Evaluating ChatGPT 4.0 as a Tool for Nuclear Medicine Board Preparation
Pierce Herrmann, Kayvon Yazdanbakhsh, Golnaz Lotfian, Keyur Parekh, Sumeet Virmani, Alex Tegeler, Pokhraj P Suthar

TL;DR
This study evaluates how well ChatGPT 4.0 can help nuclear medicine students prepare for certification exams by answering practice questions.
Contribution
The study is one of the first to assess ChatGPT 4.0's accuracy on nuclear medicine board questions, revealing topic-specific performance variations.
Findings
ChatGPT 4.0 achieved an overall accuracy of 86.95% on nuclear medicine board questions.
The model performed poorly in pediatric nuclear medicine (75%) but perfectly in nuclear cardiology and radiopharmacy.
Performance did not correlate with the number of questions per chapter.
Abstract
Due to their potential use in medical education, large language models (LLMs), a type of generative artificial intelligence (AI), have become increasingly popular. The accuracy of ChatGPT 4.0 (OpenAI, San Francisco, CA) in responding to multiple-choice questions from a standardized board preparation resource for nuclear medicine certification examinations is assessed in this study. A total of 115 text-based questions from 12 chapters were chosen in total; image-dependent questions were not included because of ChatGPT's restrictions on text-only input. Section-by-section and overall accuracy were calculated by comparing the model's replies to the official answer key. ChatGPT performed the worst in pediatric nuclear medicine (75%), while achieving a total accuracy of 86.95%. It received perfect marks in nuclear cardiology and radiopharmacy. Interestingly, model performance did not…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1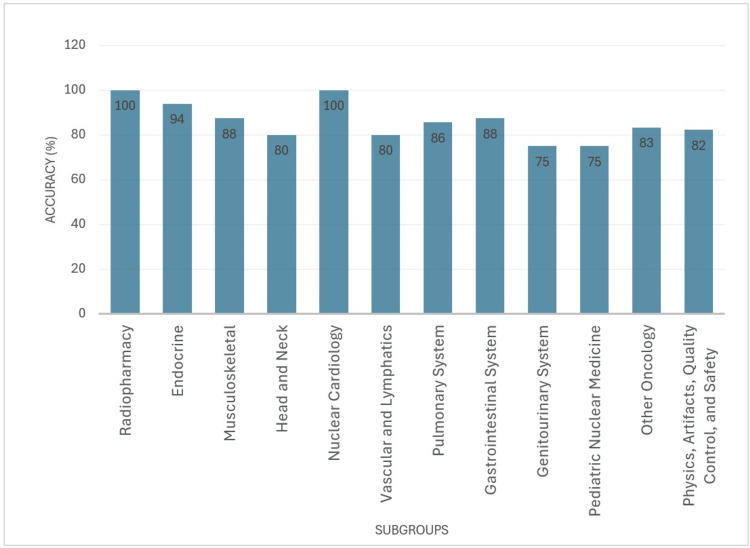 Figure 2
Figure 2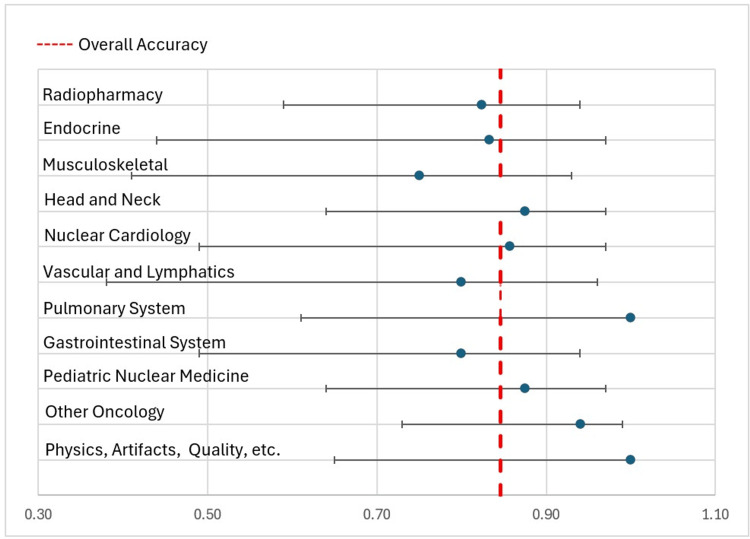 Figure 3
Figure 3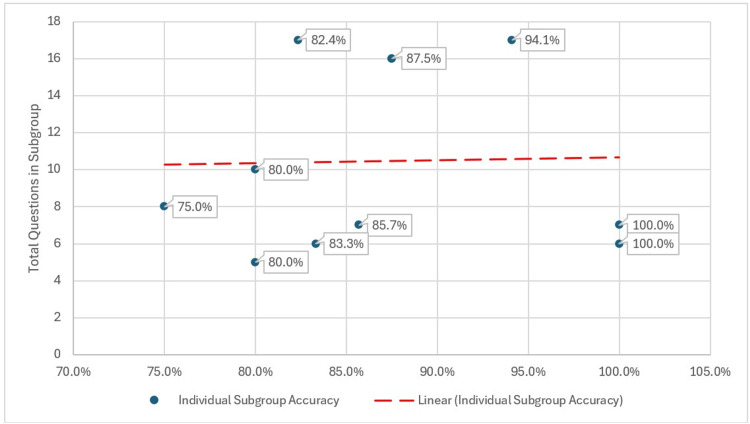 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Radiomics and Machine Learning in Medical Imaging · COVID-19 diagnosis using AI
Introduction
Large language models (LLMs), in particular, have become increasingly popular across a wide range of industries due to advancements in artificial intelligence (AI). With hundreds of millions of users worldwide, ChatGPT (OpenAI, San Francisco, CA), which was made available to the public in November 2022, has emerged as one of the most popular LLMs [1-3]. Interest in its use in healthcare and medical education has grown due to its accessibility and capacity to produce logical, contextually relevant solutions [4-6].
Because radiology relies on both image-based and text-based interpretation, it is particularly well-suited for LLM integration. Although previous research has examined the usefulness of LLM in clinical support and summary tasks, little is known about how well they perform on standardized board review content [7,8]. To date, only limited studies have evaluated LLM performance on medical board-style examinations, and none have explicitly focused on nuclear medicine question banks. This study, therefore, addresses an important and largely unexplored area of LLM application in medical education.
