Generalised machine learning models outperform personalised models for cognitive load classification in real-life settings
Christoph Anders, Ipsita Bhaduri, Bert Arnrich

TL;DR
This study shows that general machine learning models perform well in classifying cognitive load using wearable sensors, even in real-life settings.
Contribution
The study introduces a balanced data collection approach combining controlled and uncontrolled environments and achieves high classification performance.
Findings
Generalized models like Logistic Regression achieved F1 scores up to 0.91 for two-class cognitive load classification.
Differences in smartwatch indices and biomarkers were observed between low- and high-load scenarios.
The study design and anonymized dataset were made publicly available.
Abstract
By issuing work-break reminders, for example, personal assistants for cognitive load could be beneficial in maintaining health and life satisfaction in society. Wearable sensors facilitate the necessary real-time collection of physiological data. Still, publicly available real-life data sets obtained with wearable sensors are scarce, especially considering multi-modal recordings. Furthermore, data is usually recorded in either completely controlled or uncontrolled environments, missing the opportunity to study participants across optimal laboratory and realistic real-life settings. This work collected data from ten university students during given and self-chosen cognitive load tasks, resembling typical working environments from over 40% of the OECD population, and investigated if commercially available sensors suffice for building cognitive load assistants. The study design accounted…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
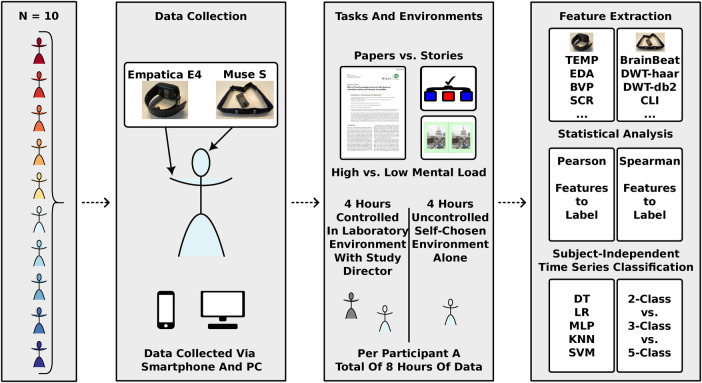 Figure 1
