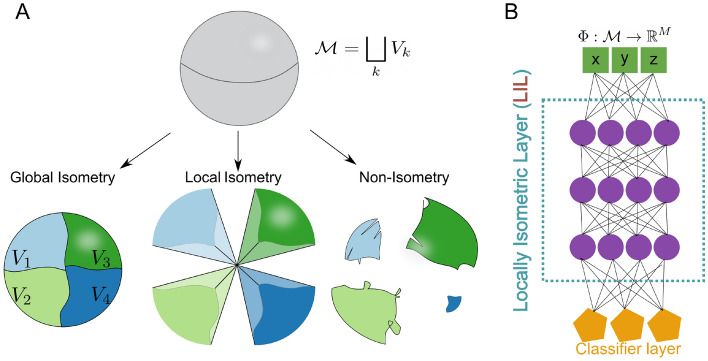 Figure 1
Figure 1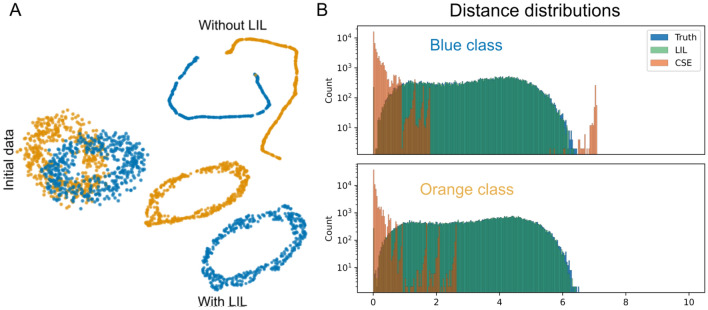 Figure 2
Figure 2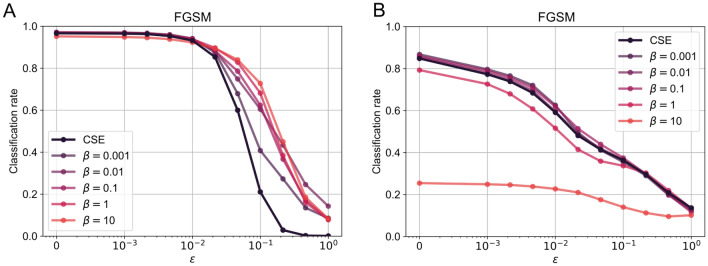 Figure 3
Figure 3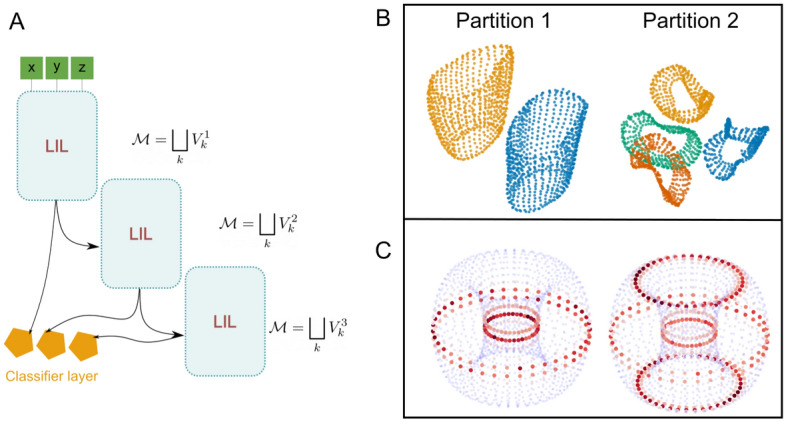 Figure 4
Figure 4- —https://doi.org/10.13039/100010665H2020 Marie Skłodowska-Curie Actions
- —https://doi.org/10.13039/501100005366Universitetet i Oslo
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdversarial Robustness in Machine Learning · Cell Image Analysis Techniques · Anomaly Detection Techniques and Applications
Introduction
Using neuroscience as an inspiration to enforce properties in machine learning has roots dating back to the birth of artificial neural networks^1,2^. One way to study natural and artificial neural networks is to look at how they transform specific structural properties of input data. The output of such a transformation is typically called a neural, or latent, representation, and it carries information about the computational role of a brain region or network layer^3–5^. Different properties of representations are helpful in different ways for both organisms and artificial agents. Some examples of this are efficient coding^6^, mixed selectivity^7^, sparse coding^8^, response normalization^9^, efficiency and smoothness^10^ and expressivity^11,12^ among others.
