Recurrent issues with deep neural network models of visual recognition
Timothee Maniquet, Hans Op de Beeck, Andrea Ivan Costantino

TL;DR
This study compares recurrent and feedforward deep neural networks in modeling human visual recognition behavior, finding that model size often matters more than recurrence.
Contribution
The study reveals nuanced relationships between model size, recurrence, and human-like performance in visual recognition tasks.
Findings
Performance improvements were primarily driven by model size, not recurrence or architecture.
Larger models aligned better with human difficulty patterns across visual manipulations.
Recurrent models showed a negative size effect in matching human confusion matrices.
Abstract
Object recognition requires flexible and robust information processing, especially in view of the challenges posed by naturalistic visual settings. The ventral stream in visual cortex is provided with this robustness by its recurrent connectivity. Recurrent deep neural networks (DNNs) have recently emerged as promising models of the ventral stream, surpassing feedforward DNNs in the ability to account for brain representations. In this study, we asked whether recurrent DNNs could also better account for human behaviour during visual recognition. We assembled a stimulus set that includes manipulations that are often associated with recurrent processing in the literature, like occlusion, partial viewing, clutter, and spatial phase scrambling. We obtained a benchmark dataset from human participants performing a categorisation task on this stimulus set. By applying a wide range of model…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
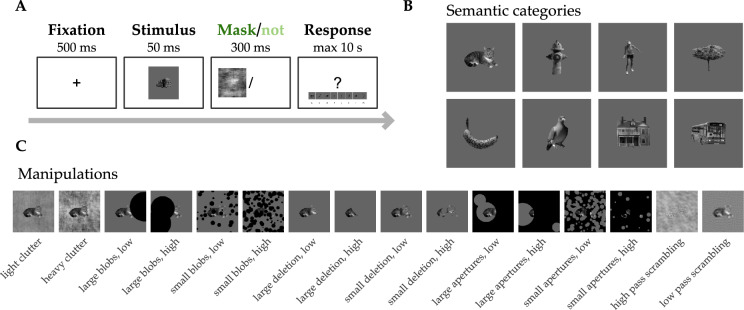 Figure 1
Figure 1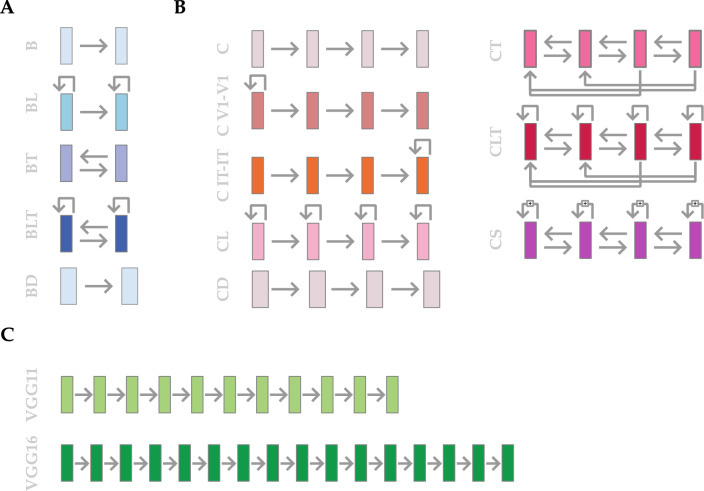 Figure 2
Figure 2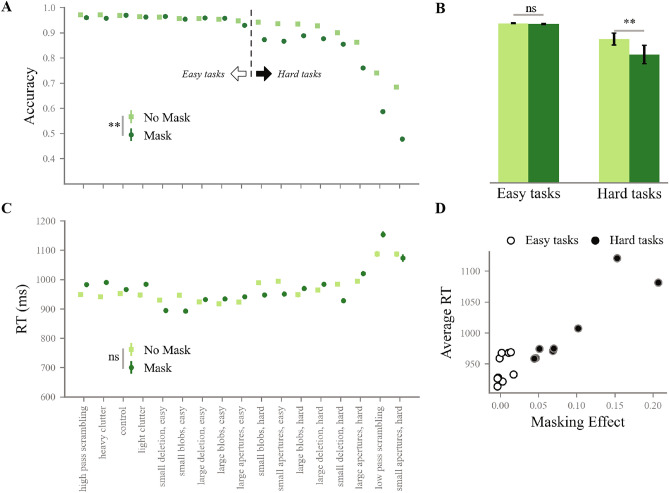 Figure 3
Figure 3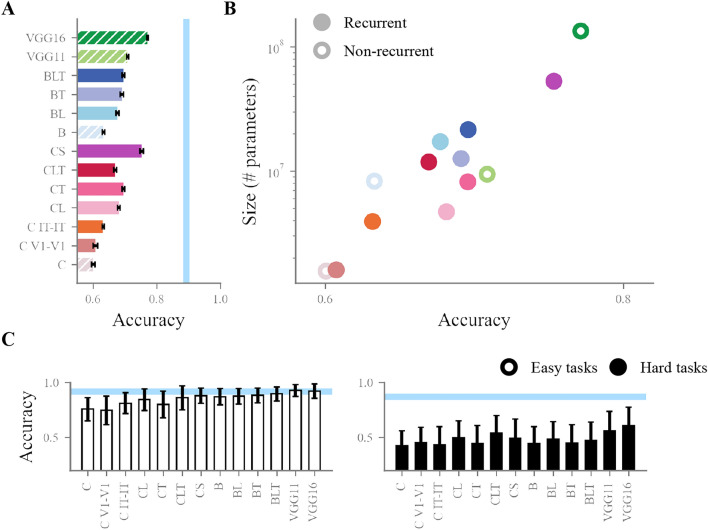 Figure 4
Figure 4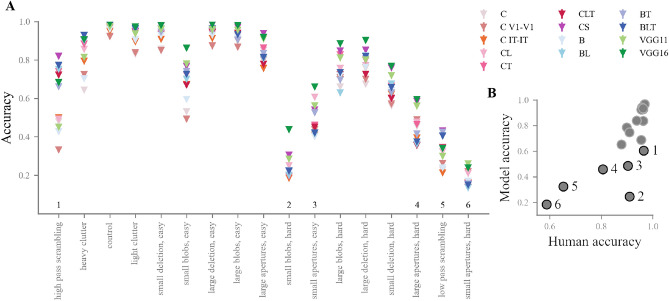 Figure 5
Figure 5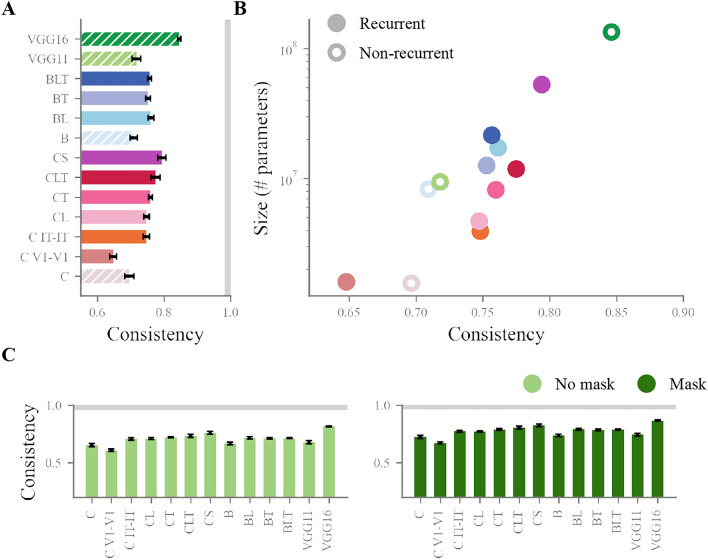 Figure 6
Figure 6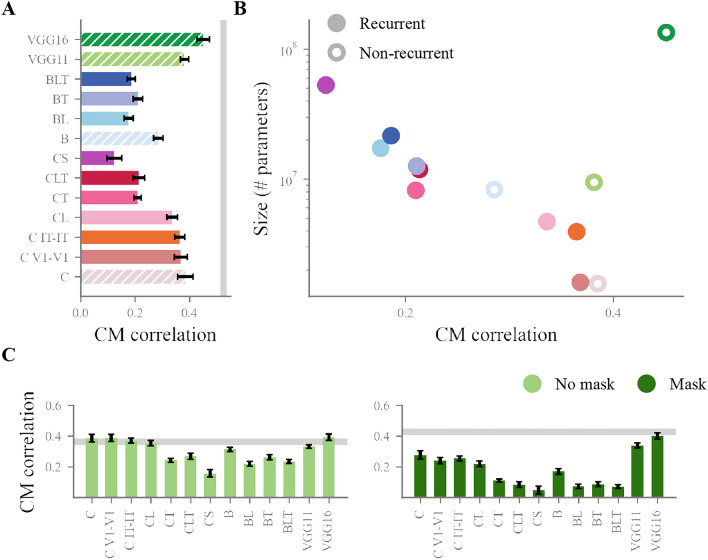 Figure 7
Figure 7- —Fonds voor Wetenschappelijk Onderzoek
- —Flemish Government
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNeural dynamics and brain function · Face Recognition and Perception · Visual perception and processing mechanisms
Introduction
Visual recognition is at the core of human cognition, and an impressive feature of our brain. Understanding the visual world seems effortless, which hides the computational difficulty of real-world object recognition. The visual complexity of scenes from everyday life calls for flexible and robust processing in order to decode the identity of objects in the environment^1–3^. This feat is accomplished seamlessly by the ventral stream in visual cortex, whose connectivity allows for such extraordinary abilities. While it is often modelled as a bottom-up network, every feedforward connection it contains is paralleled by one or several non-feedforward connections^4–8^. It is hence better understood as a highly recurrent network.