Figure 1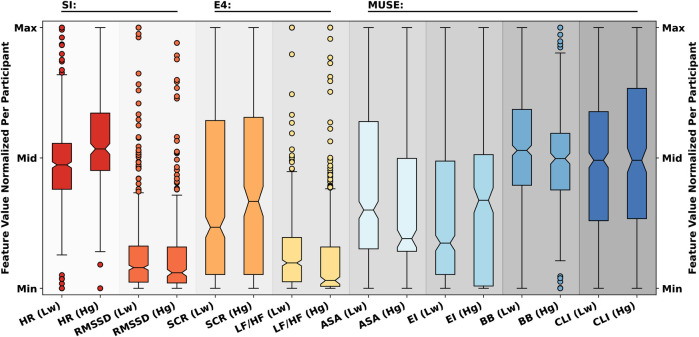 Figure 2
Figure 2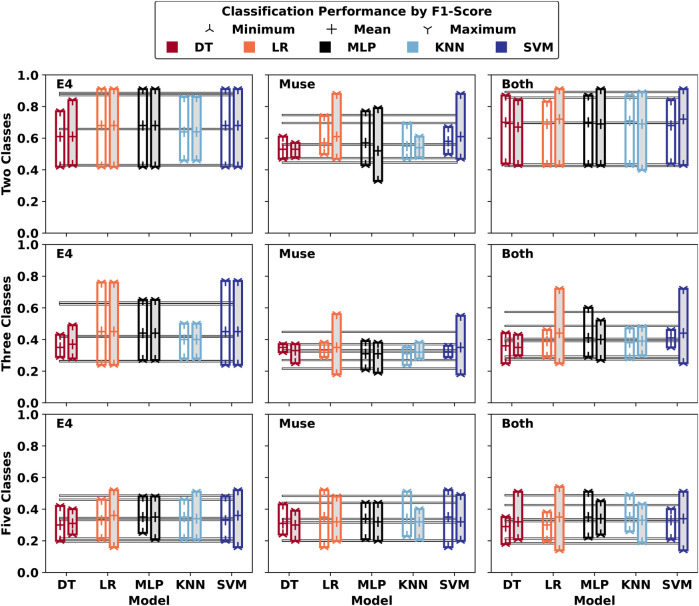 Figure 3
Figure 3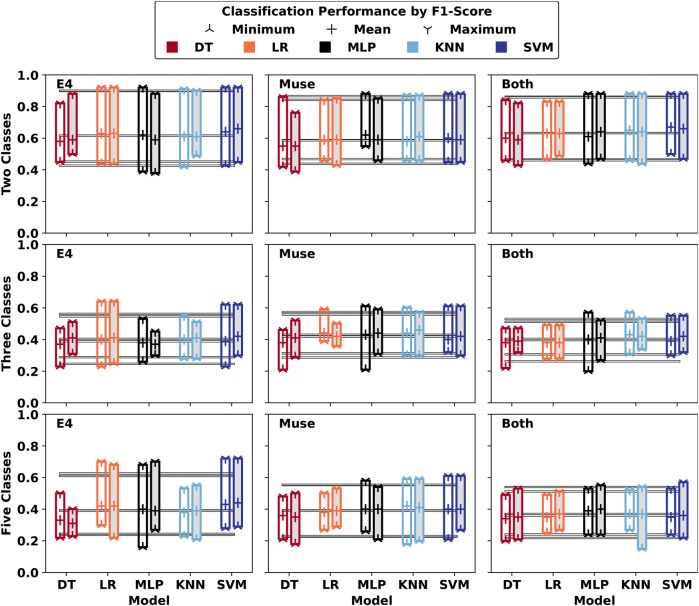 Figure 4
Figure 4| Feature | Both Modalities Set | Muse S Set | Empatica E4 Set |
|---|---|---|---|
| Twelve DWT-features |
|
| – |
| TemporalDeltaPower | – |
| – |
| PrefrontalGammaPower | – |
| – |
| TemporalThetaPower | – |
| – |
| TemporalBetaPower | – |
| – |
| TemporalGammaPower | – |
| – |
| EngagementIndex | – |
| – |
| AsymmetryIndexPrefrontal | – |
| – |
| CLI | – |
| – |
| max-scr |
| – |
|
| HRV-SDNN |
| – |
|
| HRV-RMSSD |
| – |
|
| Max-Heart-Rate |
| – |
|
| max-skt |
| – |
|
| max-scl |
| – |
|
| HRV-MeanNN |
| – |
|
| HRV-ratio-LF-HF |
| – |
|
| min-scr | – | – |
|
| num-scr-peaks | – | – |
|
| min-scl | – | – |
|
| mean-scl | – | – |
|
| min-skt | – | – |
|
| mean-skt | – | – |
|
| HRV-LF | – | – |
|
| HRV-HF | – | – |
|
| Min-Heart-Rate | – | – |
|
| Mean-Heart-Rate | – | – |
|
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCognitive Science and Mapping · Time Series Analysis and Forecasting
Introduction
1
Cognitive load (CL) was defined by (1) as “the difference between the capacities of the information processing system that are required for task performance to satisfy performance expectations and the capacity available at any given time”. Three additive aspects of CL have since been distinguished in the field, namely germane (acquisition of knowledge), intrinsic (task-specific), and extraneous (information design) load as outlined by (2). According to (3), stress can be defined as arousal during an uncontrollable challenge leading to anxiety in an individual. Stress and mental workload can be connected factors found to modulate each other, as presented by (4), which can lead to cognitive overload and fatigue (5).
