Pipeline monitoring data recovery using novel deep learning models: an engineering case study
Yong Zhao, Xinpeng Zhang, Yanli Liu, Xuecheng Mao, Xi Chen, Yasheng Maimaitituerxun, Weidong He

TL;DR
A new deep learning model called PDO-BiGRU-GAN is proposed to recover missing pipeline monitoring data, improving structural health evaluation and infrastructure safety.
Contribution
The novel PDO-BiGRU-GAN model integrates PDO, BiGRU, and GAN for efficient and accurate recovery of missing pipeline monitoring data.
Findings
The PDO-BiGRU-GAN model achieves an R2 score exceeding 0.93 across various missing data scenarios.
The model outperforms eight existing deep learning models in recovery accuracy and error metrics.
The model performs optimally when the missing data ratio is below 20/24.
Abstract
Pipeline monitoring frequently encounters missing data, leading to incomplete evaluation and hindering a comprehensive assessment of the pipeline’s structural health. To address this issue, this study proposes a novel PDO-BiGRU-GAN model for missing data recovery. The model integrates three components: the prairie dog optimization algorithm (PDO) for hyperparameter tuning, the bidirectional gated recurrent unit (BiGRU) for effective temporal feature extraction, and the generative adversarial network (GAN) for data generation and completion. A comprehensive monitoring database was established using field data from an open-source pipeline project. The contributions of individual modules to the overall performance were evaluated via hyperparameter sensitivity analysis and ablation studies. The impact of missing data ratio and the number of missing sensors on the model’s recovery…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
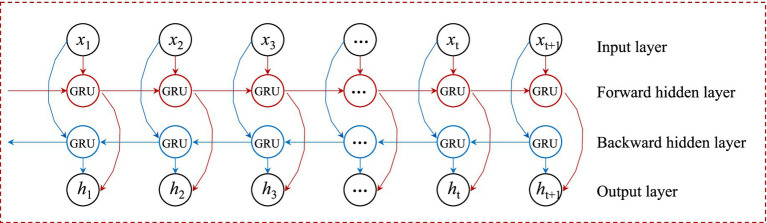 Figure 1
Figure 1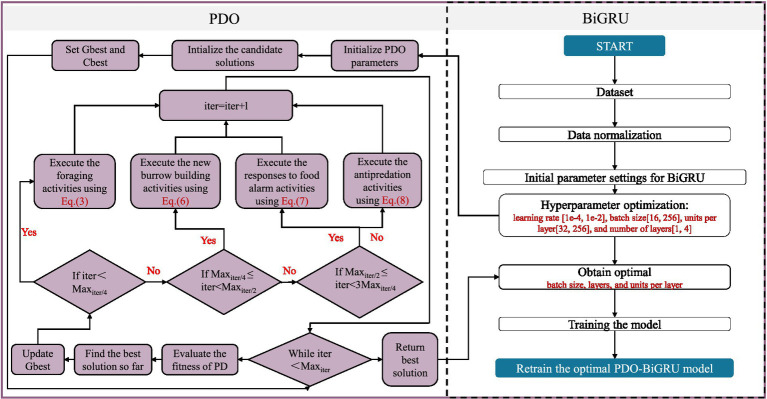 Figure 2
Figure 2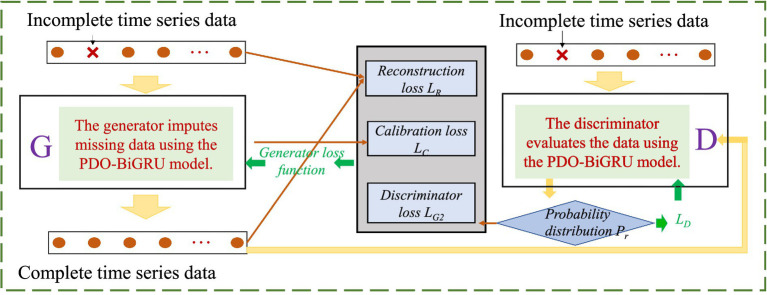 Figure 3
Figure 3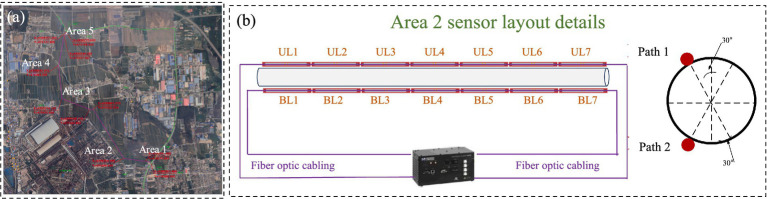 Figure 4
Figure 4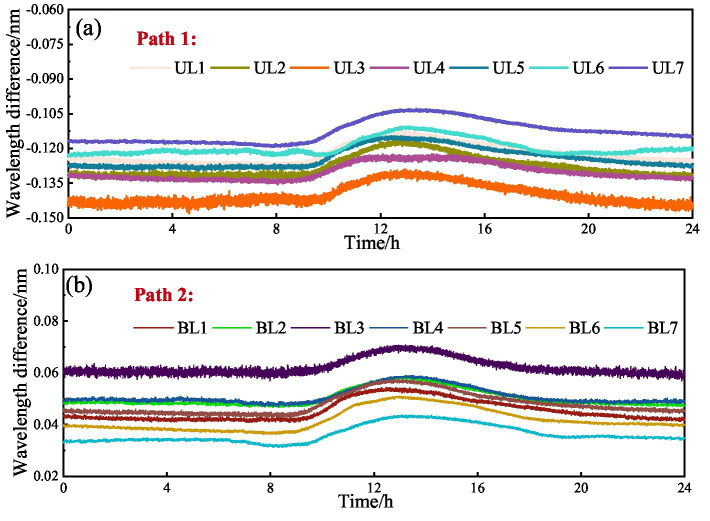 Figure 5
Figure 5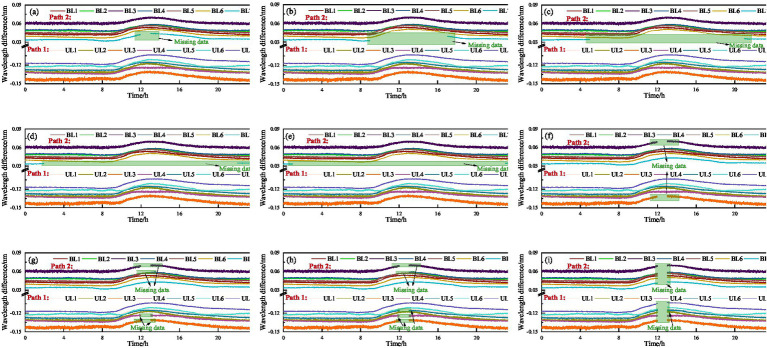 Figure 6
Figure 6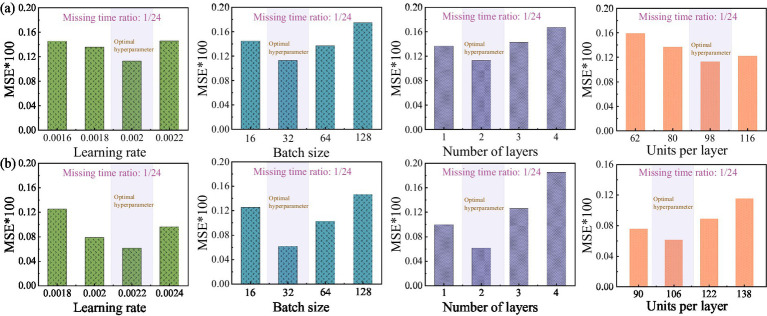 Figure 7
Figure 7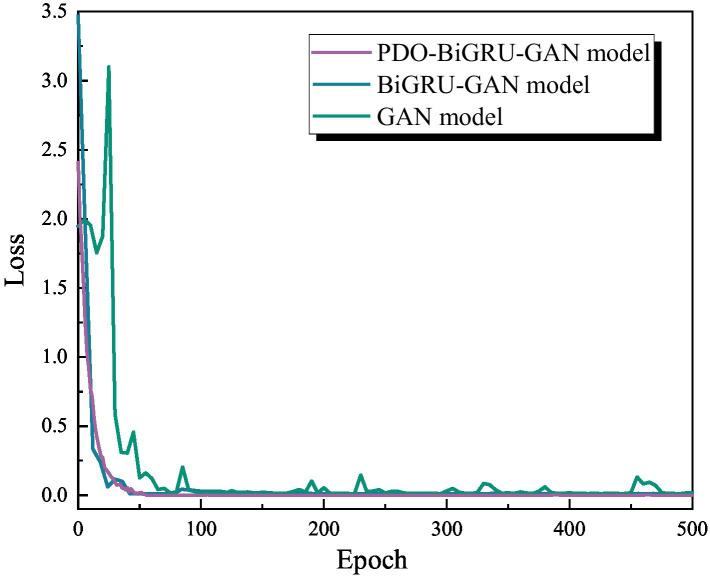 Figure 8
Figure 8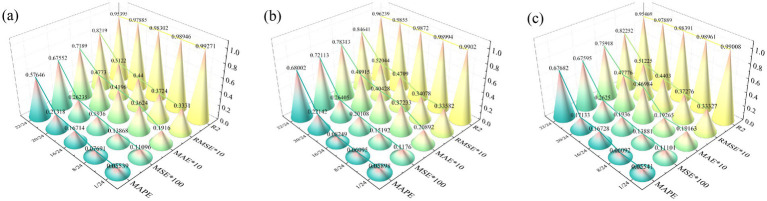 Figure 9
Figure 9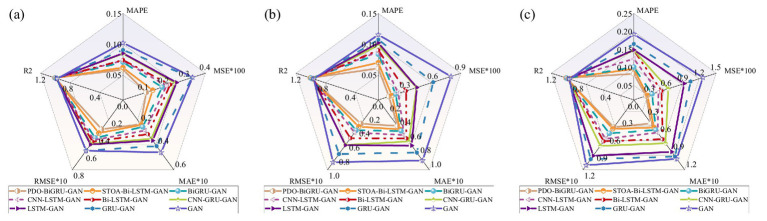 Figure 10
Figure 10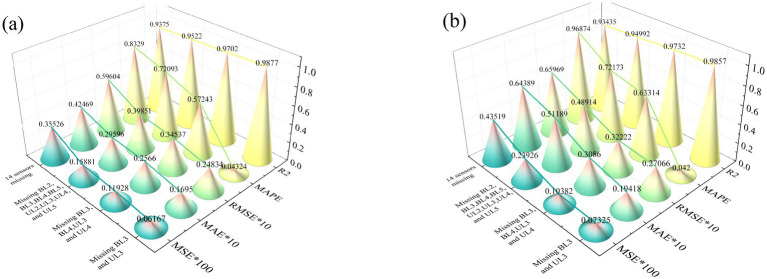 Figure 11
Figure 11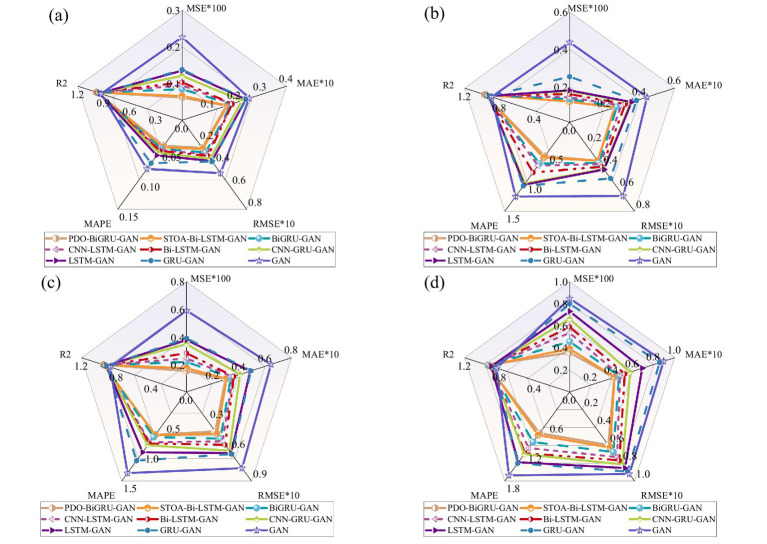 Figure 12
Figure 12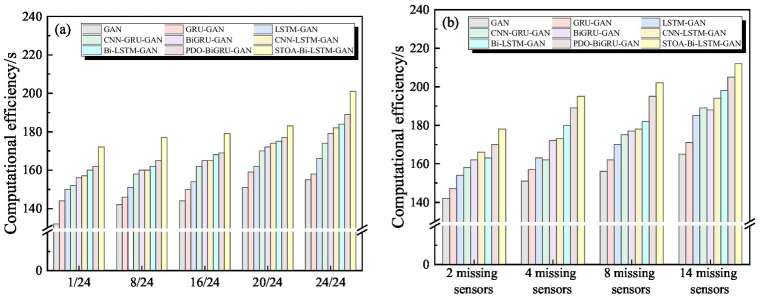 Figure 13
Figure 13| Statistical information | Corresponding results | |
|---|---|---|
| Sampling frequency | 1HZ | |
| Total number of sensors | 14个 | |
| Types of missing data | Different missing data ratios | 1/24 |
| 8/24 | ||
| 16/24 | ||
| 20/24 | ||
| 22/24 | ||
| Different numbers of missing sensors | 2 (BL3, UL3) | |
| 4 (BL3, UL3, BL4, UL4) | ||
| 8 (BL2, UL2, BL3, UL3, BL4, UL4, BL5, UL5) | ||
| 14 | ||
| Hyperparameters | Missing data ratio | Multiple-sensor data loss | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1/24 | 8/24 | 16/24 | 20/24 | 24/24 | 2 Missing sensors | 4 Missing sensors | 8 Missing sensors | 14 Missing sensors | |
| Learning rate | 0.002 | 0.0018 | 0.0016 | 0.0013 | 0.0011 | 0.0022 | 0.0018 | 0.0018 | 0.0012 |
| Batch size | 32 | 64 | 64 | 64 | 128 | 32 | 64 | 64 | 128 |
| Units per layer | 98 | 122 | 148 | 175 | 196 | 106 | 130 | 164 | 208 |
| Number of layers | 2 | 3 | 3 | 3 | 3 | 2 | 2 | 3 | 3 |
| Model | Module | Proportion | Performance metrics | ||||||