The accuracy of ChatGPT 4.0 in responding to board-style multiple-choice questions from Nuclear Medicine: A Core Review by Shah et al. [9] is examined in this study. The objective is to assess the validity of ChatGPT in the context of radiology education and investigate its potential as an additional aid for board preparation.
Materials and methods
This study was designed as a cross-sectional diagnostic accuracy study to evaluate ChatGPT's performance on text-based nuclear medicine board review questions. A total of 115 multiple-choice questions were selected from Nuclear Medicine: A Core Review by Shah et al. [9], spanning all 12 chapters. The chosen items included a mix of three-, four-, and five-option multiple-choice questions, consistent with the original textbook format. To ensure balanced representation and reduce selection bias, we included the first 15 text-based questions per chapter, when available. Although the order of questions in the textbook is not randomized, we selected the first 15 text-based items per chapter to provide a consistent, reproducible sampling frame; potential differences in difficulty between early and later items are acknowledged as a study limitation. For shorter chapters, all non-image-based questions were used. This strategy provided a standardized and reproducible sampling framework across the breadth of topics and was conducted between March and April 2025.
Image-dependent questions were excluded to minimize confounding from the model's image interpretation limitations. Although the publicly available March 2024 version of ChatGPT-4.0 (OpenAI) possesses multimodal functionality, this study deliberately focused on text-only performance to isolate its language reasoning and recall capabilities.
Each question was entered into the ChatGPT interface independently using a uniform prompt: "What is the correct answer to the following multiple-choice question?" To avoid context contamination, no prior interactions were visible to the model, and each query was treated as a separate session, and only a single attempt per question was recorded.
Responses, including both the selected answer and explanatory text, were recorded verbatim. Three board-certified radiologists independently validated ChatGPT's reactions against the textbook answer key. Reviewers were blinded to each other's assessments, and discrepancies were resolved by consensus.
Data were entered into Microsoft Excel (Microsoft Corp., Redmond, WA) and organized by chapter and content domain. Accuracy was calculated at both the chapter level and for the entire dataset. Excluded questions were tracked separately to document the final denominator.