If high levels of CL and stress are prolonged and regularly exceed the individual’s capacities, the individual can develop serious health consequences, ranging from fatigue over depression to cardiovascular diseases (6). One of the United Nations’ sustainable development goals (SDG) is healthy lives and well-being for all at all ages, according to the (7). Therefore, modulators need to be found to accurately identify and intervene in situations of prolonged cognitive overload and stress. The recent surge in wearable devices, as surveyed and quantified by (8), is likely to support this cause. An example of an existing application is continuous heart monitoring through smartwatches. As presented by (9), such applications can issue an alarm via the wearable following a coronary event and subsequently suggest or automatically call for medical care. While these applications consider some immediately life-threatening conditions, events occurring over longer periods remain underaddressed. Smartwatch manufacturers present various (stress) indices to bridge this gap, but the proprietary nature of their algorithms hinders an evaluation of their accuracy in addressing challenges regarding prolonged CL and stress.
Across populations, knowledge workers are especially at risk for cognitive overload and prolonged (mild) stress levels. Setz et al. (10) used wearable electrodermal activity (EDA) sensors to distinguish CL from stress. Muaremi et al. (11) used smartphone activity, questionnaires, and a chest belt to classify the stress levels of 35 participants over four months, without strict control over the activities. Work-interruption management—based on CL classification—was investigated by (12). Following a machine learning challenge on CL classification of data from the Microsoft Band 2, (13) found that the submitted answers struggled to overcome intersubject variability. Wilson et al. (14) investigated an eye-tracker and the Empatica E4 in classifying CL in a plane’s cockpit, finding Photoplethysmogram (PPG) and EDA features to be most indicative. Giorgi et al. (15) found a strong positive correlation between data from wearable sensors—particularly the Empatica E4 and Muse S—and gold-standard versions of the underlying measurement technologies. Fine et al. (16) investigated CL for pre-defined tasks across 21 participants and found indicators of heart-rate variability to be correlated with CL.
Gasparini et al. (17) investigated classifying CL during movement-related (non-office) tasks, and found that task type as well as CL level could be classified using PPG, Electromyography (EMG), and Galvanic Skin Response (GSR) data. It is important to note that, while similar modalities and sensors can be used, CL and (mild) stress classification are distinct from activity recognition. To exemplify, while the movement patterns used to identify a walking activity, the CL might be vastly different if the individual is relaxing or focused on a phone call. Hence, the same activities can be combined with arbitrary levels of CL.
González Ramírez et al. (18) performed a scoping review of 40 studies on stress management and found most experiments were conducted in controlled environments, underlining the need for more real-life experiments. An example of such experiments is the work of (19), which focused on classifying laboratory-task-induced stress using physiological and video data. Liu et al. (20) used an eye-tracker and the Empatica E4 to classify CL levels during cooking activities. Beiramvand et al. (21) utilised mobile electroencephalogram (EEG) and showcased that discrete wavelet transform (DWT) features could be used to distinguish mental workload in an imbalanced three-class classification problem. While (22) investigated CL in both controlled and uncontrolled environments and published over 315 h of wearable sensor data, their work did not consider office tasks comparable across participants. A systematic review of CL found few works on real-life tasks, such as office or learning tasks (23), while practitioners suggest a combination of CL concepts (24), and many data collections use well-established tasks, such as the N-Back contrasted with the operation of semi-autonomous vehicles (25).
Despite recent advancements, multiple aspects of CL and stress quantification with wearable sensors remain understudied: (i) a mixed-control environment study design, (ii) utilisation of real-life office tasks, and (iii) the investigation of feature importance remains to be explored further. This work contributed to the field by addressing these challenges through a novel study design presented in Figure 1.
