A Markov Chain Replacement Strategy for Surrogate Identifiers: Minimizing Re-Identification Risk While Preserving Text Reuse
John D. Osborne, Andrew Trotter, Tobias O’Leary, Chris Coffee, Micah D. Cochran, Luis Mansilla-Gonzalez, Akhil Nadimpalli, Alex McAnnally, Abdulateef I. Almudaifer, Jeffrey R. Curtis, Salma M. Aly, Richard E. Kennedy

TL;DR
This paper introduces a new method for replacing personal health information in text to reduce re-identification risks while maintaining data utility for analysis.
Contribution
A novel Markov model strategy for PHI replacement that reduces re-identification risk more effectively than existing methods.
Findings
The Markov strategy significantly reduces PHI leakage compared to standard substitution methods.
Modern deep learning methods perform similarly across all strategies, but older techniques are affected by context changes.
The Markov strategy achieves up to 99.6% reduction in document-level PHI leakage at low error rates.
Abstract
“Hiding in Plain Sight” (HIPS) strategies for Personal Health Information (PHI) replace PHI with surrogate values to hinder re-identification attempts. We evaluate three different HIPS strategies for PHI replacement, a standard Consistent replacement strategy, a Random replacement strategy, and a novel Markov model strategy. We evaluate the privacy-preserving benefits and relative utility for information extraction of these strategies on both a simulated PHI distribution and real clinical corpora from two different institutions using a range of false negative error rates (FNER). The Markov strategy consistently outperformed the Consistent and Random substitution strategies on both real data and in statistical simulations. Using FNER ranging from 0.1% to 5%, PHI leakage at the document level could be reduced from 27.1% to 0.1% and from 94.2% to 57.7% with the Markov strategy versus the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
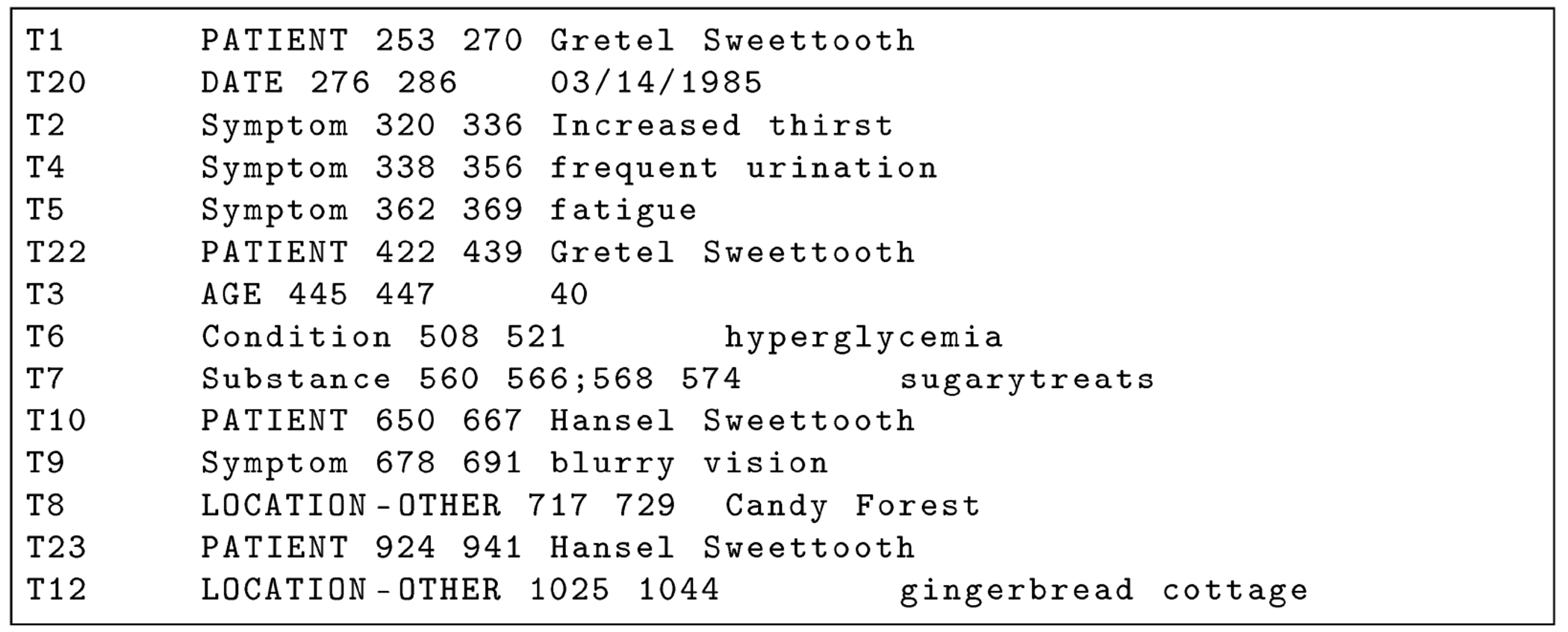 Figure 1