Recurrence in a system allows for the dynamic processing of information. Visual recognition, although fast and largely bottom-up^9–11^, is therefore a dynamic process. Across cycles of extra-feedforward processing, recurrent activity modulates and integrates visual information. As a result, it is responsible for many perceptual phenomena known to occur particularly in ambiguous, complex visual situations, e.g. stimulus-context modulation, predictive processing and figure-ground segmentation^12–15^. Through the processing flexibility that it confers, recurrence is hence largely implicated in the presence of non-canonical, non-trivial contexts. Evidence for this role comes from studies using backward masking, a technique known to selectively disrupt recurrent processing^16,17^. Given the temporal unfolding that is inherently linked with recurrent processing, it is possible to selectively impact it, while leaving initial feedforward processing intact through the use of masking. Several studies have taken advantage of this, and found that it selectively impaired visual recognition under challenging conditions, but not under non-challenging ones^18–20^.
While the basic principles of feedforward processing in visual recognition are well understood, there is no universal account of how it integrates with recurrence, or of the exact mechanisms served by the latter. Across the visual cortex, various specific forms of recurrence have been studied and linked to specific perceptual phenomena. For instance: uncertainty computation^21^ and pattern completion^22^ by lateral connections within V1, edge detection in cluttered images through lateral connections in V1^23^, prediction about occluded shapes by feedback from the prefrontal cortex (PFC) to V4^24^, figure-ground modulation by feedback from V4 to V1^25,26^, and interactions with spatial frequency transformations by feedback from frontal areas^27,28^. The literature points to a wide range of roles played by a wide range of recurrent connections, operating various computations on incoming sensory information. Overall, recurrent processing seems to determine an important part of visual perception, and of the brain dynamics underlying it.
The importance of recurrence in brain dynamics is also supported by studies using deep neural networks (DNNs). Optimised on recognition tasks, DNNs are considered good models of the ventral stream, mimicking its hierarchical structure and categorising objects with human-like accuracy^29^. Moreover, DNNs have been found to display representational similarity with the ventral stream^30,31^. Strikingly, this similarity increases with recurrent DNNs^32,33^, indicating that the representational dynamics of the visual cortex fit better with these of a recurrent network, compared to feedforward-only. The aforementioned studies of backward masking also included DNNs to show that models equipped with recurrence, but also deeper models, show more resilience to challenging conditions than feedforward-only models.
At the behavioural level, recent evidence showed that recurrent DNNs better explain human reaction time (RT) than size-matched feedforward models^34^. Altogether, with a better fit to the brain, improved resilience to image challenges, and being better models of human RT, recurrent DNNs are a promising tool to identify the various roles of recurrence, and understand its function in the ventral stream. This is especially important given that at similar sizes, more biologically plausible, recurrent DNNs tend to better predict brain activity than non-recurrent DNNs, all the while being time-wrapped equivalents of size-matched feedforward DNNs^35^. However, it remains unclear recurrent DNNs are also better models of human behaviour under challenging visual conditions, when recurrent processing matters the most. This is in part due to a lack of investigations into the pattern of errors and confusions of DNNs^36,37^. In order to test whether recurrence also improves model fit to human behaviour when faced with visual complexity, such investigations should include a wide range of architectures, and a wide range of visual conditions, to emulate the variety of recurrent connections and of phenomena they are associated with.
The present study aimed at taking a step in this direction by running an extensive test of model performance including different types of DNN recurrence and several image conditions. We adopted the approach of testing our DNNs on a carefully crafted stimulus set^38–40^, and combined a variety of image manipulations known to involve recurrence in humans^18–20,28,41^ in one large experiment, in which we tested and compared human participants and DNN models. We implemented different types of architecture, including different flavours of recurrence, in a number of DNNs, and compared their performance and error patterns on a classification task with that of humans. Taking advantage of the architectural diversity of our models, we asked whether recurrent models would perform better in the resolution of different kinds of visual complexity, and whether they would better explain the patterns of human behaviour, as compared to non-recurrent models.
We found that recurrence in DNNs helped them match with human performance, but not more than added computational (layer) depth. This feeds into the observation that recurrent neural networks can be considered time-wrapped equivalents of size-matched feedforward neural networks^35^. However, our results go a step further, as we also found a decrease in model match with human confusion matrices when equipped with recurrence. Additionally, we found that our recurrent models displayed mostly similar patterns of performance, despite variations in the type of recurrence implemented. This indicates that our DNNs are unlikely candidates to reproduce the variability of phenomena that recurrence is responsible for in the brain. All together, our behavioural testing does not allow to dissociate between model architecture beyond size, suggesting that recurrence, in its present implementation, does not help in capturing human behaviour.
Materials and methods
Participants
A total of 231 subjects participated in the study (195 females, age (mean±SEM): 18.7 ± 1.7), of which 13 were excluded due to low performance (average accuracy below 0.7). All participants gave their informed consent before taking part. The task took place online and lasted approximately 30 minutes. All experiments were approved by the ethics committee at KU Leuven, and all methods were performed in accordance with the relevant guidelines and regulations.
Stimuli
Images of objects were selected from real-world scenes of the publicly available online databases MS COCO^42^ and ADE20K^43^. Eight object categories were included: person, cat, bird, tree, fire hydrant, building, bus, and banana (see Fig. 1). The categories were chosen to cover a diverse range of levels of animacy, real world size and aspect ratio. Stimuli were segmented out from their backgrounds, transformed to a 700 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 700 pixel size, and equalised on their contrast and average luminance levels. 10 exemplar objects were picked for each category, resulting in a stimulus set of 80 images.
Challenging manipulations
Object recognition was rendered challenging by applying several types of visual manipulations on the stimulus set (see Fig. S1). Each one of the manipulation was selected based on literature demonstrating that it is linked to recurrent processing, as evidenced by psychophysical, neuroimaging, or DNN data. We implemented a total of 16 visual manipulations, each a variation of one of the following image transformations: adding clutter in the background of the object, adding occluding blobs on top of the object, removing parts of the object, adding a full occluder with apertures on top of the object, and phase scrambling the object image. The control condition showed the segmented object on a grey background.