|---|---|---|---|---|---|---|---|---|---|
| GAN | KOA | GPS | MAPE | MSE*100 | MAE*10 | RMSE*10 | R2 | ||
| GAN (baseline) | 1/24 | 0.10232 | 0.33849 | 0.45093 | 0.5818 | 0.9588 | |||
|
| 8/24 | 0.11543 | 0.7928 | 0.86601 | 0.89039 | 0.9421 | |||
| 16/24 | 0.19215 | 1.25729 | 1.01144 | 1.12129 | 0.94 | ||||
| BiGRU-GAN | 1/24 | 0.07082 | 0.19048 | 0.23163 | 0.43643 | 0.985 | |||
|
|
| 8/24 | 0.08376 | 0.18989 | 0.44451 | 0.43577 | 0.98 | ||
| 16/24 | 0.10064 | 0.33225 | 0.51753 | 0.57641 | 0.9778 | ||||
| PDO-BiGRU-GAN | 1/24 | 0.05898 | 0.11278 | 0.20892 | 0.33582 | 0.9902 | |||
|
|
|
| 8/24 | 0.06095 | 0.11613 | 0.37233 | 0.34078 | 0.98994 | |
| 16/24 | 0.08249 | 0.22174 | 0.40428 | 0.4709 | 0.9872 | ||||
| Model | Technical advantage | Limitations | Accuracy–computational cost trade-off |
|---|---|---|---|
| GAN | Basic generative modeling for missing data recovery | No temporal dependency modeling, limited sequence feature capture | Low accuracy, Very Low computational cost |
| GRU-GAN | Unidirectional GRU captures short-term temporal patterns | Limited ability for long-term dependencies | Moderate accuracy, Low computational cost |
| LSTM-GAN | Unidirectional LSTM captures long-term dependencies | Limited local feature extraction | Moderate-high accuracy, Moderate-Low computational cost |
| CNN-GRU-GAN | Convolution extracts local features + GRU handles temporal dependencies | Complex architecture, higher training cost | High accuracy, Moderate-High computational cost |
| CNN-LSTM-GAN | Convolution + LSTM captures both local and long-term dependencies | Large number of parameters, long training time | High accuracy, High computational cost |
| Bi-GRU-GAN | Bidirectional GRU captures past and future dependencies | Weak in local feature extraction | High accuracy, Moderate-High computational cost |
| Bi-LSTM-GAN | Bidirectional LSTM captures short- and long-term dependencies | Complex architecture, relatively long training time | High accuracy, High computational cost |
| STOA-Bi-LSTM-GAN | Bidirectional LSTM + STOA hyperparameter optimization | Hyperparameter search overhead, long training time | Very high accuracy, Very High computational cost |
| PDO-BiGRU-GAN | Bidirectional LSTM + STOA hyperparameter optimization | Computational cost during hyperparameter optimization | Very high accuracy, High computational cost; similar or better precision than STOA with lower overhead |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsWater Systems and Optimization · Non-Destructive Testing Techniques · Anomaly Detection Techniques and Applications
Introduction
1
Pipeline systems are essential infrastructure supporting multiple urban functions such as water supply, drainage, heating and gas distribution (Mazumder et al., 2018; Xiong et al., 2020). Their safe operation is vital for ensuring stable urban systems and sustainable daily life. However, pipelines are typically laid across regions, over long distances, and beneath the ground (Li et al., 2022; Quej-Ake et al., 2020; Shirazi et al., 2023). They often traverse diverse geological formations and complex subsurface terrains. During service, pipelines are prone to structural damage due to geostress variations, soil-induced degradation, and hydrochemical reactions, potentially leading to deformation and leakage (Sharma et al., 2024; Wong and McCann, 2021). To address these challenges, a comprehensive system spanning the entire lifecycle of pipeline infrastructure is necessary for monitoring and assessment.