Figure 1 Figure 2
Figure 2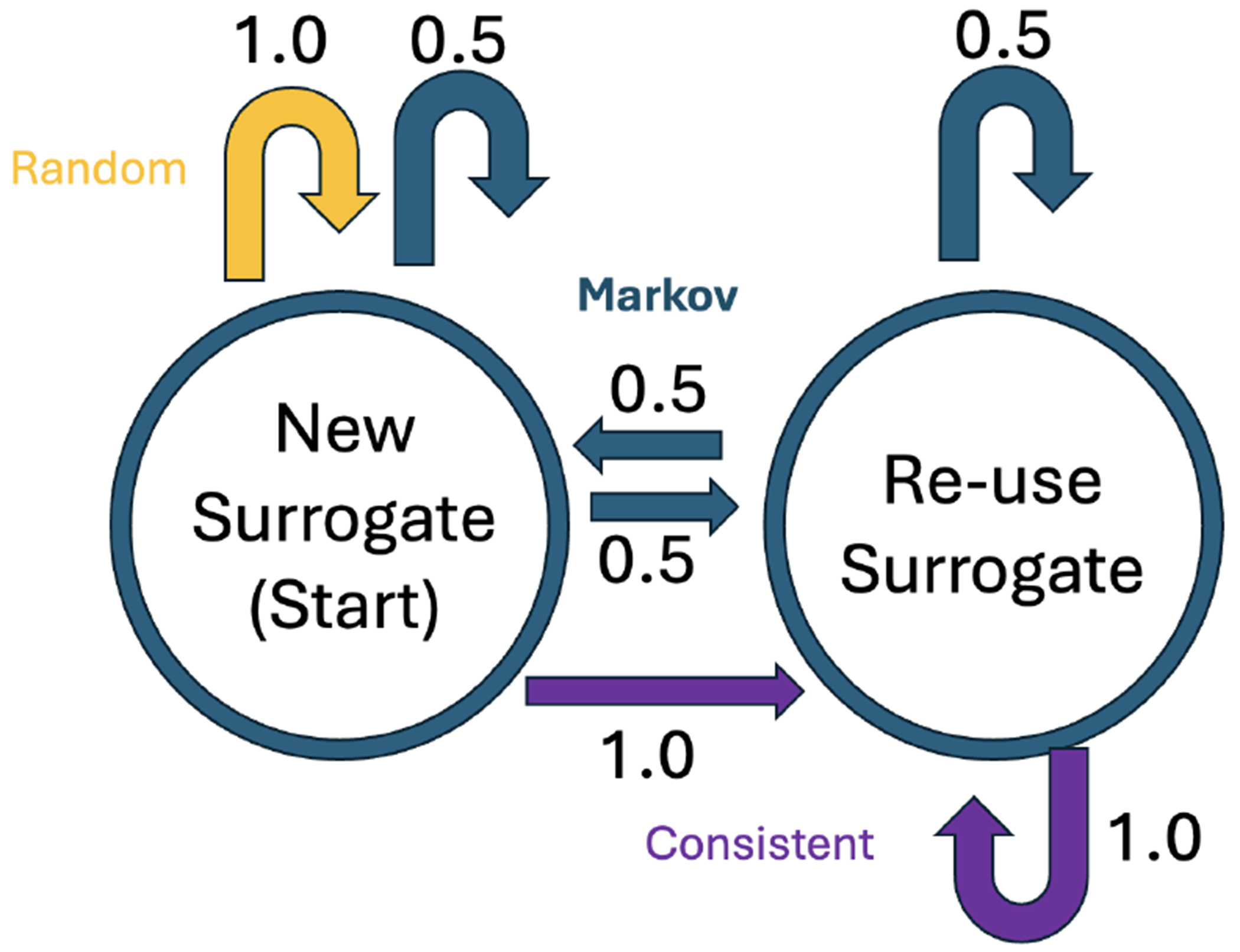 Figure 3
Figure 3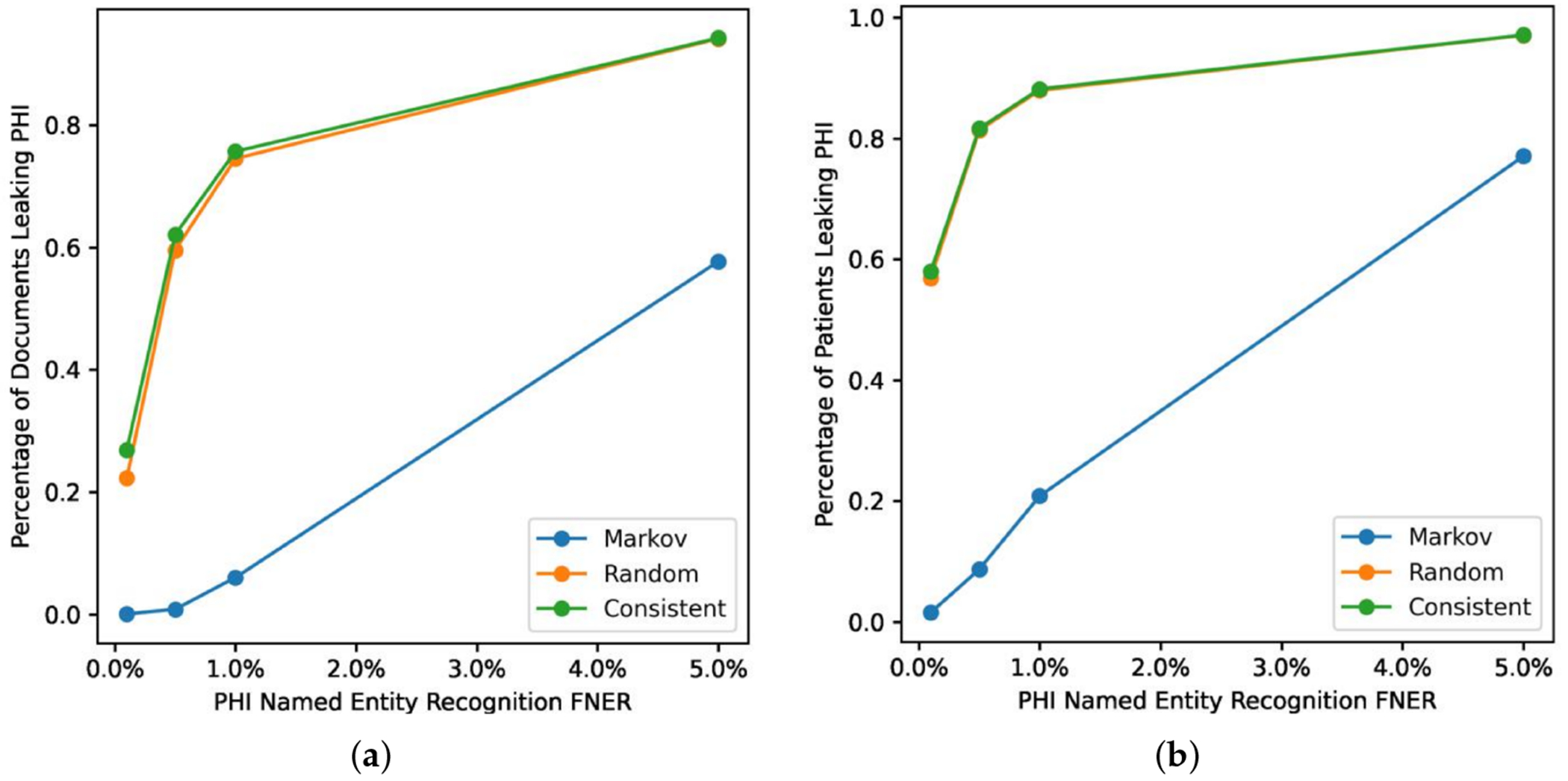 Figure 4
Figure 4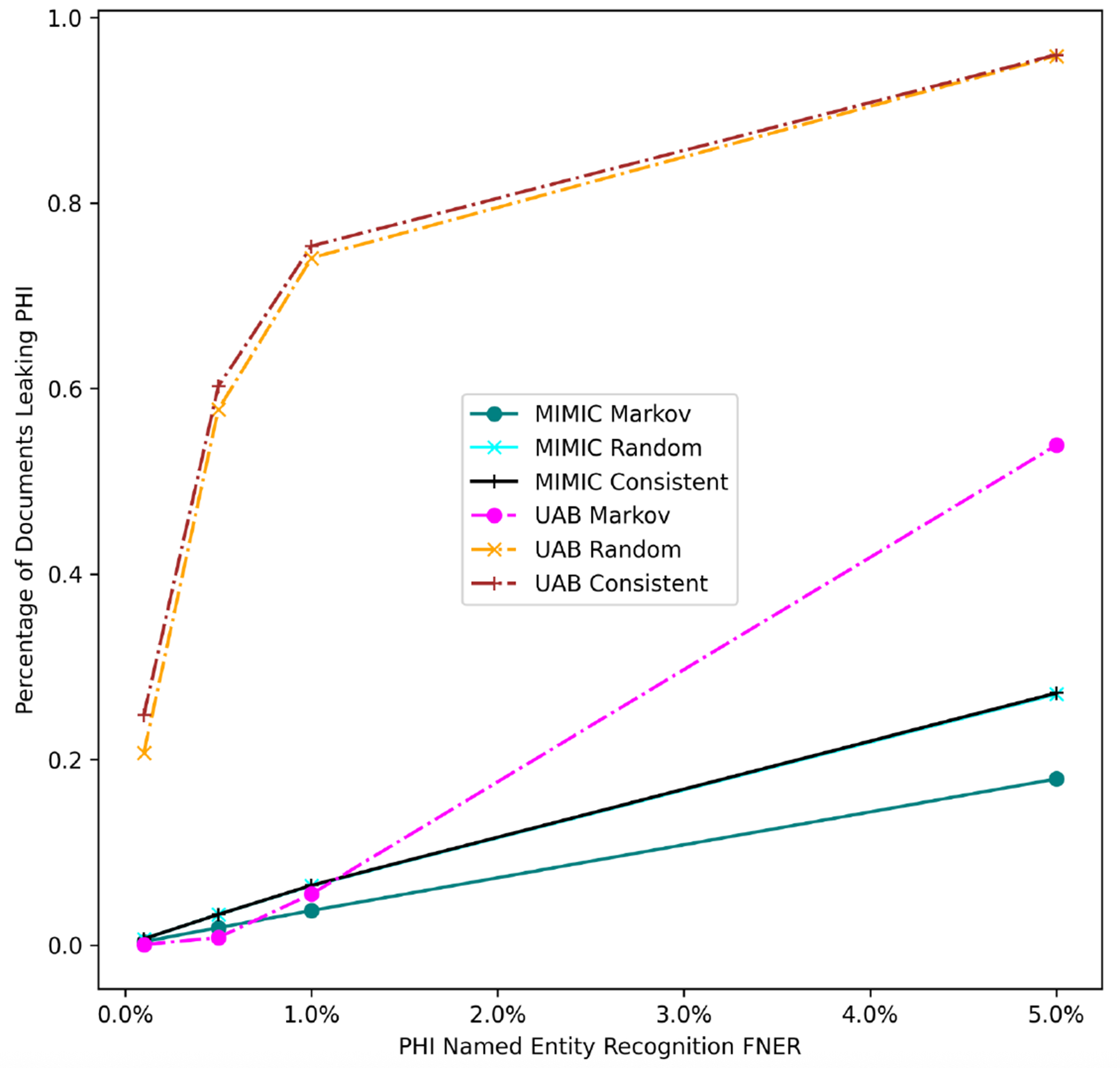 Figure 5
Figure 5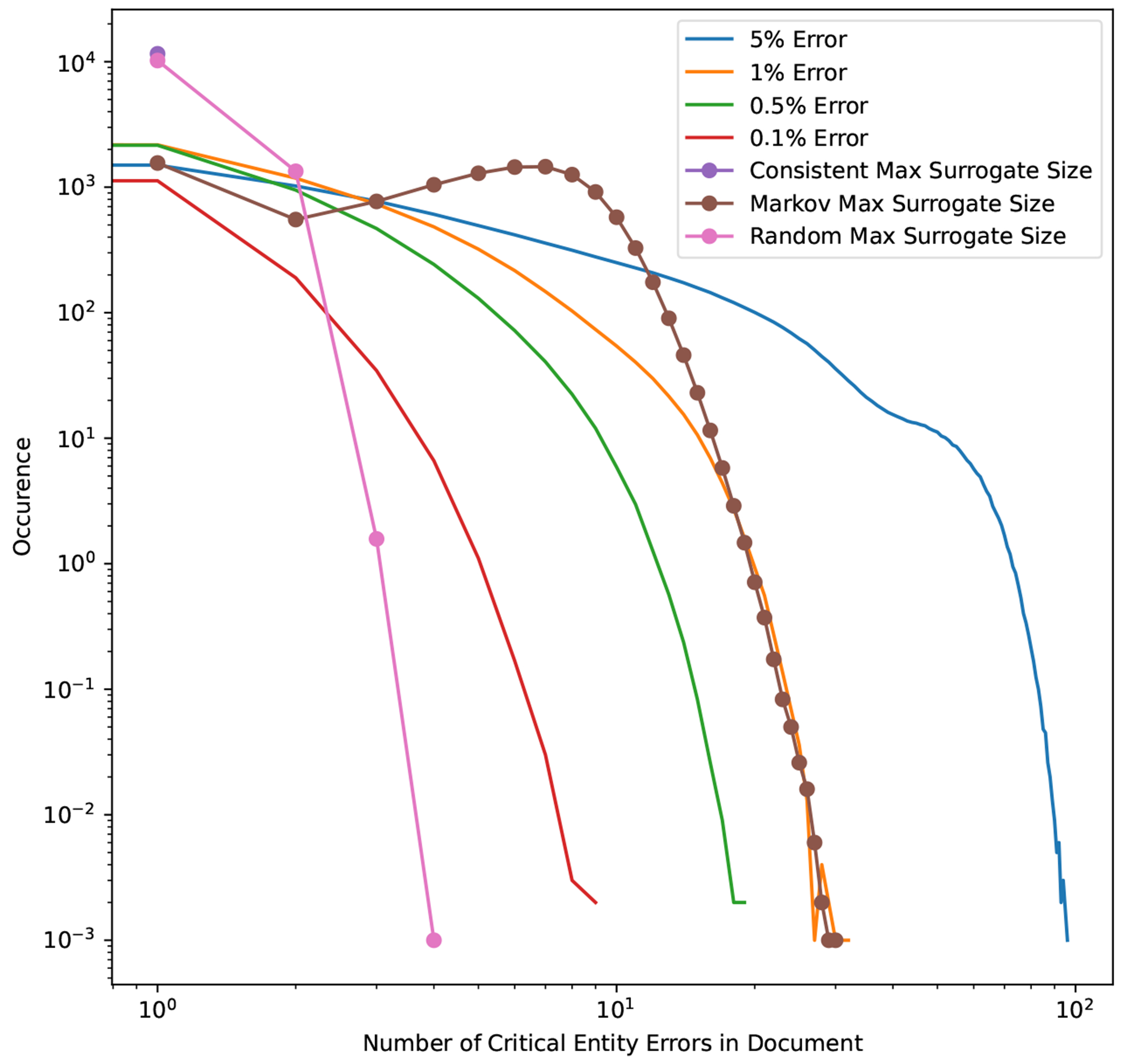 Figure 6
Figure 6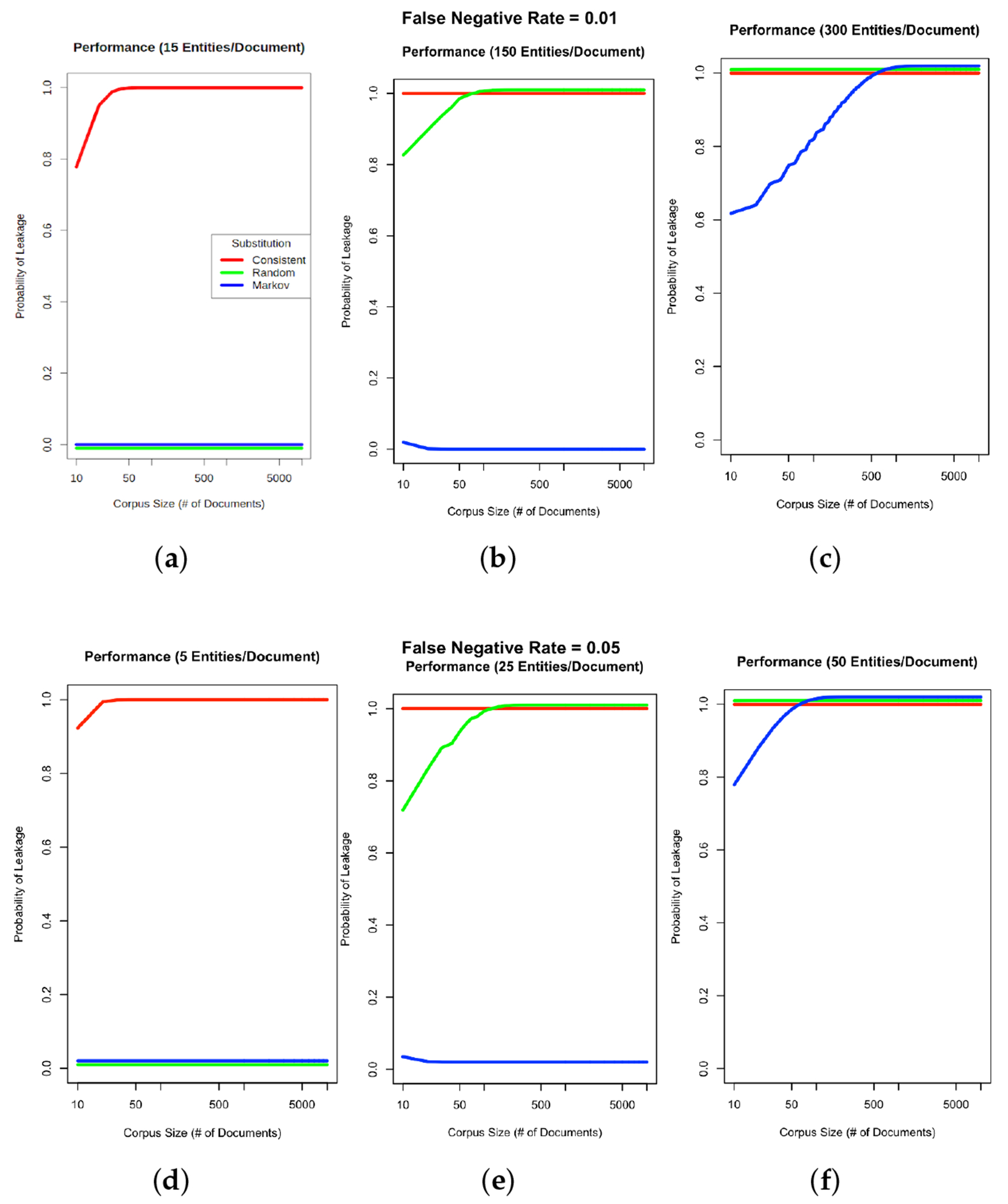 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTopic Modeling · Data Quality and Management · Natural Language Processing Techniques
Introduction
The removal of Personal Health Information (PHI) from medical records to prevent patient re-identification is driven by privacy considerations, legal mandates or other ethical imperatives. Synthetic text may be useful in some circumstances [1–3], but real text typically serves as the ground truth for evaluation even when synthetic text is used for training. The removal of PHI in the healthcare context is termed “de-identification”. In the United States, the governing legal framework for privacy in healthcare is the Health Insurance Portability and Accountability Act (HIPAA), which under section 164.512 of the Privacy Rule provides both the standard and implementation guidelines for two methods of de-identification. The “safe harbor” de-identification method specifies which data elements to remove. Although these elements may be targeted by de-identification software [4], this software may not replace identified PHI with realistic surrogate text. For instance, redacted text may be replaced by the category label of the PHI removed and not resemble the original text, potentially making it more difficult to train machine learning algorithms where training and test data should be similar. The challenge of creating high quality de-identified synthetic text for use with machine learning may lead even large, multi-national corporations to skip the process entirely, leading to PHI data leaks [5]. Most patient re-identification occurs when data is not de-identified according to existing standards [6].
Replacement Text in Existing Software
1.1.