We cluttered objects by placing cluttered images in their backgrounds. These were obtained by phase scrambling randomly selected natural scenes from the MS COCO dataset, and measuring an index of spatial coherence (SC) and contrast energy (CE) for each image, the combination of which gives a proxy of how cluttered an image is^44^. We defined two levels of clutter by selecting lightly cluttered backgrounds and heavily cluttered backgrounds at each end of the spectrum, with 2 clutter conditions as a result.
We added black, circular blobs to occlude 40% (low) or 80% (high) of objects. These blobs were either many small or a few large ones, resulting in 4 blobs conditions.
Parts of objects were deleted, with 40% (low) or 80% (high) of objects deleted. The deletion was operated through circular disks, which could also be many small or a few large ones. This resulted in 4 deletion conditions.
A full occluder was placed on top of objects, on which apertures were made so that either 40% or 80% of the objects would be hidden. A similar approach with many small or a few large apertures was adopted, with 4 occluder conditions as a result.
Phase scrambled images were made by randomising their phase spectrum, adopting an approach similar to that of^28^. Images were Fourier transformed, and their phase spectrum was replaced by random noise, on either side of a spatial frequency threshold of 1.5 cycles per degree (with images assumed to subtend 10 degrees of visual angle on screen). The origin of the phase spectrum was left intact. Images were then transformed back into image space. This resulted in 2 phase scrambling conditions: a low-pass and high-pass phase scrambled version of each image.
Experimental task
Participants were given a categorisation task, where each image was to be classified in one of the eight possible categories of the stimulus set. All trials had the same timeline (see Fig. 1): after a fixation cross, a target image appeared for 50 ms. Targets were either followed by an empty screen or by a mask. The instructions asked for an accurate answer that could be registered as soon as the target was presented. All trials ended with the presentation of a reminder of the eight categories and their associated response keys. The latter appeared at the bottom of the screen 200 ms after the mask (or empty screen) disappeared.Fig. 1. Experimental design & stimuli. (A) Design of the classification task performed by human participants. A 500ms fixation cross (+ 0–300 ms of a randomly long blank interval) was followed by the short presentation of a target stimulus (50 ms), which was then either masked (presentation of a phase scrambled pattern for 300 ms) or not (blank screen). Finally, a reminder appeared on screen after the mask/blank screen for participants to recall the category-response key mapping. Trials ended upon response or after a maximum of 10 s post stimulus. (B) The eight semantic categories included in the stimuli. Top row, from left to right: cat, fire hydrant, person, tree; bottom row, from left to right: banana, bird, building, bus. (C) Challenging manipulations implemented in the stimulus set (the control condition corresponds to the example categories shown in B).
Masks were phase-scrambled versions of natural scenes taken from MS COCO.@ Images were randomly selected from the dataset, resized to match target images (700 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 700), and taken to the Fourier space where their phase spectrum was fully replaced by random noise (except for the origin, left intact) before reconstruction into the image space.
In total, 16 experimental conditions and one control made 17 conditions, all of which to be presented with and without masking. The resulting 34 conditions were divided into sub-experiments: occlusion made up 2 sub-experiments (few large occluder disks and many small occluder disks, 6 conditions each). Phase scrambling and clutter were joined together into one other sub-experiment (4 conditions). These three sub-experiments were ran with and without masking, resulting in 6 experiments in total. An extra unmasked control condition was added to all three of the masked experiments to serve as a comparable baseline. All of them were conducted online over the same period, and no participant took part more than once. Data from all six experiments were pooled together, after confirmation that results on the unmasked control, which was similar for all participants, did not differ significantly across experiments (one-way ANOVA on accuracy with experiment as factor, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F = 0.68, p=0.64$$\end{document} ).
Deep neural network architectures
We investigated fifteen distinct DNN models, each varying in architecture and recurrent connections (see Fig. 2). These models were specifically chosen to represent a range of complexities, from basic feedforward structures to more sophisticated recurrent networks. We categorised these models into three groups: CORnet models, B models, and VGG models (see Table S1 for a detailed overview, and Tables S2–S16 for a layer-by-layer description of each model).Fig. 2. Model architectures. All recurrent and non-recurrent models included in the study. (A) The four available models of the B family were used. These models share a baseline 2-layer architecture (B), with the addition of either lateral connections (BL), top-down connections (BT), or both (BLT). We crafted an additional, larger feedforward version of B called BD. (B) Models from the CORnet family (here called C for facility) including three readily available and four custom-made models. From^45^, the base FF model CORnet Z (C), the lateral connections-equipped CORnet RT (CL) and the highest-performing CORnet S (CS). Custom-made versions of these architectures include full top-down connections (CT), full top-down and lateral connections (CLT), specific lateral connections in layers V1 (C V1–V1) and IT (C IT–IT). We also crafted an additional, larger feedforward version of C called CD. (C) VGG models were used as feedforward controls to the recurrent models. We used the state-of-the-art VGG16 model, as well as a custom-made, smaller VGG11 to better match the size of our recurrent models. Rightward arrows represent feedforward connections. Backward arrows above layers represent lateral connections. Leftward arrows and arrows below layers represent feedback connections. The arrows of CS represent the ResNet-inspired residual block structures.
CORnet models
From the CORnet family, we included the foundational models CORnet Z, CORnet RT, and CORnet S^45,46^. While CORnet Z uses a simple feed-forward architecture, CORnet RT enhances this design by integrating biologically-inspired additive recurrent mechanisms within each block. CORnet S further advances this architecture by adding additional convolutional layers in a bottleneck ResNet-like block structure, thereby enriching its internal dynamics and significantly increasing its parameter count relative to its simpler counterparts. For better readability, CORnet is hereafter abbreviated C, and models are branded after the recurrent element of connectivity they contain (L for lateral connections, T for top-down connections). We therefore selected C (CORnet Z), CL (CORnet RT) and CS (CORnet S). We custom-extended the C series for this research, by adding the following: C V1-V1, featuring within-layer connections in its initial convolutional layer; C IT-IT, implementing similar within-layer connections but in its terminal convolutional layer; CT, designed with top-down connections extending from higher to lower layers; and CLT, a specialized version of CL augmented with top-down connections analogous to those in CT.
Finally, we designed an additional feed-forward, deeper control model, CORnet D (hereafter referred to as CD), whose parameters count roughly matches that of CORnet S. To achieve this, three additional CORblock_Z_no_pool blocks–each consisting of a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3{\times }3$$\end{document} convolution, batch-normalisation, and ReLU—were appended before the original convolutional CORblock_Z of every layer (V1, V2, V4, IT). The added blocks omit max-pooling (retained only in the final block) so that spatial dimensions and channels number remain unchanged. CD therefore serves as a parameter-matched feed-forward benchmark that isolates the effects of computational (layer) depth from those of recurrence.
B models
B models^47^ include B, BL, BT , and BLT models. BL is characterized by lateral connections, BT by top-down connections, while the BLT model combines both lateral and top-down mechanisms. All models were used with their publicly available PyTorch implementations and pretrained weights^48^.
We also introduced a deeper feed-forward variant, BD. BD retains the overall architecture of B, but adds two extra feed-forward BLT_Conv blocks (with no input pooling to preserve dimensionality) to each layer (v1, v2, v4, it) after the original BLT_Conv block. This strategy raises the parameter count to match BLT, thereby disentangling the contribution of recurrence from that of parameters count.
VGG models
The VGG models, specifically VGG11 and VGG16^49^, served as the feedforward control group. Their architecture, lacking feedback mechanisms, is deeper, providing a baseline comparison against recurrent models. VGG11 is a custom implementation of VGG16 featuring only 11 trainable layers and a smaller decoding head with a single linear layer. This modification was made to create a VGG16-like very deep feedforward network, but with a number of learnable parameters more comparable to the recurrent models.
Training regimen
Our model training process was divided into two distinct phases: a training phase on the ImageNet dataset, followed by a phase of fine-tuning on the specific 8 categories contained in our dataset.