For example, one subsection of theories related to efficient coding proposes that neural circuits should generate discontinuous and high-dimensional representations to pack the most information possible into a network^6,13^. On the other hand, empirical results point out that neural circuits generate low dimensional smooth representations of the data^14,15^. This apparent contradiction has already been rigorously discussed in^10^. According to the work of^10^, neural circuits try to be as efficient as possible while smoothly mapping inputs. Without this smoothness constraint, infinitesimal perturbations of input stimuli could drastically change the output, thereby making such circuits non-robust to some perturbations. Given the empirical support, it seems likely for these properties to hold in early sensory systems and thus to be important for a broad class of machine learning algorithms.
Organisms seem particularly robust to random input perturbations. However, artificial models suffer from a lack of robustness to adversarial attacks^16^. One argument for why this happens can be deduced from^17^, in which the authors use a topological approach based on persistent homology^18,19^, to study the mappings realized by neural networks performing a classification task. They claim that, in classification problems, neural networks implement structure-breaking (non-homeomorphic) mappings, and as argued above, models implementing such mappings are unlikely to be robust. There are many ways to improve the robustness of a network^20–22^. Nevertheless, of particular interest to us are strategies that try to solve this problem by restricting the properties of the mapping realized by a network. Examples of this are Jacobian regularization^23^, spectral regularization^24,25^, Lipschitz continuity^26,27^, topological regularization^28^ and manifold regularization^29^ among others.
It is well known that the visual system of mammals is hierarchically structured^30^ and the features in the later regions in the ventral stream, represent more and more complex object features^31^. Thus if we follow the solution identified by evolution, representations should not only be smooth, but there also has to be some mechanism by which they can be split into hierarchies of different resolutions. Despite focusing on visual cortex, there is nothing inherently visual about hierarchically structured smooth representations, so this principle can be applied to any type of data.
Furthermore, while regularities in neural representations help with robustness, they do not necessarily guarantee that the input and output representations will have the same metric relationships, thereby reflecting the actual structure of the data. To our knowledge, there are still no methods to preserve the class metric structure while allowing for robust hierarchical classification. To achieve this behavior, we create a neural network model with, what we call, Locally Isometric Layers (LILs) and study the representations generated by training such networks. These networks are then also extended to generate representations in a hierarchical manner, which makes them helpful in performing classification at different resolutions. We train LILs on MNIST and CIFAR10, and show that the isometry condition leads to an improvement in network robustness to Fast Gradient Sign Method (FGSM) adversarial attacks. We also study toy datasets of manifolds with hierarchical structure, in which we show that such networks split them while keeping the metric structure, by cutting the manifolds around the predetermined classification boundary.
Background and methods
In this section, we summarize the mathematical background of some of the different mappings that a neural network can implement and introduce LILs. We treat both training and test data as being sampled from a manifold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {M}$$\end{document} and the neural network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {N}$$\end{document} as a set of maps \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {N} = \{f_i^l | f_i^l: \mathcal {M} \rightarrow \mathbb {R}\}$$\end{document} , with l denoting the layer and i - the index of a neuron. Another way to interpret the action of a neural network, which will become useful later on, is to define its mapping layer-wise.
Definition 2.1
A Neural Network \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {N}$$\end{document} with L layers acting on a manifold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {M}$$\end{document} is a set of functions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{F^l: \mathcal {M} \rightarrow \mathbb {R}^{n_l}\}_{l=1}^L$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n_l$$\end{document} is the number of neurons in a particular layer.