The study was conducted and reported in accordance with the Standards for Reporting Diagnostic Accuracy Studies (STARD) guidelines, ensuring transparency and reproducibility.
Figure 1 outlines the overall input and validation workflow.
Illustration of provided prompt and associated ChatGPT responses The questions and their associated answers were sourced from the textbook Nuclear Medicine: A Core Review by Shah et al. [9].Image credit: Golnaz Lotfian
Results
Our study found that ChatGPT's performance on nuclear medicine multiple-choice practice questions varied depending on the subject of the question bank, with its accuracy ranging from 75% to 100%. The mean ChatGPT correct score was 86.95%, with a median of 85.55% and a standard deviation of 7.28% (Figure 2 and Figure 3).
ChatGPT's performance across all subgroupsChatGPT achieved an overall accuracy of 86.95%, with a standard deviation of 7.3 across all subgroups. Notably, it performed perfectly in two subgroups of radiopharmacy and nuclear cardiology.
Forest plot across all selected subgroupsForest plot (accuracy with 95% confidence interval) showing individual subgroup accuracy versus baseline (overall accuracy).
ChatGPT scored a perfect score in the radiopharmacy and nuclear cardiology sections, correctly answering all seven questions in the former and all six questions in the latter. Given the limited number of items in these sections, these perfect scores should be interpreted with caution, as they may not represent performance on a larger sample of questions. These chapters are outliers for ChatGPT, as they are the only sections with a score more than one standard deviation from the mean of its performance. ChatGPT scored the worst on pediatric nuclear medicine, another outlier, as it was the only score more than one standard deviation below the mean, at 75%, missing two out of eight questions. We hypothesized that, assuming ChatGPT has access to equal amounts of information regarding every chapter, the probability of getting a better score would correlate with the number of questions per section. However, we did not find this to be the case. As seen in Figure 3, there was no correlation between the percentage of correct answers and the total number of questions in that section, as seen in Figure 4.
Lack of correlation of accuracy versus total questions available in each subgroup
Discussion
There has been a rapid surge in advancements in artificial intelligence, particularly in the development and deployment of large language models (LLMs). ChatGPT, developed by OpenAI and released in 2022, represents one of the most widely adopted and capable LLMs available today. Its accessibility and broad application across industries have driven interest in its potential use in medicine, especially within radiology, where interpreting complex, structured information is central to both education and clinical care [10,11].
The potential application of LLMs in radiology is significant. These models have demonstrated the ability to rapidly process text-based inputs, offering potential benefits in streamlining workflows, supporting decision-making, stratifying clinician tasks, and enhancing diagnostic capabilities [8,12]. Our study focused specifically on evaluating ChatGPT's performance in nuclear medicine board-style multiple-choice questions, offering insight into how such tools might be leveraged in medical education.
ChatGPT 4.0 demonstrated strong overall performance, achieving an average accuracy of 86.95% in answering board-style nuclear medicine questions. However, the results revealed variability across topic categories. The model performed flawlessly in specific domains, such as radiopharmacy and nuclear cardiology, but struggled in others, including pediatric nuclear medicine. One hypothesis is that performance may be influenced by the volume of publicly available training data for specific topics. However, our study did not assess training data composition directly, so this theory remains speculative and warrants further investigation. We also found no correlation between the number of questions per chapter and accuracy, suggesting that other factors, such as question complexity, information density, or context, may contribute to this variability. Prior research has proposed that performance in LLMs can fluctuate based on the diagnostic clues provided in each question, a variable not assessed in our study but worth exploring in future work [13].
Model reliability and interpretability
Although ChatGPT demonstrated high accuracy in this assessment, consistency and reliability remain challenges for educational or diagnostic applications. The model's responses are not deterministic; repeating the same prompt may yield slightly different answers, particularly for nuanced or context-heavy questions. This variability, while acceptable in general use, raises concerns in medical settings where reproducibility and precision are critical [11,14].
Another concern is the model's lack of transparent reasoning [12,15]. ChatGPT provides direct answers without citing references or explaining its rationale, limiting its utility as a teaching tool. In medical education, the ability to follow the logic behind a conclusion is essential for learners to develop critical thinking skills. Without insight into how a model arrives at its answer, users may accept incorrect or oversimplified responses at face value, potentially reinforcing misconceptions [15].
