A systematic approach to classifying and evaluating heterogeneity measures
Ramona Ottow

TL;DR
This paper presents a framework to classify and evaluate different ways of measuring heterogeneity in networks, showing how each method captures unique aspects of network structure.
Contribution
The paper introduces a systematic classification of heterogeneity measures and clarifies their distinct structural interpretations.
Findings
Dispersion-based, expected-difference, and divergent measures capture different structural aspects of heterogeneity.
Graph heterogeneity measures consider global topology beyond degree counts.
Inconsistencies across measures reflect the complex nature of heterogeneity, not flaws in methodology.
Abstract
This study introduces a systematic framework for analysing heterogeneity through three principal measure classes: dispersion-based, expected-difference and divergent approaches. I demonstrate that these classes capture distinct structural aspects, with graph heterogeneity measures incorporating global topology beyond degree counts while degree-focused approaches quantify connectivity variation. Key findings establish that apparent inconsistencies across measures reflect heterogeneity’s complex nature rather than methodological flaws. The framework enables context-appropriate measure selection for applications ranging from epidemiological modelling to cyber security, while highlighting the critical distinction between degree-focused and topology-aware heterogeneity quantification. The work advances network science by mapping methodological trade-offs and proposing future development of…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
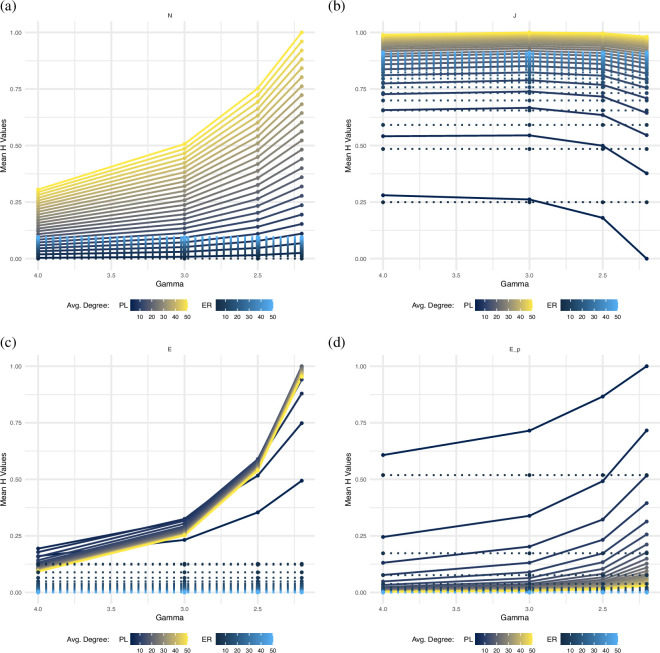 Figure 1
Figure 1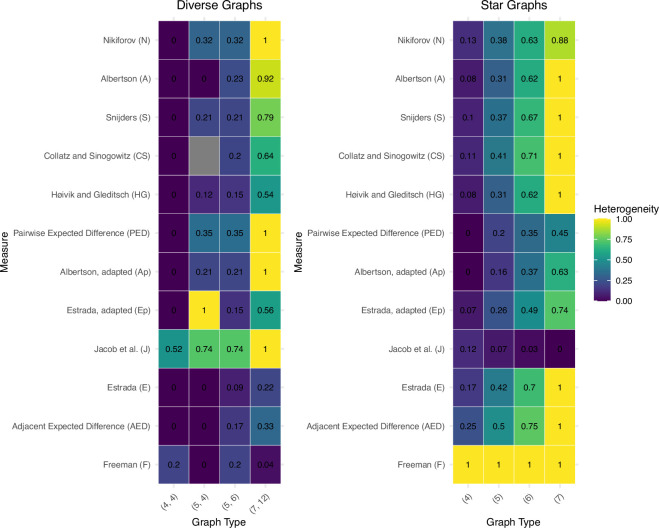 Figure 2
Figure 2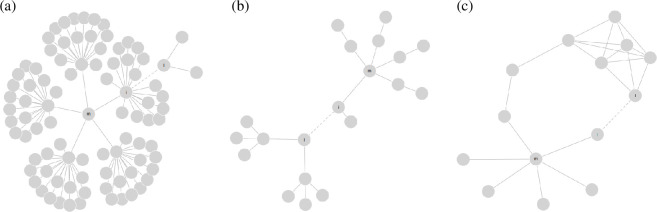 Figure 3
Figure 3|
class |
definitions (§2) |
section |
|---|---|---|
|
|
§4.1 | |
|
global |
centrality/position-based graph heterogeneity (§2.3) and degree heterogeneity (§2.1) | |
|
adjacent pairwise |
topological graph heterogeneity (§2.2) | |
|
pairwise |
degree heterogeneity (§2.1) | |
|
|
§4.2 | |
|
adjacent expected |
topological graph heterogeneity (§2.2) | |
|
pairwise expected |
degree heterogeneity (§2.1) | |
|
|
topological graph heterogeneity (§2.2) and degree heterogeneity (§2.1) |
§4.3 |
|
parameter |
ER networks |
PL networks |
details |
|---|---|---|---|
|
|
100 000 |
100 000 |
fixed for all networks |
|
|
2 to 50 |
2 to 50 |
same mean degree for ER and PL |
|
|
— |
4, 3, 2.5, 2.2 |
PL only |
|
|
100 |
100 |
per parameter setting |
|
|
2500 |
10 000 |
total: 12 250 |
|
measure class |
measure |
transfer |
addition |
replication |
|---|---|---|---|---|
|
global dispersion aggregation |
|
|
✓ |
|
|
|
✓ |
✓ |
✓ | |
|
|
|
✓ |
| |
|
|
|
✓ |
| |
|
adjacent pairwise dispersion |
|
|
✓ |
|
|
|
|
✓ |
| |
|
pairwise dispersion |
|
✓ |
✓ |
|
|
|
|
✓ |
| |
|
expected difference |
|
|
|
|
|
|
|
✓ |
| |
|
special measures |
|
|
✓ |
✓ |
|
|
|
|
|
|
measure |
before rewiring |
after rewiring |
figure reference |
|---|---|---|---|
|
|
1342.00 |
1350.00 |
|
|
|
46.30 |
46.60 |
|
|
|
15.40 |
15.50 |
|
|
|
17.6 |
17.6 |
|
|
|
15.40 |
15.70 |
|
|
|
0.38 |
0.41 |
|
|
|
1.47 |
1.70 |
|
|
|
1.47 |
1.49 |
|
|
measure |
measure type |
graph model analysis |
regular graph behaviour |
diverse-star differentiation |
principle alignment |
|---|---|---|---|---|---|
|
| |||||
|
|
degree |
differentiates ER/PL networks; weak for |
zero when degree equals mean |
moderate distinction |
complies with all three principles |
|
|
degree |
differentiates ER/PL networks; weak for low mean degrees |
zero when all degrees equal mean |
moderate distinction |
addition only |
|
|
degree |
strong differentiation of ER/PL; weak for |
zero when all degrees identical |
strong contrast; identifies stars as most heterogeneous |
addition only |
|
| |||||
|
|
graph |
differentiates ER/PL networks; weak for low mean degrees and when |
zero through identity of adjacent degree pairs |
moderate distinction |
addition only |
|
|
graph |
differentiates ER/PL networks; stable across changing mean degrees; weak for |
zero through identity of adjacent degree pairs |
strong topology contrast |
addition only |
|
| |||||
|
|
degree |
differentiates ER/PL; weak for low mean degrees |
zero when all nodes have equal degrees |
inconsistent differentiation |
addition, transfer |
|
|
degree |
differentiates ER/PL; weak for |
zero when all nodes have equal degrees |
inconsistent differentiation |
addition only |
|
| |||||
|
|
graph |
differentiates ER/PL networks; weak for |
zero from equal adjacent degrees |
strong topology contrast |
one |
|
|
degree |
differentiates ER/PL; weak for low mean degrees |
zero when degree distribution uniform |
inconsistent differentiation |
addition only |
|
| |||||
|
|
degree |
inconsistent differentiation; often reverses expected rankings |
zero through uniform degree distribution |
strong topology contrast; identifies stars as homogeneous |
addition, replication |
|
|
graph |
differentiates ER/PL networks; weak for |
zero when graph is regular (spectral property) |
moderate distinction |
none |
- —H2020 European Research Councilhttp://dx.doi.org/10.13039/100010663
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsComplex Network Analysis Techniques · Opinion Dynamics and Social Influence · Mental Health Research Topics
Introduction: heterogeneity in networks
Heterogeneity is a key concept in network science, but there is a lack of clarity and consensus in the literature as to how to define and quantify it. An important difference is the distinction between graph heterogeneity, which looks at the overall structural differences and irregularities in the whole network, and degree heterogeneity, which specifically examines the variability in the number of connections each node has. Based on many existing measures, the level of heterogeneity affects the dynamics of disease spread on social contact networks, the robustness to attacks on computer networks and the stability of ecological systems [1–3]. The scientific areas in which the concept is used are as diverse as the definitions and approaches to measure it. Networks with degrees that follow a Poisson distribution are often characterized as homogeneous, and ones that follow a power-law (PL) distribution as heterogeneous. However, depending on the chosen heterogeneity measure, there exist cases in which networks of each kind have the same heterogeneity value [4]. So far, there have been efforts to compare commonly used measures and derive bounds [5–8], but a comprehensive up-to-date overview, categorization and evaluation of degree and graph heterogeneity definitions, measures and demands is missing. Filling this gap is important to provide guidance and consistency to researchers when choosing the appropriate heterogeneity measure for their work and thus improving predictions in epidemiology, computer security, ecology and many other fields.
In this work, I start by collecting common definitions of graph and degree heterogeneity and show that they can be grouped into three main categories: (1) degree heterogeneity; (2) topological graph heterogeneity; and (3) centrality and position-based graph heterogeneity.
I further provide an overview of the diverse criteria and requirements that researchers place on the measures. These can be grouped into: (i) general properties, like aiming for a measure that is a single, unique value; (ii) local topological properties, focusing on incorporation of local information, like differences in neighbouring degrees; (iii) global properties, which deal mainly with claims that the measures should recognize specific types of networks as hetero- or homogeneous; and (iv) properties related to the behaviour of the measure to manipulation of the network, like rewiring of edges.