Schematic overview of the study design and data analysis pipeline. Participants enrolled in the experiment were provided with the wearable sensors Empatica E4 and Muse S. Each participant recorded data for four hours in a controlled laboratory environment and four hours in self-chosen environments. Screenshot of scientific publication reproduced from: “Effect of Yeast Fermentation of Green Coffee Beans on Antioxidant Activity and Consumer Acceptability” by Han Sub Kwak, Yoonhwa Jeong and Misook Kim, licensed under CC BY 4.0. Image of St. Paul's Cathedral reproduced with permission from: https://www.spotthedifference.com/.
Materials and methods
2
In line with previous research [e.g., (15, 22)], the wearable sensors Muse S and Empatica E4 were utilised in this study to investigate CL and (mild) stress levels in knowledge workers (i.e., university students). A study design tackling the lack of mixed-control environment study designs utilising real-life tasks was defined.
Participants ( ; 23 to 51 years old, mean age of 30 years, STD of 8 years; 5 female: 5 male) were invited to a first data recording session, in a regular office room with whiteboards, windows for natural light, and controlled temperature. The room and hallway leading to it were monitored to ensure no interruptions occurred while data was recorded. During this session, the study design was explained, participants were shown how to wear the sensors, and any open questions were answered before the data recording started. While data was recorded, participants were guided through computerised tasks and questionnaires, implemented in Python 3.8 and using the PsychoPy platform (v2022.2.1).
The tasks posed to participants were the Stroop Color and Word Test (SCWT; four colors (red, blue, yellow, and green); less than 1.5 s to answer to stimuli), the N-back continuous performance task (two-back; thirteen different colors (Blue, Yellow, Burlywood, Green, Cyan, Hotpink, Red, Lightpink, Lightsalmon, Lightseagreen, Lightskyblue, Maroon, Olive); less than two seconds per iteration), and two reading and summarizing tasks. As literature for the reading and summarizing tasks, six scientific publications (26–31) were chosen as difficult texts, and six short-stories from famous English writers [Edgar Allan Poe (“The Gift of the Magi”, “The Masque of the Red Death”, “The Cask of Amontillado”, and “The Black Cat”), Oscar Wilde (“The Devoted Friend”), and Charlotte Brontë (“The Search After Happiness”)] were chosen as easy texts.
A ten-minute relaxation video (first ten minutes from https://www.youtube.com/watch?v=mLwlGsRhNIU) was presented at the beginning of the computerised experiment to ensure that all participants started the experiment calmly. Before the relaxation video and after the last task was completed, the participants performed a one-minute eye-closing session. In between tasks, the participants answered the questionnaires pairwise NASA Task Load Index (NASA-TLX) and Likert-Scales for Mental Workload and Stress, to report on their subjective mental workload level, experienced stress, etc., for the preceding task/activity. In total, each experiment in the controlled environment lasted approximately two hours.
Following the data recording, participants were instructed on how to perform recordings on their own, and the sensors and chargers were handed out alongside a folder with questionnaires and contact information of the study directors. During their uncontrolled data recordings, participants were free to choose the environment(s) in which they would feel most comfortable and natural. There, participants had to follow the pre-defined study protocol for self-chosen environments: eye-closing baseline of one minute, questionnaires, relaxation task of ten minutes, questionnaires, mental workload task (twenty minutes reading and ten minutes summarising of a text), questionnaires, and finally another eye-closing baseline of one minute.
The same questionnaires used in the laboratory recording were used in the uncontrolled environment. As a relaxation task, the spot-the-difference game was utilized (https://www.spotthedifference.com/). A random subset of scientific publications and short stories was chosen for the mental workload tasks, ensuring no text was read twice. Once participants had finished approximately four hours of data recordings in their self-chosen environment(s) (0 to 4 recordings per participant, mean of 2.3 and STD of 1.1 recordings), another appointment for a second recording in the controlled laboratory environment was made.
In the second recording in the controlled laboratory environment, participants completed a second iteration of the same protocol described for the first session. The study protocol and randomisation processes ensured that the scientific publications and short stories were not repeated. Consequently, each scientific publication and short story was read and summarised at most once by the participant. In total, each participant recorded about eight hours of data over the two controlled and uncontrolled sessions.