Software has been developed to de-identify clinical text; however, cost, availability, and licensing restrictions have limited public evaluations to only a subset of software [7,8]. Software evaluated has included Amazon’s Comprehend Medical [9], CliniDeID [10,11], National Library of Medicine’s Scrubber [12], NeuroNER [4] and MITRE Identification Scrubber Toolkit [13,14], Massachusetts Institute of Technology de-identification software [15] and Emory Health Information DE-identification (HIDE) software [16]. However, most de-identification software does not provide the option to output realistic replacement text, which is unfortunate because PHI identification at detection time could suggest a more appropriate replacement. Some exceptions to this include CliniDeID, Stanford’s HIPS [17] and nference De-Id [18]. CliniDeID uses entity-specific randomly selected values that are applied consistently across the record as surrogates, HIPS [17] uses curated lists to generate realistic replacements and nference De-Id [18] uses a more complex strategy including applying “entity-specific rules and heuristics to improve the fidelity of the surrogate” including pronoun and ethnicity adjustments. A summary of this software is shown in Table 1.
Single Occurrence Re-Identification Vulnerability in Existing HIPS Replacement Methods
1.2.
A recent systematic review [22] of different de-identification methods indicates that contemporary machine learning and hybrid approaches can yield binary token-level F1-scores of over 98%. Although this number may appear high at first glance, the high occurrence of PHI in a sufficiently realistic and large corpus will still generate false negatives for HIPAA-covered entities, thereby leaking PHI. Realistic surrogate text generation strategies can address the “residual PHI problem” [23] by limiting the ability of human readers to identify approximately 70% of PHI in clinical text [24]. This “hiding-in-plain sight” (HIPS) [13] strategy is based on similarity between the original text and the synthetic replacement, making the leaked PHI inconspicuous. Thus, a HIPS approach is preferable from a re-identification perspective versus simply replacing PHI with the detected entity type, a common default output of PHI Named Entity Recognition (NER) software and used in the widely distributed MIMIC corpus. However, existing HIPS implementations consistently replace the PHI so that the patient or provider name is always replaced by the same surrogate value. The advantage of this consistent replacement strategy is the provisioning of more realistic text, the disadvantage is that the presence of a single critical missing personal identifier (such as a patient name) gives an attacker the ability to identify the patient, even without complex statistical analysis. Thus, a HIPS corpus utilizing a consistent strategy of surrogate replacement has the same “Single Occurrence Re-identification Vulnerability” (SORV) as PHI replaced by entity names. This vulnerability could expose two-thirds of the leaked PHI in an attack utilizing machine learning; therefore, further improvements to ensure privacy protection are warranted [24] given the increasing prevalence of machine learning. Another machine learning approach that HIPS is vulnerable to are “parrot attacks”, where an attacker employs a similar annotation and de-identification method on the target text as the de-identification corpus provider. The attacker then examines any false negatives to infer that PHI has been missed [25]. A HIPS approach that removed the SORV would be preferable.
Need for Improved HIPS Strategies
1.3.
The increasing power of Large Language Models (LLMs) can render traditional HIPS strategies (“Consistent” substitution) less effective for PHI leakage. Using a similar strategy to ours, Patsakis and Lykousas [26] used the Faker library to perform a synthetic substitution of PHI to use surrogates for 11 identifiers for short snippets of text describing 20 famous celebrities. Each celebrity had 46 to 61 descriptions, with a mean count of 54 descriptions. Initially, GPT-3 [27] could identify 72.6% of celebrity descriptions, but none when celebrities were de-identified using a “Consistent” strategy. However, simple prompt engineering allowed for the identification of 69.44% of the descriptions, indicating that a “Consistent” HIPs strategy is not sufficient for the protection of PII/PHI when using LLMs. Recent advances in LLM are likely to exacerbate this situation.
Contribution: Evaluation of Novel HIPS Strategies
1.4.
In this paper, we implement and evaluate novel HIPS surrogate replacement strategies in which PHI mentions are replaced by surrogate text without the “traditional” constraint that such a replacement must be consistent with previous replacements of the same type. For example, each mention of a patient name in a document could be replaced by a randomly selected name in our “Random” strategy or by a name selected from a Markov chain in our “Markov” strategy. We implement these two strategies and statistically quantify their privacy preserving benefits relative to the traditional “Consistent” surrogate replacement strategy. To our knowledge, no statistical evaluation has been done on these PHI substitution strategies using either synthetic or realistic clinical data sets and we provide the first such implementation. Finally, we quantify the impact of these substitution strategies on selected information extraction tasks on three different data sets, to determine the extent to which these strategies may impair the utility of the text for information extraction tasks since. This is because although the effect of surrogates is believed to be minimal “where identifiers are not crucial”, it is otherwise believed to have “a great impact on data utility” [28], although this has not been explored.
Materials and Methods
Software Implementation
2.1.
We make our tool (version 0.4) and source code publicly available at https://github.com/uabnlp/BRATsynthetic (accessed on 6 September 2025). BRATsynthetic uses the BRAT [29] annotation format and the associated text file (if available) to create surrogate PHI independent of the software originally used to identify that PHI. BRATsynthetic generates realistic text for 27 categories of PHI as described in the Section 2.2.1 below. Dates and ages are offset by a random number. PHI categories are stored as entities (“T” labels) in BRAT files; associated, non-PHI annotations (attributes “A” and events “E”) may also be stored in these files, and BRATsynthetic properly maintains mapping of non-PHI annotations to PHI categories after synthetic replacements. Prior to replacement, we normalize line endings, require paired .txt/.ann files (example Figures 1 and 2), restrict substitutions to the PHI tag set, and update spans in reverse-offset order to preserve alignment. Synthetic values are produced with Faker 13.7 using a defined seed from the configuration, with format and case-preserving rules for IDs, names, and codes. Each PHI category uses a custom Maker class with unique rules for handling regular expression patterns, edge cases, and Faker function calls. Within-document mention repetition follows a two-state first-order Markov policy (reuse vs. resample) as shown in Figure 3. Automated and manual verification includes counting the number of entities, events, and attributes before and after synthetic replacement, and ensuring spans correctly align for non-PHI annotations with their corresponding synthetically replaced PHI categories. The header text, “PERSONAL IDENTIFYING INFORMATION (PHI) IN THIS DOCUMENT HAS BEEN REPLACED WITH SYNTHETIC TEXT. ANY CORRESPONDENCE TO THE PHI OF ANY REAL PERSON IS UNINTENTIONAL” is prefixed to the start of the file to reduce the risk of potential legal issues associated with the unintentional match to real persons that can occur in all HIPS strategies.