To perform classification, one usually tries to train a network to realize a particular function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Phi :\mathcal {M} \rightarrow \mathbb {R}^{n_L}$$\end{document} , which holds easily separable representations of the data. After this, a simple linear layer can be used for the final classification. This procedure requires the specification of a cost function. Here we will consider the following example:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {L}(X,T) = T\log {\sigma [\Phi (X)]}+\frac{1}{N^2}||G \odot D_{\mathcal {M}}-G \odot D_\Phi ||^2_F\ = \mathcal {L}_{CSE}+\mathcal {L}_{ISO}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X=\{x_1,...,x_N\}$$\end{document} are the inputs, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T=\{t_1,...,t_N\}$$\end{document} are the desired labels, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma$$\end{document} is the Softmax function, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$||\cdot ||_F$$\end{document} is the Frobenius norm, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\odot$$\end{document} is the Hadamard product, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_\mathcal {M}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_\Phi$$\end{document} are the distance matrices in the input and output space generated by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d(x_i,x_j)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d(\Phi (x_i),\Phi (x_j))$$\end{document} respectively and G is an indexing matrix. The distance functions can be any metric, but in this work, we stick to the Euclidean distance. Given a partition of the training set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V = \bigsqcup _k V_k, \ V_k \subset \mathcal {M}$$\end{document} , the indexing matrix G is defined in the following way:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} G(x_i,x_j)= {\left\{ \begin{array}{ll} 1 & \text {if } x_i, \, x_j \in V_k \,, \\ 0 & \text {otherwise}\,. \end{array}\right. } \end{aligned}$$\end{document}This indexing term forces the network to maintain the local distance relationships between the input points in the output layer. The metric preservation is enforced within each class separately, which helps the network find representations that are easy to classify while also preserving the relational information of the data. This second loss term works hand in hand with the first loss term, which is just the usual cross-entropy loss regularly used in classification problems and helps to separate the different classes. This procedure might seem reminiscent of a triplet loss, which is widely used in contrastive learning^32,33^. The vital difference is that instead of minimizing the distance between points in the same class, it enforces the distances between them to be the same as in the input data. As we will discuss, this approach is complementary to work based on regularizing the Lipschitz constant^34,35^ of deep neural networks and learning with local errors^36^.
In this context, it is also important to mention the work of^37^, where the authors imposed a similar metric constraint on ReLU networks to explain the emergence of localized receptive fields. However, they were not attempting to solve classification tasks and, as a result, did not adapt their loss function only to preserve metric relationships within the class. A similar loss function, without the local within-class indexing term G, is also one of the main components behind some unsupervised dimensionality reduction algorithms^38^, especially those based on multidimensional scaling. The main difference between our method from such algorithms is that they are used to project data to a low-dimensional space in which it can be visualized. Additionally, they are usually not realized by neural networks and are not used for classification.
Three types of mappings
One can describe the mappings of neural networks in many ways^39–42^, but the main property which is of interest to us is that of metric preservation. Using such a description, we end up with three types of mappings: global isometries, local isometries, and non-isometries. Visual representations of these different mappings are given in Fig. 1A. A definition of these concepts is in order.
Fig. 1(A) Visualization of the three types of mappings. (B) The architecture of a Locally Isometric layer (LIL). Green nodes correspond to an input layer, purple to hidden layers and orange to a classification layer.
Definition 2.2
Given a metric space (X, d) and a mapping \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F:X \rightarrow Y$$\end{document} . F is an isometry (i.e. preserves the metric) if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d(x,y)=d(F(x),F(y))$$\end{document} . If this property only holds locally, meaning \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d(x,y)=d(F(x),F(y))$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x,y \in V$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V \subset X$$\end{document} , we call it a local or piecewise isometry.
It is important to note that we do not restrict V to be connected as in the context of machine learning we will try to maintain distances between samples from the same class, which can be located in disconnected subsets of X. In such cases, the term within class isometry might be more appropriate than local isometry.