I classify the existing heterogeneity quantitative measures conceptually into three classes. The first class comprises dispersion-based approaches, which mainly consider heterogeneity as the deviation from regularity or variation within the set of degrees, and aggregate degree differences. The second comprises expected-difference-based approaches, which are inspired by the Gini coefficient and use the expected absolute difference in degrees as the underlying concept to measure heterogeneity. The third class comprises divergent approaches, which take a completely different approach.
Finally, I systematically evaluate and discuss each class accordingly to the desired properties. I provide analytical proofs where possible, with general conditions outlined otherwise. In cases, where measures do not fulfil properties, I present counter-examples for specific measures. Additionally, I use simulations to explore properties related to random graph models, also for specific measures. This discussion and explanation of reasons behind breaches or compliance with requirements can enhance the understanding of measures and their real-world applicability.
Challenges in measurement development
1.1.
Four main challenges can be identified in the literature regarding heterogeneity in networks. The most fundamental is the definition of heterogeneity itself. At the moment there exist many different understandings of homogeneity and heterogeneity, not only between different fields of study, but also within the same [4,9,10]. Some definitions have a node-level perspective, focusing on degree variability. Others take a network-level perspective, focusing on the shape of the degree distribution, structural properties like connection patterns, regularity or topology of the network. These different ways of understanding heterogeneity can lead to errors and difficulties in the development and application of heterogeneity measures. For instance, if it is understood that heterogeneity is not only based on node degrees, but should also consider the associated topological structure, selecting a measure that accounts exclusively for degrees may lead to inaccuracies. Certain measures yield identical values for networks with identical degree distributions but different topologies. Consequently, this mismatch can lead to incorrect predictions about how information or diseases spread, since these processes often depend on more than just the number of connections [11]. It is important to distinguish between degree heterogeneity, a concept that focuses on the degree variability, and graph heterogeneity, which focuses on more broader structural features.
The second problem concerns translation from definition to quantification. The measure needs to actually capture what is intended, while ensuring that measures align with the definition. For example, if a graph is defined as heterogeneous based on the existence of nodes with significantly larger degree than the average degree of the network, the developed measure must capture this property. The definition should be correctly translated to the formula for the measure.
The third problem is the kind of quantification of heterogeneity. There are different approaches that call their developed formula an index, indicator, measure, metric or score [4,9,10,12]. The clarification and verification of the definition is often missing, so that it is not clear if, for example, a developed ‘measure’ is indeed a measure in the mathematical (non-negativity, -additivity, etc.) or colloquial sense. For example, a statistical index is a statistic that combines several indicators or variables to a single values, like the Human Development Index, with the aim of simplifying and summarizing complex issues. On the other hand, mathematical metrics are used to quantify distances or dissimilarities between elements, for example distances between places in route planning.
The fourth challenge concerns the desirable properties. It is not clear what desired or necessary properties a measure should actually have. In a few works on heterogeneity measures are the minimum value set to zero and defined as homogeneity, but the maximal value is unknown or missing. For example, in [13] the measure yields zero for regular graphs, which are assumed to be homogeneous. All networks with non-zero values are heterogeneous. On the one hand this dichotomous assignment is very simple but on the other hand, it becomes impossible to rank networks according to how heterogeneous they are. Exceptional contributions to this area include the work of [14] and [6], which provide valuable properties by examining measures for various graph classes and determining their extreme values, while [7] makes a significant contribution by developing fundamental principles that heterogeneity measures should ideally satisfy.
Notation
1.2.
In this section, I introduce the basic symbols and notation that I will use throughout the rest of the article.
Given a finite undirected graph (or network) with no loops and multiple edges and nodes and edges. is called the density of and is the largest (or dominant) eigenvalue of the graph’s adjacency matrix.
The number of incident edges of a node is called its degree . The mean degree of the graph is denoted as and the set of all node degrees by . The degrees are distributed according to the degree distribution , where is the number of nodes with degree .
A graph is called an -regular graph if all nodes have the same degree and a star graph consists of one central node and all other nodes of the network are only connected to that central node. Diverse graphs, on the other hand, are characterized by a broad node degree distribution, indicating that the nodes have a wide range of degrees rather than a single dominant hub [10]. A completely diverse graph is defined as a diverse graph with only one non-unique degree value.
In this paper, I refer to any formula that aims to quantify graph or degree heterogeneity as ‘measure’ without strict compliance to the mathematical definition of a measure in measure theory.
Definitions of heterogeneity
In the literature, heterogeneity is described using a wide range of definitions, which I group into two distinct, but related concepts: degree heterogeneity and graph heterogeneity.
Degree heterogeneity is commonly conceptualized as the dispersion or diversity in degrees, capturing the range and variety of degrees of a network (presented in §2.1).
Graph heterogeneity, on the other hand, is conceptualized from two main perspectives: first, a topological-based approach that focuses on irregularities not only in degrees, but also includes local information on degree disparities (presented in §2.2); and second, a centrality and position-based approach that emphasizes the position of nodes within a network (presented in §2.3).
The following sections present the different definitions found in the literature.
Degree heterogeneity
2.1.
This set of definitions characterizes heterogeneity by degree variation and is grounded in three concepts: inequality, dispersion/diversity and irregularity.
Hu & Wang [4] define heterogeneity as inequality in node degrees, corresponding to the idea of income inequality in economics. It is commonly quantified using the Lorenz curve and Gini coefficient, which are classical tools for assessing distributional inequality [15]. This aligns with [7], who emphasize that heterogeneity corresponds to distributional inequality, requiring heterogeneity measures to consistently reflect changes in the equality/inequality of a distribution.
A second approach to define degree heterogeneity focuses on spread and diversity in connectivity. Snijders [16] defines degree heterogeneity through dispersion of the degrees, measured by the degree variance, where greater dispersion in node degrees corresponds to higher heterogeneity.
Liu et al. [17] emphasize the disparity between low- and high-degree nodes in network controllability. They hypothesize that high degree nodes have an important role in many processes on networks, such as the stability of networks, the diffusion on networks, etc., and controlling these therefore must be a crucial part in controlling the network. Liu et al. [17] are interested in the relationship between the cardinality of the set of driver nodes, which are those nodes that can direct network dynamics, and high degree nodes and they find that driver nodes typically are not high degree nodes. They define heterogeneity as the disparity in connectivity between these groups.
A distinct angle is introduced by [10], who differentiate between dispersion and diversity of node degrees. As an example, one can consider the degrees of a star network to have high dispersion because the degree range is high, but since only two different degrees exist, the diversity in degrees is low.
A third perspective, rooted in graph theory, defines degree heterogeneity through the concept of Abweichung von der Regularität (German for ‘deviation from regularity’). Von Collatz & Sinogowitz [13] derive bounds for the largest eigenvalue for finite, connected graphs. They find that the mean degree is smaller or equal to the largest eigenvalue while equality holds if and only if the graph is regular. They propose the difference between these values as a measure of irregularity, called Defekt (German for ‘defect’), which clearly has a lower bound of zero for regular graphs. Many following research adopt this view considering irregularity, i.e. a deviation from regularity as one aspect of heterogeneity [6,7,18].
Topological graph heterogeneity
2.2.
While §2.1 examines heterogeneity through node degree distributions, the following definition focuses additionally on structural irregularities arising from topological relationships, emphasizing how edges and node neighbourhoods collectively shape structural irregularities.
Estrada [18] defines graph heterogeneity as deviations arising from both the degree distribution (e.g. hubs in scale-free networks), and local edge configurations (e.g. hubs linked to low-degree versus high-degree nodes). This dual perspective captures a ‘higher-order’ heterogeneity: two networks with identical degree distributions can exhibit distinct graph heterogeneity levels depending on edge arrangements.
Centrality and position-based graph heterogeneity
2.3.
The second group of graph heterogeneity definitions is based on the idea of centrality and node positions. Bavelas [19] works on the problem of communication in team-work, in particular on the communication pattern and the effect on the group’s performance. They define the distance between group members as the minimum number of other members in the communication path between both, plus one. They assume that this distance as well as the communication structure between all group members, with respect to distance, is related to the communication performance between them and within the group. The closer, that is the smaller the number of other members in the communication path, a person is to one or more colleagues, the better the communication and the more central is this person. The more distant all workers are from each other, the more complex and heterogeneous is the network. Therefore, Bavelas [19] defines heterogeneity based on node positions.
Although the author’s work is not about structural or degree variations in a network, I include it in this work, because it is the first definition on which many centralization measures are based. One example of these subsequent measures is the work of [14]. They approach the topic from the perspective of social science theory and formalize their ideas of social structure on integration, polarization and centralization through graphs and graph theory. First, they define node centrality based on position in the network (central or peripheral) and define graph heterogeneity as the disparity between central and peripheral nodes (centralization). A graph is called heterogeneous (centralized) if there are great differences in the node positions.
The next definition in this line of work is the commonly used Freeman centrality measure from 1978 [20]. Building upon the foundational work of [19] and [14], [20] similarly defines heterogeneity based on the position or centrality of nodes in relation to the most central node. They define heterogeneity as the centralization of a network—the extent to which the most central node tends to be more central than all other nodes in the network. This approach aligns with numerous other studies in social network communication [21–25].
The next definition in this line of work is the commonly used Freeman centrality measure from 1978 [20]. Like [19] and [14], as well as many others coming from communication in social networks [20–25] define heterogeneity based on the position or centrality of nodes in relation to the most central node. They define heterogeneity as the centralization of a network—the extent to which the most central node tends to be more central than all other nodes in the network.
Finally, [12] follows the centrality-based definitions of [20], but their work leads to a new perspective. Butts [12] extends Freeman’s work and finds that heterogeneity in a network, considering the network’s density and size, is reflected by the excess maximum degree over and above its minimal possible value in relation to the maximal possible excess.
Centrality and position-based definitions concern graph heterogeneity and focus on structural properties in relation to the node’s positions within the network and aim to capture properties, like diversity in communication paths or node roles.
Desirable and necessary measure properties
This section provides an overview of the properties that researchers deem desirable or necessary in formulating their proposed heterogeneity measures. This includes properties of obtaining extreme measurement values for specific graphs, but I do not include research on finding their bounds here. I also omit discussion of properties that are based on specific applications, as it is beyond the scope of this article.
Section 3.1 describes general properties, §3.2 describes local properties, mainly those focusing on relationships between degrees, §3.3 describes global properties, which mainly connect demands to specific graphs or random graph models, and §3.4 describes properties of how heterogeneity measures should behave in case of changes in the input network.
General properties
3.1.