Ethical clearance for the study was obtained from the institutional review board under review number 02/2023. Inclusion criteria required participants to be between 18 and 68 years old, fluent in English, and to regularly perform performance-evaluated work. Potential participants were excluded from participation if they were either retired or needed to regularly take medication for any neurological disease (e.g., depression, brain damage, or similar). Additionally, pregnant women, participants with hypertension, and participants who could have been in a dependent relationship with the study directors were excluded from participation.
From the Muse S, the data modalities electroencephalography (EEG; sampled at 256 Hz from AF7, AF8, TP9, TP10, and referenced at FpZ, according to the 10–20 system for electrode placement), gyroscope sampled at 50 Hz, as well as photoplethysmography (PPG; sampled at 64 Hz) were recorded. The Empatica E4 recorded skin temperature at 4 Hz, PPG at 64 Hz, electrodermal activity at 4 Hz, and acceleration data at 32 Hz. Once the data was recorded, the questionnaires were digitised, and the respective labels were extracted for each activity performed by the participants. The data collected was published in anonymised form, publicly available without any restrictions from https://doi.org/10.5281/zenodo.15681262.
Additionally, the Muse S and Empatica E4 data were synchronised based on a shaking protocol. For the recordings in the controlled environments, this data was synchronised with the log data stored by the PsychoPy application. Based on timestamps, the labels were aligned with the respective data. Power line interference was filtered by notch-filtering the recorded data at 50 Hz, but no further specific data cleaning or artefact rejection was performed.
Subsequently, the time series data was split into windows of 60 s, and hand-crafted features were extracted. For Muse S, the individual EEG channels (AF7, AF8, TP9, TP10) were used, and various projections were created: mean (across all channels), prefrontal (mean across AF7 and AF8), temporal (mean across TP9 and TP10) and asymmetry (right vs. left cerebral hemisphere). For each of the projected channels, band power was extracted using the Fast Fourier Transform for each of the channels Delta ( Hz), Theta ( , 4 Hz to 8 Hz), Alpha ( , 8 Hz to 12 Hz), Beta ( , 12 Hz to 30 Hz), and Gamma ( , 30 Hz to 45 Hz). Subsequently, various indices were extracted, as reported in the literature. As such, the Engagement Index (32), the Brain Beat (33) and the CLI (34, 35) were extracted. In addition, inspired by related work (36), discrete wavelet transform (DWT) was performed on the notch-filtered as well as the mean data. For the DWT, the Python package pywt (https://github.com/PyWavelets/pywt) was used with the two mother wavelet functions “db2” and “haar”, and the decomposition level was set to eight. Nine of the resulting coefficients were used as features: cA8, cD8, cD7, cD6, cD5, cD4, cD3, cD2, and cD1. For each of the coefficients, the features STD, MEAN, MIN, MAX, Skewness, RelativeWaveletEnergy, Kurtosis, and ZeroCrossing were extracted. Per participant, the features were normalized using z-score normalization.
For Empatica E4, various features were extracted from each modality. The minimum, mean, and maximum values for the time window were extracted from the skin temperature. The minimum and maximum skin conductance response, the number of skin conductance response peaks, and the minimum, mean, and maximum level of skin conductance were extracted for each time window from the electrodermal activity signal. The widely used features of HRV_MeanNN, HRV_SDNN, HRV_RMSSD, HRV_LF, HRV_HF, HRV_ratio_LF_HF, and the minimum, mean, and maximum heart rate were extracted from the photoplethysmography signal. Processing of the Empatica E4 data was facilitated by NeuroKit2, presented by (37).