ImageNet training
Models lacking pre-existing ImageNet-trained weights or featuring custom recurrent mechanisms (i.e. all of them, except CS) were trained in-house. For CS, publicly available weights were used (see GitHub repository for the weights, and the original publication for ImageNet training details ^46^). This phase involved a single cycle of 25 epochs, using a fixed seed of 42 and a batch size of 256 (see Fig. S2 for more details). A one-cycle learning rate policy ^50^, as implemented in the fastai ^51^ library, was employed. The maximum learning rate for the fit_one_cycle algorithm was set by multiplying the optimal rate, determined using fastai’s implementation of the learning rate finder ^52^, by a factor of 10. The training was performed on the ILSVRC2012 challenge subset of the ImageNet dataset ^53^, which includes 1,000 classes and approximately 1.2 million images for training and an additional 50,000 for validation purposes. During the training phase, each image was normalized using the mean and standard deviation statistics from ImageNet, followed by a random crop with a minimum scale of 0.35 which was then resized to 224 x 224 pixels (or 128 x 128 pixels for the B models). In the validation phase, images were directly normalized and resized, omitting the cropping process.
Fine-tuning
For fine-tuning, we conducted 20 independent training runs on the same ImageNet-trained model, each with a distinct fixed seed. This approach ensured varied initializations for the new classifier head (adapted from 1000 output units to the 8 units needed for our classification task), for the dataloaders and different seed settings for essential libraries (e.g., NumPy, PyTorch, fastai, and CUDA). Each run comprised 3 cycles, each with 9 epochs, amounting to 27 epochs in total. The initial 6 epochs of each cycle focused on training the model’s classifier and the last convolutional layer before the classifier. This strategy was adopted to preserve low-level features learned from ImageNet, aligning with our goal to model human-like visual processing by retaining features from a dataset rich in natural visual variance. In the last 3 epochs of each cycle, the full model was trained, allowing for a comprehensive adaptation to our 8-way classification task. The learning rate for each cycle was dynamically determined using the learning rate finder algorithm from fastai at the start of each cycle. The fit_one_cycle method parameters were set with lr_max as the optimal learning rate multiplied by 10.
The fine-tuning dataset included a total of 32,000 images taken from the same datasets as these used to build the human dataset (see “Stimuli”), with an equal distribution of 4,000 images per category. Each category was divided to include half the images with their original background (split equally between colored and black and white) and half against a neutral gray background (also divided equally between colored and black and white). This approach allowed us to train the network to accurately categorize images irrespective of background variations and color cues (see Fig. S3 for more details).
This dual-phase training approach produced 20 uniquely fine-tuned versions of each model, ensuring robust adaptation to our classification task while preserving foundational ImageNet-acquired knowledge. The Adam optimizer with a Cross Entropy loss function was employed throughout both phases of training. Training was executed in parallel on 3 NVIDIA GeForce RTX 2080 GPUs. The models were implemented using PyTorch version 2.1.2 ^54^, TorchVision version 0.16.2 ^55^, and fastai version 2.7.13 ^56^.
Model sizes and connections
A comprehensive overview of the model architectures is provided in Fig. 2. Models that implemented at least one type of recurrent connection (i.e., top-down or within-layer recurrent mechanism) have an added time dimension due to the iterative nature of recurrent dynamic. Here, we set the total time-steps to 5 during both training and testing phases, in line with the publicly released implementation of CORnet-RT (CLT). A time-step here represents an end-to-end (from input to output) processing of the input image.
Top-down connections
Top-down mechanisms were implemented in three of the models used here: CT, CLT and BLT. The implementation of top-down mechanisms in the CT and CTL architectures, inspired by the CORnet model, and the BLT model, reveals distinct approaches to incorporating feedback connections in deep neural networks.
The BLT architecture incorporates top-down connections through transposed convolutional layers between consecutive layers, enabling the model to integrate abstract, higher-level information back into earlier stages of processing. The de-convolution and reintegration process could be seen as part of a predictive coding strategy, where the model minimizes prediction errors between higher level predictions and actual sensory input – akin to generative models that seek to enhance feature selectivity and reconstruct low-level sensory inputs from higher-level abstractions. The additive nature of the de-convolved signal in the implementation used here could lead to a direct influence of higher-level representations on lower-level processing, but offers less capacity for non-linear integration of the bottom-up and top-down signals compared to our other networks.
In CT and CLT models, on the other hand, each block is uniquely structured to integrate top-down inputs from all higher blocks, not just the adjacent one, through a specialized top-down pathway before being combined with the feedforward input through an additional convolutional layer. Such a design facilitates a more sophisticated non-linear integration of hierarchical information, allowing for the integration of bottom-up data with top-down information from all higher layers. This method fosters richer representation at each processing stage at the cost of increased computational complexity and a partial information loss due to channel averaging.
Specifically, in the CT and CLT models, a block processes a bottom-up input \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x$$\end{document} (the output of the previous block at time-step \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t-1$$\end{document} ) and combines it with top-down feedback \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M$$\end{document} , derived from the aggregated outputs of higher-level blocks at time-step \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t-1$$\end{document} . In instances where top-down input is absent – such as during the initial time-step when no higher-level info is available – \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M$$\end{document} is set to zero.
The feedforward path \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$FF$$\end{document} and the top-down path \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$TD$$\end{document} each involve convolution (*), Group Normalization (N), and ReLU activation (R):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} FF(x) = R\left( N\left( x * \theta _{ff} \right) \right) , \quad TD(M) = R\left( N\left( M * \theta _{td} \right) \right) \end{aligned}$$\end{document}The weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta _{ff}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta _{td}$$\end{document} represent distinct sets of learned weights for the feedforward and top-down convolutions, respectively.
The integrated top-down input \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M$$\end{document} is formed by processing the outputs from higher layers \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m_1, m_2, \ldots , m_n$$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} M = \text {Concat}\left( \text {ProcessTopDown}(m_1, x), \text {ProcessTopDown}(m_2, x), \ldots , \text {ProcessTopDown}(m_n, x) \right) \end{aligned}$$\end{document}Given a top-down input tensor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m_i$$\end{document} from layer i and a bottom-up input tensor x, the function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {ProcessLayer}(m_i, x)$$\end{document} is defined as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \hat{m}_i = \text {AdaptiveAvgPool2d}(H_x)(m_i), \quad \text {ProcessTopDown}(m_i, x) = \frac{1}{C} \sum _{c=1}^{C} \hat{m}_i^{(c)} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_x$$\end{document} is the height of the bottom-up input tensor x, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{m}_i$$\end{document} is the tensor obtained after applying adaptive average pooling to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m_i$$\end{document} with a target spatial dimension of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_x$$\end{document} , and the function computes the mean across the channel dimension of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{m}_i$$\end{document} , resulting in a tensor with a single channel and same spatial dimensions as the bottom-up input.
The final output \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y$$\end{document} of the block is generated by concatenating the feedforward and top-down outputs and applying convolution, normalization, and ReLU:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} y = O\left( \text {Concat}\left( FF(x), TD(M) \right) \right) \end{aligned}$$\end{document}with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z = \text {Concat}(FF(x), TD(M))$$\end{document} , where concatenation occurs along the channel dimension. The output operation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O$$\end{document} applies convolution, normalization, and ReLU activation on the concatenated tensor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z$$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} O(z) = R\left( N\left( z * \theta _{o} \right) \right) \end{aligned}$$\end{document}In this setup, the feedforward path ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$FF$$\end{document} ) processes input from the preceding block, while the top-down path ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$TD$$\end{document} ) integrates inputs from multiple higher layers, creating a comprehensive feedback mechanism. This design allows for a dynamic interplay of bottom-up perceptual data and high-level predictions. Top-down connections facilitate a backward flow of information, refining feedforward outputs with knowledge acquired from more abstract representations. This approach mirrors the concept of biologically plausible models, where visual information processing involves not only a feedforward pathway but also feedback loops that dynamically adjust and refine their understanding of visual inputs^35^.