To get these different regimes, we can weigh the loss in the following way,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {L} = \alpha \mathcal {L}_{CSE}+\beta \mathcal {L}_{ISO}, \end{aligned}$$\end{document}with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta =0$$\end{document} , we only maintain the standard cross-entropy term and obtain discontinuous representations. For \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta >0$$\end{document} , one gets locally isometric maps. The case with global isometry can be obtained by setting \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G_{ij}=1, \ \forall {i,j}$$\end{document} since then, the isometry loss is enforced for all points independent of their class. We will refer to layers whose weights are updated with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta >0$$\end{document} as Locally Isometric Layers (LIL). As mentioned before, by partitioning the data manifold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {M}$$\end{document} into different subsets, the network enforces isometry on different local patches or at different resolutions.
Experiments
Our initial experiments were done on relatively low dimensional data so that we could use small and tractable neural networks made up of 4 layers consisting of 20 neurons with hyperbolic tangent activation functions. So for both the entangled rings and torus task, each LIL had the following feedforward architecture - [D,20,20,20,20,C], where D is the dimension of the dataset the LIL receives and C is the number of neurons in the final classifying layer. The networks in the toy datasets were trained for 10000 epochs with a batch size equal to the number of training points using the Adam optimizer^43^ in PyTorch^44^. The choice of a large batch size guarantees that each time the gradient is computed, there will be more points in the same class, and thus the distance relationships between them will contribute more to the loss. If these networks are trained solely by stochastic gradient descent with a batch size of 1, the isometric term will not contribute anything to the loss, which would be equivalent to only using the cross-entropy term.
When training on MNIST, we slightly increased the network size to 100 neurons and did not use any hierarchical structure as that is not present in the labeling of MNIST. The classification was done with a single LIL of 4 layers with 100 neurons each. We used a batch size of 100 for five epochs for the training. To test the robustness obtained by adding the isometric loss term, we trained six networks with the following \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} parameters - [0,0.001,0.01,0.1,1,10]. We performed \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_\infty$$\end{document} FGSM adversarial attacks with a step size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} varying logarithmically from 0.01 to 1. Mathematically these attacks are described by perturbing a sample x through the expression,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} x_{new} = x+\gamma \text { sgn}(\nabla _x \mathcal {L}). \end{aligned}$$\end{document}In order to train the network on CIFAR10, we started by using a pretrained vgg13 convolutional neural network, with the final classification layer removed. We then attached a single LIL with 3 layers of 1000 neurons each and only optimized its parameters. All other parameter choices were the same as the training for MNIST.
Results
Disentangling entangled data
Inspired by^17^, we generated a dataset in which the two classes take the shape of two topologically entangled rings in a 3-dimensional embedding space, which means that there is no way to separate the two without cutting one of them apart. However, the rings are not entangled in the same way in higher dimensional spaces, as one can move one of the rings in the direction of the fourth dimension, thereby putting it in a different subspace. Given that neural networks project to spaces of much higher dimension, an operation like this should be simple to implement. After training a network with LILs, we find a mapping that disentangles the two manifolds while preserving their topological structure. This solution is very different from the one achieved by only using the cross-entropy loss, where as expected, the topological structure is lost—see Fig. 2A.
Fig. 2(A): The initial dataset and UMAP projections (number of neighbors=40 and minimal distance = 0.25) of the last layer with and without LIL. Note that the exact distances might be visually exaggerated due to the non-linear nature of UMAP projections. (B): The distance distributions between the embeddings in the last hidden layer for each of the two rings, trained solely with CSE (orange) and with the isometric term included (light green).
In order to visualize the rings in the network’s last layer, we use the UMAP dimensionality reduction algorithm^45^. In addition, we show the distance distributions between the points in each ring after passing through the two networks, which heavily supports the idea that the LIL implementation manages to preserve the within-class distance relationships almost perfectly Fig. 2B. In contrast, using the cross-entropy loss results in no preservation of structure and instead brings points closer together, as indicated by the exponential shape of the orange histograms, which appears even when a log scale is used.
Isometric mappings are robust
As seen in the previous section, imposing isometry as a condition on the output layer of a neural network leads to a within-class continuous mapping. We propose that this is a result of the following properties:
Definition 3.1
A function is called K-Lipschitz continuous if there exists a constant \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K \ge 0$$\end{document} , for which \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d(F(x),F(y))\le K d(x,y)$$\end{document} .