From the questionnaires, the mental workload labels were utilized to form three types of classification problems: a two-class classification into low and high mental workload; a three-class classification into low, neither low nor high, and high mental workload; as well as a five-class classification into very low, low, neither low nor high, high, and very high mental workload. As labels, the participant-given labels were extracted from the log files of the PsychoPy experiments as well as from the digitized pen-and-paper questionnaires answered by the participants. An exploratory data analysis of selected features was performed, contrasting low and high load, and the results are visualized in Figure 2.
Boxplot comparison of selected features for low (Lw) and high (Hg) cognitive load across participants. Common Smartwatch-Index (SI) features Heart Rate (HR) and Root Mean Square of Successive Differences (RMSSD) used to derive smartwatch stress states [according to (39)]; common E4 features Skin Conductance Response (SCR) and the low Frequency-to-High Frequency (LF/HF) Ratio [according to (40)]; common Muse features ASymmetry index across All channels (ASA), Engagement Index (EI), Brain Beat (BB), and Cognitive Load Index (CLI) [according to (32–35, 41)]. Differences can be seen between HR (SI), LF/HF (E4), ASA and EI (Muse).
Based on these mental workload labels, a Pearson correlation analysis and a Spearman correlation analysis were performed to investigate the relationship between the feature values and the labels to analyze how much information a feature provides for mental workload classification, and between the features themselves to analyze which features influence each other and might be redundant. The results from the Spearman correlation analysis were used for a feature selection process to investigate the usage of a smaller subset of features, after it had been found that DWT-features with the “haar” mother function consistently provided the best correlation coefficients for binary, three-class, and five-class classification.
The standard machine learning classifiers DecisionTreeClassifier (DT), LogisticRegression (LR), MLPClassifier (MLP), KNeighborsClassifier (KNN), and LinearSVC (SVM) available in the scikit-learn package (38), were used for time-series classification. In addition to the previously described z-score normalisation, features were min-max normalised. All models were evaluated using leave-one-participant-out cross-validation with both classification accuracy and weighted F1 score as evaluation metrics. The source code for the data processing and the machine learning models was made publicly available via GitHub at https://github.com/HPI-CH/mw_office_2025.
The criteria gini and entropy were used with the splitters best and random and a max_depth increasing in 5-point steps from 5 to 305 for the DT classifier. Various combinations of the solvers lbfgs, liblinear, sag, and saga were used with the penalty values l1, l2, and None for the LR classifier. For the MLP classifier, the activation function was chosen to be either logistic, tanh, or relu, and the hidden layer size was set to 3, 10, 30, or 50. A leaf size ranging from 1 to 50, a number of neighbors ranging from 1 to 30, and a p-value of either 1 or 2 was used for the KNN classifier. The penalties l1 and l2 were used in combination with the C values of 0.001, 0.01, 0.1, 1, 10, 100, and 1,000 for the SVM classifier.
Results
3
The correlations of the features with the mental workload labels provided by the participants, as quantified with the Spearman Correlation Coefficient, are low. The averaged absolute correlation coefficients rarely exceed a value of 0.08. This strongly suggests that the correlations observed for this general population of ten participants are negligible. For the individuals, however, different features reach low correlation values above 0.2. A similarity across both Pearson correlation analysis and Spearman correlation analysis could be observed: Most of the DWT (db2) features (Kurtosis, ZeroCrossing, MIN, MEAN, and MAX), and the DWT (haar) feature ZeroCrossing are present across both sets of features across all electrode positions (AF7, AF8, TP9, and TP10) with the highest correlation coefficients with the, by the participants self-assigned, labels for CL, between 0.2 and 0.24.
Due to the large number of automatically extracted features ( ) using DWT ( ), and the insights derived from both the exploratory data analysis and the correlation analysis presented in Figure 2 , the impact of feature selection on time-series classification performance was investigated for three sets of features (both sensors; Muse S alone; Empatica E4 alone), as detailed in Table 1.