Evaluation Corpora
2.2.
To assess the impact of surrogate substitution strategy on privacy protection, we evaluated BRATsynthetic on an in-house corpus of de-identified clinical text from 165 patients collected under IRB Protocol #300002331 (NIH Grant R01AG060993-03S1, Automating Delirium Identification and Risk Prediction in Electronic Health Records). Those notes were de-identified under IRB Protocol #300002212 “U-BRITE Deidentified Translational Data Repository for Research and Education” at the University of Alabama at Birmingham that we previously used [30] to generate .ann files as input for BRATsynthetic. The corpus includes all available EHR notes for those patients, specifically 3617 documents including 1,489,362 critical entities from both inpatient and outpatient encounters from 2014 to 2021. The UAB Discharge corpus is a subset of the main UAB Corpus containing only discharge summaries. The MIMIC Corpus is a set of MIMIC discharge summaries that was obtained as part of participation in SemEval 2014 Task 7 “Analysis of Clinical Text” [31] and are sourced from outside UAB [32]. The Opioid Use Disorder (OUD) Corpus [33] is a UAB-derived data set consisting of 3295 clinical notes from 59 patients (23 controls) from physician case referrals between 2016 and 2021. These data sets contain human-annotated BRAT files and are used to evaluate changes in the information extraction performance of the different HIPS strategies, specifically if a particular strategy uniquely affects document structure and downstream language model evaluation tasks.
Resynthesis Elements
2.2.1.
BRATsynthetic generates a superset of i2b2 2014 personal health information entity types [34], including standard HIPAA Safe Harbor Categories, as well as more specific category types under the BRATsynthetic “Replacement Type” column in Table 2. There is a many-to-many correspondence, where some data elements map to multiple BRATsynthetic types (ex. NAMES), others are a one-to-one mapping (ex. EMAIL), and others condense different Safe Harbor Elements into a single BRATsynthetic type (ex. IDNUM). Table 3 summarizes this and other label differences between Safe Harbor Elements and BRATsynthetic categories. BRATsynthetic does provide additional resynthesis capacity by the inclusion of the PROFESSION category (shared with I2B2) and the TIME category (not required either under HIPAA Safe Harbor or used by the I2B2), which we include due to the increasing availability of second and sub-second data collected from personal devices not anticipated in the original guidelines. BRATsynthetic currently lacks UNIQUE text resynthesis ability, where UNIQUE corresponds to a section of text that could potentially reveal personal identity such as “governor’s wife” or details of unusual accidents.
Surrogate Substitution Strategies
2.2.2.
BRATsynthetic implements three HIPS substitution strategies: Consistent, Random, and Markov as well as a baseline “Simple” non-HIPS strategy, where identified PHI entities are replaced by the entity name. An example substitution is shown in Table 4. All three HIPS strategies are implemented as a Markov chain with two states, one that creates a new surrogate value and another that repeats the previous surrogate value. The traditional Consistent strategy can be considered a simple, degenerate Markov chain with self-transition probability of 1.0. The initial state always creates a new surrogate value, but the subsequent transitions vary between strategies, as shown in Figure 3. The Consistent strategy always maintains the previous surrogate value, the Markov strategy selects a new surrogate half the time, and the Random strategy always selects a new surrogate. The surrogate values are selected at random from the faker [35] library for each occurrence of each type of entity.
Maximum Surrogate Repeat Size (MSRS)
2.2.3.
The “Single Occurrence Re-identification Vulnerability” (SORV) occurs with the Consistent strategy of surrogate generation because the use of the same replacement value means that a single occurrence of a false negative (FN) will be identifiable as PHI. However, should an FN occur once in the de-identified document for that entity type (leaving in the patient’s real name for example), it may not be immediately obvious with the Random strategy that the real name was not just another surrogate value. This is true when the number of FN errors of that critical type is lower than the maximum number of times the same surrogate value is repeated when more than one surrogate value is used. We refer to this latter value as the “Maximum Surrogate Repeat Size” (MSRS). The Markov substitution strategy operates in the same way as the Random strategy, but previously used surrogate values are much more likely to occur due to the 0.5 state transition probability. This generates a larger maximum number of times a surrogate value is repeated (larger MSRS) for each critical entity so it can better “mask” FN errors. A sample run of these strategies is shown on an entity note with six names in Table 4. BRATsynthetic applies substitutions at the document level, a patient level replacement strategy operating over multiple documents is also desirable, but not currently implemented.
PHI Leakage Evaluation on Real Corpora
2.3.
We evaluate the protective ability of surrogate addition on the UAB Corpus, UAB Discharge Corpus, and the MIMIC Corpus by focusing on “critical” PHI as specified in Table 2 under the “Critical PHI” column. Table 5 provides corpus statistics on the critical entity distributions of these corpora. We define an entity as “critical” if a single FN for that entity (MRN is one such example) is sufficient to identify a patient and require immediate legal disclosure of the breach. An FN by de-identification software or humans in this critical category of PHI may be commonly identified even in a haphazard fashion by a casual reader of the document when the document employs no surrogate substitution (like MIMIC) or uses substituted text as shown in Table 4 under the Consistent strategy. However, a single FN would not be obvious to a reader if a Random or Markov strategy is used, since the real name would not constitute the largest minority surrogate class. Thus, the ability to detect the real name as shown in Table 4 is dependent on the overall FNER, the distribution of critical entities and FN errors within those entities and the substitution strategy used. Using our UAB and MIMIC Corpora, we simulate and assess three different resynthesis strategies for surrogate information: “Consistent”, “Random”, and “Markov” under four different FNER (0.1%, 0.5%, 1%, and 5%). Leakage rates are computed at the document level. A leak is considered to occur if the PHI signal (measured by the critical PHI FN count) exceeds the injected noise as measured by MSRS. In essence, MSRS represents the maximum frequency with which a given surrogate can repeat within a document; when the number of false negatives does not exceed this number, any leaked PHI is statistically indistinguishable from synthetic surrogates. In practice, this means that for the Consistent strategy where the same surrogate is repeated, any FN in a critical entity constitutes a document leak, whereas for the Random, and Markov strategies this only occurs when FN errors exceed the MSRS. A leak at the patient level as one or more document leaks. Since results can vary depending on the distribution of FN errors in a corpus, we average our results over 1000 FN error generation simulations using different random seeds. Our leakage calculations and simulations are available at https://github.com/uabnlp/BRATsynthetic (accessed on 6 September 2025) [21] and were performed using Python version 3.9.