A graph heterogeneity measure should quantify the graph’s heterogeneity [18], be a single, unique parameter or value [18,26] and be interpretable [12,20]. The measure should furthermore allow the comparison between a variety of networks and be applicable to different network types [7]. In particular, the requirement of independence of degree distribution is widely demanded for both graph [4,26] and degree heterogeneity measures [10]. The measure should enable the comparison of networks with entirely different degree distributions and be applicable to networks that can fit various degree distribution models [18].
Local topology properties
3.2.
Local topological properties on heterogeneity measures focus on the relationship between node degrees rather than the global topology of the network. The most common criteria concerning these relationships can be organized into two distinct groups. The first group requires that a graph heterogeneity measure should account for the extent to which the highest degree or a group of high-degree nodes exceeds all others [12,20]. The second group demands that a heterogeneity measure should capture differences in degrees between nodes—whether local or global, weighted or relative [16,18,20].
Global properties
3.3.
Global properties concern the behaviour of measures for specific graphs or topologies. In terms of graph heterogeneity, the measure should increase from lowest values for regular graphs (considered as homogeneous) to Erdős–Rényi (ER) networks to scale-free networks (PL) with decreasing degree exponent (considered as heterogeneous) [17,18,26]. This corresponds to the claims of [18,26] that regular graphs are homogeneous while star-like graphs are heterogeneous.
By contrast, when considering degree heterogeneity, a different approach is proposed by [10]. They argue that a degree heterogeneity measure should reach its maximum for networks where all nodes except one have distinct degrees, with only two nodes sharing the same degree. This alternative view emphasizes capturing the diversity of node degrees, focusing on the variety of different degrees present in a network.
Behaviour to manipulation
3.4.
The final group of properties stated by researchers considers the response of measures to small changes in the network. Badham [7] developed three principles that they require. The transfer principle states that the heterogeneity measure should decrease when an edge from a given node is rewired from a higher-degree node to another node with a lower degree, without reversing their degree order. This principle reflects the idea that such a change reduces the disparity in node degrees within the network, thereby lowering its overall heterogeneity. The addition principle considers the situation in which all node degrees are increased by the same amount. It claims that either the heterogeneity measure does not change, which would be the case for measures based on variation about the mean or absolute differences, or that the measure decreases, which is the case for relative measures [7]. The third principle is called the replication principle. Badham [7] claims for global and local measures to be the same for replications of the network (integer multiple or a non-inter multiple), independent of the number of replications. For instance, for a given network with a specific degree distribution, one could create a second network that consists of two components, where each component is the initial network. This new network has twice the amount of each degree of the initial network, but the degree distribution is the same. The principle claims that for the initial and for the replicated (here doubled) network, the measures should be the same. In case of non-integer replication, the problem arises that the number of node degrees in the new network might be non-integer. This is solved by scaling all counts with the smallest value that ensures an integer count.
Classification of existing measures
In this section, I introduce three main classes of heterogeneity measures. This classification is based on the general mathematical formulas that group measures according to their construction methods, rather than the definitions from §2.
The first class, dispersion aggregation (§4.1), includes three variants: global (deviations from a network statistic), adjacent pairwise (differences between neighbouring nodes), and pairwise (differences between all node pairs). The second class, expected difference (§4.2), comprises measures based on the expected degree differences, inspired by the Gini coefficient, with adjacent pairwise and pairwise variants. The third class, special approaches (§4.3), covers unique formulations not included in the previous classes.
Table 1 summarizes how these classes relate to the definitions introduced earlier. The following subsections provide a detailed presentation of each class.
Dispersion aggregation
4.1.
This section contains three subclasses. The first class in §4.1.1 focuses on measures that concerns degree heterogeneity as a deviation from or in relation to a network statistic. The second and third classes (§4.1.2 and §4.1.3) address measures by aggregating local differences in node degrees, either by adjacent (graph heterogeneity) or across all pairs of nodes (degree heterogeneity).
Global dispersion aggregation
4.1.1.
Measures in this class consider degree heterogeneity as the deviation of all degrees from a specific network statistic of interest, like the maximum or mean degree. These measures can be described by the general formula:
where is a scaling factor, for example the inverse of the number of nodes, a convex function with global minimum at zero, usually square or absolute value, and a constant function of the node degrees, representing the statistic of interest, like the maximum or average. Employing a convex function with minimum value obtained at zero gives less weight to differences that are small and higher weight to larger differences.
4.1.1.1. Statistic of interest: maximum degree
Approaches falling under this group are among the first that researchers developed to measure graph heterogeneity in networks. Reference [19] and in particular [14] introduce the concept of centrality and centralization (compare definitions in §2.3, which attracted a lot of attention and advancement over following years [27–29]). The idea is that each node has a specific centrality property that measures its position within the network ranging from ‘not central’, peripheral to most central, or important. Centralization then refers to their dispersion throughout the global network topology in relation to the most central node. Centralization is an aggregate of the local centralities that measures to what extent node centralities differ from the most central node. Network topologies that show a large value and therefore are considered as centralized are said to be heterogeneous and those with a smaller value homogeneous.
Bavelas [19] defines the centrality of a node as the sum of all distances from that node to all others. Their work initiated the development of many other ways to define the centrality of a node in a network and therefore as well the ways to define centralization of a whole network [14,20].
One of these is the work of [14]. Like [19] they start with a distance-based view on centrality, but adapt it to a degree-based, which means that the centrality of a node is defined by the node degree. As a result, the developed measure captures degree heterogeneity rather than overall graph heterogeneity. The measure quantifies how dispersed the node positions (whether peripheral or central) are, relative to the most central node in the graph.
They define the degree of a node as measure of local centrality (degree) of the node and the degree-based centralization measure as the sum over all differences in node centrality to the most central node:
Note that this expression appears in the general formula (4.1) having a scaling parameter , negative identity function and the maximum function .
The smaller this sum, the more similar the nodes in the network are to the most central node, and the more homogeneous the degrees become. Conversely, the larger the sum, the more nodes differ in centrality from the most central node, meaning that a higher dispersion in node centralities is interpreted as indicating higher heterogeneity in degrees.
Freeman [20] derived their measure from a local view of centrality to a global one. They start deriving three possible local centrality measures from the star graph—since, in their view, the star graph represents an extreme example of a heterogeneous network—and then derive requirements on their graph heterogeneity measure. The middle node in a star graph is unique and special (most central) because of three reasons. First, it has the highest attainable degree (degree-centrality). Second, it lies along the shortest route connecting the greatest number of node pairs (betweenness-centrality). Third, it is close with respect to distance to all other nodes (closeness-centrality). For each of these three local centralities, [20] create a global measure. They require that the global measure both (i) quantifies how much more important the most central node is compared with all other nodes, and (ii) is expressed as a ratio relative to its maximum possible value so that it attains its extreme values in the most extreme cases. For the degree centrality the degree heterogeneity measure by [20] is:
The measure is therefore a scaled version of the Høivik & Gleditsch [14] measure with scaling factor , which is the smallest total difference for a graph with points, no matter how many connections it has. They concluded that the maximum sum in the denominator is reached for a star or wheel graph with value . Furthermore, in case of a five star node [20] prove that the measure is maximal for star or wheel graphs, minimal for circle or complete graphs, but also show that between these extremes are remarkable differences.
The most recent approach by [12] renormalizes the Freeman [20] centrality and achieves a relative measure for fixed density and graph size that measures the excess maximum degree over the minimal possible maximum degree. The reason is that there is only a feasible area for centralization scores, given a density and size of a network, for example owing to combinatorial reasons. Therefore it is necessary, that if one normalizes the measure, one should take the bounds of that area into account, so that the measure is better interpretable and useful. Butts [12] reformulated the Freeman [20] formula, depending on maximum degree and density and uses an affine transformation for normalizing it. They derive and employ bounds on the maximum degree, depending on the density, to create a density-normalized centralization score from the reformulated score:
The reformulation yields a degree heterogeneity measure between values of for extreme cases like the null or complete graph, and , the maximum value. The advantage of the new measure is the normalization with respect to feasible bounds, given density and network size.
The second large subgroup base their definition of heterogeneity on the deviation of the node degrees from the mean degree in a network as described in the next paragraph. Those measures only concern degree heterogeneity.
4.1.1.2. Statistic of interest: mean degree
Another concept is to measure the deviation from the mean degree as a representation of the degree heterogeneity in a graph. The higher the dispersion, the more heterogeneous the degrees. Snijders [16] favours this approach, because it considers not only the differences in relation to one most central node, but differences in all degree pairs. In particular, in real-world networks there can be not only more than one peripheral node, but also more than one central node, not to mention the nodes between the central and peripheral node(s). Therefore, Snijders [16] suggests the commonly used variance of degrees to measure degree heterogeneity or dispersion, in particular along with the graph density as an equivalent to mean and variance as descriptive statistics for numerical data. The measure is:
Here, the scaling constant is simply , the square function and the mean function . Like the previous approaches, Snijders [16] provides normalized versions with respect to null models and maximal possible values. The heterogeneity measure normalized with respect to the maximum value is defined as:
The minimum value of this measure is clearly zero in case of a regular graph. Snijders [16] shows that the other extreme is reached in case of graphs that consist of a group of central nodes, a group of peripheral nodes and one in between node, where [16] derive the sizes of each group so that the maximum variance is reached.
The most important advantage is that it captures if more than one node is central, unlike the Freeman [20] approach where only the most central node is considered. Furthermore, the usage of the mean as the statistic of interest has the advantage that the measure accounts for the existence of more than one high degree node, contrary to the case where only the most central node, respectively the node with the highest degree, is used as the reference point. The most important disadvantage is that, as all degree heterogeneity measures, it can fail to capture structural variations in a network owing to the focus on degree variability.
In general, similar versions of equation (4.8) are possible that capture the dispersion of the degrees [16]. For all on monotonically non-decreasing convex functions [16] suggest as general measures:
The last measure of this group, also a degree heterogeneity measure, was developed by [6] and captures the extent to which individual node degrees deviate from the mean degree. It quantifies heterogeneity by summing the absolute differences between each node degree and the average degree of the graph:
Therefore, the scaling parameter is , the function is the absolute value function and is the mean function. They mainly focus in their work on finding and exploring the tightness of upper and lower bounds for different classes of graphs. In particular, they consider star and complete bipartite graphs.
Adjacent pairwise dispersion aggregation
4.1.2.