With this definition in mind, one can see that:
Proposition 3.1
Isometric mappings are 1-Lipschitz continuous.
Proof
Given the definition of an isometry: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d(x,y)=d(F(x),F(y))$$\end{document} . Simply let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K=1+\epsilon$$\end{document} and obtain the inequality \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(1+\epsilon )d(x,y)\ge d(F(x),F(y))$$\end{document} . The smallest value for which the equality holds is 1, which is the Lipschitz constant. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\square$$\end{document}
Such a mapping has additional desirable properties like being almost everywhere differentiable due to Rademacher’s theorem^46^ and having derivatives bounded by the Lipschitz constant.
Proposition 3.2
K-Lipschitz continuous mappings have a bounded derivative.
Proof
Rearrange the inequality from the previous proposition to: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{d(F(x),F(y))}{d(x,y)} \le K$$\end{document} . Then take \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x=y+\delta$$\end{document} , this leads to the derivative \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$||\nabla F||_\infty \le K$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\square$$\end{document}
All of these properties improve robustness to adversarial attacks since they enforce the gradients of the loss with respect to the data to be bounded. To see this consider the gradient computed in a fast gradient sign method (FGSM).
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \nabla _x\mathcal {L}(x,t) = \nabla _x\alpha \mathcal {L}_{CSE}+\nabla _x\beta \mathcal {L}_{ISO}. \end{aligned}$$\end{document}By expanding these terms and applying the chain rule, we obtain the following inequality, which bounds each term of the gradient,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \alpha ||\nabla _x\mathcal {L}_{CSE}||_\infty = -\alpha \left| \left| \sum _i \frac{t}{ \sigma (\Phi (x_i))}\frac{\partial \sigma (\Phi (x_i))}{\partial \Phi (x_i)}\frac{\partial \Phi (x_i)}{\partial x}\right| \right| _\infty \le -\alpha \sum _i\frac{t}{\sigma (\Phi (x_i))}\frac{\partial \sigma (\Phi (x_i))}{\partial \Phi (x_i)}K, \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \beta ||\nabla _x\mathcal {L}_{ISO}||_\infty = \beta \left| \left| \frac{2}{N^2}\sum _{(i,j)_G}[H_{i,j}J_{i,j}-H_{i,j}J_{i,j}^\phi \nabla _x\Phi (x_i)]\right| \right| _\infty \le \frac{2\beta }{N^2}\sum _{(i,j)_G}[H_{i,j}J_{i,j}-H_{i,j}J_{i,j}^\phi K]. \end{aligned}$$\end{document}Here we have compressed our notation and redefined the distance matrix difference as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_{i,j}=d(x_i,x_j)-d(\Phi (x_i),\Phi (x_j))$$\end{document} , the difference between the mapping at two different points as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J_{i,j} = \frac{x_i-x_j}{d(x_i,x_j)}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$J^\phi _{i,j} = \frac{\Phi (x_i)-\Phi (x_j)}{d(\Phi (x_i),\Phi (x_j))}$$\end{document} . The sums go over \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(i,j)_G$$\end{document} which represents all pairs for which \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G(x_i,x_j)\ne 0$$\end{document} . To see a more detailed derivation of Eq. (6), see Appendix A.1.
Thus, by exploiting the isometric property, one can enforce neural networks to implement mappings with a bounded derivative, which is expected to improve robustness because it keeps gradients with respect to the data small.
Robustness to adversarial attacks on MNIST and CIFAR10
To show this empirically, we trained the LIL model on MNIST and CIFAR10, as described in “Experiments”. We see a stark improvement in robustness to FGSM attacks as the constant \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} controlling the importance of the isometry condition is increased. The results are shown in Fig. 3. However, this improvement does not come without a cost; see Table 1, showing that increasing the importance of isometry leads to a degradation in terms of performance. At the same time, smaller values keep the performance around the cross-entropy baseline. Thus models which perform mappings very close to isometry are much more robust, but they pay the price for that by having sub-optimal performance in the absence of perturbations. To see the impact of the isometry loss on the distance distribution we also compared the histograms of the pairwise distances of samples sharing the same labels in Fig. 1 in the appendix.