Study limitations and model scope
There are various restrictions on this study. First, although image-based questions are essential to the profession, the analysis was limited to questions from a single source: Nuclear Medicine: A Core Review. Therefore, the assessment does not fully represent the range of nuclear medicine board examinations; instead, it only evaluates ChatGPT's performance on text-based knowledge. Although this was necessary because ChatGPT cannot currently understand images, it restricts the extent to which the results can be utilized. In addition, some subspecialty domains contained relatively few questions; thus, perfect scores in these areas should be interpreted cautiously and may not reflect performance across a larger item pool.
Furthermore, we did not examine the effects of clinical vignettes, question structure, or distractions on performance elements that are increasingly recognized as crucial in assessing LLM behavior [16]. To evaluate how effectively the model handles clinical logic versus factual recall, future research should examine these factors more closely, possibly utilizing larger and more diverse datasets. While we hypothesized that topic representation within publicly available training data could influence performance, our study did not directly assess model training data composition; this remains speculative and warrants further investigation.
Lastly, ChatGPT is a general-purpose language model that has not been specially adjusted for medical board examinations or nuclear medicine. It nevertheless had outstanding results in some categories. Its non-transparent and non-domain-specific training data, however, raise concerns over the repeatability of its performance in increasingly complex or specialized diagnostic settings [16].
Conclusions
ChatGPT 4.0 demonstrated strong overall accuracy (86.95%) in answering nuclear medicine board review questions, with perfect scores in radiopharmacy and nuclear cardiology, and its weakest performance in pediatric nuclear medicine. These results highlight both the promise of AI as a supplemental educational tool and the variability in performance across subspecialty domains, potentially reflecting gaps in topic representation within the model's training data. Notably, no correlation was observed between chapter size and performance, suggesting that factors such as question complexity, answer framing, or prevalence of conditions may play a greater role.
While these findings support the potential role of ChatGPT in radiology education and board preparation, the variability underscores the continued importance of human expertise. AI can serve as a valuable adjunct to enhance comprehension and engagement, but it cannot replace the judgment, experience, and critical reasoning of trained physicians. Future studies should further investigate the factors that influence AI accuracy and explore strategies for integrating these tools responsibly into medical training.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Impact of Chat GPT on medical chatbots as a disruptive technology Front Artif Intell Chow JC Sanders L Li K 1166014620233709130310.3389/frai.2023.1166014 PMC 10113434 · doi ↗ · pubmed ↗
- 2Creation and adoption of large language models in medicine JAMA Shah NH Entwistle D Pfeffer MA 86686933020233754896510.1001/jama.2023.14217 · doi ↗ · pubmed ↗
- 3Large language models in medicine: the potentials and pitfalls: a narrative review Ann Intern Med Omiye JA Gui H Rezaei SJ Zou J Daneshjou R 21022017720243828598410.7326/M 23-2772 · doi ↗ · pubmed ↗
- 4From big data to big artificial intelligence?KI Kersting K Meyer U 38322018
- 5Large language models in medicine Nat Med Thirunavukarasu AJ Ting DS Elangovan K Gutierrez L Tan TF Ting DS 193019402920233746075310.1038/s 41591-023-02448-8 · doi ↗ · pubmed ↗
- 6Large language models in medical and healthcare fields: applications, advances, and challenges Artif Intell Rev Wang D Zhang S 299572024
- 7Comparing the diagnostic performance of GPT-4-based Chat GPT, GPT-4V-based Chat GPT, and radiologists in challenging neuroradiology cases Clin Neuroradiol Horiuchi D Tatekawa H Oura T 7797873420243880679410.1007/s 00062-024-01426-y · doi ↗ · pubmed ↗
- 8Evaluating GPT as an adjunct for radiologic decision making: GPT-4 versus GPT-3.5 in a breast imaging pilot J Am Coll Radiol Rao A Kim J Kamineni M Pang M Lie W Dreyer KJ Succi MD 9909972020233735680610.1016/j.jacr.2023.05.003PMC 10733745 · doi ↗ · pubmed ↗