The next class measures graph heterogeneity by aggregating pairwise degree differences of connected nodes:
where again is a scaling factor and a convex function with minimum obtained in zero for emphasizing larger differences and down-weight smaller ones. Here, is a function of the node degrees, which usage can additionally account for relative differences between node degrees. That means a fixed difference of amount between two small degree nodes is accounted for differently than the same difference of between two high degree nodes, when for example choosing
This group contains the widely known Albertson graph heterogeneity measure [30]. The idea of [30] is that local heterogeneities (called ‘edge imbalance’) can be aggregated to create an overall heterogeneity measure, the ‘graph irregularity’, for the whole graph. They sum the local heterogeneity, measured as absolute differences in degrees between a pair of nodes, to an overall measure:
where the scaling factor is constant , the convex function equals the absolute value function and the node degree function is the identity function.
The smallest value of is reached if all nodes have the same degree, which is the case for a regular graph. Estrada [18] says that the measure reaches its highest value for a certain type of complex graph. This graph is made up of three parts: first, a closely connected group of points, second, a group of points where none are connected, and third, some connections between a point in the first group and a point in the second group [31].
Jacob et al. [10] point out that the aggregation of all differences does not account for differences in topologies in networks. In particular, the maximum value of the measure is not always reached for star graphs as desired by some researchers [13,18].
Another possible disadvantage of the measure is that it is only meaningfully applicable to connected graphs and it does not fulfil the definition of an irregularity measure [9]. In case of an unconnected graph with regular components the measure assigns the value zero, independent of the actual variety or uniformity of the degree value in each component. Boaventura-Netto [9] tackles the problem and derives an extended measure of the Albertson measure, that includes an additional correction parameter . The proposed measure enables the assignment of a non-zero value to graphs that consist of regular, disconnected subgraphs.
The second graph heterogeneity measure in the class of adjacent pairwise dispersion aggregation approaches was developed by [18] and captures, like the Albertson measure, local discrepancies in degrees. They conclude that in heterogeneous networks nodes with high degrees must exist, which further must be connected to low degree nodes, including therefore an topological aspect in their approach. They construct a local measure of irregularity on individual edges and then aggregating these measures to obtain a measure for the entire network. They define local irregularity on edges as with and build their measure through aggregation of the local, relative irregularities on edges:
Here, the scaling factor again equals , the convex function corresponds to the square function and the node degree function is the inverse of the square root. Although the authors point out that any function can be chosen for , they opt for the inverse of the square root as it allows them to express the measure using the quadratic form of the network’s Laplacian matrix and further to the Randić Index [18].
The authors consider graphs that have a Poissonian degree distribution as almost regular, since the degrees are close to the average degree (in regular graphs all degrees correspond to the average degree) [18]. Contrary to this, they consider graphs with scale-free degree distribution that show a high probability for degrees that are very different (higher) than the mean degree as heterogeneous, because they show a higher deviation of the degrees from the mean degree. Based on these assumption the extremal cases for the measure are regular graphs for the minimum and star-like graphs for the maximum value. The normalized version with respect to the bounds for star-like and regular, connected graphs of their measure is:
which leads to a graph heterogeneity measure with values between (homogeneous) and (heterogeneous).
One advantage is that this measure is independent of the degree distribution and a comparison of graph heterogeneity values between networks with different degree distributions is possible. Moreover, the usage of the Randić Index enables the spectral representation and projection that reflects the different heterogeneity values in networks following the ER and Barabási–Albert (BA) model.
Pairwise dispersion aggregation
4.1.3.
The next class measures degree heterogeneity by aggregating pairwise degree differences of all nodes:
Again, is a scaling factor and a convex function with minimum obtained in zero for emphasizing larger differences and down-weight smaller ones. is a function of the node degrees, which usage can additionally account for relative differences between node degrees. That means a fixed difference of amount between two small degree nodes is accounted for differently than the same difference of between two high degree nodes, when for example choosing
The main difference between this measure and adjacent pairwise dispersion aggregation measures in §4.1.2 is that the latter considers degree differences only between connected nodes, capturing local topological irregularities and neighbourhood structure. By contrast, the global pairwise measure considers all node pairs, reflecting the overall degree distribution without local connectivity information. Thus, the adjacent pairwise version is a graph heterogeneity measure, able to capture clustering and local patterns, while the global pairwise version is a degree heterogeneity measure focused on degree variability across the entire network.
For example, in a uniformly connected network where all nodes share similar connectivity, both the degree differences between neighbouring nodes and those computed across all node pairs remain small. By contrast, in a network with an uneven topology, with dense clusters and sparsely connected regions, the global measure of degree differences over all nodes is high because it reflects the wide range of connectivity across the entire graph. However, within the dense clusters, neighbouring nodes tend to all have high degrees, so the local degree differences remain small within those regions.
Thus I define the adapted Albertson and Estrada measure (equations (4.14)—(4.15)) accordingly:
and
Expected difference
4.2.
The approaches in this class transfer the idea of the Gini coefficient from economics to measure heterogeneity in networks. Researchers adopt the approach to network degrees and define heterogeneity as the inequality of degrees. Gini developed several versions of the coefficient to measure income inequality [32]. Most commonly known is the version visualizable by the Lorenz curve, which displays on the x-axis the cumulative proportion of people from lowest to highest income and on the y-axis the cumulative proportion of income earned [15]. In case of absolute equality the curve corresponds to the bisectrix of the first quadrant. The higher the inequality, the more it falls below the bisectrix. The Gini coefficient is defined as the ratio between the area between the bisectrix and the Lorenz curve, divided by the complete area between the bisectrix and the x-axis [15]. This ratio is a value between , the case of absolute equality (homogeneity), and , the other extreme of absolute inequality (heterogeneity).
The value can be calculated as one half of the relative mean difference, which is one half of the expected value of the absolute difference of two discrete, identically and independently distributed random variables with discrete uniform probability distribution , scaled by the inverse of the mean.
There are two subclasses: adjacent expected difference (AED; §4.2.1) and pairwise expected difference (PED; §4.2.2). In AED, the expected value of absolute degree differences is computed only for neighbouring nodes, while in PED, it is calculated for all possible node pairs. Both approaches capture the variability of network structure similarly to the adapted Albertson (cf. equation (4.21) ) and adapted Estrada measures (cf. equation (4.22)). AED aggregates local degree differences among adjacent nodes, capturing consistent connectivity patterns within clusters (graph heterogeneity), whereas PED aggregates differences across all node pairs, reflecting overall network variability (degree heterogeneity).
Adjacent expected difference
4.2.1.
In this class, assumptions are as follows: first, the degree of a node is determined by the number of incident edges; and second, the degrees of two adjacent nodes are interdependent. Therefore, the degrees are conditional on the edges. Consequently, the distribution is a conditional distribution based on the network’s structure and edge dependencies. This distribution is estimated from the network data and typically does not result in a uniform distribution.
The general formula for the graph heterogeneity measure in this class is:
with the conditional distribution being the probability that a randomly chosen existing edge connects nodes with degree and , conditioned on the edge existing.
Pairwise expected difference
4.2.2.
Measures in this class assume that the degrees of nodes are independent of the edges. They calculate the expected absolute difference in degrees between any pairs of nodes by using the product of the degree probabilities, without considering any edges. This means that the probability distribution is assumed to be marginal, meaning it considers the degree distribution across all nodes, instead of being dependent on specific edges as the AED approach in §4.2.1.
The general formula for the degree heterogeneity measures in this class is the expected absolute difference in degrees between two randomly chosen nodes and :
where the degrees are realizations of random variables , that are assumed to be independently and identically distributed with expected value . The sum simply is the expected value of the absolute difference: , also named as mean absolute difference. In case of it is called relative expected value, or relative mean absolute difference.
The first of the two degree heterogeneity measures in this class is developed by [4] who comments that connecting the definition of heterogeneity only to ER and PL networks, like BA networks, is not sufficient. They develop a measure that is independent of the underlying theoretical distribution of a network. They choose to measure the inequality of degrees in a network by adapting the idea of the Lorenz curve and Gini coefficient, because it enables the independence from the degree distribution and the comparability of heterogeneity between networks with different theoretical distributions.
The measure by [4] is defined as of the relative mean absolute difference of the degrees with discrete uniform distribution :
This measure represents the mean inequality of connections within a network. The value ranges from to and the larger the value, the more heterogeneous the degrees. The authors show that is an upper bound for exponential networks and that the value is between and for networks whose degree distribution follow an infinite PL if and only if the degree exponent is between and . Their findings demonstrate that for every network characterized by a degree distribution adhering to a PL with a degree exponent exceeding , there exists an alternative network with an exponential degree distribution that shares the same value.
Consequently linkage between the network model (ER and BA) and the heterogeneity measure is ambiguous. Even so, the measure is applicable for networks independently of their degree distribution and additionally does not require similar network statistics, like other measures when comparing different networks (for example equation (4.8) requires the same mean degree).
The second degree heterogeneity measure in this class was developed by [17]. They view homo- and heterogeneity as the range between low and high degree nodes. They are coming from the area of network controllability and hypothesize as well as test, if high degree nodes (so called hubs) have an important role for the stability of and diffusion on networks, and therefore controlling those hubs is an important part of controlling the network. Their measure is defined as the relative mean absolute difference with discrete probability distribution :
equals zero in networks where all nodes have the same degree, e.g. random regular digraph (in- and out-degrees are fixed to , nodes connected randomly). The value increases in order from random regular networks, over networks following the ER model, to PL networks with decreasing degree exponent. One disadvantage is mentioned by [26], who claims that the measure fails to connect large Cayley graphs with high degrees to heterogeneity.
Special heterogeneity measures
4.3.
One of the first graph heterogeneity measures was introduced by [13] in their work on spectra of finite graphs. They define heterogeneity as the deviation from regularity and call it defect. This measure qualifies as a graph heterogeneity measure rather than merely a degree heterogeneity measure because it uses spectral properties (the largest eigenvalue) that capture topological information about the network structure and relationships between connected nodes, not just the degree distribution. They derive bounds for the mean degree and largest eigenvalue of a finite, connected network and find that a network is regular if and only if the mean degree equals the largest eigenvalue. That leads to the measure:
which obtains a value of zero for regular graphs and is maximum value for star graphs (up to five nodes [13]) and several other families of graphs [33].