Fig. 3(A) Robustness of a LIL to an FGSM adversarial attack for MNIST. (B) Robustness to an FGSM adversarial attack on CIFAR10.
Table 1MNIST and CIFAR10 test performance as a function of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} parameter which controls to what extent the isometry property contributes to the loss.Model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} = 0 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} = 0.001 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} = 0.01 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} = 0.1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} = 1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} = 10MNIST0.9664 0.9714 0.96790.97010.96930.9517CIFAR100.84790.8593 0.8675 0.85450.79280.2542Best performing models are in [bold].
Locally isometric layers and hierarchical representations
Another way to use LILs is by model stitching^47,48^ in which the output and input layers of separate LILs are stacked together, in order to glue or cut subsets of the data manifold, as shown in Fig. 4A. The first LIL implements some function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Phi : \mathcal {M} \rightarrow \mathbb {R}^{n_L}$$\end{document} , which splits the original manifold into C submanifolds (corresponding to the number of classes) while maintaining the distances between the points. After the first split is performed, the following LIL operates on the representation already split by the previous layer, giving a new partition \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {M}=\bigsqcup _k V_k$$\end{document} . Depending on the choice of the partition, each following LIL can be used to either glue or cut out pieces of the original manifold. For the gradients not to interfere, we impose the condition that for each LIL, gradients are backpropagated only to their preceding LIL, which avoids the biologically implausible mechanism of global gradients, but this assumption can be relaxed. In this work, we also use a separate classification layer, for which we need to train the linear projection from each LIL separately.
Fig. 4(A) Stacked LILs, implementing different locally isometric maps depending on the partitioning (labeling) of the input data. Each LIL connects to a different classifier layer, represented by an orange pentagon. (B) UMAP visualizations (number of neighbors = 10, minimal distance = 1) of the representations in a classification task in hierarchically stacked LILs. (C) Saliency maps over the samples of the torus. The regions in red match the locations near which the torus has to be cut in order to separate it into the predefined classes.
In this example case, we use a stacked LIL model to look at a simple torus split into cylindrical regions Fig. 4B. We sampled 1600 points from the standard three-dimensional parametrization of the torus and added a small amount of noise \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\nu \sim \mathcal {N}(0,0.001)$$\end{document} to it. We set the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta =10$$\end{document} , which is relatively high. We used only one batch, consisting of all the sampled points from a torus. This way, the isometric condition is applied fully in all epochs. This is a rather simple example case, and the network has to perform the task by separating the different regions of the torus into locally isometric submanifolds—Fig. 4. Because, in this case, we make use of the hierarchical version of our model, the regions of the torus are partitioned with different degrees of coarseness across layers. The stacked LIL network manages to separate the classes well while maintaining a high classification rate ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$>0.99$$\end{document} ) on each level of the hierarchy. We additionally computed the saliency maps^49^ with respect to each input point, and color-coded the norm of the gradient in Fig. 4. As one can see, this gradient norm is maximized around the decision regions, reflecting the lack of isometry around decision boundaries.
Discussion
Advantages of isometric mappings
In this work, we developed a method for classification while maintaining the local metric relationships between points in the input data. This type of mapping is beneficial for the truthful representation of structural relationships in data and for improved robustness to targeted perturbations like those used in adversarial attacks. We used a Euclidean metric to represent the structural relationships between data points. However, the approach can also be extended to other metrics more suitable to the data being analyzed. In our toy dataset experiments, we show that the LIL implementation completes a classification task without destroying the local structure within each class.
At the same time, standard neural networks trained solely with cross-entropy perform non-homeomorphic mappings. This result complements the reasoning in^17^, which argues that non-homeomorphic mappings are necessary to disentangle topologically entangled data, simplifying the topology of the data and allowing for separation by hyperplanes. Using LILs, comparable classification performance is made possible while the topology and even the metric structure of the initial data manifold are preserved within each class throughout the network. From a mathematical perspective, this is expected as one can disentangle data in higher-dimensional spaces obtained with a projection of wide neural network layers.