PHI Leakage Evaluation on Simulated Corpora
2.4.
We calculated the expected leakage probability of critical information over a range of corpus sizes, ranging from 10 to 10,000 documents. For this calculation, we considered a leak to occur if the expected number of unremoved (false negative) PHI entities in the corpus was greater than a set threshold for each of the substitution methods. For Consistent substitution, the threshold was set at 0, since even a single instance of a real patient entity can be readily distinguished from the single fake entity. For Random and Markov substitution, the threshold was set as the expected number of fake entities [36] based on a pool of 1000 fake entities from which to randomly select using the transition probabilities described above. The threshold for a Random substitution was calculated as 1.015 and for a Markov substitution it was 2.028. We allowed the number of entities per document to assume the values of 15, 150, and 1500, and allowed the FNER to assume the values of 1% and 5%. We then calculated the expected number of real patient entities in the corpus as the product of the FNER times the number of entities per document times the number of documents. We used the binomial distribution to determine the p-value of whether the expected number of real patient entities exceeded the threshold. Calculations were performed using R v4.1.2.
Assessment of HIPS Strategy on Information Extraction Efficacy
2.5.
As shown in Table 4, the Random and Markov strategies generate text that differs from the original text or a Consistent HIPS strategy. This can potentially cause problems for Natural Language Processing (NLP) algorithms seeking to extract information from corpora generated using these substitution strategies. To assess the impact of this, we compare the relative performance of the different strategies on a variety of information extraction NLP tasks using different generations of NLP software. This includes the popular MedSpacy [37] software, a third-party evaluation by TriNetx that utilized a Support Vector Machine (SVM) [38] based genomic marker pipeline from Averbis and a BioBERT [39]-based encoder models for Named Entity Recognition (NER) and clinical modifiers from our prior work [40]. While it is not feasible to test all NLP tasks, the clinical modifier pipeline was selected as likely to be particularly susceptible to PHI context, especially for the “Subject” modifier, which evaluates whether an extracted Named Entity is associated with the patient or someone else, a task made more challenging when the surrogate name for the patient may change in the same document. For the MedSpacy [37] evaluation, we used the “en_core_sci_sm” model on the OUD corpus with default parameters for all tasks but “Spans”, which utilizes MedSpacy custom “TargetRules” to identify OUD entities with regular expressions. Sentences were segmented with PyRuSH, a python implementation of RuSH [41]. We computed Jenson–Shannon divergence [42] to compare distributions. The Averbis genomic marker pipeline utilized by TriNetX, first tokenizes the input text, then performs dictionary lookup for mention finding, disambiguates with a linear Support Vector Machine (SVM) that considers the context, applies rules for specific patterns, and finally performs the final classification with a linear SVM. Evaluation on the genomic marker pipeline was done on a set of 144 documents, and the results are reported and errors analyzed only for the five documents where results differed. For the BERT-based evaluation, we replicated our previous work [40], but replaced PHI using Simple replacement or one of the three HIPS strategies. We used Shapiro–Wilks tests to examine the normality of the mean F1 scores, with p > 0.05 indicating that the scores for Consistent, Markov, Random, and Simple are from the same normal distribution and are not significantly different from results for the original text.
BRATsynthetic Runtime Experiment
2.6.
Runtime performance was evaluated on a superset of the UAB corpus consisting of 28,547 documents that have been de-identified using a BERT [43] based de-identification tool [44], but have not been manually reviewed. Corpus statistics and experimental parameters are in Table 6.
Results
Surrogate Replacement Strategy: PHI Leakage Assessment
3.1.
Figure 4 shows the Markov strategy shows a lower document leakage rate on the UAB corpus. At a lower FNER (1% or less) its impact is more pronounced, with leakage eliminated at the lowest error rate. Even at a 5% error rate the strategy still performs substantially better than the two other strategies, which leak PHI close to 100% of the time. Figure 5 compares PHI leakage between the UAB and MIMIC corpus at the document level for discharge summaries only and indicates a similar substitution strategy performance between the two corpora, but dramatically lowers PHI leakage rates for the MIMIC corpus which contains significantly fewer critical PHI entities per discharge summary relative to UAB. The Markov substitution also has the highest performance on the synthetic corpora in Figures 6 and 7.
Surrogate Replacement Strategy: Effect on Information Extractions Tasks
3.2.
Our results on the OUD dataset (Table 7) indicate that for context sensitive information extraction tasks, an encoder model fine-tuned on the target data set is not impacted by the surrogate substitution strategy. This is also true for most other information extraction tasks (Table 8), including entity extraction, even when the entity extraction model is not fine-tuned for the target dataset as is the case for MedSpacy. However, MedSpacy rule-based context prediction was impacted (1st row of Table 8) as was the SVM-based Averbis genomic marker pipeline as shown in Table 9. However, all MedSpacy divergences were <10^−4^ bits, confirming negligible distributional change. A sample of errors for MedSpacy POS-tagging and dependency parsing are shown in Tables 10 and 11 respectively. In general, the differences between the output of different surrogate substitution strategies did not correspond to our human intuition of the expected error types, as conceptually insignificant changes in numbers for ages and dates could result in unanticipated changes in the POS tag or the dependency class.
Discussion
PHI Leakage Replacement Strategy Evaluation
4.1.
Our results indicate that a Markov replacement strategy can significantly reduce the chance of PHI leakage relative to a corpus released without substitution or using a traditional Consistent substitution strategy. This effect is seen in simulated PHI distributions (Figure 7) as well as real data from the UAB Discharge and MIMIC corpora (Figure 5), with the effect much more pronounced in the MIMIC corpora, which has almost no leakage at lower error rates. This discrepancy is due to the lower number of critical PHI entities contained in MIMIC corpus versus UAB Discharge. Since the release of our BRATsynthetic tool [46] and preprint [47], Simancek and Vydiswaran [48] have shown the effectiveness of a Markov chain-based surrogate replacement strategy using a Longformer BERT model for clinical text de-identification on a set of 400 discharge summaries. In this real-world data set, the average name leakage rate decreased from 13.1% with random replacement to 3.8% with Markov replacement of surrogates. In both real-world and simulated data the Markov substitution strategy is effective because it adds a variable amount of noise to a document data set (see Figure 6), at levels exceeding any original PHI signal that may not have been removed by the de-identification process. This shape of the Markov substitution strategy curve in Figure 5 is controlled by the state transition rate, which determines how often a surrogate is repeated. This could be adjusted in future work to reflect the expected number of FN errors in any entity to better conceal PHI leakage.