Within-layer connections
The CORblock RT block, used in the original implementation of CL^45^), was used here to model within-layer connections in models with within-layer connections only (i.e., CL, C V1–V1 and C IT–IT) to keep our custom implementations closer to the original. In these models, lateral connections are established within the block, where the output of a block at one timestep is used as an additional input in the next timestep (see^45^ for more details). On the other hand, within-layer connections are implemented through temporal depth (i.e., through several iterations over the same block) in CORnet S, with skip connections that facilitates the preservation and integration of information across multiple passes of the same block, effectively approximating a very deep network architecture with shared weights. In contrast, lateral connections are implemented in BLT through specific convolutional layers that are dedicated to processing inputs from the same layer at previous timesteps. These layers are specifically tasked with processing the output of the same block from the previous timestep, effectively allowing the block to integrate its past state with the current input at the “cost” of additional parameters.
A different approach was used to model within-layer connections for C LT, due to the more complex shapes and different natures of the top-down, bottom-up and lateral inputs. For each CLT block, during the forward pass for an input \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x$$\end{document} at a given timestep \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t$$\end{document} , a previous state \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s_{t-1}$$\end{document} , and top-down input \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$td$$\end{document} , the output \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_t$$\end{document} and the updated state \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s_t$$\end{document} can be described as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} ff&= FF\left( x\right) , \\ td&= TD\left( M\right) , \\ rr&= R\left( N\left( s_{t-1} * \theta _{\text {rr}} \right) \right) , \\ x'&= \text {Concat}(ff, rr, td), \\ y_t&= R\left( N\left( x' * \theta _{\text {out}} \right) \right) , \\ s_t&= y_t, \end{aligned} \end{aligned}$$\end{document}In this representation, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ff$$\end{document} corresponds to the output of the feedforward pass, computed by convolving the input \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x$$\end{document} with the weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta _{\text {ff}}$$\end{document} , followed by normalization \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N$$\end{document} and ReLU activation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R$$\end{document} . The processed top-down input, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$td$$\end{document} , is obtained by applying a sequence of operations defined by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {ProcessTopDown}$$\end{document} on the concatenated top-down input \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M$$\end{document} (see “Top-down connections” for more details). The term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$rr$$\end{document} represents the within-layer processing of the previous state \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s_{t-1}$$\end{document} , convolved with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta _{\text {rr}}$$\end{document} with kernel size and stride of 1 to preserve spatial dimensions, and then normalized and ReLU-activated. The concatenation operation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Concat}$$\end{document} merges the outputs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ff$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$rr$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$td$$\end{document} into a single tensor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x'$$\end{document} along the channel dimension. This concatenation preserves the spatial dimensions of the feature maps, and effectively pools the distinct features extracted from each individual path into a unified representation for subsequent layers. Finally, the output \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_t$$\end{document} of the block at timestep \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t$$\end{document} and the updated state \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s_t$$\end{document} are obtained by convolving \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x'$$\end{document} with the output weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta _{\text {out}}$$\end{document} , followed by normalization and ReLU activation. This output serves both as the response of the block at the current timestep and the state for the next timestep.
This recurrent structure enables the layer to integrate both current and previous activations, thereby enriching the artificial system with temporal dynamics and mimicking the recurrent mechanisms observed in biological visual systems^32,33^.
Model evaluation and statistical analysis
After training and fine-tuning, each model was tested against our test dataset. The test dataset included 800 black and white images (100 images for each of the same 8 categories) on a gray background. The dataset was presented to the network in a control or challenging condition (see “Challenging manipulations” for more details).
To evaluate the performance of each DNN model we employed a Top-1 Error Rate metric, which assesses classification accuracy based on the top prediction. Classification accuracy for each item in the test dataset was recorded for each model and each training seed, resulting in one confusion matrix per model across all the seeds.
Results
In this study, we compared humans and DNN models on a categorisation task in order to investigate whether recurrent DNNs would better fit with human behaviour than feedforward DNNs. To capture these potential differences we developed a rich stimulus set that would be sensitive enough to allow for a fine-grained test of model fit to human data. The stimulus set quality was twofold. First, it implemented a variety of visual challenges (occlusion, phase scrambling, clutter), aimed at reproducing the diversity of natural scene complexity, while maintaining control over the degree of challenge. Second, it included a high number of object categories (eight categories: people, cats, birds, trees, bananas, buses, buildings and fire hydrants, see Fig. 1), thereby requiring a focus upon multiple features and dimensions to solve the task. We chose to compare model types on their performance on a challenging recognition task, as recurrent processing in the brain has been extensively evidenced to play a role in the context of challenging visual inputs.
During the experiment, images were presented either manipulated (challenging conditions, 16 conditions) or non-manipulated (control condition, segmented objects on a plain background), for a total of 17 conditions to solve. Models and humans were asked to label the category the image belonged to on every trial, with human participants instructed to do so as fast and accurately as possible. We measured performance across visual manipulations, expecting that the advantages of adding various types of recurrent connections to our DNN models would especially show in the challenging conditions.
For humans only, half of the trials were masked. In masked trials, a phase scrambled noise pattern was presented shortly after the stimulus. This allowed for the selective impairing of recurrent processing, and served to confirm that the visual manipulations we implemented were linked to recurrence. With masked trials allowing for less contribution of recurrent processing in the brain, we expected that recurrent DNNs would show a better fit to non-masked trials, as compared to feedforward DNNs.
Different DNN models were trained and tested that covered a wide range of architectures and sizes (see Fig. 2). The architectures we focused on were either purely feedforward or contained recurrence. Within our recurrent models, different types of recurrent connections were implemented. We used existing models from three families: C, B, and VGG^45,47,49^. While the VGG family is purely feedforward and aims at maximising performance through layer depth, both the C and B families involve recurrence and are built as biologically plausible architectures. Conversely to the B models where all cases of feedback and lateral connectivity are explored, the C models included only a base, feedforward model (C Z, referred to hereafter as C), a fully laterally connected model (C RT, referred to hereafter as CL), and a high-performance, enhanced version of the latter (C S). To increase the spectrum of recurrent architectures in this family, we built four extra recurrent C architectures: C V1–V1, C IT–IT, CT and CLT. On top of C, CL and CS, these new models allowed us to separately look at the role of lateral and feedback connections in the C family too. With recurrent models in the C and B families being larger than their feedforward, baseline equivalents, we expanded our range of models by building CD and BD. Both are large and feedforward-only, and serve as better size controls for recurrent models within their families. In addition to architecture, we had large model size variation across our DNNs, with smaller models (e.g. C, 4.5 m parameters) more than twenty times smaller than our bigger ones (e.g. VGG 16, 110 m parameters). Overall, we used a range of models capable of dissociating between the effects of layer depth, size, and recurrent connectivities on performance. All our models underwent a similar regimen of training: first on ImageNet, then fine-tuned on a custom dataset of images from the eight selected categories.
Visual manipulations trigger recurrent processing
To evaluate the effect of backward masking on task performance, two t-tests were run to compare average accuracy and average reaction RT with and without masking. Results showed a significantly lower average accuracy in the presence of masking ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t=-3.12$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.006$$\end{document} , see Fig. 3A). Across manipulations, a wide range of accuracies were found, with some conditions linked to large increases in difficulty with masking, and others not. To elaborate on this difference, manipulations were split in two groups based on performance: an easy group (average accuracy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$>0.9$$\end{document} , 9 conditions) and a hard group (average accuracy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$<0.9$$\end{document} , 8 conditions), and compared average accuracy with and without masking within each group. As anticipated, this revealed significantly lower accuracy in the presence of masking in the hard manipulations ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t=-4.47$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.002$$\end{document} ) but not in the easy manipulations ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t=-1.39$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.2$$\end{document} , see Fig. 3B).