Commonly used pipeline monitoring techniques include acoustic detection, fiber-optic sensing, electromagnetic induction, pressure monitoring, and image recognition (Adegboye et al., 2019; Ho et al., 2020; Sun et al., 2025a). Acoustic detection offers rapid response and is effective for leak localization; however, it is highly susceptible to environmental noise and interference (Xu et al., 2013). Electromagnetic induction is suitable for detecting corrosion in metallic pipelines and benefits from non-contact operation, but it is limited to conductive materials and suffers from rapid signal attenuation (Vasagar et al., 2024). Pressure monitoring is structurally simple and cost-effective, providing basic insights into operational conditions, though it lacks multidimensional data and cannot effectively identify structural damage (Ciang et al., 2008; Lopez and Sarigul-Klijn, 2010). Image recognition enables intuitive visualization but relies on favorable environmental conditions and has limited coverage over large areas (Cai et al., 2019; Zhou, 2023). In contrast, fiber-optic sensing provides high sensitivity, supports long-distance continuous monitoring, and is relatively cost-effective (Sun et al., 2025b). Therefore, fiber-optic sensing systems offer significant potential for widespread application in pipeline monitoring.
However, similar to traditional electrical sensors, fiber-optic sensing technology still faces data loss (Feng et al., 2019). First, signal interruptions may occur at sensor splicing points due to manufacturing defects or mechanical stress (Kuntoğlu et al., 2021). Second, prolonged use can cause sensor material aging, resulting in failure to acquire valid data. Additionally, external factors such as geological shifts, construction disturbances, and chemical corrosion can damage sensors, affecting data continuity and accuracy (Wright et al., 2019). Moreover, fiber-optic systems typically require long-distance signal transmission, during which signal attenuation at splicing points accumulates along the transmission path and may result in the loss or distortion of valid data (Sun et al., 2025c). Furthermore, environmental noise can obscure or disrupt the original measurement signals, causing further loss of valid information.
Data loss undermines the monitoring system’s ability to perceive critical operational states in real time, compromises data integrity, and reduces analytical accuracy (Lei et al., 2023; Tan et al., 2016). Moreover, it increases the response delay and uncertainty in fault detection. In severe cases, data loss may obscure early risk indicators, weakening the system’s warning capability (Avula, 2021; Jieyang et al., 2023). Furthermore, prolonged data gaps can lead to insufficient accumulation of historical data, impairing trend analysis of pipeline structural performance and lifespan prediction. Consequently, this affects the scientific basis for pipeline safety assessment and management strategy development. Therefore, it is imperative to develop effective solutions addressing data loss in fiber-optic sensing systems.
To address data loss issues, deep learning provides effective technical solutions (Bao et al., 2025; Li et al., 2025a; Ressi et al., 2022, 2024a; Sun et al., 2024a). Deep learning is a machine learning approach based on artificial neural networks, whose core concept is inspired by the structure of the human brain (Liu et al., 2025a; Sun et al., 2024b; Wang et al., 2025a, 2025b, 2025c). It employs multiple layers of nonlinear transformations to automatically extract complex features from data, enabling efficient modeling of large-scale information (Wei et al., 2025). Compared to traditional machine learning, deep learning automatically captures intricate nonlinear relationships within data, thereby reducing reliance on manual feature engineering (Sun et al., 2024c). In the field of data recovery, deep learning leverages spatiotemporal dependencies in incomplete datasets to reconstruct missing information with high accuracy (Lei et al., 2021). Common models for data loss recovery include the standard GAN (Sun et al., 2025c), LSTM-GAN (Pu et al., 2022; Kumari et al., 2024), GRU-GAN (Huang et al., 2022; Shen et al., 2022), Bi-LSTM-GAN (Jiang et al., 2023), and STOA-Bi-LSTM-GAN (Sun et al., 2025c), all of which have demonstrated promising effectiveness in preliminary applications.
Nevertheless, existing models still exhibit several limitations. When applied to time-series data, the standard GAN often suffers from unstable training of the generator and discriminator. It fails to effectively capture sequential dependencies, resulting in imputed values that deviate from actual dynamic patterns (Ren and Xu, 2019). LSTM-GAN and GRU-GAN alleviate this issue by employing recurrent neural networks (LSTM or GRU), thereby improving the ability to model long-term dependencies. However, these models remain vulnerable to vanishing or exploding gradients when processing multivariate or long-sequence data. Their performance is also highly sensitive to hyperparameter settings, such that minor deviations can lead to overfitting or unstable generation (Wan and Liu, 2023). BiLSTM-GAN enhances modeling by leveraging both past and future contextual information, yet it is still prone to mode collapse, unstable convergence, and challenging hyperparameter optimization (Wan, et al., 2023). STOA-BiLSTM-GAN demonstrates strong results across multiple benchmark datasets, but its high complexity and intensive training requirements hinder scalability in large-scale industrial applications. Therefore, there is an urgent need for a novel deep learning framework that maintains recovery accuracy while reducing model complexity and computational cost, thereby enhancing practicality and scalability.
Based on this, the study proposes a novel PDO-BiGRU-GAN model that integrates the prairie dog optimization algorithm (PDO), bidirectional gated recurrent units (BiGRU), and generative adversarial network (GAN). This model is designed to recover missing fiber-optic sensing data. Monitoring data from an open-source pipeline project were used to construct a pipeline monitoring dataset. Hyperparameter sensitivity analysis and ablation experiments were performed to evaluate the necessity and contribution of each module. The impact of ratios of missing data and the number of missing sensors on the recovery performance of the PDO-BiGRU-GAN model was analyzed. Furthermore, the model’s accuracy and computational efficiency were compared with eight existing deep learning models.
The main contributions and innovations of this study are as follows: First, a novel PDO-BiGRU-GAN deep learning framework was developed. This framework integrates the hyperparameter optimization capability of the PDO module, the temporal feature extraction capability of the BiGRU module, and the data generation and imputation ability of the GAN module. Second, fiber-optic monitoring data were obtained from an open-access pipeline project, and the model was systematically evaluated through hyperparameter sensitivity analysis and ablation studies. Additionally, the proposed model was compared with eight existing mainstream models in terms of accuracy and computational efficiency under varying missing-data scenarios. Overall, the proposed framework provides a new approach for imputing missing pipeline monitoring data and plays a crucial role in ensuring the completeness of pipeline monitoring information.
Motivation for developing the PDO-BiGRU-GAN network
2
To address the issue of missing monitoring data, numerous studies have focused on developing techniques for managing missing values in time-series data. Traditional approaches can be broadly categorized into two types. The first involves case deletion, which removes observations containing missing values to avoid their impact on analytical results (Schafer and Graham, 2002; Silva and Zárate, 2014). The second includes statistical methods, such as spline interpolation, matrix completion, and mean imputation, which replace missing data points based on statistical estimates (Gu et al., 2021). However, these methods have notable limitations. First, they exhibit limited capability in modeling temporal dependencies and often fail to capture complex dynamic relationships among variables. Second, their performance becomes unstable under conditions with a high missing ratio, leading to substantial errors (Zhang and Wang, 2024). Finally, they struggle to accurately reconstruct the underlying data distribution, particularly when the interactions among multiple features are intricate (Zhang and Wang, 2024). Consequently, traditional methods often fail to meet the accuracy and reliability requirements for reconstructing pipeline monitoring data.
In recent years, researchers have explored the use of GANs to recover missing data. Unlike traditional methods, GANs can model the underlying data distribution, thereby enabling high-quality data imputation. This capability enhances the completeness and reliability of the recovered data. The advantages of GANs are particularly pronounced in multivariate time-series analysis. They can not only impute individual missing values but also maintain complex dependencies among variables (Oh et al., 2021). Moreover, the generative framework of GANs enables adaptation to diverse missing data patterns, improving the robustness and flexibility of recovery outcomes (Gong et al., 2022). Studies have demonstrated that GANs achieve high accuracy in handling missing data, providing strong support for data analysis, prediction, and decision-making across various domains (Kachuee et al., 2020).