Another measure that does not fit the classification of above, but is worth including is developed by [10]. They define degree heterogeneity as the diversity of node degrees and not their dispersion, and in particular they are not interested in diversity of the network structure. The more different degree values exist, the more heterogeneous the degrees. This leads to different extreme cases of the measure. The star network, typically labelled as having the most heterogeneous degree distribution, is classified as homogeneous in [10], since the diversity in degrees is low (only two different degree values). The network with the most heterogeneous degree distribution is here one of nodes where all nodes, but one, have a different degree value. They define the degree heterogeneity measure as:
In case of completely homogeneous degrees, the measure has a value of zero and in case of complete heterogeneity, that is every possible degree exists once, the value is , which can be approximated by for large networks. With these bounds they define the normalized measure with respect to complete heterogeneity in a network with the same number of nodes as:
The biggest advantage is that only knowledge about the degree distribution of the network is necessary for this measure. Furthermore, the measure can be calculated for any type of degree distribution or network structure and in case of the normalized measure a comparison of the heterogeneity of even differently sized large networks is possible. A disadvantage of the measures that only consider the degree sequence is that it is insensitive to changes in topologies, under the fixed degree sequence. Therefore a specific value of heterogeneity can belong to very different types of graphs (which all have the same degree sequence) and the measure does not provide a unique result. The main disadvantage of the measure is that there is a tendency to homogeneity for larger networks [10]. The reason for this might not necessarily be the size of the networks, but its density. Additionally their results of the measure behaviour for fixed/varying density and network size suggests that the density is an important factor [10].
Evaluation against properties
This section evaluates how heterogeneity measure classes fulfil the properties established in §3. I present the methodology in §5.1, results in §5.2, and discussion and implications in §5.3. The analysis covers general properties, local topology features, global structural characteristics and responses to network manipulations, guiding researchers in selecting appropriate heterogeneity measures for specific analytical needs.
Methodology
5.1.
This section presents a multi-faceted evaluation framework that examines heterogeneity measure classes across different properties and network contexts. The nature of each evaluation component naturally necessitates specific methodological approaches, ranging from theoretical analysis for property fulfilment to simulation for graph model comparison to mathematical proofs for regular graphs. These different approaches, driven by analytical requirements rather than methodological preferences, collectively provide a comprehensive assessment of how the heterogeneity measure classes perform across theoretical and practical dimensions.
General and local property evaluation
5.1.1.
This section describes the approach used to assess whether each heterogeneity measure class fulfils the desired general (e.g. ability to quantify heterogeneity, uniqueness) and local topology properties (e.g. inclusion of relational structure or degree excess). To determine whether a class fulfils a given requirement, I reviewed its mathematical formulation and properties as described in §4. For example, for local topology properties, I examined whether the general measure explicitly incorporates relational information about nodes, such as degree relations or degree excess.
The following section outlines the methodology for assessing heterogeneity measures across standard network topologies using simulated random graphs.
Graph model analysis framework
5.1.2.
This section outlines the methodology for evaluating heterogeneity measures across standard network topologies using simulated networks. I generated ER networks, where node pairs are connected with uniform probability , resulting in a binomial degree distribution, and PL networks, which have degree distributions , with as the degree exponent.
Following the simulation set-up in [17], I created networks with 1 00 000 nodes and mean degrees ( ) ranging from 2 to 50. For ER networks, the connection probability was set as . For PL networks, I examined degree exponents of 4, 3, 2.5 and 2.2, ensuring the number of edges matched the corresponding ER networks to maintain comparable mean degrees.
All simulations were performed using the sample_gnp, and sample_fitness_pl functions from the igraph [34, 35] package in R. Initial tests indicated that the heterogeneity measures showed low variability across 100 simulation runs. Therefore, I used 100 runs for each parameter setting to make sure the estimates were stable and reliable. A summary of the simulation set-up, including parameter ranges and total number of simulated networks, is provided in table 2.
In following section, I next describe the approach for analysing how heterogeneity measures behave on regular graphs, which serve as a theoretical baseline for minimal heterogeneity.
Regular graph evaluation
5.1.3.
This section details the analytical approach for determining whether each heterogeneity measure assigns zero heterogeneity to regular graphs. Several researchers require that heterogeneity measures attain their extrema for specific graph types [10,18,26]. A regular network, defined by all nodes sharing the same degree, should therefore exhibit minimal heterogeneity (measure = 0) because of its uniformity. I examine whether measures belonging to each class consistently classify regular graphs as homogeneous.
I analytically examined whether the generalized formulas of the heterogeneity measures yield a value of zero for regular graphs. By substituting the properties of regular graphs into these formulas, I derived theoretical results and provided formal proofs to verify the conditions under which each measure class classifies regular graphs as completely homogeneous.
The subsequent subsection details the methodology for comparing measure responses to structurally extreme cases: star and completely diverse networks.
Diverse-star topology comparison
5.1.4.
The following describes the method for comparing heterogeneity measure responses to structurally extreme cases: star graphs (one central hub, all other nodes peripheral) and completely diverse graphs (nearly every node has a unique degree). These cases represent fundamentally different connectivity patterns and test measure sensitivity to structural extremes. Proofs for measure maximization are not provided.
Star networks are sparse and highly centralized, while diverse graphs have a broad degree distribution. For example, the degree sequence (1, 1, 1, 3) in a star graph reflects a single hub connected to three peripheral nodes, while (1, 2, 2, 3) in a diverse graph shows a more balanced distribution. Measures emphasizing extremes may rate star graphs as more heterogeneous, while those considering overall distribution may favour diverse networks.
Direct comparison is challenging: star graphs are inherently sparse, while diverse graphs quickly become dense as size increases, making it difficult to match edge densities and control for density effects. Identifying truly diverse networks, where each node has a unique degree, is also combinatorially difficult for larger sizes. Therefore, I restrict the analysis to the smallest non-trivial star and diverse networks with increasing order of 4 to 7 (see appendix D for network statistics and degree sequences) to gain insight into the behaviour of the measures relative to network type and network size.
Limitations include the small sample size and varying edge densities (0.29−0.67), which may confound results. Because edge density can affect degree variability and topology, differences in heterogeneity values may reflect either structural differences or density effects. Additionally, normalization of heterogeneity values across the sample does not guarantee that observed maxima represent theoretical maxima.
This analysis serves as an initial exploration; future work should examine larger and intermediate topologies and consider normalization for edge density.
Next, I outline the methodology for testing how the measures respond to network manipulation.
Network manipulation testing
5.1.5.
Finally, I present the methodology for testing how heterogeneity measures respond to network manipulations, including edge rewiring, uniform degree increase and network replication, corresponding to the three principles by [7] presented in §3.4. For the three dispersion aggregation classes, I derived sufficient mathematical conditions for compliance through formal analysis of their formulations, examining how components such as the convex function , reference statistic , and aggregation method influence behaviour. For other classes, general conditions could not be derived owing to mathematical complexity; instead, I constructed and analysed specific counter-examples to demonstrate non-compliance.
This combined analytical and example-based approach highlights both the general theoretical properties and the practical behaviours of heterogeneity measures in response to structural changes. The results reveal key differences in how these measures respond to network modifications, as discussed below.
With these methodologies established, I now present the results of evaluating the heterogeneity measures across the outlined network properties and structures.
Results
5.2.
General and local property fulfilment
5.2.1.
My evaluation reveals that all heterogeneity measure classes successfully quantify heterogeneity according to their respective definitions and produce interpretable, unique values. These measures can be applied to various network types and sizes with one exception: only measure proposed by [13] specifically requires networks to be connected.
My analysis shows that most heterogeneity measures require more than just the degree distribution as input. Only the measure can operate with the degree distribution alone as its primary input. All other measures, including those in the adjacent dispersion aggregation and AED classes, as well as the measure, require additional network information beyond the degree distribution.
Regarding local topology, I find systematic differences between measure classes: first, all dispersion aggregation classes, except the global dispersion aggregation class, incorporate information about local topology by considering the relational structure of the network. Second, the global dispersion aggregation class uniquely accounts for degree excess, distinguishing it from other measure classes. Third, adjacent pairwise dispersion aggregation, pairwise dispersion aggregation and both expected difference subclasses (adjacent and pairwise) incorporate weighted or relative degree relationships in their calculations.
All measure classes successfully fulfil almost all general properties required of heterogeneity measures and only show differences regarding the degree distribution as input and all local topology properties.
Having presented the baseline properties, I next continue with the performance results across standard network models.
Graph model heterogeneity patterns
5.2.2.
Figure 1 presents the results of four selected1 heterogeneity measures ( , , and ) across simulated ER and PL networks. Each plot shows normalized heterogeneity values scaled to the unit interval based on minimum and maximum values across all networks for each measure. These four measures represent the variety of behaviours exhibited across all heterogeneity measures: (figure 1a) represents the typical behaviour of most dispersion aggregation and expected difference measures; (figure 1b) exhibits inconsistent behaviour; and and (figure 1c,d) show different behaviour in differentiating network topologies at higher mean degrees.
Panels show normalized heterogeneity values for simulated ER and PL networks, illustrating how heterogeneity changes with decreasing degree exponent (γ) and varying mean degrees (from 2 to 50). In general, most measures assign higher heterogeneity values to PL networks than ER networks, with differences becoming more pronounced with increasing network density. Moreover, among PL networks, most measures assign higher heterogeneity values as the degree exponent decreases. (a) This plot exemplifies the typical behavior of dispersion aggregation and expected difference measures. Measures consistently show higher heterogeneity values for PL networks than for ER networks across all γ values. (b) The degree heterogeneity measure HJ exhibits inconsistent behavior. Differentiation between ER and PL networks is unreliable, with reversals in heterogeneity ranking at lower γ values and poor distinction for networks with low mean degrees. (c) The measure assigns higher heterogeneity values to PL networks as the degree exponent decreases. For mean degrees above 20 the heterogeneity values tend to stabilize. (d) The measure HEp mirrors the pattern in figure 1c with increasing heterogeneity for lower γ. For networks with mean degrees higher than 20, the values are uniformly low, lessening the differentiation between ER and PL networks.
Most heterogeneity measures consistently identify PL networks as more heterogeneous than ER networks across all parameter settings. This distinction is clearly visible in figure 1a, where the most yellow line (PL networks) consistently ranks above the most blue line (ER networks). This reflects the fundamental difference between ER networks’ uniform connectivity and PL networks’ hub-based structure.