Robustness to adversarial attacks
Our results on MNIST indicate an improvement in robustness to adversarial attacks, despite not being competitive with the state of the art (data not shown). One possible explanation for this improvement is that the isometry condition imposes a small Lipschitz constant on the function mapping data or stimuli to neural representations. This makes the derivatives of such mappings bounded. As a result, perturbation strategies that rely on computing gradients with respect to data, like those employed in FGSM and PGD, will be weaker. One might also use similar reasoning to explain the increased robustness observed when adding either smoothness or more direct Lipschitz constraints, as seen in^23,25,27–29^, among others.
On the other hand, it is unclear what the Lipschitz constant of a traditional cross-entropy trained neural network is, despite attempts to provide an estimate^26^. If such networks turned out to have an even smaller Lipschitz constant almost everywhere except at a few breaking points where the topological structure is not maintained, they would still be expected to be robust. In that case, there would have to be a different explanation for the improvement in robustness that we observe.
We also point out that using the LIL strategy with large \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} values decreases classification performance. This implies that, at least in this example case, there is a trade-off between performance and robustness. This trade-off has also been found in other work^50^ and might be a necessity or a feature of how we achieve robustness. In any case, it is an interesting problem to explore in future work.
Hierarchical splitting of representations
Finally, we have also allowed our model to take advantage of hierarchical structure in labeled data. Hierarchical classification has been attempted previously^51–54^. However, to our knowledge, this has not been done while also maintaining the local within-class structure of the data. At least intuitively, by mapping the data to the first class partition in a locally isometric manner, one guarantees that the following more fine-grained classification network will work with a truthful representation of the data. While we have not explored this intuition further in this work, we believe that this is something that would be interesting to investigate in hierarchically structured datasets like Imagenet^55^ or in many of the other publicly available and more specialized alternatives^56^ in the future. Another possible application of these concepts is in the area of dimensionality reduction and data visualization. For example, one can use hand-labeling or unsupervised hierarchical clustering algorithms to obtain plausible data labels. Given such labeling, LILs can be used to project the data to a low dimensional space in which the different classes are separated while the metric structure is maintained.
Conclusion
To summarize, we have extended the existing regularization methods by introducing a local isometry condition that keeps the structure within classes consistent across network layers. Nevertheless, such a mapping still allows for different classes to be separated, which is a necessary feature of classification. Additionally, we have explored some peculiar features of this type of regularization. For one, due to the isometry property, it is capable of continuously untying entangled data. We have also shown that in virtue of such properties, gradients with respect to the input data are bounded, which is expected to improve robustness to adversarial attacks. This is empirically demonstrated in simulations on MNIST. Finally, we propose that our LIL model can be stacked to improve hierarchical classification.
Supplementary Information
Supplementary Information.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Raghu, M., Poole, B., Kleinberg, J., Ganguli, S. & Sohl-Dickstein, J. On the expressive power of deep neural networks. In International Conference on Machine Learning 2847–2854 (PMLR, 2017).
- 2Goodfellow, I. J., Shlens, J. & Szegedy, C. Explaining and harnessing adversarial examples. ar Xiv:1412.6572 (2014).
- 3Edelsbrunner, H. & Harer, J. L. Computational Topology: An Introduction (American Mathematical Society, 2022).
- 4Madry, A., Makelov, A., Schmidt, L., Tsipras, D. & Vladu, A. Towards deep learning models resistant to adversarial attacks. ar Xiv:1706.06083 (2017).
- 5Silva, S. H. & Najafirad, P. Opportunities and challenges in deep learning adversarial robustness: a survey. ar Xiv:2007.00753 (2020).
- 6Hoffman, J., Roberts, D. A. & Yaida, S. Robust learning with jacobian regularization. ar Xiv:1908.02729 (2019).
- 7Miyato, T., Kataoka, T., Koyama, M. & Yoshida, Y. Spectral normalization for generative adversarial networks. ar Xiv:1802.05957 (2018).
- 8Nassar, J., Sokol, P. A., Chung, S., Harris, K. D. & Park, I. M. On 1/n neural representation and robustness. ar Xiv:2012.04729 [cs] (2020).