GANs have been widely applied to data recovery tasks. However, existing GAN-based approaches often neglect the interrelationships among variables and the bidirectional temporal dependencies inherent in time-series data (Wu et al., 2021). An ideal time-series imputation method should capture both characteristics while accurately modeling the underlying data distribution. Integrating temporal feature extraction modules into the GAN framework can therefore enhance model performance. Among temporal feature extraction networks, recurrent neural networks (RNNs) are particularly well-suited for modeling complex temporal dependencies. Nevertheless, they exhibit inherent limitations, including a restricted ability to extract fine-grained information and susceptibility to gradient explosion and vanishing. These issues reduce training efficiency and limit their applicability in temporal feature extraction tasks (Li et al., 2024). Recent advances in RNN architectures have addressed some of these challenges. In particular, the development of GRUs mitigates the vanishing gradient problem, accelerates convergence, and reduces computational uncertainty (Noh, 2021). Building on this, BiGRUs were introduced to process sequences in both forward and backward directions. Compared with BiLSTMs, BiGRUs retain the ability to model long-term dependencies. They also maintain a simpler structure, have fewer parameters, offer higher computational efficiency, and enable more stable training. They also demonstrate reduced sensitivity to overfitting in small datasets or noisy environments. BiGRUs excel at capturing both local temporal patterns and global trends, effectively lowering predictive uncertainty and alleviating forgetting effects. Therefore, embedding a BiGRU module within a GAN framework leverages the generative adversarial mechanism to approximate the original data distribution. It also fully exploits bidirectional temporal dependencies for feature modeling. This approach achieves higher accuracy and more robust performance in time-series missing value recovery tasks.
Furthermore, the performance of the BiGRU-GAN network is strongly influenced by hyperparameter configurations (Richter et al., 2024). Existing studies typically rely on manual trial-and-error to identify optimal parameter combinations, a process that is both inefficient and prone to producing suboptimal predictive results. Consequently, the use of advanced optimization algorithms for automated hyperparameter search is essential. Inspired by prairie dogs’ natural behaviors, Ezugwu et al. (2022) proposed the PDO algorithm. They compared PDO with several classical optimization methods, including the arithmetic optimization algorithm (Abualigah et al., 2021), grey wolf optimizer (Mirjalili et al., 2014; Sun et al., 2024d), differential evolution optimizer (Kosorukoff, 2001), salp swarm optimizer (Mirjalili et al., 2017), biogeography-based optimizer (Simon, 2008), sine cosine optimizer (Mirjalili, 2016), particle swarm optimizer (Kennedy and Eberhart, 1995; Sun et al., 2023a), and dwarf mongoose optimizer (Agushaka et al., 2022). Experimental results demonstrate that PDO excels in searching for the global optimum and exhibits a more stable convergence process than many of these algorithms. Statistical analyses further confirm its robustness in balancing exploration and exploitation. By leveraging these advantages, PDO can be integrated into the BiGRU-GAN framework to significantly improve hyperparameter search efficiency, thereby enhancing predictive accuracy and model stability. Based on this approach, the present study develops a PDO-BiGRU-GAN network to better capture the spatiotemporal correlations between missing and available data.
Basic principles of the PDO-BiGRU-GAN network
3
This study proposes a novel hybrid model, PDO-BiGRU-GAN, for missing data imputation. This model consists of three components: the PDO module, the BiGRU module, and the GAN module. The BiGRU module models the bidirectional temporal dependencies between available and missing data, thereby enhancing the representation of time series information (Du et al., 2019). The PDO module optimizes critical hyperparameters of the BiGRU model (learning rate, batch size, units per layer, and number of layers) to improve training efficiency and generalization performance. The GAN module introduces an adversarial mechanism to further enhance the realism and distribution consistency of the recovered data. The following sections provide a detailed explanation of the principles underlying each module of the PDO-BiGRU-GAN network.
BiGRU module
3.1
The GRU is an improved variant derived from the long short-term memory (LSTM) network. It merges the forget gate and the input gate of the LSTM into a single update gate (Richter et al., 2024). By integrating the cell state and hidden state of the LSTM, the GRU effectively mitigates the vanishing and exploding gradient problems encountered in modeling long-term dependencies. Furthermore, this architecture enhances both the convergence speed and computational efficiency of the model. The GRU primarily consists of two gates: the reset gate and the update gate, which, respectively, regulate the forgetting and retention of information before and after data transmission. This mechanism enables effective control and propagation of information within the neural units. The computational formulas of the GRU are presented in Equation 1.
Where r_t_ denotes the reset gate; Z_t_ represents the update gate; h_t_ is the output; is the candidate activation; and σ denotes the sigmoid activation function.
BiGRU is an extension of the GRU model that integrates information flow from both forward and backward directions, thereby enhancing its ability to process time series data. By simultaneously capturing dependencies in both directions, the model achieves a more comprehensive understanding of the dynamic patterns within time series. Compared to the unidirectional GRU, BiGRU more effectively captures intricate temporal features, significantly improving prediction accuracy. This model maximizes the extraction of key features relevant to forecasting, resulting in enhanced precision and stability. The computational formulas of the model are shown in Equation 2. A schematic diagram of the BiGRU architecture is presented in Figure 1.
Structure diagram of the BiGRU model.
PDO module
3.2
The hyperparameters of the BiGRU network (learning rate, batch size, number of neurons per layer, and number of layers) significantly affect its performance in data recovery. Selecting appropriate hyperparameters is crucial for enhancing the model’s training effectiveness and overall predictive accuracy. In view of this, this study employs the PDO module to optimize the BiGRU’s hyperparameters. The PDO algorithm is inspired by two primary behaviors of prairie dogs: foraging and burrowing (Ezugwu et al., 2022; Sun et al., 2024e). During the foraging phase, prairie dogs search for new food sources within a certain area and communicate the location of food to other individuals. They also estimate the required burrowing effort based on the quality of the discovered food. In the burrowing phase, prairie dogs move according to the shared food location information and hide in burrows to evade predators. The algorithm divides the total number of iterations into four equal stages: the first two simulate foraging behavior, while the last two simulate burrowing behavior. This staged approach allows PDO to balance exploration and exploitation dynamically, thereby enhancing the effectiveness of hyperparameter optimization.
During the foraging phase, the algorithm further divides the total number of iterations evenly. When the iteration count satisfies t < Max_iter/4, individuals explore new food sources across the entire search space. The position update method for this phase is given by Equation 3.
Where GBest_i,j_ represents the global best position, ρ denotes the food source alert level, CX_i,j_ refers to the random cumulative effect of all individuals, and CBest_i,j_ indicates the current best position. The function Levy(n) follows the Levy distribution, which enhances the diversity of food source exploration and strengthens the algorithm’s global search capability.
The calculation formulas for GBest_i,j_ and CX_i,j_ are presented in Equations 4 and 5, respectively.
Where Δ represents the difference between individuals; ub and lb denote the upper and lower bounds of the search space, respectively; rX refers to the position of a randomly selected individual.
When the iteration count satisfies Max_iter/4 ≤ t ≤ Max_iter/ 2, the algorithm enters the phase of evaluating food quality and determining the mining intensity, as detailed in Equation 6.
Where DS represents the mining intensity.
During the first half of the burrowing activities, when the iteration count satisfies Max_iter / 2 ≤ t < 3 Max_iter / 4, the algorithm evaluates the quality of the food sources. The position update method is as follows:
Where ε represents the quality of the food source, and rand is a random number between 0 and 1.
When the iteration count satisfies 3Max_iter /4 ≤ t < Max_iter, the prairie dogs retreat to their burrows to observe predators.
Where PE represents the predator effect, as defined in Equation 9.
Based on the above principle, this study integrates the PDO module with the BiGRU model. The PDO module systematically explores near-optimal combinations of hyperparameters (learning rate, batch size, the number of neurons per layer, and the number of network layers) by employing a predefined behavioral mechanism. Specifically, the learning rate is optimized within the range of [1e-4, 1e-2], ensuring a stable and efficient training process while preventing gradient explosion or slow convergence. The batch size is set between 16 and 256, enabling adaptive adjustments during mini-batch gradient descent; this facilitates efficient GPU memory utilization while preserving the model’s generalization capability. The number of layers is restricted to 1–4 to effectively mitigate gradient explosion during deep network training (Yang et al., 2016). The number of neurons per layer is optimized within the range of 32–256 to enhance the model’s capacity to capture temporal features while minimizing the risk of overfitting (Siami-Namini et al., 2019). In each iteration, the algorithm identifies a relatively optimal solution and updates the current configuration according to a specific replacement strategy. Through continuous iteration, the quality of the hyperparameter configuration progressively improves. Figure 2 illustrates the overall architecture of the PDO-BiGRU model.
Flowchart of the PDO-BiGRU model.
GAN module
3.3
GANs are innovative deep learning architectures that demonstrate superior performance in data generation and complex distribution modeling tasks. The model consists of two main components: a generator and a discriminator. The generator learns the distribution characteristics of real data to produce highly similar synthetic samples, while the discriminator aims to distinguish whether the input data originates from the real dataset. These components are trained jointly through an adversarial process, where continuous competition drives ongoing improvements in model performance (Alqahtani et al., 2021). During training, the generator attempts to create samples that can “fool” the discriminator, whereas the discriminator strives to accurately differentiate between real and generated data. The loss functions for both components, which measure adversarial effectiveness and training convergence, are presented in Equations 10, 11.