For degree exponents of 3 and 4, several measures ( , , , , , and ) still identify PL networks as more heterogeneous, but assign similar low values to both. It is important to note that almost half of the measures, including , , , and do not effectively differentiate between PL and ER models when the networks are sparse (i.e. at low mean degree).
Analysing the effects of network parameters on heterogeneity values demonstrates distinct patterns for both degree exponent and mean degree variations.
Degree exponent effects: for almost all measures, heterogeneity values increase as the degree exponent ( ) decreases, even in sparse networks. In figure 1a,c,d, networks with consistently show the highest heterogeneity values, while those with show the lowest. This pattern reflects how smaller exponents create more extreme hub-and-spoke structures with greater connectivity differences.
Mean degree effects: the distinction between ER and PL networks becomes more pronounced with increasing mean degrees for most heterogeneity measures. However, this is not universal. The Estrada measure (figure 1c) shows values that stabilize for mean degrees 20 and higher, while the adapted Estrada measure (figure 1d) assigns similar low values to all networks with mean degree larger than 20−30 (see also figure 5 in appendix A).
While most measures exhibit consistent patterns, the degree heterogeneity measure demonstrates behaviour that deviates significantly from the general trends.
fails to consistently differentiate between ER and PL networks, even reversing its assignments for values of at 2.5 and lower (see figure 1b). also demonstrates an unexpected ranking pattern among PL networks. For mean degree 20, ranks heterogeneity as , contradicting the pattern seen in other measures where lower exponents correspond to higher heterogeneity. Additionally, shows limited ability to distinguish networks with small mean degrees, further differentiating it from other heterogeneity measures.
Regular graph zero-value conditions
5.2.3.
Regular graphs, characterized by uniform node degrees, should yield a heterogeneity value of zero (indicating perfect uniformity). My analysis confirms that all examined measures assign zero to regular graphs, though through different mathematical mechanisms specific to each measure class. Table 6 in appendix B summarizes these conditions.
In the global dispersion aggregation class (cf. equation (4.1)), regular graphs are classified as completely homogeneous when the difference between the degree and the statistic ( ) equals one of the roots of the convex function . The formal proposition and its proof, which derive these conditions, are provided in appendix B.
For both the adjacent pairwise and pairwise dispersion aggregation classes (generalized by equations (4.13)–(4.20)), the heterogeneity measures are minimized for regular graphs when the scaling factor is positive. This occurs, because the function attains its minimum of value zero at zero, by definition.
Similar reasoning applies to the expected difference class (see equations (4.23)—(4.24)), where regular graphs are considered as completely homogeneous if the scaling factor is positive.
Finally, the special measures and are defined such that they evaluate to zero when applied to regular graphs. For all finite, connected graphs the inequality holds true and in any -regular graph, both the dominant eigenvalue and mean degree are equal (Satz 2 in [13]). This equality ensures that (cf. equation (4.27)) is zero; therefore, the measure is minimized for -regular graphs.
For an -regular graph the degree distribution is defined by for and zero otherwise. This leads directly to a heterogeneity value of zero for the non-negative heterogeneity measure of [10], shown in equation (4.28).
These findings demonstrate that all heterogeneity measure classes (with only modest conditions) uniformly classify regular graphs as homogeneous with value zero. Every specific measure examined in this work assigns regular graphs the minimum heterogeneity value of zero, though through different mathematical mechanisms.
Diverse-star topology differentiation
5.2.4.
Figure 2 presents normalized heterogeneity values for 12 measures across two contrasting network topologies: star graphs (centralized structure with one dominant node) and diverse graphs (distributed structure with nearly unique degrees). My analysis reveals three key findings: first, most measures assign higher heterogeneity values to star graphs than diverse graphs. By contrast, assessments of diverse graphs are more variable and lack the consistent, size-dependent trends seen in star graphs. Second, measure consistently identifies star graphs as highly heterogeneous across all sizes. Third, the degree heterogeneity measure uniquely recognizes diverse graphs as more heterogeneous, contrary to other measures’ assessments.
Heat maps of normalized heterogeneity values (0−1) comparing diverse graphs (left, with nearly unique node degrees) and star graphs (right, with one high-degree central node connected to all other nodes). Each row represents one of twelve heterogeneity measures, while columns represent specific graph configurations labelled by node count and edges (e.g. (7, 12): diverse graph with seven nodes, 12 edges; (7): star graph with seven nodes). Key findings include: (i) most measures assign higher values to star graphs, reflecting sensitivity to centralized structures; (ii) HF consistently assigns maximum values (1.0) to all star graphs; (iii) HJ uniquely assigns maximum values to diverse graphs, particularly graph (7,12); and (iv) pairwise measures (HPED, HAp, HEp) show inconsistent differentiation patterns, sometimes assigning maximum values to diverse graphs rather than stars. Most measures demonstrate increasing heterogeneity values with network size for star graphs, while diverse graphs produce more variable assessments across measures. These contrasting behaviours demonstrate how different mathematical conceptualizations of heterogeneity can lead to fundamentally different network assessments.
Heterogeneity values for star graphs show clear trends as network size increases. Most measures assign values that increase with graph size, reflecting the growing structural irregularity as the central node’s dominance becomes more pronounced in larger networks.
The measures , , and effectively differentiate between diverse and star graphs. Specifically, consistently assigns maximum values (1.0) to all star graphs while giving low values ( 0.2) to diverse graphs. Conversely, consistently assigns high values to diverse graphs (with a maximum of 1.0 to graph (7,12)) and progressively lower values to star graphs. Both and show clear, increasing trends with network size for star graphs, reflecting their sensitivity to increasingly centralized structures.
All pairwise measures ( , , ) show increasing trends for star graphs but exhibit high variability for diverse graphs without consistent patterns. Notably, and both assign their maximum value (1.0) to the diverse graph (7,12), rather than to any star graph. uniquely assigns its maximum value (1.0) to the diverse graph (5,4), showing distinct behaviour from the other measures.
The remaining measures ( , , , , ) generally assign higher values to star graphs than diverse graphs and provide good discrimination between graph types. Notably, the diverse graph (7,12) receives relatively high values from these measures, comparable with those assigned to larger star graphs.
The heat maps in figure 2 highlight significant variation in how effectively different measures distinguish between these contrasting topologies. While most measures assign higher values to star graphs, suggesting greater sensitivity to centralized structures, provides an opposite assessment, assigning higher values to diverse graphs. This contrasting behaviour reflects fundamental differences in how heterogeneity is mathematically conceptualized across measures, with some focusing on centralization structures and others on degree diversity.
Network manipulation responses
5.2.5.
The evaluation of heterogeneity measures against network manipulation principles revealed that only 1 of 12 measures ( ) satisfies all three network manipulation principles, while two ( and ) comply with none. The addition principle shows highest compliance (10 out of 12 measures), with transfer and replication principles each satisfied by only 2 out of 12 measures. Most measures (8 out of 12) comply with exactly one principle, typically addition. Table 3 summarizes these findings, with non-compliance cases illustrated in figure 3 and table 4. For dispersion aggregation measures, I derived sufficient conditions for compliance, detailed in table 7 (appendix C).
Networks illustrating counter-examples where heterogeneity measures increase after rewiring, violating the transfer principle (see table 4 for corresponding numerical values). Dashed lines indicate the new connections. (a) Counter-example for the graph heterogeneity measures HA, HE, HEP and HAED. (b) Counter-example for the graph heterogeneity measure HPED and the degree heterogeneity measures HJ. (c) Counter-example for the graph heterogeneity measures HCS.
Global dispersion aggregation measures (cf. equation (4.1)) demonstrate distinct compliance patterns. All four measures, (cf. equation (4.8)), (cf. equation (4.12)), (cf. equation (4.2)) and (cf. equation (4.5)), comply with the addition principle. However, only additionally satisfies both the transfer and replication principles, making it uniquely compliant with all three principles.
For the transfer principle, compliance requires the network statistic to remain unchanged during rewiring ( ) with specific functional conditions satisfied. The addition principle compliance occurs when network statistics increase proportionally with node degrees or when is monotone increasing and . For the replication principle, compliance occurs only when the replication process maintains the network statistic and scaling factors satisfy .
(Adjacent) pairwise dispersion measures exhibit similar compliance patterns. Most breach the transfer principle, as shown in table 4: increases from 1342 to 1350, from 46.3 to 46.6 and from 15.4 to 15.7. Only the pairwise measure complies with the transfer principle. All measures in both classes comply with the addition principle but fail the replication principle, with adjacent measures scaling linearly and adjacent pairwise measures scaling quadratically with the replication factor.
Expected difference measures (cf. equation (4.24)) and (cf. equation (4.23)) breach the transfer principle, with increasing from 1.47 to 1.7 (figure 3c) and from 15.4 to 15.5 (figure 3a) after rewiring. complies with the addition principle while does not. Neither satisfies the replication principle.
Special measures (cf. equation (4.28)) and (cf. equation (4.27)) breach the transfer principle, with increasing from 0.38 to 0.41 and from 1.47 to 1.49. uniquely satisfies the replication principle because it depends solely on the degree distribution (unchanged during replication), while breaches all principles.
Having established the empirical compliance patterns of heterogeneity measures across the classes, I now interpret these findings to understand their theoretical foundations and practical implications.
Discussion
5.3.
This section presents a multifaceted evaluation of heterogeneity measures through four complementary analyses. The graph model analysis reveals how measures distinguish between uniform ER networks and heterogeneous PL networks with decreasing degree exponents. The regular graph analysis confirms the mathematical mechanisms by which measures assign zero values to regular networks. The diverse-star comparison examines measure sensitivity to contrasting network architectures that embody different organizational principles. Finally, the network manipulation analysis investigates measure compliance with principles of edge transfer, degree addition and network replication. Collectively, these evaluations demonstrate how different mathematical formulations of heterogeneity lead to distinct behaviours across network contexts, highlighting the importance of measure selection based on specific research requirements.
Graph model heterogeneity interpretation
5.3.1.
The simulation study reveals that most heterogeneity measures successfully distinguish between the uniform structure of ER networks and the heterogeneous architecture of PL networks, while also ranking PL networks according to their degree exponent, though with varying sensitivities to network parameters.
ER networks exhibit uniform connectivity patterns that remain independent of changes in mean degree, typically yielding lower heterogeneity values reflecting their homogeneity. By contrast, PL networks display heterogeneous connectivity. Decreasing the degree exponent in PL networks produces a heavier tail in the degree distribution, resulting in increased probability of hubs within the network. This leads to a greater contrast between a few highly connected nodes and many sparsely connected ones. Increasing the mean degree, while maintaining the number of nodes fixed, leads to an increase of degree for both hubs and less connected nodes. Although the hubs’ absolute degree increases, the relative difference between them and all other nodes remains the same, because the entire degree distribution is shifted upwards rather than being reshaped.