The time-series classification performance of generalised Machine Learning models obtained via Leave-One-Participant-Out cross-validation (LOO-CV) is given in Figure 3. The classification performance using all features is given with a transparent background, and the performance of time-series classification using the reduced feature sets is given with a grey background colour. The models DT, LR, MLP, KNN, and SVM show strongly varying classification performances dependent on the classification difficulty. As can be seen across two, three, and five-class classification, the impact of feature reduction on this particular dataset is, however, mostly negligible. While in some cases beneficial, the opposite also holds, and the overall average minimum, mean, and maximum F1-scores of generalised LOO-CV models are nearly identical across classification tasks. For these generalised models, the minimum and maximum F1 scores achieved are 0.33 and 0.91, 0.18 and 0.77, and 0.14 and 0.54 for two, three, and five-class classifications, respectively.
Subject-Independent (Minimum, Mean, Maximum) LOO-CV Results (F1) of generalised models across participant-specific personalised labels. The models which were trained with a reduced feature set selected after feature selection are marked with gray background colour. Average values for (Minimum, Mean, Maximum) across models are given.
Across the 900 best participant-independent models, most used the following parameters: “criterion: gini, max_depth:5, splitter: random (DT)”; “penalty: l2, solver: lbfgs (LR)”; “activation: relu, hidden_layer_sizes: 30 (MLP)”; “leaf_size: 1, n_neighbors: 9, p: 1 (KNN)”; and “C: 0.01, penalty: l2 (SVM)”.
Across the literature, the observation can be made that similar wearable devices can be used for activity recognition as well as for CL classification, as exemplified for instance by (42) in their work on human activity recognition (HAR) of activities of daily living, who used the Empatica E4, a device used as well in this work. Hypothesising that context information could be beneficial for CL classification, the idea was investigated how CL classification might change if HAR were able to classify the works done in this experiment. Following through on this thought-experiment, personalised machine learning (ML) models were built using the previously stated reduced feature sets and the activity features Relaxation, Load, Summary, Reading, and Game, represented as additional one-hot encoded features. The personalised ML models were trained using five-fold cross-validation, and time-series classification results, reported as F1 score, are given in Figure 4. For personalised models, the minimum and maximum F1 scores achieved are 0.38 and 0.92, 0.21 and 0.64, and 0.15 and 0.72 for two-, three-, and five-class classifications, respectively. For this data, the information added by activity features did not significantly change classification results.
Averaged (Minimum, Mean, Maximum) Five-Fold CV Results (F1) across Participant-Specific Personalised Models. The models that received the cognitive load activity as features are marked with a grey background colour. Average values for (Minimum, Mean, Maximum) across models are given.
Discussion
4
While Wavelet Transform is usually used to denoise an input signal as performed by (43), some works also utilize Wavelet Transform to extract meaningful features for subsequent time-series classification [e.g., (44, 45)]. Inspired by this line of investigation, this work utilized Discrete Wavelet Transform (DWT) for feature extraction. In this work, the wavelet-based features extracted from the EEG data were the most stable characteristics in the investigated population. Furthermore, supporting previous research that found the prefrontal cortex to be heavily involved in the processing of mental workload and stress (46, 47), the electrode locations AF7 and AF8 appear 1.4 times more often in the most-important features than TP9 and TP10, which are electrode positions usually associated with the encoding of memory and emotions (48).
Building on the underlying idea that context information is important—and that the wearables Muse S and Empatica E4, or the E4’s successor EmbracePlus, could be concealed to enable unobtrusive, real-time CL monitoring—the hypothesis arose that time series classification results might be even better when combining the classification of CL and stress levels with predictions of the type of office activity performed by the individual. In the broader field of mental state classification, (49) pushed conditionally automated driving applications using physiological data by extracting reliable features, yet their work was unable to classify the specific type of task, a necessary step to include context information. However, as presented by (17), it is possible to simultaneously classify the type of task and mental state of a participant using devices similar to those used in this work. If, in the future, a perfect classification of task type would be possible using the same wearable sensors, this information could be used as context information in mental state classification.