We did not find a significant effect of masking on average RT (see Fig. 3C). The effect of backward masking on RT is less straightforward, as it can make responses slower or faster. While intuition would suggest that disrupting visual information would make a response more difficult, and hence longer to produce, an alternative interpretation is that further processing an input that has been made irrelevant by masking would not be useful anymore, and could therefore result in shorter RTs.Fig. 3. Human behavioural results. (A) Average accuracy across image manipulations, with and without masking. Manipulations are arranged along the x axis in order of average accuracy. A significant difference was found on average between the masked and non-masked condition. Manipulations were split into an easy and a hard group based on a 0.9 average accuracy threshold. (B) Average accuracy across masked and non masked trials, for the easy and hard manipulations. A significant masking effect was found only in the hard manipulations, confirming their interaction with recurrent processing. (C) Average RT across manipulations, with and without masking. The order on the x axis is the same as (A). No significant difference was found between average RT with and without masking. (D) Average RT and masking effect on accuracy per condition, across manipulation difficulty groups. The two measures of recurrent processing are correlated ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r = 0.93$$\end{document} ).
The masking effects found in our hard conditions indicate the implication of recurrent processing in solving the visual manipulations they contain. To support this interpretation, we turned to RT. Masking effect and RT are traditionally used to measure recurrence in visual recognition, but separately. Longer RTs are typically taken as indicators of extra, post-feedforward computations, while backward masking effects are direct evidence for the need of recurrent processing to solve the task. Here, we quantified the relationship of these two indicators by correlating the manipulation-wise average RT and backward masking effect (defined here as the average difference in accuracy between non masked and masked trials, see Fig. 3D).
We found a strong, positive correlation between average RT and masking effect (Pearson’s correlation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r = 0.92$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p = 7.04e-08$$\end{document} ), which remains strong even after the exclusion of low-pass phase scrambling and small apertures, hard, which have the largest masking effect and average RT (both top-right dots on the scatter plot in Fig. 3D, Pearson’s correlation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r = 0.86$$\end{document} , p = 4.5e \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-05$$\end{document} ). The concurrence of both measures of recurrence in our results shows that our conditions covary on difficulty and need for recurrent processing.
Larger models perform better across tasks
Having established the role of recurrent processing in our stimulus set, we next asked how our models would perform on it. We started by comparing model average performances, in order to see whether added recurrence or larger model size would lead to an improvement at all. Average accuracy per model was collected for each of the 20 random initiation seeds (see Fig. 4A). Performances were first compared across models by running a one-way ANOVA on accuracy with model as a main factor. Results showed a significant effect of models ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F = 471.15$$\end{document} , p = 9.28e \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-188$$\end{document} ). Post-hoc comparisons of model average accuracies showed significant differences across almost all pairs of models (Tukey test; all pair-wise comparisons significant, except: C-C V1-V1, B-C IT-IT, CL-CT, CL-CLT, BT-CL, BT-CT, BT-CLT, BL-CL, BL-CT, BLT-BT, BLT-CLT). In particular, VGG16 showed significantly higher accuracy than all models ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p < 0.001$$\end{document} , Tukey test). This reflects a striking difference in performance, with VGG16 on average 10% more accurate than other models.Fig. 4. Average model performance. (A) Average model accuracy across all manipulations. Error bars show a 95% confidence interval around the mean calculated from the 20 random initialisations of each model. Hatched bars indicate non-recurrent models. The blue bar indicates average human performance on the task (0.89). (B) Average model performance per model size, in number of parameters (note the logarithmic scale of the y axis). Non recurrent models are indicated by a white-filled dot. (C) Average model performance on easy and hard manipulations separately. Blue bars indicate average human performance (easy manipulations: 0.92, hard manipulations: 0.87). Error bars show a confidence interval around the mean as in (A).
While the larger, recurrent DNNs (CL, CT, CLT, CS, BL, BT & BLT) perform higher than their baseline, smaller, feedforward-only counterparts (CL, CT, CLT and CS \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$> 95$$\end{document} % CI of C; BT and BLT \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$>= 95$$\end{document} % CI of B), little differences exist between recurrent and feedforward models of similar sizes (c and C V1-V1, BD and BLT, CD and CLT). To check whether performance across models was linked to size rather than architecture type, we correlated model parameter number with model average performance (see Fig. 4B). Results showed a large correlation (Pearson’s correlation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r=0.69$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.004$$\end{document} ), suggesting a strong link between model size and model performance. To compare the statistical effect of architecture and size on model performance, we ran a linear mixed effects model with architecture (recurrent or non-recurrent) and size (number of trainable parameters) as fixed effects ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N=15$$\end{document} ). Results show that when controlling for size, model architecture does not significantly affect accuracy ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta =0.013$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.34$$\end{document} ), while size retains a large influence on accuracy ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta \approx 0.0$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p<0.001$$\end{document} ).
With recurrence particularly helpful in challenging visual settings, we next checked whether this relationship with model size would hold across task difficulty. To this end, we ran a similar correlation, including only the easy or the hard manipulations, as defined above (see Fig. 3B). Results showed a stronger size-performance correlation in the hard conditions (Pearson’s correlation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r=0.75$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.001$$\end{document} ) than in the easy conditions (Pearson’s correlation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r=0.55$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.03$$\end{document} , see Fig. 4C for model accuracy on easy and hard manipulations).
Better performing models are more consistent with human performance patterns across image manipulations
While performance is a good indicator of how well a given model can solve the complexity of our stimulus set, it does not take into account the variability in task difficulty across the challenging manipulations. A model could have a lower overall performance but a better condition-wise fit with humans. To look beyond accuracy, we asked which models most consistently fitted the pattern of performance of humans. We computed 17 average accuracy values (one for each manipulation) per model and for humans, and correlated the pattern of accuracy across manipulations between each model and the human pattern (for detailed task-by-task model performance see S17).Fig. 5. Consistency between model and human patterns of task performance. (A) Model consistencies, calculated as the correlations between human and model patterns of performance across manipulations. Error bars show a 95% confidence interval around the mean correlated calculated from the 20 random initialisations of each model. Hatched bars indicate non-recurrent models. The grey bar indicates the average split-half reliability of human accuracy across conditions (0.99) calculated over 100 iterations. The human data used for this plot combines both masked and non-masked trials. (B) Model consistency with humans per model size, in number of parameters (note the logarithmic scale of the y axis). Non recurrent models are indicated by a white-filled dot. The human data on this plot is also from masked and non-masked trials binned together. (C) Model consistencies on masked and non masked trials separately. Grey bars indicate average split-half reliability calculated as in (A) (reliability from non masked trials: 0.98, reliability from masked trials: 0.99). Error bars show a confidence interval around the mean as in (A).
Results from this analysis (see Fig. 5A) show an overall high correlation ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$> 0.65$$\end{document} ), indicating that DNNs are on average consistent with humans and agree on which manipulation is easier or more difficult. Once again, models equipped with recurrent connectivity are more consistent than their smaller, feedforward counterpart, but are not more consistent than similarly sized feedforward counterparts (BD: correlation of 0.77, above all other B models; CD: correlation of 0.8, above all C models). Notably, VGG16 is the most consistent model (correlation of 0.85). This analysis points to model size as the main driver of consistency with human accuracy patterns. To test this, we correlated parameter number and consistency, and found a strong, positive relationship between them (Pearson’s correlation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r=0.67$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.006$$\end{document} ), which again points to size as the main driver of model fit with human behaviour, above model architecture (see Fig. 5B).
We found this correlation to be consistent across masked trials ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r=0.65$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.009$$\end{document} ) and unmasked trials ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r=0.69$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.004$$\end{document} ), where one could have expected recurrent models would be more consistent with humans in the absence of masking, when full recurrent processing is allowed to take place (see Fig. 5C). However, we note that our data is not the most fit to find such a dissociation, as human results are highly consistent across levels of masking.Fig. 6. Performance across manipulations per models. (A) Model per human average accuracy across manipulations. Conditions of special interest are pointed out with reference to the numbers on (B). (B) Each diamond represents the average performance of a model on a given manipulation (bars on the diamonds indicate SEM). Manipulations are ordered on the x axis similarly to Fig. 3A, C. For a larger, colourblind friendly version of this figure, see Fig. S4. Performance across manipulations per models. (A) Model per human average accuracy across manipulations. Outliers are pointed out with reference to the numbers on (B). (B) Each diamond represents the average performance of a model on a given manipulation (bars on the diamonds indicate SEM). Manipulations are ordered on the x axis similarly to Fig. 3A, C.