Where L_D_ and L_G_ denote the discriminator and generator loss functions, respectively. P_r_ is the true data distribution derived from the training set. P_z_ is the distribution of the data generated by the generator. The variable z is a latent variable drawn from a predefined prior distribution. D(x) indicates the discriminator’s output score for a real data sample x. G(z) refers to the synthetic data sample produced by the generator given the input z. D(G(z)) reflects the discriminator’s assessment of the generated data sample.
PDO-BiGRU-GAN network
3.4
This study proposes a time series imputation model—PDO-BiGRU-GAN—that integrates the PDO, BiGRU, and GAN. The model leverages BiGRU’s capability in capturing bidirectional temporal dependencies, PDO’s efficiency in hyperparameter optimization, and GAN’s potential in generating high-quality data. When addressing missing values in time series, the proposed approach demonstrates superior accuracy and robustness. In the modeling process, the generator receives time series data with missing values and utilizes a PDO-BiGRU architecture to extract bidirectional temporal features. Through adversarial training, it continuously generates data samples that increasingly resemble the real ones. Meanwhile, the discriminator distinguishes between generated and original samples, providing gradient feedback to the generator to enhance output quality. The training process is grounded in game-theoretic principles, where the generator and discriminator undergo iterative adversarial optimization, progressively enhancing the model’s imputation capability. To improve training stability, gradient penalty is applied to the discriminator. These strategies collectively reduce training oscillations and prevent overfitting, ensuring robust and reliable model convergence. The corresponding loss functions are defined in Equations 12–16.
Where L_R_ denotes the reconstruction loss, which measures the discrepancy in alignment of the model-generated sequence with the original incomplete input. L_C_ refers to the calibration loss, which quantifies the deviation between the forward- and backward-generated sequences in a time series. L_G2_ represents the discriminator loss, which evaluates the authenticity of the generated data. k serves to modulate the relative impact of the discriminator loss compared to the reconstruction loss in the total loss formulation.
Based on this approach, the study employs the PDO-BiGRU-GAN network to learn spatiotemporal dependencies from available data to infer missing values, thereby enabling the recovery of pipeline monitoring data. Figure 3 presents the network architecture, illustrating the workflow of the proposed model. The pseudocode of the PDO-BiGRU-GAN network is provided in Appendix 1.
Illustration of the PDO-BiGRU-GAN network architecture.
Introduction to the engineering case
4
The data used in this study were obtained from an open-access monitoring database released by the project owner. All data were standardized according to a unified format to facilitate subsequent data analysis and model development. The implementation of the open-access mechanism has significantly improved the accessibility and reusability of engineering monitoring data, providing a reliable and authentic foundation for this research. A brief overview of the project background is presented below.
This study is based on a typical open-access data project from a natural gas pipeline engineering initiative in Hebei Province, China. The project, organized and implemented by the owner, deployed an advanced fiber optic sensing monitoring system along an operational gas pipeline. This system covers five key monitoring areas to enable real-time and continuous surveillance of the pipeline’s operational status (Figure 4). Upon project completion, the collected monitoring data were made available to research institutions, providing a multidimensional platform for academic analysis and methodological validation.
Pipeline layout and monitoring areas: (a) Five key areas; (b) Schematic diagram of sensor deployment in area.
This study focuses on Area 2 as the primary research area, emphasizing the analysis of monitoring data collected by long-gauge fiber Bragg grating (FBG) sensors within this area. A dual-end data acquisition mode is employed, which enhances system stability and improves fault tolerance in the event of single-point sensor failure. Figure 4B illustrates the layout of the long-gauge FBG sensors in Area 2. All sensors were installed in strict accordance with national technical standards and industry regulations (DB32/T 2880-2016, 2016; TSG D7005-2018, 2018). Data acquisition was performed using the MOI Sm125-500 demodulator, ensuring high precision and reliability. The construction cost of the monitoring system approached one million yuan. The system was completed and put into operation on November 1, 2023, with data collection commencing on the same day.
Database construction and preprocessing
5
Database construction
5.1
Section 3 briefly introduces the basic overview of the pipeline monitoring project. Based on the project’s open-source data, this study conducted relevant analyses. Fiber-optic monitoring data exhibit high sensitivity to environmental factors. Under normal weather conditions, the data primarily correlate with variations in temperature and pipeline deformation. However, under rainy conditions, the changes in fiber-optic monitoring data become more complex, influenced by multiple factors such as rainfall, temperature, pipeline deformation, and groundwater levels. As an initial exploration into pipeline monitoring data recovery, this study focuses on analyzing the feasibility of recovering fiber-optic monitoring data under normal weather conditions. Specifically, the data were collected on January 15, 2024, with sensors sampling at 1 Hz. A total of 86,400 data sets were obtained that day, each containing monitoring information from 14 sensors. Subsequently, a database was constructed based on this data set. Two methods were considered for database construction: (1) Strain-based method: This method derives strain data by removing the temperature component from wavelength shifts. However, it requires additional temperature sensors, which may introduce measurement errors and reduce the spatiotemporal consistency of the dataset. (2) Wavelength difference method: This method calculates the difference between the wavelength measured on the collection day and the reference wavelength recorded on November 1, 2023. Because wavelength shifts inherently reflect both strain and temperature effects, directly using wavelength differences better preserves the spatiotemporal characteristics of the sensor data and improves the reliability of data recovery. Given these advantages, this study adopts the wavelength difference method for database construction. The constructed database is shown in Figure 5.
Database construction: (a) Path 1; (b) Path 2.
On this basis, it is necessary to further examine the causes and potential types of missing data to enable the construction of an incomplete dataset. Unlike conventional electrical sensors, the FBG sensors used in this study include multiple measurement points along a single optical fiber. This configuration results in distinctive data loss mechanisms. The main causes are as follows: (1) construction activities near the pipeline may render multiple sensors within localized regions unavailable. (2) Optical fibers are typically spliced, and splice points are prone to breakage, leading to partial data loss. (3) Individual FBG sensors may fail due to damage or aging. In this case, the optical path remains intact, but valid measurements cannot be obtained (Wu et al., 2020). (4) Signal attenuation occurs during long-distance optical transmission. Without proper amplification, excessive attenuation prevents correct data interpretation at the receiving end, resulting in data loss (Torres et al., 2011). Collectively, these factors contribute to the occurrence of missing data in pipeline monitoring.
FBG monitoring systems typically perform signal demodulation via single-end wiring. However, a break in the optical fiber may prevent downstream sensors from functioning. To mitigate this risk, a dual-end redundant wiring strategy was implemented in this study (Figure 4). This strategy ensures that a fault in one sensor does not compromise the monitoring of others, thereby minimizing the overall system impact. Based on this sensor architecture and relevant literature (Jiang et al., 2022; Tien et al., 2024), missing sensor data are classified into two types: single-sensor loss and multiple-sensor loss. To investigate these scenarios, several incomplete datasets were constructed to simulate different conditions: (1) Single-sensor loss with proportions of 1/24, 8/24, 16/24, 20/24, and 22/24; and (2) Multiple-sensor loss involving 2/14, 4/14, 8/14, and 14/14 sensors. Figure 6 illustrates the incomplete datasets, while Table 1 summarizes key information. This completes the construction of the incomplete database.
Database preprocessing
5.2
Section 5.1 presents the construction of various types of incomplete datasets based on engineering data. Before inputting these multi-condition incomplete datasets into the PDO-BiGRU-GAN network, data normalization is a critical preprocessing step (Liu et al., 2025b; Sun et al., 2025d). Normalization eliminates dimensional inconsistencies among features, ensuring that variables vary within comparable numerical ranges (Lv et al., 2023; Sun et al., 2023b). This reduces the risk of gradient shift and enhances model stability during training. Moreover, mapping raw data to a unified scale improves training efficiency, accelerates convergence, and mitigates the likelihood of the model becoming trapped in local minima (Li et al., 2025b). The specific normalization formula is provided in Equation 17 (Xie et al., 2025a).
Where Qi and G_i_ are the original and normalized values of measured data, respectively. Qmax and Qmin are the maximum and minimum values of measured data, respectively.
Analysis of data recovery results based on the PDO-BiGRU-GAN network
6
Using incomplete datasets and the PDO-BiGRU-GAN network, this study investigates data recovery performance under various missing data scenarios. The experiments were conducted on the TensorFlow platform with hardware comprising 256 GB of memory, an NVIDIA TITAN X (Pascal) GPU, and two Intel Xeon(R) E5-2696 v4 processors, ensuring efficient handling of large-scale computations. Specifically, Section 6.1 analyzes the model’s hyperparameter sensitivity to demonstrate the necessity of integrating the PDO module. Section 6.2 employs ablation experiments to evaluate the contribution of each module to overall performance. Section 6.3 examines recovery performance across different missing data ratios (1/24, 8/24, 16/24, 20/24, and 22/24). Section 6.4 further assesses recovery under multiple sensor missing scenarios (2/14, 4/14, 8/14, and 14/14). Section 6.5 examines the model’s computational time. Additionally, to comprehensively evaluate the proposed model’s effectiveness, it is compared against eight existing deep learning methods.