This hypothesis was tested in this work for binary, three-class, and five-class classification with reduced feature sets, by passing a numeric value representative of the task type to the ML model as a one-hot encoded feature. The best classification results of generalised models changed to F1 scores (min, avg, max) of [0.43, 0.72, 0.91], [0.24, 0.45, 0.74], and [0.18, 0.34, 0.56], respectively, suggesting at best a minor performance increase (detailed results not shown).
For personalised models, a similar negligible change in classification performance was obtained. To summarise, in the evaluation performed in this work, no significant added benefit through additional information about task types could be observed. Future work should investigate how context information could be incorporated differently, and if variability in labels obtained from participants explains current results.
However, this work has two limitations due to the participant and feature selection process applied. Firstly, with , a selection bias might be present regarding the individuals who took part in the study. Secondly, as the feature selection was not performed on a separate part of the data, but rather built on the insights derived from the statistical analysis using all the data, the risk of overfitting is present in the reported results.
Also, future work should focus on combining research on office-work break interface design with mental state classification, as investigated by (50). Consequently, tangible interventions for office work well-being as reviewed by (51), building on targeted and personalized mental workload and stress classification models using physiological data from wearables, would push the workforce of the 21st century closer to the United Nations sustainable development goal (SGD) of “healthy lives and well-being for all at all ages”.
This work presented a novel study paradigm enabling researchers to investigate CL and stress in realistic settings with ground-truth values obtained in controlled laboratory environments. Feature importances were investigated, and (assumed) smartwatch indices (SI) were compared with features widely used in the literature. Differences between low and high CL can be seen, especially between HR (SI), LF/HF (Empatica E4), ASA and EI (Muse S). Despite at best low correlation coefficients between extracted features and subjective CL labels, well-performing generalised CL models can be built using standard ML models.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Gopher D Donchin E. Workload: an examination of the concept. In: Handbook of Perception and Human Performance, Vol. 2: Cognitive Processes and Performance. John Wiley & Sons (1986). p. 1–49.
- 2Sweller J. Element interactivity and intrinsic, extraneous, and germane cognitive load. Educ Psychol Rev. (2010) 22:123–38. 10.1007/s 10648-010-9128-5 · doi ↗
- 3Fink G. Stress, definitions, mechanisms, and effects outlined: lessons from anxiety. In: Fink G, editor. Stress: Concepts, Cognition, Emotion, and Behavior, Volume 1 of the Handbook of Stress Series. San Diego: Elsevier inc. (2016). p. 3–11.
- 4Sandi C. Stress and cognition. Wiley Interdiscip Rev Cogn Sci. (2013) 4:245–61. 10.1002/wcs.122226304203 · doi ↗ · pubmed ↗
- 5Cezar BGS Maçada ACG. Cognitive overload, anxiety, cognitive fatigue, avoidance behavior and data literacy in big data environments. Inf Process Manag. (2023) 60:103482. 10.1016/j.ipm.2023.103482 · doi ↗
- 6Kocielnik R Sidorova N Maggi FM Ouwerkerk M Westerink JHDM. Smart technologies for long-term stress monitoring at work. In: Proceedings of the 26th IEEE International Symposium on Computer-Based Medical Systems (CBMS). IEEE (2013). p. 53–8. 10.1109/CBMS.2013.6627764 · doi ↗
- 7United Nations Department of Economic and Social Affairs. The sustainable development goals report. In: Ross J, editor. The Sustainable Development Goals Report 2023: Special Edition. New York, NY: United Nations (2023). p. 80. 10.18356/9789210024914 · doi ↗
- 8Ometov A Shubina V Klus L Skibińska J Saafi S Pascacio P, et al. A survey on wearable technology: history, state-of-the-art and current challenges. Comput Netw. (2021) 193:108074. 10.1016/j.comnet.2021.108074 · doi ↗