Larger Corpus Size
4.2.
Our work suggests that the Markov substitution strategy allows for a larger release corpus size with the same or lower PHI leakage risk relative to Consistent or Random substitution strategies. This is true for a range of PHI entity counts and FNERs, as shown in Figure 7. Our results in Figures 4–6 focus on critical PHI, but the protective effect shown in Figure 7 applies to any PHI entity. We evaluated critical PHI because of the difficulty in assessing the impact or liability of inadvertent non-critical PHI release, similar to other work that focused on names only [48].
HIPS Strategy vs NER for PHI Protection
4.3.
Our results in Figure 4 for real-world data and Figure 7 for simulated data show that the implementation of an effective surrogate replacement strategy using Markov models can have a greater impact on patient privacy protection than marginal gains in PHI NER performance provided by additional training data. For example, Dernoncourt et al. [4] show increased performance for artificial neural network and conditional random field de-identification algorithms with additional training data, but the total improvement as measured by F1 score shows that the maximum improvement difference was only about 2% between using 5% of available training data versus using all available training data for the MIMIC dataset. Our results indicate that the surrogate replacement strategy can have a greater impact in protecting PHI compared to even a 4% improvement in recall (from 5% to a 1%) in PHI NER software, depending on the total amount and distribution of PHI.
Impact on Information Extraction Tasks
4.4.
Our results in Section 3.2 show that common information extraction tasks are not significantly impaired by the use of non-traditional PHI substitution strategies such as Markov or Random substitutions. The only clear exception to this is the MedSpacy “Context” task that includes the determination of the subject of a medical condition, something which Random or Markov replacement could interfere with. However, this was not replicated with the fine-tuned BioBERT used to generate results for Table 7, suggesting that this result may be more a limitation of the MedSpacy model.
Comparison to LLM-Based De-Identification Methods
4.5.
LLM-based de-identification methods can produce contextually natural text, often exceeding template-driven systems in generation quality. However, they are computationally intensive, more expensive to operate and raise concerns about auditability and potential privacy leakage if safeguards are not rigorously applied. BRATsynthetic, on the contrary, is an inexpensive, efficient, and transparent deterministic surrogate substitution without specialized hardware, although at the cost of a more constrained narrative variety. In practice, these approaches should be viewed as complementary, with LLMs excelling in realism and adaptability, while BRATsynthetic offers practical scalability and predictable control, and its relative weakness in creating smooth transitions is less problematic in clinical documentation, where narratives are typically fragmented.
Limitations
4.6.
BRATsynthetic uncouples surrogate generation from PHI NER and can thus leverage any independent improvements in PHI NER. The tradeoff is that PHI NER software is best positioned to recognize an appropriate substitution (such as one that maintains non-standard date formatting or even typos) whereas BRATsynthetic relies on PHI categories or its own regular expression-based interpretation of the text (if available) to generate the surrogate.
In assessing the impact of non-traditional replacement strategies for re-use, we sample only a limited set of task and datasets. However, we selected a clinical modifier task particularly well suited for the evaluation of surrogate changes, since it incorporates modifiers for Subject and DocRelTime whose mentions would be modified heavily in a Random or Markov corpus.
Both the faker library and BRATsynthetic are open source code, which could potentially assist an attacker since some synthetic surrogates are generated from lists including patient and location names. This vulnerability will be mitigated by private, user-provided pools of PHI for use as replacement values in an updated version of BRATsynthetic. Other forms of surrogate values, such as dates and randomly generated identifiers consisting of alphanumeric text, do not have this vulnerability. Finally, we have not performed a complexity or runtime analysis on the faker library, but scaling on large datasets is feasible, as shown in Table 6.
Conclusions
We show that a Markov substitution strategy can reduce PHI leakage on two real world corpora and on synthetic PHI distributions using a range of realistic false negative PHI NER rates and entity distributions and make our software freely available. Although our work here shows the theoretical and statistical utility of the Markov-based surrogate substitution method, further evaluation of the software implementation on a wider range of benchmarks including human validation would be useful, as would an assessment against more complex re-identification attempts including parrot [25] and LLM-based attacks [26].
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Li J; Zhou Y; Jiang X; Natarajan K; Pakhomov SV; Liu H; Xu H Are synthetic clinical notes useful for real natural language processing tasks: A case study on clinical entity recognition. J. Am. Med. Inform. Assoc 2021, 28, 2193–2201.34272955 10.1093/jamia/ocab 112PMC 8449609 · doi ↗ · pubmed ↗
- 2Kumichev G; Blinov P; Kuzkina Y; Goncharov V; Zubkova G; Zenovkin N; Goncharov A; Savchenko A Medsyn: Llm-based synthetic medical text generation framework. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Cham, Switzerland, 2024; pp. 215–230.
- 3Hiebel N; Ferret O; Fort K; Névéol A Clinical Text Generation: Are We There Yet? Annu. Rev. Biomed. Data Sci 2025, 8, 173–198.40101215 10.1146/annurev-biodatasci-103123-095202 · doi ↗ · pubmed ↗
- 4Dernoncourt F; Lee JY; Uzuner O; Szolovits P De-identification of patient notes with recurrent neural networks. J. Am. Med. Inform. Assoc 2016, 24, 596–606.
- 5Schneble CO; Elger BS; Shaw DM Google’s Project Nightingale highlights the necessity of data science ethics review. EMBO Mol. Med 2020, 12, e 12053.32064790 10.15252/emmm.202012053 PMC 7059004 · doi ↗ · pubmed ↗
- 6Emam KE; Jonker E; Arbuckle L; Malin B A Systematic Review of Re-Identification Attacks on Health Data. P Lo S ONE 2011, 6, e 28071.22164229 10.1371/journal.pone.0028071 PMC 3229505 · doi ↗ · pubmed ↗
- 7Heider PM; Obeid JS; Meystre SM A Comparative Analysis of Speed and Accuracy for Three Off-the-Shelf De-Identification Tools. AMIA Summits Transl. Sci. Proc 2020, 2020, 241–250.32477643 PMC 7233098 · pubmed ↗
- 8Steinkamp JM; Pomeranz T; Adleberg J; Kahn CE; Cook TS Evaluation of Automated Public De-Identification Tools on a Corpus of Radiology Reports. Radiol. Artif. Intell 2020, 2, e 190137.33937843 10.1148/ryai.2020190137 PMC 8082401 · doi ↗ · pubmed ↗