Recurrence types do not dissociate across visual manipulations
While size seems the main determinant of model consistency, manipulation-specific effects could remain: some manipulations could fall out of the human-DNN consensus, and instead be better solved by humans or by models. To check for this, we looked for outliers on the human-model agreement (see Fig. 6A). While most conditions seem to fall within this agreement, some are worth pointing out.
In the occlusion conditions, the small apertures, hard (6 in Fig. 6A) and small blobs, hard (2 in Fig. 6A) pair falls out of distribution, with models performing surprisingly well on the former and surprisingly low on the latter. This might be due to the high number of black pixels in these manipulations (see Fig. 1). The apertures images, indeed, have on average more black pixels than the blobs images ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$301\textrm{e}{3}$$\end{document} v. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$137\textrm{e}{3}$$\end{document} black pixels per image, on average). These black pixels might create a visual transient that could distract participants and interfere with performance, which could explain the unexpectedly low human accuracy. This could also explain why the small apertures, easy and the large apertures, hard (3 and 4 in Fig. 6A, respectively) show similar levels of performance for DNNs, while humans perform better on the easier, more visible condition.
In the phase scrambling condition, the low pass and high pass pair, surprisingly, shows models performing better than expected on the former, and worse than expected on the latter. This clashes with the generally accepted notion that DNNs rely on high-frequency information to perform classification^40,57^.
In our results, better performing DNNs are on average more consistent with humans. This correspondence between general performance and consistency suggests that solving the categorisation task better leads to matching humans patterns better. However, this does not rule out model-specific effects, or connection-specific effects, whereby some conditions could be better solved by some models than others. There remains a lot of within-condition variability, and a given manipulation could be better solved by a model exhibiting, for instance, lateral recurrence, with that model not performing best overall (see Fig. 6B). To look for such effects and try to dissociate between types of recurrence, we checked whether the relationship between size and performance (see Fig. 4) was repeated across conditions, and whether there were exceptions to size driving performance. For each condition, one vector of accuracy values was created with the average performance of each DNN model. Each vector (17 vectors in total, one per manipulation) was then correlated to the overall model order of performance.
Overall, the rankings of model performance across conditions seem to converge with the overall results: all conditions show a positive (Pearson’s \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r > 0.49$$\end{document} , 0.63 on average) correlation with the order of model performance, with the only exceptions of small apertures, hard (correlation of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-0.2$$\end{document} , 6 in Fig. 6A) and large apertures, hard (correlation of 0.26, 4 in Fig. 6A. Both deviate from the global trend, with baseline models reaching better accuracies than expected (e.g. VGG11 surpasses VGG16 in small apertures hard, and recurrent B models score surprisingly low on both, see Fig. 6 for full details). While it is not yet clear why these manipulations fall out of the general trend, they are noticeably more difficult than average, and might show a floor effect due to the black pixel effect explained above. We further address this point in the discussion. Overall, the convergence of within-condition with overall model performance ranking indicates that models do not display strong condition-specific effects that could link architectural features to particular manipulation challenges.
Recurrence does not make model mistakes more human-like
While model size seems to drive overall performance and consistency with human condition-wise behaviour, recurrence could make DNNs a better fit to human behaviour through a better match with the classification errors made by participants. We investigated this by comparing confusion matrices. Confusion matrices are built by calculating the number of times each of the eight categories was given as a response, when each of the eight categories was presented. The result is a 8x8 matrix where each cell counts the number of responses to a given category. As a result, confusion matrices reflect the intrinsic overlap in feature representations that models and human participants use to perform classification. A confusion matrix was built for humans, and for each DNN model (matrices visible in Figs. S5 and S6). The resulting matrices were correlated to quantify the agreement of each model with humans (matrices were correlated without diagonal values using Pearson’s R, see Fig 7).Fig. 7. Correlation between confusion matrices from human and model behaviour. (A) Correlation with the average human confusion matrix, per model. Error bars show a 95% confidence interval around the mean confusion matrix correlation, calculated from the 20 random initialisations of each model. Hatched bars indicate non-recurrent models. The grey bar indicates the average split-half reliability of the human confusion matrix (0.52) calculated over 100 iterations. The human data used for this plot combines both masked and non-masked trials. (B) Model correlation with human confusion matrix per model size, in number of parameters (note the logarithmic scale of the y axis). Non recurrent models are indicated by a white-filled dot. The human data on this plot is also from masked and non-masked trials binned together. (C) Model correlation with human confusion matrix, extracted from masked and non masked trials separately. Grey bars indicate average split-half reliability calculated as in (A) (reliability from non masked trials: 0.36, reliability from masked trials: 0.43). Error bars show a confidence interval around the mean as in (A).
Strikingly, results show a disadvantage of adding recurrence, with models including more recurrent connections performing worse than their baseline counterparts in the two families of models that we included. We found a negative correlation between model size and model correlation with human confusion matrix for all recurrent DNNs pooled together (Pearson’s \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r = -0.84$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.005$$\end{document} ), which we did not see for feedforward models (Pearson’s \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r = 0.36$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.27$$\end{document} , see Fig. 7A,B). We confirmed these results by taking the more conservative approach of calculating correlations at the individual participant level and building confidence intervals around the mean of these correlations (see Fig. S7). Within recurrent models, the trend observed in previous analyses is reversed, with larger models performing worse than smaller ones.
To control for the effect of masking and the possibility that recurrent models would fit better with human behaviour in the absence of it, we replicated this analysis on trials with and without masking (see Fig. 7C). Results indicate similar trends, with recurrent models showing a worse fit to human confusion matrices than feedforward models both with masking (Pearson’s correlation, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r=0.15$$\end{document} v. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r=0.3$$\end{document} ) and without masking (Pearson’s correlation, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r=0.3$$\end{document} v. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r=0.36$$\end{document} ). This is especially striking in comparison to the feedforward models CD and VGG16, which reach noise ceiling-level correlations with both masked and non masked trials.
The results of our analyses show that model size drives performance and consistency with humans, with model architecture not playing a significant role. Although this could fit with the idea that recurrent models are equivalent to time-unrolled feedforward models, we found that adding recurrence made models worse at replicating human classification errors. Additionally, we found that VGG16, the deep, large, feedforward-only model, fits human data the best. Overall, we could not find any particular advantage of adding recurrent connectivity in DNNs as a better strategy to achieve a categorisation task in a more human-like fashion, as compared to layer depth and overall size.
Discussion
We explored the role of recurrent processing in DNN models of visual recognition, testing the hypothesis that added recurrence in a model would make it solve object identity in a more human-like fashion. We designed a stimulus set with challenging visual features, and tested human participants with and without backward masking, to compare recurrent and non recurrent DNNs on their fit with human data in conditions where recurrence matters. Firstly, from the widespread observation that recurrence serves the visual system particularly in difficult visual conditions, we expected to find advantages of recurrent models in particularly challenging manipulations. Secondly, from the evidence that backward masking selectively impairs recurrent processing while leaving feedforward processing intact, we expected recurrent models to better fit with human behaviour in non-masked trials.
When looking at model accuracy, contrary to our expectations, we found a nuanced relationship between recurrence, model size, and performance. The inclusion of recurrent connections in DNNs improved performance, however, this improvement was tied to the overall size of the network. Larger models fared better on our manipulations than smaller ones, with VGG16 performing best. This pattern of results did not change for difficult conditions, where we expected recurrent DNNs to show an advantage.