Hyperparameter sensitivity analysis
6.1
This study employs the PDO module to optimize four key hyperparameters: learning rate, batch size, units per layer, and number of layers. The rationale for focusing on these hyperparameters is explained as follows. The learning rate controls the speed of parameter updates. An excessively high learning rate can cause oscillation or divergence, while a rate that is too low may result in slow convergence or entrapment in local optima (Dohare et al., 2024). Batch size directly affects both generalization and computational efficiency. Smaller batches increase the stochasticity of gradient estimates, thereby enhancing generalization, whereas larger batches enable faster computation and more stable convergence (Offiong et al., 2023). The number of neurons per layer determines the representational capacity of each layer. Too few neurons can lead to underfitting, while too many may cause overfitting and substantially increase computational cost. Network depth, indicated by the number of layers, reflects the model’s capacity for feature extraction. Shallow networks may fail to capture long-term dependencies, while excessively deep networks can suffer from vanishing gradients, overfitting, and training instability (Offiong et al., 2023). Given these considerations, the PDO module focuses on optimizing these four hyperparameters to enhance model performance while controlling computational costs. In contrast, secondary hyperparameters, such as dropout rate or regularization coefficients, exert only indirect effects. Including them would significantly expand the search space, potentially increasing computational costs and reducing optimization efficiency (Bian and Priyadarshi, 2024). Therefore, this study excludes them from the optimization process.
Illustration of the incomplete dataset: (a) Missing data ratio 1/24; (b) Missing data ratio 8/24; (c) Missing data ratio 16/24; (d) Missing data ratio 20/24; (e) Missing data ratio 22/24; (f) Missing data from 2 sensors; (g) Missing data from 4 sensors; (h) Missing data from 8 sensors; (i) Missing data from 14 sensors.
To evaluate the effectiveness of the PDO module in hyperparameter optimization, this study conducts a hyperparameter sensitivity analysis. This approach assesses the model’s performance variations across different hyperparameter configurations, thereby demonstrating the necessity of integrating the PDO module. Table 2 presents the configurations of learning rate, batch size, units per layer, and number of layers automatically selected by the PDO module across various recovery tasks. These results indicate that the PDO module can select appropriate hyperparameter combinations based on task characteristics. Specifically, when the missing ratio is relatively low (e.g., 1/24), the model tends to adopt a higher learning rate (0.02), a smaller batch size (32), a shallow two-layer structure, and an asymmetric distribution of units (98). This “low-capacity–shallow” configuration reduces complexity and mitigates overfitting while preserving temporal features. In contrast, under a higher missing ratio (e.g., 20/24), the model prefers a lower learning rate (0.0011), a larger batch size (128), a larger number of units (196), and a deeper three-layer stacked structure. Such a configuration enhances the generative adversarial network’s ability to model sparse data and enables it to capture long-term dependencies through increased depth. Further analysis involves varying each hyperparameter sequentially to assess the tuning effect of the PDO module, as shown in Figure 7. It is evident that the hyperparameter configurations selected by the PDO module yield the lowest MSE, thereby achieving optimal tuning and enhanced model performance. Overall, the hyperparameter sensitivity analysis demonstrates that the PDO module exhibits strong adaptability to varying task complexities by dynamically adjusting hyperparameter settings, thereby enhancing the accuracy of data recovery.
Hyperparameter sensitivity analysis: (a) Missing data ratio 1/24; (b) 2 Missing sensors.
Ablation study analysis
6.2
Ablation experiments selectively remove specific components of a model to evaluate their impact on overall performance. This approach effectively confirms the necessity and contribution of each module in the model architecture. Based on this methodology, the present study analyzed three models—GAN, BiGRU-GAN, and PDO-BiGRU-GAN—via selective module removal (Table 3). Initially, loss curves were plotted for the three models under a missing data ratio of 1/24 (Figure 8). The basic GAN model exhibited a rapid decrease in loss; however, its loss curves displayed pronounced fluctuations, indicating instability in missing data recovery tasks. Incorporating the BiGRU module (BiGRU-GAN) produced smoother loss curves, demonstrating that the integration of temporal information enhances model stability and generalization. Further addition of the PDO module in PDO-BiGRU-GAN achieved more favorable convergence characteristics. Loss decreased rapidly and stabilized at a low level, indicating that PDO-based hyperparameter optimization significantly improves training efficiency and overall model performance. The contributions of each component were further assessed under varying data missing ratios of 1/24, 8/24, and 16/24 (Table 3). The results indicate that removing either the PDO module or the BiGRU structure degrades the model’s predictive capability. Specifically, when the missing data ratio ranges from 1/24 to 16/24, excluding the PDO module leads to increases in mean absolute error (MAE) by 9.80–21.88%, root mean square error (RMSE) by 18.30–23.05%, mean absolute percentage error (MAPE) by 16.72–27.23%, and MSE by 33.26–40.79%, while coefficient of determination (R^2^) decreases by 0.53–1.00%. Further removal of the BiGRU structure causes more pronounced performance deterioration: MAE increases by 53.67–60.03%, RMSE by 42.28–61.73%, MAPE by 42.35–57.07%, MSE by 66.68–85.35%, and R^2^ declines by 3.27–5.08%. These findings indicate that the GAN module provides fundamental generative capability, the BiGRU structure captures temporal dependencies to improve reconstruction accuracy, and the PDO module optimizes key hyperparameters to enhance training efficiency and generalization (Ezugwu et al., 2022). The synergistic effect of these three components enables PDO-BiGRU-GAN to achieve optimal performance in data imputation tasks, confirming the necessity and contribution of each module in the model architecture.
Loss curves of the three models (GAN, BiGRU-GAN, and PDO-BiGRU-GAN) under a missing data ratio of 1/24.
Data recovery results of the PDO-BiGRU-GAN model under different missing data ratios
6.3
The pipeline project employed a total of 14 sensors. This section focuses on analyzing three sensors: BL1, BL4, and BL7. The recovery performance of these sensors was evaluated using the PDO-BiGRU-GAN model under varying missing data ratios of 1/24, 8/24, 16/24, 20/24, and 22/24. Figure 9 illustrates five performance metrics of data recovery based on the PDO-BiGRU-GAN model. Notably, all data were normalized to eliminate the influence of differing measurement units (Liu et al., 2025c; Sun et al., 2025e). Overall, the PDO-BiGRU-GAN model demonstrated strong recovery capabilities across all missing data ratios, with the R^2^ consistently above 0.95. Further analysis revealed that as the missing data ratio increased, error metrics (MSE, RMSE, MAPE, and MAE) showed an increasing trend, while R^2^ values gradually decreased. Particularly, a sharp decline in model performance occurred when the missing ratio increased from 20/24 to 22/24. This performance drop is attributed to the significant reduction of available historical data, which impairs the model’s ability to capture the intrinsic temporal patterns of the time series, thus weakening the imputation effect. Under conditions of extreme data sparsity, the model struggles to accurately restore complex features, resulting in substantially higher error metrics and notably lower R^2^ values. Therefore, when employing the PDO-BiGRU-GAN model for data recovery, the missing data ratio within incomplete data windows should be maintained below 20/24 to ensure optimal recovery performance.
Data recovery results based on the PDO-BiGRU-GAN network: (a) BL1; (b) BL4; (c) BL7.
This section presents a detailed comparison between the proposed PDO-BiGRU-GAN model and eight representative data recovery models, aiming to demonstrate its superior performance. These models span from basic generative frameworks to advanced architectures, providing a comprehensive overview of mainstream techniques in time-series recovery tasks. The selected models include the traditional GAN, GRU-GAN, LSTM-GAN, CNN-GRU-GAN, CNN-LSTM-GAN, Bi-GRU-GAN, Bi-LSTM-GAN, and STOA-Bi-LSTM-GAN. These models span from basic generative frameworks to advanced architectures, providing a comprehensive overview of commonly used techniques in time-series recovery tasks. Specifically, the traditional GAN serves as a baseline generative model. GRU-GAN and LSTM-GAN emphasize unidirectional temporal dependencies, making them suitable for capturing long-term trends. Bi-GRU-GAN and Bi-LSTM-GAN capture both past and future dependencies through bidirectional sequence modeling, thereby improving recovery accuracy for rare events or edge cases. CNN-GRU-GAN and CNN-LSTM-GAN extract local temporal features via convolutional layers and combine them with recurrent structures to model multivariate dependencies, thereby enhancing recovery of complex patterns. The STOA-Bi-LSTM-GAN represents the state-of-the-art approach, integrating bidirectional recurrent modeling with optimized training strategies to achieve greater adaptability and stability. To ensure a fair comparison between PDO-BiGRU-GAN and the eight baseline models, all models were trained under identical data preprocessing and normalization conditions (Sun et al., 2024f; Xie et al., 2025b), and with the same computational resources. Notably, PDO-BiGRU-GAN employs the PDO algorithm for automated optimization, whereas STOA-Bi-LSTM-GAN uses the STOA algorithm. The hyperparameters of the remaining seven baseline models were not taken directly from literature values, as optimal settings can vary across different data recovery tasks. Instead, a grid search was conducted to tune these models, ensuring they achieved their best possible performance for the current task and maintaining the objectivity of the comparison.