As expected, degree and graph heterogeneity measures generally assign higher values to PL graphs than to ER graphs, reflecting their greater structural variability. Within PL networks, decreasing exponents correspond to increasing measure values for most metrics, capturing the greater degree variability and hub formation characteristic of networks with heavier-tailed distributions.
The degree heterogeneity measures and capture the uniform variation in ER graphs and the increasing variation in degrees that comes from the heavier tail in PL networks with smaller degree exponents, by measuring the variation around the mean degree.
The degree heterogeneity measure inconsistently differentiates between ER and PL networks as the degree exponent decreases. This occurs because of competing effects: decreasing increases highly connected nodes (individually contributing more to heterogeneity), while simultaneously concentrating the distribution among fewer high-degree nodes (reducing overall degree diversity). Although adding new hubs increases individual contributions, merely recognizes new degrees without adequately weighting their magnitude relative to other nodes. Thus, despite higher individual contributions, the reduced diversity in degree types ultimately lowers the measure’s value.
The degree heterogeneity measure assesses differences between node degrees and the maximum degree node. As PL exponents decrease, the increasing probability of hubs leads to greater differences between maximum degree and other nodes, effectively capturing hub formation.
Measures based on degree differences ( , , ) capture structural variations by focusing on local and global degree disparities. These measures are particularly sensitive to the growing presence of hubs in PL networks with decreasing exponents. As the exponent decreases, the disparity between highly connected hubs and low-degree nodes becomes more pronounced, resulting in increased measure values.
The degree heterogeneity measures and are pairwise measures and have heterogeneity values dependent on degree differences between all nodes. In networks with many low-degree nodes, differences between these nodes contribute little to overall heterogeneity. However, comparisons between low-degree nodes and high-degree hubs produce significantly larger differences. As degree exponents decrease, hub prevalence increases, amplifying the disparity between sparsely connected nodes and highly connected hubs, leading to greater contribution from these larger differences and increasing overall heterogeneity.
The degree heterogeneity measure offers a unique perspective by dampening the contribution of hubs relative to low-degree nodes through a square root transformation. In PL networks with lower degree exponents where hubs become more prevalent, the absolute differences in degrees increase. However, the measure dampens these differences through its transformation, reducing the extreme contributions from high-degree hubs. As a result, tends to perceive the overall network structure as more homogeneous than other measures might suggest.
Across all measures, the graph heterogeneity measure demonstrates unique stability across changing mean degrees, suggesting it may be particularly suitable to reveal connectivity disparities among moderate-degree nodes that would otherwise be overshadowed by hubs. By contrast, most other measures showed sensitivity to mean degree changes, highlighting the importance of controlling for network density when comparing heterogeneity across networks.
For degree exponents of 3 and 4, several measures ( , , , , , and ) assign similar low values to both PL and ER networks while still ranking PL networks as more heterogeneous. This observation aligns with previous research suggesting that for PL networks with exponents above 2.5, there exists an ER network with equivalent heterogeneity values [4].
While most measures successfully differentiate between network structures, their sensitivity varies substantially with network parameters. The divergent behaviour of compared with other measures highlights how different conceptualizations of heterogeneity can lead to dramatically different conclusions about the same network. These findings underscore the importance of selecting heterogeneity measures based on specific research questions and theoretical frameworks.
This study demonstrates that degree and graph heterogeneity measures capture complementary aspects of network organization. Researchers should consider employing multiple measures to gain comprehensive insights into network structure, particularly when analysing complex real-world networks where heterogeneity manifests in various forms. Future work might explore how these measures perform on empirical networks with more complex structural properties beyond the idealized ER and PL models examined here.
Regular graph zero-value mechanisms
5.3.2.
The analysis confirms that all measures return a value of zero for regular graphs. However, this common outcome masks important distinctions in the underlying theoretical mechanisms by which different measure classes arrive at this conclusion.
Measures in the adjacent pairwise dispersion aggregation and expected difference classes (cf. equations (4.13)–(4.23)) reach zero through direct mathematical consequences of their definitions. These measures are constructed directly on differences between node degrees or transformations of these differences. Because regular graphs are defined by uniform node degrees (where all nodes have identical degrees), these differences inherently vanish, leading to a zero value by mathematical construction.
By contrast, measures in the global dispersion aggregation class (cf. equation (4.1)) employ a fundamentally different, centrality-based perspective. These measures also assign a zero value for regular graphs, but only under specific mathematical conditions. As proved in appendix C, for these measures to reach zero, the difference between the network’s node degree ( ) and the key statistic must exactly match one of the roots of the convex function . This additional requirement reflects their underlying centrality view rather than a direct focus on degree differences.
This distinction highlights that while the outcome is the same, the theoretical approaches and built-in conditions of these measures differ.
An important limitation emerges from this analysis: the current set of heterogeneity measures cannot distinguish between different types of regular graphs that might vary in other structural properties. For example, two regular graphs with identical degree distributions but different patterns of edge arrangement (evenly distributed versus clustered connections) would receive identical heterogeneity scores of zero. This limitation suggests that researchers interested in capturing more nuanced aspects of homogeneity beyond degree regularity may need to employ complementary measures that can detect differences in edge distribution patterns or other structural properties.
Diverse-star topology sensitivity
5.3.3.
Heterogeneity measures vary in their ability to distinguish between star-like and diverse network topologies, with only some measures ( , , and ) clearly differentiating these structures while others show limited sensitivity despite the contrasting organizational principles these topologies represent.
The expected behaviour of the heterogeneity measures can be summarized as follows: first, graph heterogeneity measures that quantify local degree irregularities are expected to recognize star graphs, which exhibit high local degree differences, as heterogeneous. Second, measures capturing deviations from a most central point in the network should assign high values to star graphs because of their extreme centralization, while diverse graphs might be assigned lower scores owing to their more distributed nature. Third, degree heterogeneity measures, aiming to capture variability in degrees, should distinguish both topologies well.
Measures such as the graph heterogeneity measures and that incorporate local degree differences effectively recognize the structural differences between star and diverse networks. Specifically, assigns high values to star graphs because of the pronounced degree difference between the central hub and its neighbours. Similarly, distinguishes between the two topologies well while capturing degree irregularities.
Degree heterogeneity measures and aim to quantify deviations from a most centralized point in the network. employs normalization against the theoretical maximum possible centralization, using perfect star topology as the reference point. This normalization approach explains its distinctive binary classification behaviour observed in the heat map in figure 2, where star graphs consistently achieve maximum heterogeneity scores (1.0), while diverse graphs receive substantially lower values ( 0.2). measures the relative deviations from the most central node without explicit normalization against a theoretical maximum, which leads to increasing values for increasing star graphs as well as a good distinction from diverse graphs.
The set of degree heterogeneity measures aim to capture variability in node degrees across the network. successfully distinguishes between diverse and star networks by recognizing the broad range of degrees in diverse graphs. and are more focused on the deviation around the mean degree, and given the small network sizes with limited variation around the mean, these measures do but not strongly differentiate between the two topologies. Measures which are based on pairwise irregularities ( , , ) exhibit more inconsistent results. One reason is that in star graphs irregularities involving the central node are few and most degree pair irregularities yield zero. For diverse graphs with nearly unique degrees, more pairs have non-zero differences. This can lead to maximum heterogeneity values in diverse graphs rather than star graphs in some cases.
In future work, it would be valuable to relax the strict definitions of the extreme cases used in the current study. Instead of focusing solely on networks that are completely star-like or entirely diverse, exploring networks that exhibit high, but not absolute, diversity could provide a more realistic image of many real-world systems. By considering such intermediate cases, one could examine how heterogeneity measures perform across a broader spectrum of network configurations. Additionally, larger networks and adjustments such as normalizing by edge density or applying theoretical bounds may also provide further insights into how these measures capture centralized versus distributed network structures.
Compliance with network manipulation principles
5.3.4.
This discussion examines how heterogeneity measures respond to three fundamental network principles proposed by [7]: transfer, addition and replication. By analysing mathematical properties across measure classes, I discuss why certain measures comply with these principles while others exhibit counter-intuitive behaviours.
The transfer principle states that network heterogeneity should decrease when an edge is rewired from a higher-degree node to a lower-degree node (while maintaining the condition that the target node’s degree remains higher than the originating node’s degree). While degree heterogeneity measures are directly influenced by node degrees, their response depends on how variations are quantified. Graph heterogeneity measures present more complex behaviour, particularly those based on centrality or ones that capture both degree distribution and topological structure.
The addition principle requires that heterogeneity should not increase when all node degrees are uniformly increased. For measures based on absolute differences (like variation around the mean), values should remain constant, while measures of relative differences should decrease. Degree heterogeneity measures would be expected to satisfy this principle because of their direct dependence on degree distribution scaling. Graph heterogeneity measures incorporating the networks structure are also expected to reflect changes, as increasing all degrees changes the network’s topology, but the direction of change depends on how nodes are connected.
The replication principle holds that heterogeneity values should remain unchanged when a network is replicated (whether by integer or non-integer multiples). For integer replication, the degree distribution remains unchanged, while non-integer replication requires proportional scaling of node counts. Measures focusing solely on degree distribution are expected to comply, while those incorporating structural properties may reflect the topological changes introduced by creating disconnected components.
Global dispersion aggregation measures quantify heterogeneity by comparing node properties to a network-wide statistic. Their response to the three principles varies based on their mathematical formulation and the network statistics they employ.
Regarding the transfer principle, these measures (cf. equation (4.1)) respond differently to edge rewiring based on their reference statistic ( ) and aggregation function ( ). Mean-based measures exhibit contrasting behaviours: (cf. equation (4.12)) quantifies absolute deviations, detecting changes only when rewiring causes degrees to cross the mean threshold, while (cf. equation (4.8)) uses squared differences that ensure all deviations contribute positively without cancellation, fully complying with the principle. Maximum-based measures (cf. equation (4.2)) and (cf. equation (4.5)) breach the principle when rewiring occurs among non-maximum degree nodes, as changes in nodes’ degrees simply cancel out without affecting the reference statistic. Their sensitivity depends primarily on whether the rewiring affects the maximum degree node.