In a comparable way, when looking at performance consistency across conditions, we did not find that recurrent models aligned better with human difficulty perception. Instead, a similar pattern emerged whereby larger models aligned more consistently with humans, with model size broadly predicting how well a given model would do. Additionally, the accuracy ranking of models collapsed when task difficulty reached a certain level (notably on the MS blobs high occlusion manipulation, see “Recurrence types do not dissociate across visual manipulations”), which seems to match with reports of DNNs failing to replicate human performance in highly difficult conditions^38,58^. Overall, we found an agreement between models and humans on task difficulty, in line with other reports showing a tendency of DNNs to generally fail when humans fail^59^. We also found this agreement to be performance-dependent, with larger models displaying more consistency than smaller ones, in line with other reports^60^. Consequently, at similar sizes, model architecture seemed to matter little, again in line with other reports (e.g. similar rankings on Brain-Score for very different model architectures^61^ but also^62^). This result is particularly important as it could have been the case that models performing worse overall would have matched human patterns of difficulty better. Although we set up our design to be sensitive to such distinctions, we did not find any, which challenges the idea that better performing models tend to become worse models of human ^63^. We also did not find any difference between masked and non masked trials, while an advantage for recurrent models was expected for the latter.
We set up our experiment to be able to distinguish between different types of recurrence. By choosing and building DNNs that contained different types of recurrence in different layers, we aimed at finding manipulation-dependent effects of recurrent processing. However, we did not find any such distinctions in our results, as evidenced by the overall consensus of performance ranking across conditions (see “Better performing models are more consistent with human performance patterns across image manipulations”). This null result is surprising considering the ample evidence for region-specific perceptual phenomena in the brain. One could have expected, for instance, C V1-V1 to behave differently in conditions requiring figure-ground modulation (e.g. clutter tasks) given the known role of recurrent processing in V1 in this phenomenon^6,23^. This result, combined with the general performance-dependent model consistency, shows that the recurrent connections we implemented do not critically change the behaviour of our models.
When considering task performance and consistency, our results align well with the notion that recurrent neural networks can be considered time-wrapped equivalents of size-matched feedforward networks^35,64^. Recurrent architectures, though, could be considered superior because more brain-like. Furthermore, recurrence allows to increase the number of computations without an increase in the number of neurons. Thus, if we were to express model size in terms of the number of units rather than the number of parameters, then recurrence results in an improved performance without an increase in ‘size’.
However, even with this handy way out to promote recurrence as a solution with unique benefits, recurrence faces other challenges. Our examination of confusion matrices provided a finer-grained comparison of models, and showed, contrary to expectations, a drop in the alignment of recurrent models, specifically CS and BLT, with human behaviour. This observation is made striking by the negative correlation we found between model size and model correlation with the human confusion matrix, for recurrent but not for feedforward models. This corroborates reports showing that DNNs rely on different strategies to operate visual recognition^65–67^, and possibly highlights that the additional computational flexibility brought by recurrent connections exacerbates this effect. Importantly, we found a characteristic tradeoff between overall performance and fit with human data^63,68^ within the recurrent model families C and B, but not VGG.
This puts in perspective the observation that recurrent models better mimic the representational patterns of the brain^32,33,47,69^ or the patterns of human behaviour^34^ than non-recurrent ones. While recurrent models are reported to match better the brain’s functioning, our study suggests that they could simultaneously be worse models of human behaviour, in line with observations in the field that DNNs do not yet approximate human visual perception behaviour^37^. The present work therefore joins others in emphasising the importance of behavioural benchmarks to assess model goodness^36,37^.
Strikingly, although we used a design equipped for it, we found no clear dissociations between the effect of specific types of recurrence. Lateral connections did not induce specific effects compared to top-down connections, either in general or in a layer-dependent way. This lack of dissociation could mean that the implementation of recurrence within DNNs does not inherently alter the mechanisms of information processing. Rather than fundamentally reshaping how inputs are processed, recurrent processing, in its current implementation, seems to operate similarly to added layer depth, as a tool adding to the computational power of a network. This is in line with our observation that despite vast differences in architecture, the approach to visual recognition, as indexed by confusion matrices, remains relatively homogeneous for a given model size (see Fig. S8). A potential way to probe for stronger differences between what is learned in feedforward versus various types of recurrent connections is through training. While we set out model training to be as similar as possible across our models, training on challenges specifically designed to target recurrent processing could be one way into maximising the differences between model architectures.
One possible avenue for finding dissociations between types of recurrent connections is to look at model dynamics. Here, we did not set this as our primary goal, and instead looked at our model performances at only one time step, focusing on the comparison with human data. However, a more in-depth investigation into the temporal patterns of performance seems worthwhile, as it has been shown that time step can significantly change the performance of recurrent DNNs ^34^. Temporal dynamics could hence be a way into dissociating between the phases of recurrent connectivity ^13^, and how each is linked to resolving specific conditions.
It is noticeable that each of the recurrent connection in our models can be implemented in multiple ways. Here, we adhered to the common implementation as it is used by architectures such as C and B, yet, there is a wide range of other options and frequent developments in the field^69–75^. Another avenue into exploring the role of recurrence in the computations underlying object recognition is to test a base model to which different types of such recurrent connections are added, which can provide a clear control for the effect of recurrence (as done in ^47,76^). In addition, even though the visual challenges that we created were motivated by previous research that referred to a potential specific role of lateral versus top-down connections^18,19,27^, there might be better manipulations to be found. Overall, before we can accept the hypothesis that the type of recurrence does not matter, further studies are needed with more refined, biologically plausible implementations of recurrence and with additional visual challenges.
The need to search further in the space of visual manipulations also finds support in the wide variety we found across our 17 manipulations. Interesting distinctions emerged, with seemingly similar manipulations bringing surprisingly different results. The implementation of small apertures, for instance, brought two such experimental conditions: small apertures, hard and small blobs, hard. While in the former, both humans and models see significant drops in their performance, the latter shows disagreement, with humans finding it much less difficult. A similar distinction can be found by comparing phase scrambling in the low pass condition and high pass condition. Even in the absence of model-specific effects, our results highlight the behavioural variability that can be measured using a rich stimulus set.
In conclusion, contrary to our expectations, our findings highlight the limitations of recurrence as implemented in our models. Furthermore, they point out the overall discrepancy of visual processing in DNNs compared to humans. While we reproduce the general DNN ability to capture patterns of task difficulty, our results do not support that recurrent models outperform feedforward counterparts in capturing human visual recognition processes. As a consequence, we stress the importance of behavioural fidelity as a metric in developing new models, and emphasise the need for refined, biologically plausible implementations of recurrence.
Supplementary Information
Supplementary Information.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bracci, S. & Op de Beeck, H. P. Understanding human object vision: A picture is worth a thousand representations. Ann. Rev. Psychol.74, 113–135 (2023).10.1146/annurev-psych-032720-04103136378917 · doi ↗ · pubmed ↗
- 2Felleman, D. J. & Van Essen, D. C. Distributed hierarchical processing in the primate cerebral cortex. Cereb. Cortex (New York, N.Y.: 1991)1, 1–47 (1991 Jan-Feb).10.1093/cercor/1.1.1-a 1822724 · doi ↗ · pubmed ↗
- 3Riesenhuber, M. Object recognition in cortex: Neural mechanisms, and possible roles for attention. In Neurobiology of Attention. 279–287 (Elsevier, 2005).
- 4Wyatte, D., Jilk, D. J. & O’Reilly, R. C. Early recurrent feedback facilitates visual object recognition under challenging conditions. Front. Psychol.5 (2014).10.3389/fpsyg.2014.00674 PMC 407701325071647 · doi ↗ · pubmed ↗
- 5Shin, H. et al. Recurrent pattern completion drives the neocortical representation of sensory inference (2023).10.1038/s 41593-025-02055-5PMC 1258615840954310 · doi ↗ · pubmed ↗
- 6Bowers, J. S. et al. Deep Problems with Neural Network Models of Human Vision (2022).10.1017/S 0140525 X 2200281336453586 · doi ↗ · pubmed ↗
- 7Geirhos, R. et al. Comparing deep neural networks against humans: Object recognition when the signal gets weaker (2018). ar Xiv:1706.06969.
- 8Geirhos, R. et al. Generalisation in humans and deep neural networks. ar Xiv:1808.08750 [cs, q-bio, stat] (2020).