For clarity, this study selected the recovery results of sensor BL4 under three missing data ratios: 1/24, 8/24, and 16/24. Figure 10 presents radar charts of the performance metrics for all models under these conditions. The results indicate that PDO-BiGRU-GAN consistently achieves the lowest error metrics (MSE, RMSE, MAPE, MAE) and the highest R^2^ across all three scenarios, demonstrating its superior data recovery capability. In contrast, the remaining eight models exhibit varying degrees of performance degradation across the five evaluated metrics. For example, at a missing ratio of 1/24, the PDO-BiGRU-GAN model attained an R^2^ of 0.9902, MSE of 0.001128, RMSE of 0.03358, MAPE of 0.05898, and MAE of 0.02089. Compared to other models, PDO-BiGRU-GAN improved R^2^ by 0.197–3.28%, reduced MSE by 21.77–66.68%, RMSE by 11.55–42.28%, MAPE by 5.25–42.36%, and MAE by 2.93–53.67%. To verify the statistical significance of these performance differences, Wilcoxon signed-rank tests were conducted on R^2^, MAE, RMSE, MSE, and MAPE [see Taheri and Hesamian (2013) and Woolson (2007) for calculation details]. The results indicate that PDO-BiGRU-GAN significantly outperforms all eight baseline models across all metrics (p < 0.05), confirming that its performance improvements are statistically robust and not due to random variation. Overall, the PDO-BiGRU-GAN model exhibits optimal recovery performance across various missing data conditions.
Performance comparison between PDO-BiGRU-GAN and eight models: (a) 1/24; (b) 8/24; (c) 16/24.
Data recovery results of the PDO-BiGRU-GAN model under different numbers of missing sensors
6.4
To assess the model’s robustness in the face of multi-sensor data loss, this section investigates the recovery capabilities of the PDO-BiGRU-GAN model under varying degrees of sensor unavailability. Four missing data scenarios were designed: missing 2 sensors (BL3, UL3), missing 4 sensors (BL3, UL3, BL4, UL4), missing 8 sensors (BL2, UL2, BL3, UL3, BL4, UL4, BL5, UL5), and missing 14 sensors. In all scenarios, data from UL3 and BL3 were reconstructed. To simplify the analysis, only the recovery results of sensors UL3 and BL3 were evaluated. Figure 11 presents the performance metrics of the PDO-BiGRU-GAN model for recovering UL3 and BL3 under different levels of sensor loss. All performance metrics were computed using normalized values to ensure comparability and mitigate the impact of differences in data magnitude. Overall, the results indicate that the PDO-BiGRU-GAN model consistently demonstrates strong recovery performance across all scenarios. The R^2^ values remain generally above 0.93, suggesting that the model effectively captures spatiotemporal features and reconstructs missing data by leveraging latent dynamic correlations among sensors. However, as the number of missing sensors increases, the R^2^ value gradually decreases. Meanwhile, error metrics (MSE, RMSE, MAPE, MAE) increase accordingly, indicating a decline in model performance. This degradation can be attributed to two primary factors: the diminishing volume of available reference data and the growing complexity of underlying data patterns, both of which increase the difficulty of accurately estimating missing values. Despite the observed degradation as the number of missing sensors increases, the PDO-BiGRU-GAN model still exhibits remarkable recovery performance when dealing with multi-sensor data loss. Its advanced capacity for learning temporal–spatial dependencies and modeling nonlinear relationships makes it particularly suitable for recovering critical sensor information under complex operating conditions. These advantages highlight the model’s significant potential for application in intelligent monitoring systems and structural health diagnostics, offering both wide applicability and notable engineering value.
Data recovery results for sensors UL3 and BL3 with multiple missing sensors using the PDO-BiGRU-GAN model: (a) UL3; (b) BL3.
Furthermore, this section provides a comprehensive evaluation of the PDO-BiGRU-GAN model’s recovery performance compared to eight other models under multi-sensor data loss conditions. For brevity, sensor UL3 is chosen as the representative for multi-model comparison. Figure 12 presents the performance metrics of PDO-BiGRU-GAN and the eight compared models. The results demonstrate that PDO-BiGRU-GAN consistently achieves the best performance across all evaluation metrics, exhibiting the lowest error levels and the highest R^2^ values. For example, with eight sensors missing, PDO-BiGRU-GAN attains an R^2^ of 0.9522, MSE of 0.001588, RMSE of 0.03985, MAPE of 0.7209, and MAE of 0.02960. Compared to other models, its R^2^ improves by 0.197 to 3.28%; MSE decreases by 21.77 to 66.68%; RMSE reduces by 11.55 to 42.28%; MAPE declines by 5.25 to 42.36%; and MAE lowers by 2.93 to 53.67%. Consistent with Section 6.3, Wilcoxon signed-rank tests were conducted on the five performance metrics across different numbers of missing sensors. The results show that PDO-BiGRU-GAN outperforms all eight comparison models, with p-values below 0.05 for all metrics, indicating that the performance differences are statistically significant. Overall, the comparison among the nine models indicates that PDO-BiGRU-GAN maintains superior recovery accuracy for UL3 data across different sensor loss scenarios. Furthermore, the model shows similar stable advantages in recovering data from other sensors; however, these results are not detailed here due to space constraints. In summary, PDO-BiGRU-GAN demonstrates excellent imputation capability under multi-sensor data loss conditions and represents a promising approach for this problem.
Data recovery performance of UL3 under multiple missing sensors: (a) 2 Missing sensors; (b) 4 Missing sensors; (c) 8 Missing sensors; (d) 14 Missing sensors.
Computational efficiency analysis
6.5
The PDO-BiGRU-GAN model has a relatively complex architecture and many parameters, resulting in higher computational costs during training and inference. To evaluate its feasibility and deployment potential in practical applications, a systematic assessment of its computation time is necessary. This section compares the computation time of PDO-BiGRU-GAN with eight existing methods under identical task conditions, as shown in Figure 13. Compared with simpler models (standard GAN, GRU-GAN, and LSTM-GAN), PDO-BiGRU-GAN’s computation time increases by approximately 8.77 to 15.11%. Despite this increase, the additional cost is acceptable given the significant improvement in recovery accuracy. Further comparisons show that, relative to more complex architectures (CNN-GRU-GAN, CNN-LSTM-GAN, Bi-LSTM-GAN, and BiGRU-GAN), PDO-BiGRU-GAN’s computation time increases only by 1.25 to 7.32%, indicating that slight computational overhead yields substantial performance gains. Additionally, relative to the most complex STOA-Bi-LSTM-GAN model, PDO-BiGRU-GAN reduces computation time by approximately 3.17 to 7.27%. Overall, PDO-BiGRU-GAN incurs only a slight increase in computational cost compared to simpler models, while outperforming the most complex ones in efficiency. This advantage results from two main factors. First, the PDO algorithm employs a more efficient hyperparameter search strategy, significantly reducing ineffective computations during training (Biswas et al., 2024; Izci et al., 2024). Second, the model architecture preserves essential feature extraction capabilities while avoiding redundant layer stacking, effectively controlling resource consumption and ensuring improved recovery efficiency. In summary, PDO-BiGRU-GAN achieves substantial improvements in recovery accuracy while maintaining controlled computation time, making it a promising model for pipeline monitoring data recovery tasks.
Computation time comparison of nine models across different data recovery tasks: (a) Varying missing data ratios; (b) Multiple missing sensors.
Summary of comparative analysis between PDO-BiGRU-GAN and eight existing models
6.6
Sections 6.3–6.5 systematically compare the performance of PDO-BiGRU-GAN with eight existing models—GAN, GRU-GAN, LSTM-GAN, CNN-GRU-GAN, CNN-LSTM-GAN, BiGRU-GAN, BiLSTM-GAN, and STOA-BiLSTM-GAN—on data reconstruction tasks. This section further summarizes the advantages and limitations of each model and the trade-offs between accuracy and computational cost, as shown in Table 4. In the pipeline monitoring project examined in this study, PDO-BiGRU-GAN emerged as the optimal model based on a trade-off between accuracy and computational efficiency. For future research, investigators can select an appropriate model based on the characteristics in Table 4 and the specific requirements of their projects for data reconstruction.