When considering the addition principle, these measures satisfy its requirements because the relative differences among node degrees remain unchanged after uniform increase. This consistent behaviour contrasts with their variable responses to the transfer principle.
For the replication principle, these measures comply only if the network statistic remains unchanged (i.e. ) and the relationship between scaling factor ( ) and measure constants satisfies . Otherwise, they scale with replication, like and . This scaling behaviour results from the linear addition of nodes during replication. For example, decreases when replicated because while the degree differences within each component remain unchanged, the reference value (maximum possible difference) increases substantially, reducing the normalized measure. Detailed proofs are provided in appendix C.
Adjacent and pairwise dispersion aggregation measures quantify heterogeneity through local and global degree differences, showing varied responses to network modifications across the three principles.
Regarding the transfer principle, these measures exhibit counter-intuitive behaviour. While one might expect them to satisfy this principle (since rewiring should reduce degree differences between connected nodes), they often breach it because of neighbourhood effects. For measures (cf. equation (4.14)) and (cf. equation (4.15)), graph heterogeneity can increase even when the rewired edge’s degree difference decreases, as shown in figure 3a. This occurs when the node losing an edge connects to high-degree neighbours while the node gaining a connection links to low-degree neighbours, amplifying overall heterogeneity.
For degree heterogeneity measures aggregating across all node pairs, compliance with the transfer principle depends critically on the choice of functions and constants. While the Albertson measure (adapted for all pairs) fulfils the principle (proof in appendix C), the adapted Estrada measure (cf. equation (4.22)) with parameter , functions and can increase after rewiring. For the network in figure 3b, this measure increases from to . This occurs because the inverse square root function down-weights high-degree nodes while the quadratic function amplifies larger differences, allowing small increases in lower-degree node differences to outweigh decreases from higher-degree nodes.
For the addition principle, these measures generally comply as expected, since uniformly increasing node degrees preserves pairwise differences. This holds particularly for measures using the identity function as (proof in appendix C).
Under replication, both measure classes breach the principle by scaling with network replication. Adjacent pairwise measures scale linearly with the replication factor, as the same sum of differences is computed for each network copy and aggregated over the edge set. Pairwise measures scale quadratically, as they sum over every combination of nodes from the original network and its copies, causing the measure to grow as the square of the replication factor.
Expected difference measures adapt the Gini coefficient concept to quantify how much nodes differ in their degrees on average. These measures display varied behaviours across the three network principles.
Regarding the transfer principle, measures and (cf. equations (4.23)–(4.24)) behave differently depending on degree distribution assumptions. Under uniform distribution, they reduce to scaled versions of either the Albertson measure or its adaptation. While the adapted version complies with the principle (proof in appendix C), the original measure breaches it (see figure 3a). Under non-uniform distributions, both measures can breach the principle as rewiring affects not only absolute differences but also joint probability distributions. This complexity is demonstrated in figure 3c, where the PED increases from 1.47 to 1.7 after rewiring, while in figure 3a, the AED increases from 15.4 to 15.5.
For the addition principle, one might expect these measures to satisfy it, since increasing node degrees consistently should preserve expected differences. The measures indeed respond differently: satisfies the principle because its independence assumption ( ) ensures that uniform degree increases preserve both distribution and absolute differences (proof in appendix C). By contrast, can increase after uniform degree addition because new edges form, contributing to the expected difference, even if having a small contribution because of the conditional degree distribution or absolute degree difference to their neighbouring nodes. This sensitivity to neighbourhood changes mirrors its behaviour under the transfer principle.
Under the replication principle, expected difference measures follow patterns identical to those of (adjacent) pairwise dispersion aggregation measures. Rather than remaining unchanged, they scale proportionally with network replication ( scales linearly with the replication factor while scales quadratically). This scaling occurs because replication creates multiple disconnected components, which these measures interpret as increased heterogeneity—a property that could be valuable in applications requiring sensitivity to network fragmentation.
Special heterogeneity measures exhibit distinctive behaviours across the three network principles, reflecting their unique mathematical foundations.
The degree heterogeneity measure (cf. equation (4.28)) quantifies degree diversity by assessing frequency distribution of degrees. Under the transfer principle, can breach expectations when rewiring creates a more evenly distributed degree pattern. In figure 3b, heterogeneity increases from 0.38 to 0.41 after rewiring, as the degree distribution becomes more uniform, changing from (0.00, 0.55, 0.30, 0.00, 0.10, 0.05) to (0.00, 0.55, 0.25, 0.05, 0.15). Notably, remains unchanged when rewiring produces a permutation of the original degree distribution, indicating its insensitivity to structural changes that preserve degree frequency.
By contrast, fully complies with the addition principle because adding the same constant to all node degrees preserves the shape of the degree distribution. This demonstrates that as long as the degree distribution structure remains constant, changes in connectivity patterns or total edge count do not affect this measure’s evaluation. also complies fully with the replication principle because it depends solely on degree distribution, which remains unchanged during replication.
The graph heterogeneity measure (cf. equation (4.27)) quantifies heterogeneity through deviation from regularity, measuring the difference between the adjacency matrix’s largest eigenvalue and mean degree. Under the transfer principle, generally does not comply because rewiring does not necessarily transform the graph towards regularity. Figure 3c shows heterogeneity increasing from 1.47 to 1.49 after rewiring. However, when rewiring occurs from a more influential node to a less influential node (by eigenvector centrality), this measure decreases (proof in appendix C), capturing aspects beyond simple degree changes.
For the addition principle, shows inconsistent behaviour because although uniform degree increase raises the mean degree accordingly, the addition principle does not specify how new edges connect nodes. Because multiple network topologies can exist for a given degree distribution, each potentially yielding different eigenvalues, could increase, decrease, or remain unchanged depending on the specific topology. breaches the replication principle by design, as it cannot be applied to the disconnected structures created through replication, revealing a fundamental limitation of this spectral-based heterogeneity measures.
These contrasting behaviours highlight the importance of understanding measure-specific mathematical properties when selecting appropriate heterogeneity measures for network analysis.
Conclusion
This study advances the systematic analysis of network heterogeneity through three foundational steps: synthesizing existing definitions into a unified conceptual framework, classifying measures into mathematically coherent classes, and evaluating these classes against desirable and necessary properties. The resulting framework resolves ambiguities in heterogeneity measurement while providing actionable guidance for researchers.
A key contribution lies in formalizing three perspectives on heterogeneity through conceptual synthesis. By analysing existing definitions, I distinguish degree heterogeneity (variability in node connectivity), topological heterogeneity (structural irregularities in edge configurations) and centrality and position-based heterogeneity (variations in nodes’ positional influence and structural roles within the network). The inclusion of a broader concept of heterogeneity provides important insights about the conceptual differences.
Mathematically, I derive six measure classes: global dispersion aggregation, (adjacent) pairwise dispersion, (adjacent) PED and special measures, by identifying unifying formulas under which existing measures fall through specific function choices. This classification reveals previously unrecognized relationships between supposedly distinct measures, such as the degree variance and Freeman centrality.
Systematic evaluation against properties (table 5) clarifies critical trade-offs. While most measures differentiate ER and PL networks, sensitivity depends on parameters like mean degree and the degree exponent . Only satisfies all network manipulation principles, whereas uniquely inverts star/diverse rankings, which is a finding that underscores how mathematical formulations and different conceptual approaches implicitly prioritize different aspects of heterogeneity.
Based on these findings, researchers should select heterogeneity measures according to their analytical focus and research objectives. For degree heterogeneity, global dispersion measures ( , ) effectively capture variation around mean degree for applications like epidemic modelling, while pairwise measures ( , , ) suit global assessments where differences in all potential connections matter. The special measure uniquely quantifies degree variety, suitable for examining structural complexities in dynamical systems. For topological heterogeneity, adjacent pairwise measures ( , ) can be useful in infrastructure analysis where neighbouring connections matter, while the AED measure could also provide valuable insights for social network community formation. The special measure effectively captures local topological information through network spectra. Centrality-based questions are best addressed with global dispersion measures like or , which quantify central node dominance and prove valuable for identifying influential individuals in social networks.
Two key limitations should be acknowledged. First, evaluations used controlled network models; real-world systems with community structure or temporal dynamics may exhibit different behaviours. Second, the diverse-star comparison focused on small networks, leaving open questions about scaling effects. Future work should develop hybrid measures combining degree and structural variability, test framework scalability on large real-world networks and expand principle compliance analysis to dynamic systems.
By bridging definitional clarity with operational guidance, this work establishes a foundation for rigorous, context-aware heterogeneity analysis. It demonstrates how the choice of measure critically shapes structural interpretation, whether in tracking epidemic spread through degree variability, optimizing infrastructure using topological aspects, or mapping power structures with centrality measures. Together, these contributions advance the methodology of network science.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Großmann G, Backenköhler M, Wolf V. 2021 Heterogeneity matters: contact structure and individual variation shape epidemic dynamics. P Lo S ONE 16, e 0250050. (10.1371/journal.pone.0250050)34283842 PMC 8291658 · doi ↗ · pubmed ↗
- 2Havlin S. 2010 Complex networks: structure, robustness and function. Cambridge, UK: Cambridge University Press. (10.1017/CBO 9780511780356) · doi ↗
- 3Landi P, Minoarivelo HO, Brännström Å, Hui C, Dieckmann U. 2018 Complexity and stability of ecological networks: a review of the theory. Popul. Ecol. 60, 319–345. (10.1007/s 10144-018-0628-3) · doi ↗
- 4Hu HB, Wang XF. 2008 Unified index to quantifying heterogeneity of complex networks. Phys. A 387, 3769–3780. (10.1016/j.physa.2008.01.113) · doi ↗
- 5Bell FK. 1992 A note on the irregularity of graphs. Linear Algebra Appl. 161, 45–54. (10.1016/0024-3795(92)90004-T) · doi ↗
- 6Nikiforov V. 2006 Eigenvalues and degree deviation in graphs. Linear Algebra Appl. 414, 347–360. (10.1016/j.laa.2005.10.011) · doi ↗
- 7Badham JM. 2013 Commentary: measuring the shape of degree distributions. Netw. Sci. 1, 213–225. (10.1017/nws.2013.10) · doi ↗
- 8Estrada E. 2019 Degree heterogeneity of graphs and networks. I. Interpretation and the ‘heterogeneity paradox’. J. Interdiscip. Math. 22, 503–529. (10.1080/09720502.2019.1643553) · doi ↗