Discussion
7
This study tackles the prevalent issue of missing data in pipeline monitoring by proposing a novel PDO-BiGRU-GAN framework. The framework integrates three key components: the PDO module for hyperparameter optimization, the BiGRU module for temporal feature extraction, and the GAN module for data generation and distribution approximation. To validate the method, a pipeline monitoring dataset was established using field data collected from actual pipeline projects. The study first analyzes the model’s sensitivity to hyperparameters, demonstrating the necessity of the PDO module in the optimization process. Ablation experiments were then conducted to assess the independent contribution of each module. Furthermore, the proposed model is compared with eight mainstream deep learning models in terms of prediction accuracy and computational efficiency. Overall, the PDO-BiGRU-GAN framework effectively reconstructs missing information in pipeline monitoring from a data-driven perspective, thereby providing more complete and reliable support for pipeline performance evaluation.
Although the proposed PDO-BiGRU-GAN model demonstrates high accuracy in recovering missing data in pipeline monitoring, it has several key limitations. These limitations can be categorized into three areas: the model itself, engineering applicability, and the intelligence of the pipeline monitoring system. Regarding the limitations of the model itself, the PDO-BiGRU-GAN model can generate samples that closely match the statistical characteristics of real data. However, it may struggle to capture rare fault patterns or extreme anomalies, such as those occurring under heavy rain, snow, or pipeline malfunctions. This limitation could potentially pose risks in pipeline monitoring. Future research could focus on modeling such exceptional operating conditions to enhance the model’s learning capability and robustness. Due to the focus and length constraints of the current study, the model’s performance across datasets of varying scales was not examined. Broader investigations into diverse data loss scenarios are required to address this gap. The approach also heavily depends on training data. When historical data are biased or incomplete, the model may produce misleading patterns, compromising the reliability of decisions. To mitigate this, future studies could incorporate physical model constraints, expert knowledge, or multi-source data into the PDO-BiGRU-GAN framework. This would reduce reliance on single historical datasets and improve both anomaly detection and overall predictive performance. Additionally, due to space limitations, this study only explored the combination of GAN and BiGRU modules and validated its effectiveness. Future research could explore the integration of GANs with other recurrent architectures, such as Transformer-based models or temporal convolutional networks, to assess data recovery performance across different frameworks. Finally, the PDO-BiGRU-GAN model is inherently a black-box model, lacking transparency and interpretability in its generation process. In practical applications, false positives or false negatives could complicate responsibility assignment and regulatory compliance. Future work could incorporate interpretability-enhancing techniques, coupled with uncertainty quantification and human-in-the-loop verification, to ensure the safety and reliability of data recovery.
Regarding engineering applicability, several limitations should be noted. First, the model has only been validated on the pipeline project in Tangshan, Hebei. Its generalizability across different pipelines or regions remains unassessed. Future studies could investigate the model’s transferability and adaptability across various pipeline types, geographic regions, and operating conditions. Second, the model requires significant computational resources during training, limiting direct deployment on low-power devices. In this study, it required approximately 2 GB of GPU memory and 4.9 GFLOPs. Future work could explore model lightweighting, parameter compression, and efficient inference strategies to enable deployment on low-power or edge devices. Third, the model can function as a data recovery module within pipeline monitoring systems and can be seamlessly integrated with existing optical fiber or other sensor data acquisition systems. While training in this study was conducted on a high-performance workstation, practical deployment can leverage a single GPU or high-performance CPU depending on data scale and real-time requirements, meeting computational demands for data recovery. From a software perspective, the model was developed on the TensorFlow platform and can interface with existing industrial pipeline monitoring systems, supporting deployment and extension across mainstream deep learning frameworks. Finally, this study applied the model solely to optical fiber sensor data recovery. Future research could extend the model to other sensor types, such as pressure, flow, and temperature, to systematically evaluate its applicability, stability, and cross-sensor generalization. This would further validate the model’s versatility across multi-source heterogeneous monitoring data.
In the context of intelligent pipeline monitoring, blockchain technology can be leveraged to enhance system reliability and automation. It ensures the integrity and traceability of both raw sensor data and AI-reconstructed data. Moreover, smart contracts can automatically trigger alerts or initiate maintenance actions based on recovered signals. For example, when a recovered signal indicates a potential risk, a smart contract can immediately activate warning mechanisms or execute pre-defined maintenance tasks, thereby reducing manual intervention and improving response efficiency. Furthermore, blockchain-based decentralized learning frameworks can improve privacy and robustness in multi-site deployments (Ressi et al., 2024b). Overall, the integration of blockchain, artificial intelligence, and other advanced technologies holds significant promise for advancing intelligent pipeline monitoring and providing a more robust technical foundation for the long-term safety of pipelines.
Conclusion
8
This study developed a novel PDO-BiGRU-GAN network to efficiently recover missing pipeline data. The model’s performance was evaluated using real engineering monitoring data under various types of data loss. The main findings are summarized as follows:
This study developed a novel PDO-BiGRU-GAN network, which integrates the hyperparameter optimization capability of the PDO module, the temporal feature extraction strength of the BiGRU module, and the data generation and imputation functionality of the GAN module. The proposed network was subsequently applied to recover missing data in pipeline monitoring systems.Using an open-access pipeline project, a pipeline monitoring dataset was obtained. This dataset was employed to evaluate the proposed PDO-BiGRU-GAN network. Hyperparameter sensitivity analysis and ablation experiments were conducted to assess the model. The sensitivity analysis demonstrated that the PDO module substantially improved model performance by guiding optimal hyperparameter selection. Ablation experiments further showed that removing either the PDO or BiGRU module led to significant performance degradation, underscoring their essential roles in enhancing data recovery accuracy.The study evaluated the data recovery capability of the PDO-BiGRU-GAN model under various missing-data scenarios. Results demonstrated that the model accurately reconstructed missing values by effectively leveraging underlying spatiotemporal dependencies, achieving an R^2^ greater than 0.93. Furthermore, to maintain optimal recovery performance, the missing data ratio within any given window should not exceed approximately 20/24.The study compared the proposed PDO-BiGRU-GAN model with eight existing models in terms of accuracy and computational efficiency. Results indicated that PDO-BiGRU-GAN achieved the lowest values across all error metrics (MSE, RMSE, MAPE, MAE) and the highest R^2^, demonstrating a clear advantage in accuracy. Moreover, the model’s computation time increased only marginally. Overall, PDO-BiGRU-GAN substantially improved data recovery accuracy while maintaining efficient computational performance, highlighting its promise for pipeline monitoring applications.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abualigah L.Diabat A.Mirjalili S.Abd Elaziz M.Gandomi A. H. (2021). The arithmetic optimization algorithm. Comput. Methods Appl. Mech. Eng. 376:113609. doi: 10.1016/j.cma.2020.113609 · doi ↗
- 2Adegboye M. A.Fung W. K.Karnik A. (2019). Recent advances in pipeline monitoring and oil leakage detection technologies: principles and approaches. Sensors 19:2548. doi: 10.3390/s 19112548, PMID: 31167413 PMC 6603558 · doi ↗ · pubmed ↗
- 3Agushaka J. O.Ezugwu A. E.Abualigah L. (2022). Dwarf mongoose optimization algorithm. Comput. Methods Appl. Mech. Eng. 391:114570. doi: 10.1016/j.cma.2022.114570 · doi ↗
- 4Alqahtani H.Kavakli-Thorne M.Kumar G. (2021). Applications of generative adversarial networks (GA Ns): an updated review. Arch. Comput. Methods Eng. 28, 525–552. doi: 10.1007/s 11831-019-09388-y · doi ↗
- 5Avula R. (2021). Addressing barriers in data collection, transmission, and security to optimize data availability in healthcare systems for improved clinical decision-making and analytics. Applied Research in Artificial Intelligence and Cloud Computing 4, 78–93.
- 6Bao X.Xu K.Liu J.Jin L. (2025). A physics-informed transformer model for long-sequence time-history response prediction of containment structures under mainshock-aftershock sequences. Eng. Struct. 343:121005. doi: 10.1016/j.engstruct.2025.121005 · doi ↗
- 7Bian K.Priyadarshi R. (2024). Machine learning optimization techniques: a survey, classification, challenges, and future research issues. Arch. Comput. Methods Eng. 31, 4209–4233. doi: 10.1007/s 11831-024-10110-w · doi ↗
- 8Biswas S.Shaikh A.Ezugwu A. E. S.Greeff J.Mirjalili S.Bera U. K.. (2024). Enhanced prairie dog optimization with levy flight and dynamic opposition-based learning for global optimization and engineering design problems. Neural Comput. & Applic. 36, 11137–11170. doi: 10.1007/s 00521-024-09648-4 · doi ↗